Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Amebaにおける Platform Engineeringの実践
Search
Kumo Ishikawa
April 07, 2025
Technology
1.6k
7
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Amebaにおける Platform Engineeringの実践
Kumo Ishikawa
April 07, 2025
More Decks by Kumo Ishikawa
See All by Kumo Ishikawa
Platform Engineering as a Product: Criteria for Improvement and Multi-Tenant Design
kumorn5s
0
570
「OSSがあるなら自作するな」は AI時代も正しいか ── Build vs Adopt の新しい判断基準
kumorn5s
7
3.4k
Efficient EKS Pod Communication: A Practical Implementation Using Cloudflare Zero Trust and CoreDNS
kumorn5s
2
440
Ameba Falco Security
kumorn5s
0
83
PEK2025: Multi-Tenancy Design in Ameba
kumorn5s
1
1.6k
Ameba CI/CD: Terraform and Argo CD Improvements
kumorn5s
9
3.2k
同一クラスタ上でのFluxCDとArgoCDのリソース最適化の話
kumorn5s
0
690
HA構成のArgoCD パフォーマンス最適化への道
kumorn5s
3
720
Other Decks in Technology
See All in Technology
Playwright × AI Agent でE2Eテストはどう変わるか AI駆動テストの可能性と実用検証の結果
taiga7543
1
220
「早く出す」より「事業に効く」 ── 顧客の業務サイクルから逆算するAI時代の二重ループ開発と「変化の設計者」 / devsumi2026
rakus_dev
1
400
End-to-Endで考える信頼性 — LINEアプリにおける クライアント開発×SRE連携の実践
maruloop
4
4.6k
Genie Ontologyは銀の弾丸かを考える / Is Genie Ontology a Silver Bullet?
nttcom
0
400
穢れた技術選定について
watany
17
5.6k
LLM/Agent評価:トップ営業の発言を「正解」にする 〜暗黙的正解による評価を営業資産に変える〜
takkuhiro
1
230
“それは自分の仕事じゃない"を 越えて行け
yuukiyo
1
480
型は壁、Rustでもバグを直すな、表現できなくせよ
nwiizo
14
2.1k
オブザーバビリティ、本当に活用できてる? 〜API連携×生成AIで成熟度を自動評価〜
dmmsre
1
3.6k
Amplify Gen2でbackend.tsにCDKを定義する/しない事によるCDKの挙動の違いとユースケース
smt7174
1
420
そのドキュメント、自動化しませんか?
yuksew
1
300
