Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
パタヘネ輪読: 第五章
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
kota-yata
December 01, 2024
Programming
88
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
パタヘネ輪読: 第五章
SFC RG Archでの輪読資料
kota-yata
December 01, 2024
More Decks by kota-yata
See All by kota-yata
Arch輪読: 詳解システムパフォーマンス 第二版 第6章
kota_yata
0
50
RG-Arch 輪講資料: Binary Hacks Rebooted 数値演算など
kota_yata
0
71
結局QUICで通信は速くなるの?
kota_yata
10
8k
RG-Arch輪考資料: QUIC is not Quick Enough over Fast Internet
kota_yata
0
170
RG-Arch輪考資料: Implementation and Performance Evaluation of the QUIC Protocol in Linux Kernel
kota_yata
0
200
2024年秋 中村研 WIP発表資料
kota_yata
0
100
パタヘネ輪読: 第一章
kota_yata
0
340
2023年秋 中村研 WIP発表資料
kota_yata
0
150
2023年春 中澤大越研 WIP発表資料
kota_yata
0
110
Other Decks in Programming
See All in Programming
型も通る、synthも通る、それでも危ない 〜AIのCDKの権限とコストを機械で検証する〜 / It Passes Type Checks, It Passes Synth Checks, but It’s Still Risky — Automatically Verifying Permissions and Costs in AI’s CDK —
seike460
PRO
1
370
Laravel Boostに学ぶ、AIにPHPを書かせる技術 〜OSSの実装から蒸留するエージェント制御の王道〜
kentaroutakeda
3
490
継続モナドとリアクティブプログラミング
yukikurage
3
610
Apache Hive: Toward a Cloud Native Lakehouse
okumin
0
140
フィードバックで育てるAI開発
kotaminato
1
120
ITヒヤリハットを整理してみた ~ライフサイクルと原因から考える再発防止策~
koukimiura
1
110
【やさしく解説 設計編 #0】DDDのコード、読めるのに分からない人へ
panda728
PRO
2
270
共通化で考えるべきは、実装より公開する型だった
