NVIDIA CUDA is a tool kit for development of GPU accelerated applications. For specific types of applications and computational patterns the GPU allows you to deploy thousands of cores for processing in a very cost effective manner.
While getting the full benefit of GPU acceleration can take a considerable amount of knowledge and effort, considerable speedups can be achieved with minimal program changes.
This talk provides an overview of what CUDA is, where it can be effective, and then does a deep dive to convert a simple, sequential data processing loop running as a single thread on the CPU into a massively parallel operation running on the GPU.
![Lloyd Moore, President [email protected] www.CyberData-Robotics.com CUDA Without a PhD](https://files.speakerdeck.com/presentations/3a238ab3a86949638b83c0ebefc58872/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
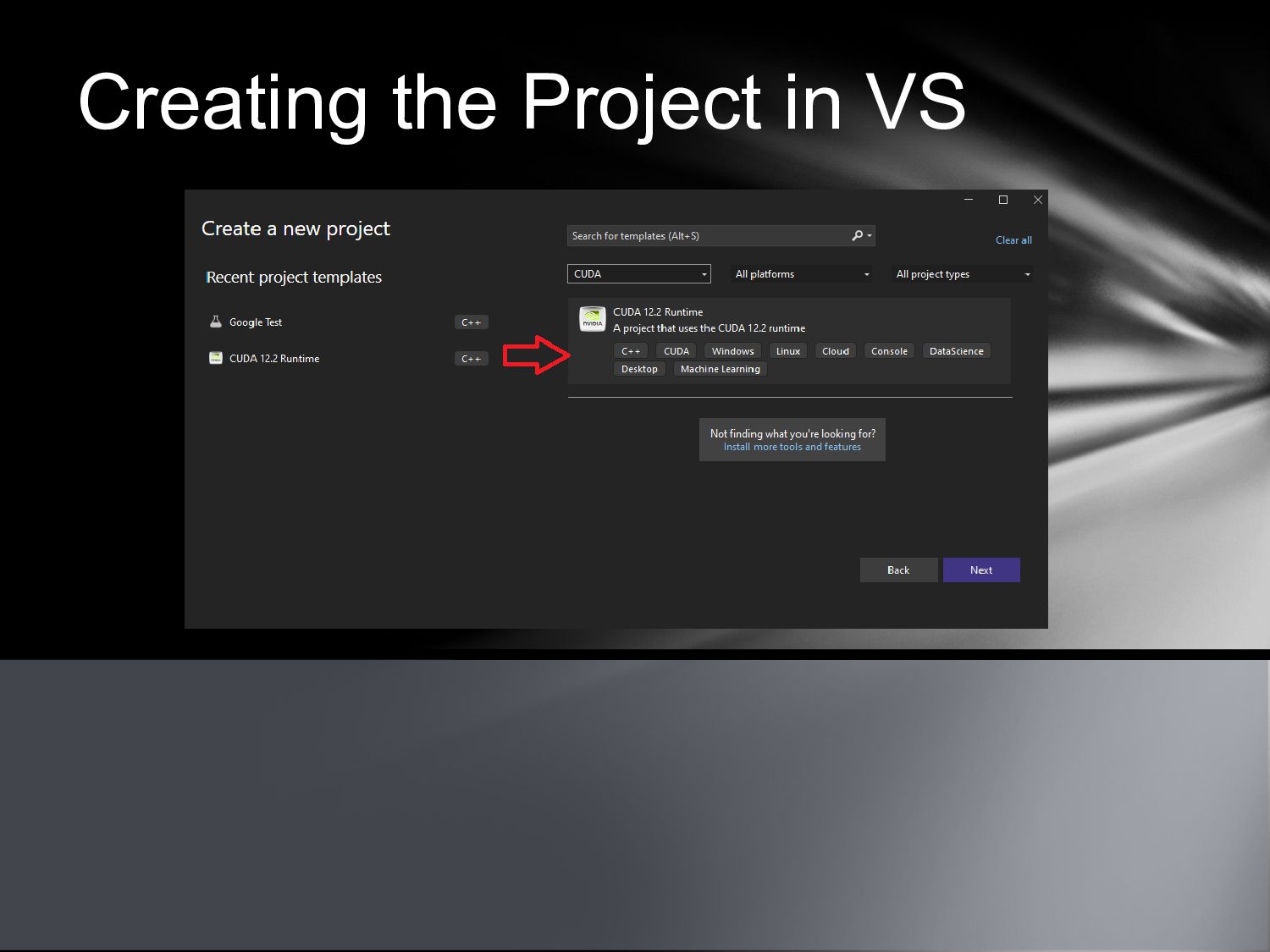{kind=link}
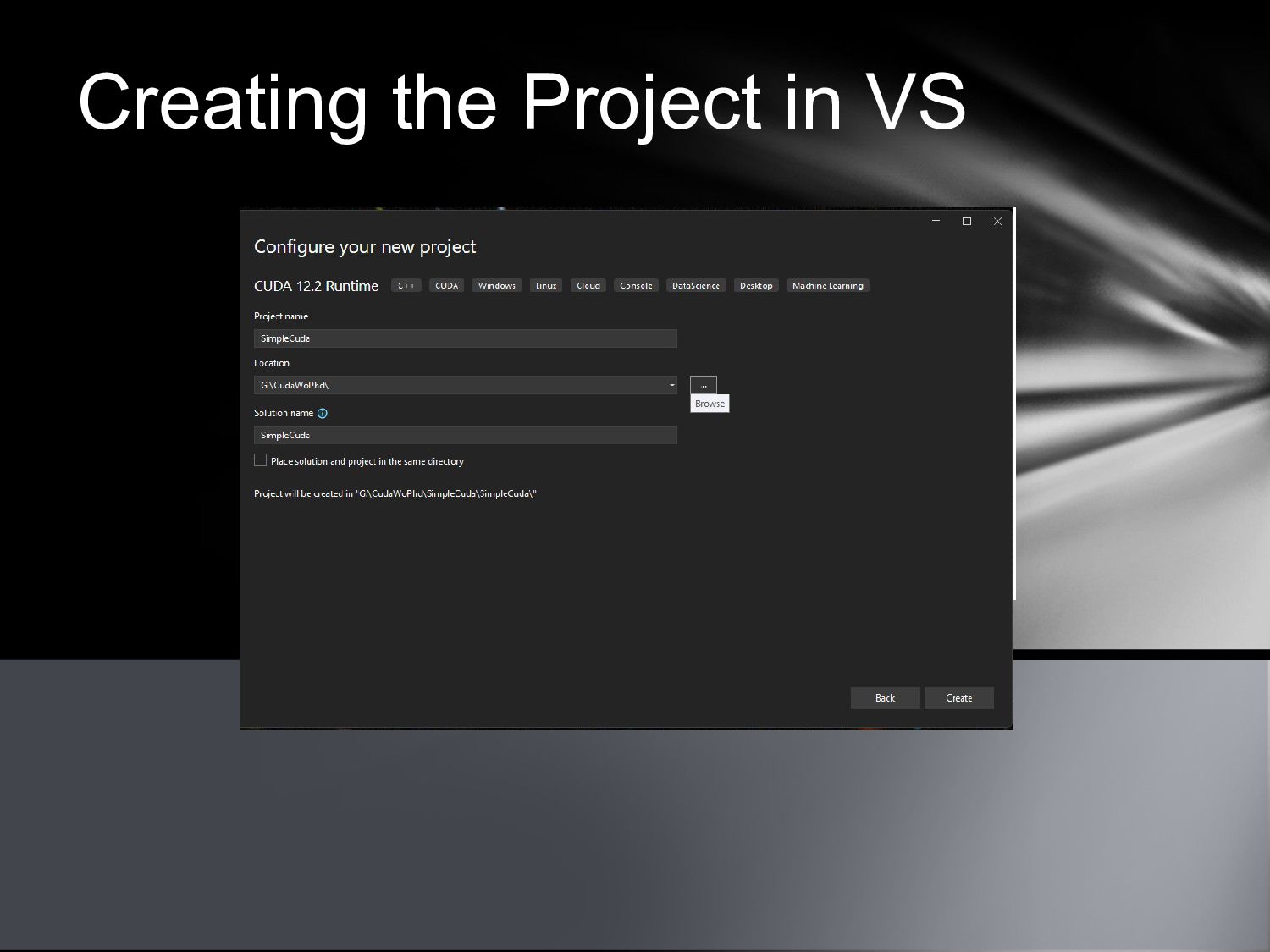{kind=link}
