유한한) 값으로 변환하는 과정 특히 딥러닝 모델을 경량화 하거나 성능을 최적화할 때 많이 사용 모델의 파라미터를 낮은 정밀도로 변환하여 메모리 사용량을 줄이고 계산 효율을 높힘 Ex) 16-bit float. => 4-bit INT. Quantization with LLM Compressor NAVER
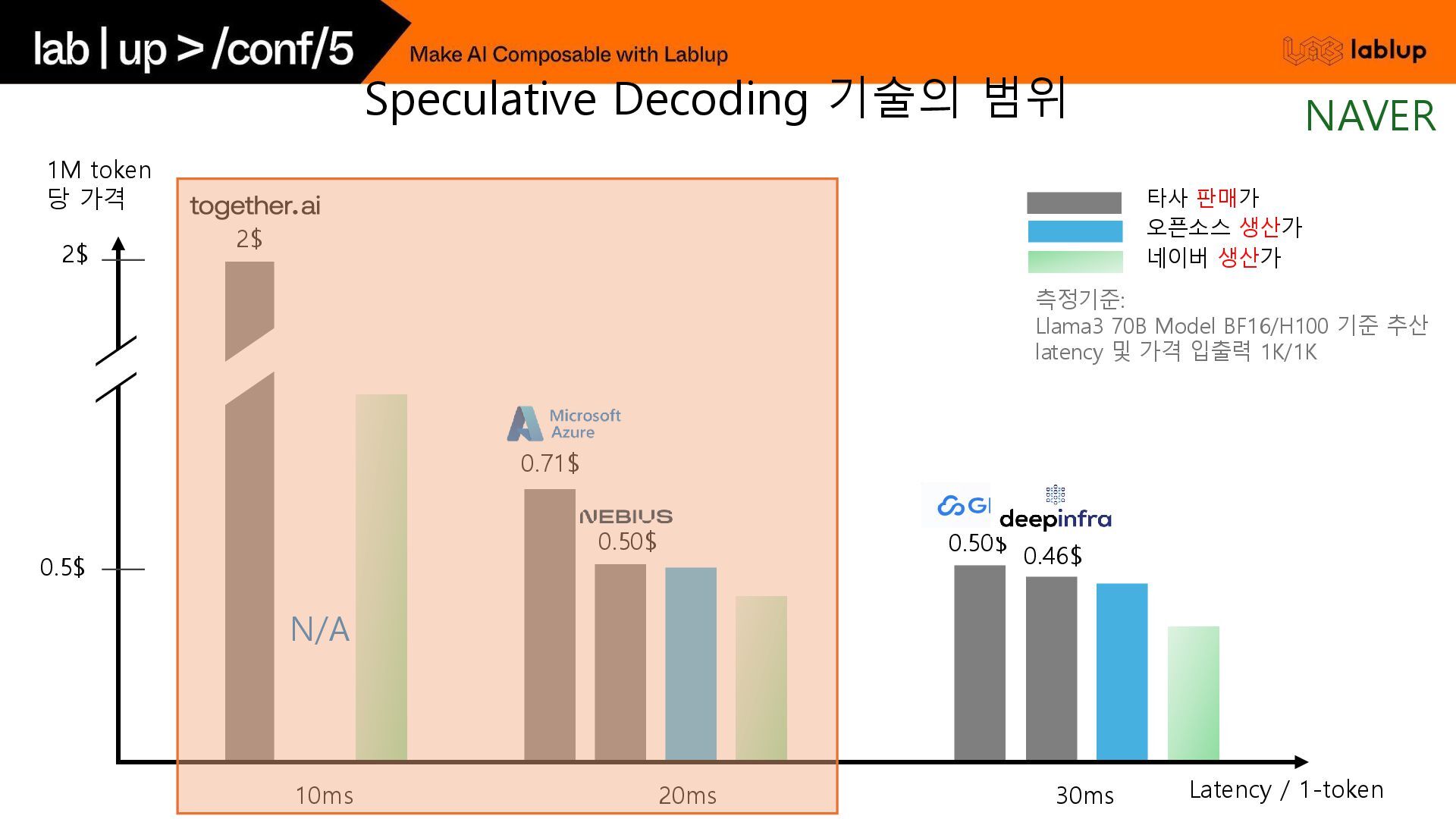
