I'm Laney Kuenzel, and I'm a software engineer on the product infrastructure team at Facebook. Back in January at ReactJS Conf, my teammates Dan Schafer and Jing Chen introduced Relay, a data fetching framework for React, as well as the query language that it uses, called GraphQL. In my talk today, I'll start with a description of Relay and GraphQL for those who haven't seen their talk or need a refresher, and then I'll dive into some specific parts of the Relay framework.
doing client development a year ago. At that point, we had developed the React framework as well as the Flux architecture, which provides a pattern for one-way data flow through an application. By using both React and Flux, we found that we could move faster in the development process and build more robust, reliable applications. However, there's one big question that every client developer faces that neither React nor Flux addresses: how do we fetch data from the server and organize that data once it reaches the client?
were doing client development a year ago. At that point, we had developed the React framework as well as the Flux architecture, which provides a pattern for one-way data flow through an application. By using both React and Flux, we found that we could move faster in the development process and build more robust, reliable applications. However, there's one big question that every client developer faces that neither React nor Flux addresses: how do we fetch data from the server and organize that data once it reaches the client?
at Facebook were doing client development a year ago. At that point, we had developed the React framework as well as the Flux architecture, which provides a pattern for one-way data flow through an application. By using both React and Flux, we found that we could move faster in the development process and build more robust, reliable applications. However, there's one big question that every client developer faces that neither React nor Flux addresses: how do we fetch data from the server and organize that data once it reaches the client?
application built with React and Flux. I'll use this example of a news feed story that I wrote about JSConf and in particular its like and comment section. This like and comment box was one of the first pieces of our website that we wrote with React and Flux. It's a very central part of Facebook, and it's a part that engineers across several different teams need to change frequently to update designs or introduce new features.
get the data that it needs? Well, the data comes from the server and gets passed down through the component tree. So CommentBox gets some set of data and it passes a subset of that into CommentList. CommentList uses subsets of its data to create each CommentItem. In this model, each component has to be aware of what data its children need so that it can pass that data along, and the server endpoint needs to be aware of the data required by every single component in the tree. In other words, the implementation details of each component are leaked to its parent components and to the server endpoint. Why does this matter?
get the data that it needs? Well, the data comes from the server and gets passed down through the component tree. So CommentBox gets some set of data and it passes a subset of that into CommentList. CommentList uses subsets of its data to create each CommentItem. In this model, each component has to be aware of what data its children need so that it can pass that data along, and the server endpoint needs to be aware of the data required by every single component in the tree. In other words, the implementation details of each component are leaked to its parent components and to the server endpoint. Why does this matter?
get the data that it needs? Well, the data comes from the server and gets passed down through the component tree. So CommentBox gets some set of data and it passes a subset of that into CommentList. CommentList uses subsets of its data to create each CommentItem. In this model, each component has to be aware of what data its children need so that it can pass that data along, and the server endpoint needs to be aware of the data required by every single component in the tree. In other words, the implementation details of each component are leaked to its parent components and to the server endpoint. Why does this matter?
get the data that it needs? Well, the data comes from the server and gets passed down through the component tree. So CommentBox gets some set of data and it passes a subset of that into CommentList. CommentList uses subsets of its data to create each CommentItem. In this model, each component has to be aware of what data its children need so that it can pass that data along, and the server endpoint needs to be aware of the data required by every single component in the tree. In other words, the implementation details of each component are leaked to its parent components and to the server endpoint. Why does this matter?
that if you come along and try to introduce sticker comments, you can't just make a change in CommentItem. You also need to change CommentList, CommentBox, and the data-fetching logic on the server. It's not cool to have to change all those different files—especially when you have different people all coming in, trying to make their changes, and needing to modify each of these files every time. You end up with more conflicts and a generally slower development process.
that if you come along and try to introduce sticker comments, you can't just make a change in CommentItem. You also need to change CommentList, CommentBox, and the data-fetching logic on the server. It's not cool to have to change all those different files—especially when you have different people all coming in, trying to make their changes, and needing to modify each of these files every time. You end up with more conflicts and a generally slower development process.
that if you come along and try to introduce sticker comments, you can't just make a change in CommentItem. You also need to change CommentList, CommentBox, and the data-fetching logic on the server. It's not cool to have to change all those different files—especially when you have different people all coming in, trying to make their changes, and needing to modify each of these files every time. You end up with more conflicts and a generally slower development process.
that if you come along and try to introduce sticker comments, you can't just make a change in CommentItem. You also need to change CommentList, CommentBox, and the data-fetching logic on the server. It's not cool to have to change all those different files—especially when you have different people all coming in, trying to make their changes, and needing to modify each of these files every time. You end up with more conflicts and a generally slower development process.
that if you come along and try to introduce sticker comments, you can't just make a change in CommentItem. You also need to change CommentList, CommentBox, and the data-fetching logic on the server. It's not cool to have to change all those different files—especially when you have different people all coming in, trying to make their changes, and needing to modify each of these files every time. You end up with more conflicts and a generally slower development process.
that if you come along and try to introduce sticker comments, you can't just make a change in CommentItem. You also need to change CommentList, CommentBox, and the data-fetching logic on the server. It's not cool to have to change all those different files—especially when you have different people all coming in, trying to make their changes, and needing to modify each of these files every time. You end up with more conflicts and a generally slower development process.
confusing when your data-fetching logic lives on the server but your rendering logic is on the client. Maybe you look at your server endpoint and see that you're fetching the birthdays of all the commenters. It's really hard to know at a glance whether and where that birthday data is being used in your application. Maybe someone ran an A/B test a few months ago where they showed the birthday of every commenter, but the test didn’t perform well so they removed that birthday code from the client. Now we have an overfetching problem where we're unnecessarily loading this data and sending it to the client each time we render a comment box, but never doing anything with it. Maybe we would try to do a good deed and remove this birthday-fetching code from the server to clean things up—without realizing that it actually *is* still being used in some corner of our application. Now we've introduced an underfetching bug on the client where we try to render a birthday that we don't have. It's pretty easy for the data fetching code and the rendering code to get out of sync like this, often resulting in overfetching or underfetching.
confusing when your data-fetching logic lives on the server but your rendering logic is on the client. Maybe you look at your server endpoint and see that you're fetching the birthdays of all the commenters. It's really hard to know at a glance whether and where that birthday data is being used in your application. Maybe someone ran an A/B test a few months ago where they showed the birthday of every commenter, but the test didn’t perform well so they removed that birthday code from the client. Now we have an overfetching problem where we're unnecessarily loading this data and sending it to the client each time we render a comment box, but never doing anything with it. Maybe we would try to do a good deed and remove this birthday-fetching code from the server to clean things up—without realizing that it actually *is* still being used in some corner of our application. Now we've introduced an underfetching bug on the client where we try to render a birthday that we don't have. It's pretty easy for the data fetching code and the rendering code to get out of sync like this, often resulting in overfetching or underfetching.
pretty confusing when your data-fetching logic lives on the server but your rendering logic is on the client. Maybe you look at your server endpoint and see that you're fetching the birthdays of all the commenters. It's really hard to know at a glance whether and where that birthday data is being used in your application. Maybe someone ran an A/B test a few months ago where they showed the birthday of every commenter, but the test didn’t perform well so they removed that birthday code from the client. Now we have an overfetching problem where we're unnecessarily loading this data and sending it to the client each time we render a comment box, but never doing anything with it. Maybe we would try to do a good deed and remove this birthday-fetching code from the server to clean things up—without realizing that it actually *is* still being used in some corner of our application. Now we've introduced an underfetching bug on the client where we try to render a birthday that we don't have. It's pretty easy for the data fetching code and the rendering code to get out of sync like this, often resulting in overfetching or underfetching.
pretty confusing when your data-fetching logic lives on the server but your rendering logic is on the client. Maybe you look at your server endpoint and see that you're fetching the birthdays of all the commenters. It's really hard to know at a glance whether and where that birthday data is being used in your application. Maybe someone ran an A/B test a few months ago where they showed the birthday of every commenter, but the test didn’t perform well so they removed that birthday code from the client. Now we have an overfetching problem where we're unnecessarily loading this data and sending it to the client each time we render a comment box, but never doing anything with it. Maybe we would try to do a good deed and remove this birthday-fetching code from the server to clean things up—without realizing that it actually *is* still being used in some corner of our application. Now we've introduced an underfetching bug on the client where we try to render a birthday that we don't have. It's pretty easy for the data fetching code and the rendering code to get out of sync like this, often resulting in overfetching or underfetching.
confusing when your data-fetching logic lives on the server but your rendering logic is on the client. Maybe you look at your server endpoint and see that you're fetching the birthdays of all the commenters. It's really hard to know at a glance whether and where that birthday data is being used in your application. Maybe someone ran an A/B test a few months ago where they showed the birthday of every commenter, but the test didn’t perform well so they removed that birthday code from the client. Now we have an overfetching problem where we're unnecessarily loading this data and sending it to the client each time we render a comment box, but never doing anything with it. Maybe we would try to do a good deed and remove this birthday-fetching code from the server to clean things up—without realizing that it actually *is* still being used in some corner of our application. Now we've introduced an underfetching bug on the client where we try to render a birthday that we don't have. It's pretty easy for the data fetching code and the rendering code to get out of sync like this, often resulting in overfetching or underfetching.
confusing when your data-fetching logic lives on the server but your rendering logic is on the client. Maybe you look at your server endpoint and see that you're fetching the birthdays of all the commenters. It's really hard to know at a glance whether and where that birthday data is being used in your application. Maybe someone ran an A/B test a few months ago where they showed the birthday of every commenter, but the test didn’t perform well so they removed that birthday code from the client. Now we have an overfetching problem where we're unnecessarily loading this data and sending it to the client each time we render a comment box, but never doing anything with it. Maybe we would try to do a good deed and remove this birthday-fetching code from the server to clean things up—without realizing that it actually *is* still being used in some corner of our application. Now we've introduced an underfetching bug on the client where we try to render a birthday that we don't have. It's pretty easy for the data fetching code and the rendering code to get out of sync like this, often resulting in overfetching or underfetching.
confusing when your data-fetching logic lives on the server but your rendering logic is on the client. Maybe you look at your server endpoint and see that you're fetching the birthdays of all the commenters. It's really hard to know at a glance whether and where that birthday data is being used in your application. Maybe someone ran an A/B test a few months ago where they showed the birthday of every commenter, but the test didn’t perform well so they removed that birthday code from the client. Now we have an overfetching problem where we're unnecessarily loading this data and sending it to the client each time we render a comment box, but never doing anything with it. Maybe we would try to do a good deed and remove this birthday-fetching code from the server to clean things up—without realizing that it actually *is* still being used in some corner of our application. Now we've introduced an underfetching bug on the client where we try to render a birthday that we don't have. It's pretty easy for the data fetching code and the rendering code to get out of sync like this, often resulting in overfetching or underfetching.
pretty confusing when your data-fetching logic lives on the server but your rendering logic is on the client. Maybe you look at your server endpoint and see that you're fetching the birthdays of all the commenters. It's really hard to know at a glance whether and where that birthday data is being used in your application. Maybe someone ran an A/B test a few months ago where they showed the birthday of every commenter, but the test didn’t perform well so they removed that birthday code from the client. Now we have an overfetching problem where we're unnecessarily loading this data and sending it to the client each time we render a comment box, but never doing anything with it. Maybe we would try to do a good deed and remove this birthday-fetching code from the server to clean things up—without realizing that it actually *is* still being used in some corner of our application. Now we've introduced an underfetching bug on the client where we try to render a birthday that we don't have. It's pretty easy for the data fetching code and the rendering code to get out of sync like this, often resulting in overfetching or underfetching.
confusing when your data-fetching logic lives on the server but your rendering logic is on the client. Maybe you look at your server endpoint and see that you're fetching the birthdays of all the commenters. It's really hard to know at a glance whether and where that birthday data is being used in your application. Maybe someone ran an A/B test a few months ago where they showed the birthday of every commenter, but the test didn’t perform well so they removed that birthday code from the client. Now we have an overfetching problem where we're unnecessarily loading this data and sending it to the client each time we render a comment box, but never doing anything with it. Maybe we would try to do a good deed and remove this birthday-fetching code from the server to clean things up—without realizing that it actually *is* still being used in some corner of our application. Now we've introduced an underfetching bug on the client where we try to render a birthday that we don't have. It's pretty easy for the data fetching code and the rendering code to get out of sync like this, often resulting in overfetching or underfetching.
a perfect world? Ideally, if we wanted to introduce sticker comments, we would only need to change the CommentItem component. More generally, rather than having our data-fetching logic strewn throughout the application and on the server, it would reside in just one place—the same place where we do our rendering. This is the idea at the core of Relay: that to make development easier, we should keep our logic for data fetching and rendering in the same place—namely, within the React component.
a perfect world? Ideally, if we wanted to introduce sticker comments, we would only need to change the CommentItem component. More generally, rather than having our data-fetching logic strewn throughout the application and on the server, it would reside in just one place—the same place where we do our rendering. This is the idea at the core of Relay: that to make development easier, we should keep our logic for data fetching and rendering in the same place—namely, within the React component.
the data that it needs in the form of a data query. This way, if you want to make a small change, you can just find the relevant component and change both its data query and its render method—and you're done—no need to change parent components or touch the server. With the data query and the rendering logic in one place, it's also much easier to detect when we're fetching data that we don't use or trying to use data that we didn't fetch, so we're less likely to end up with those overfetching or underfetching issues like in that birthday example. In order to achieve all these benefits of putting the data query within the component, we needed a common way for a component to declare its data requirements.
query might look. Consider what data we need about a comment's author. We want the ID, the person's name, and some information about their profile picture.
query might look. Consider what data we need about a comment's author. We want the ID, the person's name, and some information about their profile picture.
how a GraphQL query might look. Consider what data we need about a comment's author. We want the ID, the person's name, and some information about their profile picture.
concrete example of how a GraphQL query might look. Consider what data we need about a comment's author. We want the ID, the person's name, and some information about their profile picture.
width: 50, height: 50 } } Let's look at a concrete example of how a GraphQL query might look. Consider what data we need about a comment's author. We want the ID, the person's name, and some information about their profile picture.
width: 50, height: 50 } } Look at what happens when we highlight the field names and remove the values: we end up with this query—which happens to be a GraphQL query. As you can see, the query not only expresses what data we need but also describes the precise nested structure that the response data should have.
Look at what happens when we highlight the field names and remove the values: we end up with this query—which happens to be a GraphQL query. As you can see, the query not only expresses what data we need but also describes the precise nested structure that the response data should have. GraphQL is designed to be a thin layer over an existing data model, so that clients get the benefit of writing queries like this one without the server needing to be totally re-written.
the composition of queries. This means that one GraphQL query can be built up from other GraphQL queries. So, on the one hand, a component tree like this one shows us how we build the view for an application—each parent component renders its children.
the composition of queries. This means that one GraphQL query can be built up from other GraphQL queries. So, on the one hand, a component tree like this one shows us how we build the view for an application—each parent component renders its children.
the composition of queries. This means that one GraphQL query can be built up from other GraphQL queries. So, on the one hand, a component tree like this one shows us how we build the view for an application—each parent component renders its children.
the composition of queries. This means that one GraphQL query can be built up from other GraphQL queries. So, on the one hand, a component tree like this one shows us how we build the view for an application—each parent component renders its children.
the composition of queries. This means that one GraphQL query can be built up from other GraphQL queries. So, on the one hand, a component tree like this one shows us how we build the view for an application—each parent component renders its children.
step back to see how Relay works overall. Each Relay component contains a query expressed using GraphQL and a render method. Relay takes the queries from each component in the tree, builds up an overall query, and sends that to the server. The server response comes back, and Relay puts all the response data into a single store. It uses the data to construct props that it sends out to the components for rendering. At its core, this is a Flux application. The only difference is that rather than having several or many stores, a Relay application uses just one store that contains generic logic for dealing with GraphQL data. Having this single GraphQL store provides a number of nice benefits. For one, it eliminates the need for much of the Flux boilerplate. It also helps with data consistency across different parts of the application. Finally, it lets us build certain common product patterns—like paginating through a list of items—right into Relay so that engineers don't need to implement them from scratch every time.
a step back to see how Relay works overall. Each Relay component contains a query expressed using GraphQL and a render method. Relay takes the queries from each component in the tree, builds up an overall query, and sends that to the server. The server response comes back, and Relay puts all the response data into a single store. It uses the data to construct props that it sends out to the components for rendering. At its core, this is a Flux application. The only difference is that rather than having several or many stores, a Relay application uses just one store that contains generic logic for dealing with GraphQL data. Having this single GraphQL store provides a number of nice benefits. For one, it eliminates the need for much of the Flux boilerplate. It also helps with data consistency across different parts of the application. Finally, it lets us build certain common product patterns—like paginating through a list of items—right into Relay so that engineers don't need to implement them from scratch every time.
a step back to see how Relay works overall. Each Relay component contains a query expressed using GraphQL and a render method. Relay takes the queries from each component in the tree, builds up an overall query, and sends that to the server. The server response comes back, and Relay puts all the response data into a single store. It uses the data to construct props that it sends out to the components for rendering. At its core, this is a Flux application. The only difference is that rather than having several or many stores, a Relay application uses just one store that contains generic logic for dealing with GraphQL data. Having this single GraphQL store provides a number of nice benefits. For one, it eliminates the need for much of the Flux boilerplate. It also helps with data consistency across different parts of the application. Finally, it lets us build certain common product patterns—like paginating through a list of items—right into Relay so that engineers don't need to implement them from scratch every time.
a step back to see how Relay works overall. Each Relay component contains a query expressed using GraphQL and a render method. Relay takes the queries from each component in the tree, builds up an overall query, and sends that to the server. The server response comes back, and Relay puts all the response data into a single store. It uses the data to construct props that it sends out to the components for rendering. At its core, this is a Flux application. The only difference is that rather than having several or many stores, a Relay application uses just one store that contains generic logic for dealing with GraphQL data. Having this single GraphQL store provides a number of nice benefits. For one, it eliminates the need for much of the Flux boilerplate. It also helps with data consistency across different parts of the application. Finally, it lets us build certain common product patterns—like paginating through a list of items—right into Relay so that engineers don't need to implement them from scratch every time.
take a step back to see how Relay works overall. Each Relay component contains a query expressed using GraphQL and a render method. Relay takes the queries from each component in the tree, builds up an overall query, and sends that to the server. The server response comes back, and Relay puts all the response data into a single store. It uses the data to construct props that it sends out to the components for rendering. At its core, this is a Flux application. The only difference is that rather than having several or many stores, a Relay application uses just one store that contains generic logic for dealing with GraphQL data. Having this single GraphQL store provides a number of nice benefits. For one, it eliminates the need for much of the Flux boilerplate. It also helps with data consistency across different parts of the application. Finally, it lets us build certain common product patterns—like paginating through a list of items—right into Relay so that engineers don't need to implement them from scratch every time.
works, we can return to our example from before and see how much easier Relay makes our lives as we try to add sticker comments. Rather than needing to make changes in a bunch of files up the whole component tree and on the server, we only need to change the CommentItem component.
works, we can return to our example from before and see how much easier Relay makes our lives as we try to add sticker comments. Rather than needing to make changes in a bunch of files up the whole component tree and on the server, we only need to change the CommentItem component.
} More specifically, let's say that this is part of the CommentItem query. Whereas before we were only fetching the text of the comment, we can now also fetch the sticker and use that in the render method. And now we can go build other awesome stuff during the time that we would have spent changing four different files.
} More specifically, let's say that this is part of the CommentItem query. Whereas before we were only fetching the text of the comment, we can now also fetch the sticker and use that in the render method. And now we can go build other awesome stuff during the time that we would have spent changing four different files.
}, } More specifically, let's say that this is part of the CommentItem query. Whereas before we were only fetching the text of the comment, we can now also fetch the sticker and use that in the render method. And now we can go build other awesome stuff during the time that we would have spent changing four different files. Relay solves that big problem of how to fetch data in a way that scales very nicely to a complex application being developed by a large engineering team. Because the data query and render method are encapsulated within the component, it's easy for a lot of people to work on a lot of different parts of an application simultaneously. I can easily make my changes, and my teammates can easily make their changes, and people on other teams can make their changes, and we don't need to worry about stepping on each other's toes.
}, } More specifically, let's say that this is part of the CommentItem query. Whereas before we were only fetching the text of the comment, we can now also fetch the sticker and use that in the render method. And now we can go build other awesome stuff during the time that we would have spent changing four different files. Relay solves that big problem of how to fetch data in a way that scales very nicely to a complex application being developed by a large engineering team. Because the data query and render method are encapsulated within the component, it's easy for a lot of people to work on a lot of different parts of an application simultaneously. I can easily make my changes, and my teammates can easily make their changes, and people on other teams can make their changes, and we don't need to worry about stepping on each other's toes.
But a framework would have limited usefulness if it didn't also support a write path by providing an easy way for developers to let users take actions in an application, such as liking a story. Maybe even liking your own story. I'll be using the term “mutations” to refer to these actions that a user can take, which for the Facebook application might be anything from sharing a link to RSVPing to an event to poking a friend. For the rest of this talk, I'll be discussing Relay's mutation framework.
But a framework would have limited usefulness if it didn't also support a write path by providing an easy way for developers to let users take actions in an application, such as liking a story. Maybe even liking your own story. I'll be using the term “mutations” to refer to these actions that a user can take, which for the Facebook application might be anything from sharing a link to RSVPing to an event to poking a friend. For the rest of this talk, I'll be discussing Relay's mutation framework.
mutations in a pre-Relay world. When I first joined Facebook just over three years ago, I was part of the news feed product team working on the homepage of our website. And I got pretty familiar with writing mutations like this: I'd write some custom Javascript, that would call a custom server endpoint I had added to do the actual write, and then I would return data in basically any format I chose back to the JavaScript, which would update the views accordingly, usually by manually updating the DOM.
we built mutations in a pre-Relay world. When I first joined Facebook just over three years ago, I was part of the news feed product team working on the homepage of our website. And I got pretty familiar with writing mutations like this: I'd write some custom Javascript, that would call a custom server endpoint I had added to do the actual write, and then I would return data in basically any format I chose back to the JavaScript, which would update the views accordingly, usually by manually updating the DOM.
about how we built mutations in a pre-Relay world. When I first joined Facebook just over three years ago, I was part of the news feed product team working on the homepage of our website. And I got pretty familiar with writing mutations like this: I'd write some custom Javascript, that would call a custom server endpoint I had added to do the actual write, and then I would return data in basically any format I chose back to the JavaScript, which would update the views accordingly, usually by manually updating the DOM.
want to talk about how we built mutations in a pre-Relay world. When I first joined Facebook just over three years ago, I was part of the news feed product team working on the homepage of our website. And I got pretty familiar with writing mutations like this: I'd write some custom Javascript, that would call a custom server endpoint I had added to do the actual write, and then I would return data in basically any format I chose back to the JavaScript, which would update the views accordingly, usually by manually updating the DOM.
to call that same endpoint from another part of the client, I would need to shove more messy logic into the endpoint to make sure it returned all the data needed to do the update in each spot.
to call that same endpoint from another part of the client, I would need to shove more messy logic into the endpoint to make sure it returned all the data needed to do the update in each spot.
Data Format If I wanted to call that same endpoint from another part of the client, I would need to shove more messy logic into the endpoint to make sure it returned all the data needed to do the update in each spot.
Data Format If I wanted to call that same endpoint from another part of the client, I would need to shove more messy logic into the endpoint to make sure it returned all the data needed to do the update in each spot.
Data Format The key word here is “custom”—basically every time my teammates and I wanted to add a new mutation, we would start from scratch. I personally really disliked this pattern of building mutations with these custom endpoints and this custom client code; it felt repetitive and error-prone. In my mind, this pattern here was pretty much synonymous with “writing JavaScript,” so I came to think of JavaScript as something that I didn't like and didn't want to write. It wasn't until I was introduced to React and Flux that I realized that I don't really dislike JavaScript, I just dislike this crummy way of using it. I definitely never would have guessed three years ago that I would be writing JavaScript most of the time and that I would be taking part in a JavaScript conference, but here I am.
right direction by introducing a more structured API for clients to do writes as part of our Graph API. This gave the client a standardized way to specify which write to perform and to provide the necessary inputs in a structured way. But what about the data that the server returns? Since each write endpoint in this API was used by multiple different clients, there wasn't a great way to ensure that the server would return all of the data that any client might need to update itself after doing the write. Instead, we usually provided pretty minimal responses from these endpoints — often just an ID (for example, the ID of a newly-written comment) or even just a boolean indicating whether the write succeeded. At that point, there are two main options for updating data on the client: you can guess how things change and update the cached data accordingly, or you can make another round trip to the server to fetch the updated data you need. The first option has potential issues with correctness, and the second has issues with efficiency, so neither one is ideal.
the right direction by introducing a more structured API for clients to do writes as part of our Graph API. This gave the client a standardized way to specify which write to perform and to provide the necessary inputs in a structured way. But what about the data that the server returns? Since each write endpoint in this API was used by multiple different clients, there wasn't a great way to ensure that the server would return all of the data that any client might need to update itself after doing the write. Instead, we usually provided pretty minimal responses from these endpoints — often just an ID (for example, the ID of a newly-written comment) or even just a boolean indicating whether the write succeeded. At that point, there are two main options for updating data on the client: you can guess how things change and update the cached data accordingly, or you can make another round trip to the server to fetch the updated data you need. The first option has potential issues with correctness, and the second has issues with efficiency, so neither one is ideal.
a step in the right direction by introducing a more structured API for clients to do writes as part of our Graph API. This gave the client a standardized way to specify which write to perform and to provide the necessary inputs in a structured way. But what about the data that the server returns? Since each write endpoint in this API was used by multiple different clients, there wasn't a great way to ensure that the server would return all of the data that any client might need to update itself after doing the write. Instead, we usually provided pretty minimal responses from these endpoints — often just an ID (for example, the ID of a newly-written comment) or even just a boolean indicating whether the write succeeded. At that point, there are two main options for updating data on the client: you can guess how things change and update the cached data accordingly, or you can make another round trip to the server to fetch the updated data you need. The first option has potential issues with correctness, and the second has issues with efficiency, so neither one is ideal.
took a step in the right direction by introducing a more structured API for clients to do writes as part of our Graph API. This gave the client a standardized way to specify which write to perform and to provide the necessary inputs in a structured way. But what about the data that the server returns? Since each write endpoint in this API was used by multiple different clients, there wasn't a great way to ensure that the server would return all of the data that any client might need to update itself after doing the write. Instead, we usually provided pretty minimal responses from these endpoints — often just an ID (for example, the ID of a newly-written comment) or even just a boolean indicating whether the write succeeded. At that point, there are two main options for updating data on the client: you can guess how things change and update the cached data accordingly, or you can make another round trip to the server to fetch the updated data you need. The first option has potential issues with correctness, and the second has issues with efficiency, so neither one is ideal.
mutations. We took a step in the right direction by introducing a more structured API for clients to do writes as part of our Graph API. This gave the client a standardized way to specify which write to perform and to provide the necessary inputs in a structured way. But what about the data that the server returns? Since each write endpoint in this API was used by multiple different clients, there wasn't a great way to ensure that the server would return all of the data that any client might need to update itself after doing the write. Instead, we usually provided pretty minimal responses from these endpoints — often just an ID (for example, the ID of a newly-written comment) or even just a boolean indicating whether the write succeeded. At that point, there are two main options for updating data on the client: you can guess how things change and update the cached data accordingly, or you can make another round trip to the server to fetch the updated data you need. The first option has potential issues with correctness, and the second has issues with efficiency, so neither one is ideal.
