"Kafka vs. Pulsar, which is faster?" - A question faced by everyone when selecting a modern data streaming platform. We took up the challenge to answer that question rigourously.
LINEヤフー is a rare company which uses large scale production clusters of both Apache Kafka and Apache Pulsar. Following the merger, former LINE Kafka team and the former Yahoo Pulsar team brought together the know-how they have cultivated through large-scale production operations of their respective platforms.
Leveraging these strengths, we present the results of a Kafka vs. Pulsar benchmark comparing multiple workload scenarios. Focusing on throughput and latency, we will explore how bottlenecks arise in both products and determine which is faster.
{kind=link}
{kind=link}
{kind=link}
![© LY Corporation Mathew Arun [マテュ アルン] Server Side Engineer](https://files.speakerdeck.com/presentations/eee703f7107c42d49757b94410c15a7e/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
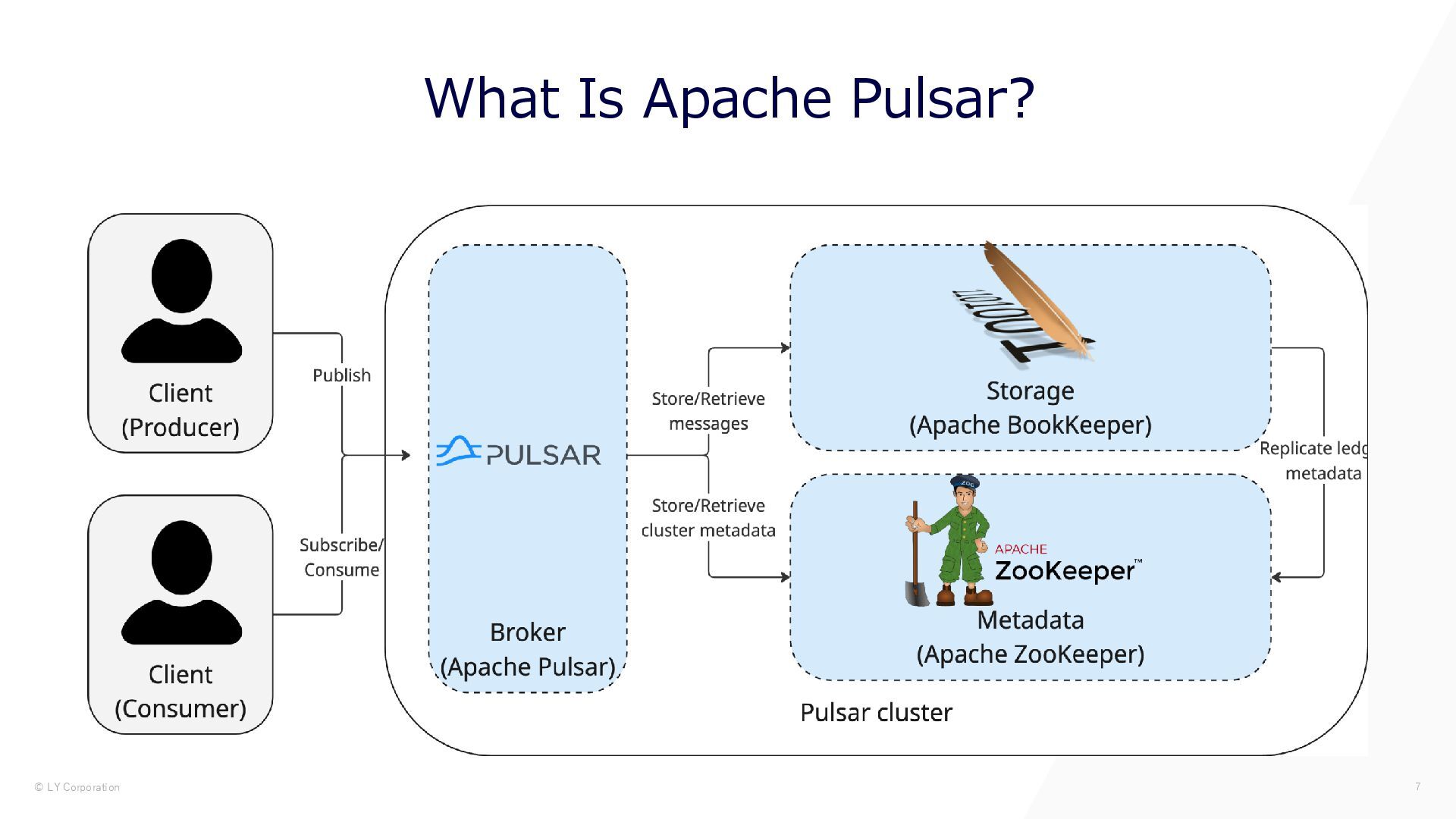{kind=link}
{kind=link}
