Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
AI時代に必要なデータプラットフォームの要件とは by @Kazaneya_PR / 2025...
Search
風音屋 (Kazaneya)
PRO
November 07, 2025
Technology
5.4k
13
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
AI時代に必要なデータプラットフォームの要件とは by @Kazaneya_PR / 20251107
技術カンファレンス「Data Tech 2025」の資料です。
https://kazaneya.com/28570d0c5ac88015a18cc84b632ff932
風音屋 (Kazaneya)
PRO
November 07, 2025
More Decks by 風音屋 (Kazaneya)
See All by 風音屋 (Kazaneya)
セマンティック概論 - #GoogleCloudNext '26 Recap by @Kazaneya_PR / 20260604
kazaneya
PRO
27
8.5k
Excelデータ分析で学ぶディメンショナルモデリング ~アジャイルデータモデリングへ向けて~ by @Kazaneya_PR / 20251126
kazaneya
PRO
3
1.8k
Data Engineering Guide 2025 #data_summit_findy by @Kazaneya_PR / 20251106
kazaneya
PRO
12
8k
大学のIR担当者になったら知っておきたい 「民間企業におけるデータ基盤の構築・運用」入門 / 20251021
kazaneya
PRO
2
1k
Google Cloud で学ぶデータエンジニアリング入門 2025年版 #GoogleCloudNext / 20250805
kazaneya
PRO
43
16k
30分でわかるデータ分析者のためのディメンショナルモデリング #datatechjp / 20250120
kazaneya
PRO
39
25k
大学生はAIをどう活用しているのか? 次世代人材に向けたテクノロジー教育最前線 #devsumi / 20240216
kazaneya
PRO
4
3.8k
アナリティクスエンジニアのキャリアとデータモデリング 〜資料「30分でわかるデータモデリング」を読む前に知ってほしいこと〜 / 20240116
kazaneya
PRO
18
9.2k
データマネジメント入門 - DX推進を支えるデータ基盤の重要性 / 20240125
kazaneya
PRO
16
4.6k
Other Decks in Technology
See All in Technology
データベース研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
660
文字起こし基盤の信頼性
abnoumaru
0
150
Claude Code並行開発環境の ムダ‧ムラ‧ムリを見直した話
muranakaaa
0
290
AIで楽になるはずが、なぜ疲れる?
kinopeee
0
130
AIエージェントがあれば技術書なんてすぐ書けるでしょ→無理でした
watany
6
1.1k
システム監視を 「システムを監視するだけ」で 終わらせないために
seiud
0
150
2026年のソフトウェア開発を考える(2026/07版) / Agentic Software Engineering 2026-07 Findy Edition
twada
PRO
31
20k
WEBフロントエンド研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
720
書籍セキュアAPIについて
riiimparm
0
380
データエンジニアこそ組織のオントロジーに向き合うべき — 問いに答えるAIから、事業を動かすAIへ
gappy50
4
1.2k
自己解決や回答速度を上げる、サポート業務へのAIの組み込み方【SORACOM Discovery 2026】
soracom
PRO
0
100
AWS環境のセキュリティ不安を解消した企業事例 ~よくある課題と対策を一挙公開~
asanoharuki
0
240
Featured
See All Featured
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
Between Models and Reality
mayunak
4
380
Utilizing Notion as your number one productivity tool
mfonobong
4
480
Un-Boring Meetings
codingconduct
0
350
Test your architecture with Archunit
thirion
1
2.3k
Evolving SEO for Evolving Search Engines
ryanjones
0
250
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
310
Dominate Local Search Results - an insider guide to GBP, reviews, and Local SEO
greggifford
PRO
0
220
Bootstrapping a Software Product
garrettdimon
PRO
307
120k
Prompt Engineering for Job Search
mfonobong
0
390
AI Search: Implications for SEO and How to Move Forward - #ShenzhenSEOConference
aleyda
1
1.3k
Leo the Paperboy
mayatellez
8
1.9k
Transcript
AI時代に必要なデータプラットフォームの要件とは 2025-11-07 DataTech 2025 特別講演 株式会社風音屋 横山 翔(Sho Yokoyama) @yuzutas0
っ で 、 でCMで 。
None
None
None
None
データエンジニア・ データコンサルタント 採用中 Speakerdeck公開版
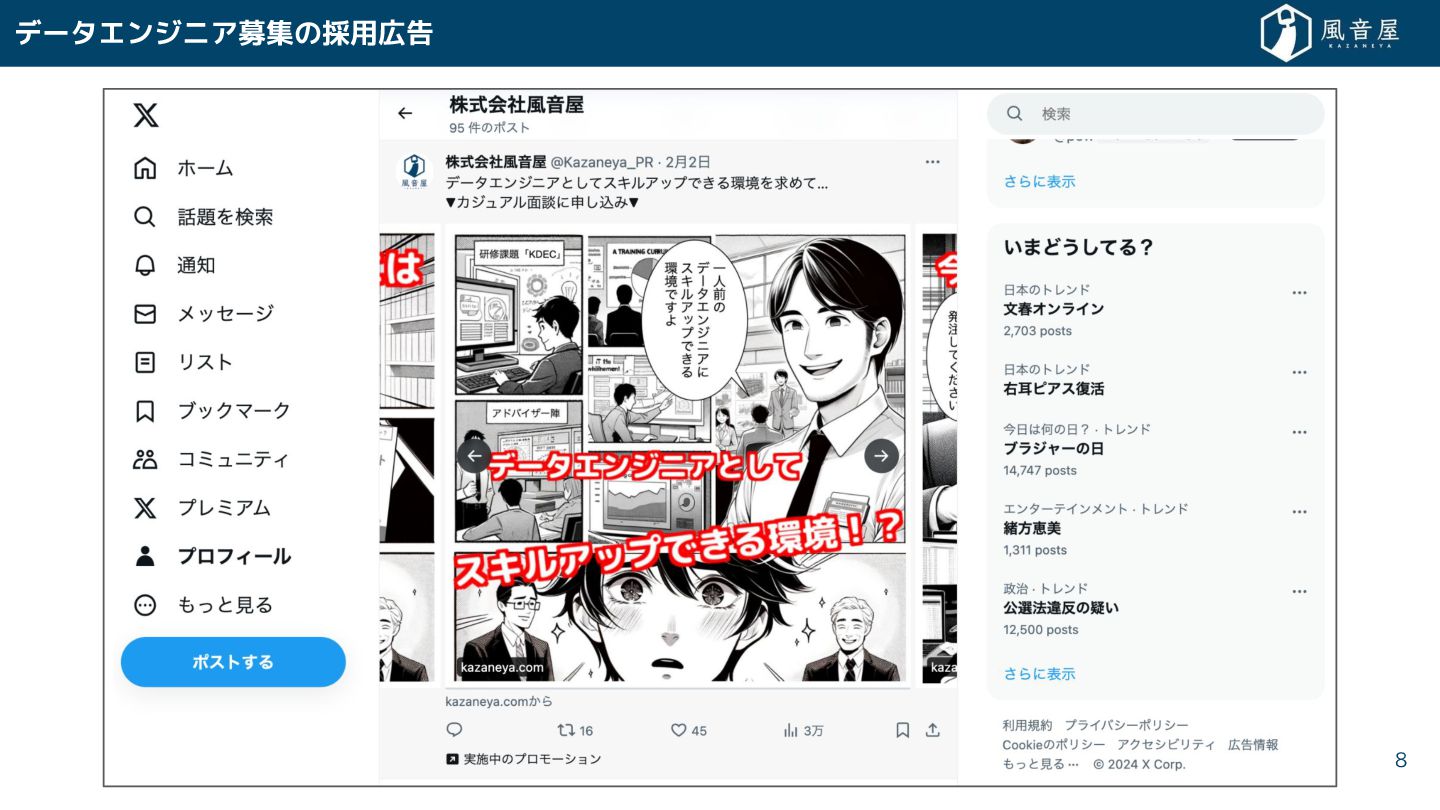
データエンジニア募集の採用広告 8
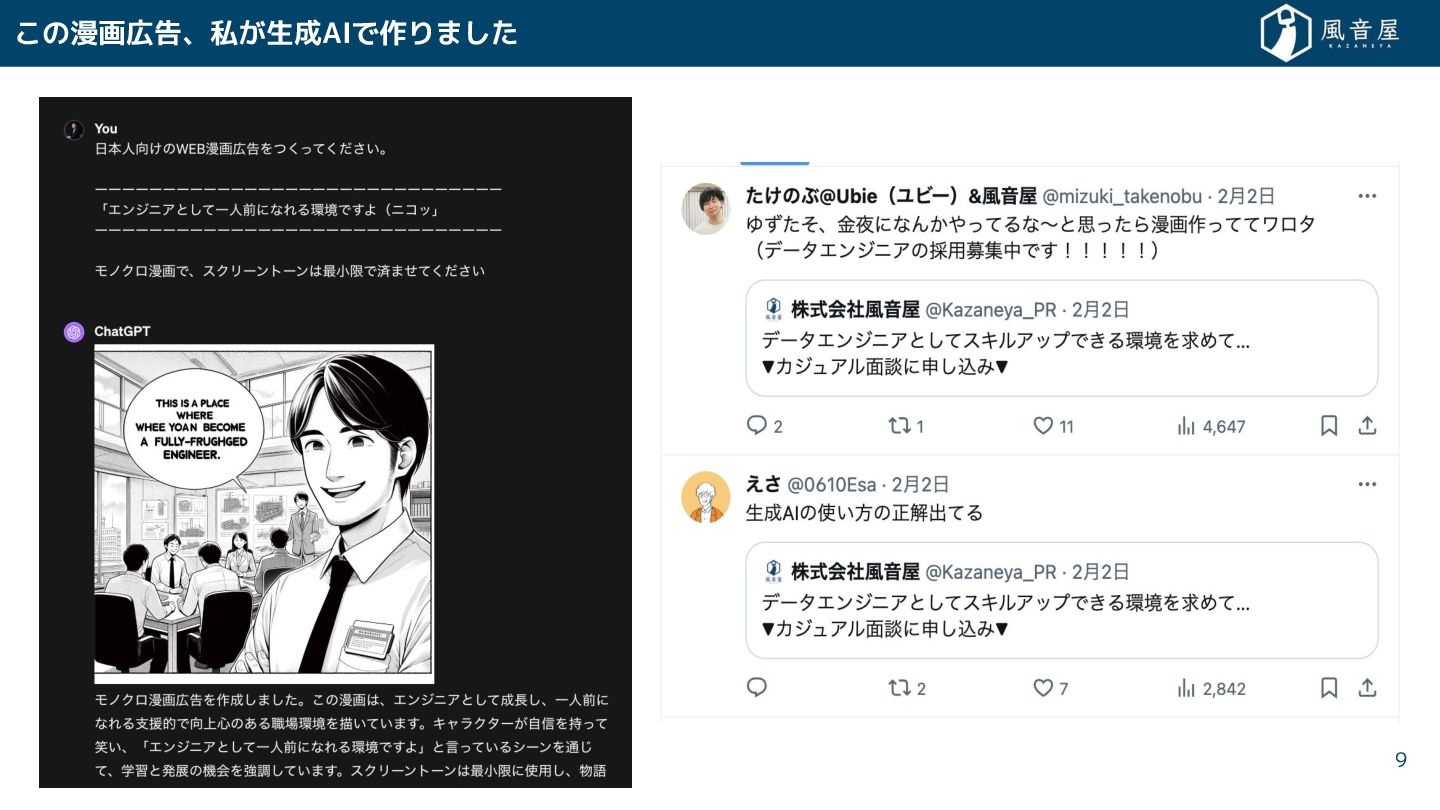
の漫画広告、私 生成AIで作りま 9
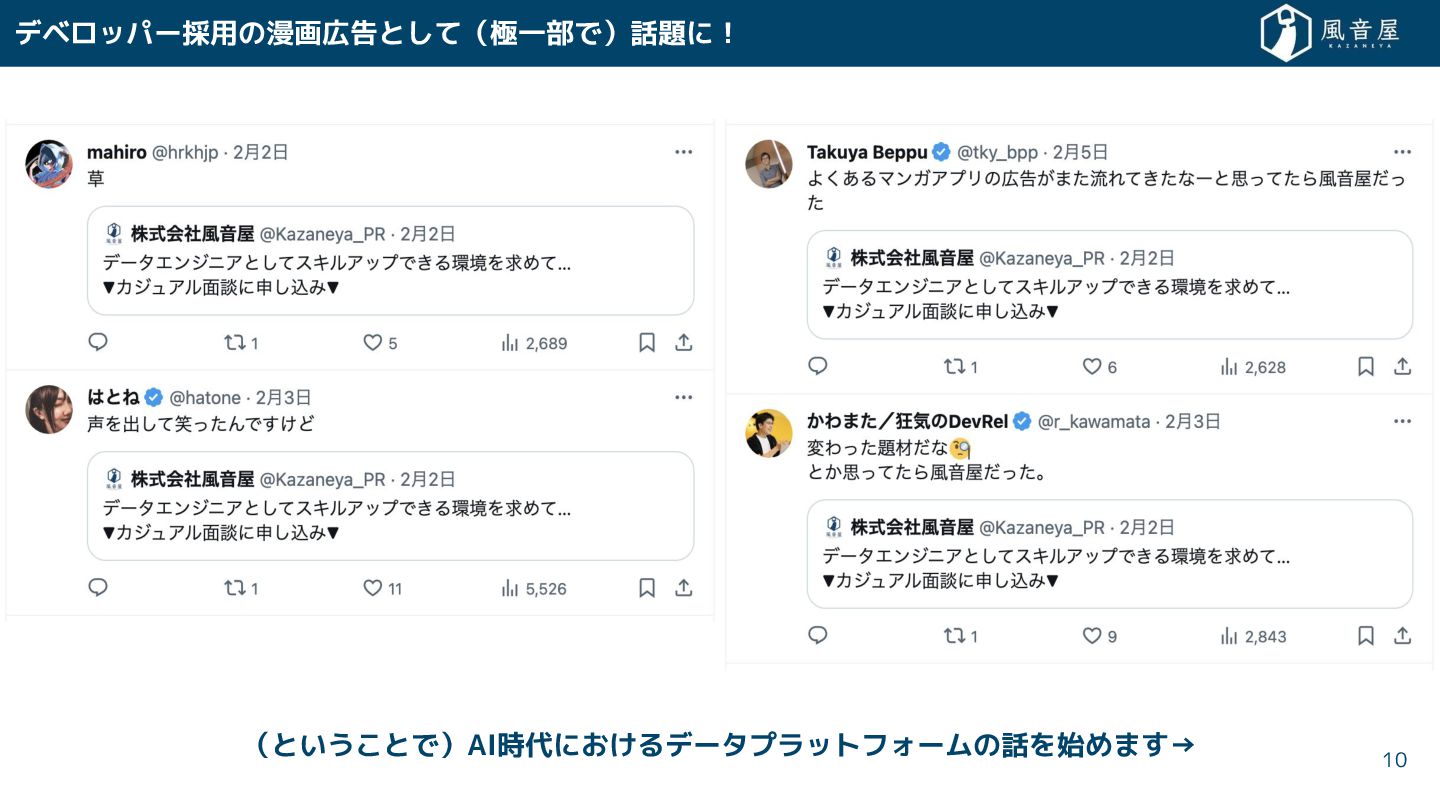
デベロッパー採用の漫画広告と て(極一部で)話題に! 10 (という とで)AI時代に るデータプラットフォームの話を始めま →
1. は めに
注意事項 1. 本資料は許諾 範囲内でのみ 利用 い。無断転載ならびに複写を禁 ま 。 2. 本資料に記載
れている会社名・製品名などは、一般に各社の登録商標ま は商標、商品名で 。資 料内では ©, ®, ™ マーク等は省略 てい いて りま 。 3. 本資料は特定企業の情報公開や称賛・批判を意図 るものではありま ん。社名 提示 れていない ケーススタディやシステム構成は、原則的に複数企業の事例を踏まえ ダミー情報となりま 。 4. 説明を簡略化 る めに、用語やツールの紹介は厳密な定義に則っていない場合 ありま 。 自身 や所属チームでの理解・解釈 紹介内容と異なる場合は、適宜読み替えてい ると幸いで 。 12
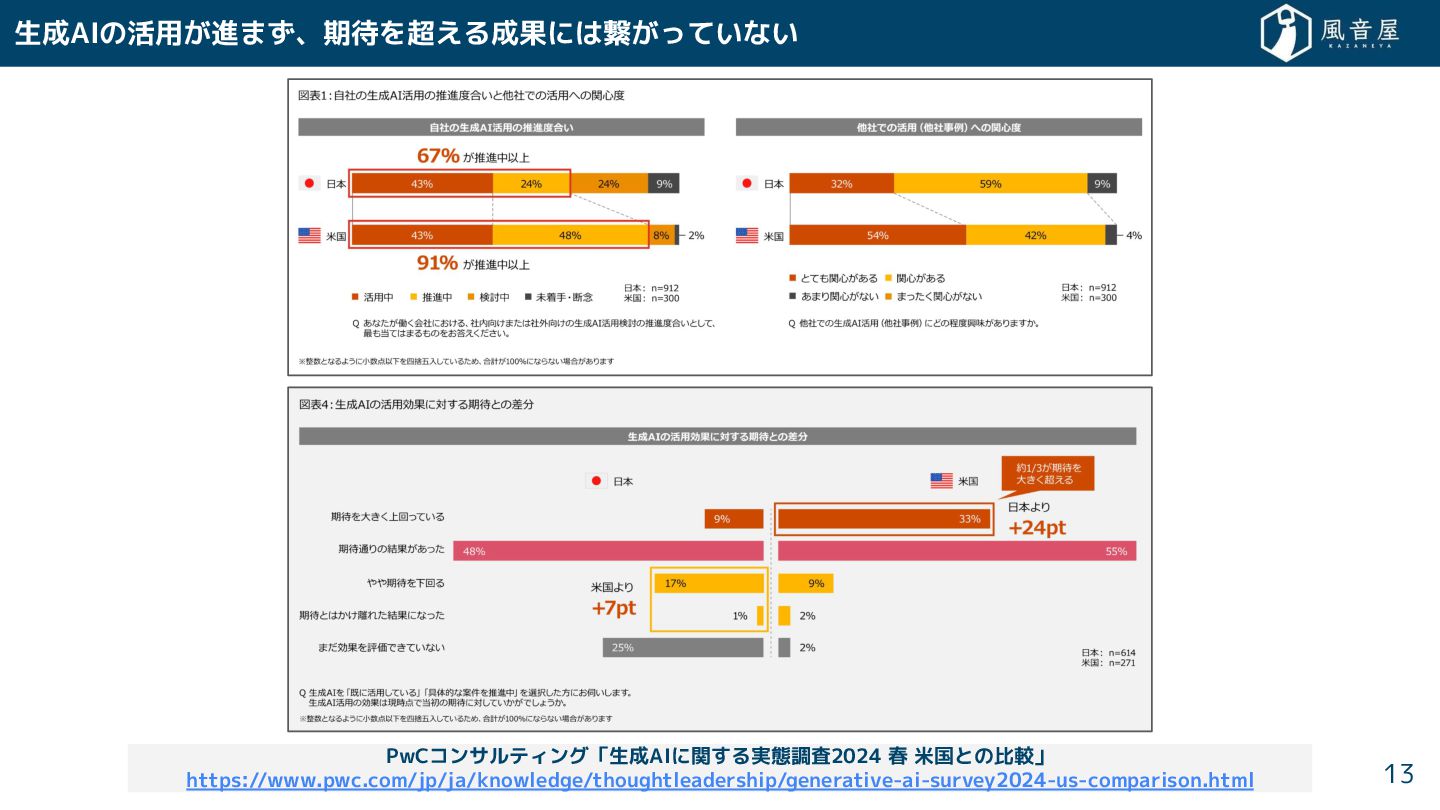
生成AIの活用 進ま 、期待を超える成果には繋 っていない 13 PwCコンサルティング「生成AIに関 る実態調査2024 春 米国との比較」 https://www.pwc.com/jp/ja/knowledge/thoughtleadership/generative-ai-survey2024-us-comparison.html
生成AIの活用効果 「期待以上」となる要因の2位は日米ともに「データ品質」 14 PwCコンサルティング「生成AIに関 る実態調査2024 春 米国との比較」 https://www.pwc.com/jp/ja/knowledge/thoughtleadership/generative-ai-survey2024-us-comparison.html
データの質・量 不十分 日本国内686社の調査で、データ活用の課題2位と て「質・量を備え データの取得」 挙 られている。 NEDO(2019)「産業分野に る人工知能及び の内の機械学習の活用状況及び人工知能技術の安全性に関
る調査」 ならびに https://ainow.ai/2020/07/05/224999/ 15
データのサイロ化(分断) アジア太平洋 よび欧州中近東の企業調査にて、テクノロジー部門の上級意思決定者670人中73% 、 データのサイロ化によって「必要と るデータを提供で ていない」「目標を達成で ていない」と回答。 Oracle Corporation
(2020) “Moving the Needle: Data Management for the Multi-Hybrid Age of IT” ならびに https://prtimes.jp/main/html/rd/p/000000003.000057729.html 16
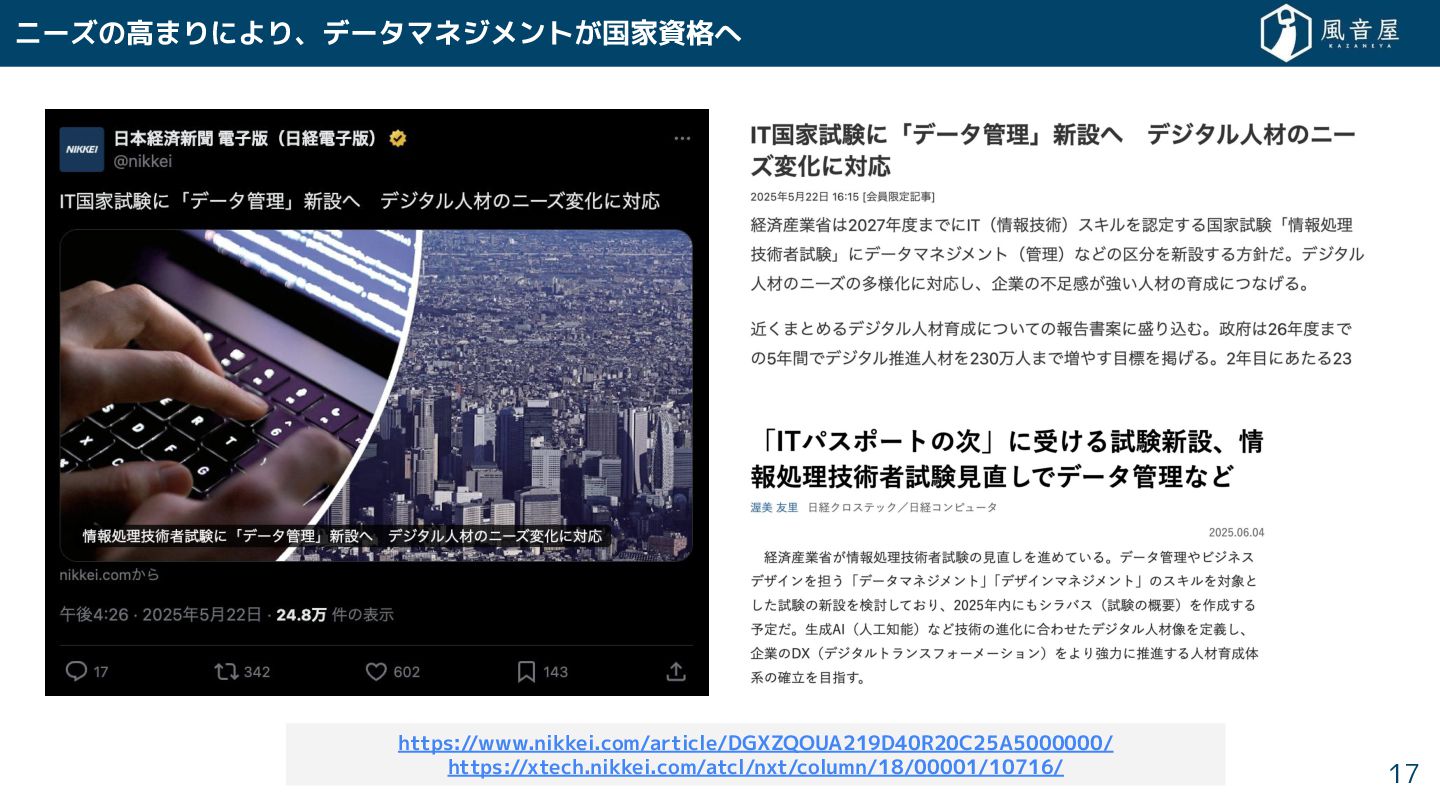
ニーズの高まりにより、データマネジメント 国家資格へ 17 https://www.nikkei.com/article/DGXZQOUA219D40R20C25A5000000/ https://xtech.nikkei.com/atcl/nxt/column/18/00001/10716/
本講演の 題 AI活用 盛んになるにつれ、データプラットフォームに求められる要件は刻々と変化 ていま 。 んな中、レガシーなプラットフォームを刷新 ようにもど ら着手 べ
分 らない、 ま 実際に刷新 ても保守運用 うま 回ら 使い物にならないなど、 ま まな課題に直面 ている企業も多い とで ょう。 で本講演では、企業のデータ基盤システム構築 ら保守運用までを支援 て り、 「ゆ 」と てブログやSNSなどでの情報発信も行っている横山氏 、 「AI時代に必要となるデータプラットフォームの要件」をテーマに講演。 データプラットフォーム刷新に いてIT部門 直面 な課題を洗い出 な ら、AI 台頭 ている今、 プラットフォームを再構築 る際に押 えるべ ポイントやアーキテクチャの要件などを解説 ま 。 18
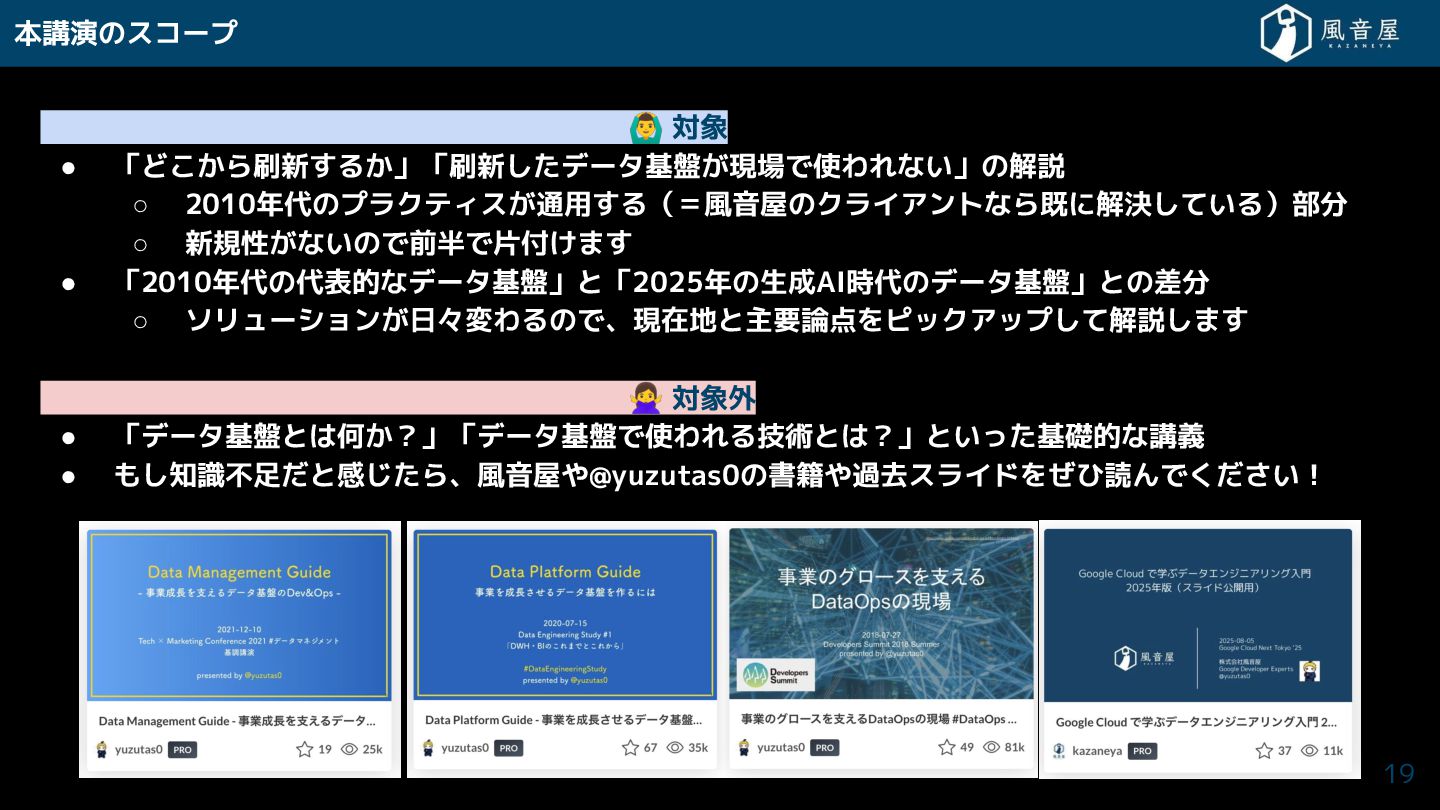
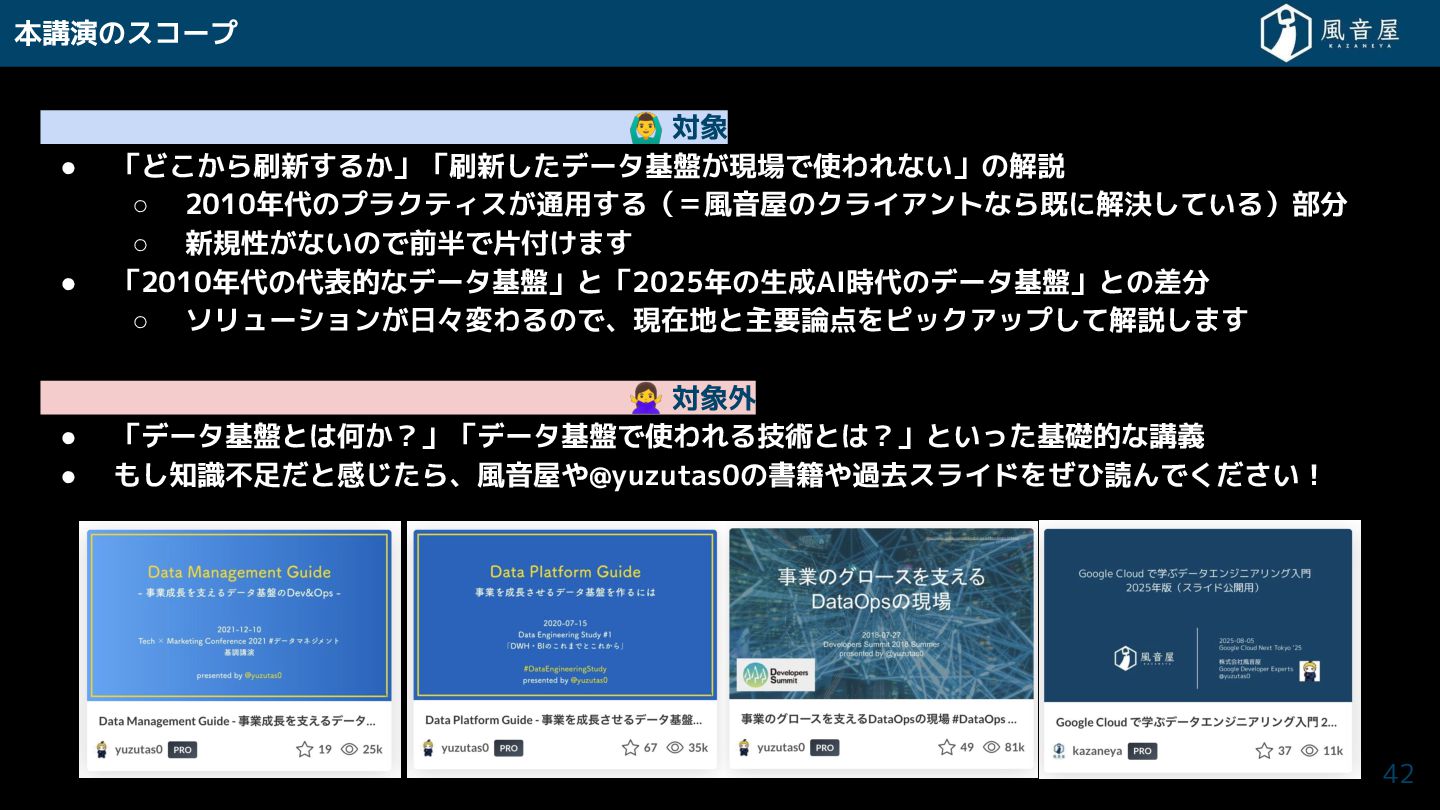
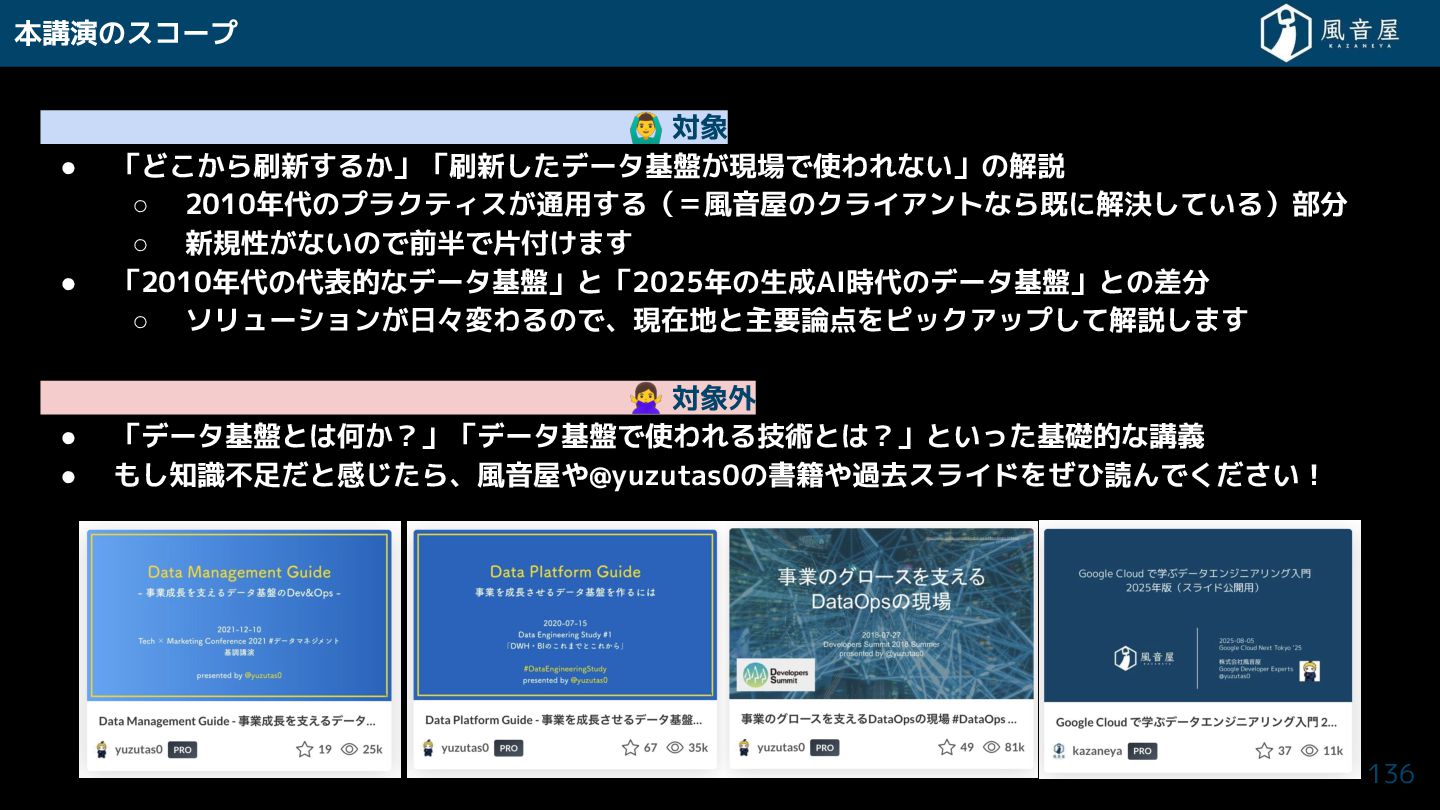
本講演のスコープ 対象 • 「ど ら刷新 る 」「刷新 データ基盤 現場で使われない」の解説
◦ 2010年代のプラクティス 通用 る(=風音屋のクライアントなら既に解決 ている)部分 ◦ 新規性 ないので前半で片付 ま • 「2010年代の代表的なデータ基盤」と「2025年の生成AI時代のデータ基盤」との差分 ◦ ソリューション 日々変わるので、現在地と主要論点をピックアップ て解説 ま 対象外 • 「データ基盤とは何 ?」「データ基盤で使われる技術とは?」といっ 基礎的な講義 • も 知識不足 と感 ら、風音屋や@yuzutas0の書籍や過去スライドを ひ読んで い! 19
ま ソリューション 揃っていない点に注意 20
本日のタイムスケジュール 開始目安 所要時間 アジェンダ ① 13:00 3分 は めに ②
