to do anything at all, until eventually we can’t move, we can’t add new features or solve problems. Tim Hockin Kubernetes Co-Founder, Google KubeCon NA 2023 Keynote Speech
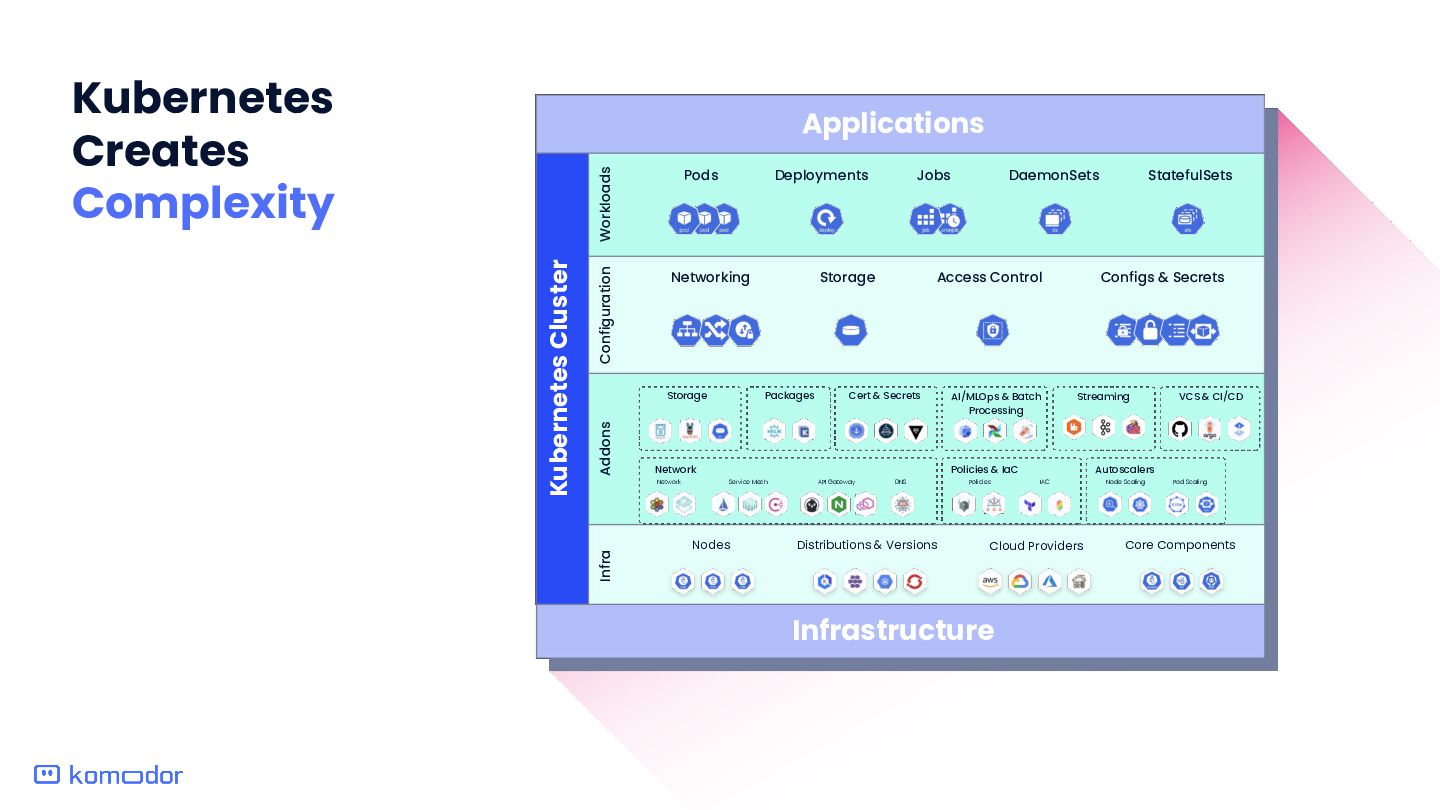
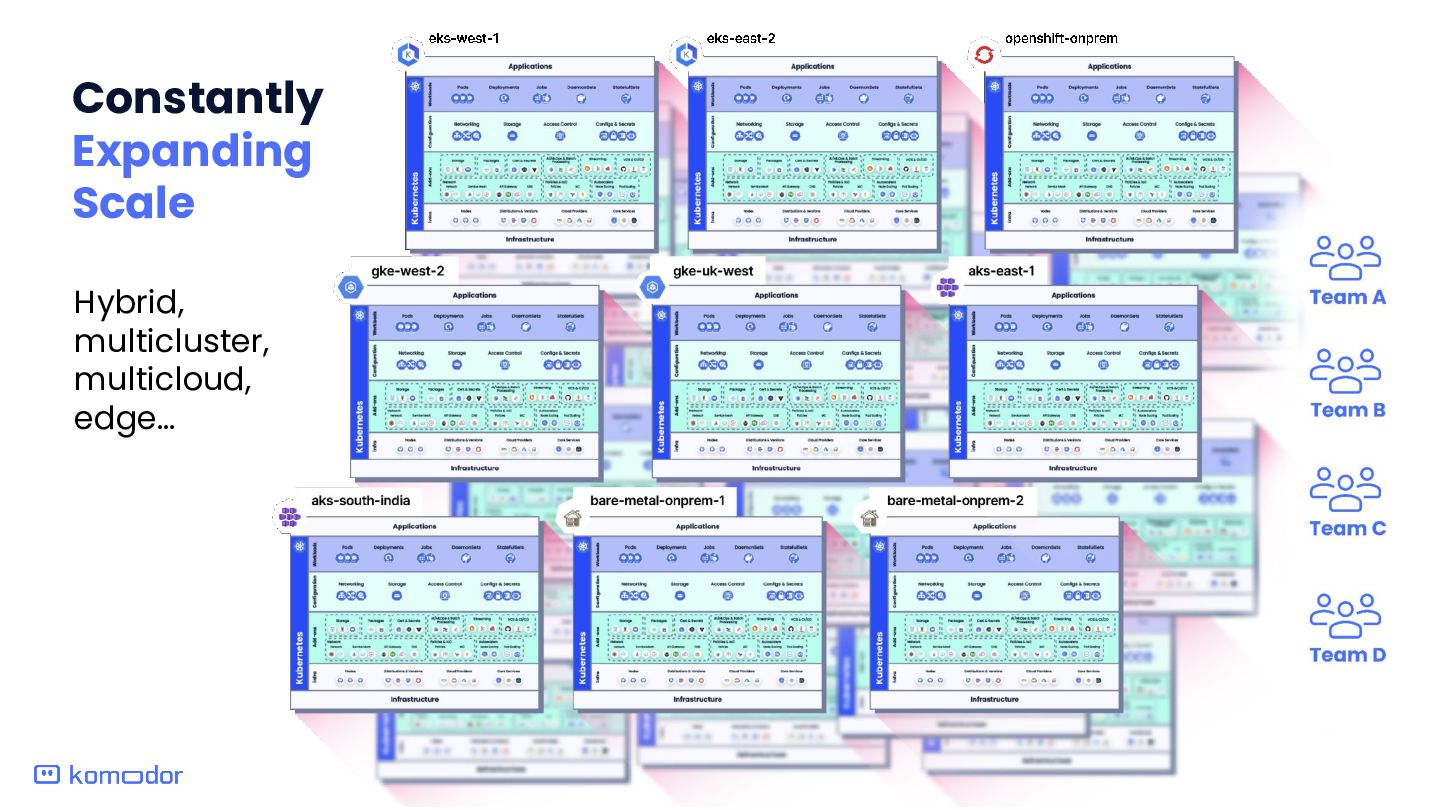
Kubernetes stack at scale imposes significant toil, including handling numerous resources Complex Correlation: Teams must manage tasks like autoscaling, network policies, and service meshes (e.g., Istio), consistently applying best practices and optimizing configurations to ensure seamless service availability across the cluster. Risk of Downtime: Misconfigurations or delays with critical