Hadoop in 10 minutes – HDFS – MapReduce – Code example Hadoop using Spring – Code examples – Hadoop specific configurations – Pig through Spring Questions
is Important? Delivers performance and scalability at low cost Handles large amounts of data Resilient in case of infrastructure failures Transparent application scalability
Open-source Apache project out of Yahoo! in 2006 Distributed fault-tolerant data storage and batch processing Linear scalability on commodity hardware
Great at – Reliable storage for huge data sets – Batch queries and analytics – Changing schemas Not so great at – Changes to files (can’t do it…) – Low-latency responses (like OLTP applications) – Analyst usability
Hierarchical UNIX-like file system for data storage – sort of Splitting of large files into blocks Distribution and replication of blocks to nodes Two key services – Master NameNode – Many DataNodes Secondary/Checkpoint Node
Works - Writes DataNode A DataNode B DataNode C DataNode D NameNode 1 Client 2 A1 3 A2 A3 A4 Client contacts NameNode to write data NameNode says write it to these nodes Client sequentially writes blocks to DataNode
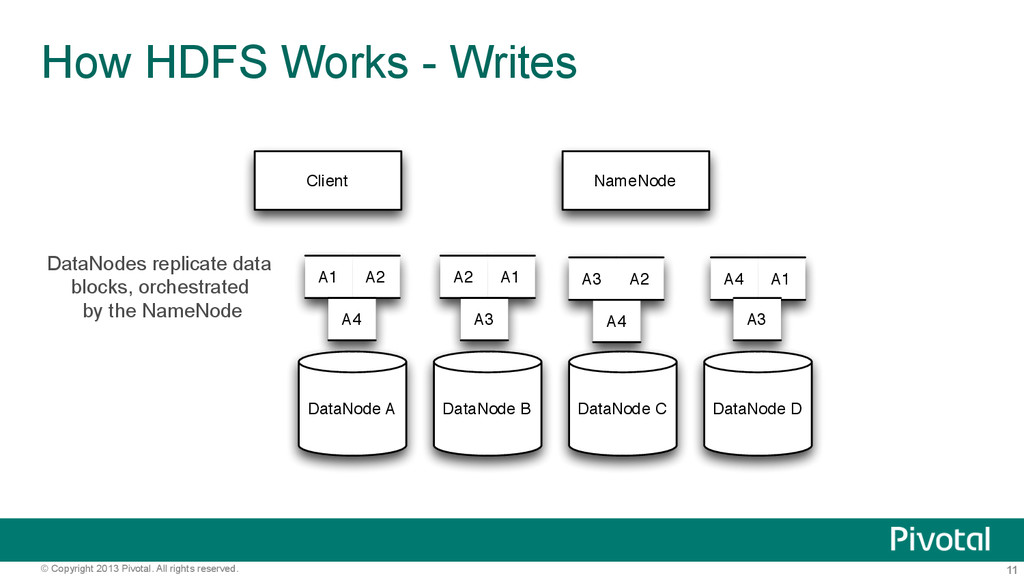
Works - Writes DataNode A DataNode B DataNode C DataNode D NameNode Client A1 A2 A3 A4 A1 A1 A2 A2 A3 A3 A4 A4 DataNodes replicate data blocks, orchestrated by the NameNode
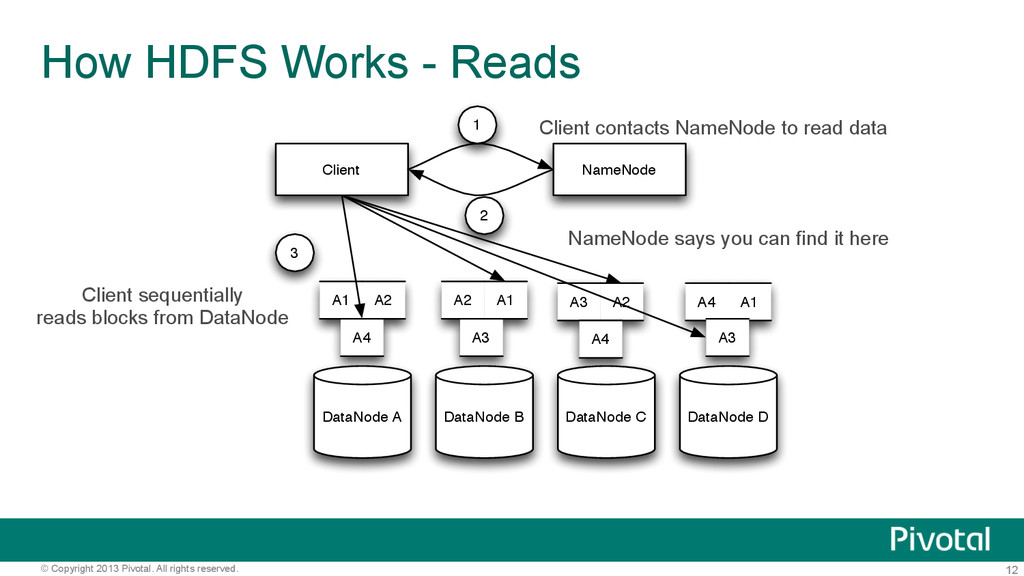
