Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
パッチワークでAIアシスタントを作ろう
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
kosmosebi
March 29, 2025
310
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
パッチワークでAIアシスタントを作ろう
meetup app osaka@9
https://meetupapp.connpass.com/event/348237/
kosmosebi
March 29, 2025
More Decks by kosmosebi
See All by kosmosebi
Azure Speech で音声対応してみよう
kosmosebi
0
250
ローカルでLLMを使ってみよう
kosmosebi
0
300
Global Azure 2025 @ Kansai / Hyperlight
kosmosebi
0
310
Visual StudioとかIDE関連小ネタ話
kosmosebi
1
600
使ってみよう Azure AI Document Intelligence
kosmosebi
2
1.9k
たぶんAzureとかでAIが多めな話
kosmosebi
0
150
Featured
See All Featured
BBQ
matthewcrist
89
10k
Building Better People: How to give real-time feedback that sticks.
wjessup
370
20k
The Straight Up "How To Draw Better" Workshop
denniskardys
239
140k
Neural Spatial Audio Processing for Sound Field Analysis and Control
skoyamalab
0
370
What does AI have to do with Human Rights?
axbom
PRO
1
2.2k
Building Adaptive Systems
keathley
44
3.1k
Paper Plane
katiecoart
PRO
1
52k
[RailsConf 2023 Opening Keynote] The Magic of Rails
eileencodes
31
10k
StorybookのUI Testing Handbookを読んだ
zakiyama
31
6.8k
Become a Pro
speakerdeck
PRO
31
6k
Docker and Python
trallard
47
3.9k
AI in Enterprises - Java and Open Source to the Rescue
ivargrimstad
0
1.4k
Transcript
パッチワークで AIアシスタントを作ろう @kosmosebi meetup app osaka@9 2025-03-29
Self Introduction { "name": "Keiji KAMEBUCHI", "corporation": "pnop Inc.", "web":
