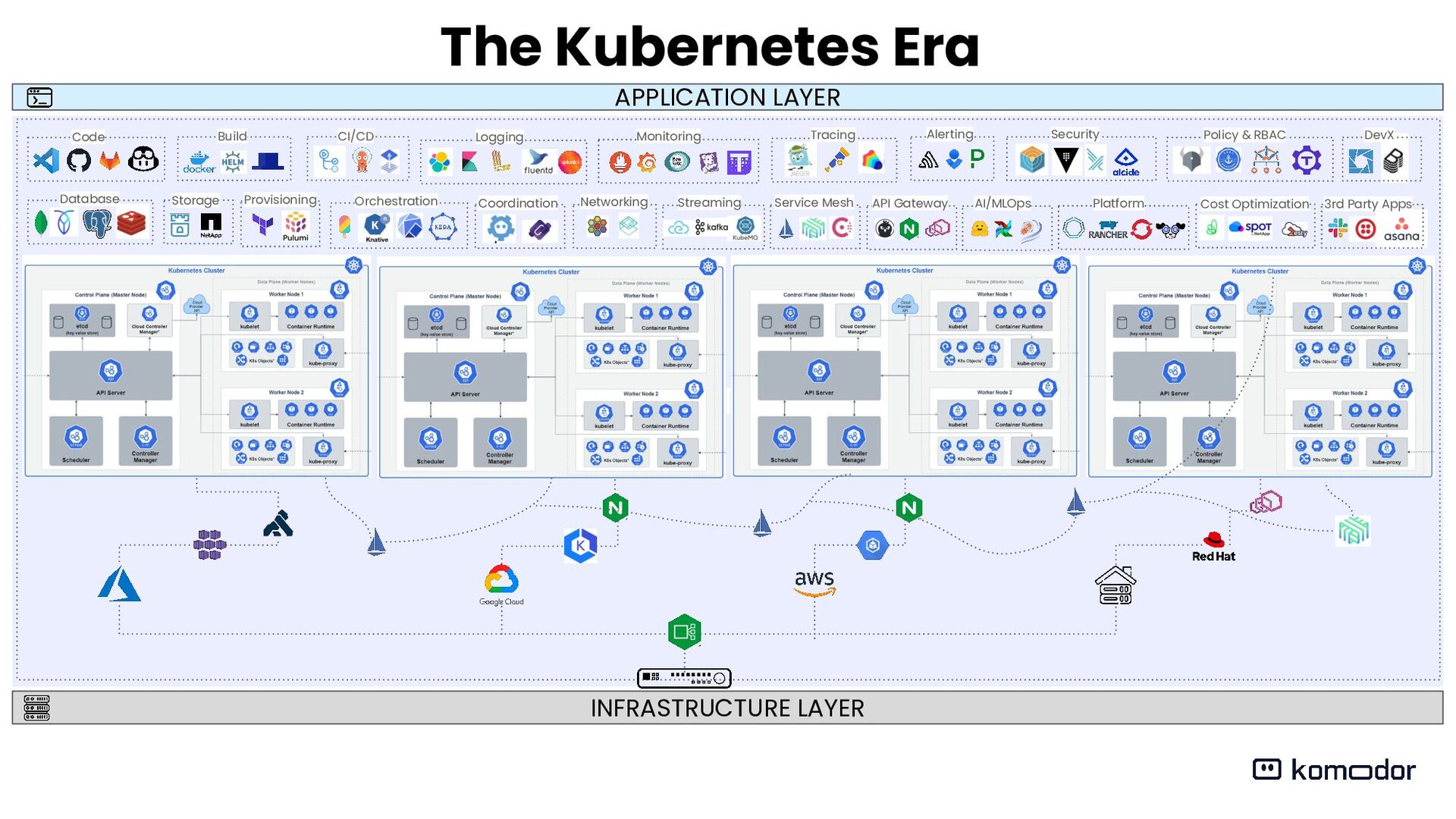
In 2024 everyone already knows that deploying and managing a single vanilla cluster is pretty easy, but past a certain scale, things become messy and very unmanageable.
Join Komodor's own Marino Wijay for an exclusive LIVE workshop focused on enhancing Kubernetes Reliability. In this session, we'll explore the tools and cultural shifts required for a successful implementation of Kubernetes, that actually delivers on its promised value!
This live workshop is designed to provide you with the knowledge and skills needed to achieve elite DevOps standards in your Kubernetes environments and provide a superior developer experience for your application teams.
