Share
風音屋のプライベートセミナー「GoogleCloudNext '26 風音屋 Recap」の投影資料を一部抜粋・調整したものとなります。 風音屋の取引先各社、アドバイザー、業務委託、従業員、講座受講生を対象とした非公開イベントとなります。 「セマンティック、セマンティックレイヤー、オントロジー、ナレッジグラフ、グラフDBとは何か」について解説しています。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
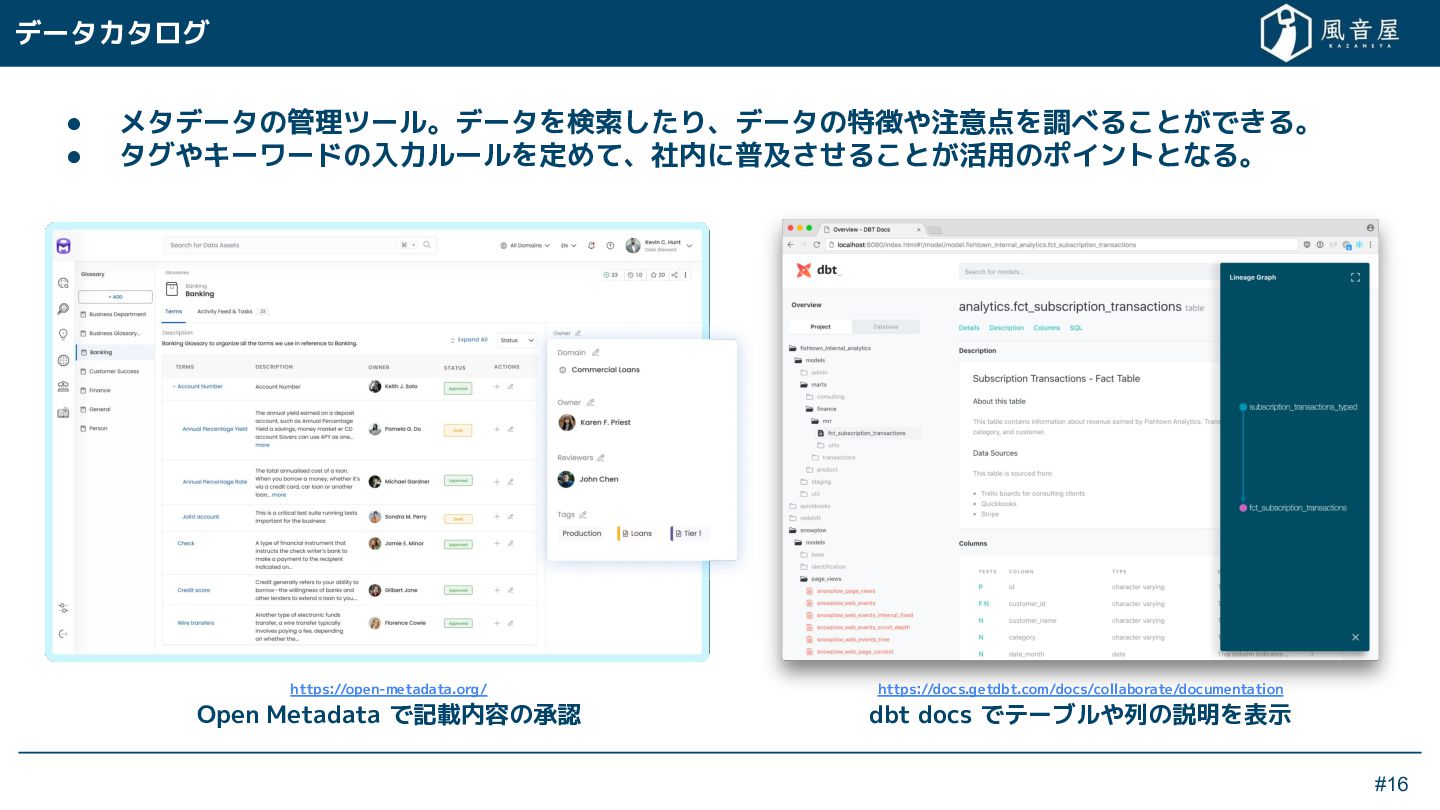{kind=link}
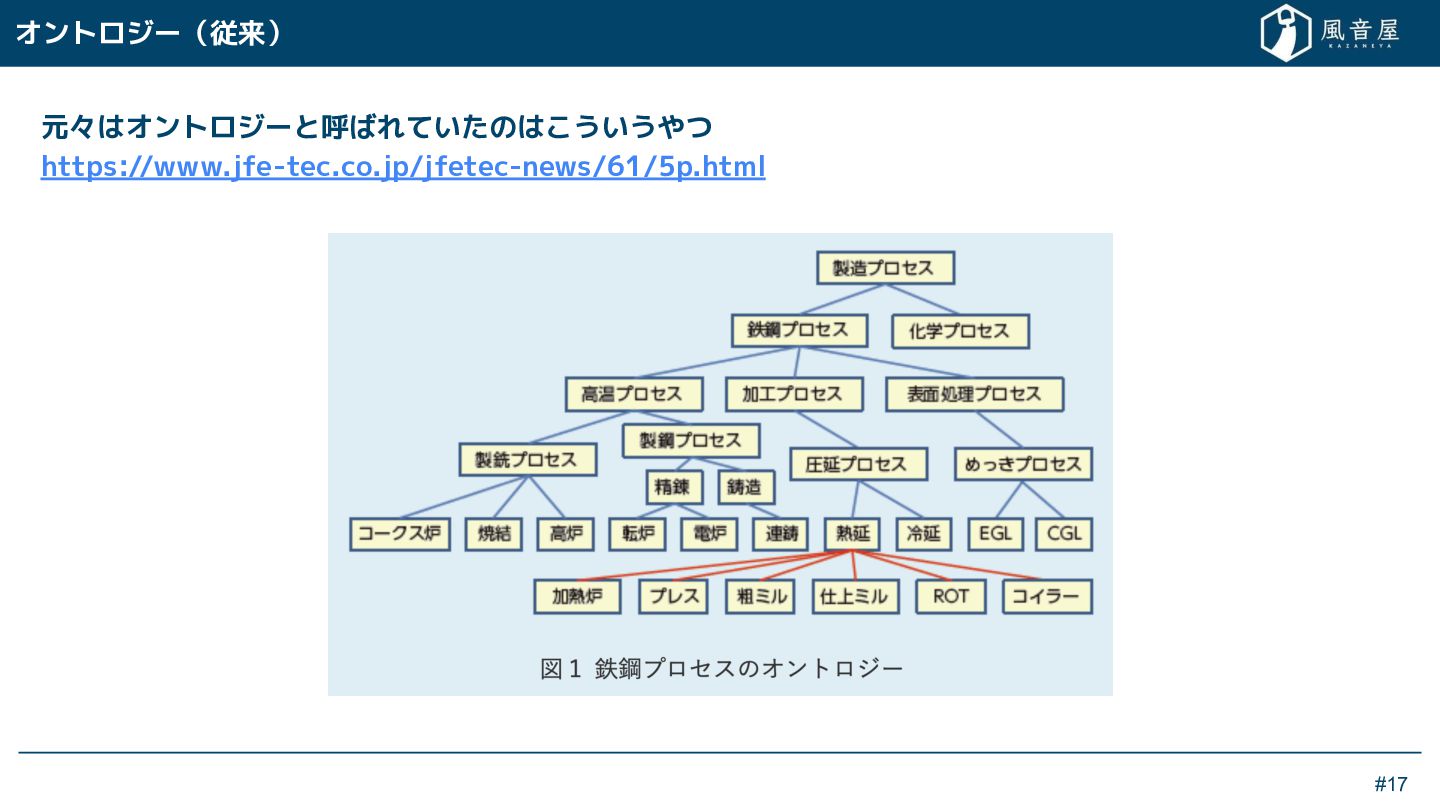{kind=link}