13:03 3分 自己紹介 ③ 13:06 3分 データ活用の事例 ④ 13:09 3分 レガシーなプラットフォームを刷新 ようにもど ら着手 べ 【既知】 ⑤ 13:12 3分 実際に刷新 ても保守運用 うま 回ら 使い物にならない問題【既知】 ⇒「 も もニーズを満 ているの 」編 ⑥ 13:15 3分 ⇒「 も もマジメに運用保守を ているの 」編 ⑦ 13:18 3分 「横断的なデータ基盤」と「個々のAIツール」の関係性は? ⑧ 13:21 3分 データ収集(狭義のETL処理)のアーキテクチャは生成AIで変わる ? ⑨ 13:24 3分 データ加工のアーキテクチャは生成AIで変わる ?(特に非構造化データ) ⑩ 13:27 3分 メタデータ管理のアーキテクチャは生成AIで変わる ? ⑪ 13:30 3分 開発・運用プロセスを支える めのアーキテクチャは生成AIで変わる ? ⑫ 13:33 3分 「業務システム」と「データ基盤」の関係性は生成AIで変わる ? ⑬ 13:36 3分 わりに 21
2. 自己紹介
登壇者(カジュアル版) ゆ (@yuzutas0) リクルートやメルカリでデータ活用を推進後、AWSを経て、風音屋( ねや)を創業。 独立行政法人情報処理推進機構(IPA)にて情報処理技術者試験委員を兼任。 データ基盤やダッシュボードの構築について積極的に情報発信 て り、主な著書・訳書に『実践的データ 基盤への処方箋』『データマネジメント
30分でわ る本』『アジャイルデータモデリング』 ある。 1,800人 参加 るSlackコミュニティ datatech-jp、延べ参加者15,640人の勉強会 Data Engineering Study の立 上 に関わるなど、日本のデータエンジニアリング業界の発展をリード て 。 23 Now Writing…
登壇者(詳細版) 横山 翔(@yuzutas0) • リクルートやメルカリにてデータ活用を推進 後、AWSを経て独立 、株式会社風音屋を創業 • 広告配信の最適化、店舗営業のインセンティブ改善など、データ分析によって数億円規模のインパクトを創出 •
独立行政法人情報処理推進機構(IPA)にて情報処理技術者試験委員を兼任(2025〜) • 東京大学 経済学研究科 金融教育研究センター 特任研究員を兼任(2023〜2025) 主な登壇・発表 • Pythonのカンファレンス「PyCon JP 2017」にてベストトークアワード優秀賞 • 翔泳社主催「Developers Summit 2018 Summer」にてベストスピーカー賞 • Google主催「Google Cloud Day」(‘21, ‘23),「Google Cloud Next Tokyo」(‘23, ‘25) • 日本統計学会 第16回春季集会 主な執筆・翻訳・出版 • 講談社サイエンティフィク『アジャイルデータモデリング』 • 技術評論社『実践的データ基盤への処方箋』 • 技術評論社『Software Design 2020年7月号 - ログ分析特集』『同 2025年7月号 - SQL特集』 • 風音屋『データマネジメント 30分でわ る本』 • 内閣府「経済分析 第208号 - 景気動向分析の新 な潮流」 主なコミュニティ活動 • Google 認定 る技術エキスパート「Google Cloud Champion Innovator / Google Developer Experts」に選出(2023〜) • 1,800人以上 参加 るSlackコミュニティ「datatech-jp」の立 上 ・運営 • 延べ参加者15,640人以上の勉強会「Data Engineering Study」の立 上 ・モデレーター(2020〜2025) • 国内最大規模の技術カンファレンス「Developers Summit」コンテンツ委員会(2022〜2026) 24
大手 らスタートアップまで幅広いクライアント企業のデータ活用を支援 るITコンサルティング企業。 100社のデータ経営を実現 、諸産業の活性化に貢献 る とをミッションと て掲 ていま 。
データエンジニア 技術相談やノウハウ共有 あう副業ギルドと て始まり、 日本全国 ら多数の 相談・ 要望を受 て法人化。 ステークホルダーの皆様に 協力い な ら、会社組織と てアジャイルに成長 て ま 。 スタートアップCEO らの推薦コメント 風音屋( ねや) 25 支援先(一部抜粋) • ランサーズ株式会社 • エイベックス株式会社 • 株式会社クラシコム • 株式会社商船三井 • 株式会社ビズリーチ • NE株式会社 • 株式会社リクルート • 福岡地所株式会社 • 住友化学株式会社
データエンジニア&ITコンサルタントを募集中! 26
データエンジニアリングの書籍 読み放題で ! 風音屋オフィス(Library) 27
風音屋 提供 るサービス 28 データ基盤構築 データ分析
「Excelで学ぶデータマネジメント入門」研修 & 風音屋データマネジメント検定 29 【研修実績】 • 全社研修:500名の社員にデータマネジメントの全体像と勘所をインプット • 新入社員研修:ゼミのレポートを題材と て、データ管理の
Do’s & Don’ts を学習 • IT部門研修:データ基盤の実践的なシステム構成例、開発・運用プロセスまで踏み込んで 紹介 【ポイント①】Excelファイルに例えな らデータマネジメントの作法を解説 • 「Excelファイルで◯◯を工夫 るのと同 ように、本格的なITシステムでは〜」フォーマットで説明 • 業務部門とIT部門 スムーズに連携で るように知識の橋渡 を行う 【ポイント②】理解度チェックテスト(風音屋データマネジメント検定)を活用 柔軟な研修デザイン • 講義の前と後にテスト → 研修による学習効果を計測・評価 • 分割講義で都度テスト → 講義内容の理解をサポート • 満点獲得まで繰り返 → 講義内容の理解を徹底強制 、セキュリティテストと同 位置付 に • 講義の後に単発テスト → 組織アセスメントや人事評価、配属検討に利用可能
採用文脈でオンライン講座を提供 30
累計260ページ・18万文字の超豪華な研修教材を読み、データ基盤構築のハンズオンを行いま 。 データ基盤構築のインプット&ハンズオン 31
データエンジニアへの転職は無理なの !? 32
本日のタイムスケジュール 開始目安 所要時間 アジェンダ ① 13:00 3分 は めに ②
13:03 3分 自己紹介 ③ 13:06 3分 データ活用の事例 ④ 13:09 3分 レガシーなプラットフォームを刷新 ようにもど ら着手 べ 【既知】 ⑤ 13:12 3分 実際に刷新 ても保守運用 うま 回ら 使い物にならない問題【既知】 ⇒「 も もニーズを満 ているの 」編 ⑥ 13:15 3分 ⇒「 も もマジメに運用保守を ているの 」編 ⑦ 13:18 3分 「横断的なデータ基盤」と「個々のAIツール」の関係性は? ⑧ 13:21 3分 データ収集(狭義のETL処理)のアーキテクチャは生成AIで変わる ? ⑨ 13:24 3分 データ加工のアーキテクチャは生成AIで変わる ?(特に非構造化データ) ⑩ 13:27 3分 メタデータ管理のアーキテクチャは生成AIで変わる ? ⑪ 13:30 3分 開発・運用プロセスを支える めのアーキテクチャは生成AIで変わる ? ⑫ 13:33 3分 「業務システム」と「データ基盤」の関係性は生成AIで変わる ? ⑬ 13:36 3分 わりに 33
3. データ活用の事例
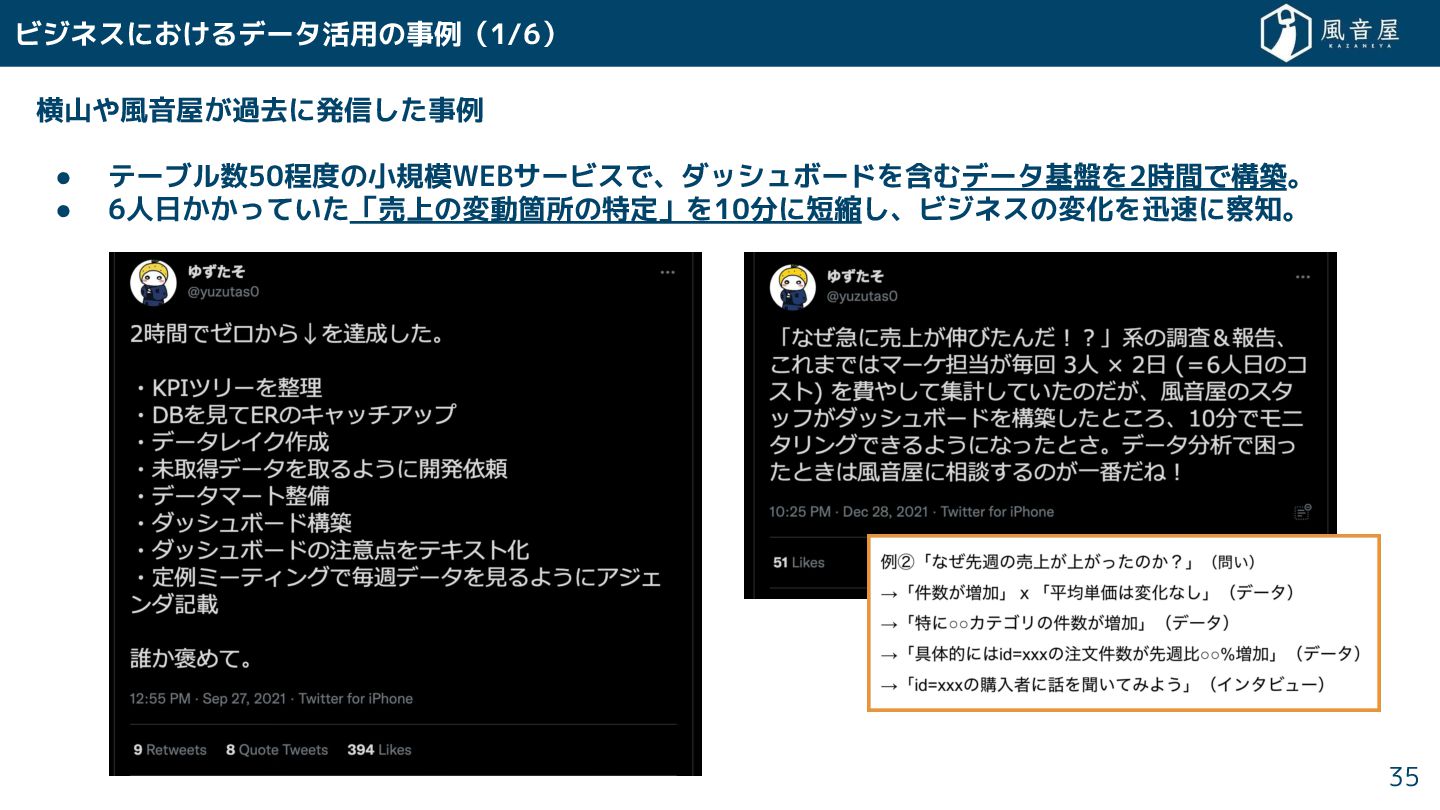
横山や風音屋 過去に発信 事例 • テーブル数50程度の小規模WEBサービスで、ダッシュボードを含むデータ基盤を2時間で構築。 • 6人日 ってい 「売上の変動箇所の特定」を10分に短縮 、ビジネスの変化を迅速に察知。
ビジネスに るデータ活用の事例(1/6) 35
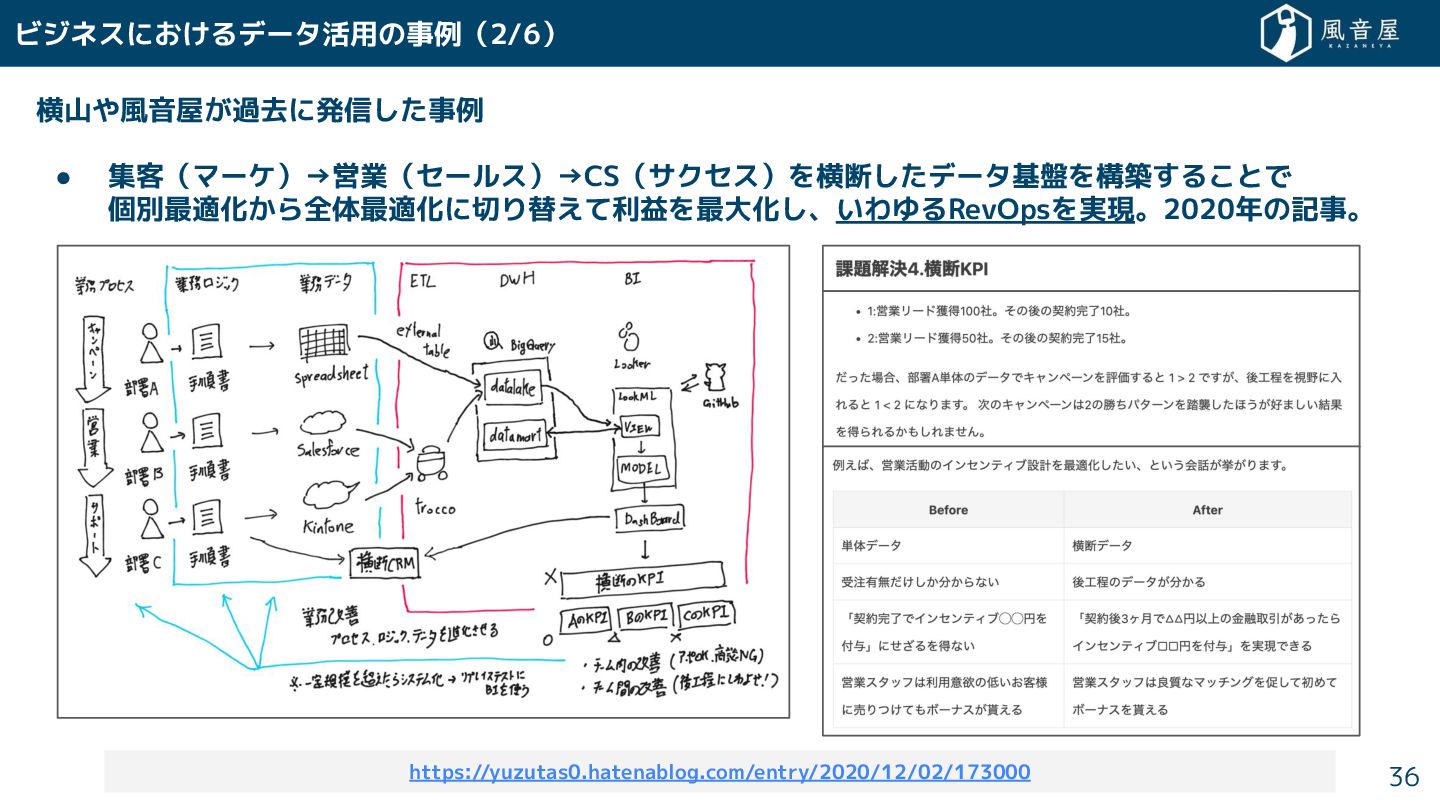
横山や風音屋 過去に発信 事例 • 集客(マーケ)→営業(セールス)→CS(サクセス)を横断 データ基盤を構築 る とで 個別最適化 ら全体最適化に切り替えて利益を最大化
、いわゆるRevOpsを実現。2020年の記事。 ビジネスに るデータ活用の事例(2/6) 36 https://yuzutas0.hatenablog.com/entry/2020/12/02/173000
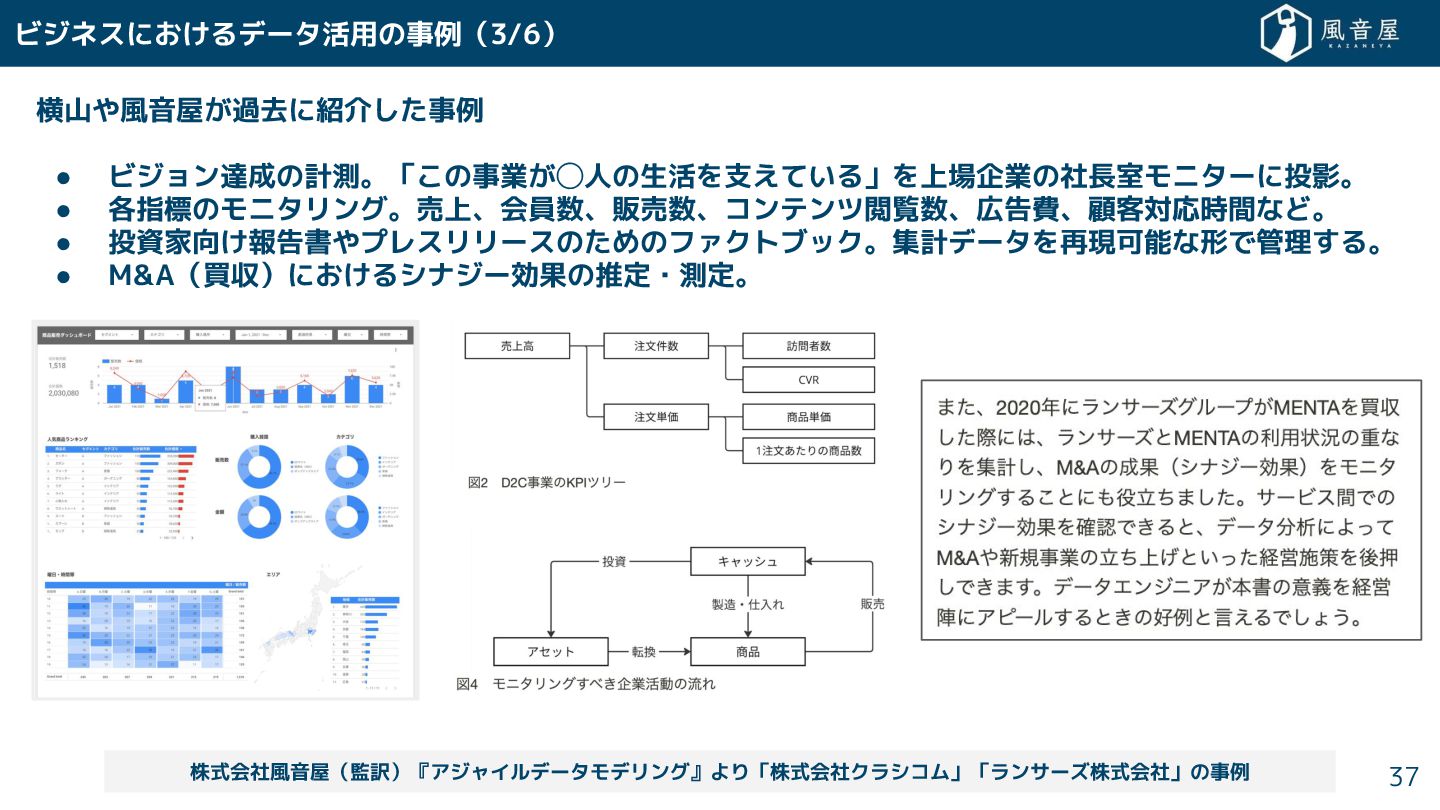
横山や風音屋 過去に紹介 事例 • ビジョン達成の計測。「 の事業 ◯人の生活を支えている」を上場企業の社長室モニターに投影。 • 各指標のモニタリング。売上、会員数、販売数、コンテンツ閲覧数、広告費、顧客対応時間など。 •
投資家向 報告書やプレスリリースの めのファクトブック。集計データを再現可能な形で管理 る。 • M&A(買収)に るシナジー効果の推定・測定。 ビジネスに るデータ活用の事例(3/6) 株式会社風音屋(監訳)『アジャイルデータモデリング』より「株式会社クラシコム」「ランサーズ株式会社」の事例 37
横山や風音屋 過去に紹介 事例 • 顧客セグメントや商品ジャンル別の傾向分析。ロイヤル顧客の特徴やリピート商品を特定 る。 • キャンペーン施策の効果測定。 の後のリピートに繋 っ
、需要の先食いは起 ていない 。 • エンタテイメント領域に るコンテンツ企画。視聴数 多い曜日・時間帯 ら分析。 • 工場に る製造プロセス改善や機械の故障検知。 ビジネスに るデータ活用の事例(4/6) 株式会社風音屋(監訳)『アジャイルデータモデリング』より「住友化学株式会社」の事例 38
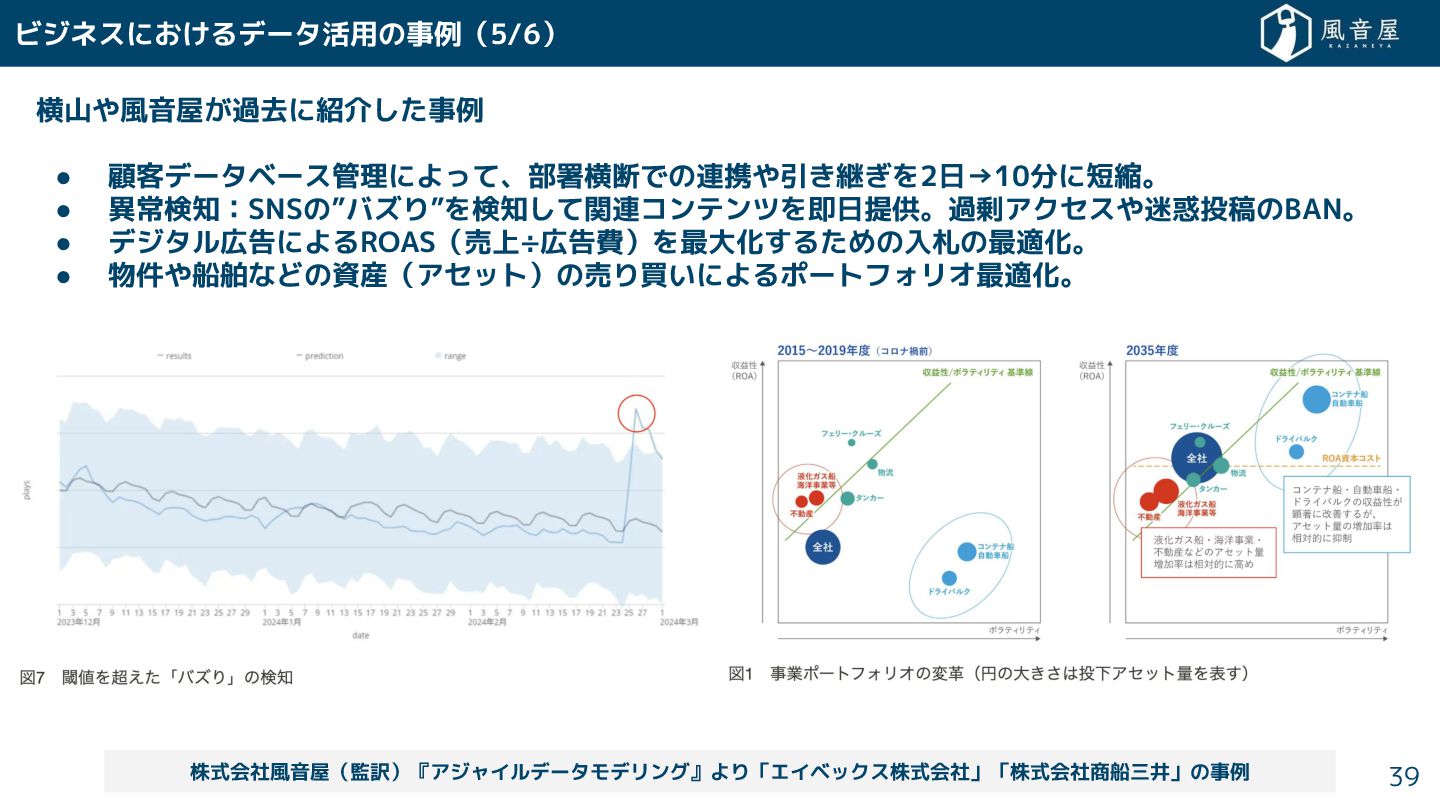
横山や風音屋 過去に紹介 事例 • 顧客データベース管理によって、部署横断での連携や引 継 を2日→10分に短縮。 • 異常検知:SNSの”バズり”を検知 て関連コンテンツを即日提供。過剰アクセスや迷惑投稿のBAN。
• デジタル広告によるROAS(売上÷広告費)を最大化 る めの入札の最適化。 • 物件や船舶などの資産(アセット)の売り買いによるポートフォリオ最適化。 ビジネスに るデータ活用の事例(5/6) 株式会社風音屋(監訳)『アジャイルデータモデリング』より「エイベックス株式会社」「株式会社商船三井」の事例 39
横山や風音屋 過去に紹介 事例 • レコメンド:類似商品の推薦、クリック率を最大化 る表示順、マッチング期待値 高い人材の紹介。 • 経路探索:自動車ドライバーや月面探査機のルート最適化。 •
動産(アート)や不動産(物件)など交渉で価格 決まる「1点モノ」のプライシング(値付 )。 • 従量課金やレベニューシェア、ダイナミックプライシングによる、取引単価の最大化。 ビジネスに るデータ活用の事例(6/6) 事業のグロースを支えるDataOpsの現場 https://speakerdeck.com/yuzutas0/20180727 40
本日のタイムスケジュール 開始目安 所要時間 アジェンダ ① 13:00 3分 は めに ②
13:03 3分 自己紹介 ③ 13:06 3分 データ活用の事例 ④ 13:09 3分 レガシーなプラットフォームを刷新 ようにもど ら着手 べ 【既知】 ⑤ 13:12 3分 実際に刷新 ても保守運用 うま 回ら 使い物にならない問題【既知】 ⇒「 も もニーズを満 ているの 」編 ⑥ 13:15 3分 ⇒「 も もマジメに運用保守を ているの 」編 ⑦ 13:18 3分 「横断的なデータ基盤」と「個々のAIツール」の関係性は? ⑧ 13:21 3分 データ収集(狭義のETL処理)のアーキテクチャは生成AIで変わる ? ⑨ 13:24 3分 データ加工のアーキテクチャは生成AIで変わる ?(特に非構造化データ) ⑩ 13:27 3分 メタデータ管理のアーキテクチャは生成AIで変わる ? ⑪ 13:30 3分 開発・運用プロセスを支える めのアーキテクチャは生成AIで変わる ? ⑫ 13:33 3分 「業務システム」と「データ基盤」の関係性は生成AIで変わる ? ⑬ 13:36 3分 わりに 41
本講演のスコープ 対象 • 「ど ら刷新 る 」「刷新 データ基盤 現場で使われない」の解説
