Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Agentic Workflow自動生成に向けた取り組み
Search
Keita Yanome
November 11, 2025
11k
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Agentic Workflow自動生成に向けた取り組み
Keita Yanome
November 11, 2025
Featured
See All Featured
Become a Pro
speakerdeck
PRO
31
6k
Test your architecture with Archunit
thirion
1
2.3k
Impact Scores and Hybrid Strategies: The future of link building
tamaranovitovic
0
340
The Hidden Cost of Media on the Web [PixelPalooza 2025]
tammyeverts
2
360
Accessibility Awareness
sabderemane
1
160
The Limits of Empathy - UXLibs8
cassininazir
1
510
How to Talk to Developers About Accessibility
jct
2
400
WENDY [Excerpt]
tessaabrams
11
38k
Music & Morning Musume
bryan
47
7.3k
What's in a price? How to price your products and services
michaelherold
247
13k
B2B Lead Gen: Tactics, Traps & Triumph
marketingsoph
0
170
実際に使うSQLの書き方 徹底解説 / pgcon21j-tutorial
soudai
PRO
201
75k
Transcript
© LayerX Inc. Agentic Workflow の⾃動⽣成 に向けた取り組み 2025/11/11 LayerX Ai
Workforce事業部 リサーチエンジニア ⽮野⽬
2 Confidential © 2025 LayerX Inc. • 名前 ◦ 矢野目
佳太 • ポジション ◦ LayerX Ai Workforce事業部 リサーチエンジニア (業務委 託) • これまで ◦ 大学院在学中に、微分可能レンダラーを活用した単眼画像 からの3次元形状復元、およびマルチモーダル確率的生成 モデルを用いたロボティクス把持技術の研究をする ◦ AI SaaS企業2社にて、機械学習エンジニア兼プロダクトマ ネージャーとして、ベイズ最適化のアルゴリズム開発やプロ ダクト開発に従事 • 現在 ◦ プロンプト最適化アルゴリズム開発・ライブラリ開発 ◦ ワークフロー最適化アルゴリズム開発 ⾃⼰紹介
本日のトピック
4 Confidential © 2025 LayerX Inc. 本⽇のトピック • ワークフロー⾃動最適化に取り組んだ経験を、⼿法⽴案から⼿法開発の流れを通し て共有します
5 Confidential © 2025 LayerX Inc. アジェンダ 1. 背景 2.
先⾏研究の調査 3. 解決アプローチの設計 4. ⼿法開発 5. 得られた知⾒と今後の改善アイデア
背景
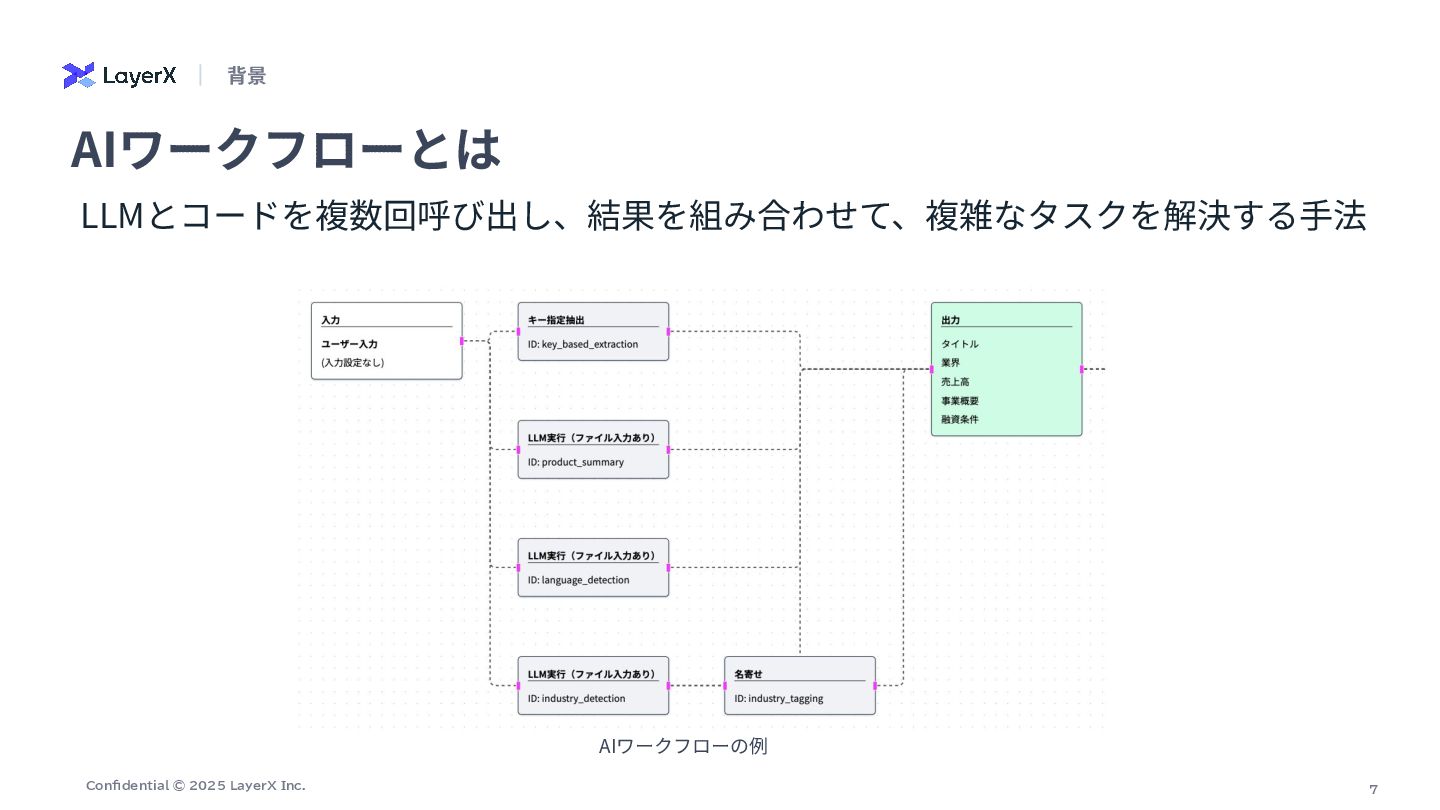
7 Confidential © 2025 LayerX Inc. LLMとコードを複数回呼び出し、結果を組み合わせて、複雑なタスクを解決する⼿法 AIワークフローとは AIワークフローの例 背景
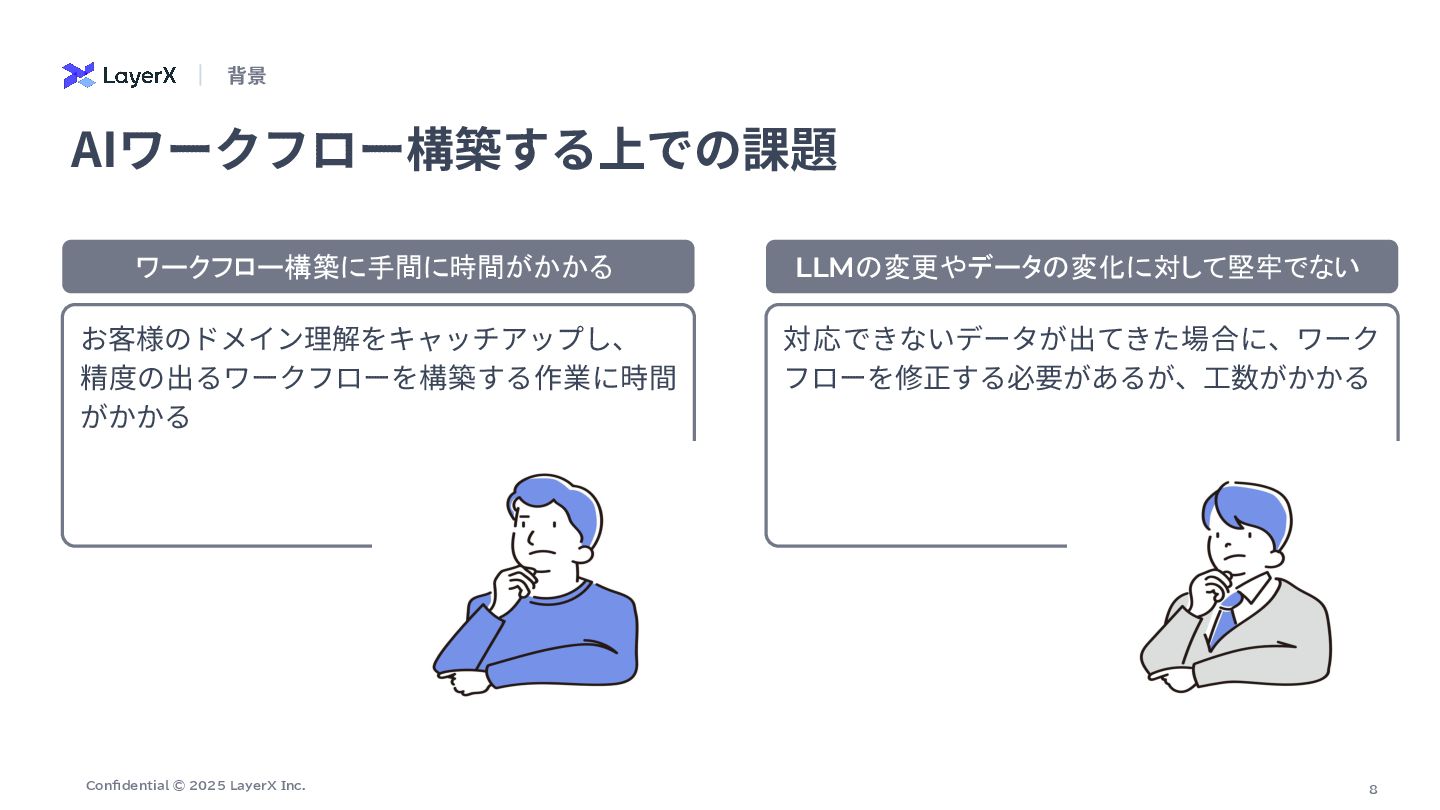
8 Confidential © 2025 LayerX Inc. AIワークフロー構築する上での課題 お客様のドメイン理解をキャッチアップし、 精度の出るワークフローを構築する作業に時間 がかかる