Works - Reads DataNode A DataNode B DataNode C DataNode D NameNode Client A1 A2 A3 A4 A1 A1 A2 A2 A3 A3 A4 A4 1 2 3 Client contacts NameNode to read data NameNode says you can find it here Client sequentially reads blocks from DataNode
1.x Moves the code to the data JobTracker – Master service to monitor jobs TaskTracker – Multiple services to run tasks – Same physical machine as a DataNode A job contains many tasks A task contains one or more task attempts
Works DataNode A A1 A2 A4 A2 A1 A3 A3 A2 A4 A4 A1 A3 JobTracker 1 Client 4 2 B1 B3 B4 B2 B3 B1 B3 B2 B4 B4 B1 B2 3 DataNode B DataNode C DataNode D TaskTracker A TaskTracker B TaskTracker C TaskTracker D Client submits job to JobTracker JobTracker submits tasks to TaskTrackers Job output is written to DataNodes w/replication JobTracker reports metrics
Data processing system with two key phases Map – Perform a map function on key/value pairs Reduce – Perform a reduce function on key/value groups Groups created by sorting map output
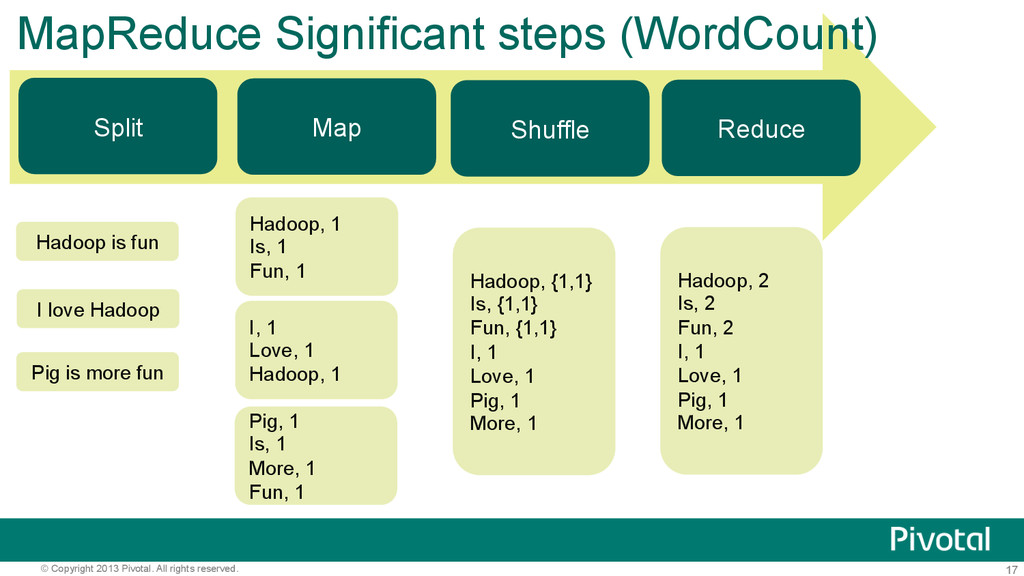
Shuffle Reduce MapReduce Significant steps (WordCount) Hadoop is fun I love Hadoop Pig is more fun Hadoop, 1 Is, 1 Fun, 1 I, 1 Love, 1 Hadoop, 1 Pig, 1 Is, 1 More, 1 Fun, 1 Hadoop, {1,1} Is, {1,1} Fun, {1,1} I, 1 Love, 1 Pig, 1 More, 1 Hadoop, 2 Is, 2 Fun, 2 I, 1 Love, 1 Pig, 1 More, 1