So, back to mutations. We took a step in the right direction by introducing a more structured API for clients to do writes as part of our Graph API. This gave the client a standardized way to specify which write to perform and to provide the necessary inputs in a structured way. But what about the data that the server returns? Since each write endpoint in this API was used by multiple different clients, there wasn't a great way to ensure that the server would return all of the data that any client might need to update itself after doing the write. Instead, we usually provided pretty minimal responses from these endpoints — often just an ID (for example, the ID of a newly-written comment) or even just a boolean indicating whether the write succeeded. At that point, there are two main options for updating data on the client: you can guess how things change and update the cached data accordingly, or you can make another round trip to the server to fetch the updated data you need. The first option has potential issues with correctness, and the second has issues with efficiency, so neither one is ideal.
second round trip? guess? So, back to mutations. We took a step in the right direction by introducing a more structured API for clients to do writes as part of our Graph API. This gave the client a standardized way to specify which write to perform and to provide the necessary inputs in a structured way. But what about the data that the server returns? Since each write endpoint in this API was used by multiple different clients, there wasn't a great way to ensure that the server would return all of the data that any client might need to update itself after doing the write. Instead, we usually provided pretty minimal responses from these endpoints — often just an ID (for example, the ID of a newly-written comment) or even just a boolean indicating whether the write succeeded. At that point, there are two main options for updating data on the client: you can guess how things change and update the cached data accordingly, or you can make another round trip to the server to fetch the updated data you need. The first option has potential issues with correctness, and the second has issues with efficiency, so neither one is ideal.
second round trip? guess? second round trip? Updated Client So, back to mutations. We took a step in the right direction by introducing a more structured API for clients to do writes as part of our Graph API. This gave the client a standardized way to specify which write to perform and to provide the necessary inputs in a structured way. But what about the data that the server returns? Since each write endpoint in this API was used by multiple different clients, there wasn't a great way to ensure that the server would return all of the data that any client might need to update itself after doing the write. Instead, we usually provided pretty minimal responses from these endpoints — often just an ID (for example, the ID of a newly-written comment) or even just a boolean indicating whether the write succeeded. At that point, there are two main options for updating data on the client: you can guess how things change and update the cached data accordingly, or you can make another round trip to the server to fetch the updated data you need. The first option has potential issues with correctness, and the second has issues with efficiency, so neither one is ideal.
second round trip? guess? second round trip? guess? Updated Client So, back to mutations. We took a step in the right direction by introducing a more structured API for clients to do writes as part of our Graph API. This gave the client a standardized way to specify which write to perform and to provide the necessary inputs in a structured way. But what about the data that the server returns? Since each write endpoint in this API was used by multiple different clients, there wasn't a great way to ensure that the server would return all of the data that any client might need to update itself after doing the write. Instead, we usually provided pretty minimal responses from these endpoints — often just an ID (for example, the ID of a newly-written comment) or even just a boolean indicating whether the write succeeded. At that point, there are two main options for updating data on the client: you can guess how things change and update the cached data accordingly, or you can make another round trip to the server to fetch the updated data you need. The first option has potential issues with correctness, and the second has issues with efficiency, so neither one is ideal.
second round trip? guess? second round trip? guess? second round trip? Updated Client So, back to mutations. We took a step in the right direction by introducing a more structured API for clients to do writes as part of our Graph API. This gave the client a standardized way to specify which write to perform and to provide the necessary inputs in a structured way. But what about the data that the server returns? Since each write endpoint in this API was used by multiple different clients, there wasn't a great way to ensure that the server would return all of the data that any client might need to update itself after doing the write. Instead, we usually provided pretty minimal responses from these endpoints — often just an ID (for example, the ID of a newly-written comment) or even just a boolean indicating whether the write succeeded. At that point, there are two main options for updating data on the client: you can guess how things change and update the cached data accordingly, or you can make another round trip to the server to fetch the updated data you need. The first option has potential issues with correctness, and the second has issues with efficiency, so neither one is ideal.
information the client needs to update itself. So let's think about liking a story. For a mobile client that just shows the number of likes, we want the server to return the new like count. For a web client, instead of just showing the number of likes, we show what we call the “like sentence,” an internationalized string generated on the server that provides social context about who likes the story. For this client, we would want the server to return the new like sentence.
exactly the information the client needs to update itself. So let's think about liking a story. For a mobile client that just shows the number of likes, we want the server to return the new like count. For a web client, instead of just showing the number of likes, we show what we call the “like sentence,” an internationalized string generated on the server that provides social context about who likes the story. For this client, we would want the server to return the new like sentence.
exactly the information the client needs to update itself. So let's think about liking a story. For a mobile client that just shows the number of likes, we want the server to return the new like count. For a web client, instead of just showing the number of likes, we show what we call the “like sentence,” an internationalized string generated on the server that provides social context about who likes the story. For this client, we would want the server to return the new like sentence.
would contain exactly the information the client needs to update itself. So let's think about liking a story. For a mobile client that just shows the number of likes, we want the server to return the new like count. For a web client, instead of just showing the number of likes, we show what we call the “like sentence,” an internationalized string generated on the server that provides social context about who likes the story. For this client, we would want the server to return the new like sentence.
would contain exactly the information the client needs to update itself. So let's think about liking a story. For a mobile client that just shows the number of likes, we want the server to return the new like count. For a web client, instead of just showing the number of likes, we show what we call the “like sentence,” an internationalized string generated on the server that provides social context about who likes the story. For this client, we would want the server to return the new like sentence.
would contain exactly the information the client needs to update itself. So let's think about liking a story. For a mobile client that just shows the number of likes, we want the server to return the new like count. For a web client, instead of just showing the number of likes, we show what we call the “like sentence,” an internationalized string generated on the server that provides social context about who likes the story. For this client, we would want the server to return the new like sentence.
the server would contain exactly the information the client needs to update itself. So let's think about liking a story. For a mobile client that just shows the number of likes, we want the server to return the new like count. For a web client, instead of just showing the number of likes, we show what we call the “like sentence,” an internationalized string generated on the server that provides social context about who likes the story. For this client, we would want the server to return the new like sentence.
the server would contain exactly the information the client needs to update itself. So let's think about liking a story. For a mobile client that just shows the number of likes, we want the server to return the new like count. For a web client, instead of just showing the number of likes, we show what we call the “like sentence,” an internationalized string generated on the server that provides social context about who likes the story. For this client, we would want the server to return the new like sentence.
the mobile client to also show profile pictures for the likers? Then we would need to update that server endpoint to also return the picture of the new liker, so we could update the client correctly. And if our designers changed their minds and we didn't want those profile pictures anymore, we would need to clean up that logic from the server so that we weren't unnecessarily fetching and sending the profile picture each time someone liked a story. This situation should feel familiar to you—it's very similar to what we saw with data reads, where the server endpoint needs to be aware of the details of the client's rendering logic. If we change the client rendering, we need to change what we return from the write endpoint on the server, and it gets tough and time-consuming to keep the two parts of the codebase in sync.
the mobile client to also show profile pictures for the likers? Then we would need to update that server endpoint to also return the picture of the new liker, so we could update the client correctly. And if our designers changed their minds and we didn't want those profile pictures anymore, we would need to clean up that logic from the server so that we weren't unnecessarily fetching and sending the profile picture each time someone liked a story. This situation should feel familiar to you—it's very similar to what we saw with data reads, where the server endpoint needs to be aware of the details of the client's rendering logic. If we change the client rendering, we need to change what we return from the write endpoint on the server, and it gets tough and time-consuming to keep the two parts of the codebase in sync.
to change the mobile client to also show profile pictures for the likers? Then we would need to update that server endpoint to also return the picture of the new liker, so we could update the client correctly. And if our designers changed their minds and we didn't want those profile pictures anymore, we would need to clean up that logic from the server so that we weren't unnecessarily fetching and sending the profile picture each time someone liked a story. This situation should feel familiar to you—it's very similar to what we saw with data reads, where the server endpoint needs to be aware of the details of the client's rendering logic. If we change the client rendering, we need to change what we return from the write endpoint on the server, and it gets tough and time-consuming to keep the two parts of the codebase in sync.
we wanted to change the mobile client to also show profile pictures for the likers? Then we would need to update that server endpoint to also return the picture of the new liker, so we could update the client correctly. And if our designers changed their minds and we didn't want those profile pictures anymore, we would need to clean up that logic from the server so that we weren't unnecessarily fetching and sending the profile picture each time someone liked a story. This situation should feel familiar to you—it's very similar to what we saw with data reads, where the server endpoint needs to be aware of the details of the client's rendering logic. If we change the client rendering, we need to change what we return from the write endpoint on the server, and it gets tough and time-consuming to keep the two parts of the codebase in sync.
we wanted to change the mobile client to also show profile pictures for the likers? Then we would need to update that server endpoint to also return the picture of the new liker, so we could update the client correctly. And if our designers changed their minds and we didn't want those profile pictures anymore, we would need to clean up that logic from the server so that we weren't unnecessarily fetching and sending the profile picture each time someone liked a story. This situation should feel familiar to you—it's very similar to what we saw with data reads, where the server endpoint needs to be aware of the details of the client's rendering logic. If we change the client rendering, we need to change what we return from the write endpoint on the server, and it gets tough and time-consuming to keep the two parts of the codebase in sync.
we wanted to change the mobile client to also show profile pictures for the likers? Then we would need to update that server endpoint to also return the picture of the new liker, so we could update the client correctly. And if our designers changed their minds and we didn't want those profile pictures anymore, we would need to clean up that logic from the server so that we weren't unnecessarily fetching and sending the profile picture each time someone liked a story. This situation should feel familiar to you—it's very similar to what we saw with data reads, where the server endpoint needs to be aware of the details of the client's rendering logic. If we change the client rendering, we need to change what we return from the write endpoint on the server, and it gets tough and time-consuming to keep the two parts of the codebase in sync.
to change the mobile client to also show profile pictures for the likers? Then we would need to update that server endpoint to also return the picture of the new liker, so we could update the client correctly. And if our designers changed their minds and we didn't want those profile pictures anymore, we would need to clean up that logic from the server so that we weren't unnecessarily fetching and sending the profile picture each time someone liked a story. This situation should feel familiar to you—it's very similar to what we saw with data reads, where the server endpoint needs to be aware of the details of the client's rendering logic. If we change the client rendering, we need to change what we return from the write endpoint on the server, and it gets tough and time-consuming to keep the two parts of the codebase in sync.
us solve this problem. It turns out GraphQL doesn't just support data reads—it also supports mutations. How does this work? To do a data read in GraphQL, you just provide a GraphQL query and you get the response back. To do a mutation,…
of mutation you want to perform, any necessary inputs, and a query for the data you need to do a post-write update. For the example of liking a story, the type is story_like. The only input we need to provide is the id of the story we want to like. And we need two pieces of data in the response: whether the viewer likes the story, so we know whether to make the thumb blue, and the new likers count. When we send this information to GraphQL, it will perform the write, run that query, and…
type of mutation you want to perform, any necessary inputs, and a query for the data you need to do a post-write update. For the example of liking a story, the type is story_like. The only input we need to provide is the id of the story we want to like. And we need two pieces of data in the response: whether the viewer likes the story, so we know whether to make the thumb blue, and the new likers count. When we send this information to GraphQL, it will perform the write, run that query, and…
the type of mutation you want to perform, any necessary inputs, and a query for the data you need to do a post-write update. For the example of liking a story, the type is story_like. The only input we need to provide is the id of the story we want to like. And we need two pieces of data in the response: whether the viewer likes the story, so we know whether to make the thumb blue, and the new likers count. When we send this information to GraphQL, it will perform the write, run that query, and…
information: the type of mutation you want to perform, any necessary inputs, and a query for the data you need to do a post-write update. For the example of liking a story, the type is story_like. The only input we need to provide is the id of the story we want to like. And we need two pieces of data in the response: whether the viewer likes the story, so we know whether to make the thumb blue, and the new likers count. When we send this information to GraphQL, it will perform the write, run that query, and…
information: the type of mutation you want to perform, any necessary inputs, and a query for the data you need to do a post-write update. For the example of liking a story, the type is story_like. The only input we need to provide is the id of the story we want to like. And we need two pieces of data in the response: whether the viewer likes the story, so we know whether to make the thumb blue, and the new likers count. When we send this information to GraphQL, it will perform the write, run that query, and…
information: the type of mutation you want to perform, any necessary inputs, and a query for the data you need to do a post-write update. For the example of liking a story, the type is story_like. The only input we need to provide is the id of the story we want to like. And we need two pieces of data in the response: whether the viewer likes the story, so we know whether to make the thumb blue, and the new likers count. When we send this information to GraphQL, it will perform the write, run that query, and…
of information: the type of mutation you want to perform, any necessary inputs, and a query for the data you need to do a post-write update. For the example of liking a story, the type is story_like. The only input we need to provide is the id of the story we want to like. And we need two pieces of data in the response: whether the viewer likes the story, so we know whether to make the thumb blue, and the new likers count. When we send this information to GraphQL, it will perform the write, run that query, and…
three pieces of information: the type of mutation you want to perform, any necessary inputs, and a query for the data you need to do a post-write update. For the example of liking a story, the type is story_like. The only input we need to provide is the id of the story we want to like. And we need two pieces of data in the response: whether the viewer likes the story, so we know whether to make the thumb blue, and the new likers count. When we send this information to GraphQL, it will perform the write, run that query, and…
} story_like {story_id: ...} …you need to provide three pieces of information: the type of mutation you want to perform, any necessary inputs, and a query for the data you need to do a post-write update. For the example of liking a story, the type is story_like. The only input we need to provide is the id of the story we want to like. And we need two pieces of data in the response: whether the viewer likes the story, so we know whether to make the thumb blue, and the new likers count. When we send this information to GraphQL, it will perform the write, run that query, and…
then the client will update with that new data. Relay uses GraphQL mutations for all of its data writes, providing a standardized way to perform writes and update the data on the client afterwards.
then the client will update with that new data. Relay uses GraphQL mutations for all of its data writes, providing a standardized way to perform writes and update the data on the client afterwards.
} story_like {story_id: ...} Let's look back at those three pieces of information that the client needs to provide to perform a GraphQL mutation. One of the more interesting problems that we faced when working on Relay mutations was how to determine what this query should be. Our goal is to get the client data store consistent with the new post-mutation state of the world, so we need to query for anything we had in the store that changed as a result of the mutation. One option is to have the developer write these queries manually. So for this example, they would just need does_viewer_like and the likers count. But then consider what happens when someone else comes in and adds these profile pictures.
} story_like {story_id: ...} story { does_viewer_like, likers { count } } Let's look back at those three pieces of information that the client needs to provide to perform a GraphQL mutation. One of the more interesting problems that we faced when working on Relay mutations was how to determine what this query should be. Our goal is to get the client data store consistent with the new post-mutation state of the world, so we need to query for anything we had in the store that changed as a result of the mutation. One option is to have the developer write these queries manually. So for this example, they would just need does_viewer_like and the likers count. But then consider what happens when someone else comes in and adds these profile pictures.
} story_like {story_id: ...} story { does_viewer_like, likers { count } } Let's look back at those three pieces of information that the client needs to provide to perform a GraphQL mutation. One of the more interesting problems that we faced when working on Relay mutations was how to determine what this query should be. Our goal is to get the client data store consistent with the new post-mutation state of the world, so we need to query for anything we had in the store that changed as a result of the mutation. One option is to have the developer write these queries manually. So for this example, they would just need does_viewer_like and the likers count. But then consider what happens when someone else comes in and adds these profile pictures.
We perform our mutation, get the result back, go to update the client, and we don't have the new profile picture in the right size. To avoid this bug, that person adding profile pictures would need to remember to go find the story_like mutation query and add the profile picture in there. More generally, every time someone changed the rendering logic, they would need to make sure that all of the relevant mutation queries were updated as well. This wasn't a great option for us, since with Relay we really wanted to minimize these situations where making a small change in one place requires changing a bunch of other places too.
? We perform our mutation, get the result back, go to update the client, and we don't have the new profile picture in the right size. To avoid this bug, that person adding profile pictures would need to remember to go find the story_like mutation query and add the profile picture in there. More generally, every time someone changed the rendering logic, they would need to make sure that all of the relevant mutation queries were updated as well. This wasn't a great option for us, since with Relay we really wanted to minimize these situations where making a small change in one place requires changing a bunch of other places too.
query into Relay itself. How does this work? Well, intrinsic to each GraphQL mutation is the set of data that *can* change when we perform that mutation. This is independent of what any client renders; it's a property of the mutation itself. Here is the set of things that can change when a story_like occurs. If we always queried for everything that *could* change every time we did a mutation, we would certainly end up with a consistent state on the client since we would have updated anything that could possibly change, but we could also potentially be fetching a lot of data that we don't need, which is wasteful. So we have Relay keep track for each ID in its store of what set of data the client has retrieved for that ID and put into its store. Here's the set of data that we might have fetched and stored for my story. To build the mutation query, Relay intersects this set of things that *can* possibly change with what we actually have in the store. This ensures that we query for exactly the set of fields that needs to be updated. In this case, we end up with this query.
the correct mutation query into Relay itself. How does this work? Well, intrinsic to each GraphQL mutation is the set of data that *can* change when we perform that mutation. This is independent of what any client renders; it's a property of the mutation itself. Here is the set of things that can change when a story_like occurs. If we always queried for everything that *could* change every time we did a mutation, we would certainly end up with a consistent state on the client since we would have updated anything that could possibly change, but we could also potentially be fetching a lot of data that we don't need, which is wasteful. So we have Relay keep track for each ID in its store of what set of data the client has retrieved for that ID and put into its store. Here's the set of data that we might have fetched and stored for my story. To build the mutation query, Relay intersects this set of things that *can* possibly change with what we actually have in the store. This ensures that we query for exactly the set of fields that needs to be updated. In this case, we end up with this query.
we put the logic to determine the correct mutation query into Relay itself. How does this work? Well, intrinsic to each GraphQL mutation is the set of data that *can* change when we perform that mutation. This is independent of what any client renders; it's a property of the mutation itself. Here is the set of things that can change when a story_like occurs. If we always queried for everything that *could* change every time we did a mutation, we would certainly end up with a consistent state on the client since we would have updated anything that could possibly change, but we could also potentially be fetching a lot of data that we don't need, which is wasteful. So we have Relay keep track for each ID in its store of what set of data the client has retrieved for that ID and put into its store. Here's the set of data that we might have fetched and stored for my story. To build the mutation query, Relay intersects this set of things that *can* possibly change with what we actually have in the store. This ensures that we query for exactly the set of fields that needs to be updated. In this case, we end up with this query.
we’ve stored Instead, we put the logic to determine the correct mutation query into Relay itself. How does this work? Well, intrinsic to each GraphQL mutation is the set of data that *can* change when we perform that mutation. This is independent of what any client renders; it's a property of the mutation itself. Here is the set of things that can change when a story_like occurs. If we always queried for everything that *could* change every time we did a mutation, we would certainly end up with a consistent state on the client since we would have updated anything that could possibly change, but we could also potentially be fetching a lot of data that we don't need, which is wasteful. So we have Relay keep track for each ID in its store of what set of data the client has retrieved for that ID and put into its store. Here's the set of data that we might have fetched and stored for my story. To build the mutation query, Relay intersects this set of things that *can* possibly change with what we actually have in the store. This ensures that we query for exactly the set of fields that needs to be updated. In this case, we end up with this query.
... } } story { does_viewer_like, like_sentence, likers, } what can change what we’ve stored Instead, we put the logic to determine the correct mutation query into Relay itself. How does this work? Well, intrinsic to each GraphQL mutation is the set of data that *can* change when we perform that mutation. This is independent of what any client renders; it's a property of the mutation itself. Here is the set of things that can change when a story_like occurs. If we always queried for everything that *could* change every time we did a mutation, we would certainly end up with a consistent state on the client since we would have updated anything that could possibly change, but we could also potentially be fetching a lot of data that we don't need, which is wasteful. So we have Relay keep track for each ID in its store of what set of data the client has retrieved for that ID and put into its store. Here's the set of data that we might have fetched and stored for my story. To build the mutation query, Relay intersects this set of things that *can* possibly change with what we actually have in the store. This ensures that we query for exactly the set of fields that needs to be updated. In this case, we end up with this query.
... } } story { does_viewer_like, like_sentence, likers, } what can change what we’ve stored ∩ Instead, we put the logic to determine the correct mutation query into Relay itself. How does this work? Well, intrinsic to each GraphQL mutation is the set of data that *can* change when we perform that mutation. This is independent of what any client renders; it's a property of the mutation itself. Here is the set of things that can change when a story_like occurs. If we always queried for everything that *could* change every time we did a mutation, we would certainly end up with a consistent state on the client since we would have updated anything that could possibly change, but we could also potentially be fetching a lot of data that we don't need, which is wasteful. So we have Relay keep track for each ID in its store of what set of data the client has retrieved for that ID and put into its store. Here's the set of data that we might have fetched and stored for my story. To build the mutation query, Relay intersects this set of things that *can* possibly change with what we actually have in the store. This ensures that we query for exactly the set of fields that needs to be updated. In this case, we end up with this query.
... } } story { can_viewer_like, does_viewer_like, likers { count }, comments { ... } } story { does_viewer_like, like_sentence, likers, } story { does_viewer_like, like_sentence, likers, } what can change what we’ve stored ∩ Instead, we put the logic to determine the correct mutation query into Relay itself. How does this work? Well, intrinsic to each GraphQL mutation is the set of data that *can* change when we perform that mutation. This is independent of what any client renders; it's a property of the mutation itself. Here is the set of things that can change when a story_like occurs. If we always queried for everything that *could* change every time we did a mutation, we would certainly end up with a consistent state on the client since we would have updated anything that could possibly change, but we could also potentially be fetching a lot of data that we don't need, which is wasteful. So we have Relay keep track for each ID in its store of what set of data the client has retrieved for that ID and put into its store. Here's the set of data that we might have fetched and stored for my story. To build the mutation query, Relay intersects this set of things that *can* possibly change with what we actually have in the store. This ensures that we query for exactly the set of fields that needs to be updated. In this case, we end up with this query.
} Instead, we put the logic to determine the correct mutation query into Relay itself. How does this work? Well, intrinsic to each GraphQL mutation is the set of data that *can* change when we perform that mutation. This is independent of what any client renders; it's a property of the mutation itself. Here is the set of things that can change when a story_like occurs. If we always queried for everything that *could* change every time we did a mutation, we would certainly end up with a consistent state on the client since we would have updated anything that could possibly change, but we could also potentially be fetching a lot of data that we don't need, which is wasteful. So we have Relay keep track for each ID in its store of what set of data the client has retrieved for that ID and put into its store. Here's the set of data that we might have fetched and stored for my story. To build the mutation query, Relay intersects this set of things that *can* possibly change with what we actually have in the store. This ensures that we query for exactly the set of fields that needs to be updated. In this case, we end up with this query.
... } } story { does_viewer_like, like_sentence, likers, } what can change what we’ve stored The nice part of this is that if someone came along and replaced the number of likes here with the like sentence, this part of Relay that keeps track of what we store would know that we had fetched the like_sentence and not the likers count for my story, and therefore the intersected query would correctly ask for the like_sentence and not the likers count.
... } } story { does_viewer_like, like_sentence, likers, } what can change what we’ve stored The nice part of this is that if someone came along and replaced the number of likes here with the like sentence, this part of Relay that keeps track of what we store would know that we had fetched the like_sentence and not the likers count for my story, and therefore the intersected query would correctly ask for the like_sentence and not the likers count.
story { does_viewer_like, like_sentence, likers, } what can change what we’ve stored The nice part of this is that if someone came along and replaced the number of likes here with the like sentence, this part of Relay that keeps track of what we store would know that we had fetched the like_sentence and not the likers count for my story, and therefore the intersected query would correctly ask for the like_sentence and not the likers count.
part of this is that if someone came along and replaced the number of likes here with the like sentence, this part of Relay that keeps track of what we store would know that we had fetched the like_sentence and not the likers count for my story, and therefore the intersected query would correctly ask for the like_sentence and not the likers count.
mutations work—the user takes an action, and we send the name of the mutation and any inputs along to Relay. Relay performs that intersection to determine the mutation query and sends that query along with the inputs to the server. The write occurs on the server and the GraphQL endpoint returns a response to Relay, which Relay puts into its store and then notifies any affected views by sending them new props. You'll notice that this diagram is quite similar to the one I showed you earlier for the read path; in particular, the second part is identical for the two flows: GraphQL sends some data, Relay stores it, and then Relay delivers props to the relevant views. These parallels between the read and write flows are no coincidence; just like Flux, Relay treats data writes as first-class citizens by using the same core logic and code for reads and writes. If you've written mutations before, you know that even when you have v1 working—so, the write is happening on the server and the client is being updated correctly—there's often a lot more work to be done. You have to think about things like making the app feel more responsive by doing faking updates instantaneously, you have to figure out the best way to handle errors, timeouts, and retries, and you have to worry about tricky race conditions. Because Relay has this centralized mutation framework, we were able to build logic dealing with these common mutation issues into Relay itself, so that developers don't have to solve them again and again with each new mutation.
Relay mutations work—the user takes an action, and we send the name of the mutation and any inputs along to Relay. Relay performs that intersection to determine the mutation query and sends that query along with the inputs to the server. The write occurs on the server and the GraphQL endpoint returns a response to Relay, which Relay puts into its store and then notifies any affected views by sending them new props. You'll notice that this diagram is quite similar to the one I showed you earlier for the read path; in particular, the second part is identical for the two flows: GraphQL sends some data, Relay stores it, and then Relay delivers props to the relevant views. These parallels between the read and write flows are no coincidence; just like Flux, Relay treats data writes as first-class citizens by using the same core logic and code for reads and writes. If you've written mutations before, you know that even when you have v1 working—so, the write is happening on the server and the client is being updated correctly—there's often a lot more work to be done. You have to think about things like making the app feel more responsive by doing faking updates instantaneously, you have to figure out the best way to handle errors, timeouts, and retries, and you have to worry about tricky race conditions. Because Relay has this centralized mutation framework, we were able to build logic dealing with these common mutation issues into Relay itself, so that developers don't have to solve them again and again with each new mutation.
basics of how Relay mutations work—the user takes an action, and we send the name of the mutation and any inputs along to Relay. Relay performs that intersection to determine the mutation query and sends that query along with the inputs to the server. The write occurs on the server and the GraphQL endpoint returns a response to Relay, which Relay puts into its store and then notifies any affected views by sending them new props. You'll notice that this diagram is quite similar to the one I showed you earlier for the read path; in particular, the second part is identical for the two flows: GraphQL sends some data, Relay stores it, and then Relay delivers props to the relevant views. These parallels between the read and write flows are no coincidence; just like Flux, Relay treats data writes as first-class citizens by using the same core logic and code for reads and writes. If you've written mutations before, you know that even when you have v1 working—so, the write is happening on the server and the client is being updated correctly—there's often a lot more work to be done. You have to think about things like making the app feel more responsive by doing faking updates instantaneously, you have to figure out the best way to handle errors, timeouts, and retries, and you have to worry about tricky race conditions. Because Relay has this centralized mutation framework, we were able to build logic dealing with these common mutation issues into Relay itself, so that developers don't have to solve them again and again with each new mutation.
those are the basics of how Relay mutations work—the user takes an action, and we send the name of the mutation and any inputs along to Relay. Relay performs that intersection to determine the mutation query and sends that query along with the inputs to the server. The write occurs on the server and the GraphQL endpoint returns a response to Relay, which Relay puts into its store and then notifies any affected views by sending them new props. You'll notice that this diagram is quite similar to the one I showed you earlier for the read path; in particular, the second part is identical for the two flows: GraphQL sends some data, Relay stores it, and then Relay delivers props to the relevant views. These parallels between the read and write flows are no coincidence; just like Flux, Relay treats data writes as first-class citizens by using the same core logic and code for reads and writes. If you've written mutations before, you know that even when you have v1 working—so, the write is happening on the server and the client is being updated correctly—there's often a lot more work to be done. You have to think about things like making the app feel more responsive by doing faking updates instantaneously, you have to figure out the best way to handle errors, timeouts, and retries, and you have to worry about tricky race conditions. Because Relay has this centralized mutation framework, we were able to build logic dealing with these common mutation issues into Relay itself, so that developers don't have to solve them again and again with each new mutation.
those are the basics of how Relay mutations work—the user takes an action, and we send the name of the mutation and any inputs along to Relay. Relay performs that intersection to determine the mutation query and sends that query along with the inputs to the server. The write occurs on the server and the GraphQL endpoint returns a response to Relay, which Relay puts into its store and then notifies any affected views by sending them new props. You'll notice that this diagram is quite similar to the one I showed you earlier for the read path; in particular, the second part is identical for the two flows: GraphQL sends some data, Relay stores it, and then Relay delivers props to the relevant views. These parallels between the read and write flows are no coincidence; just like Flux, Relay treats data writes as first-class citizens by using the same core logic and code for reads and writes. If you've written mutations before, you know that even when you have v1 working—so, the write is happening on the server and the client is being updated correctly—there's often a lot more work to be done. You have to think about things like making the app feel more responsive by doing faking updates instantaneously, you have to figure out the best way to handle errors, timeouts, and retries, and you have to worry about tricky race conditions. Because Relay has this centralized mutation framework, we were able to build logic dealing with these common mutation issues into Relay itself, so that developers don't have to solve them again and again with each new mutation.
inputs So those are the basics of how Relay mutations work—the user takes an action, and we send the name of the mutation and any inputs along to Relay. Relay performs that intersection to determine the mutation query and sends that query along with the inputs to the server. The write occurs on the server and the GraphQL endpoint returns a response to Relay, which Relay puts into its store and then notifies any affected views by sending them new props. You'll notice that this diagram is quite similar to the one I showed you earlier for the read path; in particular, the second part is identical for the two flows: GraphQL sends some data, Relay stores it, and then Relay delivers props to the relevant views. These parallels between the read and write flows are no coincidence; just like Flux, Relay treats data writes as first-class citizens by using the same core logic and code for reads and writes. If you've written mutations before, you know that even when you have v1 working—so, the write is happening on the server and the client is being updated correctly—there's often a lot more work to be done. You have to think about things like making the app feel more responsive by doing faking updates instantaneously, you have to figure out the best way to handle errors, timeouts, and retries, and you have to worry about tricky race conditions. Because Relay has this centralized mutation framework, we were able to build logic dealing with these common mutation issues into Relay itself, so that developers don't have to solve them again and again with each new mutation.
we had built the story_like mutation using Relay as I've described so far. If I hit the like button here, I'd notice a significant delay between hitting like and the view updating, due to the fact that we wait for the server response to come back. It would certainly be nice for our users not to feel this delay. Lucky for us, Relay provides support for what we call “optimistic” mutations, where we immediately update the view to the expected post-write state, being optimistic that the write will go through without any issues on the server. Essentially, to make this happen, we can provide a payload mimicking the server response, and the view will change instantaneously based on that payload. The optimistic payload doesn't have to include everything that'll be in the server update. It can include as much or as little information as we need to make the change feel right.
we had built the story_like mutation using Relay as I've described so far. If I hit the like button here, I'd notice a significant delay between hitting like and the view updating, due to the fact that we wait for the server response to come back. It would certainly be nice for our users not to feel this delay. Lucky for us, Relay provides support for what we call “optimistic” mutations, where we immediately update the view to the expected post-write state, being optimistic that the write will go through without any issues on the server. Essentially, to make this happen, we can provide a payload mimicking the server response, and the view will change instantaneously based on that payload. The optimistic payload doesn't have to include everything that'll be in the server update. It can include as much or as little information as we need to make the change feel right.
we had built the story_like mutation using Relay as I've described so far. If I hit the like button here, I'd notice a significant delay between hitting like and the view updating, due to the fact that we wait for the server response to come back. It would certainly be nice for our users not to feel this delay. Lucky for us, Relay provides support for what we call “optimistic” mutations, where we immediately update the view to the expected post-write state, being optimistic that the write will go through without any issues on the server. Essentially, to make this happen, we can provide a payload mimicking the server response, and the view will change instantaneously based on that payload. The optimistic payload doesn't have to include everything that'll be in the server update. It can include as much or as little information as we need to make the change feel right.
story_like could be as simple as this, so that as soon as we hit like we see the like button turn blue. In this case, maybe it would look weird to see the blue like button without the updated count. Instead, we could use this optimistic payload so that at soon as we hit like, both the count and the color of the like button would change.
story_like could be as simple as this, so that as soon as we hit like we see the like button turn blue. In this case, maybe it would look weird to see the blue like button without the updated count. Instead, we could use this optimistic payload so that at soon as we hit like, both the count and the color of the like button would change.