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.4k
Featured
See All Featured
Leading Effective Engineering Teams in the AI Era
addyosmani
9
2.2k
How to Talk to Developers About Accessibility
jct
2
400
"I'm Feeling Lucky" - Building Great Search Experiences for Today's Users (#IAC19)
danielanewman
230
23k
A designer walks into a library…
pauljervisheath
211
24k
Documentation Writing (for coders)
carmenintech
77
5.4k
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.8k
HTML-Aware ERB: The Path to Reactive Rendering @ RubyCon 2026, Rimini, Italy
marcoroth
2
340
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
Prompt Engineering for Job Search
mfonobong
0
380
Scaling GitHub
holman
464
140k
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillation
inesmontani
PRO
3
2.3k
Rails Girls Zürich Keynote
gr2m
96
14k
Transcript
Amebaにおける Platform Engineeringの実践 谷成 雄 Yu Taninari 石川 雲 Kumo
Ishikawa
谷成 雄 •2014年新卒入社 •現在: Service Reliability Group (SRG) •Ameba Platform
チーム •最近開発などで利用した技術: EKS GKE kubernetes on-premise Amazon Aurora Github Actions SRG技術記事
1.背景と課題 2.初期の構成と技術選定 3.リリース以来の改善 4.これから目指すこと
最初に 本日お話すること AmebaPlatformを構築するに至った経緯 構築する際に利用した技術の選定や背景について 運用する上で出てきた改善点をいくつか紹介 これから考えている施策・方向性について 本日お話しできないこと 技術選定や改善ステップなどの技術詳細ついての深堀り(DeepDive) どこか登壇できる場所を探しつつ発表の機会を伺う 時間の都合上スキップしたスライドは後ほどSpeakerDeckで公開
1.背景と課題 2.初期の構成と技術選定 3.リリース以来の改善 4.これから目指すこと
Amebaとは? Amebaはブログを中心とした メディアプラットフォーム
Ameba Platformとは? Amebaとして統合されたアーキテクチャを軸に システムを再構築するために作成されたPlatform
