Introduction into working with processes and threads in Ruby, together with a deeper look into some underlying differences between various Ruby versions and implementations
X, QNX, Solaris • Mostly POSIX-compliant: GNU/Linux, *BSD • Ruby implements lots of POSIX functionality, and often - with exactly the same API (Kernel#fork for fork(2), Process.wait for wait(2), etc) Monday, April 22, 13
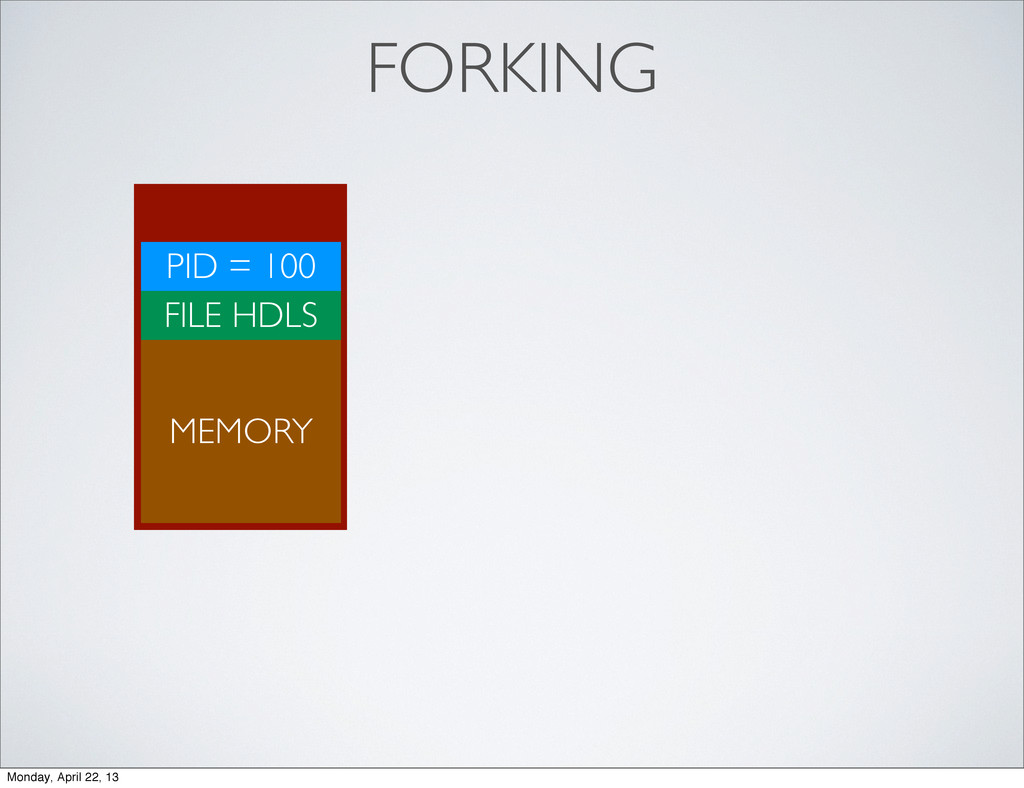
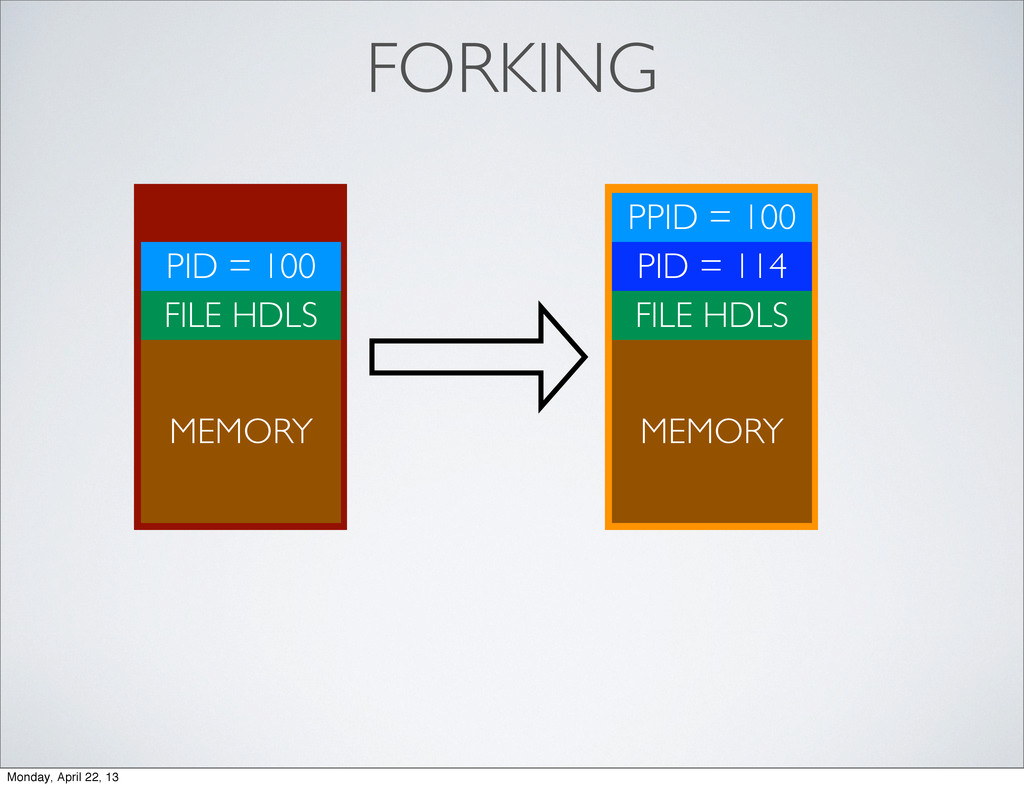
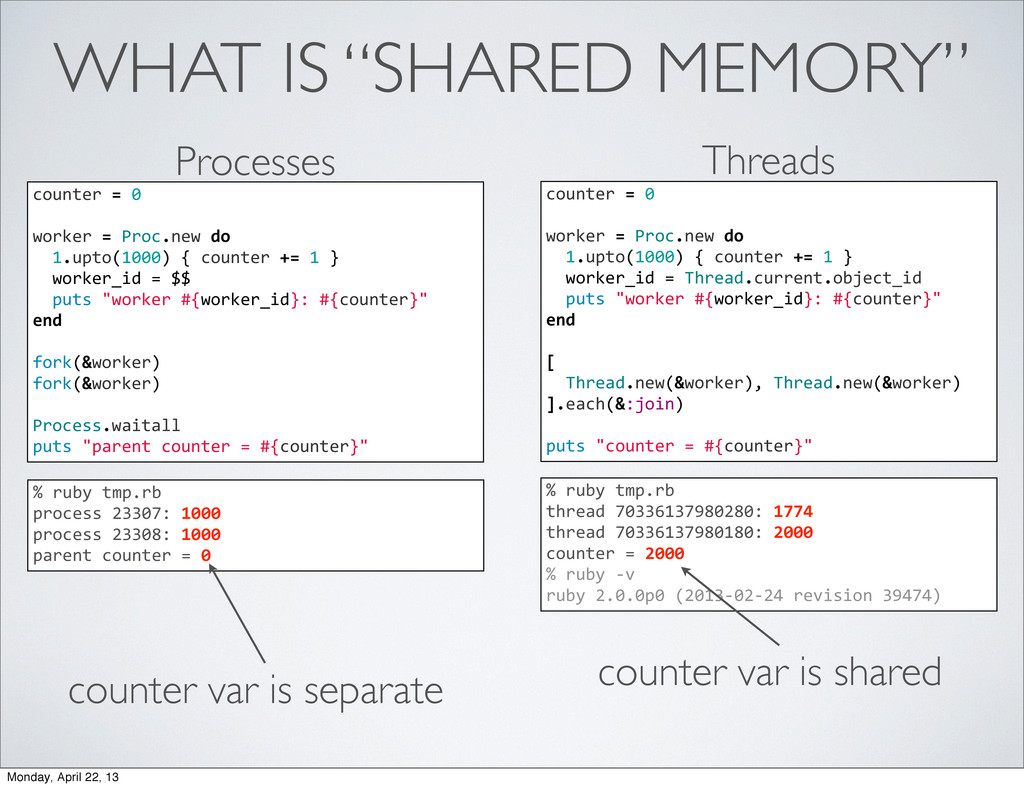
parent’s PID is child’s PPID • child receives a copy of parent’s memory • child receives parent’s open file descriptors (files, sockets, etc) • child’s memory is independent of parent’s memory Monday, April 22, 13
block" else puts "executing else block" end % ruby tmp.rb executing if block executing else block Confusing? Let’s rewrite it a bit Monday, April 22, 13
fork puts "executing if block in #{Process.pid}" else puts "executing else block #{Process.pid}" end % ruby tmp.rb I am 18290 executing if block in 18290 executing else block in 18291 Monday, April 22, 13
fork puts "executing if block in #{Process.pid}" else puts "executing else block #{Process.pid}" end % ruby tmp.rb I am 18290 executing if block in 18290 executing else block in 18291 Kernel#fork returns: •in child process - nil •in parent process - pid of the child process Monday, April 22, 13
code puts "I am a child" end # parent process code puts "I am the parent" •child process exits at the end of the block •parent process skips the block Monday, April 22, 13
• use case: fork child processes to run memory-hungry code WHY? - Ruby is bad at releasing memory back to the system - so ruby processes grow, but don’t shrink Monday, April 22, 13
0 usually indicates success, 1 and other - error • but it is merely a matter of interpretation • “errors” can be interpreted as program-specific responses Monday, April 22, 13
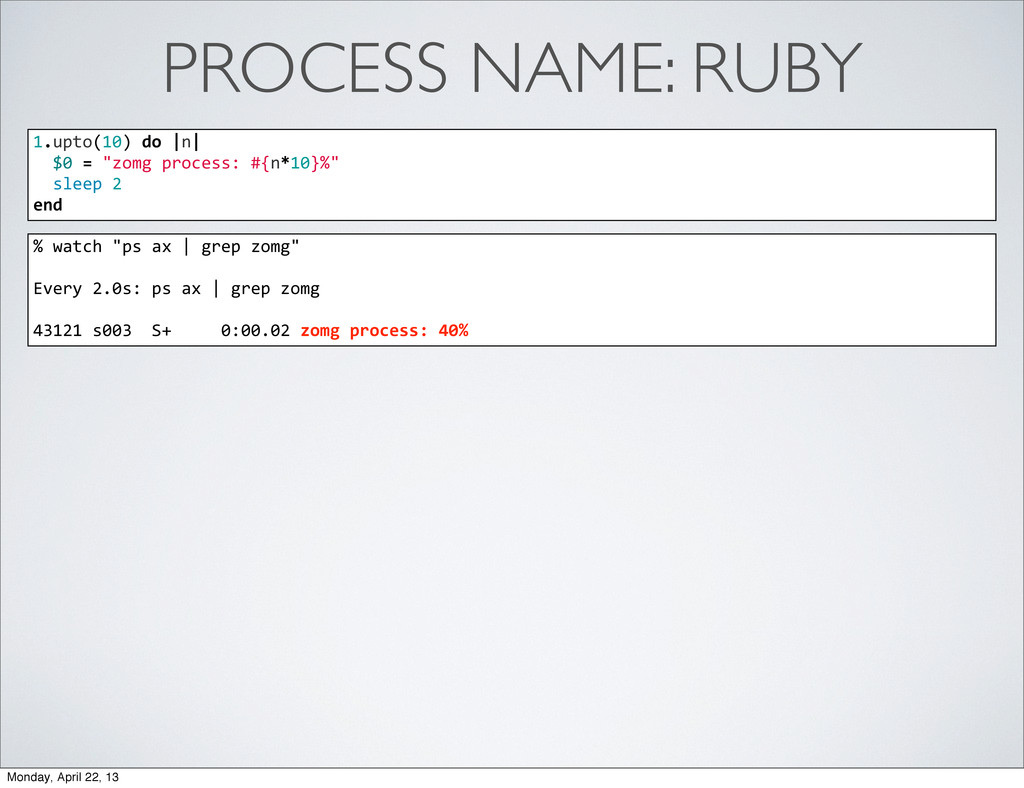
process: #{n*10}%" sleep 2 end % watch "ps ax | grep zomg" Every 2.0s: ps ax | grep zomg 43121 s003 S+ 0:00.02 zomg process: 40% Process name can communicate any status: •task progress •request being executed •job being run •number of workers •etc Monday, April 22, 13