"https://azure.moe/", "X": "@kosmosebi", "awards": [ "Microsoft MVP for Azure", "Microsoft Regional Director“ ], "location": "Osaka, Japan", "YouTube": "https://www.youtube.com/@kosmosebi” } Senior Fellow @kosmosebi
Introduction • なんかAIに助けてもらいたい • エージェント、アシスタント … • そろそろ継ぎ接ぎしたらそれっぽく作れそう
AITuberKit • https://github.com/tegnike/aituber-kit • 対話 • YouTubeコメントを拾って会話 • 外部連携してあれこれ •
スライド発表 (要台本) • Custom License • これでええやん (完)
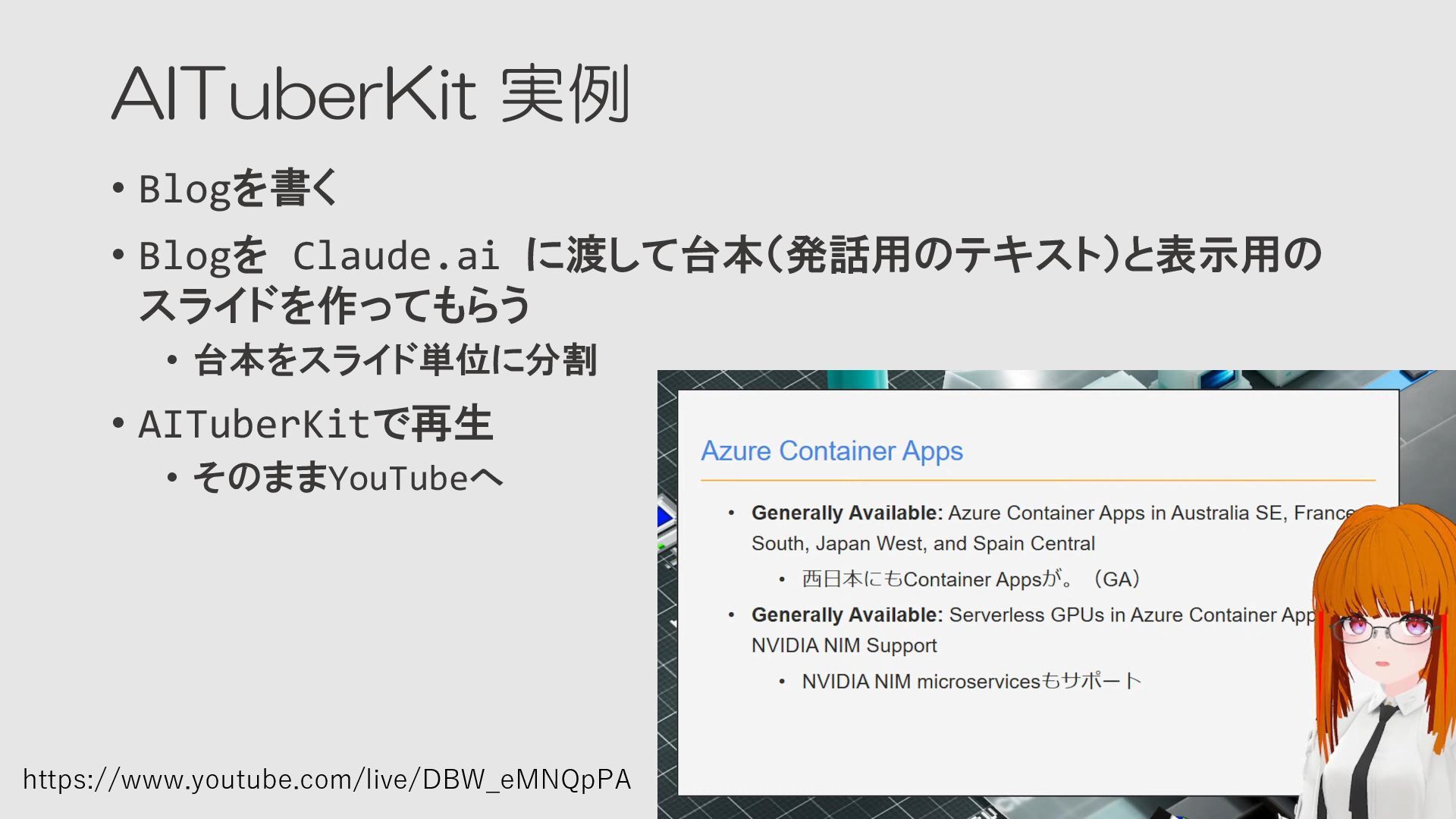
AITuberKit 実例 • Blogを書く • Blogを Claude.ai に渡して台本(発話用のテキスト)と表示用の スライドを作ってもらう •
台本をスライド単位に分割 • AITuberKitで再生 • そのままYouTubeへ https://www.youtube.com/live/DBW_eMNQpPA
ChatdollKit / AIAvatarKit • https://github.com/uezo/ChatdollKit • https://github.com/uezo/aiavatarkit • 対話 •
外部連携してあれこれ • Apache License 2.0 • これでええやん (完2)
各要素
LLM/SLM部分 • OpenAI, Azure OpenAI, Google Gemini, Groq, Cohere, Claude,
Mistral, Perplexity, Lama, DeepSeek R1, Phi-*, Nemotoron, Sarashina, PLaMo, rinna, … • API利用(オンライン) • 要ネットワーク • API利用料 • ガードレールやコンテンツフィルターあり • お手軽 • オフライン • 自由 • おおむねタダ (なおGPU代…) • 微調整したり蒸留したりしなかったり • 最近だとReasoningできるのもある
TTS/STT (話す・聞く) • Whisper, Azure AI services (TTS/STT), Google TTS,
Koemotion, にじボイス, VOICEVOX, Style-Bert-VITS2, … • オンライン • お手軽, レイテンシー, API利用料 • GPT-4oのRealtime APIみたいにLLMと音声が一緒になって低遅延を実現してる ケースもある (下手したらローカルより速い) • 音声 → STT → LLM → TTS → 音声 を 音声 → LLM → 音声 にできる • オフライン • GPU/CPU…, 低レイテンシー (スペックによる) • OS標準機能もあり • 好みの音声にできるかどうかとか、仕組み的に低レイテンシーでないと ダメかどうかとか
見る • Webカメラの内容や画像などを認識 • マルチモーダルなモデルを使う or 個別に処理
ビジュアル • AITuberKit, ChatdollKit, Warudo, VTube Studio, … • VRM
(3D), Live2D, etc. • 画像だけでも表情差分があってちょっと動いたらだいたいかわいい • 思考させてるのと連動したり、プリセットにない動きをさせたいが…
