[Snowflake World Tour Tokyo 2025 BC-212]
Snowflake Intelligence × Document AI で“使いにくいデータ”を“使えるデータ”に
〜構造化データと非構造データを活用した次世代データ分析最前線〜
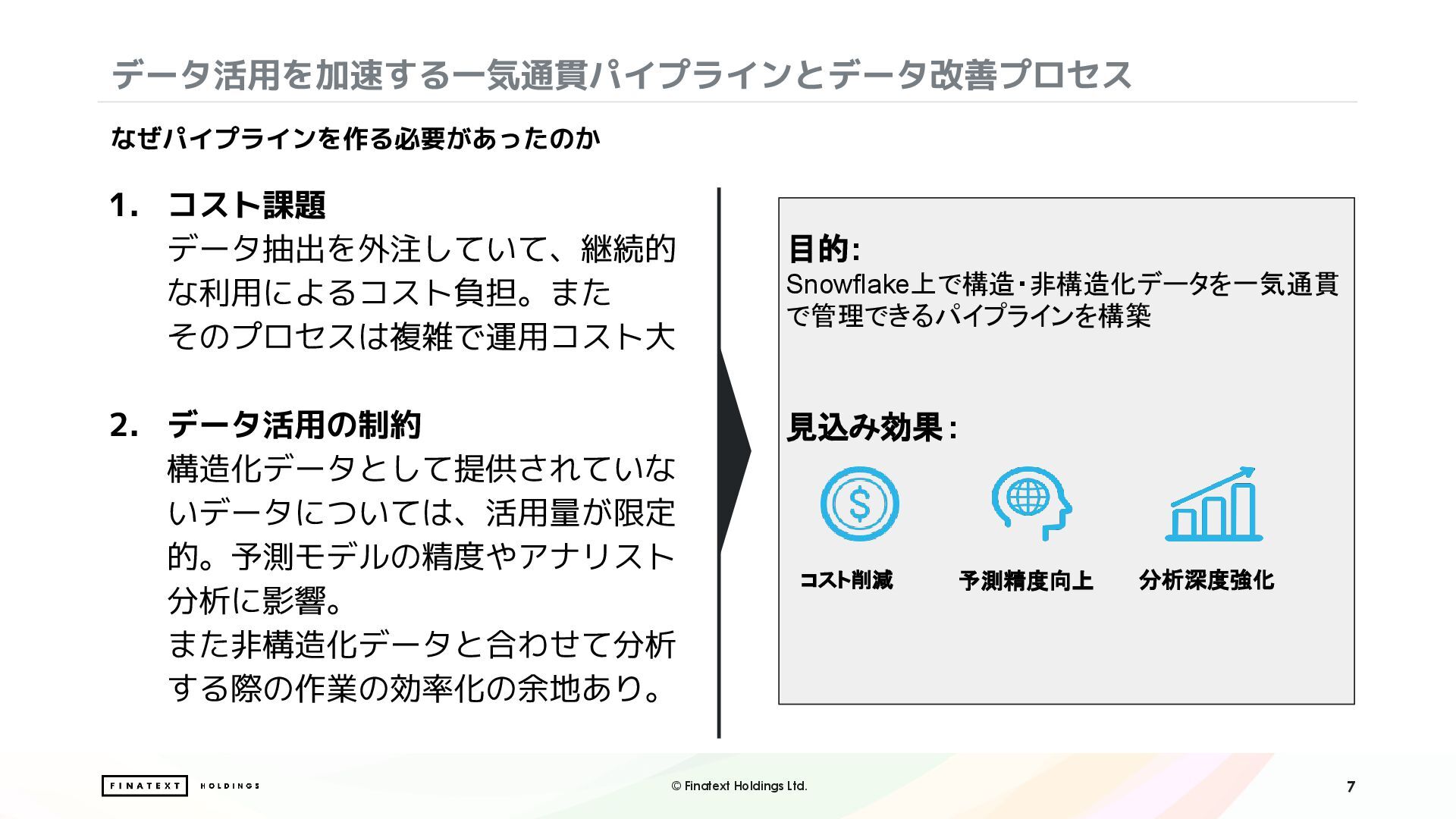
