Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
事業拡大と共に歩むプラットフォームへの道 Google Cloudによる拡張可能なデータ基盤
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Keisuke Tagashira
February 25, 2026
91
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
事業拡大と共に歩むプラットフォームへの道 Google Cloudによる拡張可能なデータ基盤
Keisuke Tagashira
February 25, 2026
More Decks by Keisuke Tagashira
See All by Keisuke Tagashira
データモデリングを通じて管理会計のオペレーションを再設計する
ktagashira
0
1.5k
ADKを活用して事業部横断の企業検索エージェントを作成した話
ktagashira
3
1.5k
Findyのユーザーサクセス面談を支えるデータ技術
ktagashira
1
960
Featured
See All Featured
A brief & incomplete history of UX Design for the World Wide Web: 1989–2019
jct
2
420
The browser strikes back
jonoalderson
0
1.4k
Cheating the UX When There Is Nothing More to Optimize - PixelPioneers
stephaniewalter
287
14k
A Tale of Four Properties
chriscoyier
163
24k
DBのスキルで生き残る技術 - AI時代におけるテーブル設計の勘所
soudai
PRO
67
56k
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.6k
We Have a Design System, Now What?
morganepeng
55
8.2k
The innovator’s Mindset - Leading Through an Era of Exponential Change - McGill University 2025
jdejongh
PRO
1
220
Documentation Writing (for coders)
carmenintech
77
5.4k
Writing Fast Ruby
sferik
630
63k
StorybookのUI Testing Handbookを読んだ
zakiyama
31
6.8k
Done Done
chrislema
186
16k
Transcript
事業拡大と共に歩むプラットフォームへの道 Google Cloudによる拡張可能なデータ基盤 Google Cloud Community Tech Surge 2026 ファインディ株式会社
