Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
LegalドメインにおけるRAG精度改善フロー
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
LegalOn Technologies, Inc
PRO
December 12, 2025
560
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
LegalドメインにおけるRAG精度改善フロー
LegalOn Technologies, Inc
PRO
December 12, 2025
More Decks by LegalOn Technologies, Inc
See All by LegalOn Technologies, Inc
Devsumi 2026 Summer 人もAIも使える共通基盤を事業の加速装置にする~デザインシステム運用に学ぶ組織レバレッジ~ 渡辺 凌央
legalontechnologies
PRO
0
96
AI時代でも楽しくエンジニアリングするには
legalontechnologies
PRO
1
180
AI Coding Agent と歩むプロダクト開発 〜現場とデザイナーの変化〜
legalontechnologies
PRO
0
250
アクセシビリティ1年生、専任になるまでとこれから
legalontechnologies
PRO
1
150
AI導入だけでは価値提供が速くならない ― Findy Team+活用でわかった、アウトカムにつながる土台とプロセス再構築のポイント
legalontechnologies
PRO
0
280
QAプロセスAI支援ツールキットの導入とその効果について
legalontechnologies
PRO
0
1.1k
全社で推進するAI活用 ― ダブルCoE体制とLegalRikaiが支えるリーガルテックの進化
legalontechnologies
PRO
0
3.3k
OpenProvenceを自社の評価データで検証してみた
legalontechnologies
PRO
0
560
LegalOn Assistantの契約書検索
legalontechnologies
PRO
0
540
Featured
See All Featured
Fashionably flexible responsive web design (full day workshop)
malarkey
408
67k
The Invisible Side of Design
smashingmag
301
52k
Ethics towards AI in product and experience design
skipperchong
2
330
No one is an island. Learnings from fostering a developers community.
thoeni
21
3.8k
Context Engineering - Making Every Token Count
addyosmani
9
1k
Self-Hosted WebAssembly Runtime for Runtime-Neutral Checkpoint/Restore in Edge–Cloud Continuum
chikuwait
0