1, } } Instead, we could use this optimistic payload so that at soon as we hit like, both the count and the color of the like button would change. If I wanted to do an optimistic update like this back when I was writing mutations on the news feed team, I would write code to manually update the DOM. In a React application, I could call setState to get my component to re-render with the optimistic data. In Relay, I just provide this optimistic payload and the framework automatically updates the views.
1, } } Instead, we could use this optimistic payload so that at soon as we hit like, both the count and the color of the like button would change. If I wanted to do an optimistic update like this back when I was writing mutations on the news feed team, I would write code to manually update the DOM. In a React application, I could call setState to get my component to re-render with the optimistic data. In Relay, I just provide this optimistic payload and the framework automatically updates the views.
scenes. Even though the view changes immediately with an optimistic update, Relay doesn't immediately overwrite the data in its central GraphQL store. Instead, we maintain a queue of in- flight mutations (that is, mutations for which we've done the optimistic update but have not yet received the server response.) When we read data from the store for the views, we read through the queue. How does this look? Let's say that this is a representation of the data in our store for my story. The UI at this point will reflect what's in the store. Now, we do a like. The UI updates to reflect the optimistic update, but you'll notice that the store remains unchanged. If we then add a comment, the UI again updates immediately with the optimistic update, but we still have not touched the store. Now, let's say that the like succeeded on the server and we get back the resulting payload. At this point, we can save that payload in the store and remove the like mutation from the queue. What happens if we get a server error from our comment? If we had immediately written that comment update into the store, this error would put us in a sticky situation where we would need to undo our changes and make sure we hadn't mucked anything up. In this case, we haven't put that comment into the store at all, so all we need to do is remove the comment mutation from the queue and we're done.
the scenes. Even though the view changes immediately with an optimistic update, Relay doesn't immediately overwrite the data in its central GraphQL store. Instead, we maintain a queue of in- flight mutations (that is, mutations for which we've done the optimistic update but have not yet received the server response.) When we read data from the store for the views, we read through the queue. How does this look? Let's say that this is a representation of the data in our store for my story. The UI at this point will reflect what's in the store. Now, we do a like. The UI updates to reflect the optimistic update, but you'll notice that the store remains unchanged. If we then add a comment, the UI again updates immediately with the optimistic update, but we still have not touched the store. Now, let's say that the like succeeded on the server and we get back the resulting payload. At this point, we can save that payload in the store and remove the like mutation from the queue. What happens if we get a server error from our comment? If we had immediately written that comment update into the store, this error would put us in a sticky situation where we would need to undo our changes and make sure we hadn't mucked anything up. In this case, we haven't put that comment into the store at all, so all we need to do is remove the comment mutation from the queue and we're done.
behind the scenes. Even though the view changes immediately with an optimistic update, Relay doesn't immediately overwrite the data in its central GraphQL store. Instead, we maintain a queue of in- flight mutations (that is, mutations for which we've done the optimistic update but have not yet received the server response.) When we read data from the store for the views, we read through the queue. How does this look? Let's say that this is a representation of the data in our store for my story. The UI at this point will reflect what's in the store. Now, we do a like. The UI updates to reflect the optimistic update, but you'll notice that the store remains unchanged. If we then add a comment, the UI again updates immediately with the optimistic update, but we still have not touched the store. Now, let's say that the like succeeded on the server and we get back the resulting payload. At this point, we can save that payload in the store and remove the like mutation from the queue. What happens if we get a server error from our comment? If we had immediately written that comment update into the store, this error would put us in a sticky situation where we would need to undo our changes and make sure we hadn't mucked anything up. In this case, we haven't put that comment into the store at all, so all we need to do is remove the comment mutation from the queue and we're done.
work behind the scenes. Even though the view changes immediately with an optimistic update, Relay doesn't immediately overwrite the data in its central GraphQL store. Instead, we maintain a queue of in- flight mutations (that is, mutations for which we've done the optimistic update but have not yet received the server response.) When we read data from the store for the views, we read through the queue. How does this look? Let's say that this is a representation of the data in our store for my story. The UI at this point will reflect what's in the store. Now, we do a like. The UI updates to reflect the optimistic update, but you'll notice that the store remains unchanged. If we then add a comment, the UI again updates immediately with the optimistic update, but we still have not touched the store. Now, let's say that the like succeeded on the server and we get back the resulting payload. At this point, we can save that payload in the store and remove the like mutation from the queue. What happens if we get a server error from our comment? If we had immediately written that comment update into the store, this error would put us in a sticky situation where we would need to undo our changes and make sure we hadn't mucked anything up. In this case, we haven't put that comment into the store at all, so all we need to do is remove the comment mutation from the queue and we're done.
mutations work behind the scenes. Even though the view changes immediately with an optimistic update, Relay doesn't immediately overwrite the data in its central GraphQL store. Instead, we maintain a queue of in- flight mutations (that is, mutations for which we've done the optimistic update but have not yet received the server response.) When we read data from the store for the views, we read through the queue. How does this look? Let's say that this is a representation of the data in our store for my story. The UI at this point will reflect what's in the store. Now, we do a like. The UI updates to reflect the optimistic update, but you'll notice that the store remains unchanged. If we then add a comment, the UI again updates immediately with the optimistic update, but we still have not touched the store. Now, let's say that the like succeeded on the server and we get back the resulting payload. At this point, we can save that payload in the store and remove the like mutation from the queue. What happens if we get a server error from our comment? If we had immediately written that comment update into the store, this error would put us in a sticky situation where we would need to undo our changes and make sure we hadn't mucked anything up. In this case, we haven't put that comment into the store at all, so all we need to do is remove the comment mutation from the queue and we're done.
at how these optimistic mutations work behind the scenes. Even though the view changes immediately with an optimistic update, Relay doesn't immediately overwrite the data in its central GraphQL store. Instead, we maintain a queue of in- flight mutations (that is, mutations for which we've done the optimistic update but have not yet received the server response.) When we read data from the store for the views, we read through the queue. How does this look? Let's say that this is a representation of the data in our store for my story. The UI at this point will reflect what's in the store. Now, we do a like. The UI updates to reflect the optimistic update, but you'll notice that the store remains unchanged. If we then add a comment, the UI again updates immediately with the optimistic update, but we still have not touched the store. Now, let's say that the like succeeded on the server and we get back the resulting payload. At this point, we can save that payload in the store and remove the like mutation from the queue. What happens if we get a server error from our comment? If we had immediately written that comment update into the store, this error would put us in a sticky situation where we would need to undo our changes and make sure we hadn't mucked anything up. In this case, we haven't put that comment into the store at all, so all we need to do is remove the comment mutation from the queue and we're done.
work behind the scenes. Even though the view changes immediately with an optimistic update, Relay doesn't immediately overwrite the data in its central GraphQL store. Instead, we maintain a queue of in- flight mutations (that is, mutations for which we've done the optimistic update but have not yet received the server response.) When we read data from the store for the views, we read through the queue. How does this look? Let's say that this is a representation of the data in our store for my story. The UI at this point will reflect what's in the store. Now, we do a like. The UI updates to reflect the optimistic update, but you'll notice that the store remains unchanged. If we then add a comment, the UI again updates immediately with the optimistic update, but we still have not touched the store. Now, let's say that the like succeeded on the server and we get back the resulting payload. At this point, we can save that payload in the store and remove the like mutation from the queue. What happens if we get a server error from our comment? If we had immediately written that comment update into the store, this error would put us in a sticky situation where we would need to undo our changes and make sure we hadn't mucked anything up. In this case, we haven't put that comment into the store at all, so all we need to do is remove the comment mutation from the queue and we're done.
how these optimistic mutations work behind the scenes. Even though the view changes immediately with an optimistic update, Relay doesn't immediately overwrite the data in its central GraphQL store. Instead, we maintain a queue of in- flight mutations (that is, mutations for which we've done the optimistic update but have not yet received the server response.) When we read data from the store for the views, we read through the queue. How does this look? Let's say that this is a representation of the data in our store for my story. The UI at this point will reflect what's in the store. Now, we do a like. The UI updates to reflect the optimistic update, but you'll notice that the store remains unchanged. If we then add a comment, the UI again updates immediately with the optimistic update, but we still have not touched the store. Now, let's say that the like succeeded on the server and we get back the resulting payload. At this point, we can save that payload in the store and remove the like mutation from the queue. What happens if we get a server error from our comment? If we had immediately written that comment update into the store, this error would put us in a sticky situation where we would need to undo our changes and make sure we hadn't mucked anything up. In this case, we haven't put that comment into the store at all, so all we need to do is remove the comment mutation from the queue and we're done.
behind the scenes. Even though the view changes immediately with an optimistic update, Relay doesn't immediately overwrite the data in its central GraphQL store. Instead, we maintain a queue of in- flight mutations (that is, mutations for which we've done the optimistic update but have not yet received the server response.) When we read data from the store for the views, we read through the queue. How does this look? Let's say that this is a representation of the data in our store for my story. The UI at this point will reflect what's in the store. Now, we do a like. The UI updates to reflect the optimistic update, but you'll notice that the store remains unchanged. If we then add a comment, the UI again updates immediately with the optimistic update, but we still have not touched the store. Now, let's say that the like succeeded on the server and we get back the resulting payload. At this point, we can save that payload in the store and remove the like mutation from the queue. What happens if we get a server error from our comment? If we had immediately written that comment update into the store, this error would put us in a sticky situation where we would need to undo our changes and make sure we hadn't mucked anything up. In this case, we haven't put that comment into the store at all, so all we need to do is remove the comment mutation from the queue and we're done.
to deal with retries. So let's look again at the scenario where we write a comment. We hit post, and the optimistic update is added to the queue. A server error comes back. Instead of just removing the comment from the queue, like in the last example, we can leave it there but mark it as having an error state. The UI can detect this error state and show a message to the user asking if they want to try again. If they do, it's simple to perform that retry since we have the original comment action sitting in the queue and it contains all the information necessary to re-send itself to the server. Hopefully it goes through the second time, and everything works nicely.
simple to deal with retries. So let's look again at the scenario where we write a comment. We hit post, and the optimistic update is added to the queue. A server error comes back. Instead of just removing the comment from the queue, like in the last example, we can leave it there but mark it as having an error state. The UI can detect this error state and show a message to the user asking if they want to try again. If they do, it's simple to perform that retry since we have the original comment action sitting in the queue and it contains all the information necessary to re-send itself to the server. Hopefully it goes through the second time, and everything works nicely.
pretty simple to deal with retries. So let's look again at the scenario where we write a comment. We hit post, and the optimistic update is added to the queue. A server error comes back. Instead of just removing the comment from the queue, like in the last example, we can leave it there but mark it as having an error state. The UI can detect this error state and show a message to the user asking if they want to try again. If they do, it's simple to perform that retry since we have the original comment action sitting in the queue and it contains all the information necessary to re-send itself to the server. Hopefully it goes through the second time, and everything works nicely.
it pretty simple to deal with retries. So let's look again at the scenario where we write a comment. We hit post, and the optimistic update is added to the queue. A server error comes back. Instead of just removing the comment from the queue, like in the last example, we can leave it there but mark it as having an error state. The UI can detect this error state and show a message to the user asking if they want to try again. If they do, it's simple to perform that retry since we have the original comment action sitting in the queue and it contains all the information necessary to re-send itself to the server. Hopefully it goes through the second time, and everything works nicely.
simple to deal with retries. So let's look again at the scenario where we write a comment. We hit post, and the optimistic update is added to the queue. A server error comes back. Instead of just removing the comment from the queue, like in the last example, we can leave it there but mark it as having an error state. The UI can detect this error state and show a message to the user asking if they want to try again. If they do, it's simple to perform that retry since we have the original comment action sitting in the queue and it contains all the information necessary to re-send itself to the server. Hopefully it goes through the second time, and everything works nicely.
pretty simple to deal with retries. So let's look again at the scenario where we write a comment. We hit post, and the optimistic update is added to the queue. A server error comes back. Instead of just removing the comment from the queue, like in the last example, we can leave it there but mark it as having an error state. The UI can detect this error state and show a message to the user asking if they want to try again. If they do, it's simple to perform that retry since we have the original comment action sitting in the queue and it contains all the information necessary to re-send itself to the server. Hopefully it goes through the second time, and everything works nicely.
to deal with retries. So let's look again at the scenario where we write a comment. We hit post, and the optimistic update is added to the queue. A server error comes back. Instead of just removing the comment from the queue, like in the last example, we can leave it there but mark it as having an error state. The UI can detect this error state and show a message to the user asking if they want to try again. If they do, it's simple to perform that retry since we have the original comment action sitting in the queue and it contains all the information necessary to re-send itself to the server. Hopefully it goes through the second time, and everything works nicely.
that it provides a solution for race conditions that happen when you get a quick sequence of mutations all affecting the same object. Consider what happens when I quickly like and unlike my story several times in a row. There's a pretty high chance of something going wrong. First, there's a race condition for these mutations hitting the server; if they reach the server in the wrong order, the server might end up with the wrong final like or unlike state. Even if the server mutations work correctly, there's also a race condition for the responses coming back--let's say that I ended up unliking it, but a like mutation is the last one to come back to the client, then the client will be in the wrong state.
is that it provides a solution for race conditions that happen when you get a quick sequence of mutations all affecting the same object. Consider what happens when I quickly like and unlike my story several times in a row. There's a pretty high chance of something going wrong. First, there's a race condition for these mutations hitting the server; if they reach the server in the wrong order, the server might end up with the wrong final like or unlike state. Even if the server mutations work correctly, there's also a race condition for the responses coming back--let's say that I ended up unliking it, but a like mutation is the last one to come back to the client, then the client will be in the wrong state.
mutations is that it provides a solution for race conditions that happen when you get a quick sequence of mutations all affecting the same object. Consider what happens when I quickly like and unlike my story several times in a row. There's a pretty high chance of something going wrong. First, there's a race condition for these mutations hitting the server; if they reach the server in the wrong order, the server might end up with the wrong final like or unlike state. Even if the server mutations work correctly, there's also a race condition for the responses coming back--let's say that I ended up unliking it, but a like mutation is the last one to come back to the client, then the client will be in the wrong state.
Relay mutations is that it provides a solution for race conditions that happen when you get a quick sequence of mutations all affecting the same object. Consider what happens when I quickly like and unlike my story several times in a row. There's a pretty high chance of something going wrong. First, there's a race condition for these mutations hitting the server; if they reach the server in the wrong order, the server might end up with the wrong final like or unlike state. Even if the server mutations work correctly, there's also a race condition for the responses coming back--let's say that I ended up unliking it, but a like mutation is the last one to come back to the client, then the client will be in the wrong state.
of Relay mutations is that it provides a solution for race conditions that happen when you get a quick sequence of mutations all affecting the same object. Consider what happens when I quickly like and unlike my story several times in a row. There's a pretty high chance of something going wrong. First, there's a race condition for these mutations hitting the server; if they reach the server in the wrong order, the server might end up with the wrong final like or unlike state. Even if the server mutations work correctly, there's also a race condition for the responses coming back--let's say that I ended up unliking it, but a like mutation is the last one to come back to the client, then the client will be in the wrong state.
of Relay mutations is that it provides a solution for race conditions that happen when you get a quick sequence of mutations all affecting the same object. Consider what happens when I quickly like and unlike my story several times in a row. There's a pretty high chance of something going wrong. First, there's a race condition for these mutations hitting the server; if they reach the server in the wrong order, the server might end up with the wrong final like or unlike state. Even if the server mutations work correctly, there's also a race condition for the responses coming back--let's say that I ended up unliking it, but a like mutation is the last one to come back to the client, then the client will be in the wrong state.
feature of Relay mutations is that it provides a solution for race conditions that happen when you get a quick sequence of mutations all affecting the same object. Consider what happens when I quickly like and unlike my story several times in a row. There's a pretty high chance of something going wrong. First, there's a race condition for these mutations hitting the server; if they reach the server in the wrong order, the server might end up with the wrong final like or unlike state. Even if the server mutations work correctly, there's also a race condition for the responses coming back--let's say that I ended up unliking it, but a like mutation is the last one to come back to the client, then the client will be in the wrong state.
Payload A final nice feature of Relay mutations is that it provides a solution for race conditions that happen when you get a quick sequence of mutations all affecting the same object. Consider what happens when I quickly like and unlike my story several times in a row. There's a pretty high chance of something going wrong. First, there's a race condition for these mutations hitting the server; if they reach the server in the wrong order, the server might end up with the wrong final like or unlike state. Even if the server mutations work correctly, there's also a race condition for the responses coming back--let's say that I ended up unliking it, but a like mutation is the last one to come back to the client, then the client will be in the wrong state.
Payload A final nice feature of Relay mutations is that it provides a solution for race conditions that happen when you get a quick sequence of mutations all affecting the same object. Consider what happens when I quickly like and unlike my story several times in a row. There's a pretty high chance of something going wrong. First, there's a race condition for these mutations hitting the server; if they reach the server in the wrong order, the server might end up with the wrong final like or unlike state. Even if the server mutations work correctly, there's also a race condition for the responses coming back--let's say that I ended up unliking it, but a like mutation is the last one to come back to the client, then the client will be in the wrong state.
we have a way to detect that these mutations are dependent and guarantee that only one of the mutations is in-flight at a given time. So in this case, the optimistic mutations all happen immediately, so the user has no idea that anything interesting is going on behind the scenes, but in the background we wait for the response for the first like to come back before we send the first unlike, and so on.
have a way to detect that these mutations are dependent and guarantee that only one of the mutations is in-flight at a given time. So in this case, the optimistic mutations all happen immediately, so the user has no idea that anything interesting is going on behind the scenes, but in the background we wait for the response for the first like to come back before we send the first unlike, and so on.
a way to detect that these mutations are dependent and guarantee that only one of the mutations is in-flight at a given time. So in this case, the optimistic mutations all happen immediately, so the user has no idea that anything interesting is going on behind the scenes, but in the background we wait for the response for the first like to come back before we send the first unlike, and so on.
have a way to detect that these mutations are dependent and guarantee that only one of the mutations is in-flight at a given time. So in this case, the optimistic mutations all happen immediately, so the user has no idea that anything interesting is going on behind the scenes, but in the background we wait for the response for the first like to come back before we send the first unlike, and so on.
framework—are already being used in production at Facebook, including in our standalone groups app and our mobile ads manager app, where we’re using Relay with React Native. I want to spend the last few minutes discussing a part of Relay that we're currently working on, that's not yet in production. I showed this diagram earlier to explain mutations in Relay. As I described, Relay can receive a mutation payload from GraphQL, store it, and send new props to any affected views. In this diagram, the action originates from the person using the application. But that doesn't have to be the case.
inputs All of what I've described so far—Relay and its mutations framework—are already being used in production at Facebook, including in our standalone groups app and our mobile ads manager app, where we’re using Relay with React Native. I want to spend the last few minutes discussing a part of Relay that we're currently working on, that's not yet in production. I showed this diagram earlier to explain mutations in Relay. As I described, Relay can receive a mutation payload from GraphQL, store it, and send new props to any affected views. In this diagram, the action originates from the person using the application. But that doesn't have to be the case.
his phone, and that action goes into the cloud. At that point, we can use this same path to send his mutation payload to Relay, put it in the store, and then update the views to show his comment. We call this a subscription, so if I’m looking at a news feed story, I can subscribe to all new comments on that story and provide a GraphQL query for what specific data I want about each new comment, and then with the support of a pub-sub system in the backend, we can ensure that all of those mutation payloads are delivered to me whenever someone adds a comment and that Relay automatically updates its views. Along the same lines as Meteor and Firebase, this subscriptions piece of Relay provides a simple way to build dynamic applications that feel alive with real-time updates, something that we're excited about integrating into various parts of Facebook.
from his phone, and that action goes into the cloud. At that point, we can use this same path to send his mutation payload to Relay, put it in the store, and then update the views to show his comment. We call this a subscription, so if I’m looking at a news feed story, I can subscribe to all new comments on that story and provide a GraphQL query for what specific data I want about each new comment, and then with the support of a pub-sub system in the backend, we can ensure that all of those mutation payloads are delivered to me whenever someone adds a comment and that Relay automatically updates its views. Along the same lines as Meteor and Firebase, this subscriptions piece of Relay provides a simple way to build dynamic applications that feel alive with real-time updates, something that we're excited about integrating into various parts of Facebook.
from his phone, and that action goes into the cloud. At that point, we can use this same path to send his mutation payload to Relay, put it in the store, and then update the views to show his comment. We call this a subscription, so if I’m looking at a news feed story, I can subscribe to all new comments on that story and provide a GraphQL query for what specific data I want about each new comment, and then with the support of a pub-sub system in the backend, we can ensure that all of those mutation payloads are delivered to me whenever someone adds a comment and that Relay automatically updates its views. Along the same lines as Meteor and Firebase, this subscriptions piece of Relay provides a simple way to build dynamic applications that feel alive with real-time updates, something that we're excited about integrating into various parts of Facebook.
from his phone, and that action goes into the cloud. At that point, we can use this same path to send his mutation payload to Relay, put it in the store, and then update the views to show his comment. We call this a subscription, so if I’m looking at a news feed story, I can subscribe to all new comments on that story and provide a GraphQL query for what specific data I want about each new comment, and then with the support of a pub-sub system in the backend, we can ensure that all of those mutation payloads are delivered to me whenever someone adds a comment and that Relay automatically updates its views. Along the same lines as Meteor and Firebase, this subscriptions piece of Relay provides a simple way to build dynamic applications that feel alive with real-time updates, something that we're excited about integrating into various parts of Facebook.
from his phone, and that action goes into the cloud. At that point, we can use this same path to send his mutation payload to Relay, put it in the store, and then update the views to show his comment. We call this a subscription, so if I’m looking at a news feed story, I can subscribe to all new comments on that story and provide a GraphQL query for what specific data I want about each new comment, and then with the support of a pub-sub system in the backend, we can ensure that all of those mutation payloads are delivered to me whenever someone adds a comment and that Relay automatically updates its views. Along the same lines as Meteor and Firebase, this subscriptions piece of Relay provides a simple way to build dynamic applications that feel alive with real-time updates, something that we're excited about integrating into various parts of Facebook.
my story from his phone, and that action goes into the cloud. At that point, we can use this same path to send his mutation payload to Relay, put it in the store, and then update the views to show his comment. We call this a subscription, so if I’m looking at a news feed story, I can subscribe to all new comments on that story and provide a GraphQL query for what specific data I want about each new comment, and then with the support of a pub-sub system in the backend, we can ensure that all of those mutation payloads are delivered to me whenever someone adds a comment and that Relay automatically updates its views. Along the same lines as Meteor and Firebase, this subscriptions piece of Relay provides a simple way to build dynamic applications that feel alive with real-time updates, something that we're excited about integrating into various parts of Facebook.
points I covered. The core idea of Relay is that we should keep our data fetching logic together with the rendering logic within each component. We've found that this approach scales really well to a big application being built by a big team. One of our main goals in designing Relay has been to identify problematic patterns that people face again and again when building applications and pull the complexity of those patterns into the framework itself. We saw a few examples of this today with Relay mutations, from the way that we do that automatic intersection to build the right mutation query to the way we do optimistic updates with a mutations queue to the solution for race conditions. In each case, someone using Relay gets all of these common problems solved for free and can focus on bigger and better things.