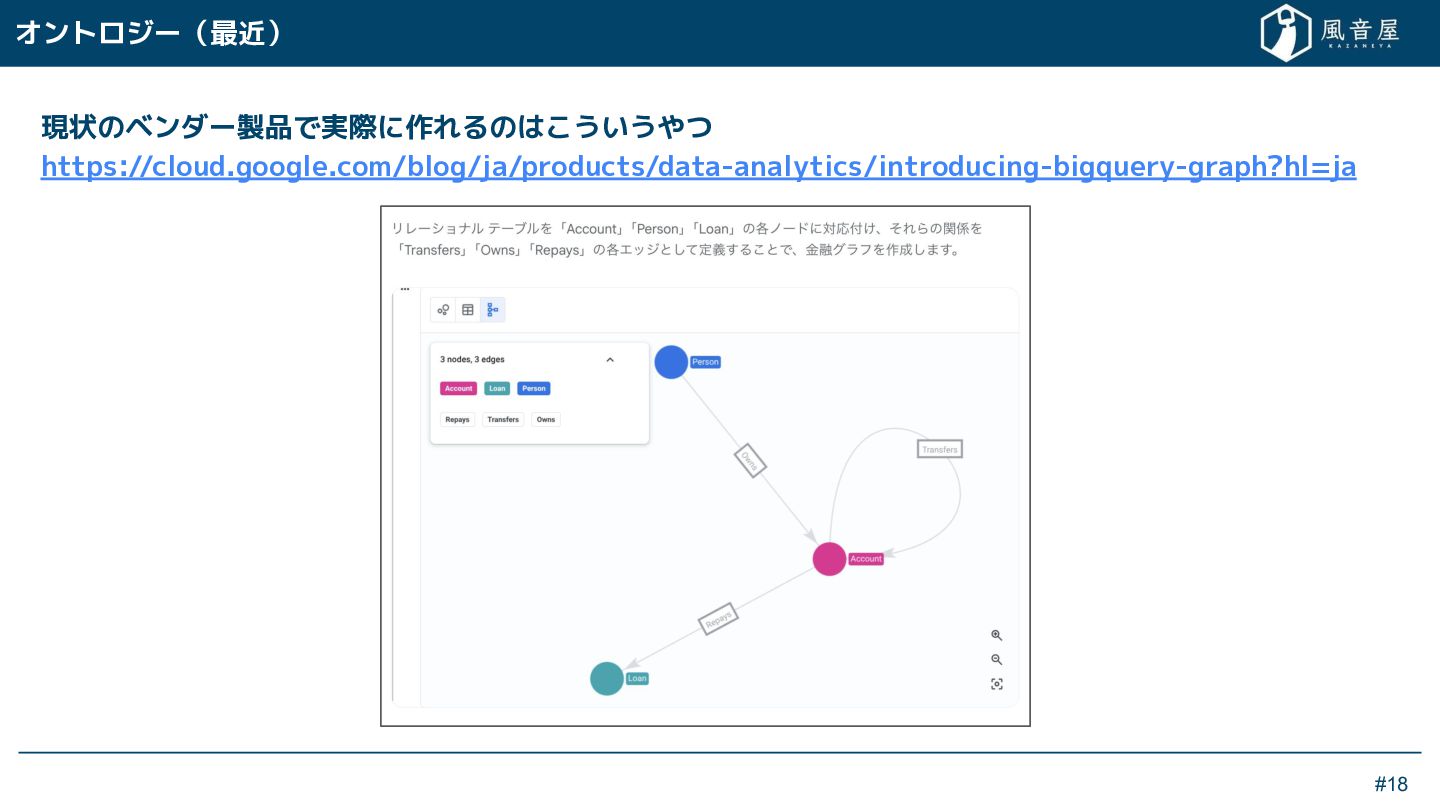{kind=link}
{kind=link}
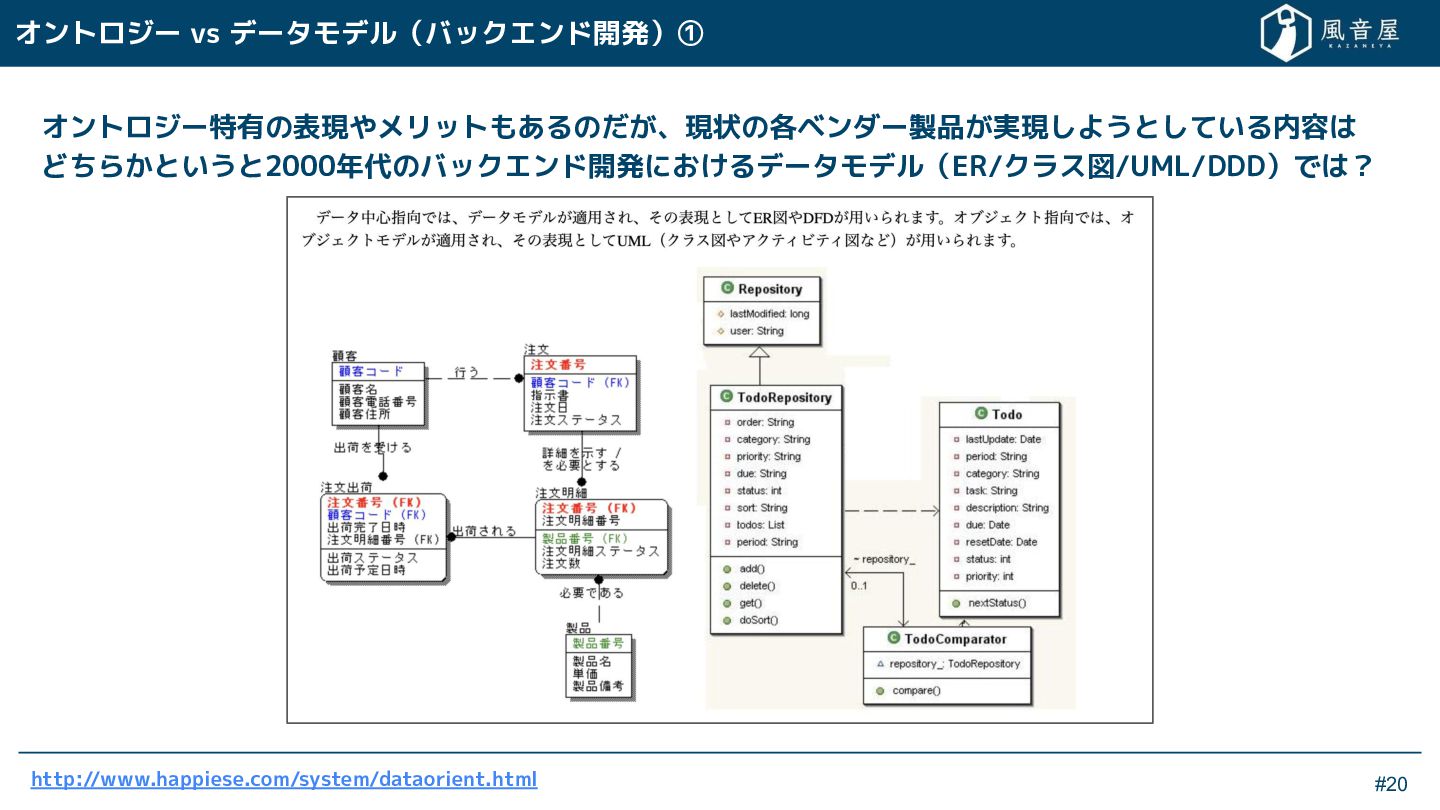{kind=link}
