compact subsets of Hilbert space and continuity of Gaussian processes. Journal of Functional Analysis, 1(3), 290-330. • Frei, S., Chatterji, N. S., & Bartlett, P. (2022, June). Benign overfitting without linearity: Neural network classifiers trained by gradient descent for noisy linear data. In Conference on Learning Theory (pp. 2668-2703). PMLR. • Nakkiran, P., Kaplun, G., Bansal, Y., Yang, T., Barak, B., & Sutskever, I. (2021). Deep double descent: Where bigger models and more data hurt. Journal of Statistical Mechanics: Theory and Experiment, 2021(12), 124003. 47 • Belkin, M., Hsu, D. J., & Mitra, P. (2018). Overfitting or perfect fitting? risk bounds for classification and regression rules that interpolate. Advances in neural information processing systems, 31. • Belkin, M., Hsu, D., Ma, S., & Mandal, S. (2019a). Reconciling modern machine-learning practice and the classical bias–variance trade-off. Proceedings of the National Academy of Sciences, 116(32), 15849-15854. • Belkin, M., Rakhlin, A., & Tsybakov, A. B. (2019b). Does data interpolation contradict statistical optimality?. In The 22nd International Conference on Artificial Intelligence and Statistics (pp. 1611-1619). PMLR. • Donsker, M. D., & Varadhan, S. S. (1983). Asymptotic