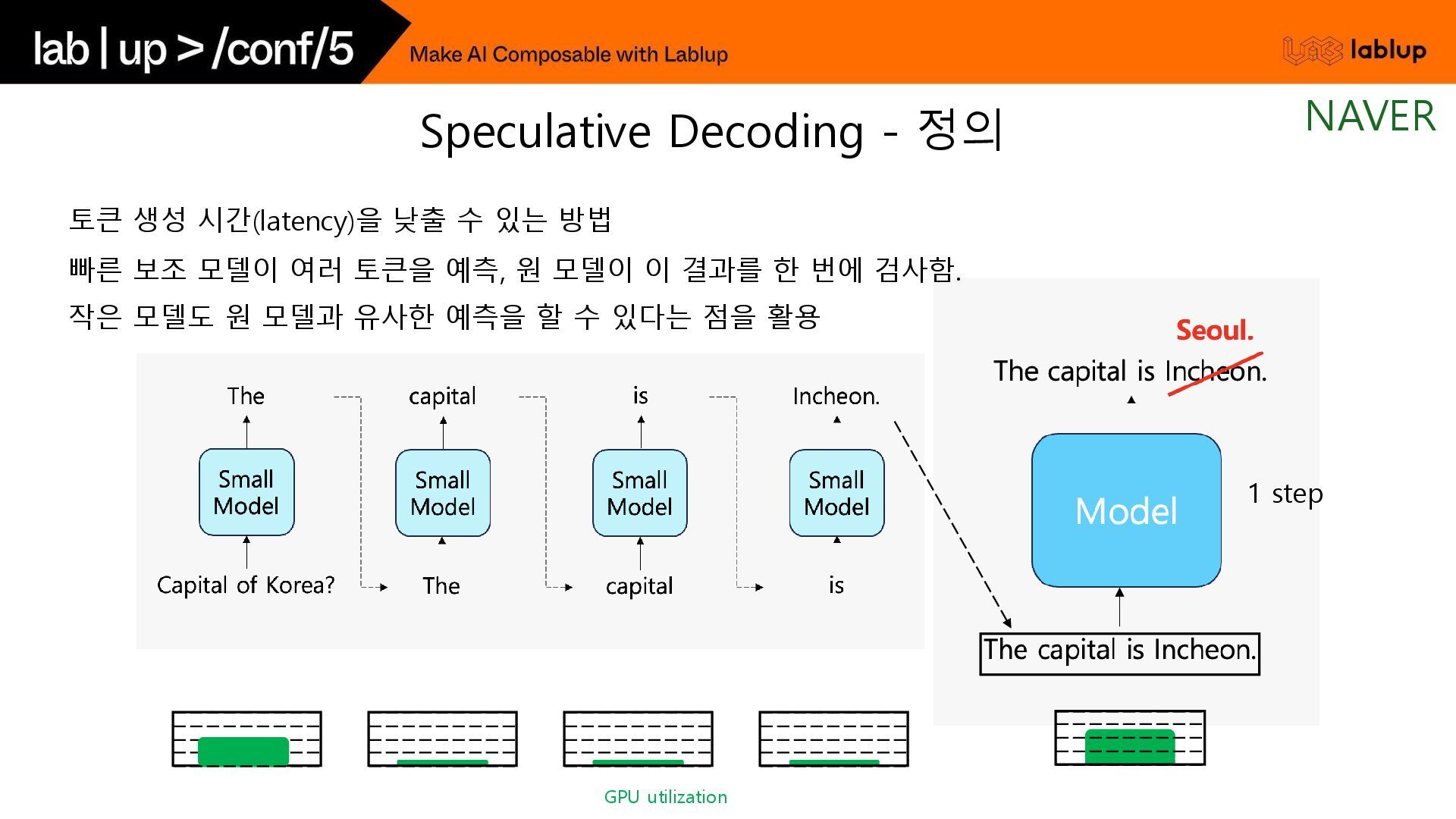
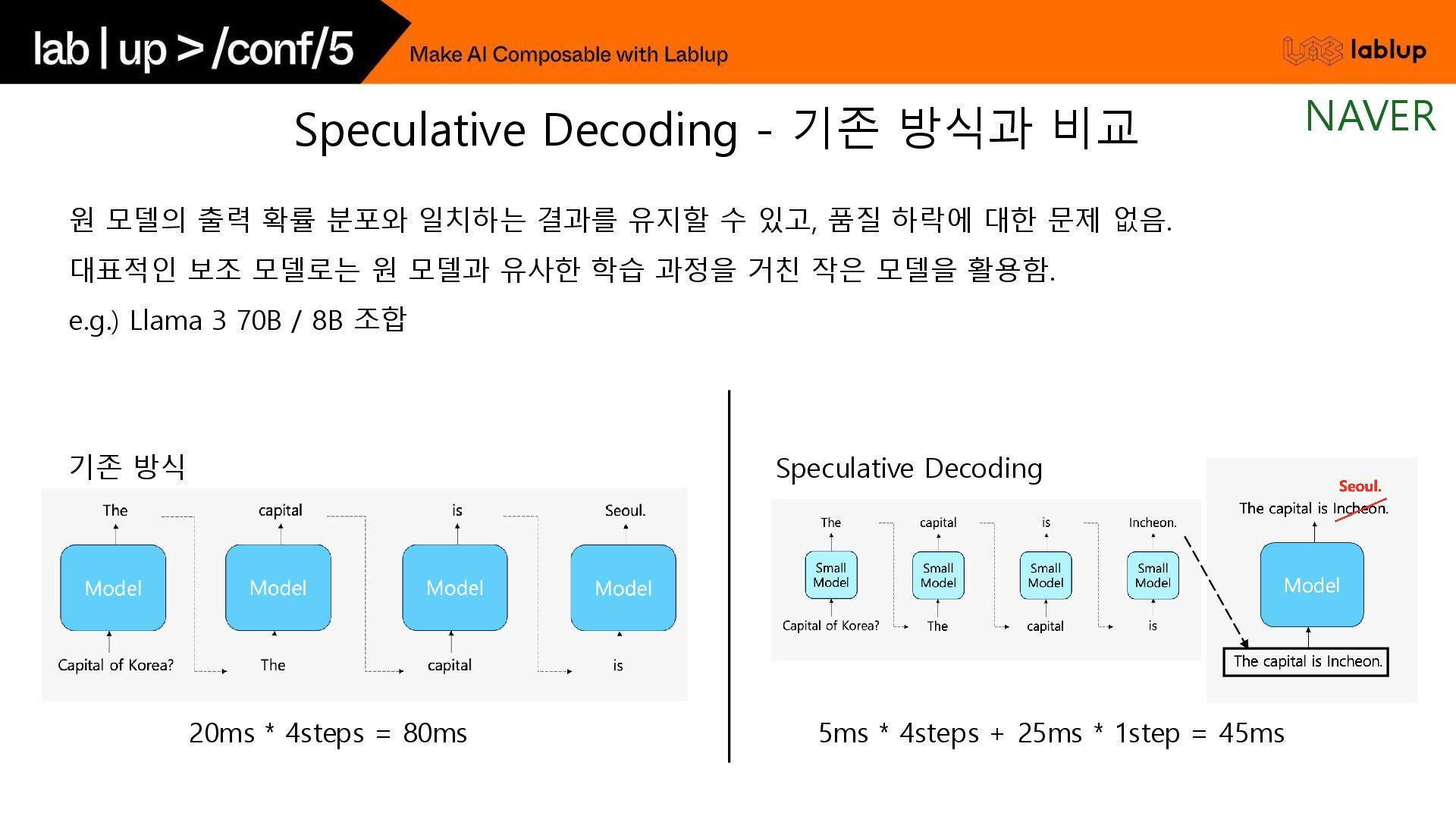
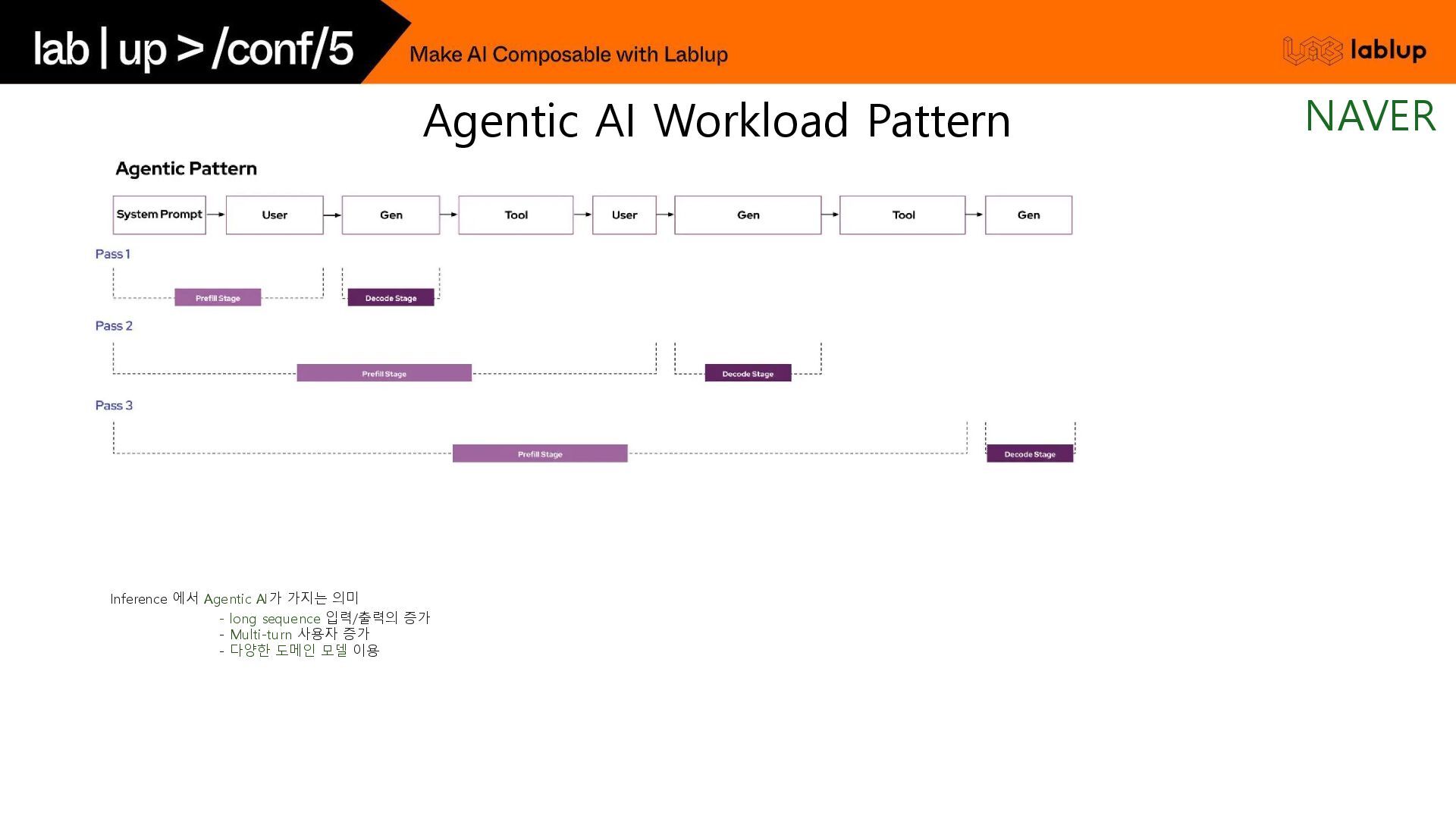
* 1step = 45ms 원 모델의 출력 확률 분포와 일치하는 결과를 유지할 수 있고, 품질 하락에 대한 문제 없음. 