Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
チームを巻き込みエラーと向き合う技術
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
maru
January 31, 2026
3.5k
5
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
チームを巻き込みエラーと向き合う技術
https://2026.srekaigi.net/
maru
January 31, 2026
More Decks by maru
See All by maru
End-to-Endで考える信頼性 — LINEアプリにおける クライアント開発×SRE連携の実践
maruloop
3
1.9k
AIネイティブな開発についてのモヤモヤを吐き出す
maruloop
0
160
SLI/SLO、「完全に理解した」から「チョットデキル」へ
maruloop
5
770
yuru sre 14
maruloop
1
780
Platform and teaming and communication and...
maruloop
3
1.3k
オブザーバビリティが育むシステム理解と好奇心
maruloop
5
3.9k
ワークロードを処理しないプラットフォームに専念する
maruloop
0
900
When Walking like SREs
maruloop
6
1.8k
チームと成長するSRE
maruloop
2
2.2k
Featured
See All Featured
Leading Effective Engineering Teams in the AI Era
addyosmani
9
2.1k
What the history of the web can teach us about the future of AI
inesmontani
PRO
1
630
Data-driven link building: lessons from a $708K investment (BrightonSEO talk)
szymonslowik
1
1.2k
Unlocking the hidden potential of vector embeddings in international SEO
frankvandijk
0
870
Marketing Yourself as an Engineer | Alaka | Gurzu
gurzu
0
260
Visualization
eitanlees
152
17k
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.6k
Why Mistakes Are the Best Teachers: Turning Failure into a Pathway for Growth
auna
0
180
AI: The stuff that nobody shows you
jnunemaker
PRO
8
770
The Art of Delivering Value - GDevCon NA Keynote
reverentgeek
16
2k
Faster Mobile Websites
deanohume
310
32k
Groundhog Day: Seeking Process in Gaming for Health
codingconduct
0
240
Transcript
© LY Corporation © LY Corporation Public チームを巻き込み エラーと向き合う技術 LINE
ヤフー株式会社 Embedded SRE @maru in SRE Kaigi 2026 1 / 56
© LY Corporation © LY Corporation Public 信頼性は会話です 2 /
56
© LY Corporation © LY Corporation Public 信頼性は会話です SRE NEXT
2025 のテーマも「Talk NEXT 」でした。 3 / 56
© LY Corporation © LY Corporation Public SRE 拡大期の失敗: SRE
が「見えない変更の発信源」になった 1 人SRE の頃:SWE と一緒に議論・レビューしながら改善 3 人になった頃:小さな改善が SRE 内で完結するようになった 高速に回る/デリバリも増える ある日SWE から一言: 「SRE が何をやってるか分からなくなった」 4 / 56
© LY Corporation © LY Corporation Public SRE 拡大期の失敗: SRE
が「見えない変更の発信源」になった 1 人SRE の頃:SWE と一緒に議論・レビューしながら改善 3 人になった頃:小さな改善が SRE 内で完結するようになった 高速に回る/デリバリも増える ある日SWE から一言: 「SRE が何をやってるか分からなくなった」 SRE の改善が、SWE チームの認知負荷のキャパシティを超えてしまった 5 / 56
© LY Corporation © LY Corporation Public SRE がチェスタトンのフェンスを立てていた チェスタトンのフェンス:
理由が分からない柵(仕組み)を、先に壊すな。 壊すなら“ なぜあるか” を理解してから “ “ 6 / 56
© LY Corporation © LY Corporation Public SRE がチェスタトンのフェンスを立てていた チェスタトンのフェンス:
SRE がやっていたこと: 仕組みを増やす/変える(= 新しい柵を立てる) でも、その 背景・意図・運用の勘所 がSRE の中に閉じた 属人化ならぬ属チーム化( 「あなたたちとわたしたち」状態) ログを追えば理解はできるが、SWE にとって自分のものという感覚ではなくなった 今後、SWE が自律的に信頼性改善をする足枷になりそうだった 理由が分からない柵(仕組み)を、先に壊すな。 壊すなら“ なぜあるか” を理解してから “ “ 7 / 56
