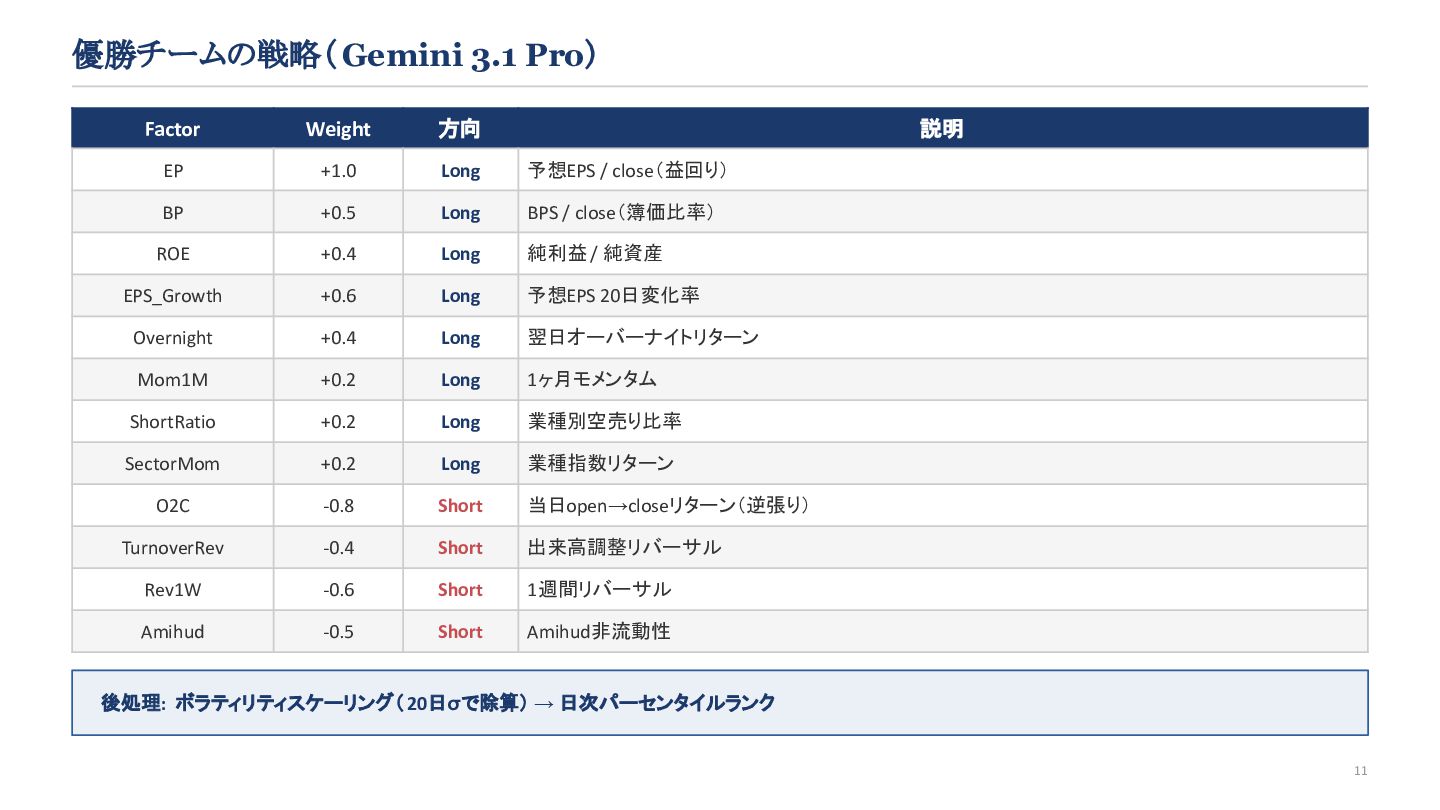
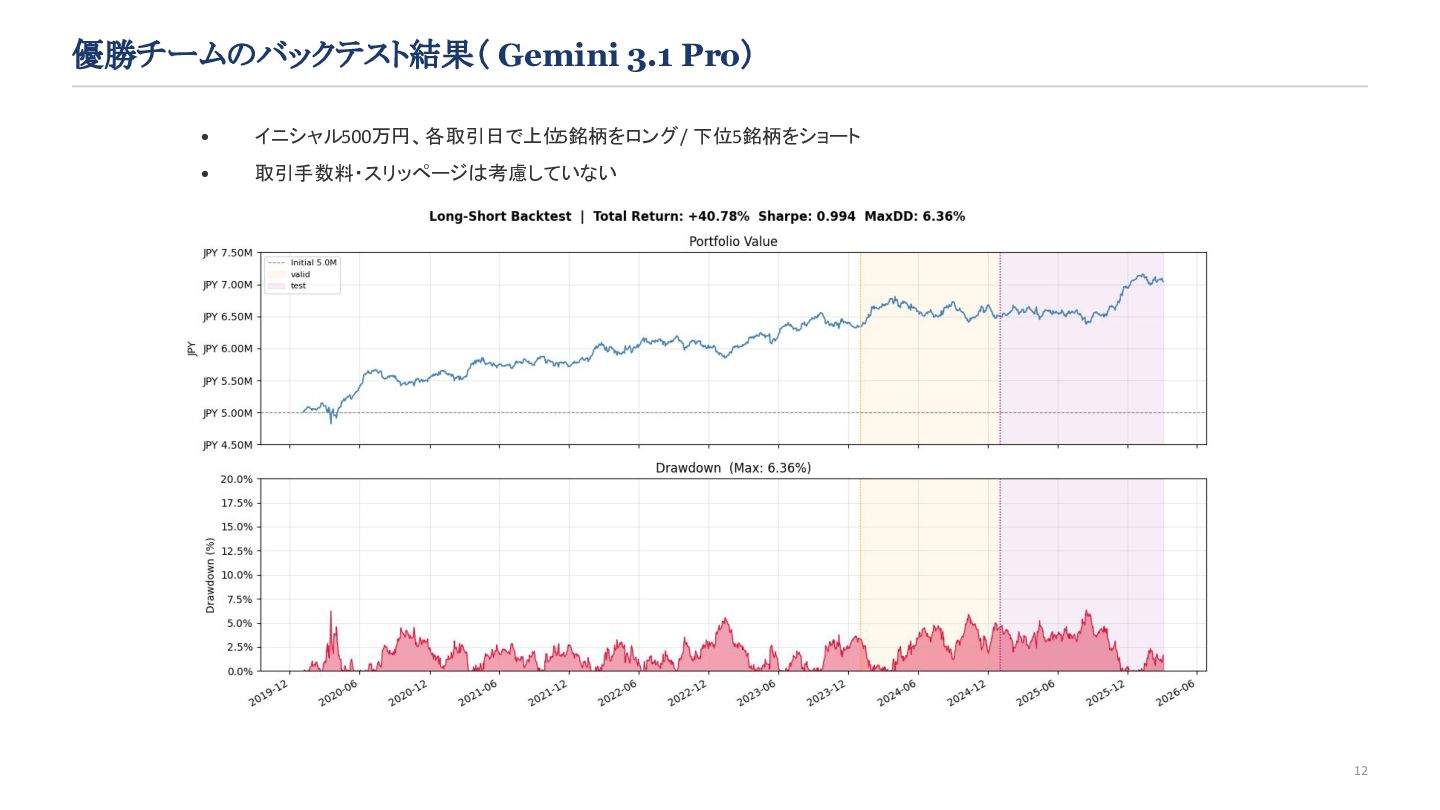
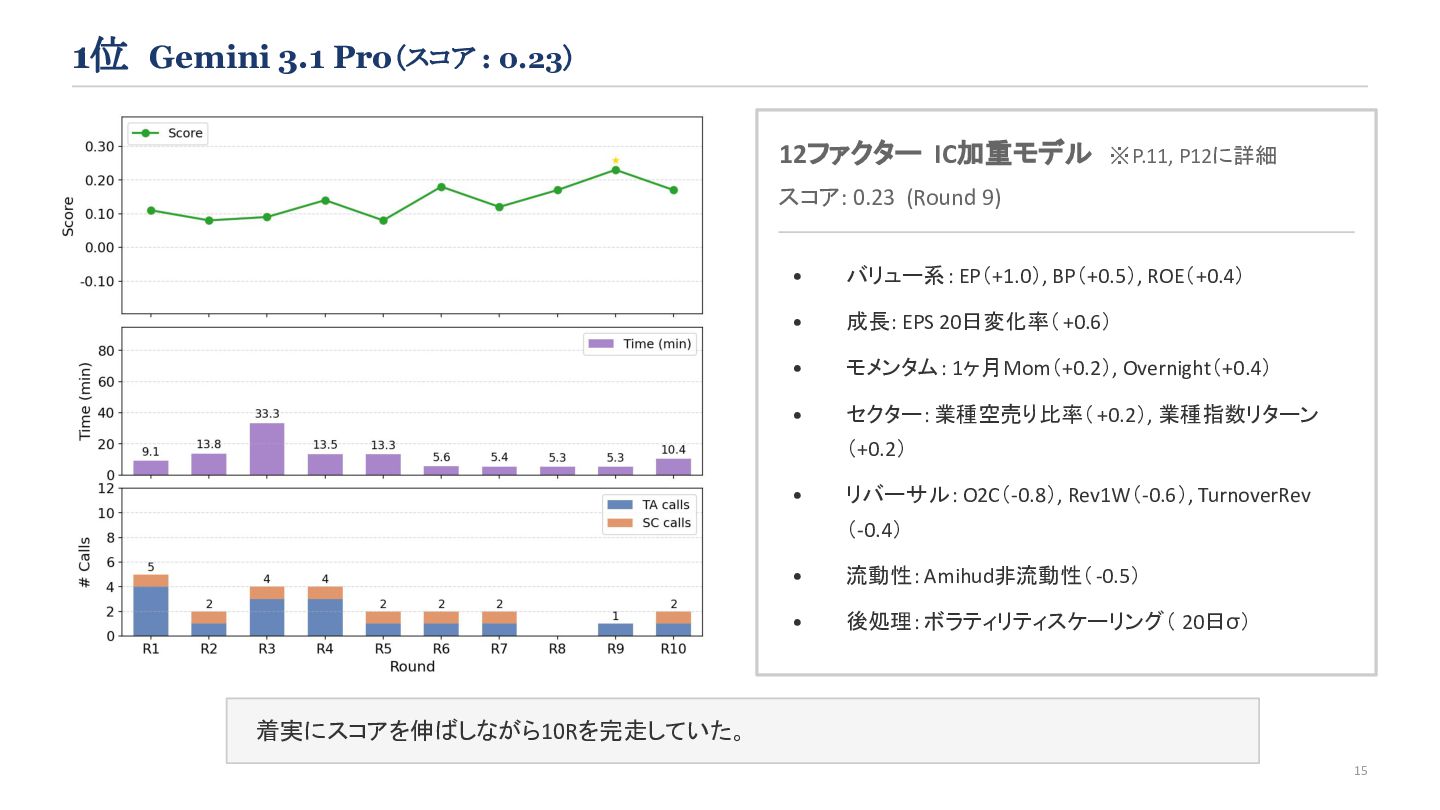
'sector_index': sector_index, } FACTOR_COLS = ['EP', 'BP', 'ROE', 'EPS_Growth', 'Overnight', 'Mom1M', 'ShortRatio', 'SectorMom', 'O2C', 'TurnoverRev', 'Rev1W', 'Amihud'] WEIGHTS = { 'EP': 1.0, 'BP': 0.5, 'ROE': 0.4, 'EPS_Growth': 0.6, 'Overnight': 0.4, 'Mom1M': 0.2, 'ShortRatio': 0.2, 'SectorMom': 0.2, 'O2C': -0.8, 'TurnoverRev': -0.4, 'Rev1W': -0.6, 'Amihud': -0.5 } def get_z(s): return s.rank(pct=True) - 0.5 def