codeegg
0
250
AWS CDK を「作」ってみた 〜フルスクラッチで見えた CDK の裏側〜 / aws-cdk-from-scratch
gotok365
3
450
初めてのKubernetes 本番運用でハマった話
oku053
0
130
PHP Application における Kubernetes 内 gRPC 通信
ganchiku
0
500
AIを活用したE2Eテスト実装効率化のあゆみ / ebisu-mobile-14-kotetu
kotetuco
0
170
Featured
See All Featured
Test your architecture with Archunit
thirion
1
2.3k
Being A Developer After 40
akosma
91
590k
コードの90%をAIが書く世界で何が待っているのか / What awaits us in a world where 90% of the code is written by AI
rkaga
62
45k
30 Presentation Tips
portentint
PRO
1
350
The Curse of the Amulet
leimatthew05
2
13k
The B2B funnel & how to create a winning content strategy
katarinadahlin
PRO
1
420
Rebuilding a faster, lazier Slack
samanthasiow
85
9.6k
Build your cross-platform service in a week with App Engine
jlugia
234
18k
The Illustrated Guide to Node.js - THAT Conference 2024
reverentgeek
1
410
KATA
mclloyd
PRO
35
15k
Fantastic passwords and where to find them - at NoRuKo
philnash
52
3.8k
Become a Pro
speakerdeck
PRO
31
6k
Transcript
パタヘネ第五章 Arch kota 1
⽬次 • 記憶の階層化 • 記憶容量の種類 • キャッシュの基礎 • キャッシュの性能向上 •
仮想記憶 • 誤り訂正/誤り検出 2
記憶の階層化 • レポートを書くために図書館に⾏き、レポートの内容に適した本を⾒つけ て机の横に積む • 最も必要であろう情報を近くに置いておき、それ以外は本棚に⽌まる ◦ これが階層化 • 必要であろう情報の性質
= 局所性 ◦ 時間的局所性:ある情報が参照された時、それはまもなく再び参照される確率が⾼い ◦ 空間的局所性:ある情報が参照されたとき、その近くにある情報もまた参照される可能 性が⾼い 3 記憶の階層化とは?(図書館の例)