対応できないデータが出てきた場合に、ワーク フローを修正する必要があるが、⼯数がかかる ワークフロー構築に手間に時間がかかる LLMの変更やデータの変化に対して堅牢でない 背景
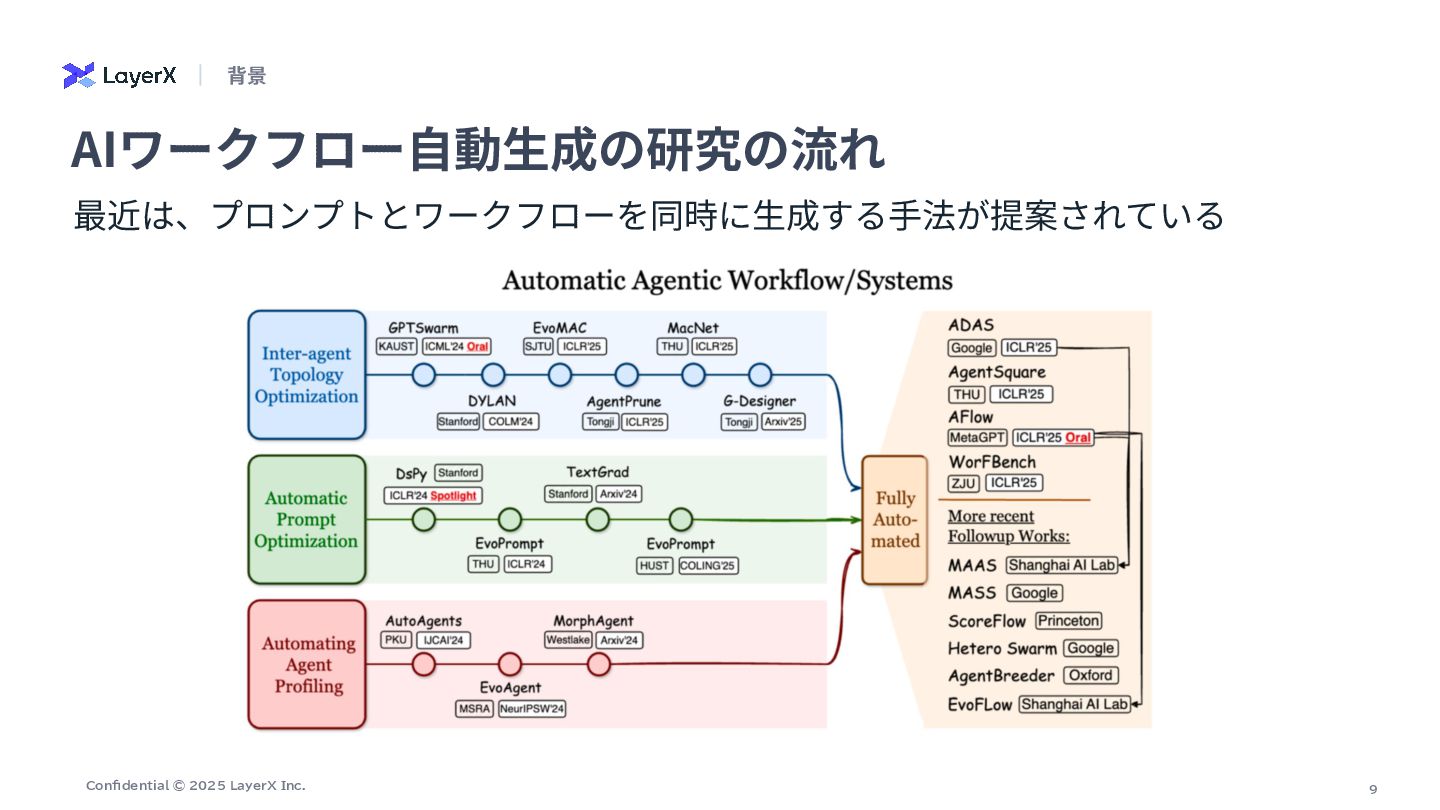
9 Confidential © 2025 LayerX Inc. 最近は、プロンプトとワークフローを同時に⽣成する⼿法が提案されている AIワークフロー⾃動⽣成の研究の流れ 背景
1. 先行研究の調査
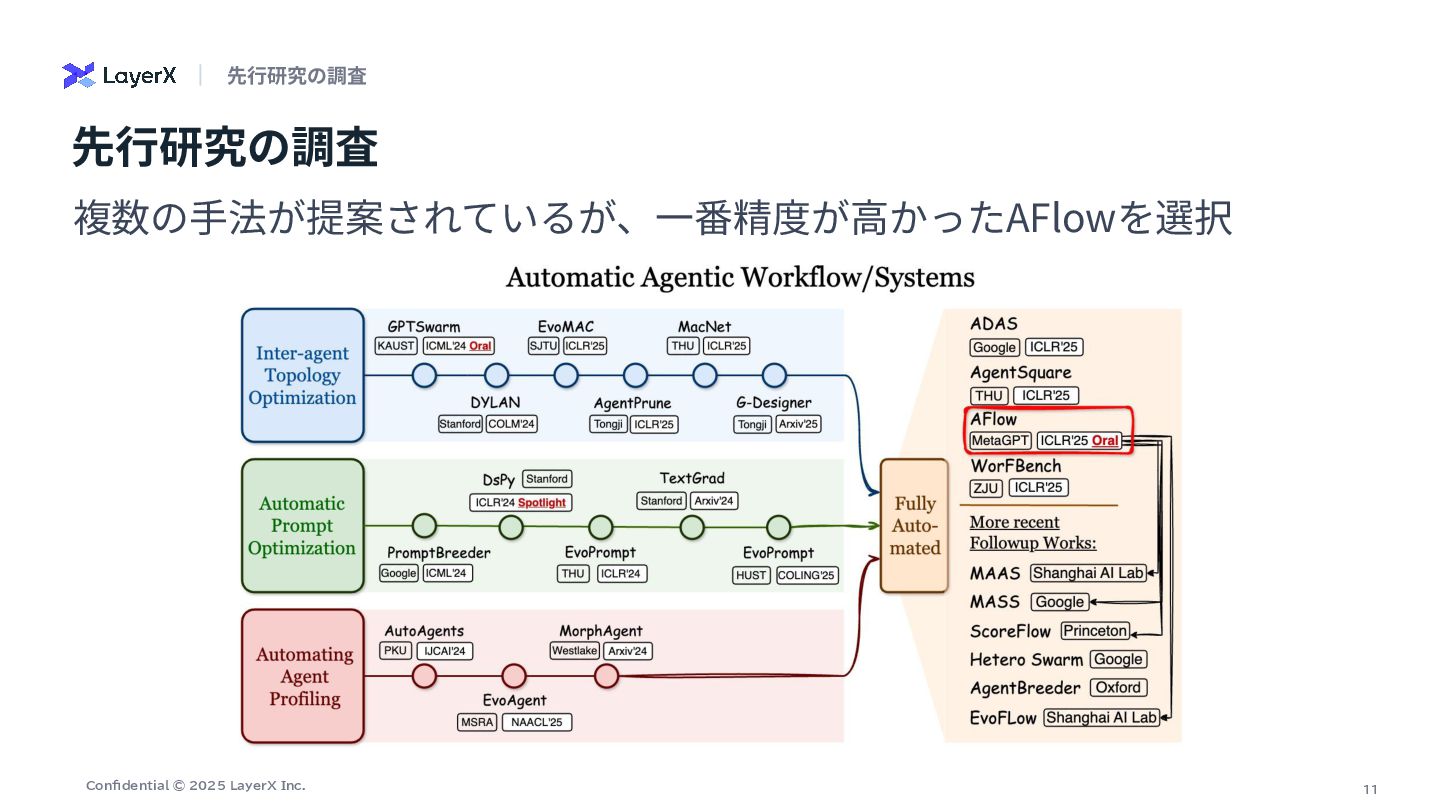
11 Confidential © 2025 LayerX Inc. 先⾏研究の調査 複数の⼿法が提案されているが、⼀番精度が⾼かったAFlowを選択 先⾏研究の調査
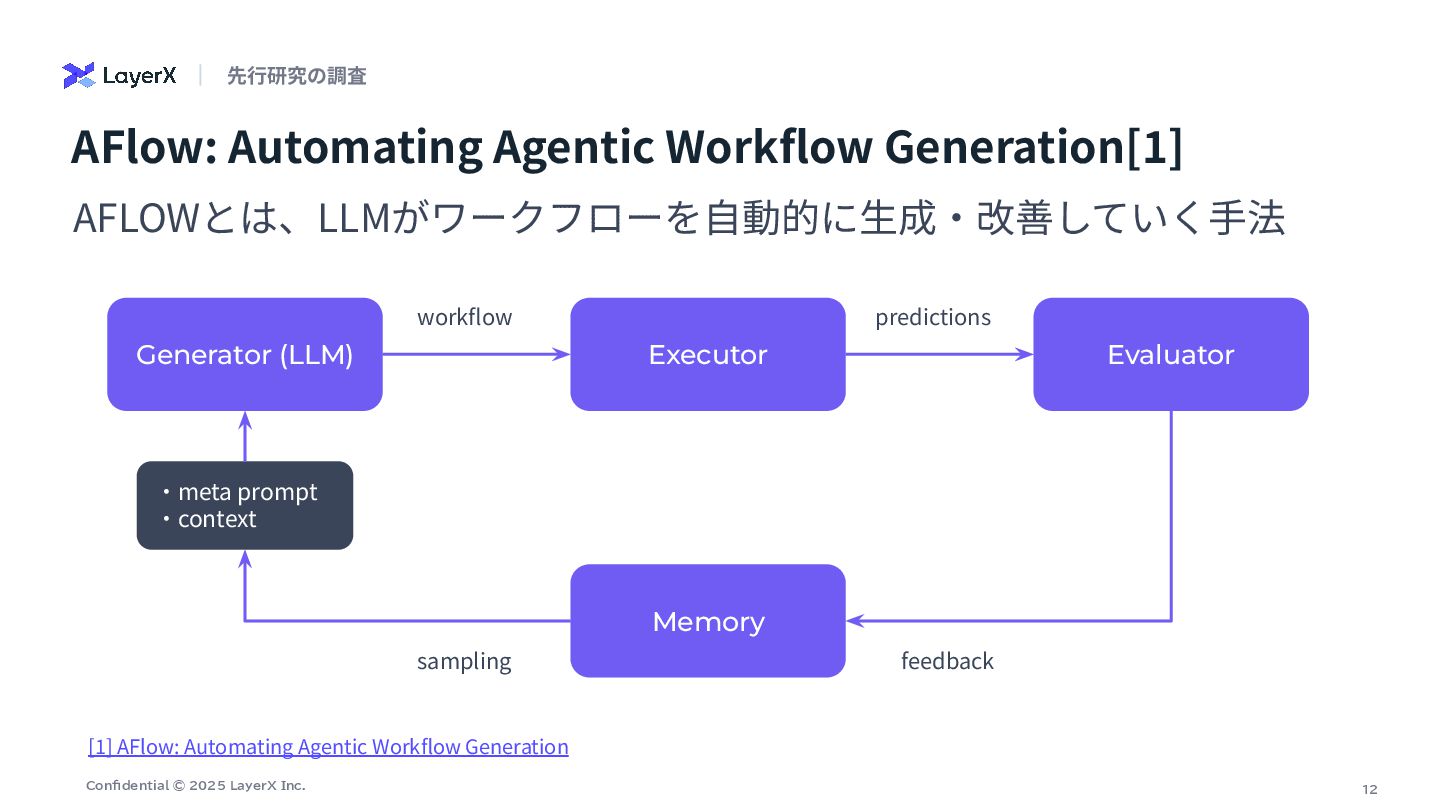
12 Confidential © 2025 LayerX Inc. AFlow: Automating Agentic Workflow
Generation[1] AFLOWとは、LLMがワークフローを⾃動的に⽣成‧改善していく⼿法 Generator (LLM) Executor Evaluator workflow predictions Memory feedback sampling ‧meta prompt ‧context [1] AFlow: Automating Agentic Workflow Generation 先⾏研究の調査
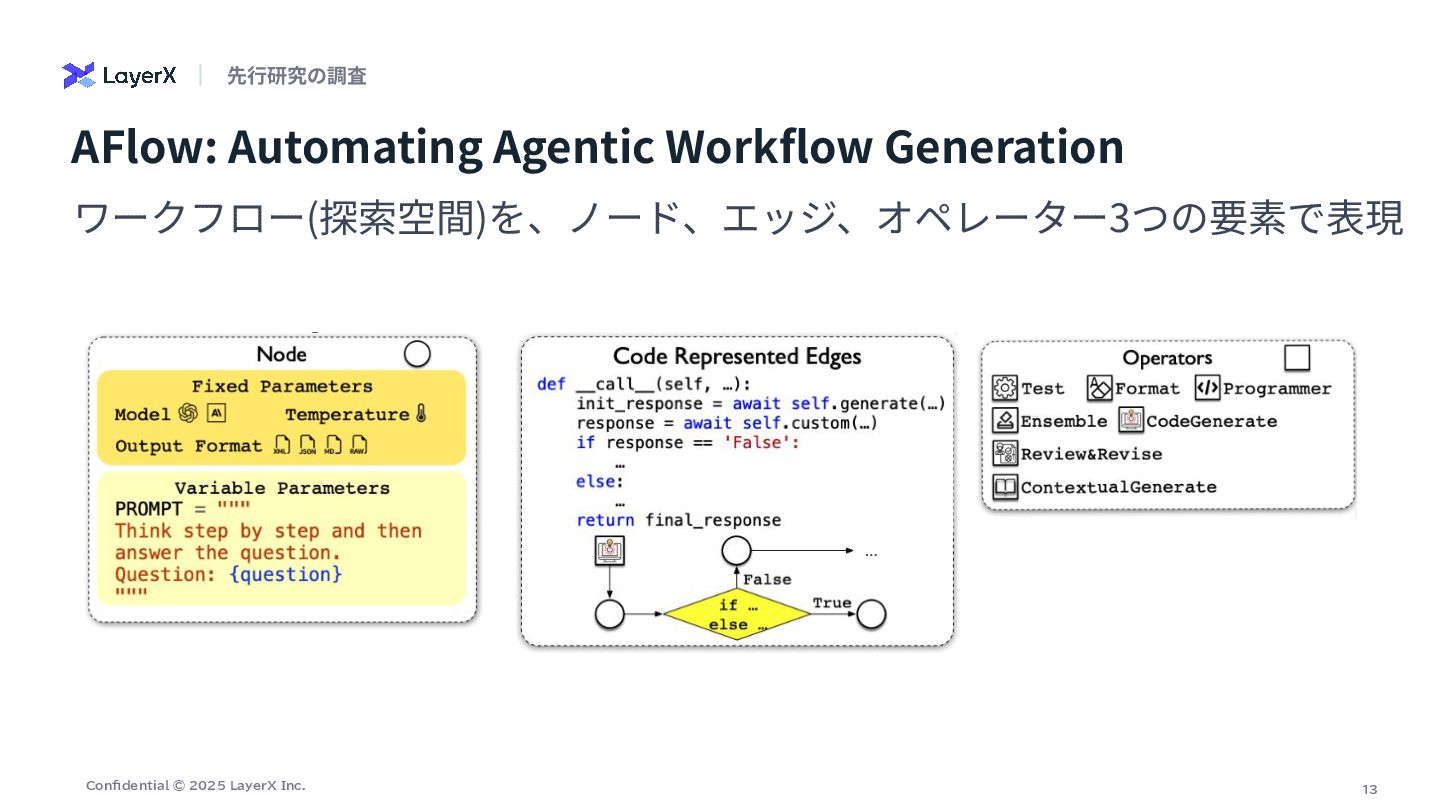
13 Confidential © 2025 LayerX Inc. AFlow: Automating Agentic Workflow
Generation ワークフロー(探索空間)を、ノード、エッジ、オペレーター3つの要素で表現 先⾏研究の調査
14 Confidential © 2025 LayerX Inc. AFlow: Automating Agentic Workflow
Generation 評価関数Gが最⼤化するWを求める問題として定式化 先⾏研究の調査 Aでワークフローの選択 (注1) 評価関数Gが最大となるWを求める (注1) A : AFLOWの探索アルゴリズムのこと
15 Confidential © 2025 LayerX Inc. AFlow: Automating Agentic Workflow
Generation 過去の改善経験をツリー構造で保存し、 確率的サンプリングを⽤いて、次のワー クフローをサンプリングし、改善を⾏う 先⾏研究の調査
16 Confidential © 2025 LayerX Inc. AFlow: Automating Agentic Workflow
Generation AFlowのアルゴリズムの全体感は以下の通り 先⾏研究の調査
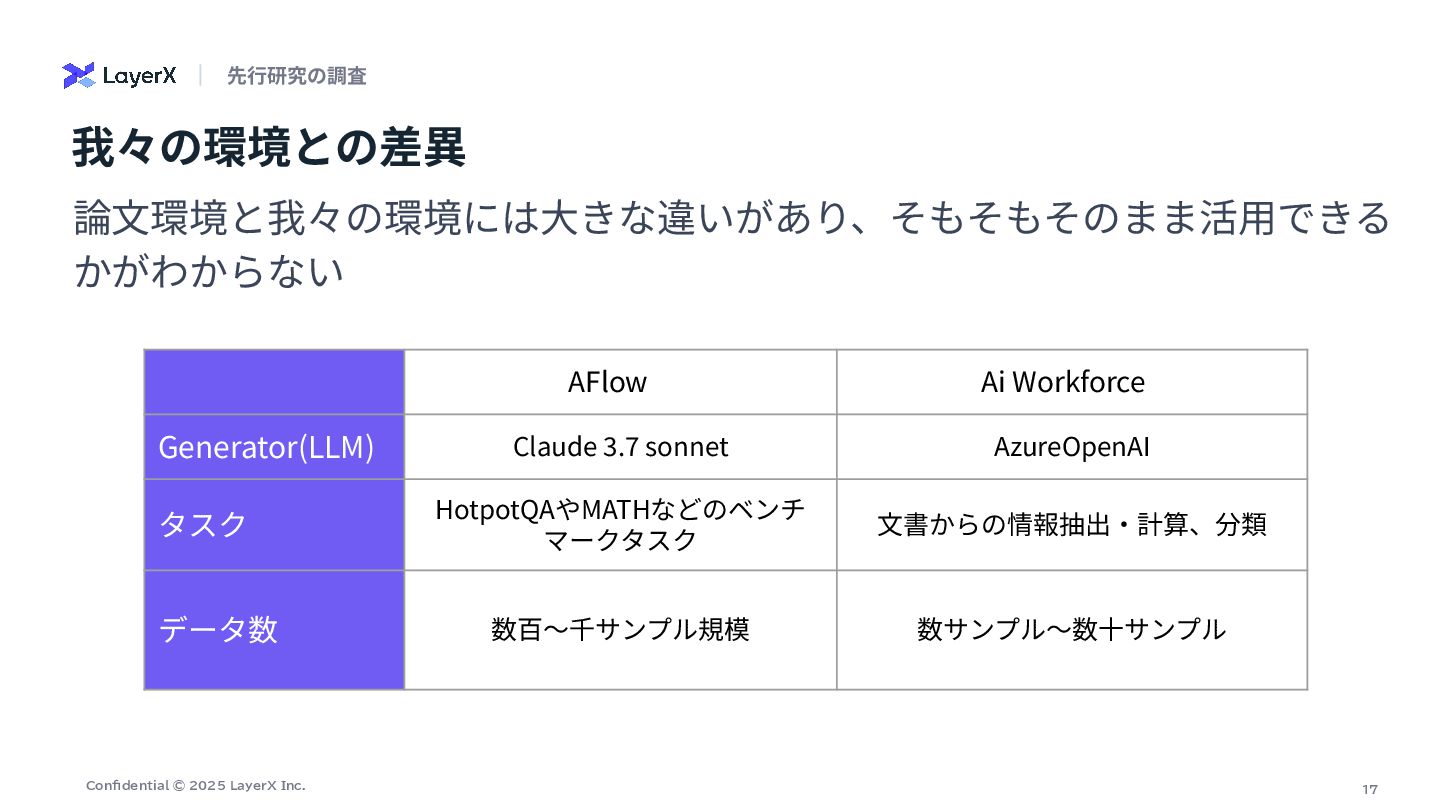
17 Confidential © 2025 LayerX Inc. 我々の環境との差異 論⽂環境と我々の環境には⼤きな違いがあり、そもそもそのまま活⽤できる かがわからない AFlow
Ai Workforce Generator(LLM) Claude 3.7 sonnet AzureOpenAI タスク HotpotQAやMATHなどのベンチ マークタスク ⽂書からの情報抽出‧計算、分類 データ数 数百〜千サンプル規模 数サンプル〜数⼗サンプル 先⾏研究の調査
18 Confidential © 2025 LayerX Inc. GeneratorのモデルをGPT-5に置き換えて検証したところ、 いくつかの問題に直⾯ フィージビリティ検証 先⾏研究の調査
解決アプローチ設計
20 Confidential © 2025 LayerX Inc. 解決アプローチ設計 プロンプト改善のみに終始してしまう 問題① Executorの部分でエラーが多発
問題② 問題点は、以下の2つ
