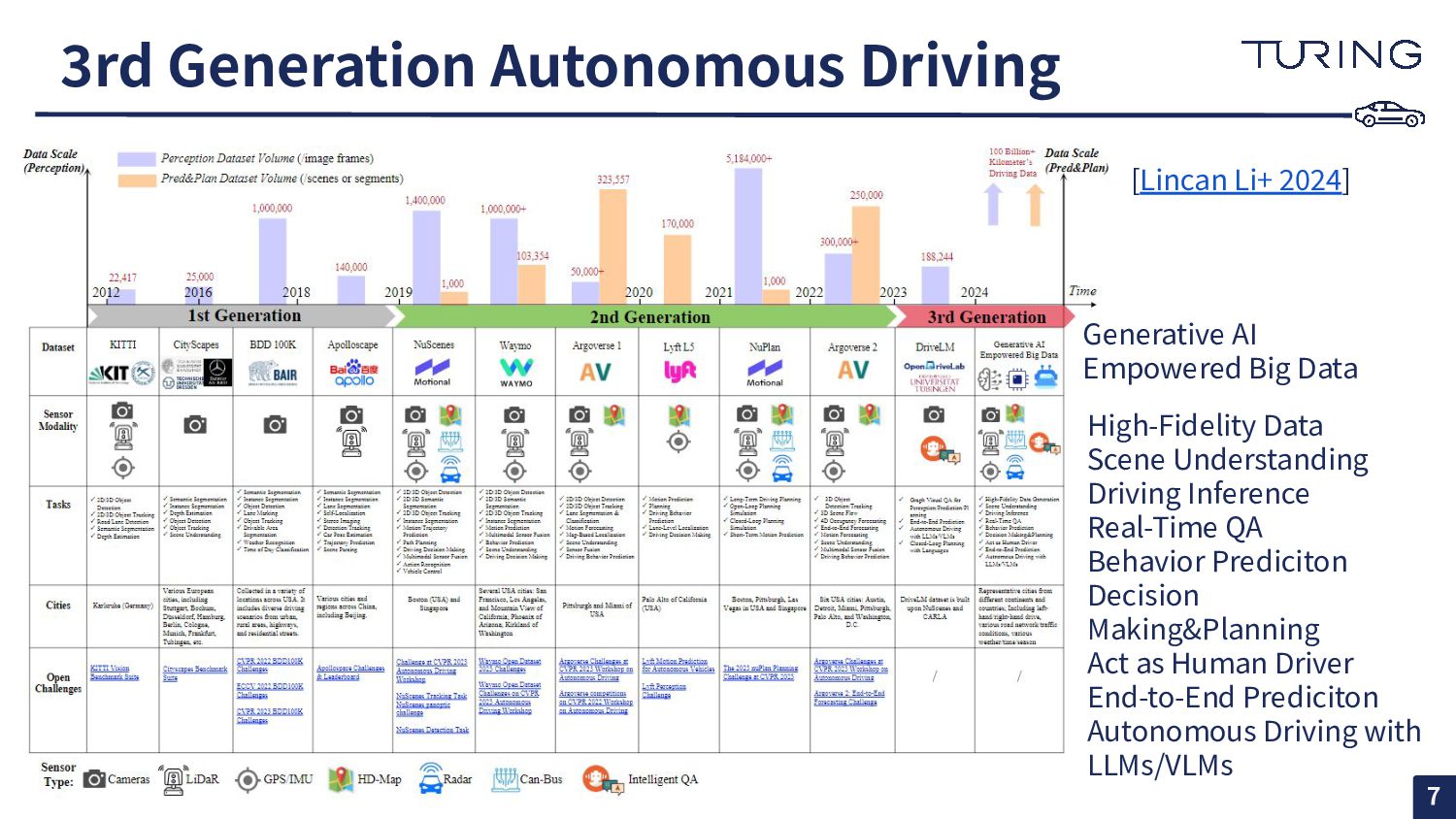
High-Fidelity Data Scene Understanding Driving Inference Real-Time QA Behavior Prediciton Decision Making&Planning Act as Human Driver End-to-End Prediciton Autonomous Driving with LLMs/VLMs [Lincan Li+ 2024]
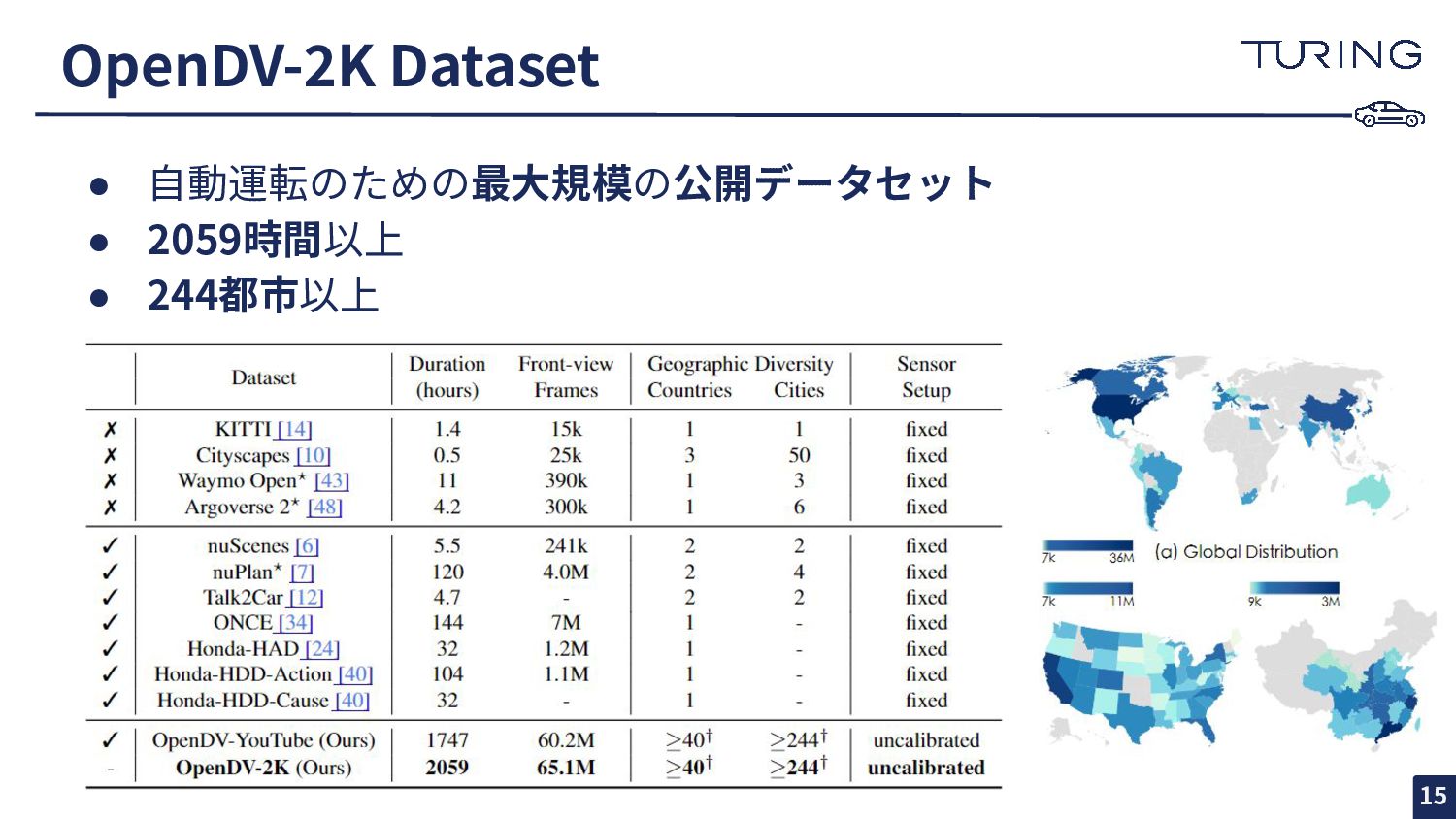
