(blog) https://medium.com/@masa_asami/quick-introduction-to-counterfactual-regression-cfr-382521eaef21
(My github repository)
[introduction_to_CFR] https://github.com/MasaAsami/introduction_to_CFR
(論文)
[Shalit et al., 2017] Shalit, Uri, Fredrik D. Johansson, and David Sontag. “Estimating individual treatment effect: generalization bounds and algorithms.” International Conference on Machine Learning. PMLR, 2017
[Johansson et al., 2016] Johansson, Fredrik, Uri Shalit, and David Sontag. “Learning representations for counterfactual inference.” International conference on machine learning. PMLR, 2016.
[Takeuchi et al., 2021] Takeuchi, Koh, et al. “Grab the Reins of Crowds: Estimating the Effects of Crowd Movement Guidance Using Causal Inference.” arXiv preprint arXiv:2102.03980, 2021.
[Ganin et al., 2016] Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; and Lempitsky, V. “Domain-adversarial training of neural networks.” Journal of Machine Learning Research 17(1):2096–2030, 2016.
(参考にしたPython実装)
[cfrnet] https://github.com/clinicalml/cfrnet
[SC-CFR] https://github.com/koh-t/SC-CFR
{kind=link}
{kind=link}
![Original Paper: [Shalit et al., 2017] Shalit, Uri, Fredrik D.](https://files.speakerdeck.com/presentations/4e4c681f01fa41b08687c3f65dbd86d8/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Two architectures [Shalit et al., 2017] [Johansson et al., 2016]](https://files.speakerdeck.com/presentations/4e4c681f01fa41b08687c3f65dbd86d8/slide_8.jpg){kind=link}
![Object function [Shalit et al., 2017] Shalit, Uri, Fredrik D.](https://files.speakerdeck.com/presentations/4e4c681f01fa41b08687c3f65dbd86d8/slide_9.jpg){kind=link}