CTO 室データソリューションチーム / データエンジニア 田頭 啓介(tagasyksk)
自己紹介
田頭啓介 / @tagasyksk ファインディ株式会社 / データエンジニア 2024年5月〜 CTO 室データソリューションチームにジョイン マルチプロダクトのデータ基盤の開発に従事
自己紹介
None
None
📖 これまでのデータ基盤のあゆみ データメッシュを採用した分散型アーキテクチャの運用 ⚠️ 事業拡大で直面した課題 プロダクト急増によるサイロ化と管理コストの増大 🔧 どう解決したか プロジェクト統合と共通化・分権のバランス再設計 🚀
今後の展望 AI Agent Readyなデータ基盤へ 本日の内容
これまでのデータ基盤のあゆみ
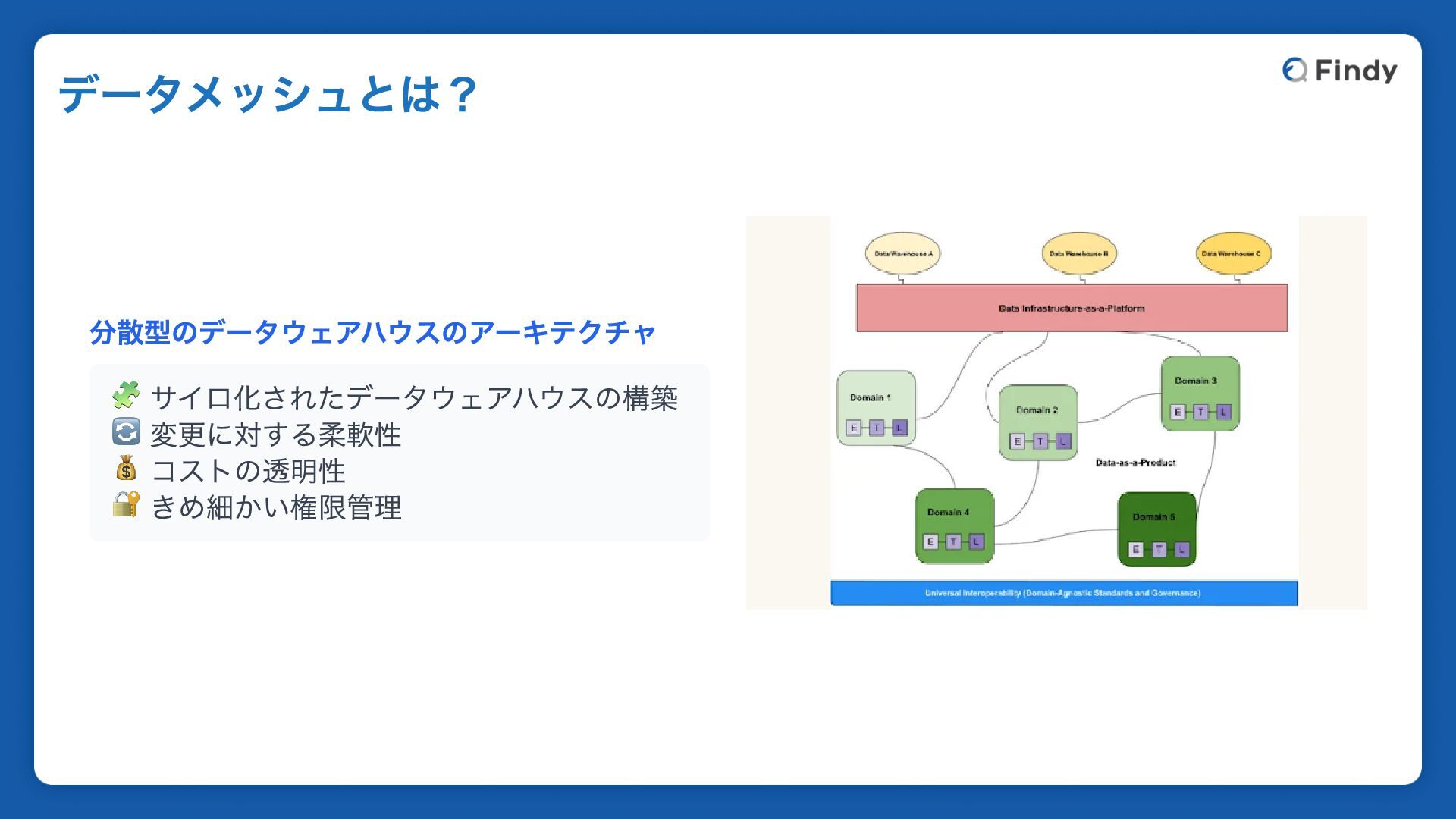
分散型のデータウェアハウスのアーキテクチャ 🧩 サイロ化されたデータウェアハウスの構築 🔄 変更に対する柔軟性 💰 コストの透明性 🔐 きめ細かい権限管理 データメッシュとは?
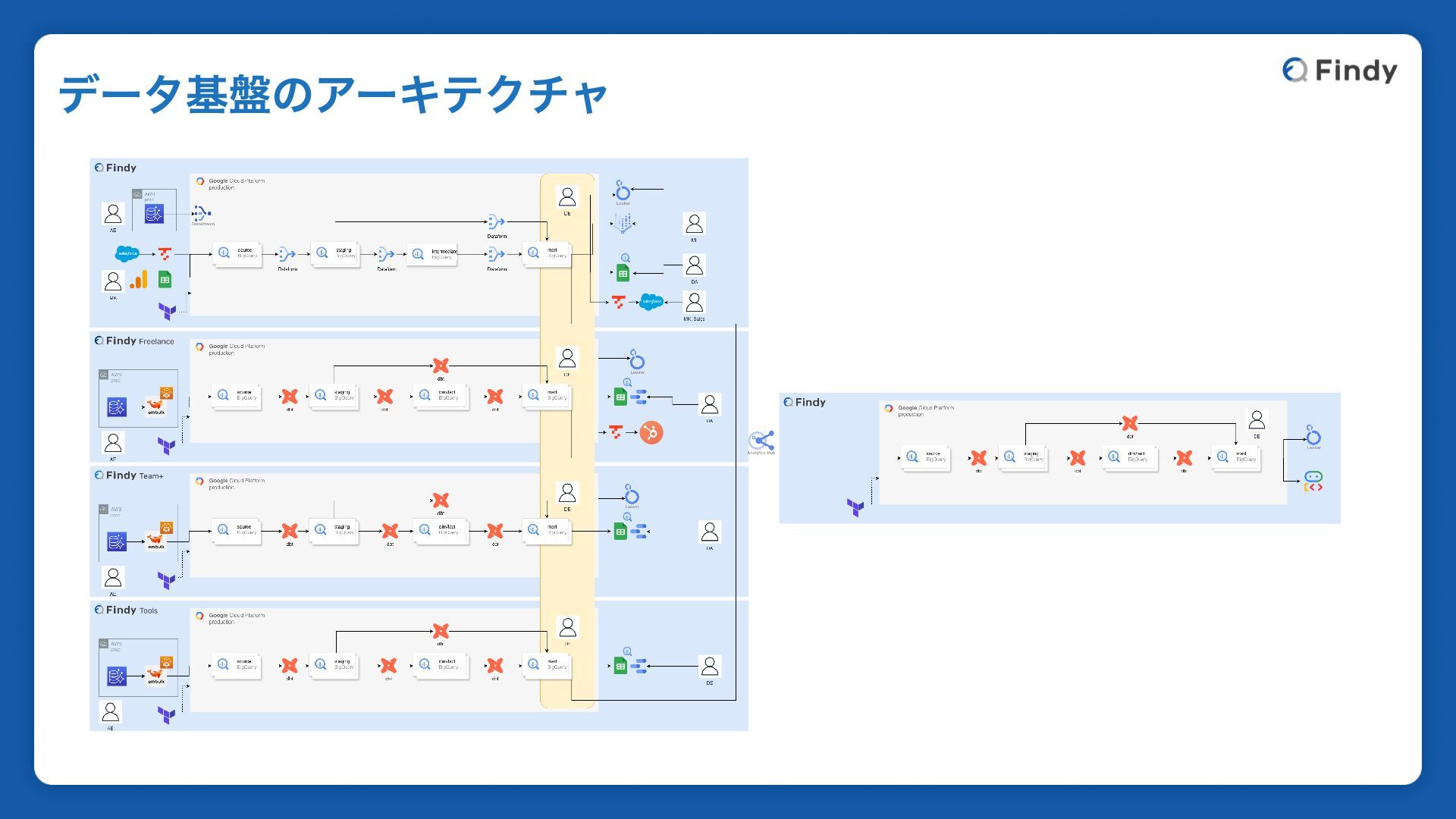
データ基盤のアーキテクチャ
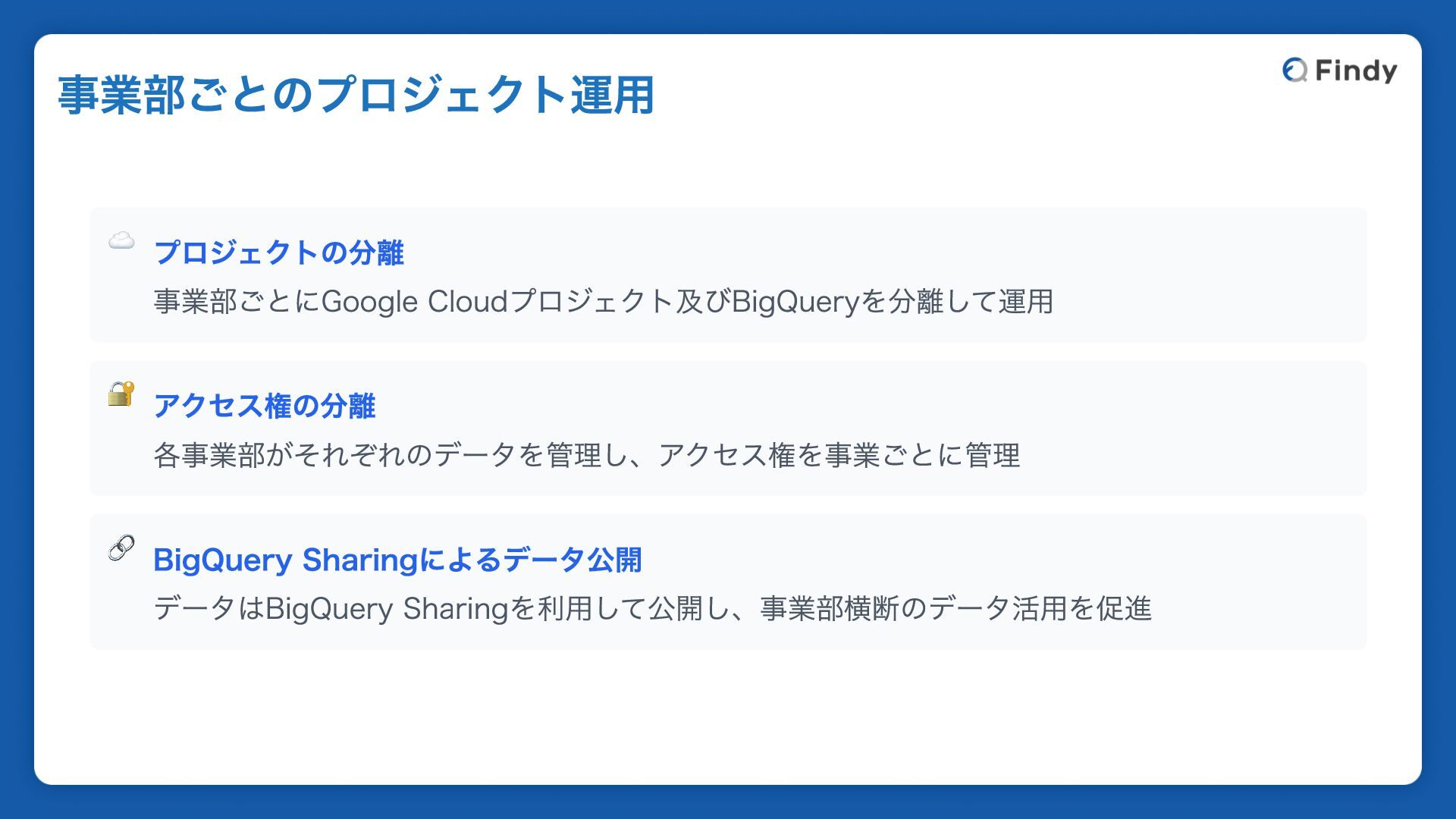
☁️ プロジェクトの分離 事業部ごとにGoogle Cloudプロジェクト及びBigQueryを分離して運用 🔐 アクセス権の分離 各事業部がそれぞれのデータを管理し、アクセス権を事業ごとに管理 🔗 BigQuery Sharingによるデータ公開
データはBigQuery Sharingを利用して公開し、事業部横断のデータ活用を促進 事業部ごとのプロジェクト運用
