Share
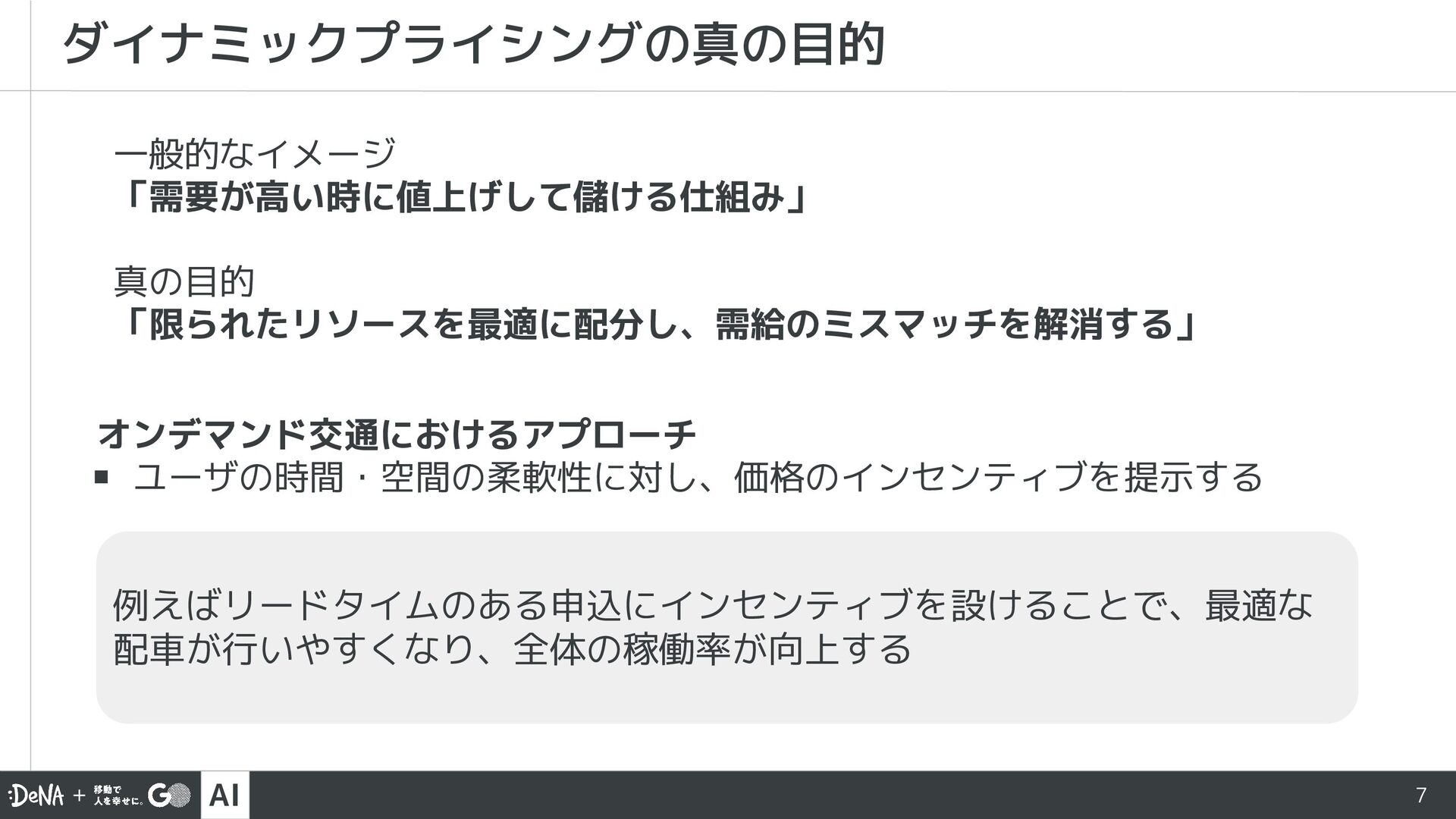
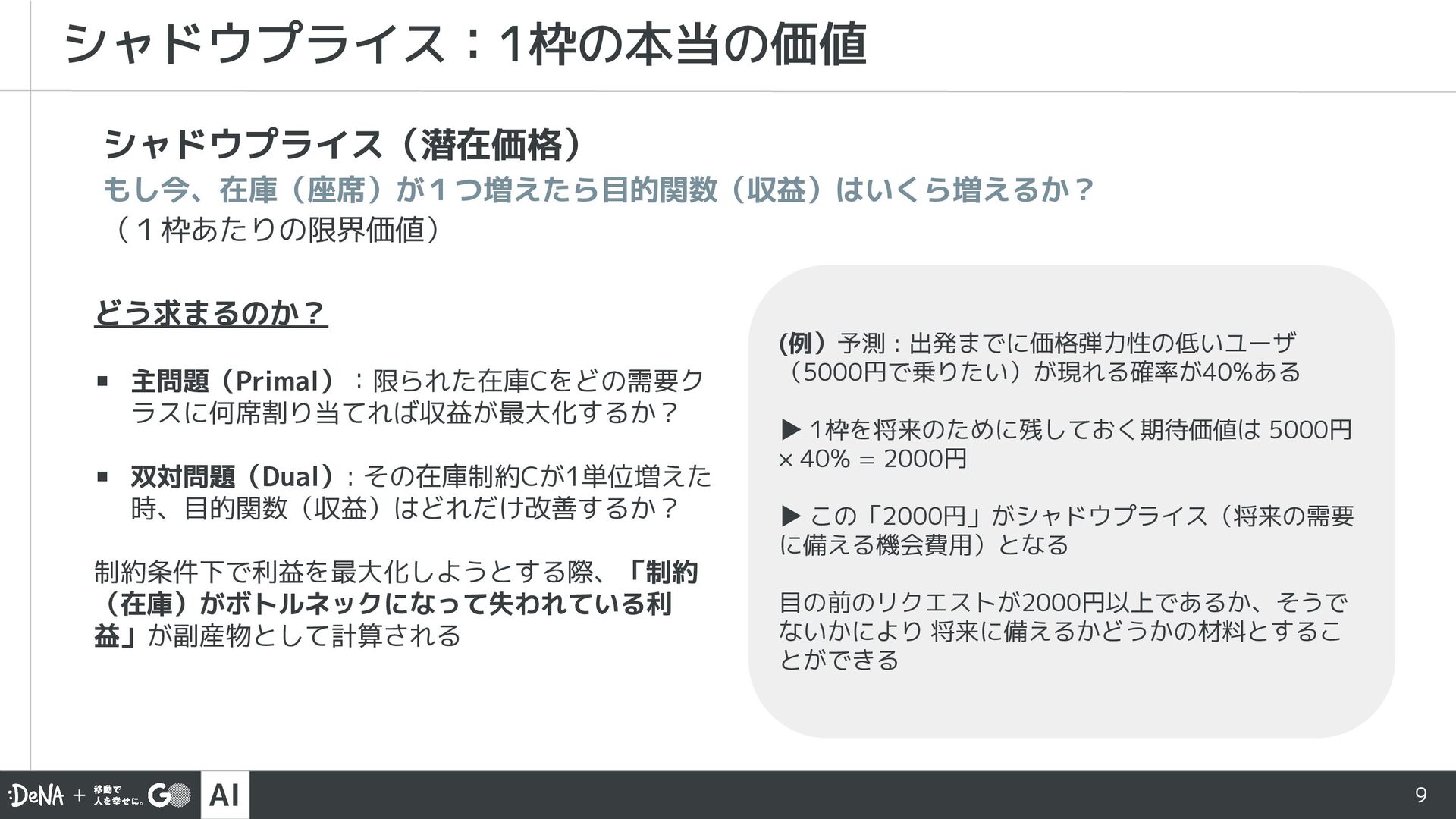
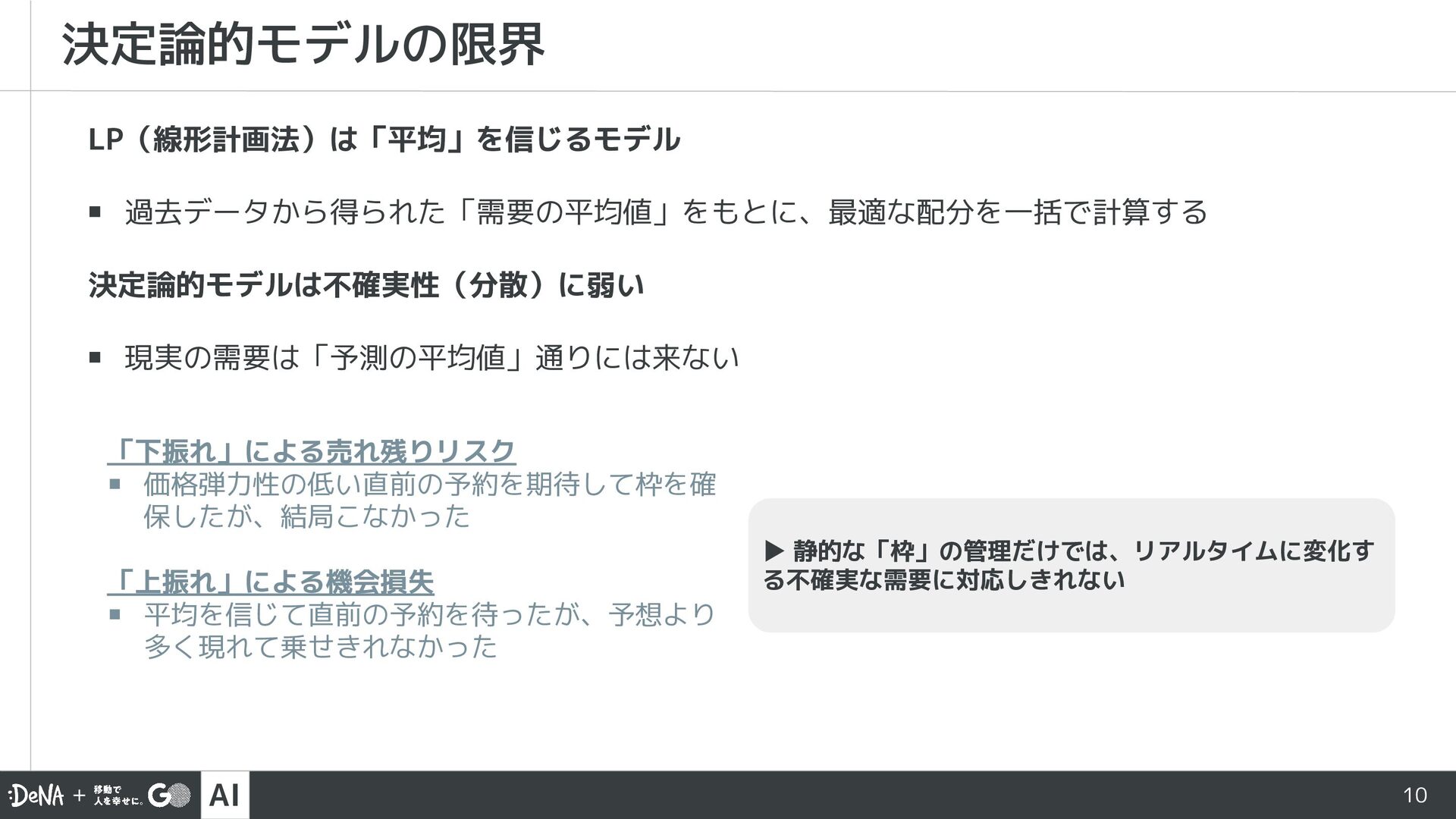
AI技術開発部の宮本が社内勉強会にて発表した資料「