![[FYI]Domain Adversarial Neural Networks 11 [Ganin et al., 2016]](https://files.speakerdeck.com/presentations/4e4c681f01fa41b08687c3f65dbd86d8/slide_10.jpg){kind=link}
{kind=link}
![Theoretical Bound (1/3) : Motivation [Shalit et al., 2017] Shalit,](https://files.speakerdeck.com/presentations/4e4c681f01fa41b08687c3f65dbd86d8/slide_12.jpg){kind=link}
{kind=link}
![Theoretical Bound (3/3) Theorem Lemma [Shalit et al., 2017]](https://files.speakerdeck.com/presentations/4e4c681f01fa41b08687c3f65dbd86d8/slide_14.jpg){kind=link}
{kind=link}
![[Shalit et al., 2017] Shalit, Uri, Fredrik D. Johansson, and](https://files.speakerdeck.com/presentations/4e4c681f01fa41b08687c3f65dbd86d8/slide_16.jpg){kind=link}
![[Shalit et al., 2017] Shalit, Uri, Fredrik D. Johansson, and](https://files.speakerdeck.com/presentations/4e4c681f01fa41b08687c3f65dbd86d8/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
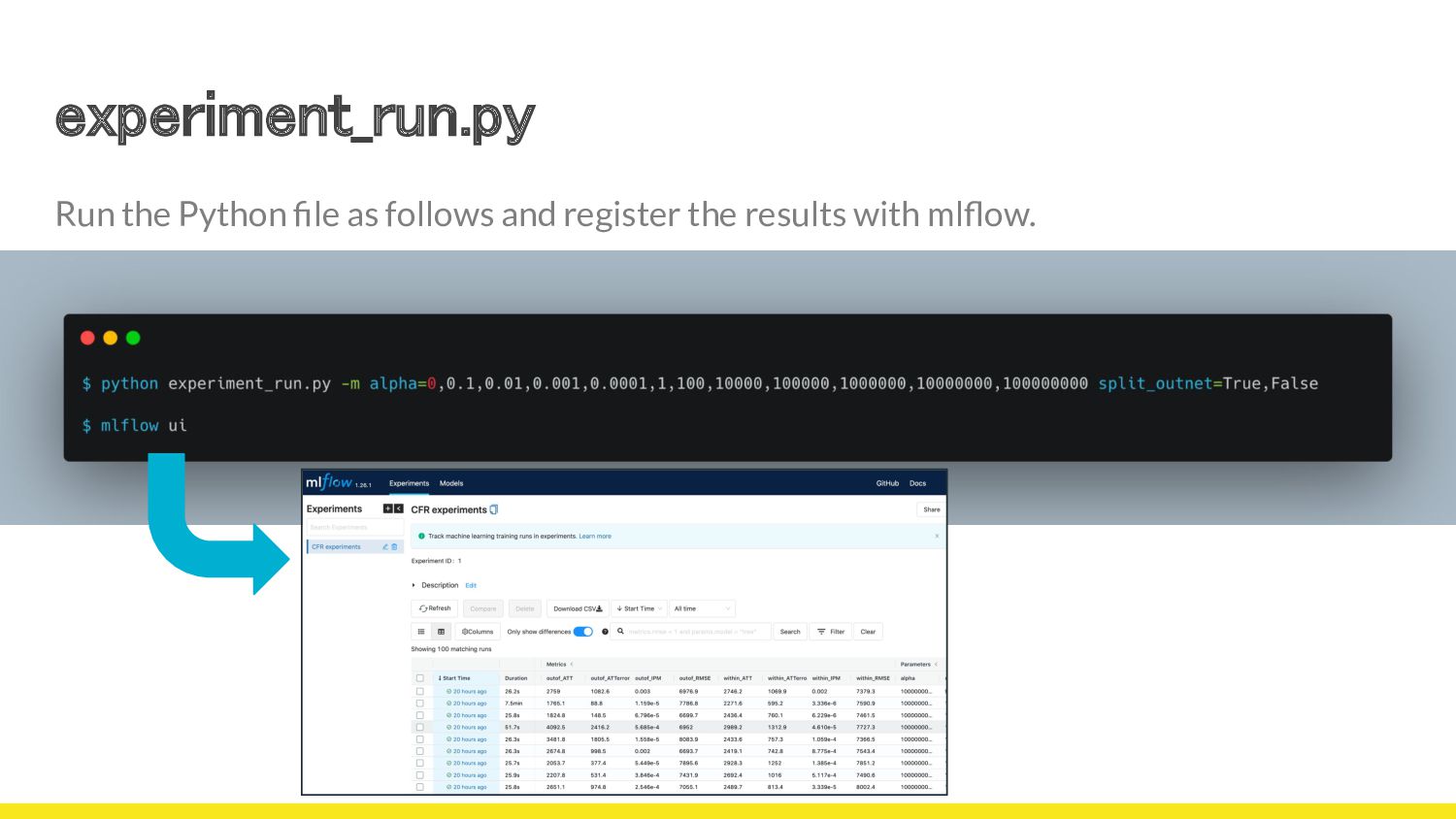{kind=link}
{kind=link}
{kind=link}
![[Shalit et al., 2017]’s results [Shalit et al., 2017] Shalit,](https://files.speakerdeck.com/presentations/4e4c681f01fa41b08687c3f65dbd86d8/slide_30.jpg){kind=link}
{kind=link}
![Lots of interesting applied research! [Takeuchi et al., 2021] Takeuchi,](https://files.speakerdeck.com/presentations/4e4c681f01fa41b08687c3f65dbd86d8/slide_32.jpg){kind=link}
![Reference 34 (Papers) • [Shalit et al., 2017] Shalit, Uri,](https://files.speakerdeck.com/presentations/4e4c681f01fa41b08687c3f65dbd86d8/slide_33.jpg){kind=link}
{kind=link}