components like storage solutions, networking plugins and other core services can lead to cluster-wide downtime or degraded performance. Lack of Visibility and Proactiveness: Not all K8s elements have standards for visibility error tracking and alerting. This results in many issues going undetected and reactive firefighting. Impact on Productivity: The burden of managing K8s clusters is time consuming and diverts focus from strategic initiatives to tactic ‘keeping the head above the water’.
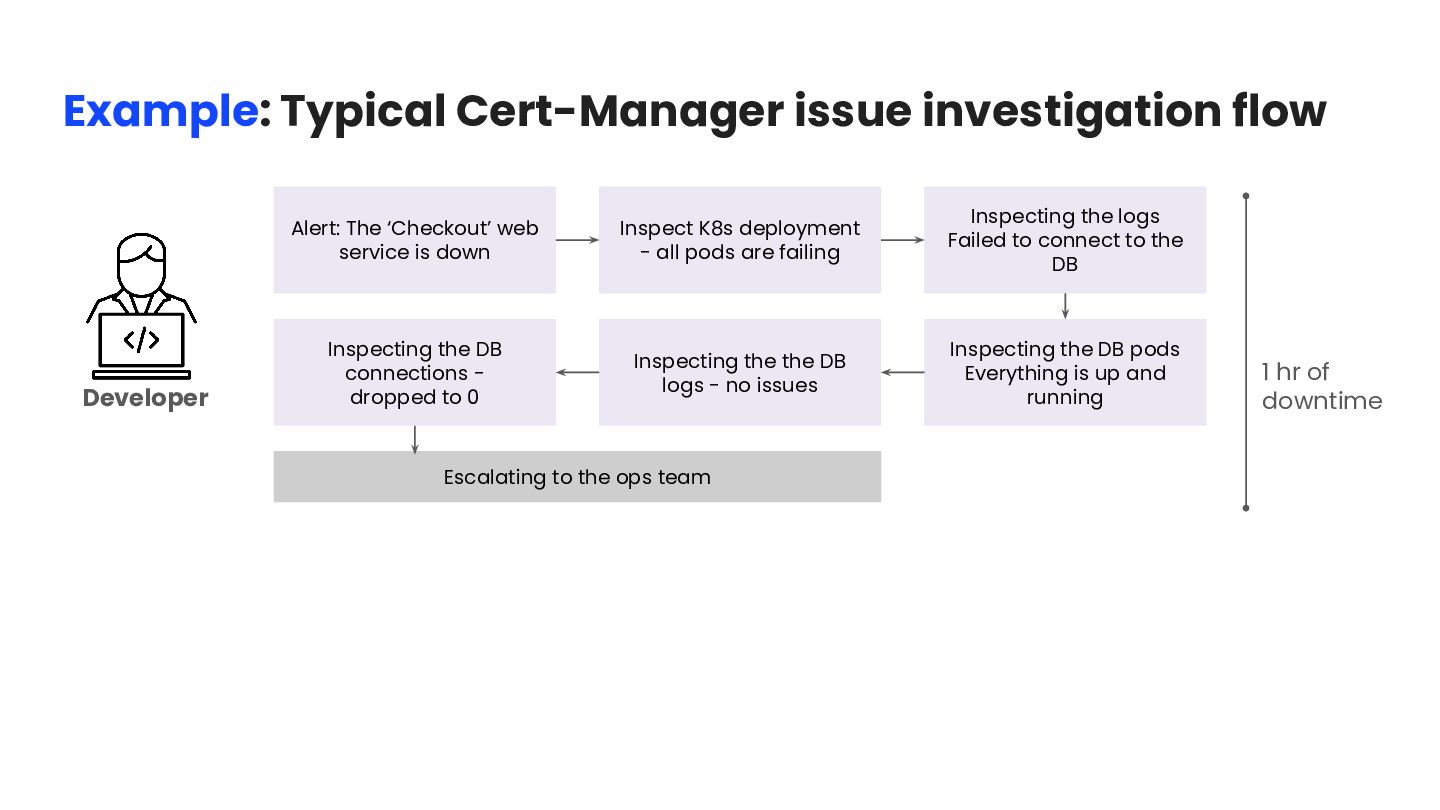
- all pods are failing Inspecting the logs Failed to connect to the DB Inspecting the DB pods Everything is up