ちょっとだけ踏み込んだダイナミックプライシング 〜オンデマンド交通への拡張〜」を公開しました。ダイナミックプライシングの基本と相乗り問題に対する拡張をまとめています。ぜひご覧ください。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![AI LP(線形計画法)による最適化 8 不確実な需要のもとで、期待総収益関数E[R(I)]を最大化するIを探す 予算重視の予約、時間重視の予約が混在すると 収益関数は凹凸のある複雑な形状となる ▶ 第1項 : 「早割」のユーザをどこまで受け入れるか(上限I)](https://files.speakerdeck.com/presentations/3589bce81bed4c0986c316f5a8c427f1/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
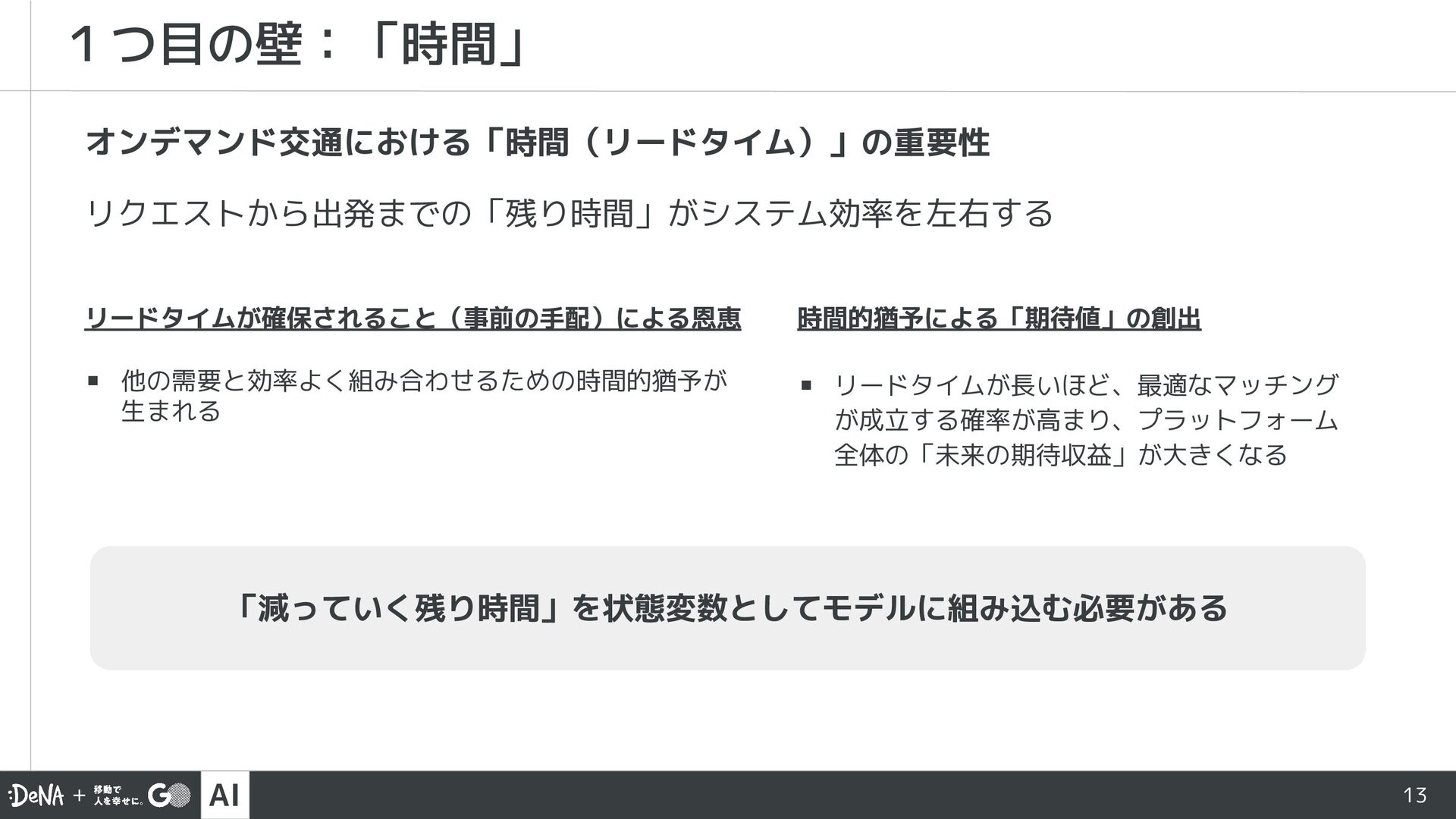{kind=link}
