2024/04/23 第40回 MLOps 勉強会
# 非同期推論システムによるコスト削減と信頼性向上
CADDiでは同期的なリアルタイム推論WebAPIを用いてサービスを構築していました。事業の成長に伴い、よりスケーラブルで疎結合に推論を行うために非同期推論のシステムを開発しています。新システムにより、コスト削減・信頼性向上を実現できそうなので事例として紹介いたします。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
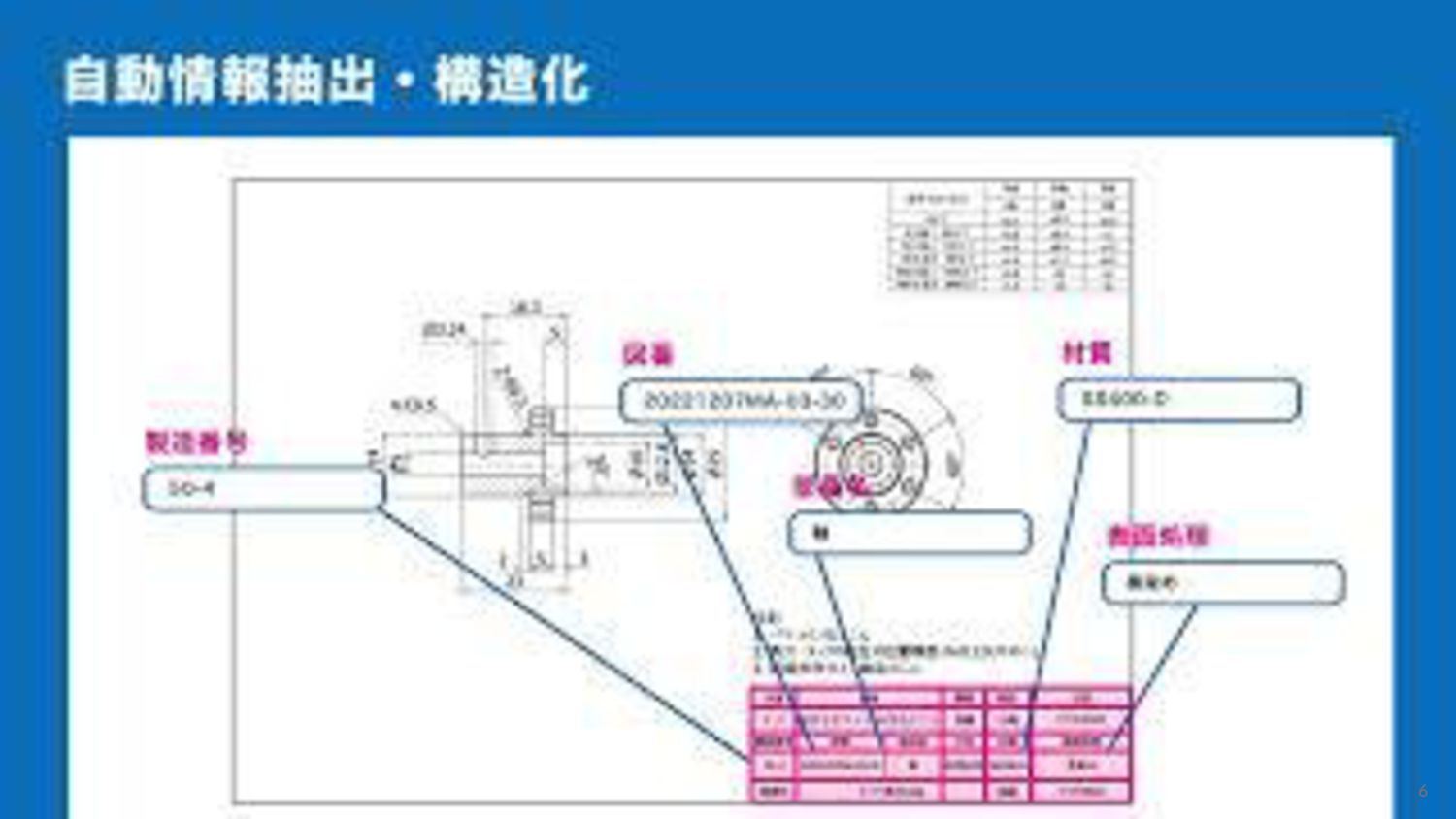{kind=link}