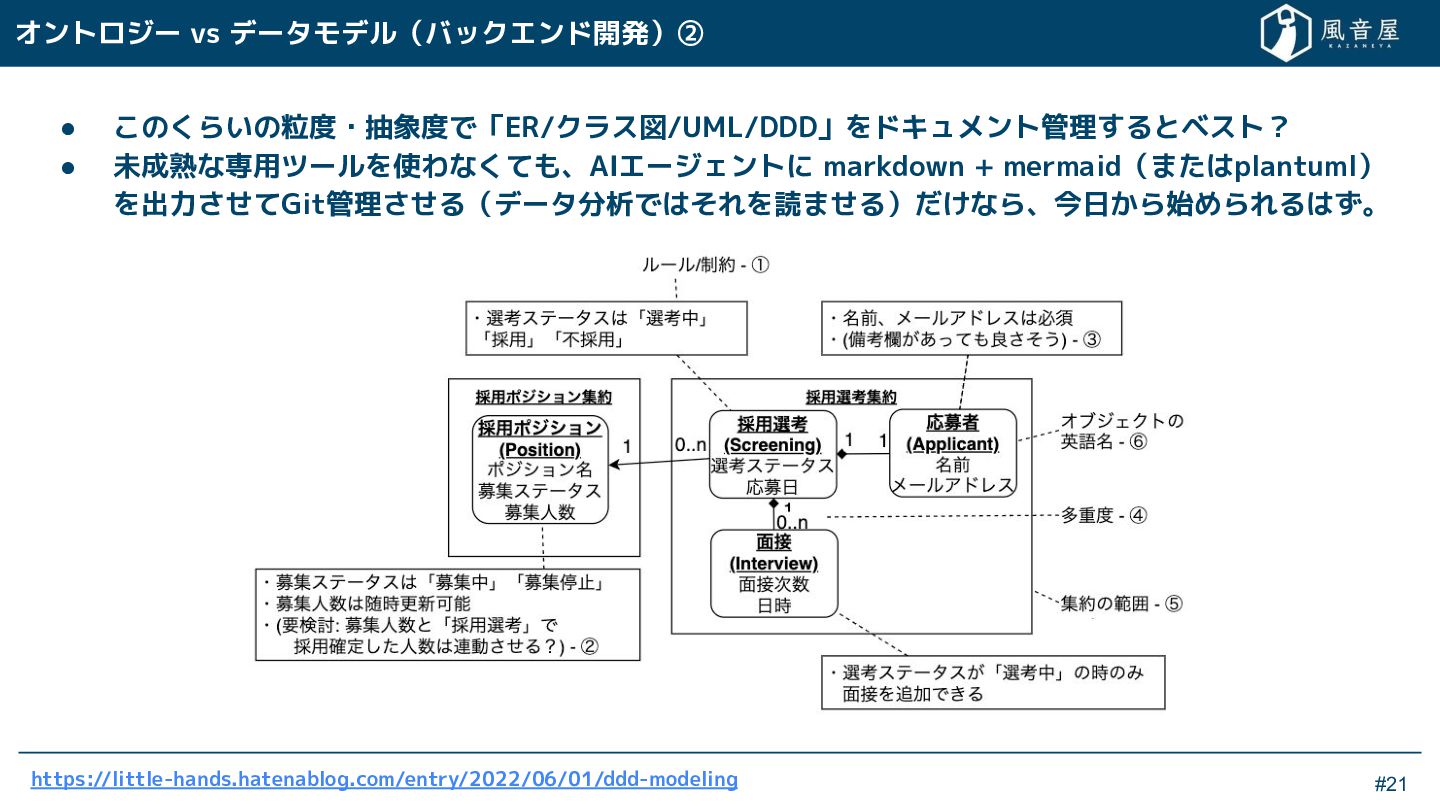{kind=link}
{kind=link}
{kind=link}