listening! If you have any questions, I’ll be around the rest of the week. My teammates Joe, Jing, and Tom are also here and we’re all excited to talk about this stuff with you guys.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
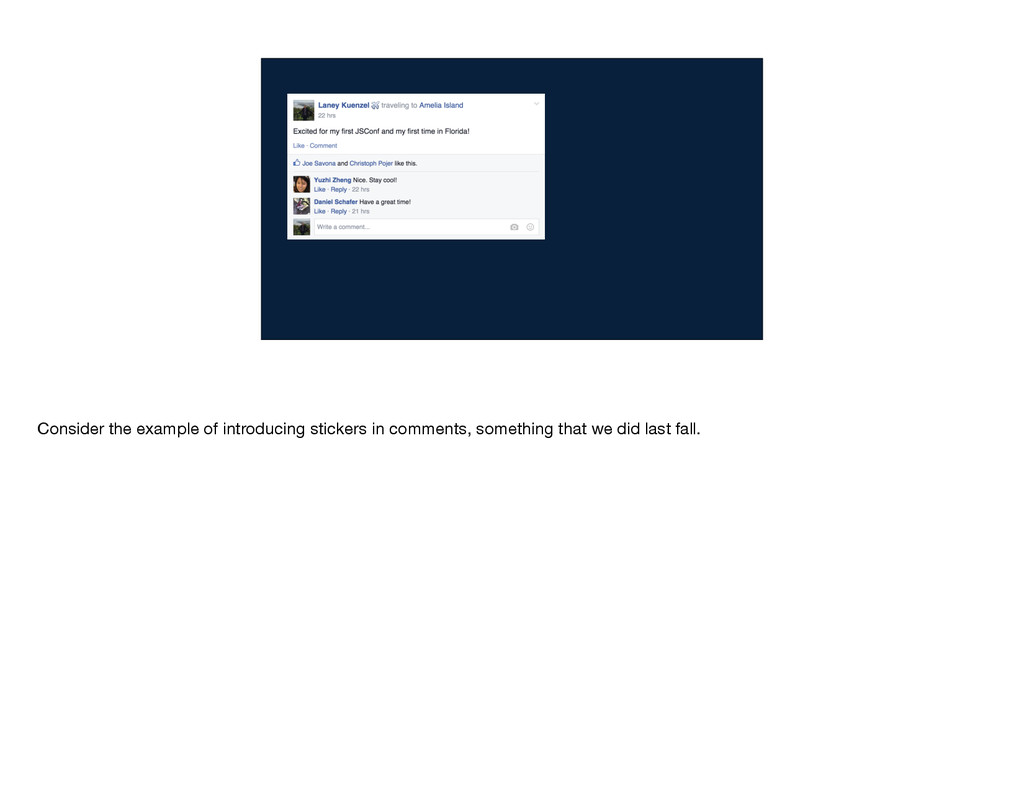{kind=link}
{kind=link}
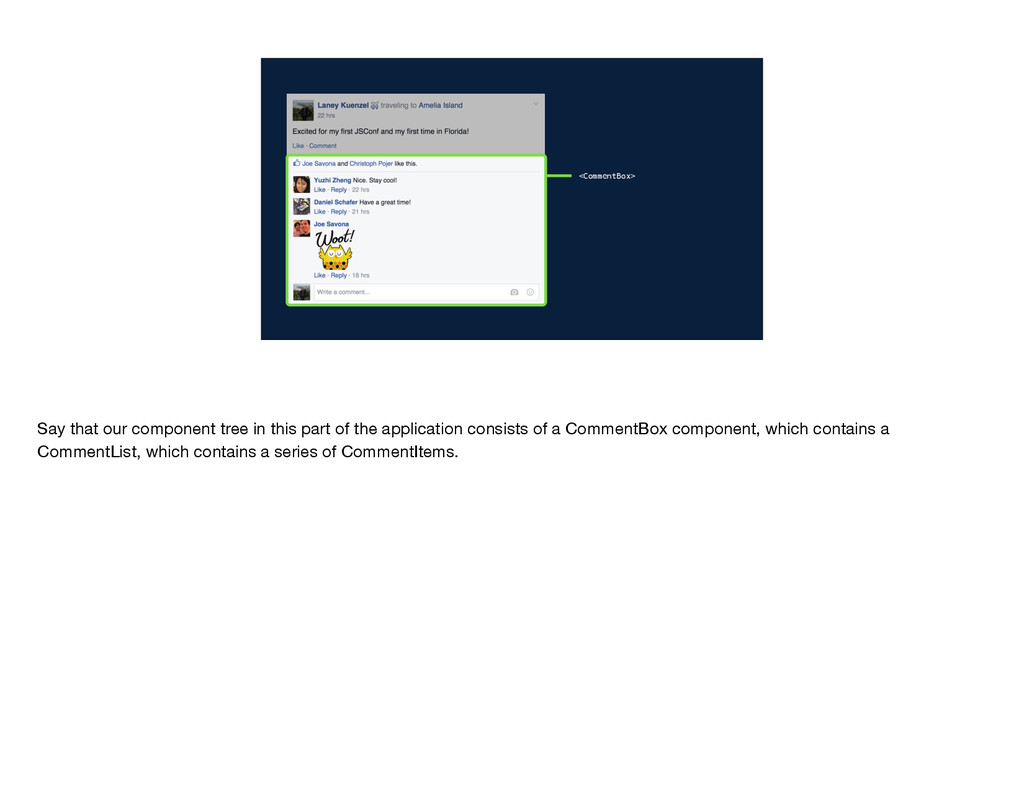{kind=link}
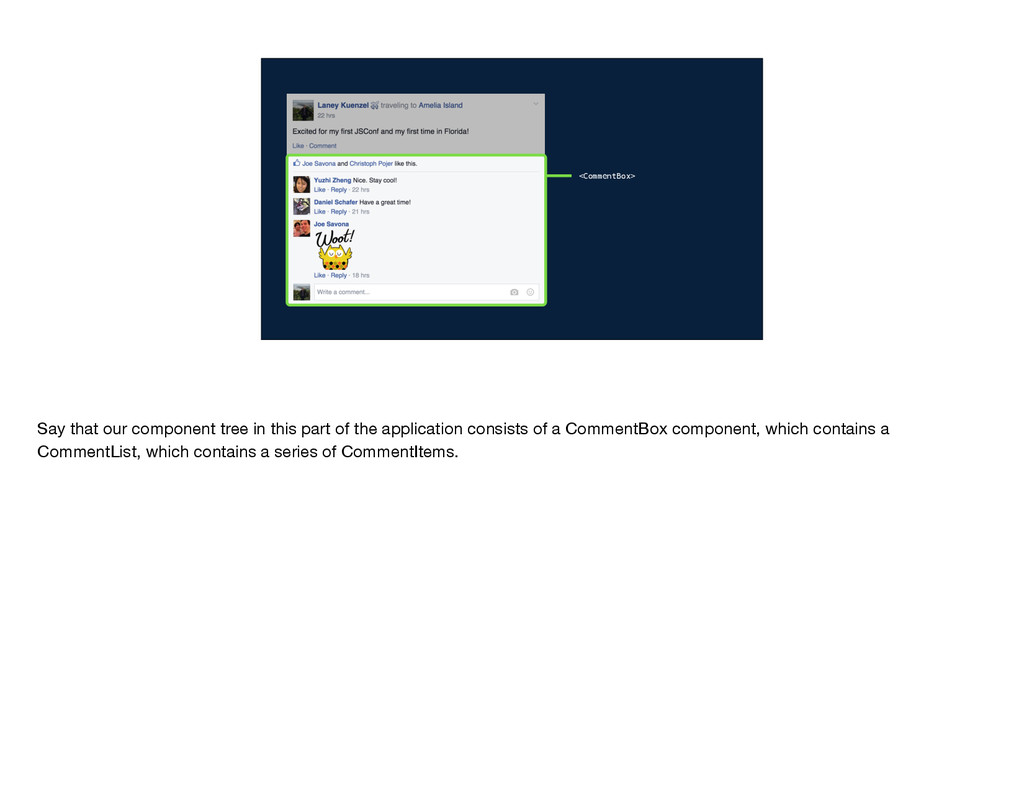{kind=link}
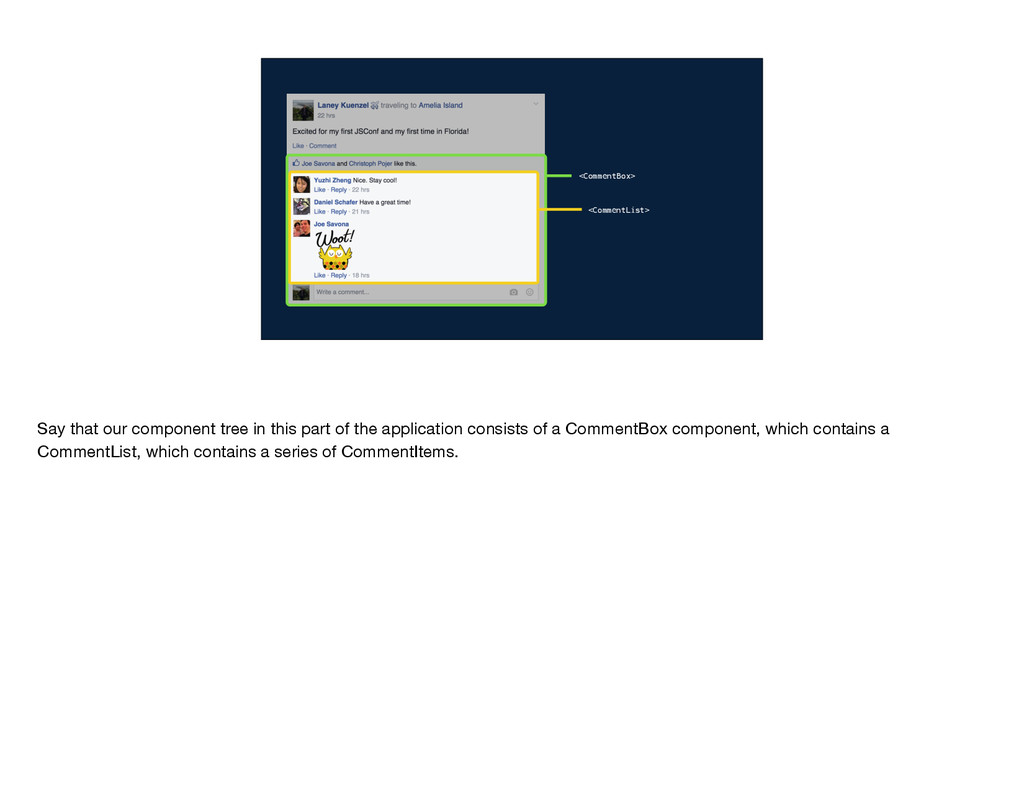{kind=link}
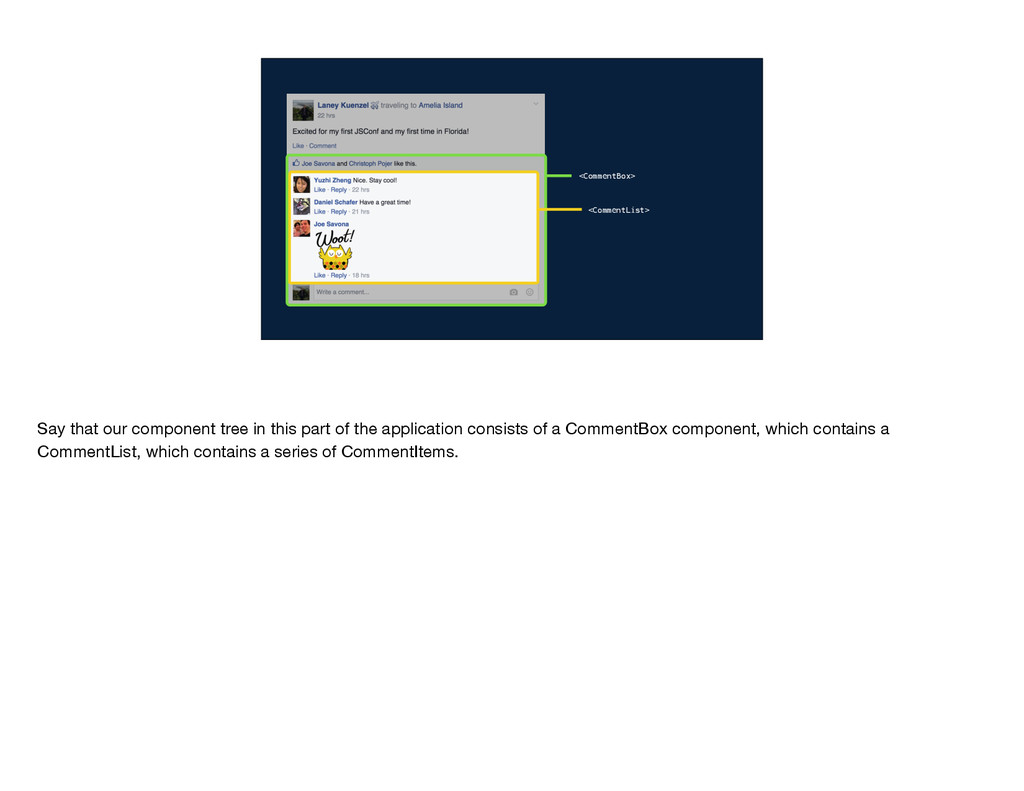{kind=link}
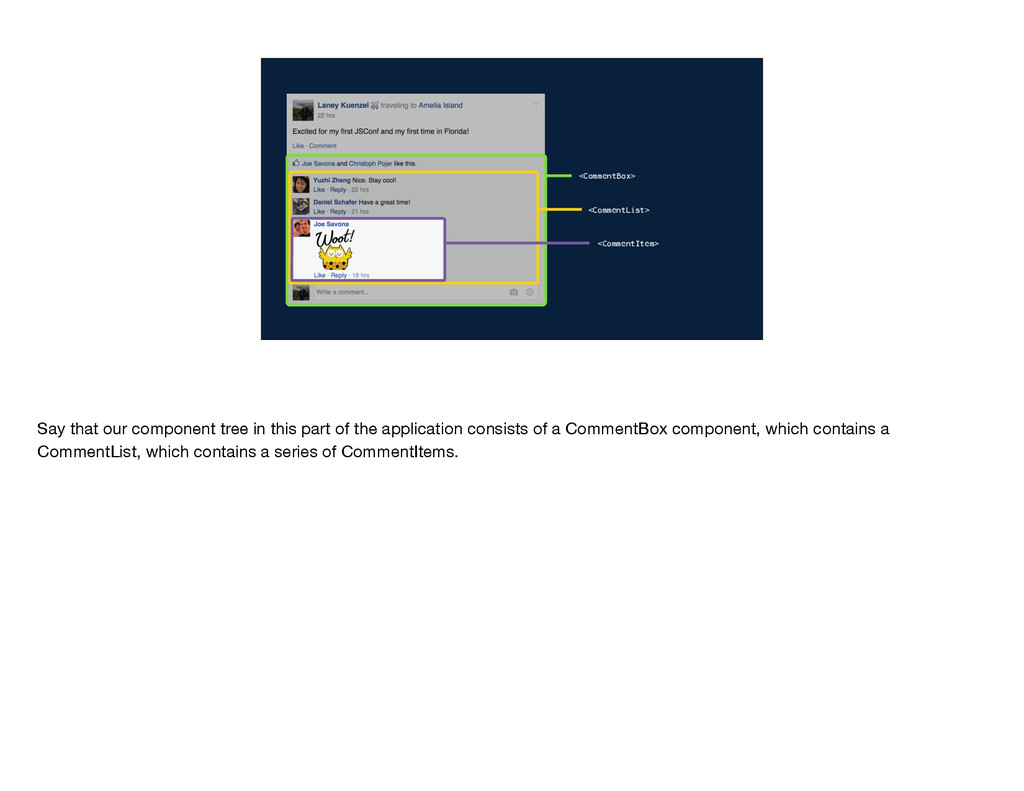{kind=link}
{kind=link}
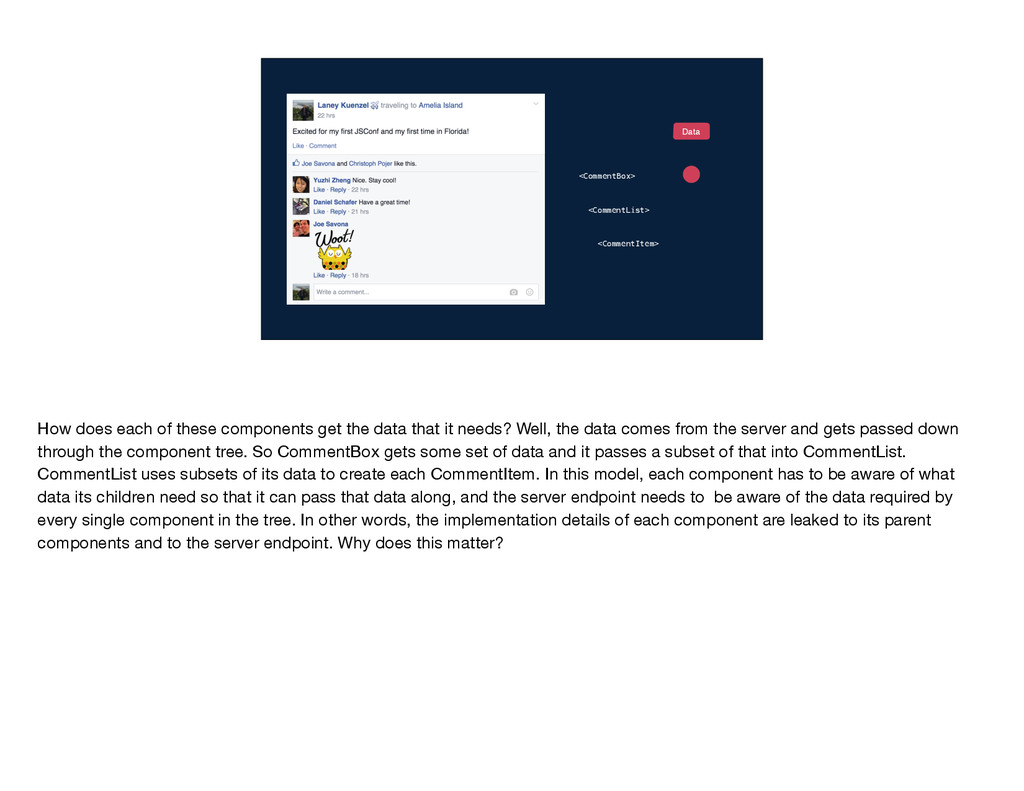{kind=link}
{kind=link}
{kind=link}
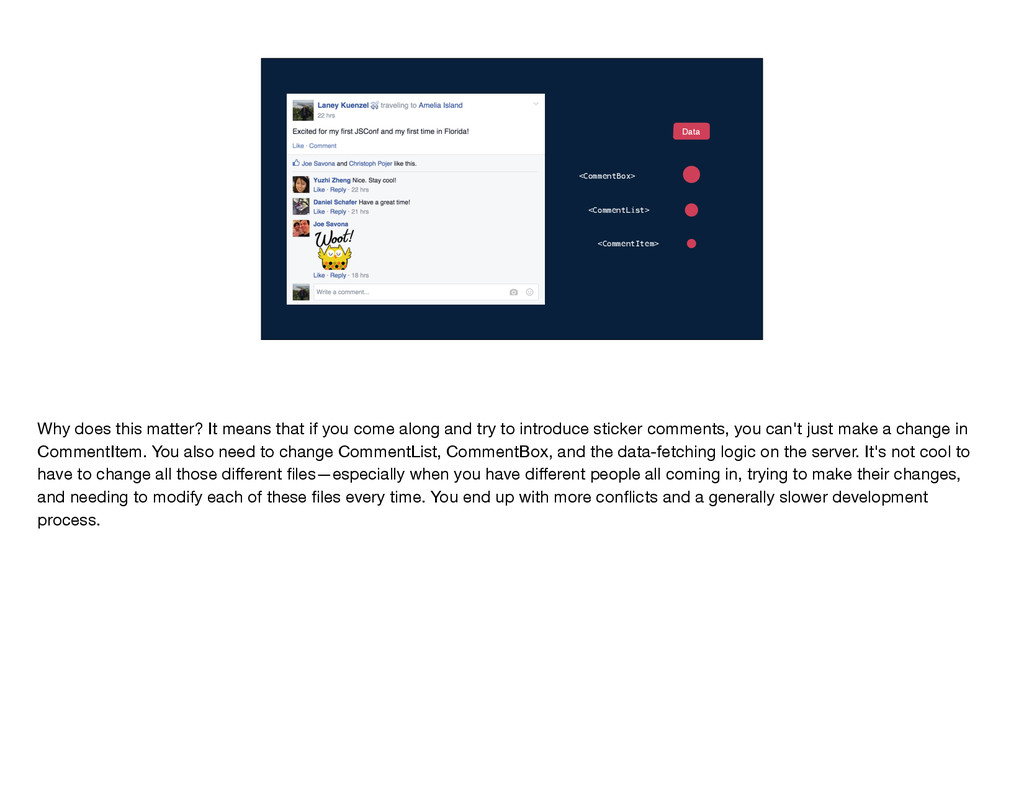{kind=link}
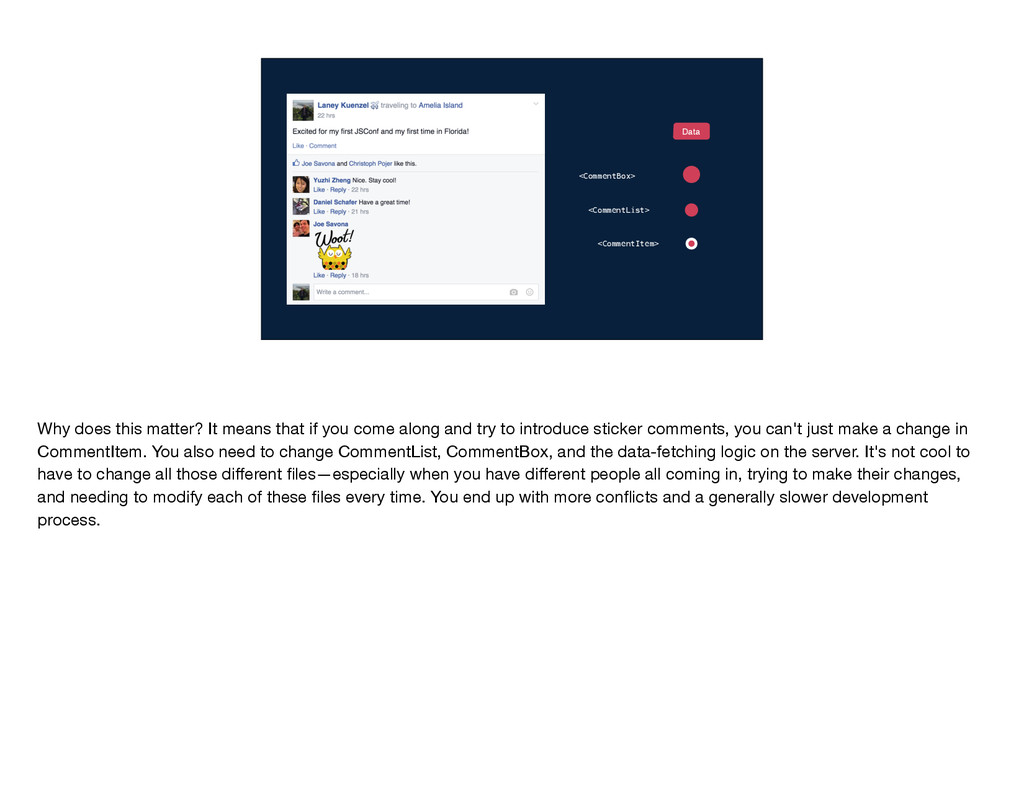{kind=link}
{kind=link}