evaluation of certain Markov process expectations for large time. IV. Communications on Pure and Applied Mathematics, 36(2), 183-212.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
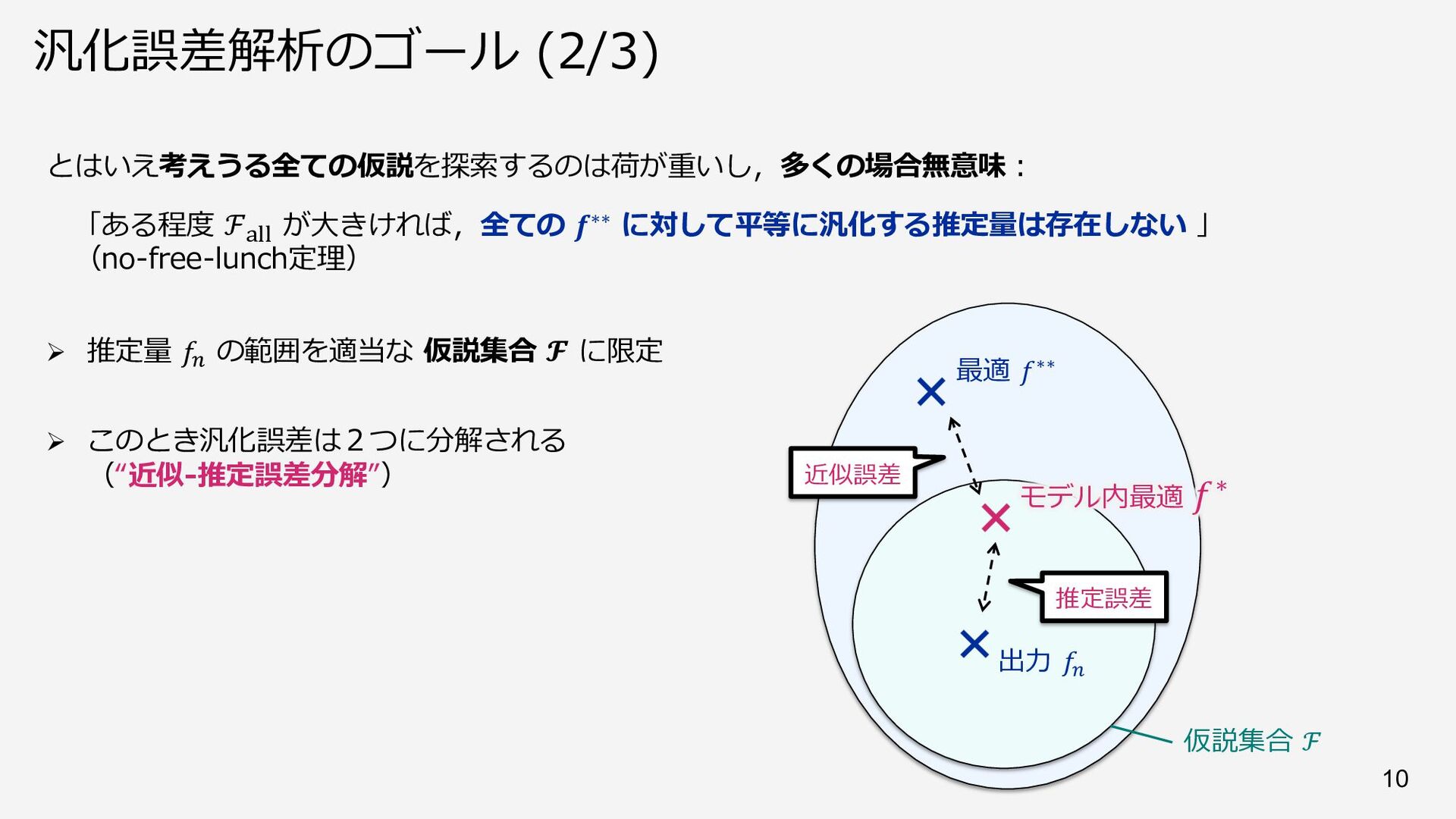{kind=link}
{kind=link}
{kind=link}