コンピュータにおける記憶の階層化 4 • 記憶容量においてやり取りされるデータの最⼩単位をブロックという ◦ ブロックには複数ワードが⼊る ◦ ブロック単位でキャッシュに乗ったり乗らなかったりする=空間的局所性 ◦ あるブロックへのアクセスが発⽣したら上位レベルのメモリにデータコピー=時間的局所性
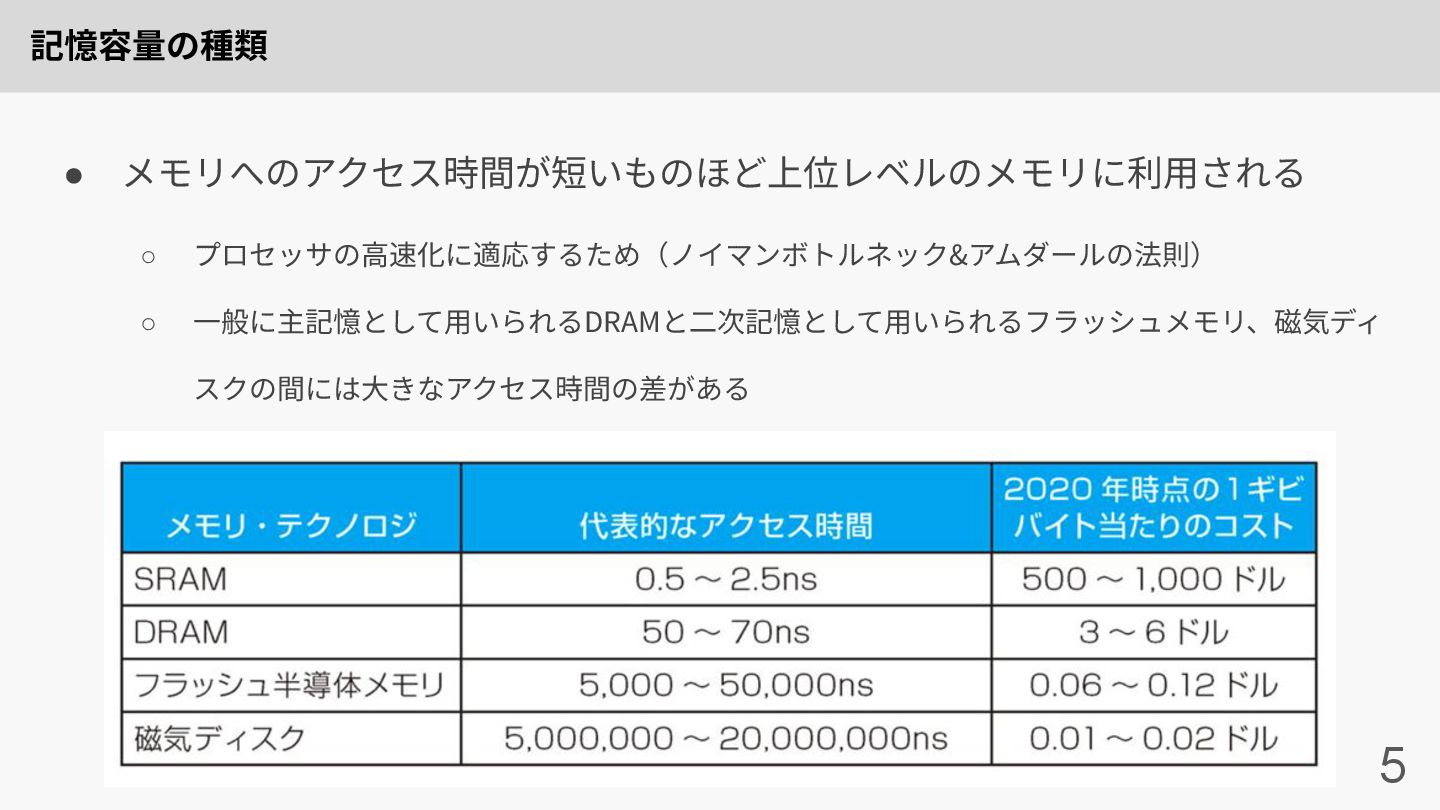
記憶容量の種類 5 • メモリへのアクセス時間が短いものほど上位レベルのメモリに利⽤される ◦ プロセッサの⾼速化に適応するため(ノイマンボトルネック&アムダールの法則) ◦ ⼀般に主記憶として⽤いられるDRAMと⼆次記憶として⽤いられるフラッシュメモリ、磁気ディ スクの間には⼤きなアクセス時間の差がある
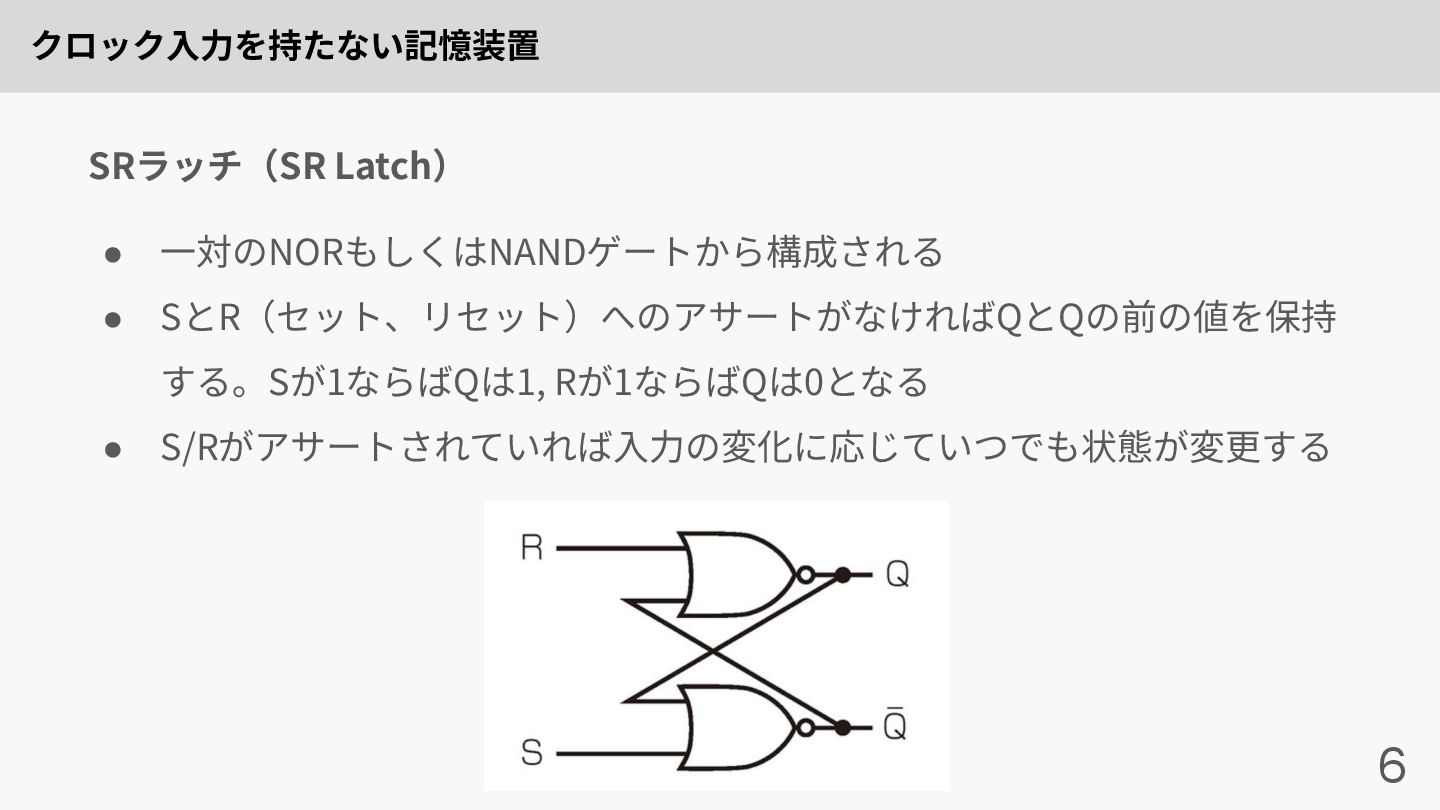
クロック⼊⼒を持たない記憶装置 6 • ⼀対のNORもしくはNANDゲートから構成される • SとR(セット、リセット)へのアサートがなければQとQの前の値を保持 する。Sが1ならばQは1, Rが1ならばQは0となる • S/Rがアサートされていれば⼊⼒の変化に応じていつでも状態が変更する
SRラッチ(SR Latch)
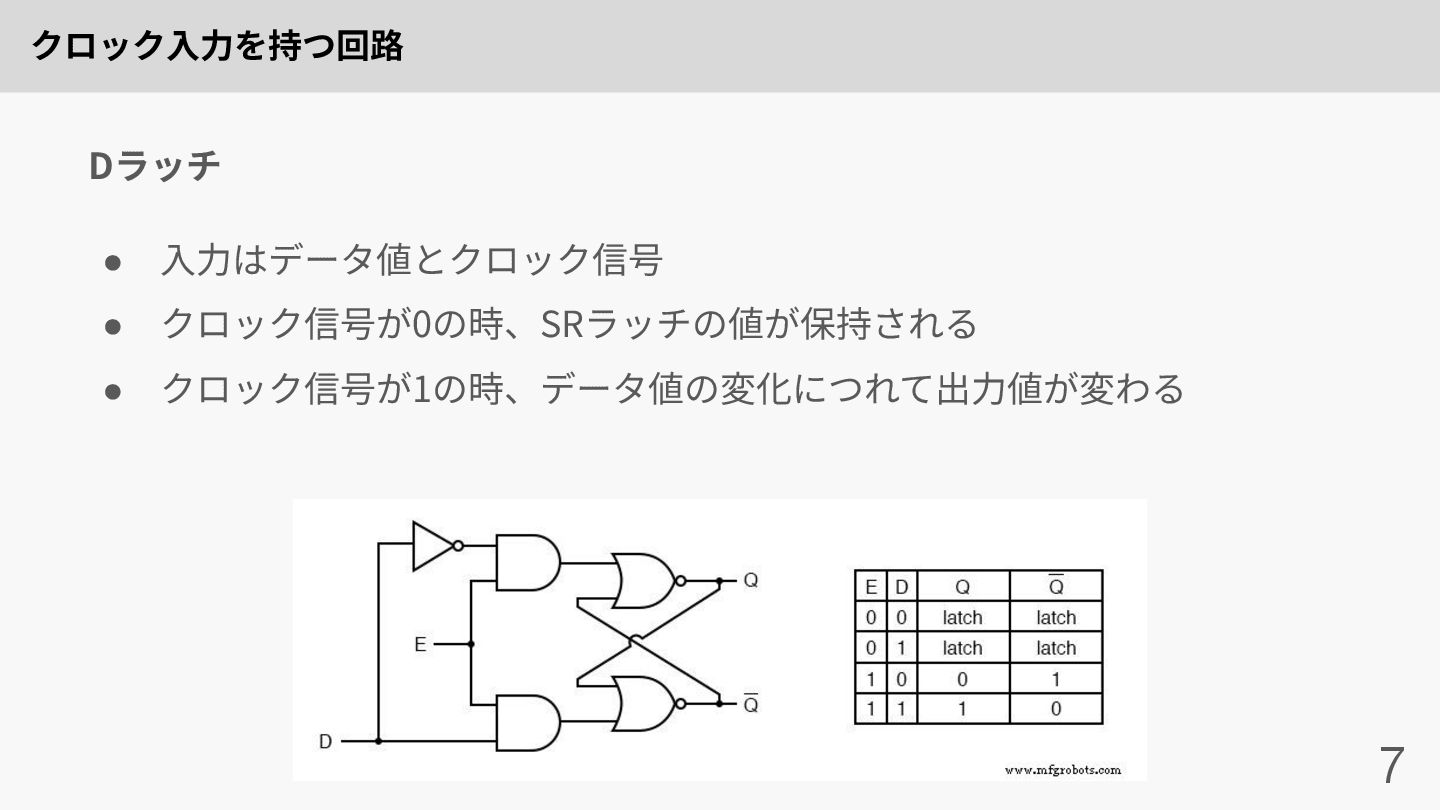
クロック⼊⼒を持つ回路 7 • ⼊⼒はデータ値とクロック信号 • クロック信号が0の時、SRラッチの値が保持される • クロック信号が1の時、データ値の変化につれて出⼒値が変わる Dラッチ
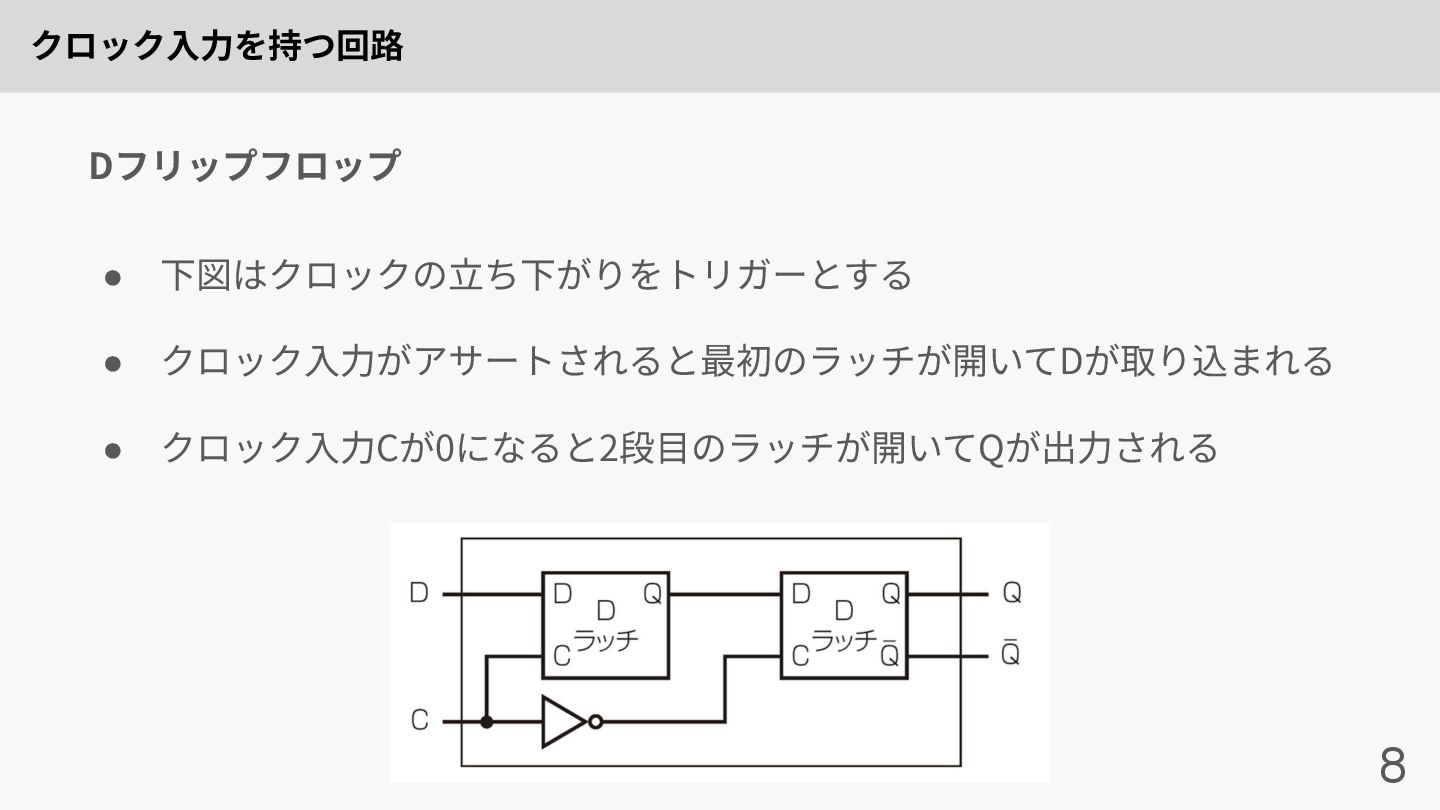
クロック⼊⼒を持つ回路 8 • 下図はクロックの⽴ち下がりをトリガーとする • クロック⼊⼒がアサートされると最初のラッチが開いてDが取り込まれる • クロック⼊⼒Cが0になると2段⽬のラッチが開いてQが出⼒される Dフリップフロップ
SRAM 9 • 配列上の記憶構造をした集積回路 • フリップフロップ回路を利⽤しているためリフレッシュ動作は必要ない • 1ビットの値の保持に6-8個のトランジスタを⽤いる • 主にキャッシュ⽤に使われ、現代ではほとんどがプロセッサチップ上に統合さ
れている
DRAM 10 • DRAMにおいては1ビットの値を保持するために必要なトランジスタは⼀つ ◦ キャパシタが蓄える電荷にアクセスするために単⼀のトランジスタを⽤いる ◦ SRAMと⽐較してビットあたりの密度が⾼くなり価格が安くなる • 値は電荷なのでリフレッシュが必要(ダイナミックと呼ばれる理由)
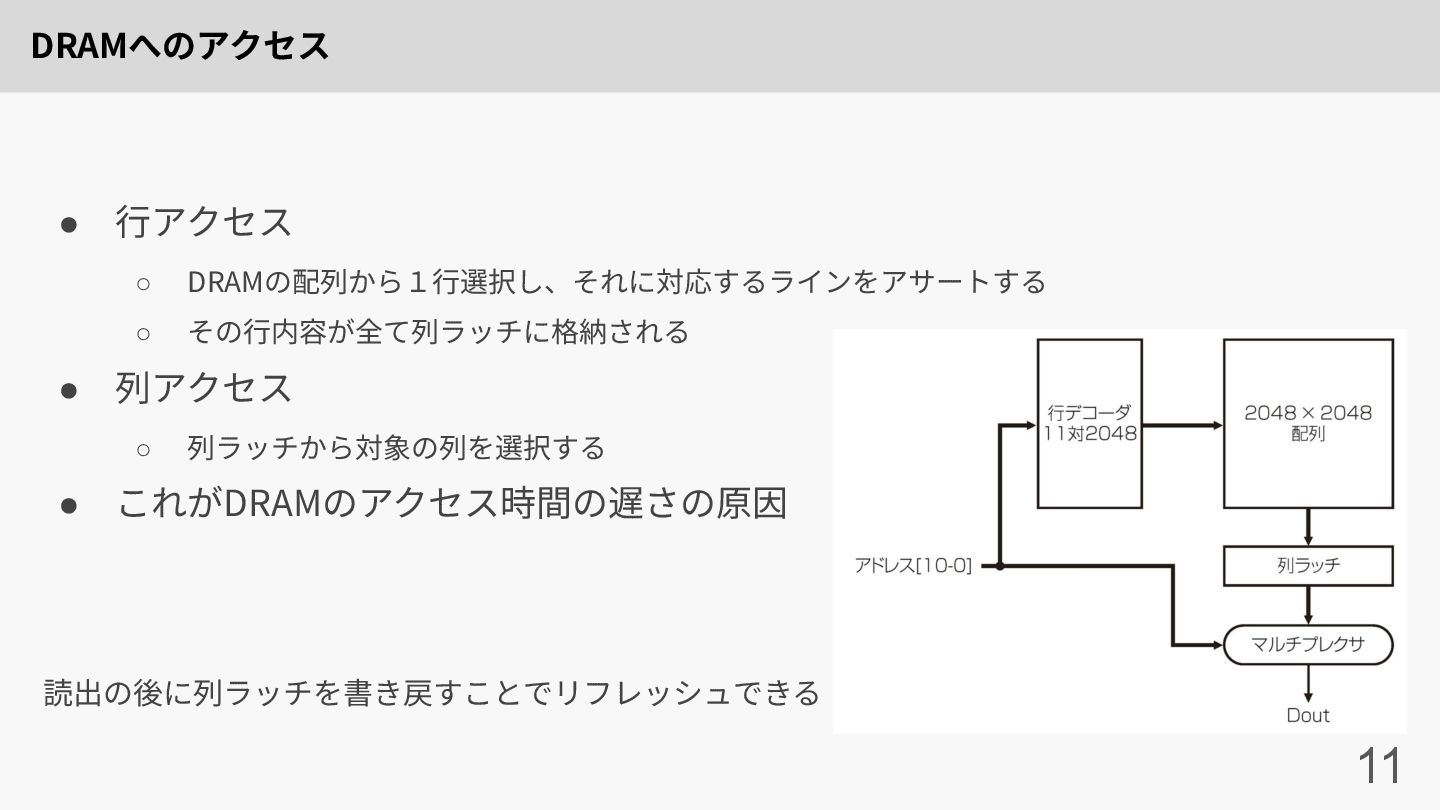
DRAMへのアクセス 11 • ⾏アクセス ◦ DRAMの配列から1⾏選択し、それに対応するラインをアサートする ◦ その⾏内容が全て列ラッチに格納される • 列アクセス
◦ 列ラッチから対象の列を選択する • これがDRAMのアクセス時間の遅さの原因 読出の後に列ラッチを書き戻すことでリフレッシュできる
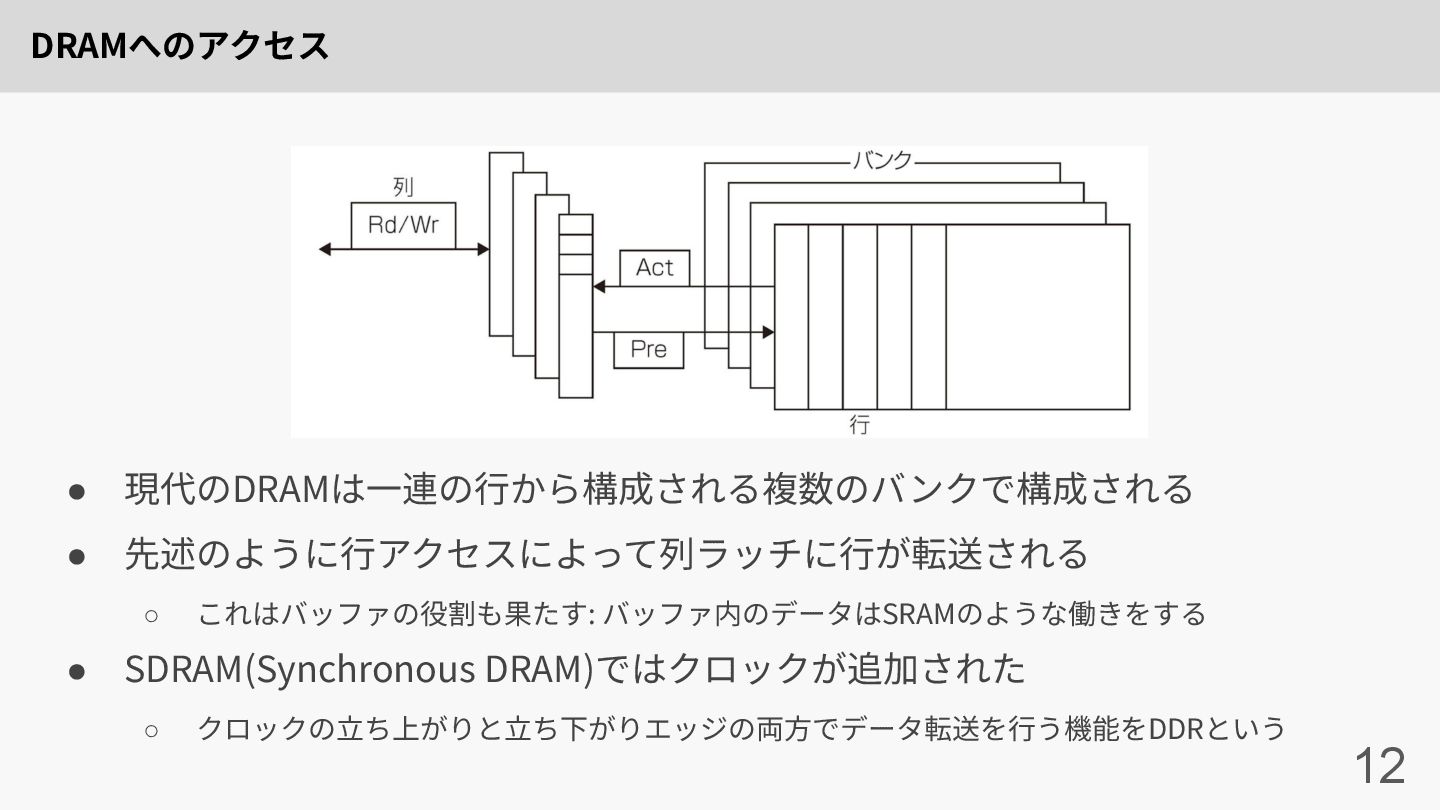
DRAMへのアクセス 12 • 現代のDRAMは⼀連の⾏から構成される複数のバンクで構成される • 先述のように⾏アクセスによって列ラッチに⾏が転送される ◦ これはバッファの役割も果たす: バッファ内のデータはSRAMのような働きをする •