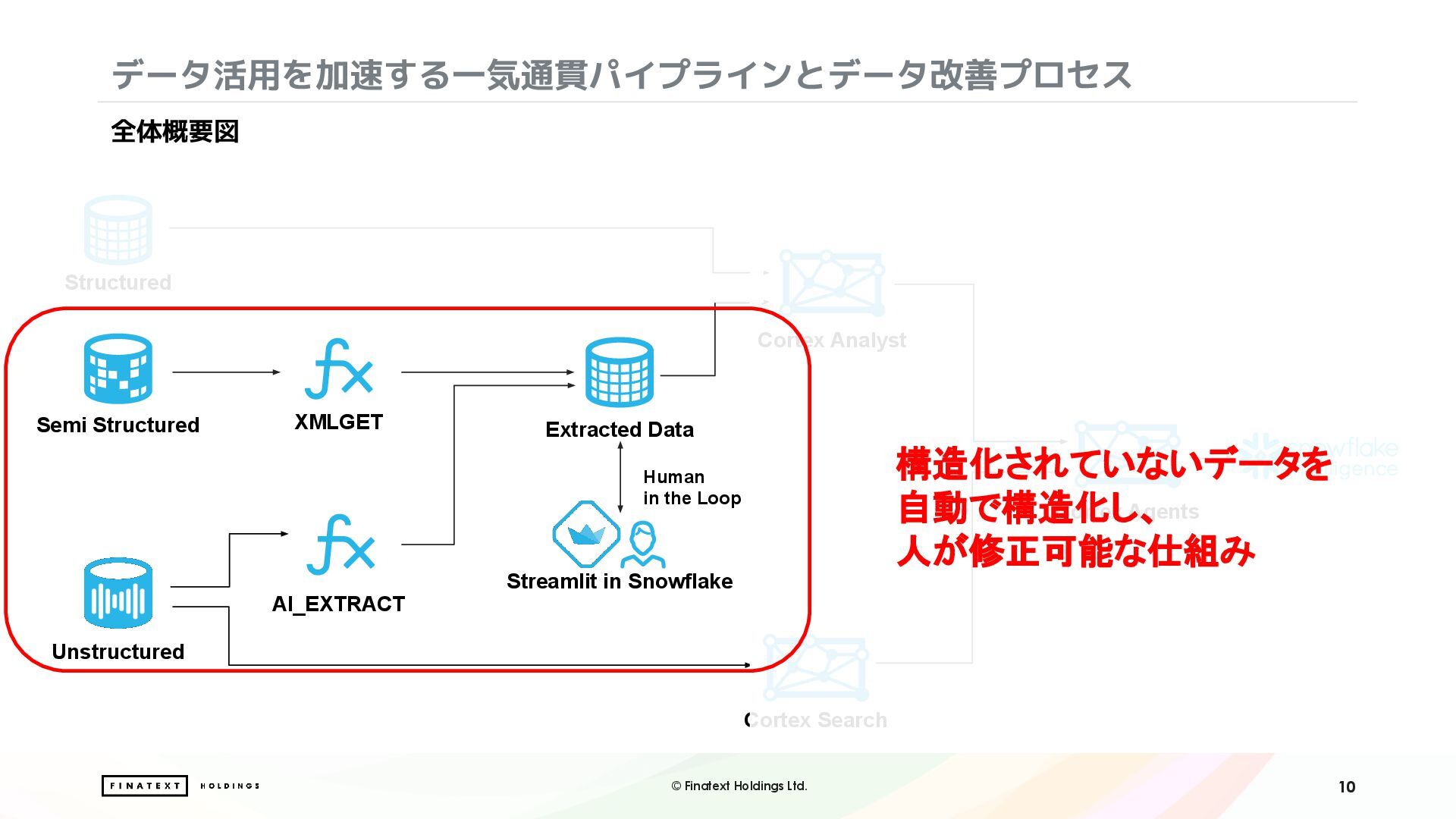
ナウキャストでは、オルタナティブデータを Snowflake 上で加工・整備し、データプロダクトとして提供しています。これらのデータと比較対象として用いる企業の財務データは構造化されていないことが多く、機械的な処理が難しいという課題がありました。