Marino will masterfully teach you how to:
1. Alleviate tooling fatigue, streamline proactive maintenance, and improve strategic planning for capacity and MTTR reduction
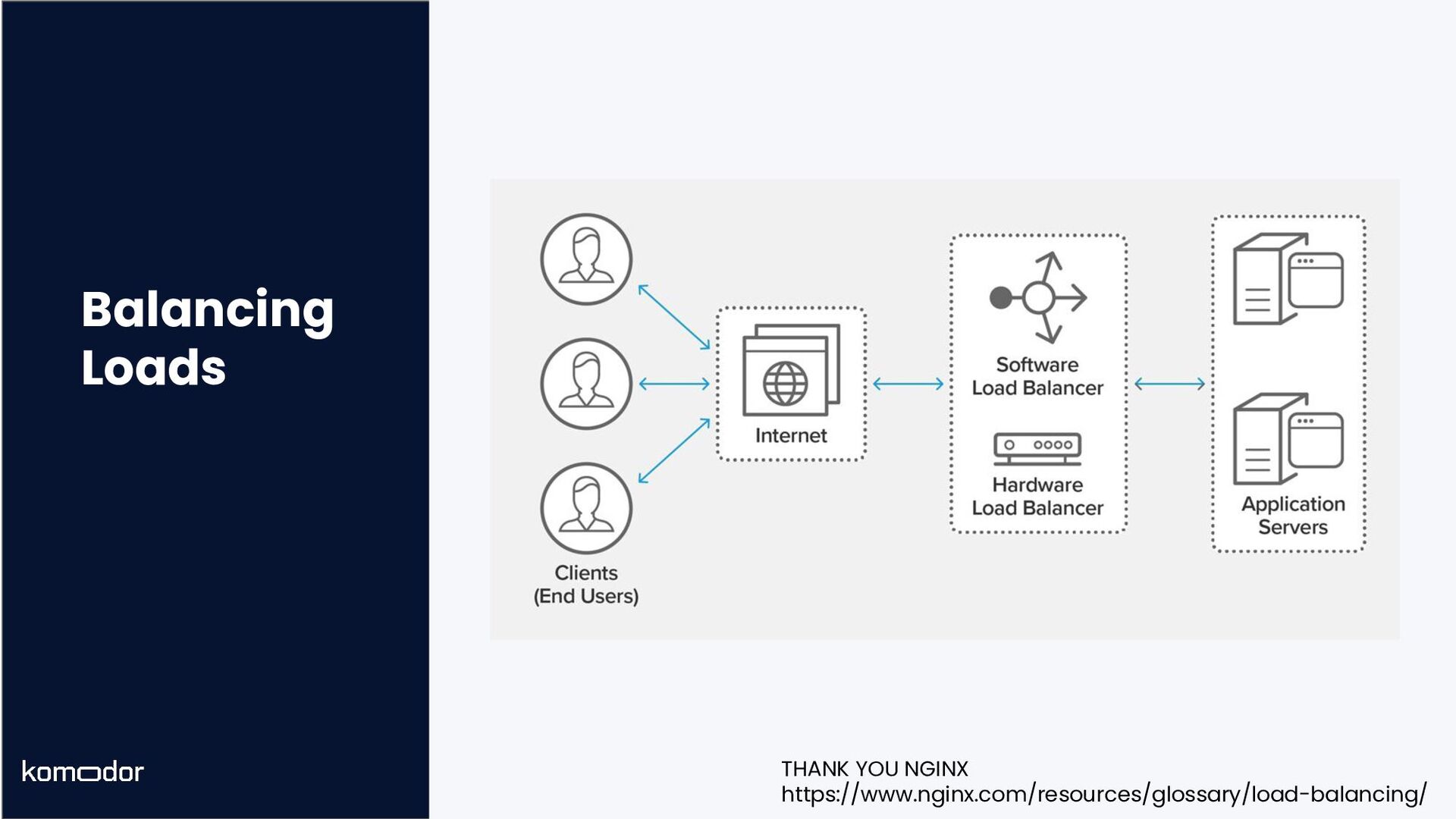
2. Cover the essentials of managing Kubernetes network performance, resiliency, metadata, events, and logs
3. Leverage advanced techniques to boost the reliability of your Kubernetes environments
The workshop will conclude with a Komodor demo session and a short Q&A.
{kind=link}
![@virtualized6ix [email protected] https://www.youtube.com/@marinowijay https://www.linkedin.com/in/mwijay/ Solutions Engineer - Komodor Organizer -](https://files.speakerdeck.com/presentations/231ace42e6e3491fad7d78cc18aaa8c0/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}