{kind=link}
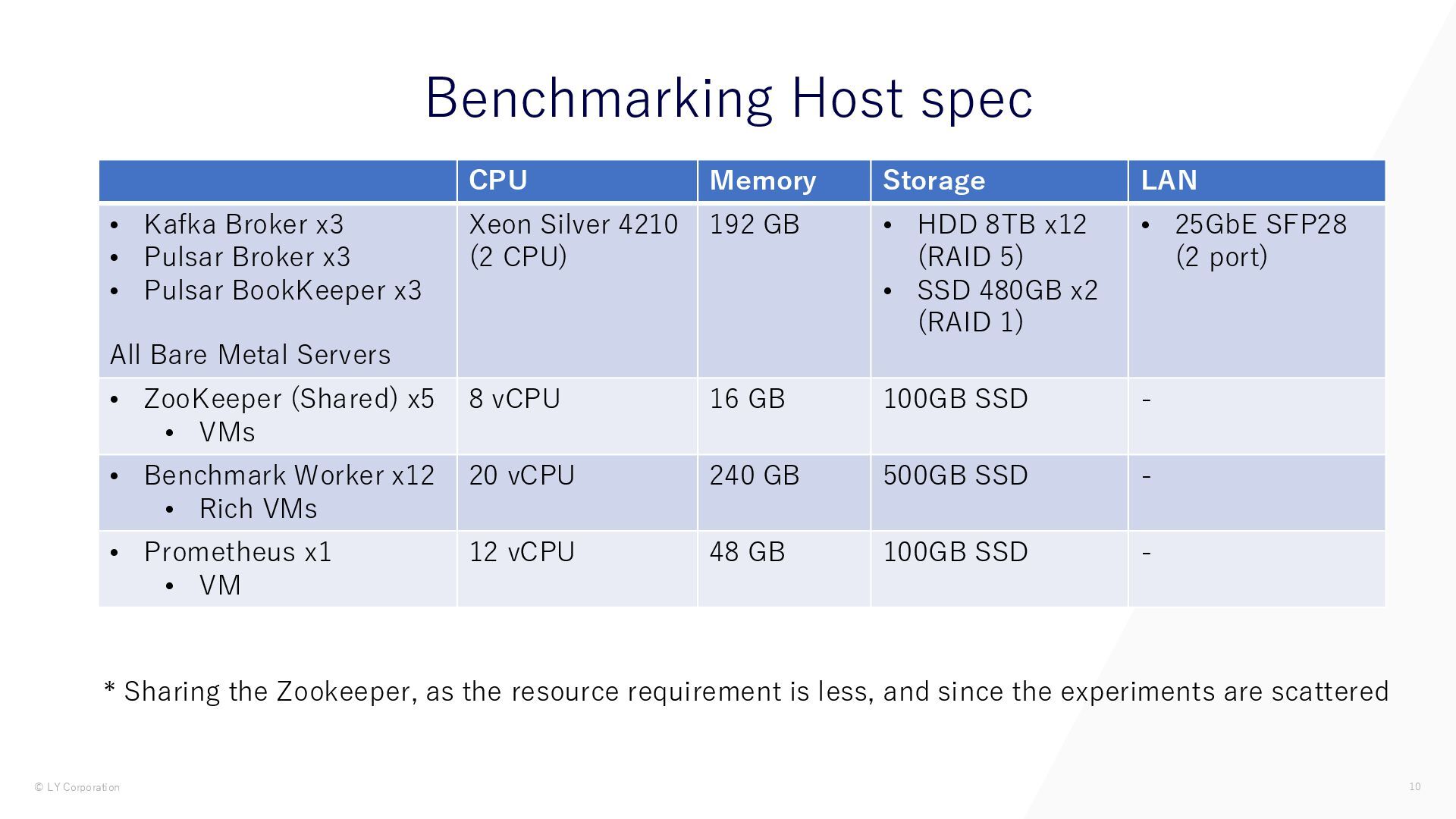{kind=link}
{kind=link}
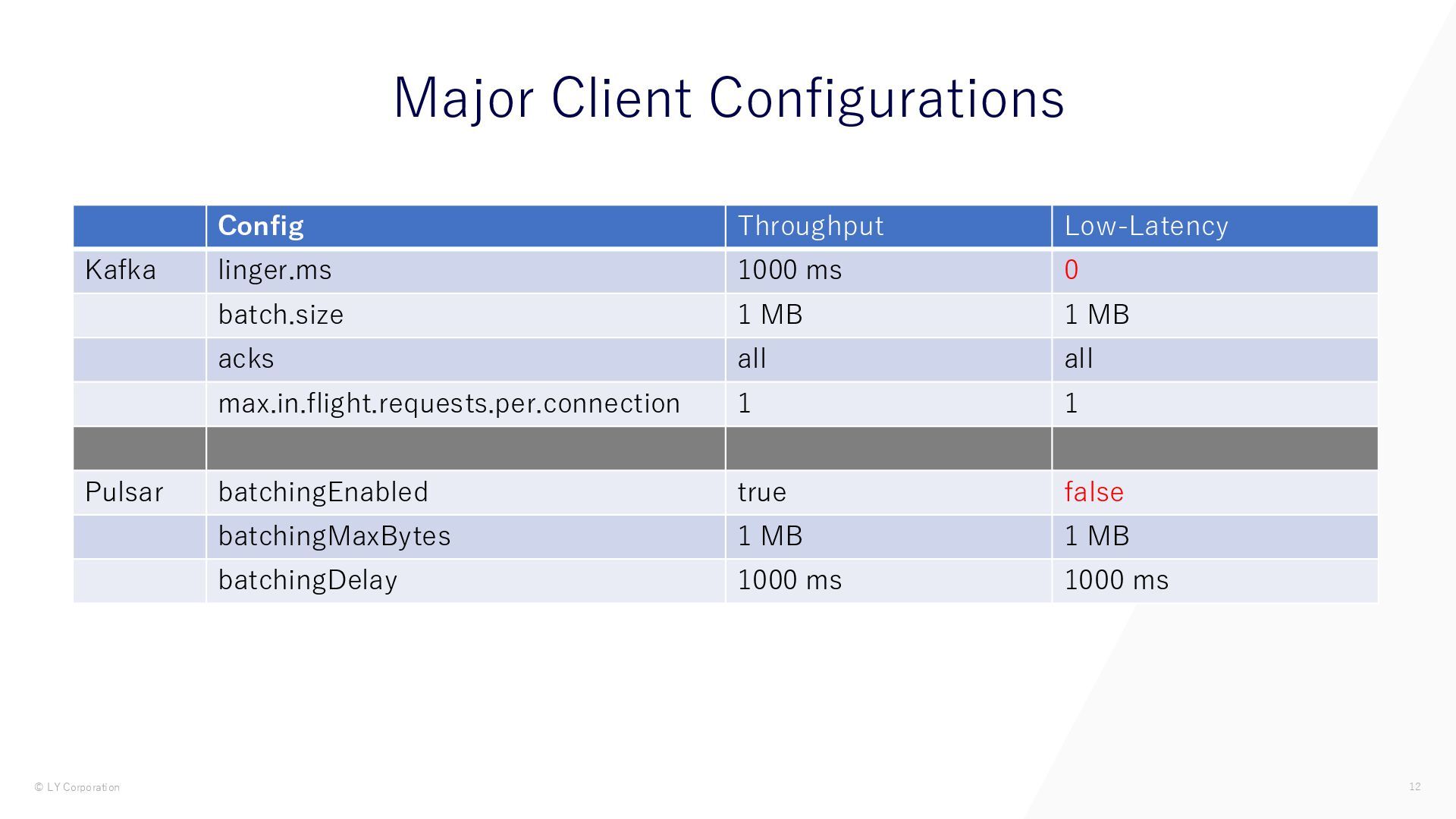{kind=link}
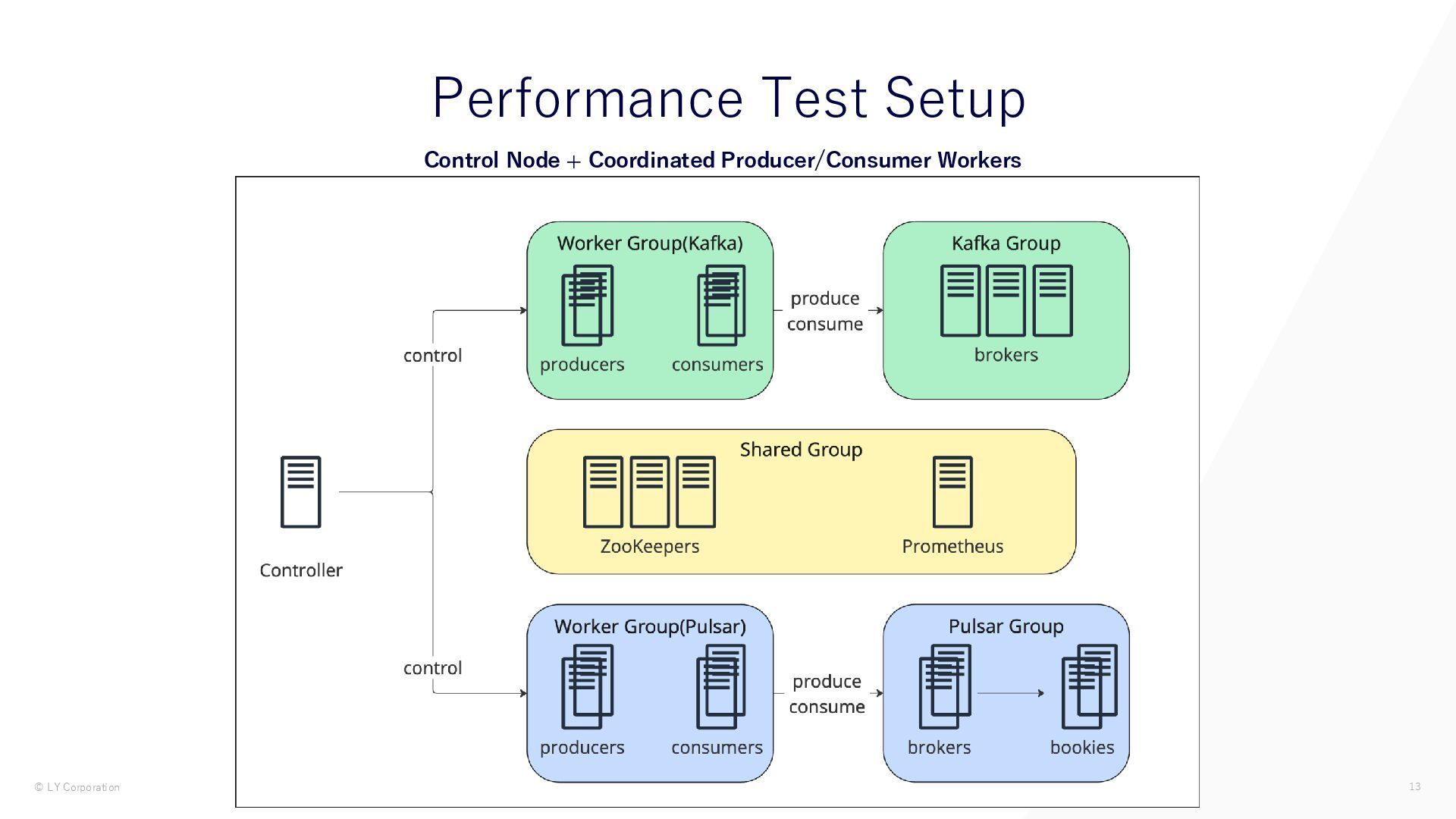{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
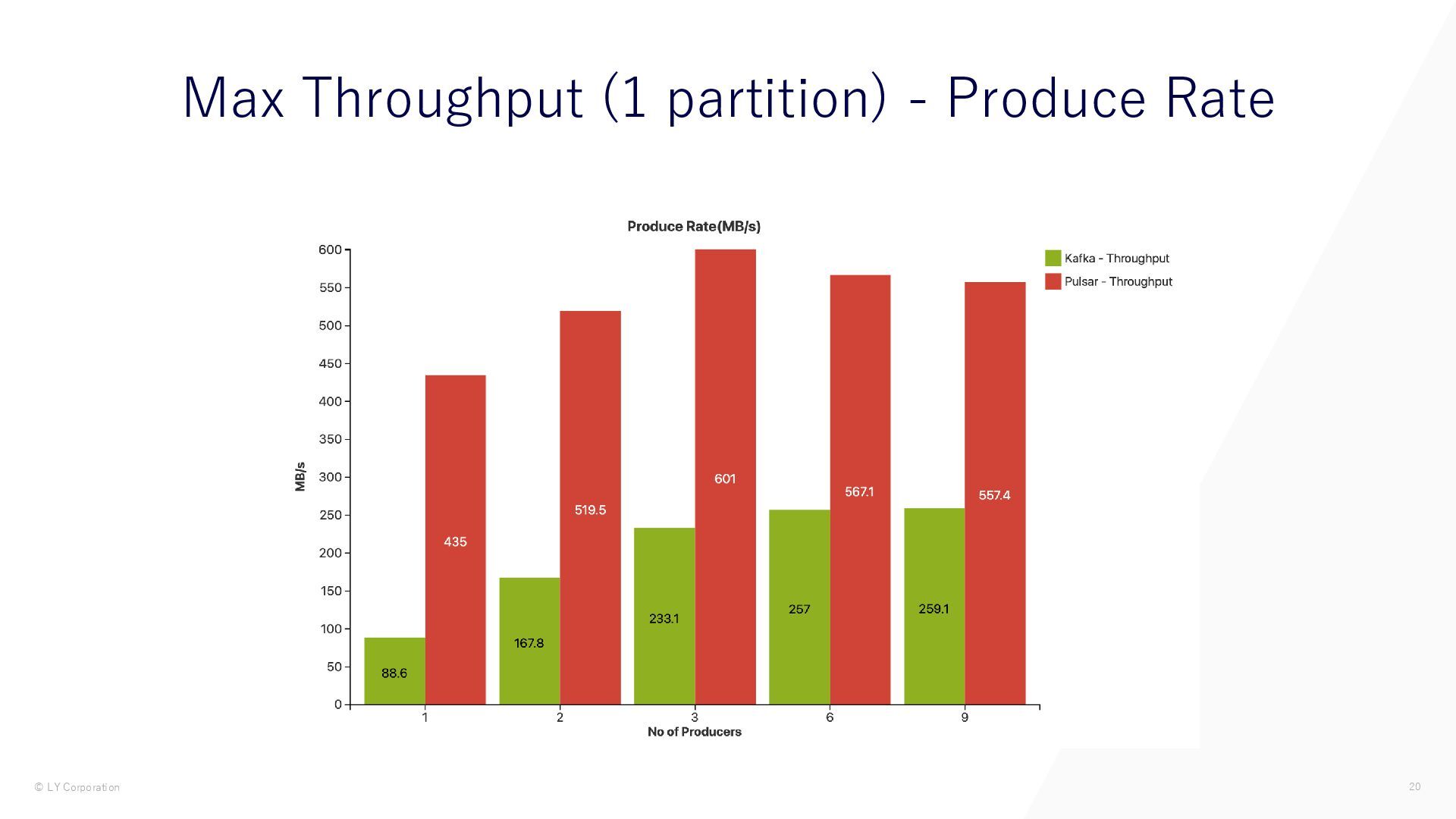{kind=link}