650
The Straight Up "How To Draw Better" Workshop
denniskardys
239
140k
Designing Experiences People Love
moore
143
24k
10 Git Anti Patterns You Should be Aware of
lemiorhan
PRO
659
62k
Chrome DevTools: State of the Union 2024 - Debugging React & Beyond
addyosmani
10
1.2k
Thoughts on Productivity
jonyablonski
76
5.2k
Documentation Writing (for coders)
carmenintech
77
5.4k
Transcript
Legalドメインにおける RAG 精度改善フロー LegalOn Technologies Maoya Sato
自己紹介 • 1社目ではチャットボットの開発 • 2社目からビジネスニュースの検索システムの開発 • 2021年7月にLegalOn Technologiesに入社し、検索チームに所属。 現在は「LegalOnアシスタント」(法務AIチャットボット)のRAG部分を開発 •
趣味: 将棋・ビリヤード・散歩
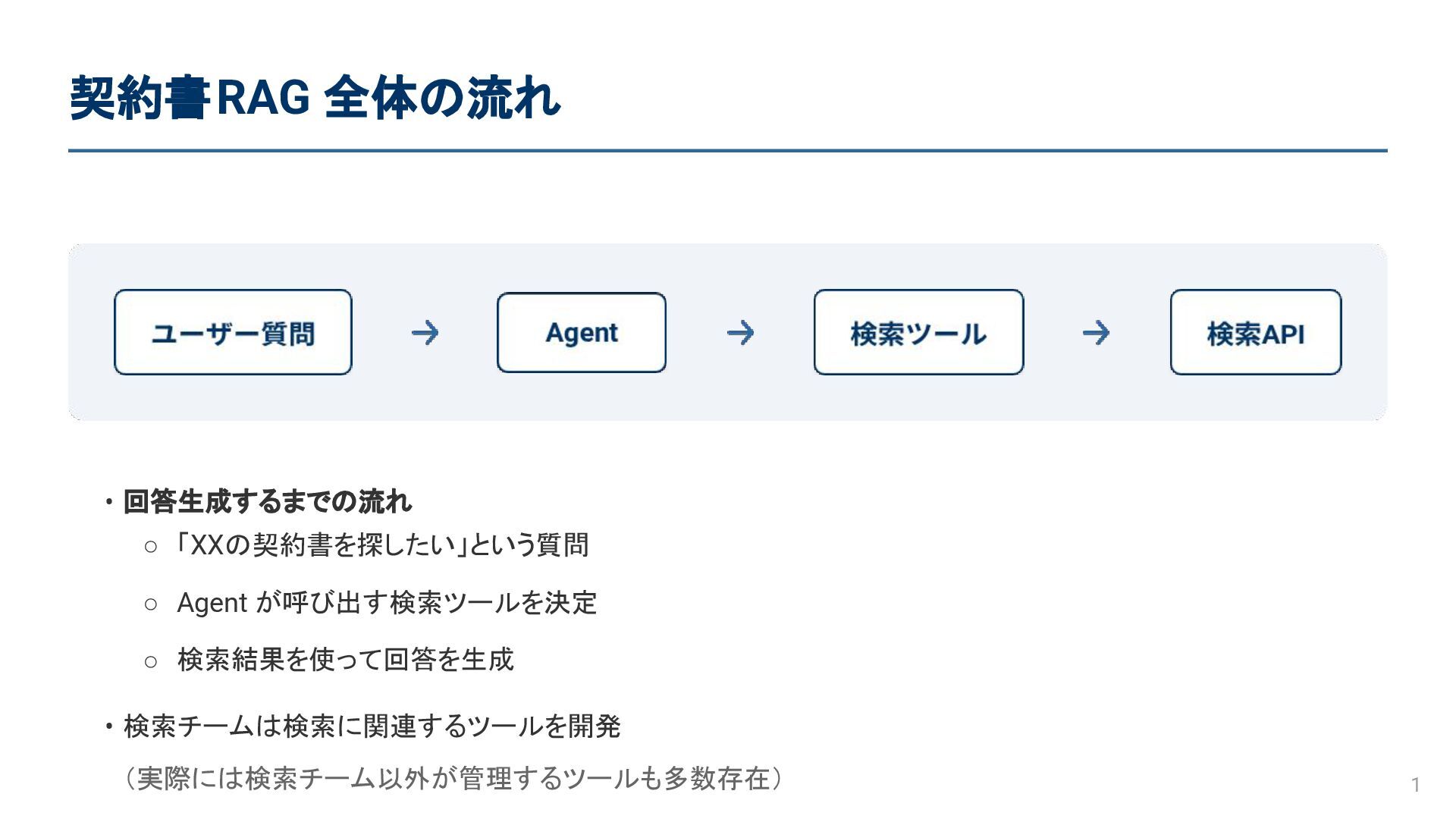
契約書RAG 全体の流れ 1 • 回答生成するまでの流れ • 検索チームは検索に関連するツールを開発 (実際には検索チーム以外が管理するツールも多数存在) ◦ 「XXの契約書を探したい」という質問