public class WordMapper extends Mapper<LongWritable, Text, Text, IntWritable> { private final static IntWritable ONE = new IntWritable(1); private Text word = new Text(); public void map(LongWritable key, Text value, Context context) { String line = value.toString(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasMoreTokens()) { word.set(tokenizer.nextToken()); context.write(word, ONE); } } }
public class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> { public void reduce(Text key, Iterable<IntWritable> values, Context context) { int sum = 0; for (IntWritable val : values) { sum += val.get(); } context.write(key, new IntWritable(sum)); } }
on Hadoop Hadoop has a poor out of the box programming model Non trivial applications often become a collection of scripts calling Hadoop command line applications Spring aims to simplify developer Hadoop applications – Leverage several Spring eco-system projects
for Hadoop - Features Consistent programming and declarative configuration model – Create, configure, and parameterize Hadoop connectivity and all job types – Environment profiles – easily move application from dev to qa to production Developer productivity – Create well-formed applications, not spaghetti script applications – Simplify HDFS access and FsShell API with support for JVM scripting – Runner classes for MR/Pig/Hive/Cascading for small workflows – Helper “Template” classes for Pig/Hive/HBase
for Hadoop – Use Cases Apply across a wide range of use cases – Ingest: Events/JDBC/NoSQL/Files to HDFS – Orchestrate: Hadoop Jobs – Export: HDFS to JDBC/NoSQL Spring Integration and Spring Batch make this possible