{kind=link}
{kind=link}
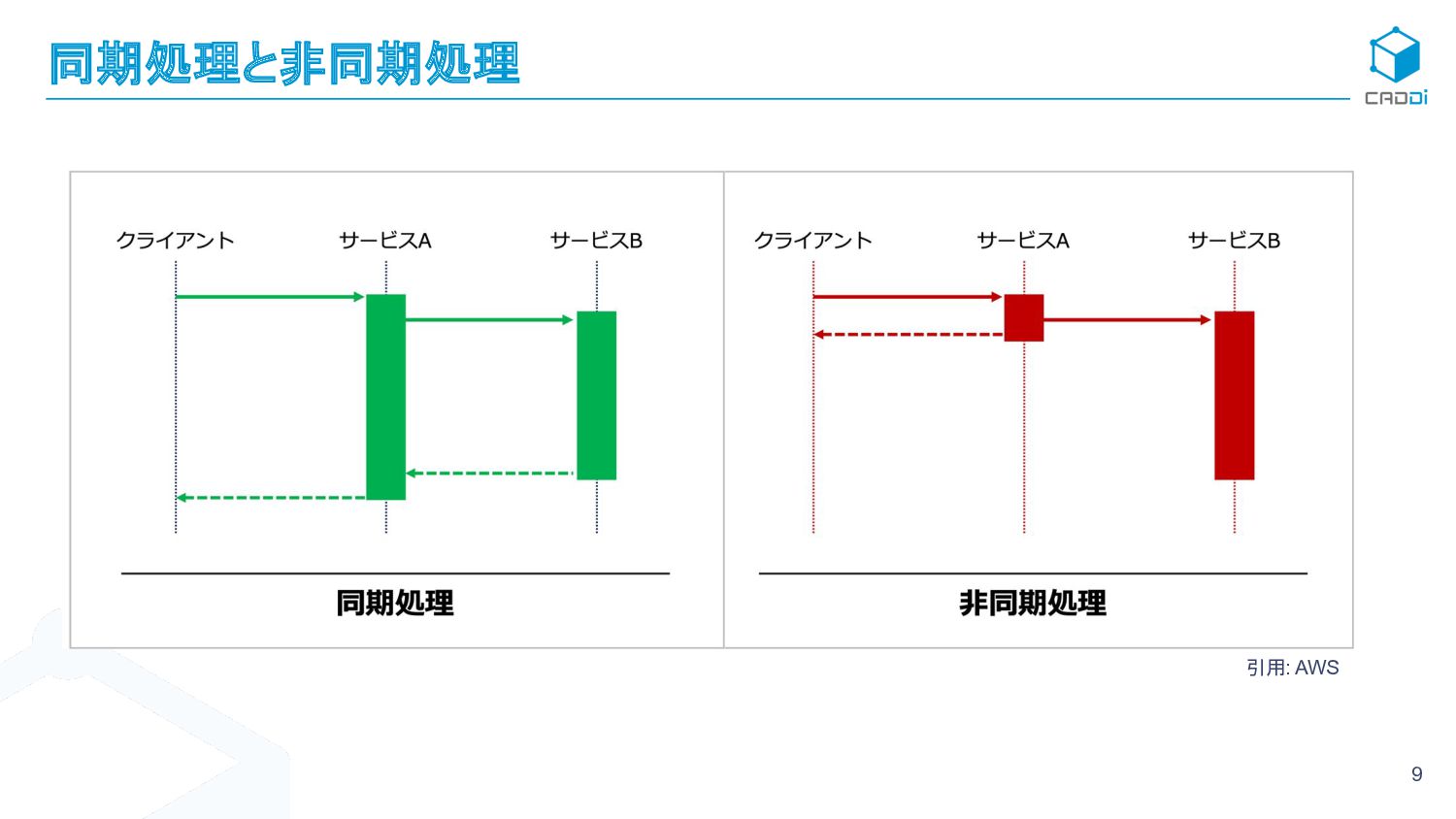{kind=link}
{kind=link}
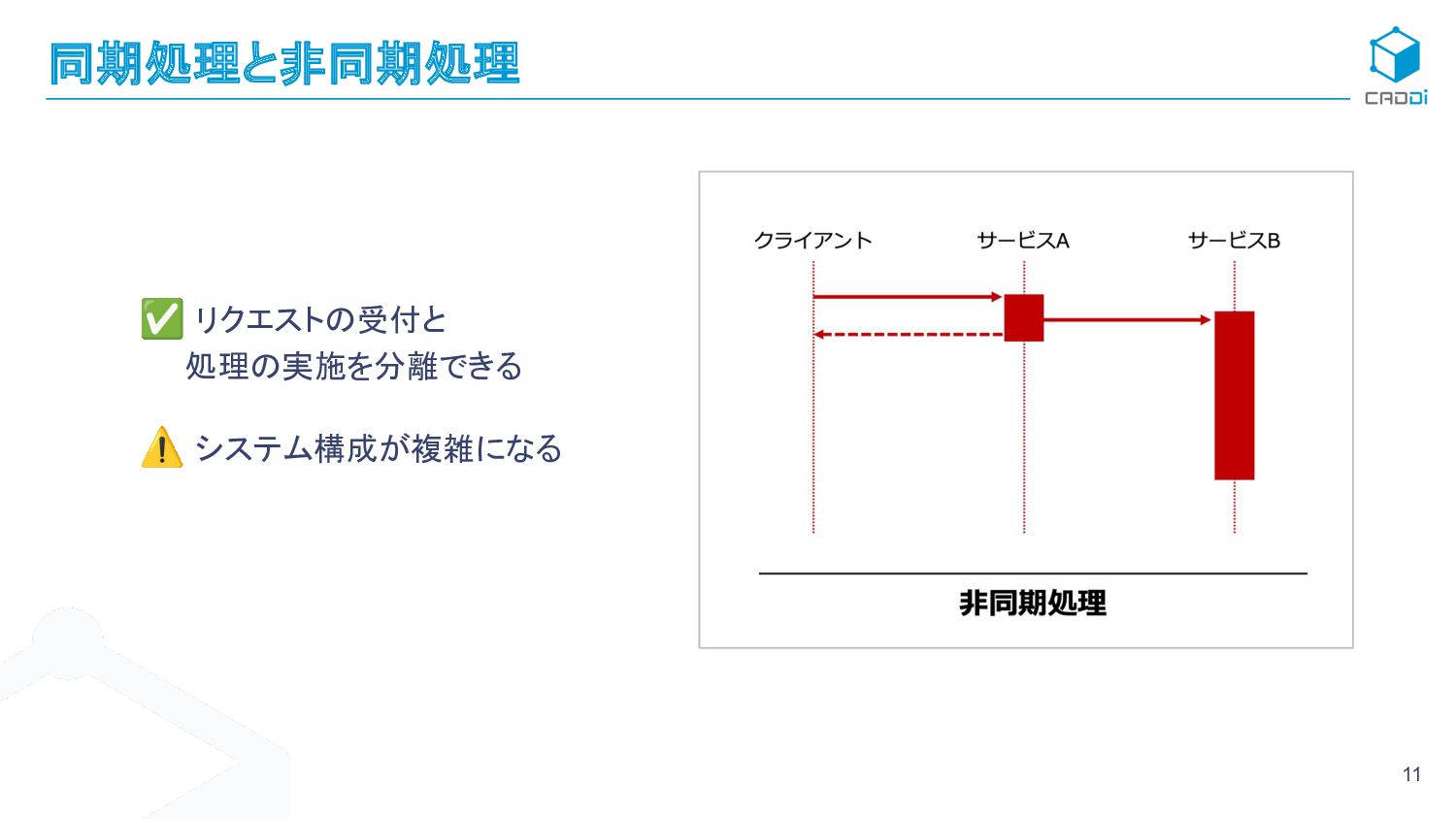{