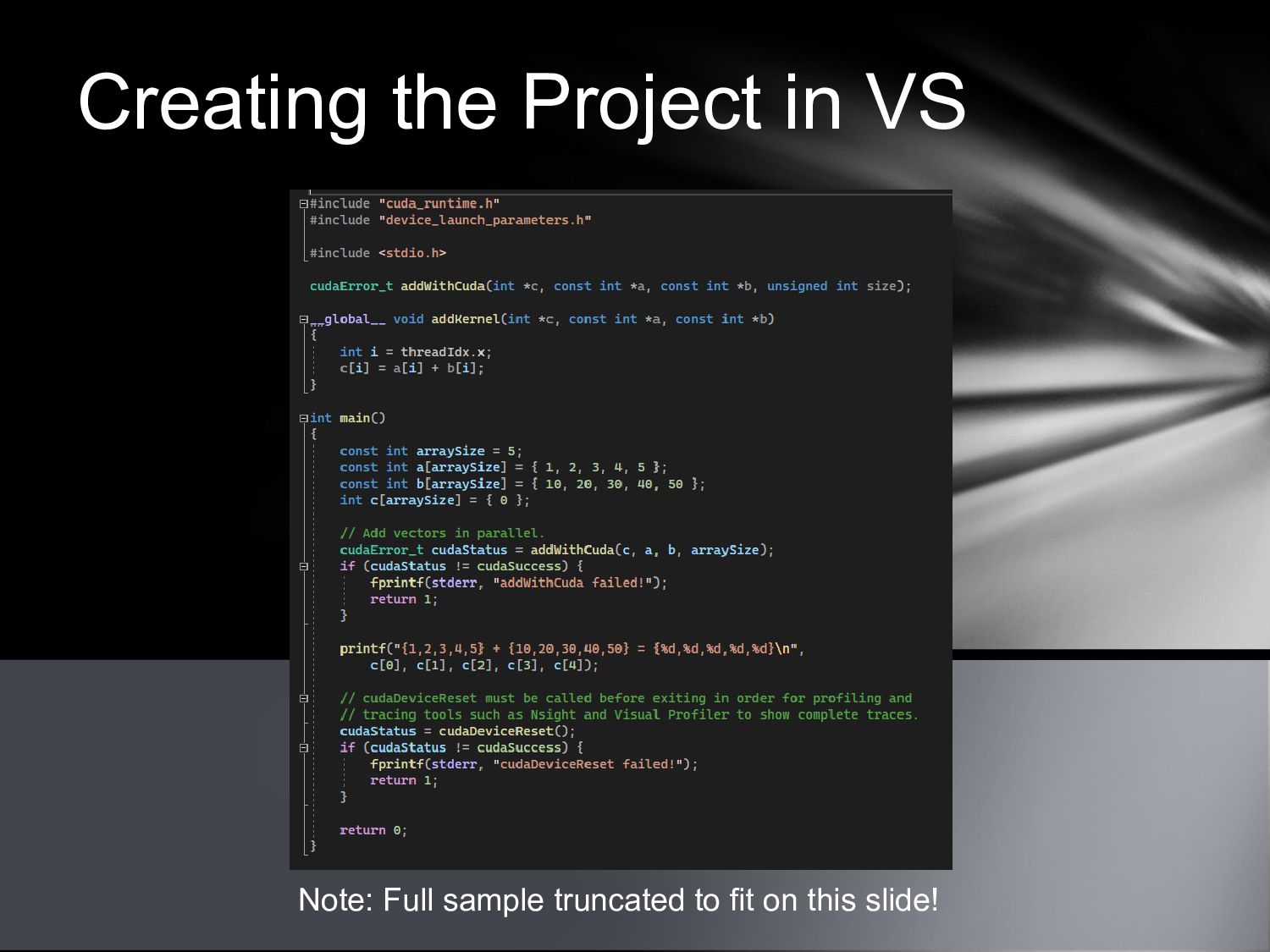{kind=link}
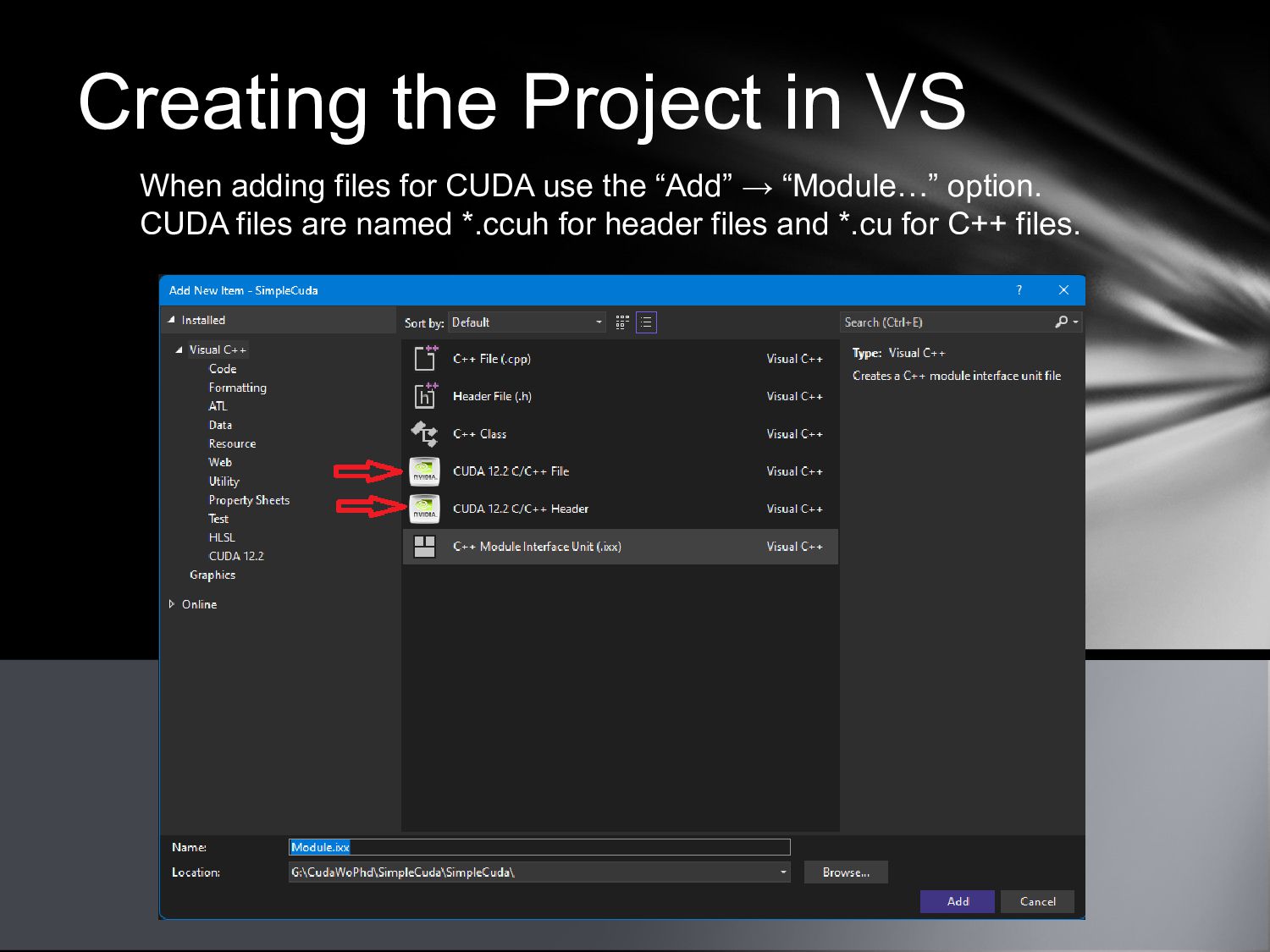{kind=link}
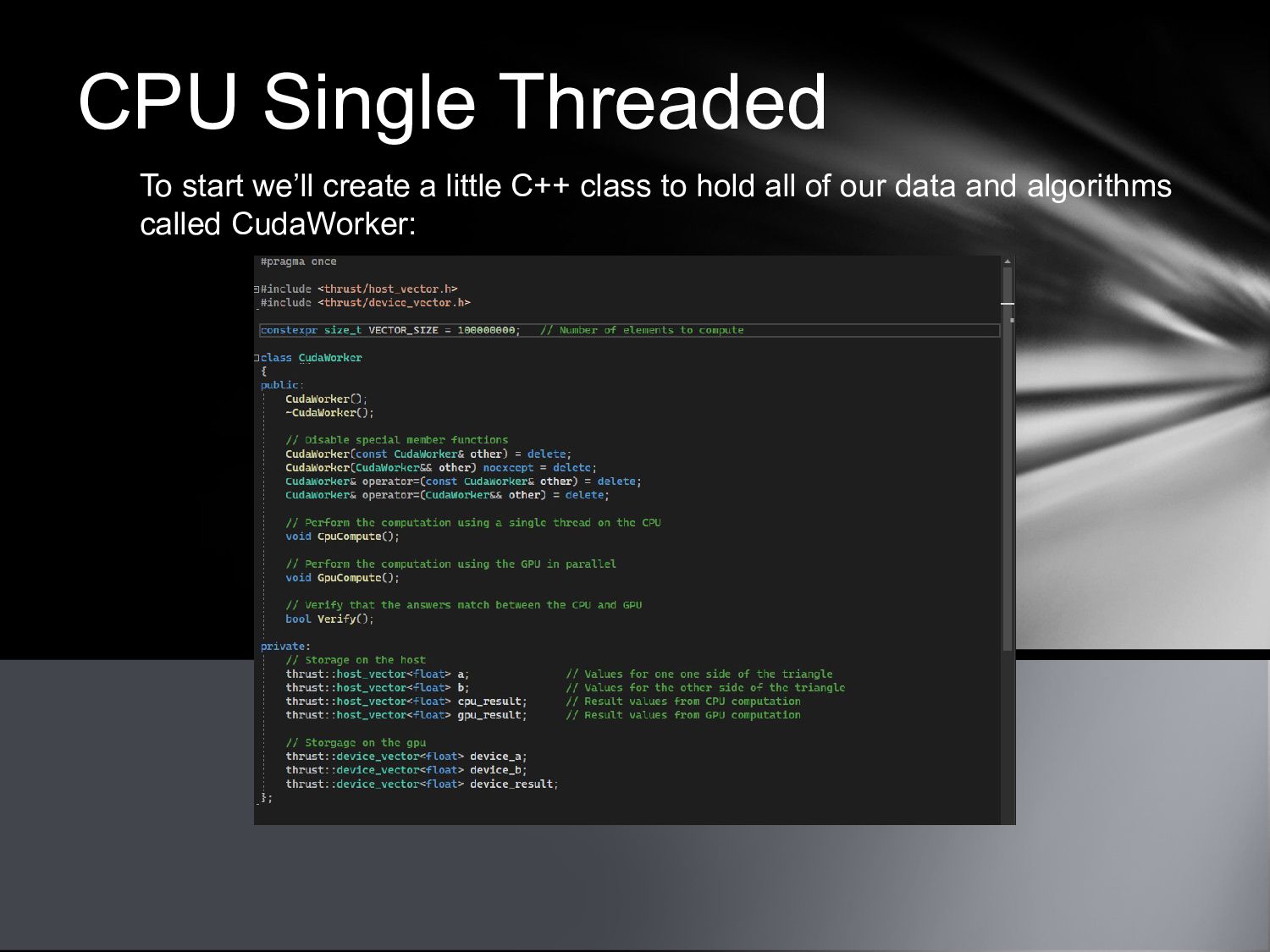{kind=link}
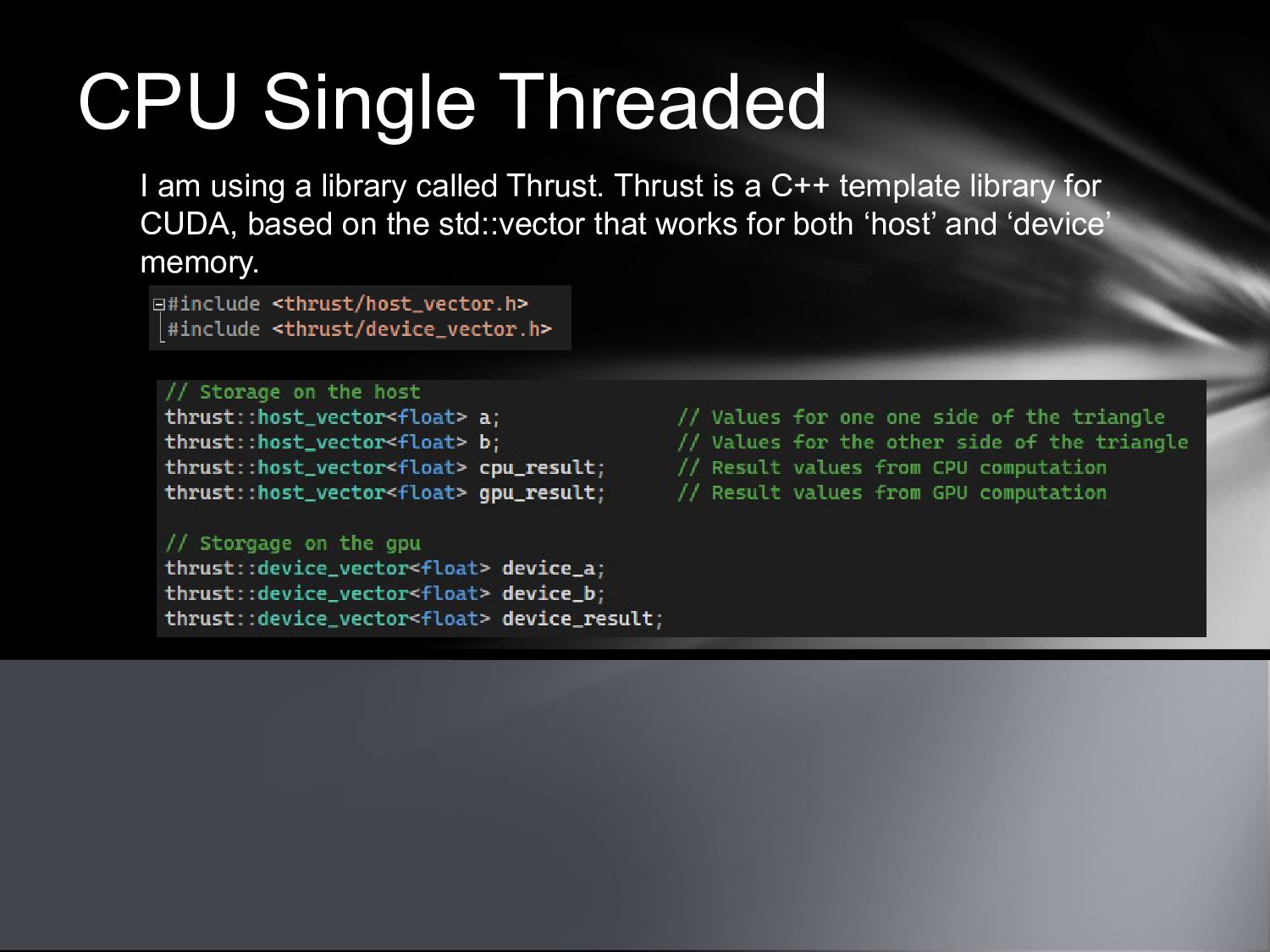{kind=link}