Use DI to obtain reference to Hadoop Job – Perform additional runtime configuration and submit public class WordService { @Autowired private Job mapReduceJob; public void processWords() { mapReduceJob.submit(); } }
all “bin/hadoop fs” commands through Spring’s FsShell helper class – mkdir, chmod, test HDFS and Hadoop Shell as APIs class MyScript { @Autowired FsShell fsh; @PostConstruct void init() { String outputDir = "/data/output"; if (fsShell.test(outputDir)) { fsShell.rmr(outputDir); } } }
Hadoop Shell as APIs FsShell is designed to support JVM scripting languages // use the shell (made available under variable fsh) if (!fsh.test(inputDir)) { fsh.mkdir(inputDir); fsh.copyFromLocal(sourceFile, inputDir); fsh.chmod(700, inputDir) } if (fsh.test(outputDir)) { fsh.rmr(outputDir) } copy-files.groovy
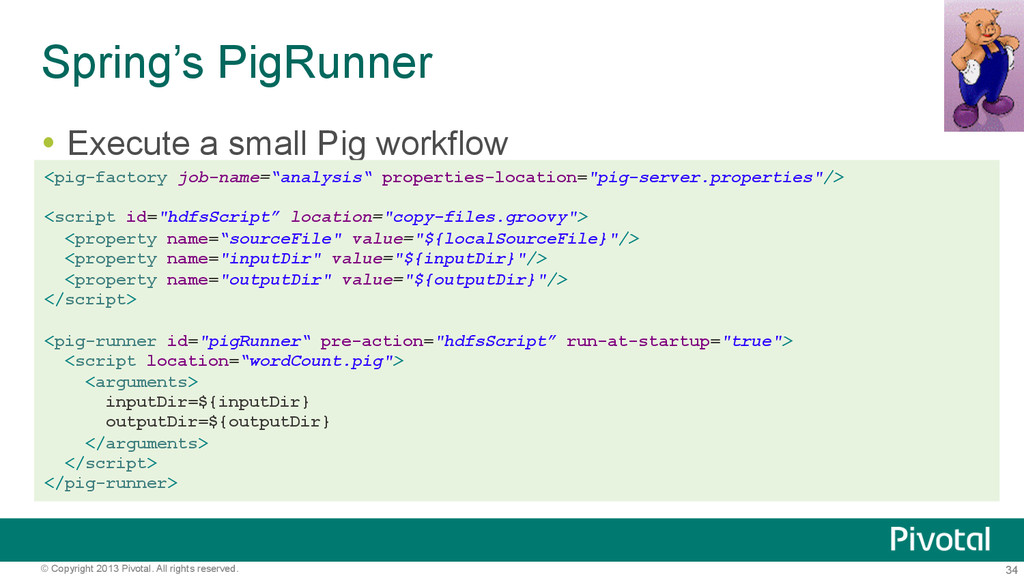
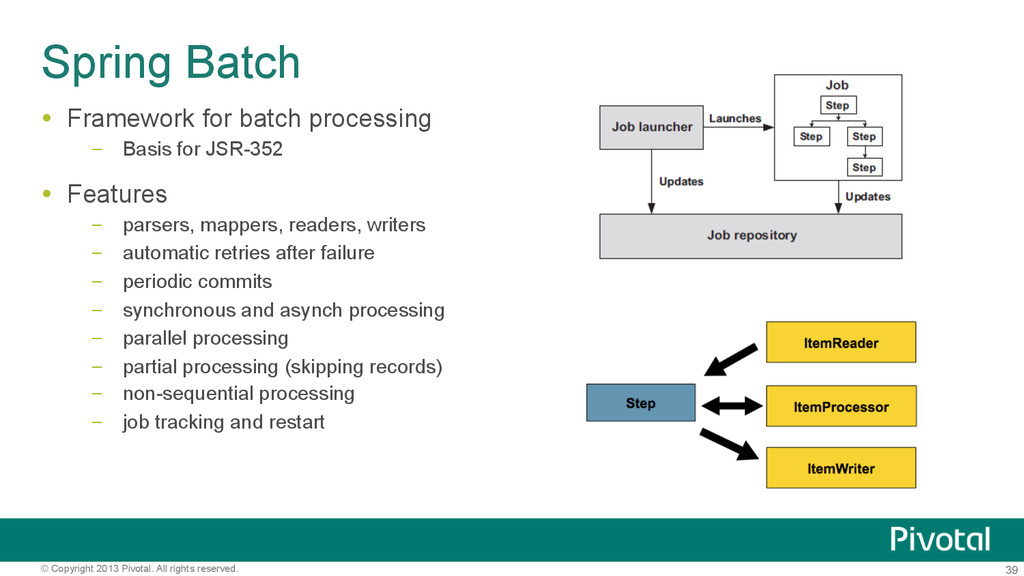
Often need the following steps – Execute HDFS operations before job – Run MapReduce Job – Execute HDFS operations after job completes Spring’s JobRunner helper class sequences these steps – Can reference multiple scripts with comma delimited names <hdp:job-runner id="runner" run-at-startup="true" pre-action="setupScript" job="wordcountJob“ post-action=“tearDownScript"/>