SDRAM(Synchronous DRAM)ではクロックが追加された ◦ クロックの⽴ち上がりと⽴ち下がりエッジの両⽅でデータ転送を⾏う機能をDDRという
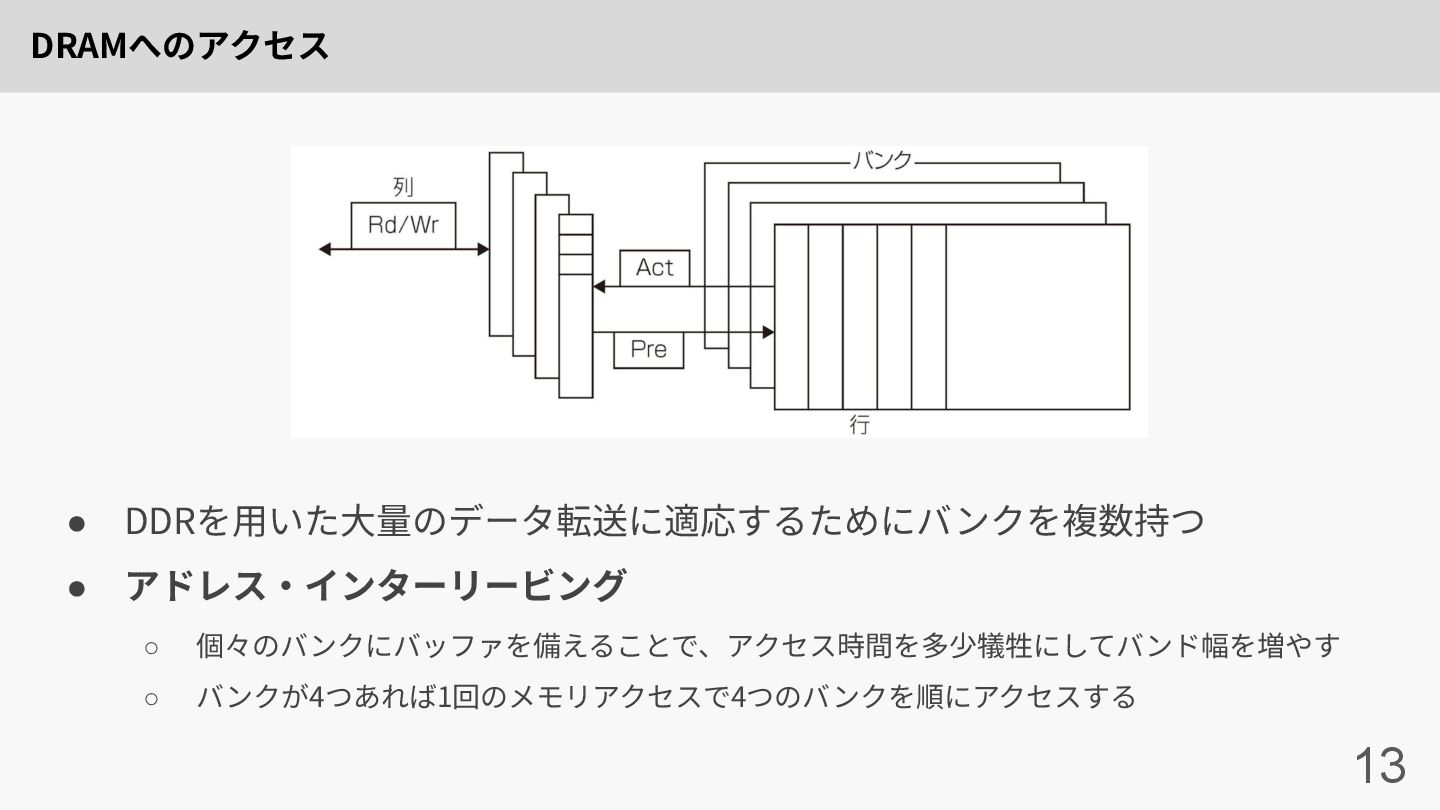
DRAMへのアクセス 13 • DDRを⽤いた⼤量のデータ転送に適応するためにバンクを複数持つ • アドレス‧インターリービング ◦ 個々のバンクにバッファを備えることで、アクセス時間を多少犠牲にしてバンド幅を増やす ◦ バンクが4つあれば1回のメモリアクセスで4つのバンクを順にアクセスする
フラッシュメモリ 14 • フラッシュメモリは書き込みを繰り返すとビットが劣化する ◦ フローティングゲートなる場所に電荷を蓄えるが、その際に電⼦は基板とゲートの間にある酸 化絶縁膜を突き破って移動する。これを繰り返すと膜が劣化して絶縁性が低下する • ビットの劣化に対応するためにウェア‧レベリングが⽤いられる ◦
何度も書き込まれたブロックへの書き込みを別のブロックへ切り替える ◦ ウェア‧レベリングを⾏うことで実質的な歩留まりの改善を⾏うこともできる
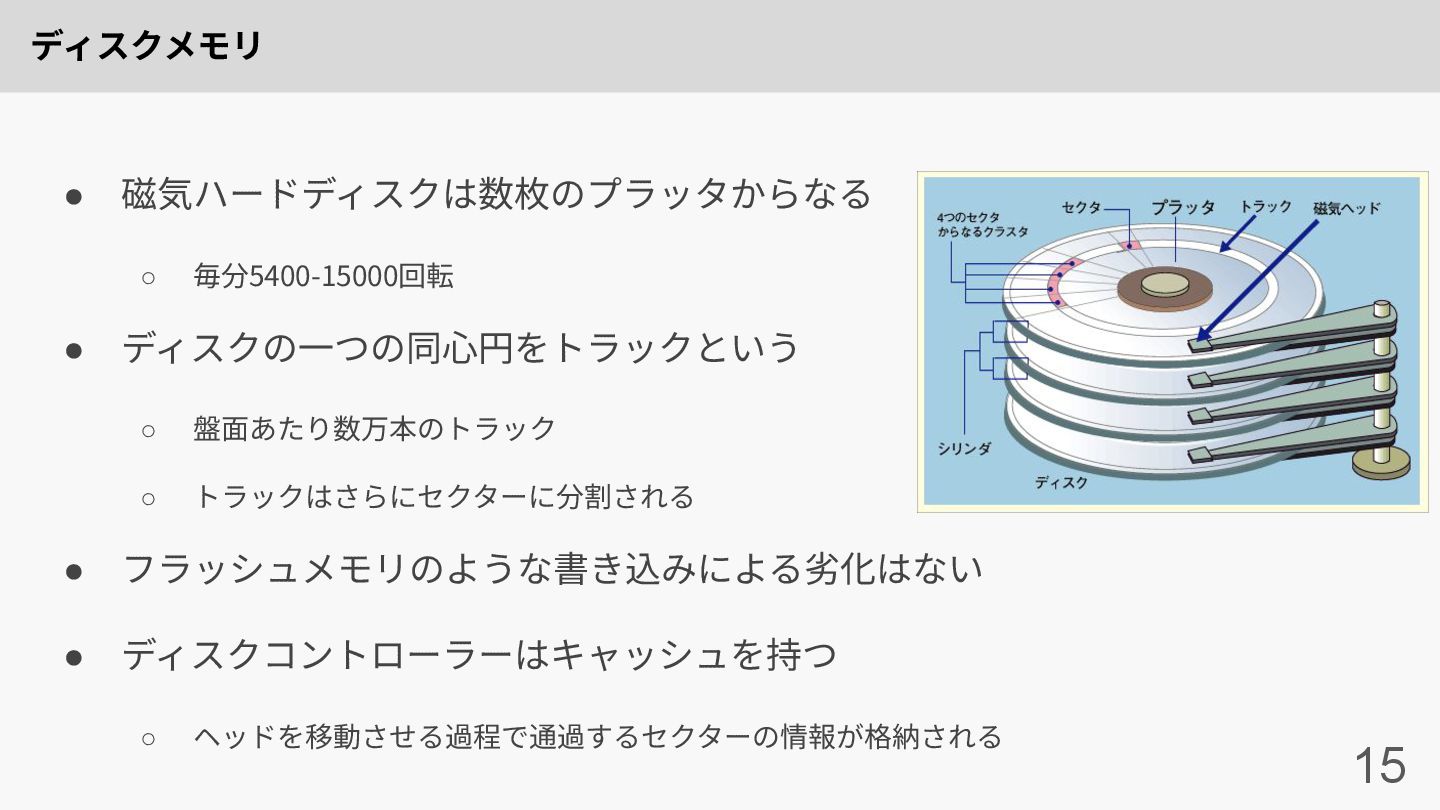
ディスクメモリ 15 • 磁気ハードディスクは数枚のプラッタからなる ◦ 毎分5400-15000回転 • ディスクの⼀つの同⼼円をトラックという ◦ 盤⾯あたり数万本のトラック
◦ トラックはさらにセクターに分割される • フラッシュメモリのような書き込みによる劣化はない • ディスクコントローラーはキャッシュを持つ ◦ ヘッドを移動させる過程で通過するセクターの情報が格納される
キャッシュ 16
キャッシュの役割 • 主記憶のうちの⼀部のブロックをプロセッサ内で持つ ◦ 命令/データへのアクセスが速くなりプロセッサの⾼速化に適応できる • 主記憶のうちどのブロックをどのように保持し、どのように書き込むのか 17
キャッシュのマッピング⽅式 18 • メモリのロケーションからキャッシュ中のロケーションを⼀意に求める ◦ ブロックアドレス % キャッシュ中のブロック数 • キャッシュ中のブロック数が2の冪乗であれば、ブロックアドレスの下位
数ビットがキャッシュ中のインデックスになり都合が良い • インデックスとして使われなかった上位ビットをタグとして付加する ◦ キャッシュ中の⼀つのインデックスに複数メモリアドレスの内容が⼊りうるため ダイレクトマップ⽅式
ダイレクトマップ 19 単純化した例:8ブロックからなるキャッシュ • メモリアドレス00001のキャッシュインデックスは001, タグは00 • メモリアドレス11001のキャッシュインデックスは001, タグは11 ◦
MIPSにおいては、実際は最下位2ビットはワード内のバイトオフセット指定に使われる • キャッシュのブロックが有効かどうかは各インデックスに有効ビットを付加し て判断する ◦ プロセッサが⽴ち上がったばかりの場合など、ブロックが有効でない場合がある