© LY Corporation © LY Corporation Public 私が目指しているSRE 開発者が自律的に、自身のサービスの信頼性を制御できるようにサポートするチーム SRE
が信頼性の責任者ではなく、いなくても回るように この姿を目指していたので、その観点でいうと明確に失敗でした。 もちろん、責任境界を作って分業をする形を目指している場合では、成功かも。 8 / 56
© LY Corporation © LY Corporation Public このセッションでは「会話」にフォーカスします 背景・意図・運用の勘所を残しながら、開発チーム(+SRE) で自律的に議論を進める姿
技術や特定サービスの話というより、意思決定とすり合わせの話 さらに公式のAskTheSpeaker に加えて、セッション内でもSlido でQ&A もやります。 持ち時間の許す限り、双方向にしたいです。 曖昧な質問や初歩的な質問も大歓迎です! *Slido のQR コードは右上から 9 / 56
© LY Corporation © LY Corporation Public 伝えたいこと どういう状況で、どこまで許容できるかを 会話して設計する
開発チーム、関係者を課題認識から巻き込む 正常と異常は2 値ではなく、グラデーションなことを理解する サクサク動く 少し遅いが使える 一部エラーが出るが目的は達成できる 見たことがある(古い)コンテンツが増える 目的が達成できない 異常時ハンドリングの実装は 適切に後回しにする やる/やらないではなく、いつやるかを議論する Facebook のProduction Engineering のエンゲージモデルを紹介 10 / 56
© LY Corporation © LY Corporation Public 自己紹介 @maru 2020:
LINE に入社(LINE スタンプ/ 着せかえ/ タブのSRE ) 2022: LYP プレミアム立ち上げSRE 2023 以降: 新サービス立ち上げSRE プロダクト開発に近い立場で、開発チームと日々協業しています。 あわせてSRE チームのリードとして、意思決定や推進も担当しています。 11 / 56
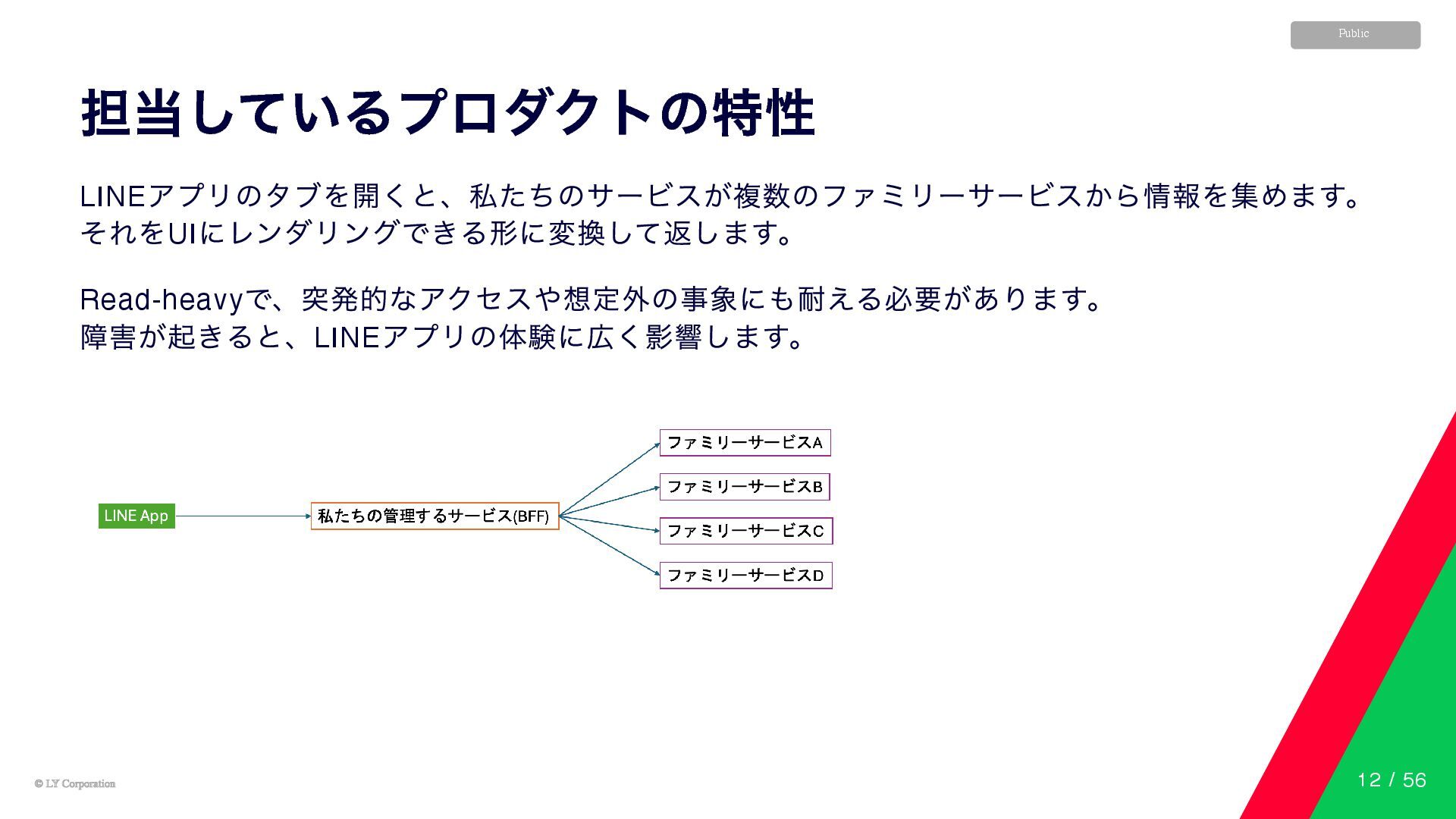
© LY Corporation © LY Corporation Public 担当しているプロダクトの特性 LINE アプリのタブを開くと、私たちのサービスが複数のファミリーサービスから情報を集めます。
それをUI にレンダリングできる形に変換して返します。 Read-heavy で、突発的なアクセスや想定外の事象にも耐える必要があります。 障害が起きると、LINE アプリの体験に広く影響します。 12 / 56
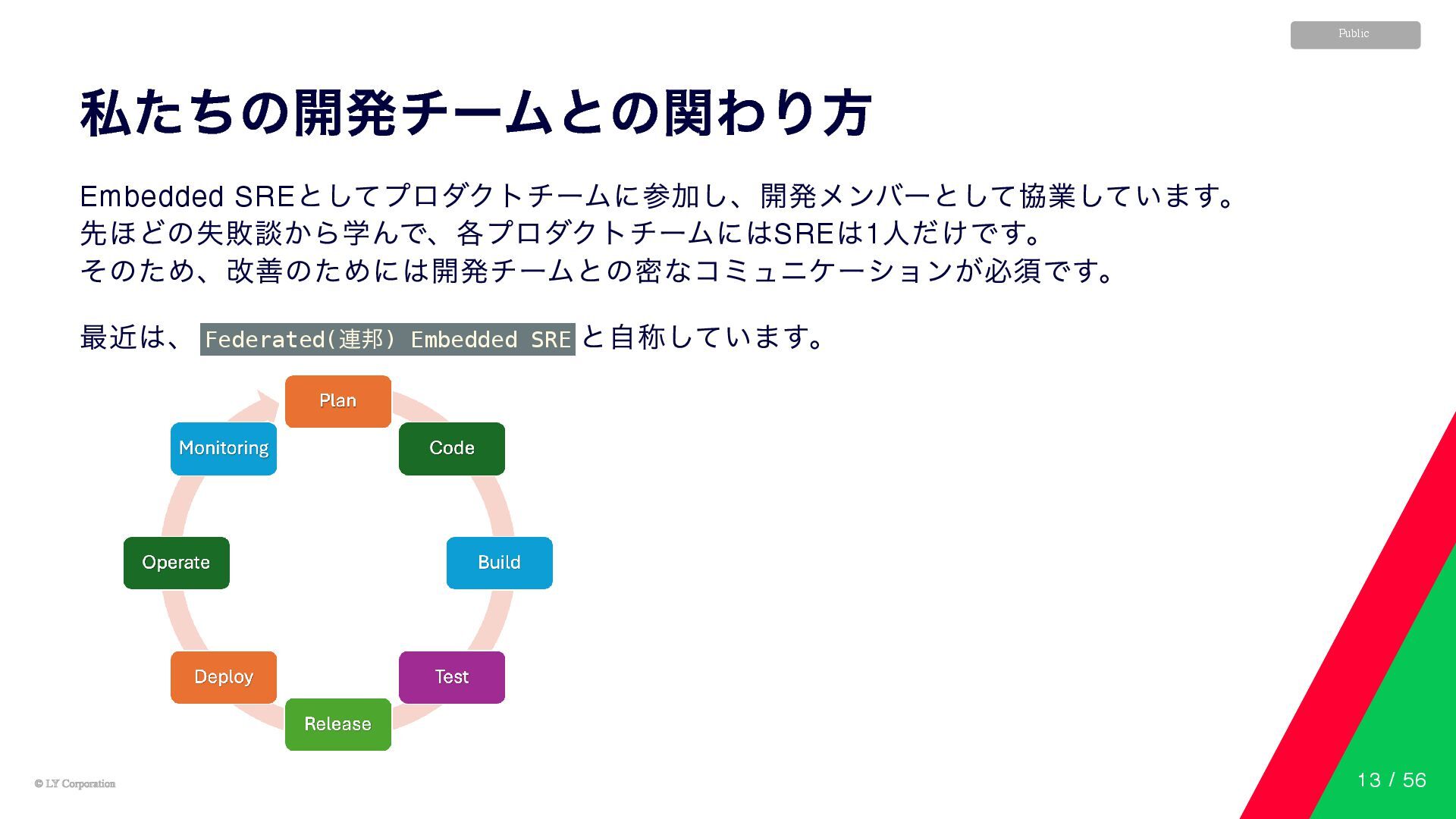
© LY Corporation © LY Corporation Public 私たちの開発チームとの関わり方 Embedded SRE
としてプロダクトチームに参加し、開発メンバーとして協業しています。 先ほどの失敗談から学んで、各プロダクトチームにはSRE は1 人だけです。 そのため、改善のためには開発チームとの密なコミュニケーションが必須です。 最近は、 Federated( 連邦) Embedded SRE と自称しています。 13 / 56
© LY Corporation © LY Corporation Public ここからはいくつかの議題について 実際に議論した流れを簡単に紹介します *
後半につれて、重い議論を紹介します たくさんの動物たちが開発チーム、 そこの自律的な議論を促す存在としてのSRE 14 / 56
© LY Corporation © LY Corporation Public 議題1: API レスポンスに
独自のエラーコードを入れるべき? 15 / 56
© LY Corporation © LY Corporation Public 議題1: API レスポンスに独自のエラーコードを入れるべき?
例えば次のように、ステータスコードとは別にエラーコードを返すべき? レスポンスボディ(エンベロープ)パターン: { "meta": {"error_code": "ID_NOT_FOUND"}, "data": null } レスポンスヘッダのパターン: HTTP/1.1 404 Not Found Error-Code: ID_NOT_FOUND {"data": null} 16 / 56
© LY Corporation © LY Corporation Public 意見交換: 独自エラーコードを持つべきか ユーザーが知る必要ないし、いらないんじゃない?
パンダさん クライアント側が実装時にデバッグしやすくなるから、あると嬉しい トラさん でも、エラーコード粒度の合意コストが継続的にかかりそう パンダさん デバッグ目的なら、エラーコード以外の手段は? ウサギさん エラーコードの代わりにトレーシングID をクライアントのログに出そう SRE 17 / 56
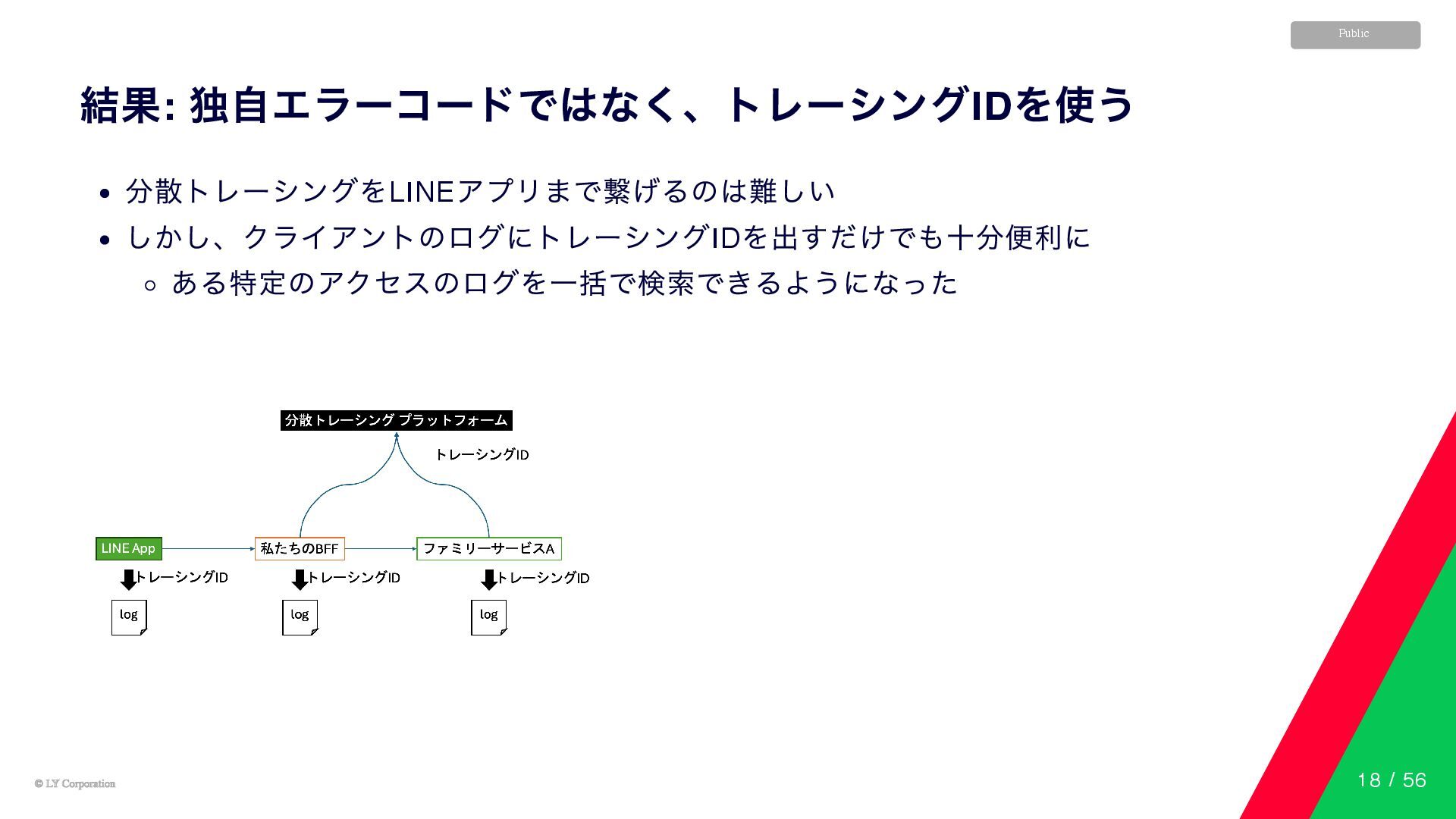
© LY Corporation © LY Corporation Public 結果: 独自エラーコードではなく、トレーシングID を使う
分散トレーシングをLINE アプリまで繋げるのは難しい しかし、クライアントのログにトレーシングID を出すだけでも十分便利に ある特定のアクセスのログを一括で検索できるようになった 18 / 56
© LY Corporation © LY Corporation Public 議題2: サーキットブレイカーは 何単位で発動すべき?