{kind=link}
{kind=link}
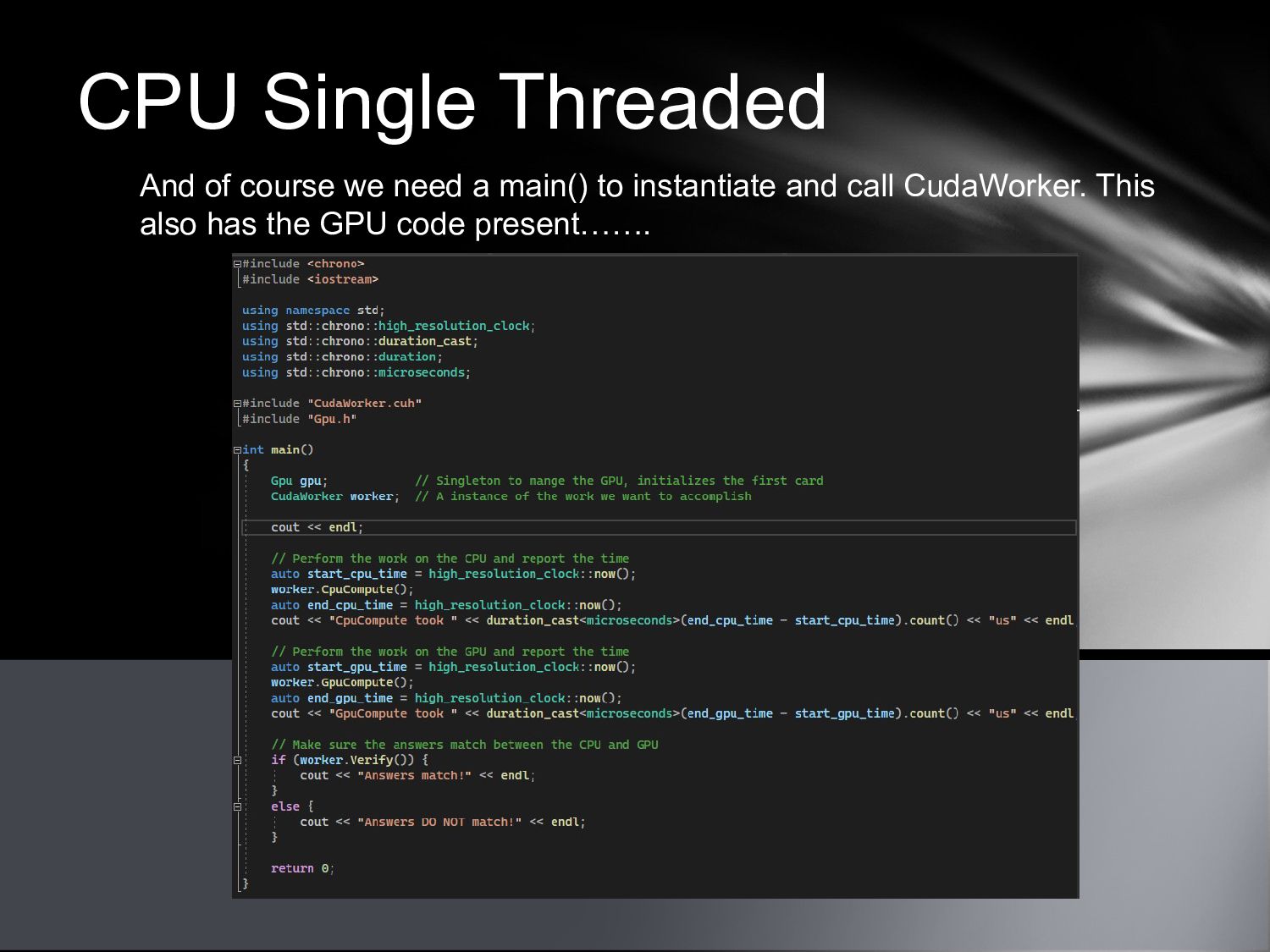{kind=link}
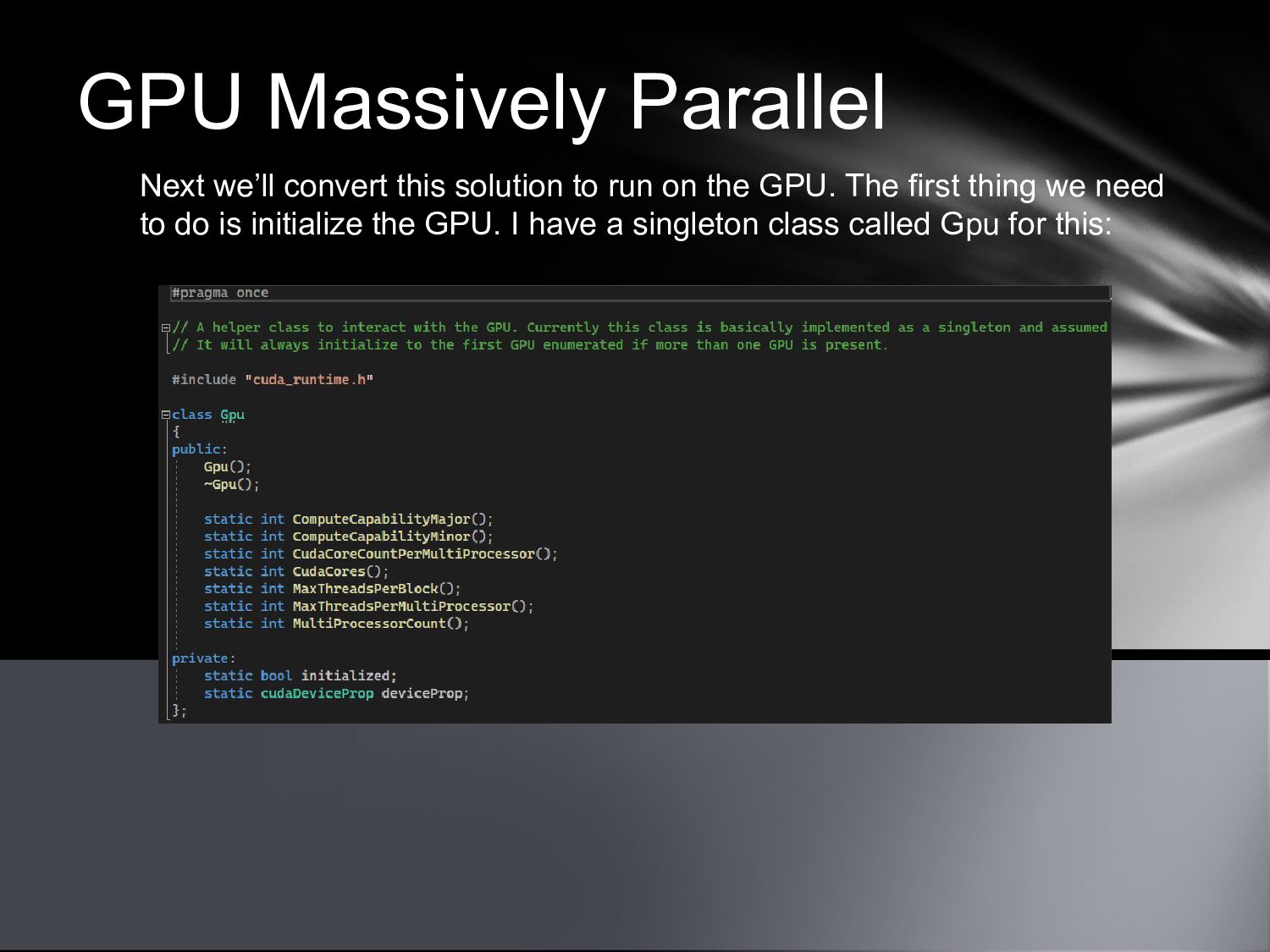{kind=link}
{kind=link}
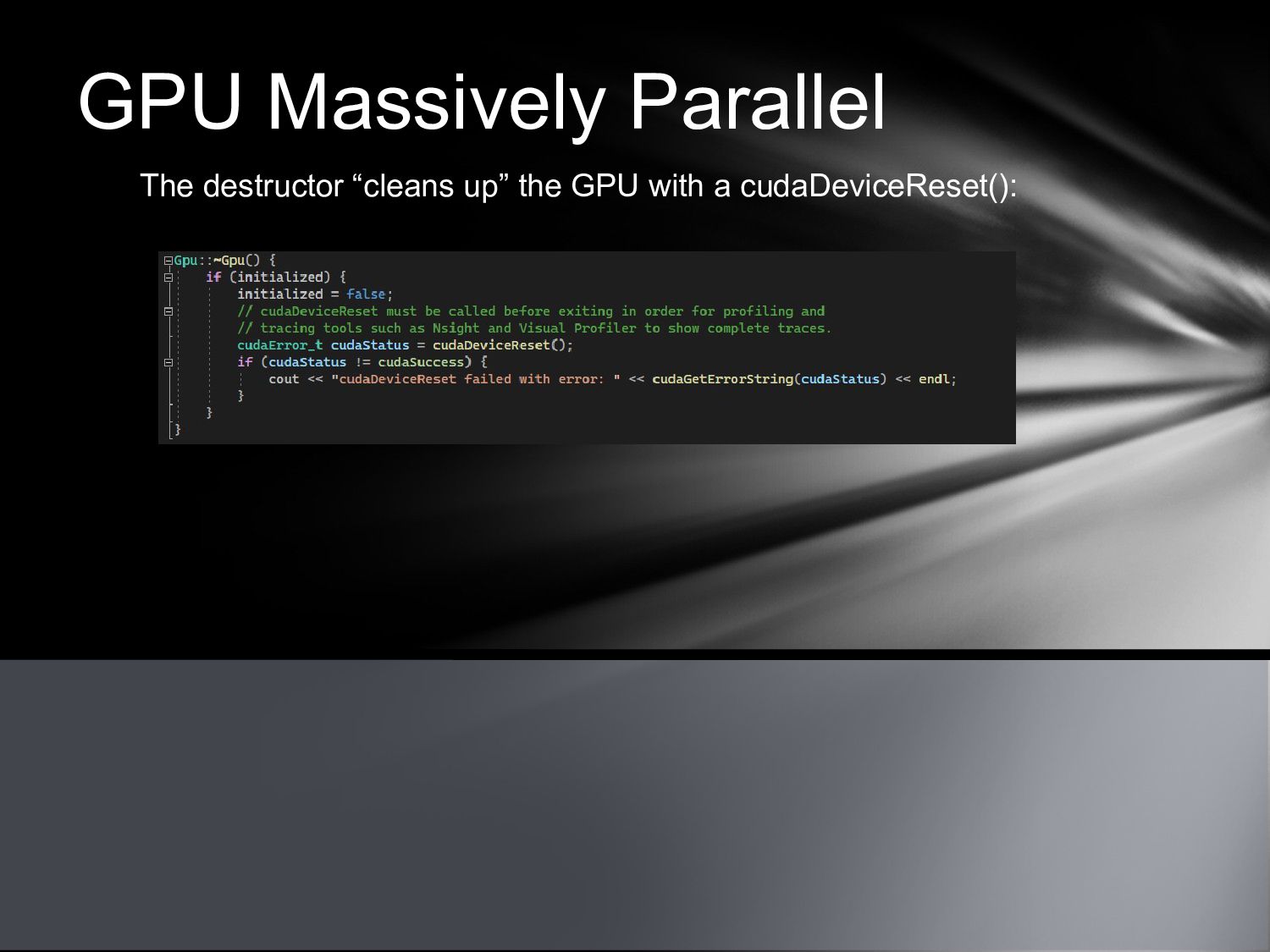