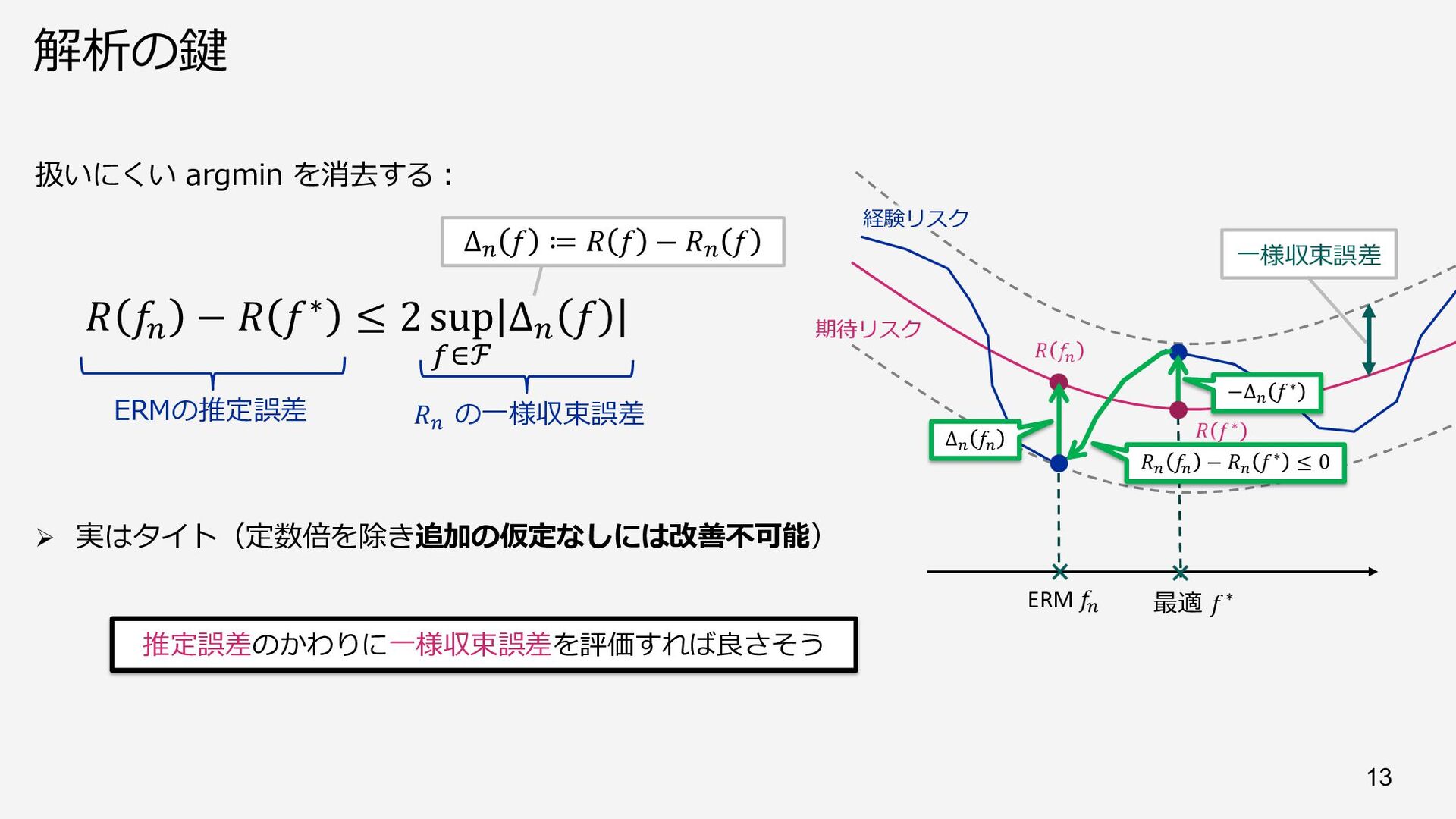{kind=link}
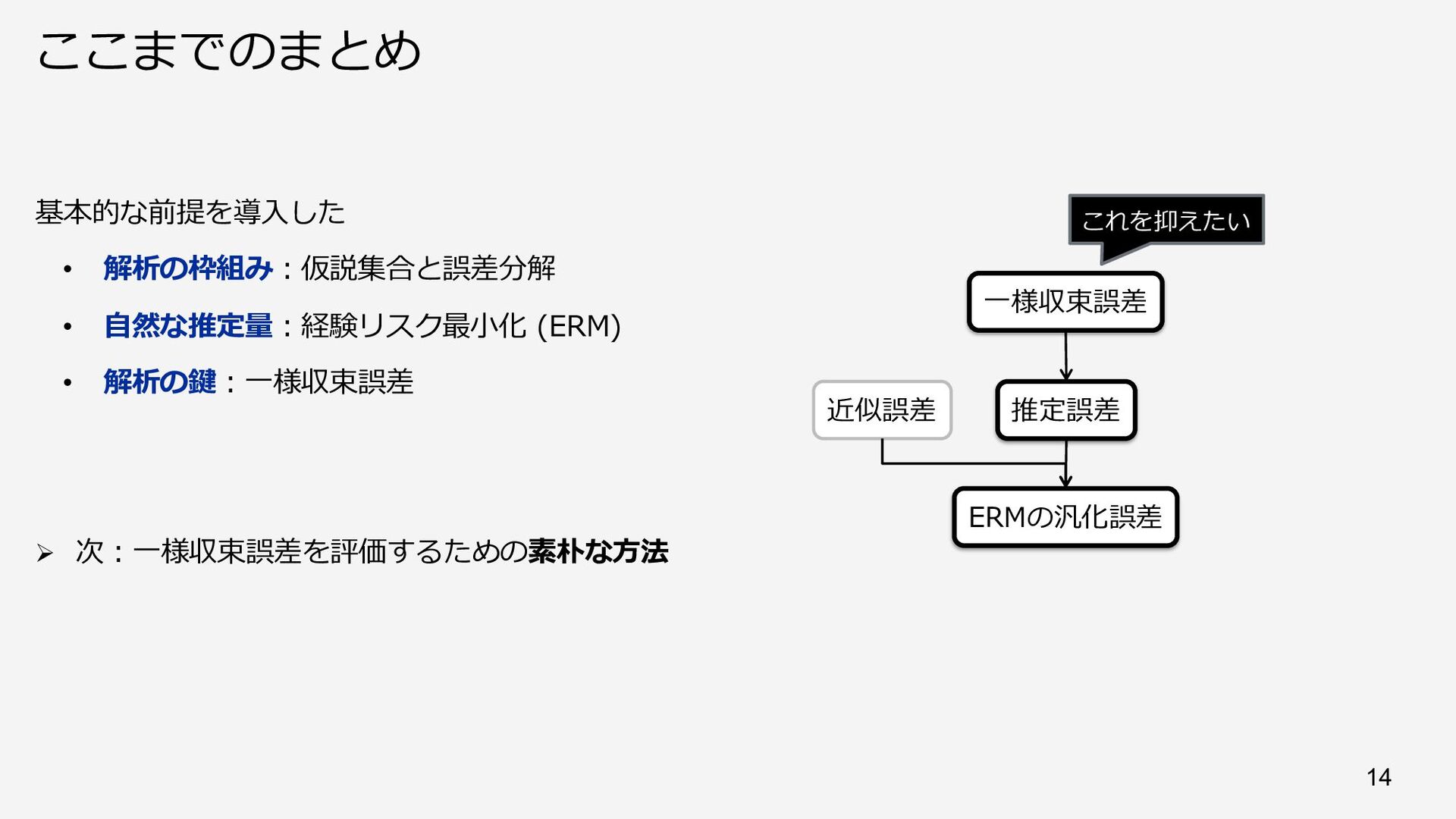{kind=link}
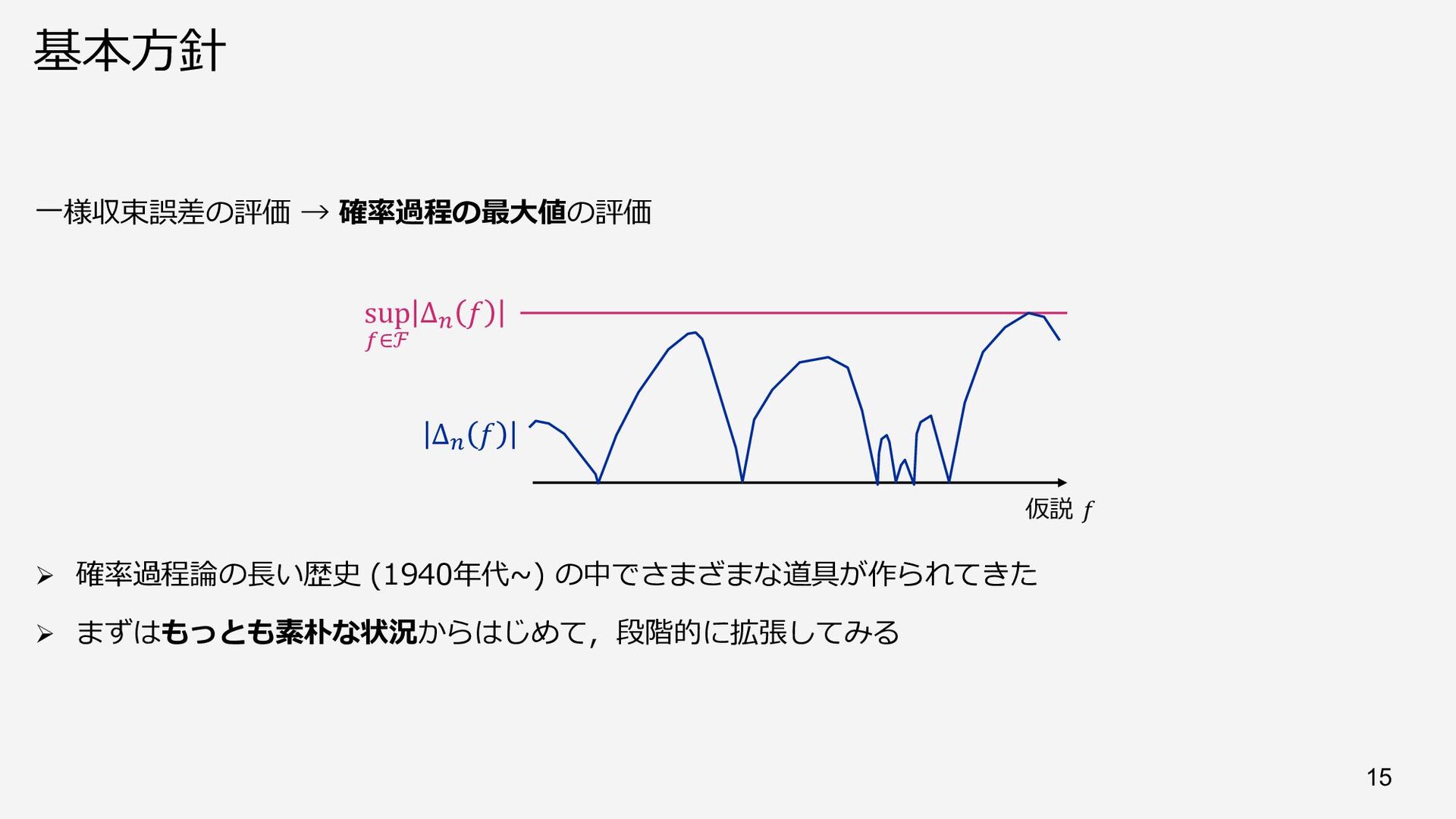{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
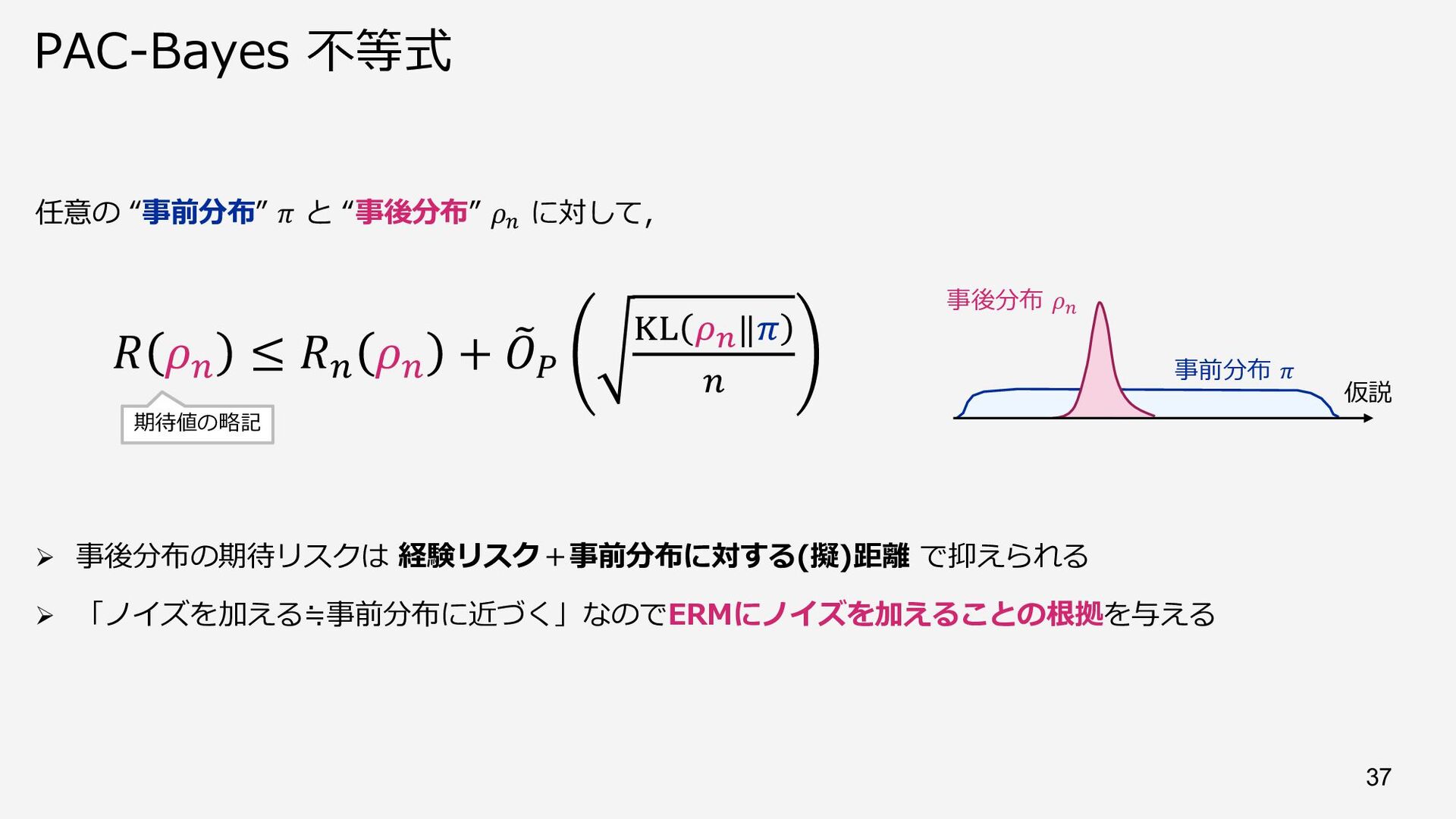
![導出(スケッチ) 1. Change-of-measure 不等式 [Donsker,Varadhan 75] で関数と引数を分離︓ 2. 