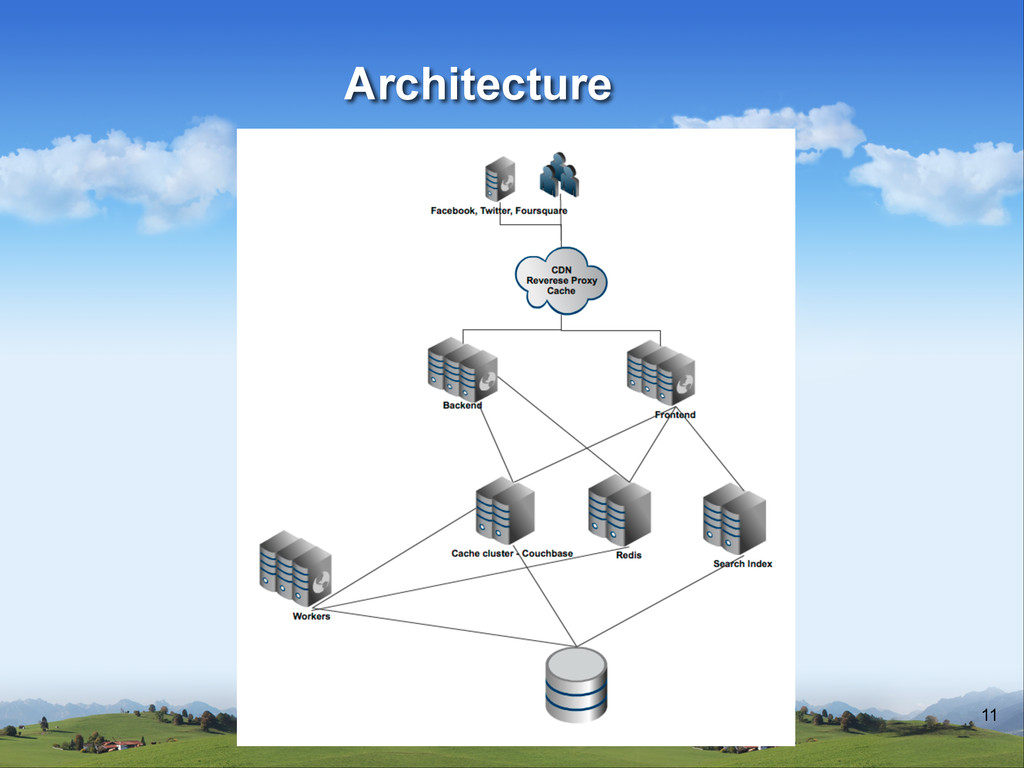
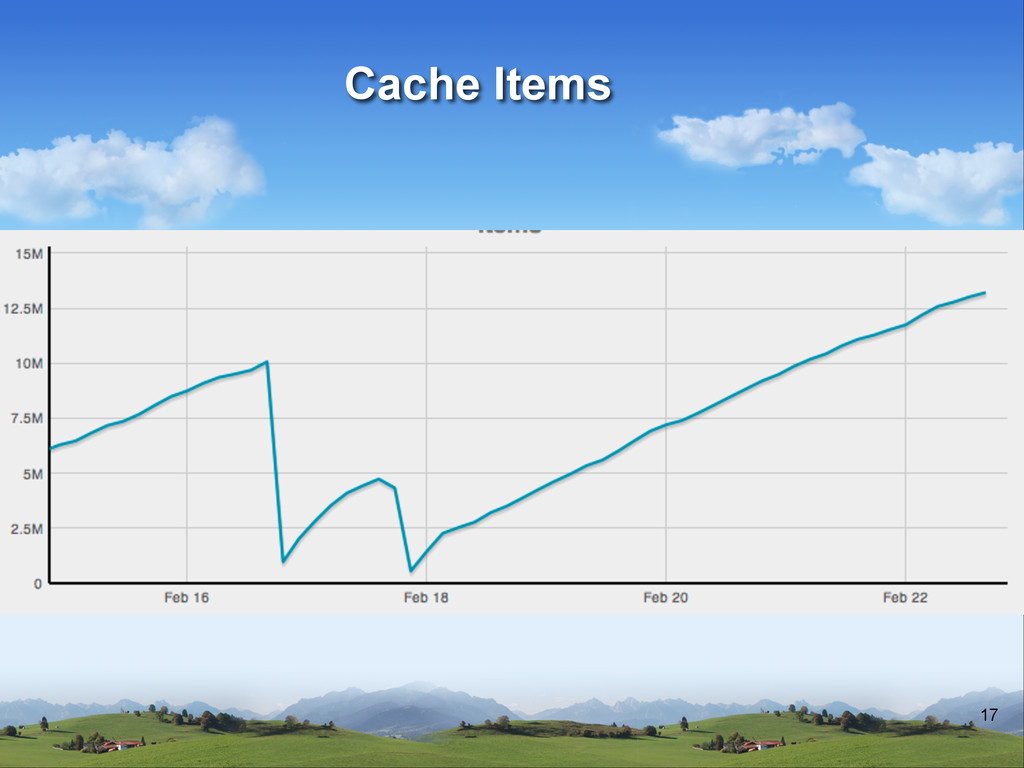
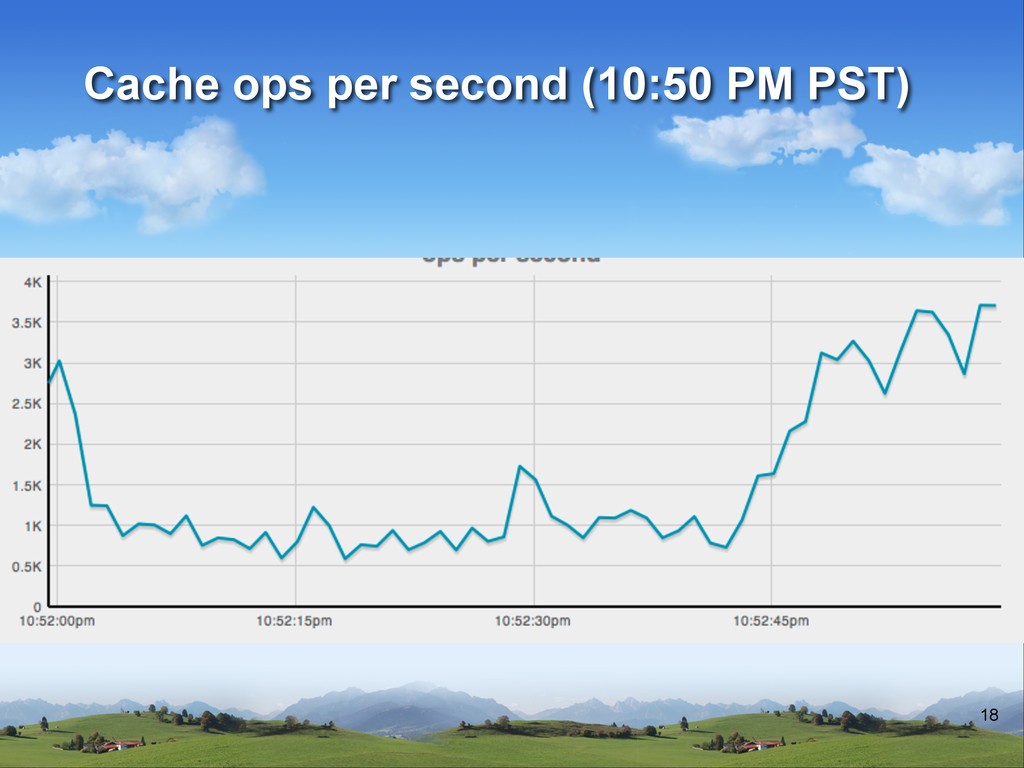
v About 50-100 instances running v .5TB of cache in the cluster when warm v 2.5-10K operation per second on cache v About 150K tasks in the workers daily v Over 2TB of data stored in Redis v AVG response time in search is 20ms (about 15million items in search) Architecture
tables have 25G of index (Sharding needed soon) v Full replication on master/slave