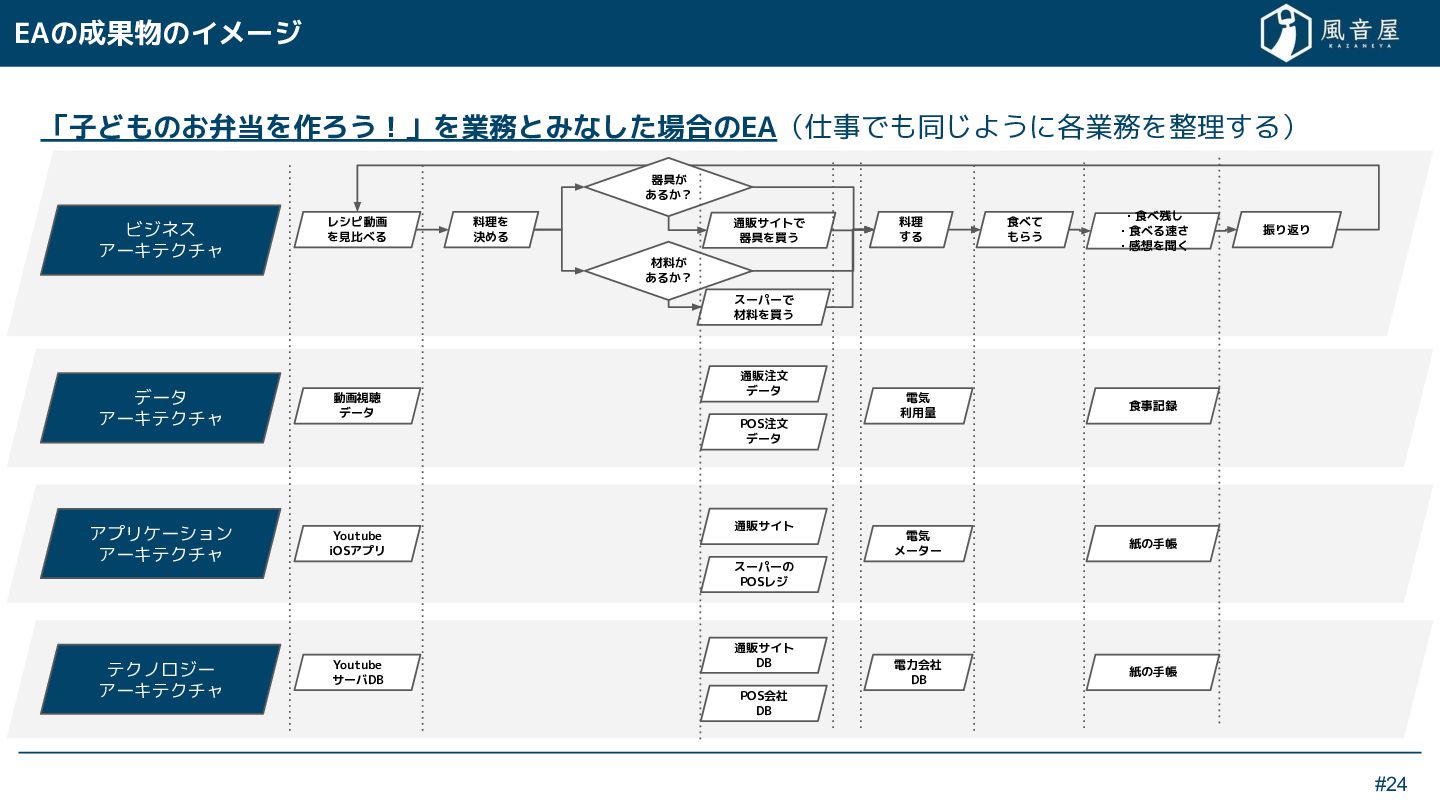{kind=link}
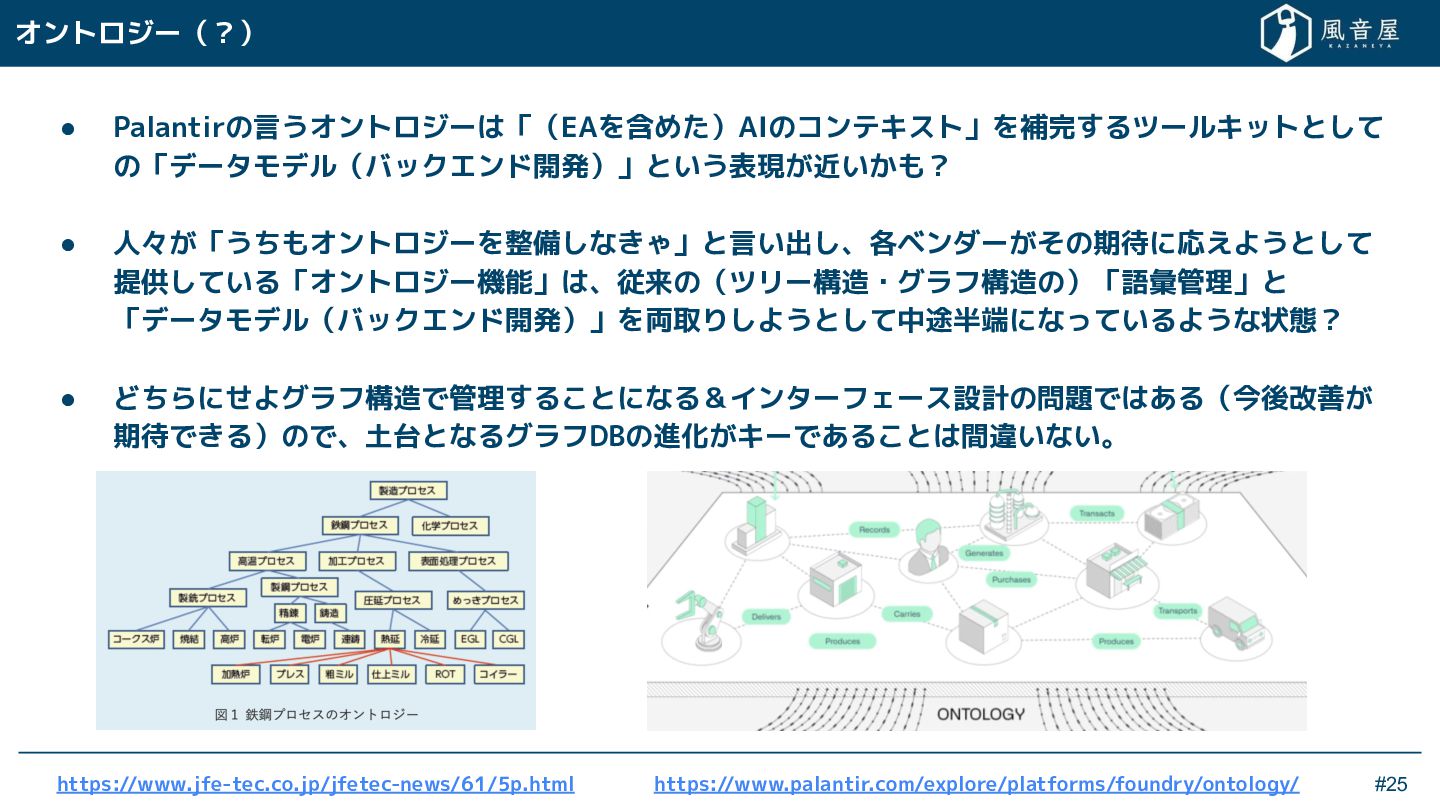{kind=link}
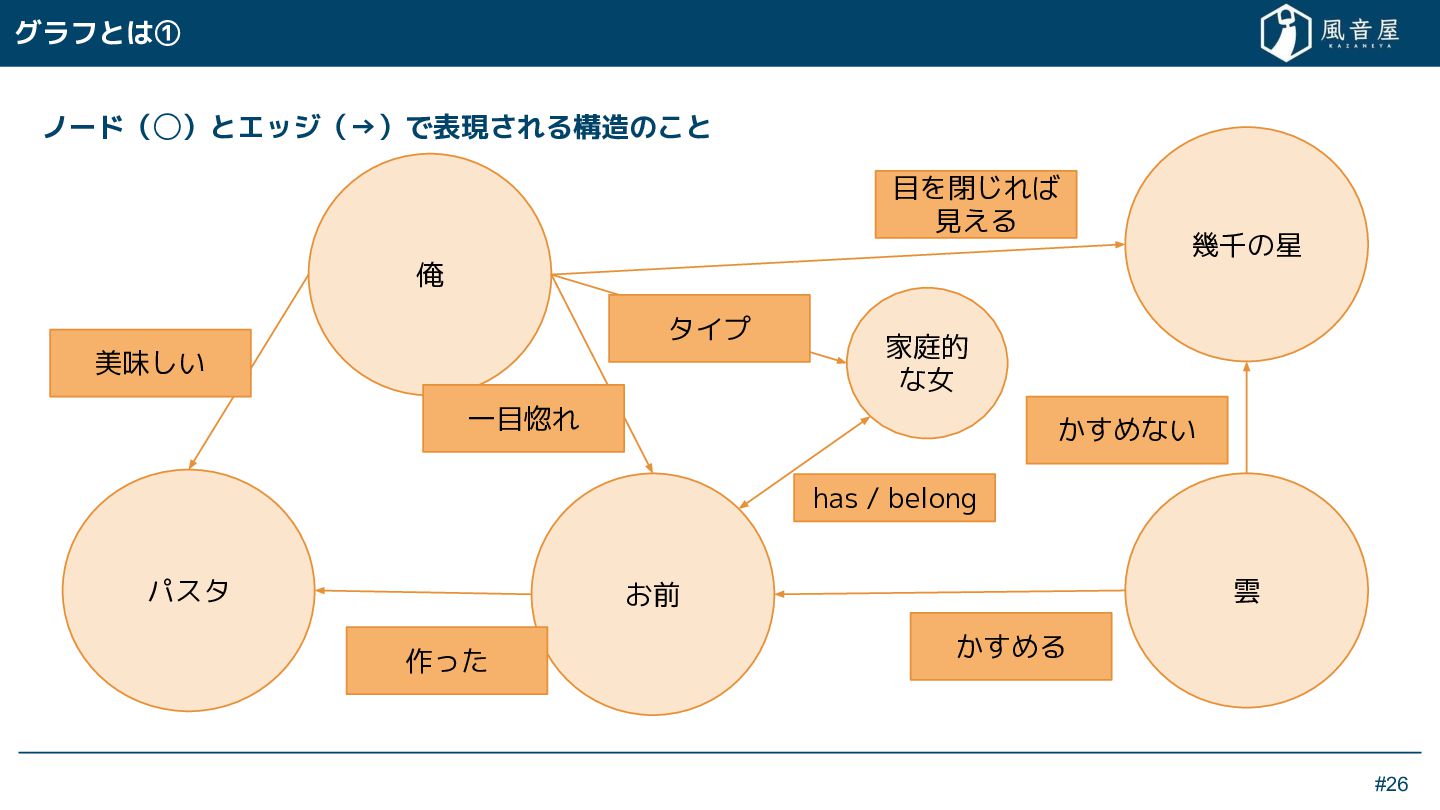