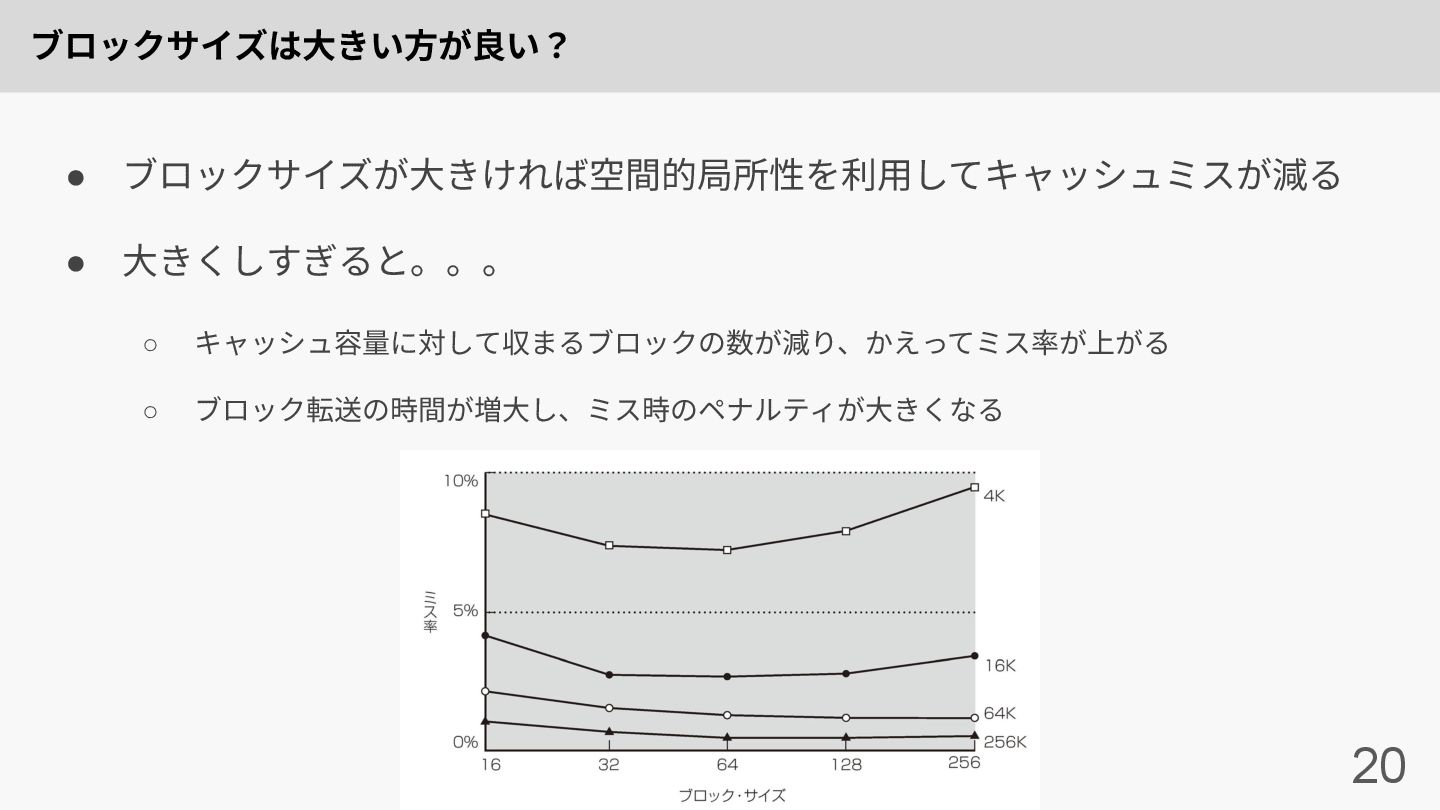
ブロックサイズは⼤きい⽅が良い? 20 • ブロックサイズが⼤きければ空間的局所性を利⽤してキャッシュミスが減る • ⼤きくしすぎると。。。 ◦ キャッシュ容量に対して収まるブロックの数が減り、かえってミス率が上がる ◦ ブロック転送の時間が増⼤し、ミス時のペナルティが⼤きくなる
キャッシュミスの取り扱い 21 • インオーダー⽅式のプロセッサであればキャッシュミスが発⽣するとコン ピュータ全体がストールする ◦ メモリアクセスが発⽣し、キャッシュにデータがコピーされるまでレジスタの内容を凍結 • 現代のアウトオブオーダー⽅式のプロセッサではその間他の命令を実⾏できる ◦
ただ実⾏速度には⼤きな影響がある
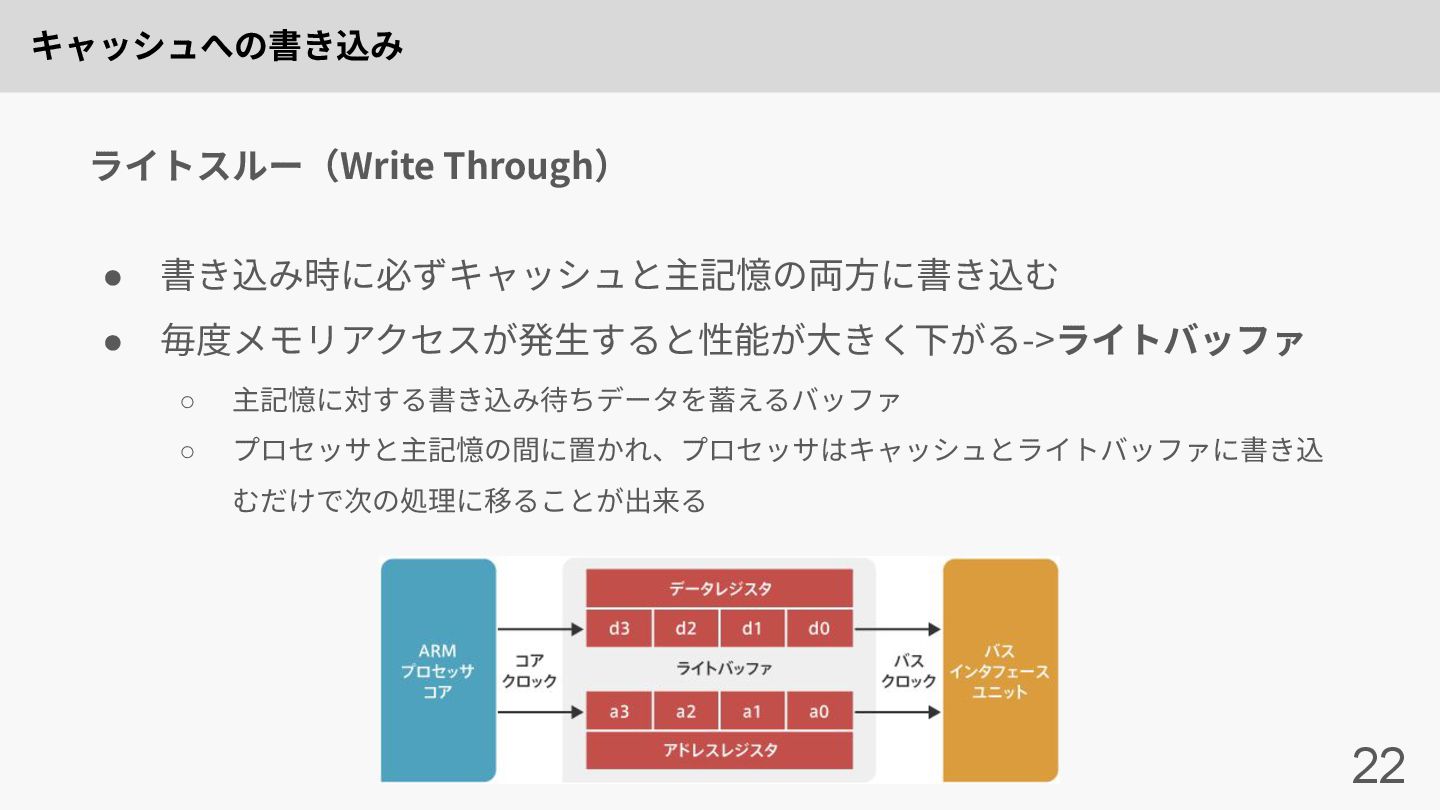
キャッシュへの書き込み 22 • 書き込み時に必ずキャッシュと主記憶の両⽅に書き込む • 毎度メモリアクセスが発⽣すると性能が⼤きく下がる->ライトバッファ ◦ 主記憶に対する書き込み待ちデータを蓄えるバッファ ◦ プロセッサと主記憶の間に置かれ、プロセッサはキャッシュとライトバッファに書き込
むだけで次の処理に移ることが出来る ライトスルー(Write Through)
キャッシュへの書き込み 23 • 新しい値はキャッシュにのみ書き込まれる • そのブロックが置き換え対象になってはじめて主記憶にも書き込まれる • プロセッサからの書き込み要求が多い場合に有効 • ブロックを置き換える際にメモリアクセスを待つ時間をなくすため、ライ
トバックバッファが⽤いられる ◦ 原理はライトバッファと同じ ◦ 置き換え対象のブロックをバッファに退避させ、新しいブロックをキャッシュに書く ◦ バッファがその後主記憶への書き込みを⾏う ライトバック(Write Back)
キャッシュへの書き込み 24 • 書き込み先がキャッシュに存在しなかった場合、、 ◦ Write allocate: 主記憶に書き込んだのちキャッシュにも書き込む ◦ No
write allocate: 主記憶にのみ書き込む • 書き込むデータが再び使われる可能性があるかどうかによる ◦ OSが主記憶中のページをゼロクリアする場合などはNo write allocateで問題ない キャッシュミスの取り扱い
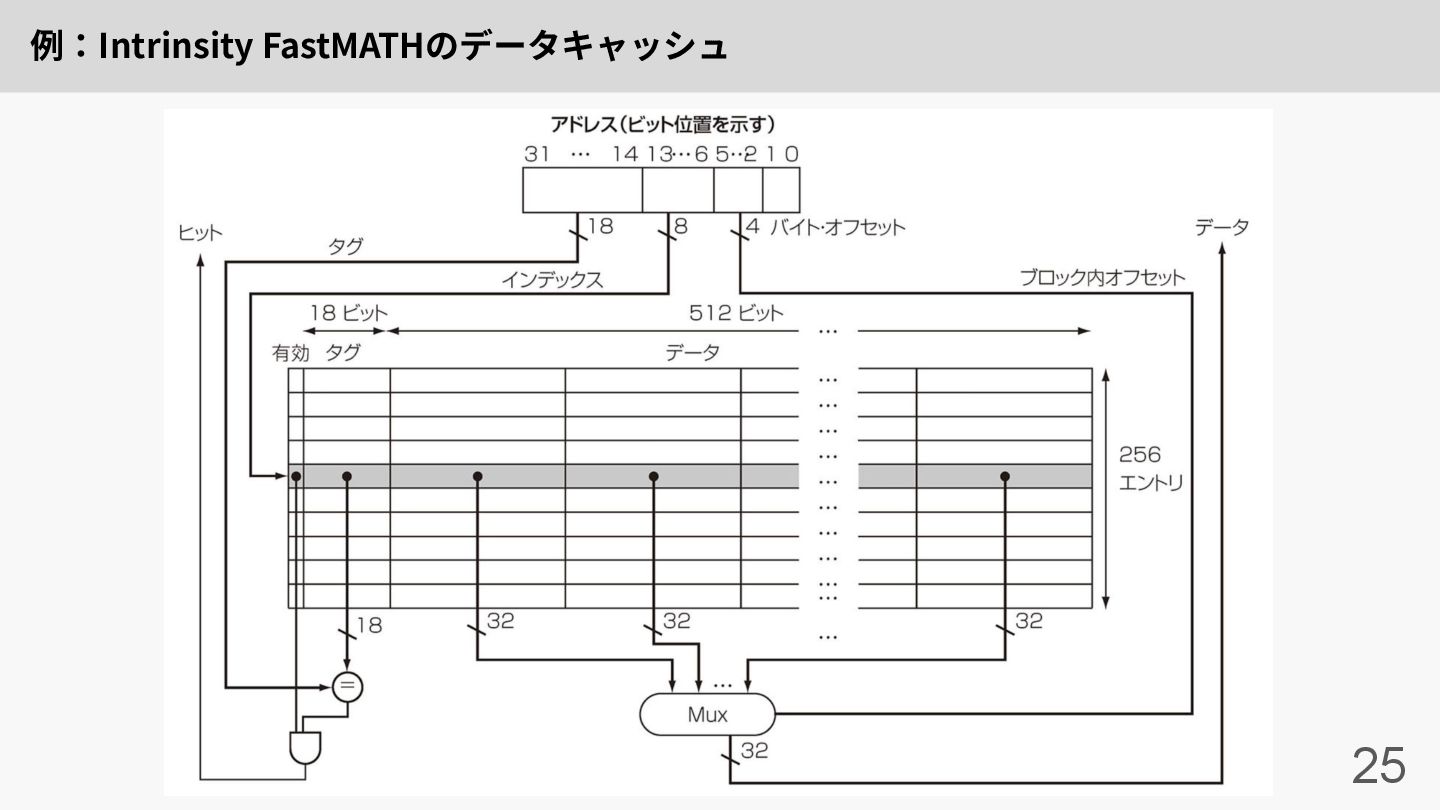
例:Intrinsity FastMATHのデータキャッシュ 25
キャッシュの性能向上 26
キャッシュの性能向上 • これまでダイレクトマップ⽅式でのマッピングでキャッシュを検討して きた • ダイレクトマップはブロックの配置場所が⼀意に決まる⼀⽅、場合に よってはあるロケーションで頻繁に置き換えが起こり、あるロケーション ではずっと何も書き込まれないといった⾮効率な事態が起きる 27 ⼯夫1:
マッピングの⼯夫
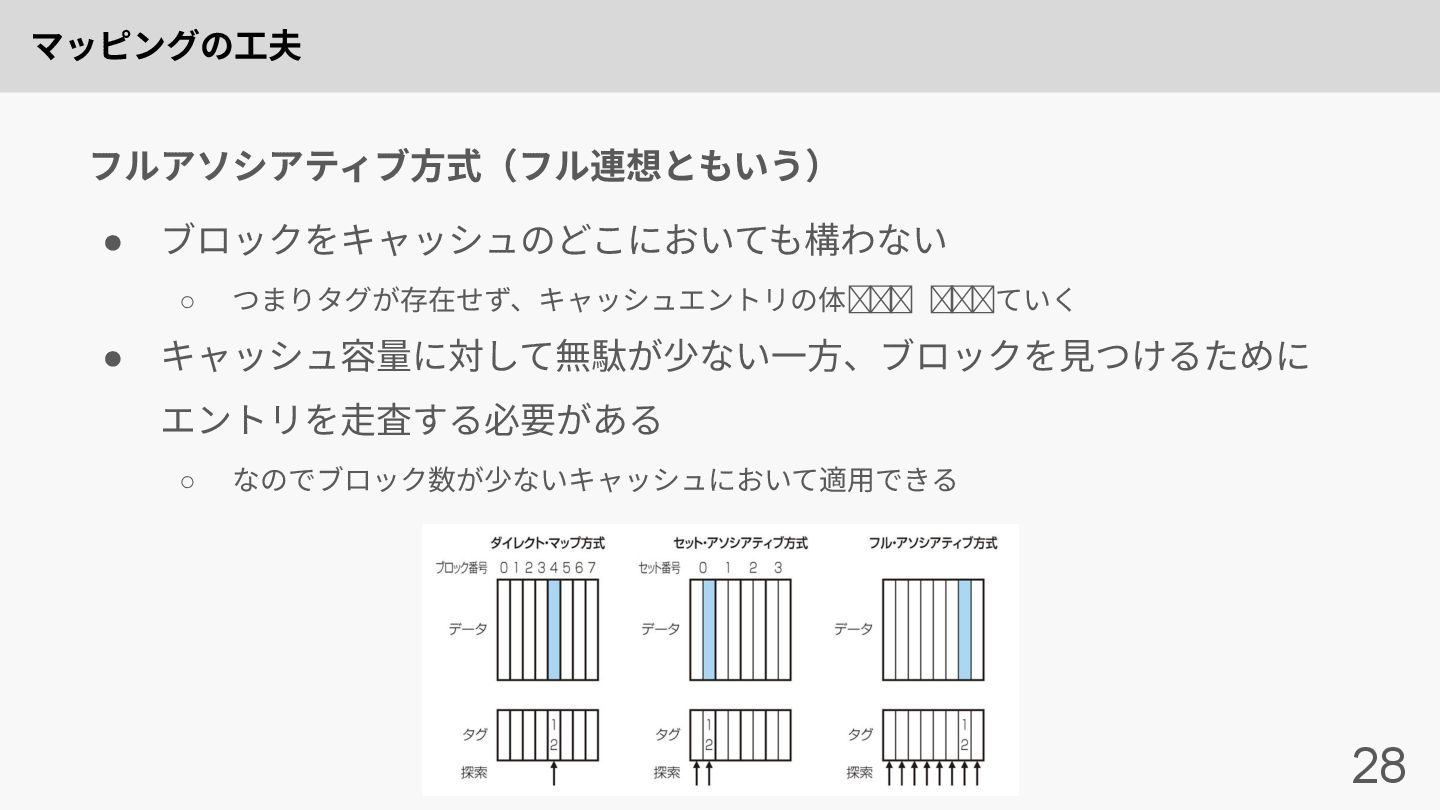