대표적인 보조 모델로는 원 모델과 유사한 학습 과정을 거친 작은 모델을 활용함. e.g.) Llama 3 70B / 8B 조합 기존 방식 Speculative Decoding Speculative Decoding - 기존 방식과 비교 NAVER
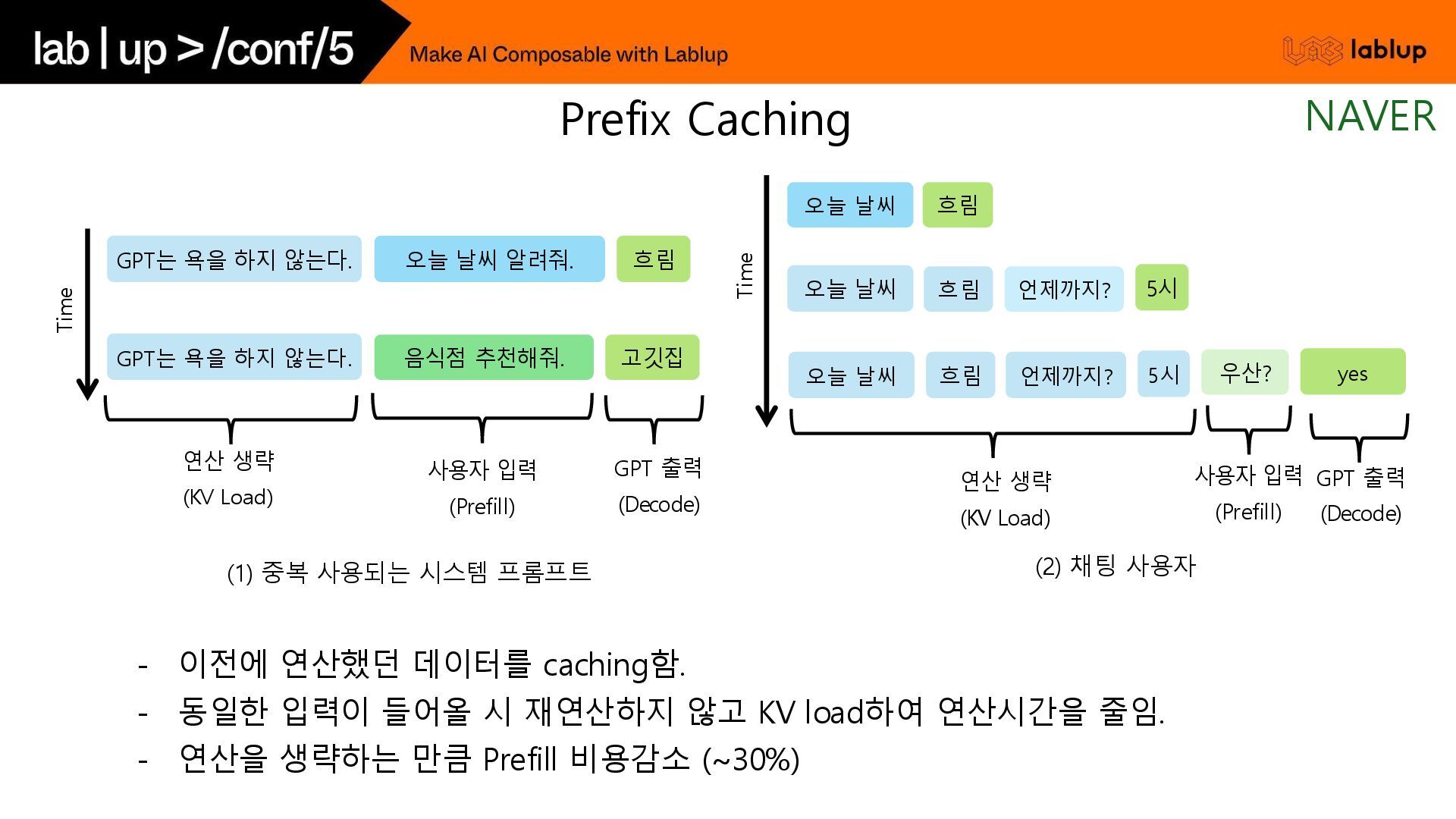
재연산하지 않고 KV load하여 연산시간을 줄임. - 연산을 생략하는 만큼 Prefill 