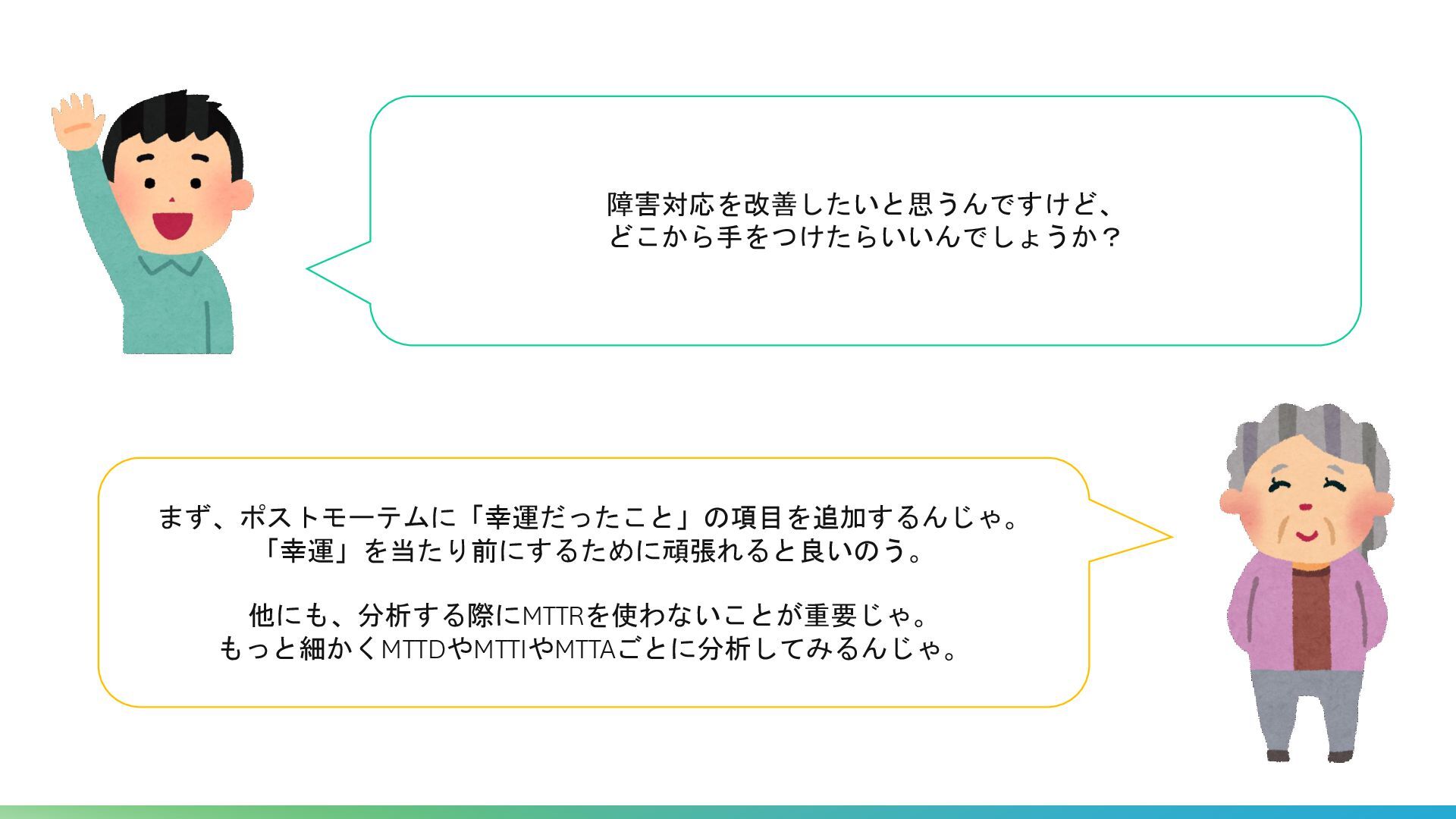
Time to Ack • 発生から原因判明(Identify)まで • Time to Identify • 発生からサービス復旧(Service Recovery)まで • Time to (Service) Recovery • 発生から次の障害発生(Between failure)まで • Time between Failures
• 発生から人間の認知(Acknowledge)まで • Time to Ack • ➔TTAの分散が大きければ、オンコール体制の整備が効果的。 • 発生から原因判明(Identify)まで • Time to Identify • 発生からサービス復旧(Service Recovery)まで • Time to (Service) Recovery • 発生から次の障害発生(Between failure)まで • Time between Failures
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![PromQLクエリにすると ((2.0 * sum(increase(requests_total{status="500"}[1m])) + 2.33 * 2.33 - (2.33](https://files.speakerdeck.com/presentations/08fa0297672e40e891df57d054bee718/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}