マッピングの⼯夫 28 • ブロックをキャッシュのどこにおいても構わない ◦ つまりタグが存在せず、キャッシュエントリの余る限りブロックを加えていく • キャッシュ容量に対して無駄が少ない⼀⽅、ブロックを⾒つけるために エントリを⾛査する必要がある ◦
なのでブロック数が少ないキャッシュにおいて適⽤できる フルアソシアティブ⽅式(フル連想ともいう)
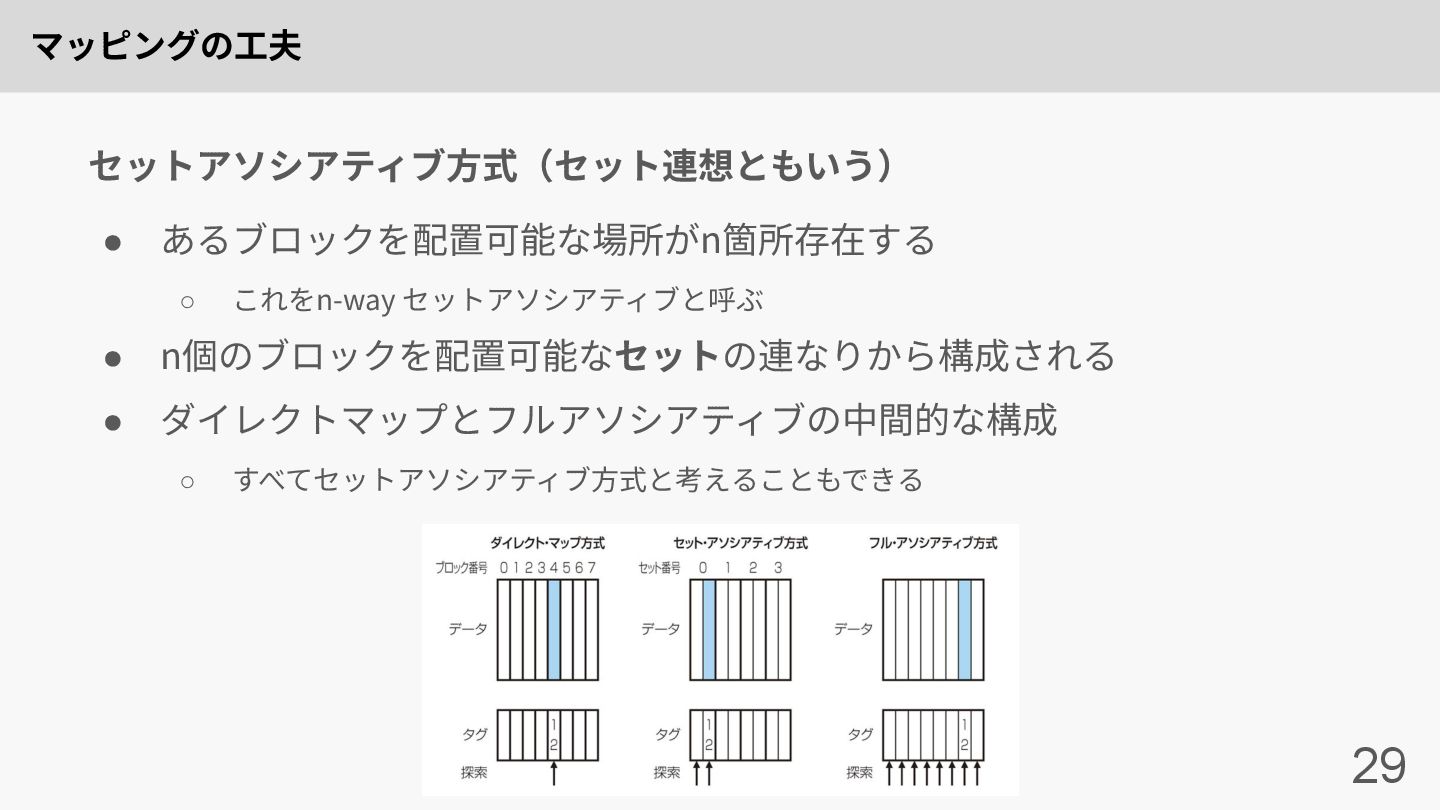
マッピングの⼯夫 29 • あるブロックを配置可能な場所がn箇所存在する ◦ これをn-way セットアソシアティブと呼ぶ • n個のブロックを配置可能なセットの連なりから構成される •
ダイレクトマップとフルアソシアティブの中間的な構成 ◦ すべてセットアソシアティブ⽅式と考えることもできる セットアソシアティブ⽅式(セット連想ともいう)
アソシアティブ⽅式における置き換えブロックの選択 30 • セット内のブロックのうち参照されたのが最も古いブロックを置き換え • 2-wayセットであれば1ビットで確実判断できる ◦ セット内の要素数が増えるにつれて正確にLeast Recentを判断するのは難しくなる ◦
参照されたら参照ビットを⽴てて、置き換えの際に参照ビットが⽴っていないものを置 き換えるという⼿法もある • 他にもランダムにブロックを置き換えるランダム法も存在する LRU法(Least Recently Used)
キャッシュの性能向上 31 • いわゆるL1, L2など、キャッシュにおけるレベルわけ • マルチレベルキャッシュにおいてL1キャッシュはクロックサイクルの短 縮に専念できる ◦ 通常単⼀レベルキャッシュと⽐べてL1キャッシュは容量が⼩さい
◦ ミスペナルティの軽減はL2キャッシュが受け持つ ⼯夫2: マルチレベルキャッシュ
仮想記憶 32
仮想記憶とは? • ディスクなどの⼆次記憶を使って主記憶容量を拡張する⼿法 ◦ 元はタイムシェア型のコンピュータにおけるリソースの共有問題から考案された ◦ 現代では特に仮想マシンにおけるリソースの共有に際して⽤いられる • 仮想記憶は概念的にはキャッシュととても似ている ◦
キャッシュにおけるブロック:仮想記憶における「ページ」 ◦ キャッシュにおけるミス:仮想記憶における「ページフォルト」 33
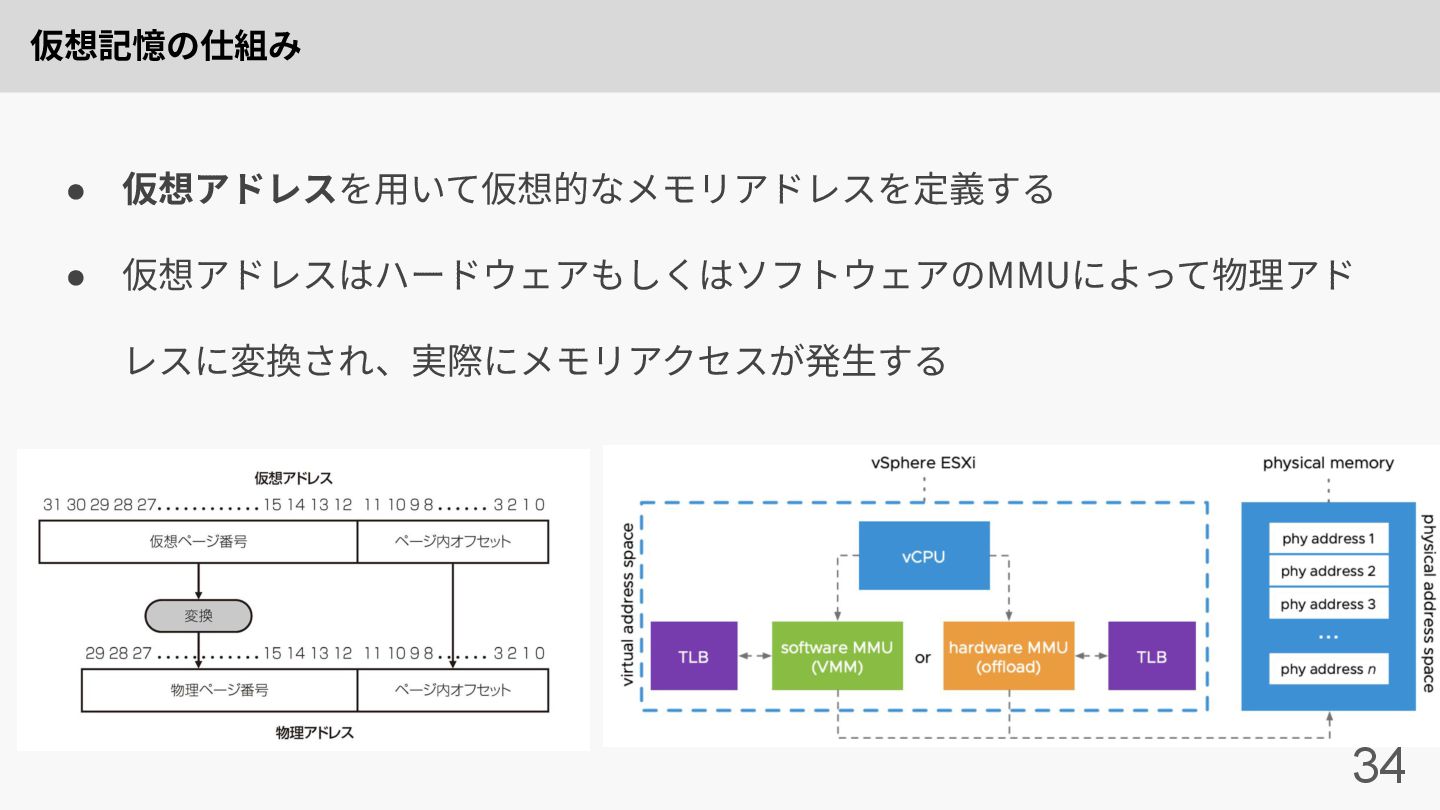
仮想記憶の仕組み 34 • 仮想アドレスを⽤いて仮想的なメモリアドレスを定義する • 仮想アドレスはハードウェアもしくはソフトウェアのMMUによって物理アド レスに変換され、実際にメモリアクセスが発⽣する
ページフォルト 35 • メモリアクセス時に主記憶にデータが存在しない場合 • ページフォルトが発⽣すると⼆次記憶にアクセスが発⽣する=激遅 ◦ 例外機構によってOSに制御が移り、⼆次記憶へのアクセスが発⽣ ◦ フラッシュメモリのアクセス時間はDRAMの100倍ほど
• 対策としてページサイズを⼤きくする⽅法がある(⼤きくしすぎるのはNG) • 主記憶内にページをフルアソシアティブで配置する ◦ 任意の場所に配置でき置き換えが減る ◦ でも全数検索は遅いのでは。。。