19 / 56
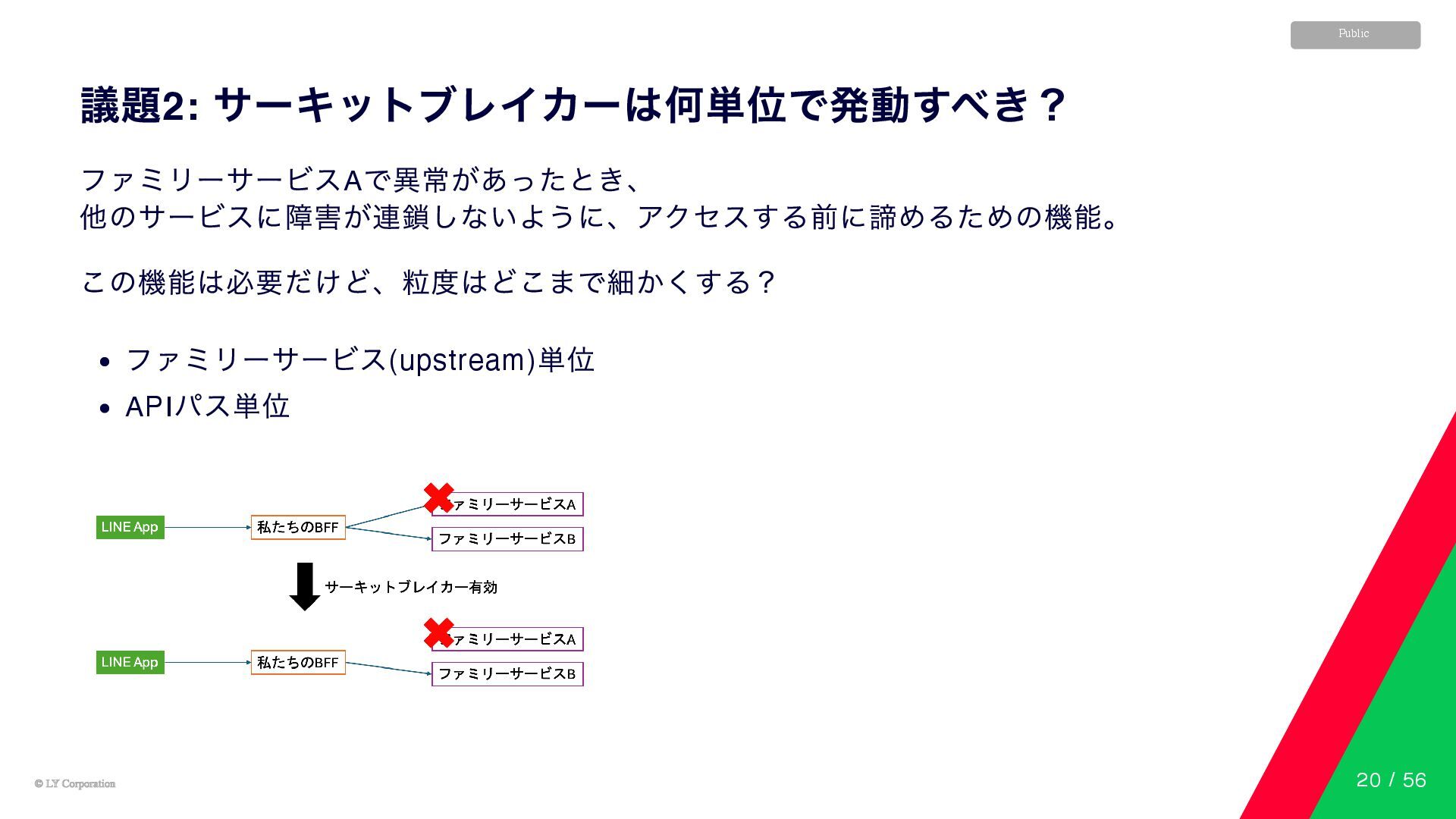
© LY Corporation © LY Corporation Public 議題2: サーキットブレイカーは何単位で発動すべき? ファミリーサービスA
で異常があったとき、 他のサービスに障害が連鎖しないように、アクセスする前に諦めるための機能。 この機能は必要だけど、粒度はどこまで細かくする? ファミリーサービス(upstream) 単位 API パス単位 20 / 56
© LY Corporation © LY Corporation Public 意見交換: サーキットブレイカーの粒度 サーキットブレイカーってどういう挙動なんだっけ?