Amebaの課題(2019年当時) 複雑なシステム構造のため、ドメイン知識のインプットのコストが大きい 組織の変化に伴いチーム構成が変化することが多く、新しく担当したサービスの開 発を開始するのに多くのリードタイムが発生する チームごとに選定された様々な技術 各チームごとに様々な技術が使用されており、サービス開発者や運用者に大きい負 担がかかっている状況が発生している 運用における責任範囲が不明瞭 運用担当者が異動や退職になると、新しい担当者がアサインされず放置されてるよ うなサービスも発生
Platformのコンセプト • 利用ユーザがKubernetesに熟知する必要がない環境を提供 KubeVela(OAMの提供) • 管理された統合CI/CDの提供 GithubActionsとArgoCDを用いたマネージドの環境を提供 • 統一されたログフローの提供 標準出力に出力されたログを必要なところに届けるシステムを提供
• 監視サービスの一元化 Datadogを使用したモニタリングやダッシュボードを提供 • 基本的なセキュリティの担保 KubeVelaを使用したSecurityContextやSecretsManagerの提供など
1.背景と課題 2.初期の構成と技術選定 3.リリース以来の改善 4.これから目指すこと
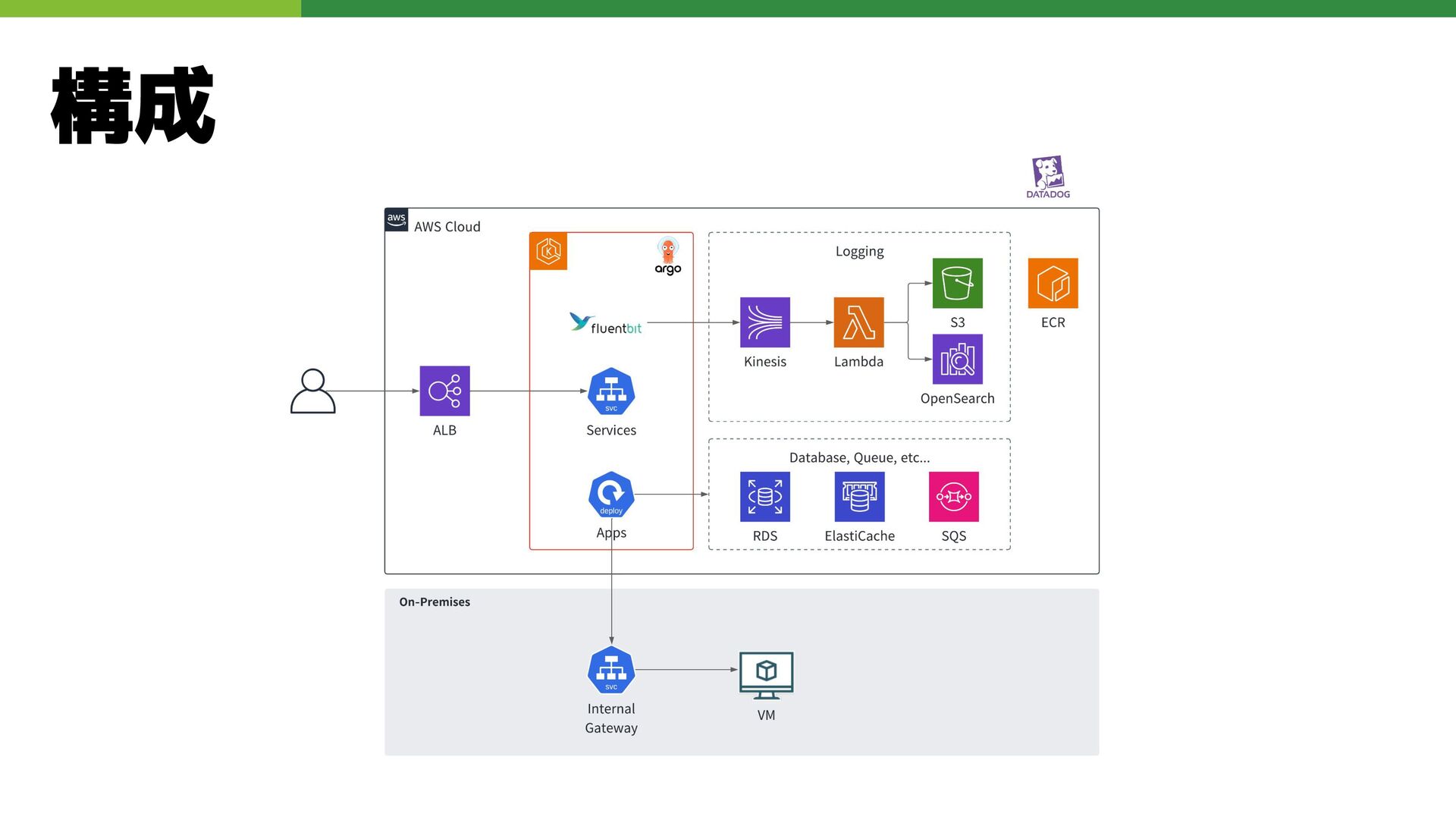
構成
技術選定: コンピューティング基盤 Kubernetes on AWS(EKS) • KubrenetesのManagedサービスを利用することにより管理者の運用負荷削減 Self-Managed-NodeGroup(当時の状況) • user_dataが流せる(社内認証によるログイン設定)
• 追加のSecurity Groupが指定できる Spot Instanceの活用 • コストを抑えるためにSpot Instanceも併用 Cluster-AutoscalerとHPA • 当時のWorkerNodeのスケールサービスだとほぼ一択 • Podに関しては特殊なスケール要件がなかったのでHPAを採用
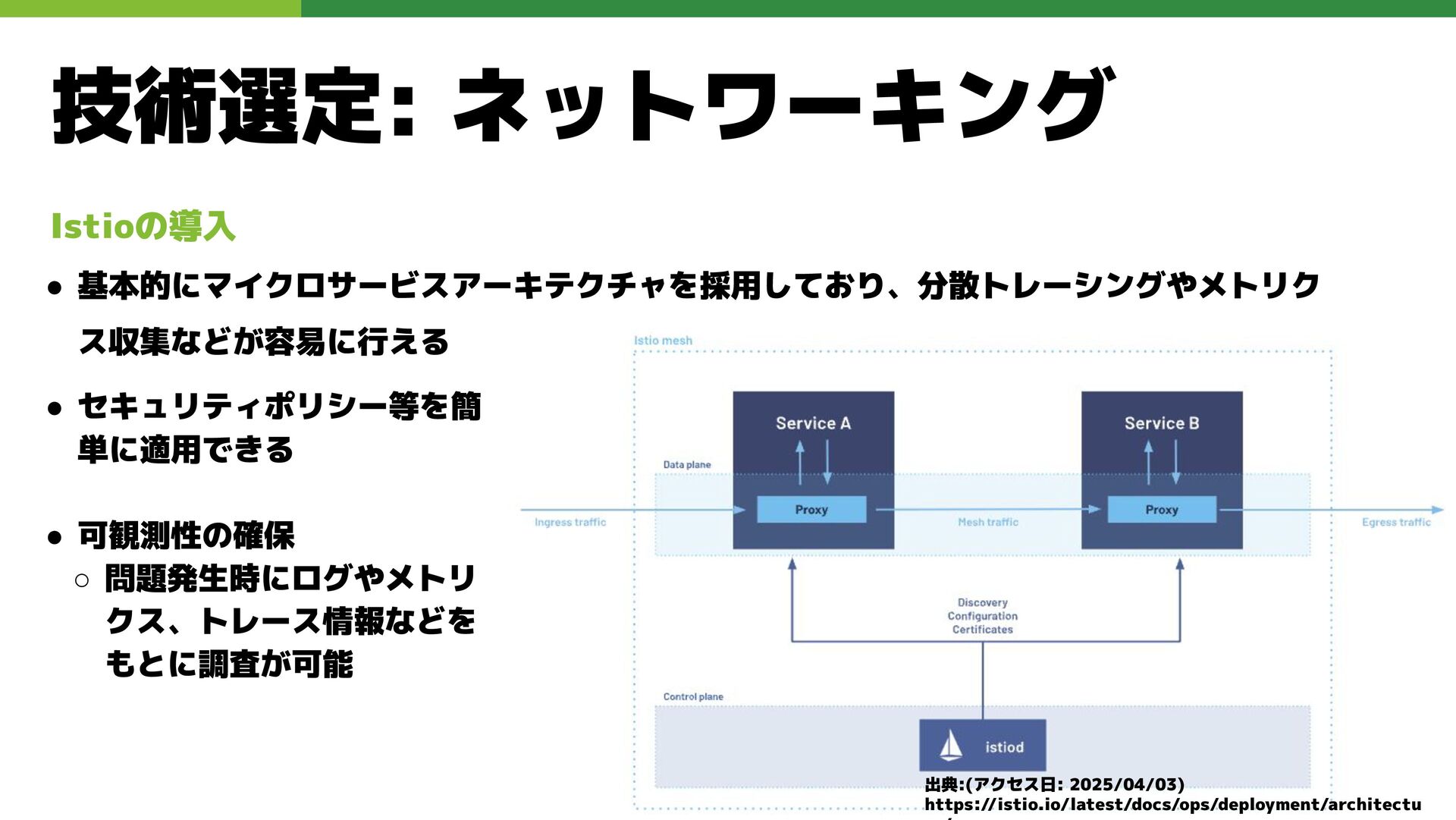
技術選定: ネットワーキング • セキュリティポリシー等を簡 単に適用できる • 可観測性の確保 ◦ 問題発生時にログやメトリ クス、トレース情報などを
もとに調査が可能 出典:(アクセス日: 2025/04/03) https://istio.io/latest/docs/ops/deployment/architectu Istioの導入 • 基本的にマイクロサービスアーキテクチャを採用しており、分散トレーシングやメトリク ス収集などが容易に行える
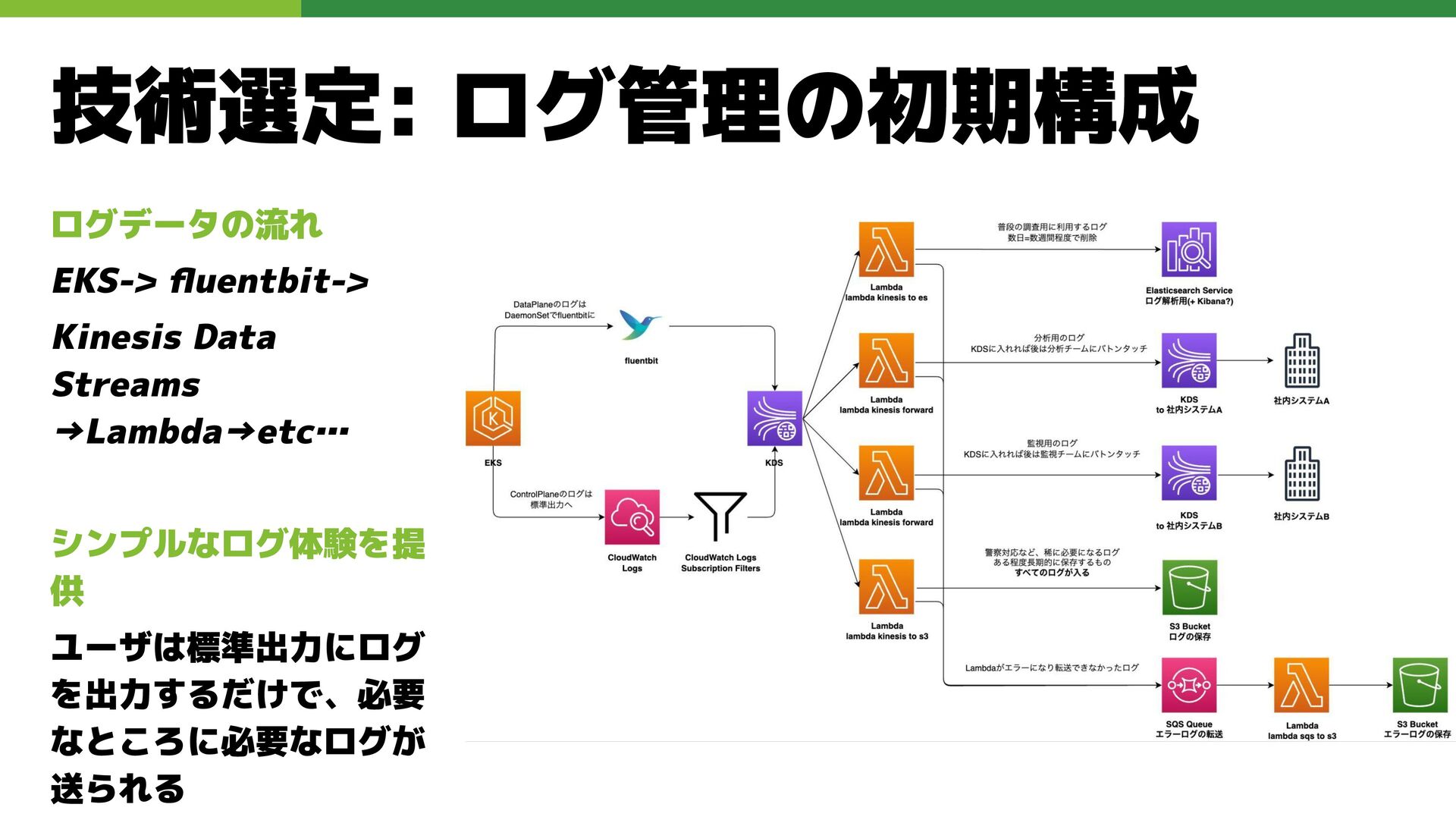
技術選定: ログ管理の初期構成 ログデータの流れ EKS-> fluentbit-> Kinesis Data Streams →Lambda→etc… シンプルなログ体験を提
供 ユーザは標準出力にログ を出力するだけで、必要 なところに必要なログが 送られる
技術選定: CI/CD GitHub Actions(CI) • 開発にGitHubを使用しており、社内にSelfHostRunnerも存在していたため採用 ArgoCD(CD) • ArgoCDは導入と管理が容易 Bootstrapのプロセスが不要で、HA構成でも単一のYAMLファイルでデプロイ可能