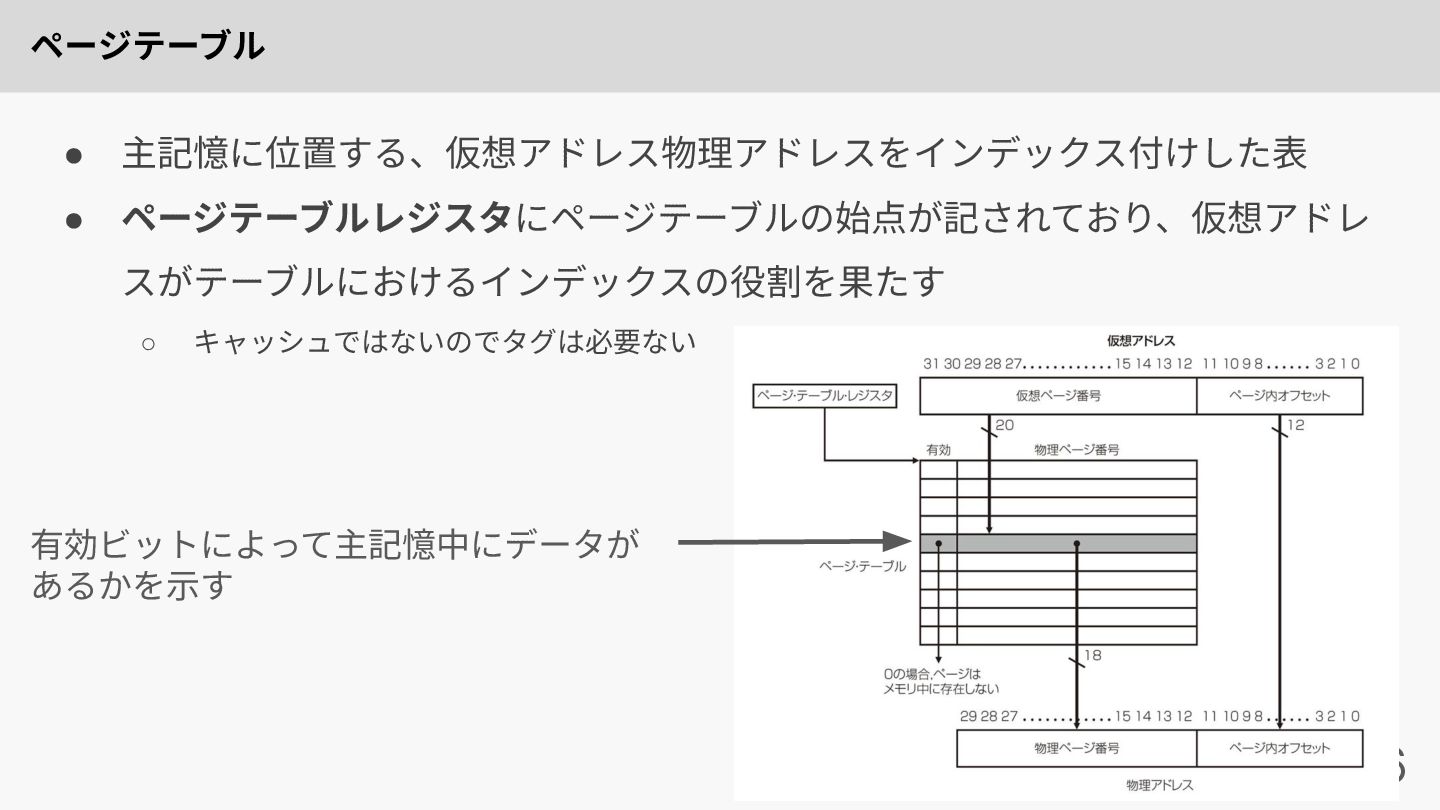
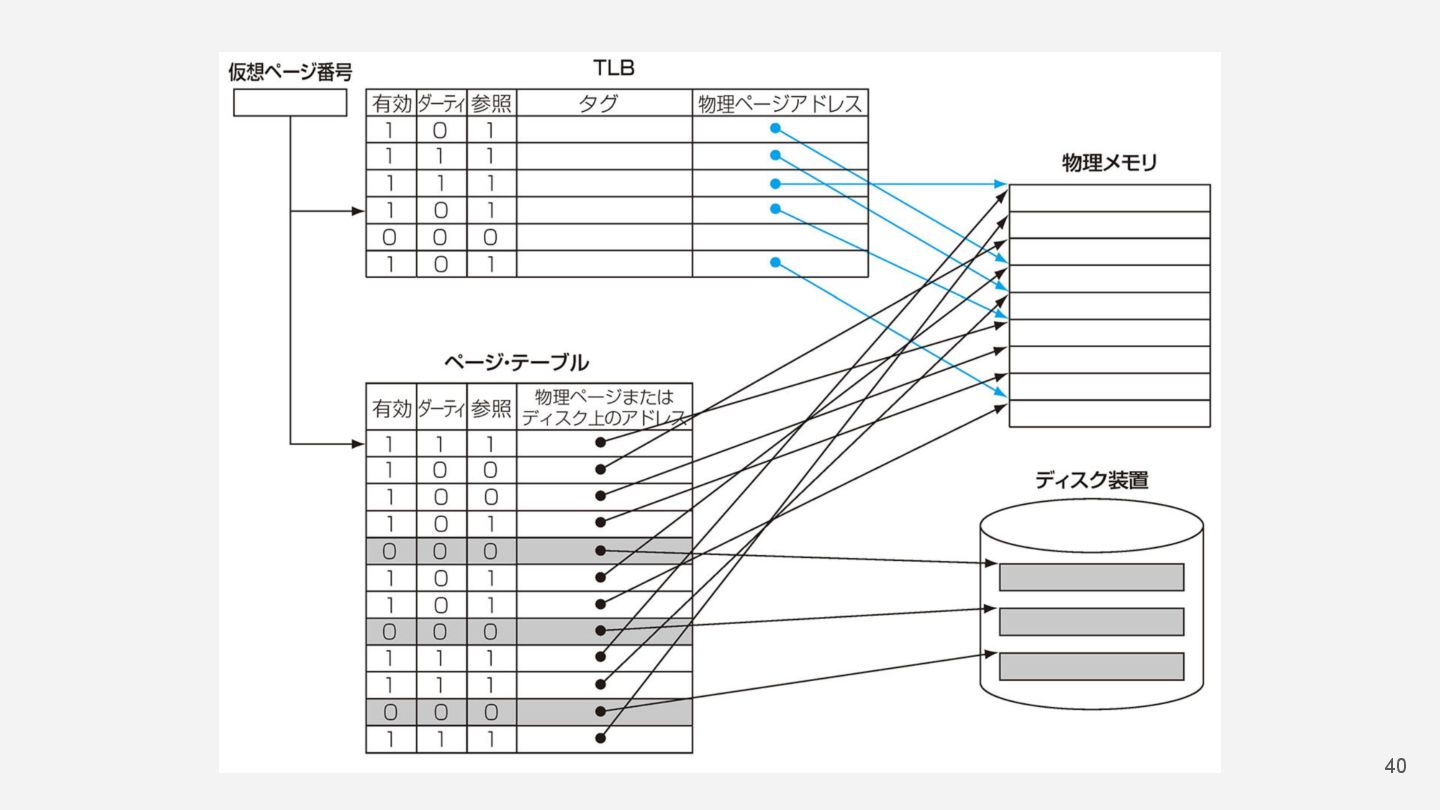
ページテーブル 36 • 主記憶に位置する、仮想アドレス物理アドレスをインデックス付けした表 • ページテーブルレジスタにページテーブルの始点が記されており、仮想アドレ スがテーブルにおけるインデックスの役割を果たす ◦ キャッシュではないのでタグは必要ない 有効ビットによって主記憶中にデータが
あるかを⽰す
ページテーブル 37 • 主記憶のページテーブルの他に、⼆次記憶に対するページテーブルも持つ ◦ 論理的には2つのテーブルは単⼀のテーブルとして考えられる ◦ 実際にはディスク上に存在するページのアドレスは全て保持する必要があるので別のデータ構 造に分けて保持する場合が多い
仮想記憶における書き込みと置き換え 38 • ライトバック⽅式を取らざるを得ない • 置き換え時に無条件に書き戻すのではなく、dirty bitを参照する ◦ ページに書き込んだ際にdirty bitを⽴てる
◦ OSがそのページを置き換えるときにdirty bitが⽴っていれば⼆次記憶に書き込みを⾏う • 置き換えについては厳密にLRU法を適⽤するのはコストが⾼い ◦ メモリ参照のたびにデータ構造を更新するのはしんどい ◦ ページがアクセスされるたびに参照ビットを⽴て、それを基に置き換え対象を決める ◦ 参照ビットを⽤いない場合はソフトウェアのアルゴリズムに頼る
アドレス変換の⾼速化 39 • ページテーブルのキャッシュ • 通常のキャッシュと同じように仮想ページ番号の⼀部をタグとして保持 • ページテーブルの代わりにTLBにアクセスするので参照ビットやダーティ ビットも含める必要がある •
TLB→主記憶のページテーブル→⼆次記憶のページテーブルの順に参照し て物理アドレスを得る TLB(Translation-Lookaside Buffer)
40
41 TLBのサイズ感 • ミス率を下げるためにフルアソシアティブ⽅式の⼩さなTLBを⽤いるケース • TLBサイズを⼤きく取り、連想度の⼩さいセットアソシアティブ⽅式を採⽤す るケース ◦ 置き換えについてはランダムに選択するコンピュータが多い
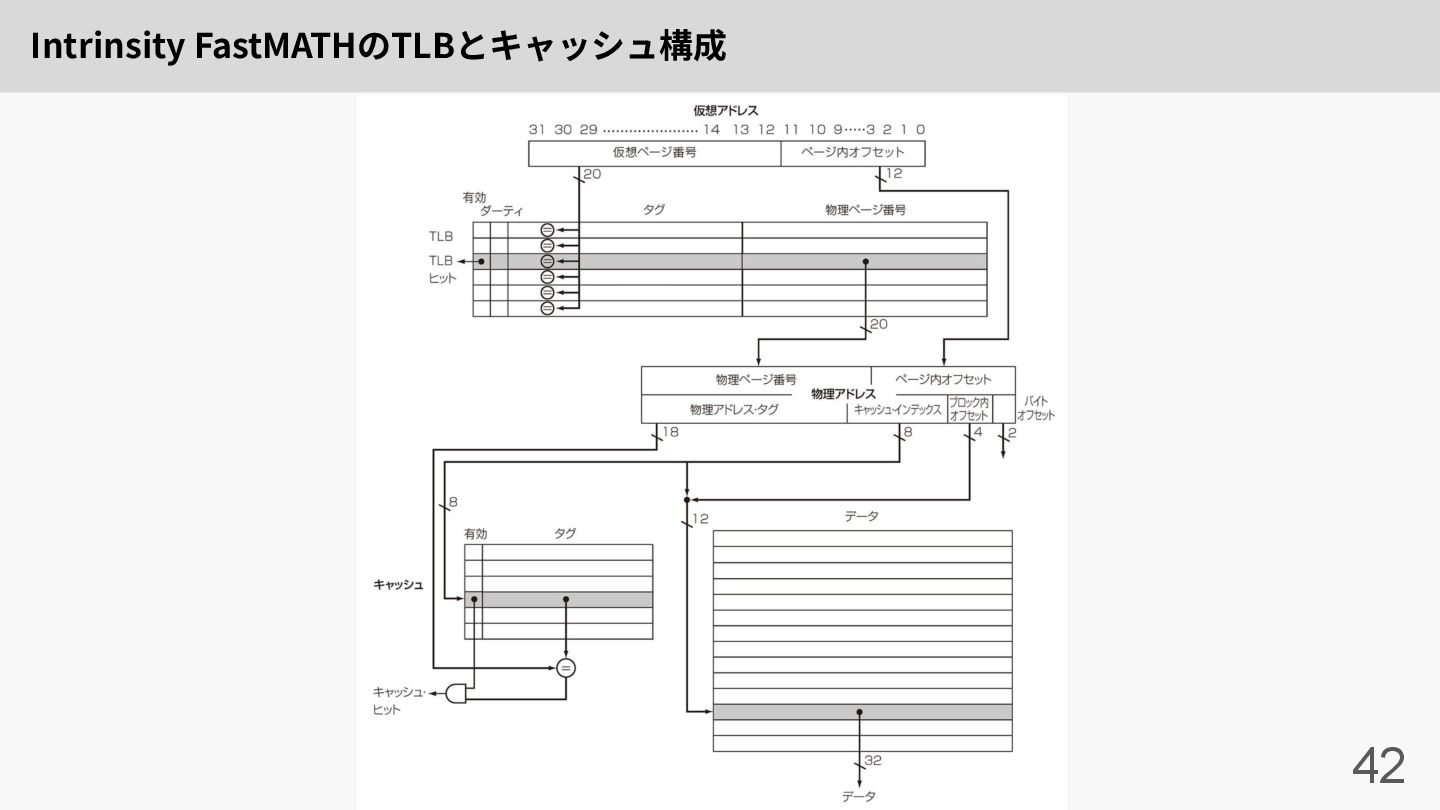
Intrinsity FastMATHのTLBとキャッシュ構成 42
マルチプロセッサとキャッシュ 43
マルチプロセッサのキャッシュにおける⼀貫性の問題 1. CPU AがブロックXを読み出す -> AのキャッシュにXが⼊る 2. CPU BがブロックXを読み出す ->
BのキャッシュにXが⼊る 3. CPU AがブロックXに書き込む -> Aのキャッシュは更新される 次にCPU BがブロックXを読み出す時、Bのキャッシュは古いままなので古いXの値 を読み出してしまう 44
誤り訂正と誤り検出 45
誤り検出 • あるビットパターンにおける1の数を数え、奇数だったら1、偶数だった ら0を末尾に加える ◦ この加えるビットをパリティビットという ◦ パリティビットを付加された後のビット列の1の数は偶数になるはず • 通信時やディスクへの書き込み時に1ビット誤りを検出できる