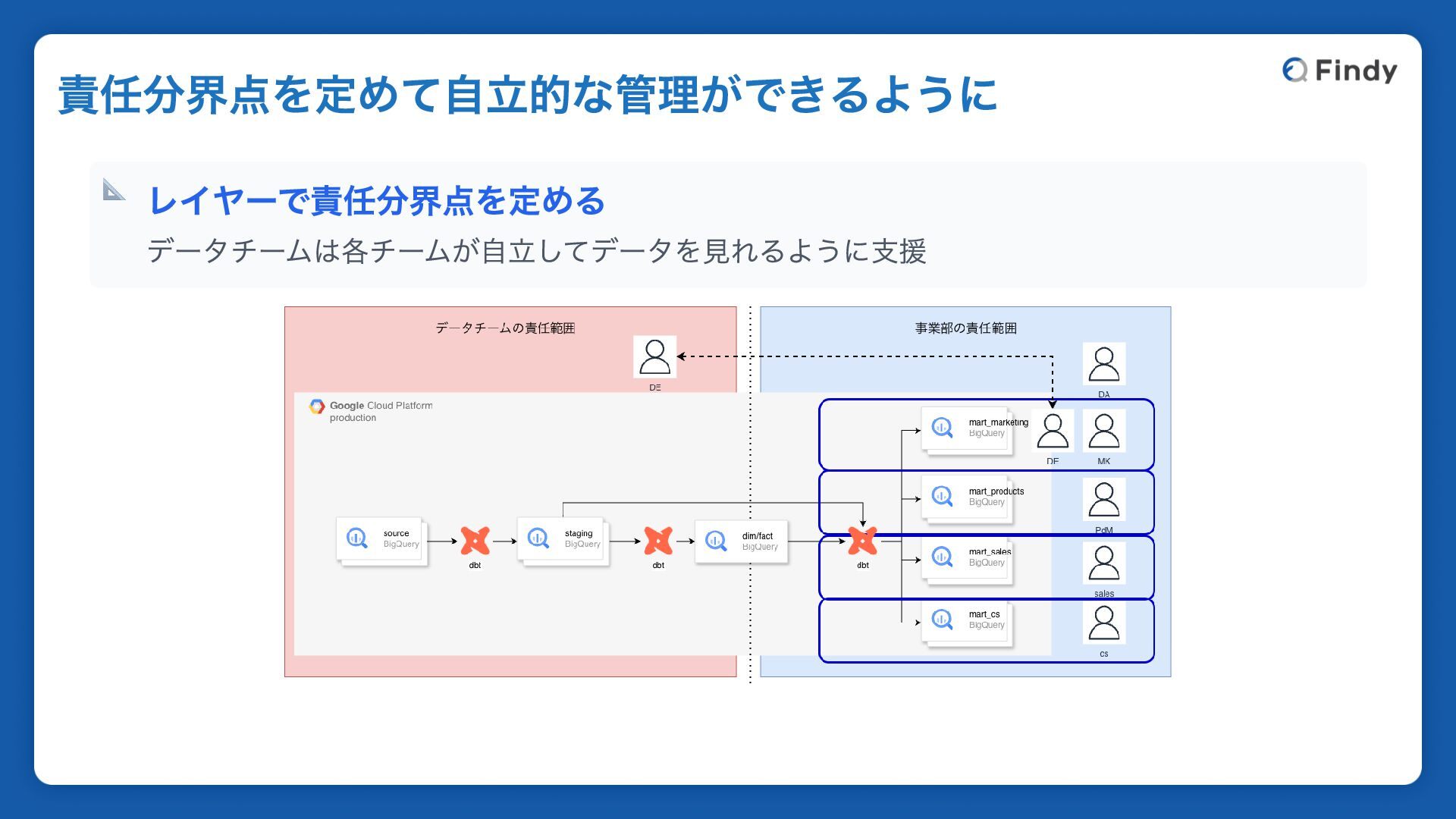
📐 レイヤーで責任分界点を定める データチームは各チームが自立してデータを見れるように支援 責任分界点を定めて自立的な管理ができるように
ADKを活用して事業部横断の企業検索エージェントを作成した話 横断データ活用の事例
マルチプロダクトのデータ基盤設計 データメッシュを運用して見えた課題と伸びしろ 参考:データメッシュの運用についての発表
課題
📢 生成AI時代の事業戦略2026を発表 4つの新規AI事業を同時に発表 (PR TIMES) 🤖 Findy Insights 🤖 Findy
AI+ 🤖 アーキテクチャ壁打ちAI 🤖 Findy AI Career 新プロダクトを続々発表
📈 プロジェクトの増殖 プロダクトごとにGoogle Cloudプロジェクトが増え続ける構造 💰 メンテナンスコストの増大 IAM・予算・リソース管理が煩雑に、スケールしない仕組みに 🔄 同じ作業の繰り返し 新しいプロダクト追加のたびに同じようなインフラ構築が必要
プロダクト増加で何が起こったか
🧩 バラバラな技術選定 事業部ごとに独立管理、メンテナが個別に好みの技術を採用 ⚠️ 実行環境の乱立 Docker / GitHub Actions /
ローカル実行 etc. 🔒 属人化 各事業部で詳しい人しかメンテナンスできない状態に サイロ化するdbt実行環境
解決