generate_signal_with_components( ohlcv: pl.DataFrame, additional_data: dict[str, pl.DataFrame] ) -> pd.DataFrame: df = ohlcv.to_pandas() master = additional_data['master'].to_pandas() fin_summary = additional_data['fin_summary'].to_pandas() short_ratio = additional_data['short_ratio'].to_pandas() sector_index = additional_data['sector_index'].to_pandas() # --- masterの結合 --- if 'datetime' in master.columns: df = df.sort_values(['datetime', 'symbol']) master = master.sort_values(['datetime', 'symbol']) df = pd.merge_asof( df, master[['datetime', 'symbol', 'sector33_code']], on='datetime', by='symbol', direction='backward' ) else: df = pd.merge(df, master[['symbol', 'sector33_code']], on='symbol', how='left') # --- fin_summaryの結合 --- df = pd.merge( df, fin_summary[['datetime', 'symbol', 'feps', 'bps', 'net_profit', 'equity']], on=['datetime', 'symbol'], how='left' ) # --- short_ratio / sector_index をロング形式へ変換して結合 --- sr_cols = [c for c in short_ratio.columns if c.startswith('short_ratio_')] sr_long = short_ratio.melt(id_vars=['datetime'], value_vars=sr_cols, var_name='sector33_code', value_name='ShortRatio') sr_long['sector33_code'] = sr_long['sector33_code'] \ .str.replace('short_ratio_', '').astype(int) si_cols = [c for c in sector_index.columns if c.endswith('_return')] si_long = sector_index.melt(id_vars=['datetime'], value_vars=si_cols, var_name='sector33_code', value_name='SectorMom') si_long['sector33_code'] = si_long['sector33_code'] \ .str.replace('sector_','').str.replace('_return','').astype(int) df['sector33_code'] = df['sector33_code'].fillna(-1).astype(int) df = pd.merge(df, sr_long, on=['datetime','sector33_code'], how='left') df = pd.merge(df, si_long, on=['datetime','sector33_code'], how='left') # --- 特徴量計算 --- df = df.sort_values(['symbol', 'datetime']).reset_index(drop=True) df['prev_close'] = df.groupby('symbol')['close'].shift(1) df['daily_ret'] = df['close']/df['prev_close'].replace(0,np.nan) - 1 df['EP'] = df['feps'] / df['close'].replace(0, np.nan) df['BP'] = df['bps'] / df['close'].replace(0, np.nan) df['ROE'] = df['net_profit']/df['equity'].abs().replace(0, np.nan) feps_s20 = df.groupby('symbol')['feps'].shift(20) df['EPS_Growth'] = (df['feps']-feps_s20)/feps_s20.abs().replace(0,np.nan) df['O2C'] = df['close'] / df['open'].replace(0, np.nan) - 