and running Inspecting the the DB logs - no issues Inspecting the DB connections - dropped to 0 Escalating to the ops team 1 hr of downtime Example: Typical Cert-Manager issue investigation flow Developer
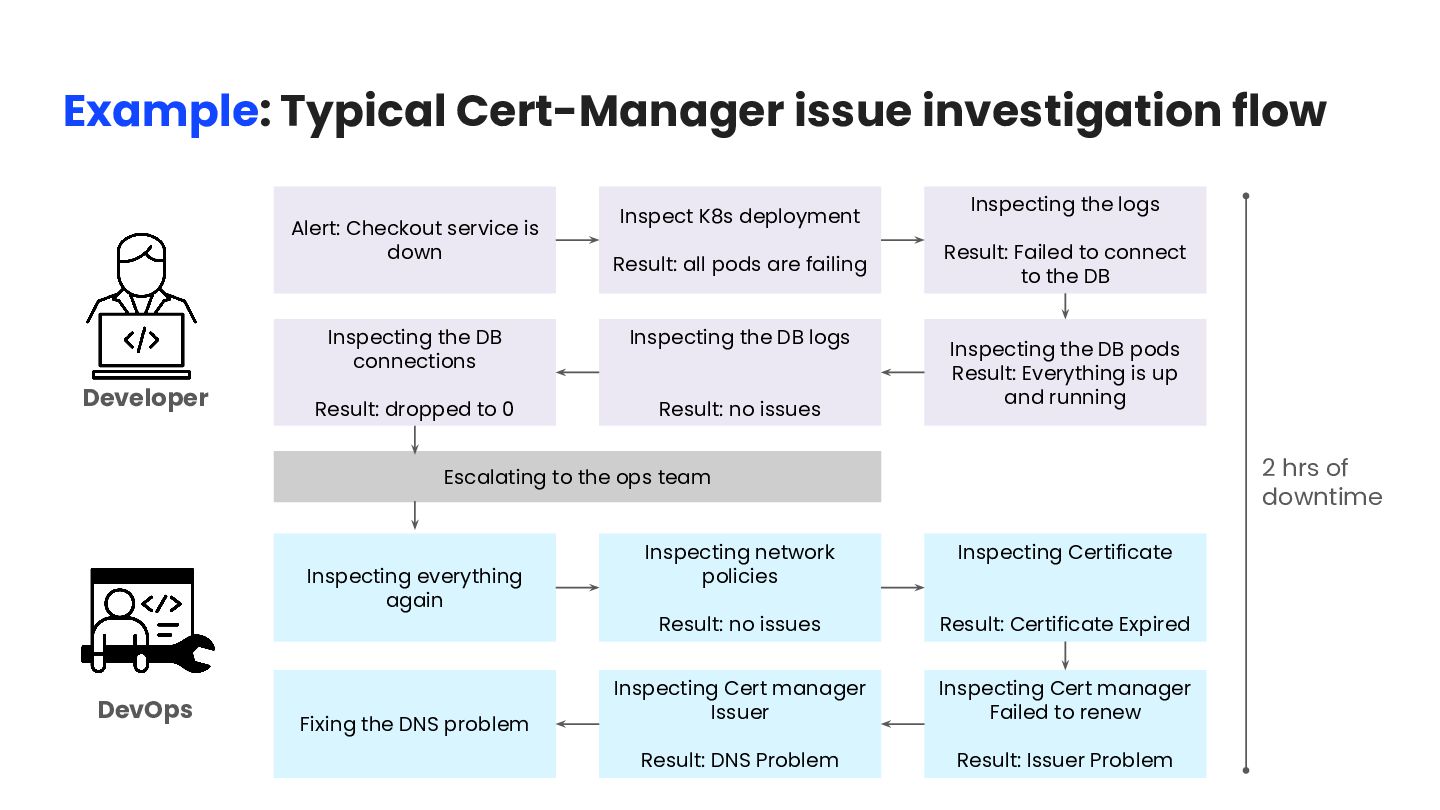
Certificate Result: Certificate Expired Inspecting Cert manager Failed to renew Result: Issuer Problem Inspecting Cert manager Issuer Result: DNS Problem Fixing the DNS problem Alert: Checkout service is down Inspect K8s deployment Result: all pods are failing Inspecting the logs Result: Failed to connect to the DB Inspecting the DB pods Result: Everything is up and running Inspecting the DB logs