:manage_memory def manage_memory old_0 = $0 begin $0 = "rails:#{request.method} #{controller_name}##{action_name}#{'.xhr' if request.xhr?}" yield ensure $0 = old_0 end end end web workers: •mostly informational in this case •but sometimes can be useful to cross-reference with other stuck processes (e.g. long db queries) Monday, April 22, 13
run_jobs old_0 = $0 while @running ActiveRecord::Base.verify_active_connections! if(@running && (job_id = (read_pipe.readline rescue nil))) job = Job.find(job_id.chomp.to_i) $0 = "stablemaster: #{job.class}##{job.id}" end end $0 = old_0 end end stable master / horses: •similar status messages for stable master and idle workers •can easily identify and kill troublesome jobs •look around in stable_master.rb for more Monday, April 22, 13
run_jobs old_0 = $0 while @running ActiveRecord::Base.verify_active_connections! if(@running && (job_id = (read_pipe.readline rescue nil))) job = Job.find(job_id.chomp.to_i) $0 = "stablemaster: #{job.class}##{job.id}" end end $0 = old_0 end end stable master / horses: ActiveRecord::Base.verify_active_connections! ProTip: AR tends to lose db connections, so reconnect in child processes Monday, April 22, 13
child per job to contain memory bloat •communicates runtime status via process names def process_job(job, &block) # ... @child = fork(job) do reconnect run_hook :after_fork, job unregister_signal_handlers perform(job, &block) exit! unless options[:run_at_exit_hooks] end if @child wait_for_child job.fail(DirtyExit.new($?.to_s)) if $?.signaled? # ... end done_working end Monday, April 22, 13
child per job to contain memory bloat •communicates runtime status via process names def process_job(job, &block) # ... @child = fork(job) do reconnect run_hook :after_fork, job unregister_signal_handlers perform(job, &block) exit! unless options[:run_at_exit_hooks] end if @child wait_for_child job.fail(DirtyExit.new($?.to_s)) if $?.signaled? # ... end done_working end @child = fork(job) do forking a child to run the job Monday, April 22, 13