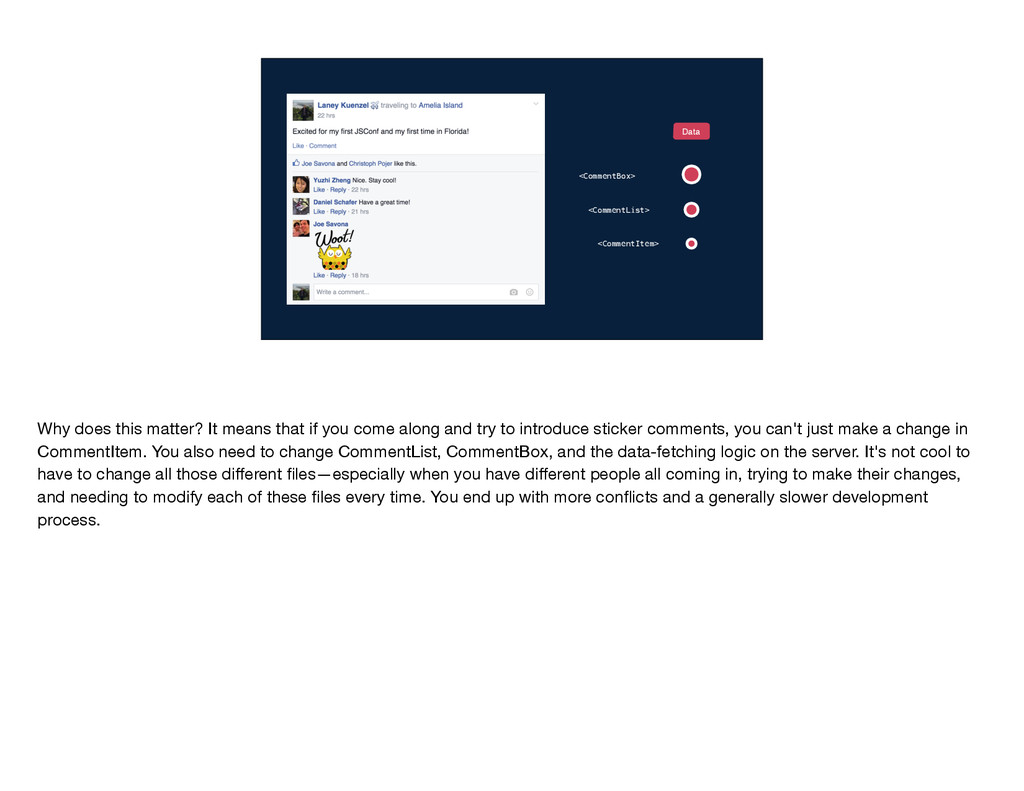{kind=link}
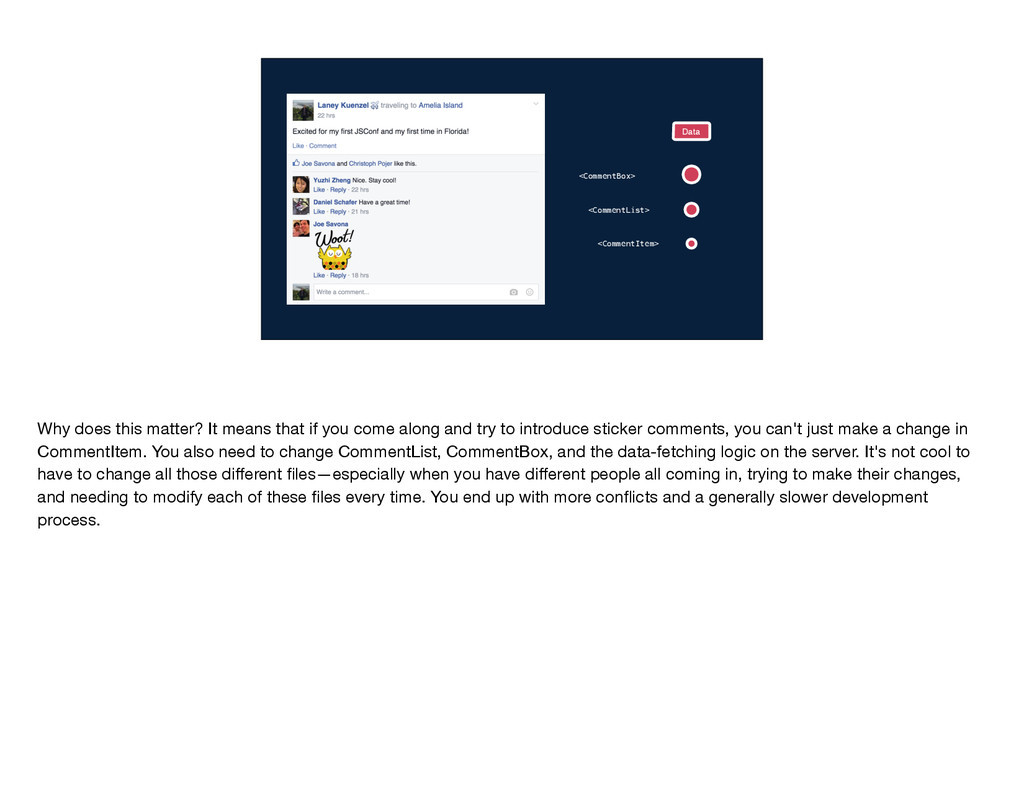{kind=link}
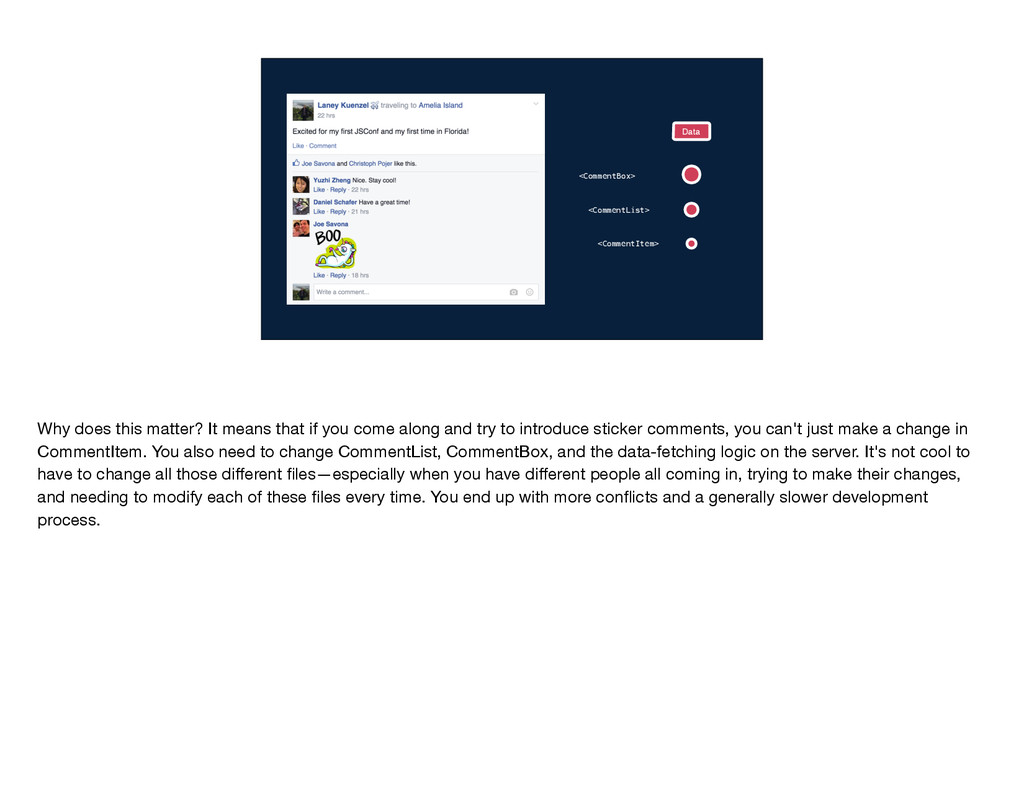{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
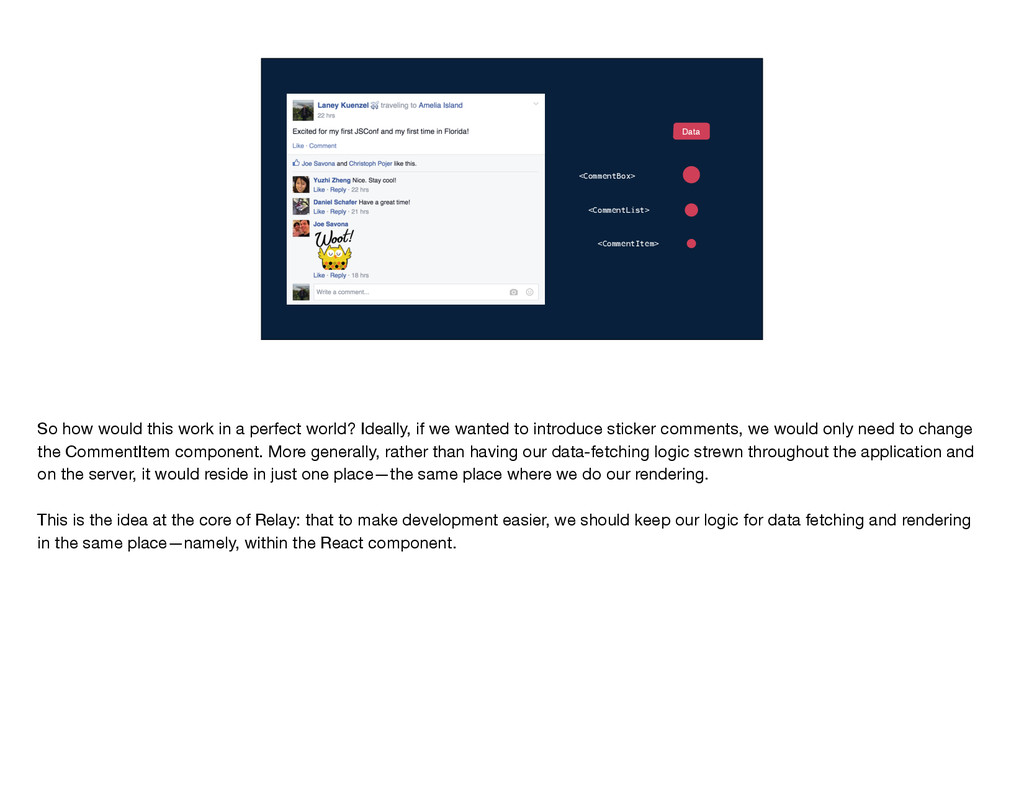{kind=link}
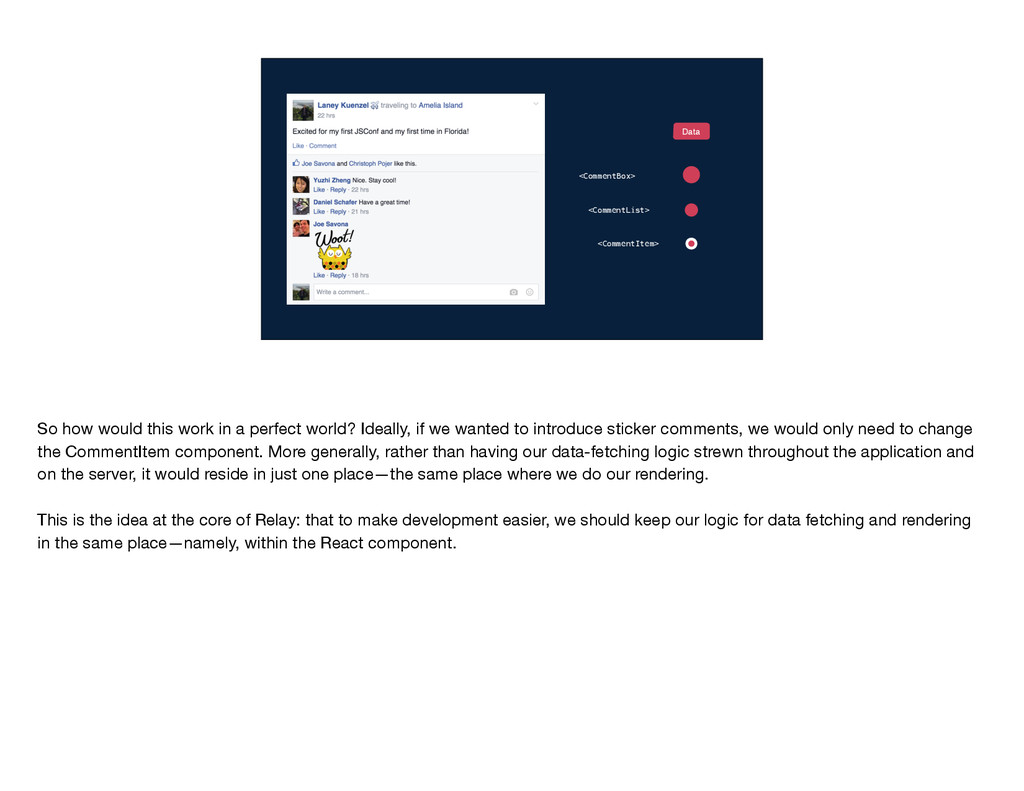{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
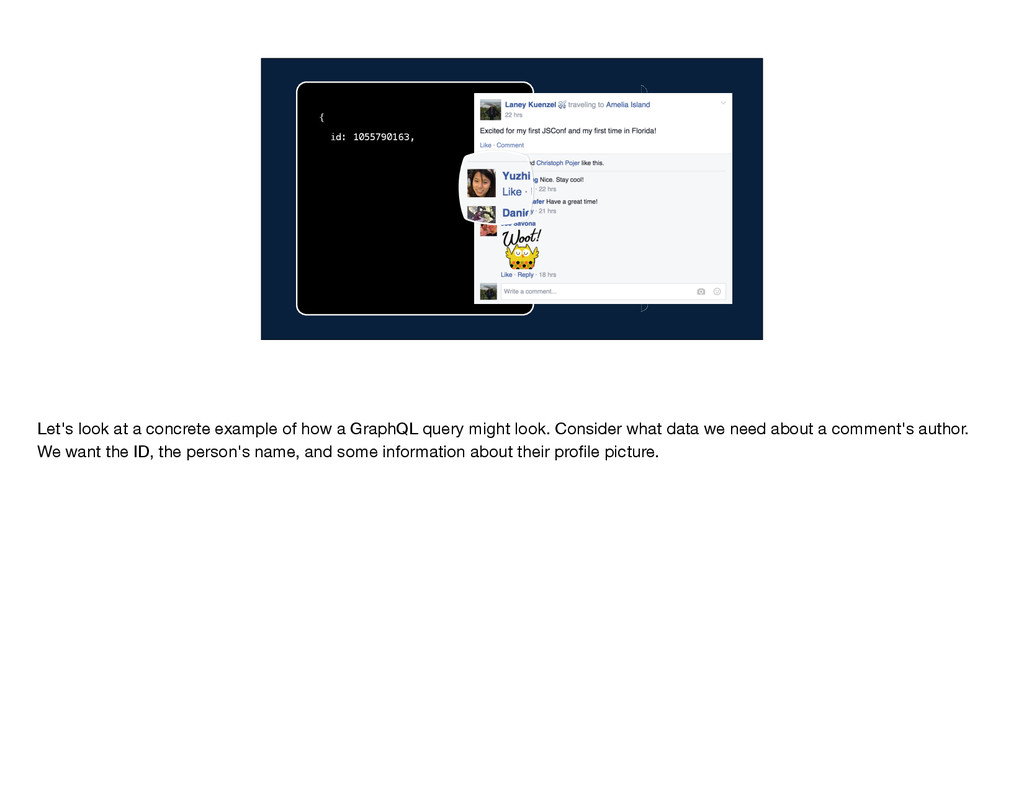{kind=link}
{kind=link}
{kind=link}
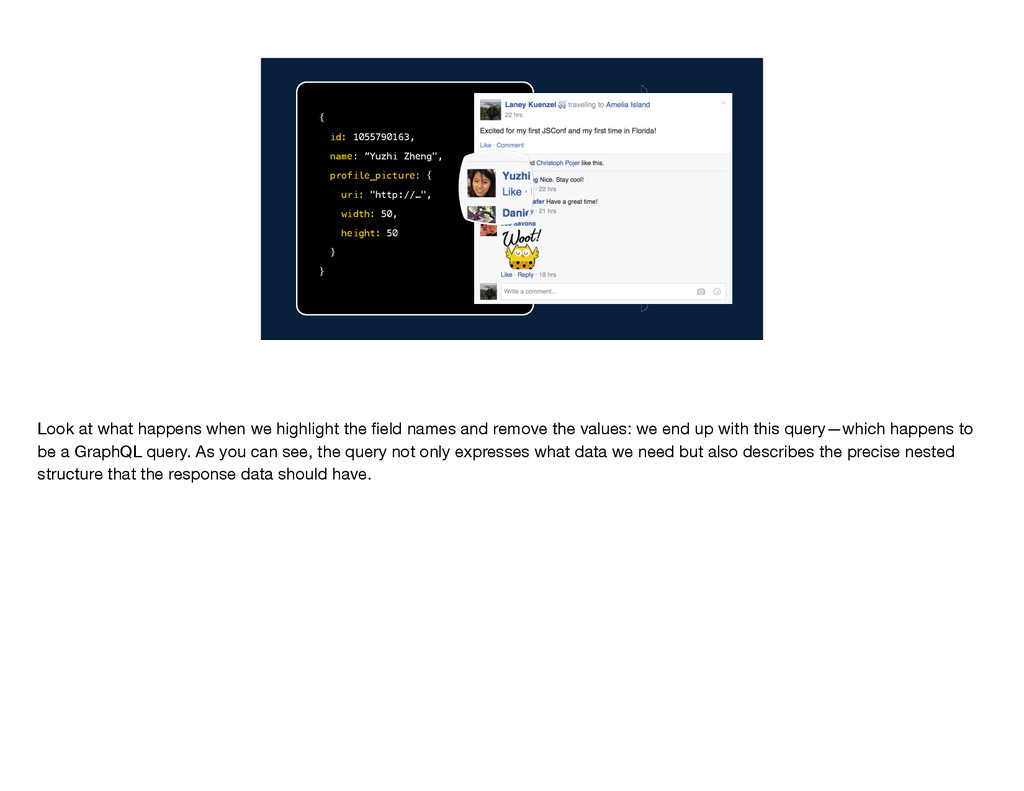{kind=link}
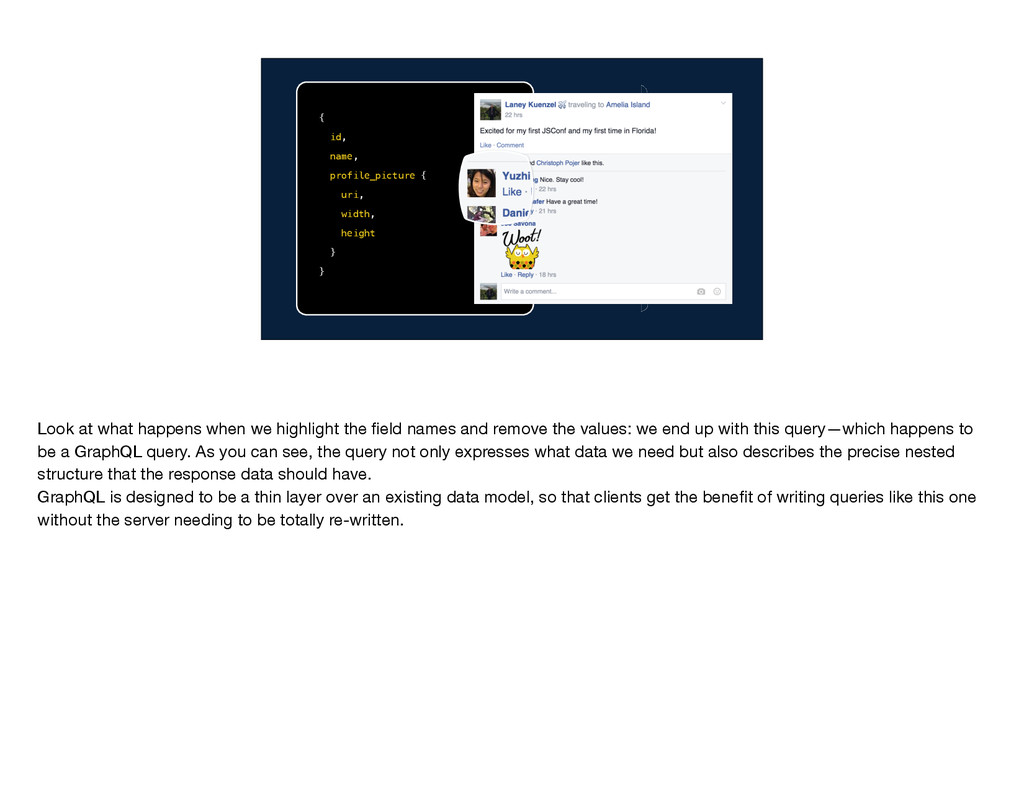{kind=link}
{kind=link}
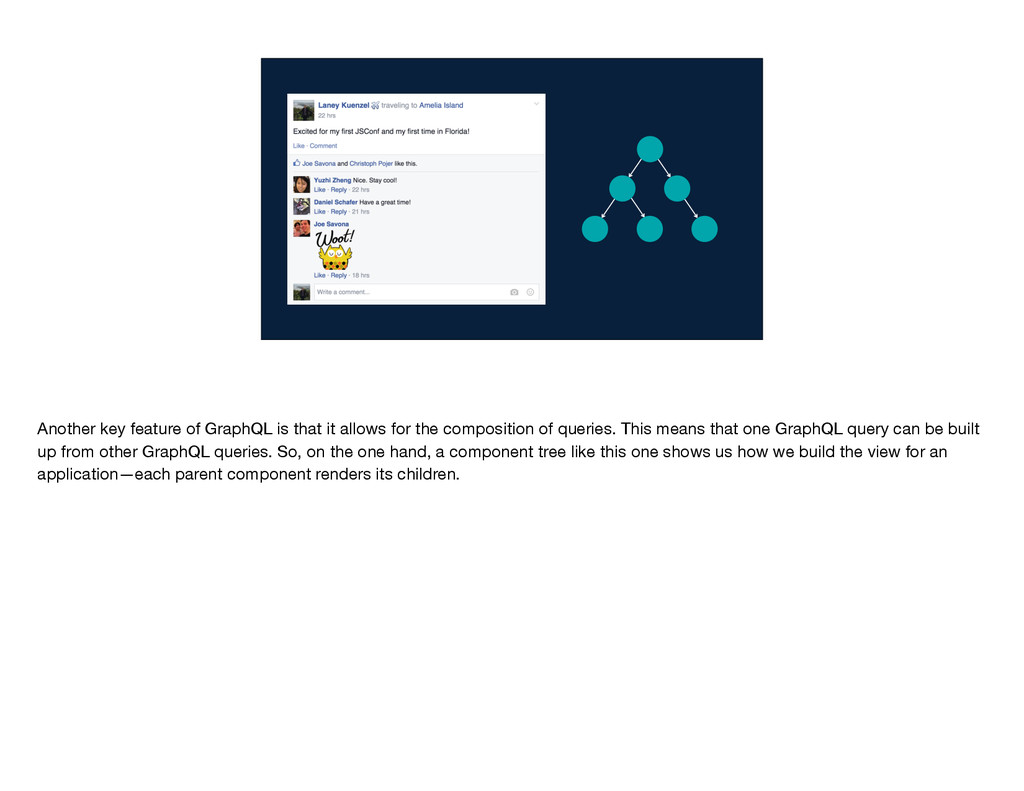{kind=link}
{kind=link}
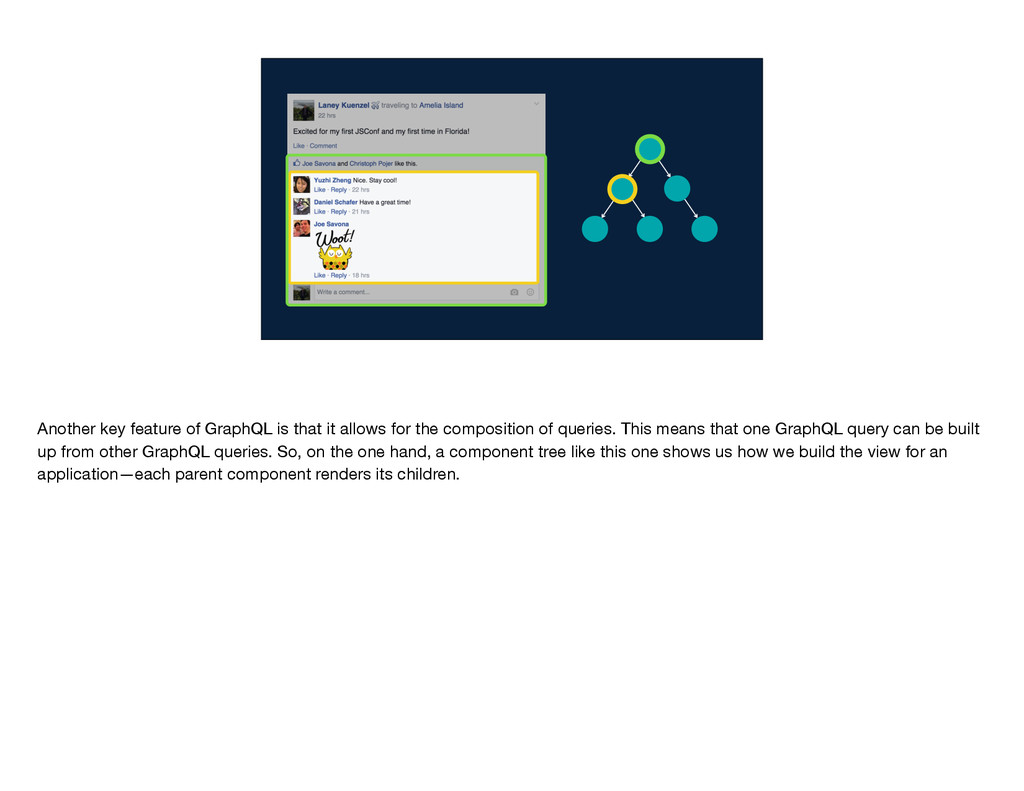{kind=link}
{kind=link}
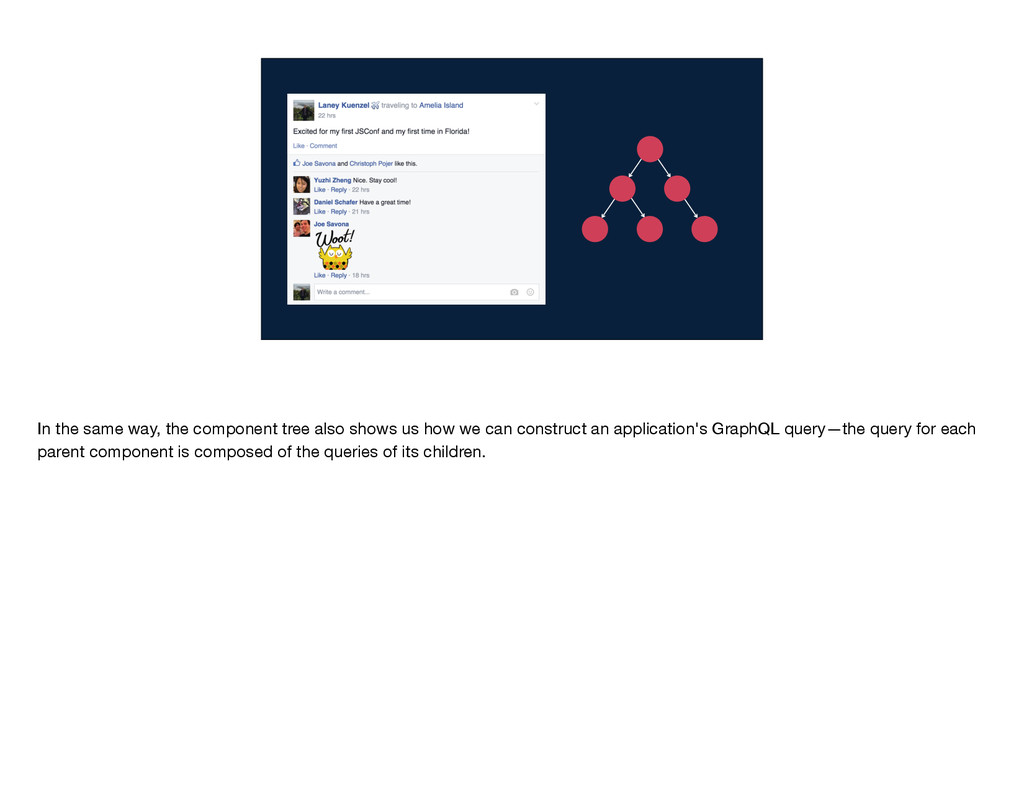{kind=link}
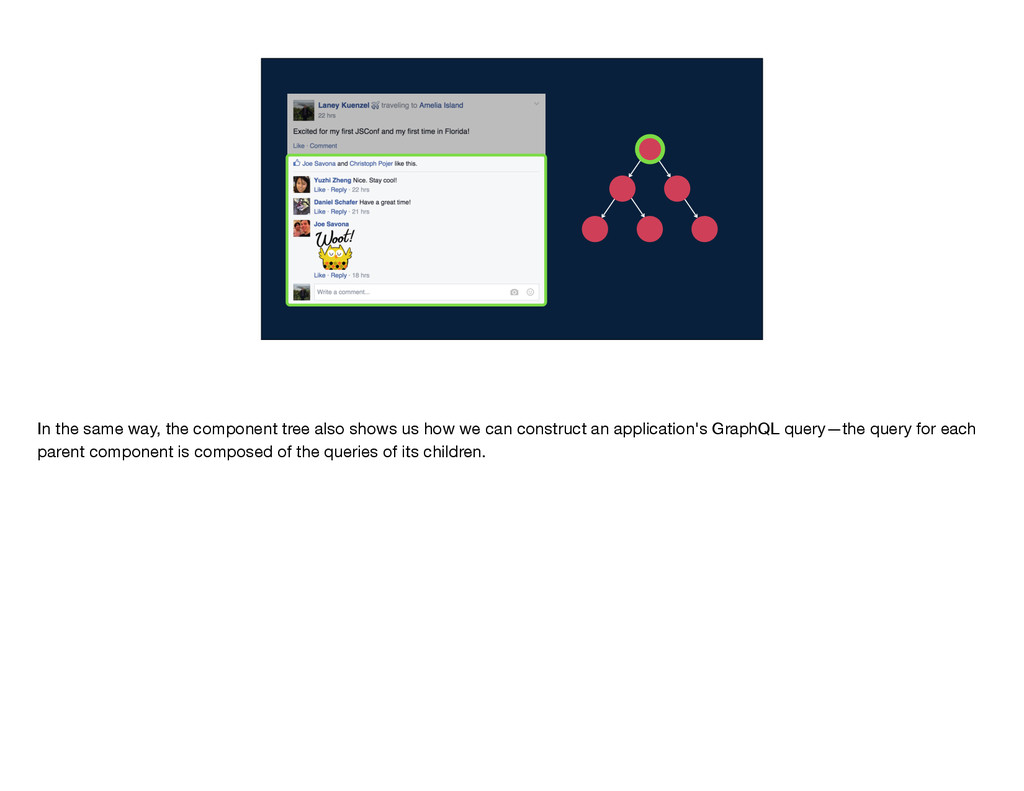{kind=link}
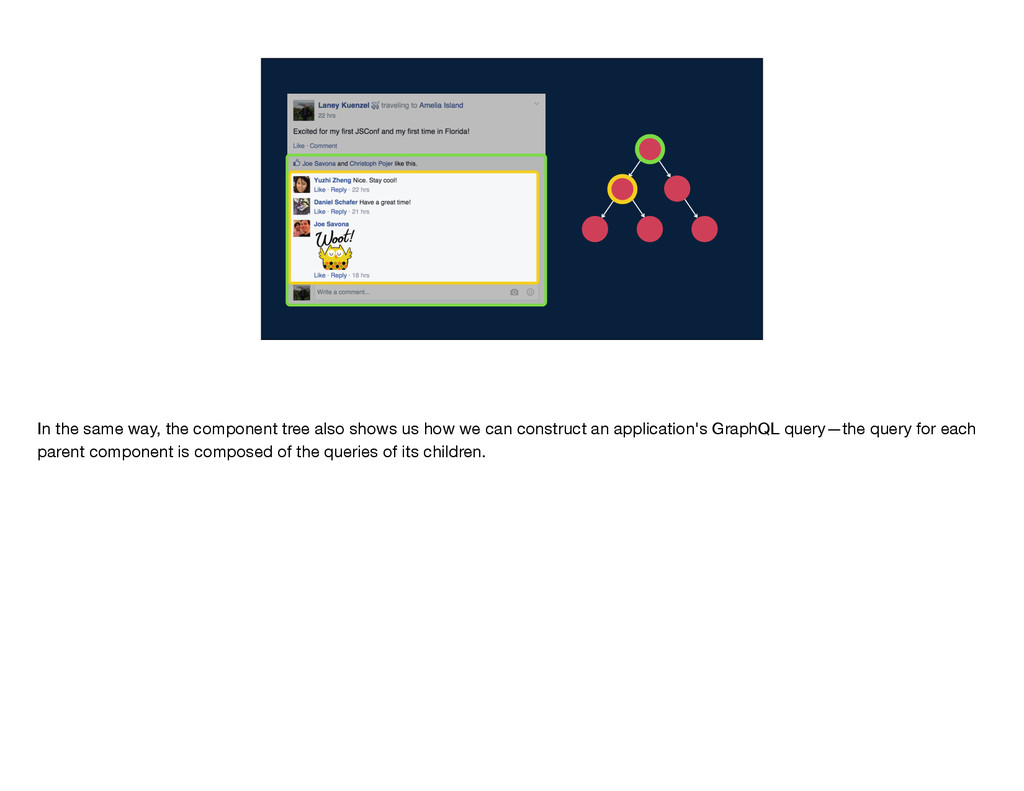{kind=link}