💡 データメッシュの再解釈 プロジェクト単位ではなく、データセット単位でドメインを分離する 🔗 プロジェクトの統合 Google Cloudプロジェクトを一つに統合し、共通化と分権の境界を明確に 📘 DMBOKに基づく規範の策定 「すべてを分散させる」のではなく、何を共通化し何を分権するかを整理
方針転換
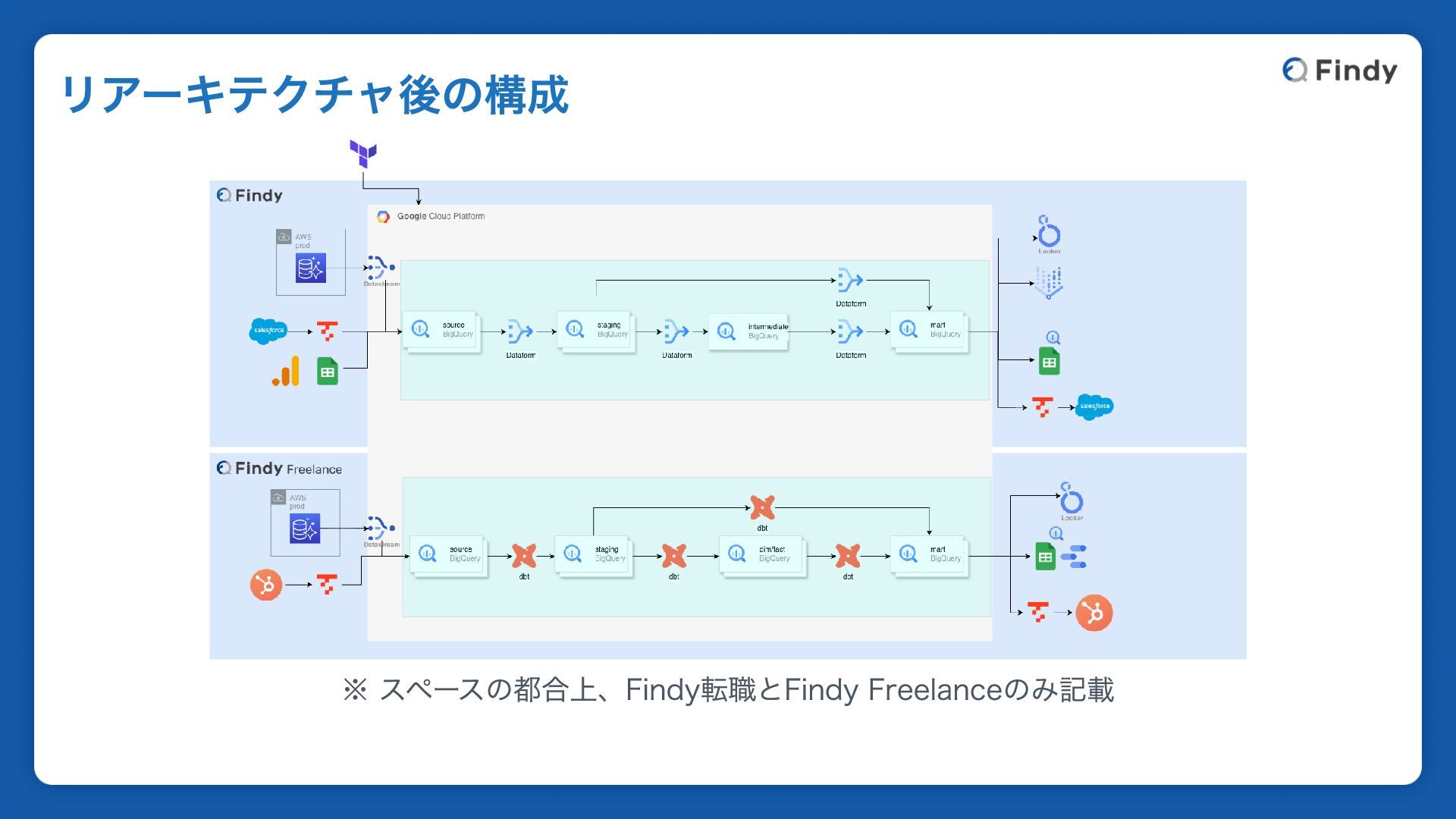
※ スペースの都合上、Findy転職とFindy Freelanceのみ記載 リアーキテクチャ後の構成
🏛️ 元々共通化済み IAM管理 / Cloud DLP / BigQuery Policy Tag
🆕 事業拡大で新たに標準化 CI検査項目 / Formatter・Linter / 実行環境(ランタイム) 🌐 引き続き分権 事業ドメイン / ビジネスイベント / データモデリング フェデレーテッド・ガバナンス
複数の実行環境をDockerに標準化 共通のDockerイメージをArtifact Registryで管理 各リポジトリはGitHub Reusable Workflowで共通Workflowを呼び出すだけ jobs: dbt-build: uses: org/shared-workflows/.github/workflows/dbt.yml@main
with: image_tag: "0.0.0" mount_path: "." dbt_args: "build --target prod" dbt ランタイムの共通化
ローカル実行時の共通コマンドをTaskfileのincludes機能で参照 各リポジトリは実装の詳細を意識せず、設定による利用のみ includes: common: taskfile: ./path/to/shared/Taskfile.yml tasks: lint: cmds: -