child per job to contain memory bloat •communicates runtime status via process names def process_job(job, &block) # ... @child = fork(job) do reconnect run_hook :after_fork, job unregister_signal_handlers perform(job, &block) exit! unless options[:run_at_exit_hooks] end if @child wait_for_child job.fail(DirtyExit.new($?.to_s)) if $?.signaled? # ... end done_working end reconnect reconnecting to the server Monday, April 22, 13
child per job to contain memory bloat •communicates runtime status via process names def process_job(job, &block) # ... @child = fork(job) do reconnect run_hook :after_fork, job unregister_signal_handlers perform(job, &block) exit! unless options[:run_at_exit_hooks] end if @child wait_for_child job.fail(DirtyExit.new($?.to_s)) if $?.signaled? # ... end done_working end perform(job, &block) and executing the job Monday, April 22, 13
child per job to contain memory bloat •communicates runtime status via process names def process_job(job, &block) # ... @child = fork(job) do reconnect run_hook :after_fork, job unregister_signal_handlers perform(job, &block) exit! unless options[:run_at_exit_hooks] end if @child wait_for_child job.fail(DirtyExit.new($?.to_s)) if $?.signaled? # ... end done_working end wait_for_child parent process waits for child to finish Monday, April 22, 13
child per job to contain memory bloat •communicates runtime status via process names def process_job(job, &block) # ... @child = fork(job) do reconnect run_hook :after_fork, job unregister_signal_handlers perform(job, &block) exit! unless options[:run_at_exit_hooks] end if @child wait_for_child job.fail(DirtyExit.new($?.to_s)) if $?.signaled? # ... end done_working end job.fail(DirtyExit.new($?.to_s)) if $?.signaled? and marks the job as failed if it’s been killed with a signal Monday, April 22, 13
child per job to contain memory bloat •communicates runtime status via process names # Processes a given job in the child. def perform(job) procline "Processing #{job.queue} since #{Time.now.to_i} [#{job.payload_class_name}]" begin run_hook :before_perform, job job.perform run_hook :after_perform, job rescue Object => e job.fail(e) failed! else Resque.logger.info "done: #{job.inspect}" ensure yield job if block_given? end end perform(job, &block) and executing the job Monday, April 22, 13