Similar runner classes available for Hive and Pig Implement JDK callable interface Easy to schedule for simple needs using Spring Can later ‘graduate’ to use Spring Batch for more complex workflows – Start simple and grow, reusing existing configuration <hdp:job-runner id="runner“ run-at-startup=“false" pre-action="setupScript“ job="wordcountJob“ post-action=“tearDownScript"/> <task:scheduled-tasks> <task:scheduled ref="runner" method="call" cron="3/30 * * * * ?"/> </task:scheduled-tasks>
Configuration Helper class that simplifies the programmatic use of Pig – Common tasks are one-liners Similar template helper classes for Hive and HBase <pig-factory id="pigFactory“ properties-location="pig-server.properties"/> <pig-template pig-factory-ref="pigFactory"/>
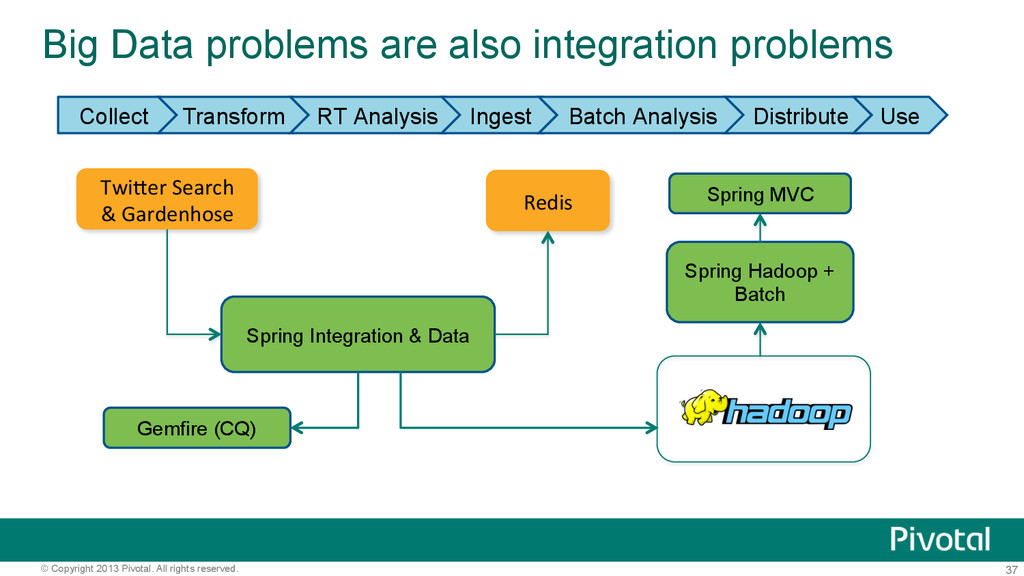
problems are also integration problems Collect Transform RT Analysis Ingest Batch Analysis Distribute Use Spring Integration & Data Spring Hadoop + Batch Spring MVC Twi$er Search & Gardenhose Redis Gemfire (CQ)
and Batch for Hadoop Ingest/Export Event Streams – Spring Integration – Examples ▪ Consume syslog events, transform and write to HDFS ▪ Consume twitter search results and write to HDFS Batch – Spring Batch – Examples ▪ Read log files on local file system, transform and write to HDFS ▪ Read from HDFS, transform and write to JDBC, HBase, MongoDB,…