{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
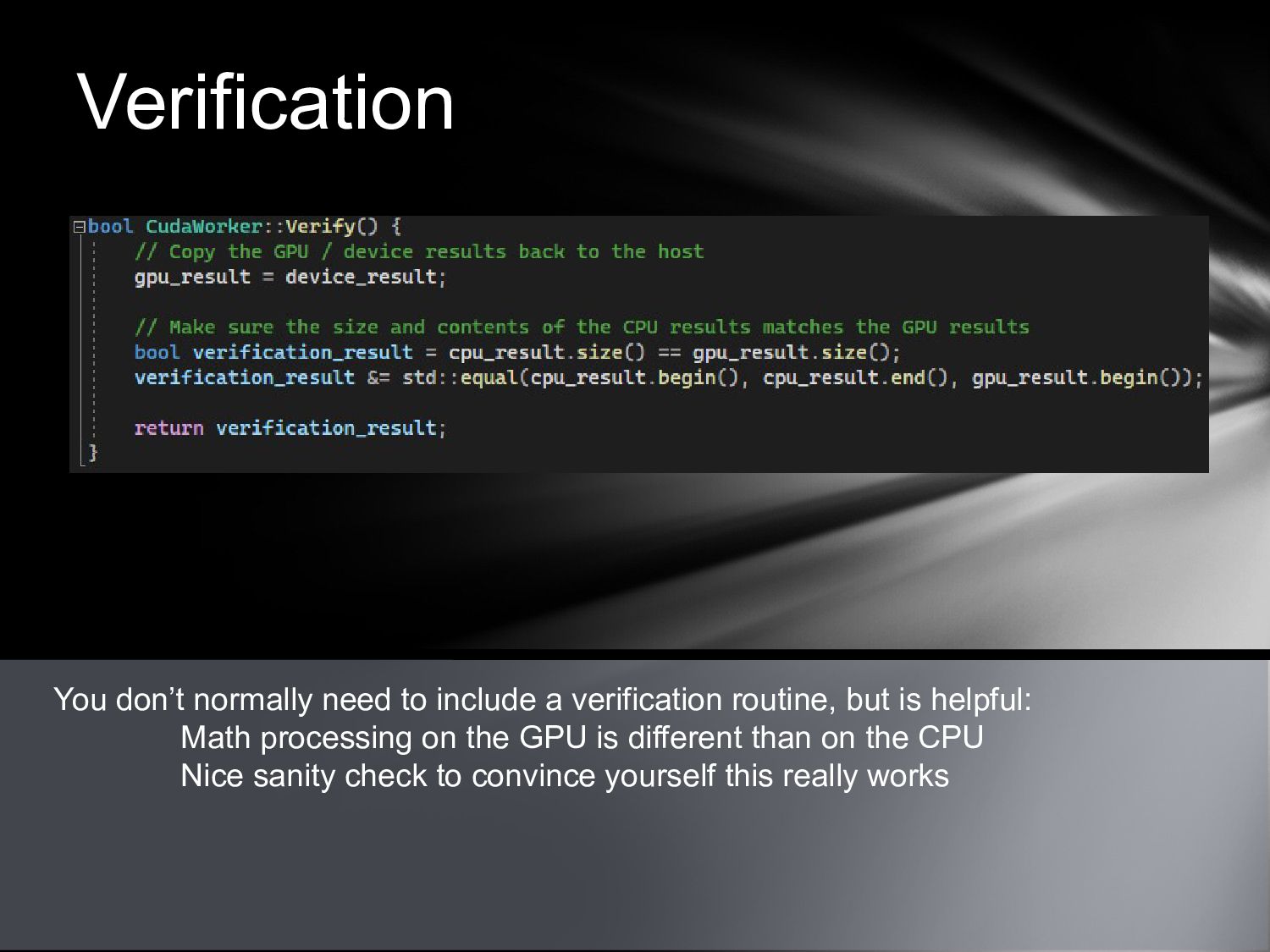{kind=link}
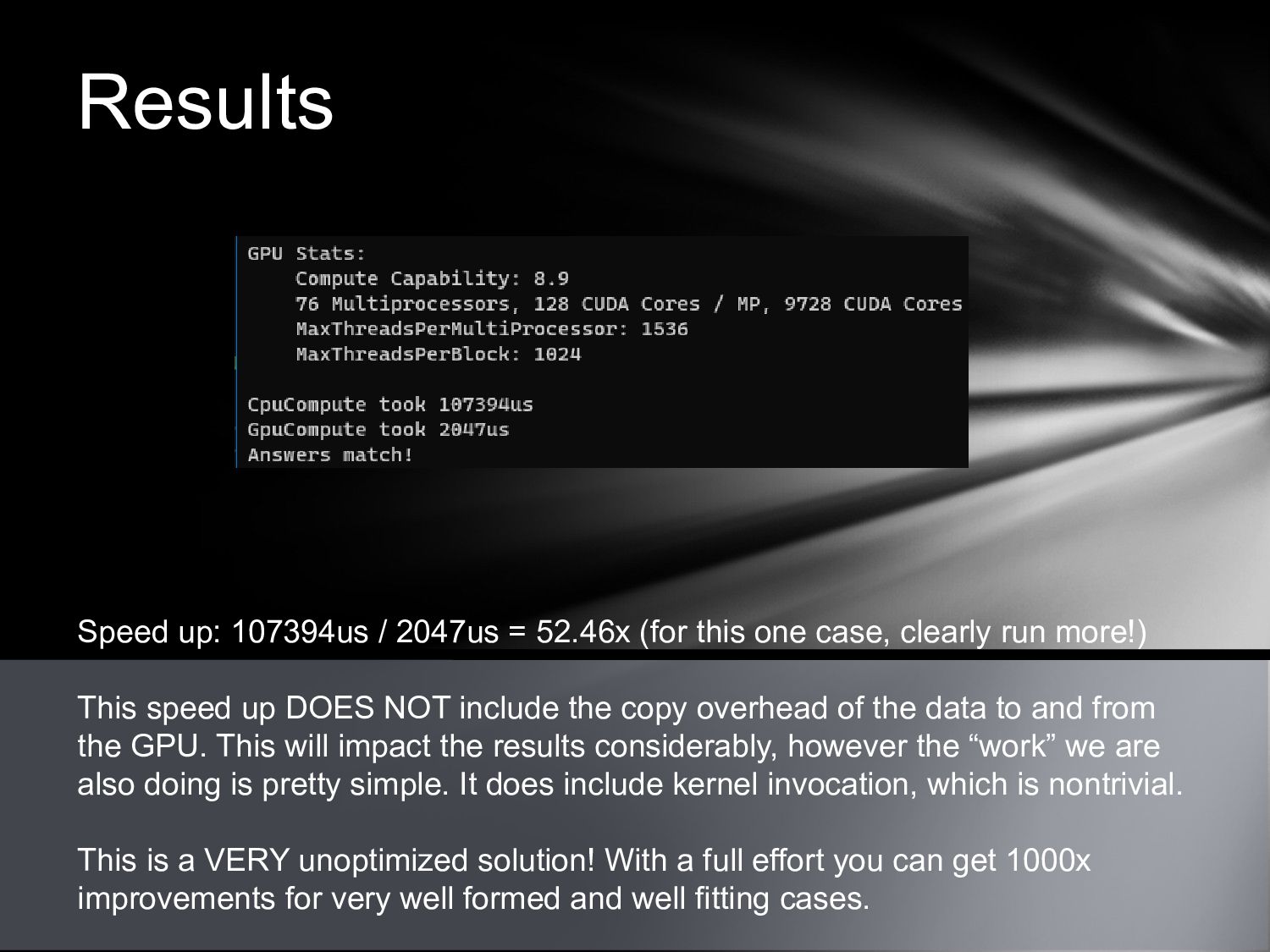{kind=link}
{kind=link}
{kind=link}
{kind=link}