• ArgoCDの優れたユーザー体験 ArgoCDのUIは速度とわかりやすさが高評価 • ArgoCDの活発なコミュニティとPlatformチームとの親和性 2020年時点で既にIncubating Projectに昇格しており、最も期待されているCDプロジェ クトの一つであった 社内Platformチームの技術スタック(Go言語が多い)と親和性が高く、Issueを提起しやす い環境
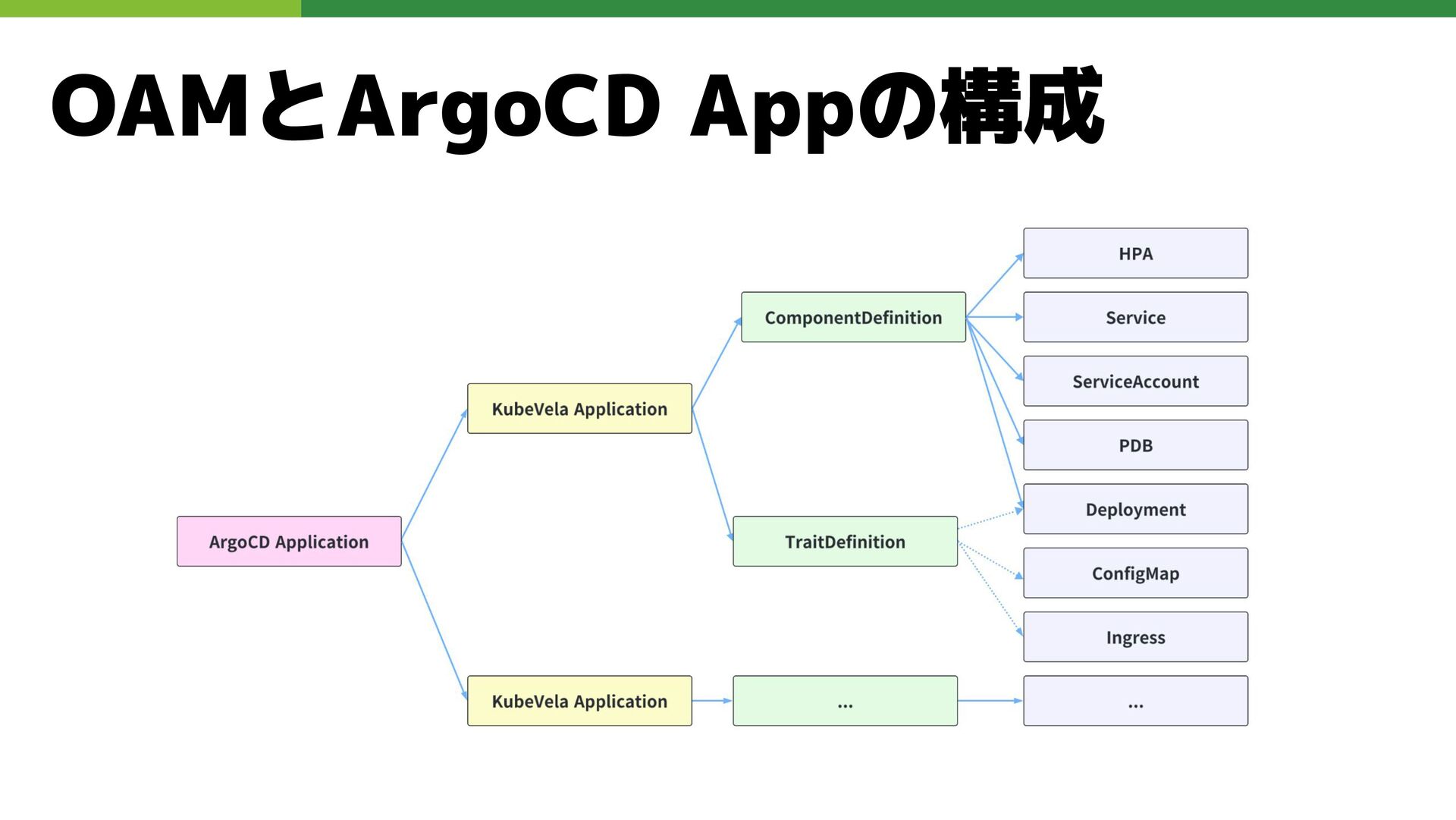
技術選定: アプリケーション定義モデル KubeVelaとは • OAMモデルを使用して開発者のデプロイを簡素化し、拡張性 を実現するツール KubeVelaの選択理由 • ユーザのk8sに対する認知負荷を減らす •
clusterを管理するうえで必須となる設定を管理者側として 強制できる KubeVelaとCUE langについて CUE langを用いて条件文やデータ変換等を行い、必要なyaml を生成する
OAMとArgoCD Appの構成
技術選定: テナント設計 サービスの分離について 環境ごとにEKSを使用し、EKS内の各サービス間の接続やNamespace間のやり取 りなどは特に制限しない構成(開発体験のシンプルさやメンテナンス性の向上が目 的) サービスの共有オーナーシップの確保 サービスの分離を最小限にすることで、担当範囲を超えて互いのサービスのサポー トをしたり、障害対応などが共同でできるような環境を用意 HNC(Hierarchical
Namespace Controller)とRBAC HNCはNamespaceを階層構造で管理することができ、リソースの継承と伝搬が 可能RBACと組み合わせることにより、Platformチームとアプリケーション開発 者が管理するリソースの分離をすることが可能
技術選定: モニタリング Datadogの採用 • メンバーの習熟度が高い • いろいろな機能が充実 • AWSとの連携も容易 アプリケーション側のDatadogの活用
• Prometheus Endpoint (Annotation)を付与することでメトリクスを収集 • GoアプリケーションにDatadogのGo SDKを組み込むことで、アプリケーション のパフォーマンスデータ(APMデータ)をDatadogへ送信し、可視化・監視
初期の構成と技術選定まとめ Platform構築初期に使用した以下の技術の選定の理由について説明 • コンピューティング • ネットワーク • ログの構成 • アプリケーション定義モデル
• テナント設計 • モニタリング
1.背景と課題 2.初期の構成と技術選定 3.リリース以来の改善 4.これから目指すこと
石川 雲 •2023年11月中途入社 •Service Reliability Group (SRG) •Ameba Platform チーム(2023/11~現在)
•担当領域: EKS Node運用(Karpenter) Security(テナント設計・ネットワーキング・Audit監 視) CI/CD(ArgoCD・FluxCD・Terraform) SRG技術記事
Platformユーザ向けの対話体制 改善活動を支える基盤 週毎のオフィスアワー(Huddle): 15min ~ 30min 半期毎のPlatform討論会: 1h ~ 2h
ユーザの声・判明した問題 • マニフェスト変更プロセスにはさらなる利便性が求められる • ログの運用管理が大変、ログ欠損発生、ログ検索性が悪い • インシデント管理体制の欠如、属人化発生 • サービス数の増加によりCI/CDのパフォーマンスが劣化 •
より厳格的なセキュリティ要件を満たすテナント設計が必要 • などなど...