Result: no issues Inspecting the DB connections Result: dropped to 0 Escalating to the ops team 2 hrs of downtime Developer DevOps Example: Typical Cert-Manager issue investigation flow
Certificate Result: Certificate Expired Inspecting Cert manager Failed to renew Result: Issuer Problem Inspecting Cert manager Issuer Result: DNS Problem Fixing the DNS problem Alert: Checkout service is down Inspect K8s deployment Result: all pods are failing Inspecting the logs Result: Failed to connect to the DB Inspecting the the DB pods Result: Everything is up and running Inspecting the DB logs Result: no issues Inspecting the the DB connections Result: dropped to 0 Escalating to the ops team 2 hrs of downtime Developer DevOps Example: Typical Cert-Manager issue investigation flow A seemingly simple issue, yet it requires 2 teams to be involved for ~2 hours & over 10 investigation steps to get to the root cause
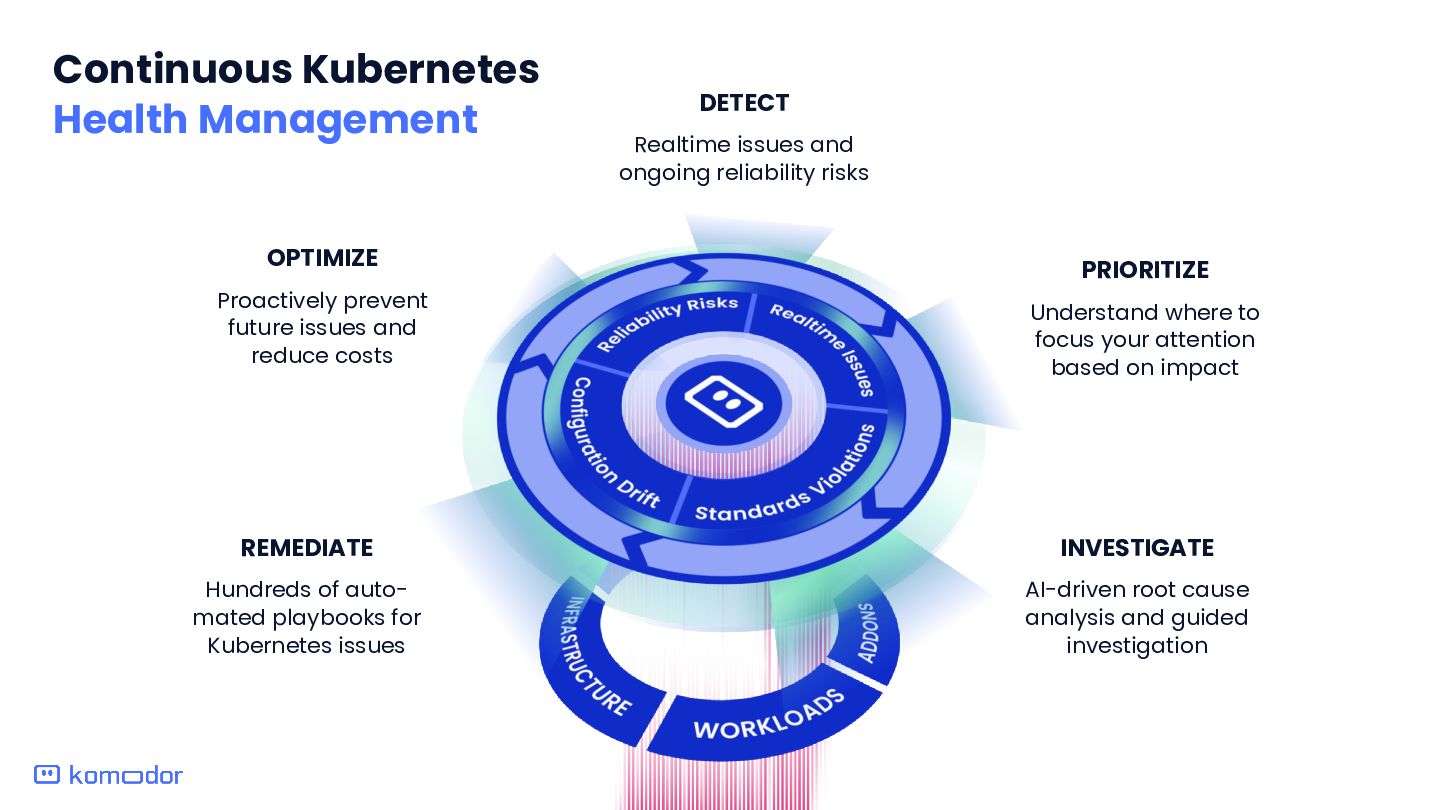
risks PRIORITIZE Understand where to focus your attention based on impact INVESTIGATE AI-driven root cause analysis and guided investigation REMEDIATE Hundreds of auto- mated playbooks for Kubernetes issues OPTIMIZE Proactively prevent future issues and reduce costs
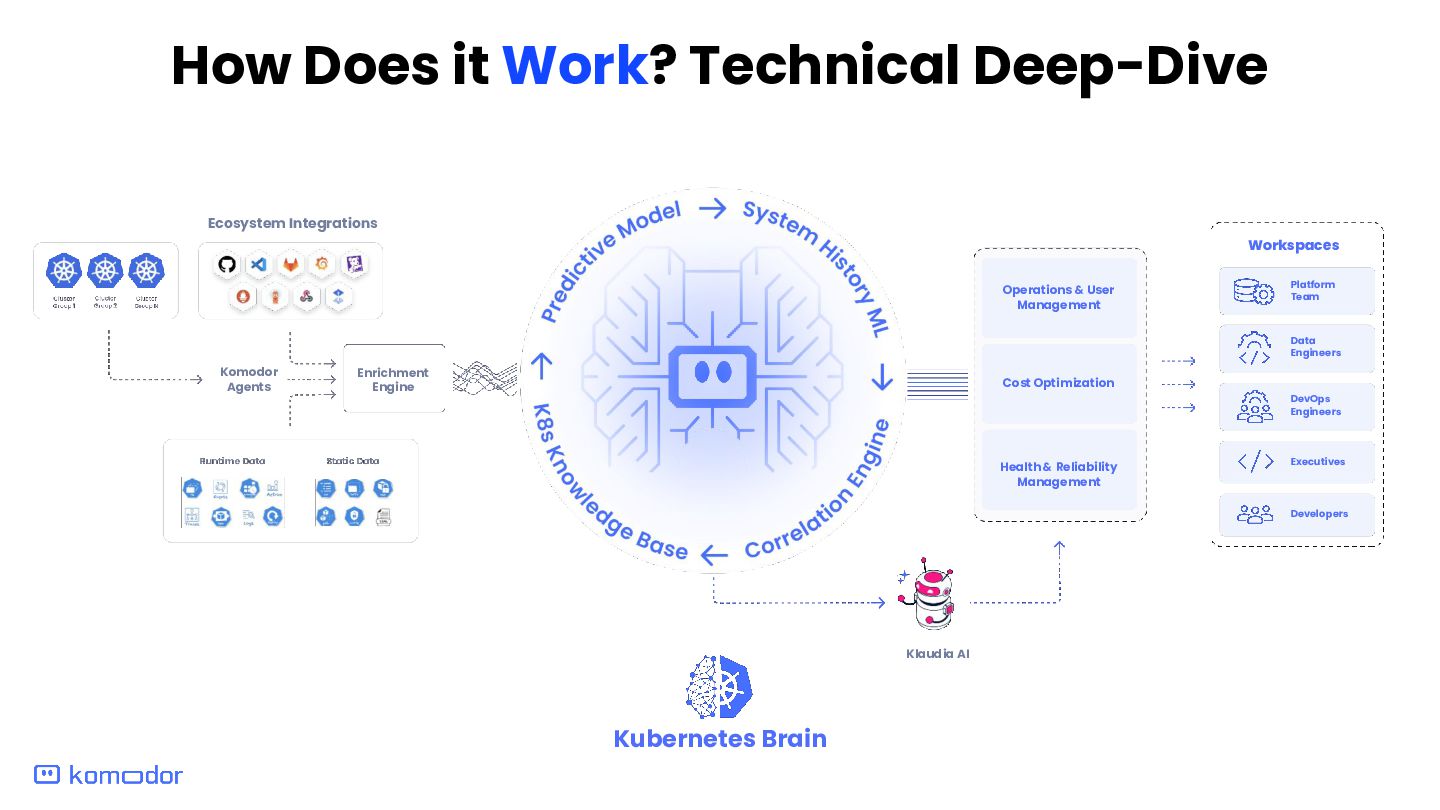
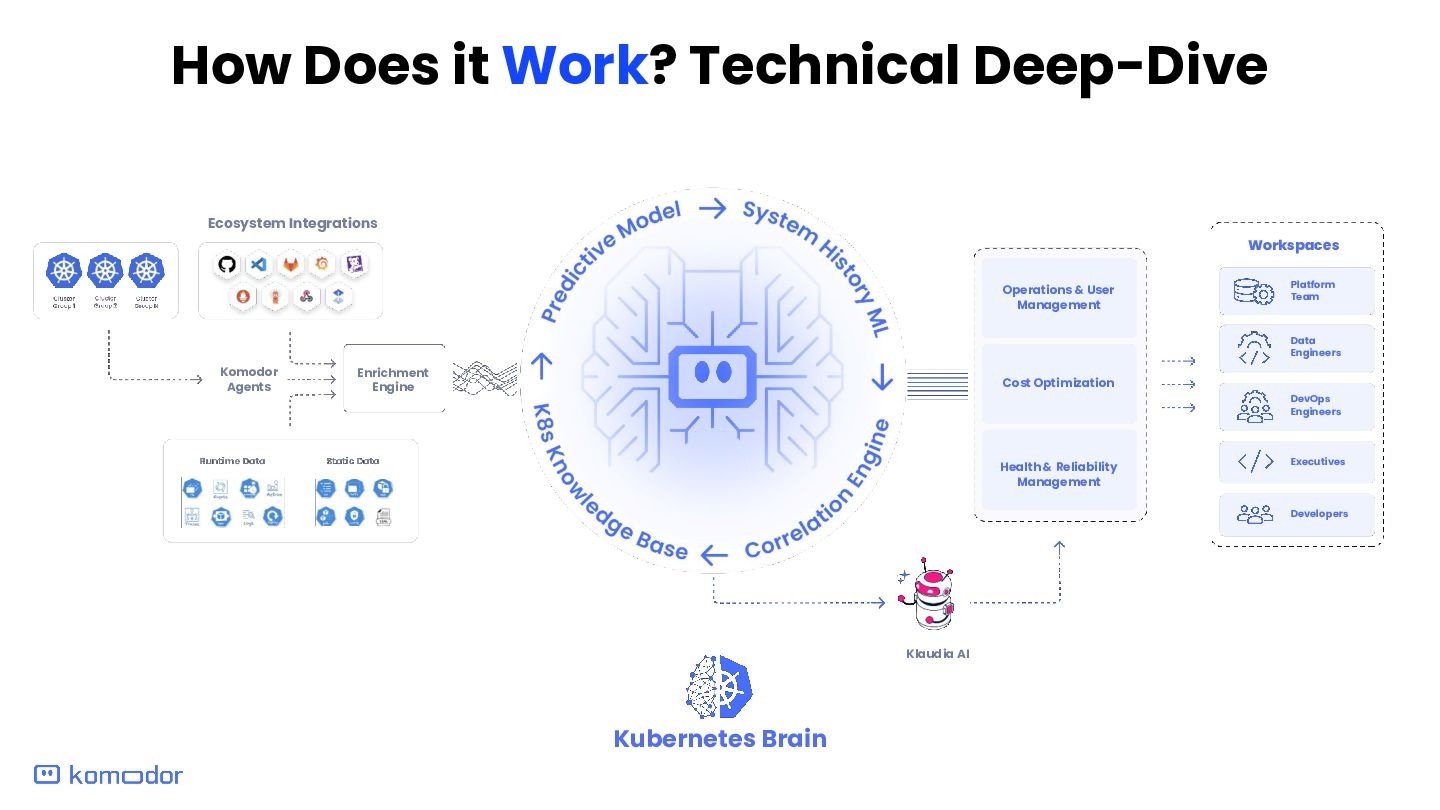