21 Confidential © 2025 LayerX Inc. プロンプト改善のみに終始してしまう 問題① 解決策: 「1度の改善に1つまでの内容を」という記述を削除
(注2) (注1) GPT-5 prompting guide 原因は、GeneartorをGPT-5に変えたことと、メタプロンプトにあった。「1度の改善に1つまで の内容を」という記述があるが、GPT-5はプロンプトに忠実であるため(注1)、ワークフローの⽣ 成をやめてしまっていた。 (注2) ⼀⽅で、⼀度に⼤きな改善をするようになり、どの改善がスコアに貢献したのかを振り返ることができなくなった。 (つまりMCTSが機能しなくなった) これについては後ほど⾔及する 解決アプローチ設計
22 Confidential © 2025 LayerX Inc. Executorの部分でエラーが多発 (import忘れなどの致命的なミスが多発していた) 問題② 解決策:
ノードとエッジを⽣成されるよ うにし、裏側で実⾏可能なワー クフローに変換した 原因は、AFlowがワークフローをPythonコードで表現していたため Pydanticを⽤いたワークフロー表現の例 → これはエンジニアリングの課題として解決 解決アプローチ設計
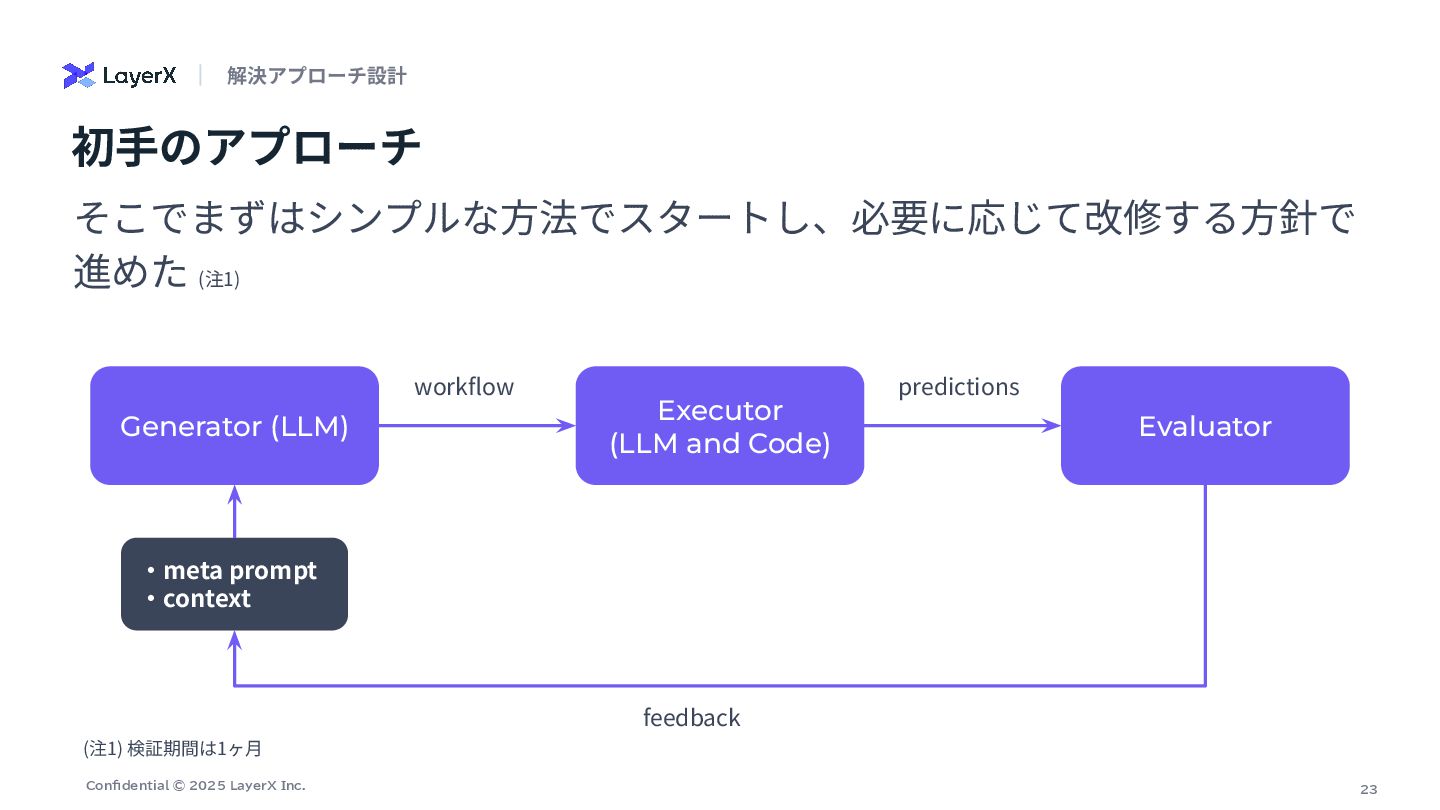
23 Confidential © 2025 LayerX Inc. (注1) 検証期間は1ヶ⽉ そこでまずはシンプルな⽅法でスタートし、必要に応じて改修する⽅針で 進めた
(注1) 初⼿のアプローチ Generator (LLM) Executor (LLM and Code) Evaluator workflow predictions feedback ‧meta prompt ‧context 解決アプローチ設計
手法開発
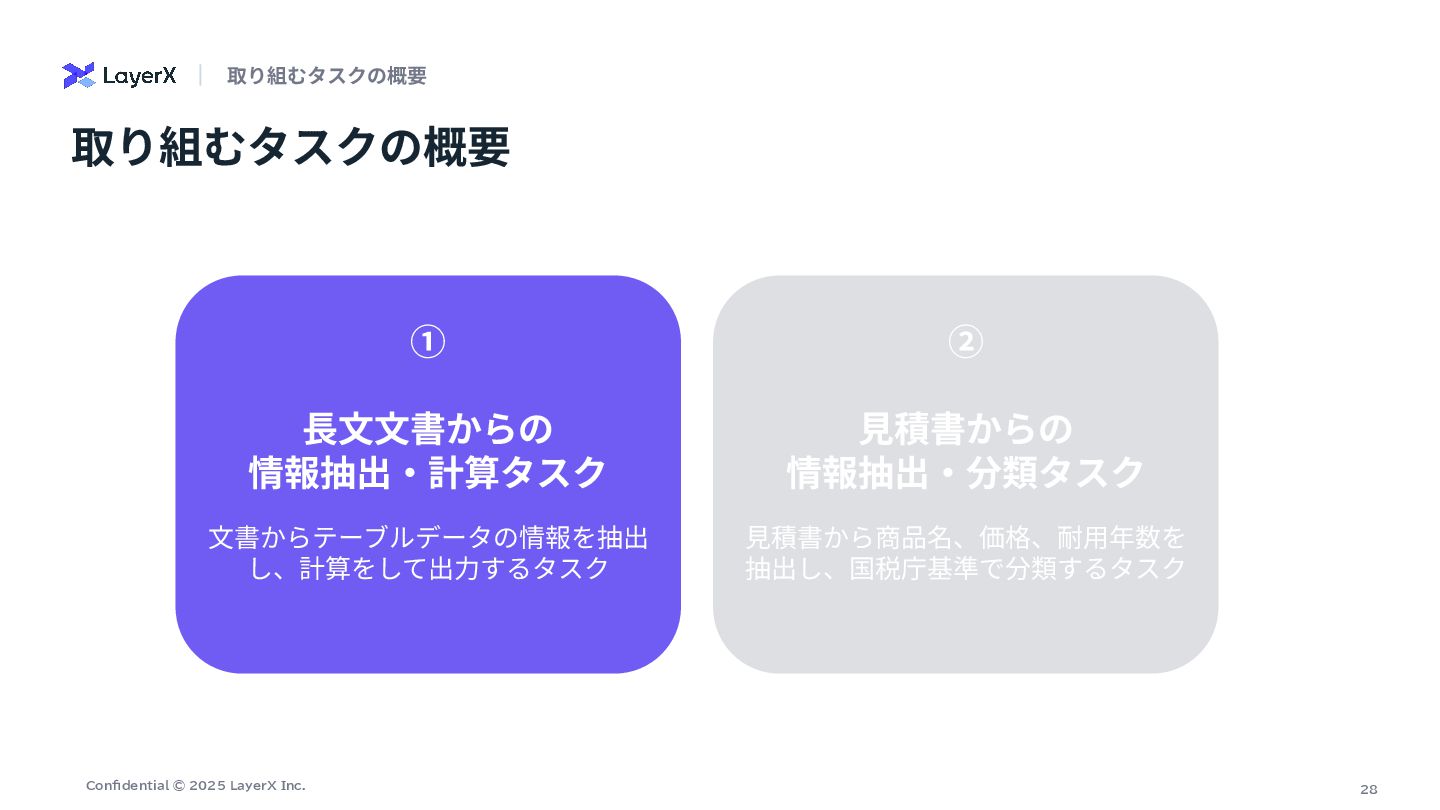
25 Confidential © 2025 LayerX Inc. 取り組むタスクの概要 まずは、2つの代表的なユースケースのタスクで検証する ① ⻑⽂⽂書からの
情報抽出‧計算タスク ⽂書からテーブルデータの情報を抽出 し、計算をして出⼒するタスク ② ⾒積書からの 情報抽出‧分類タスク ⾒積書から商品名、価格、耐⽤年数を 抽出し、国税庁基準で分類するタスク
26 Confidential © 2025 LayerX Inc. ①⻑⽂⽂書からの情報抽出‧計算タスク ②⾒積書からの情報抽出‧分類タスク 取り組むタスクのデータセットについて 2~3サンプル程度
(注1) 80サンプル程度 (注2) (注1) 利⽤したデータは公開できないため、例として令和2年国勢調査を引⽤ (注2) 合成データを作成/利⽤
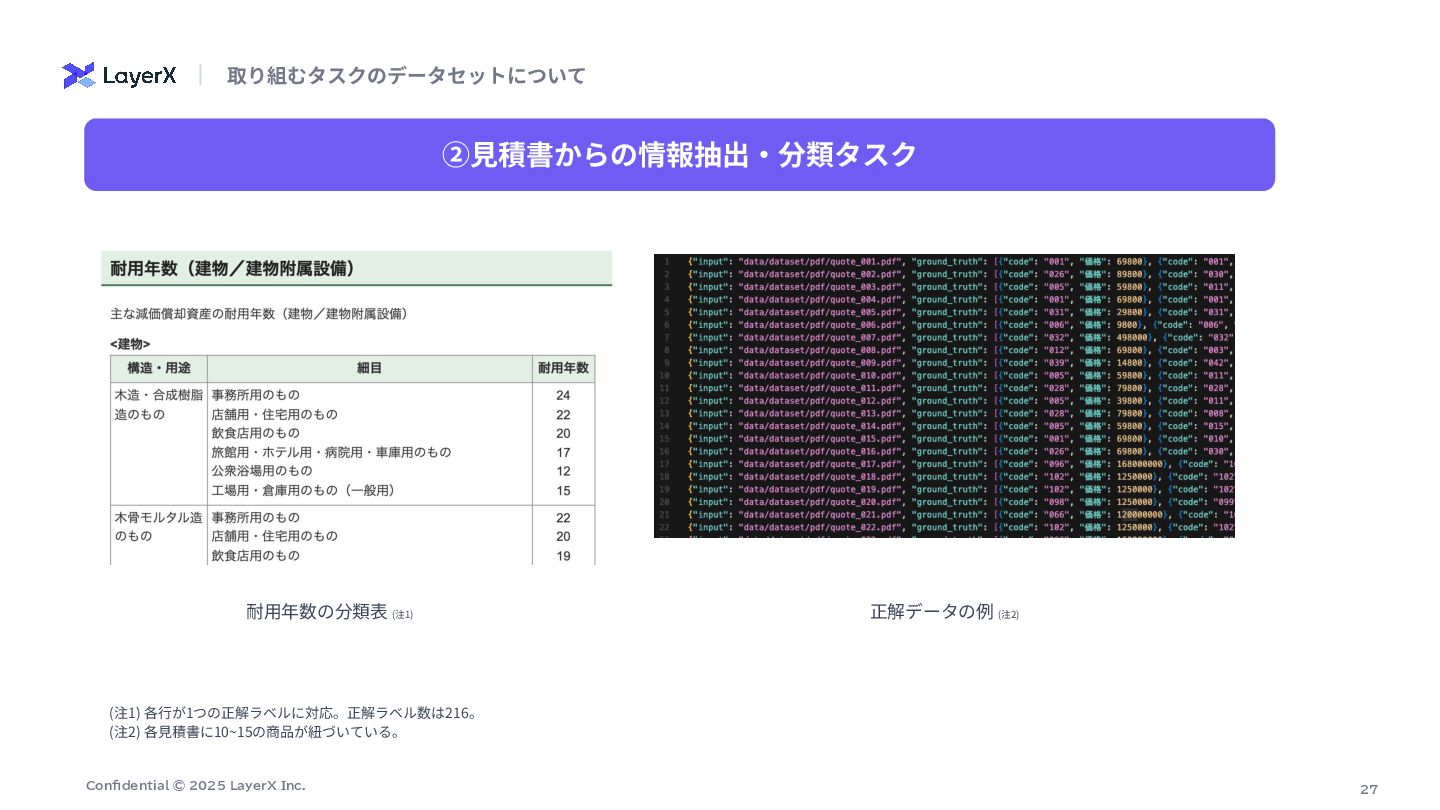
27 Confidential © 2025 LayerX Inc. ②⾒積書からの情報抽出‧分類タスク 取り組むタスクのデータセットについて 耐⽤年数の分類表 (注1)
(注1) 各⾏が1つの正解ラベルに対応。正解ラベル数は216。 (注2) 各⾒積書に10~15の商品が紐づいている。 正解データの例 (注2)
28 Confidential © 2025 LayerX Inc. 取り組むタスクの概要 ① ⻑⽂⽂書からの 情報抽出‧計算タスク
⽂書からテーブルデータの情報を抽出 し、計算をして出⼒するタスク ② ⾒積書からの 情報抽出‧分類タスク ⾒積書から商品名、価格、耐⽤年数を 抽出し、国税庁基準で分類するタスク 取り組むタスクの概要
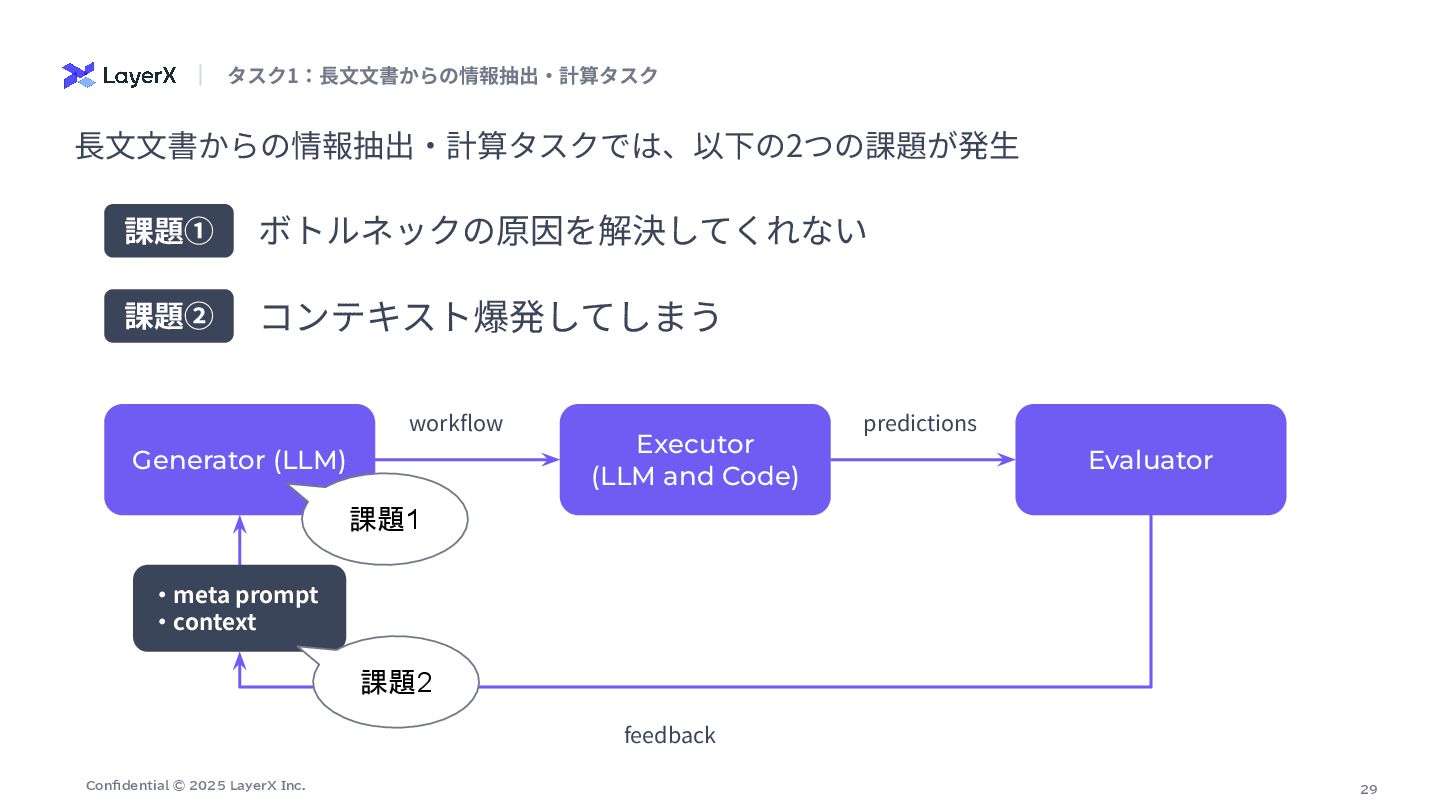
29 Confidential © 2025 LayerX Inc. ⻑⽂⽂書からの情報抽出‧計算タスクでは、以下の2つの課題が発⽣ ボトルネックの原因を解決してくれない 課題① コンテキスト爆発してしまう
課題② タスク1:⻑⽂⽂書からの情報抽出‧計算タスク Generator (LLM) Executor (LLM and Code) Evaluator workflow predictions feedback ‧meta prompt ‧context 課題1 課題2