the child. def perform(job) procline "Processing #{job.queue} since #{Time.now.to_i} [#{job.payload_class_name}]" begin run_hook :before_perform, job job.perform run_hook :after_perform, job rescue Object => e job.fail(e) failed! else Resque.logger.info "done: #{job.inspect}" ensure yield job if block_given? end end perform(job, &block) displaying job details via process name procline "Processing #{job.queue} since #{Time.now.to_i} [#{job.payload_class_name}]" Redis based processing queue •forks a child per job to contain memory bloat •communicates runtime status via process names Monday, April 22, 13
child per job to contain memory bloat •communicates runtime status via process names more source code: https://github.com/resque/resque/blob/master/lib/resque/worker.rb Monday, April 22, 13
•sets $? with Process::Status Process::Status pid child’s process id exited? true if exited normally exitstatus byte-sized exit status signalled? true if interrupted by a signed (kill’ed) success? true if exited with an exit code of 0 Monday, April 22, 13
et al to reap child processes! • Dead children become zombies (even if for a short time) • Zombies can’t be killed • Lots of zombies - something’s wrong somewhere Monday, April 22, 13
(c) Ryan Tomayko / GitHub •Mongrel minus threads plus Unix processes •leans heavily on OS kernel to balance connections and manage workers Monday, April 22, 13
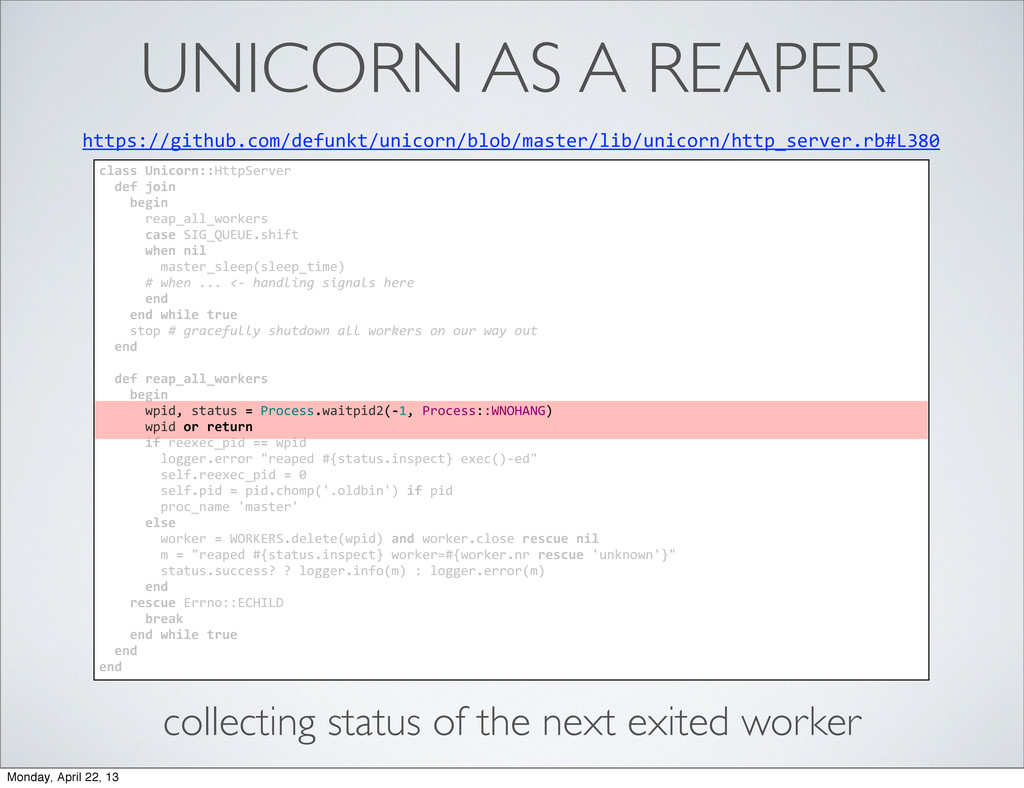
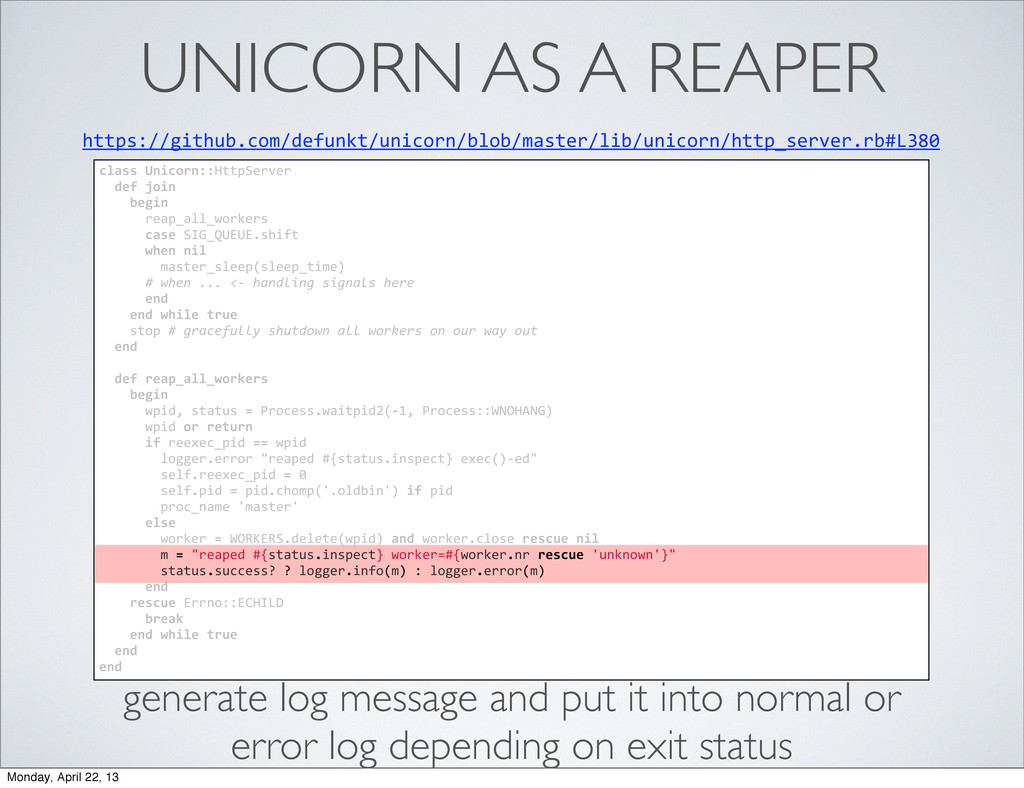
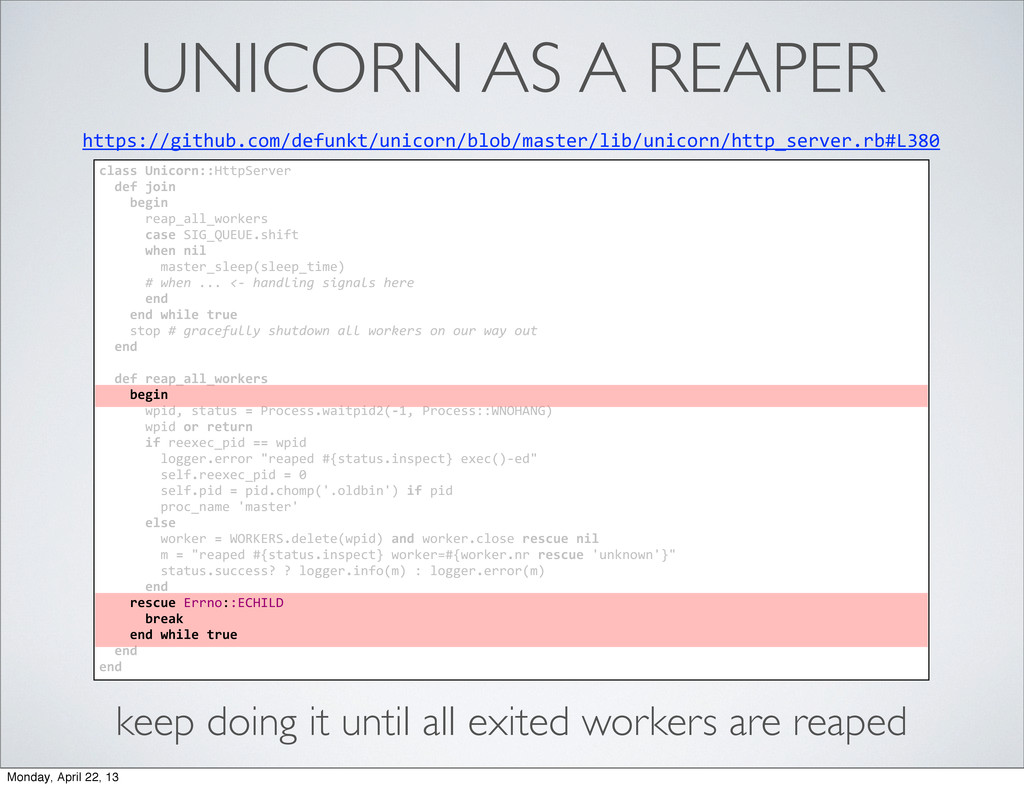
begin reap_all_workers case SIG_QUEUE.shift when nil master_sleep(sleep_time) # when ... <-‐ handling signals here end end while true stop # gracefully shutdown all workers on our way out end def reap_all_workers begin wpid, status = Process.waitpid2(-‐1, Process::WNOHANG) wpid or return if reexec_pid == wpid logger.error "reaped #{status.inspect} exec()-‐ed" self.reexec_pid = 0 self.pid = pid.chomp('.oldbin') if pid proc_name 'master' else worker = WORKERS.delete(wpid) and worker.close rescue nil m = "reaped #{status.inspect} worker=#{worker.nr rescue 'unknown'}" status.success? ? logger.info(m) : logger.error(m) end rescue Errno::ECHILD break end while true end end Monday, April 22, 13