◦ 2010年代のプラクティス 通用 る(=風音屋のクライアントなら既に解決 ている)部分 ◦ 新規性 ないので前半で片付 ま • 「2010年代の代表的なデータ基盤」と「2025年の生成AI時代のデータ基盤」との差分 ◦ ソリューション 日々変わるので、現在地と主要論点をピックアップ て解説 ま 対象外 • 「データ基盤とは何 ?」「データ基盤で使われる技術とは?」といっ 基礎的な講義 • も 知識不足 と感 ら、風音屋や@yuzutas0の書籍や過去スライドを ひ読んで い! 42
4. レガシーなプラットフォームを刷新 ようにもど ら着手 べ 【既知】
システム刷新のアプローチ(2016年書籍より) 44 レガシーなITシステム(特にソフトウェア)とは何 “保守ま は拡張 困難な既存のプロジェクトなら、 なんでも「レガシー」(legacy)と呼ぶ とに ている” レガシーなシステムに対
るアプローチ 1. リファクタリング ◦ 振る舞いを変え に中身を変える ◦ テスト自動化による振る舞いの担保 重要 2. リアーキテクティング ◦ モジュールやコンポーネントの構成を変える 3. ビッグ・リライト ◦ 年単位のプロジェクトでゼロ ら作り直 ◦ 一般的に非推奨と れる ⇒AsIs(現状)の仕様を可視化・整理 て、テストを自動化 、少 つ置 換えてい と 望ま い。 ⇒再構築PJTの最中にSnowflake 新機能を提供 、再構築 完了 頃には構成 時代遅れになっ 例。 『レガシーソフトウェア改善ガイド』
「システム刷新」を日常的に行う(2016年書籍より) 45 ボーイスカウトの原則 “ボーイスカウトには、シンプルな規則 ありま 。 「自分のい 場所は、 を出て行 時、
来 時よりも れいに な ればならない」という規則で 。 とえ、自分 来 時には既にキャンプ場 汚 っ と ても、 とえ、汚 の 自分ではな っ と ても、 れいに て ら の場を去るので 。” ど ら刷新 る ? いつ刷新 る ? • システムに変更を加える前に、該当箇所をキレイに る (= 飯を食べる前に机を片付 る) • システムに変更を加え 後に、該当箇所をキレイに る (= 飯を食べ終わっ ら机を拭 ) 『プリンシプル・オブ・プログラミング』
重点箇所をデータで分析 る(2018年の資料 by @yuzutas0) 46 「問い合わ 多い事象」「データ利用の多い部署」「利用頻度の多いデータ」「ボトルネックの処理」 などの重点領域を計測 て、優先的に刷新 る。データ利用を促
立場 率先 てデータで意思決定 る。
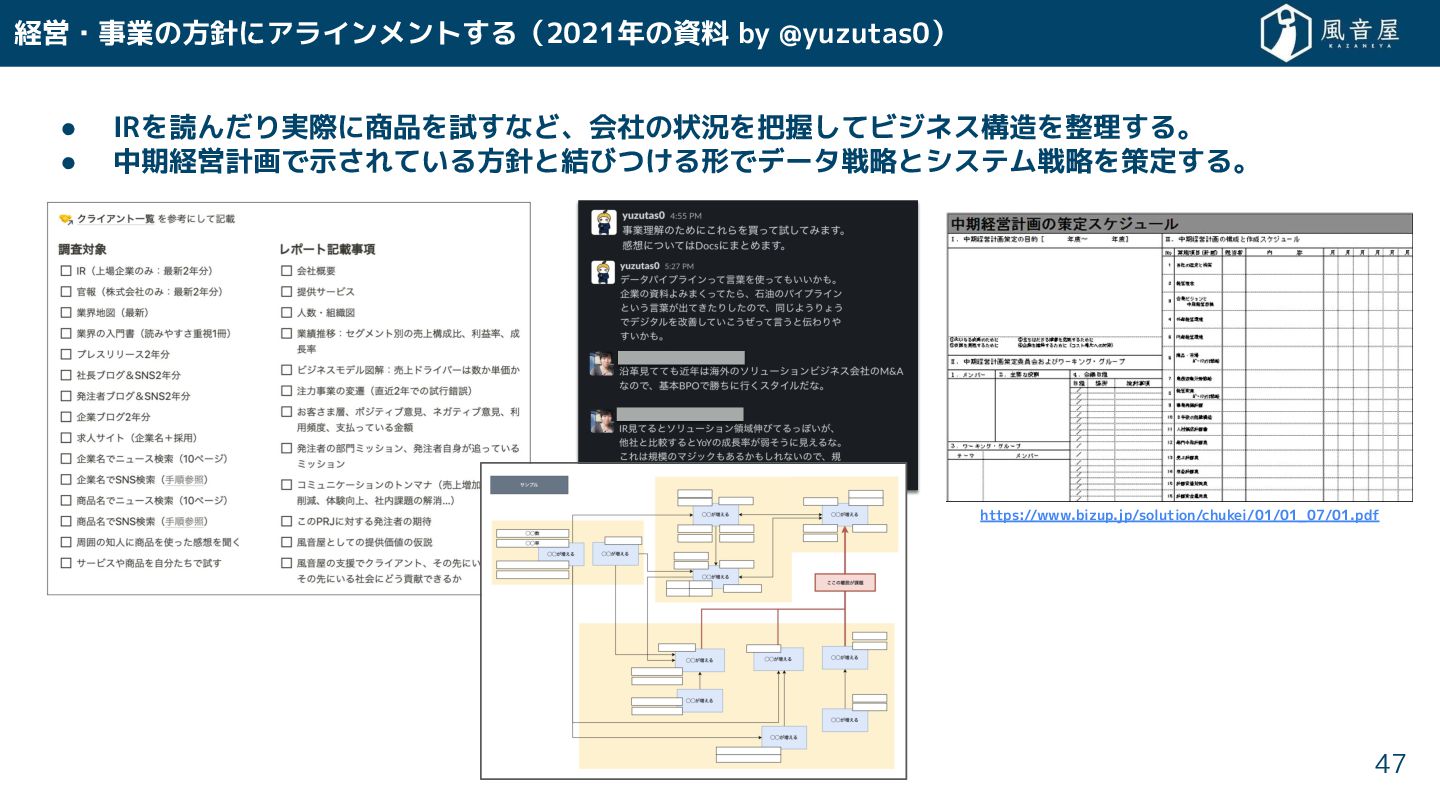
経営・事業の方針にアラインメント る(2021年の資料 by @yuzutas0) 47 • IRを読ん り実際に商品を試 など、会社の状況を把握 てビジネス構造を整理
る。 • 中期経営計画で示 れている方針と結びつ る形でデータ戦略とシステム戦略を策定 る。 https://www.bizup.jp/solution/chukei/01/01_07/01.pdf
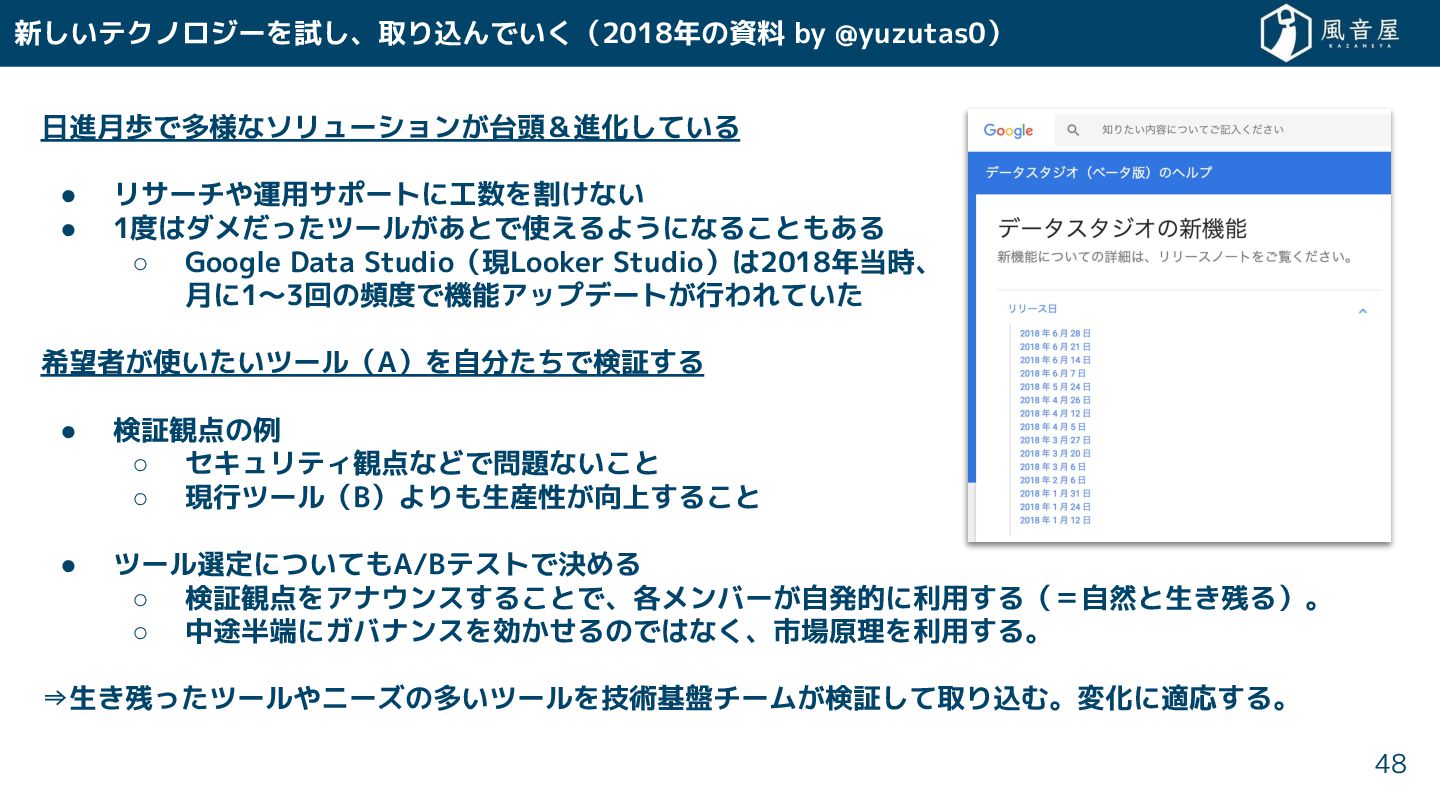
新 いテクノロジーを試 、取り込んでい (2018年の資料 by @yuzutas0) 48 日進月歩で多様なソリューション 台頭&進化 ている
• リサーチや運用サポートに工数を割 ない • 1度はダメ っ ツール あとで使えるようになる ともある ◦ Google Data Studio(現Looker Studio)は2018年当時、 月に1〜3回の頻度で機能アップデート 行われてい 希望者 使い いツール(A)を自分 で検証 る • 検証観点の例 ◦ セキュリティ観点などで問題ない と ◦ 現行ツール(B)よりも生産性 向上 る と • ツール選定についてもA/Bテストで決める ◦ 検証観点をアナウンス る とで、各メンバー 自発的に利用 る(=自然と生 残る)。 ◦ 中途半端にガバナンスを効 るのではな 、市場原理を利用 る。 ⇒生 残っ ツールやニーズの多いツールを技術基盤チーム 検証 て取り込む。変化に適応 る。
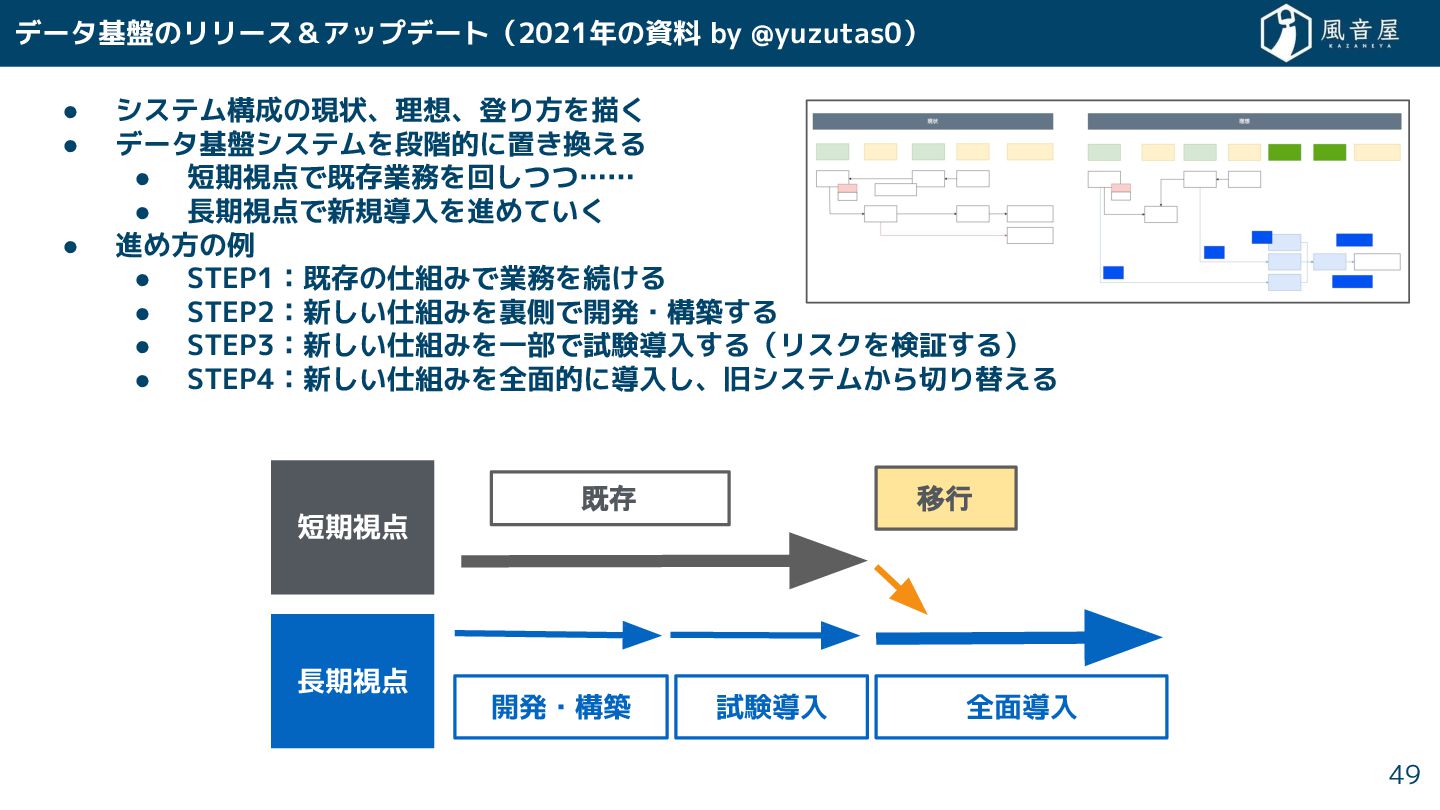
• システム構成の現状、理想、登り方を描 • データ基盤システムを段階的に置 換える • 短期視点で既存業務を回 つつ…… • 長期視点で新規導入を進めてい
• 進め方の例 • STEP1:既存の仕組みで業務を続 る • STEP2:新 い仕組みを裏側で開発・構築 る • STEP3:新 い仕組みを一部で試験導入 る(リスクを検証 る) • STEP4:新 い仕組みを全面的に導入 、旧システム ら切り替える データ基盤のリリース&アップデート(2021年の資料 by @yuzutas0) 49 短期視点 長期視点 既存 移行 開発・構築 試験導入 全面導入
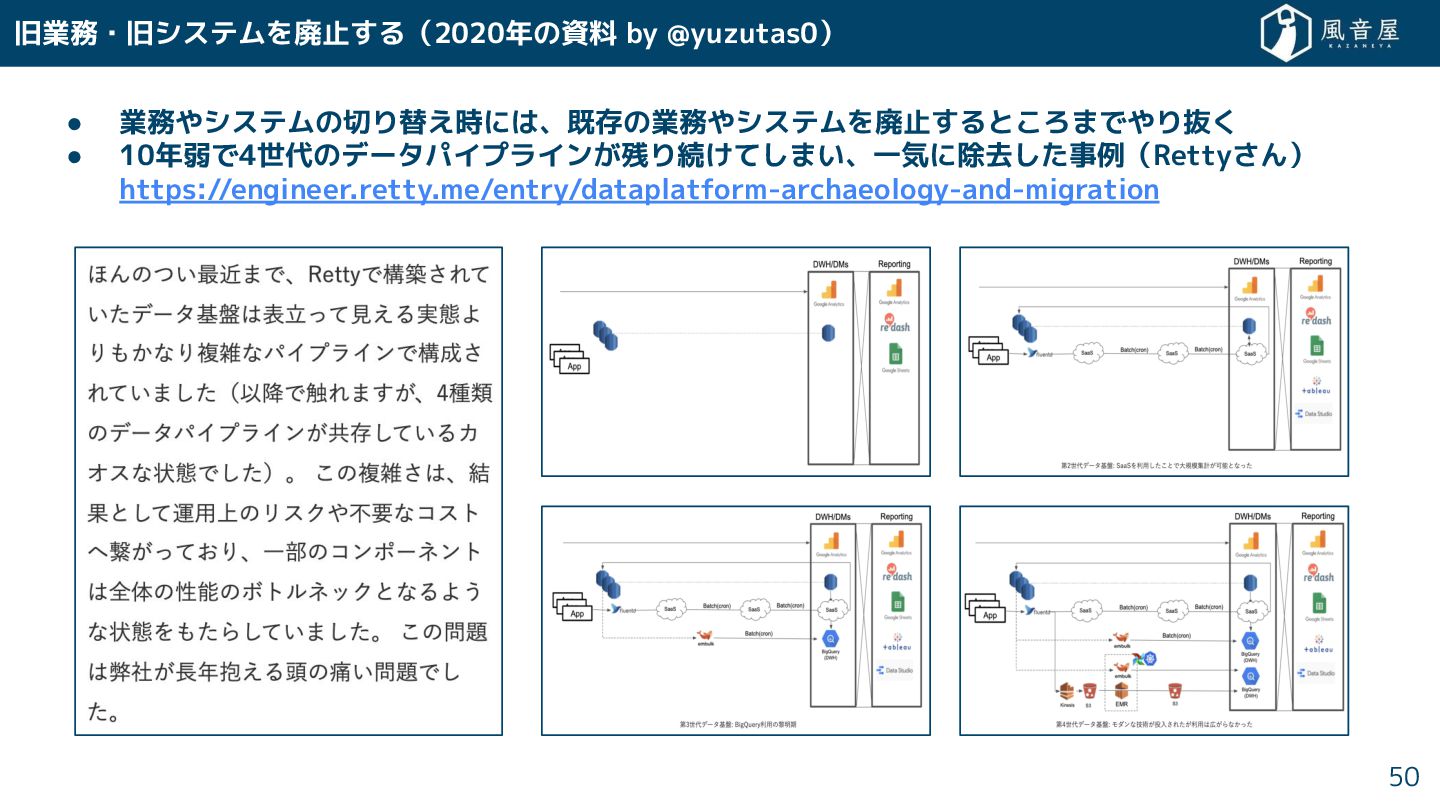
旧業務・旧システムを廃止 る(2020年の資料 by @yuzutas0) 50 • 業務やシステムの切り替え時には、既存の業務やシステムを廃止 ると ろまでやり抜 •
10年弱で4世代のデータパイプライン 残り続 て まい、一気に除去 事例(Retty ん) https://engineer.retty.me/entry/dataplatform-archaeology-and-migration
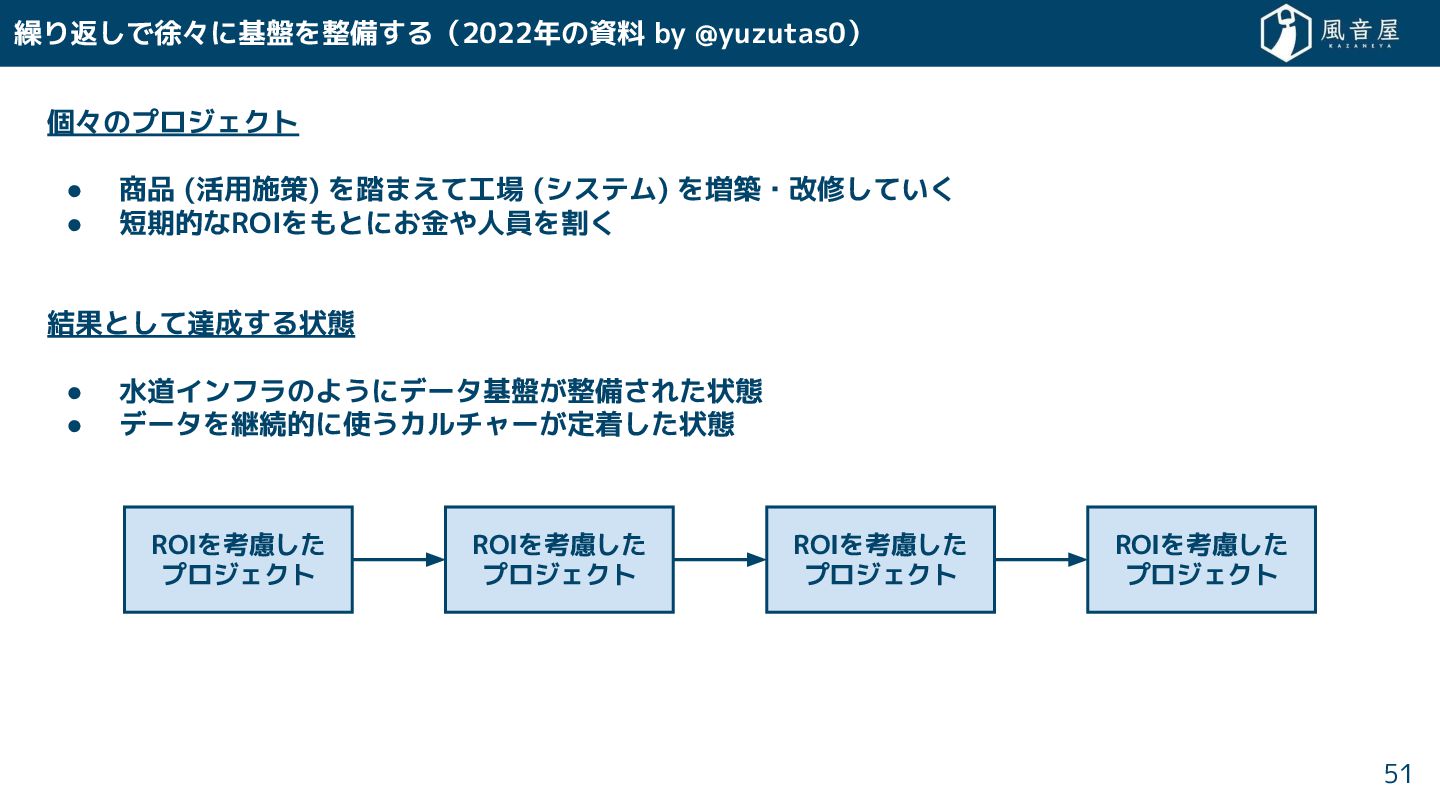
繰り返 で徐々に基盤を整備 る(2022年の資料 by @yuzutas0) 個々のプロジェクト • 商品 (活用施策) を踏まえて工場
(システム) を増築・改修 てい • 短期的なROIをもとに 金や人員を割 結果と て達成 る状態 • 水道インフラのようにデータ基盤 整備 れ 状態 • データを継続的に使うカルチャー 定着 状態 51 ROIを考慮 プロジェクト ROIを考慮 プロジェクト ROIを考慮 プロジェクト ROIを考慮 プロジェクト
本日のタイムスケジュール 開始目安 所要時間 アジェンダ ① 13:00 3分 は めに ②
13:03 3分 自己紹介 ③ 13:06 3分 データ活用の事例 ④ 13:09 3分 レガシーなプラットフォームを刷新 ようにもど ら着手 べ 【既知】 ⑤ 13:12 3分 実際に刷新 ても保守運用 うま 回ら 使い物にならない問題【既知】 ⇒「 も もニーズを満 ているの 」編 ⑥ 13:15 3分 ⇒「 も もマジメに運用保守を ているの 」編 ⑦ 13:18 3分 「横断的なデータ基盤」と「個々のAIツール」の関係性は? ⑧ 13:21 3分 データ収集(狭義のETL処理)のアーキテクチャは生成AIで変わる ? ⑨ 13:24 3分 データ加工のアーキテクチャは生成AIで変わる ?(特に非構造化データ) ⑩ 13:27 3分 メタデータ管理のアーキテクチャは生成AIで変わる ? ⑪ 13:30 3分 開発・運用プロセスを支える めのアーキテクチャは生成AIで変わる ? ⑫ 13:33 3分 「業務システム」と「データ基盤」の関係性は生成AIで変わる ? ⑬ 13:36 3分 わりに 52
5. 実際に刷新 ても保守運用 うま 回ら 使い物にならない問題【既知】 ⇒「 も もニーズを満 ているの
」編
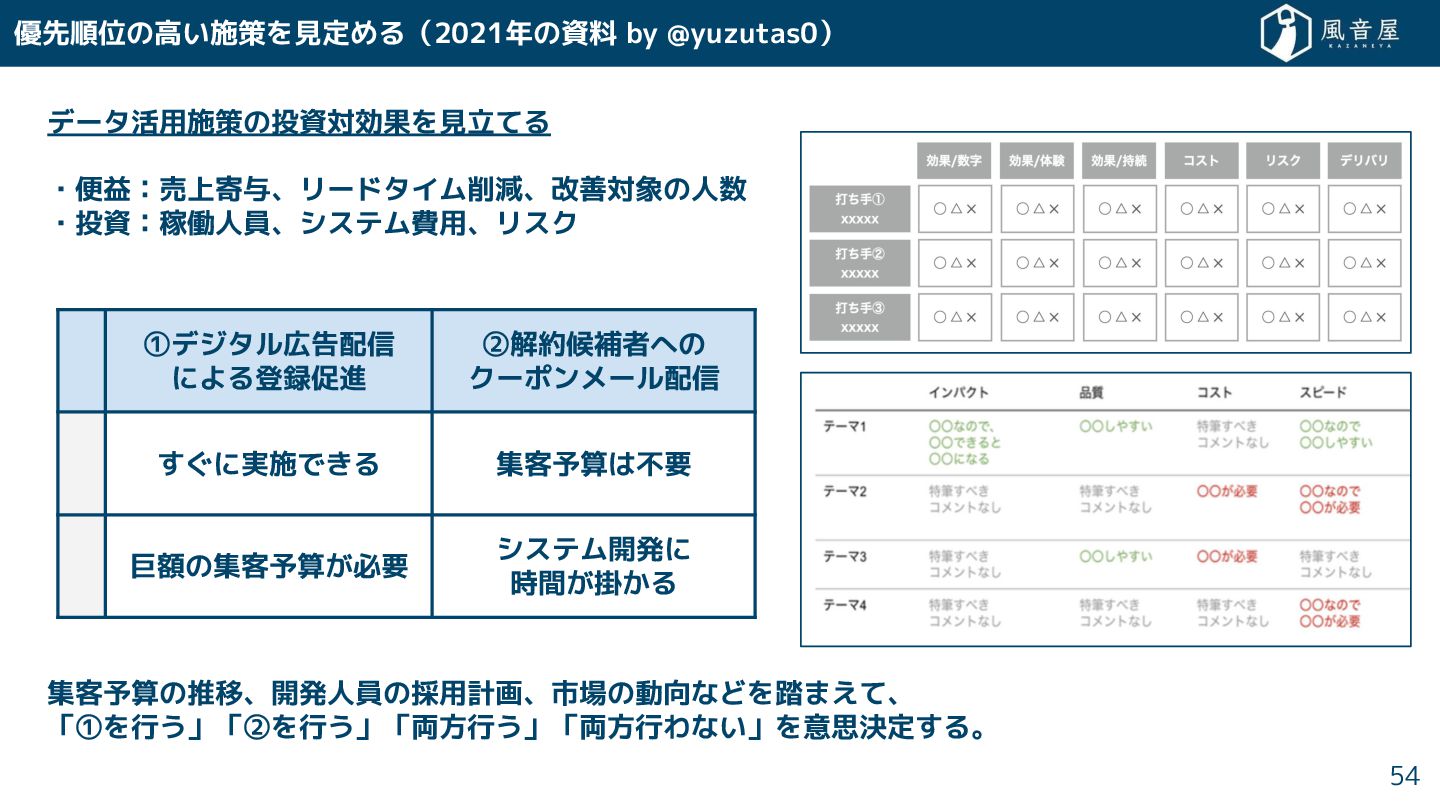
優先順位の高い施策を見定める(2021年の資料 by @yuzutas0) データ活用施策の投資対効果を見立てる ・便益:売上寄与、リードタイム削減、改善対象の人数 ・投資:稼働人員、システム費用、リスク 集客予算の推移、開発人員の採用計画、市場の動向などを踏まえて、 「①を行う」「②を行う」「両方行う」「両方行わない」を意思決定 る。 54
①デジタル広告配信 による登録促進 ②解約候補者への クーポンメール配信 に実施で る 集客予算は不要 巨額の集客予算 必要 システム開発に 時間 掛 る
データ活用施策の概要設計(2018年資料、2021年の資料 by @yuzutas0) 「どの顧客/従業員の」「どの作業/判断を」「どのように置 換える 」を書 出 • 消費者:カスタマージャーニーマップ、ジョブマップ •
事業者:バリューストリームマッピング、業務フロー図 顧客体験や業務フローをどのように改善 る ? (例) • 顧客:商品を探 → ( の手間を削減 る めに) 検索機能を作る • 経営企画部門:売上を集計 る → ( の手間を削減 る めに) 売上ダッシュボードを作る • 販促部門:クーポン配信対象を探 → ( の手間を削減 る めに) 配信システムを作る 55 https://webtan.impress.co.jp/e/2014/03/24/16722 http://gihyo.jp/dev/column/01/devops/2017/value-stream-mapping
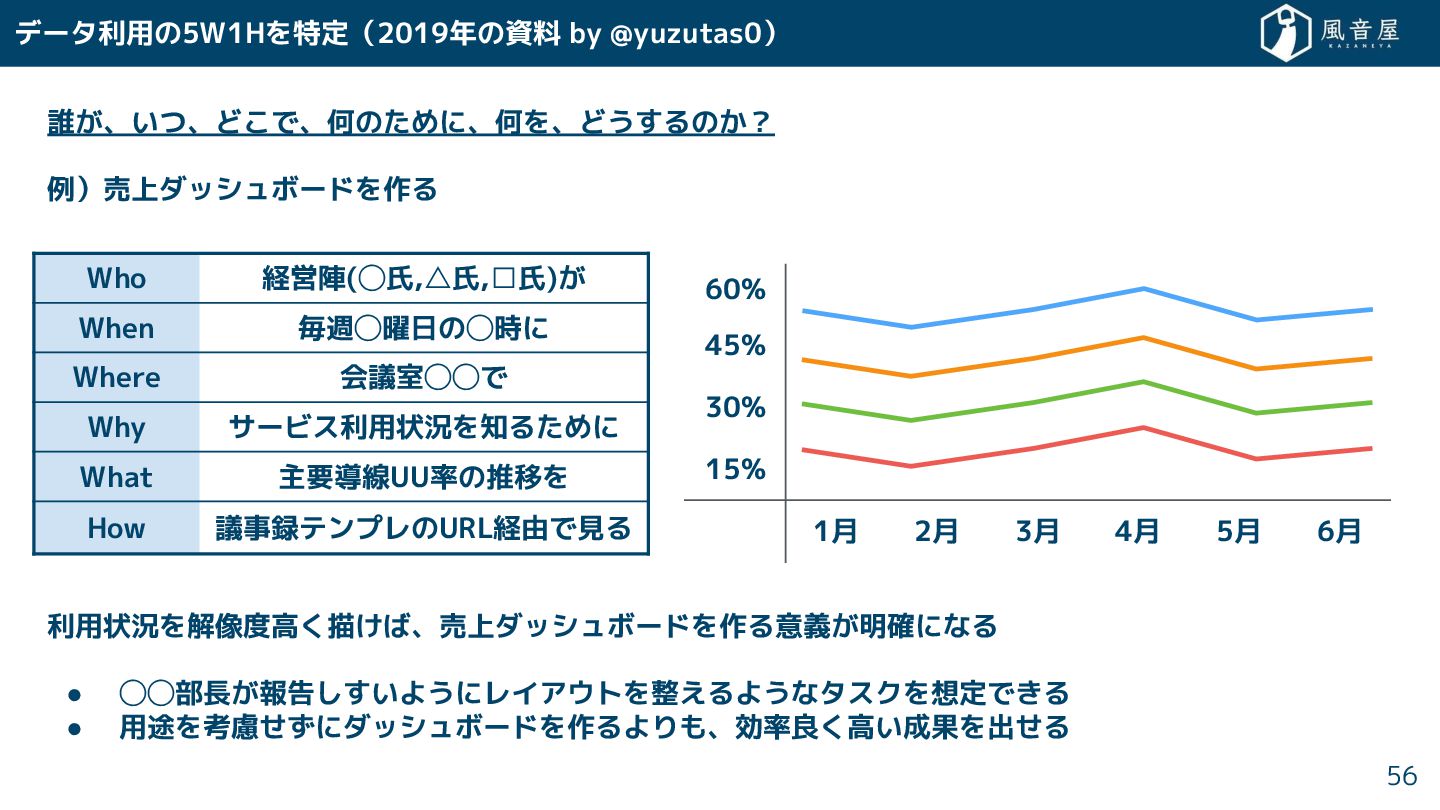
データ利用の5W1Hを特定(2019年の資料 by @yuzutas0) 誰 、いつ、ど で、何の めに、何を、どう るの ? 例)売上ダッシュボードを作る
利用状況を解像度高 描 ば、売上ダッシュボードを作る意義 明確になる • ◯◯部長 報告 いようにレイアウトを整えるようなタスクを想定で る • 用途を考慮 にダッシュボードを作るよりも、効率良 高い成果を出 る 56 60% 45% 30% 15% 1月 2月 3月 4月 5月 6月 Who 経営陣(◯氏,△氏,□氏) When 毎週◯曜日の◯時に Where 会議室◯◯で Why サービス利用状況を知る めに What 主要導線UU率の推移を How 議事録テンプレのURL経由で見る
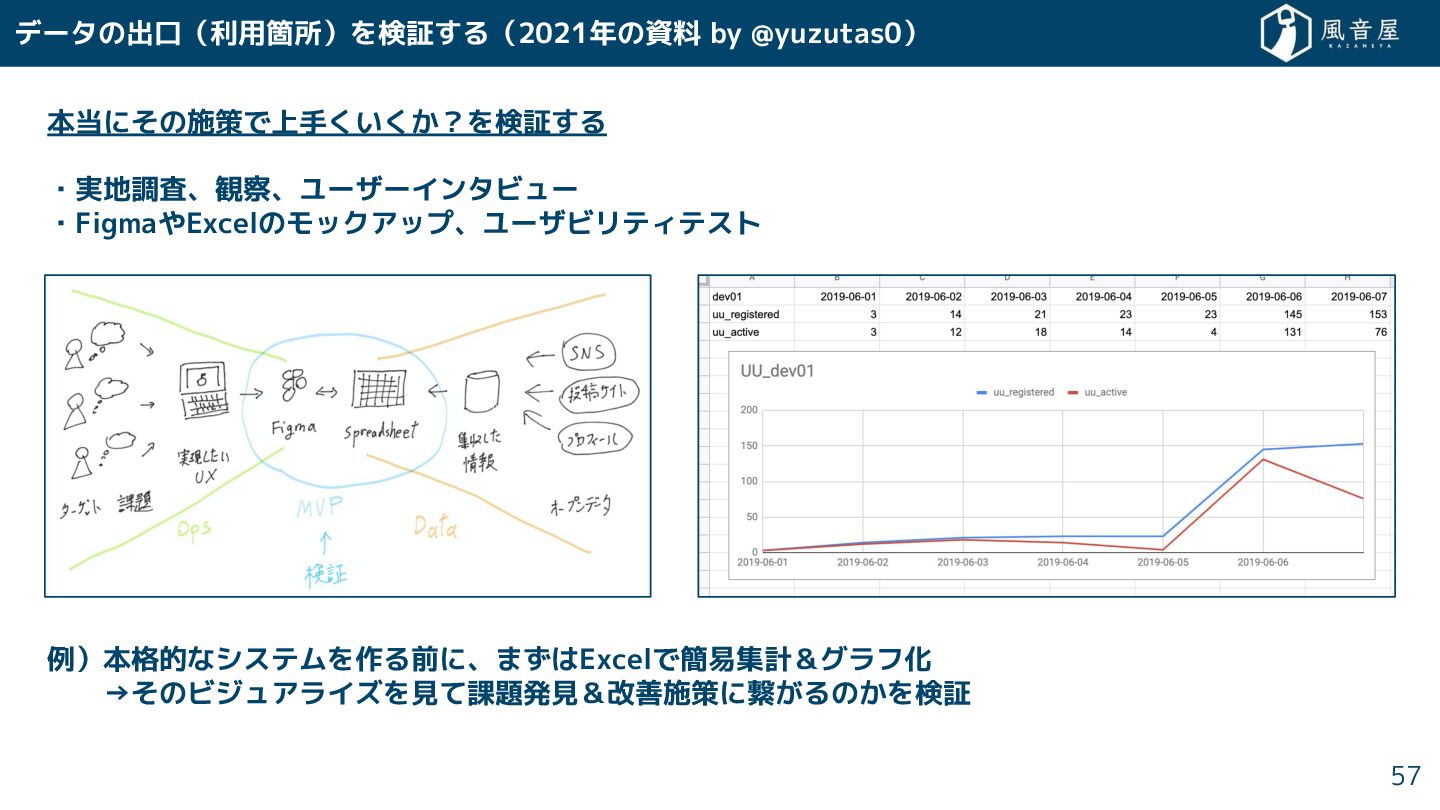
データの出口(利用箇所)を検証 る(2021年の資料 by @yuzutas0) 本当に の施策で上手 い ?を検証 る ・実地調査、観察、ユーザーインタビュー
・FigmaやExcelのモックアップ、ユーザビリティテスト 例)本格的なシステムを作る前に、ま はExcelで簡易集計&グラフ化 → のビジュアライズを見て課題発見&改善施策に繋 るの を検証 57
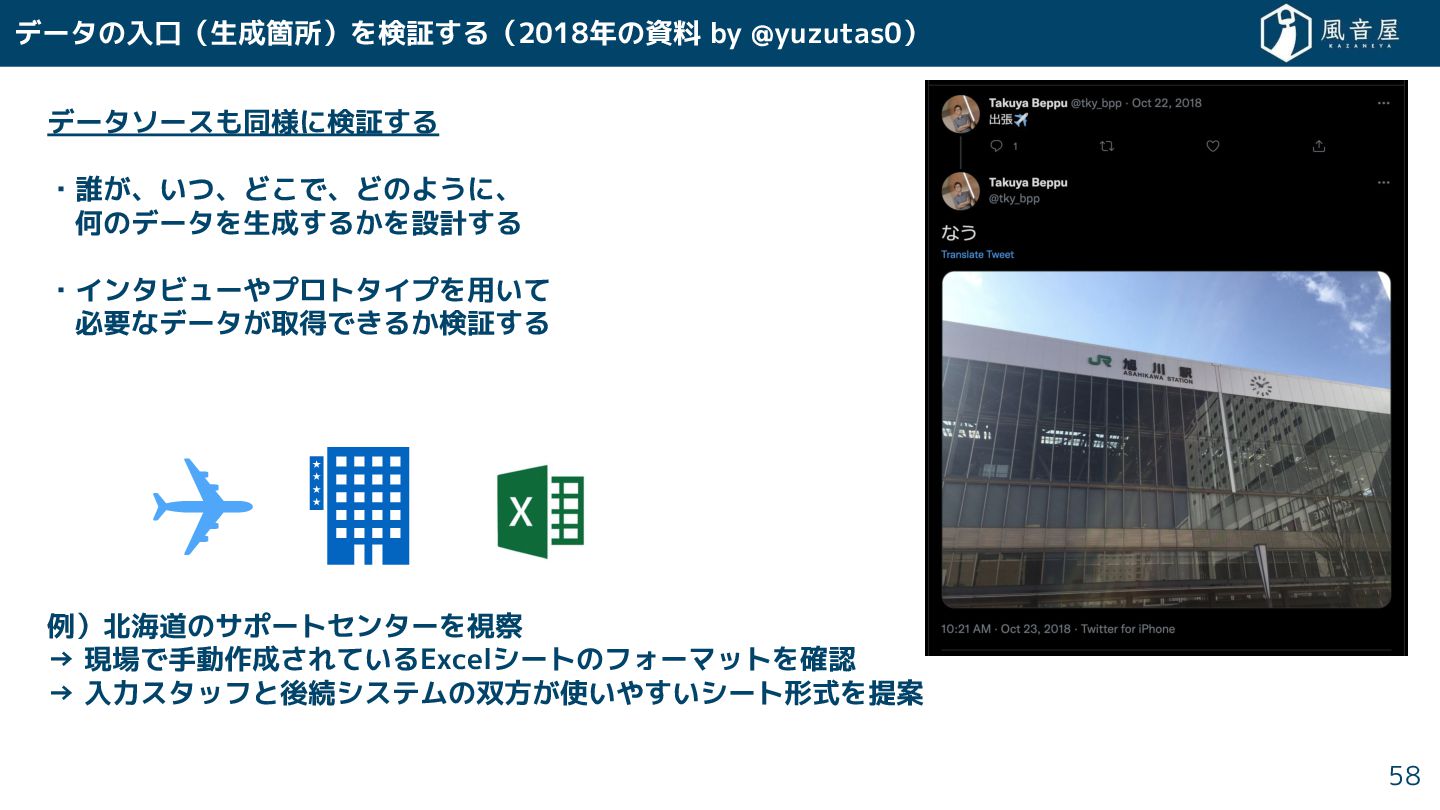
データの入口(生成箇所)を検証 る(2018年の資料 by @yuzutas0) データソースも同様に検証 る ・誰 、いつ、ど で、どのように、 何のデータを生成
る を設計 る ・インタビューやプロトタイプを用いて 必要なデータ 取得で る 検証 る 例)北海道のサポートセンターを視察 → 現場で手動作成 れているExcelシートのフォーマットを確認 → 入力スタッフと後続システムの双方 使いや いシート形式を提案 58
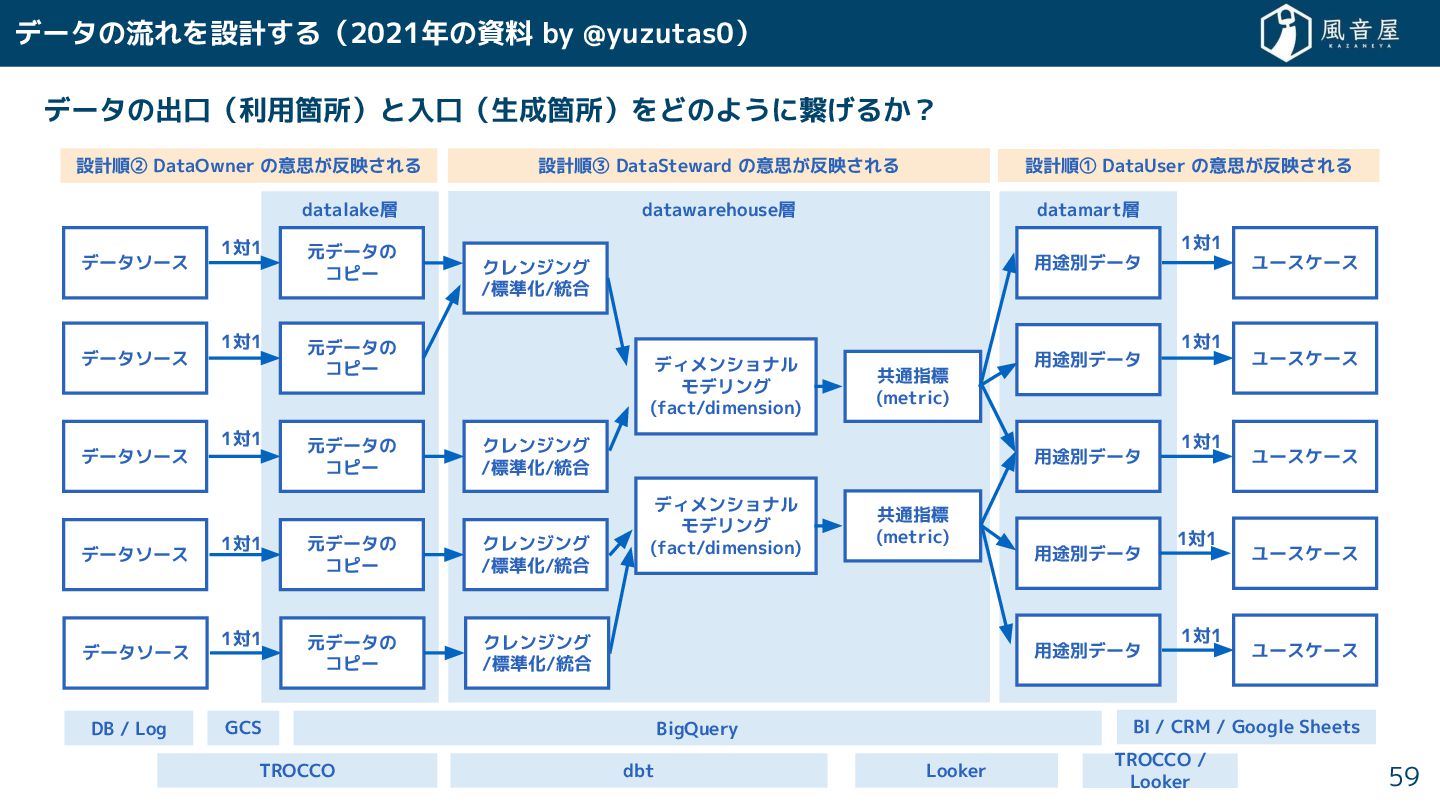
データの流れを設計 る(2021年の資料 by @yuzutas0) データの出口(利用箇所)と入口(生成箇所)をどのように繋 る ? 59 datamart層 datalake層
元データの コピー 元データの コピー 元データの コピー 用途別データ 用途別データ 用途別データ データソース データソース データソース ユースケース 元データの コピー データソース 元データの コピー データソース 用途別データ 用途別データ ユースケース ユースケース ユースケース ユースケース GCS BigQuery DB / Log TROCCO dbt Looker BI / CRM / Google Sheets TROCCO / Looker 設計順② DataOwner の意思 反映 れる 設計順① DataUser の意思 反映 れる 設計順③ DataSteward の意思 反映 れる 1対1 1対1 1対1 1対1 1対1 1対1 1対1 1対1 1対1 datawarehouse層 1対1 クレンジング /標準化/統合 クレンジング /標準化/統合 クレンジング /標準化/統合 ディメンショナル モデリング (fact/dimension) 共通指標 (metric) 共通指標 (metric) ディメンショナル モデリング (fact/dimension) クレンジング /標準化/統合