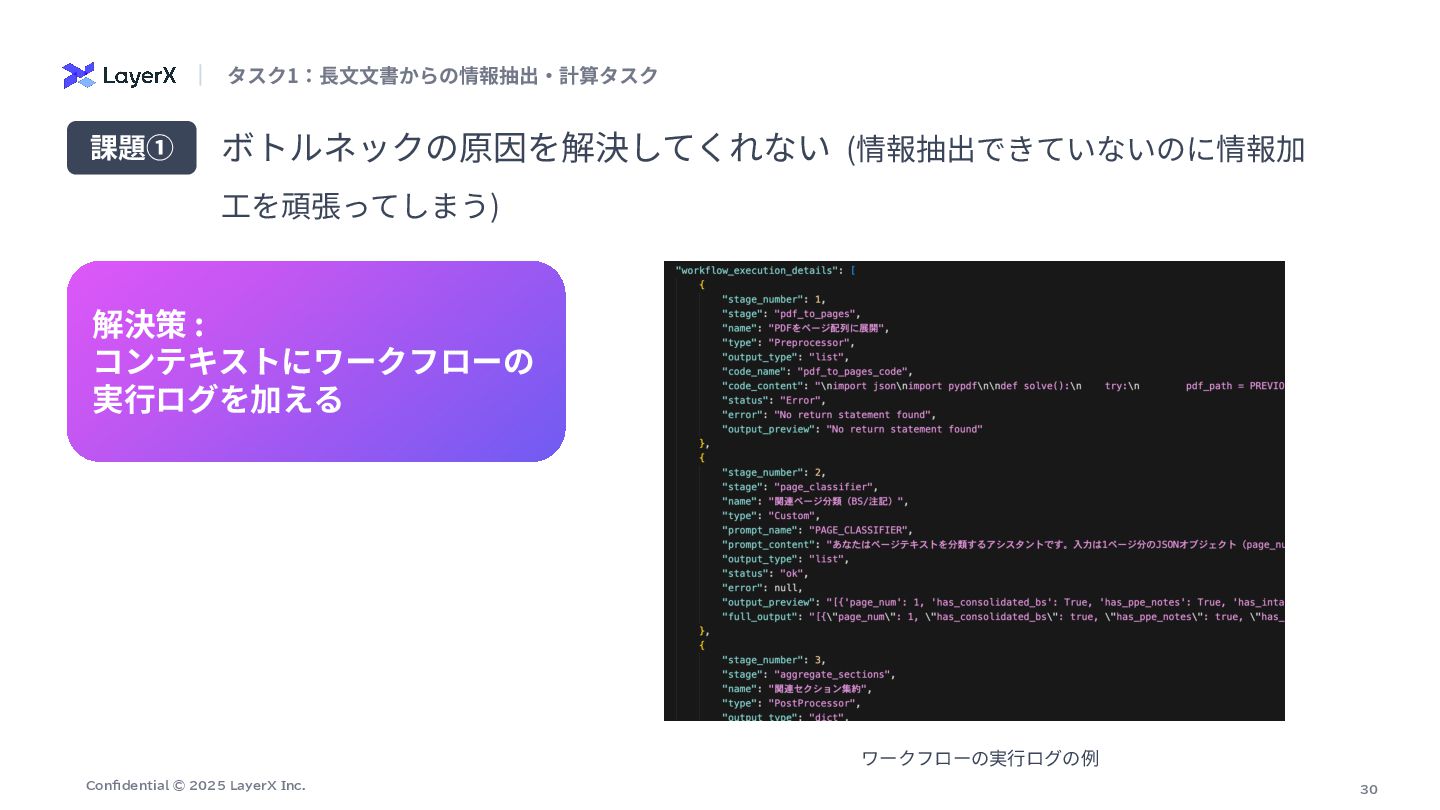
30 Confidential © 2025 LayerX Inc. ボトルネックの原因を解決してくれない (情報抽出できていないのに情報加 ⼯を頑張ってしまう) 課題①
解決策 : コンテキストにワークフローの 実⾏ログを加える タスク1:⻑⽂⽂書からの情報抽出‧計算タスク ワークフローの実⾏ログの例
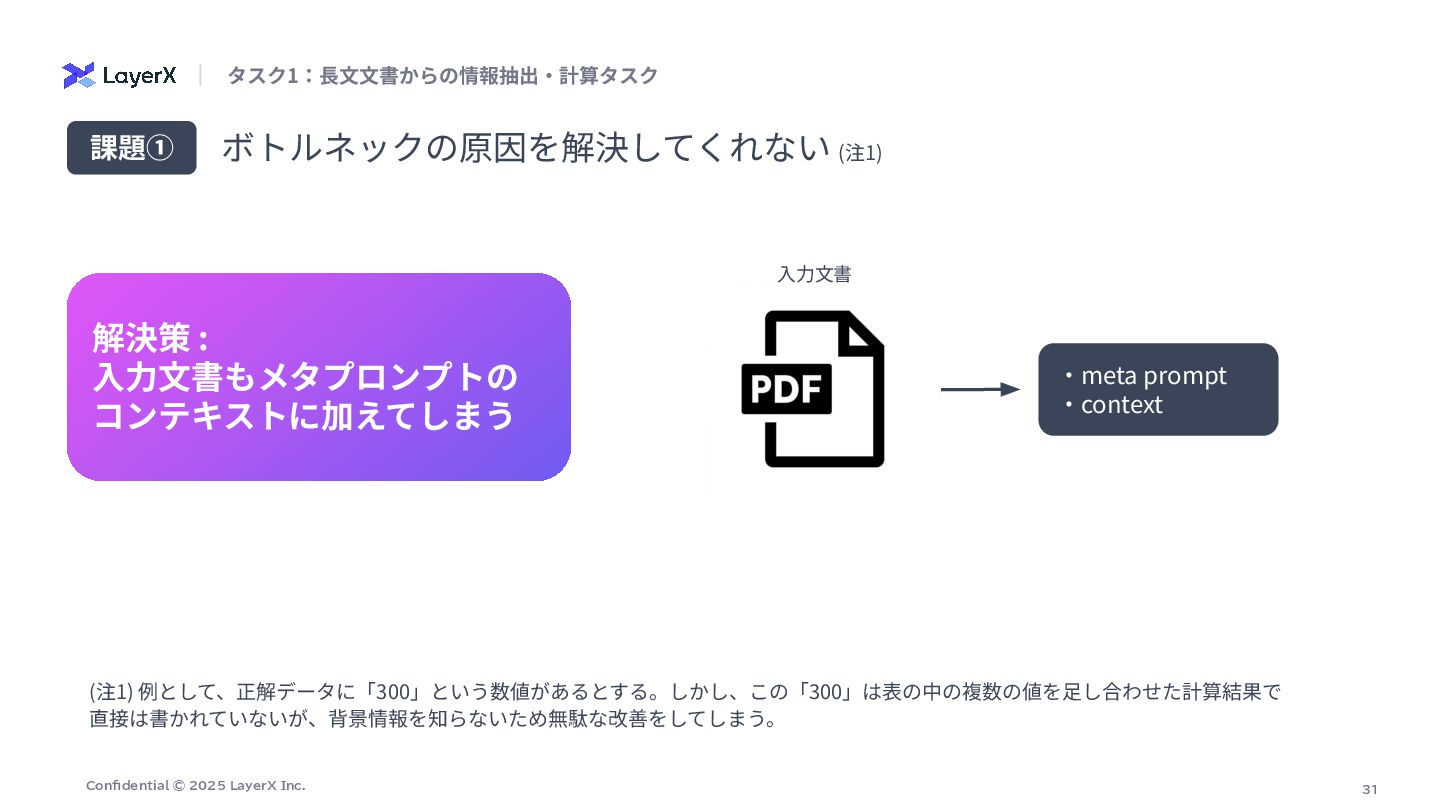
31 Confidential © 2025 LayerX Inc. ボトルネックの原因を解決してくれない (注1) 課題① 解決策
: ⼊⼒⽂書もメタプロンプトの コンテキストに加えてしまう タスク1:⻑⽂⽂書からの情報抽出‧計算タスク ‧meta prompt ‧context ⼊⼒⽂書 (注1) 例として、正解データに「300」という数値があるとする。しかし、この「300」は表の中の複数の値を⾜し合わせた計算結果で 直接は書かれていないが、背景情報を知らないため無駄な改善をしてしまう。
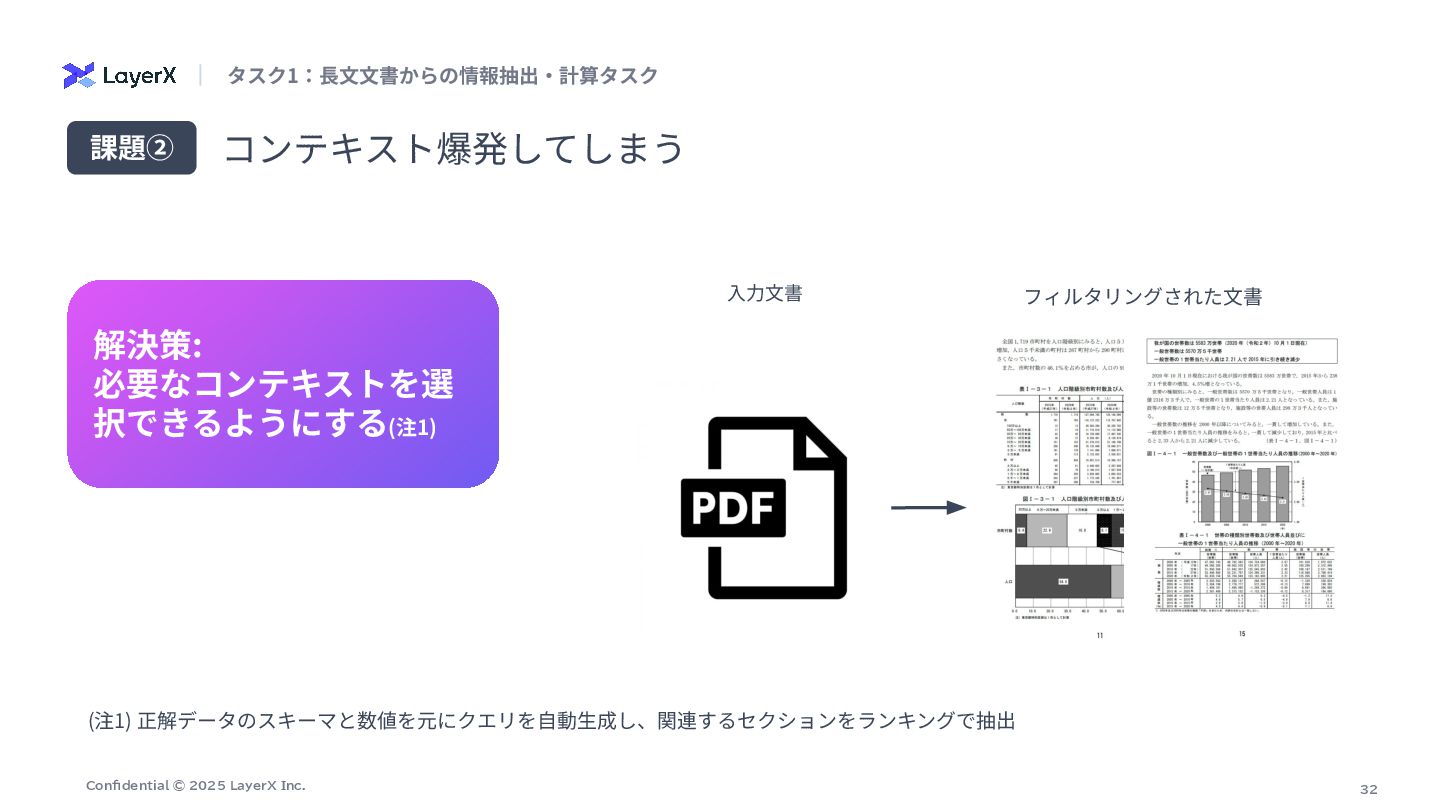
32 Confidential © 2025 LayerX Inc. (注1) 正解データのスキーマと数値を元にクエリを⾃動⽣成し、関連するセクションをランキングで抽出 コンテキスト爆発してしまう 課題②
解決策: 必要なコンテキストを選 択できるようにする(注1) タスク1:⻑⽂⽂書からの情報抽出‧計算タスク ⼊⼒⽂書 フィルタリングされた⽂書
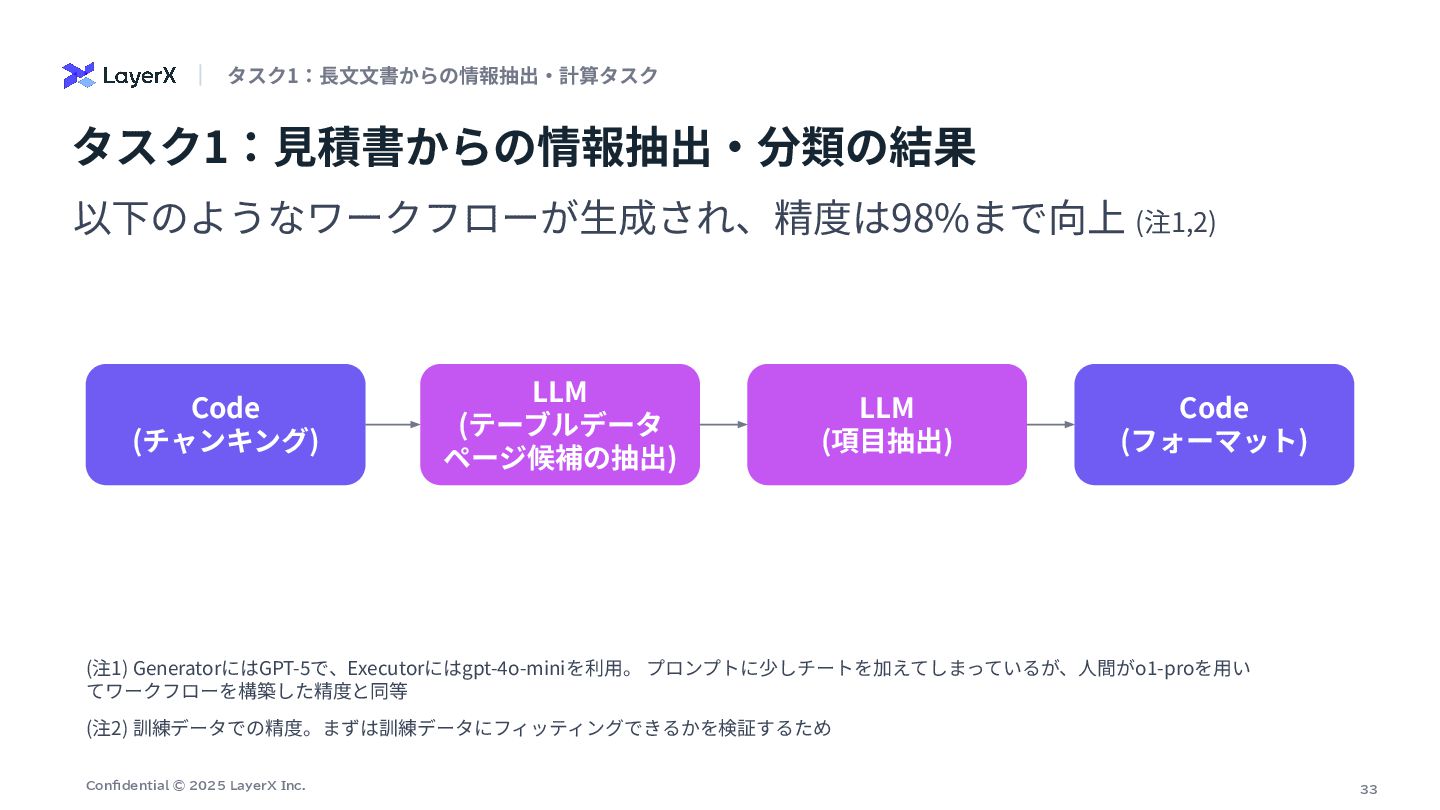
33 Confidential © 2025 LayerX Inc. (注2) 訓練データでの精度。まずは訓練データにフィッティングできるかを検証するため 以下のようなワークフローが⽣成され、精度は98%まで向上 (注1,2)
タスク1:⾒積書からの情報抽出‧分類の結果 タスク1:⻑⽂⽂書からの情報抽出‧計算タスク Code (チャンキング) LLM (テーブルデータ ページ候補の抽出) LLM (項⽬抽出) Code (フォーマット) (注1) GeneratorにはGPT-5で、Executorにはgpt-4o-miniを利⽤。 プロンプトに少しチートを加えてしまっているが、⼈間がo1-proを⽤い てワークフローを構築した精度と同等
34 Confidential © 2025 LayerX Inc. 取り組むタスクの概要 ① ⻑⽂⽂書からの 情報抽出‧計算タスク
テキストが⼊ります。テキストが⼊りま す。テキストが⼊ります。テキストが⼊ ります。 ② ⾒積書からの 情報抽出‧分類タスク ⾒積書から商品名、価格、耐⽤年数を 抽出し、国税庁基準で分類するタスク 取り組むタスクの概要
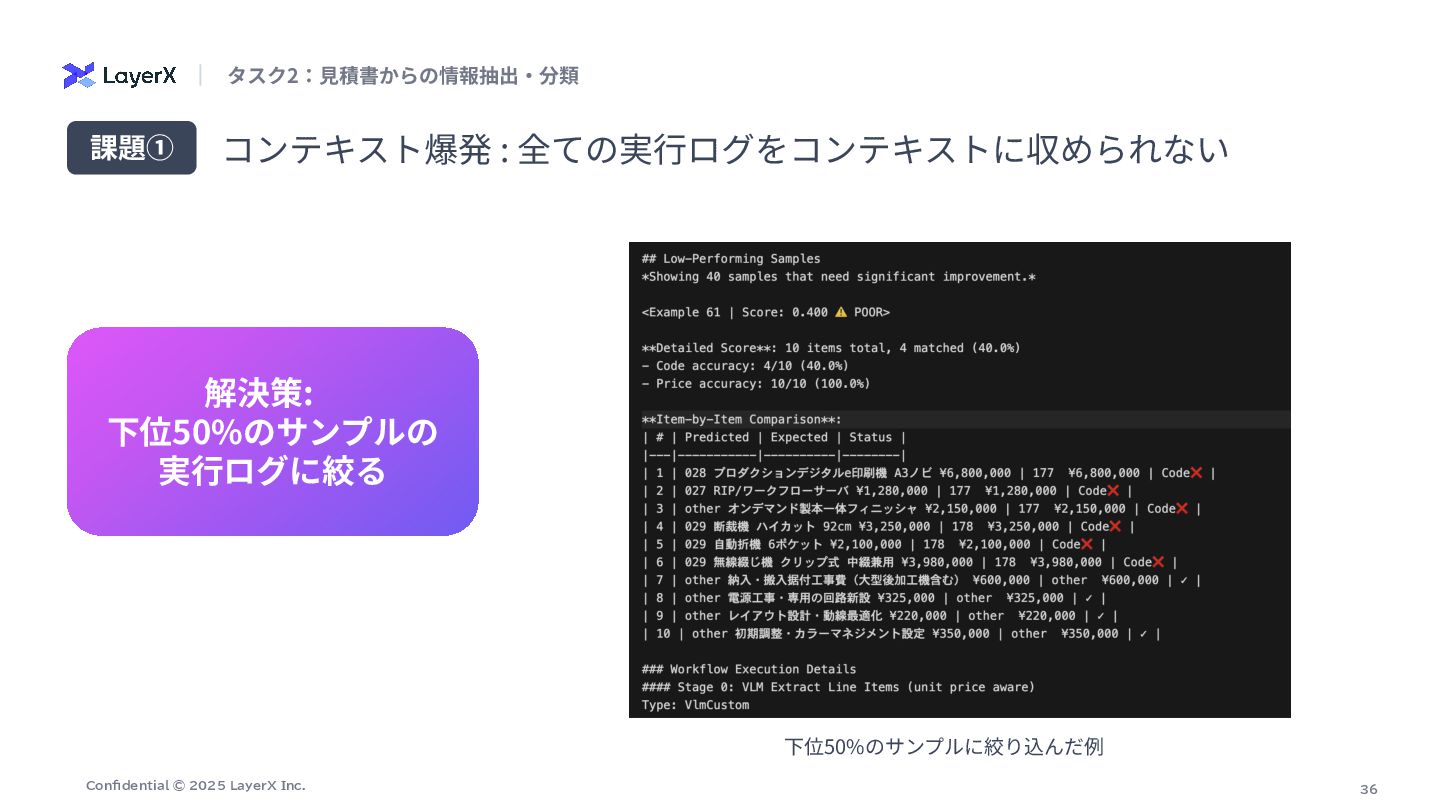
35 Confidential © 2025 LayerX Inc. ⾒積書からの情報抽出‧分類タスクに取り組む中で、以下の3つの課題にぶつかった コンテキスト爆発 : 全ての実⾏ログをコンテキストに収められない
課題① モグラ叩き問題 : 悪いサンプルを改善すると、良いサンプルが悪化する 課題② 最適化が不安定 : 10回に1回しか⾼精度が出ない 課題③ タスク2:⾒積書からの情報抽出‧分類
36 Confidential © 2025 LayerX Inc. コンテキスト爆発 : 全ての実⾏ログをコンテキストに収められない 課題①
解決策: 下位50%のサンプルの 実⾏ログに絞る タスク2:⾒積書からの情報抽出‧分類 下位50%のサンプルに絞り込んだ例
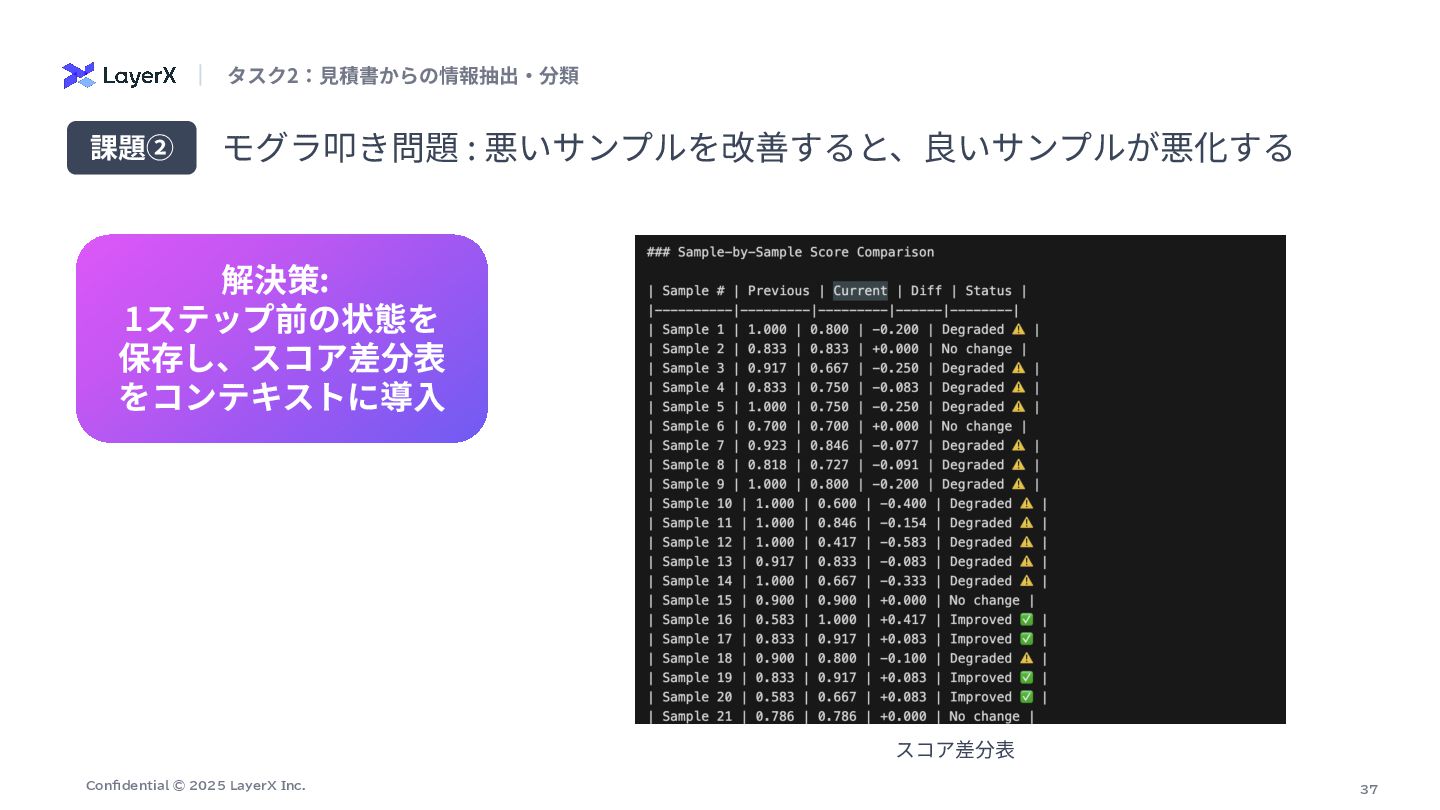
37 Confidential © 2025 LayerX Inc. モグラ叩き問題 : 悪いサンプルを改善すると、良いサンプルが悪化する タスク2:⾒積書からの情報抽出‧分類