begin reap_all_workers case SIG_QUEUE.shift when nil master_sleep(sleep_time) # when ... <-‐ handling signals here end end while true stop # gracefully shutdown all workers on our way out end def reap_all_workers begin wpid, status = Process.waitpid2(-‐1, Process::WNOHANG) wpid or return if reexec_pid == wpid logger.error "reaped #{status.inspect} exec()-‐ed" self.reexec_pid = 0 self.pid = pid.chomp('.oldbin') if pid proc_name 'master' else worker = WORKERS.delete(wpid) and worker.close rescue nil m = "reaped #{status.inspect} worker=#{worker.nr rescue 'unknown'}" status.success? ? logger.info(m) : logger.error(m) end rescue Errno::ECHILD break end while true end end begin reap_all_workers case SIG_QUEUE.shift when nil master_sleep(sleep_time) # when ... <-‐ handling signals here end end while true master loop reaps exited workers until stopped Monday, April 22, 13
begin reap_all_workers case SIG_QUEUE.shift when nil master_sleep(sleep_time) # when ... <-‐ handling signals here end end while true stop # gracefully shutdown all workers on our way out end def reap_all_workers begin wpid, status = Process.waitpid2(-‐1, Process::WNOHANG) wpid or return if reexec_pid == wpid logger.error "reaped #{status.inspect} exec()-‐ed" self.reexec_pid = 0 self.pid = pid.chomp('.oldbin') if pid proc_name 'master' else worker = WORKERS.delete(wpid) and worker.close rescue nil m = "reaped #{status.inspect} worker=#{worker.nr rescue 'unknown'}" status.success? ? logger.info(m) : logger.error(m) end rescue Errno::ECHILD break end while true end end wpid, status = Process.waitpid2(-‐1, Process::WNOHANG) wpid or return collecting status of the next exited worker Monday, April 22, 13
begin reap_all_workers case SIG_QUEUE.shift when nil master_sleep(sleep_time) # when ... <-‐ handling signals here end end while true stop # gracefully shutdown all workers on our way out end def reap_all_workers begin wpid, status = Process.waitpid2(-‐1, Process::WNOHANG) wpid or return if reexec_pid == wpid logger.error "reaped #{status.inspect} exec()-‐ed" self.reexec_pid = 0 self.pid = pid.chomp('.oldbin') if pid proc_name 'master' else worker = WORKERS.delete(wpid) and worker.close rescue nil m = "reaped #{status.inspect} worker=#{worker.nr rescue 'unknown'}" status.success? ? logger.info(m) : logger.error(m) end rescue Errno::ECHILD break end while true end end proc_name 'master' renaming the master process when doing zero- downtime deploys Monday, April 22, 13