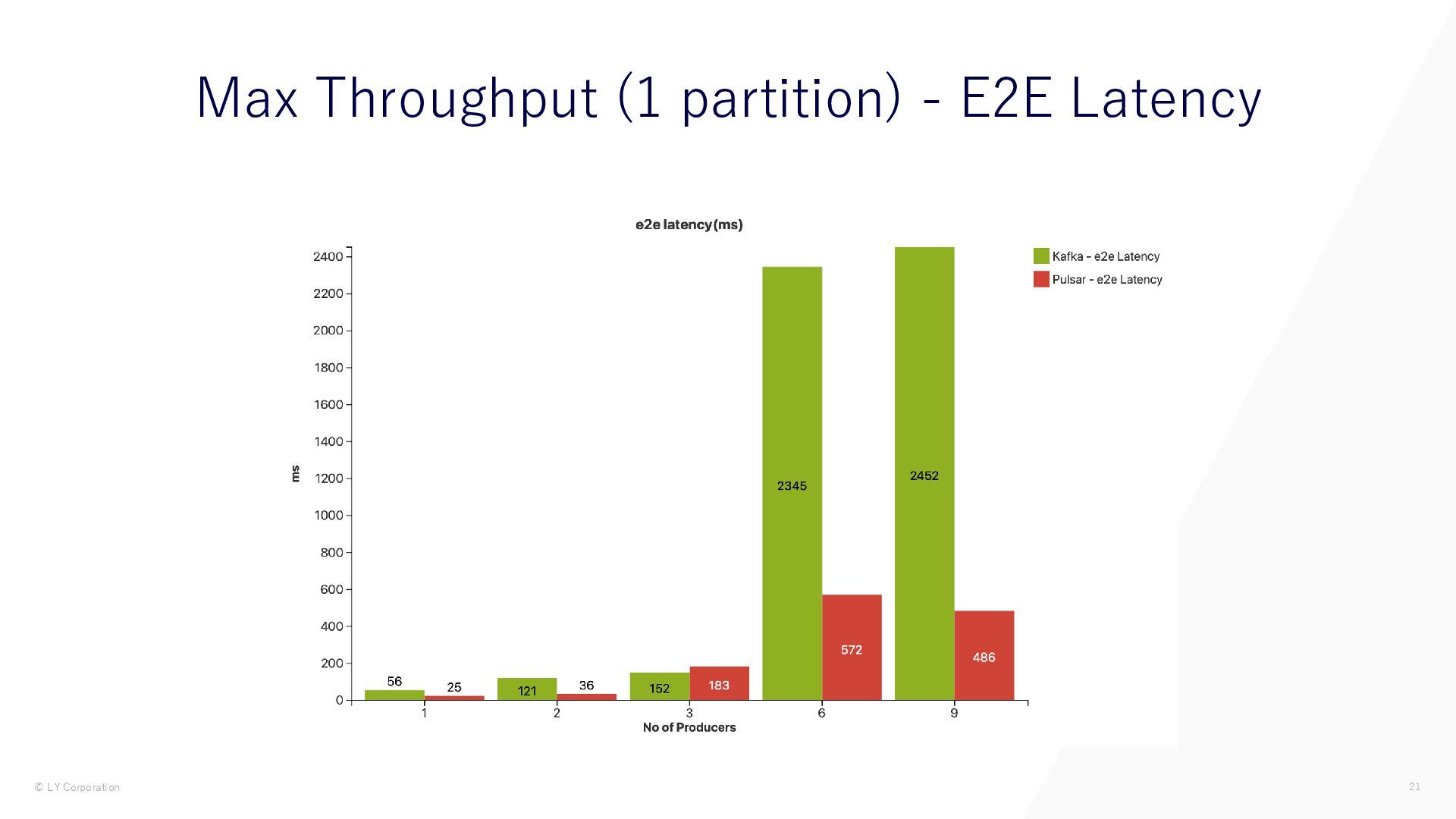{kind=link}
{kind=link}
{kind=link}
{kind=link}
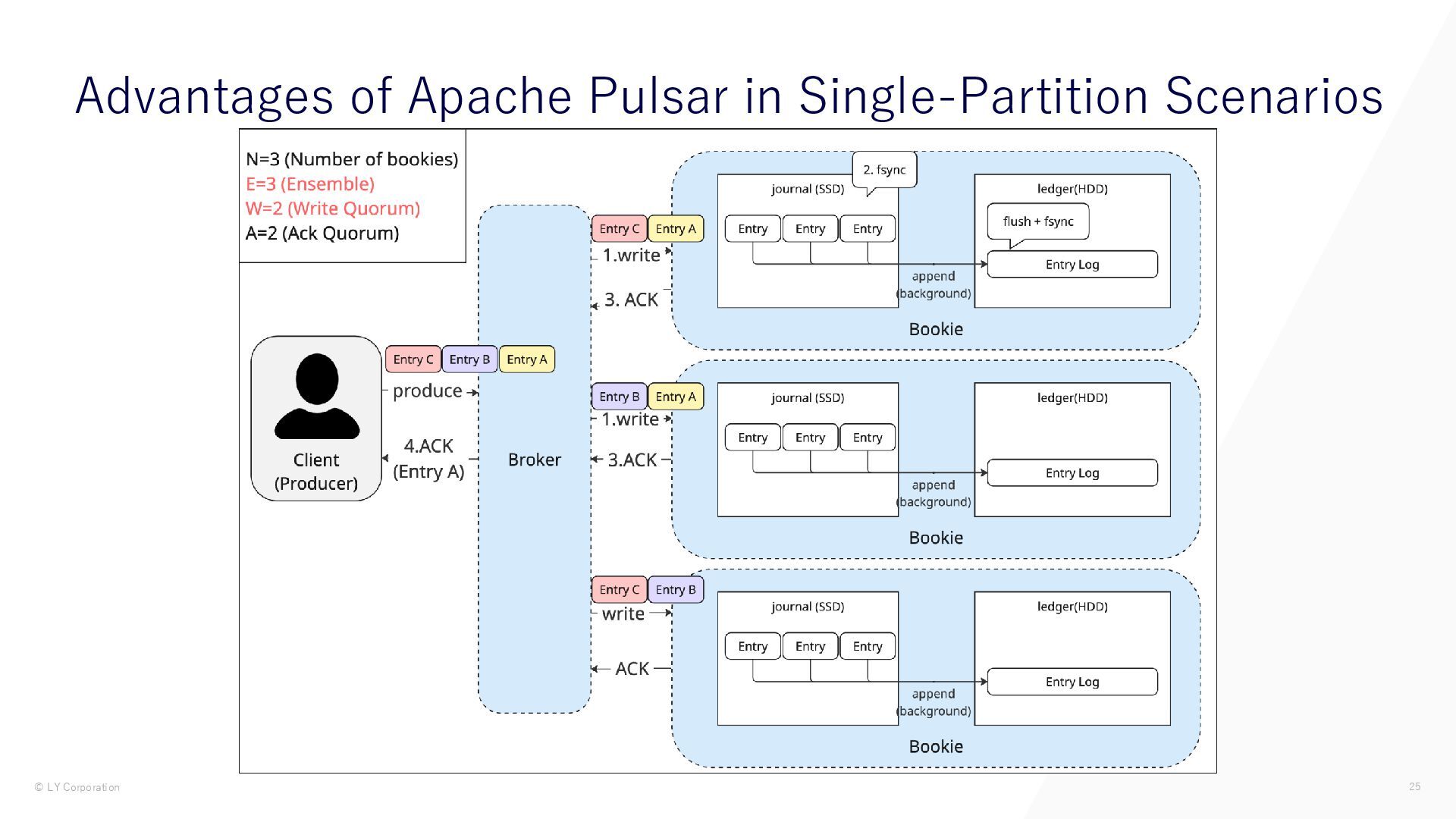{kind=link}
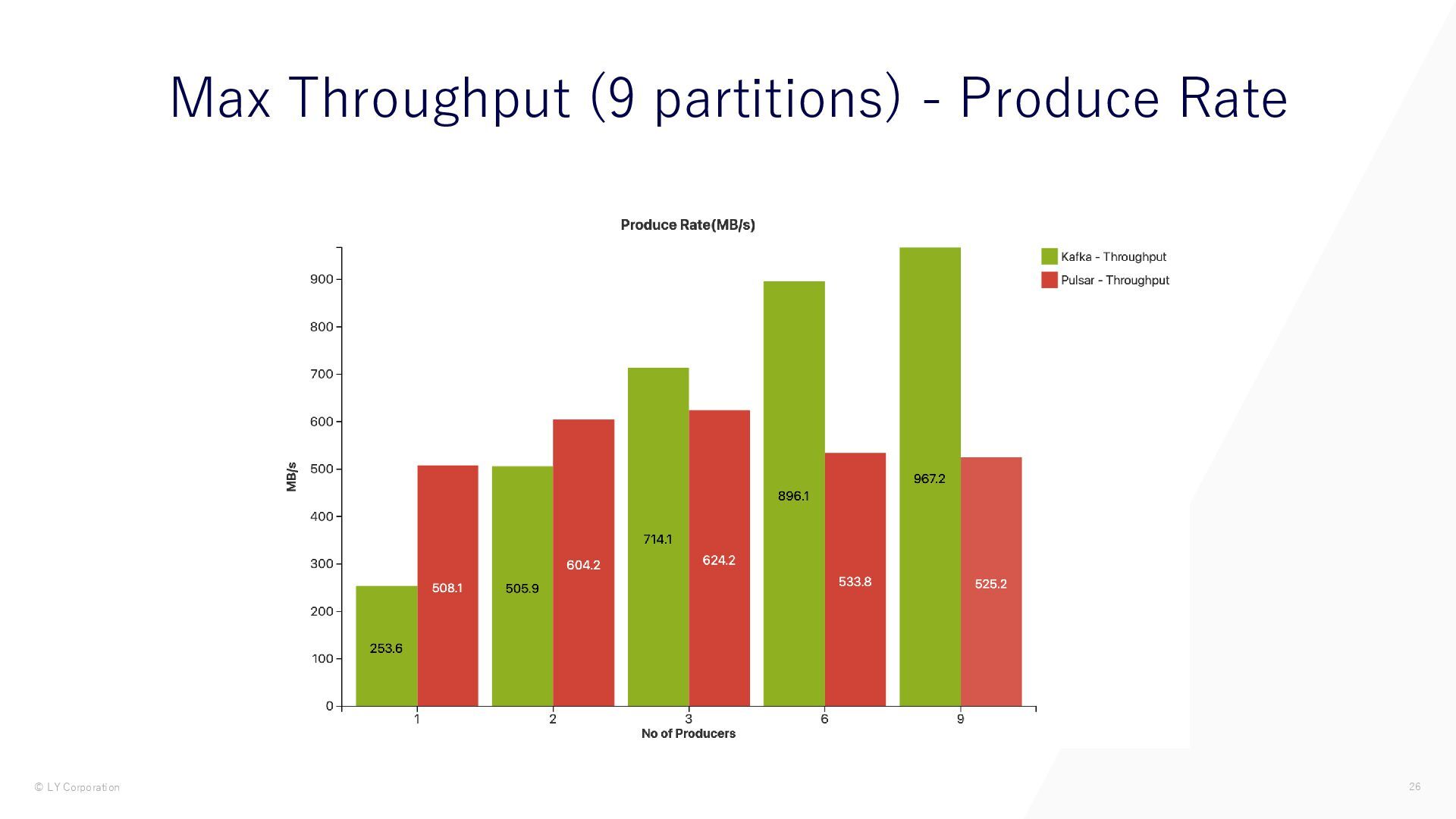{kind=link}
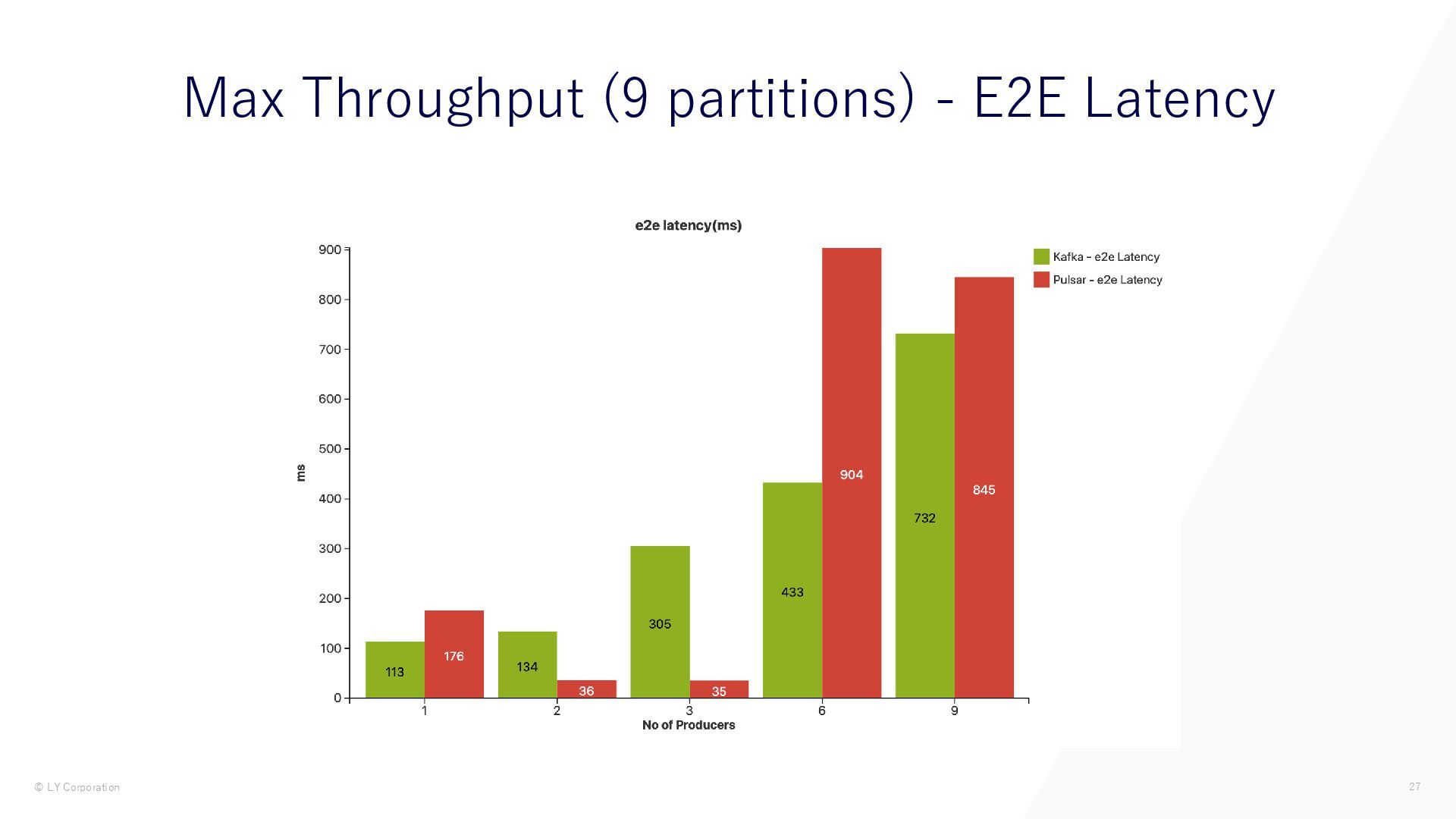{kind=link}