비용감소 (~30%) 오늘 날씨 흐림 Time (2) 채팅 사용자 언제까지? 5시 오늘 날씨 흐림 언제까지? 5시 오늘 날씨 흐림 우산? yes 연산 생략 (KV Load) 사용자 입력 (Prefill) GPT 출력 (Decode) GPT는 욕을 하지 않는다. 오늘 날씨 알려줘. 흐림 GPT는 욕을 하지 않는다. Time (1) 중복 사용되는 시스템 프롬프트 사용자 입력 (Prefill) GPT 출력 (Decode) 음식점 추천해줘. 고깃집 연산 생략 (KV Load) Prefix Caching NAVER
{kind=link}
{kind=link}
{kind=link}
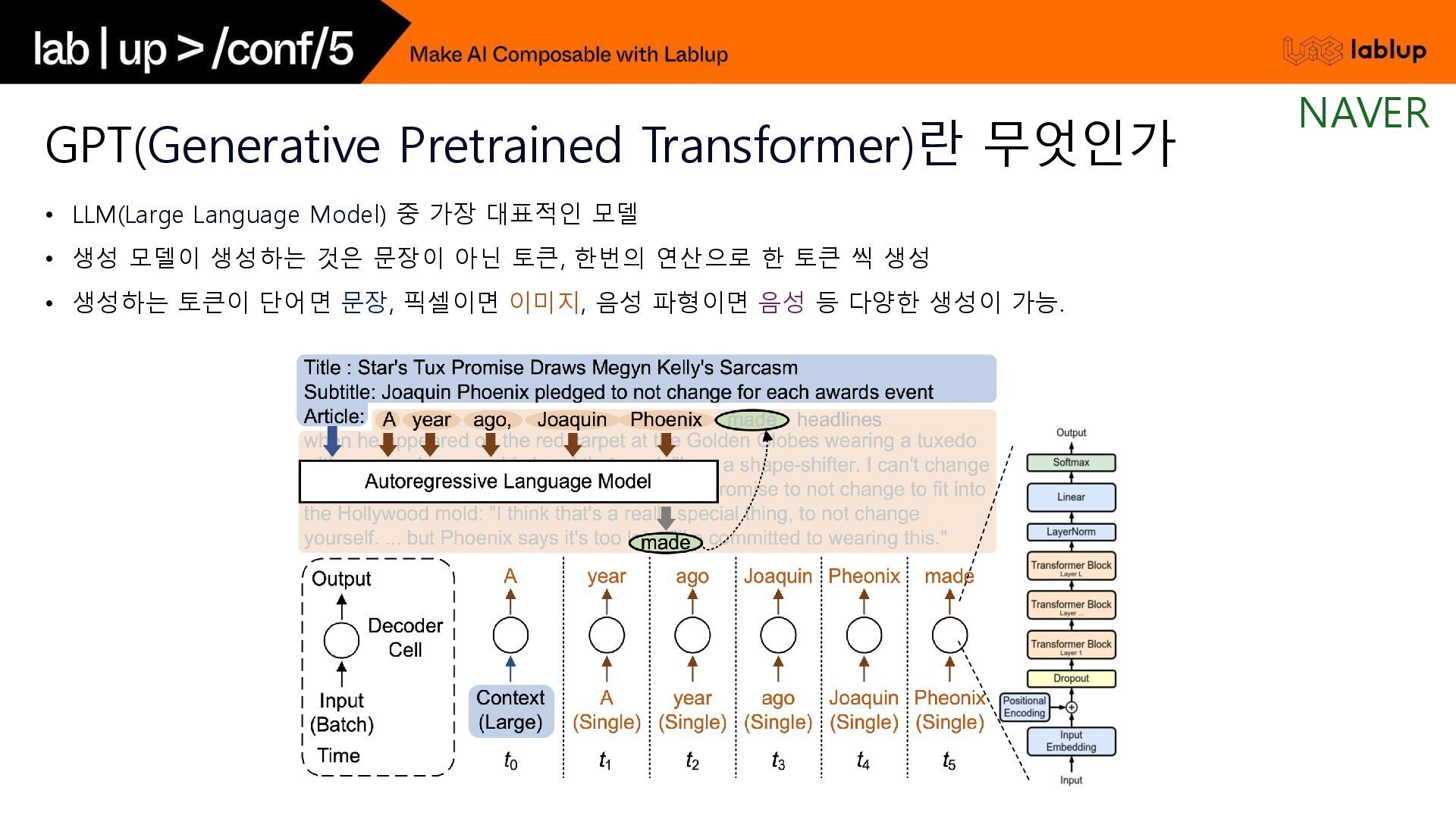{kind=link}
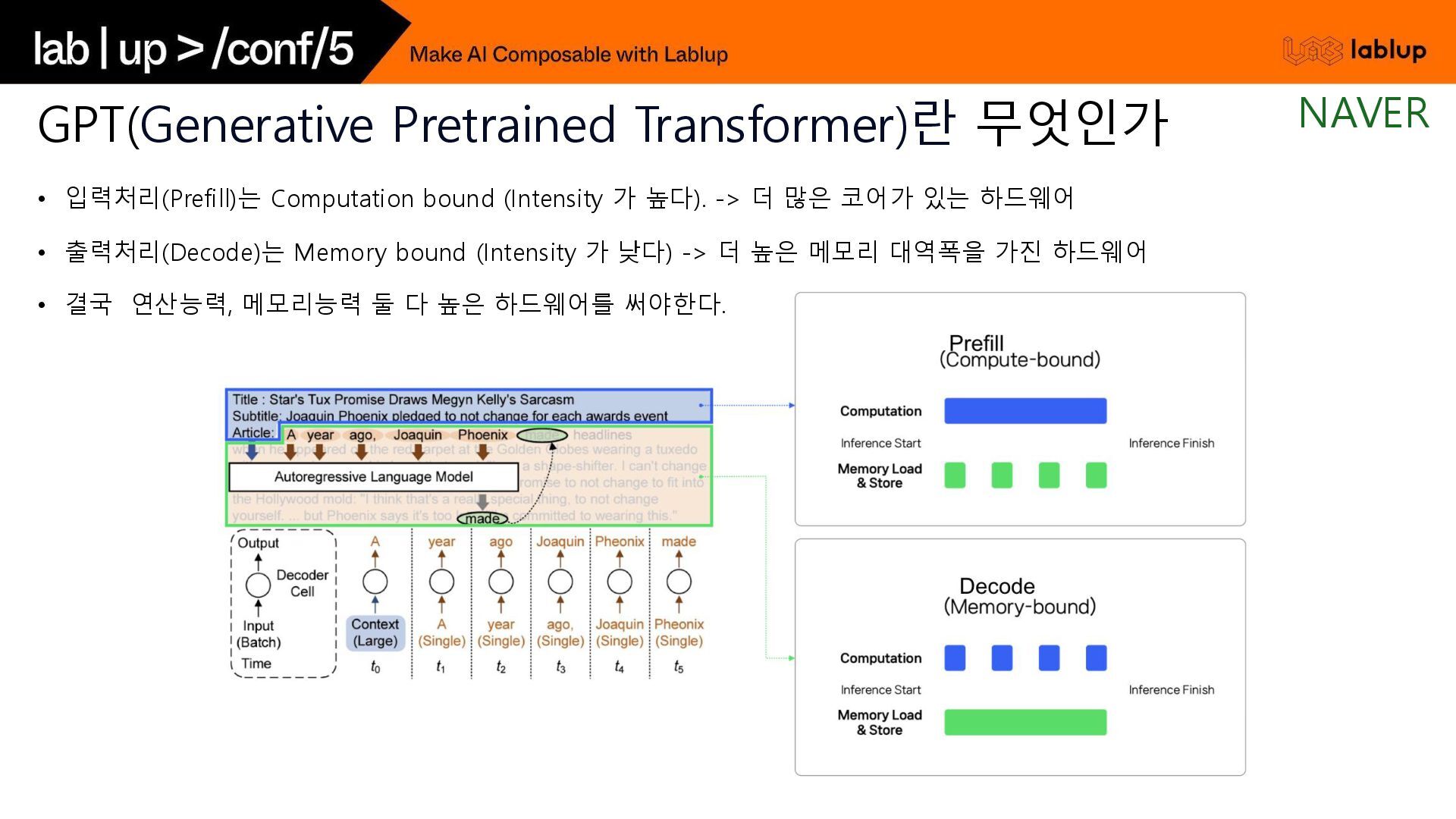{kind=link}