◦ Agent が呼び出す検索ツールを決定 ◦ 検索結果を使って回答を生成
検索ツールの例 2 • 契約書検索ツール • 関連契約書検索ツール • WebSearchツール ◦ 契約書・条文を探す際に使われる
◦ フィルタリングが可能 (例: 取引先名、契約類型、契約締結日など) ◦ 基本契約と覚書など、親子関係を特定する ◦ 法令・判例など、外部の一次情報を知る必要がある場合
Legalドメインにおける精度改善の難しさ (面白さ) 3 • 深いドメイン知識が要求される • セキュリティ要件が高い • マルチリージョン対応 ◦
法務の業務フローを深く理解する ◦ ドメインエキスパート(法務の専門家)と密にコミュニケーションを取る必要 ◦ ログや契約書データへのアクセスが制限されている ◦ ユーザーが実際に体感している精度を把握しにくい ◦ 法律がリージョンごとに異なる (× リージョン数分の評価)
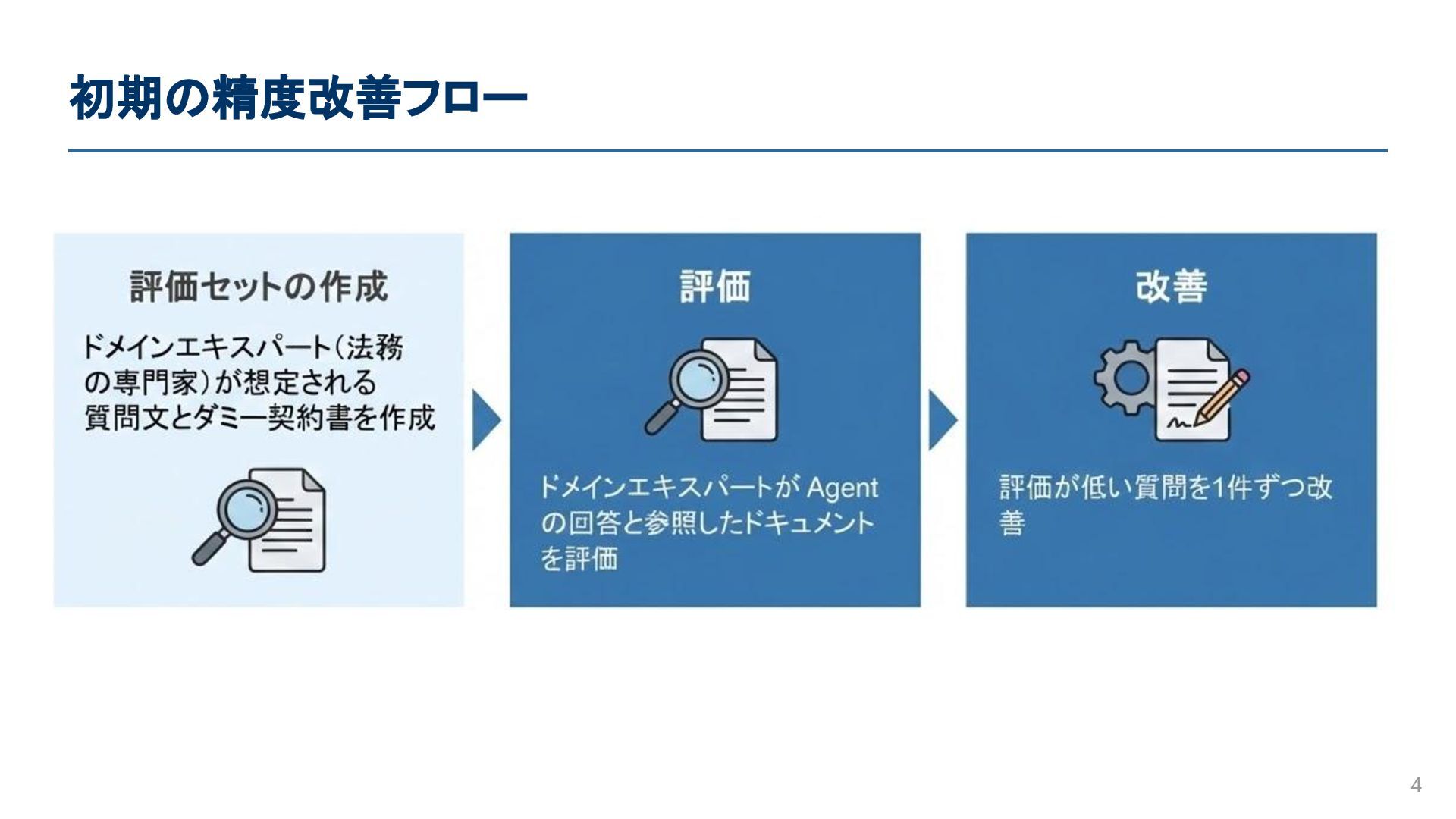
初期の精度改善フロー 4 • 評価セットの作成 • 評価 • 改善 ◦ ドメインエキスパート(法務の専門家)
が想定される質問文とダミー契約書を作成 ◦ ドメインエキスパートが Agent の回答を評価 ◦ 評価が低い質問を1件ずつ改善
課題 5 課題① 改善サイクルが長い 課題② 原因特定に時間がかかる 課題③ 局所的な修正になりがち 課題④ ユーザーが感じる精度とのギャップ
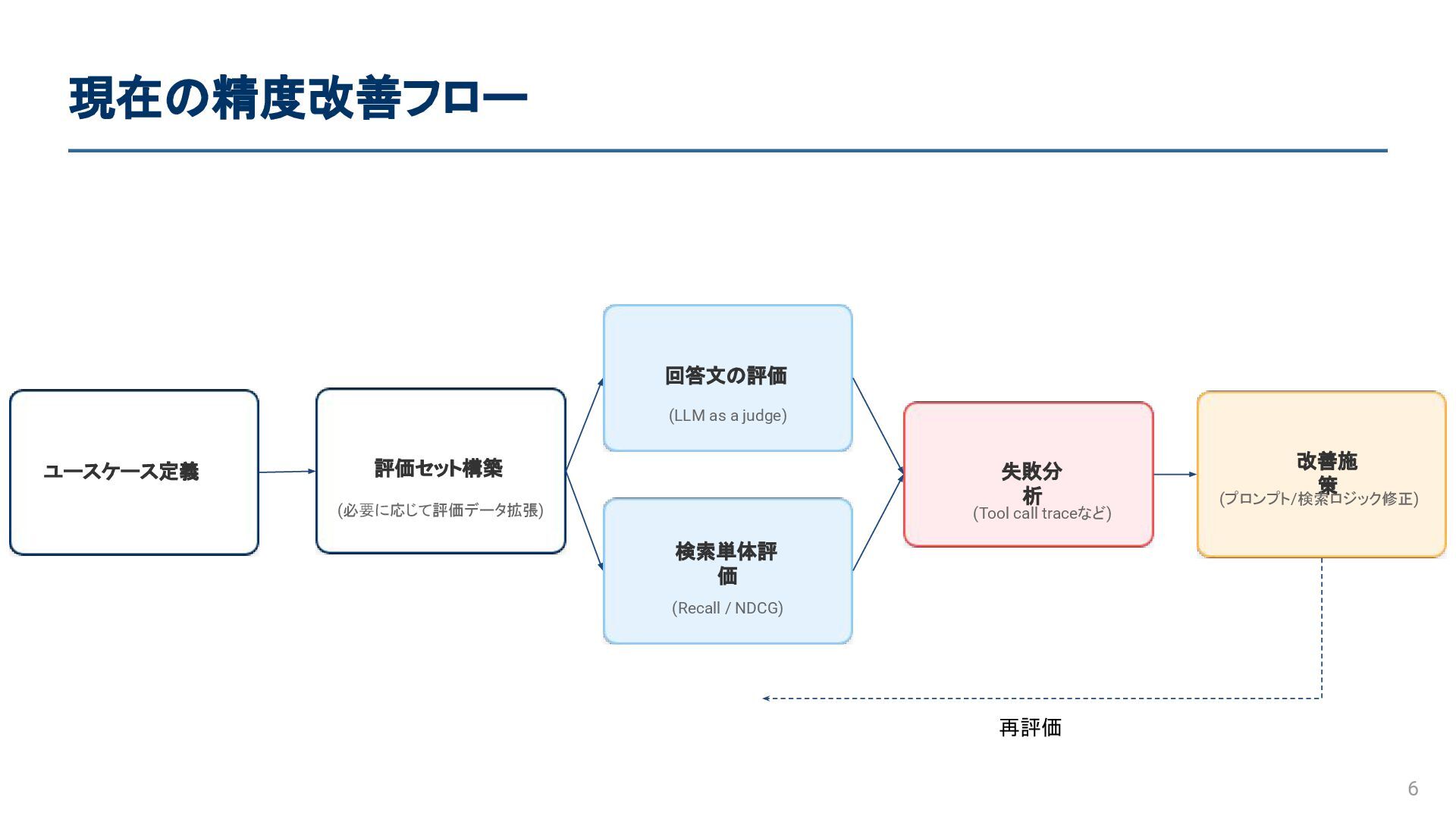
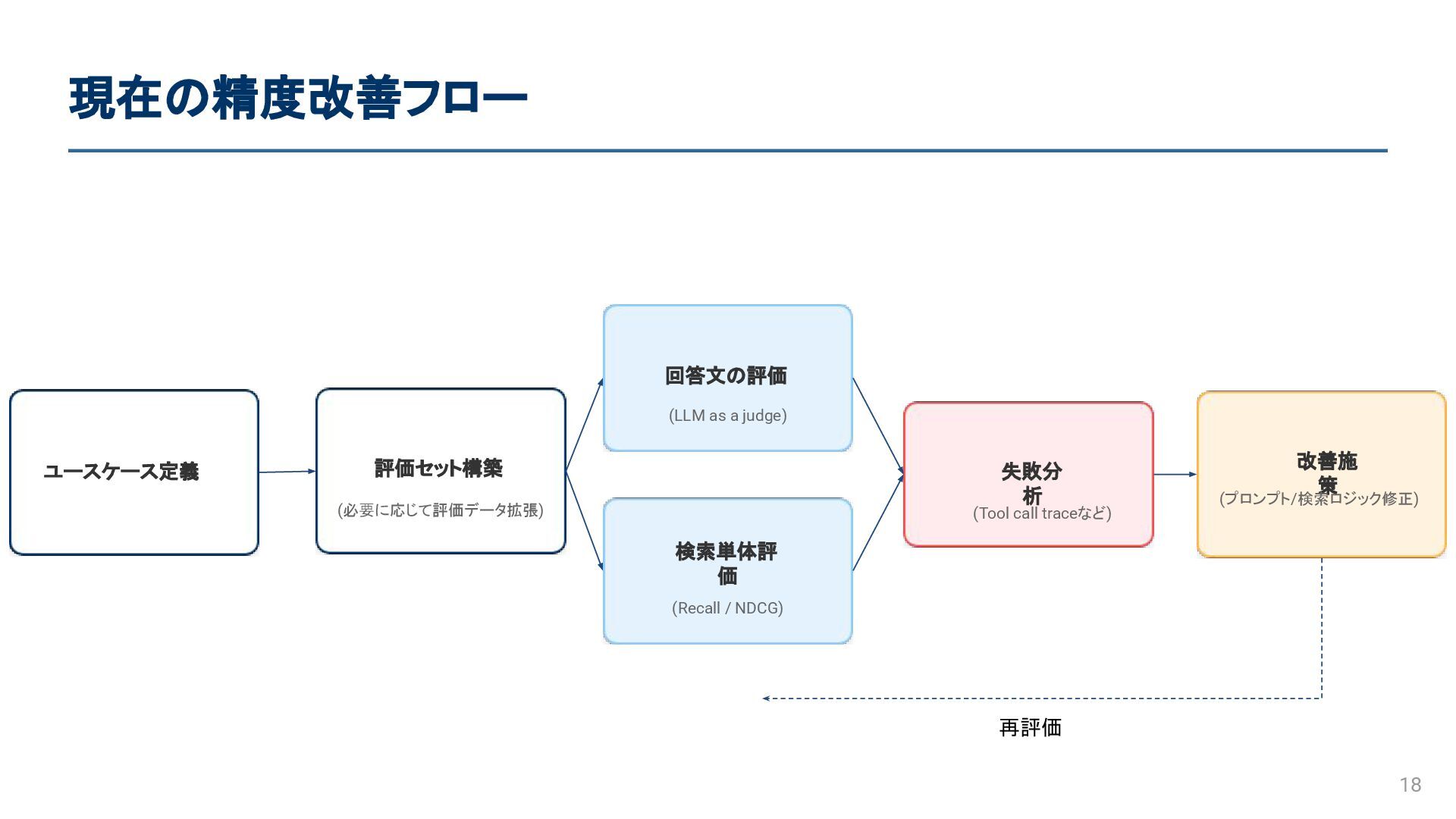
現在の精度改善フロー 6 ユースケース定義 評価セット構築 (必要に応じて評価データ拡張) 回答文の評価 (LLM as a judge)