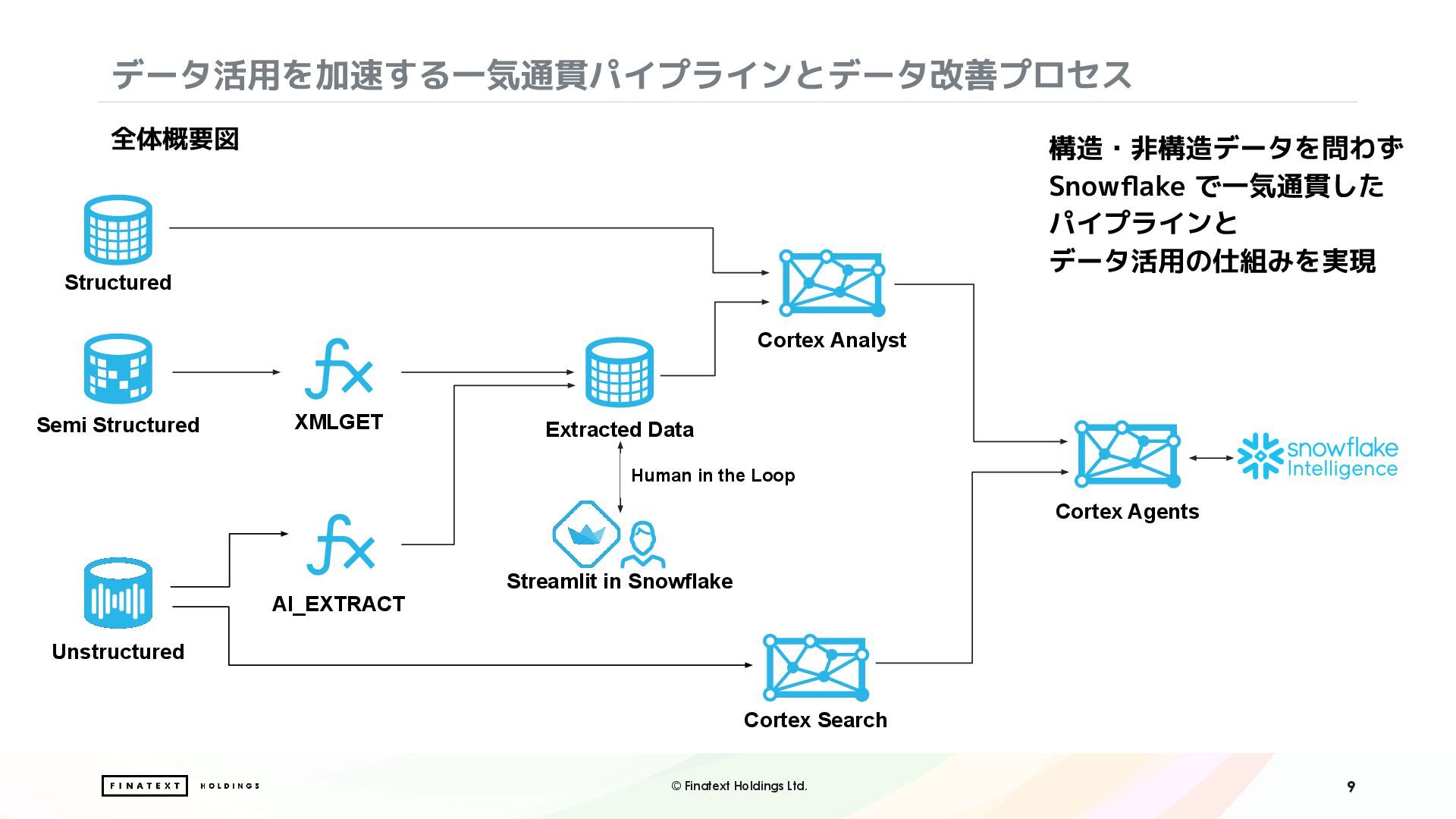
本セッションでは、こうした非構造データ活用の課題に対して Snowflake の AI 機能をどう適用したかを、以下3つのアプローチでご紹介します。
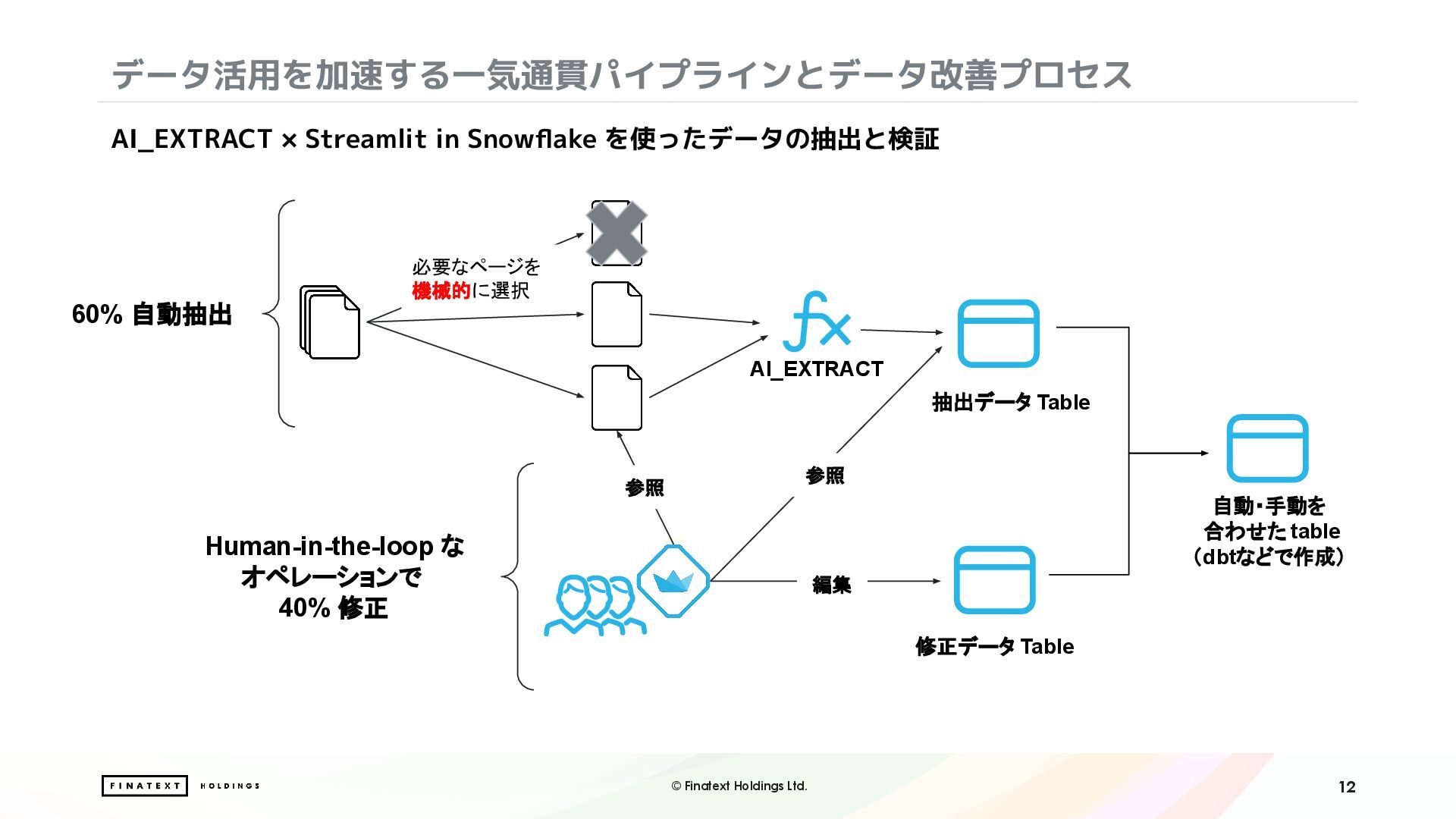