{kind=link}
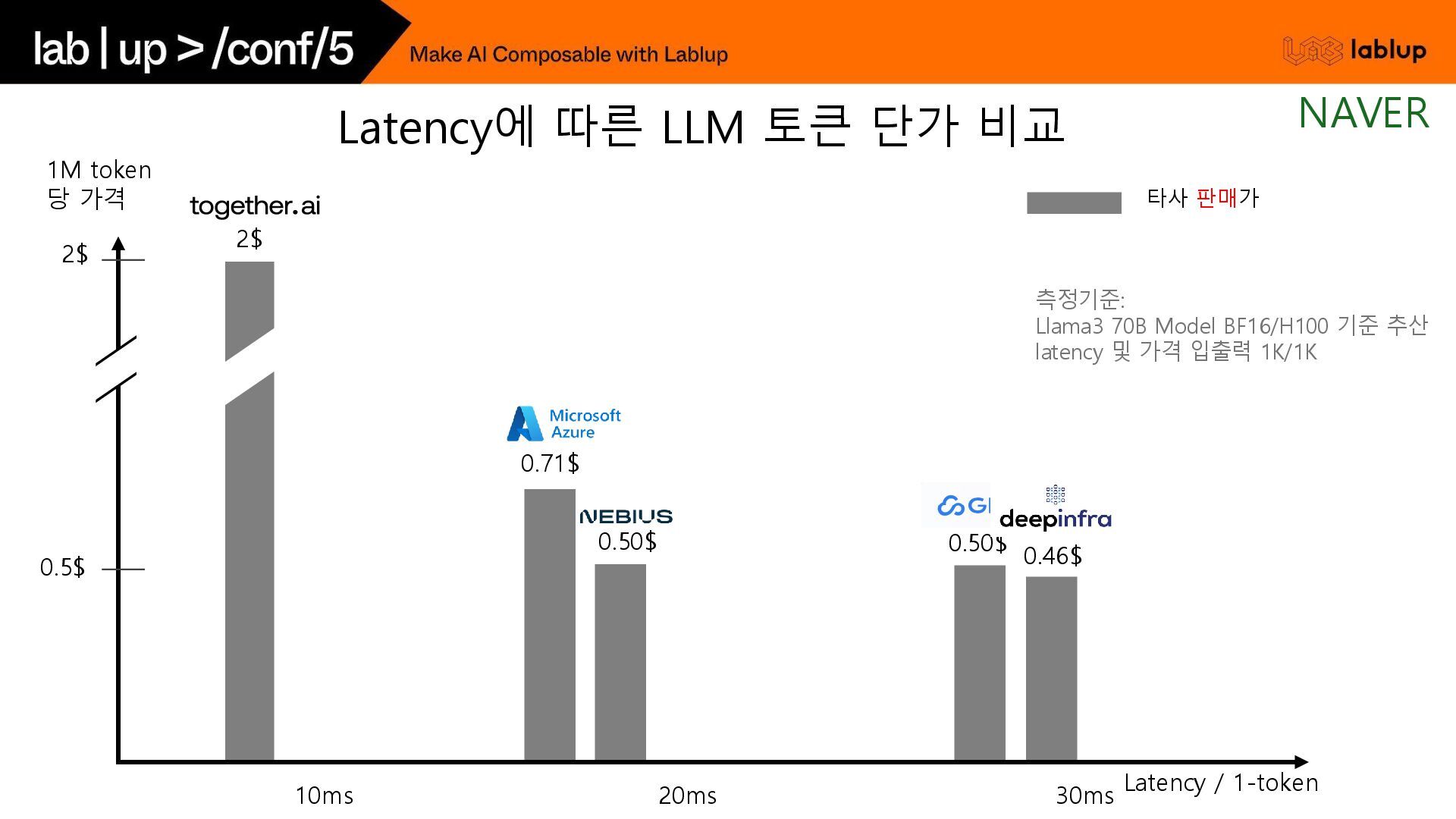{kind=link}
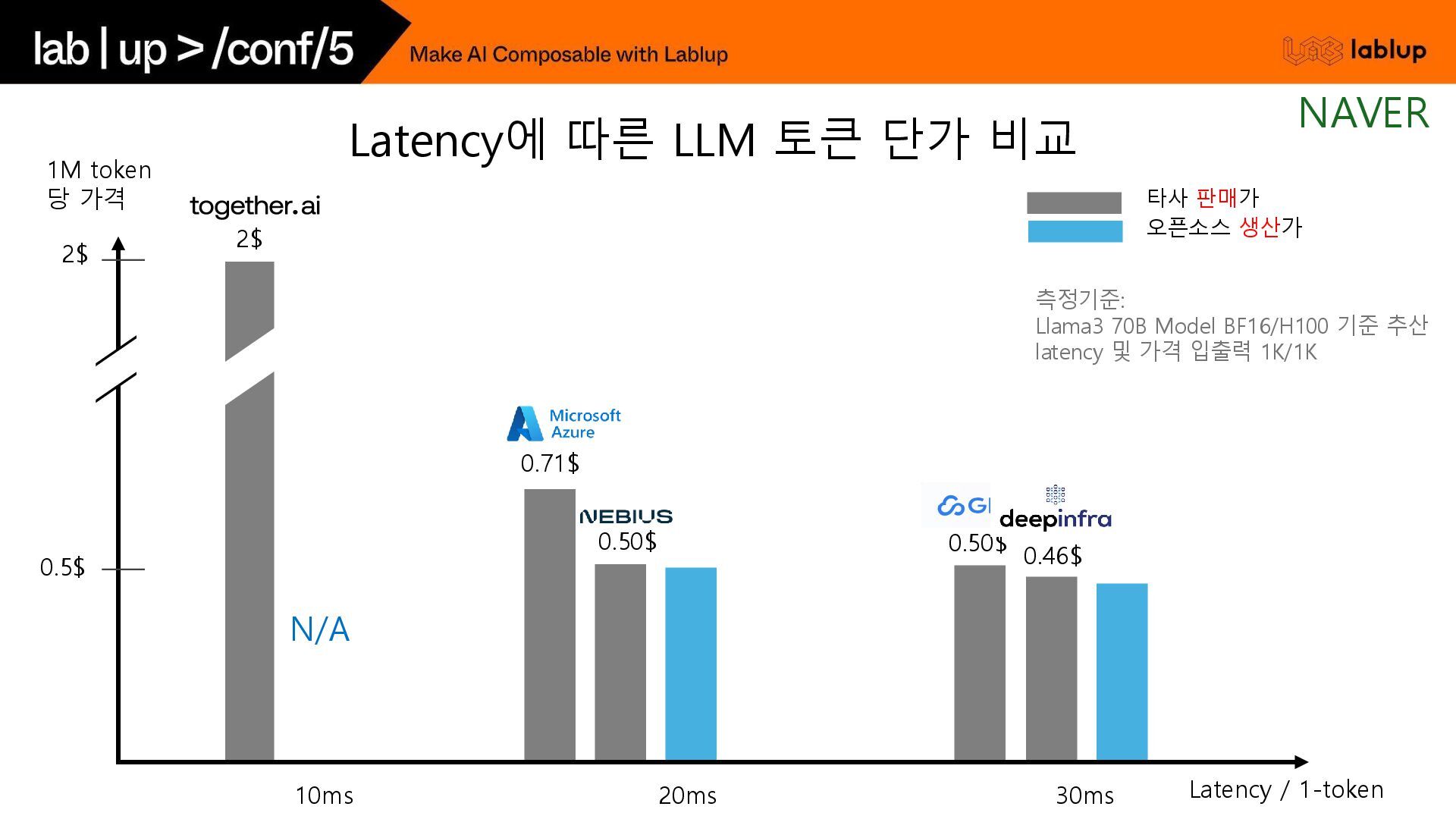{kind=link}
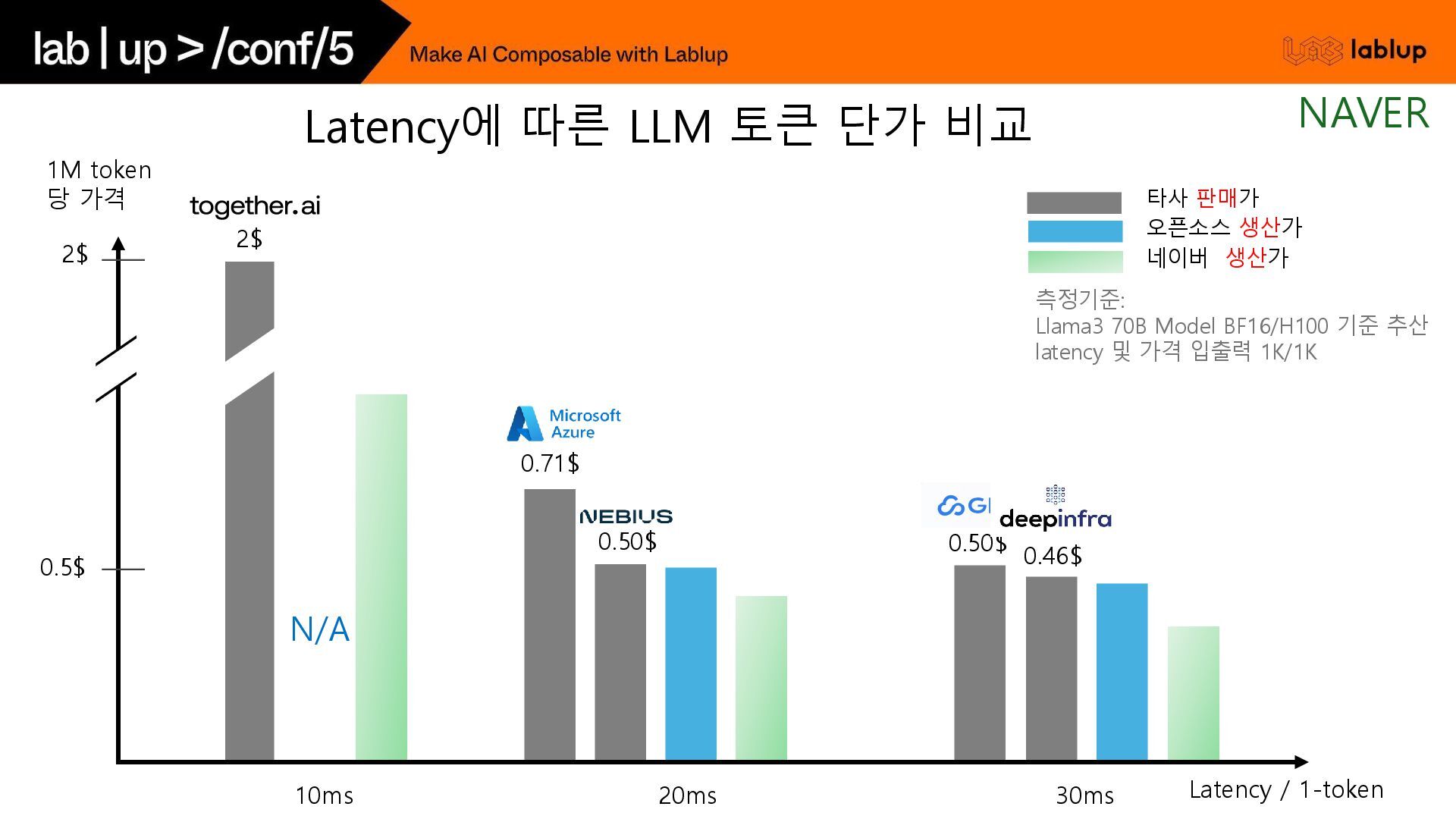{kind=link}
{kind=link}