パンダさん 今の実装は、エラー率が50% を超えたら10 秒オープン。 その後10 秒は少量(数RPS )だけ通し、それが成功してたらクローズ、失敗してたら再度オープン。 トラさん ファミリーサービス(upstream) 単位で十分な気がするね。 パンダさん でも、 /path/to/api1 が常に成功して、 /path/to/api2 が常に失敗するケースだと サーキットブレイカーがon/off を繰り返しちゃうかも。 トラさん パス単位だと、RPS が低いとサーキットブレイカーが反応しすぎちゃわない? パンダさん 低RPS ではオープンしないように設定できるから、大丈夫そう トラさん 21 / 56
© LY Corporation © LY Corporation Public 意見交換: サーキットブレイカーのテスト 実装はできたし、たぶん動くはず
パンダさん 念の為、自動のインテグレーションテストを作っておこう。 ここにバグがあると、障害になるまで気づけないから。 トラさん どうやってテストする? Upstream のMock サーバーを毎回立ち上げて、障害注入して、リクエストして、サーキットブレイカーの起動を確認するの? パンダさん そうだね。 時間が予定よりかかってもいいし、優先タスクがあれば調整するから、しっかり動くことを保証できる状態まで作り込もう。 トラさん 22 / 56
© LY Corporation © LY Corporation Public 結果: パス単位でサーキットブレイカーを設定した どれだけ事前に想定できるかが重要。
パス単位にしないと、on/off を繰り返してしまう可能性がある もしかすると、もっと細かな粒度にすべきかもしれない 異常時ハンドリングは、実装1 行・テスト100 行のようなケースも多い。 テストの実装は後回しにしない テストを後回しにするなら、実装も含めて後回しにした方が良い もしくは、テストが簡易的で済む範囲で実装する 23 / 56
© LY Corporation © LY Corporation Public 議題3: カナリアリリースしても 確率的に全ユーザーに影響する
24 / 56
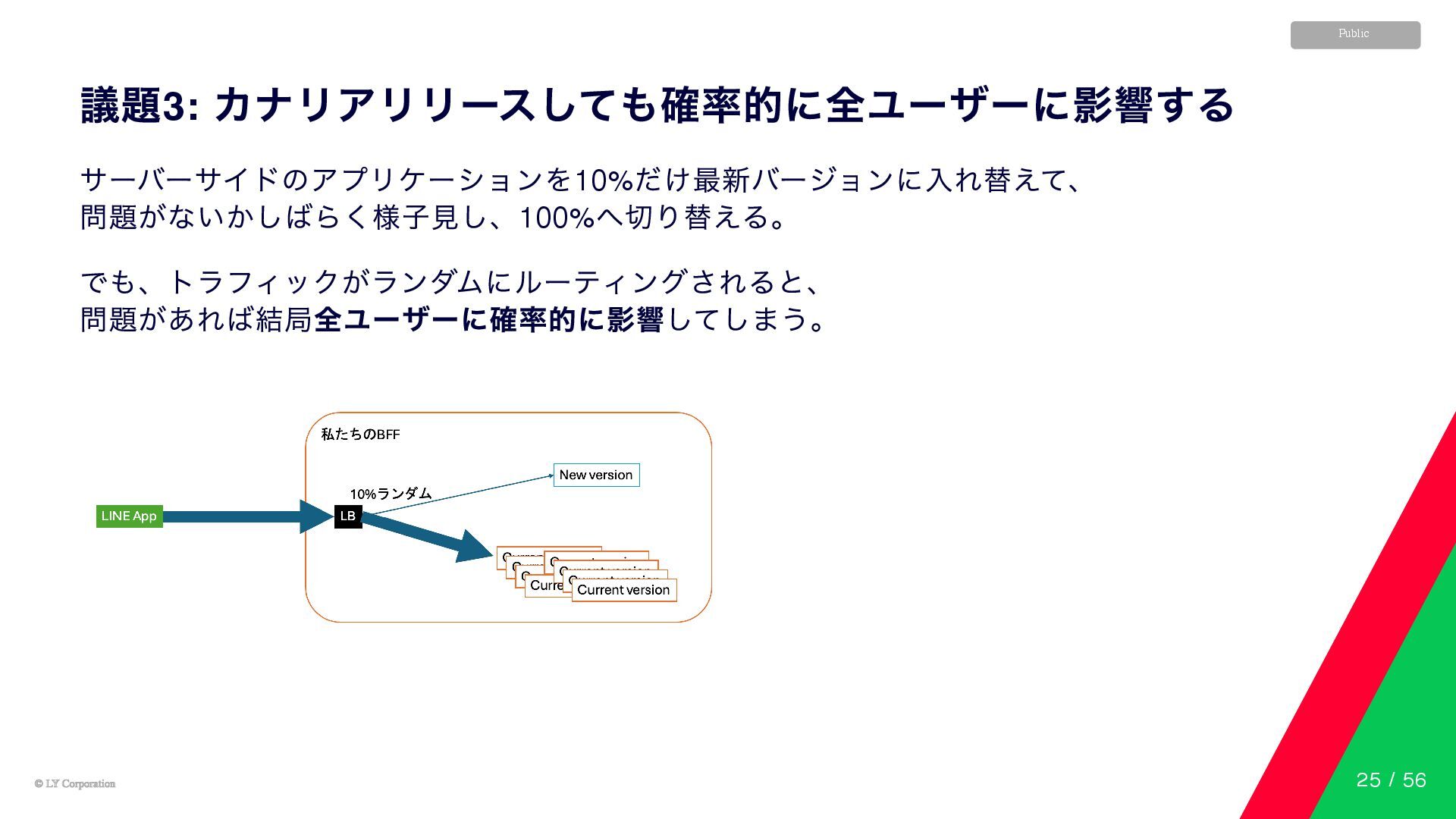
© LY Corporation © LY Corporation Public 議題3: カナリアリリースしても確率的に全ユーザーに影響する サーバーサイドのアプリケーションを10%
だけ最新バージョンに入れ替えて、 問題がないかしばらく様子見し、100% へ切り替える。 でも、トラフィックがランダムにルーティングされると、 問題があれば結局全ユーザーに確率的に影響してしまう。 25 / 56
© LY Corporation © LY Corporation Public 意見交換: カナリアリリースのトラフィックルーティング どのユーザーが最初に新バージョンを触るべきか悩ましいね・・・。
パンダさん カナリアリリースするからには、一般ユーザーに届く前にロールバックできた方がいいね トラさん ドッグフーディングみたいなものだから、社内の人をカナリアへルーティングするのがいいんじゃない? ウサギさん それなら送信元IP 使って、社内アクセスだけカナリアへ寄せれば十分かも パンダさん とはいえ、本番環境で問題があってロールバックしたことは今のところないよね 一旦ランダムのカナリアリリース自体はできてるから、設計までして実装は保留でいいか トラさん 26 / 56