Integration, & Batch for Analytics Realtime Analytics – Spring Integration & Data – Examples – Service Activator that ▪ Increments counters in Redis or MongoDB using Spring Data helper libraries ▪ Create Gemfire Continuous Queries using Spring Gemfire Batch Analytics – Spring Batch – Orchestrate Hadoop based workflows with Spring Batch – Also orchestrate non-hadoop based workflows
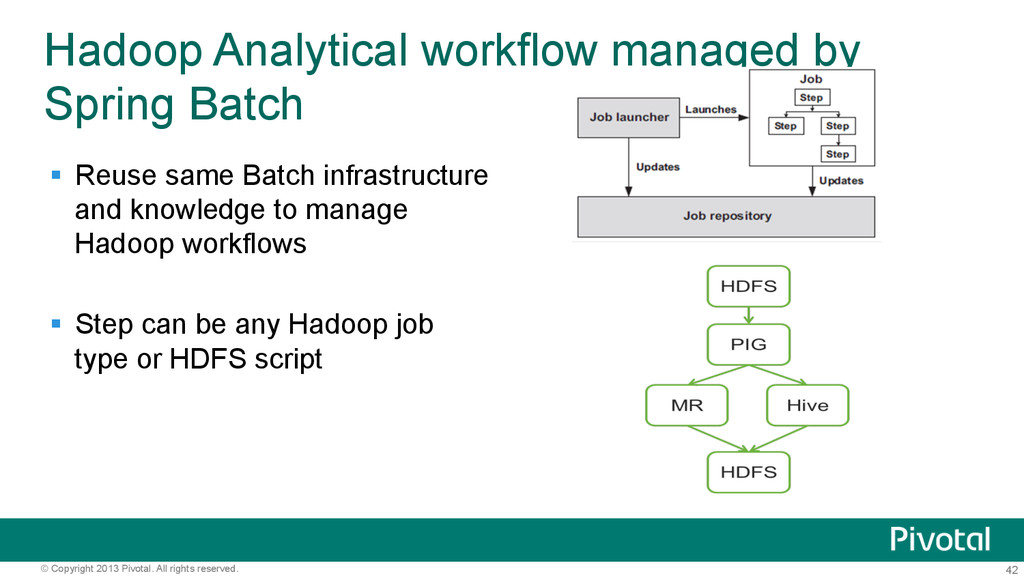
workflow managed by Spring Batch § Reuse same Batch infrastructure and knowledge to manage Hadoop workflows § Step can be any Hadoop job type or HDFS script
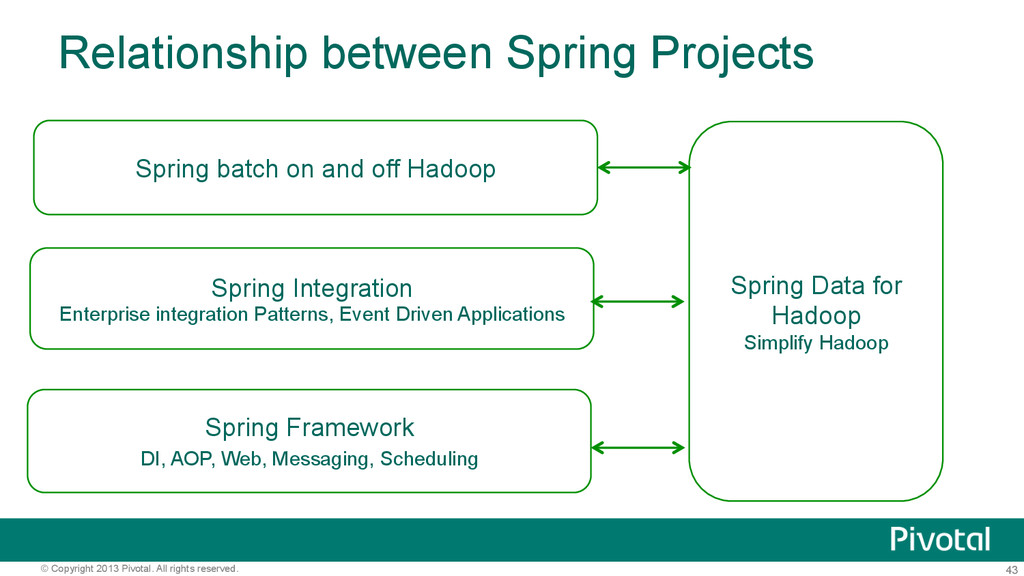
Spring Projects Spring batch on and off Hadoop Spring Integration Enterprise integration Patterns, Event Driven Applications Spring Framework DI, AOP, Web, Messaging, Scheduling Spring Data for Hadoop Simplify Hadoop
– Spring XD New open source umbrella project to support common big data use cases – High throughput distributed data ingestion into HDFS ▪ From a variety of input sources – Real-time analytics at ingestion time ▪ Gathering metrics, counting values, Gemfire CQ… – On and off Hadoop workflow orchestration – High throughput data export ▪ From HDFS to a RDBMS or NoSQL database. XD = eXtreme Data
Pivotal – goPivotal.com Spring Data – http://www.springsource.org/spring-data – http://www.springsource.org/spring-hadoop Spring Data Book - http://bit.ly/sd-book – Part III on Big Data Example Code https://github.com/SpringSource/spring-data-book Spring XD http://github.com/springsource/spring-xd
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}