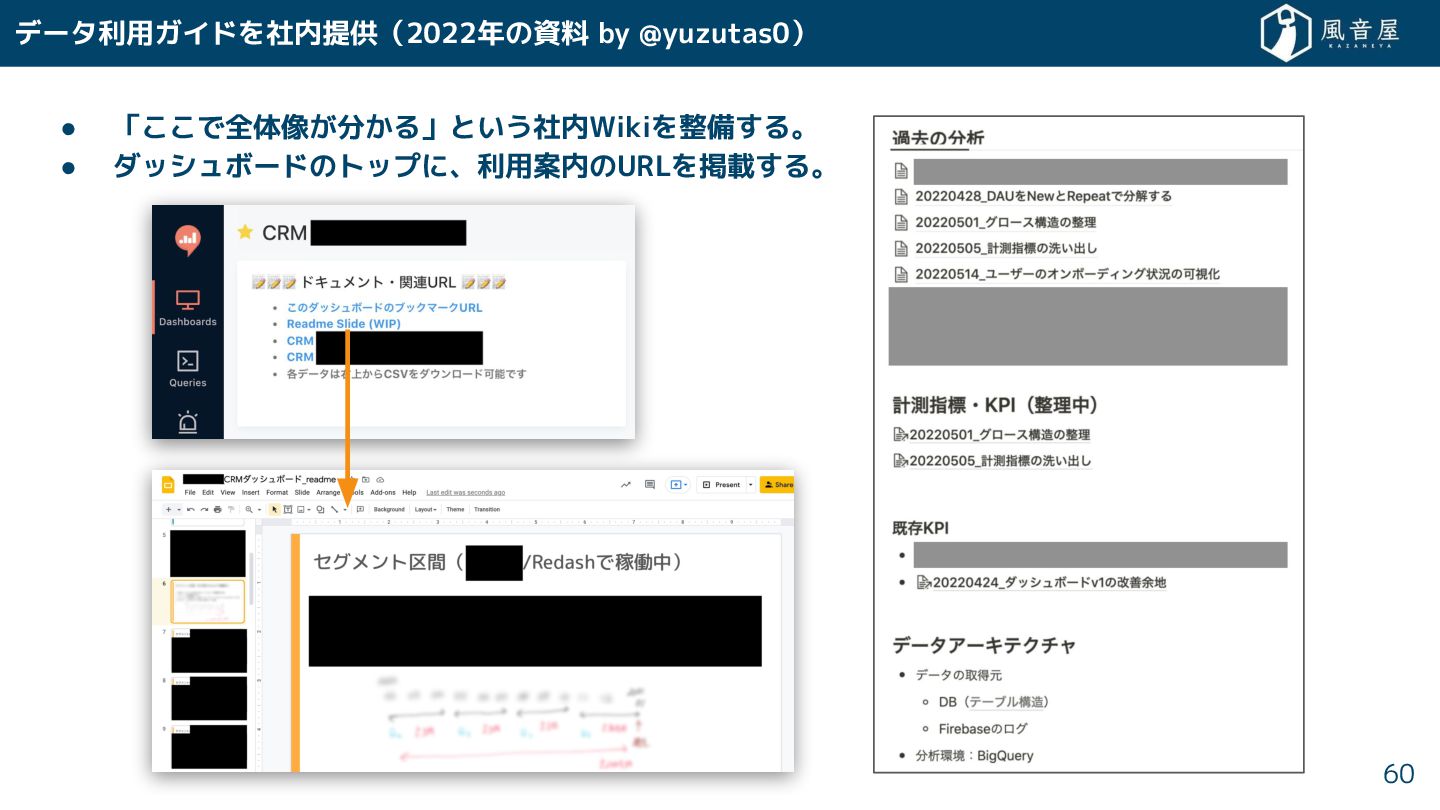
データ利用ガイドを社内提供(2022年の資料 by @yuzutas0) • 「 で全体像 分 る」という社内Wikiを整備 る。 •
ダッシュボードのトップに、利用案内のURLを掲載 る。 60
社内勉強会やハンズオン(2022年の資料 by @yuzutas0) • データ利用の流れを解説 り、実際に体験 てもらう場を設 る。 • 毎月の「相談会」で伴走
な ら分析レポートを作り、 のまま上司や経営陣、投資家に報告 る 流れになるとスムーズ。上司 ら「A案件はデータ相談会に持 もう」と声 掛 るようになる。 61
本日のタイムスケジュール 開始目安 所要時間 アジェンダ ① 13:00 3分 は めに ②
13:03 3分 自己紹介 ③ 13:06 3分 データ活用の事例 ④ 13:09 3分 レガシーなプラットフォームを刷新 ようにもど ら着手 べ 【既知】 ⑤ 13:12 3分 実際に刷新 ても保守運用 うま 回ら 使い物にならない問題【既知】 ⇒「 も もニーズを満 ているの 」編 ⑥ 13:15 3分 ⇒「 も もマジメに運用保守を ているの 」編 ⑦ 13:18 3分 「横断的なデータ基盤」と「個々のAIツール」の関係性は? ⑧ 13:21 3分 データ収集(狭義のETL処理)のアーキテクチャは生成AIで変わる ? ⑨ 13:24 3分 データ加工のアーキテクチャは生成AIで変わる ?(特に非構造化データ) ⑩ 13:27 3分 メタデータ管理のアーキテクチャは生成AIで変わる ? ⑪ 13:30 3分 開発・運用プロセスを支える めのアーキテクチャは生成AIで変わる ? ⑫ 13:33 3分 「業務システム」と「データ基盤」の関係性は生成AIで変わる ? ⑬ 13:36 3分 わりに 62
6. 実際に刷新 ても保守運用 うま 回ら 使い物にならない【既知】 ⇒「 も もマジメに運用保守を ているの
」編
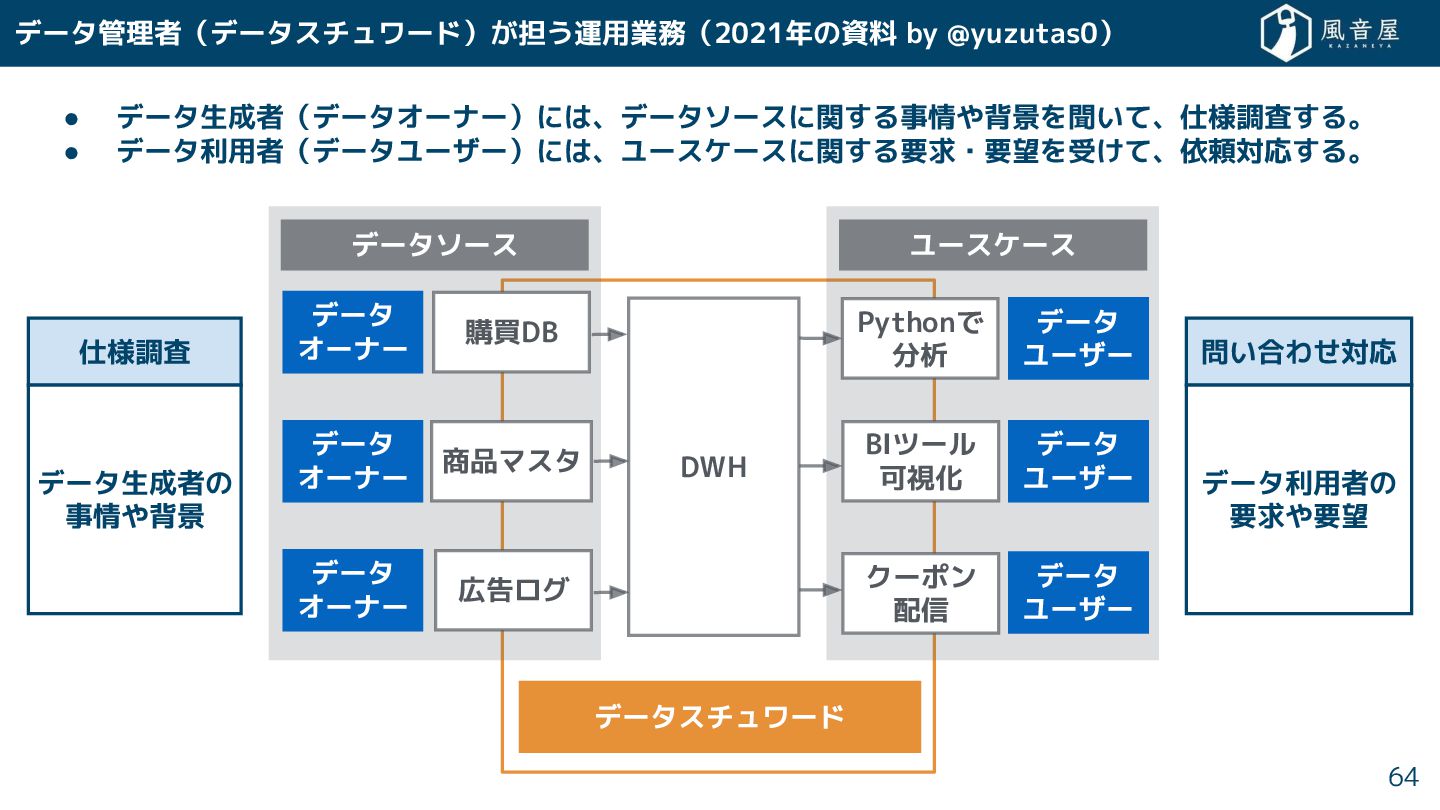
データ管理者(データスチュワード) 担う運用業務(2021年の資料 by @yuzutas0) 64 仕様調査 問い合わ 対応 データ利用者の 要求や要望
データスチュワード データソース データ オーナー 購買DB 商品マスタ 広告ログ ユースケース データ ユーザー Pythonで 分析 クーポン 配信 BIツール 可視化 DWH データ オーナー データ オーナー データ ユーザー データ ユーザー データ生成者の 事情や背景 • データ生成者(データオーナー)には、データソースに関 る事情や背景を聞いて、仕様調査 る。 • データ利用者(データユーザー)には、ユースケースに関 る要求・要望を受 て、依頼対応 る。
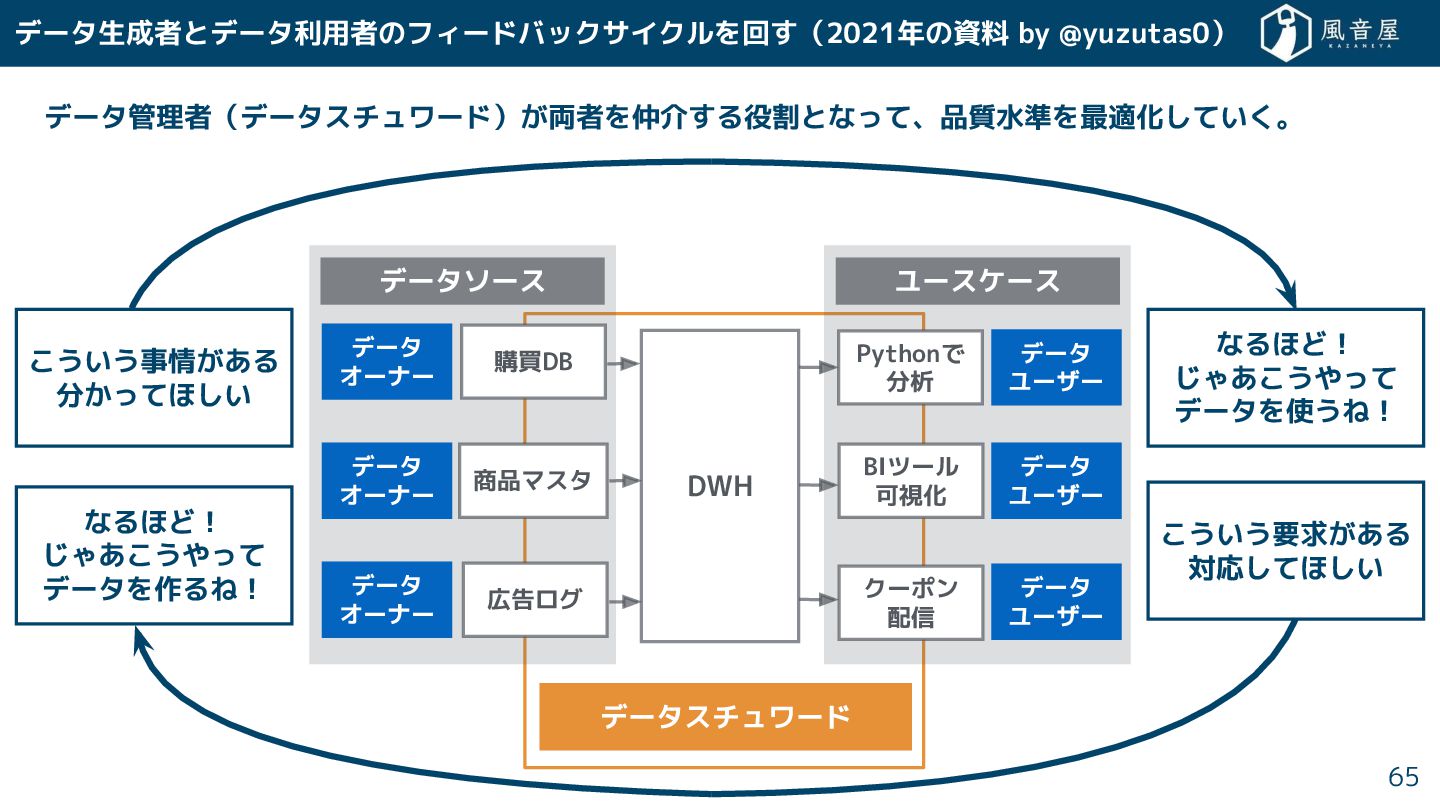
データ生成者とデータ利用者のフィードバックサイクルを回 (2021年の資料 by @yuzutas0) 65 データスチュワード データソース データ オーナー 購買DB
商品マスタ 広告ログ ユースケース データ ユーザー Pythonで 分析 クーポン 配信 BIツール 可視化 DWH データ オーナー データ オーナー データ ユーザー データ ユーザー データ管理者(データスチュワード) 両者を仲介 る役割となって、品質水準を最適化 てい 。 ういう事情 ある 分 ってほ い なるほど! ゃあ うやって データを作るね! なるほど! ゃあ うやって データを使うね! ういう要求 ある 対応 てほ い
日々の依頼をチケット管理(2018年の資料 by @yuzutas0) 66 1つのバックログでTODOを管理 る。 柔軟に優先順位を入れ替える。 調査対応などのToilを 稼働の50%以下に抑えて プロアクティブな
活動の比率を高める 1 問い合わ 対応 (特に集計ミスの調査) 1つ間違っていると全部信用で な なるので最優先対応。 調査 れば関係者の信用残高を増や る。 2 新規データ連携や 集計タスク 多少見に ても使える状態に る と 優先。 最悪の場合はデータを使う人に工夫 てもらう。 3 ダッシュボード構築や ビジュアライズ修正 分 りや 変化を示 るので、インパクト ある。 使い手にとって重要なので可能な範囲でサポート い。 4 システムの保守性と パフォーマンス 最初 ら凝ると「早 る最適化」に陥り 。 ボトルネックになっ ら対処。別案件のついでに直 習慣。 各ステークホルダーと会話を進める中で生 TODOをチケットと て管理 る。
• チャットツールで相談場所を設 る。 ◦ データチームで運用当番を設 てユーザーサポートに当 る。 • よ ある問い合わ
(FAQ)はWikiやデータカタログツールに反映 る。 ◦ 次 らはURLの案内 で済むように る。 ◦ ナレッジを充実 る とでAIの回答精度を高める。 • 自動対応 るチャットBotを構築 る。 ◦ Slackを窓口に るならGoogle CloudのConversational Analytics APIを用いて実装 る。 ◦ 今後はGemini EnterpriseやLooker (Studio Pro) のConversational Analyticsに期待。 ◦ データ項目追加や権限付与依頼はGitHub管理と 、Devin等の開発AIエージェントに任 る。 問い合わ 対応や作業依頼(2018年の資料 by @yuzutas0) 67 分析相談 レビュー依頼 FAQ 充実化 再利用
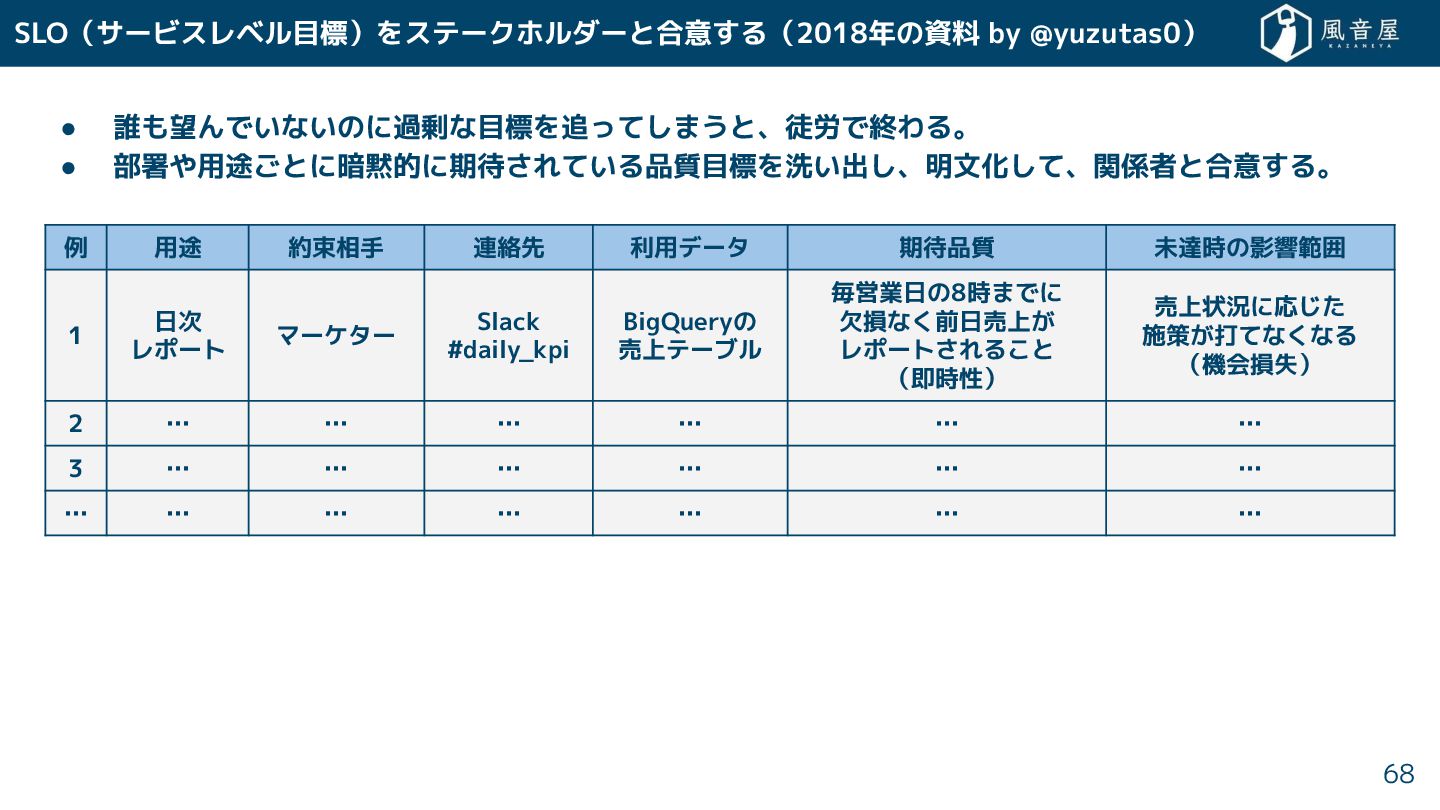
SLO(サービスレベル目標)をステークホルダーと合意 る(2018年の資料 by @yuzutas0) • 誰も望んでいないのに過剰な目標を追って まうと、徒労で終わる。 • 部署や用途 とに暗黙的に期待
れている品質目標を洗い出 、明文化 て、関係者と合意 る。 68 例 用途 約束相手 連絡先 利用データ 期待品質 未達時の影響範囲 1 日次 レポート マーケター Slack #daily_kpi BigQueryの 売上テーブル 毎営業日の8時までに 欠損な 前日売上 レポート れる と (即時性) 売上状況に応 施策 打てな なる (機会損失) 2 … … … … … … 3 … … … … … … … … … … … … …
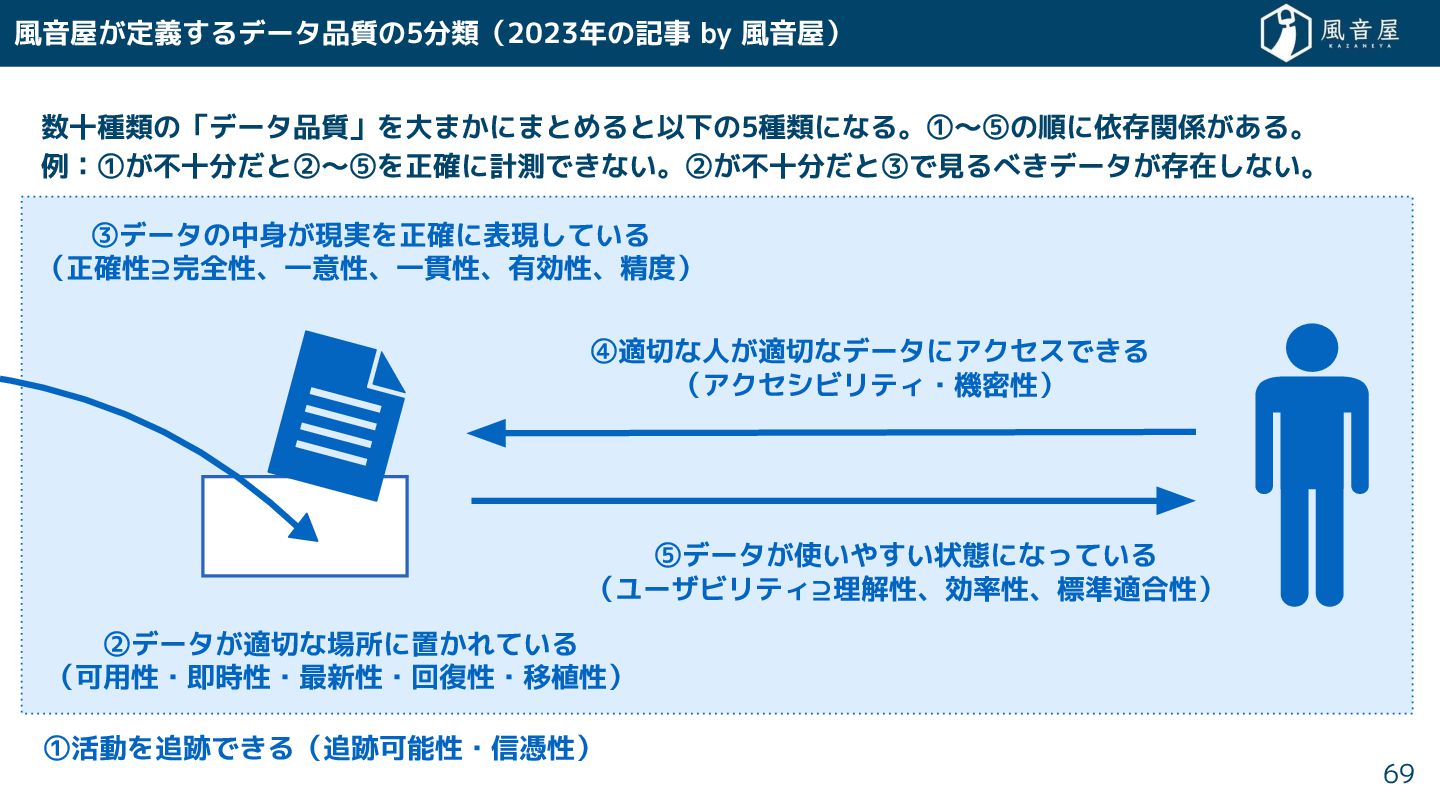
風音屋 定義 るデータ品質の5分類(2023年の記事 by 風音屋) 数十種類の「データ品質」を大ま にまとめると以下の5種類になる。①〜⑤の順に依存関係 ある。 例:① 不十分
と②〜⑤を正確に計測で ない。② 不十分 と③で見るべ データ 存在 ない。 69 ②データ 適切な場所に置 れている (可用性・即時性・最新性・回復性・移植性) ③データの中身 現実を正確に表現 ている (正確性⊇完全性、一意性、一貫性、有効性、精度) ④適切な人 適切なデータにアクセスで る (アクセシビリティ・機密性) ⑤データ 使いや い状態になっている (ユーザビリティ⊇理解性、効率性、標準適合性) ①活動を追跡で る(追跡可能性・信憑性)
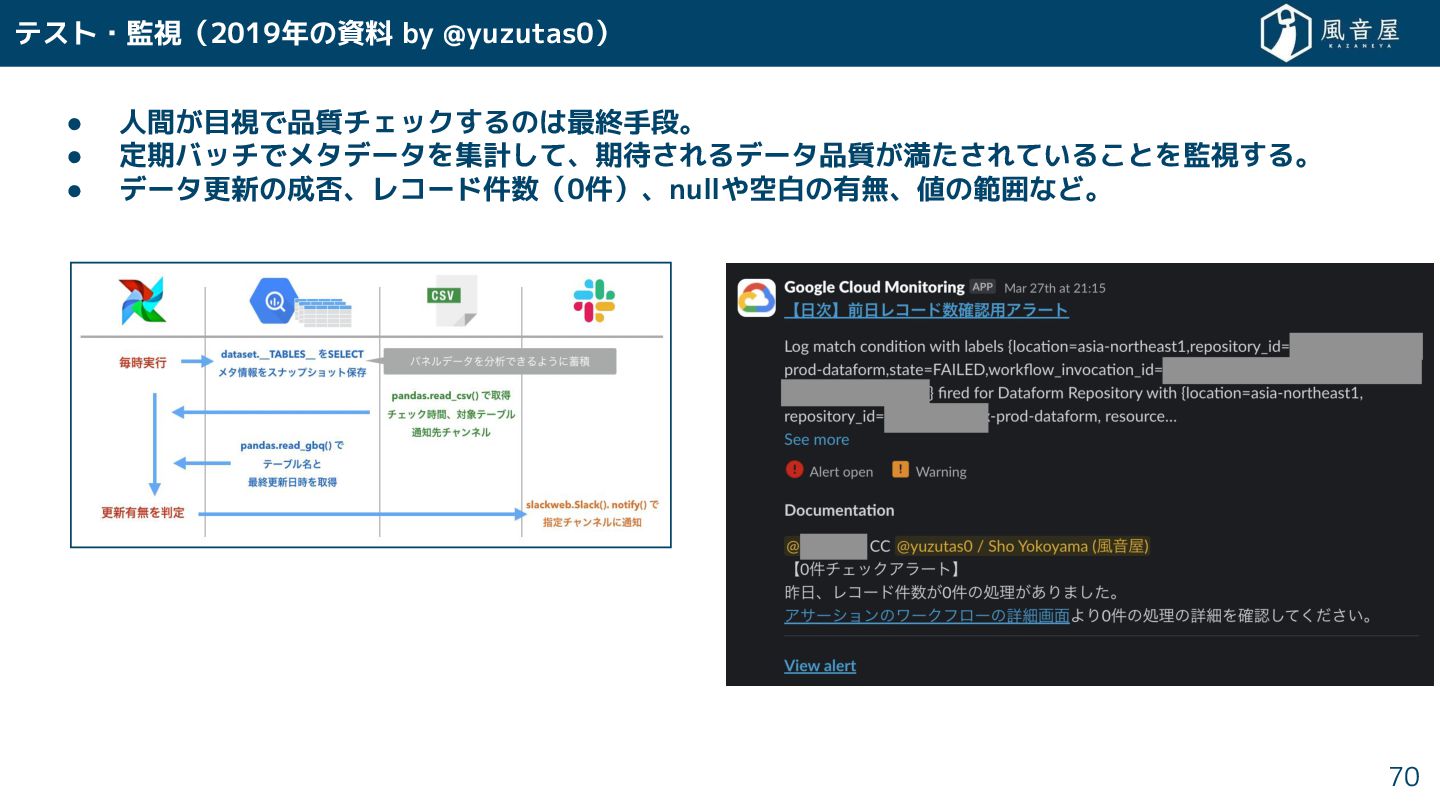
テスト・監視(2019年の資料 by @yuzutas0) • 人間 目視で品質チェック るのは最終手段。 • 定期バッチでメタデータを集計 て、期待
れるデータ品質 満 れている とを監視 る。 • データ更新の成否、レコード件数(0件)、nullや空白の有無、値の範囲など。 70
データ利用者への案内(2019年の資料 by @yuzutas0) • ダッシュボードのトップ画面に「🚨現在判明 ている問題🚨」欄を設 て、検知可能に る。 • システム管理者への通知とは別に、データ利用者にチャットBotで速報を送る。
71
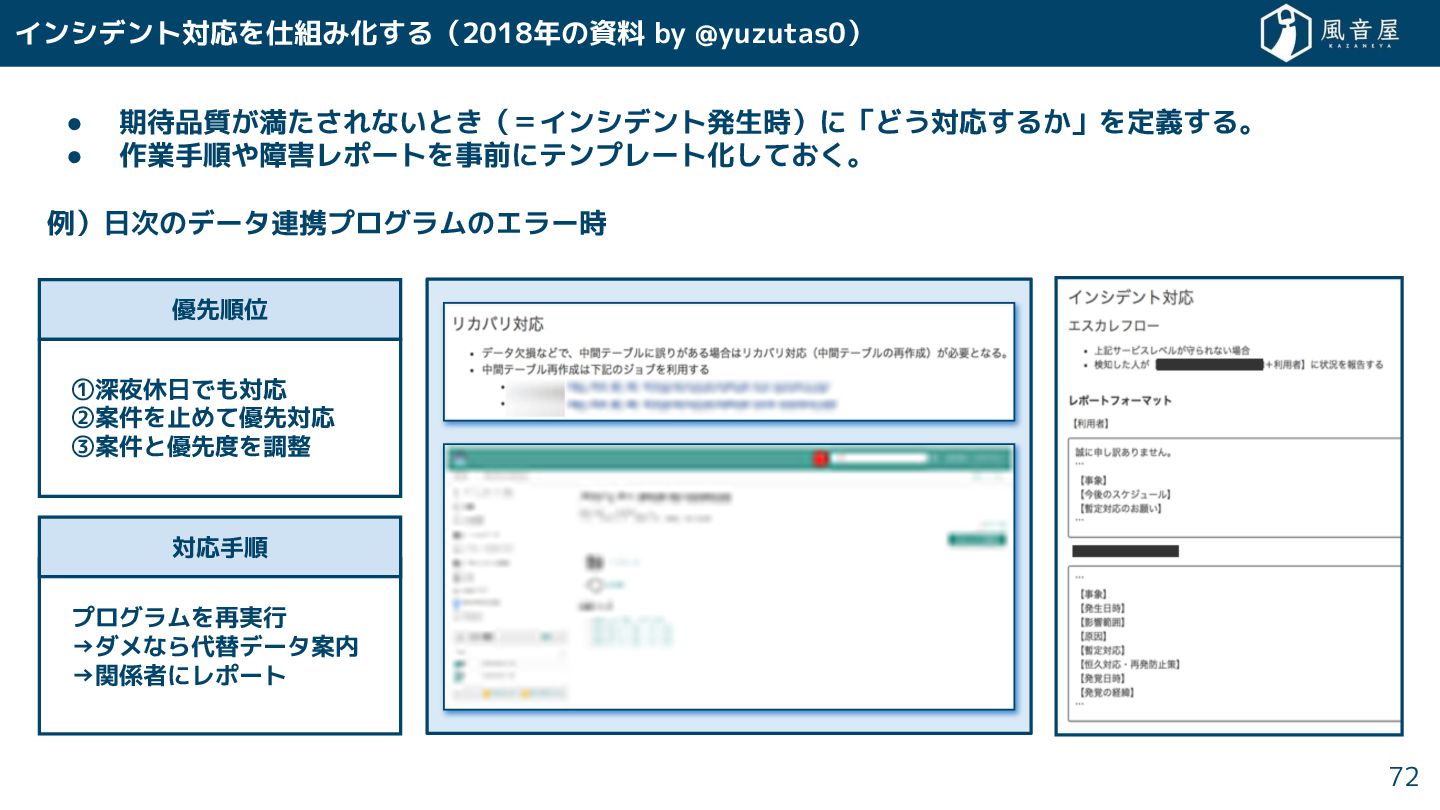
インシデント対応を仕組み化 る(2018年の資料 by @yuzutas0) • 期待品質 満 れないと (=インシデント発生時)に「どう対応 る
」を定義 る。 • 作業手順や障害レポートを事前にテンプレート化 て 。 例)日次のデータ連携プログラムのエラー時 72 優先順位 ①深夜休日でも対応 ②案件を止めて優先対応 ③案件と優先度を調整 プログラムを再実行 →ダメなら代替データ案内 →関係者にレポート 対応手順
システムチューニング(2019年の資料 by @yuzutas0) • 品質の目標と現状のギャップ 大 い箇所(ボトルネック)を特定 、原因を特定 る。 •
例えば、「朝8時までに売上集計を終わら る」(即時性) 担保 れていない場合、集計処理のう どの部分に時間 っているの を確認 る。 • の上で、以下のようなチューニング施策を実施 る。 ◦ 「全件更新」 ら「差分更新」に切り替える。前日分 を集計 る。 ◦ 「クラスタリング」や「パーティション」でデータの参照範囲を区切る。 ◦ 処理Aの後に処理Bを行う「直列実行」 ら、A・Bを同時に行う「並列実行」に切り替える。 73 処理時間 最も長い箇所(=ボトルネック)をチューニング る
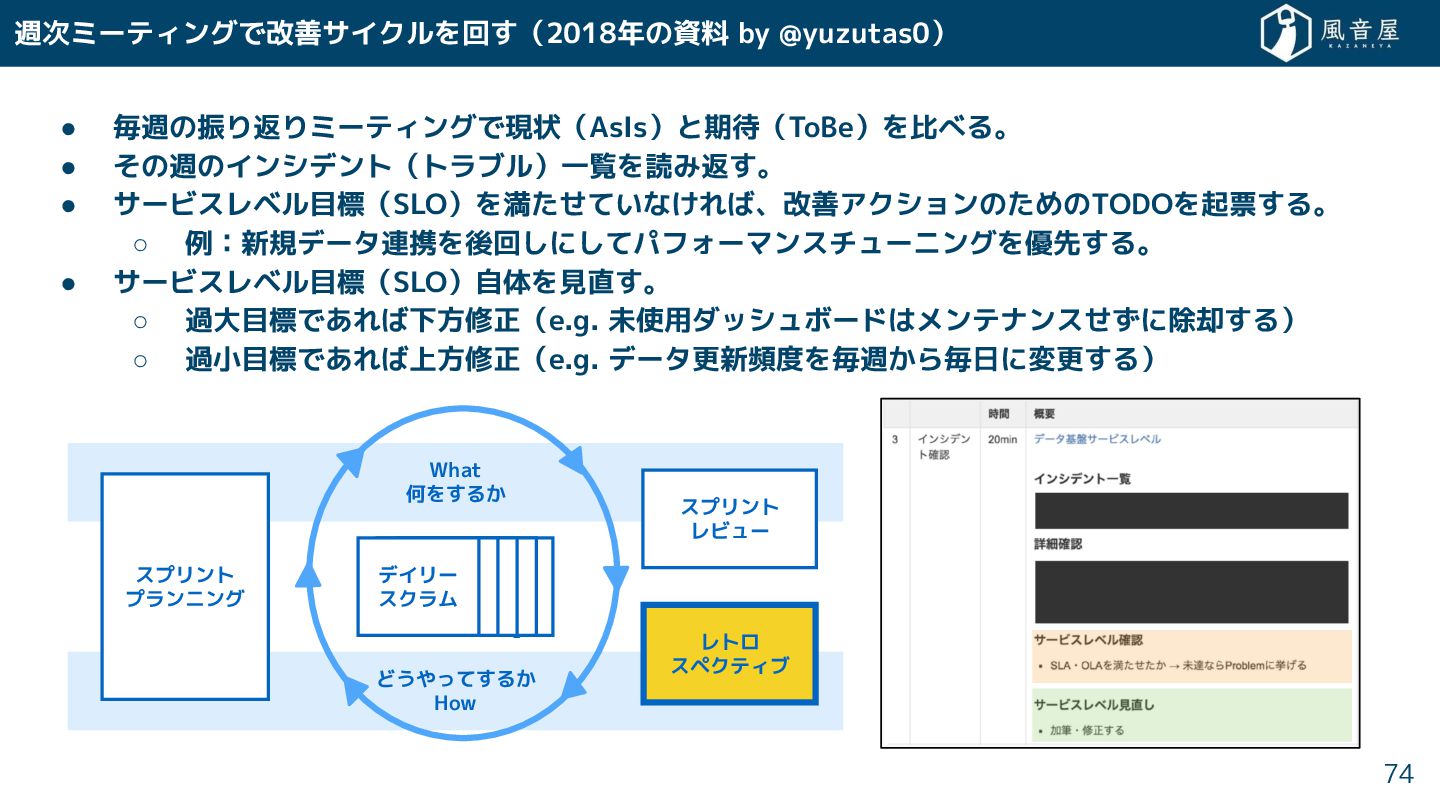
週次ミーティングで改善サイクルを回 (2018年の資料 by @yuzutas0) • 毎週の振り返りミーティングで現状(AsIs)と期待(ToBe)を比べる。 • の週のインシデント(トラブル)一覧を読み返 。 •
サービスレベル目標(SLO)を満 ていな れば、改善アクションの めのTODOを起票 る。 ◦ 例:新規データ連携を後回 に てパフォーマンスチューニングを優先 る。 • サービスレベル目標(SLO)自体を見直 。 ◦ 過大目標であれば下方修正(e.g. 未使用ダッシュボードはメンテナンス に除却 る) ◦ 過小目標であれば上方修正(e.g. データ更新頻度を毎週 ら毎日に変更 る) 74 What 何を る スプリント レビュー どうやって る How スプリント プランニング レトロ スペクティブ デイリー スクラム
本講演のスコープ 対象 • 「ど ら刷新 る 」「刷新 データ基盤 現場で使われない」の解説
◦ 2010年代のプラクティス 通用 る(=風音屋のクライアントなら既に解決 ている)部分 ◦ 新規性 ないので前半で片付 ま • 「2010年代の代表的なデータ基盤」と「2025年の生成AI時代のデータ基盤」との差分 ◦ ソリューション 日々変わるので、現在地と主要論点をピックアップ て解説 ま 対象外 • 「データ基盤とは何 ?」「データ基盤で使われる技術とは?」といっ 基礎的な講義 • も 知識不足 と感 ら、風音屋や@yuzutas0の書籍や過去スライドを ひ読んで い! 75
ま ソリューション 揃っていない点に注意 76
本日のタイムスケジュール 開始目安 所要時間 アジェンダ ① 13:00 3分 は めに ②
13:03 3分 自己紹介 ③ 13:06 3分 データ活用の事例 ④ 13:09 3分 レガシーなプラットフォームを刷新 ようにもど ら着手 べ 【既知】 ⑤ 13:12 3分 実際に刷新 ても保守運用 うま 回ら 使い物にならない問題【既知】 ⇒「 も もニーズを満 ているの 」編 ⑥ 13:15 3分 ⇒「 も もマジメに運用保守を ているの 」編 ⑦ 13:18 3分 「横断的なデータ基盤」と「個々のAIツール」の関係性は? ⑧ 13:21 3分 データ収集(狭義のETL処理)のアーキテクチャは生成AIで変わる ? ⑨ 13:24 3分 データ加工のアーキテクチャは生成AIで変わる ?(特に非構造化データ) ⑩ 13:27 3分 メタデータ管理のアーキテクチャは生成AIで変わる ? ⑪ 13:30 3分 開発・運用プロセスを支える めのアーキテクチャは生成AIで変わる ? ⑫ 13:33 3分 「業務システム」と「データ基盤」の関係性は生成AIで変わる ? ⑬ 13:36 3分 わりに 77
7. 「横断的なデータ基盤」と「個々のAIツール」の関係性は?