© LY Corporation © LY Corporation Public 結果: 社内からのトラフィックをカナリアへ寄せる 社内トラフィックのみカナリアに寄せるという決定
実装は合理的に後回しに 「本番環境のリリース時に問題が顕在化した場合の影響範囲の限定化」は 他タスクと比べると限定的な効果のため。 27 / 56
© LY Corporation © LY Corporation Public 議題4: 最新コンテンツ取得に失敗したとき、 エラーメッセージは?
28 / 56
© LY Corporation © LY Corporation Public 議題4: 最新コンテンツ取得に失敗したとき、エラーメッセージは? ユーザーの状況(電波など)やサーバーの状況によっては、
LINE アプリで表示するコンテンツを最新化できないことがある。 その結果、古いキャッシュが表示される。 古い表示は、誤った意思決定(例:価格)につながりうる。 不正確な情報でユーザーに不利益が出ることは可能な限り防ぎたい。 29 / 56
© LY Corporation © LY Corporation Public 意見交換: コンテンツ最新化失敗時のエラーメッセージ そもそも価格表示でキャッシュを使っていいんだっけ?
パンダさん 決済ページなどは当然ダメ。検索結果やレコメンド一覧は許容できる トラさん サーバー側のエラーとして返せばよさそうだね ウサギさん サーバーに届かない、サーバーがレスポンスを返せないケースも対応したいかな SRE それならクライアント側で状態を見て出し分けるしかないね。 でも、サーバーのエラーレスポンスが必要なメッセージもありそうじゃない? ウサギさん エラーメッセージの取り扱いポリシーを整理してみよう トラさん 30 / 56
© LY Corporation © LY Corporation Public 結果: エラーの文脈によって、責務を分ける ユーザーの是正が必要なエラー
ユーザーの判断と訂正が必要(入力ミスなど) サーバー側がレスポンスで返す 端末状態/ 表示状態に依存するエラー データが古い/不整合で、誤った行動につながりうる クライアント側で文脈に応じて出し分ける 31 / 56
© LY Corporation © LY Corporation Public 結果: エラーの文脈によって、責務を分ける ユーザーの是正が必要なエラー
ユーザーの判断と訂正が必要(入力ミスなど) サーバー側がレスポンスで返す 端末状態/ 表示状態に依存するエラー データが古い/不整合で、誤った行動につながりうる クライアント側で文脈に応じて出し分ける 補足: SRE は「決める」より「判断軸を守る」 原則:議論は開発チームの自律性に任せる 介入:短絡的に決まりそうなときだけ、判断軸を戻す サーバーサイドのレスポンスでは網羅できないケースの再確認 32 / 56
© LY Corporation © LY Corporation Public 議題5: ファミリーサービスを 過負荷から守るためのレートリミット
33 / 56
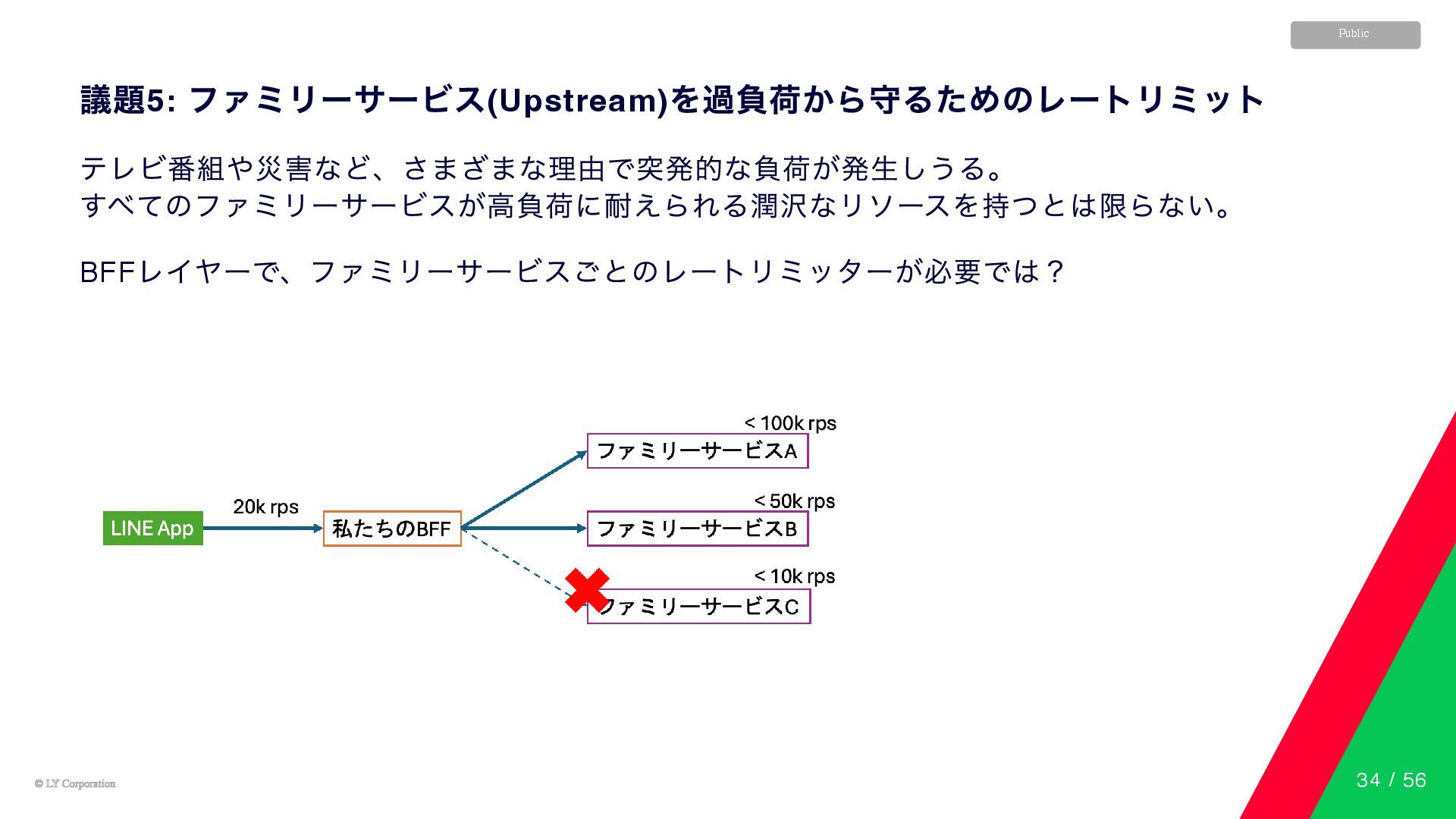
© LY Corporation © LY Corporation Public 議題5: ファミリーサービス(Upstream) を過負荷から守るためのレートリミット