begin reap_all_workers case SIG_QUEUE.shift when nil master_sleep(sleep_time) # when ... <-‐ handling signals here end end while true stop # gracefully shutdown all workers on our way out end def reap_all_workers begin wpid, status = Process.waitpid2(-‐1, Process::WNOHANG) wpid or return if reexec_pid == wpid logger.error "reaped #{status.inspect} exec()-‐ed" self.reexec_pid = 0 self.pid = pid.chomp('.oldbin') if pid proc_name 'master' else worker = WORKERS.delete(wpid) and worker.close rescue nil m = "reaped #{status.inspect} worker=#{worker.nr rescue 'unknown'}" status.success? ? logger.info(m) : logger.error(m) end rescue Errno::ECHILD break end while true end end worker = WORKERS.delete(wpid) and worker.close rescue nil wpid is PID of the reaped worker - close communication pipe and remove its data Monday, April 22, 13
begin reap_all_workers case SIG_QUEUE.shift when nil master_sleep(sleep_time) # when ... <-‐ handling signals here end end while true stop # gracefully shutdown all workers on our way out end def reap_all_workers begin wpid, status = Process.waitpid2(-‐1, Process::WNOHANG) wpid or return if reexec_pid == wpid logger.error "reaped #{status.inspect} exec()-‐ed" self.reexec_pid = 0 self.pid = pid.chomp('.oldbin') if pid proc_name 'master' else worker = WORKERS.delete(wpid) and worker.close rescue nil m = "reaped #{status.inspect} worker=#{worker.nr rescue 'unknown'}" status.success? ? logger.info(m) : logger.error(m) end rescue Errno::ECHILD break end while true end end m = "reaped #{status.inspect} worker=#{worker.nr rescue 'unknown'}" status.success? ? logger.info(m) : logger.error(m) generate log message and put it into normal or error log depending on exit status Monday, April 22, 13