検索単体評 価 (Recall / NDCG) 失敗分析 (Tool call traceなど) 改善施策 (プロンプト/ 検索ロジック 修正) 再評価
課題① 改善サイクルが長い 7 • ドメインエキスパートによる人手評価のため、2週間〜1ヶ月に1度のペース • 修正してもすぐ改善されたかがわからない
改善サイクルが長い課題への対応 LLM as a Judgeの導入 8 • ドメインエキスパートが質問文と正解データを作成 ◦ 生成結果を評価する正解データ
(回答に含まれるべきキーポイント ) ◦ 検索の正解ドキュメント (根拠として参照すべきドキュメント) 重要度 生成の評価 > 検索の評価
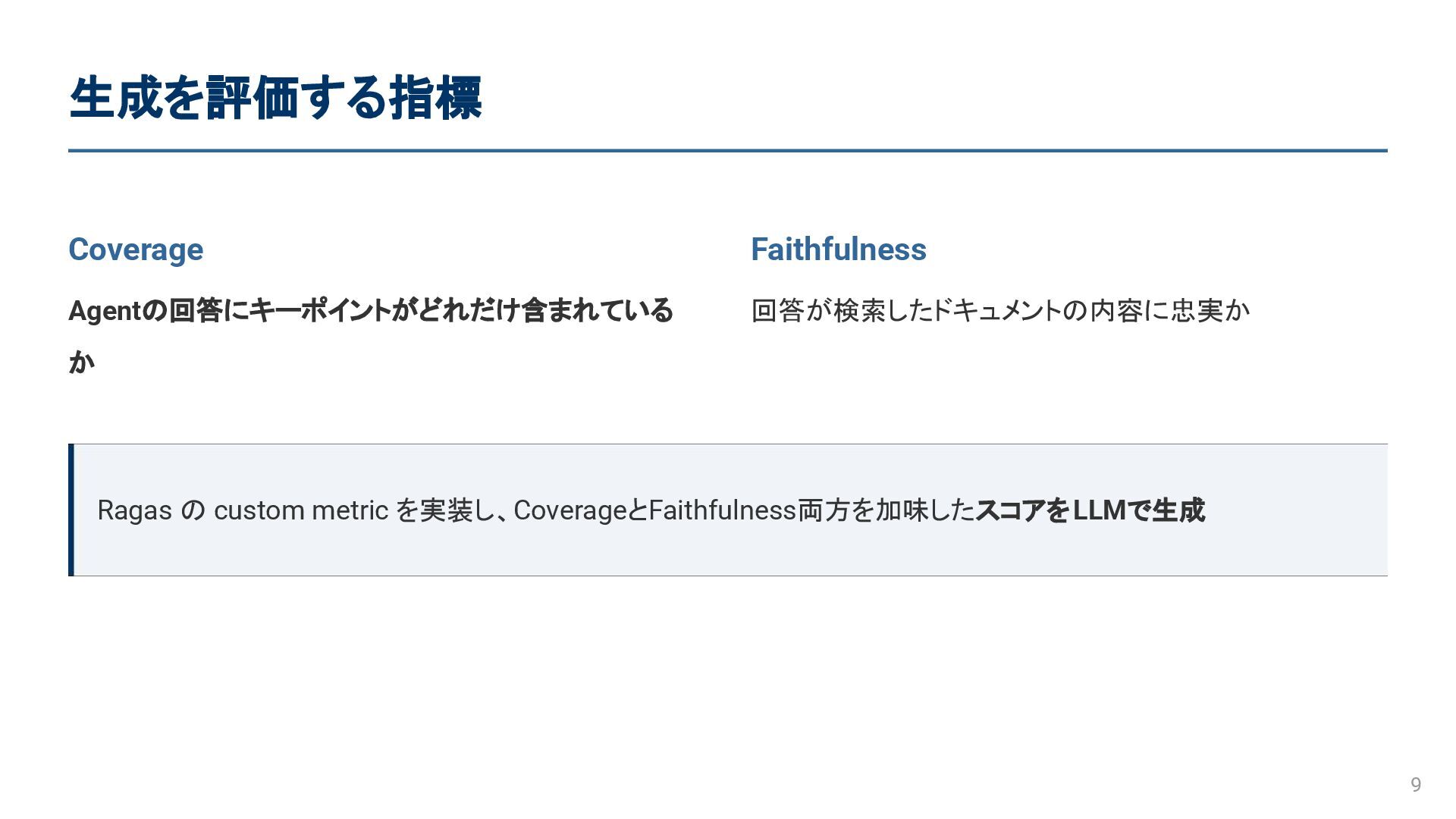
生成を評価する指標 9 Ragas の custom metric を実装し、CoverageとFaithfulness両方を加味したスコアをLLMで生成 Coverage Agentの回答にキーポイントがどれだけ含まれている か
Faithfulness 回答が検索したドキュメントの内容に忠実か
生成を評価する指標 10 • なぜキーポイントか • なぜCustom Metricを実装したか ◦ ドメインエキスパートが毎回「完全な模範解答」を作るのは負荷が高い ◦
表現の揺れは許容しつつ、重要な論点がカバーされているか ◦ Ragas標準の指標を試したが安定した結果は得られなかった
改善サイクルが長い課題への対応 検索単体の評価セット構築 11 → Agentを介さず、短時間で評価が完了 • 検索API単体の評価が必要な理由 • 評価セットの作り方 •