テレビ番組や災害など、さまざまな理由で突発的な負荷が発生しうる。 すべてのファミリーサービスが高負荷に耐えられる潤沢なリソースを持つとは限らない。 BFF レイヤーで、ファミリーサービスごとのレートリミッターが必要では? 34 / 56
© LY Corporation © LY Corporation Public 意見交換: Upstream を守るレートリミット
Upstream ごとに固定の制限値を持てば十分じゃない? パンダさん キャンペーンでUpstream がスケールアウトしても、BFF の制限値の変更する運用を忘れそう。 Upstream には余裕があるのにリクエストを拒否しちゃって障害になるよね ウサギさん Upstream からのレスポンスに残りキャパシティ情報を付けてもらう? パンダさん それはUpstream 側の仕様検討や実装の負担が大きすぎると思う トラさん Upstream からの Busy エラーをフィードバックにして、BFF の制限値を動的に変えよう SRE 35 / 56
© LY Corporation © LY Corporation Public 意見交換: Upstream を守るレートリミット
Upstream からの Busy エラーをフィードバックにして、BFF の制限値を動的に変えよう SRE そうすると、Upstream からエラーが返ってくるまではトラフィックを流しちゃうけど大丈夫かな? トラさん むしろその方がいいと思う。Upstream 側のオートスケールで対応できる可能性もあるし 私たちが勝手にリクエストを拒否してしまう方がサービス品質を悪化させかねない SRE この機能もなるべく早く実装しておいた方が良いだろうか 実現はできそうだけど、開発工数が少し大きそう トラさん 私の意見としては、サーキットブレイカーやスロットリング機能はすでにあるので この機能の優先度はそこまで高くない認識 SRE 36 / 56
© LY Corporation © LY Corporation Public 結果: レートリミットの制限値をAIMD 制御で自動調整
busy レスポンスが返るまで、制限値を少しずつ緩和する busy レスポンスが返ったら、制限値を一気に厳しくする 37 / 56
© LY Corporation © LY Corporation Public 結果: レートリミットの制限値をAIMD 制御で自動調整
busy レスポンスが返るまで、制限値を少しずつ緩和する busy レスポンスが返ったら、制限値を一気に厳しくする 補足: SRE は「全部やる」ではなく、優先度を揃える 既にCB/ スロットリングがあるなら、AIMD は“ 次の一手” 重要度とリスクで、いま作るもの/保留するものを整理する 38 / 56
© LY Corporation © LY Corporation Public 議題6: 過負荷時でも、 重要なアクセスだけは優先したい
39 / 56
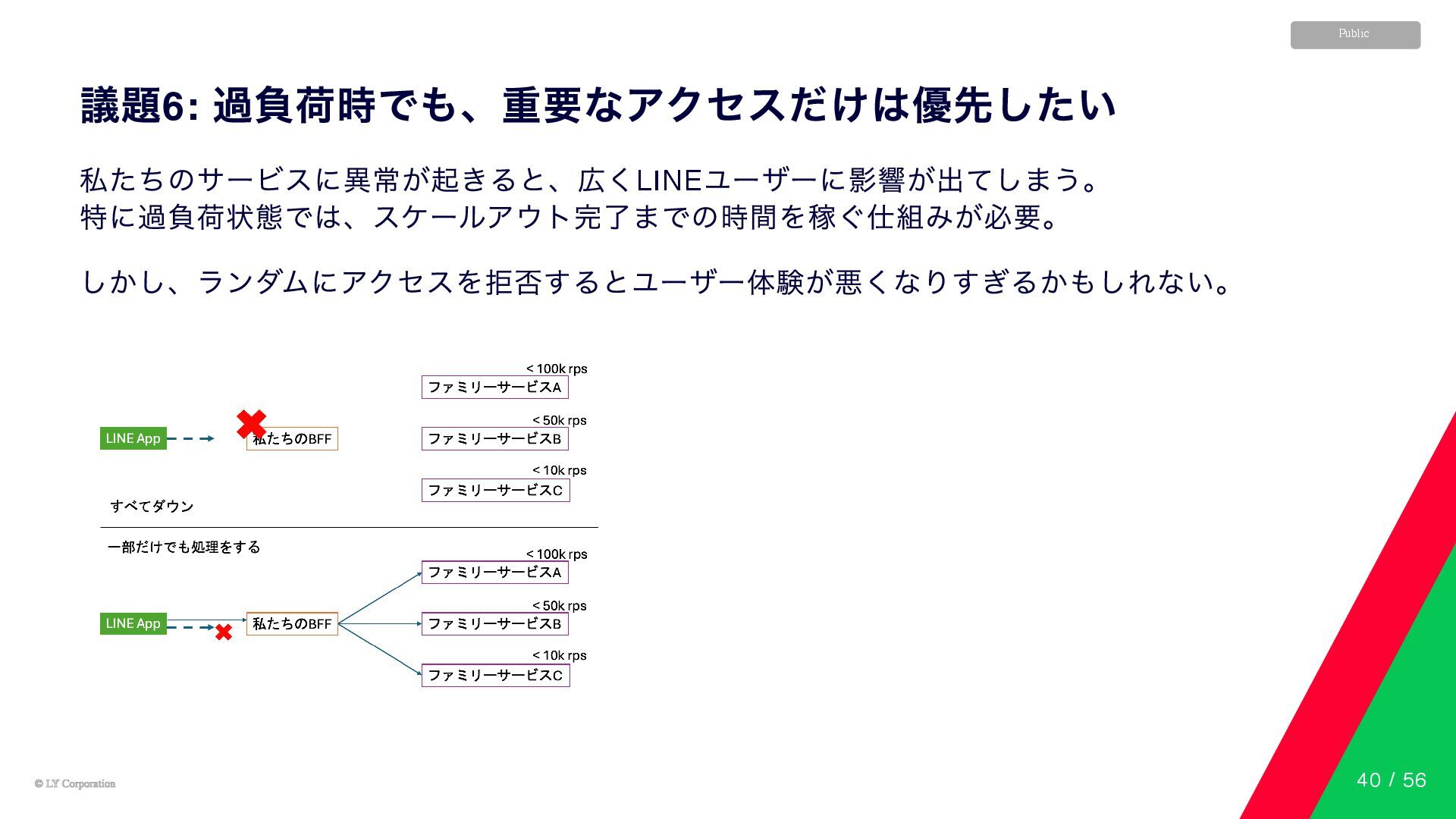
© LY Corporation © LY Corporation Public 議題6: 過負荷時でも、重要なアクセスだけは優先したい 私たちのサービスに異常が起きると、広くLINE
ユーザーに影響が出てしまう。 特に過負荷状態では、スケールアウト完了までの時間を稼ぐ仕組みが必要。 しかし、ランダムにアクセスを拒否するとユーザー体験が悪くなりすぎるかもしれない。 40 / 56