begin reap_all_workers case SIG_QUEUE.shift when nil master_sleep(sleep_time) # when ... <-‐ handling signals here end end while true stop # gracefully shutdown all workers on our way out end def reap_all_workers begin wpid, status = Process.waitpid2(-‐1, Process::WNOHANG) wpid or return if reexec_pid == wpid logger.error "reaped #{status.inspect} exec()-‐ed" self.reexec_pid = 0 self.pid = pid.chomp('.oldbin') if pid proc_name 'master' else worker = WORKERS.delete(wpid) and worker.close rescue nil m = "reaped #{status.inspect} worker=#{worker.nr rescue 'unknown'}" status.success? ? logger.info(m) : logger.error(m) end rescue Errno::ECHILD break end while true end end begin keep doing it until all exited workers are reaped rescue Errno::ECHILD break end while true Monday, April 22, 13
any thread • make sure your threads are not read-writing common data • compound operations (like ||= or +=) can be interrupted in the middle! • use Thread.current[:varname] if you need to Monday, April 22, 13
any thread • make sure your threads are not read-writing common data • compound operations (like ||= or +=) can be interrupted in the middle! • use Thread.current[:varname] if you need to Example: memoization class Client def self.channel @c ||= Channel.new end end bad class Client def self.channel Thread.current[:channel] ||= Channel.new end end better Monday, April 22, 13
• Invisible to and unmanageable by OS kernel • OS still runs a single thread by process • Concurrency, but not parallelization • Green threads are NOT UNIX Monday, April 22, 13
• Invisible to and unmanageable by OS kernel • OS still runs a single thread by process • Concurrency, but not parallelization • Green threads are NOT UNIX SUCK! Monday, April 22, 13
Allows MRI to operate with non-thread-safe C extensions • Isn’t going away any time soon Makes sure your Ruby code will NEVER run in parallel on MRI Monday, April 22, 13
worker = Proc.new do 200_000.times { Digest::SHA512.hexdigest('DEADBEEF') } end Benchmark.bm do |bb| bb.report 'single' do 5.times(&worker) end bb.report 'multi' do 5.times.map { Thread.new(&worker) }.each(&:join) end end Monday, April 22, 13
worker = Proc.new do 200_000.times { Digest::SHA512.hexdigest('DEADBEEF') } end Benchmark.bm do |bb| bb.report 'single' do 5.times(&worker) end bb.report 'multi' do 5.times.map { Thread.new(&worker) }.each(&:join) end end % ruby-‐2.0.0-‐p0 tmp.rb ... real single ... ( 1.935500) multi ... ( 2.093167) Monday, April 22, 13