評価指標: Recall, NDCG ◦ 検索ロジックだけを高速に検証したい (e.g. rerankerのモデルを検証) ◦ Agentを毎回動かすと時間がかかる & Agent起因の問題と切り分けたい ◦ Tool call トレースから検索APIの呼び出しパラメータを抽出 (クエリ、フィルタ条件、ソート条件など)
課題② 失敗原因分析に時間がかかる 12 • 失敗要因はさまざま 課題: どこで失敗したのかを特定するのに時間がかかる ◦ ツール選択のミス ◦
ツールパラメータ生成の誤り(ツール ◦ 検索ロジックの改善余地 ◦ 回答生成プロンプトの問題 ◦ Agent側の実装のバグ
原因分析に時間がかかる課題への対応 必要な情報を全て結果に出力 13 • 分析に必要な情報を CSVに出力 これにより 今後の改善案 AI Coding
Editor にCSVの全ての情報を見せて「失敗原因を自動で特定する」仕組みの導入 ◦ Tool callトレース ◦ LLM-as-a-Judgeのスコアとreasonin ◦ 正解ドキュメントの中身 ..etc これにより失敗原因の特定までの時間が短縮
課題③ 局所的な修正になりがち 14 • 特定の評価ケースに対して、プロンプトをピンポイントに修正 • そのケースは直るが、類似ケースへ対応できているかがわからない • 結果として、局所最適なプロンプトが増えていきがち
局所的な修正になる課題への対応 評価セットの拡張 15 ドメインエキスパートがチェック • 現状の評価セットのユースケースをベースに質問文を生成 効果 評価ケース数が増えることで、改善施策の効果を信頼性高く検証できる • (そもそも評価セットが少ない場合)