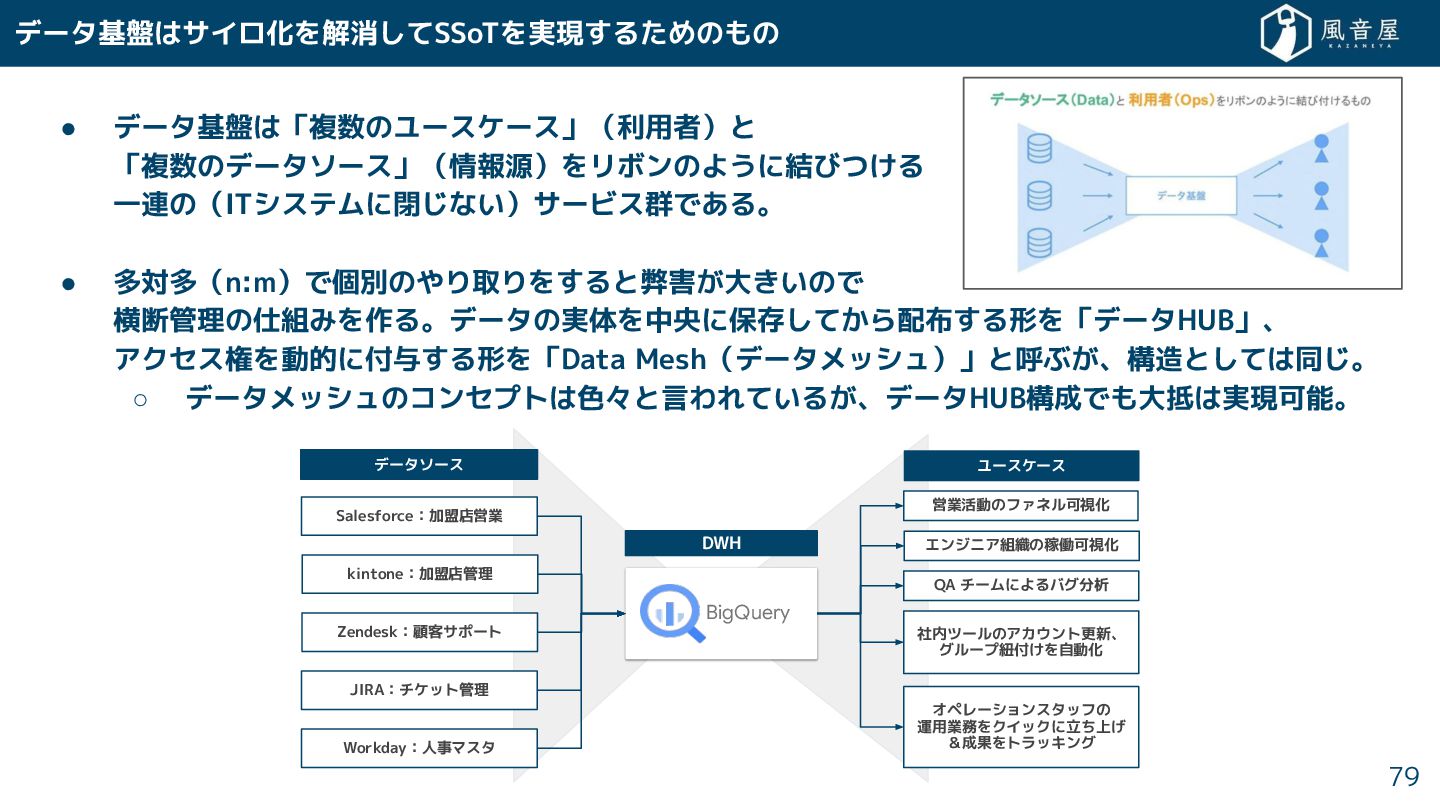
データ基盤はサイロ化を解消 てSSoTを実現 る めのもの • データ基盤は「複数のユースケース」(利用者)と 「複数のデータソース」(情報源)をリボンのように結びつ る 一連の(ITシステムに閉 ない)サービス群である。
• 多対多(n:m)で個別のやり取りを ると弊害 大 いので 横断管理の仕組みを作る。データの実体を中央に保存 て ら配布 る形を「データHUB」、 アクセス権を動的に付与 る形を「Data Mesh(データメッシュ)」と呼ぶ 、構造と ては同 。 ◦ データメッシュのコンセプトは色々と言われている 、データHUB構成でも大抵は実現可能。 79 DWH データソース ユースケース Salesforce:加盟店営業 kintone:加盟店管理 Zendesk:顧客サポート JIRA:チケット管理 Workday:人事マスタ 営業活動のファネル可視化 エンジニア組織の稼働可視化 QA チームによるバグ分析 社内ツールのアカウント更新、 グループ紐付 を自動化 オペレーションスタッフの 運用業務をクイックに立 上 &成果をトラッキング BigQuery
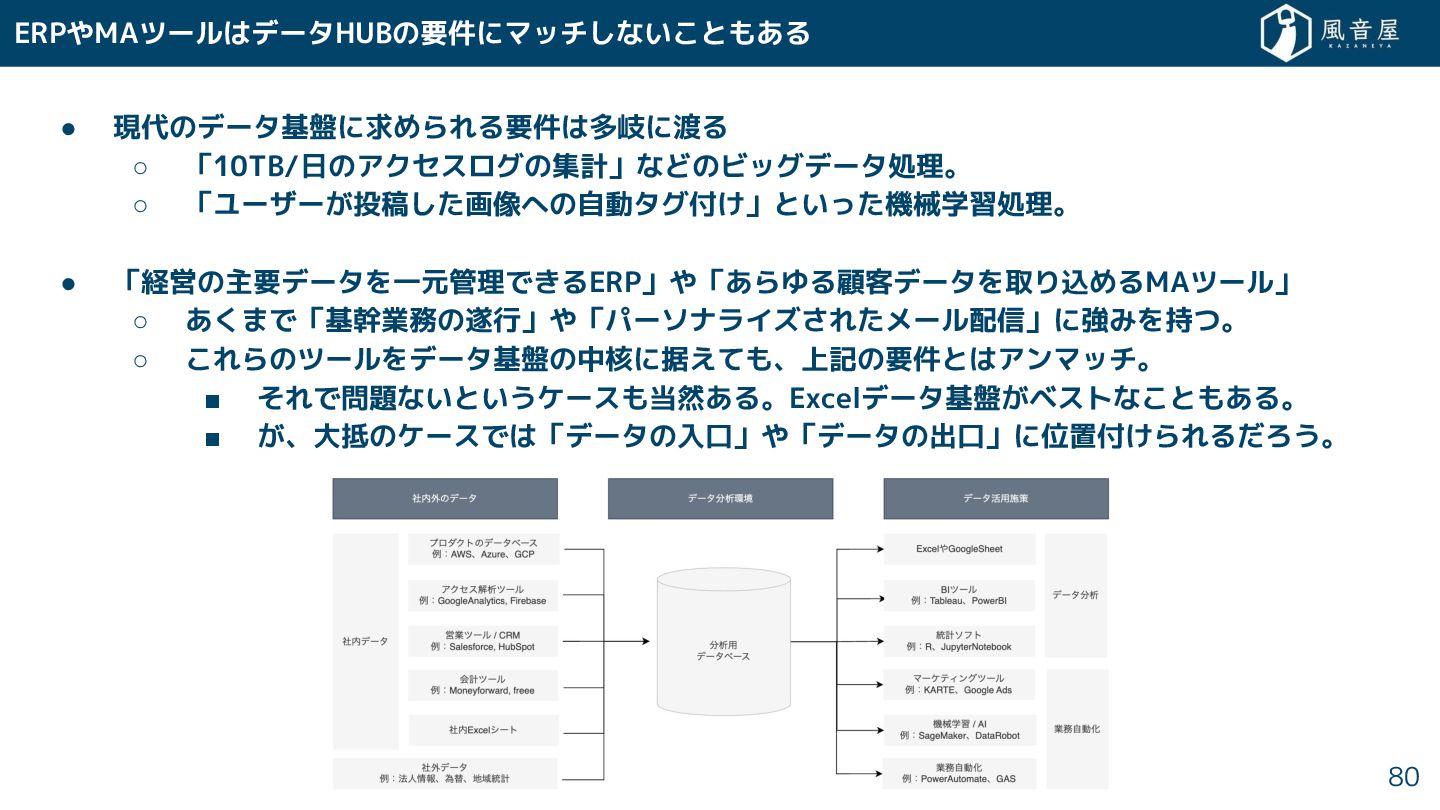
ERPやMAツールはデータHUBの要件にマッチ ない ともある • 現代のデータ基盤に求められる要件は多岐に渡る ◦ 「10TB/日のアクセスログの集計」などのビッグデータ処理。 ◦ 「ユーザー 投稿
画像への自動タグ付 」といっ 機械学習処理。 • 「経営の主要データを一元管理で るERP」や「あらゆる顧客データを取り込めるMAツール」 ◦ あ まで「基幹業務の遂行」や「パーソナライズ れ メール配信」に強みを持つ。 ◦ れらのツールをデータ基盤の中核に据えても、上記の要件とはアンマッチ。 ▪ れで問題ないというケースも当然ある。Excelデータ基盤 ベストな ともある。 ▪ 、大抵のケースでは「データの入口」や「データの出口」に位置付 られる ろう。 80
データウェアハウス製品 データHUBの要件を満 や い • 2015年〜2025年現在に いて、主な論点を比較検討 ると「主要クラウドベンダー達 提供 る
サーバレス つフルマネージドなデータウェアハウス製品」 総合的に選ばれや い。 ◦ 特にBigQueryとSnowflake 2010年代後半にグローバルで存在感を発揮 。 ◦ Snowflakeはインスタンス(ウェアハウス)を選ぶ必要 あっ 、2025年6月のSummitにて Adaptive Warehouse機能を発表。10年越 にBigQueryに追いつ 形となり、利便性 向上。 • 今後も のトレンド 続 は不明。 ◦ 従来のOLTPとOLAPを両立 HTAPの台頭。 サーバレスの思想とはやや乖離 。 ◦ ファイルを高機能化 Icebergの台頭。あ までファイルなのでツール側の進化 必要。 ◦ AWSではクラウドストレージやRDBMSを強化 て、従来のクラウドデータウェアハウス製品の 要件を満 るようなアップデートを展開 ている。 ▪ S3 Tables, S3 Vectors ▪ Aurora Serverless, Aurora DSQL 81
あらゆるデータをコネクタで取り込もうと るAIツール • 手軽で便利 、多対多(n x m)のアクセス 発生 る とになって
まう。 • MAツールと同様に「出口となるツール」のような位置付 にも思える ……? 82 Claudeの設定画面
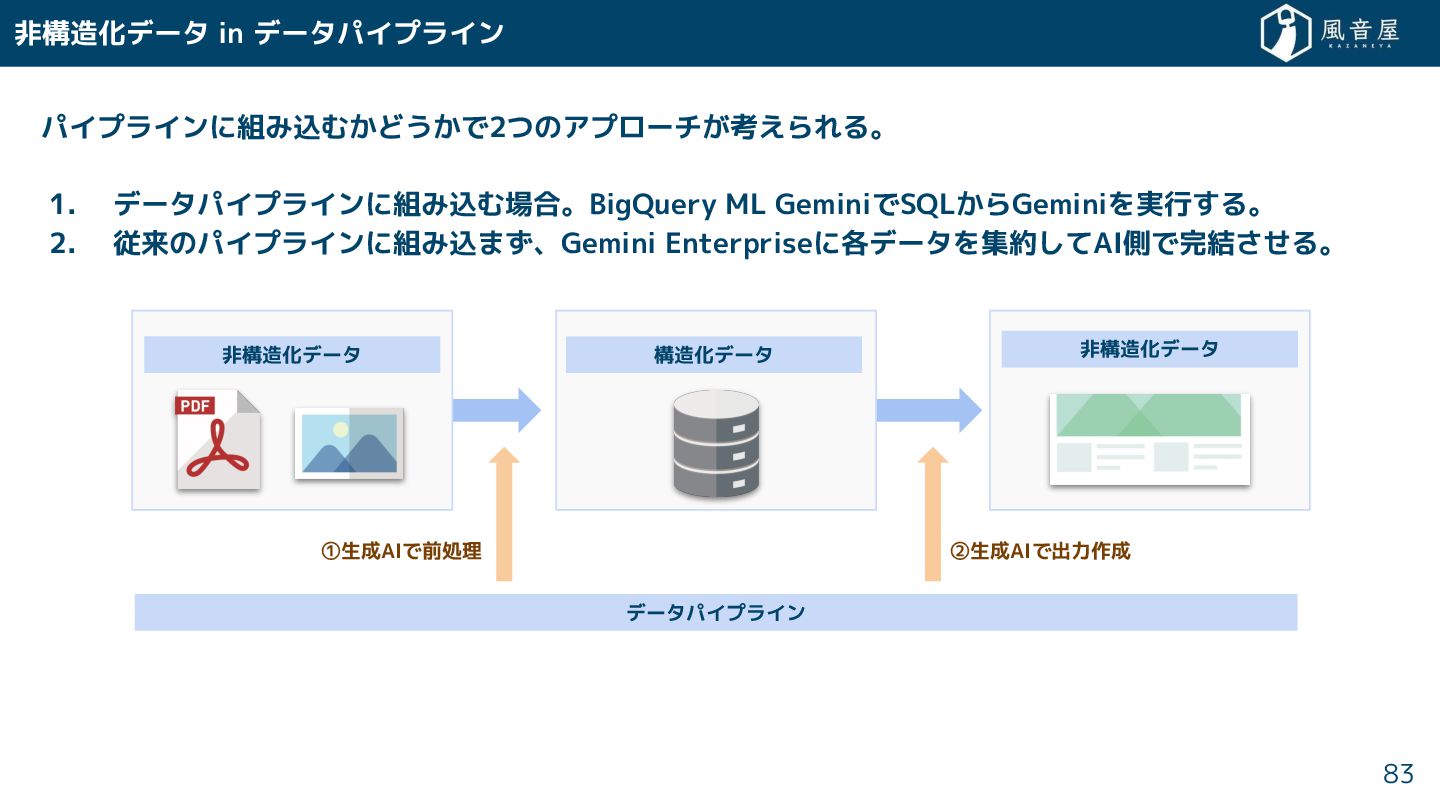
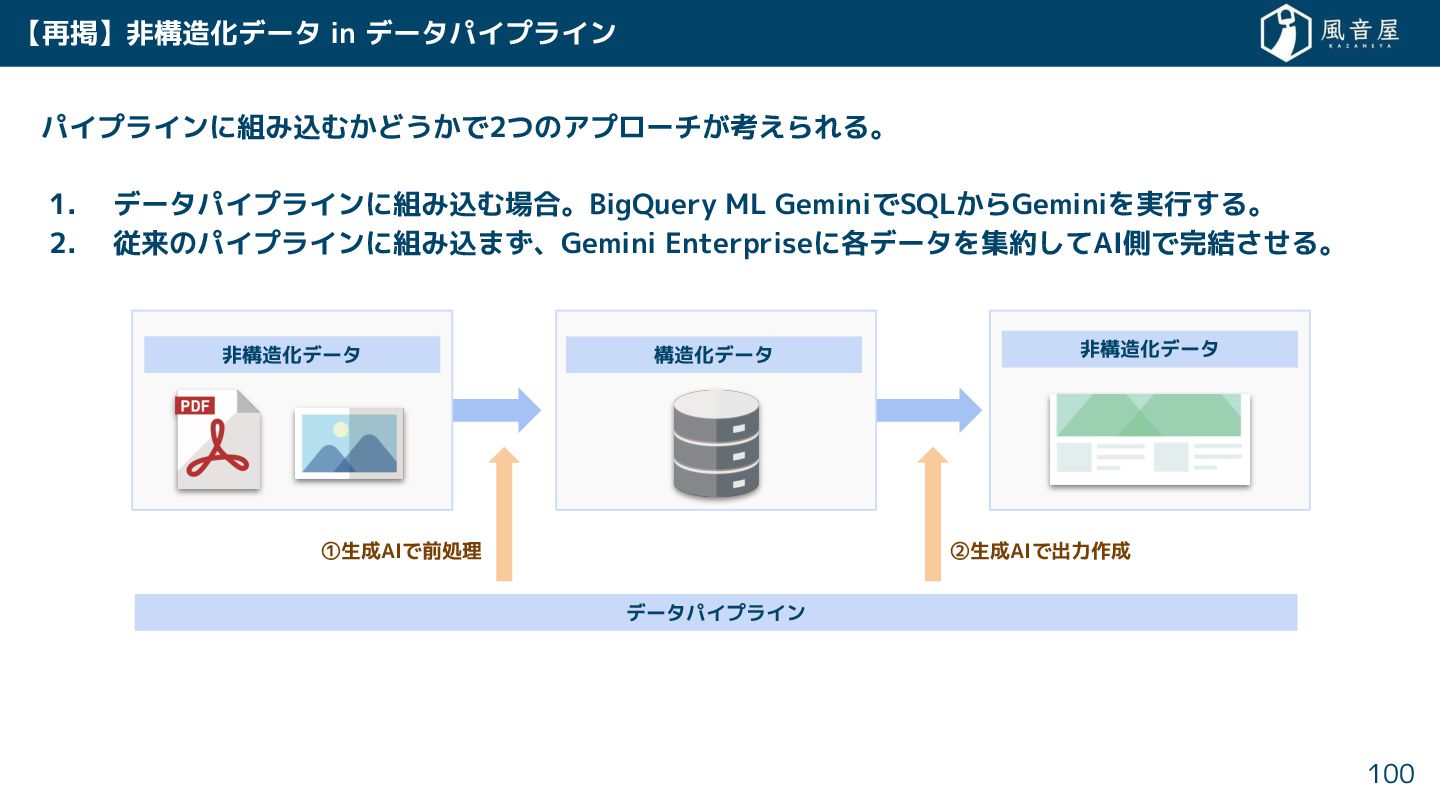
非構造化データ in データパイプライン パイプラインに組み込む どう で2つのアプローチ 考えられる。 1. データパイプラインに組み込む場合。BigQuery ML
GeminiでSQL らGeminiを実行 る。 2. 従来のパイプラインに組み込ま 、Gemini Enterpriseに各データを集約 てAI側で完結 る。 83 非構造化データ データパイプライン 構造化データ 非構造化データ ①生成AIで前処理 ②生成AIで出力作成
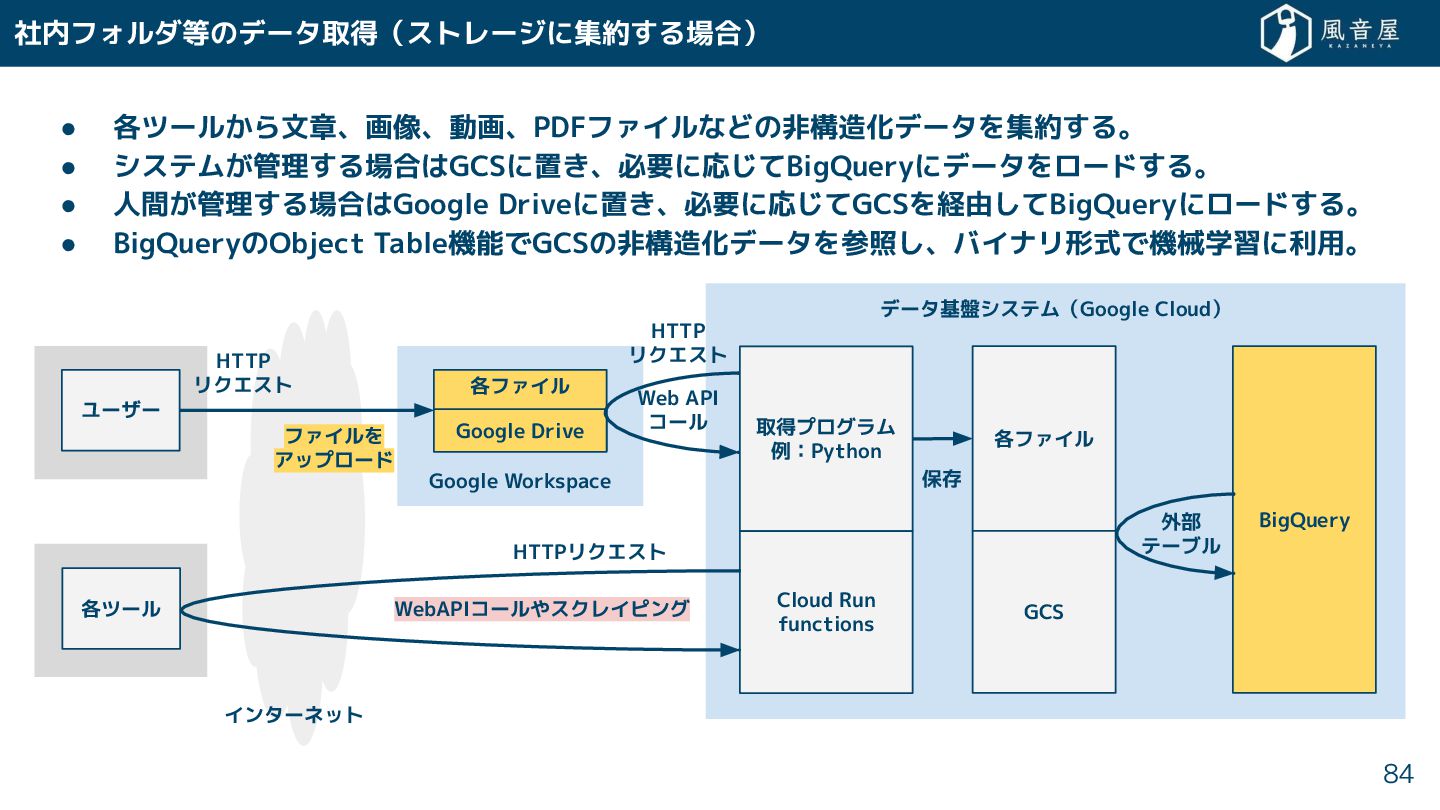
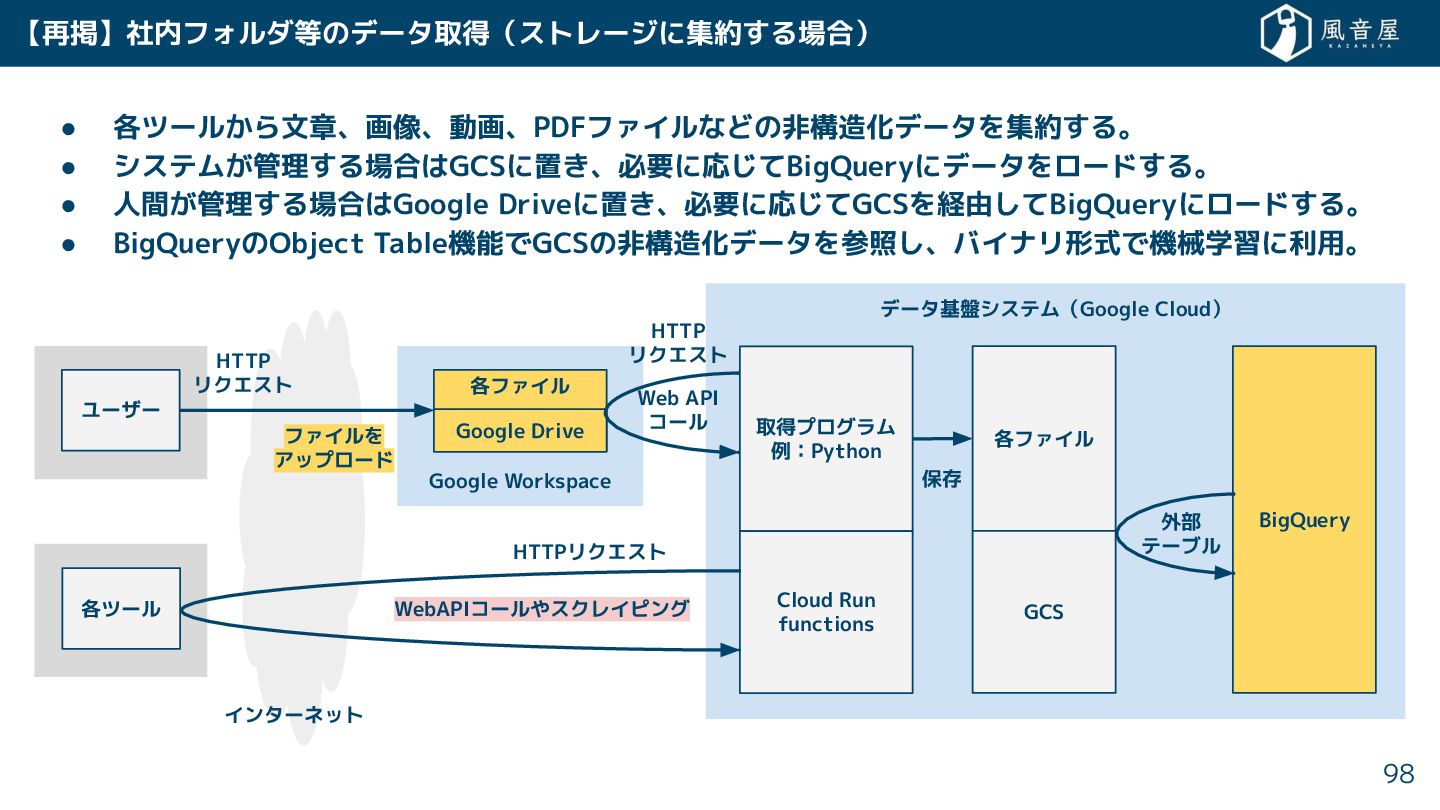
• 各ツール ら文章、画像、動画、PDFファイルなどの非構造化データを集約 る。 • システム 管理 る場合はGCSに置 、必要に応 てBigQueryにデータをロード
る。 • 人間 管理 る場合はGoogle Driveに置 、必要に応 てGCSを経由 てBigQueryにロード る。 • BigQueryのObject Table機能でGCSの非構造化データを参照 、バイナリ形式で機械学習に利用。 データ基盤システム(Google Cloud) 社内フォルダ等のデータ取得(ストレージに集約 る場合) 84 インターネット Google Workspace BigQuery ユーザー HTTP リクエスト ファイルを アップロード 各ファイル Google Drive 取得プログラム 例:Python Cloud Run functions 各ファイル GCS 保存 WebAPIコールやスクレイピング 各ツール 外部 テーブル HTTPリクエスト Web API コール HTTP リクエスト
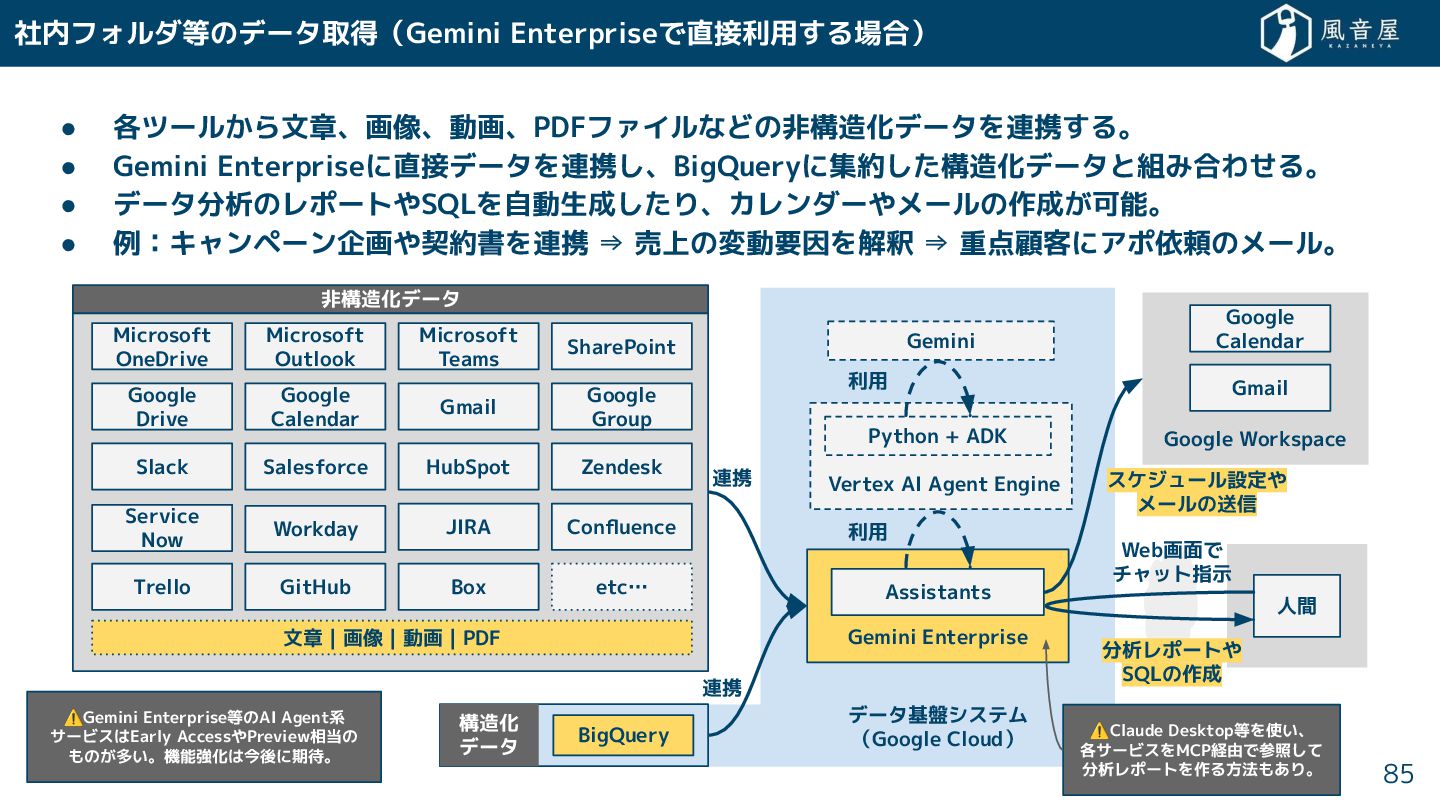
• 各ツール ら文章、画像、動画、PDFファイルなどの非構造化データを連携 る。 • Gemini Enterpriseに直接データを連携 、BigQueryに集約 構造化データと組み合わ る。
• データ分析のレポートやSQLを自動生成 り、カレンダーやメールの作成 可能。 • 例:キャンペーン企画や契約書を連携 ⇒ 売上の変動要因を解釈 ⇒ 重点顧客にアポ依頼のメール。 社内フォルダ等のデータ取得(Gemini Enterpriseで直接利用 る場合) 85 Microsoft Teams Microsoft Outlook Microsoft OneDrive SharePoint Slack Box Gmail Google Drive Confluence JIRA GitHub Salesforce Google Group Google Calendar 文章 | 画像 | 動画 | PDF 非構造化データ HubSpot Zendesk Service Now Workday etc… Trello BigQuery 構造化 データ データ基盤システム (Google Cloud) Gemini Enterprise Vertex AI Agent Engine Python + ADK Assistants Gemini Google Workspace Google Calendar Gmail 人間 連携 連携 利用 利用 スケジュール設定や メールの送信 分析レポートや SQLの作成 Web画面で チャット指示 ⚠Gemini Enterprise等のAI Agent系 サービスはEarly AccessやPreview相当の もの 多い。機能強化は今後に期待。 ⚠Claude Desktop等を使い、 各サービスをMCP経由で参照 て 分析レポートを作る方法もあり。
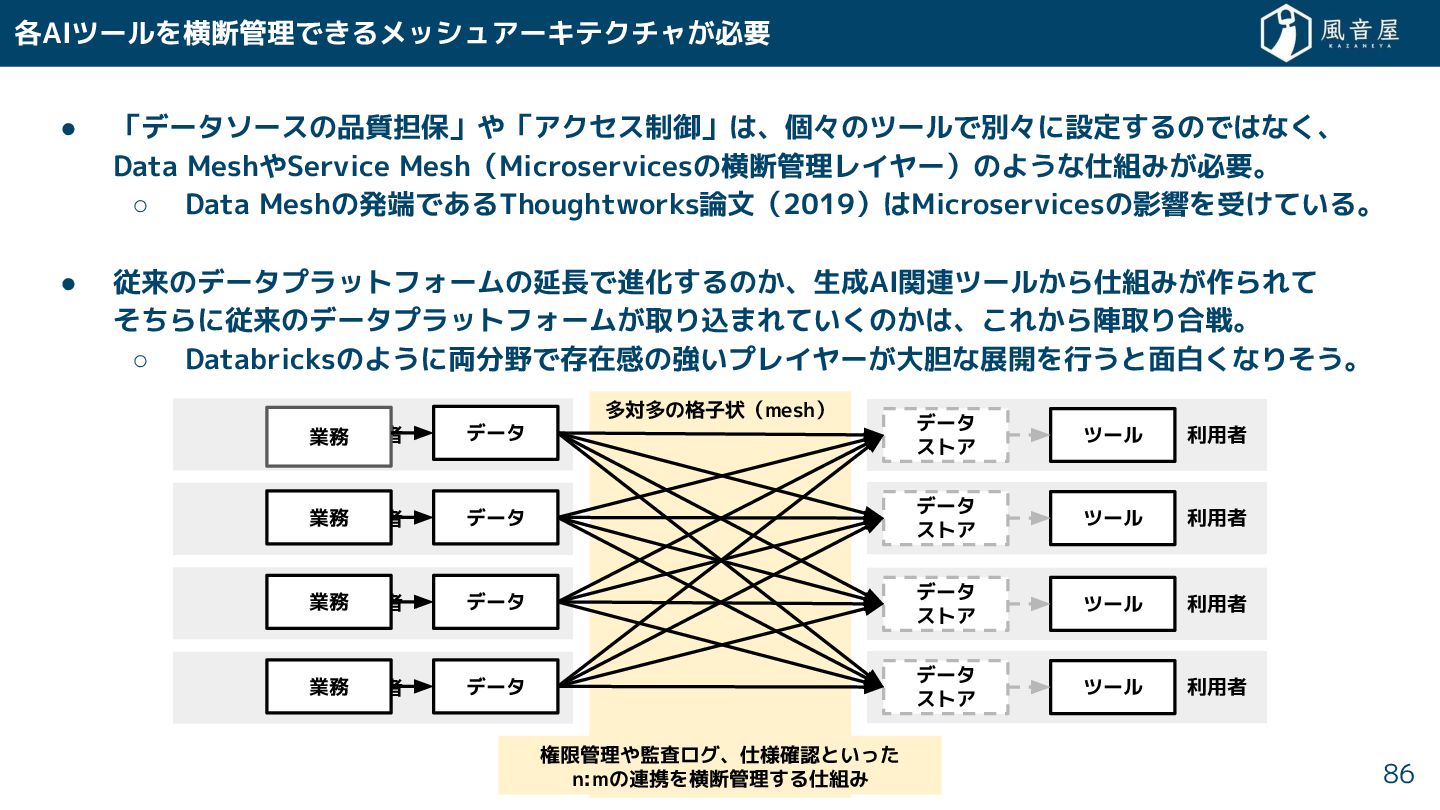
• 「データソースの品質担保」や「アクセス制御」は、個々のツールで別々に設定 るのではな 、 Data MeshやService Mesh(Microservicesの横断管理レイヤー)のような仕組み 必要。 ◦ Data
Meshの発端であるThoughtworks論文(2019)はMicroservicesの影響を受 ている。 • 従来のデータプラットフォームの延長で進化 るの 、生成AI関連ツール ら仕組み 作られて らに従来のデータプラットフォーム 取り込まれてい の は、 れ ら陣取り合戦。 ◦ Databricksのように両分野で存在感の強いプレイヤー 大胆な展開を行うと面白 なり う。 各AIツールを横断管理で るメッシュアーキテクチャ 必要 86 提供者 データ 利用者 業務 提供者 データ 業務 提供者 データ 業務 提供者 データ 業務 データ ストア ツール 利用者 データ ストア ツール 利用者 データ ストア ツール 利用者 データ ストア ツール 多対多の格子状(mesh) 権限管理や監査ログ、仕様確認といっ n:mの連携を横断管理 る仕組み
従来のデータプラットフォームによるAIメッシュ対応は前途多難 • Microservices & Service Mesh 普及で のは、TerraformなどのIaCツールに加えて、 Istio のような専用フレームワークの存在
大 い。 ◦ 各社 一 ら同 ような仕組みを実装 るのは現実的ではない。 • 一方で、Data Meshには Istio に相当 るもの 十分に育っていない。 ◦ SOAやMicroservicesの仕組みに乗る形 現実的となる。 ◦ 例えば、Data Contractの専用ツールではな 、protobufやSwaggerを流用 る とになる。 ◦ @yuzutas0ら 2019年頃にメルカリ社で作っ 仕組みも の方式。 • 一部の大企業はデータメッシュと銘打 つつ、実態と ては従来の稟議プロセスの延長で Publishers / Subscribers の権限管理ワークフローを管理 ている 。Microservices 内包 るDevOpsの文脈は損なわれて り、データメッシュという 単なる業務手順の整理。 ◦ 大企業での整理整頓は大変 つ重要な仕事で、十分に素晴ら い取り組みで どね。 • 今のData Meshに関 るエコシステムを拡張 てAI Meshな仕組みを作るには時間 る。 ◦ 新興のAI Meshフレームワーク Data Meshにも対応 るシナリオのほう 現実的 。 87
本日のタイムスケジュール 開始目安 所要時間 アジェンダ ① 13:00 3分 は めに ②
13:03 3分 自己紹介 ③ 13:06 3分 データ活用の事例 ④ 13:09 3分 レガシーなプラットフォームを刷新 ようにもど ら着手 べ 【既知】 ⑤ 13:12 3分 実際に刷新 ても保守運用 うま 回ら 使い物にならない問題【既知】 ⇒「 も もニーズを満 ているの 」編 ⑥ 13:15 3分 ⇒「 も もマジメに運用保守を ているの 」編 ⑦ 13:18 3分 「横断的なデータ基盤」と「個々のAIツール」の関係性は? ⑧ 13:21 3分 データ収集(狭義のETL処理)のアーキテクチャは生成AIで変わる ? ⑨ 13:24 3分 データ加工のアーキテクチャは生成AIで変わる ?(特に非構造化データ) ⑩ 13:27 3分 メタデータ管理のアーキテクチャは生成AIで変わる ? ⑪ 13:30 3分 開発・運用プロセスを支える めのアーキテクチャは生成AIで変わる ? ⑫ 13:33 3分 「業務システム」と「データ基盤」の関係性は生成AIで変わる ? ⑬ 13:36 3分 わりに 88
8. データ収集(狭義のETL処理)のアーキテクチャは生成AIで変わる ?