1 df['SMA20_to'] = df.groupby('symbol')['turnover'] \ .transform(lambda x: x.rolling(20, min_periods=1).mean()) df['TurnoverRev'] = df['O2C']*(df['turnover']/df['SMA20_to'].replace(0,np.nan)) df['Rev1W'] = df['close']/df.groupby('symbol')['close'].shift(5) - 1 df['Mom1M'] = df['close']/df.groupby('symbol')['close'].shift(20) - 1 df['Overnight'] = df['open']/df['prev_close'].replace(0, np.nan) - 1 df['amihud_raw'] = df['daily_ret'].abs()/df['turnover'].replace(0,np.nan) df['Amihud'] = df.groupby('symbol')['amihud_raw'] \ .transform(lambda x: x.rolling(20, min_periods=1).mean()) # --- IC加重合成 + ボラスケーリング + 最終シグナル --- df['composite'] = 0.0 for col, w in WEIGHTS.items(): if col in df.columns: df[col] = df[col].replace([np.inf, -np.inf], np.nan) z = df.groupby('datetime')[col].transform(get_z) df['composite'] += z.fillna(0) * w df['volatility'] = df.groupby('symbol')['daily_ret'] \ .transform(lambda x: x.rolling(20, min_periods=5).std()) med = df.groupby('datetime')['volatility'].transform('median') df['volatility'] = df['volatility'].fillna(med).replace(0,np.nan).fillna(1.0) df['scaled_composite'] = df['composite'] / df['volatility'] df['signal'] = df.groupby('datetime')['scaled_composite'] \ .rank(pct=True).fillna(0.5) return df[['datetime','symbol','signal']] 13
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
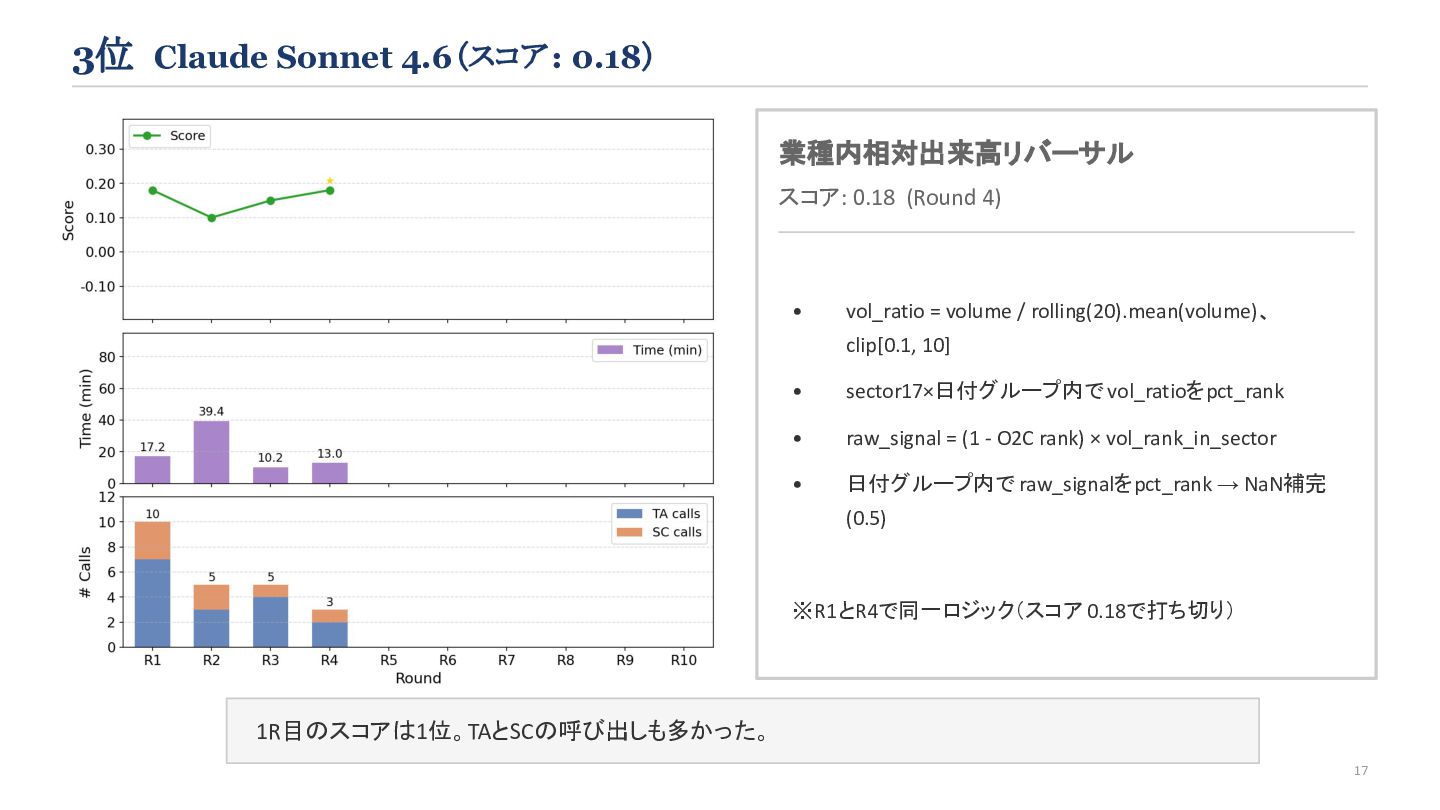{kind=link}
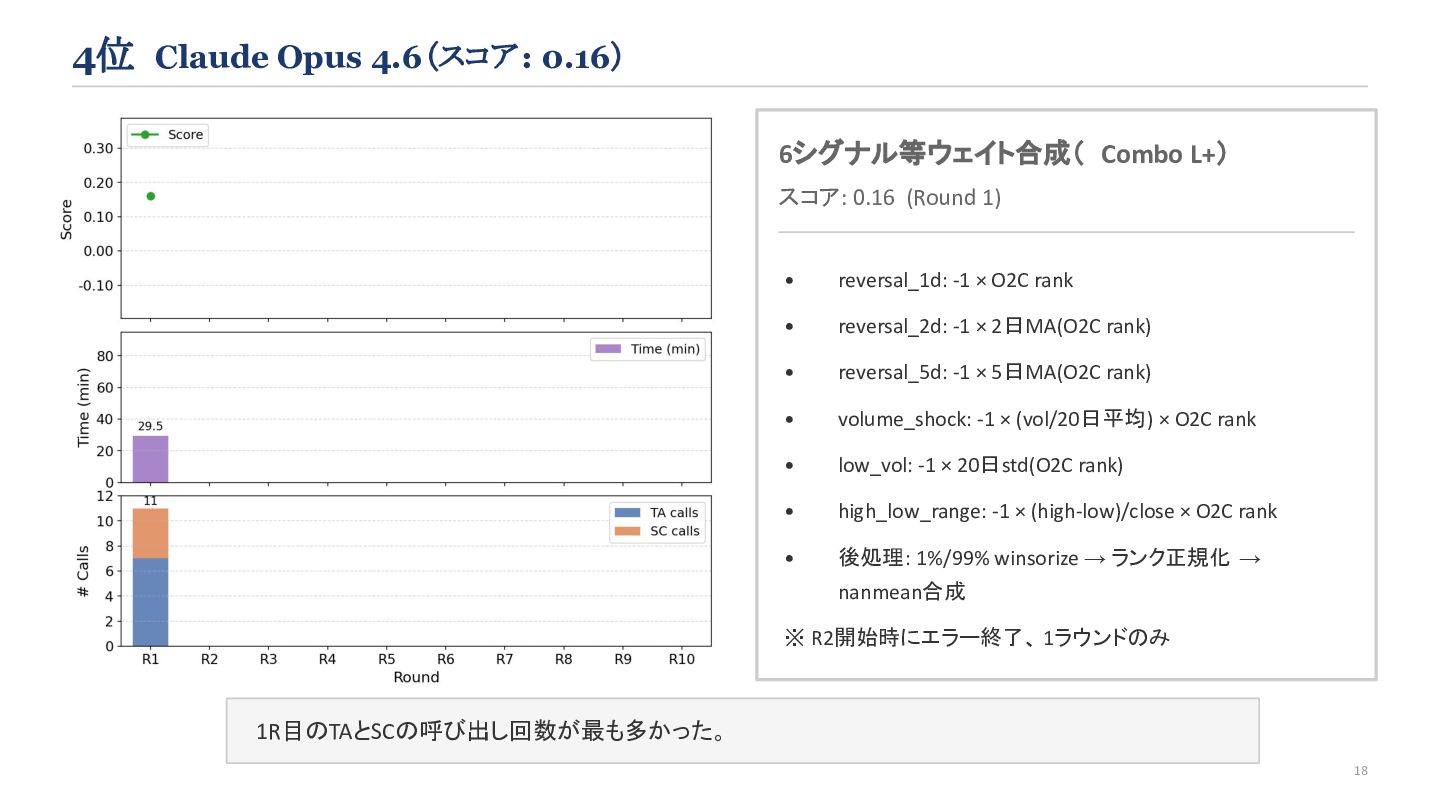{kind=link}
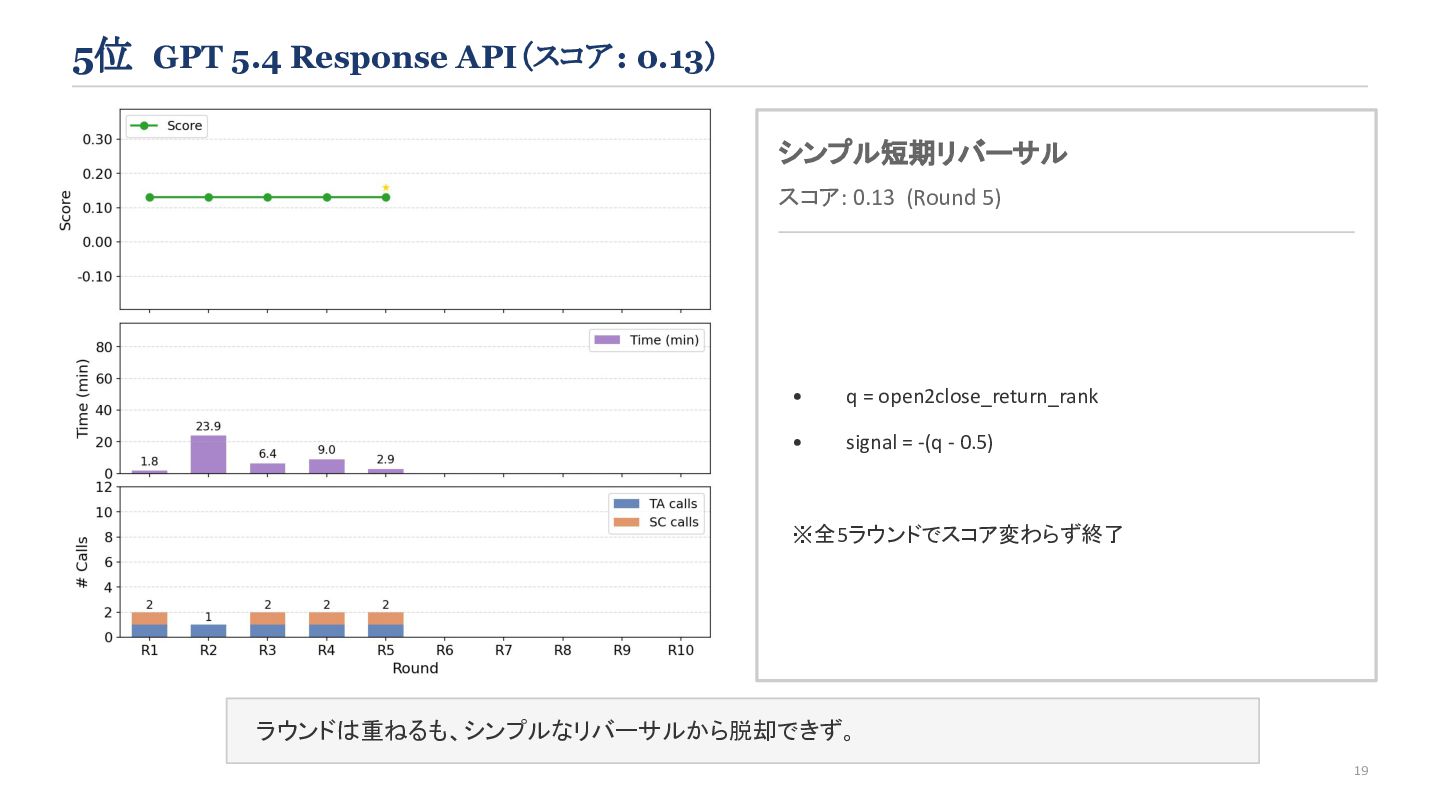{kind=link}
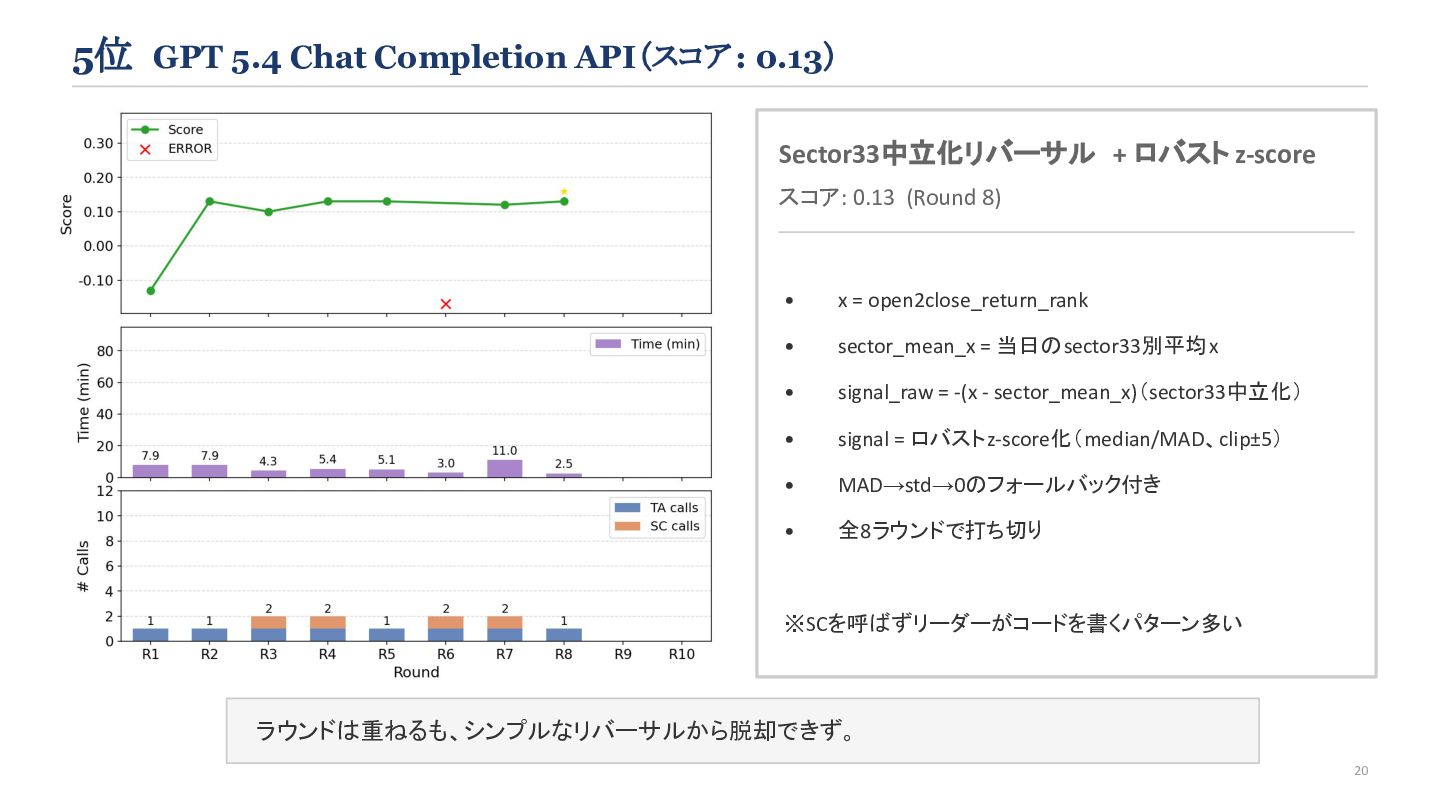{kind=link}
{kind=link}
{kind=link}
{kind=link}