本日はこれらの中から 特に注力した いくつかの改善取り組みにフォーカスしてご紹介します
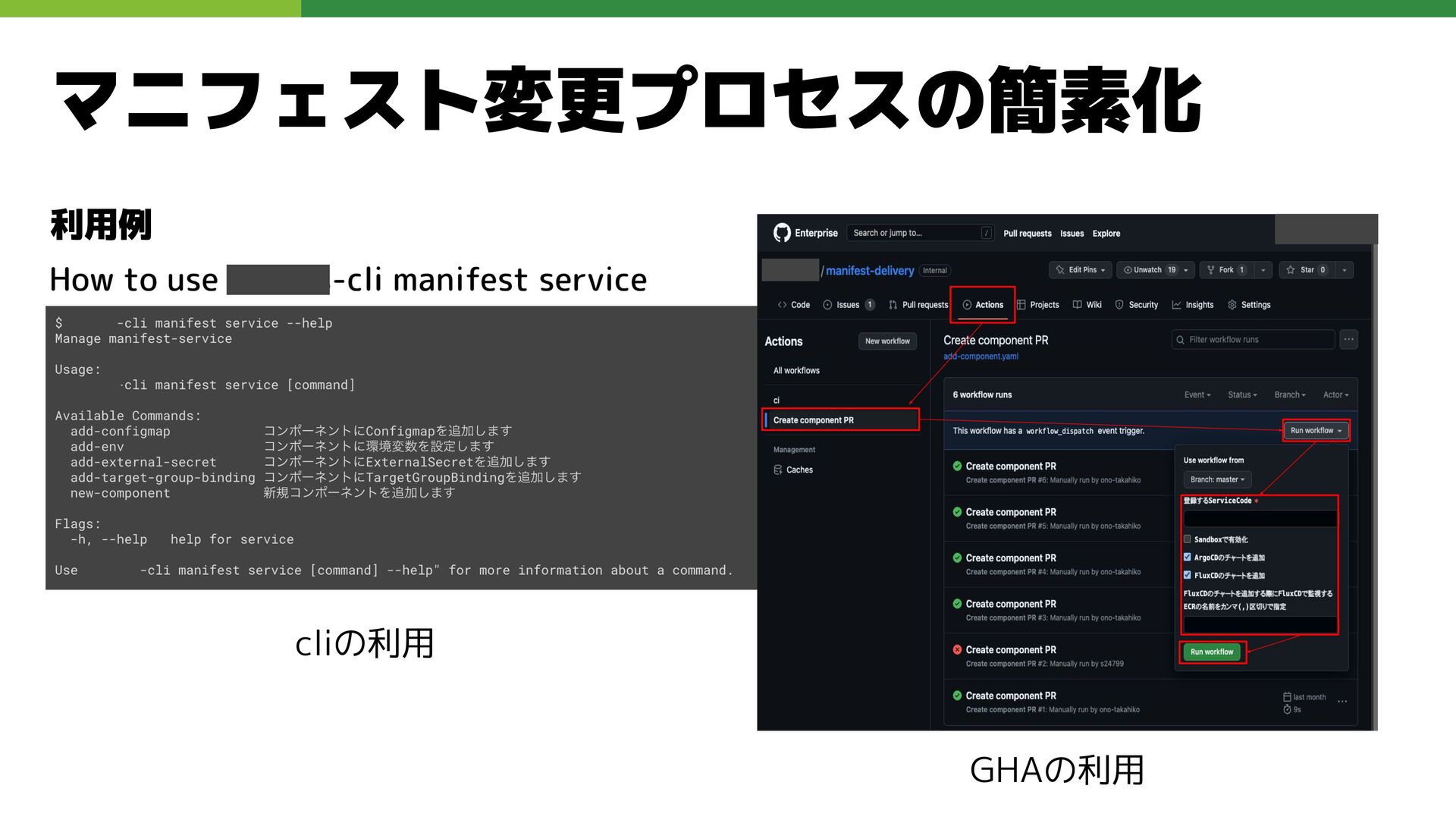
マニフェスト変更プロセスの簡素化 課題 •Applicationの追加・変更時に、複数のリポジトリ/マニフェストを横断的に修正す る必要があり、利用者にとって認知負荷が高い 例: 新規App追加時に9種類のマニフェストを書かないといけない •記述ミスや変更漏れが発生しやすく、デプロイ失敗や環境不整合のリスクがあった 解決 •専用CLIを開発し、必要なマニフェストを自動生成・一括更新できる仕組みに統一 •一部の人手によるマニフェスト変更処理は
Github Actionsに自動化
マニフェスト変更プロセスの簡素化 利用例 cliの利用 GHAの利用
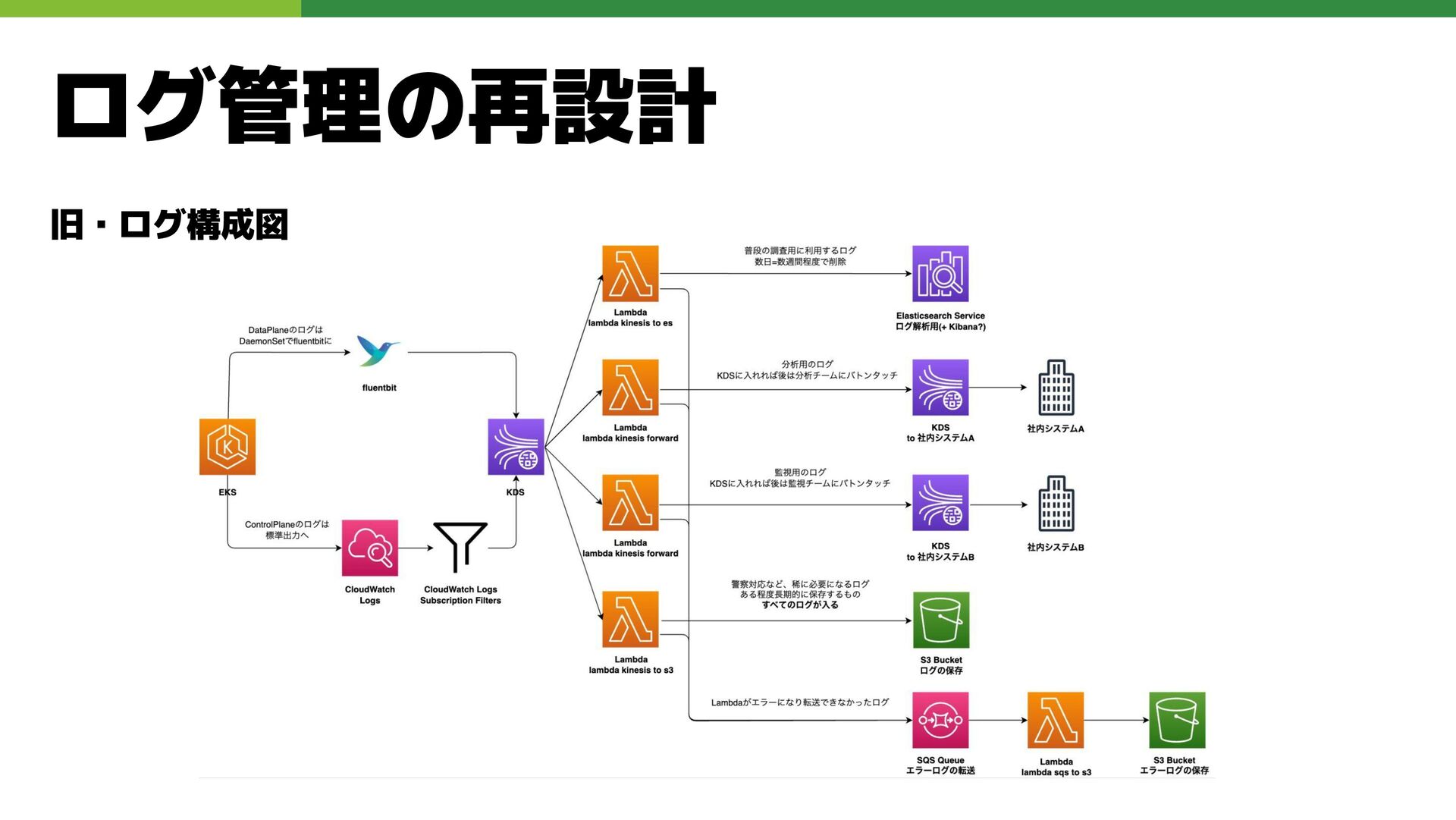
