Sun, and David Ha. Evolutionary optimization of model merging recipes, 2024. • Anthropic. Introducing the next generation of claude. available at: https://www.anthropic.com/news/ claude-3-family. • Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond, 2023. • Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the V in VQA Matter: Elevating the role of image understanding in visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017. • Drew A. Hudson and Christopher D. Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2019. • Meng Lee, Fujiki Nakamura, Makoto Shing, Paul McCann, Takuya Akiba, and Naoki Orii. Japanese stablelm base alpha 7b.
{kind=link}
![研究背景と⽬的 1 • ベースラインモデルHeron-GITを構築 • 評価ベンチマークHeron-Benchを提案 • 近年、GPT-4V[OpenAI 2023]やLLaVA[Liu+ 2023]など様々な](https://files.speakerdeck.com/presentations/3756c88d8a1c478db963d60a33d10de3/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![実験:ベースラインモデルの構築 5 ⽇本語VLMのベースラインモデルHeron-GIT DeepLを⽤いて⽇本語に翻訳したLLaVA-1.5[Liu+ 2023]の事前学習: 約558K、 視覚指⽰チューニング: 約665Kの画像-テキストペアデータセットを⽤いて学習 Tokenize &](https://files.speakerdeck.com/presentations/3756c88d8a1c478db963d60a33d10de3/slide_5.jpg){kind=link}
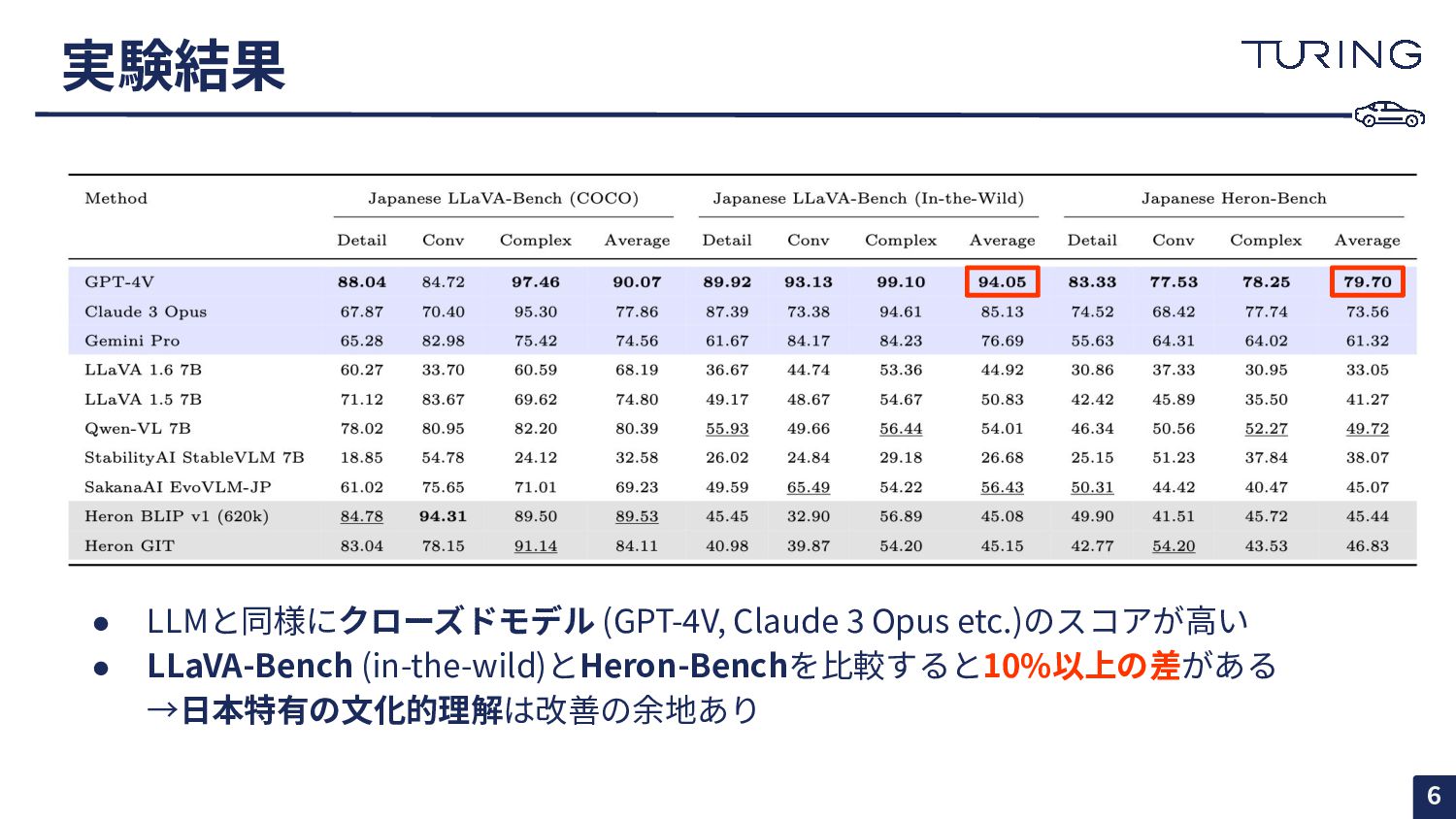{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}