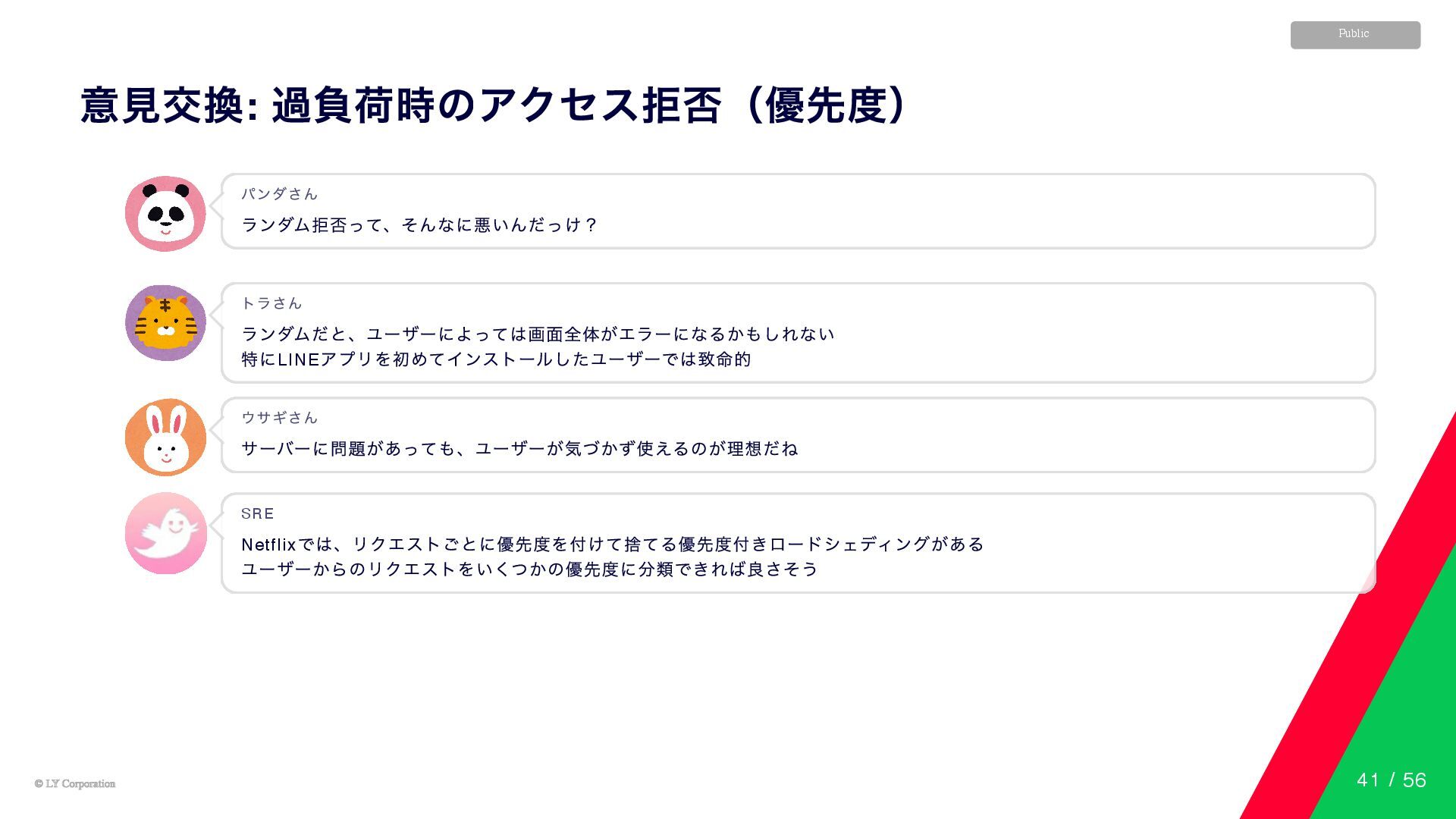
© LY Corporation © LY Corporation Public 意見交換: 過負荷時のアクセス拒否(優先度) ランダム拒否って、そんなに悪いんだっけ?
パンダさん ランダムだと、ユーザーによっては画面全体がエラーになるかもしれない 特にLINE アプリを初めてインストールしたユーザーでは致命的 トラさん サーバーに問題があっても、ユーザーが気づかず使えるのが理想だね ウサギさん Netflix では、リクエストごとに優先度を付けて捨てる優先度付きロードシェディングがある ユーザーからのリクエストをいくつかの優先度に分類できれば良さそう SRE 41 / 56
© LY Corporation © LY Corporation Public 優先度付きロードシェディング リクエストを文脈に応じて分類し、優先度に応じて処理を遅延・拒否(捨てる)することで、 重要な体験を守る方法。
優先度は3 段階 NON_CRITICAL ユーザーが気づきにくい(ログ送信、キャッシュ更新 など) DEGRADED_EXPERIENCE 気づくが致命的ではない CRITICAL 主要機能に影響する(表示できない 等) 42 / 56
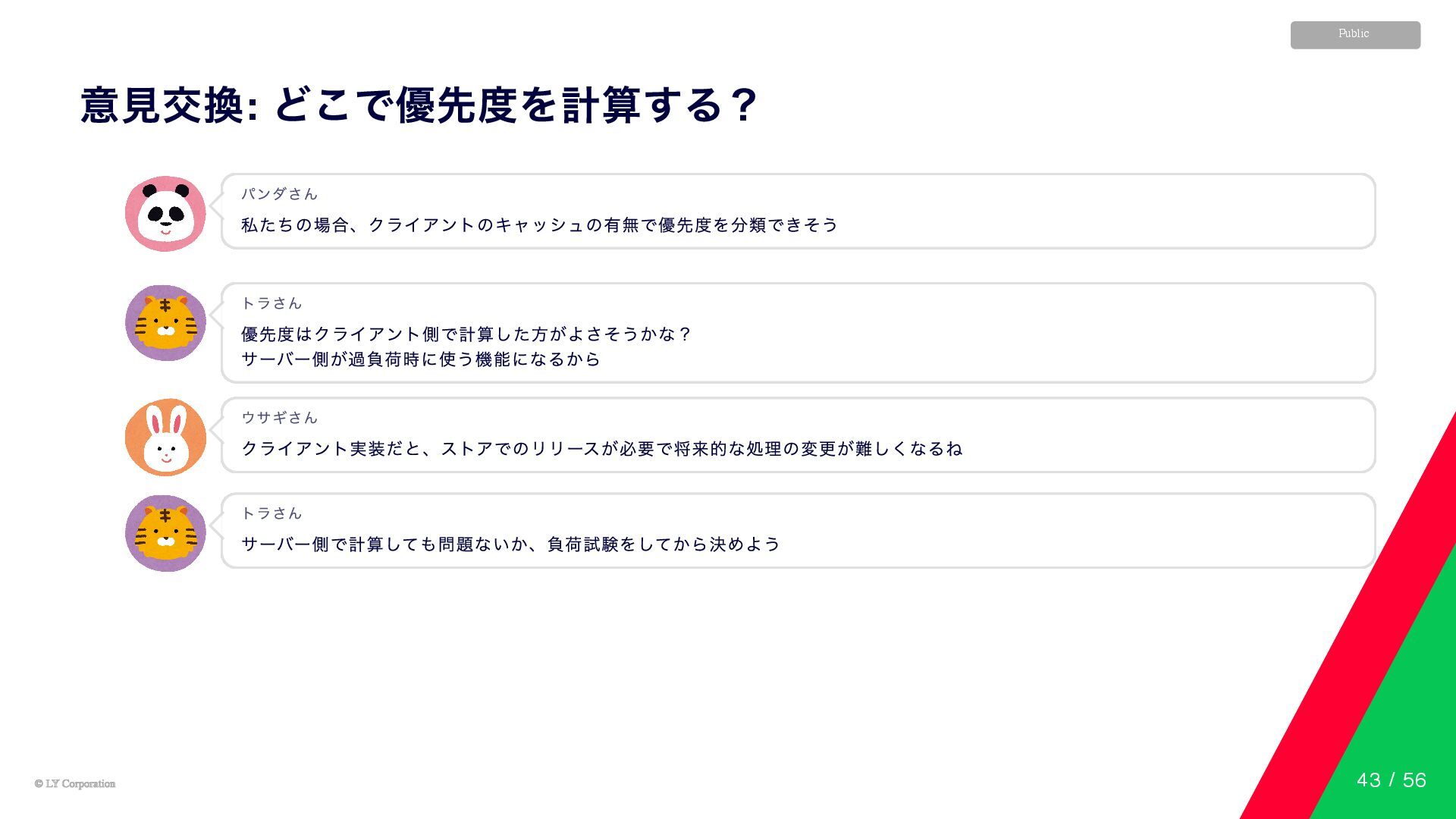
© LY Corporation © LY Corporation Public 意見交換: どこで優先度を計算する? 私たちの場合、クライアントのキャッシュの有無で優先度を分類できそう
パンダさん 優先度はクライアント側で計算した方がよさそうかな? サーバー側が過負荷時に使う機能になるから トラさん クライアント実装だと、ストアでのリリースが必要で将来的な処理の変更が難しくなるね ウサギさん サーバー側で計算しても問題ないか、負荷試験をしてから決めよう トラさん 43 / 56
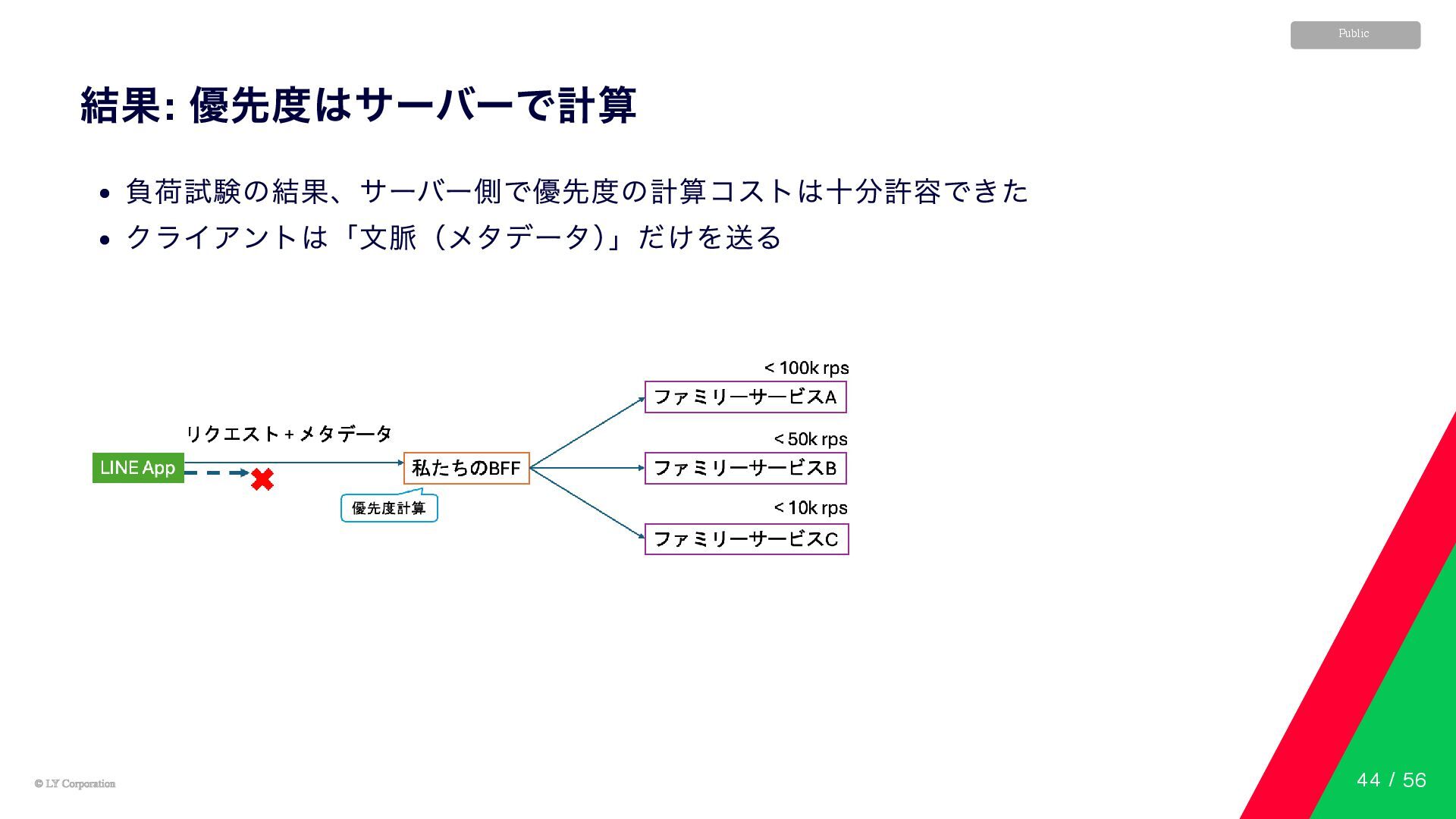
© LY Corporation © LY Corporation Public 結果: 優先度はサーバーで計算 負荷試験の結果、サーバー側で優先度の計算コストは十分許容できた
クライアントは「文脈(メタデータ) 」だけを送る 44 / 56
© LY Corporation © LY Corporation Public 意見交換: 優先度の3 値に丸めるべきか?
拒否するキャッシュヒット率を直接設定すれば十分じゃない? 優先度を計算するコストもあるし、実装もちょっと複雑になるんだけど パンダさん たしかに、キャッシュヒット率を直接設定すれば柔軟になるね トラさん 3 段階の優先度にすることは、障害時のオペレーション速度の要だよ。 レバーはシンプルにしないと、緊急時の作業は困ることになると思う SRE 障害時、責任者不在でも現場判断で切り替えられるようにする必要があるし 将来、文脈を増やしても運用インターフェイスを変えずに済むからね。 SRE たしかに。3 段階の優先度に丸めるのは維持しよう トラさん 45 / 56
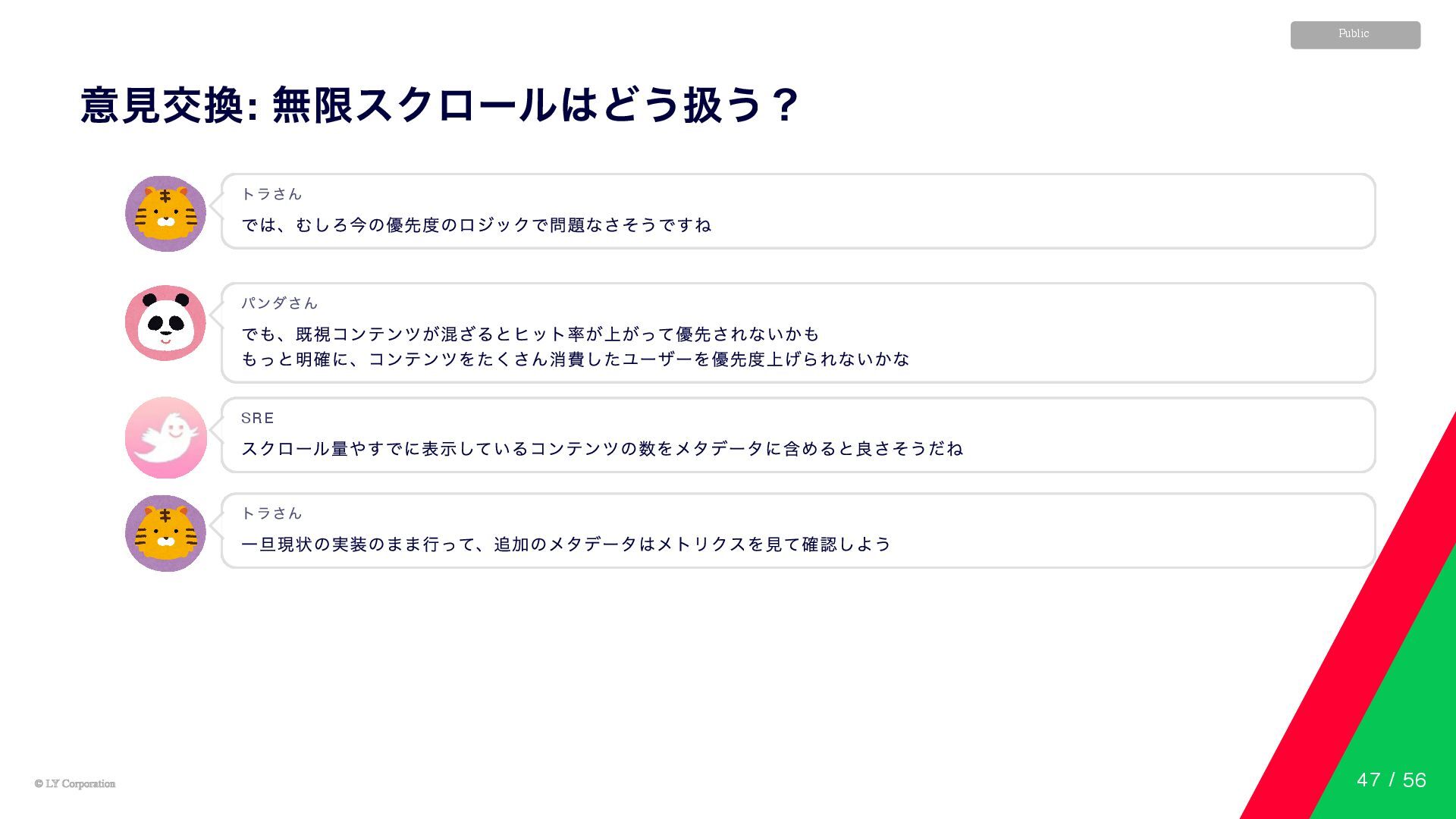
© LY Corporation © LY Corporation Public 意見交換: 無限スクロールはどう扱う? 無限スクロールのページはどうする?