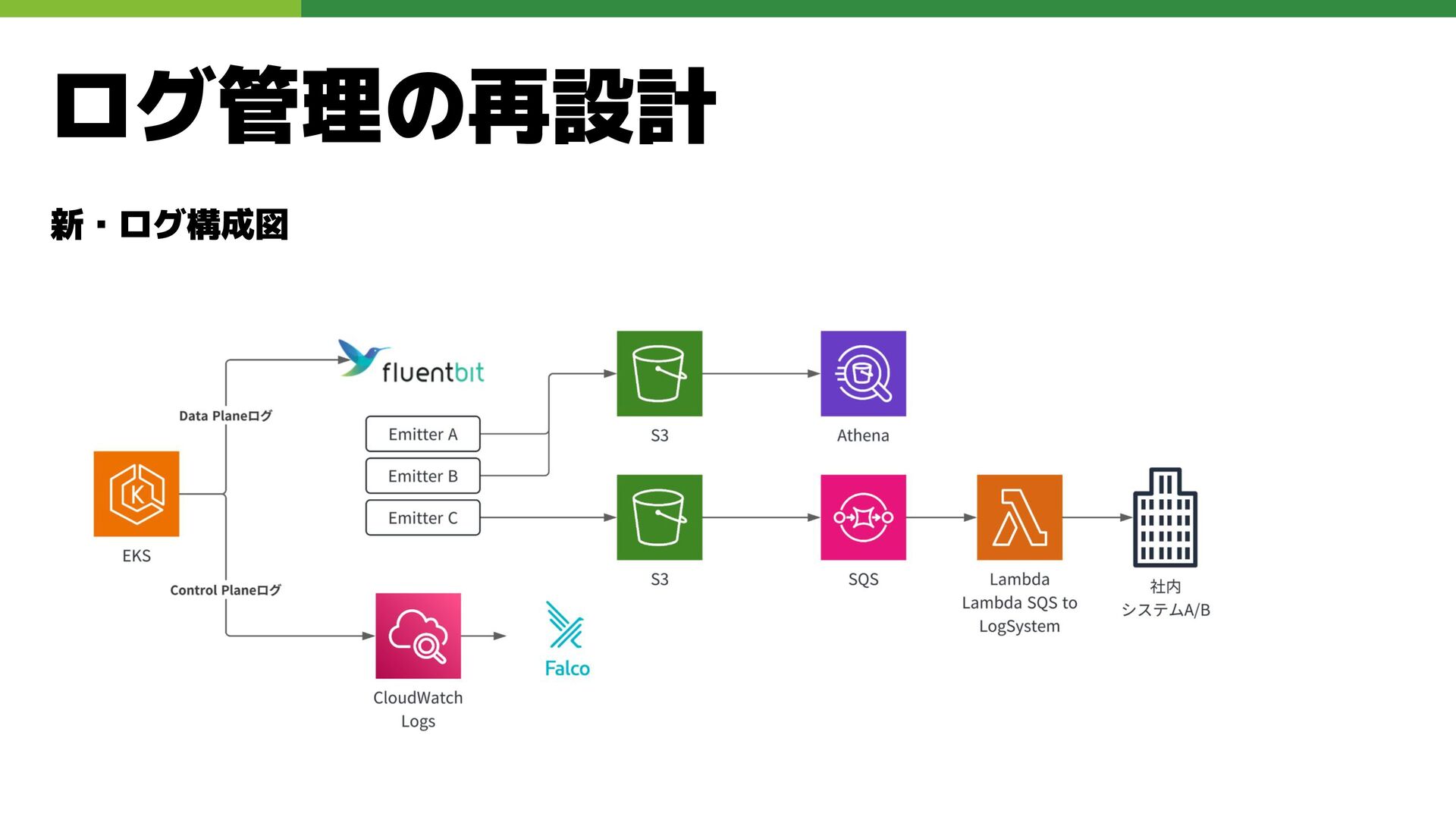
ログ管理の再設計 課題 • ログ転送経路がLambdaとKDSに依存し、ログの可用性と耐障害性に課題 • OpenSearchに全ログを格納できず、ログ検索性が低下 解決 • Fluent Bit
によりログを直接 S3 へ転送 • 必要な転送処理のみ S3 -> SQS -> Lambda で非同期実行する構成へ移行 • Athena を導入し、S3 上のログに対するクエリベースの検索を実現
旧・ログ構成図 ログ管理の再設計
ログ管理の再設計 新・ログ構成図
インシデント対応とモニタリングの改善 背景 • アラート対応が属人化し、再発・対応の遅延・ナレッジが継承されないなどが発生 • アラートとインシデント設定がGUI操作中心、設定の属人化 • インシデントの緊急度や影響と最終的解決を定量的に判断・評価しづらい状況、たまに放置 主な取り組み 1.