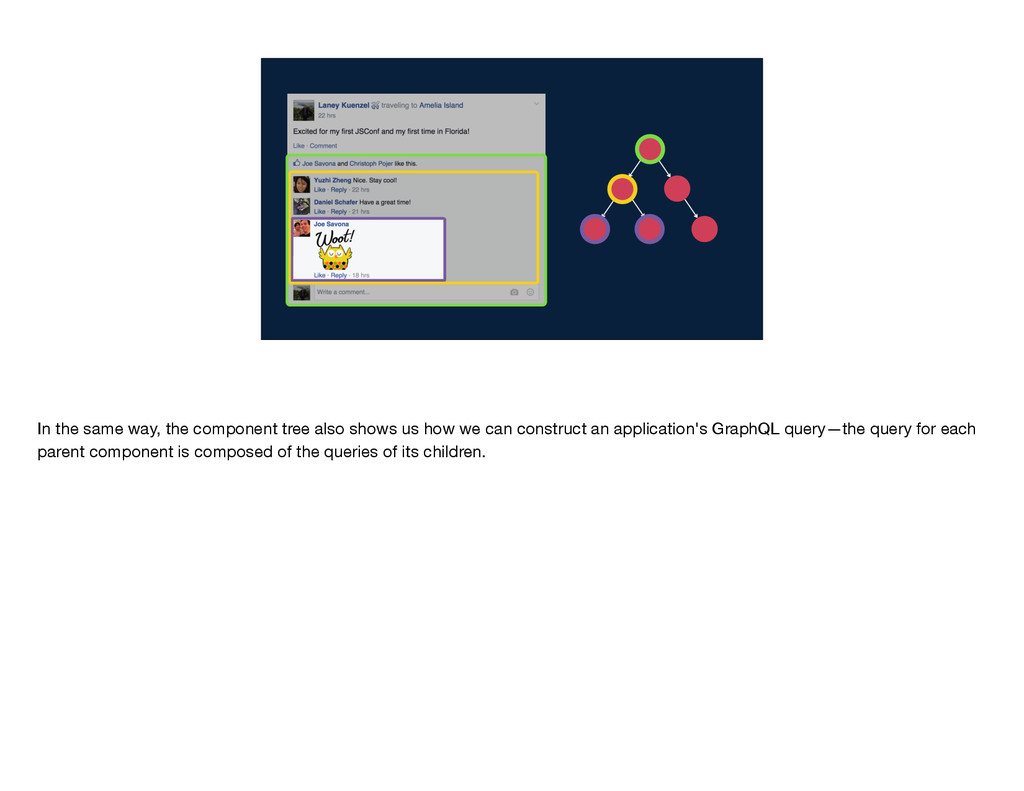{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
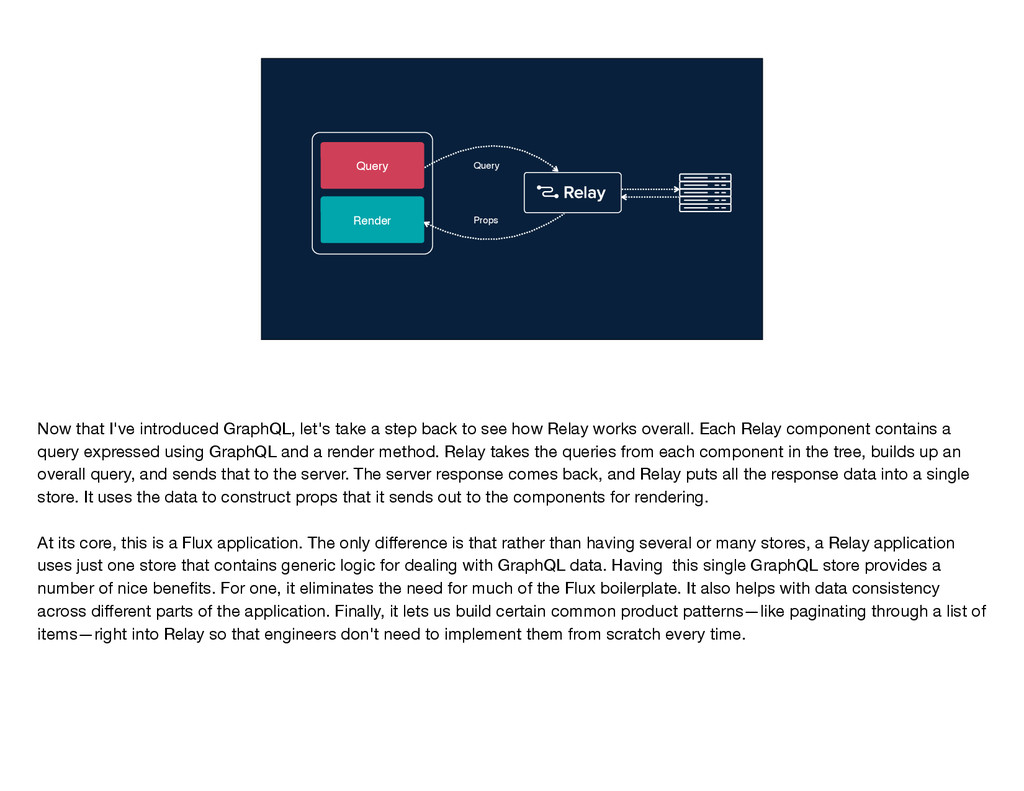{kind=link}
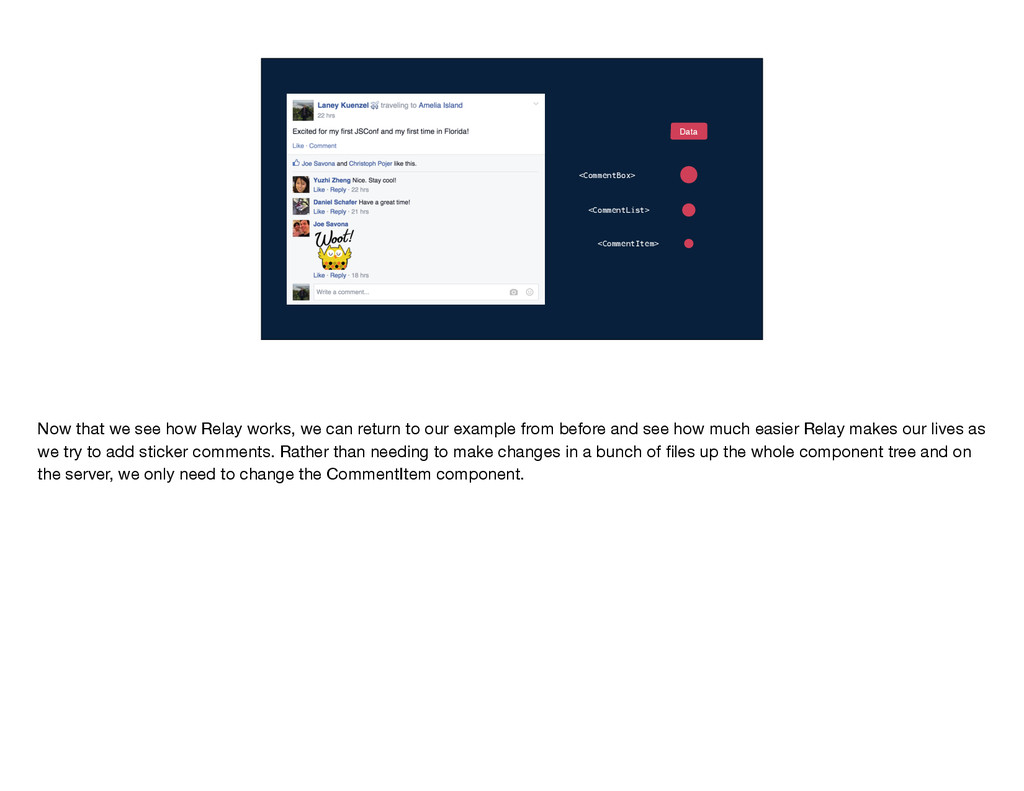{kind=link}
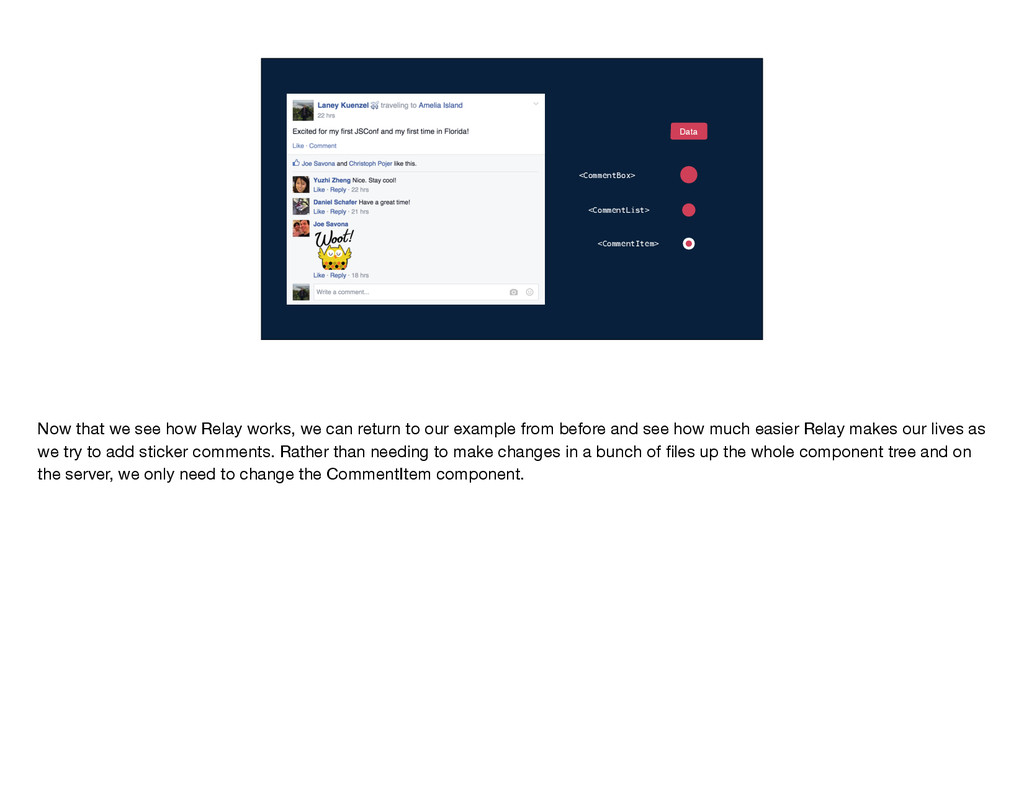{kind=link}
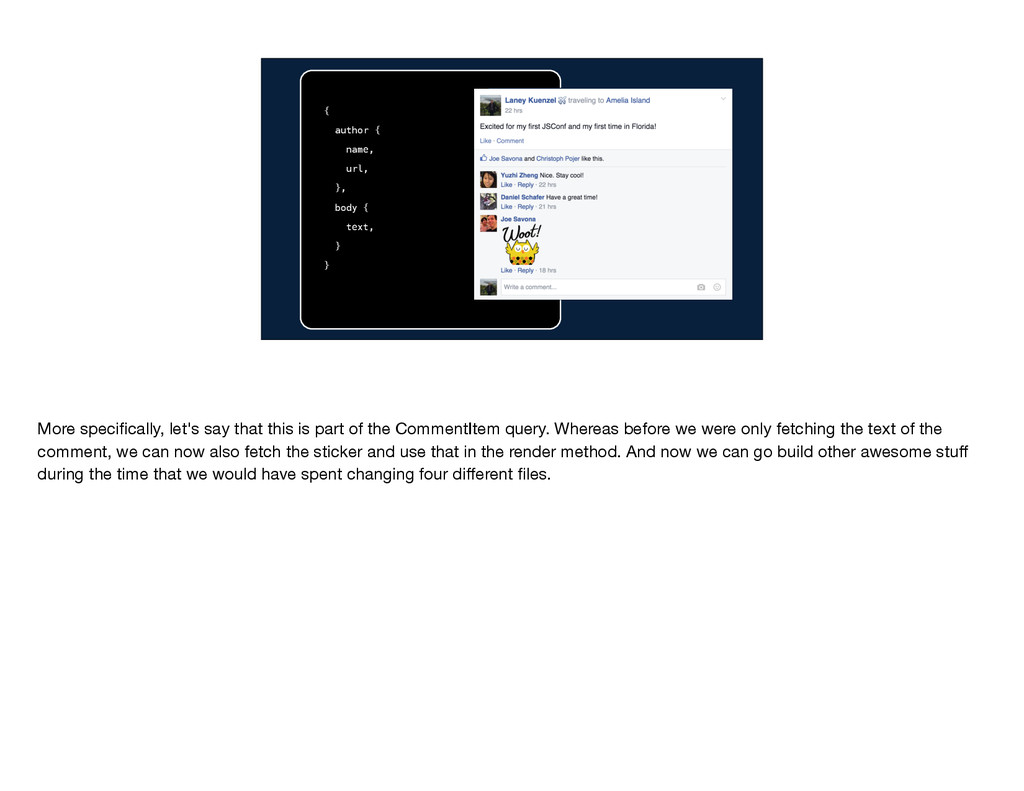{kind=link}
{kind=link}
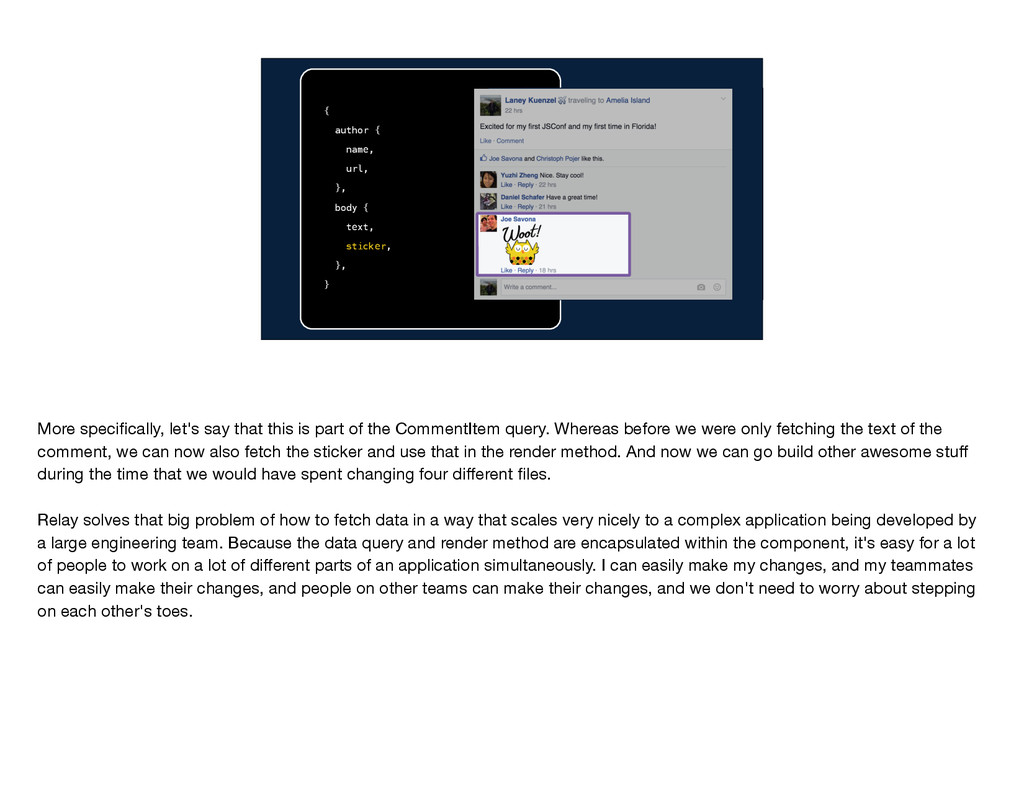{kind=link}
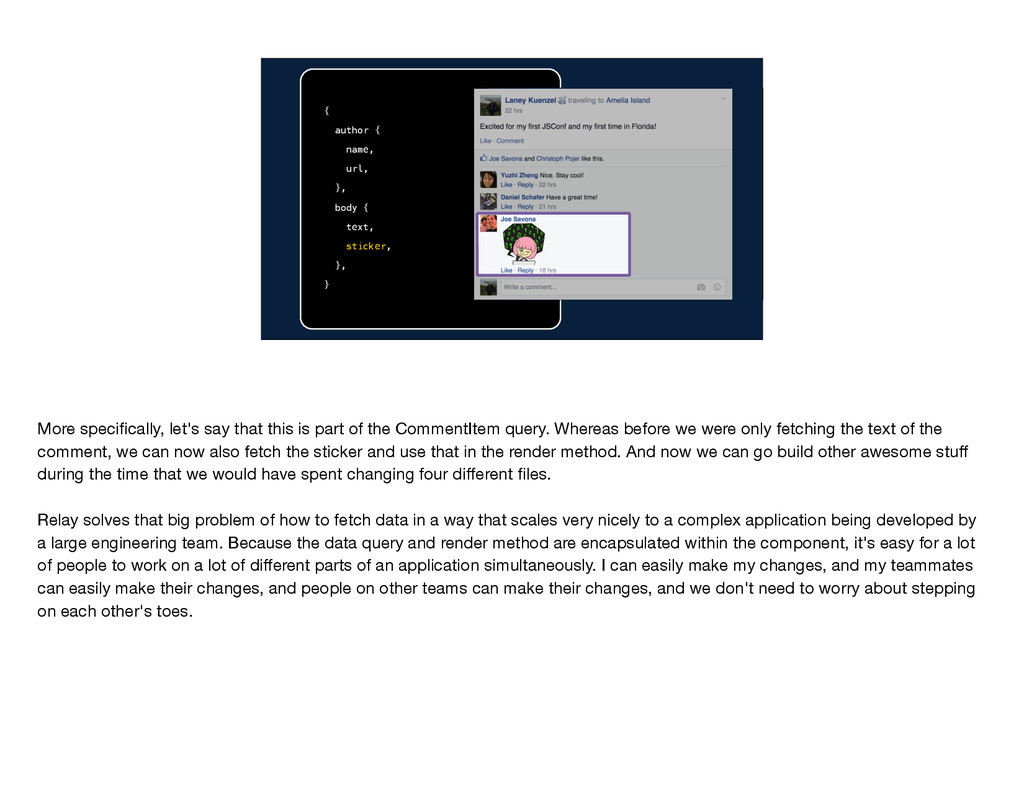{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
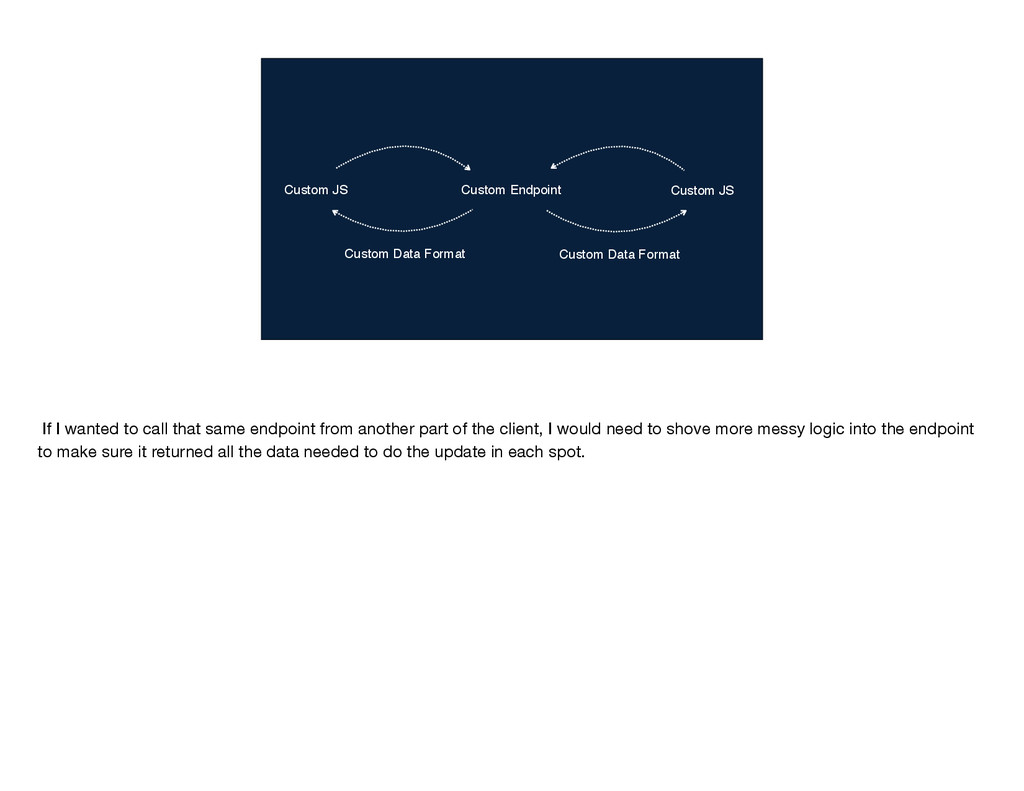{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
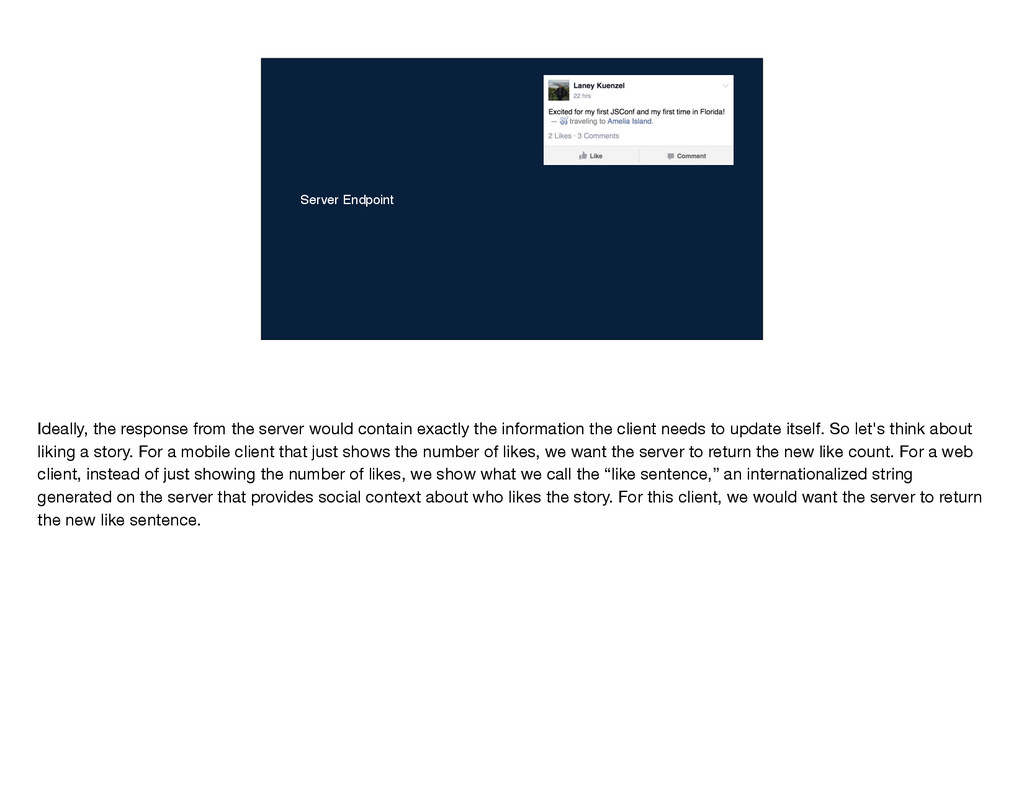{kind=link}
{kind=link}
{kind=link}
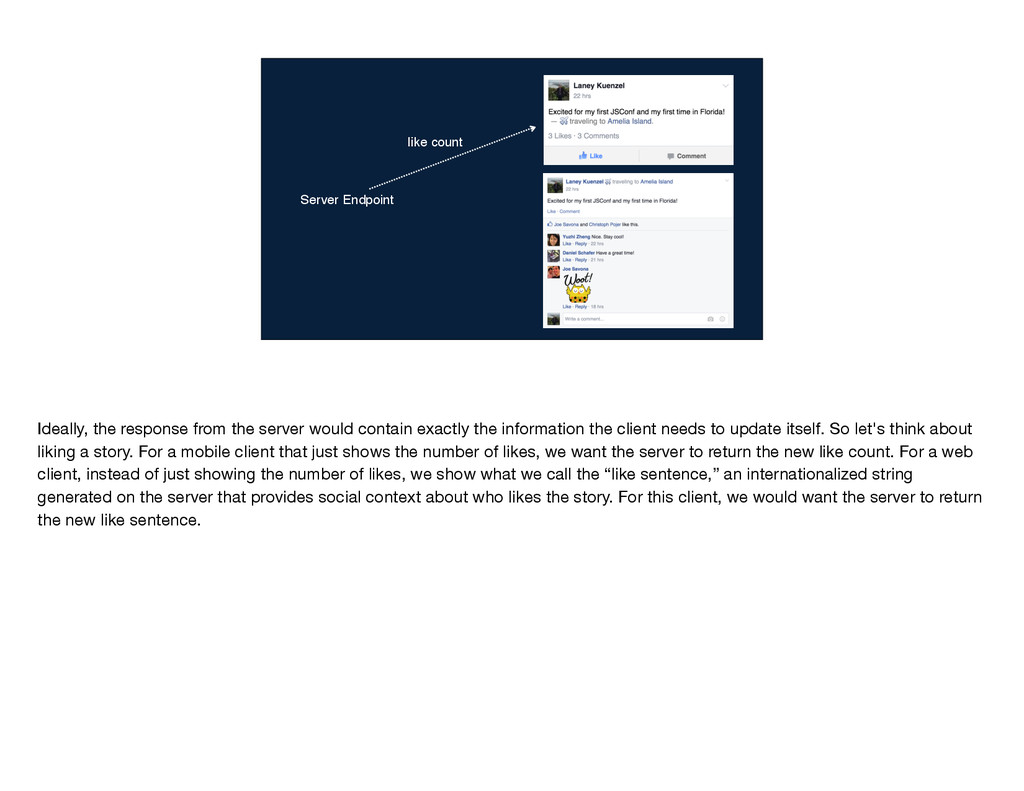{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
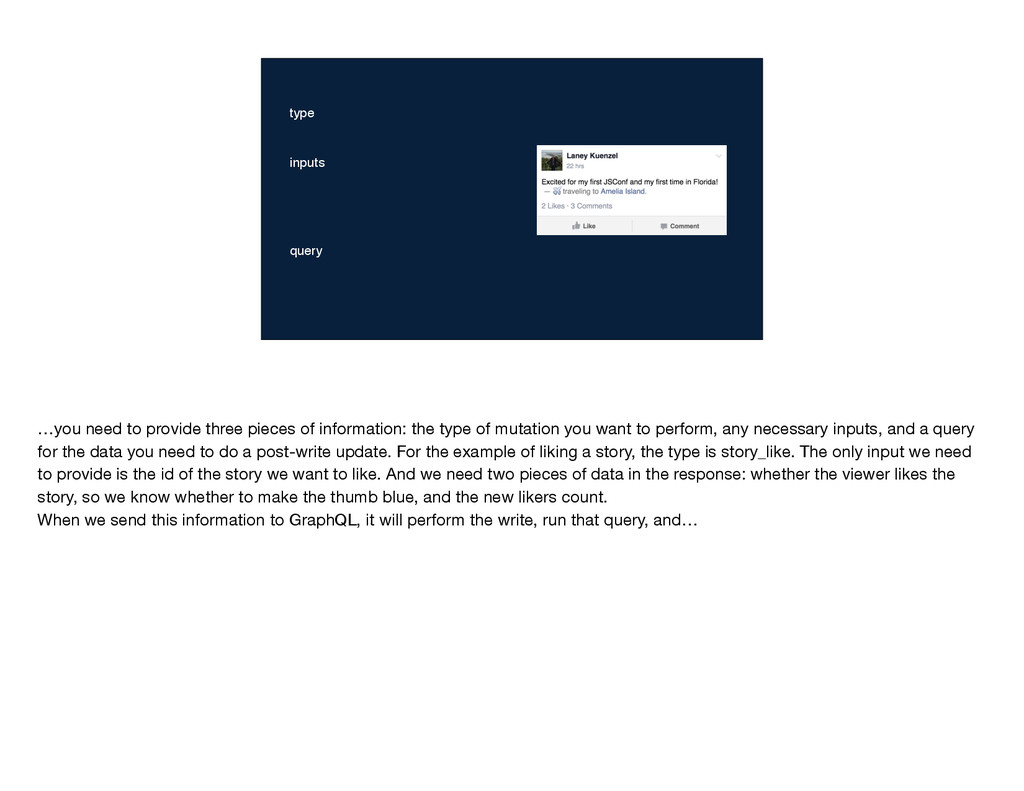{kind=link}