パンダさん 毎回新しいコンテンツが多いから、キャッシュヒット率は下がりがちだね そうなると、過負荷でも拒否できないかも トラさん すでに十分見てるコンテンツはあるし、拒否するべきだよね? パンダさん 深くスクロールして多くのコンテンツを消費するユーザーは重要。そのユーザーは優先したい Product Owner では、むしろ今の優先度のロジックで問題なさそうですね トラさん 46 / 56
© LY Corporation © LY Corporation Public 意見交換: 無限スクロールはどう扱う? では、むしろ今の優先度のロジックで問題なさそうですね
トラさん でも、既視コンテンツが混ざるとヒット率が上がって優先されないかも もっと明確に、コンテンツをたくさん消費したユーザーを優先度上げられないかな パンダさん スクロール量やすでに表示しているコンテンツの数をメタデータに含めると良さそうだね SRE 一旦現状の実装のまま行って、追加のメタデータはメトリクスを見て確認しよう トラさん 47 / 56
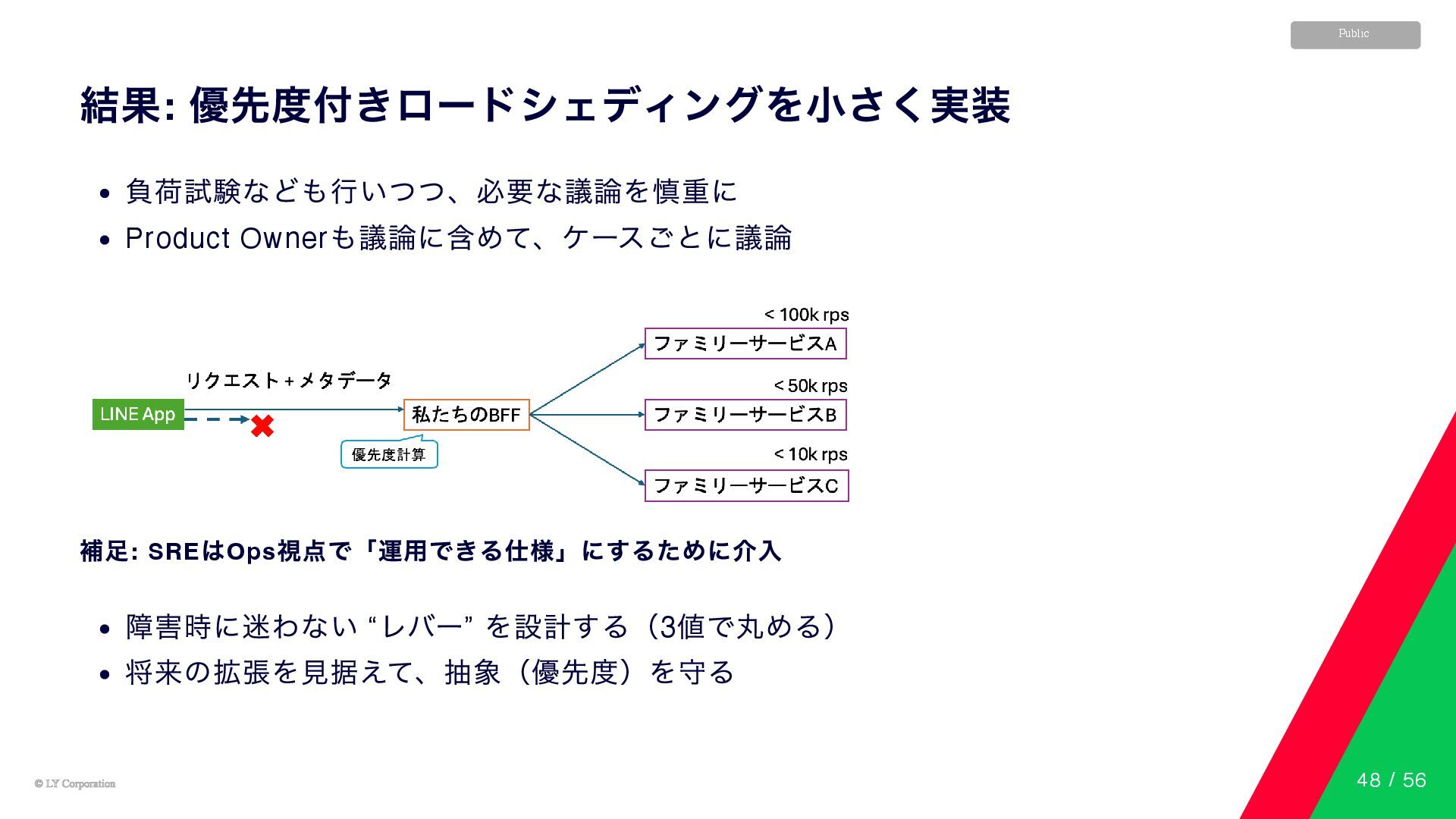
© LY Corporation © LY Corporation Public 結果: 優先度付きロードシェディングを小さく実装 負荷試験なども行いつつ、必要な議論を慎重に
Product Owner も議論に含めて、ケースごとに議論 補足: SRE はOps 視点で「運用できる仕様」にするために介入 障害時に迷わない “ レバー” を設計する(3 値で丸める) 将来の拡張を見据えて、抽象(優先度)を守る 48 / 56
© LY Corporation © LY Corporation Public このような議論ができるようになったきっかけ SRE として
Graceful Degradation (上品な劣化)PJ を立ち上げて、場を作った。 この場で、さまざまな障害時の振る舞い改善の提案が職種問わず出てきた。 49 / 56
© LY Corporation © LY Corporation Public このような議論ができるようになったきっかけ SRE として
Graceful Degradation (上品な劣化)PJ を立ち上げて、場を作った。 この場で、さまざまな障害時の振る舞い改善の提案が職種問わず出てきた。 これによって関係者(プロダクトオーナー、開発者)全体で、 障害は起きうるもの 異常時でも、ユーザー体験を少しでも維持する という認識が揃い、異常時の挙動にチームとして意識が向くように。 50 / 56
© LY Corporation © LY Corporation Public でも、その異常時のための処理はいつ実装すべき? エンジニアの開発リソースは常に不足している。 異常時に備える実装の多くは、使われる頻度が低く、費用対効果が見えにくい。
51 / 56
© LY Corporation © LY Corporation Public でも、その異常時のための処理はいつ実装すべき? エンジニアの開発リソースは常に不足している。 異常時に備える実装の多くは、使われる頻度が低く、費用対効果が見えにくい。
よくある成熟度モデル(5 段階など)は「十分成熟しているか」を教えてくれる一方で、 いま何を優先すべきか どこまでやれば今は十分か の判断には使いにくいことがある。 52 / 56
© LY Corporation © LY Corporation Public スコア制の成熟度モデルのジレンマ ユーザーにとって重要なシステムほど、実験的な機能導入は慎重になりやすい。 実験を目的とし、さまざまな試行錯誤がしやすい小さなサービスはスコアが上がりやすい。
スコア制の成熟度だけでは、重要なシステムほど未熟で、小さなシステムほど優秀に見える。 サービス間の成熟度比較によって、異常時ハンドリング実装の優先度を決めてしまうと、 特に大きなシステムの開発者からすると納得しにくい場面がある。 53 / 56
© LY Corporation © LY Corporation Public Facebook のProduction Engineering
のエンゲージモデル Facebook のSRE (Production Engineering )のエンゲージモデルが参考になる。 参照点はいま開発チームがどこに投資しているか。 54 / 56
© LY Corporation © LY Corporation Public Facebook のProduction Engineering
のエンゲージモデル Facebook のSRE (Production Engineering )のエンゲージモデルが参考になる。 参照点はいま開発チームがどこに投資しているか。 サービスのライフサイクルを意識して「今やるべきこと」を揃える。 立ち上げフェーズにやるべきこと 拡大フェーズにやるべきこと 安定フェーズにやるべきこと これをベースにすると、異常時ハンドリングも 「今はここまでにしておこう」という判断がしやすくなる。 立ち上げ期に、SRE だけが0.1% 改善のチューニングへ偏るのはミスマッチ “ “ 55 / 56
© LY Corporation © LY Corporation Public まとめ & 質疑応答
信頼性は「正解」を当てることではなく、会話で決め続けることでした。 判断軸:異常を前提に、何を守るかを決める(重要度・優先度) レバー:過負荷や失敗時に、何を捨てるかを決める( Load Shedding / 表示ポリシー / etc ) タイミング:やる/ やらないではなく、いつやるかを決める(PE Engagement model ) そして、その会話が回るように SRE は「決まったことの発信者」にならない 56 / 56
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}