連携部分 • アシスタントのキモ • Semantic Kernel, LangChain, Langflow, guidance, Dify,
Durable Functions … • 細かい機能は Model Context Protocol (MCP)に対応するとよ さそう? • 自分専用なら余計なレイヤーを挟む必要はないけどMCPサーバーが 増えればエコシステムに乗っかれる • アシスタントができることの幅につながる • LLMだけでは実現できない個性(特技)
Demo
要件定義 • 何がしたいのか • いわゆる AITuber ? • オレオレ Copilot
? • 今回のコンセプト • Teamsのミーティングで相槌うったり適当に (聴講者目線で)質問したりしてくれるアシスタント • 一人でしゃべってても寂しくならない • ライブ配信の相方的な
デモの要素集め • 音声Inputがメイン • 低レイテンシーがいい • できあいの合成音声ではない音声にしたい • VRM (3D)で動いてほしい
• Teams会議に参加してほしい
デモの要素集め • 音声Inputがメイン • → GPT-4o-mini realtime (音声 → text)
• 低遅延がいい • → GPT-4o-mini realtime • できあいの合成音声ではない独自の音声にしたい • → Style-Bert-VITS2 • VRM (3D)で動いてほしい • → ChatdollKit + ChatdollKit AITuber Controller • Teams会議に参加してほしい • → Azure Communication Services • VB-CABLE Virtual Audio Device https://vb-audio.com/Cable/
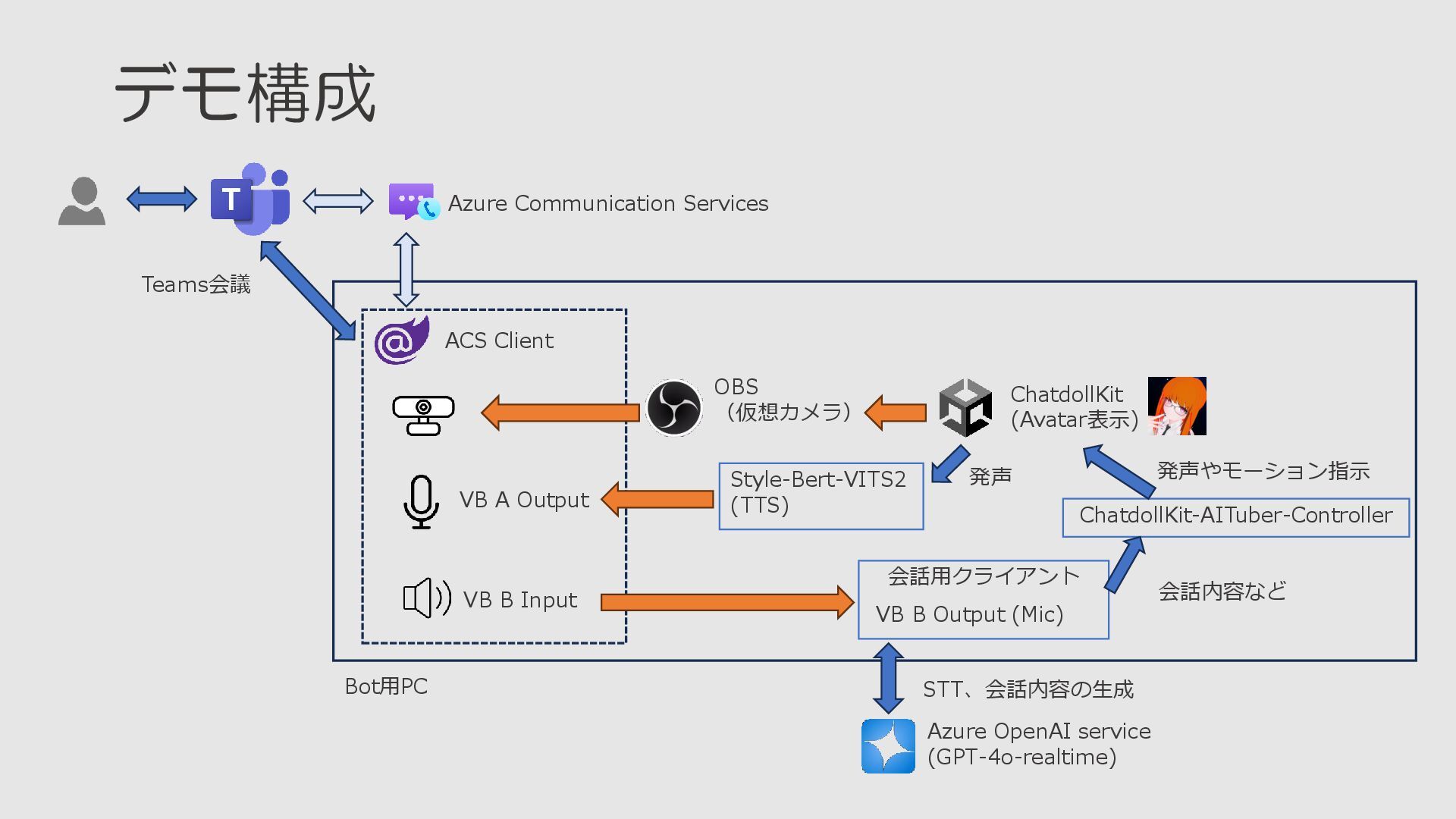
デモ構成 Azure Communication Services Teams会議 Bot用PC ACS Client OBS (仮想カメラ)
Azure OpenAI service (GPT-4o-realtime) ChatdollKit (Avatar表示) VB A Output VB B Input 会話用クライアント VB B Output (Mic) ChatdollKit-AITuber-Controller 会話内容など Style-Bert-VITS2 (TTS) 発声 発声やモーション指示 STT、会話内容の生成
デモの課題 • とりあえず大した手間もなく実現はできる • おもった回答にならない?(ありがち) • プロンプト次第か? (モデルやTTSの精度も) • 即答したい回答と熟考したい回答の併用
• 今回はTTS部分が思ったより重いかもしれない • 自然な全二重通信なやりとりって難しい • LLMのRealtimeではあいづちなど会話の区切りぐらいで良いのでは • 映像の認識 • 1フレーム抜き出してLLMに解釈させるとかはそんなに手間じゃない • どのフレームをいつ抜くとか、会話の流れとか
まとめ • それっぽいのはすぐできちゃう • 便利さとか、魂はいるかとか、かわいいとかは別問題だが • 各々ライセンスは気を付けて • 費用にも気を付けて •
個々の要素が奥深いので沼 • Model Context Protocol (MCP) が楽しそう • MoEやSLMをガチャガチャするのも楽しそう • Looking Glass Go + ミニPCで アシスタント化
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}