課題② 解決策: 1ステップ前の状態を 保存し、スコア差分表 をコンテキストに導⼊ スコア差分表
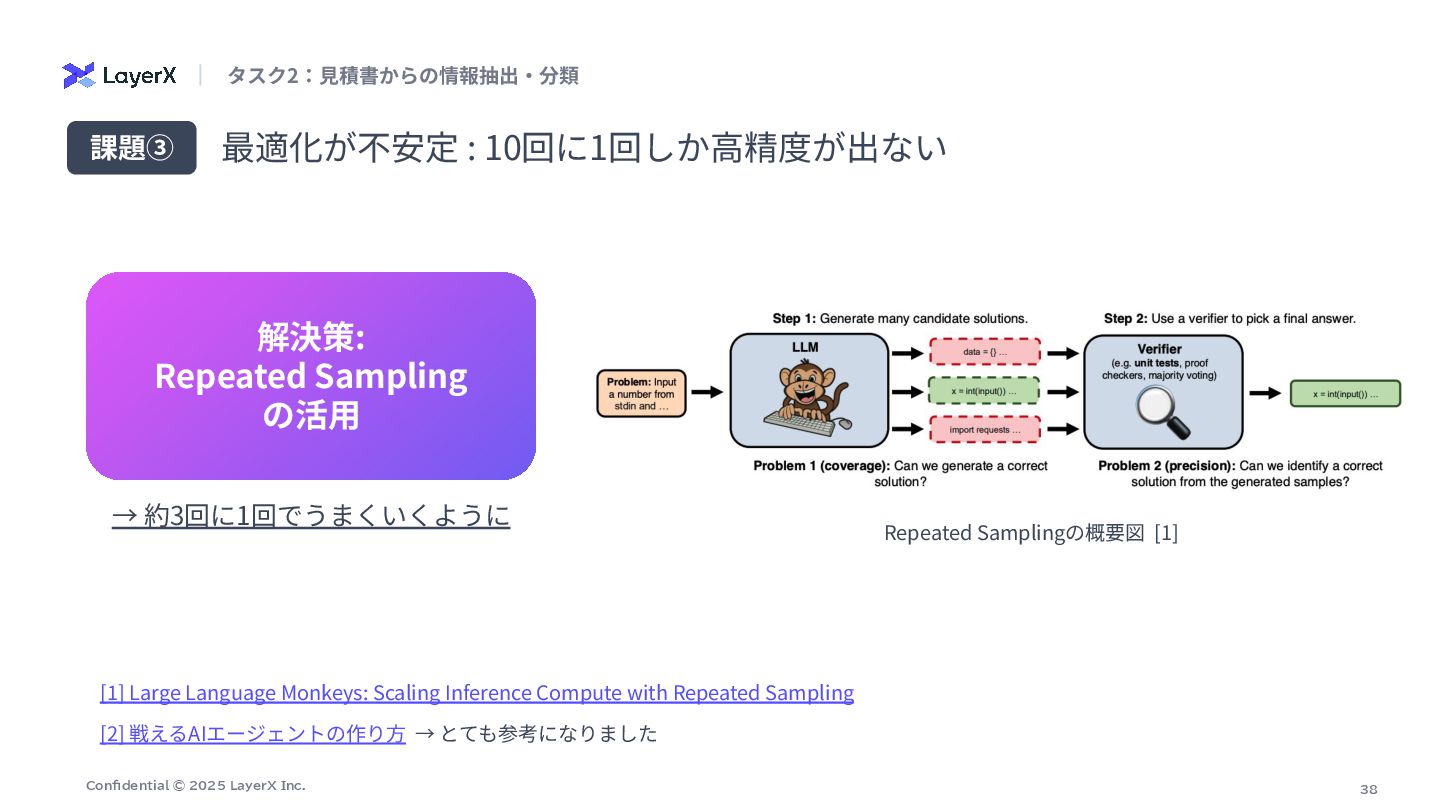
38 Confidential © 2025 LayerX Inc. 最適化が不安定 : 10回に1回しか⾼精度が出ない 課題③
解決策: Repeated Sampling の活⽤ → 約3回に1回でうまくいくように [1] Large Language Monkeys: Scaling Inference Compute with Repeated Sampling タスク2:⾒積書からの情報抽出‧分類 Repeated Samplingの概要図 [1] [2] 戦えるAIエージェントの作り⽅ → とても参考になりました
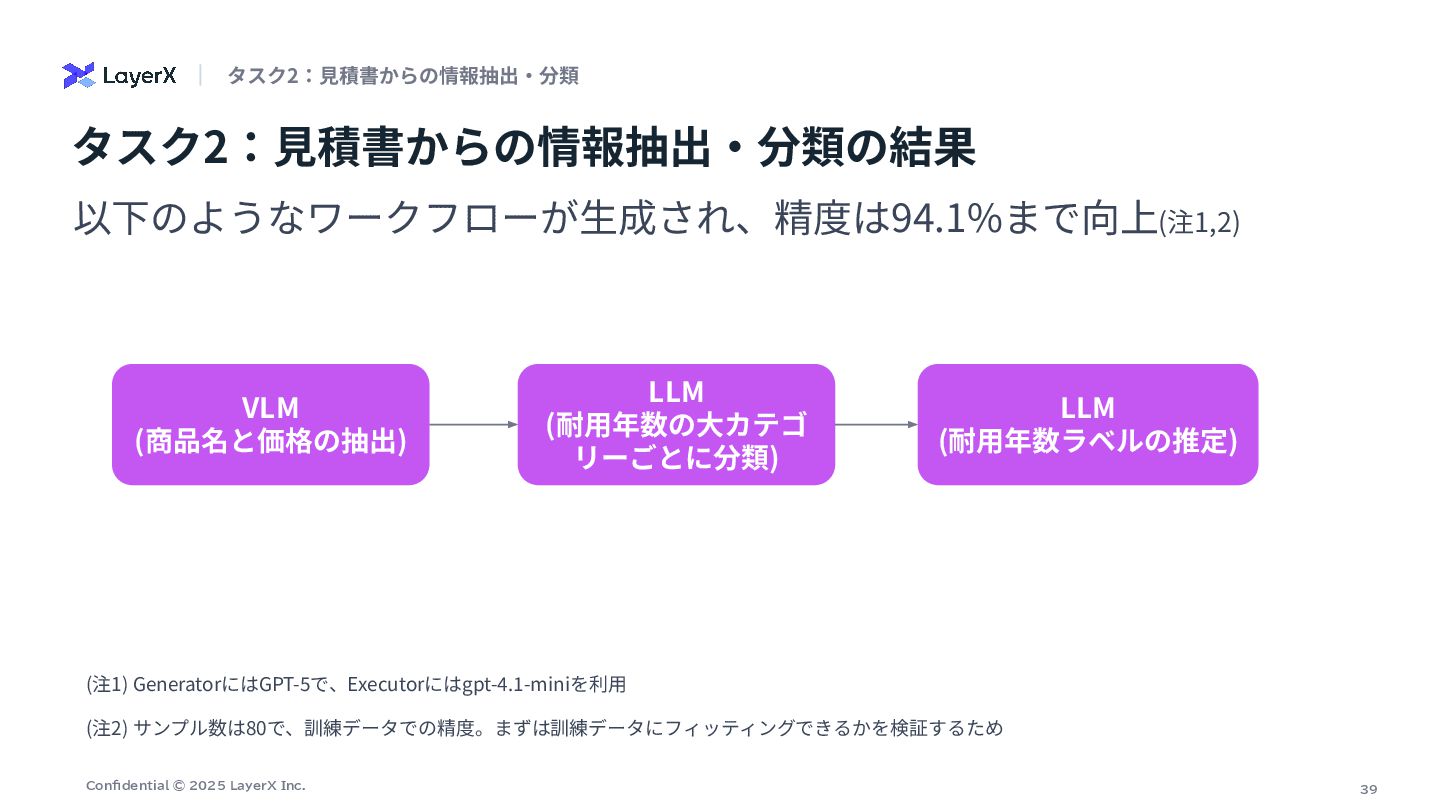
39 Confidential © 2025 LayerX Inc. タスク2:⾒積書からの情報抽出‧分類の結果 タスク2:⾒積書からの情報抽出‧分類 以下のようなワークフローが⽣成され、精度は94.1%まで向上(注1,2) (注1)
GeneratorにはGPT-5で、Executorにはgpt-4.1-miniを利⽤ VLM (商品名と価格の抽出) LLM (耐⽤年数の⼤カテゴ リーごとに分類) LLM (耐⽤年数ラベルの推定) (注2) サンプル数は80で、訓練データでの精度。まずは訓練データにフィッティングできるかを検証するため
40 Confidential © 2025 LayerX Inc. タスク2:⾒積書からの情報抽出‧分類 # この⾒積書PDFから、テーブルの⾏ごとに「商品名」「価格」を抽出します。価格は誤差を避けるため、数量と単価‧⾏合計の関係を明⽰的に読み取り、以下の⽅針で選択してくださ い。
# 抽出ポリシー(価格の選択) - ⾏内に数量(数量、Qty、台、式、セット、m、個 等)が明⽰され、明らかに数量>1の場合は「単価(unit_price)」を価格として採⽤する。 - 数量が1または数量が明確でない場合は「⾏合計(line_total)」を価格として採⽤する。 - 単価‧合計のどちらとも特定できない場合のみ price_source="unknown" とし、推測や計算はしない。 # 厳守ルール: - 計算や単位変換を⾏わない(表⽰されている整数値をそのまま採⽤)。 - OCR誤読補正をしない(⾒えた⽂字‧数字をそのまま使う)。 - 数字が複数並ぶ場合は、列⾒出しと⽔平⽅向の対応から「単価」「合計/⾦額/⼩計」欄を判断する。右端の⾦額列が合計欄であることが多いが、数量>1のときは合計ではなく単価欄を 優先する。 - ⾒出し/カテゴリ合計(例: 「その他設備」「諸費⽤」「⾞両関連」「⼯具‧器具関連」「⼩計」「合計」「消費税」等)は品⽬ではなく、row_roleを適切に付与 (heading/category_summary/subtotal/tax/grand_total/shipping_total)し、単価‧合計の選択はしない。 - 値引きは符号を保持。通貨記号やカンマは除去し整数化。 row_role と price_source: - row_role: one of ["item","service","work","discount","heading","category_summary","subtotal","tax","grand_total","shipping_total"] - price_source: one of ["unit_price","line_total","subtotal","category_total","grand_total","tax","unknown"] # 出⼒形式(JSONオブジェクト、説明⽂禁⽌) { "items": [ { "商品名": "<⾏テキスト>", "価格": <整数>, "row_role": "<上記のいずれか>", "price_source": "<上記のいずれか>", "数量": <整数またはnull>, "unit_price": <整数または null>, "line_total": <整数またはnull> } , ... ] } # 補⾜ - 「数量」「unit_price」「line_total」は判読できた範囲で記録(無ければnull)。 - サービス‧⼯事(据付/搬⼊/試運転/教育/申請 等)は row_role を "service" または "work" とする。 - 表が乱れている場合でも、その⾏テキストに最も紐づく列の値を選ぶ。 ⽣成されたプロンプト : VLM(商品名と価格の抽出)ノード
41 Confidential © 2025 LayerX Inc. あなたは⾒積明細の正規化エンジンです。⼊⼒items配列から、スコア最⼤化のために次を実施してください。 - ⽬的: 単価または⾏合計に基づく対象明細(商品‧サービス‧⼯事‧値引き)のみを残し、⾒出し‧カテゴリ合計‧⼩計‧総計‧税‧送料などの⾮対象⾏を厳格に除外する。価格は必
ず数量規則に従って再選択し、選んだ値で「価格」を強制上書きする(計算や単位変換は禁⽌)。 - 後段分類強化のため、各⾏の row_role を row_role_hint として保持する。 # [絶対遵守] 価格の再選択‧強制上書き(⾮計算‧⾮変換‧選択のみ): - ⼊⼒には各⾏ごとに {商品名, 価格, row_role, price_source, 数量, unit_price, line_total} が与えられる。 - 最終出⼒の「価格」は、以下の規則で「既に与えられている整数のいずれか(unit_price / line_total / ⼊⼒の価格)」から必ず1つを選んで置き換える。VLM出⼒の「価格」や 「price_source」があっても、下記数量規則を優先し必ず上書きする。 1) 数量が明確に>1のとき: unit_price が判読可能(⾮null)なら unit_price を採⽤し、これを「価格」に設定する。 2) 数量が1 または 数量が不明(null)のとき: line_total が判読可能(⾮null)なら line_total を採⽤し、これを「価格」に設定する。 3) 参照すべきフィールドがnull/⽋落のときは、判読可能なもう⼀⽅(unit_price または line_total)の整数を採⽤。両⽅とも無ければ⼊⼒の「価格」をそのまま残す。 4) 「千円」などの単位表記が含まれる場合でも、単位変換や推測は⾏わない。あくまで⼊⼒に存在する整数値(unit_price / line_total / 価格)の中から選ぶ。 5) 値引きは符号を保持(負値のまま)。 # [domain 推定(1つ選択)] - vehicle_fleet: トラック/バン/ダンプ/ウイング/トレーラ/ETC/ドラレコ/⾞両登録 等 - office_shop: 家具/家電/看板/ポスター/ラミネータ/プロジェクタ/パソコン/インターホン/電話/時計 等 - metal_fabrication: レーザー/パンチ/ベンダ/溶接/ショットブラスト/電解研磨/PVD 等 - textile: カード機/織機/テンター/染⾊/サイジング/ワインダー/酸化炉/黒鉛化炉/電解槽 等 - steel_building: Steel-/RC-系建物、配電盤/バスダクト/照明制御/ATS、UPS、給排⽔設備、アーケード/オーニング 等 - agri_planting: 果樹棚/ホップ棚/フェンス/サイロ/⽔路/貯⽔槽/暗渠/⼟管/集⽔桝/苗⽊ 等 - construction_equipment: タワークレーン/仮設リフト/路⾯カッター/現場発電機 等 - gas_station: スタンド設備/地中タンク/ディスペンサ/防爆照明 等 - food_process: ニーダー/充填機/冷却機/⾦属検出機/ユニットクーラ 等 - wood_forestry: ウィンチ/樹⽪むき/チッパー/キルン/集塵 等 - hotel_hospitality: ホテル‧宿泊‧接客施設向け備品/什器 等 # [出⼒形式] - JSON配列のみ、説明⽂禁⽌。 - 以下省略.... ⽣成されたプロンプト : LLMノード(耐⽤年数の⼤カテゴリーごとに分類) タスク2:⾒積書からの情報抽出‧分類