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
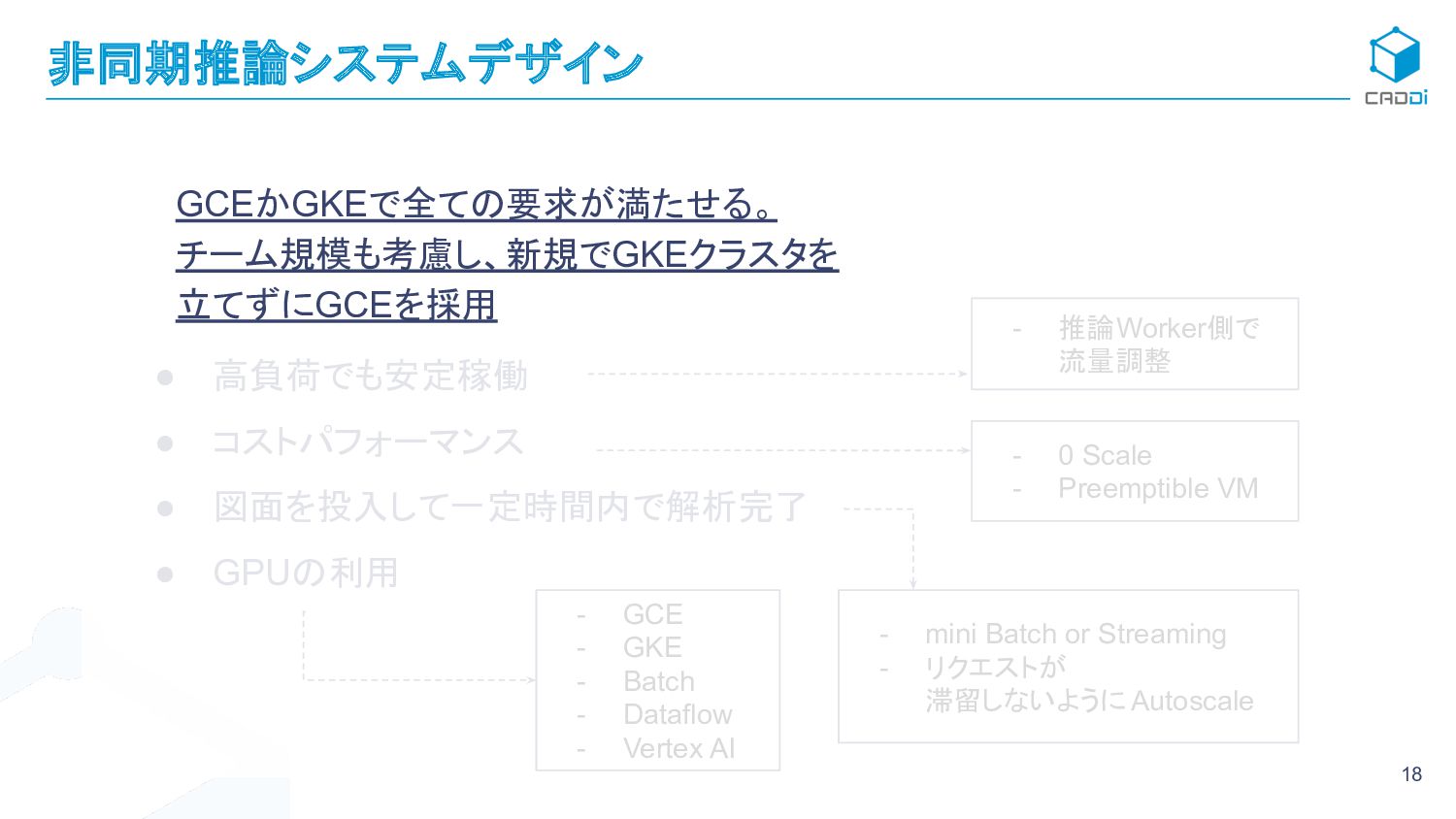{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}