{kind=link}
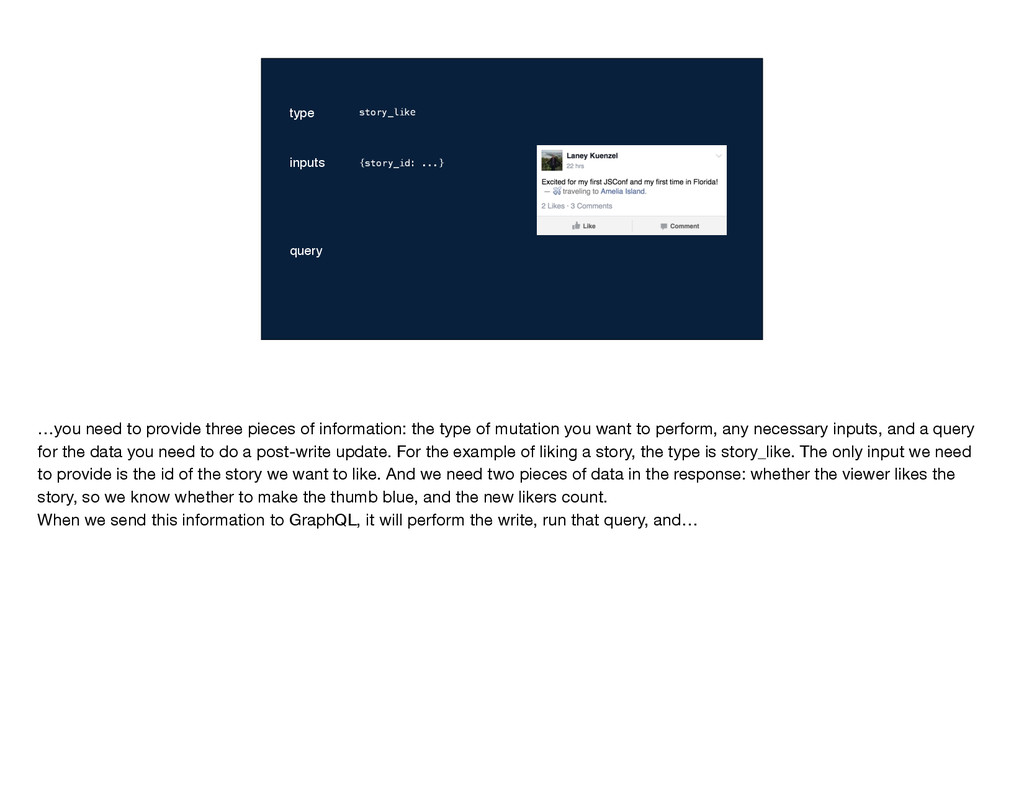{kind=link}
{kind=link}
{kind=link}
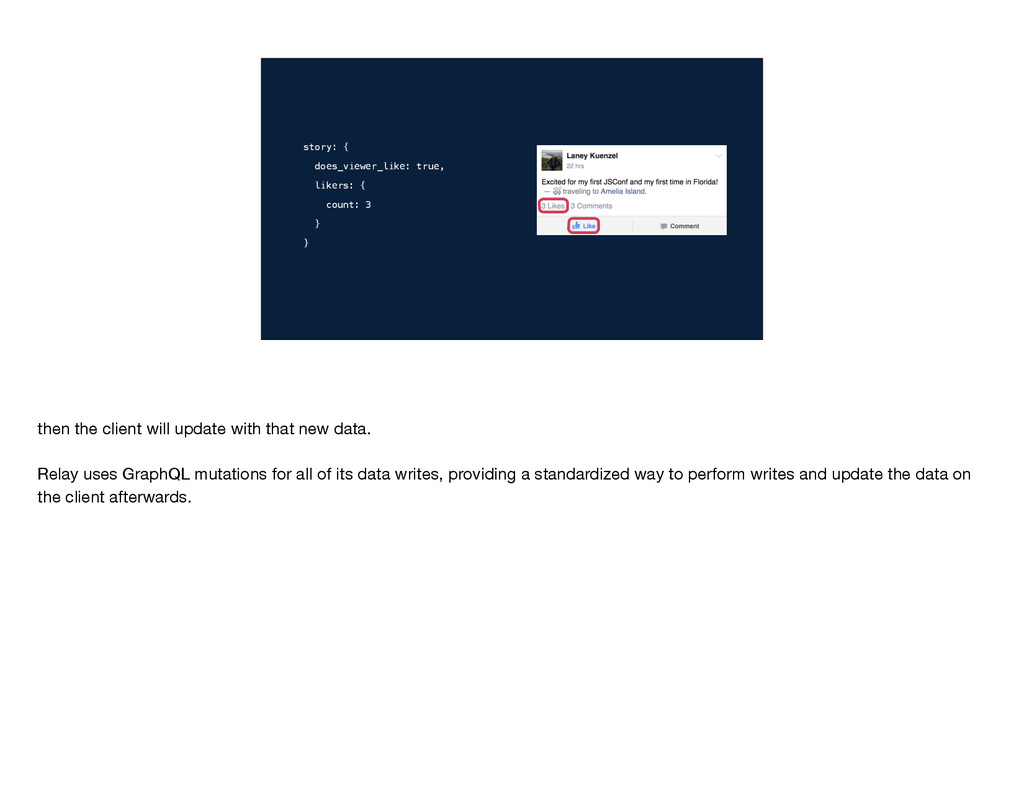{kind=link}
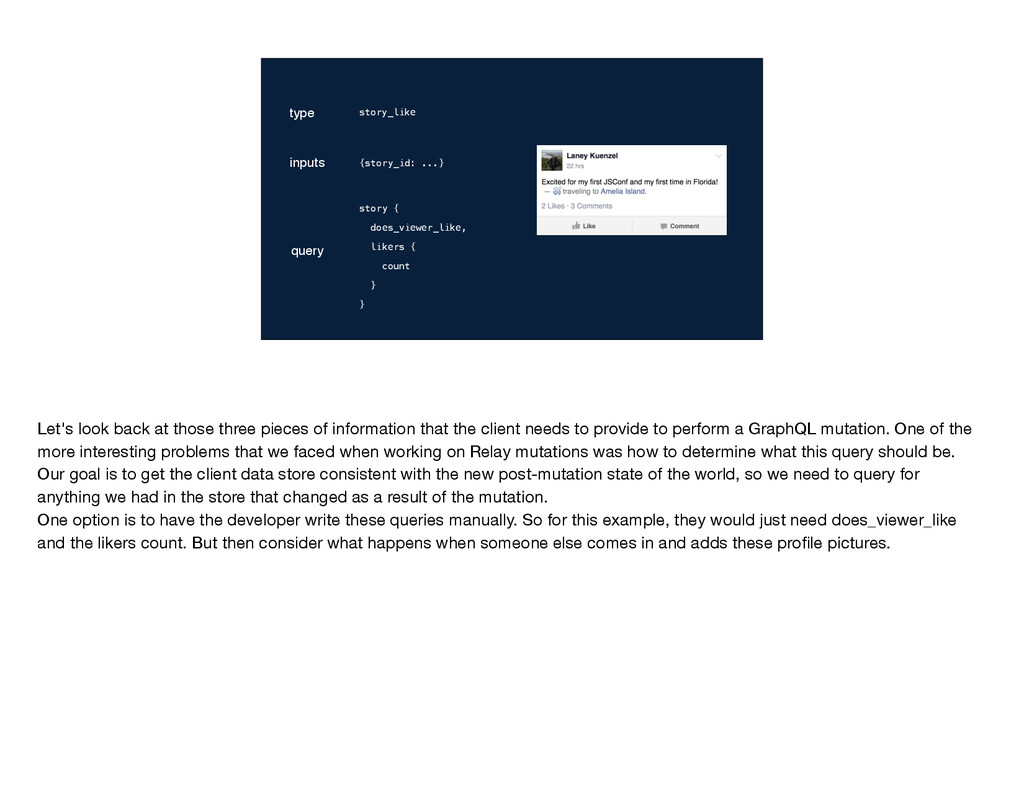{kind=link}
{kind=link}
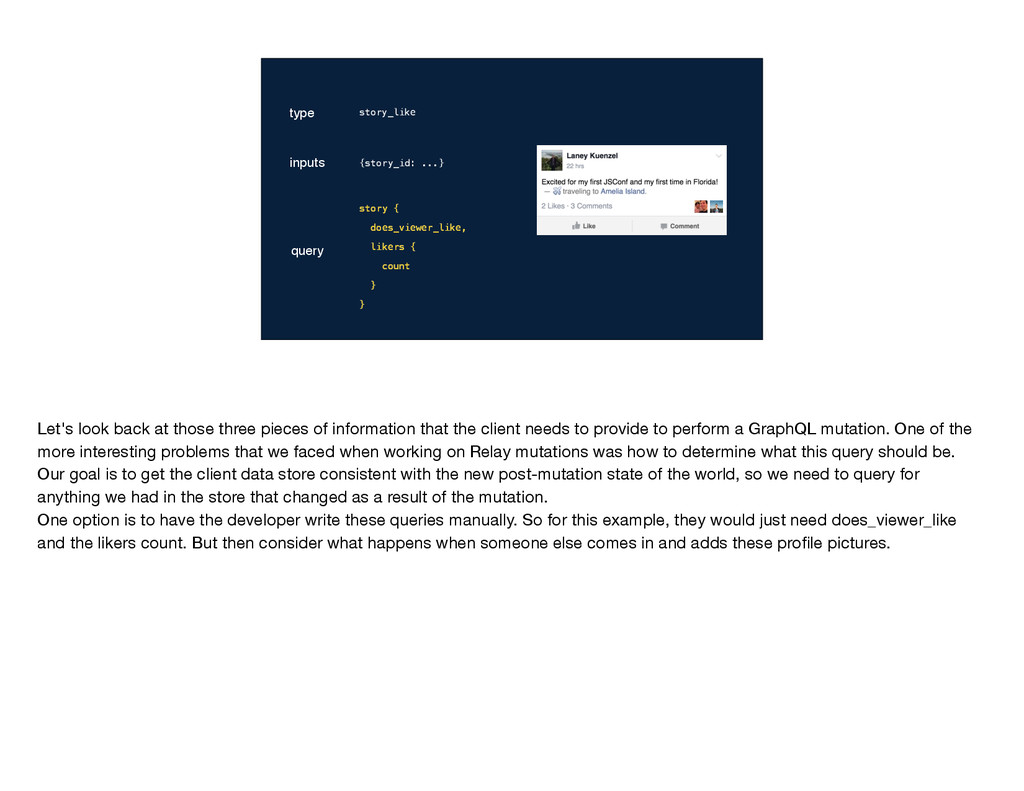{kind=link}
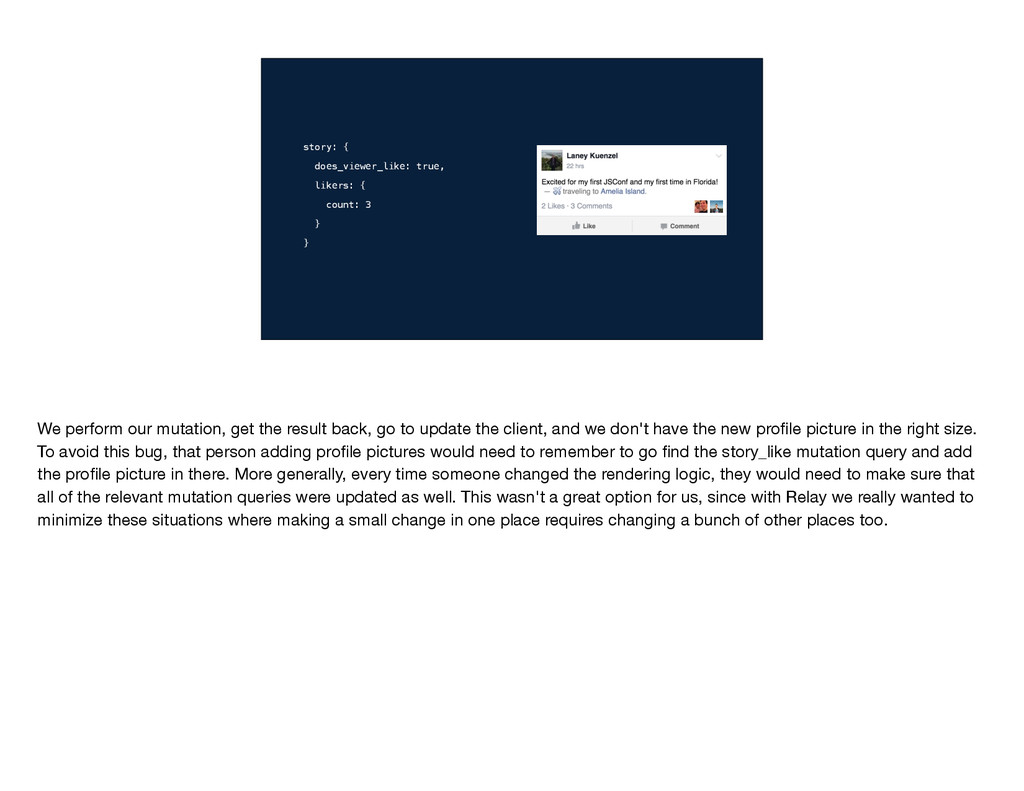{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
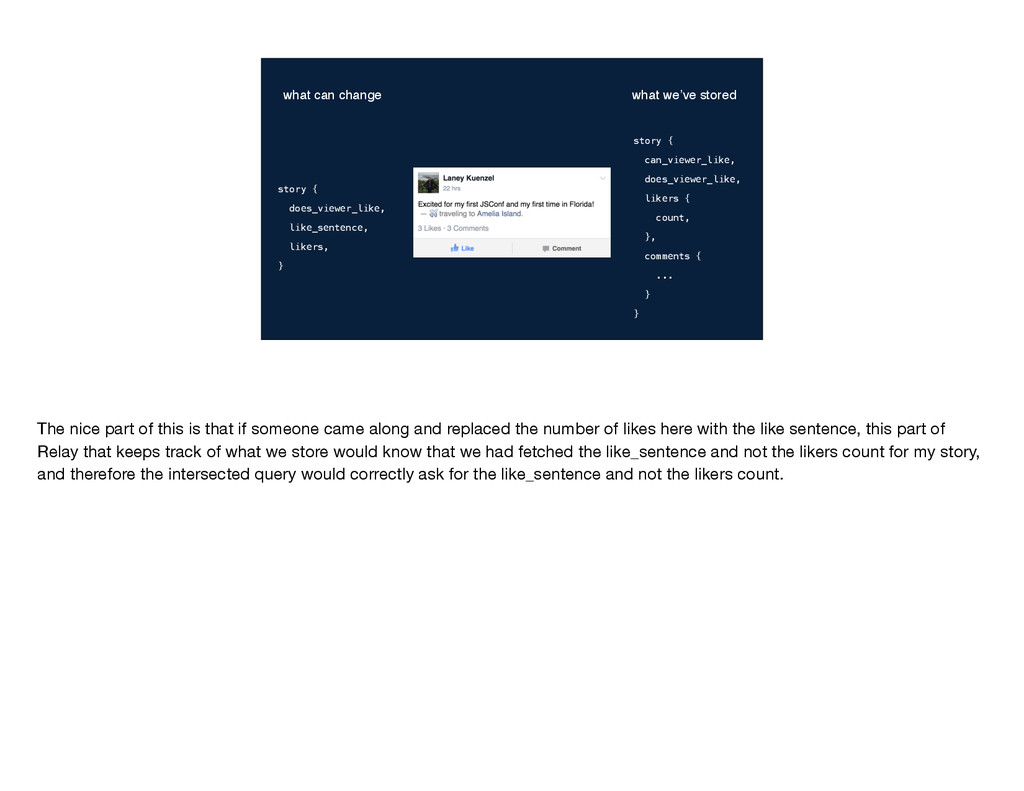{kind=link}
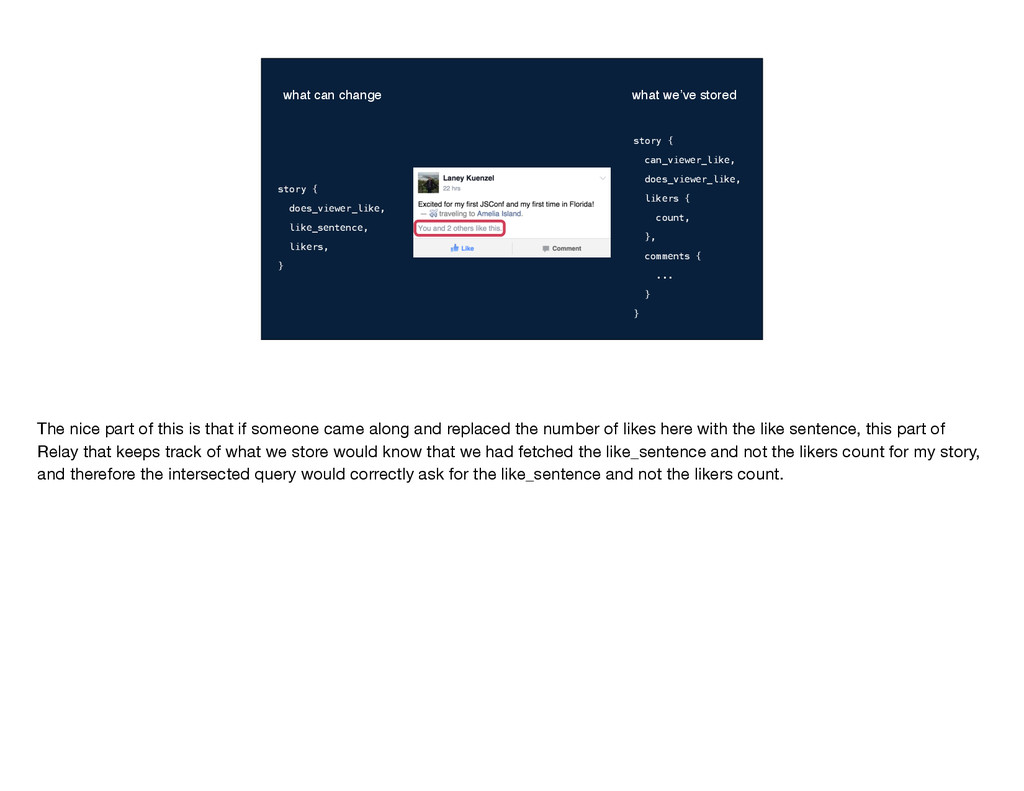{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
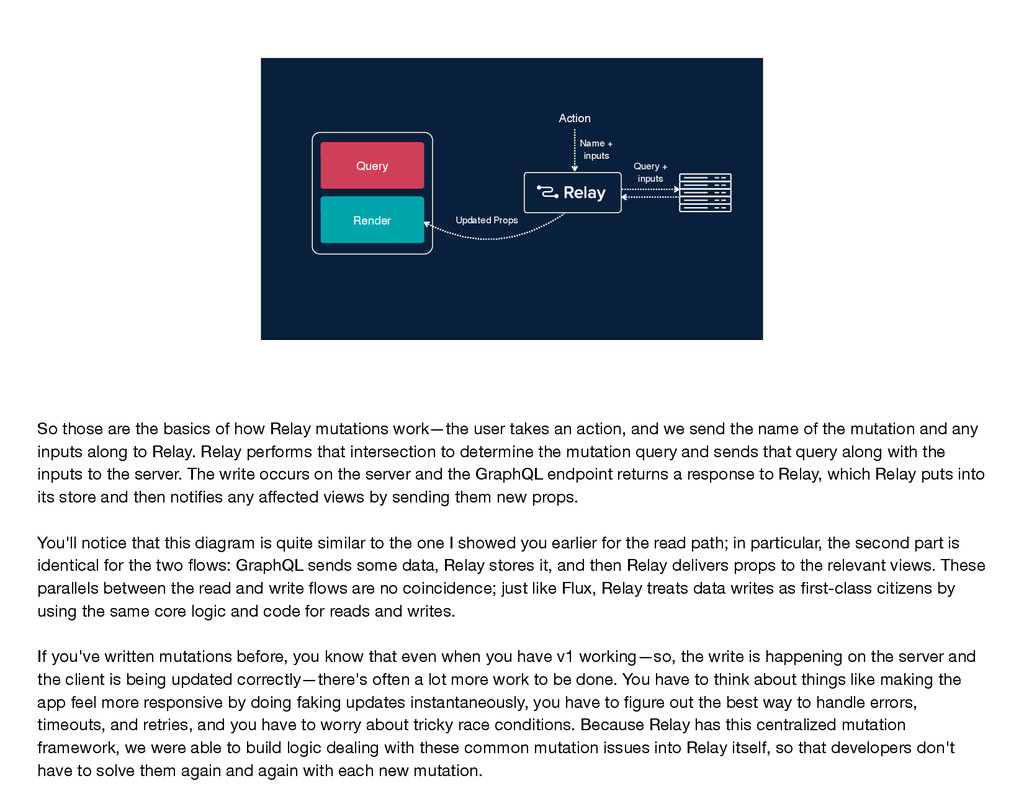{kind=link}
{kind=link}
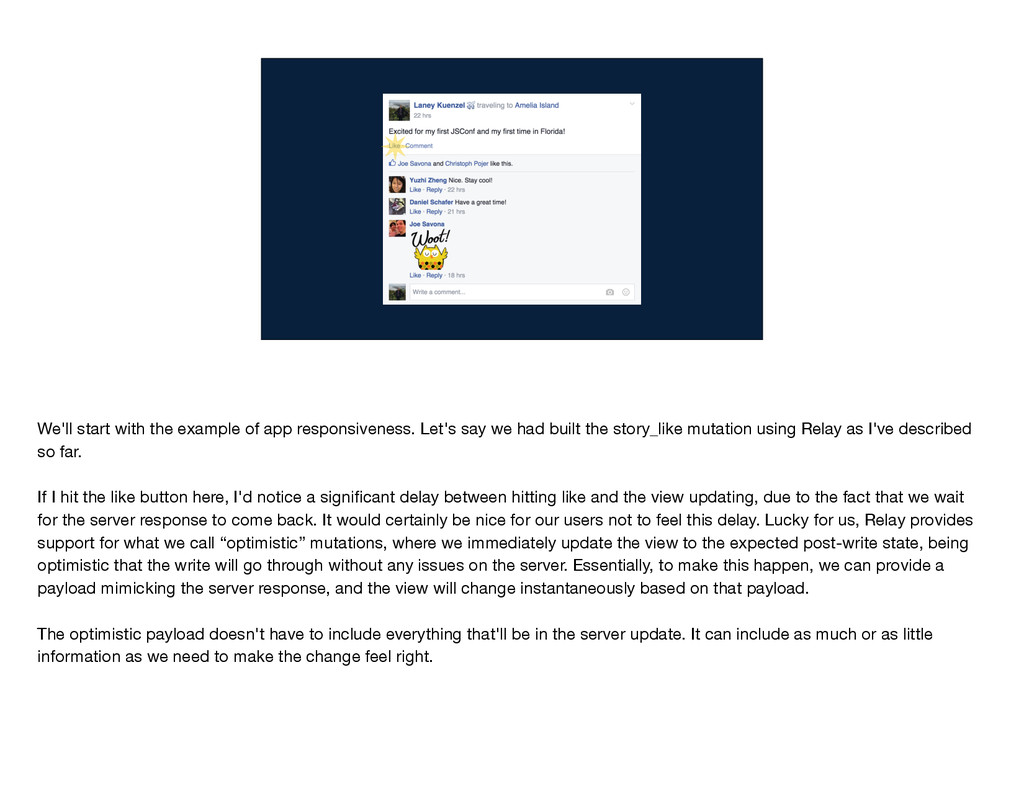{kind=link}
{kind=link}
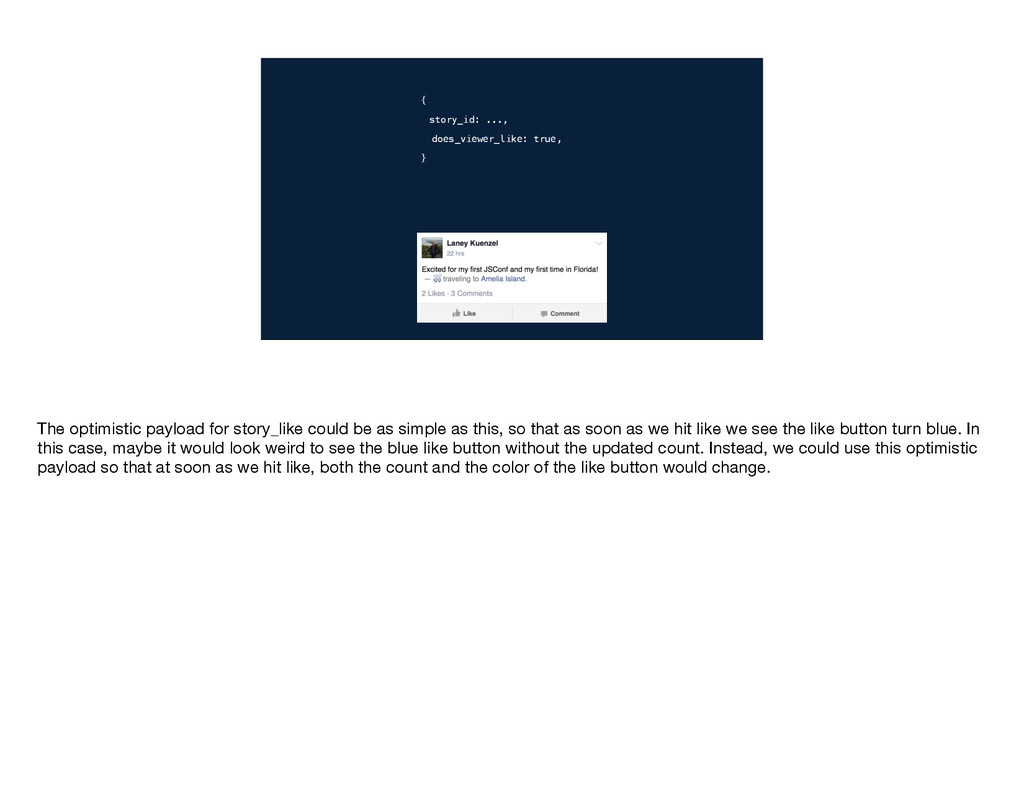{kind=link}
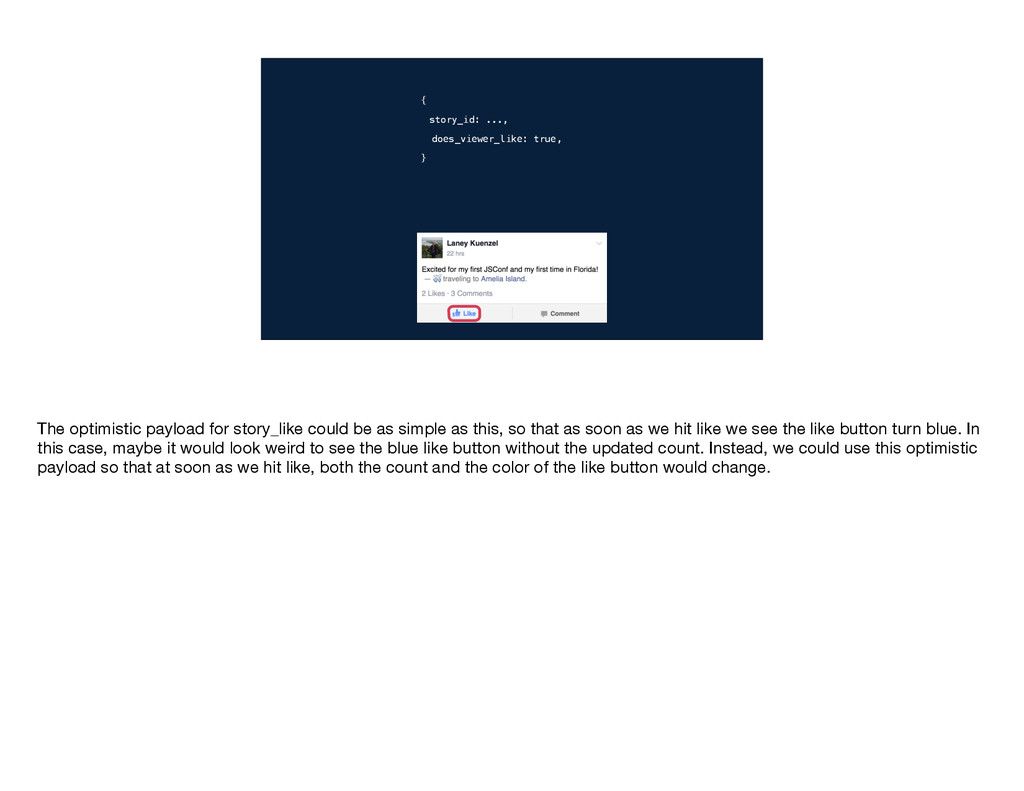{kind=link}
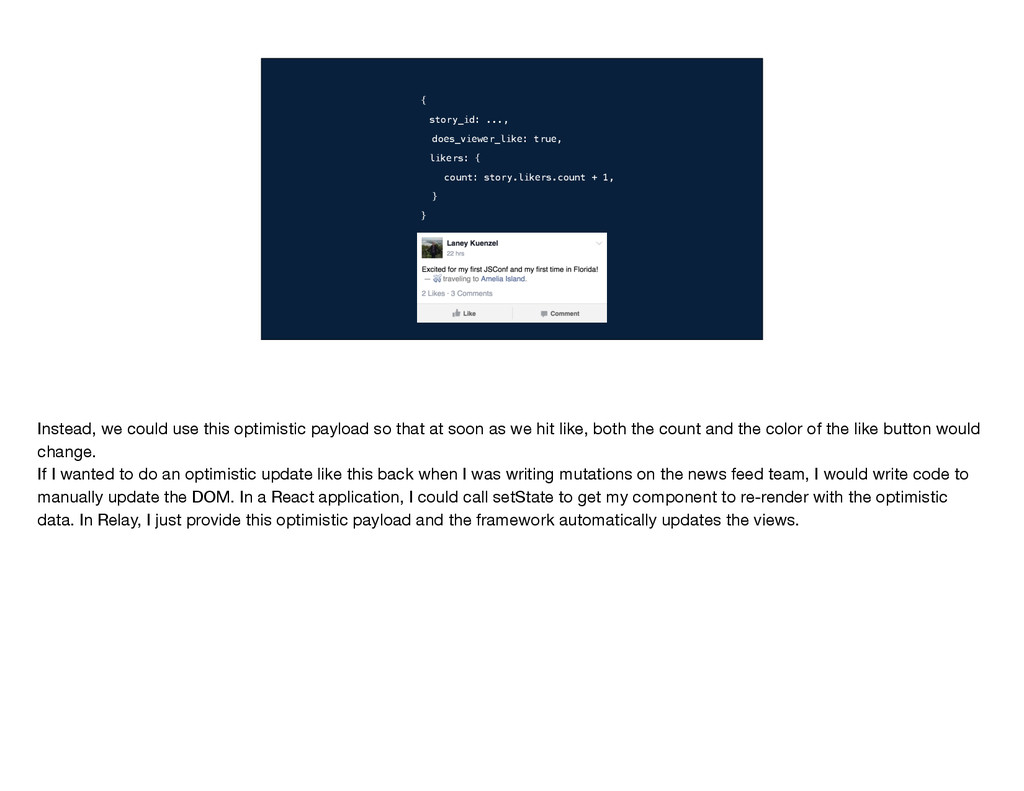{kind=link}