{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
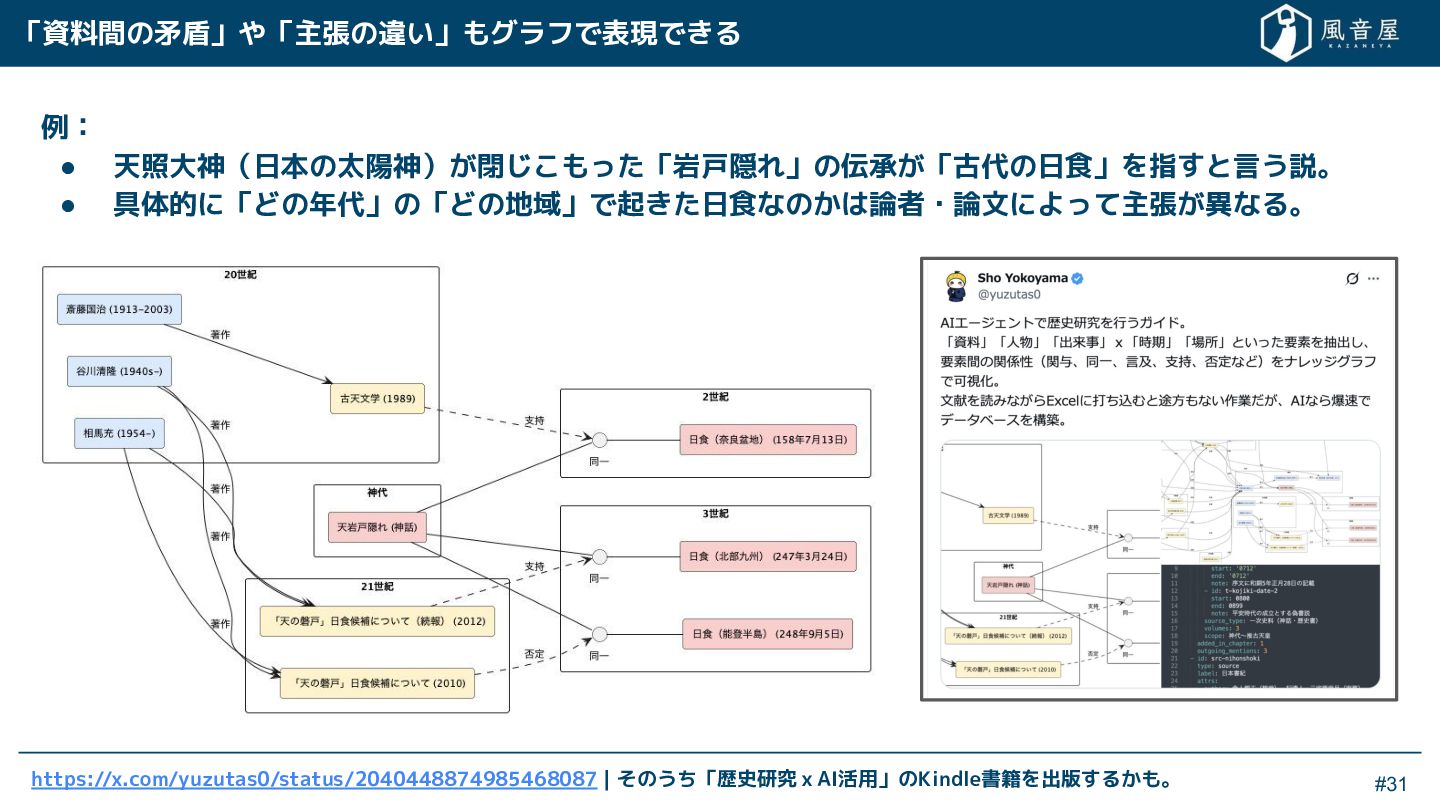{kind=link}