worker = Proc.new do 200_000.times { Digest::SHA512.hexdigest('DEADBEEF') } end Benchmark.bm do |bb| bb.report 'single' do 5.times(&worker) end bb.report 'multi' do 5.times.map { Thread.new(&worker) }.each(&:join) end end % ruby-‐2.0.0-‐p0 tmp.rb ... real single ... ( 1.935500) multi ... ( 2.093167) GIL doesn’t allow pure Ruby code to run in parallel, thus the same time as sequential code Monday, April 22, 13
worker = Proc.new do 200_000.times { Digest::SHA512.hexdigest('DEADBEEF') } end Benchmark.bm do |bb| bb.report 'single' do 5.times(&worker) end bb.report 'multi' do 5.times.map { Thread.new(&worker) }.each(&:join) end end % ruby-‐2.0.0-‐p0 tmp.rb ... real single ... ( 1.935500) multi ... ( 2.093167) % jruby-‐1.7.3 tmp.rb ... real single ... ( 2.450000) multi ... ( 1.089000) jRuby doesn’t have GIL, so fully parallel execution Monday, April 22, 13
... real single ... ( 2.450000) multi ... ( 1.089000) why only 2x faster, if we’re running 5 threads? one thread per physical CPU core Monday, April 22, 13
with GIL - execute concurrently, but not in parallel • for parallel processing - must be split into processes, or run on non-MRI implementation • scaling limited to the number of physical cores Monday, April 22, 13
do 5.times { open 'http://google.com' } end Benchmark.bm do |bb| bb.report 'single' do 5.times(&worker) end bb.report 'multi' do 5.times.map { Thread.new(&worker) }.each(&:join) end end Monday, April 22, 13
do 5.times { open 'http://google.com' } end Benchmark.bm do |bb| bb.report 'single' do 5.times(&worker) end bb.report 'multi' do 5.times.map { Thread.new(&worker) }.each(&:join) end end % ruby-‐2.0.0-‐p0 tmp.rb ... real single ... ( 13.714725) multi ... ( 3.539165) % jruby-‐1.7.3 tmp.rb ... real single ... ( 15.273000) multi ... ( 3.820000) •not affected by GIL •scale proportionally to the number of threads Monday, April 22, 13
and build concurrent apps • Allows to work with threads as with regular app objects • Easy async calls to other threads http://celluloid.io Monday, April 22, 13
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}