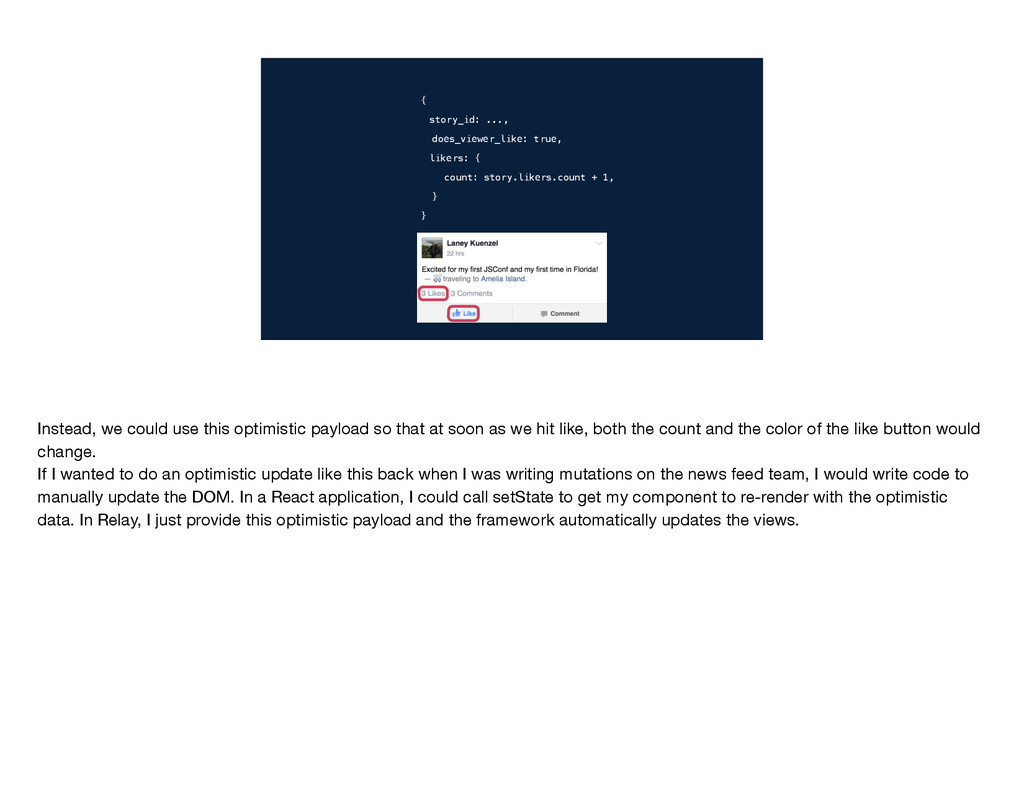{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
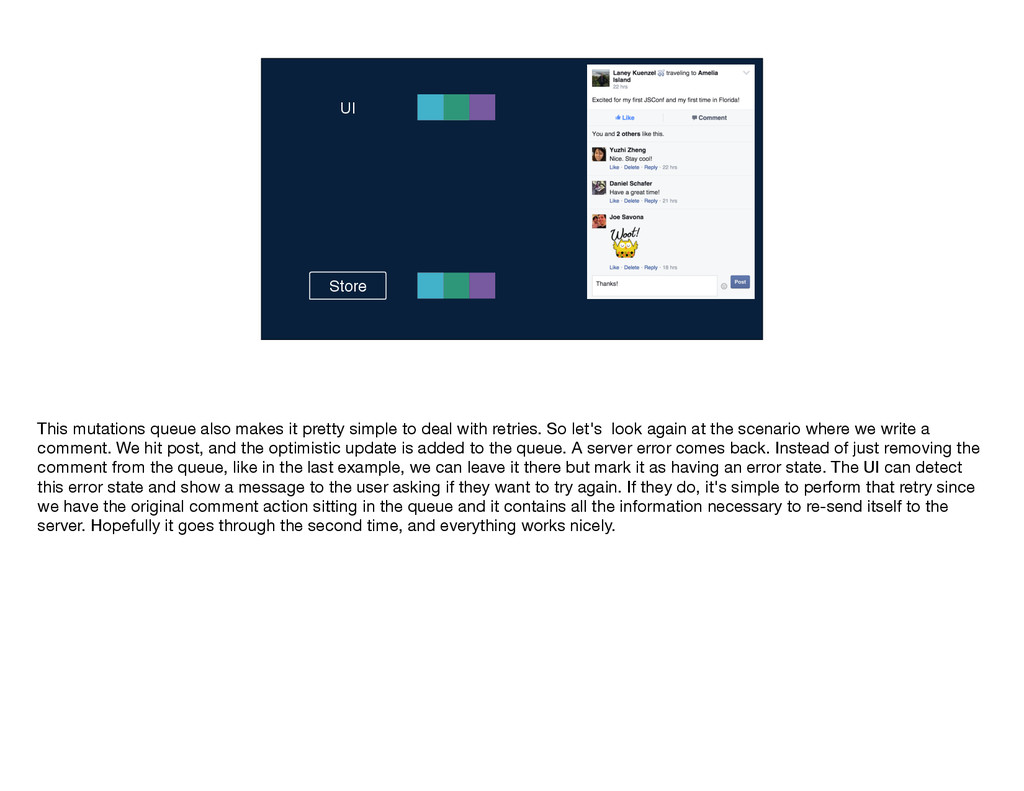{kind=link}
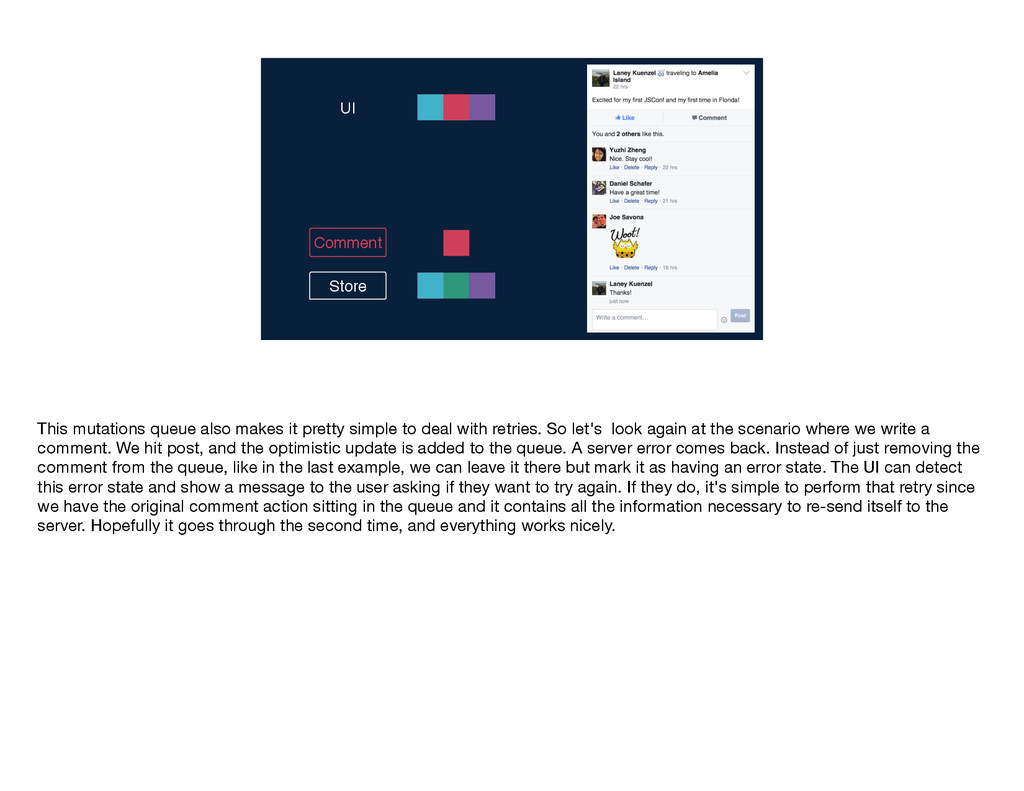{kind=link}
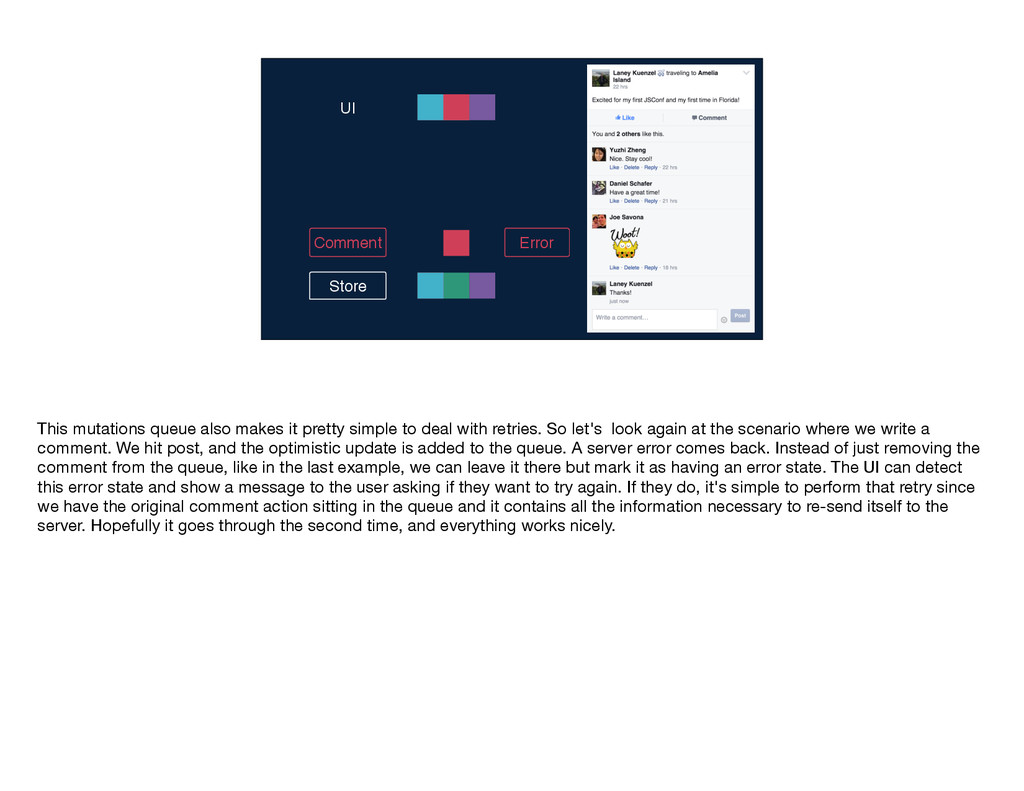{kind=link}
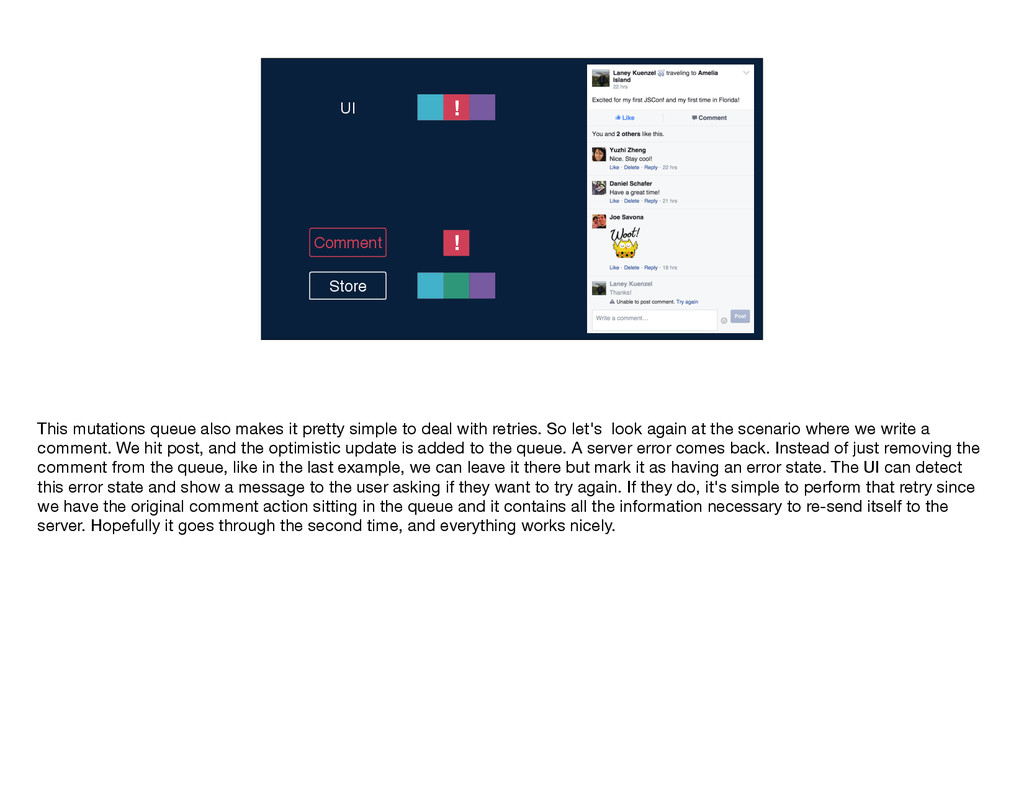{kind=link}
{kind=link}
{kind=link}
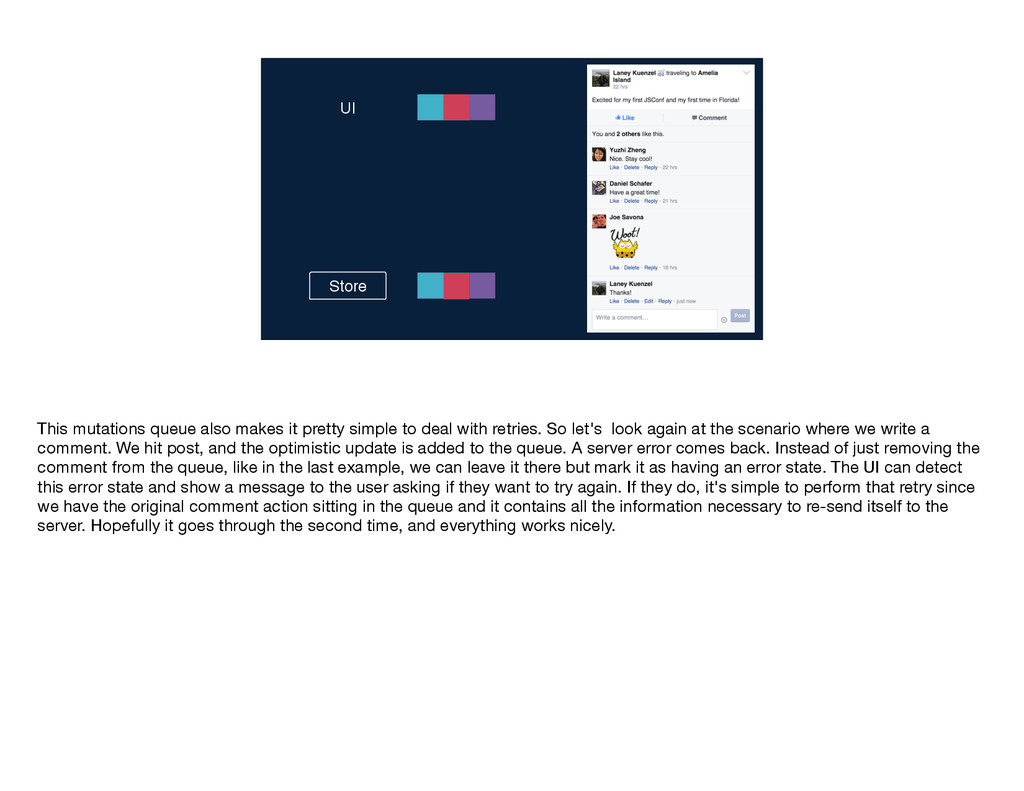{kind=link}
{kind=link}
{kind=link}
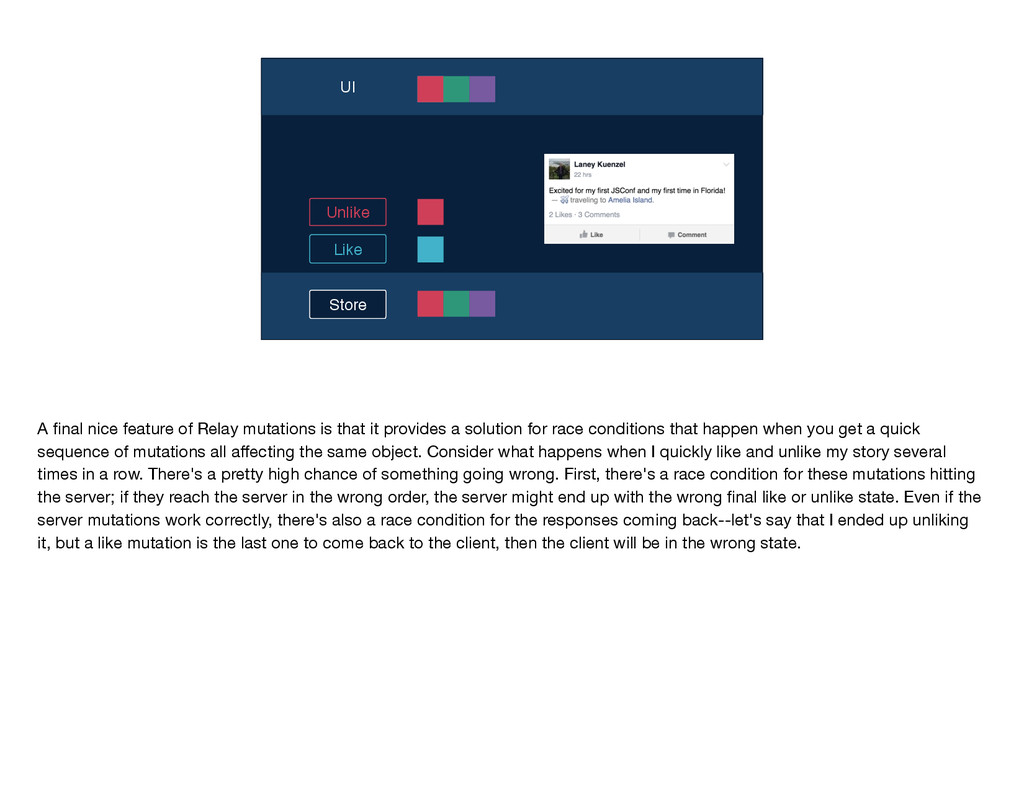{kind=link}
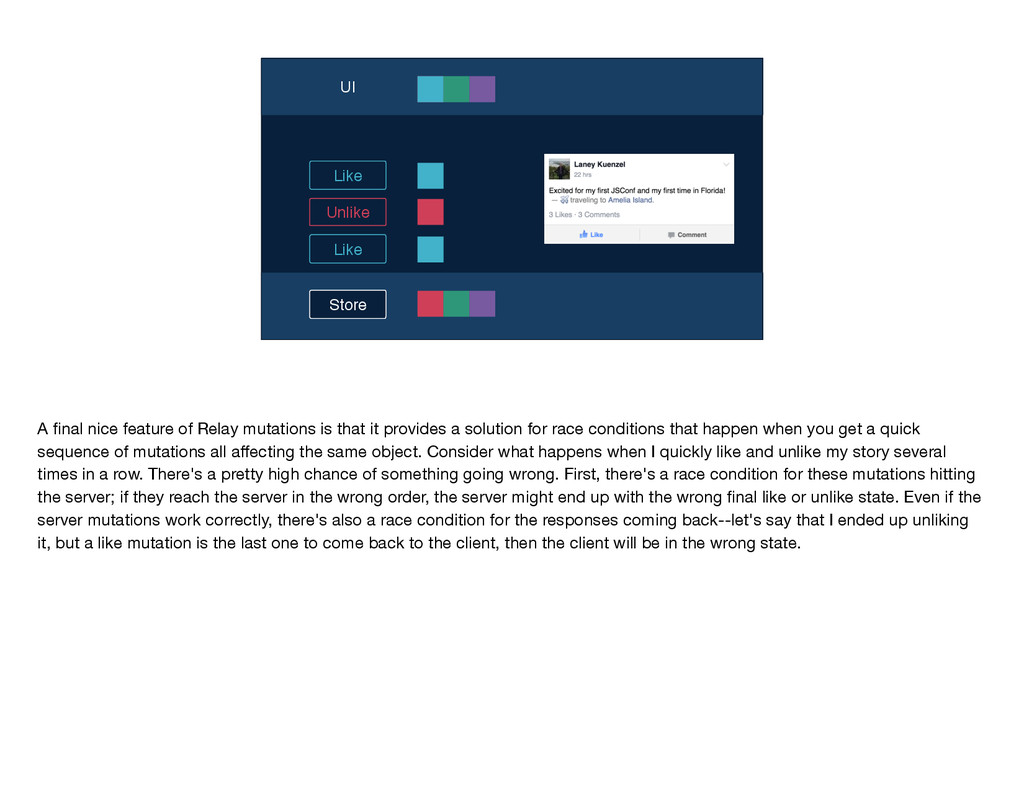{kind=link}
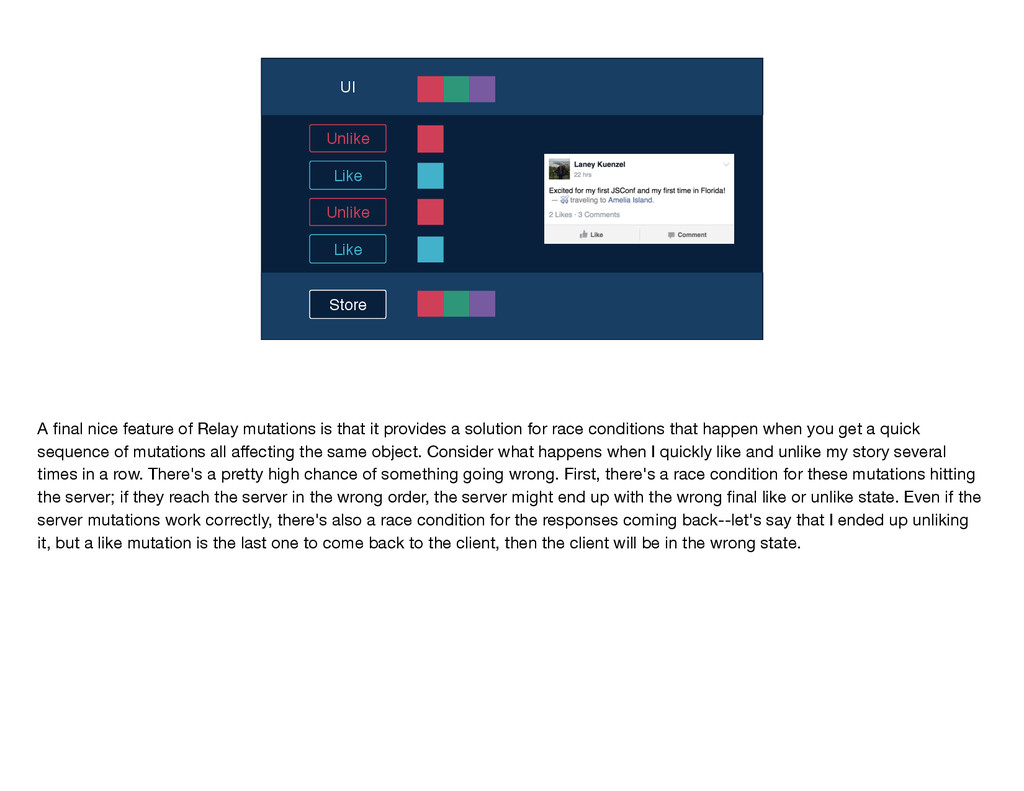{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
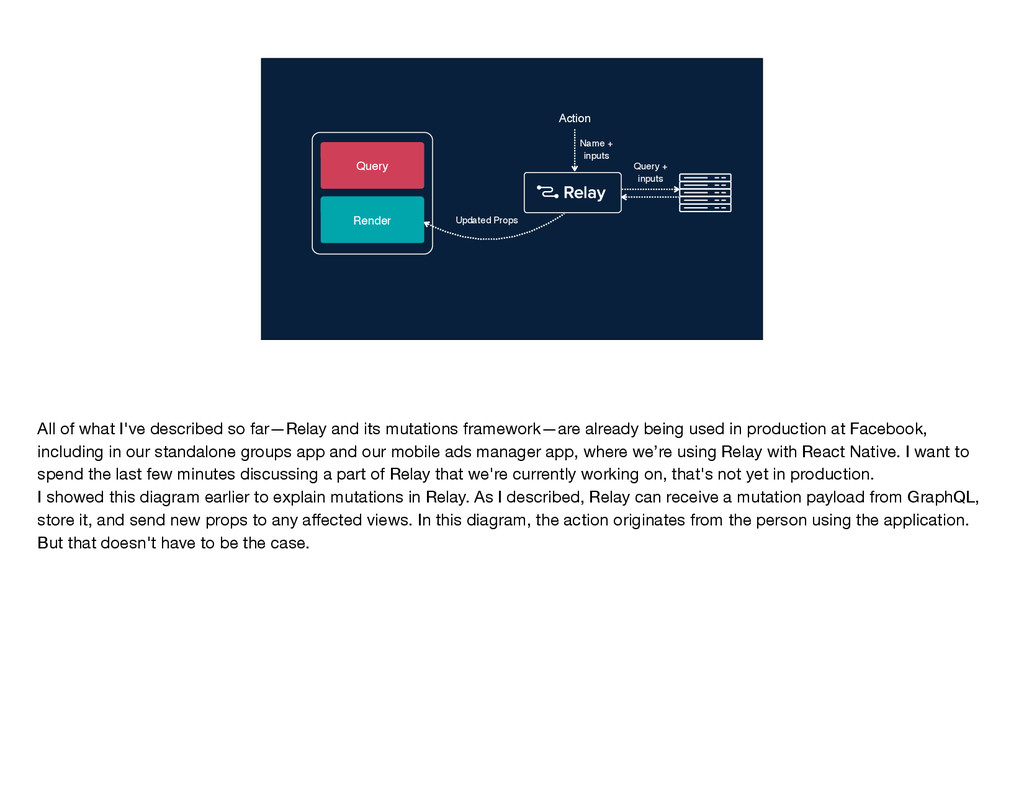{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
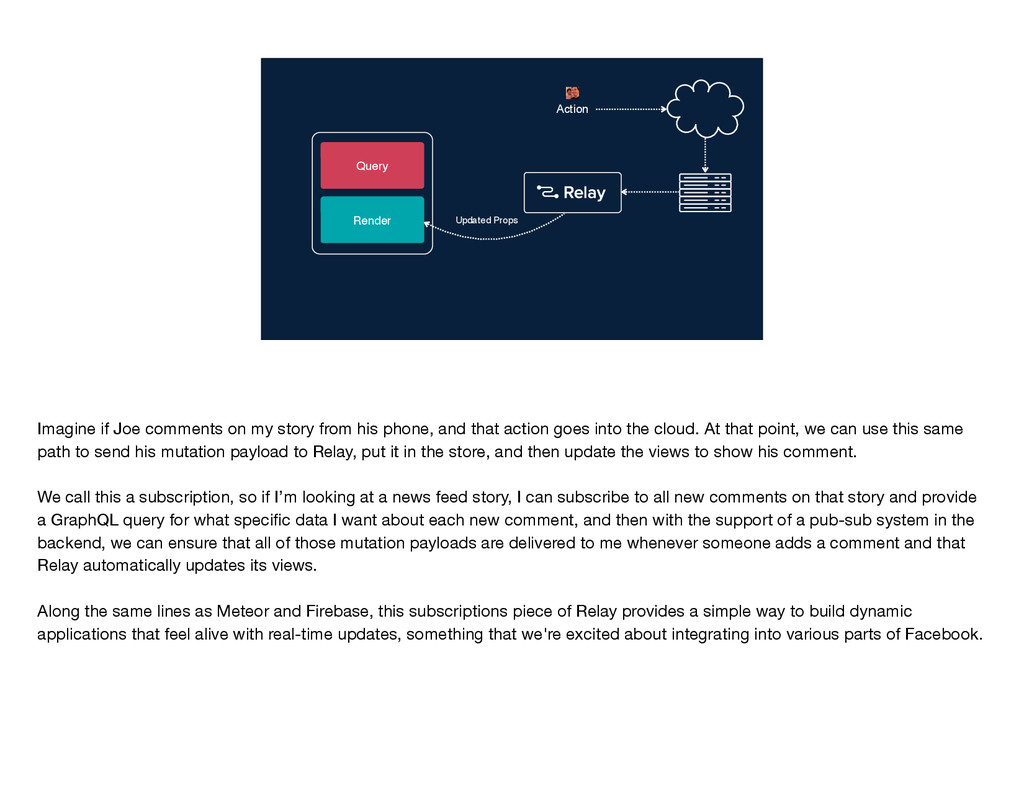{kind=link}
{kind=link}
{kind=link}