集中不等式を使って関数側を上から評価︓ 例)損失関数が有界ならば](https://files.speakerdeck.com/presentations/cc40045489ee4008b2d417570d57cd28/slide_37.jpg){kind=link}
{kind=link}
{kind=link}
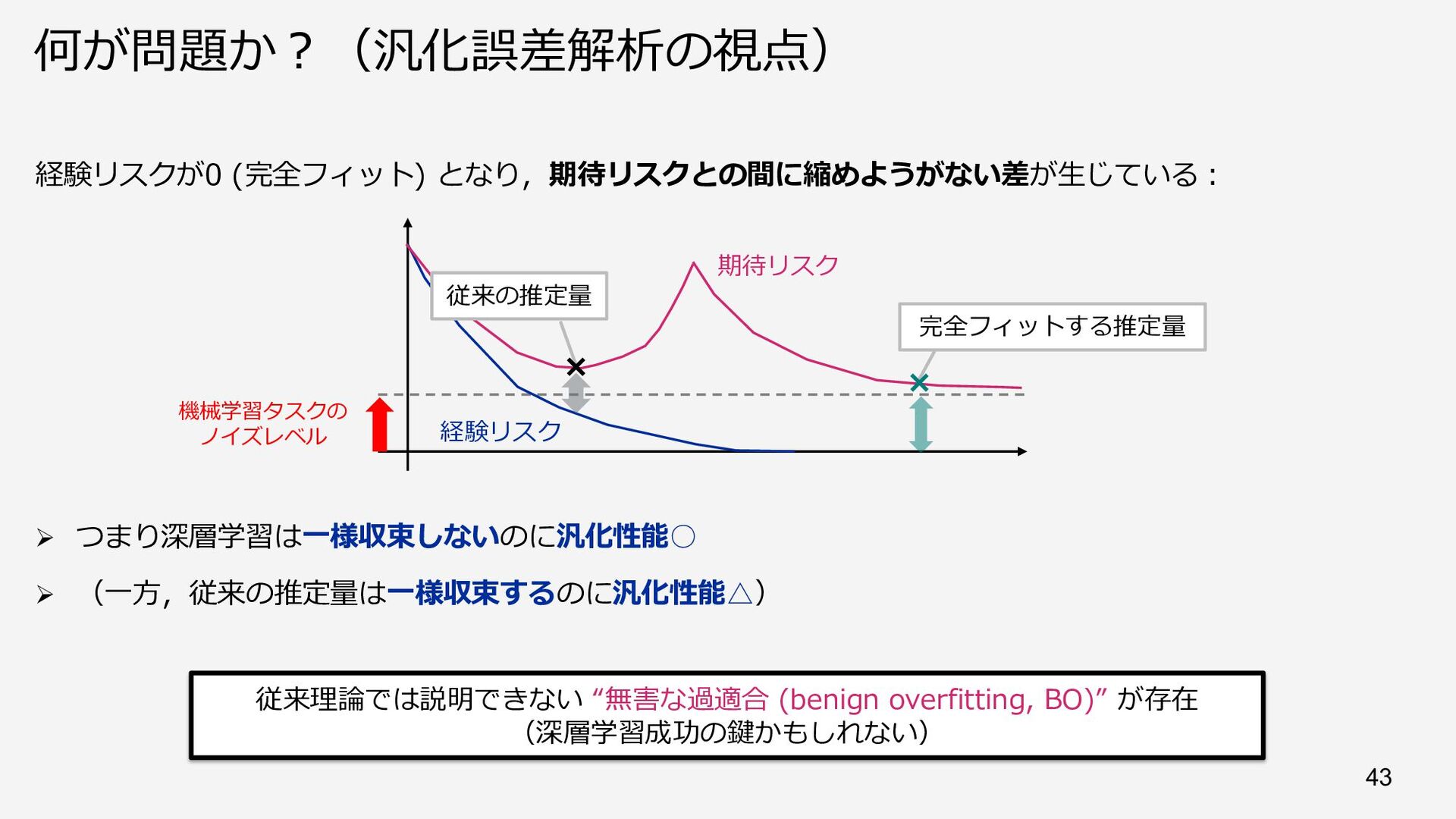
![Overparameterized な推定量 • 深層学習などでは「⼤きなモデルほど性能がよい」という経験知がある • 象徴的な現象︓⼆重降下 (double