with Round Robin algorithm between the servers v Using a special version of octopus gem Architecture
Real-time updates from Facebook and Foursquare – matching to our POI DB v Each page is personalized – scaling and performance v Real-time notifications to clients v Scoring system – personal score for each user / place Technical Challenges
planning meeting (plan only a week ahead) (1 hour) v One all hands meeting (20-30 minutes) v You do your shit, we get out of your way v What do you need? v Done! Work Methodology
If something comes in something comes out v No one sits on top of your head v Ship as fast and best you can v Work when you want v Work from home when you want Work Methodology
week v No conversation between engineers that interrupt v All work is being done inside a chat room. v You can ask a question there, if someone can, you will get an answer, if not, move on, you’ll get an answer later Work Methodology
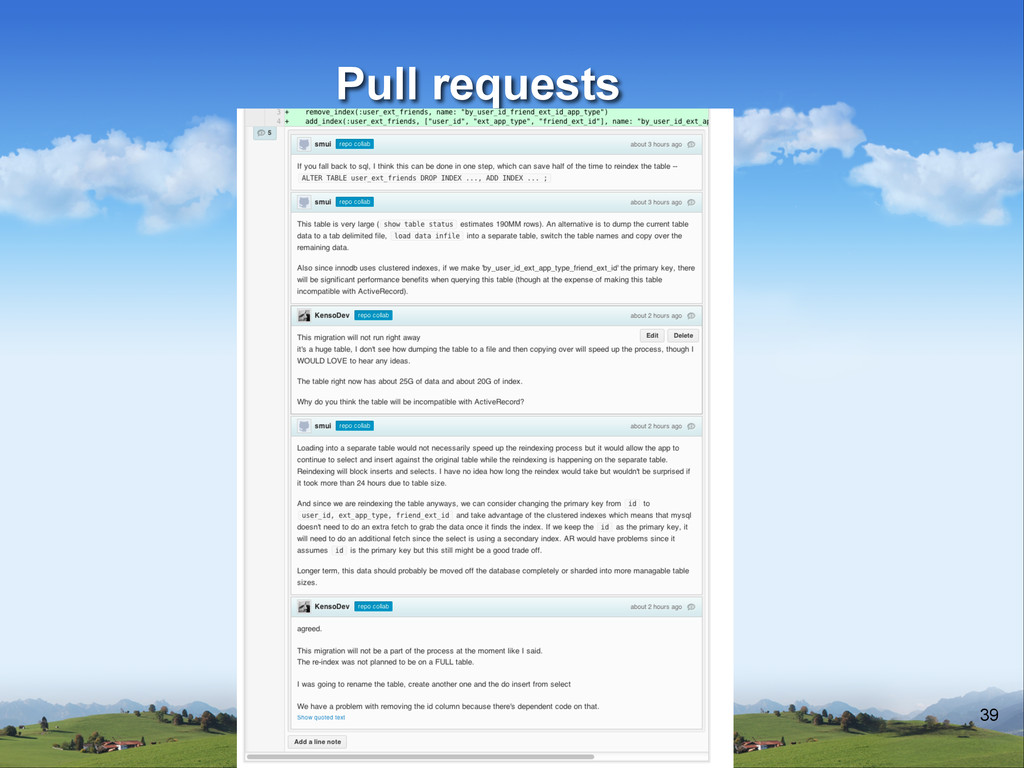
is always deployable v When you finish your work, you open a pull request and move on, don’t shout! v Anyone can review any pull request v Simple branch name + description for the branch v Get ready to rumble…!!! Pull requests
v Deploy every day v Choose deploy often to see changes v As small the change is the better, this way you can see real impact v Twitter driven deployment v Each deployment triggers QA for IE
the servers on the LB’s at once v No downtime on deploy v Users are being switched over when the serves are ready to get them v It’s probably complicated to deploy right?
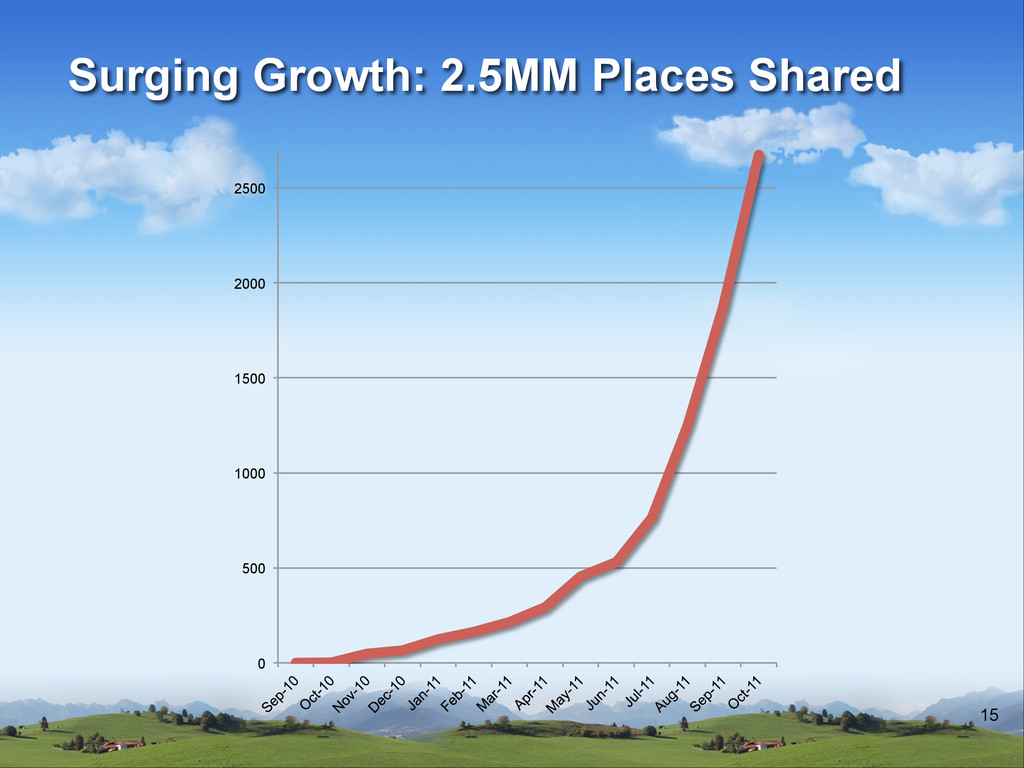
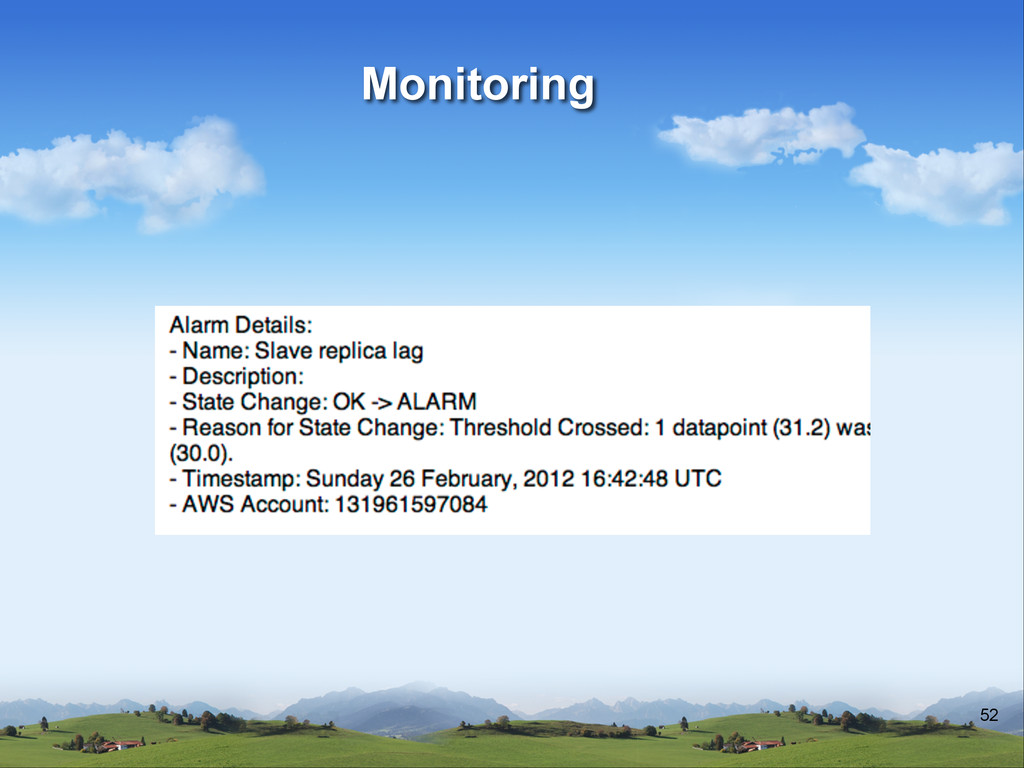
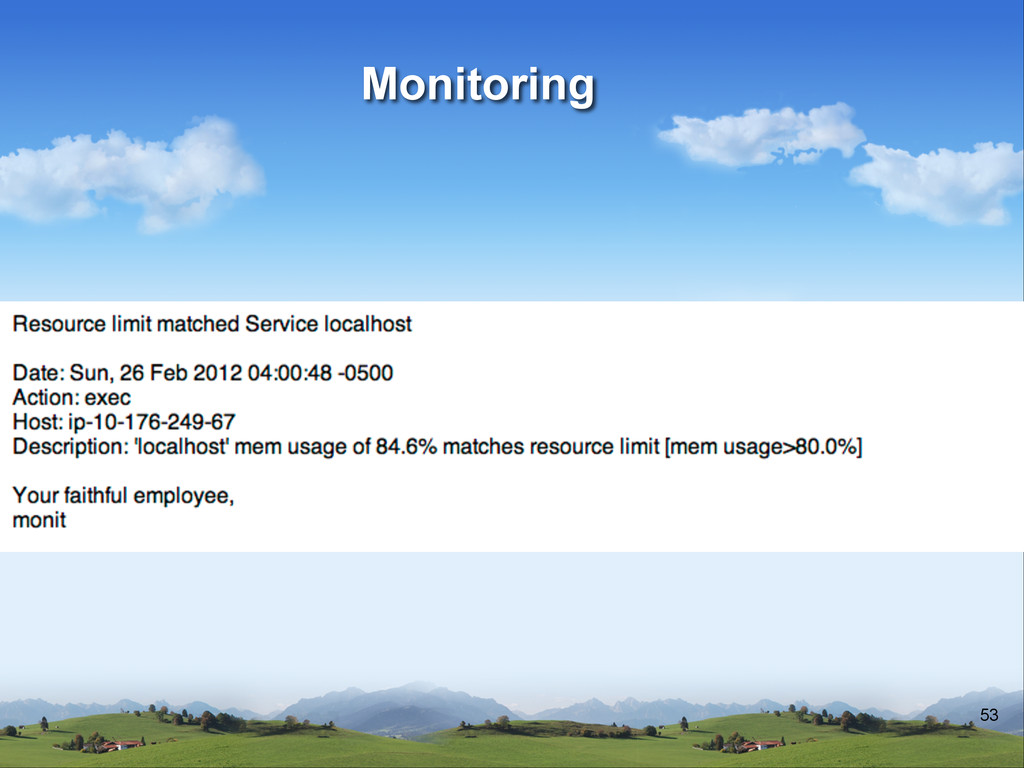
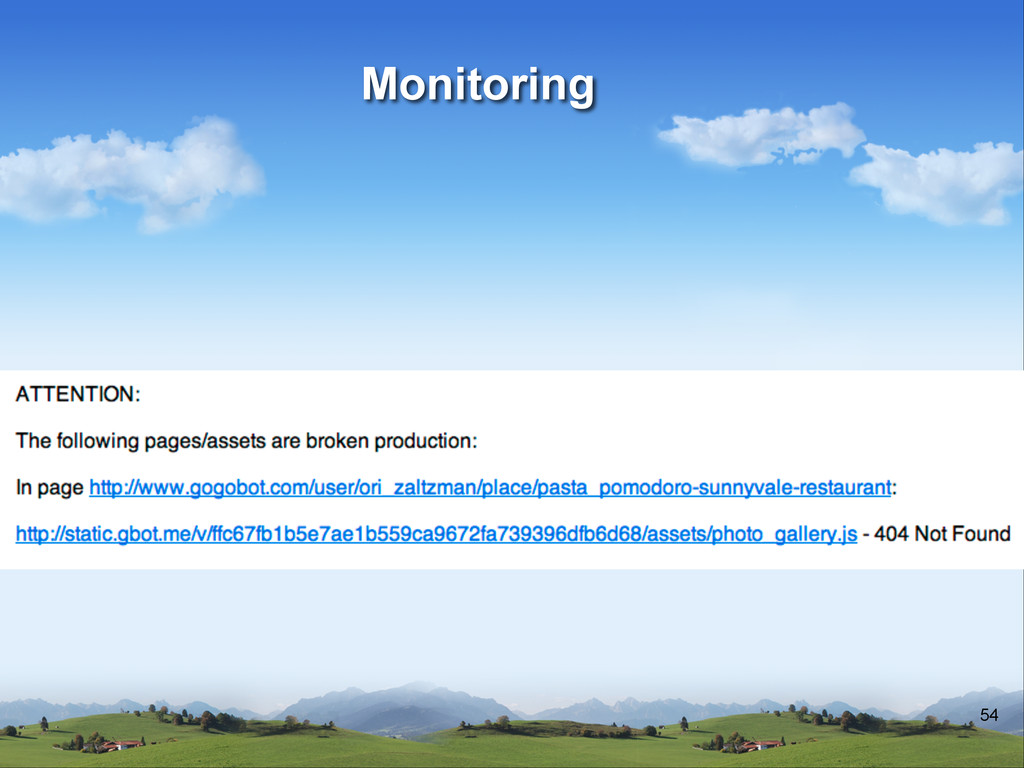
v Not only when something is down v Statistics based monitoring v How fast? v How fast was yesterday? v Number of items shared? v Number of signups?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}