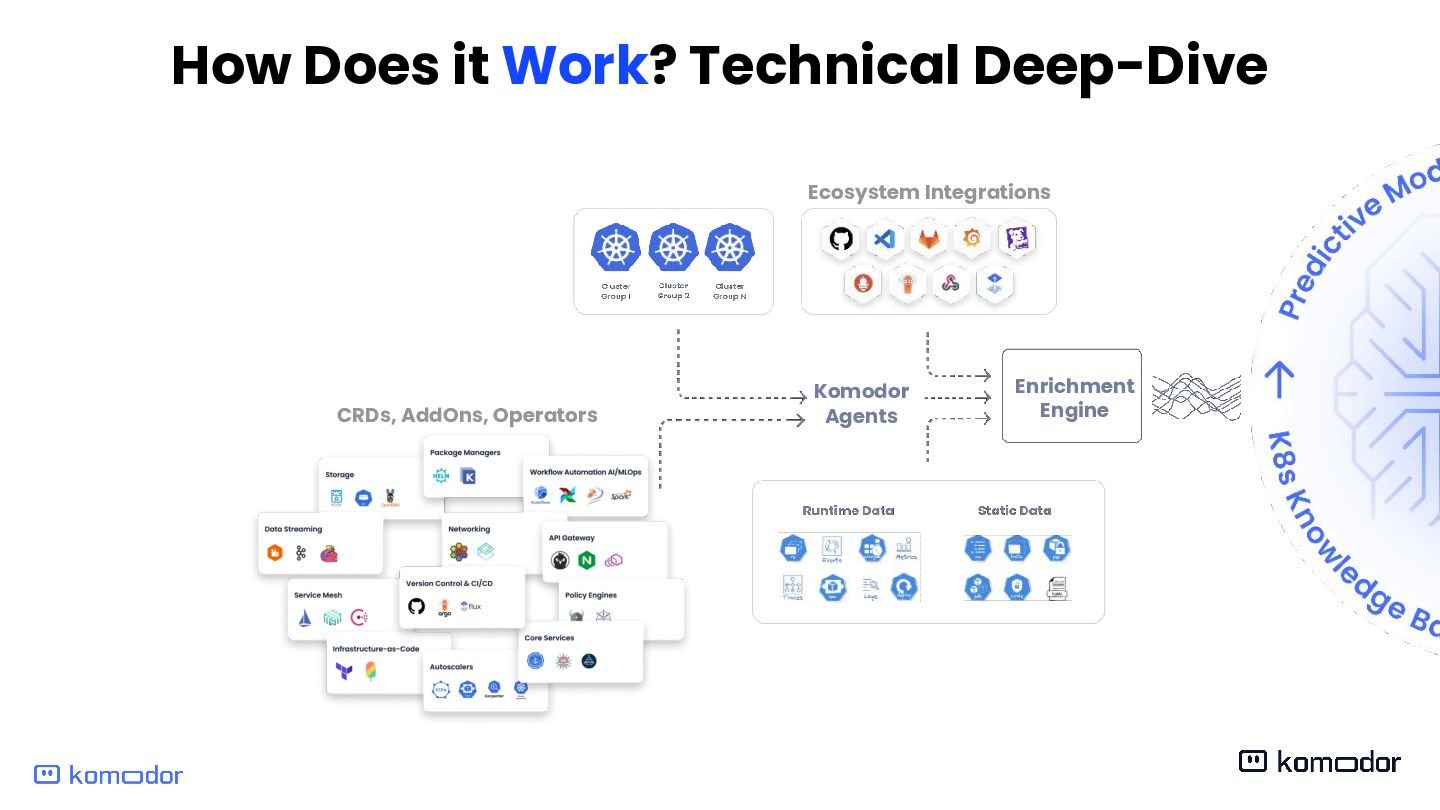
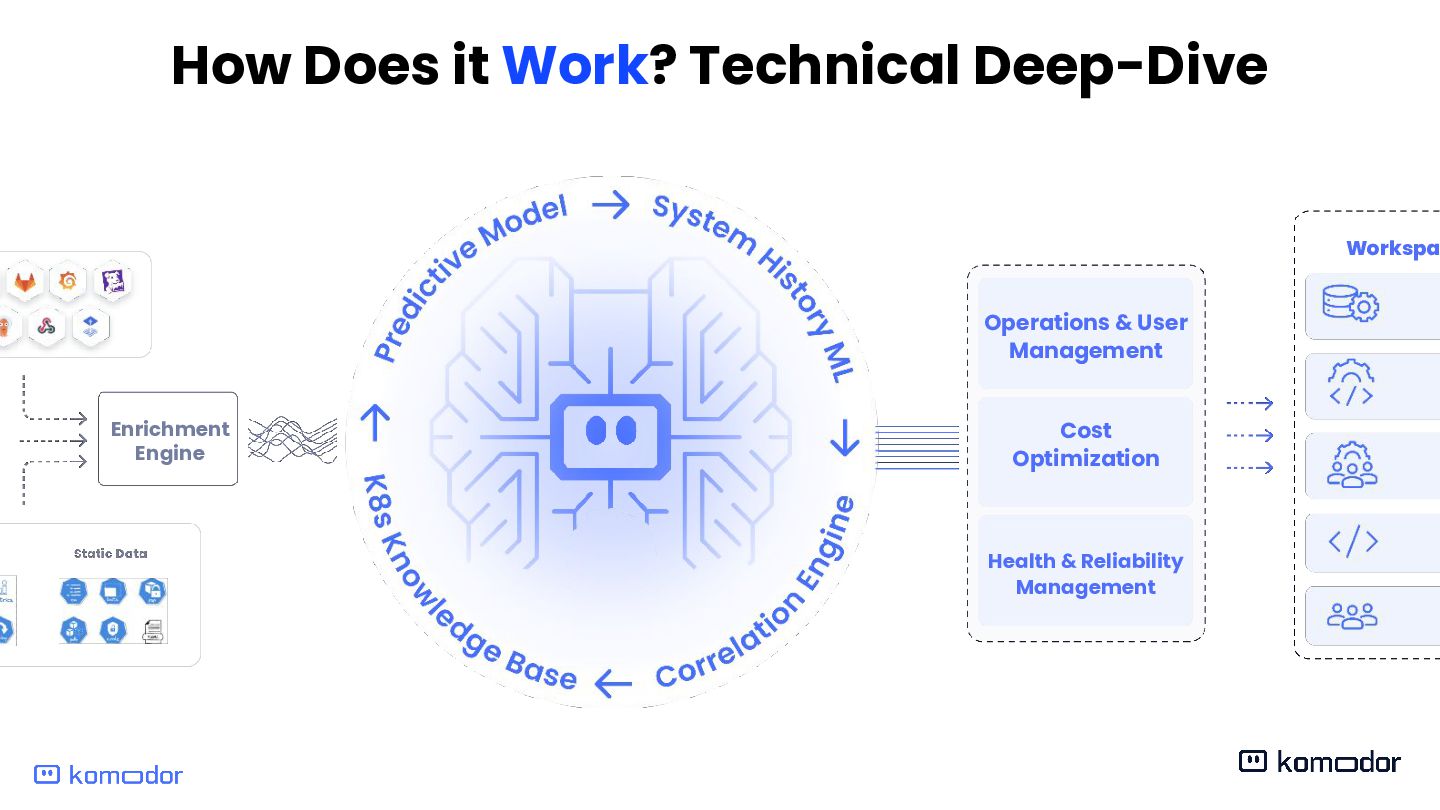
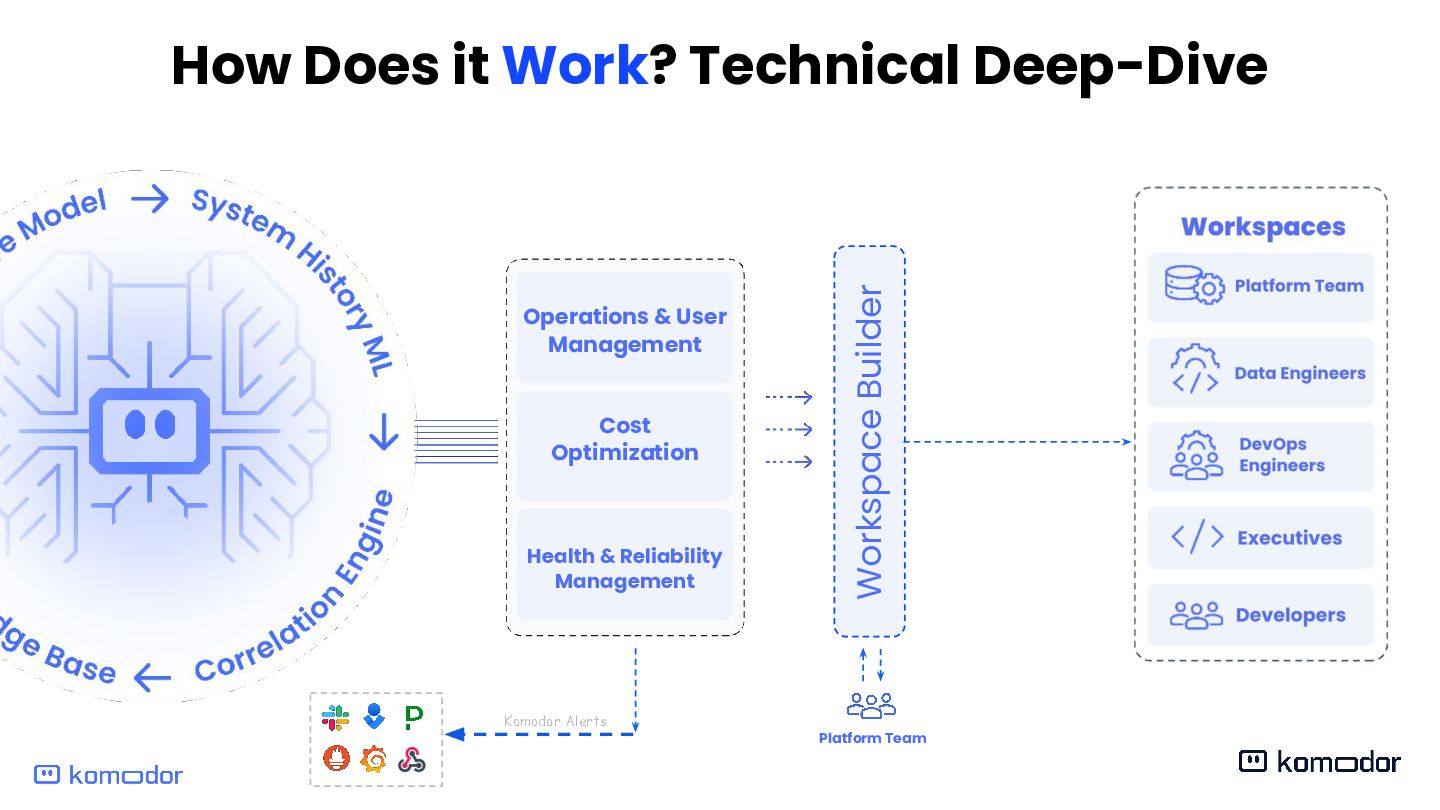
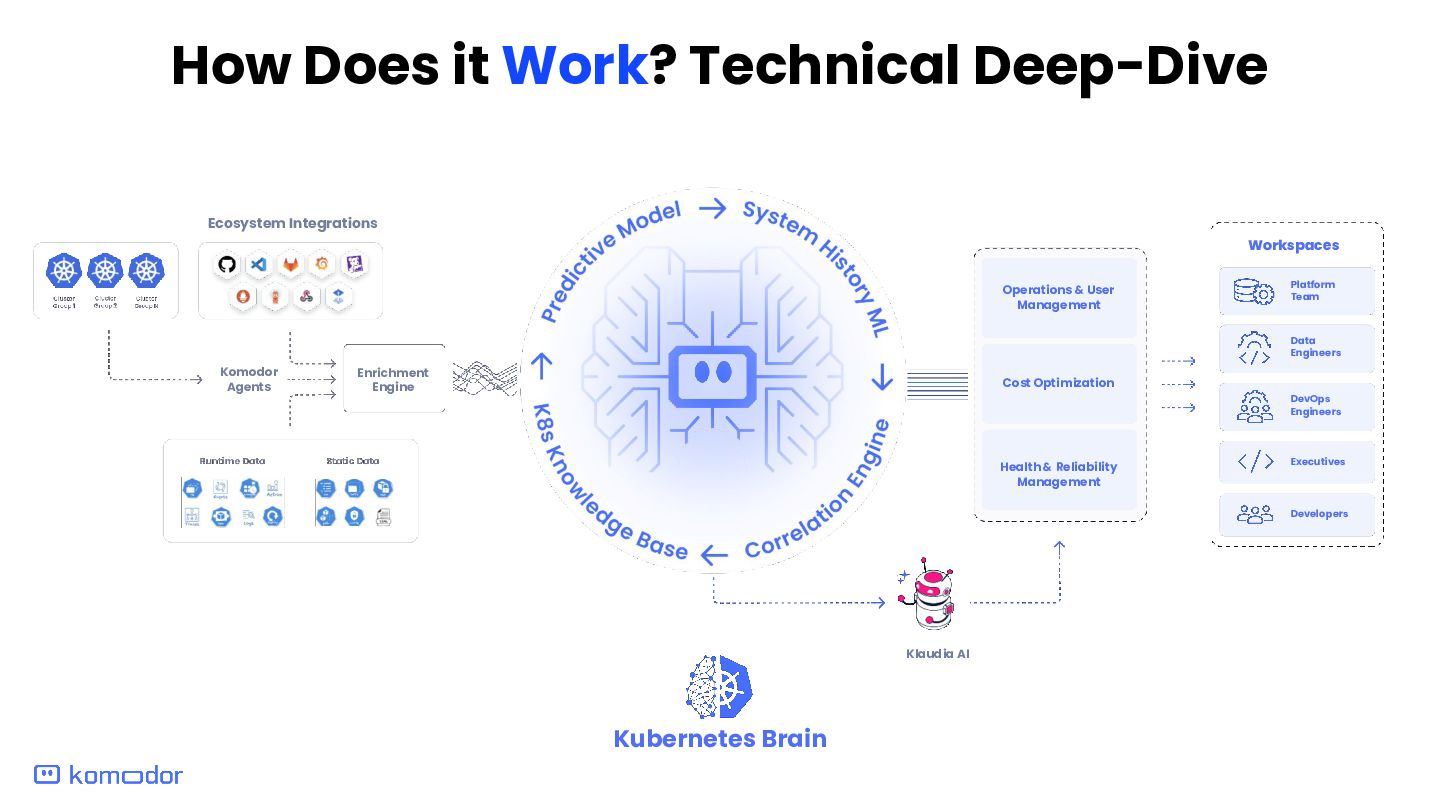
Enrichment Engine Operations & User Management Health & Reliability Management Cost Optimization Data Engineers DevOps Engineers Executives Developers Platform Team Workspaces Kubernetes Brain Klaudia AI
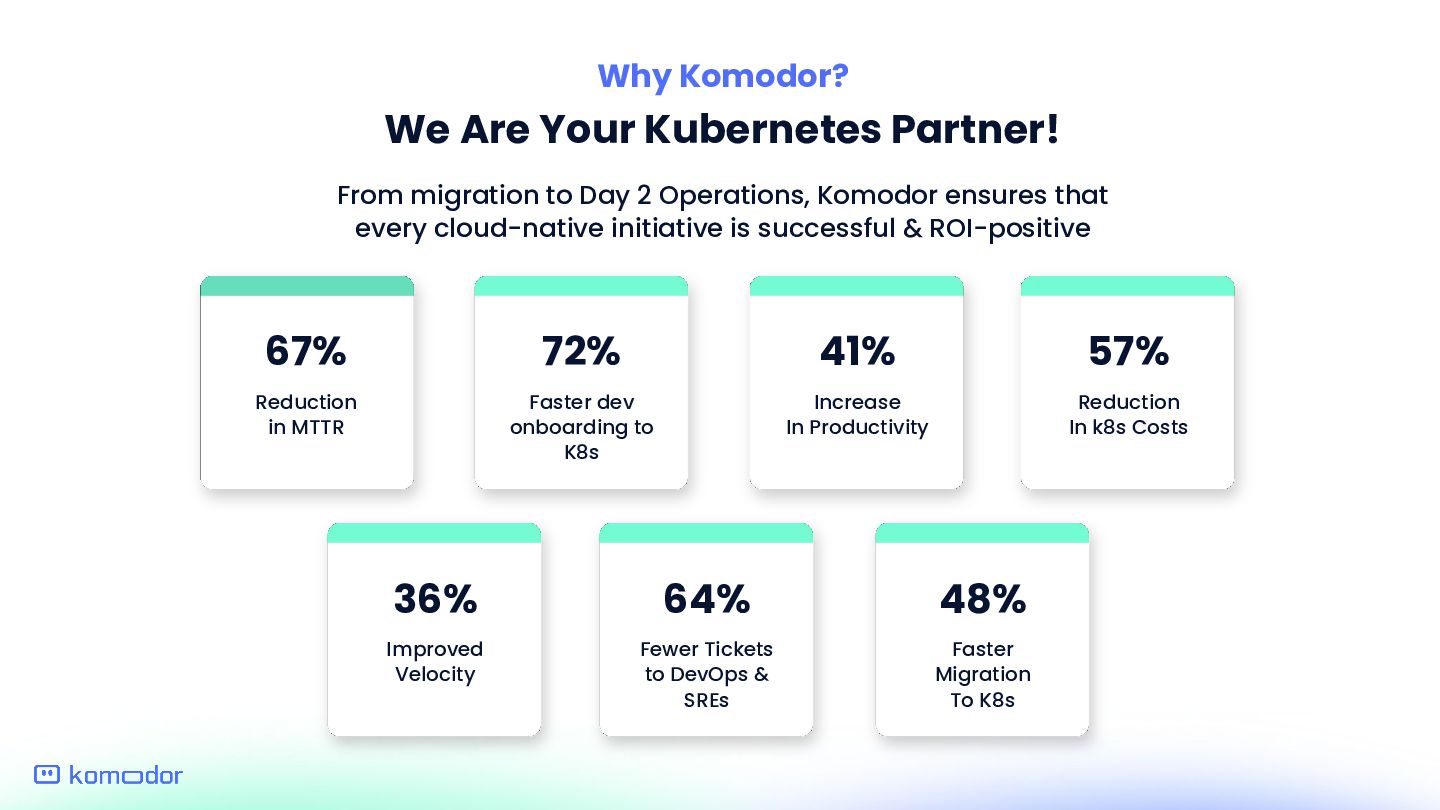
Day 2 Operations, Komodor ensures that every cloud-native initiative is successful & ROI-positive 67% Reduction in MTTR 72% Faster dev onboarding to K8s 41% Increase In Productivity 57% Reduction In k8s Costs 48% Faster Migration To K8s 64% Fewer Tickets to DevOps & SREs 36% Improved Velocity
visibility into multi-cloud/hybrid Improved reliability & resiliency Centralized access control & governance Fewer escalations & no TicketOps Developers Data Engineers Reduced cognitive load Increased developer velocity Less time spent on troubleshooting Increased ownership & accountability Support KubeFlow, Airflow, Argo Workflows Increased productivity & efficiency No longer a bottleneck for MLOps Focusing on data science & research The users were happy immediately. And every time we show a screenshot, people always say, “Wow. What tool is that and how do I get into it?” It has been nothing but a delight for all of our engineers from day one. Don’t overthink it! It was so easy to onboard, and definitely worth it in the long run. Michael Keith Senior SRE
Enrichment Engine Operations & User Management Health & Reliability Management Cost Optimization Data Engineers DevOps Engineers Executives Developers Platform Team Workspaces Kubernetes Brain Klaudia AI
Enrichment Engine Operations & User Management Health & Reliability Management Cost Optimization Data Engineers DevOps Engineers Executives Developers Platform Team Workspaces Kubernetes Brain Klaudia AI
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}