契約書からLLMで質問文と正解キーポイントを生成させる 言い回しや抽象度を変えたバリエーションを作る 改善対象のプロンプトやユースケースを元に、LLMで類似質問文を生成 •
課題④ ユーザーが感じる精度とのギャップ 16 • 課題の背景 • 結果として : オフライン評価では良くても、ユーザーの体感精度は悪いという現象が発生 ◦
評価セットのプロンプトと、実際のユーザー質問に乖離がある可能性 ◦ 評価で使っている契約書と、実際にユーザーが持っている契約書が異なる
実際の精度とのギャップがある課題への対応 17 • • 営業チームとの連携 • Dogfooding: エンジニアがプロダクトを触る時間を確保 ◦ 顧客との接点が近い営業から、重要なユースケースをヒアリング
質問ログの分析
現在の精度改善フロー (再掲) 18 ユースケース定義 評価セット構築 (必要に応じて評価データ拡張) 回答文の評価 (LLM as a
judge) 検索単体評 価 (Recall / NDCG) 失敗分析 (Tool call traceなど) 改善施策 (プロンプト/ 検索ロジック 修正) 再評価
今後の改善 19 • 評価セット構築の効率化 : ツール数 × リージョン数分の評価セットを効率よく作る • 継続的な評価
: 定期的な自動評価 (Nightly benchmark), CI上での評価実行 • 失敗原因分析の自動化 : 失敗ケースに対して、LLMが原因・改善案を提案する仕組み • ツール選択の評価セット構築 : ツールが増えていくにつれて、ツール選択の精度が重要になる
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}