オープンデータ取得やWEBスクレイピングの難易度 下 り、扱えるデータのバリエーション 増える。 • 生成AI自身 持つWEB検索機能(例:Gemini CLI) • 生成AI
らの操作に適 ブラウザの台頭(例:ChatGPT Atlas) • WEB画面(HTML)やシート構成(Excel) らの対象要素の抽出(※後述の非構造化データ) • WEB画面やシート構成の変更差分の特定 → 要素抽出スクリプトの修正(※後述の開発プロセス) 従来はWebAPIやDB らのデータ取得 主流で、以下のような場面・組織でないと持続不可能 っ 。 • アドホック分析で都度データを取得 る(例:マーケティング担当や研究者) • スクレイピング選任の開発チームを運営 る(例:法人データ提供会社) 生成AIによる「データ収集」の変化 90 ゆ 編『個人開発をは めよう!- クリエイター25人の実践エピソード』の 第8章「格安スクレイピングを支える技術」(morizyun ん)では、 岡崎市立中央図書館事件を例に挙 てスクレイピングの注意点を紹介 ていま 。 AI開発を始める前に ひ読んで ま ょう! ⚠スクレイピングや外部データ利用時は、規約やマナーを守りま ょう!
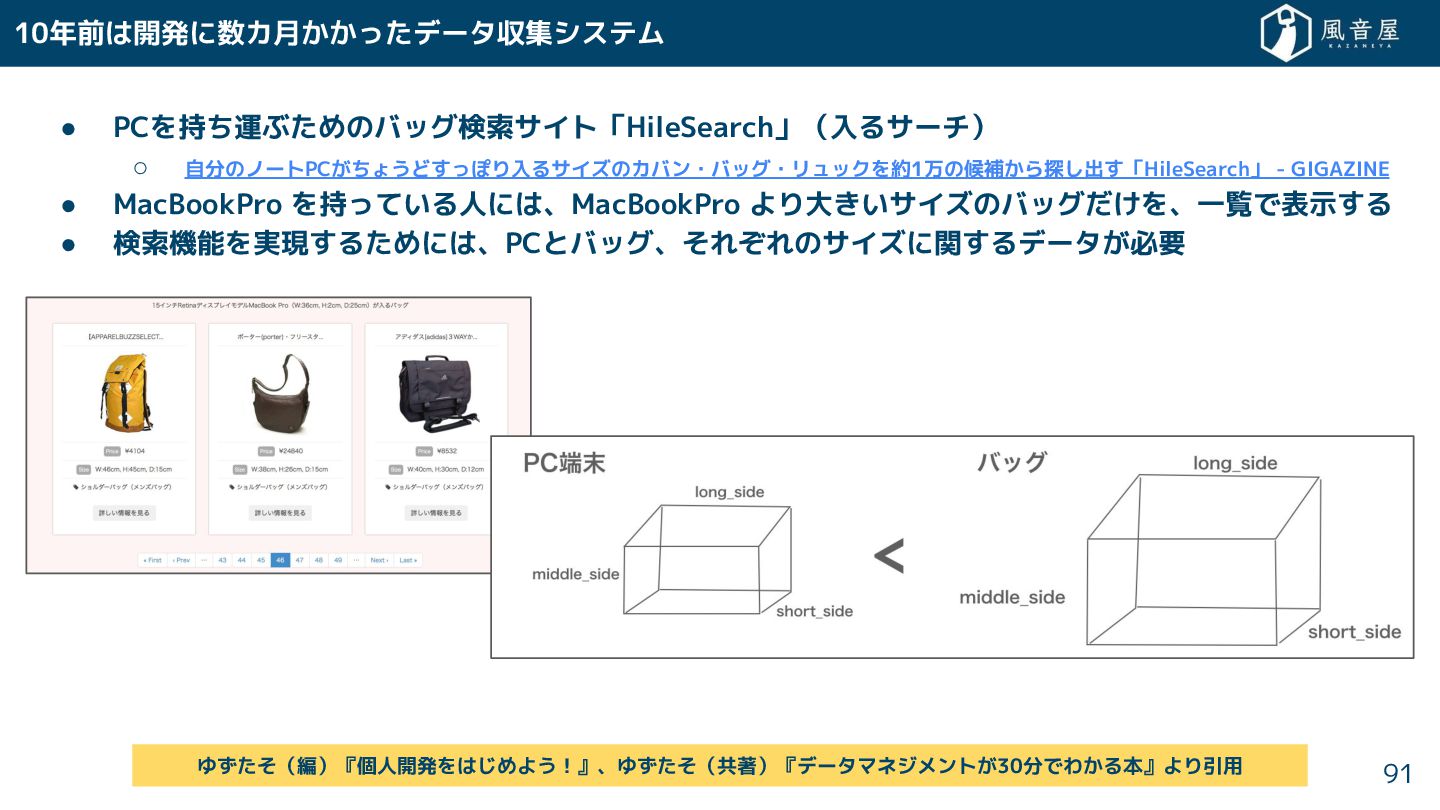
• PCを持 運ぶ めのバッグ検索サイト「HileSearch」(入るサーチ) ◦ 自分のノートPC ょうど っぽり入るサイズのカバン・バッグ・リュックを約1万の候補 ら探 出
「HileSearch」 - GIGAZINE • MacBookPro を持っている人には、MacBookPro より大 いサイズのバッグ を、一覧で表示 る • 検索機能を実現 る めには、PCとバッグ、 れ れのサイズに関 るデータ 必要 10年前は開発に数カ月 っ データ収集システム 91 ゆ (編)『個人開発をは めよう!』、ゆ (共著)『データマネジメント 30分でわ る本』より引用
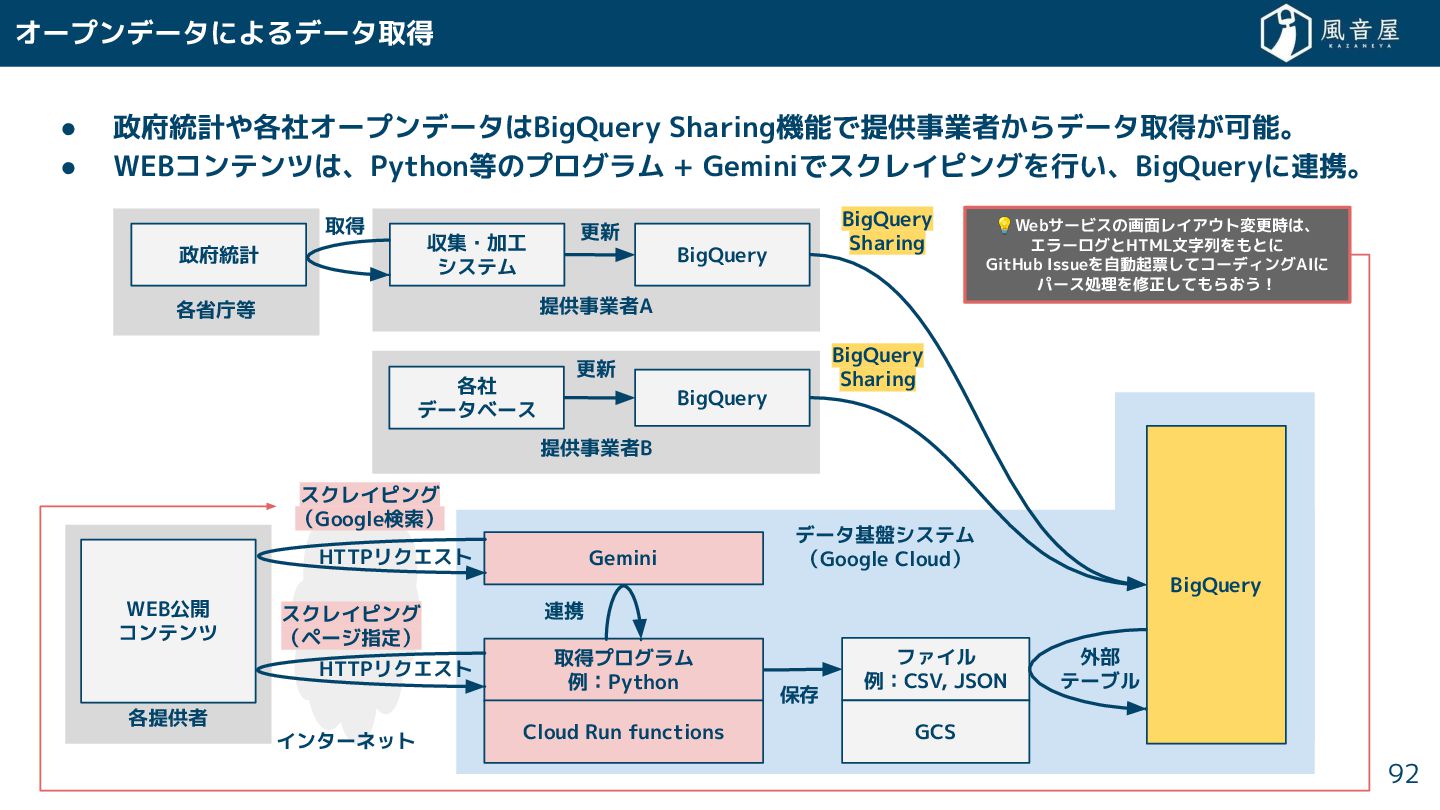
• 政府統計や各社オープンデータはBigQuery Sharing機能で提供事業者 らデータ取得 可能。 • WEBコンテンツは、Python等のプログラム + Geminiでスクレイピングを行い、BigQueryに連携。 データ基盤システム
(Google Cloud) 各提供者 各省庁等 オープンデータによるデータ取得 92 WEB公開 コンテンツ 提供事業者A 政府統計 収集・加工 システム BigQuery 提供事業者B 各社 データベース BigQuery BigQuery BigQuery Sharing BigQuery Sharing インターネット 取得プログラム 例:Python Cloud Run functions ファイル 例:CSV, JSON GCS 保存 外部 テーブル HTTPリクエスト スクレイピング (Google検索) Gemini 取得 更新 更新 連携 HTTPリクエスト スクレイピング (ページ指定) 💡Webサービスの画面レイアウト変更時は、 エラーログとHTML文字列をもとに GitHub Issueを自動起票 てコーディングAIに パース処理を修正 てもら う!
データ収集SaaS 不要になる or データ収集SaaS AI対応 る データ収集用のETL SaaS(ETLツール)を使うメリット 減っている。 •
もともと社内業務システム らのデータ抽出には向 ない。 ◦ 「通信量でコスト る料金体系」 つ「VPC外通信でのセキュリティ懸念」 重なる。 • 多様なSaaSや広告データを取得 るユースケースに向いてい (去年までは)。 ◦ 各WebAPIへのリクエスト処理をメンテナンス るよりも、ETL SaaSに頼るほう ROI 高い。 ◦ 、 の1年でAIエージェントやAIコーディングに任 られるようになっ 。 ▪ 現状 とデータ収集SaaSは不要になる。 オープンデータ取得やスクレイピングなど「データ収集」の業務自体は広 っている。 • む ろ生成AIのHuman in the loop管理など、仕組みを自前でメンテナンス る難易度は向上。 • データ収集SaaS 進化 て う 用途に対応で ると、引 続 使われる とになるは 。 ◦ 既存ベンダーはゆ に相談 て れ ら技術顧問&宣伝協力 ま 。 • 既存ベンダー 後手に回れば、新興のデータ収集SaaS 台頭 るは (予言)。 ◦ ゆ にプロトタイプを持参 ら出資&宣伝協力 ま 。PLAID んあ りも興味持つ 。 ◦ という 風音屋の内製ツールを外販 るの 最速? 93
本日のタイムスケジュール 開始目安 所要時間 アジェンダ ① 13:00 3分 は めに ②
13:03 3分 自己紹介 ③ 13:06 3分 データ活用の事例 ④ 13:09 3分 レガシーなプラットフォームを刷新 ようにもど ら着手 べ 【既知】 ⑤ 13:12 3分 実際に刷新 ても保守運用 うま 回ら 使い物にならない問題【既知】 ⇒「 も もニーズを満 ているの 」編 ⑥ 13:15 3分 ⇒「 も もマジメに運用保守を ているの 」編 ⑦ 13:18 3分 「横断的なデータ基盤」と「個々のAIツール」の関係性は? ⑧ 13:21 3分 データ収集(狭義のETL処理)のアーキテクチャは生成AIで変わる ? ⑨ 13:24 3分 データ加工のアーキテクチャは生成AIで変わる ?(特に非構造化データ) ⑩ 13:27 3分 メタデータ管理のアーキテクチャは生成AIで変わる ? ⑪ 13:30 3分 開発・運用プロセスを支える めのアーキテクチャは生成AIで変わる ? ⑫ 13:33 3分 「業務システム」と「データ基盤」の関係性は生成AIで変わる ? ⑬ 13:36 3分 わりに 94
9. データ加工のアーキテクチャは生成AIで変わる ?(特に非構造化データ)
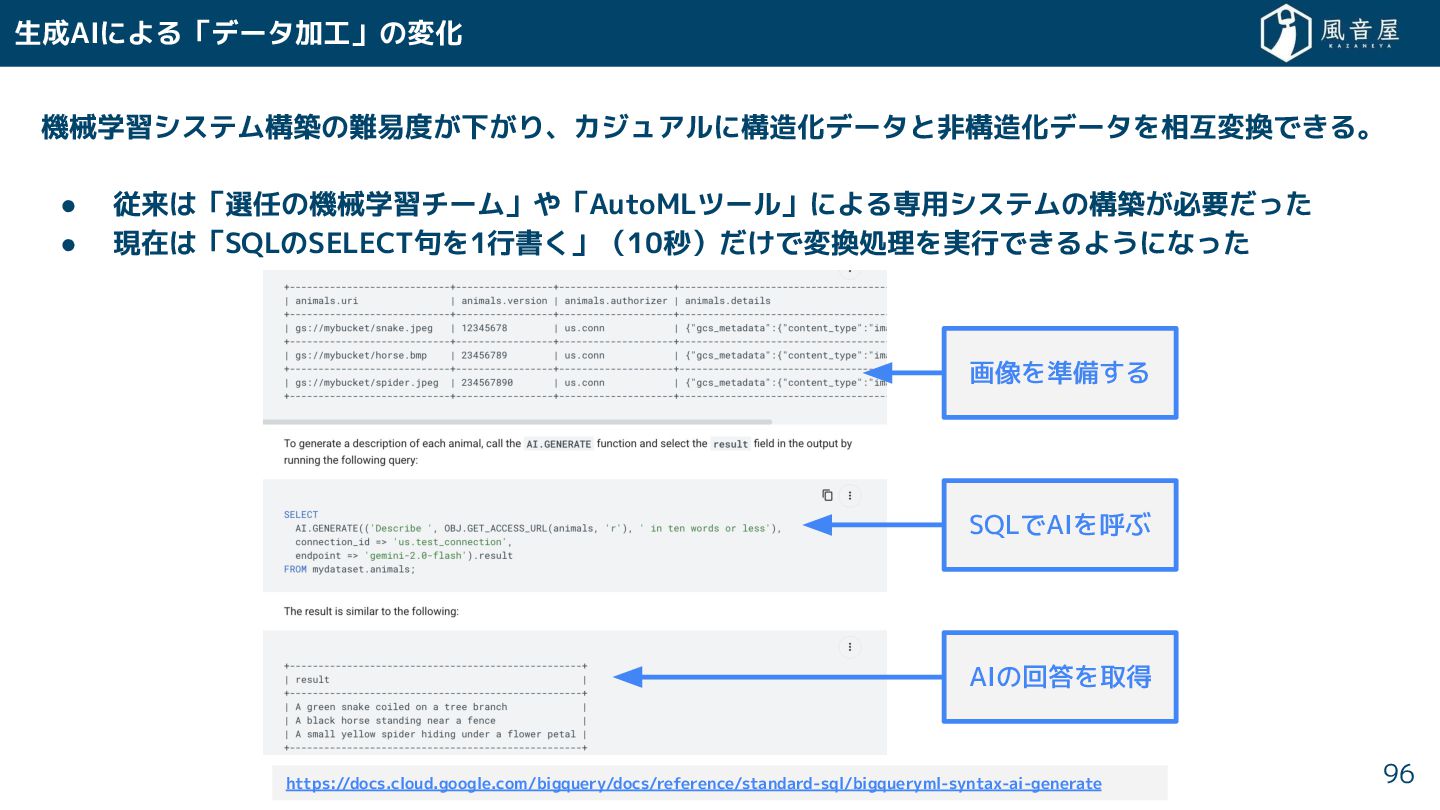
機械学習システム構築の難易度 下 り、カジュアルに構造化データと非構造化データを相互変換で る。 • 従来は「選任の機械学習チーム」や「AutoMLツール」による専用システムの構築 必要 っ • 現在は「SQLのSELECT句を1行書
」(10秒) で変換処理を実行で るようになっ 生成AIによる「データ加工」の変化 96 画像を準備する AIの回答を取得 SQLでAIを呼ぶ https://docs.cloud.google.com/bigquery/docs/reference/standard-sql/bigqueryml-syntax-ai-generate
主要クラウドベンダー各位のトレンドと て、非構造化データの取り扱いを強化 ている。 • ストレージやデータウェアハウス製品に、画像やPDFなどの非構造化データを扱う機能 増え 。 • 生成AIのユースケースと て、
れらのデータを参照 るニーズ 増えている と 主な背景。 • 従来はテーブル形式の処理 メイン っ 、対象データのバリエーション 増え 。 Analytics製品の非構造化データ対応 進む 97
• 各ツール ら文章、画像、動画、PDFファイルなどの非構造化データを集約 る。 • システム 管理 る場合はGCSに置 、必要に応 てBigQueryにデータをロード
る。 • 人間 管理 る場合はGoogle Driveに置 、必要に応 てGCSを経由 てBigQueryにロード る。 • BigQueryのObject Table機能でGCSの非構造化データを参照 、バイナリ形式で機械学習に利用。 データ基盤システム(Google Cloud) 【再掲】社内フォルダ等のデータ取得(ストレージに集約 る場合) 98 インターネット Google Workspace BigQuery ユーザー HTTP リクエスト ファイルを アップロード 各ファイル Google Drive 取得プログラム 例:Python Cloud Run functions 各ファイル GCS 保存 WebAPIコールやスクレイピング 各ツール 外部 テーブル HTTPリクエスト Web API コール HTTP リクエスト
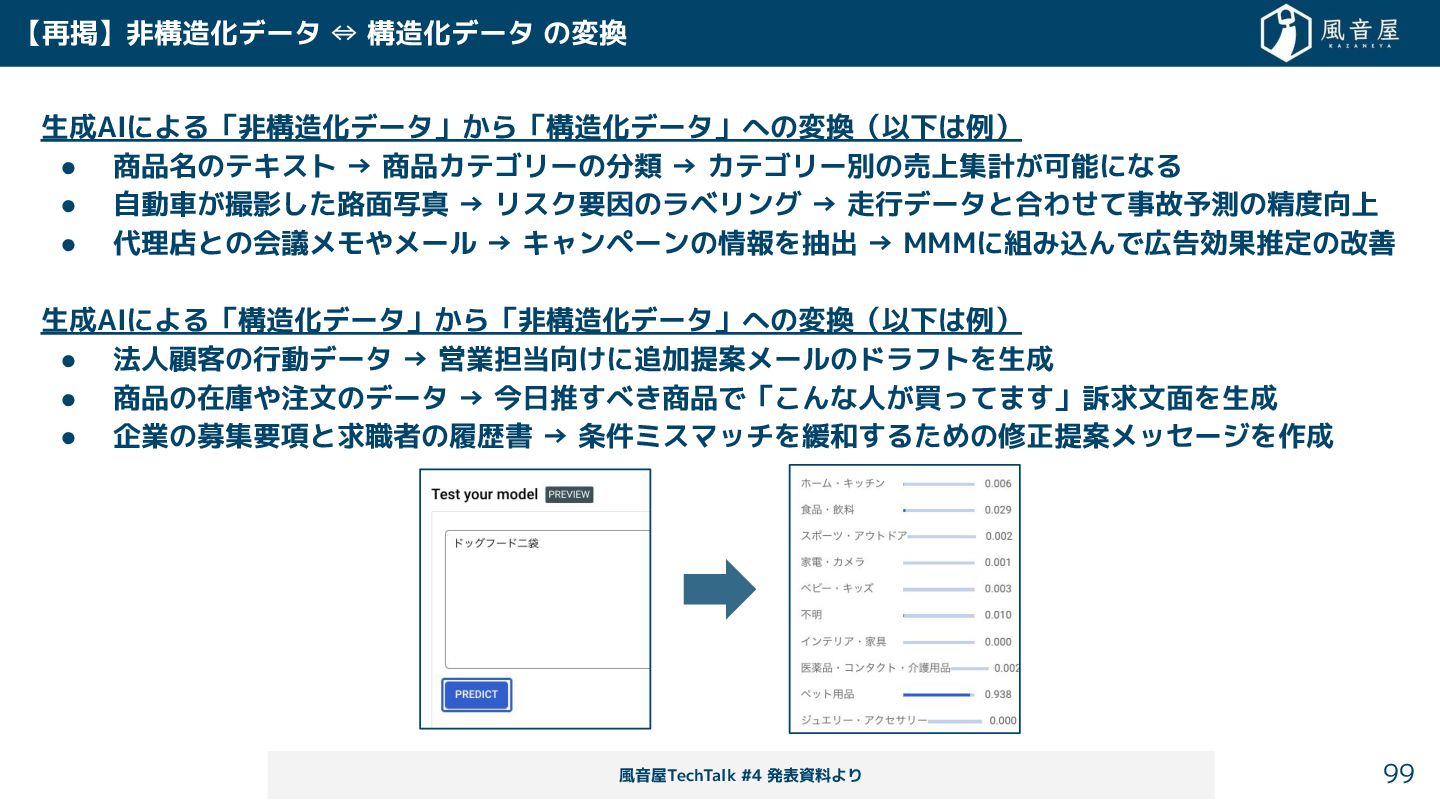
【再掲】非構造化データ ⇔ 構造化データ の変換 生成AIによる「非構造化データ」 ら「構造化データ」への変換(以下は例) • 商品名のテキスト → 商品カテゴリーの分類
→ カテゴリー別の売上集計 可能になる • 自動車 撮影 路面写真 → リスク要因のラベリング → 走行データと合わ て事故予測の精度向上 • 代理店との会議メモやメール → キャンペーンの情報を抽出 → MMMに組み込んで広告効果推定の改善 生成AIによる「構造化データ」 ら「非構造化データ」への変換(以下は例) • 法人顧客の行動データ → 営業担当向 に追加提案メールのドラフトを生成 • 商品の在庫や注文のデータ → 今日推 べ 商品で「 んな人 買ってま 」訴求文面を生成 • 企業の募集要項と求職者の履歴書 → 条件ミスマッチを緩和 る めの修正提案メッセージを作成 99 風音屋TechTalk #4 発表資料より
【再掲】非構造化データ in データパイプライン パイプラインに組み込む どう で2つのアプローチ 考えられる。 1. データパイプラインに組み込む場合。BigQuery ML
GeminiでSQL らGeminiを実行 る。 2. 従来のパイプラインに組み込ま 、Gemini Enterpriseに各データを集約 てAI側で完結 る。 100 非構造化データ データパイプライン 構造化データ 非構造化データ ①生成AIで前処理 ②生成AIで出力作成
非構造化データの3層構造 Garbage In, Garbage Out(ゴミを入れ らゴミ 出て る) • 社内文書や動画ファイルはボリューム
多い割に、品質 低 っ り、ノイズ情報も混 る。 • 生成AI 一度に記録・利用で るデータ量には上限 ある。 • ルンバ( 掃除ロボット)を動 めに、床の物を片付 るのと同 。事前に整える。 構造化データと同 ようにデータの整理 必要 • 元のファイル(入口)→整理 情報(中間)→用途に必要な情報(出口)を整備 る。 • “ゆ ”の3層構造の「データレイク層」「データウェアハウス層」「データマート層」に該当。 の領域は生成AIの台頭に伴って急進化 始まっ フェーズ • 現時点で れ というリファレンスアーキテクチャ 定まっていない。 • データの持 方も定まっていない。テキストを書 直 もの、文書ベクトル、グラフ構造 etc…? • 対応 るソリューションも違う。BigQuery、Vertex AI Feature Store、Spanner Graph etc…? ◦ グラフDBの構築はToo MuchなのでGIS機能と似 位置付 のBigQuery Graph 欲 い。 101 ソース 水源 レイク 湖 = 蓄積 る ウェアハウス 倉庫 = 管理 る マート 市場 = 売る ユーザー 利用者
「データウェアハウス製品」 ら(AWS 言う)「データレイク」への揺れ戻 ? • 非構造化データの中間加工のパターンやベストプラクティスはま 決まっていない。 ◦ ベクトル化やグラフ構造など、非構造化データを扱う めの作法
複数あり、解 定まらない。 ◦ 非構造化データモデリング分野の体系化とソリューション実装 必要なフェーズ。 • 必要なツールや機能もま 出揃っていない。 ◦ 次の3年間は状況 日々変わってい ように思える。 ◦ 現時点では既存のリファレンスアーキテクチャを踏襲 、3年後に式年遷宮でも良い も。 • クラウドストレージに元データを置いて いて、後 ら修正で るように て の 大事。 ◦ AWS 言う「データレイク」本来のコンセプトに(一周回って)立 戻る。 ◦ 一方で、2010年代はAWS + Snowflake構成 人気 っ ように、DWH製品に寄 る世界観 グローバルで受 入れられて 。 ◦ 両者の擦り合わ な れて、次の進化 起 るタイミング。ま に技術の螺旋。 102 https://speakerdeck.com/twada/understanding-the-spiral-of-technologies-2025-edition
補足:AWSに る(主にS3を中心と )データレイク データウェアハウス、データレイク、 よびデータマートは、異なるクラウドストレージソリューション で 。(中略) データウェアハウスは、構造化 れ 形式でデータを格納
ま 。 れは、分析 よびビジネスインテリ ジェンス用に前処理 れ データの中心的なリポジトリで 。(中略) データマートは、企業の財務部門、マーケティング部門、営業部門など、特定のビジネスユニットのニー ズに対応 るデータウェアハウスで 。(中略) 一方、データレイクは、生データと非構造化データの中心的なリポジトリで 。最初にデータを保存 、 後で処理で ま 。 https://aws.amazon.com/jp/compare/the-difference-between-a-data-warehouse-data-lake-and-data-mart/ https://aws.amazon.com/jp/big-data/datalakes-and-analytics/datalakes/ 103
本日のタイムスケジュール 開始目安 所要時間 アジェンダ ① 13:00 3分 は めに ②
13:03 3分 自己紹介 ③ 13:06 3分 データ活用の事例 ④ 13:09 3分 レガシーなプラットフォームを刷新 ようにもど ら着手 べ 【既知】 ⑤ 13:12 3分 実際に刷新 ても保守運用 うま 回ら 使い物にならない問題【既知】 ⇒「 も もニーズを満 ているの 」編 ⑥ 13:15 3分 ⇒「 も もマジメに運用保守を ているの 」編 ⑦ 13:18 3分 「横断的なデータ基盤」と「個々のAIツール」の関係性は? ⑧ 13:21 3分 データ収集(狭義のETL処理)のアーキテクチャは生成AIで変わる ? ⑨ 13:24 3分 データ加工のアーキテクチャは生成AIで変わる ?(特に非構造化データ) ⑩ 13:27 3分 メタデータ管理のアーキテクチャは生成AIで変わる ? ⑪ 13:30 3分 開発・運用プロセスを支える めのアーキテクチャは生成AIで変わる ? ⑫ 13:33 3分 「業務システム」と「データ基盤」の関係性は生成AIで変わる ? ⑬ 13:36 3分 わりに 104
10. メタデータ管理のアーキテクチャは生成AIで変わる ?
1)生成AI⇒メタデータ:生成AIによってメタデータ拡充 容易になる。 • メタデータの一部は「非構造化データ」であり、従来は人間 入力・編集 る必要 あっ 。 • 生成AIによって非構造化データを自動処理で
るようになり、メタデータ拡充 容易となっ 。 2)メタデータ⇒生成AI:生成AIを使う めにメタデータ拡充 必要になる。 • もともとデータカタログ機能強化のトレンド あっ 。生成AIへの需要で らに加速。 ◦ 2020年前後に大手各社でもデータウェアハウス製品 普及 、カタログ管理の課題 顕在化。 • 生成AIにコンテキストを与えて処理精度を改善 るにはメタデータの整備 必要となる。 ◦ 主要クラウドベンダー各位のトレンドと て、AIエージェント関連の機能提供とセットで メタデータ整備に関 る機能を強化・充実 ている。 生成AIによる「メタデータ整備」の変化 106
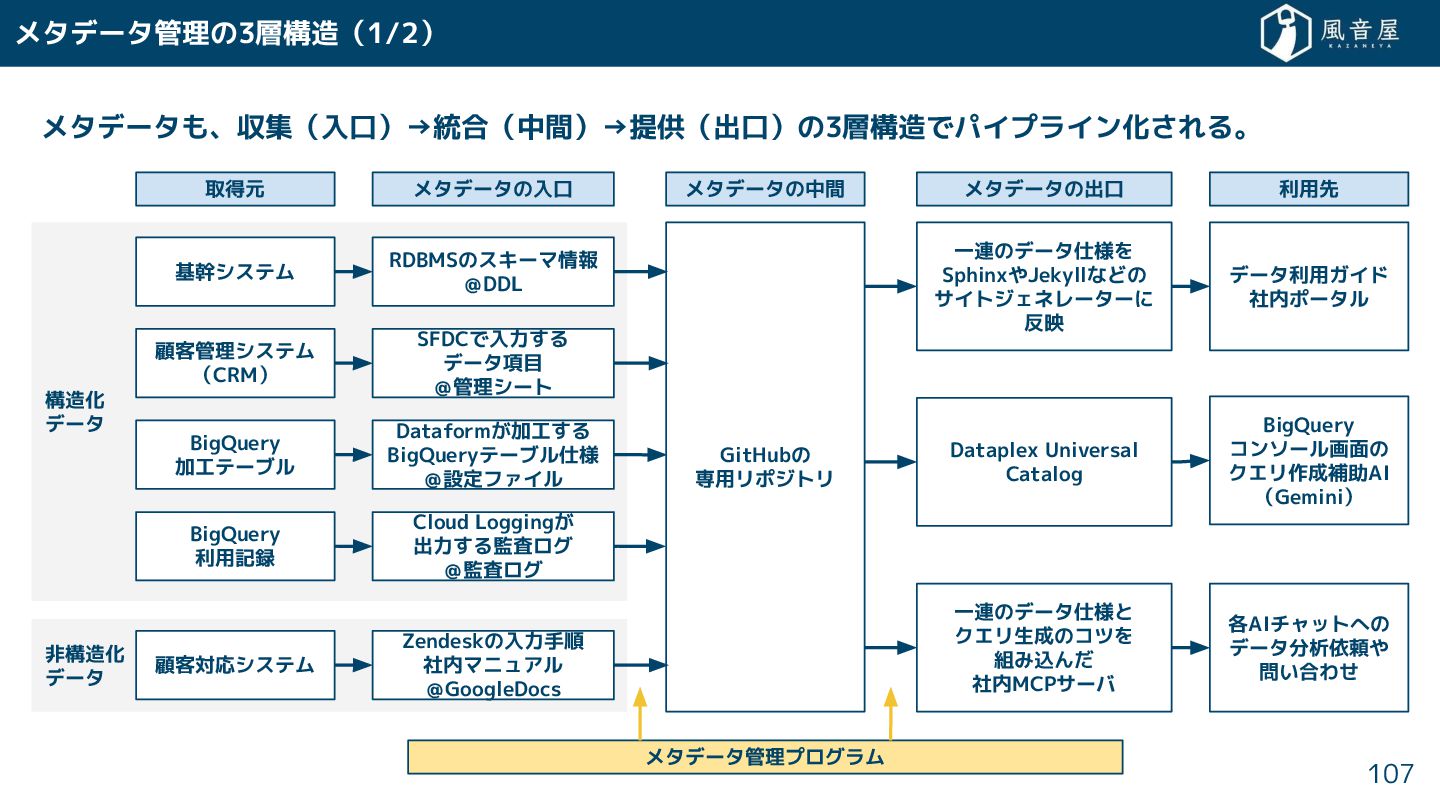
非構造化 データ 構造化 データ メタデータ管理の3層構造(1/2) メタデータも、収集(入口)→統合(中間)→提供(出口)の3層構造でパイプライン化 れる。 107 RDBMSのスキーマ情報 @DDL
SFDCで入力 る データ項目 @管理シート Dataform 加工 る BigQueryテーブル仕様 @設定ファイル BigQuery コンソール画面の クエリ作成補助AI (Gemini) 各AIチャットへの データ分析依頼や 問い合わ データ利用ガイド 社内ポータル Dataplex Universal Catalog 一連のデータ仕様と クエリ生成のコツを 組み込ん 社内MCPサーバ 一連のデータ仕様を SphinxやJekyllなどの サイトジェネレーターに 反映 基幹システム 顧客管理システム (CRM) BigQuery 加工テーブル BigQuery 利用記録 Cloud Logging 出力 る監査ログ @監査ログ 顧客対応システム Zendeskの入力手順 社内マニュアル @GoogleDocs 取得元 メタデータの入口 メタデータの出口 利用先 メタデータの中間 GitHubの 専用リポジトリ メタデータ管理プログラム
メタデータ管理の3層構造(2/2) 前提:システムで自動化で るものは自動化 、人間は人間に 扱えない情報に専念 る。 • システムで自動生成 れ メタデータは
うと分 るように自動生成のラベルをつ る。 • 人間 チェック ら認証済みのラベルを、管理部門 承認 ら「公式」ラベルをつ る。 入口:データを生成 る人 、データを生成 る箇所で、メタデータを管理 る。 • 例:SFDCの設定は管理者 シートで管理。RDBMSのスキーマはSREチーム DDLで管理。 • 理由1:データ基盤以外の通常業務でも使う め。何ら の形でメタデータは必要。 • 理由2:データ利用者 事後調査 ると1日 る。担当者本人 事前記入 ると10分で済む。 中間: れ れのメタデータを集約管理 る。 • 現状、 を満 るツール 世にない め、各社 GitHub管理の仕組みを作っている。 出口:メタデータの利用箇所に合わ 場所・形式でメタデータを連携 る。 • 例:GeminiでBigQueryを使う場合はDataplex Universal Caralogにメタデータ 必要。 108
本日のタイムスケジュール 開始目安 所要時間 アジェンダ ① 13:00 3分 は めに ②
13:03 3分 自己紹介 ③ 13:06 3分 データ活用の事例 ④ 13:09 3分 レガシーなプラットフォームを刷新 ようにもど ら着手 べ 【既知】 ⑤ 13:12 3分 実際に刷新 ても保守運用 うま 回ら 使い物にならない問題【既知】 ⇒「 も もニーズを満 ているの 」編 ⑥ 13:15 3分 ⇒「 も もマジメに運用保守を ているの 」編 ⑦ 13:18 3分 「横断的なデータ基盤」と「個々のAIツール」の関係性は? ⑧ 13:21 3分 データ収集(狭義のETL処理)のアーキテクチャは生成AIで変わる ? ⑨ 13:24 3分 データ加工のアーキテクチャは生成AIで変わる ?(特に非構造化データ) ⑩ 13:27 3分 メタデータ管理のアーキテクチャは生成AIで変わる ? ⑪ 13:30 3分 開発・運用プロセスを支える めのアーキテクチャは生成AIで変わる ? ⑫ 13:33 3分 「業務システム」と「データ基盤」の関係性は生成AIで変わる ? ⑬ 13:36 3分 わりに 109
11. 開発・運用プロセスを支える めのアーキテクチャは生成AIで変わる ?