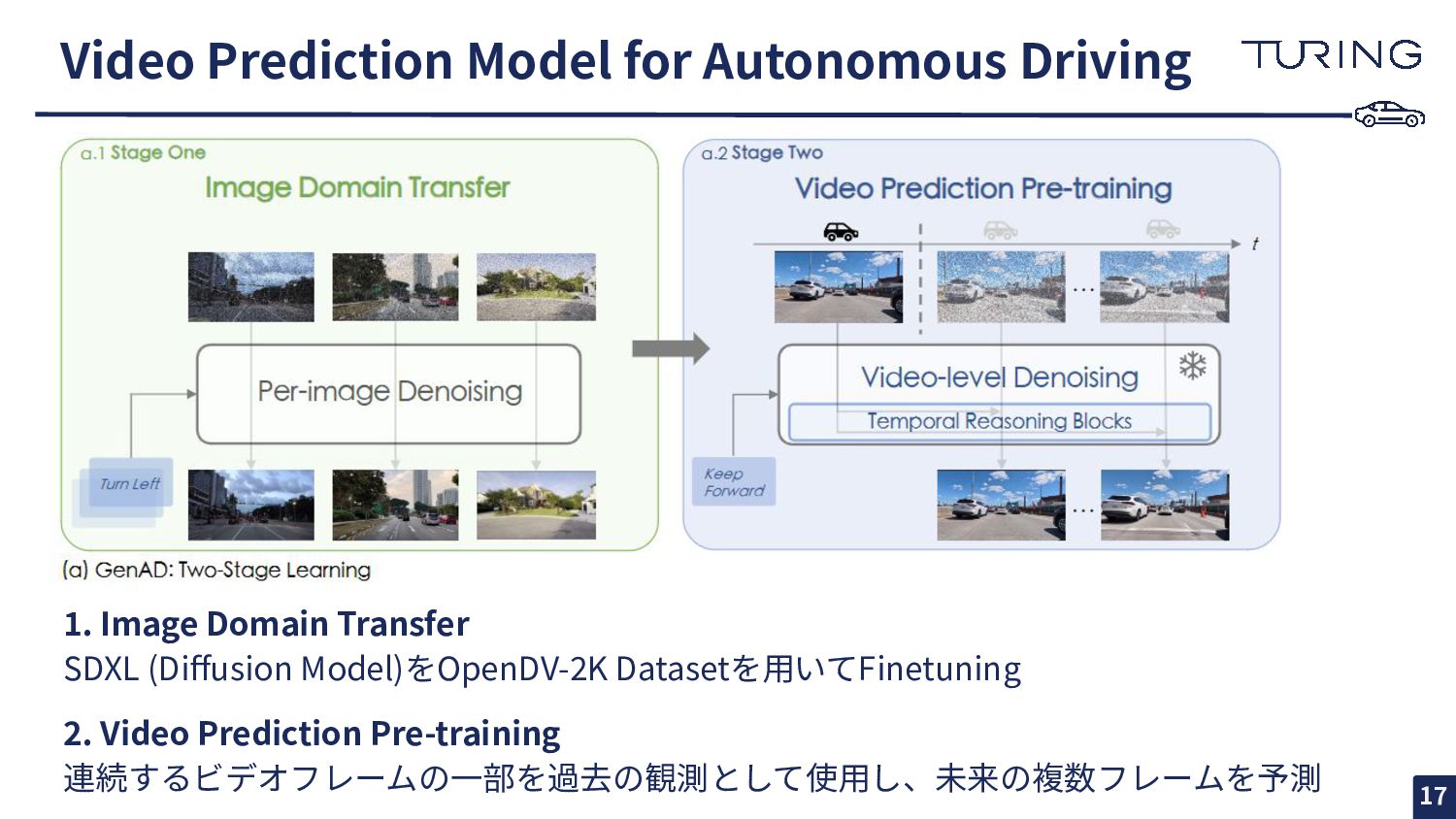
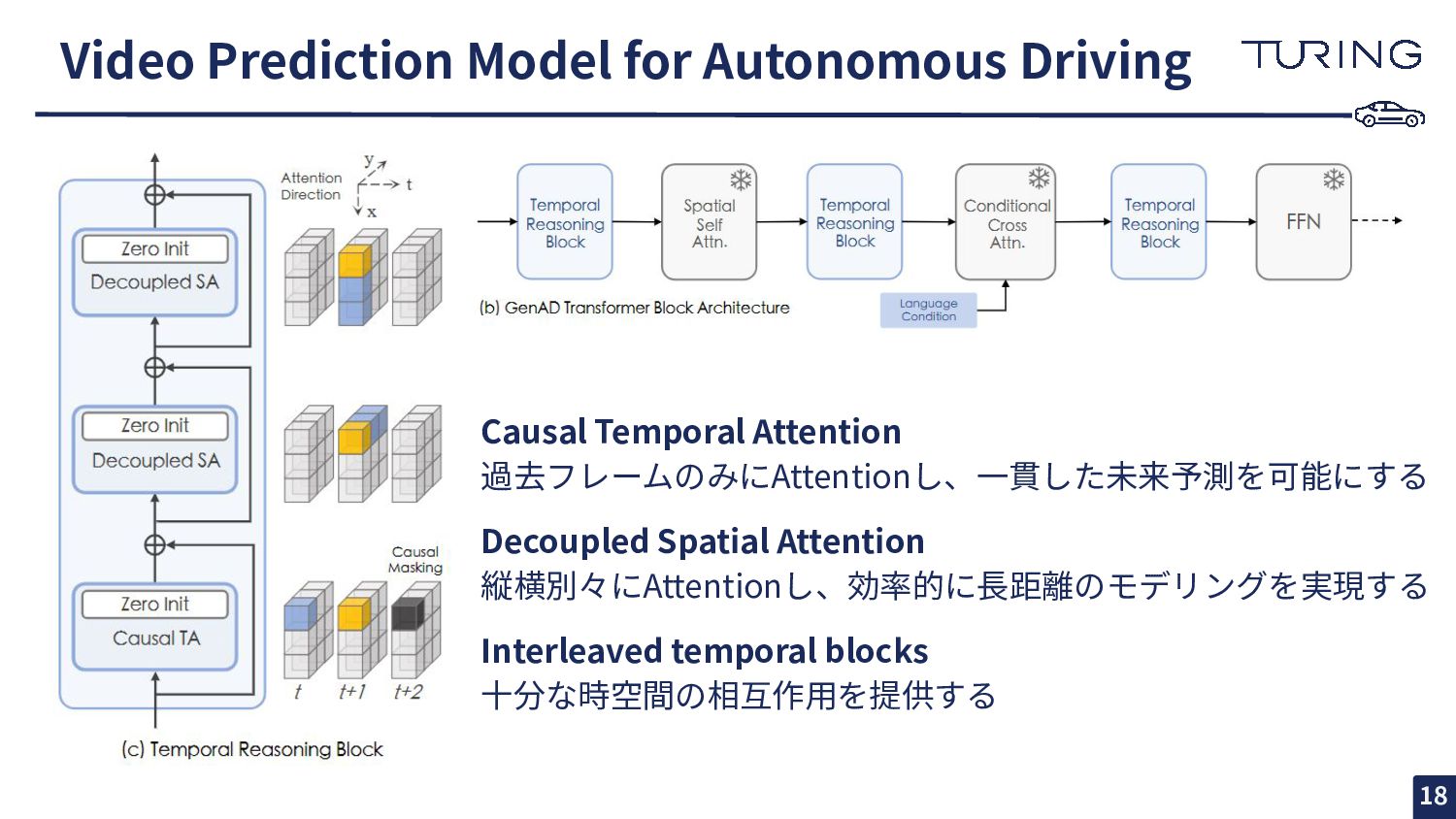
Shenyuan Gao2,1*, Yihang Qiu1*, Li Chen3,1, Tianyu Li1, Bo Dai1, Kashap Chitta4,5, Penghao Wu1, Jia Zeng1, Ping Luo3, Jun Zhang2, Andreas Geiger4,5, Yu Qiao1, Hongyang Li1. 1. OpenDriveLab and Shanghai AI Lab 2. Hong Kong University of Science and Technology 3. University of Hong Kong 4. University of Tübingen 5. Tübingen AI Center Highlight 🌠 https://openaccess.thecvf.com/content/CVPR2024/papers/Yang_Generalized_Pr edictive_Model_for_Autonomous_Driving_CVPR_2024_paper.pdf 以降、図表は論⽂からそのまま 引⽤します
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Task (4/4) Planning 22 フロントビュー画像のみを与え、Trajectory予測をすると UniAD [Yihan+ 2023]と匹敵するプランニング結果が得られる ADE: Average](https://files.speakerdeck.com/presentations/3ee5c374fd0f44ebb01c726f08129a78/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}