42 Confidential © 2025 LayerX Inc. あなたは固定資産コードの専⾨分類エンジンです。与えられた1件の明細(商品名、価格、domain、row_role_hint)に対して、最も適切な固定資産分類コードを1つ選び、code(3桁 ⽂字列)または"other"を付与してください。価格は変更せずにそのまま出⼒します。domainは補助情報であり、最終判断は商品名の意味に基づきます。 ⼊⼒(1アイテム) {
"商品名": "<明細⾏テキスト>", "価格": <整数>, "domain": "<gas_station / steel_building / vehicle_fleet / office_shop / metal_fabrication / food_process / textile / wood_forestry / agri_planting / construction_equipment>", "row_role_hint": "<item/service/work/discount>" } 出⼒: { "code": "<3桁コード or other>", "商品名": "<⼊⼒の商品名>", "価格": <⼊⼒の価格> } # 絶対遵守: - 付帯サービス(設計、申請、据付、搬⼊‧荷揚げ、基礎⼯事、配線‧配管、試運転、調整、検査、教育、研修、初期設定、ステッカー施⼯、ラッピング、架装、清掃、廃材処分、輸送 ‧陸送‧送料 など)は、row_role_hint が service/work の場合は必ず code="other"。 - ⼊⼒の価格は変更しない。迷う場合はコードではなくotherを選ぶ。 - 建物コード(096/097/081/082/071/072/093/063/066など)は、商品名にその数値が明⽰されている場合のみ採⽤する。 - 【優先ルール】商品名に「FAX」「ファクス」「ファクシミリ」「FAX機能付」のいずれかが含まれる場合は、複合機等(028)ではなく必ず030(FAX/ファクシミリ)を選ぶ。 # 拡張分類ガイド(Master Data準拠‧頻出品⽬強化): [建物‧建物附属設備] - 建物パッケージ: 商品名に 096/097/081/082/071/072/093/063/066 などがあれば該当コード。 - 098: アーケード/キャノピー/ひさし(⾦属)。 - 099: オーニング(⽇よけ、樹脂/布系)。 - 100: 店舗⽤簡易装備(レジカウンター、簡易サインスタンド/内照式サインスタンド、POSカート、ノックダウン棚、組⽴式試着室 等)。 - 101: 蓄電池電源装置‧UPS‧⾮常照明⽤バッテリー、産業⽤蓄電システム、DC電源ラック、集中電源装置。 - 102: 電気設備(配電盤、照明/照明制御、バスダクト/バスタクト、ATS、⾃動切替開閉器)。また、照明器具(LED⾼天井灯/LEDダウンライト/投光器/LED灯具⼀式/照明制御装置 /DALI関連)は102。 - 103: 給排⽔‧衛⽣‧ガス(直結増圧給⽔ユニット、汚⽔排⽔ポンプ、業務⽤給湯器、グリーストラップ、ガス減圧器/レギュレータユニット)。 [⾞両‧運搬具] - 104: 軽(軽乗⽤/0.66L以下)。 - 以下省略... ⽣成されたプロンプト : LLMノード(耐⽤年数ラベルの推定) タスク2:⾒積書からの情報抽出‧分類
得られた知見と今後の改善アイデア
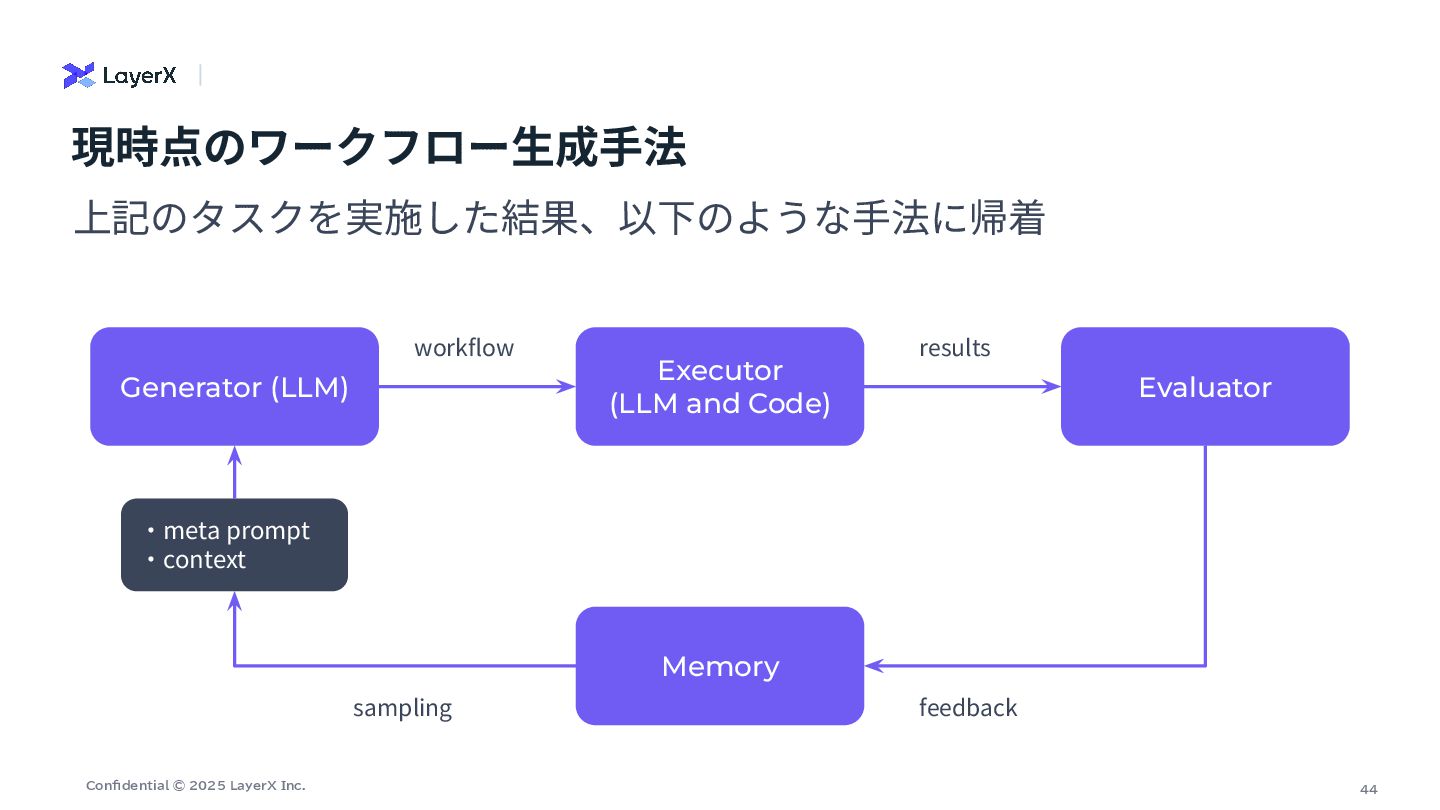
44 Confidential © 2025 LayerX Inc. 上記のタスクを実施した結果、以下のような⼿法に帰着 現時点のワークフロー⽣成⼿法 Generator (LLM)
Executor (LLM and Code) Evaluator workflow results Memory feedback sampling ‧meta prompt ‧context
45 Confidential © 2025 LayerX Inc. 得られた知⾒ 今回実施したタスクを実践したことにより、以下の知⾒を得られた • 知⾒1:コンテキストエンジニアリングが重要