インシデント対応の標準化: インシデントコマンダー制度の導入 トリアージ基準の策定 2. ツールによるプロセスの一元化、宣言的管理の実現 Datadog Incident+Slackによるインシデント管理の統一 Datadog Operator によるモニタリング設定の宣言的管理 3. インシデント対応などモニタリングの改善 Incident Metricsダッシュボードによる分析と継続的改善
リリース以来の改善まとめ • Platform改善のための対話体制 • 以下の改善にフォーカスして紹介 マニフェスト変更プロセスの簡素化: より利便性の高いセルフサービス環境の提供 ログ管理の再設計: より安価で管理しやすい設計への移行 インシデント対応とモニタリングの改善:
より効率的なインシデント対応体制などの整備 その他の改善: PDF版/SpeakerDeck版でご参照ください CI/CDの高速化・パフォーマンス最適化 Post Release Workflowの開発 AWS/EKSにおけるマルチテナント対応 Nodeスケジューリング最適化 Podリソース使用最適化
インシデントマネジメント 課題 • アラート対応が放置・属人化し、同様のインシデントが再発 • 対応フローが明確でなく、解決までに時間を要する • 過去のインシデント履歴や対処内容が整理されておらず、ナレッジが継承されにく い 解決
• Datadog Incident を中核に据え、発生〜対応〜振り返りまでのプロセスを一元 管理 • 統一されたインシデント対応フローを整備し、全チームでの共通運用を徹底 • トリアージ基準とインシデントコマンダーの役割を明確化し、対応の迅速化と属人 化の防止を実現
モニタリングの改善 課題 • アラート条件や通知設定がGUI操作中心、設定の属人化 • チーム構成が変わるたびに過去の運用知見が失われる • インシデントに対し、定量的評価ができず、緊急性の高い恒久対策が後回しにされ る傾向 解決
• Datadog Operator導入、モニタリング設定の宣言的管理を実現 • Embedded SREを各チームに配置し、プラクティス支援 • Incident Metrics ダッシュボードの整備、改善活動を追える状態に
CI/CDの進化 イメージタグ更新自動化 FluxCD Image Automation (FluxCD+ArgoCD併用) Terraform CI高速化 Git差分のみTerraform Apply
実行時間平均70%削減 CDパフォーマンス最適化 ArgoCD/FluxCD シャーディング 同期間隔やキャッシュ設定など、各種パラメータ調整 Post Release Workflow KubeVela Application Workflow導入 ArgoCD同期後、任意のリソースに任意のオペレーションが実行可能に
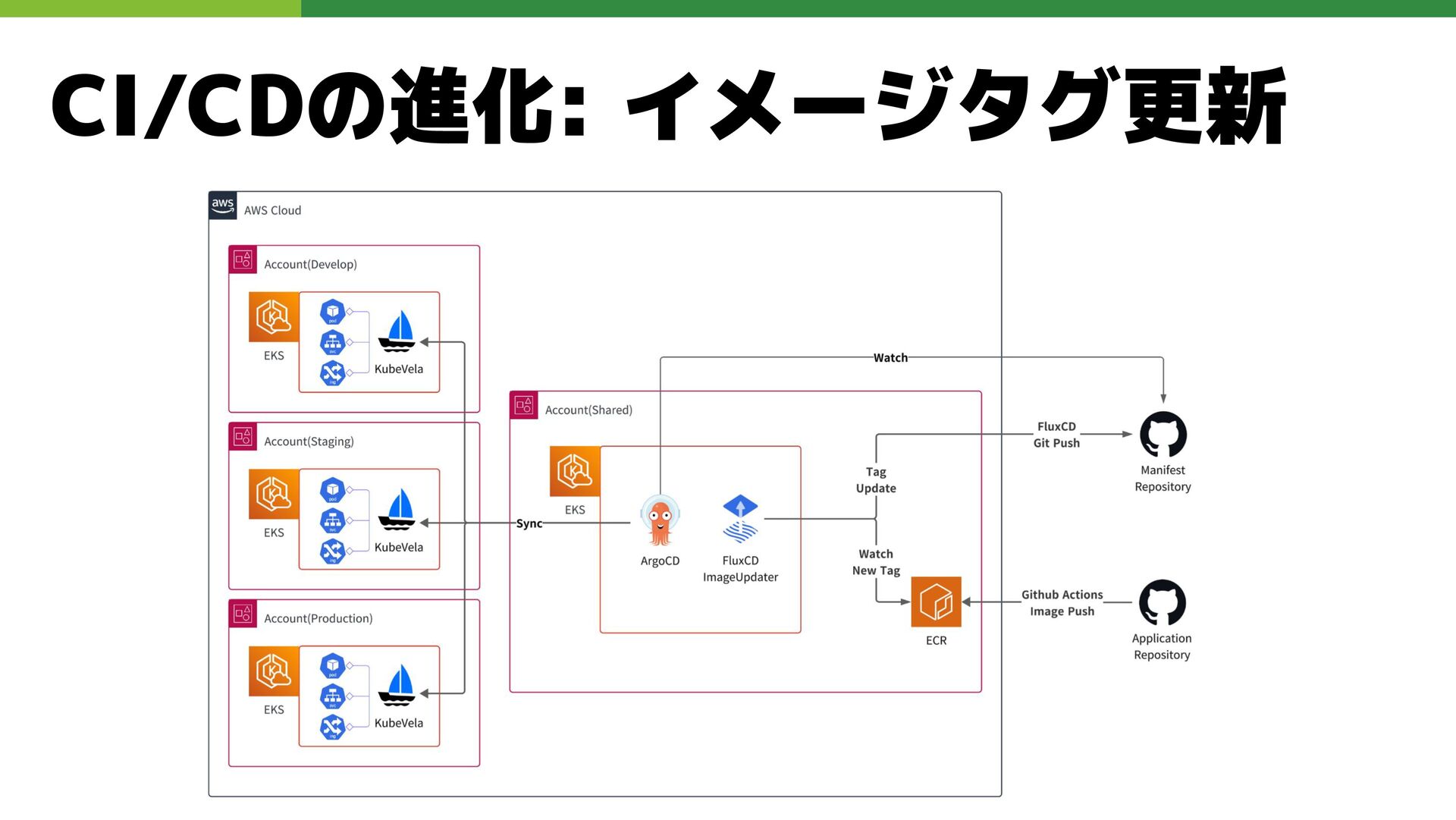
CI/CDの進化: イメージタグ更新 課題 • イメージのタグ更新は手動で行っており、更新漏れや人為的ミスのリスクが高い • 既存の ArgoCD Image Updaterでは一部要件を満たせず、利用できない
解決 • FluxCD の ImageUpdateAutomation機能を活用し、イメージのタグ更新を完 全自動化 (FluxCDとArgoCD併用)
CI/CDの進化: イメージタグ更新
CI/CDの進化: Terraform高速化 課題 • リソース数の増加により、Terraform 実行時間が 15〜30 分以上に肥大化 • 全体Apply運用のため、変更差分が見えづらく、意図しない影響のリスクがあっ
た 解決 • Git差分があったModuleのみを対象にApplyを実行する方式に切り替え • 全体Applyは定期実行+確認フェーズを設けて、安全性と効率性を両立 • 実行時間を平均70%削減した
CI/CDの進化: CD最適化 課題 • 監視対象リソースの増加により、ArgoCD の同期処理が遅延 • FluxCD の安定性が低下し、イメージ自動更新が断続的に停止 解決
• ArgoCD・FluxCD をシャーディング構成に分割し、処理の並列化と負荷分散を実 現 • 同期間隔やキャッシュ設定など、各種パラメータを最適化し、リソース消費を削減 • 結果として、同期・更新の安定性が向上し、安定した運用が可能に
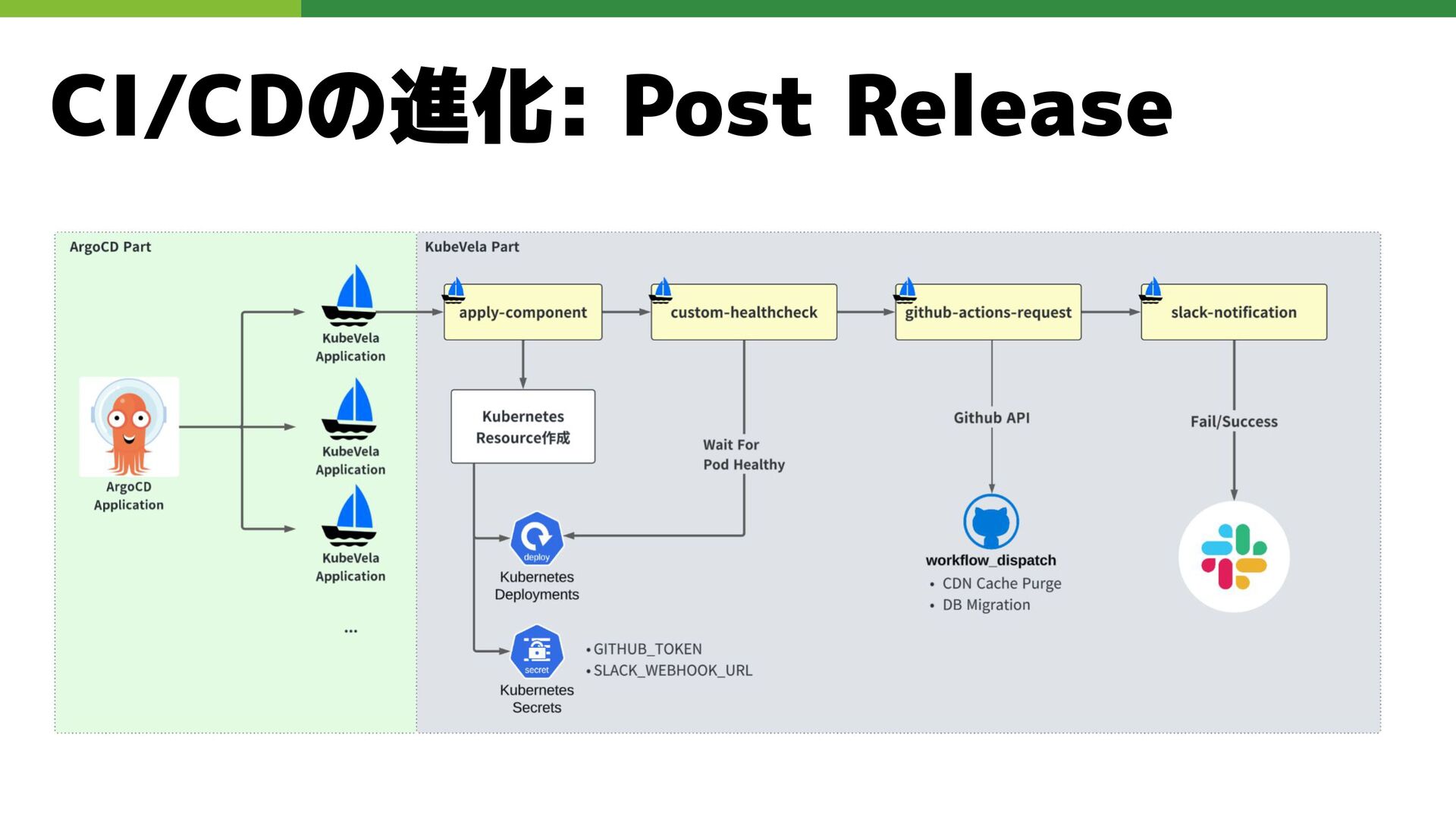