◦ 厳密には「奇数ビットの誤りがあることを検出できる」だが、確率的には1ビットの誤り 46 ハミングの誤り検出
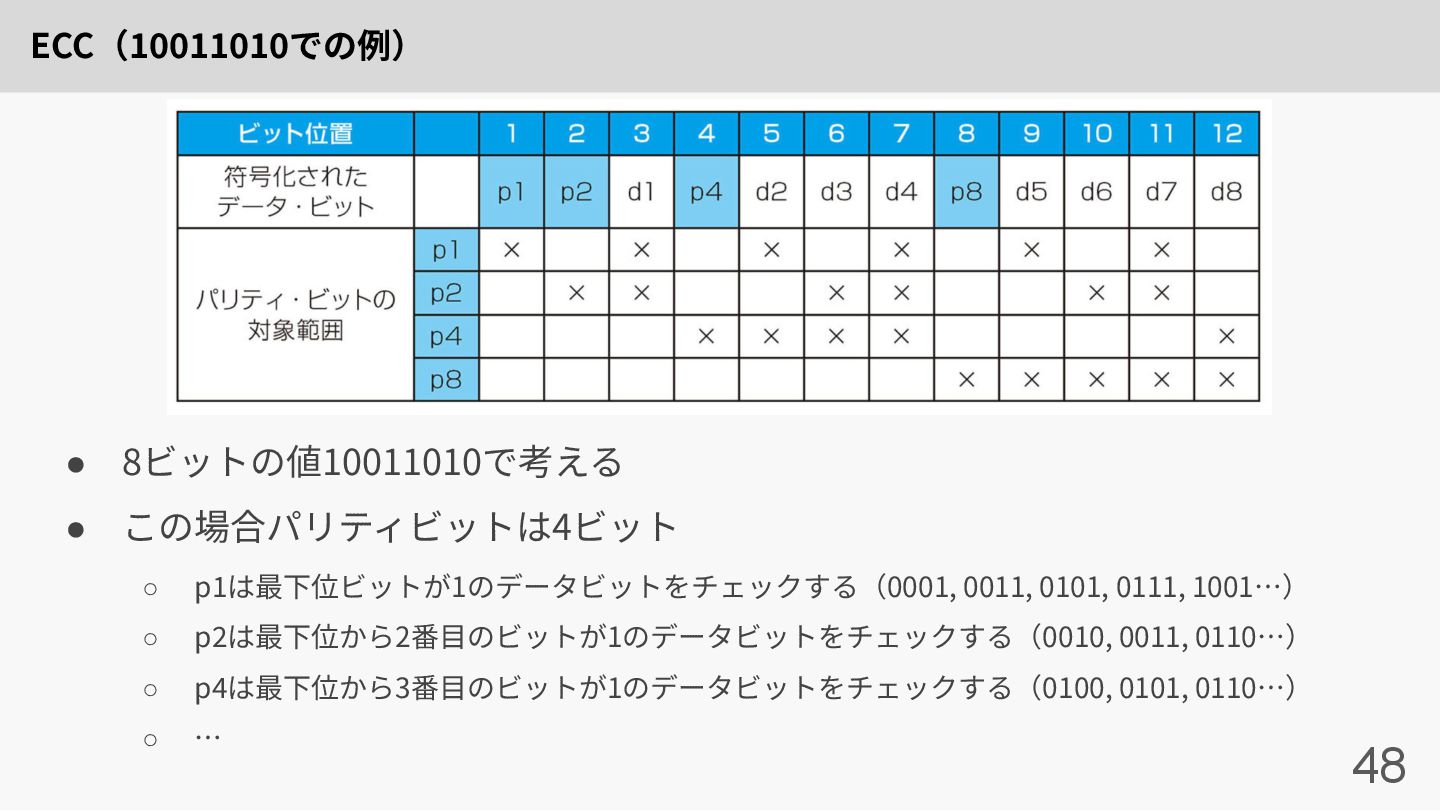
誤り訂正 47 • 誤りを検出するだけでなく誤りを訂正したい • パリティビットをさらに増やしてこれを実現する • ビットパターンの左から順に番号をふり、2の冪乗である全てのビットを パリティビットにし、それ以外をデータビットに使⽤する ハミング誤り訂正コード(ECC)
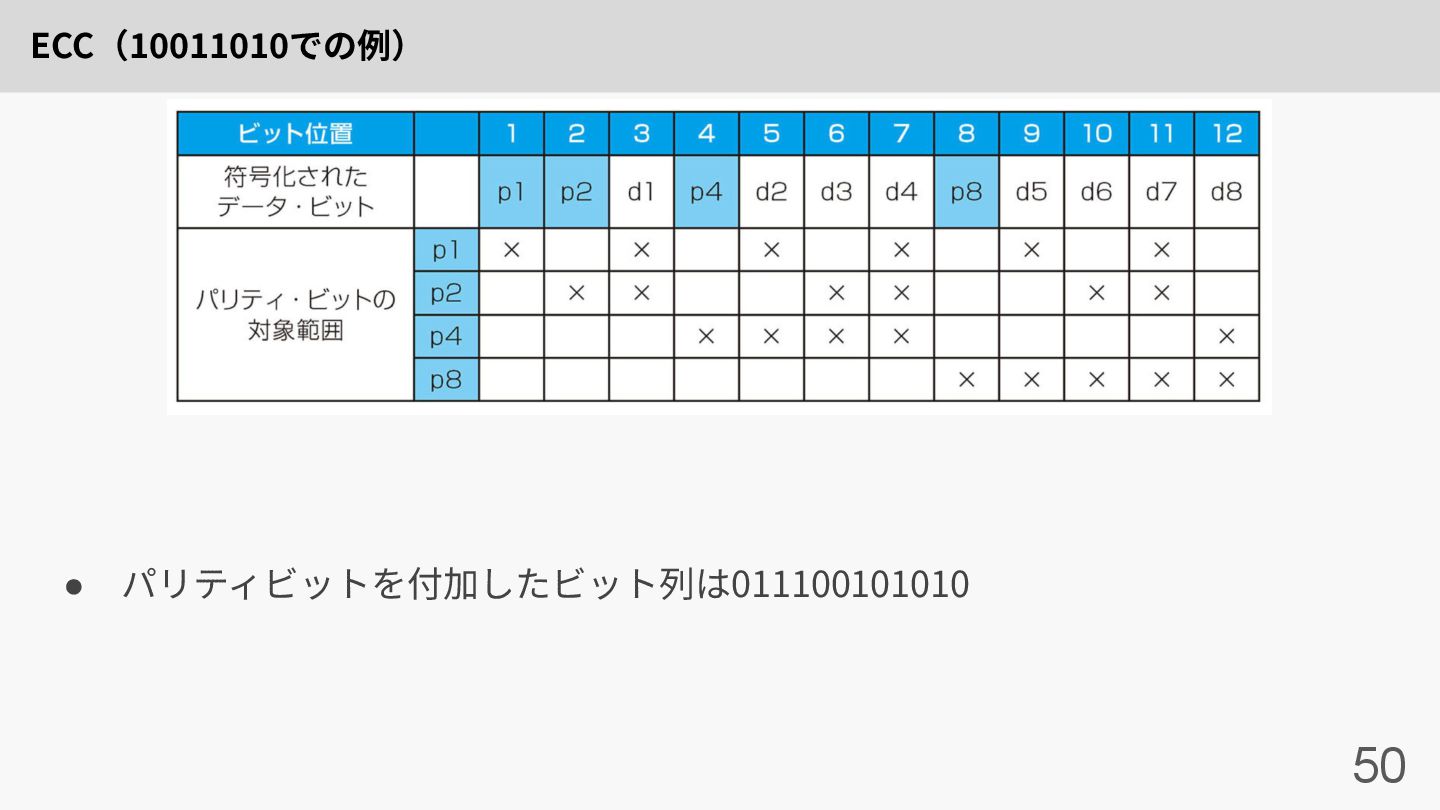
ECC(10011010での例) 48 • 8ビットの値10011010で考える • この場合パリティビットは4ビット ◦ p1は最下位ビットが1のデータビットをチェックする(0001, 0011, 0101,
0111, 1001…) ◦ p2は最下位から2番⽬のビットが1のデータビットをチェックする(0010, 0011, 0110…) ◦ p4は最下位から3番⽬のビットが1のデータビットをチェックする(0100, 0101, 0110…) ◦ …
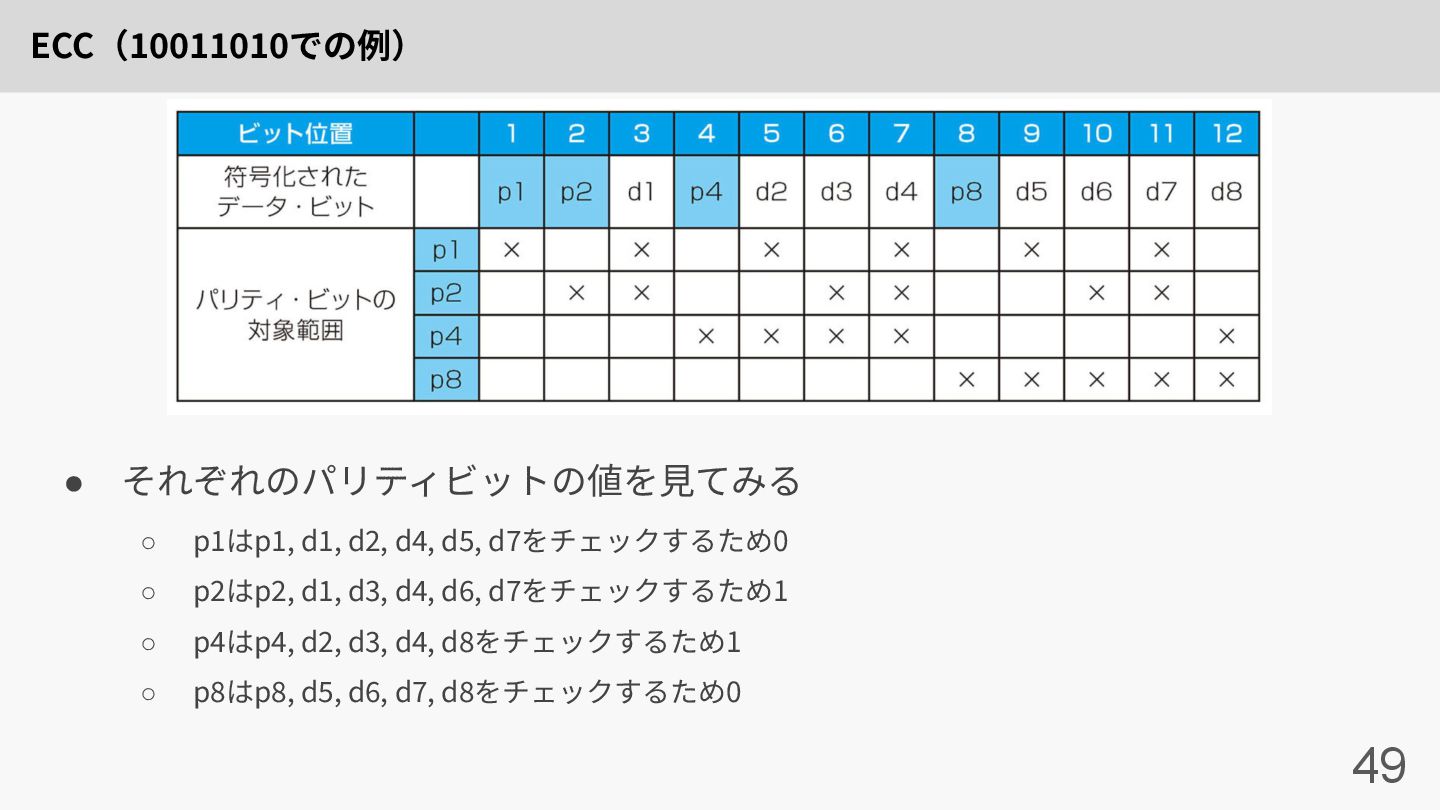
ECC(10011010での例) 49 • それぞれのパリティビットの値を⾒てみる ◦ p1はp1, d1, d2, d4, d5,
d7をチェックするため0 ◦ p2はp2, d1, d3, d4, d6, d7をチェックするため1 ◦ p4はp4, d2, d3, d4, d8をチェックするため1 ◦ p8はp8, d5, d6, d7, d8をチェックするため0
ECC(10011010での例) 50 • パリティビットを付加したビット列は011100101010
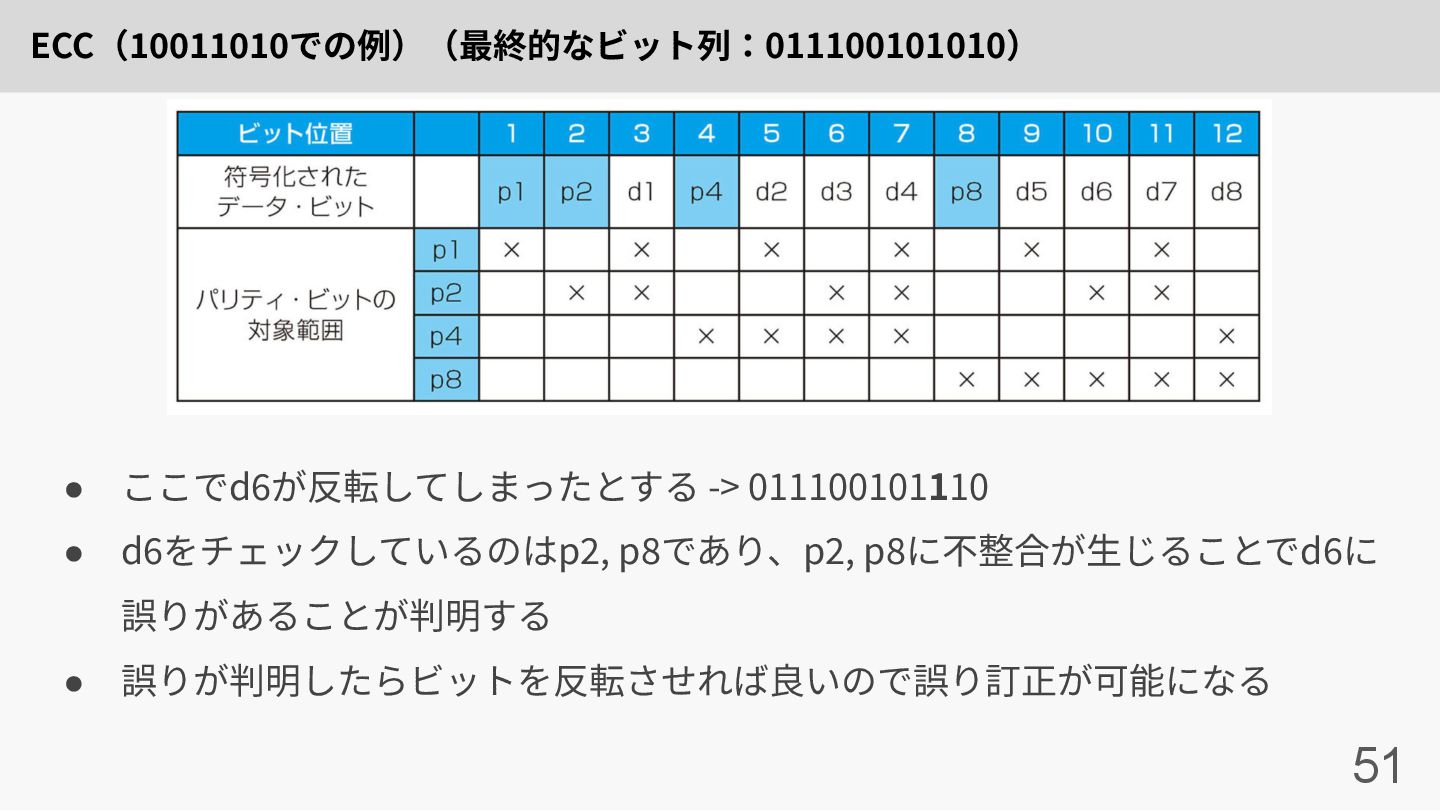
ECC(10011010での例)(最終的なビット列:011100101010) 51 • ここでd6が反転してしまったとする -> 011100101110 • d6をチェックしているのはp2, p8であり、p2, p8に不整合が⽣じることでd6に
誤りがあることが判明する • 誤りが判明したらビットを反転させれば良いので誤り訂正が可能になる
誤り訂正 52 • 上述のパリティビットに加えて、パリティビットを加えた後のビット列に 対するパリティビットをさらに末尾に加えることで2ビットの誤り検出が できる • これらを組み合わせると1ビットの誤り訂正と2ビットの誤り検出が可能 になる •
今⽇のほとんどのサーバーのメモリではこのSEC/DEDが実装されている SEC/DED(Single Error Correction / Double Error Detection)
53 以上 (キャッシュとマルチプロセッサの節はまた今度)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}