◦ 実⾏ログ、⼊⼒⽂書、スコア差分表の追加により、Generator(LLM) が適切な改善判断をできるようになり、精度向上につながった • 知⾒2:探索⽅法の⼯夫が重要 ◦ 探索⽅法をRepeated Samplingに変えることで、最適化の安定性が ⼤幅に向上した
46 Confidential © 2025 LayerX Inc. 今後の改善アイデア コンテキスト最適化 アイデア① 探索⽅法の⼯夫
アイデア②
47 Confidential © 2025 LayerX Inc. 今後の改善アイデア [1] Agentic Context
Engineering: Evolving Contexts for Self-Improving Language Models 現状の問題 • 与えているコンテキストに無駄がある ◦ ⽣データをそのまま与えており、冗⻑な情報で トークンを浪費 • 経験を再利⽤できていない ◦ Repeated samplingの実⾏ログを活⽤できず、 同じミスを繰り返してしまう 課題 • 過去の経験から有⽤な情報を選び取り、コンテキスト 爆発を抑制して性能を⾼める。 打ち⼿ • ACE (Agentic Context Engineering) [1] • → コンテキストの保存、選択などを最適化するフレー ムワーク ACE (Agentic Context Engineering)の概要図 コンテキスト最適化 アイデア①
48 Confidential © 2025 LayerX Inc. 探索⽅法の⼯夫 アイデア② AB-MCTSの概要図 [1]
現在の実装(Repeated Sampling)では、どのくらい横 に広げるかを固定パラメータでfixしてしまっているの で無駄なWF⽣成が⾏われている。 AB-MCTSを使えば幅優先探索か深さ優先を動的に選択 できるので、効率的に探索できるのではないか [1] Wider or Deeper? Scaling LLM Inference-Time Compute with Adaptive Branching Tree Search 今後の改善アイデア
最後に
50 Confidential © 2025 LayerX Inc. 最後に ① 部署横断のコミュニケーションが⼤事 →
初期段階から関係部署と議論し、必要に応じて問題設定を(現実的なラインに) 緩和‧最適化した結果、ナイーブ⼿法でも⼗分に成果を出せるようになった ② エンジニアリングで解決できるところは解決し、不確実性を抑えることが⼤事 ③ 諦めない⼼が⼤事
We are hiring! AIシニアデータエンジニア Applied R&D リサーチエンジニア https://open.talentio.com/r/1/c/layerx/pages/110834 https://open.talentio.com/r/1/c/layerx/pages/107758 MLOps
/ 機械学習基盤エンジニア https://open.talentio.com/r/1/c/layerx/pages/112898
LayerXのApplied R&D ありがとうございました!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![47 Confidential © 2025 LayerX Inc. 今後の改善アイデア [1] Agentic Context](https://files.speakerdeck.com/presentations/2cb563196a5f42ab8281301487747cb7/slide_46.jpg){kind=link}
![48 Confidential © 2025 LayerX Inc. 探索⽅法の⼯夫 アイデア② AB-MCTSの概要図 [1]](https://files.speakerdeck.com/presentations/2cb563196a5f42ab8281301487747cb7/slide_47.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}