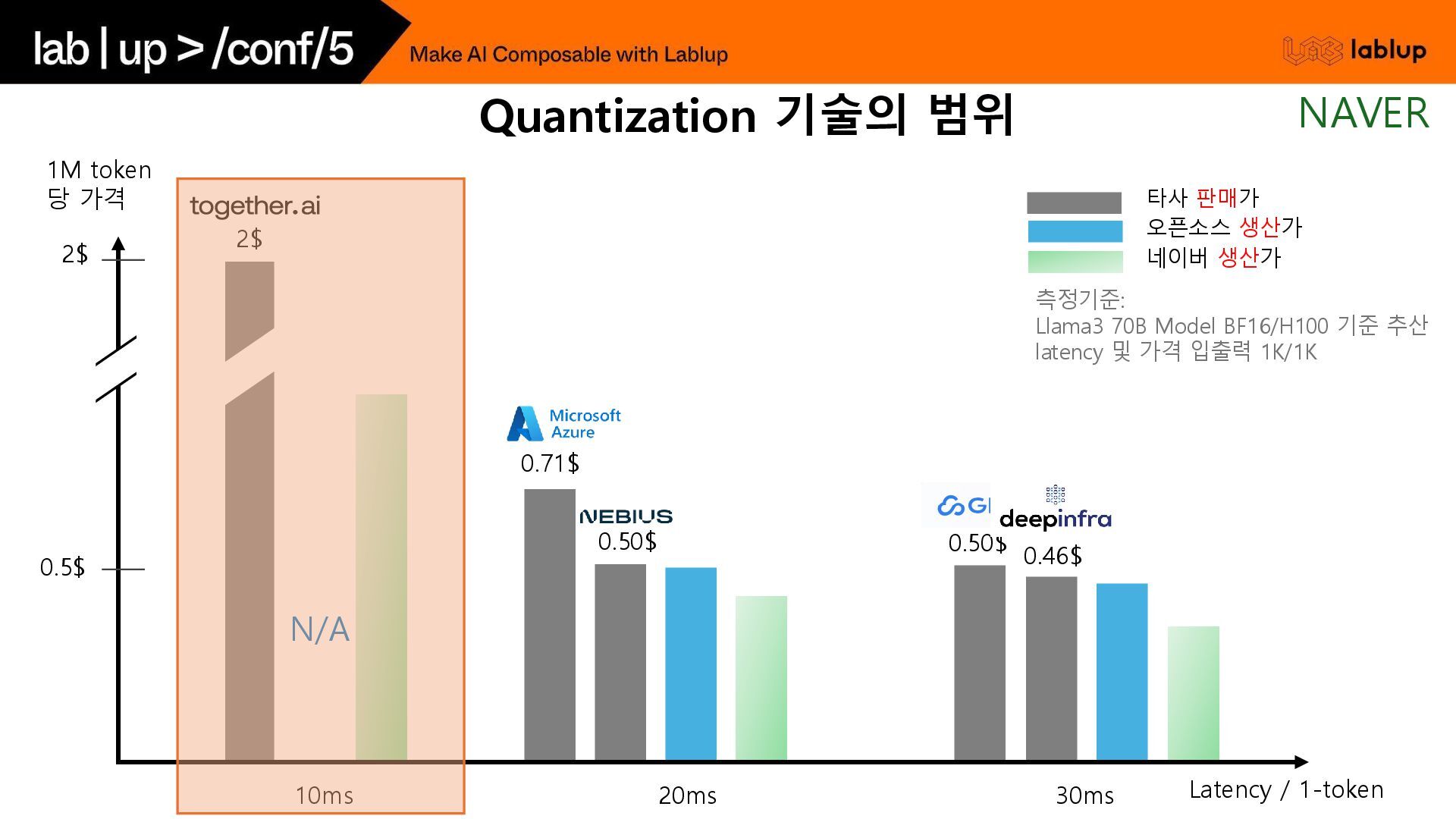{kind=link}
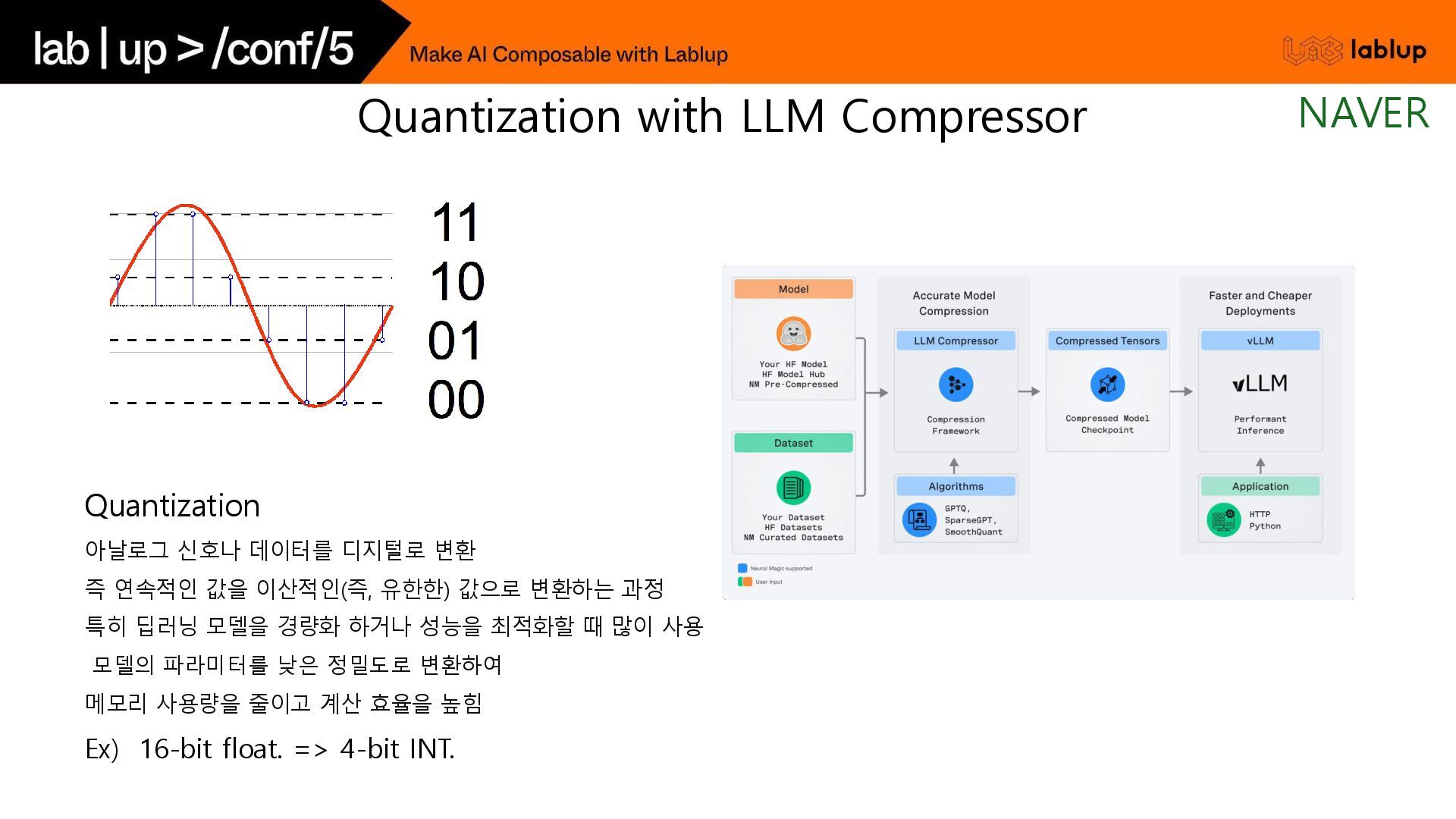{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
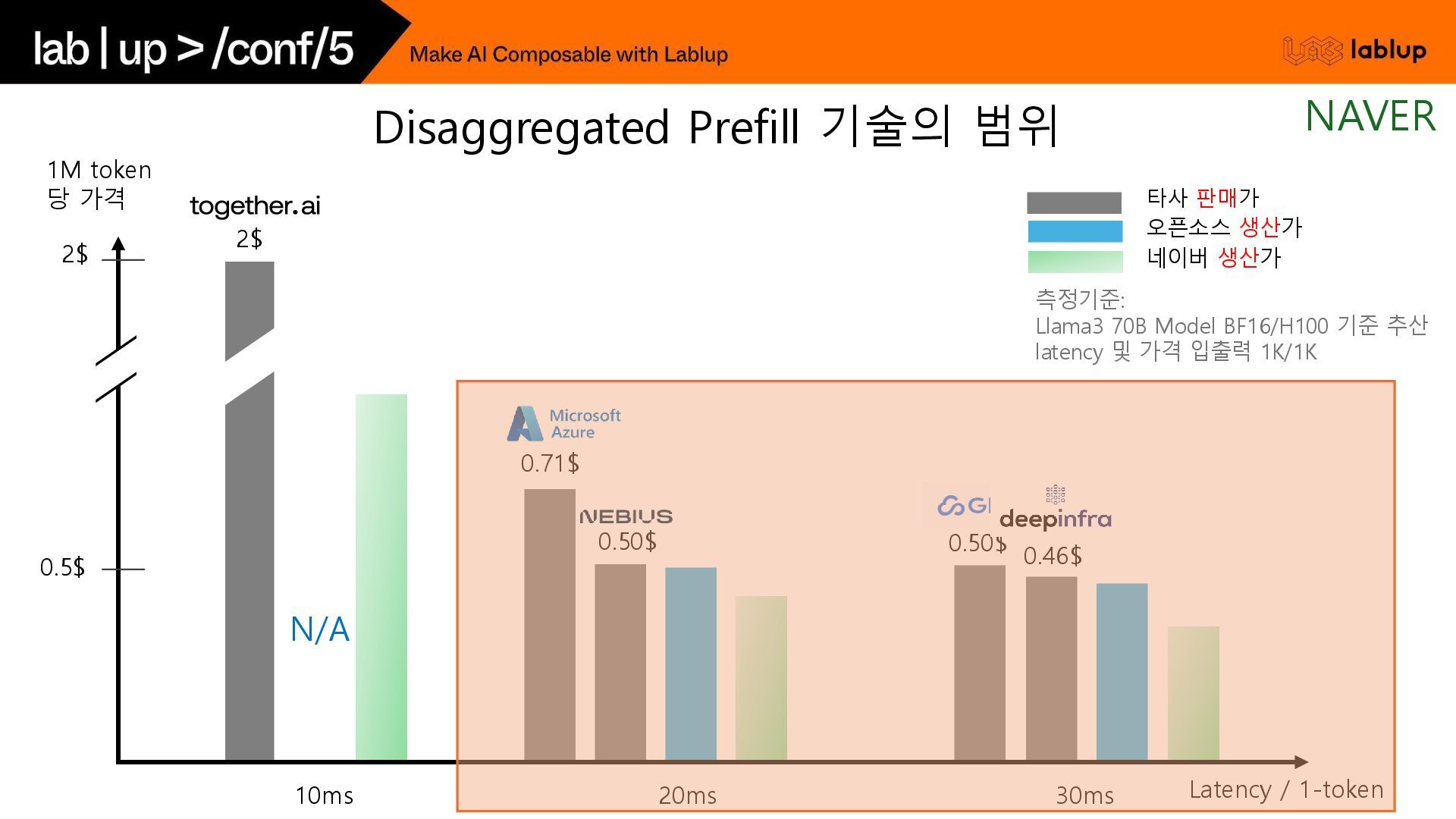{kind=link}
{kind=link}