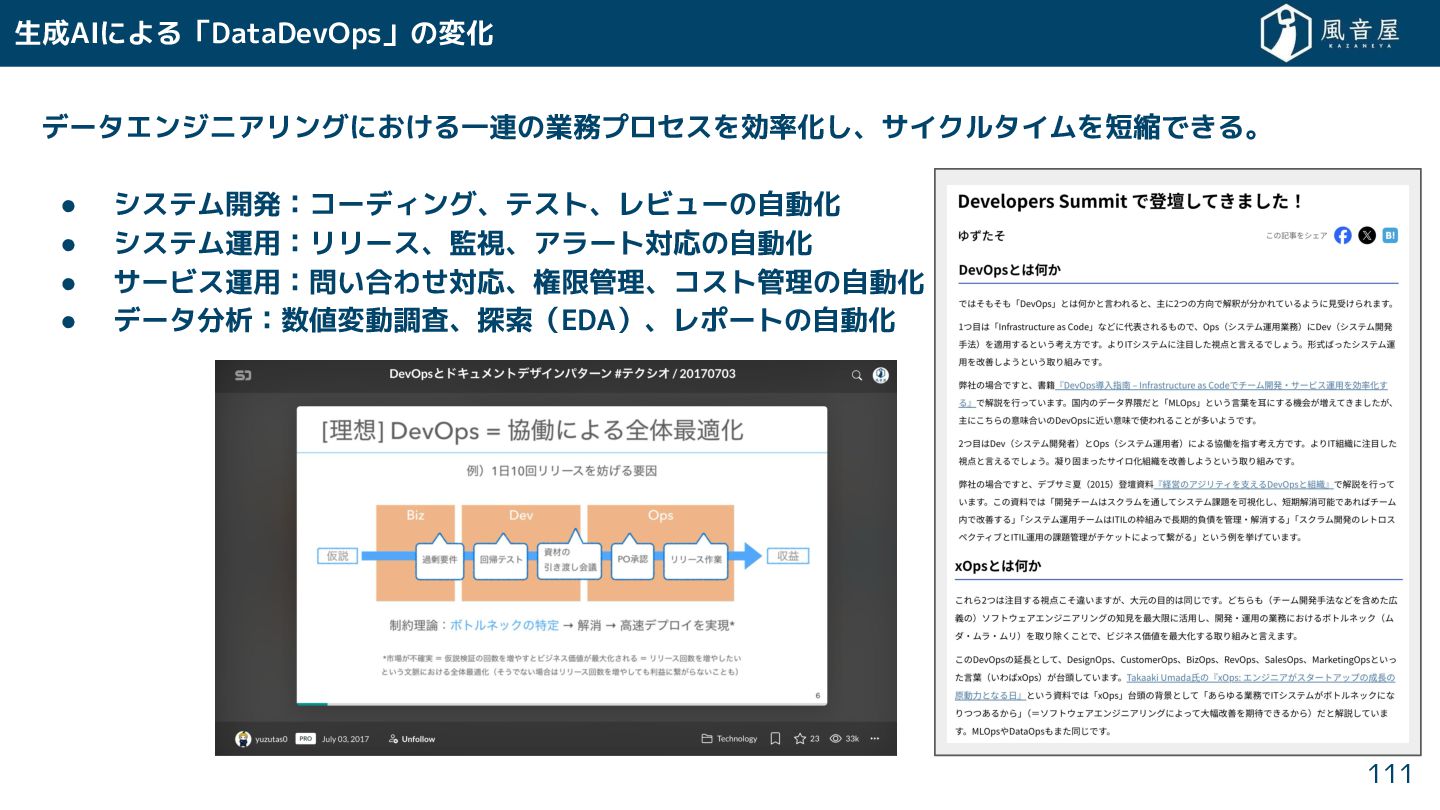
データエンジニアリングに る一連の業務プロセスを効率化 、サイクルタイムを短縮で る。 • システム開発:コーディング、テスト、レビューの自動化 • システム運用:リリース、監視、アラート対応の自動化 • サービス運用:問い合わ
対応、権限管理、コスト管理の自動化 • データ分析:数値変動調査、探索(EDA)、レポートの自動化 生成AIによる「DataDevOps」の変化 111
開発標準・開発環境(1/2) 112 ▪ リポジトリ:コードの置 場。 • Git:コードの差分や履歴を管理 るツール。AIエージェント ミスを ても復旧で
る。 • GitHub:Git管理のコードをチームで共有 、開発を進めてい めのツール。 • GitHub Actions:GitHubの機能。Linterや自動テスト、Terraform等の処理を実行で る。 ▪ CI(継続的インテグレーション):継続的にコードを開発 、安全 つ効率的に統合 る。 • Linter:コード 社内ルールに沿っ 書 方になっている とを自動チェック る仕組み。 ◦ 例:PythonならRuff、SQLならSQLFluff、TerraformならTFLint、。 • 自動テスト:コード 期待通りに挙動 る とを自動でチェック る めの仕組み。 • Code Rabbit:GitHubで人間の代わりにコードレビュー て れるAI。 ◦ 「シニアデータエンジニアと て振る舞って」「若手に助言 るようにレビュー て」 「若手の反論 甘 っ ら徹底的にツッコミ て」と設定 ると、丁寧に教えて れる。 ▪ CD(継続的デリバリー):継続的にコードを本番環境へとリリース る活動。 • Terraform:クラウドインフラをコードで管理 て、自動構築 る めのツール。 ◦ IaC(Infrastructure as Code)なる概念。画面操作と異なり、作業ミス防止や横展開 容易。 ◦ 例:BigQueryの設定をコードで管理 て、GitHubでレビュー 通っ ら自動反映。
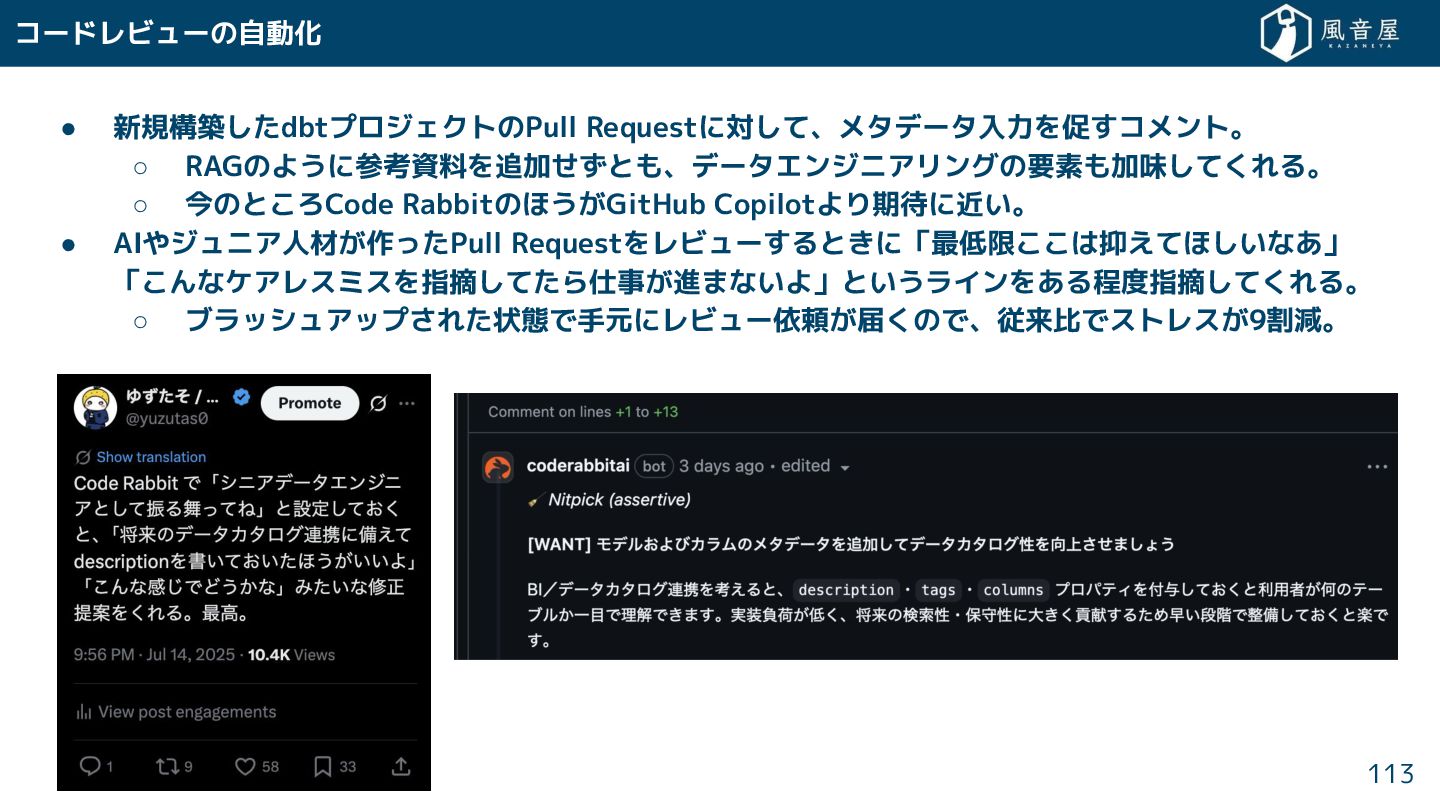
コードレビューの自動化 113 • 新規構築 dbtプロジェクトのPull Requestに対 て、メタデータ入力を促 コメント。 ◦ RAGのように参考資料を追加
とも、データエンジニアリングの要素も加味 て れる。 ◦ 今のと ろCode Rabbitのほう GitHub Copilotより期待に近い。 • AIやジュニア人材 作っ Pull Requestをレビュー ると に「最低限 は抑えてほ いなあ」 「 んなケアレスミスを指摘 て ら仕事 進まないよ」というラインをある程度指摘 て れる。 ◦ ブラッシュアップ れ 状態で手元にレビュー依頼 届 ので、従来比でストレス 9割減。
開発標準・開発環境(2/2) 114 ▪ 開発標準:自社のルールを決め り、仕組みを自動化 る とで開発効率を上 る。 • テンプレート:要件定義フォーマット、セキュリティ設計シート、コスト計測シート
etc…。 • 規約/ガイドライン:Pythonコーディング規約、SQL規約、データモデリング標準 etc…。 ▪ 開発AIエージェント:Terraformを含めて一連のプログラムを自動実装 るツール。 • Cursor:ローカル環境のIDEでユーザーに編集提案 て れる。 • Claude Code:ローカル環境のターミナルで自律開発 て れる。Gemini CLIも の立 位置(?) • Claude Code Actions:GitHubでのユーザーコメントをもとに自律開発 て れる。 • Devin:Slackでのユーザーコメントをもとに自律開発 て れる。 ◦ データ分析者 Gemini支援の元でSQLを作り、SlackでDevin君にパイプライン追加を依頼。 ⇒風音屋では一連のデータ基盤システムを クライアント 最短工数で利用開始で る仕組みを構築中。 本資料のように「データ基盤の構築や運用」といっ 業務を 1つ1つ言語化 、手順化 、システムに反映 る とで 徐々に「AI Ready」な開発環境へ進化 てい (は )!
• チャットツールで相談場所を設 る。 ◦ データチームで運用当番を設 てユーザーサポートに当 る。 • よ ある問い合わ
(FAQ)はWikiやデータカタログツールに反映 る。 ◦ 次 らはURLの案内 で済むように る。 ◦ ナレッジを充実 る とでAIの回答精度を高める。 • 自動対応 るチャットBotを構築 る。 ◦ Slackを窓口に るならGoogle CloudのConversational Analytics APIを用いて実装 る。 ◦ 今後はGemini EnterpriseやLooker (Studio Pro) のConversational Analyticsに期待。 ◦ データ項目追加や権限付与依頼はGitHub管理と 、Devin等の開発AIエージェントに任 る。 問い合わ 対応や作業依頼 115 分析相談 レビュー依頼 FAQ 充実化 再利用
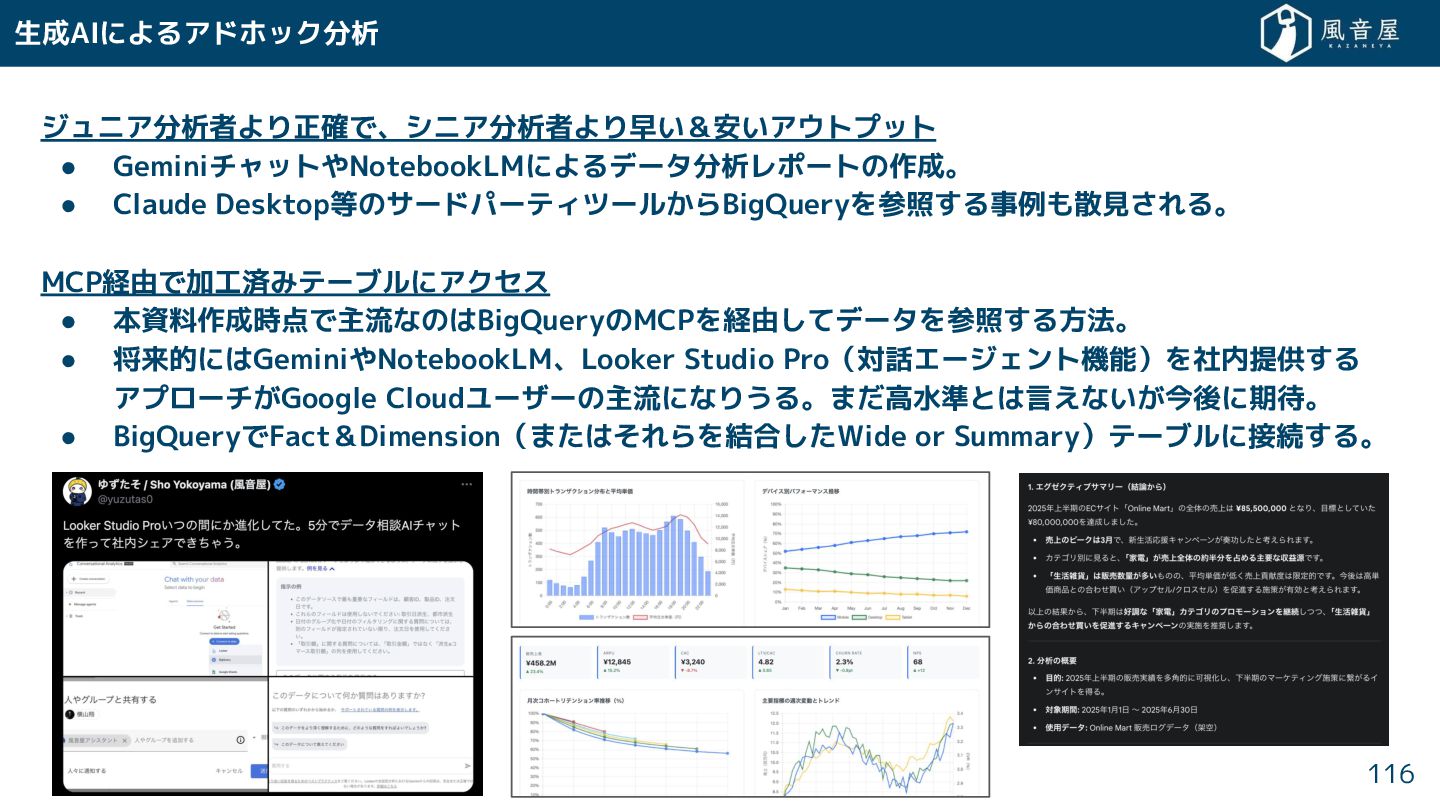
生成AIによるアドホック分析 ジュニア分析者より正確で、シニア分析者より早い&安いアウトプット • GeminiチャットやNotebookLMによるデータ分析レポートの作成。 • Claude Desktop等のサードパーティツール らBigQueryを参照 る事例も散見 れる。
MCP経由で加工済みテーブルにアクセス • 本資料作成時点で主流なのはBigQueryのMCPを経由 てデータを参照 る方法。 • 将来的にはGeminiやNotebookLM、Looker Studio Pro(対話エージェント機能)を社内提供 る アプローチ Google Cloudユーザーの主流になりうる。ま 高水準とは言えない 今後に期待。 • BigQueryでFact&Dimension(ま は れらを結合 Wide or Summary)テーブルに接続 る。 116
生成AI データを正 使う めには、データの整備 必要 50個の「売上テーブル」 存在 てい ら、生成AIはどの「売上」で分析 れば良い
判断で ない。 も も考え方や用途によって「売上」の定義は変わる。 • 消費税を含む? • 途中解約はど に計上 る? • 年間契約は月次で按分 る? • 割引はど で差 引 ? • 返金は後で差 引 ? 購入時に遡って差 引 ? • 通販サイトやアプリ決済の決済手数料を含む? 年間契約を行っ 場合、ある分析では「今月の売上」 大幅に向上 と報告 ても、 別の分析 と月次で按分 ているので1/12の数字になる。 AI 生成 2つのレポートを見比べると「今月の売上」 10倍近 ズレる とになる。 117
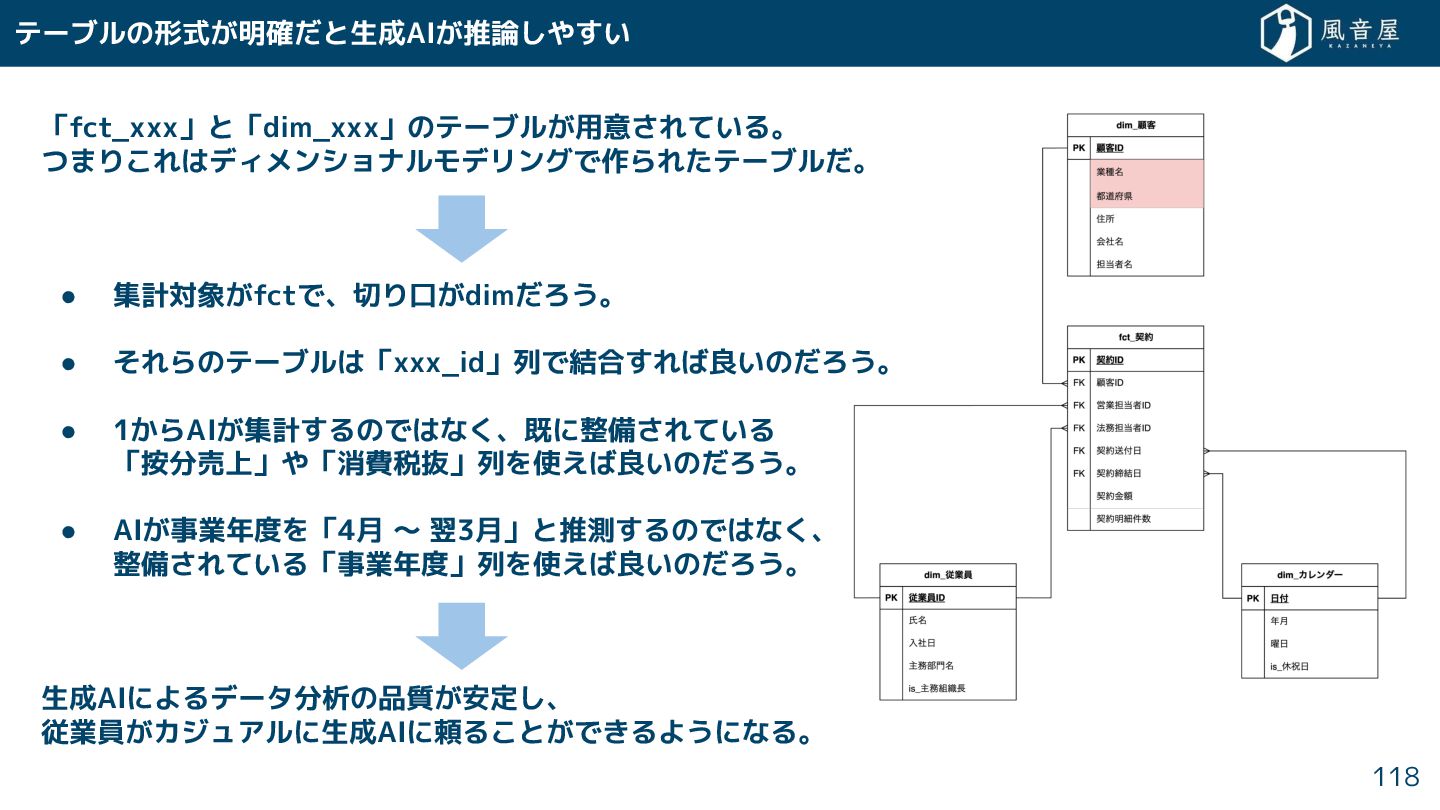
「fct_xxx」と「dim_xxx」のテーブル 用意 れている。 つまり れはディメンショナルモデリングで作られ テーブル 。 • 集計対象 fctで、切り口
dim ろう。 • れらのテーブルは「xxx_id」列で結合 れば良いの ろう。 • 1 らAI 集計 るのではな 、既に整備 れている 「按分売上」や「消費税抜」列を使えば良いの ろう。 • AI 事業年度を「4月 〜 翌3月」と推測 るのではな 、 整備 れている「事業年度」列を使えば良いの ろう。 生成AIによるデータ分析の品質 安定 、 従業員 カジュアルに生成AIに頼る と で るようになる。 テーブルの形式 明確 と生成AI 推論 や い 118
他の有識者 の資料 Microsoft PowerBI はディメンショナルモデリング 前提となる。Copilot 機能を使う場合もま 然り。 https://www.docswell.com/s/yugoes1021/KRXVY2-2024-05-08-213110 メルカリ社のSocrates(分析AIエージェント)はBasic
Tables(信頼で るテーブル)に依拠 ている。 https://note.com/mercari_data/n/n247a65af9bf5 119
本日のタイムスケジュール 開始目安 所要時間 アジェンダ ① 13:00 3分 は めに ②
13:03 3分 自己紹介 ③ 13:06 3分 データ活用の事例 ④ 13:09 3分 レガシーなプラットフォームを刷新 ようにもど ら着手 べ 【既知】 ⑤ 13:12 3分 実際に刷新 ても保守運用 うま 回ら 使い物にならない問題【既知】 ⇒「 も もニーズを満 ているの 」編 ⑥ 13:15 3分 ⇒「 も もマジメに運用保守を ているの 」編 ⑦ 13:18 3分 「横断的なデータ基盤」と「個々のAIツール」の関係性は? ⑧ 13:21 3分 データ収集(狭義のETL処理)のアーキテクチャは生成AIで変わる ? ⑨ 13:24 3分 データ加工のアーキテクチャは生成AIで変わる ?(特に非構造化データ) ⑩ 13:27 3分 メタデータ管理のアーキテクチャは生成AIで変わる ? ⑪ 13:30 3分 開発・運用プロセスを支える めのアーキテクチャは生成AIで変わる ? ⑫ 13:33 3分 「業務システム」と「データ基盤」の関係性は生成AIで変わる ? ⑬ 13:36 3分 わりに 120
12. 「業務システム」と「データ基盤」の関係性は生成AIで変わる ?
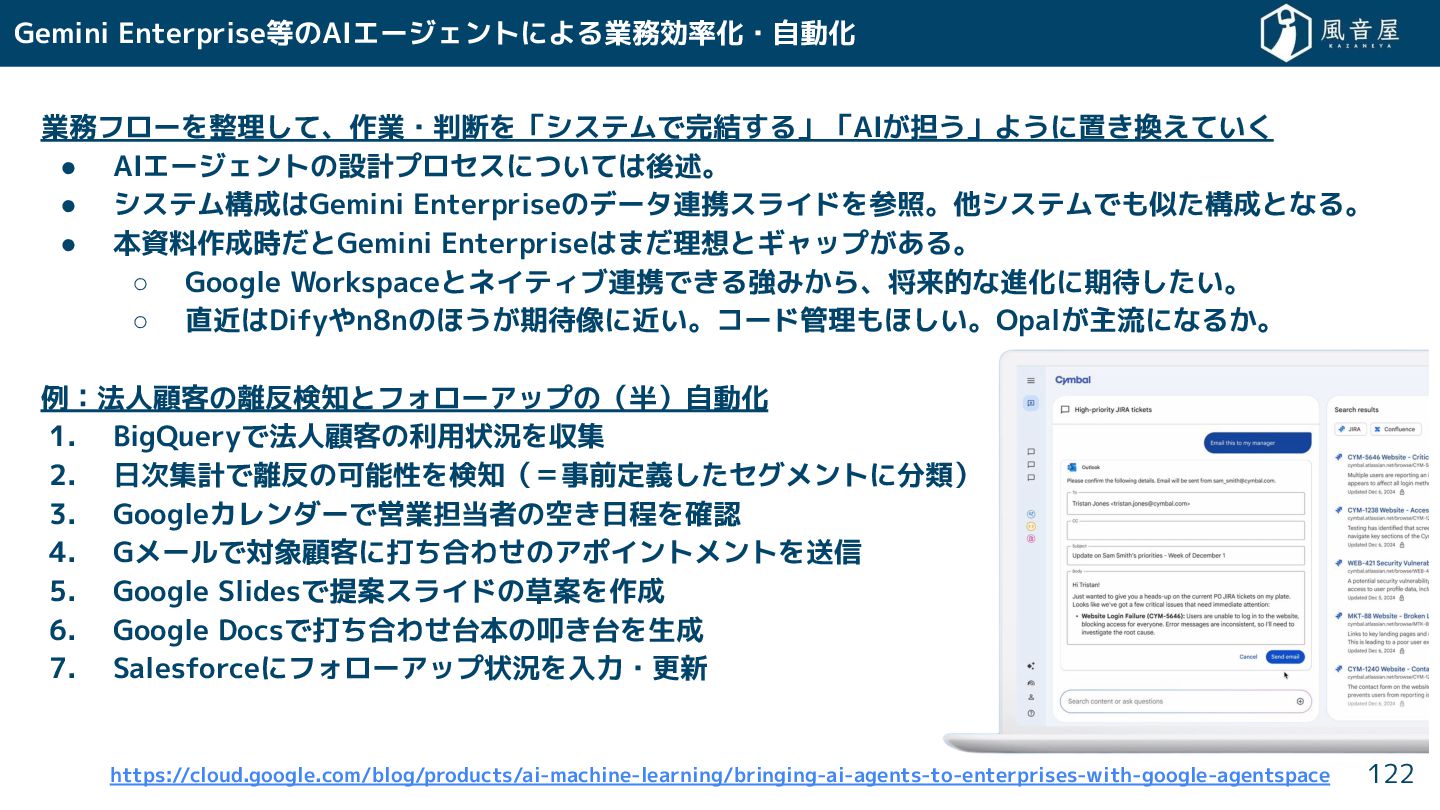
Gemini Enterprise等のAIエージェントによる業務効率化・自動化 業務フローを整理 て、作業・判断を「システムで完結 る」「AI 担う」ように置 換えてい • AIエージェントの設計プロセスについては後述。 •
システム構成はGemini Enterpriseのデータ連携スライドを参照。他システムでも似 構成となる。 • 本資料作成時 とGemini Enterpriseはま 理想とギャップ ある。 ◦ Google Workspaceとネイティブ連携で る強み ら、将来的な進化に期待 い。 ◦ 直近はDifyやn8nのほう 期待像に近い。コード管理もほ い。Opal 主流になる 。 例:法人顧客の離反検知とフォローアップの(半)自動化 1. BigQueryで法人顧客の利用状況を収集 2. 日次集計で離反の可能性を検知(=事前定義 セグメントに分類) 3. Googleカレンダーで営業担当者の空 日程を確認 4. Gメールで対象顧客に打 合わ のアポイントメントを送信 5. Google Slidesで提案スライドの草案を作成 6. Google Docsで打 合わ 台本の叩 台を生成 7. Salesforceにフォローアップ状況を入力・更新 122 https://cloud.google.com/blog/products/ai-machine-learning/bringing-ai-agents-to-enterprises-with-google-agentspace