{kind=link}
{kind=link}
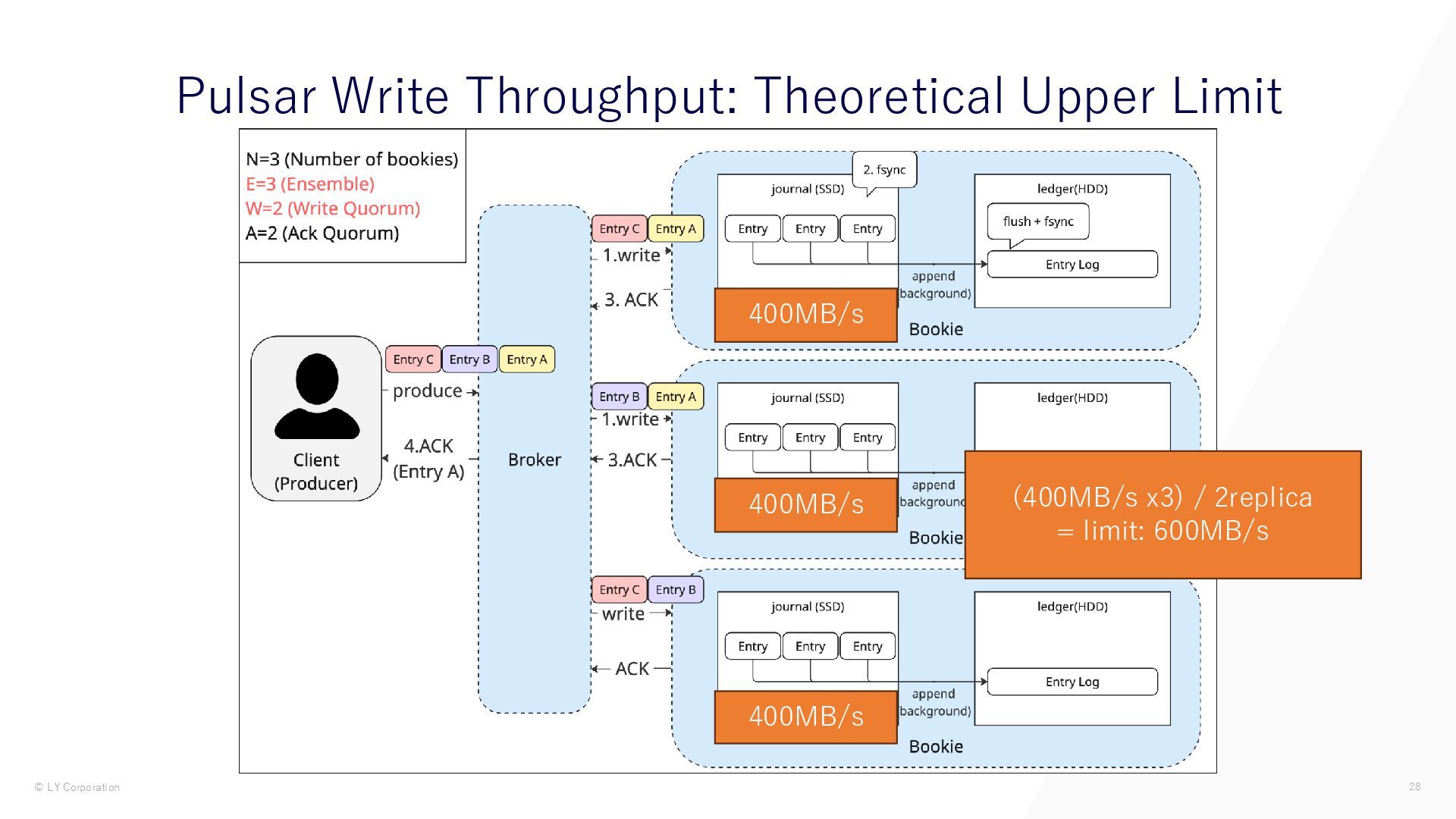
{kind=link}
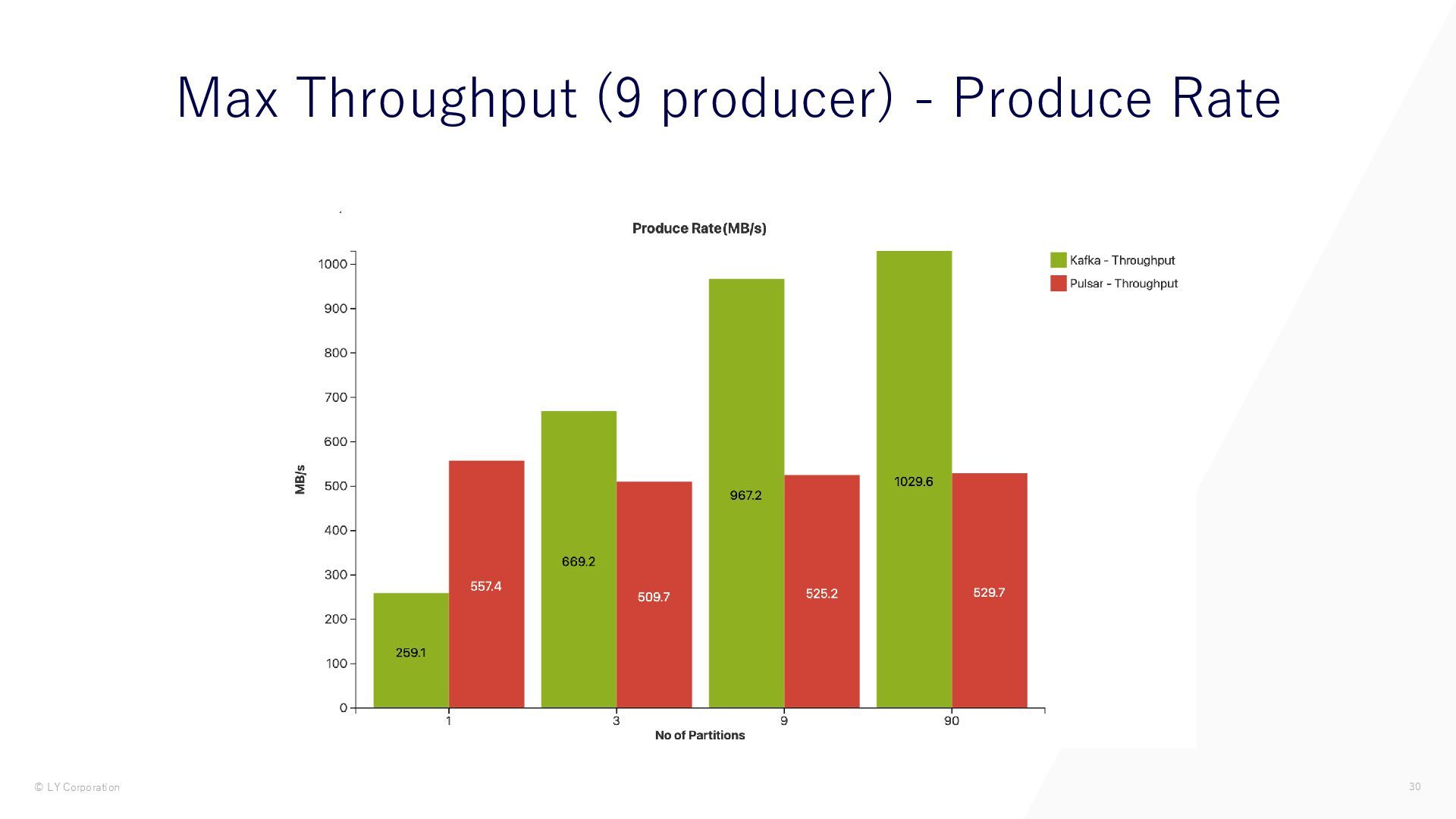
{kind=link}
{kind=link}
{kind=link}
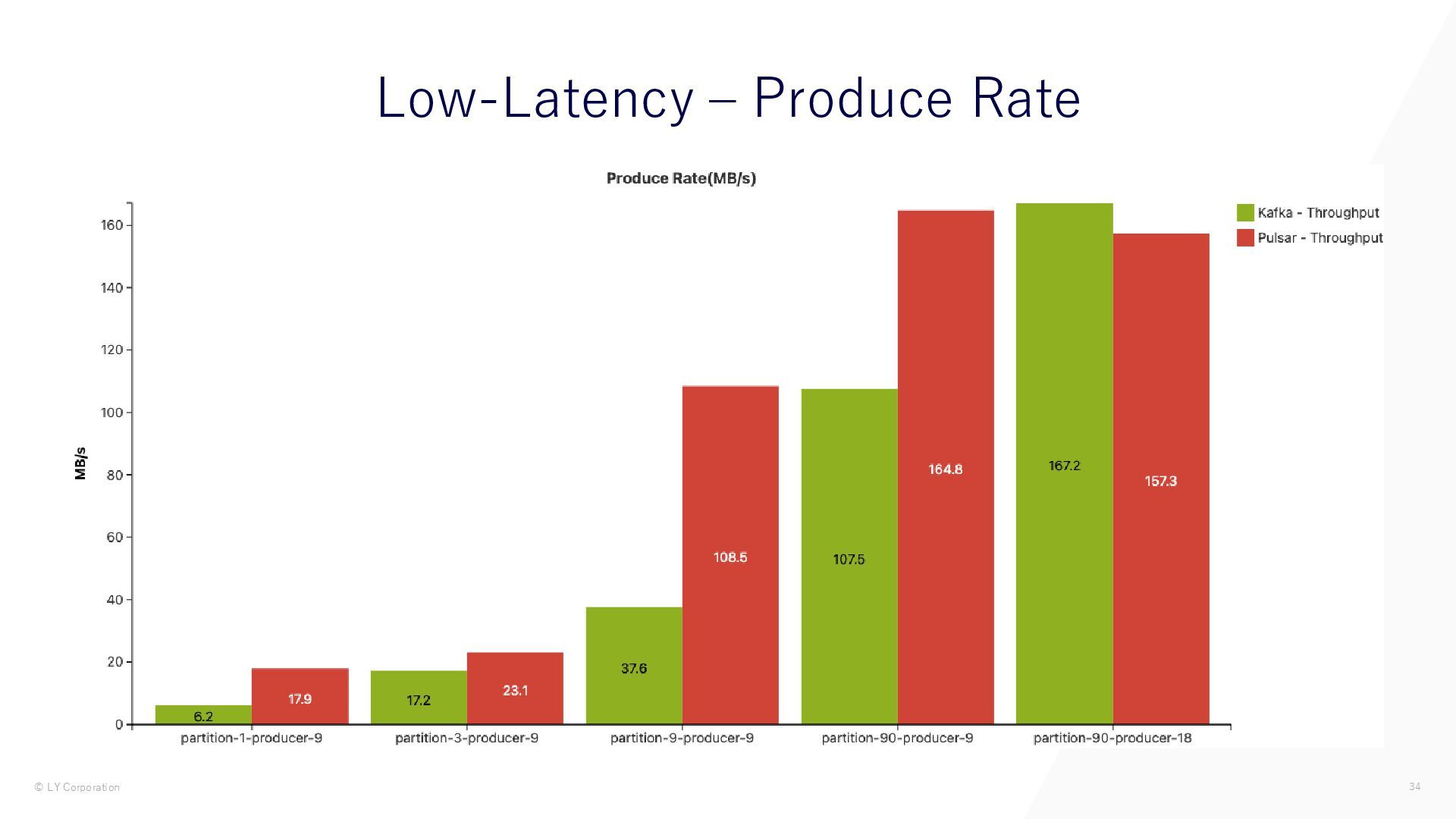{kind=link}
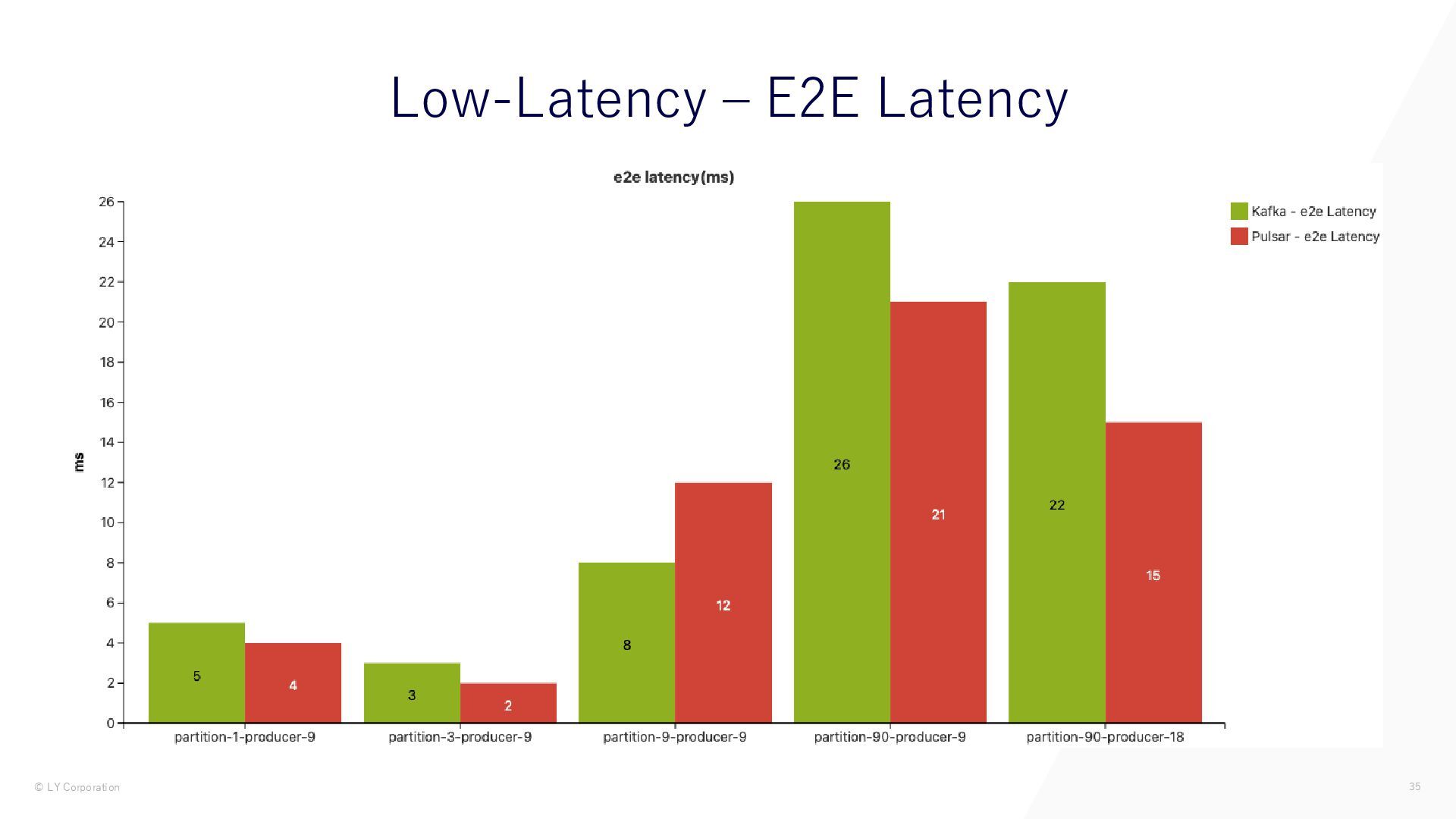{kind=link}