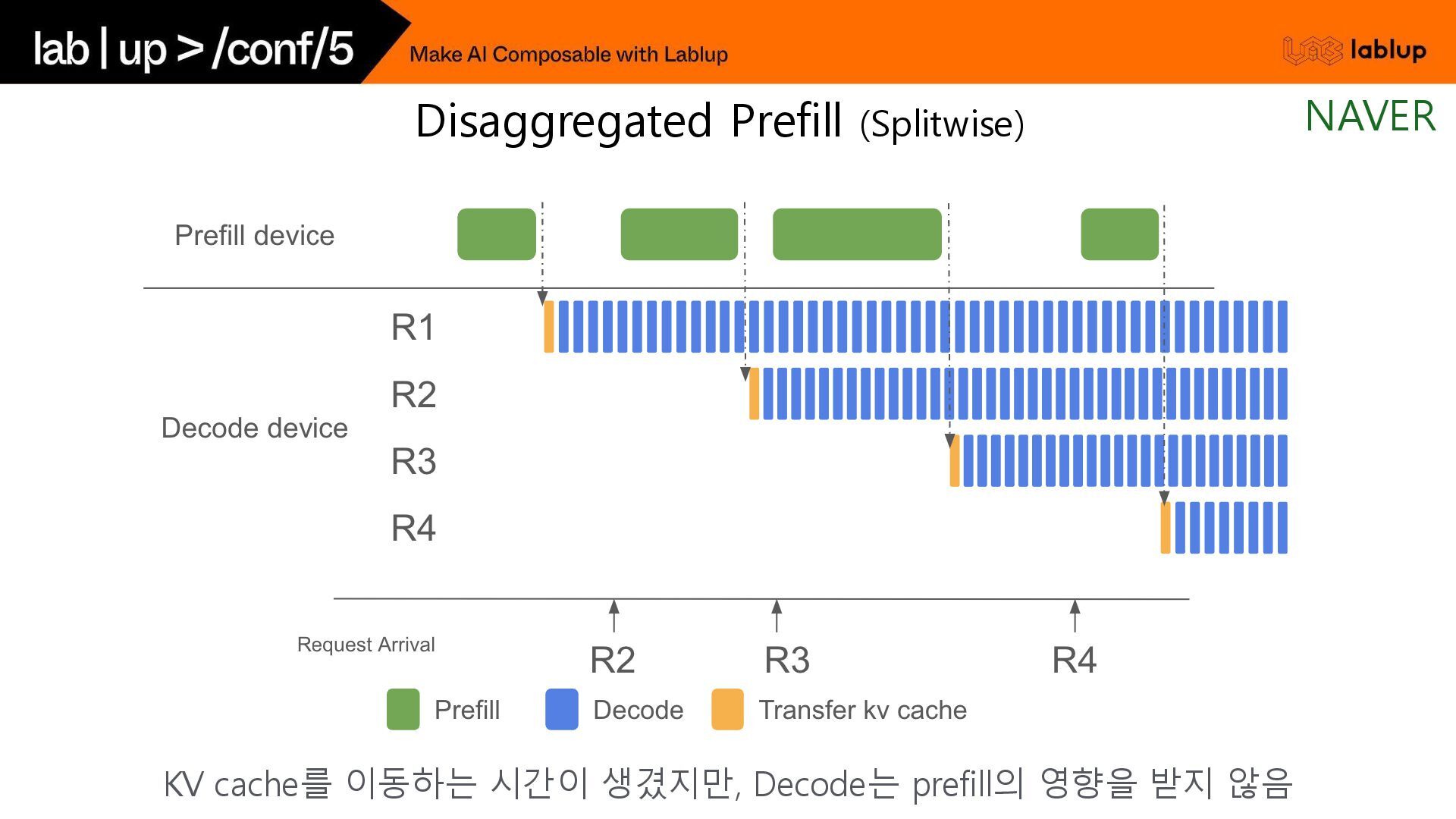{kind=link}
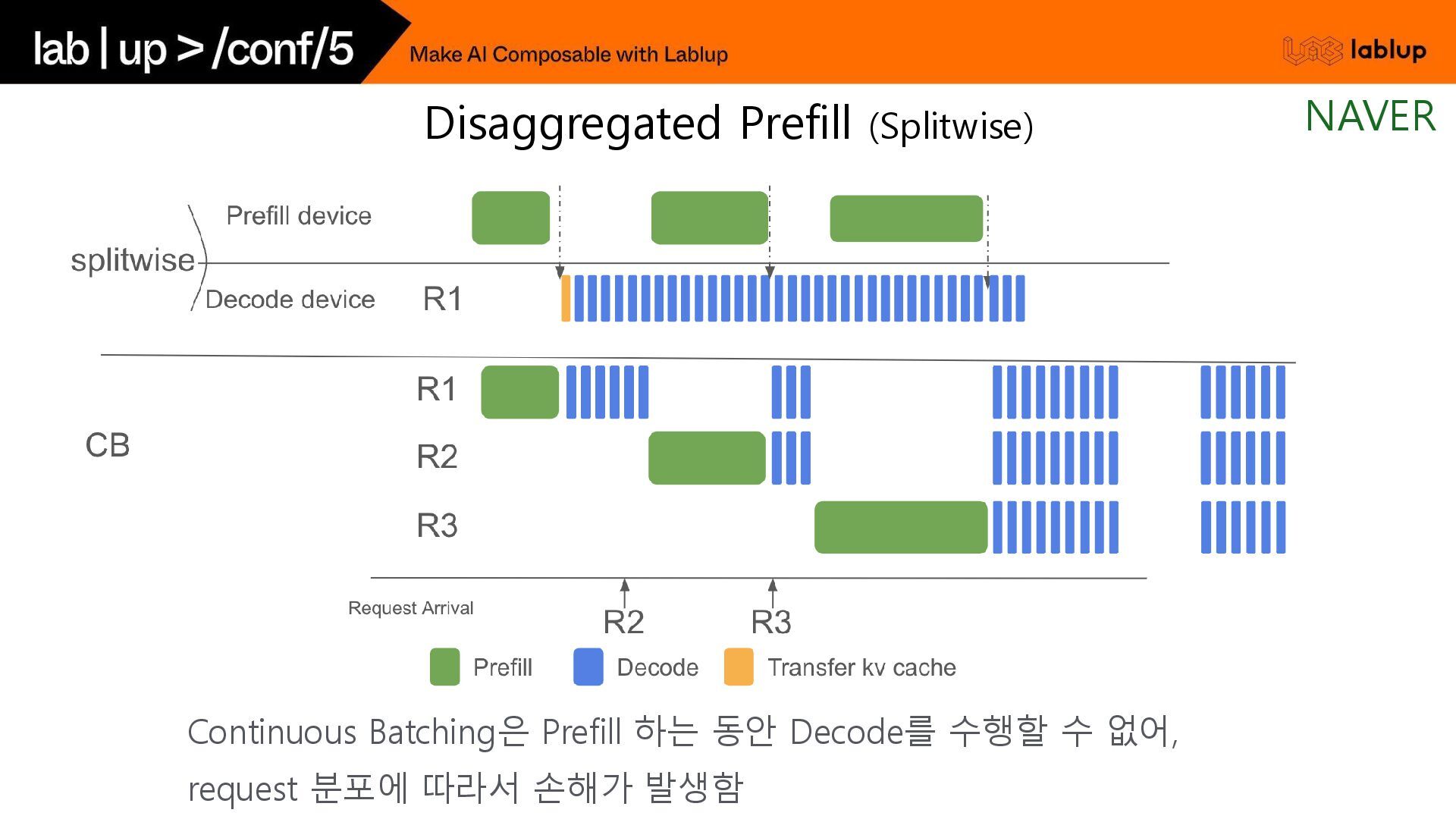{kind=link}
{kind=link}
{kind=link}
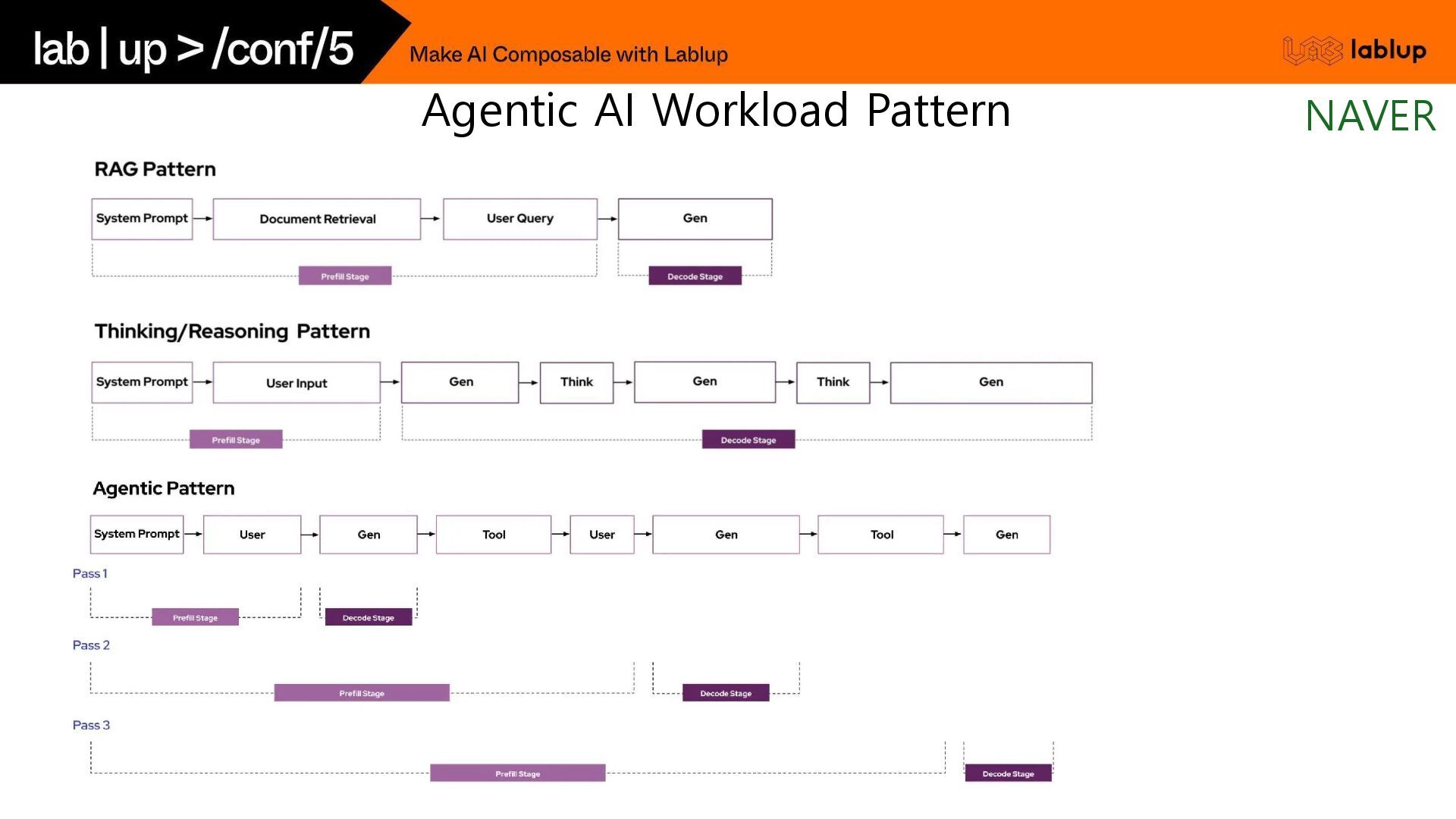{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}