descent) [Belkin+19a, Nakkiran+20]](https://files.speakerdeck.com/presentations/cc40045489ee4008b2d417570d57cd28/slide_40.jpg){kind=link}
{kind=link}
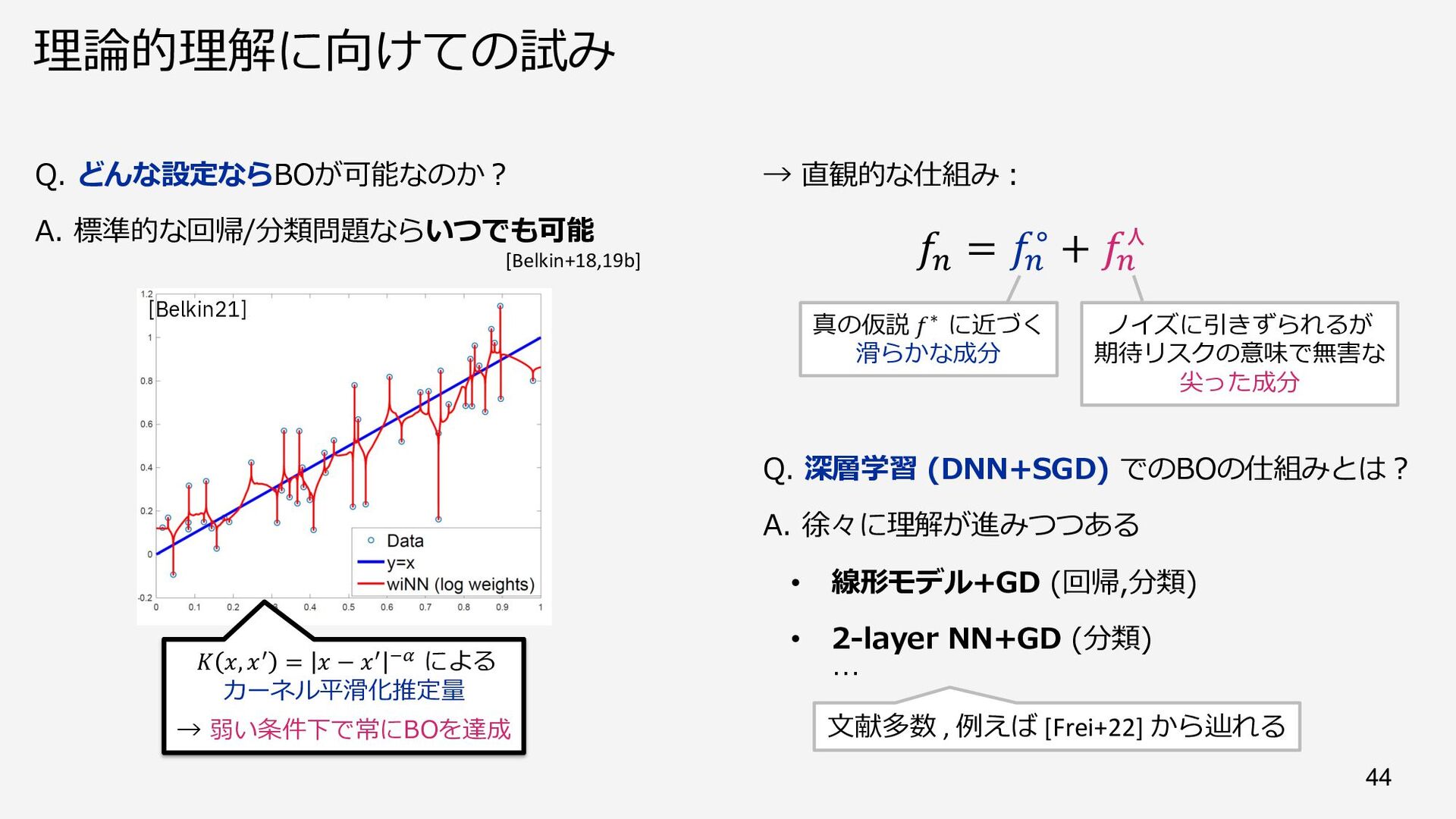{kind=link}
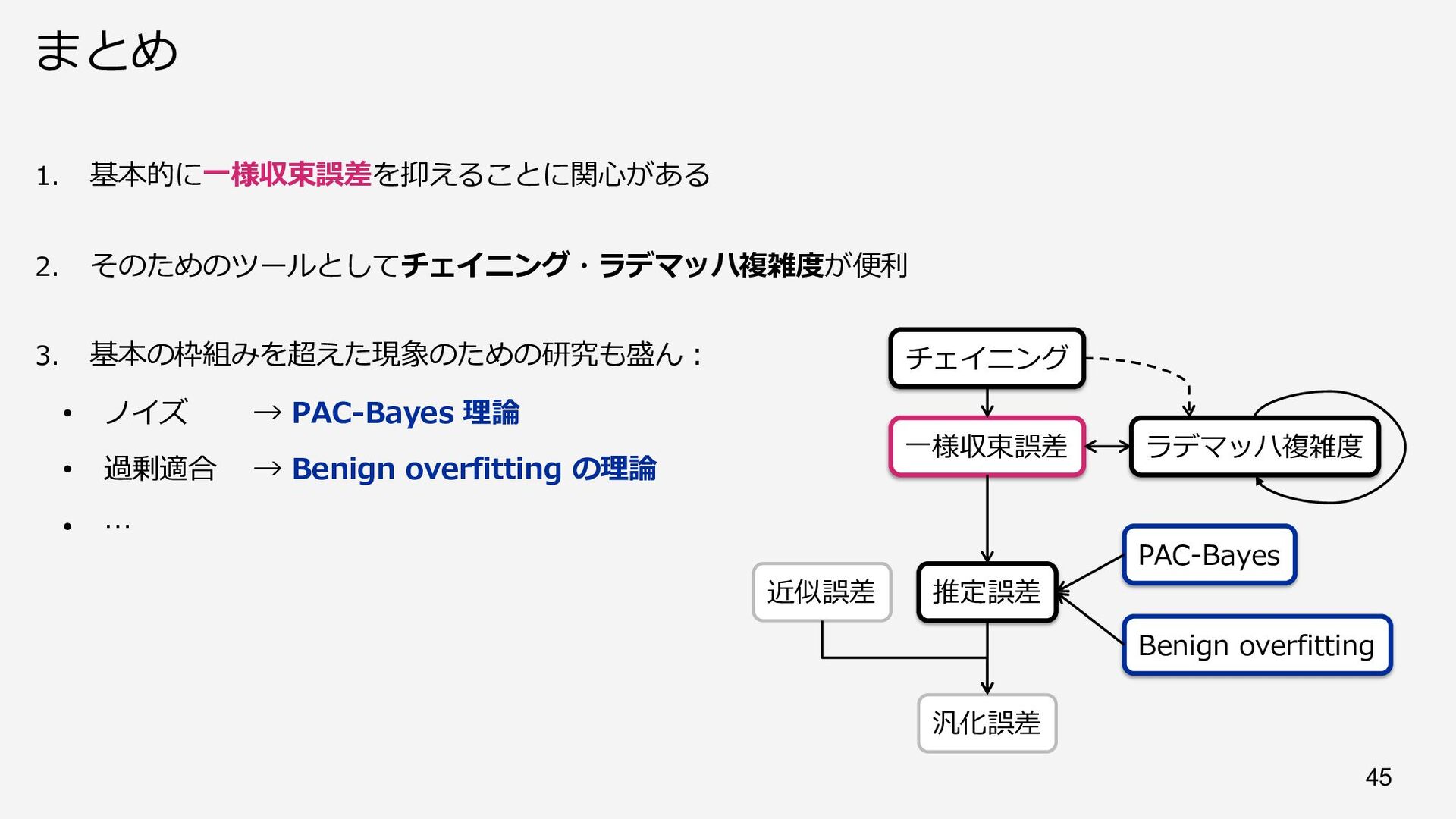{kind=link}
{kind=link}
{kind=link}
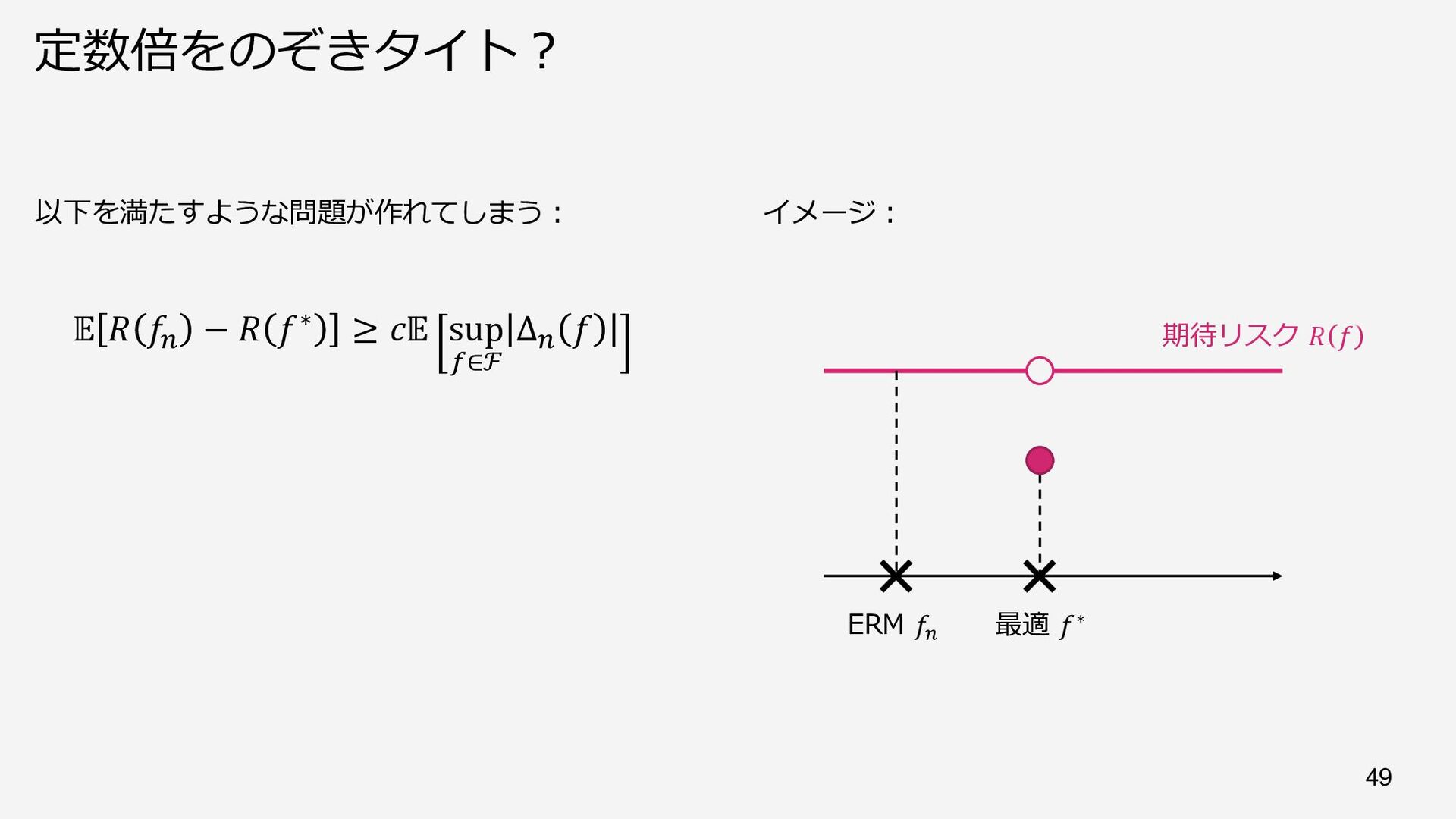{kind=link}
{kind=link}