{kind=link}
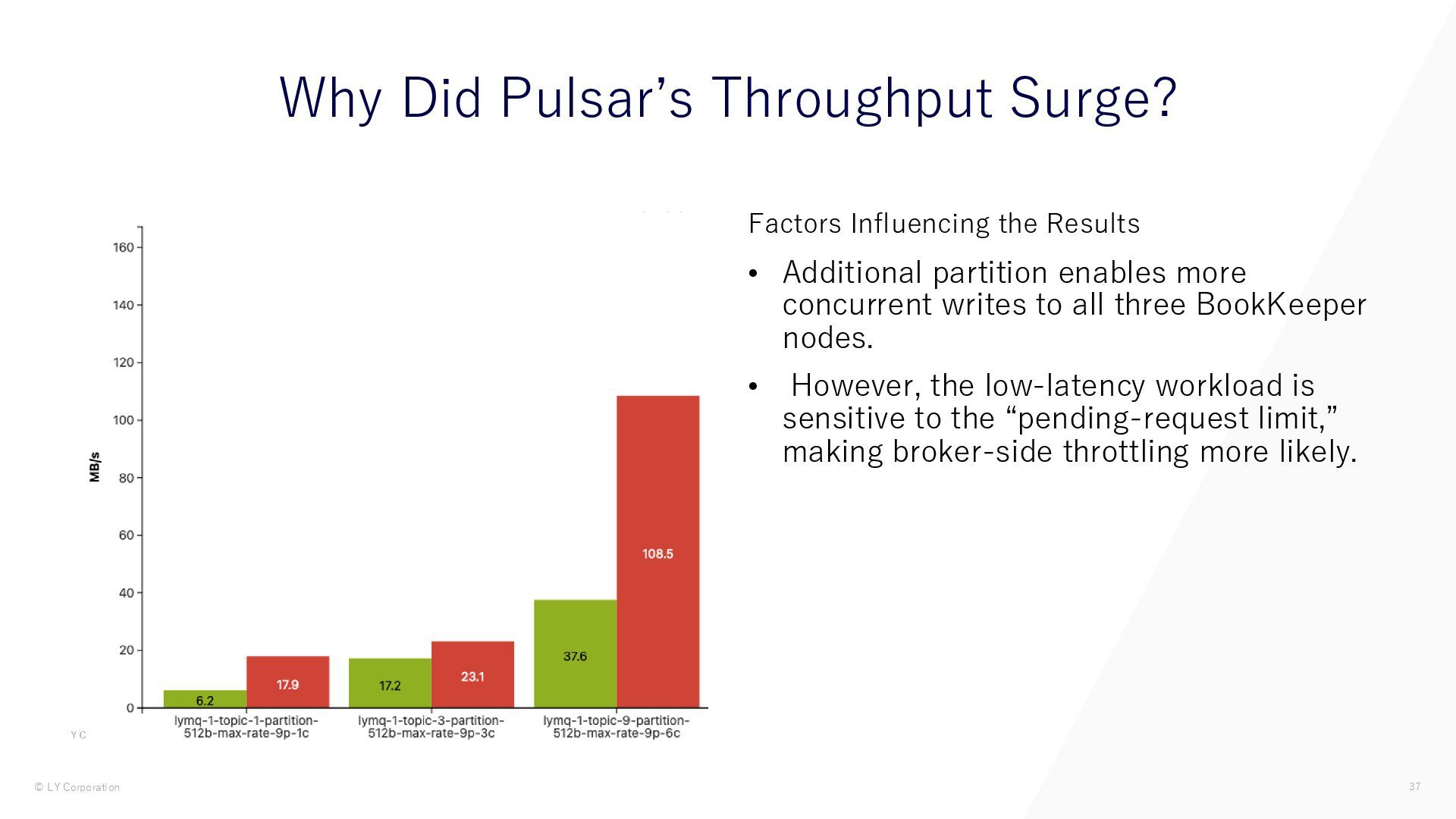{kind=link}
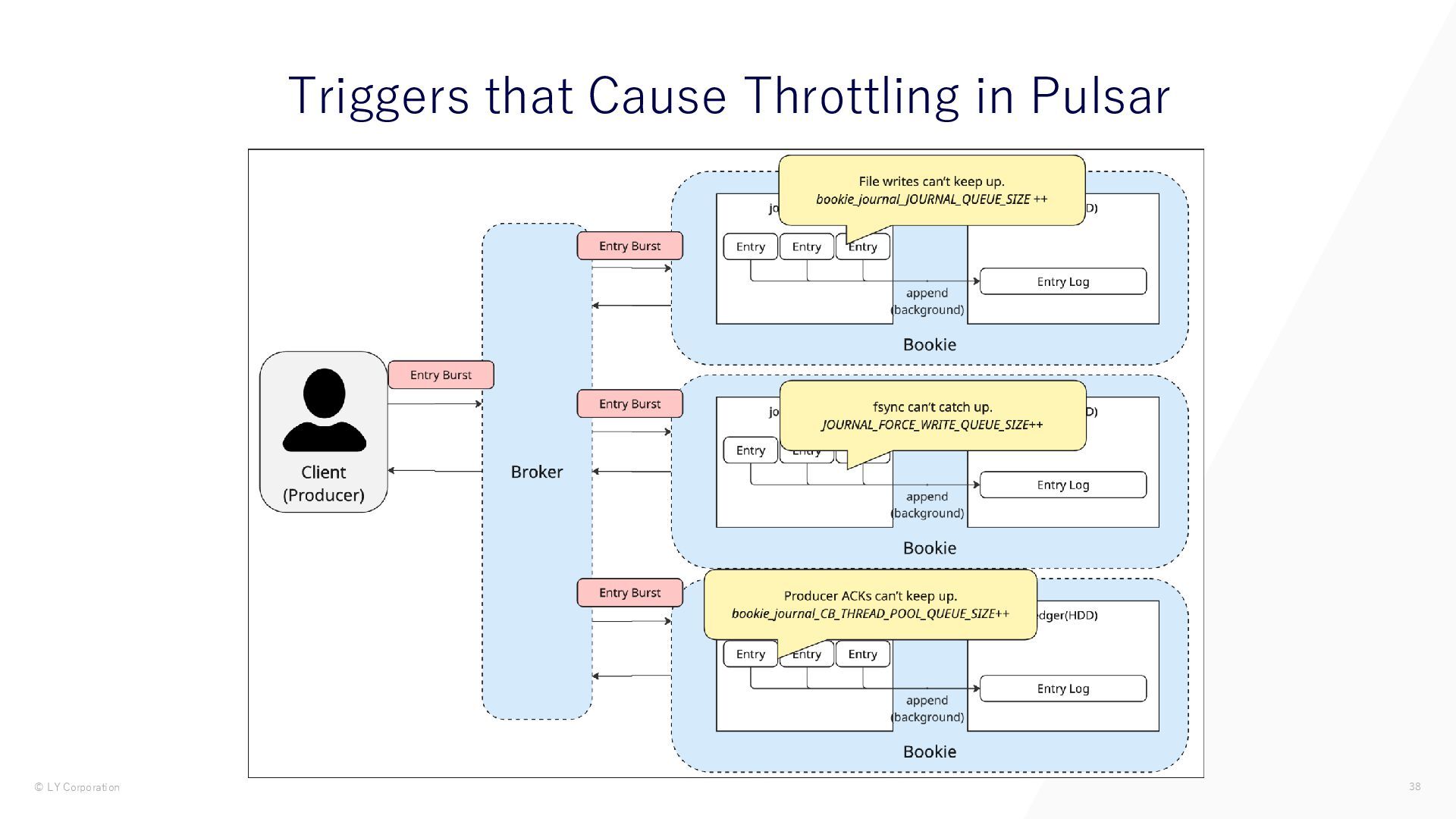{kind=link}
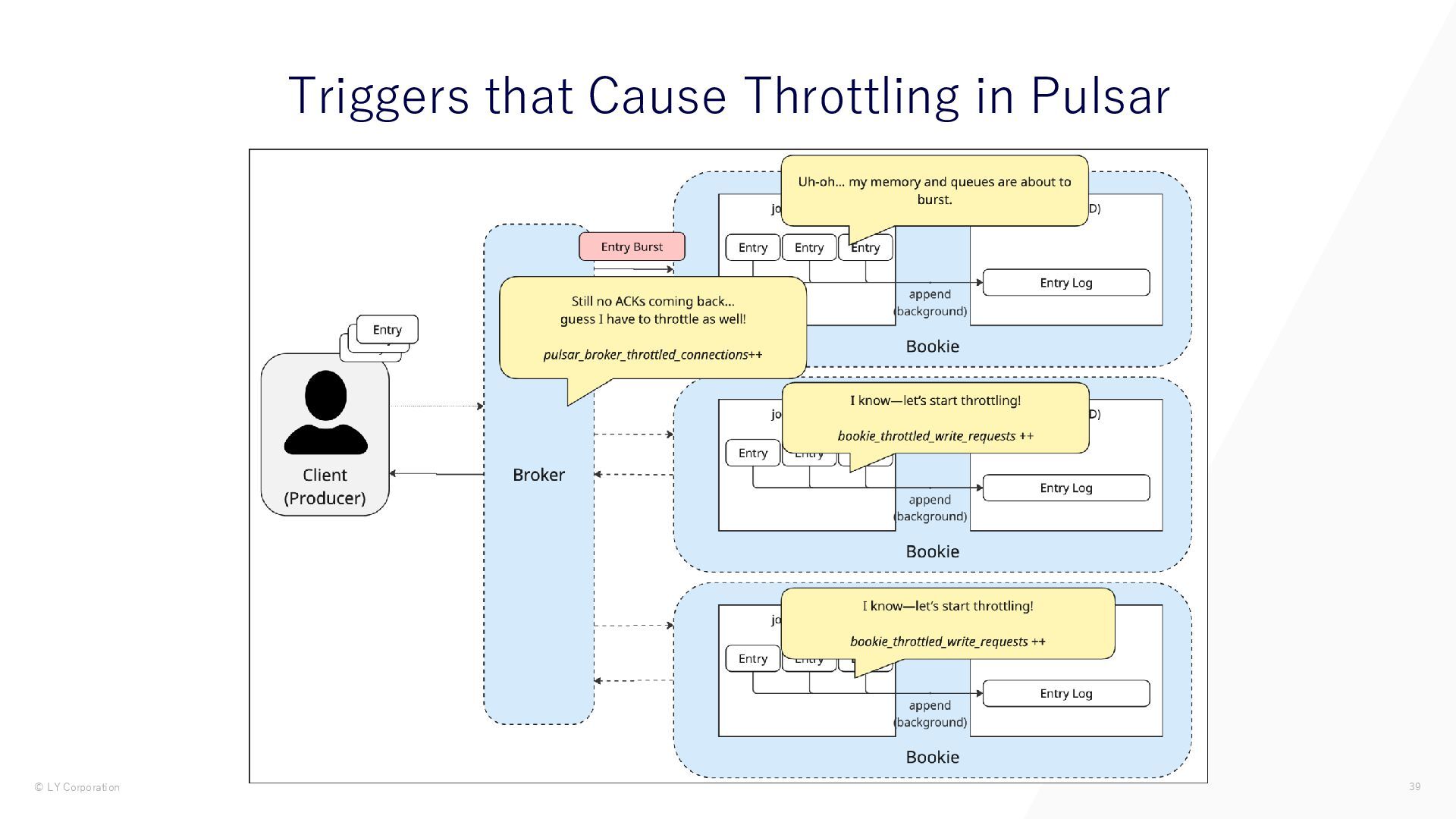{kind=link}
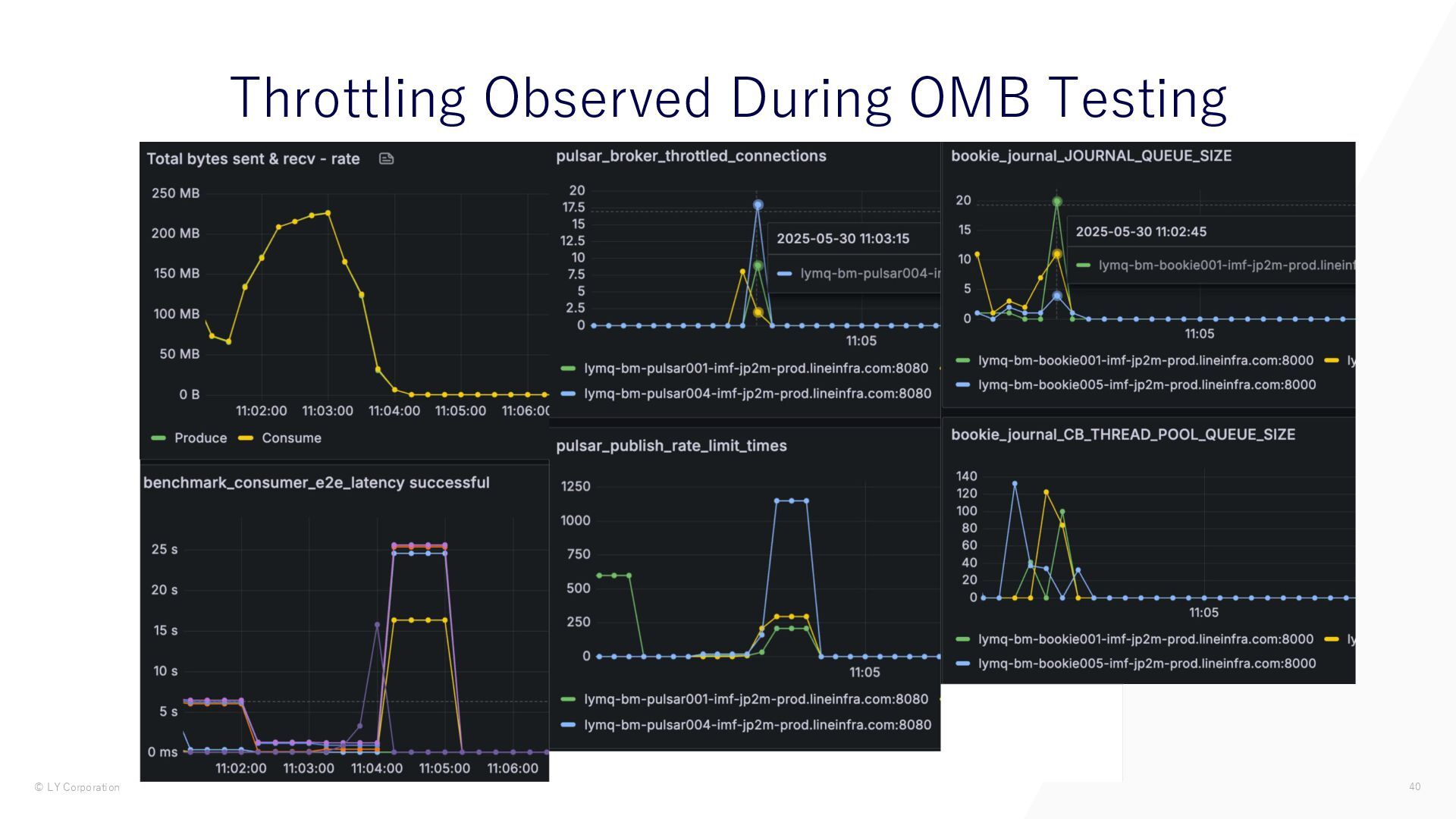{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}