CI/CDの進化: Post Release 課題 • Jenkins では対応できていたが、EKS + ArgoCD 移行後に制約が増加
• ArgoCDの同期後に何かを実行したい処理が実現しづらい • ArgoCD の Resource Hook はリソース単位での制御ができず、細かいタイミン グ制御が不可能 解決 • KubeVela Application Workflowの導入により、Application単位でPost Release処理を定義可能に • GitHub Actions 実行・外部リソース確認なども可能 • PostReleaseの処理も同一Manifestで管理可能、運用の一貫性がある
CI/CDの進化: Post Release
KubeVela 継続利用と今後の方針 課題 • 主要開発元(Alibaba Cloud)が2023年から開発中止、継続性に不安 • 複数環境に対応する Cuelang テンプレートが難読化し、保守負担増加
• 社内で十分にメンテナンスできる体制がない 検討 •KubeVelaを代替可能なプロダクトは存在せず、引き続き利用を継続(2025/4時 点) •将来的な選択肢として、KubeVela 本体へのコントリビュートを検討中
その他の改善 マルチテナント対応: 通信制御・権限分離を実現 • 通信制御:Security Groups for Pod、NetworkPolicy導入 • 権限分離:ResourceTagベースのIAM
ABAC、Kubernetes RBACの見直し Node最適化: Karpenter導入 • Podの要求に応じて、適切なインスタンスタイプを動的に割り当て • 使用率の低いNodeを自動削除し、コストを大幅削減 Pod 最適化: Cloudnatix導入 • Prod以外へVPA AutoPilot機能導入
マルチテナント化への移行 課題 • EKS Pod間、PodとAWSリソース間の通信制御と権限分離がない • セキュリティ要件が高い認証・決済系サービスが移設できない 解決 1. 通信制御
• PodとAWSリソース間: Security Groups for Pod • Pod間: Network Policy 2. 権限分離 • AWS: IAM ResourceTag ABAC導入 • EKS: Kubernetes RBAC見直し
Node最適化ツールの導入 問題 • Cluster Autoscalerでは、インスタンスタイプの最適化ができず、過剰なリ ソースとコストが発生 • Nodeの起動に時間がかかり、スケジューリングの遅延が発生することも 解決 •
Karpenterに移行し、Podのリソース要求に応じて最適なNodeを起動 • インスタンスタイプを動的に選定し、コスト効率の良い構成を自動で実現 • 使用率の低いノードは自動で削除、クラスタ全体のコストを削減
1.背景と課題 2.初期の構成と技術選定 3.リリース以来の改善 4.これから目指すこと
完全なIDPへ IDP(Internal Developer Platform ): 開発者が機能開発に集中できるよう、共通化・自動化された基盤や仕組みを提供するもの 現時点で実現できていること • 標準化されたテンプレートとCI/CDの提供 •
迷わないオンボーディング体験の整備 • Platform / 開発チーム間の明確な責任分離 これから目指していくこと • トイルの解消による開発者・運用者のペインを減らすこと • より柔軟で直感的な利用者セルフサービス体験を強化すること • プラットフォーム全体の状態と価値を、定量的に可視化・改善すること
SLI/SLOの導入 「Platform 」は見えないプロダクト、価値を定量的に示すことが難しい • どのような指標が意味があるのか、利用者視点での SLI 設計を検討している段階 • SLIの例 セルフサービス機能の利用率
デプロイ成功率 デプロイ所要時間 • 利用者視点の SLO を設定し、期待水準を明確化 • 定量的なデータに基づいた改善サイクルを回していける理想
まとめ
まとめ • AmebaのPlatform構築のきっかけや初期の技術選定について • Platform運用における問題と改善点について • これから目指しているPlatformの形について
関連記事 ca-srg.dev
採用情報 26卒 本選考 中途採用(SRG)
ありがとうございました
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}