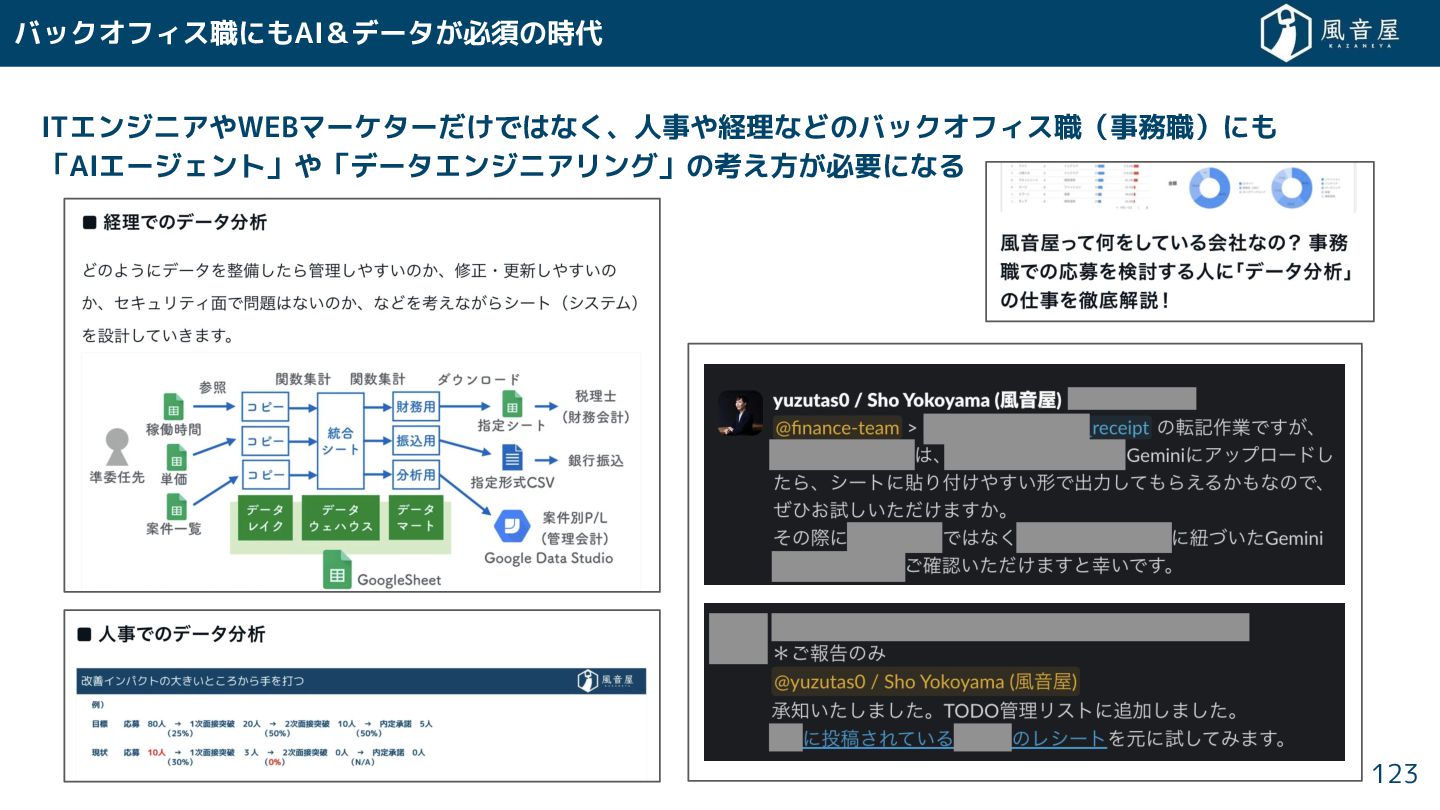
ITエンジニアやWEBマーケター ではな 、人事や経理などのバックオフィス職(事務職)にも 「AIエージェント」や「データエンジニアリング」の考え方 必要になる バックオフィス職にもAI&データ 必須の時代 123
DXの議論を踏襲 つつ、DXとの差分に注目 る 124
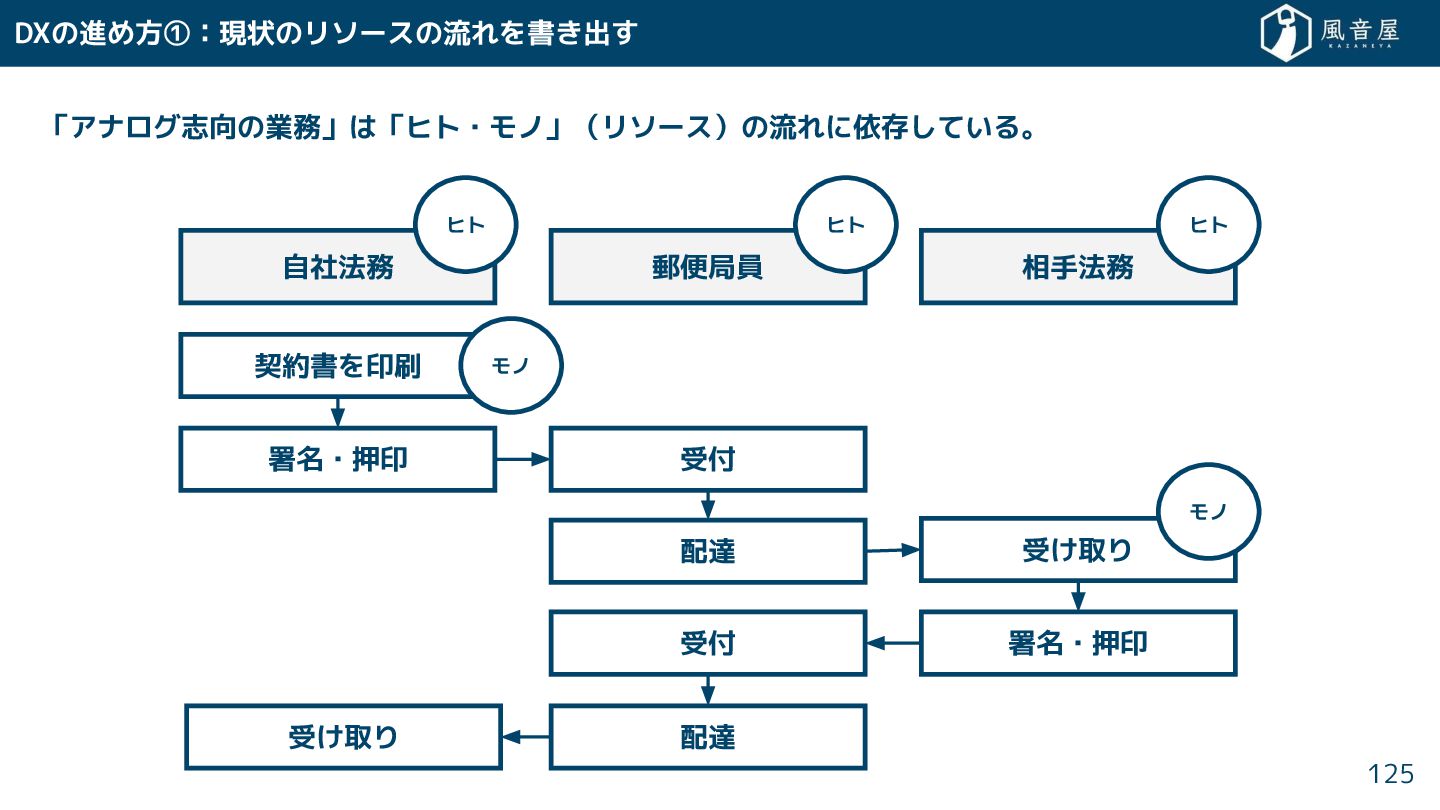
DXの進め方①:現状のリソースの流れを書 出 「アナログ志向の業務」は「ヒト・モノ」(リソース)の流れに依存 ている。 125 自社法務 郵便局員 相手法務 契約書を印刷 署名・押印
受付 配達 受付 配達 受 取り 受 取り 署名・押印 ヒト ヒト ヒト モノ モノ
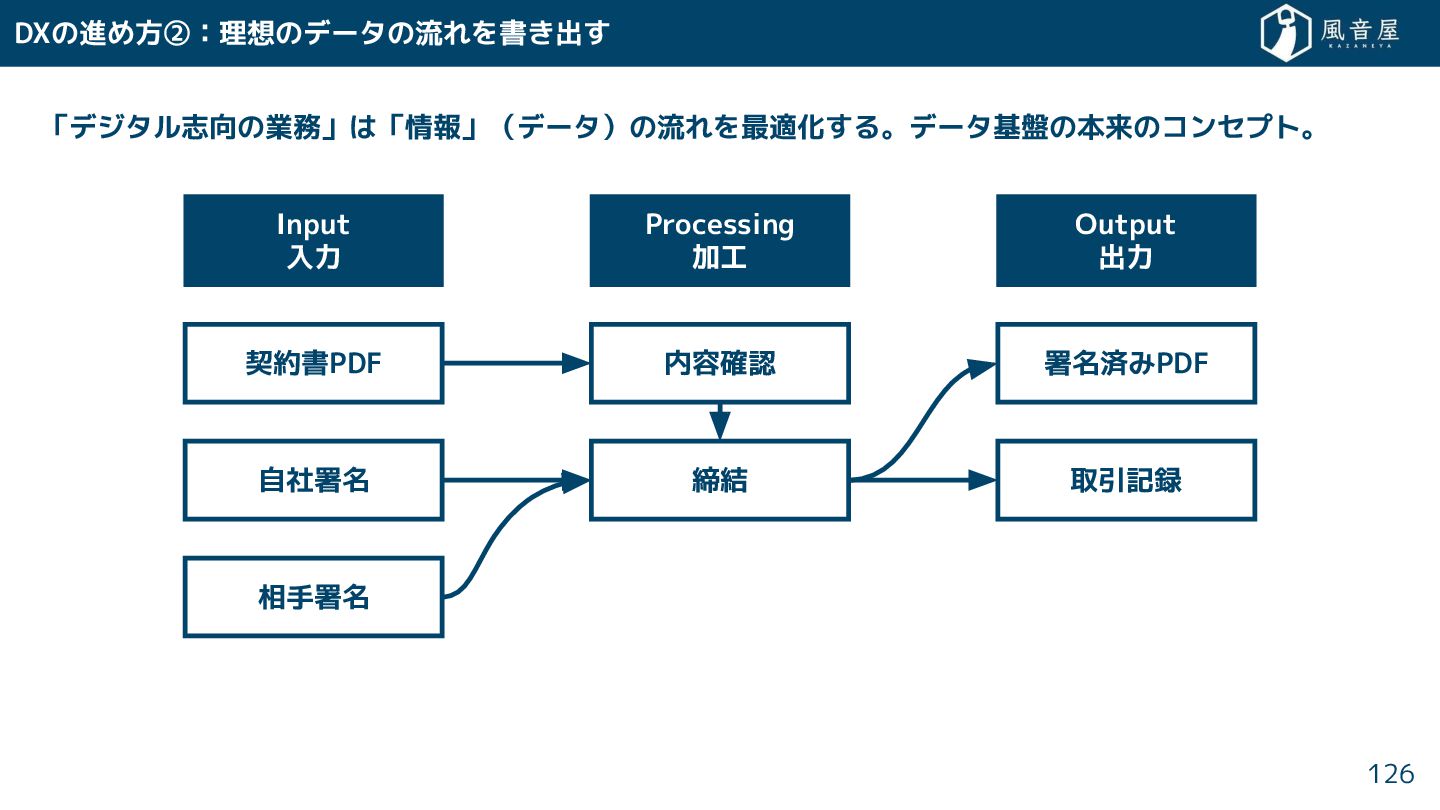
DXの進め方②:理想のデータの流れを書 出 「デジタル志向の業務」は「情報」(データ)の流れを最適化 る。データ基盤の本来のコンセプト。 126 Input 入力 Processing 加工 Output
出力 契約書PDF 自社署名 相手署名 内容確認 締結 署名済みPDF 取引記録
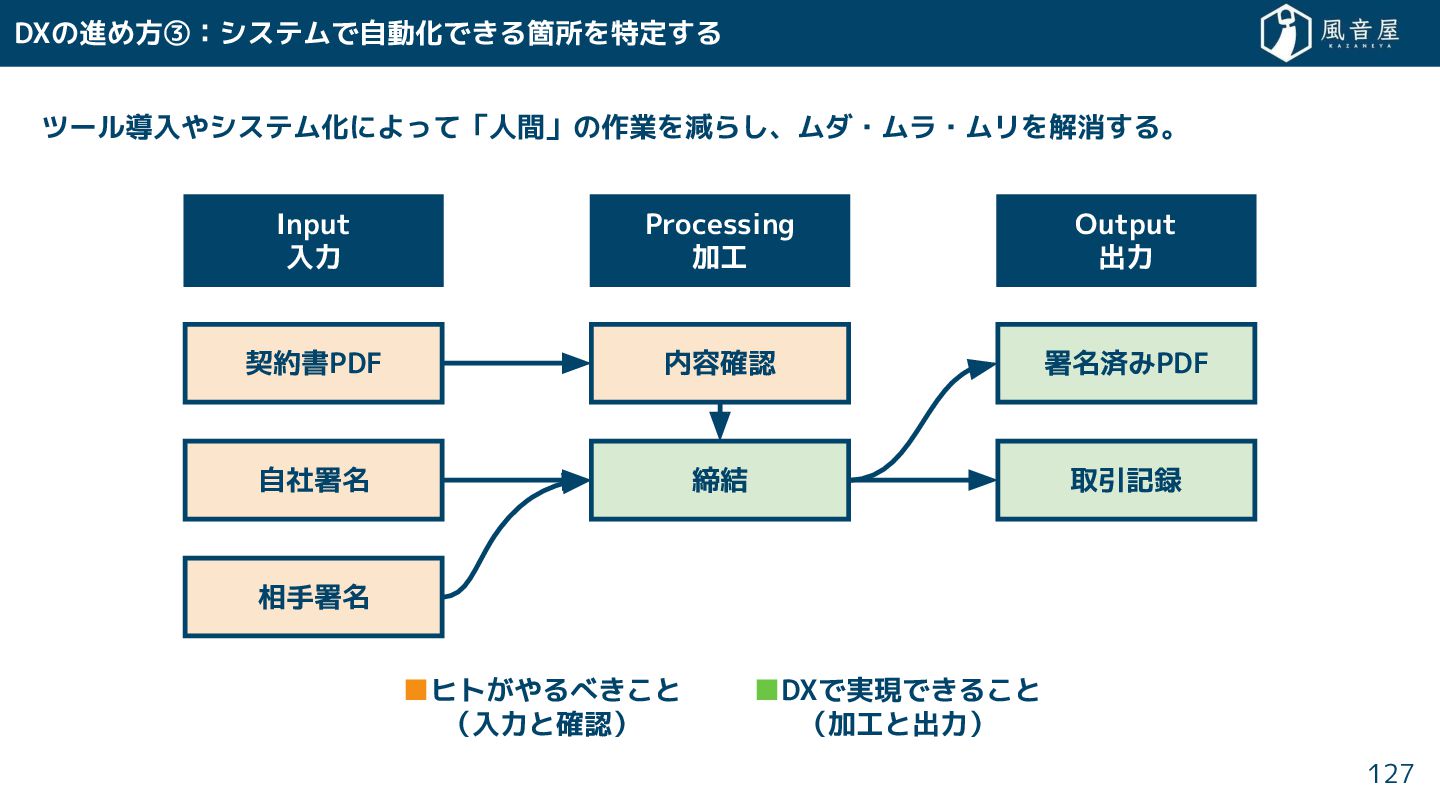
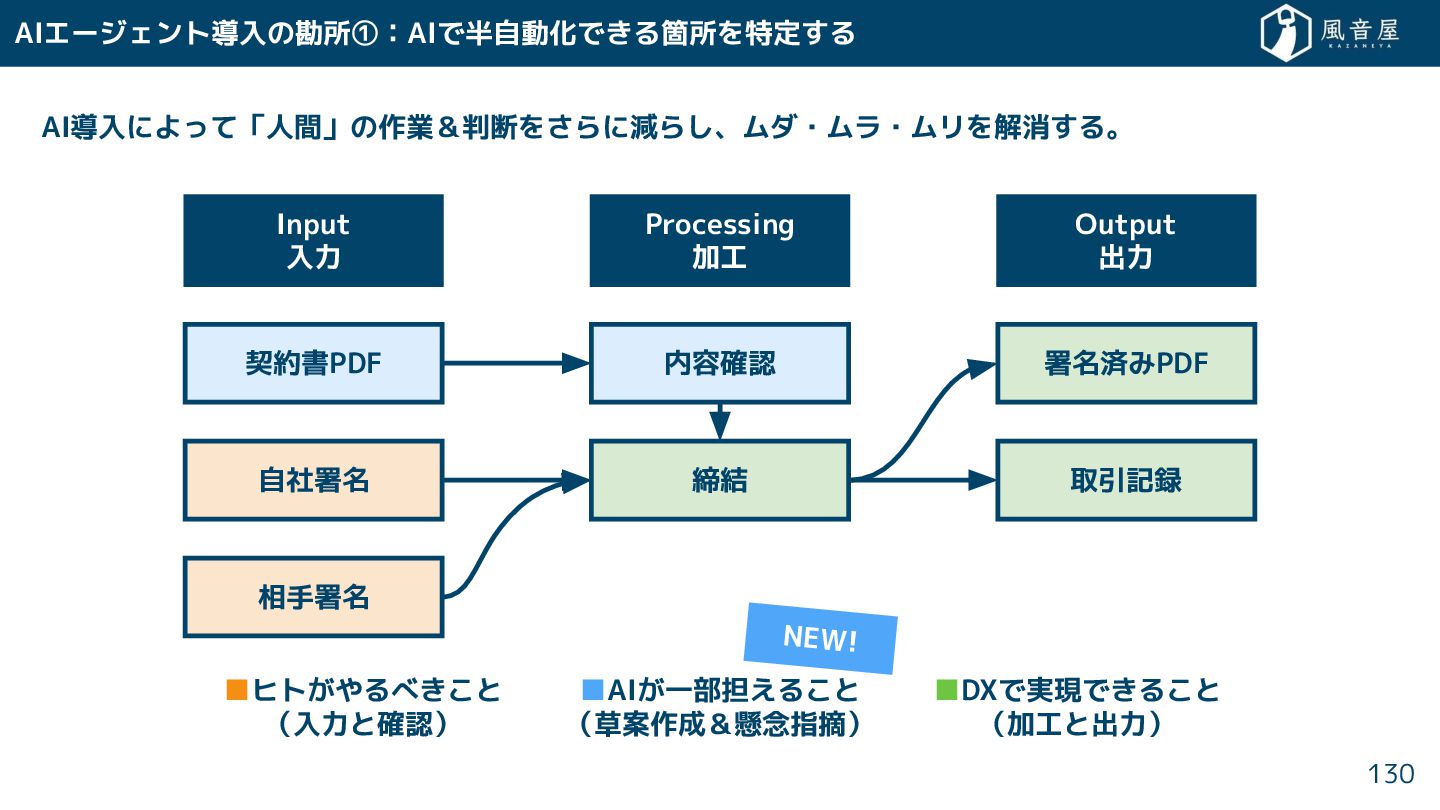
DXの進め方③:システムで自動化で る箇所を特定 る ツール導入やシステム化によって「人間」の作業を減ら 、ムダ・ムラ・ムリを解消 る。 127 Input 入力 Processing
加工 Output 出力 契約書PDF 自社署名 相手署名 内容確認 締結 署名済みPDF 取引記録 ▪ヒト やるべ と (入力と確認) ▪DXで実現で る と (加工と出力)
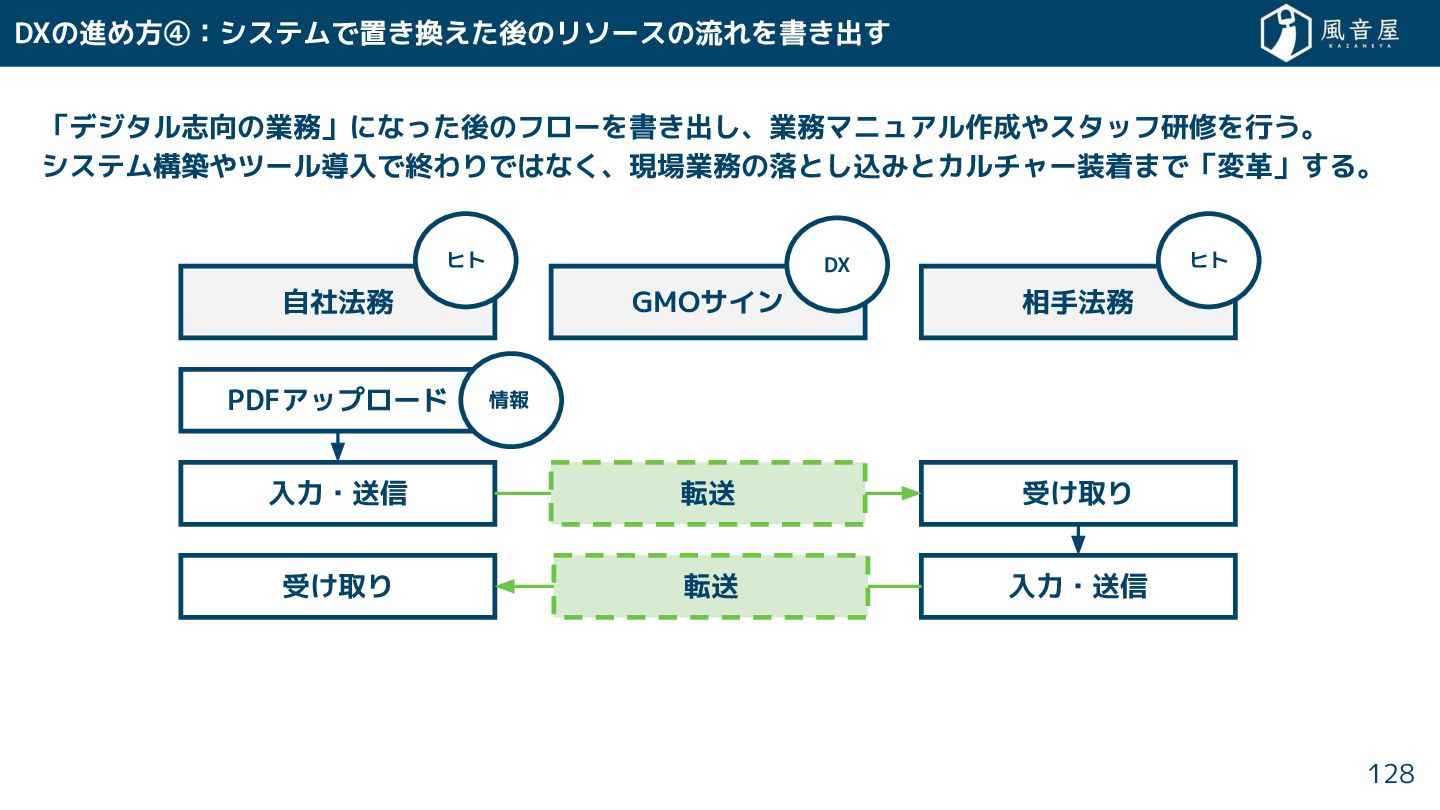
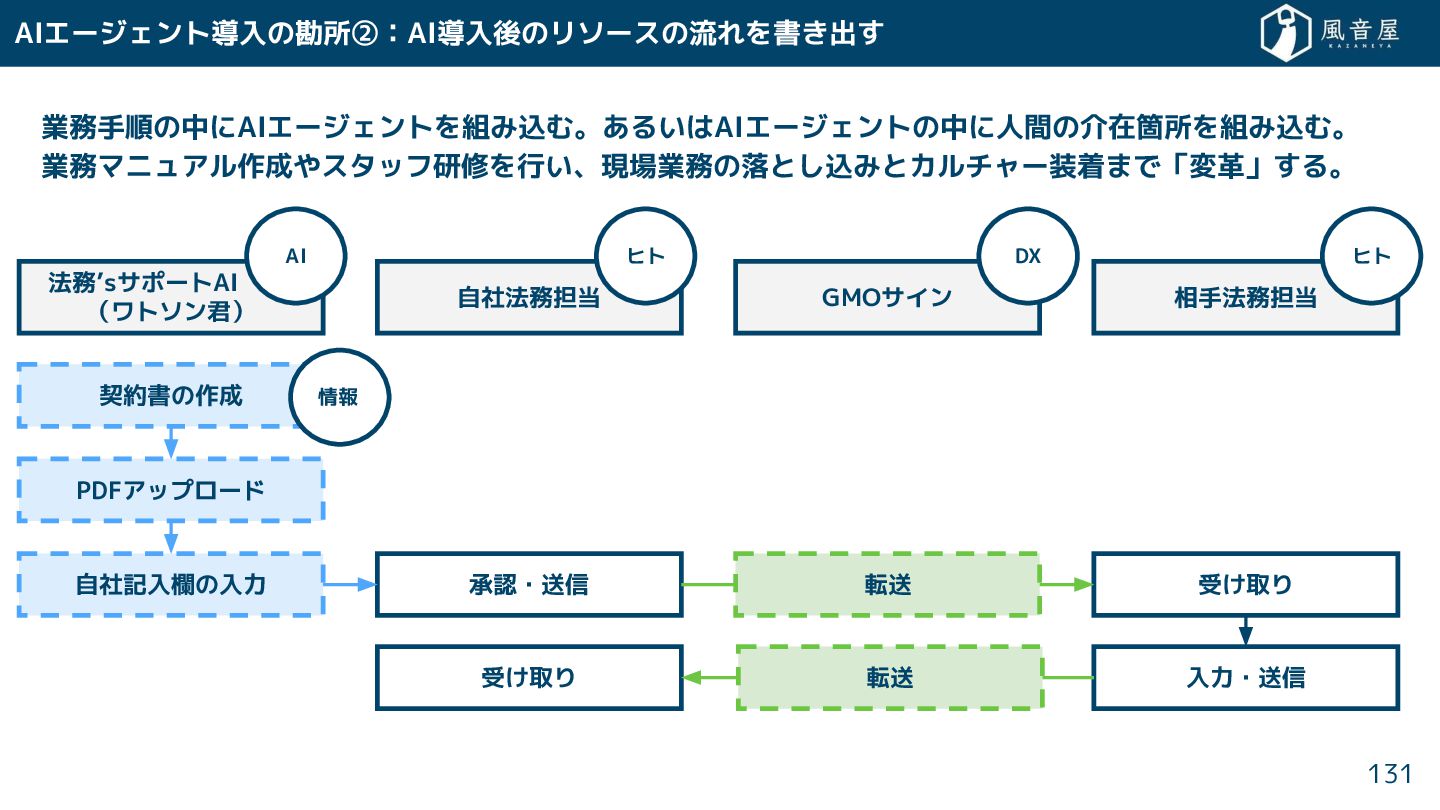
DXの進め方④:システムで置 換え 後のリソースの流れを書 出 「デジタル志向の業務」になっ 後のフローを書 出 、業務マニュアル作成やスタッフ研修を行う。 システム構築やツール導入で終わりではな 、現場業務の落と
込みとカルチャー装着まで「変革」 る。 128 自社法務 GMOサイン 相手法務 PDFアップロード 入力・送信 受 取り 入力・送信 ヒト ヒト 情報 受 取り 転送 転送 DX
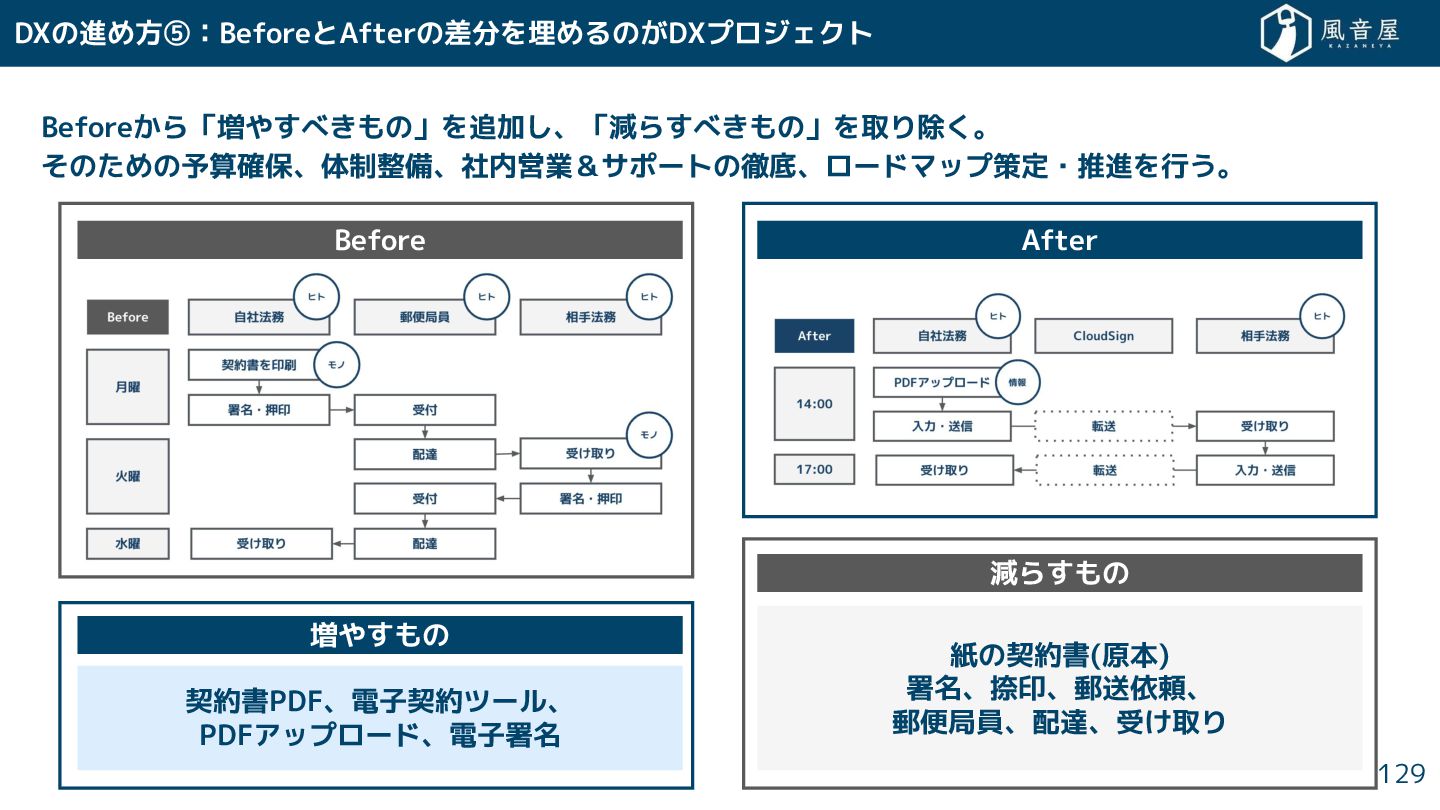
Before ら「増や べ もの」を追加 、「減ら べ もの」を取り除 。 の めの予算確保、体制整備、社内営業&サポートの徹底、ロードマップ策定・推進を行う。
DXの進め方⑤:BeforeとAfterの差分を埋めるの DXプロジェクト 129 After Before 減ら もの 増や もの 契約書PDF、電子契約ツール、 PDFアップロード、電子署名 紙の契約書(原本) 署名、捺印、郵送依頼、 郵便局員、配達、受 取り
AIエージェント導入の勘所①:AIで半自動化で る箇所を特定 る AI導入によって「人間」の作業&判断を らに減ら 、ムダ・ムラ・ムリを解消 る。 130 Input 入力
Processing 加工 Output 出力 契約書PDF 自社署名 相手署名 内容確認 締結 署名済みPDF 取引記録 ▪ヒト やるべ と (入力と確認) ▪DXで実現で る と (加工と出力) ▪AI 一部担える と (草案作成&懸念指摘) NEW!
AIエージェント導入の勘所②:AI導入後のリソースの流れを書 出 業務手順の中にAIエージェントを組み込む。あるいはAIエージェントの中に人間の介在箇所を組み込む。 業務マニュアル作成やスタッフ研修を行い、現場業務の落と 込みとカルチャー装着まで「変革」 る。 131 自社法務担当 GMOサイン 相手法務担当
PDFアップロード 承認・送信 受 取り 入力・送信 ヒト ヒト 受 取り 転送 転送 法務’sサポートAI . (ワトソン君) 契約書の作成 自社記入欄の入力 情報 DX AI
業務システムやAIシステムを高速開発で るデータテクノロジー 台頭 132
AIネイティブな時代の「ビジネス」や「オペレーション」の行 着 先 あらゆる事業(ビジネス)や業務(オペレーション)は以下の一連の活動と言える。 • 何ら のリソースを投入(Input) て • 何ら
の価値を付加(Processing) て • 何ら の財・サービスを提供(Output) る AIエージェントによって「情報」(データ)の担う部分 拡大 る。 結果、あらゆるビジネスやオペレーション 「データエンジニアリング」化 る。 • 「情報」(データ)の流れを制御 る中核システム 「データ基盤」 • 「情報」(データ)の流れを制御 る活動 「データエンジニアリング」 ⇒Development(仕組みの構築) 「データエンジニアリング」と「AIエージェント導入」と「業務定義」と「経営」と 一体化 る。 ⇒Operations(仕組みの運営) 「データ基盤」と「AIエージェント」と「業務フロー」と「事業運営」と 一体化 る。 133
本日のタイムスケジュール 開始目安 所要時間 アジェンダ ① 13:00 3分 は めに ②
13:03 3分 自己紹介 ③ 13:06 3分 データ活用の事例 ④ 13:09 3分 レガシーなプラットフォームを刷新 ようにもど ら着手 べ 【既知】 ⑤ 13:12 3分 実際に刷新 ても保守運用 うま 回ら 使い物にならない問題【既知】 ⇒「 も もニーズを満 ているの 」編 ⑥ 13:15 3分 ⇒「 も もマジメに運用保守を ているの 」編 ⑦ 13:18 3分 「横断的なデータ基盤」と「個々のAIツール」の関係性は? ⑧ 13:21 3分 データ収集(狭義のETL処理)のアーキテクチャは生成AIで変わる ? ⑨ 13:24 3分 データ加工のアーキテクチャは生成AIで変わる ?(特に非構造化データ) ⑩ 13:27 3分 メタデータ管理のアーキテクチャは生成AIで変わる ? ⑪ 13:30 3分 開発・運用プロセスを支える めのアーキテクチャは生成AIで変わる ? ⑫ 13:33 3分 「業務システム」と「データ基盤」の関係性は生成AIで変わる ? ⑬ 13:36 3分 わりに 134
13. わりに
本講演のスコープ 対象 • 「ど ら刷新 る 」「刷新 データ基盤 現場で使われない」の解説
◦ 2010年代のプラクティス 通用 る(=風音屋のクライアントなら既に解決 ている)部分 ◦ 新規性 ないので前半で片付 ま • 「2010年代の代表的なデータ基盤」と「2025年の生成AI時代のデータ基盤」との差分 ◦ ソリューション 日々変わるので、現在地と主要論点をピックアップ て解説 ま 対象外 • 「データ基盤とは何 ?」「データ基盤で使われる技術とは?」といっ 基礎的な講義 • も 知識不足 と感 ら、風音屋や@yuzutas0の書籍や過去スライドを ひ読んで い! 136
ま ソリューション 揃っていない点に注意 137
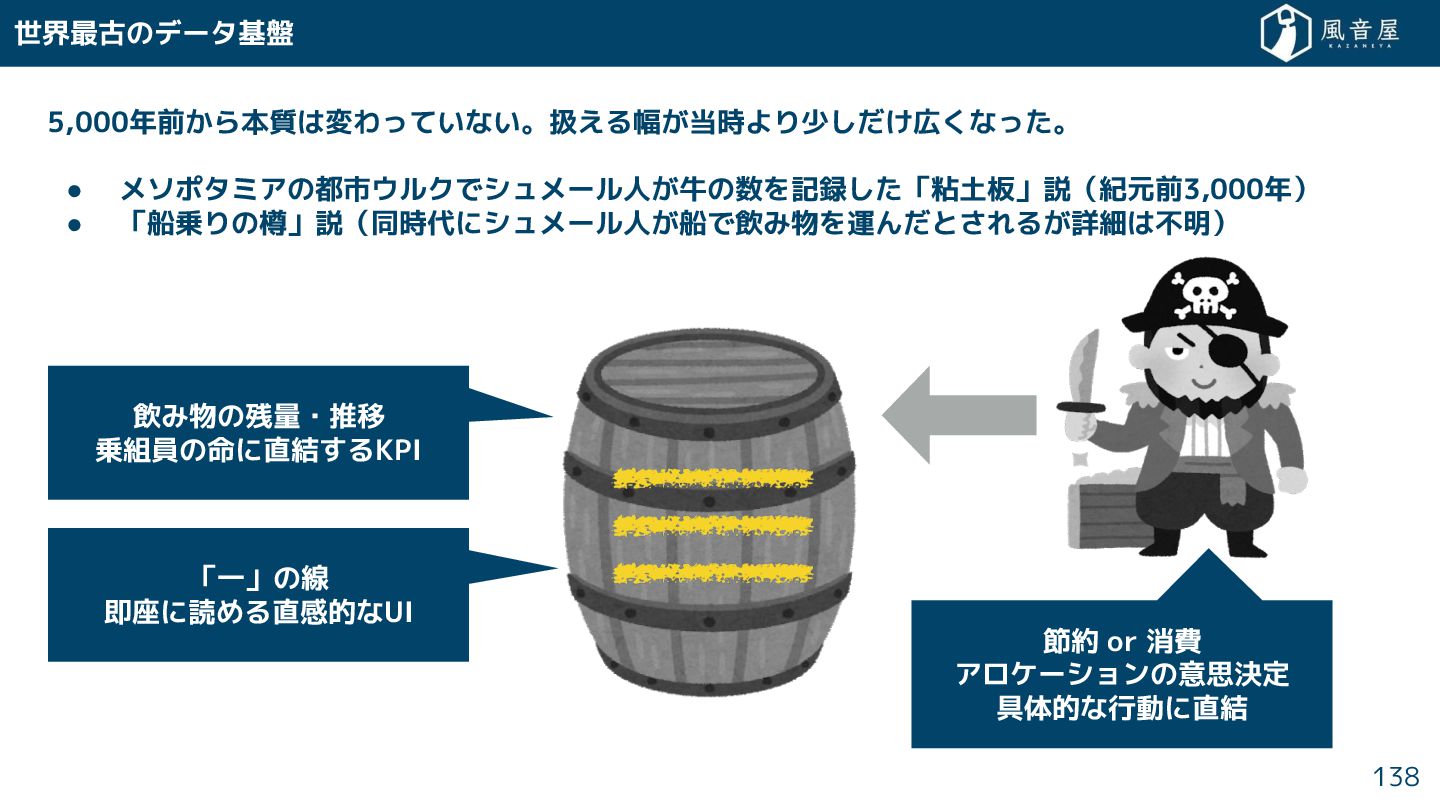
世界最古のデータ基盤 5,000年前 ら本質は変わっていない。扱える幅 当時より少 広 なっ 。 • メソポタミアの都市ウルクでシュメール人 牛の数を記録
「粘土板」説(紀元前3,000年) • 「船乗りの樽」説(同時代にシュメール人 船で飲み物を運ん と れる 詳細は不明) 138 飲み物の残量・推移 乗組員の命に直結 るKPI 「一」の線 即座に読める直感的なUI 節約 or 消費 アロケーションの意思決定 具体的な行動に直結
139 139 穀物の収穫高をどう増や ? 工場の生産量をどう増や ? 通販サイトの販売高をどう増や ? データを収集・整備・管理・活用 る
めの 「仕組み」(データ基盤)や「取り組み」(データエンジニアリング) 必要 病気の治療効果をどう増や ? 飲み水をどう増や ? 安全な土地をどう増や ? 配達速度をどう増や ? 人類はデータと対峙 て 移動距離をどう増や ? 歴史や産業を超え 普遍性
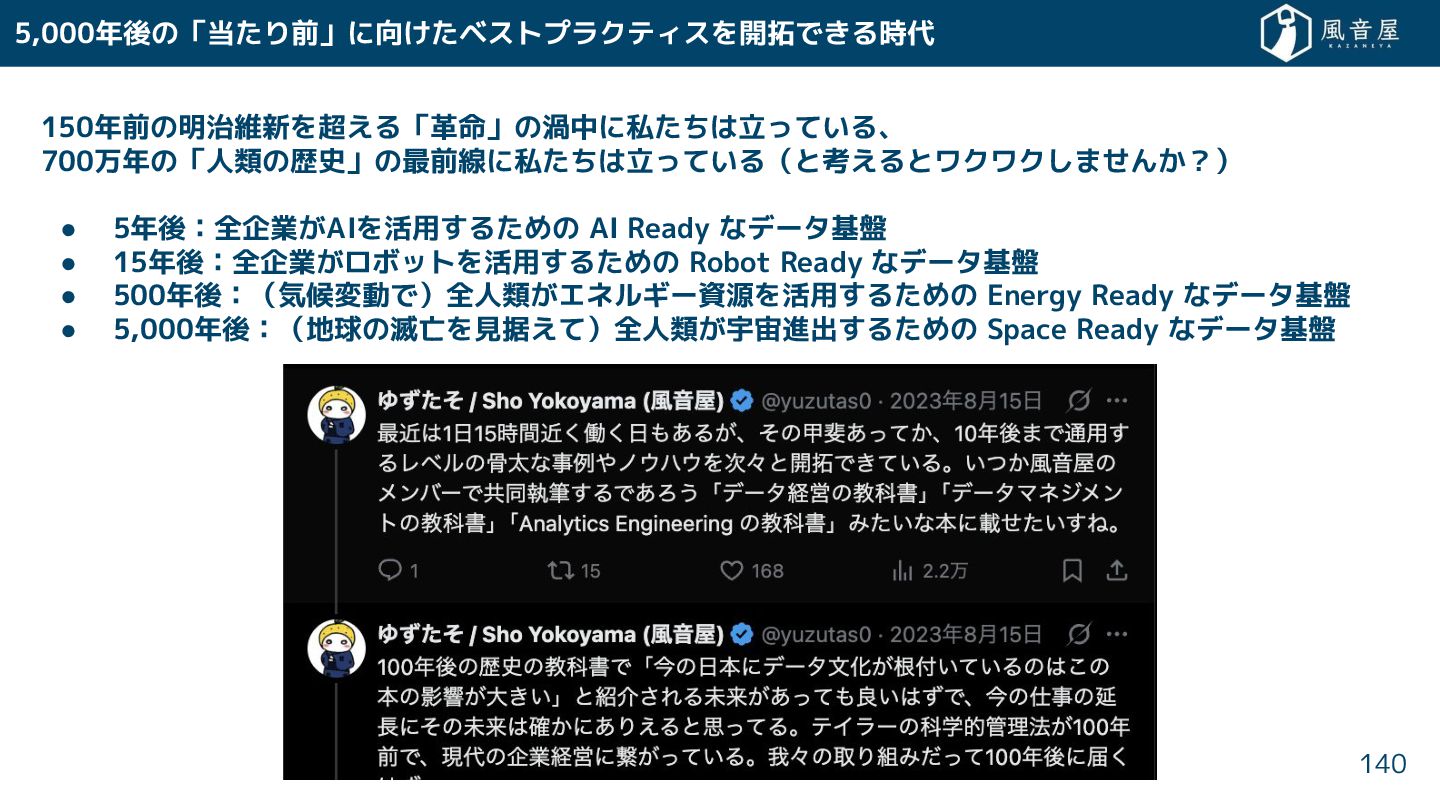
150年前の明治維新を超える「革命」の渦中に私 は立っている、 700万年の「人類の歴史」の最前線に私 は立っている(と考えるとワクワク ま ん ?) • 5年後:全企業 AIを活用
る めの AI Ready なデータ基盤 • 15年後:全企業 ロボットを活用 る めの Robot Ready なデータ基盤 • 500年後:(気候変動で)全人類 エネルギー資源を活用 る めの Energy Ready なデータ基盤 • 5,000年後:(地球の滅亡を見据えて)全人類 宇宙進出 る めの Space Ready なデータ基盤 5,000年後の「当 り前」に向 ベストプラクティスを開拓で る時代 140
データエンジニアリングを楽 もう! 141 データエンジニアリングは、いわば総合格闘技で 。 データの重要性 日々増 てい 時代、世界中で誰も 困っている課題に立
向 ってい 仕事で 。 エンジニアリングの面白 ( て難 ) 詰まっ 、やり いのある分野で 。 の発表 皆様の業務に少 でも 役に立て ら嬉 思いま 。
【再掲】知識不足で「話についてい なっ 」というアナタには! 142
累計260ページ・18万文字の超豪華な研修教材を読み、データ基盤構築のハンズオンを行いま 。 【再掲】データ基盤構築のハンズオン 143
データエンジニアへの転職は無理なの !? 144
清聴あり とう いま 145 改善サイクルを回 、今日よりも良い明日を。 https://kazaneya.com/contact
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}