・Document AI / AI_EXTRACT を用いたPDF文書からの情報抽出と構造化処理
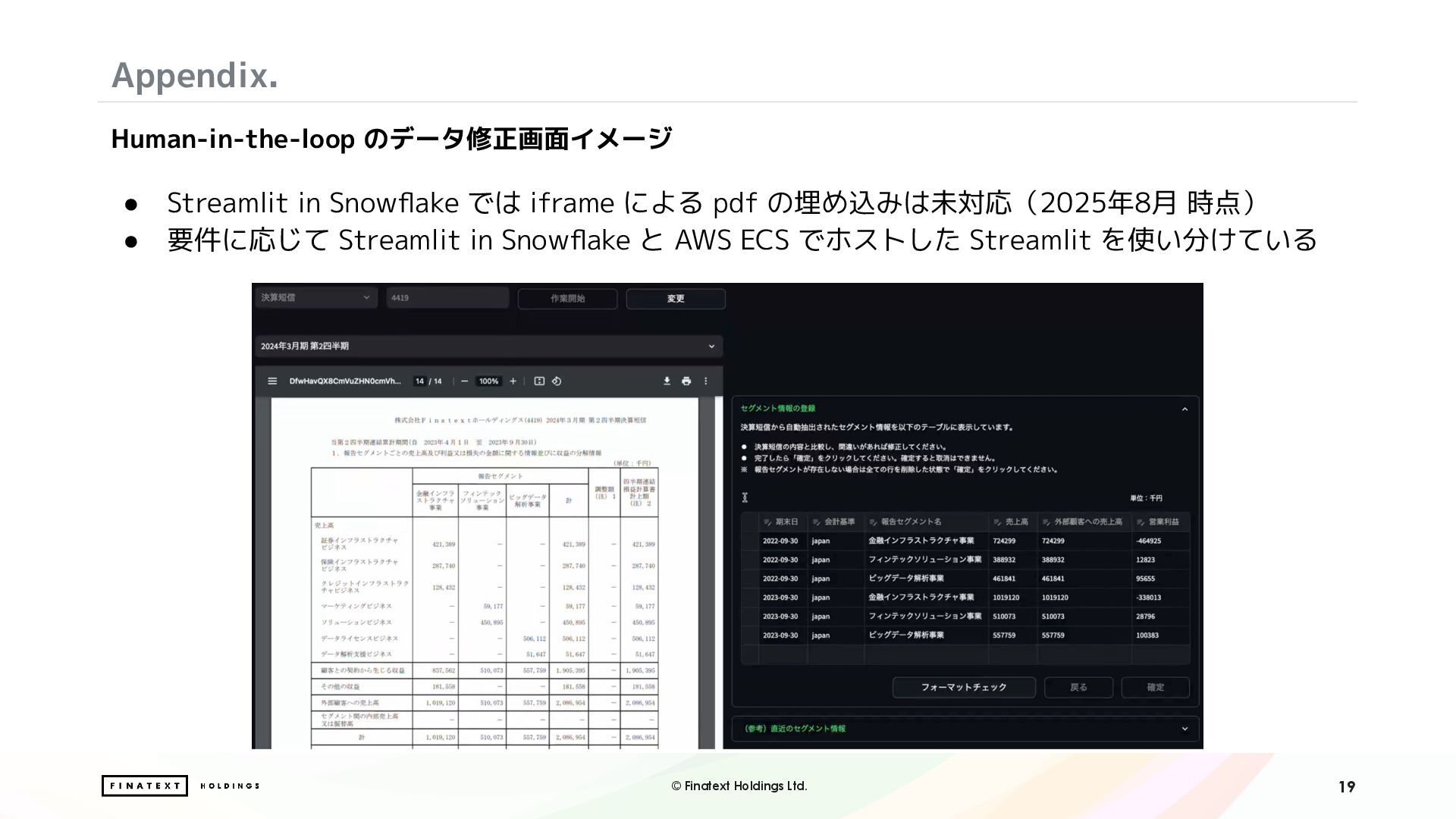
・Streamlit in Snowflake を活用した、人の目による確認・補正を組み込んだ Human-in-the-loop (HITL) ワークフローの構築
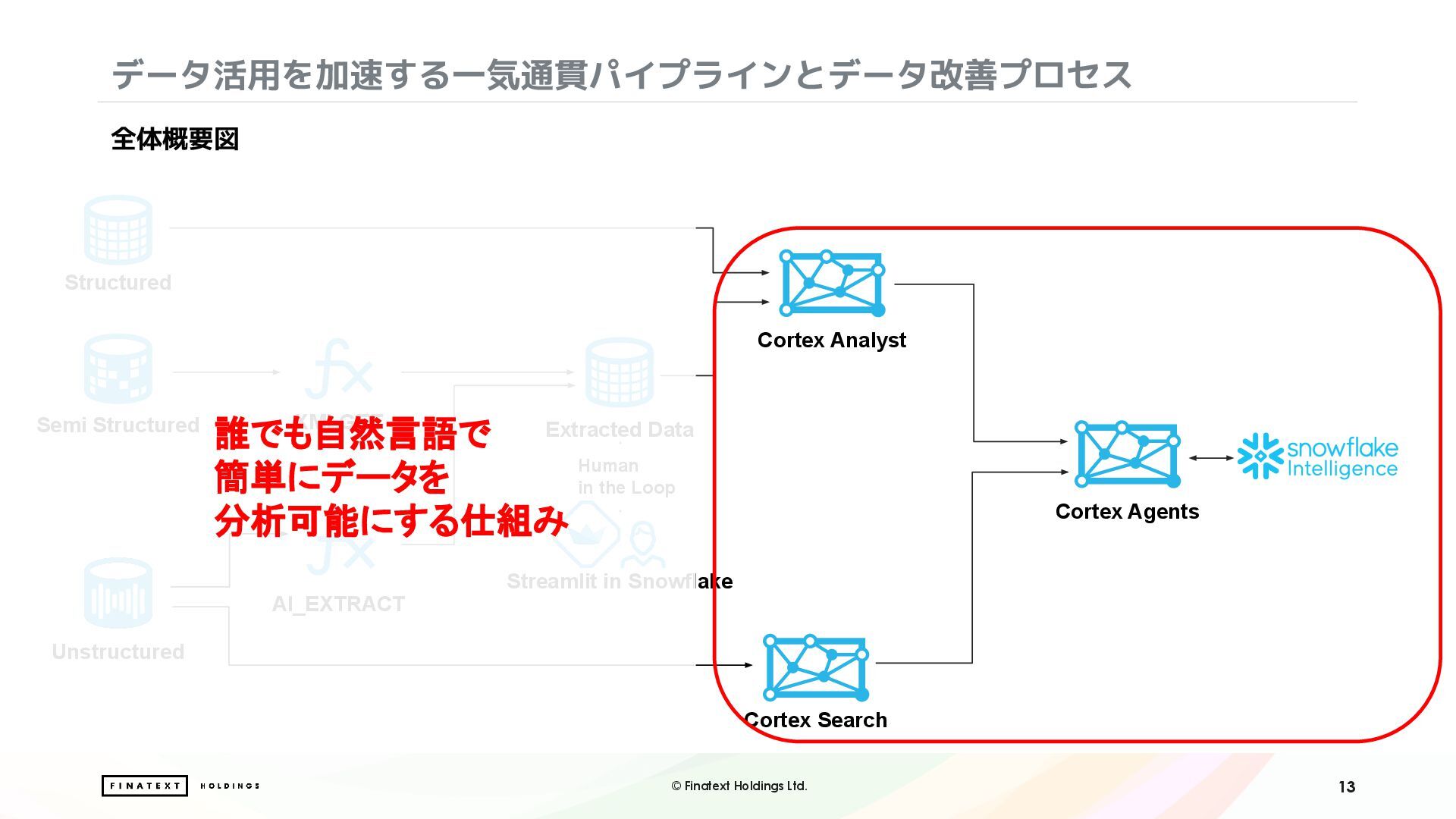
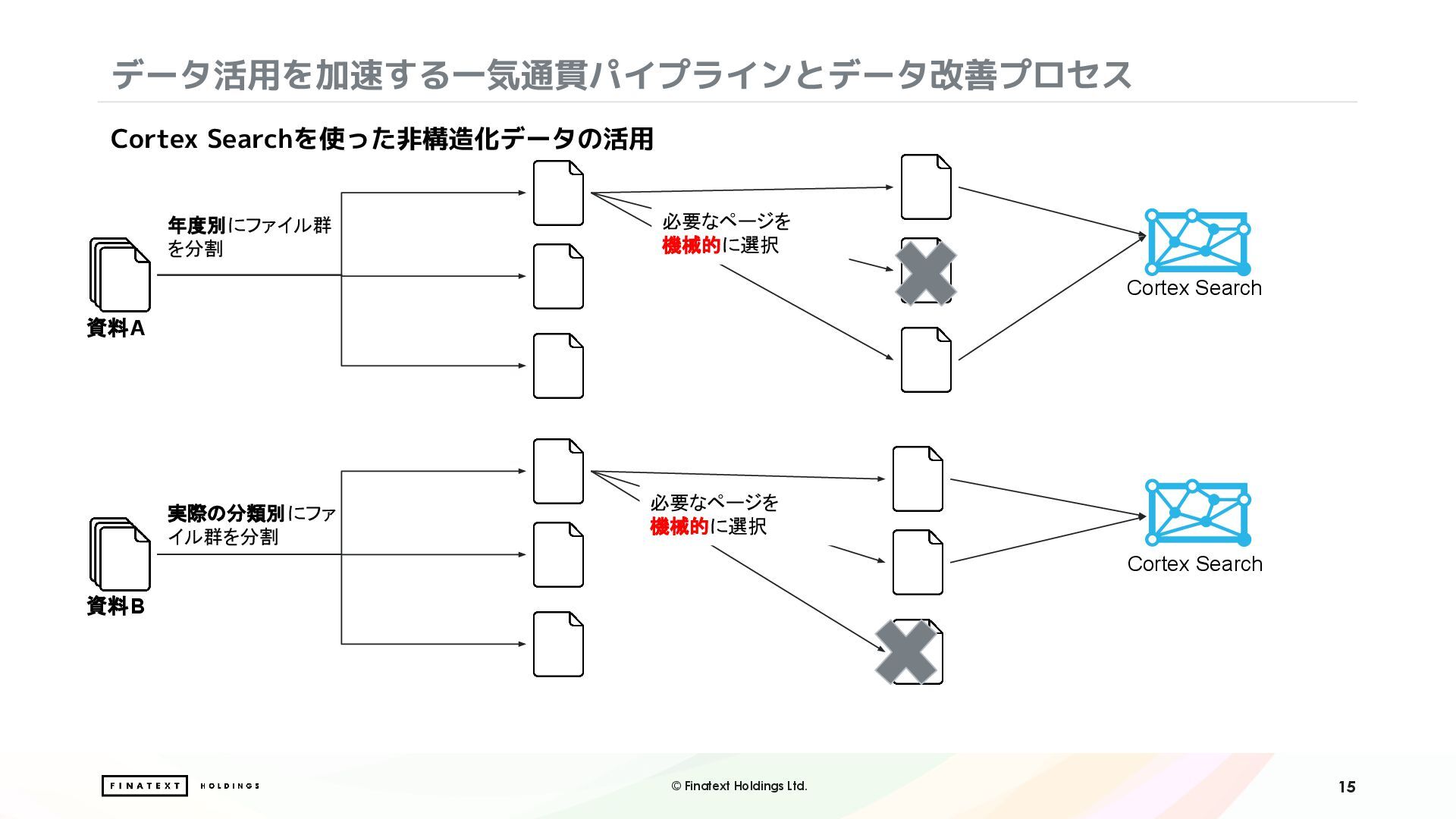
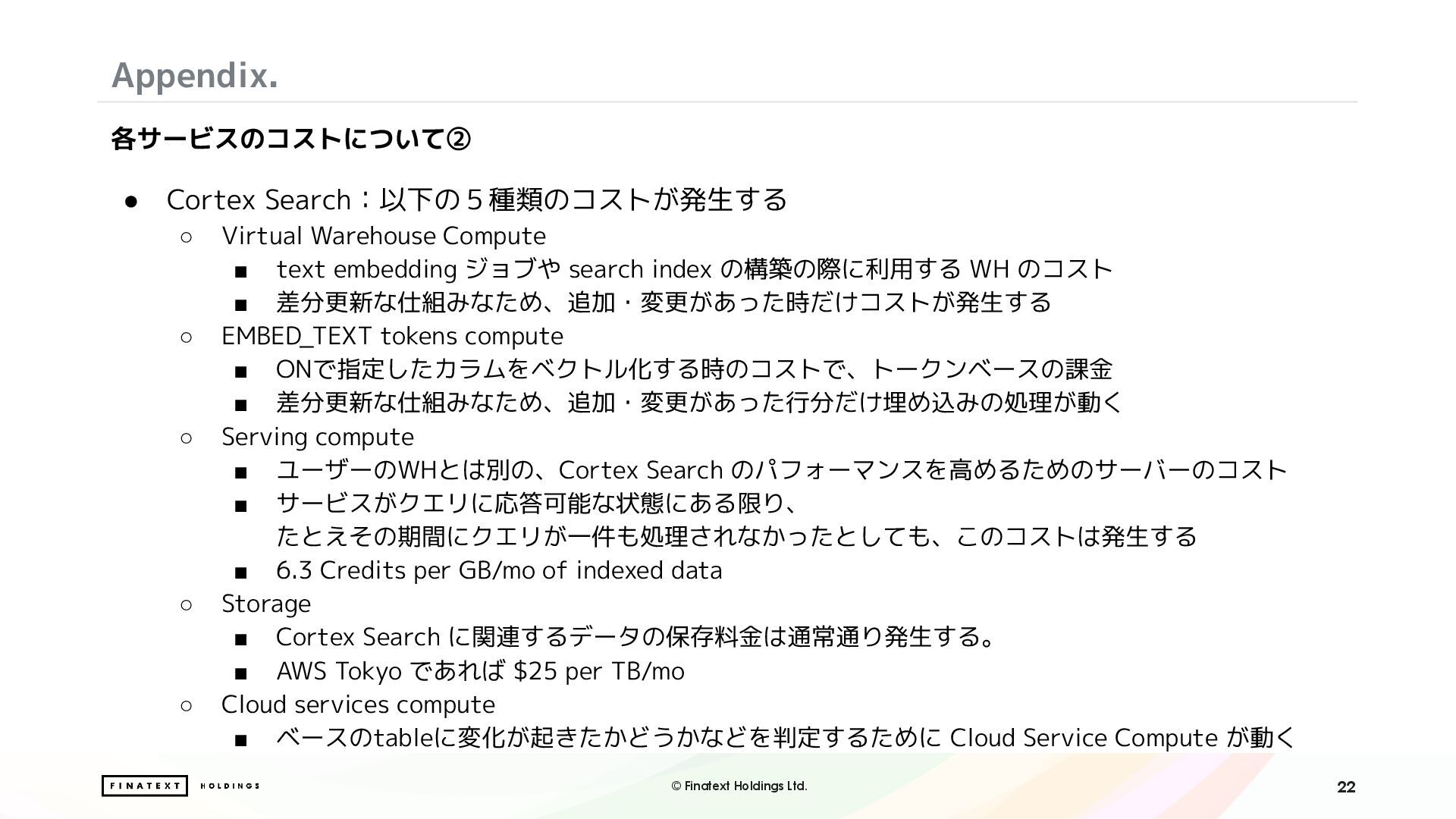
・Cortex Search による非構造情報のベクトル検索と自然言語での検索体験の実現
さらに、構造化データと非構造データを組み合わせて分析を行うにあたり、Snowflake Intelligence を活用したデータ分析レポート作成業務の効率化にも取り組みました。構造化データと非構造化データを横断する、AIを組み込んだ実践的データ分析ワークフローについて、リアルな知見をお届けします。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![© Finatext Holdings Ltd. 14 データ活用を加速する一気通貫パイプラインとデータ改善プロセス Cortex Analystを使った構造化データの活用 [1] Semantic](https://files.speakerdeck.com/presentations/0eaa1b91ec7f492e803b3d0dc0578235/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}