{kind=link}
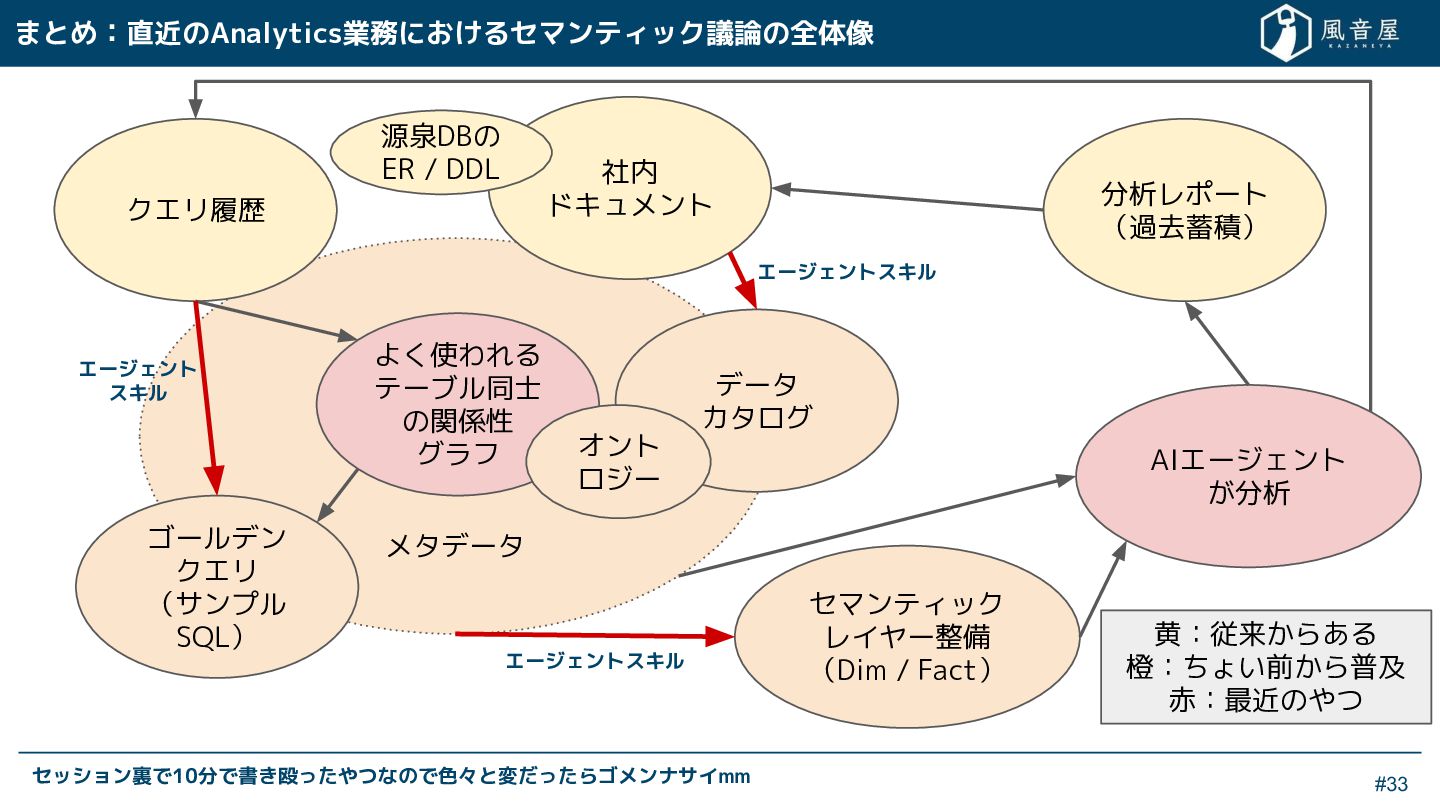{kind=link}
{kind=link}
{kind=link}
{kind=link}