task: common:lint test: cmds: - task: common:test Taskfileの活用
スプレッドシートやLooker StudioからLookerへの移行 事業部ごとに散らばっていた指標を全社横断で集約 セマンティックレイヤーの活用 ビジネスロジックを統一し、全社的な指標管理を一元化 指標の定義は事業部に委譲 データエンジニアは横断組織であることを活かしてバランスを取る役割 事業部横断の指標管理:Lookerの導入
今後の展望
🔧 さらなるプラットフォーム化の推進 事業横断データ活用の拡充、セルフサービスでデータ活用できる仕組みの強化 🤖 AI Agent Readyなデータ基盤へ AIエージェントがデータを活用できる基盤の整備、データの発見可能性・アクセシビリティの 向上 今後の展望
まとめ
📖 これまで 事業部ごとにプロジェクトを分離、データメッシュで運用 ⚠️ 課題 プロダクト増加でサイロ化、管理コスト増大 🔧 解決 プロジェクト統合、共通化と分権のバランスを再設計 事業の成長に合わせてデータ基盤も進化し続ける
まとめ
複数プロダクト横断のデータ基盤を設計・開発しています! 興味ある方はご応募、カジュアル面談お待ちしています データエンジニア絶賛募集中です!
ご清聴 ありがとうございました
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}