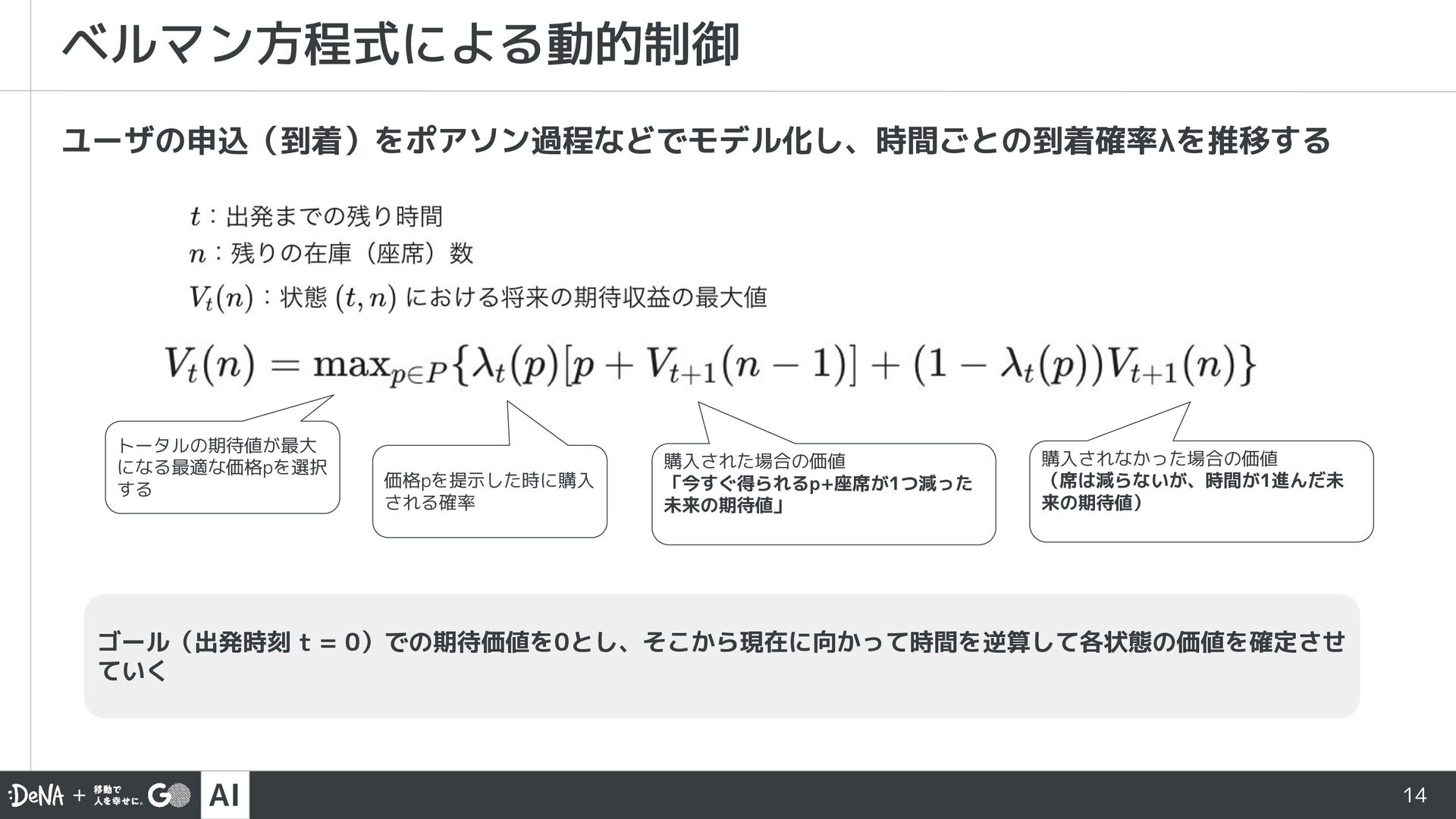{kind=link}
![AI ベルマン方程式の本質 15 ベルマン方程式を簡略化 現在の価値 = [今すぐ得られる報酬] + [未来の期待値] ▪](https://files.speakerdeck.com/presentations/3589bce81bed4c0986c316f5a8c427f1/slide_14.jpg){kind=link}
{kind=link}
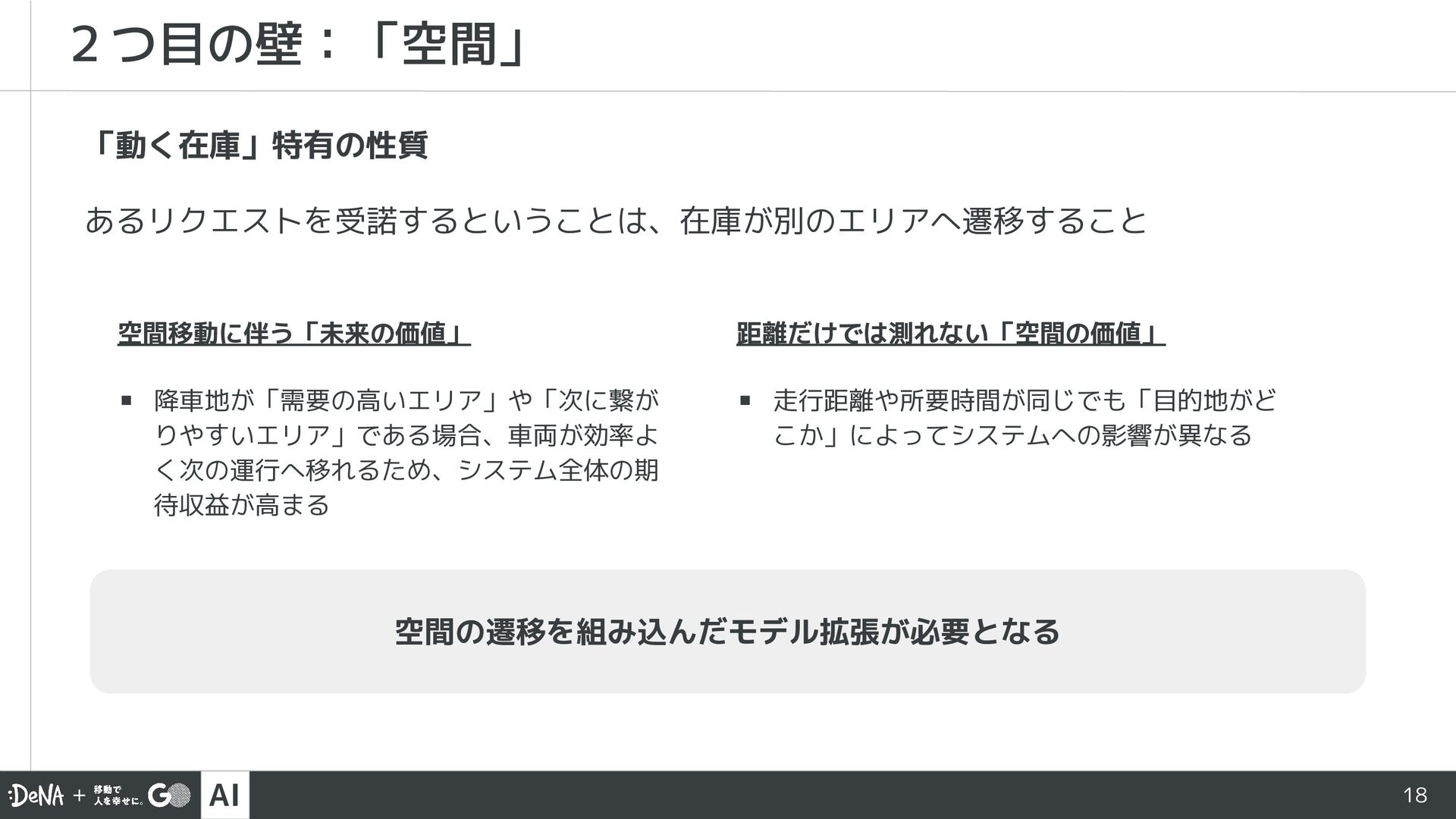
{kind=link}
{kind=link}
{kind=link}
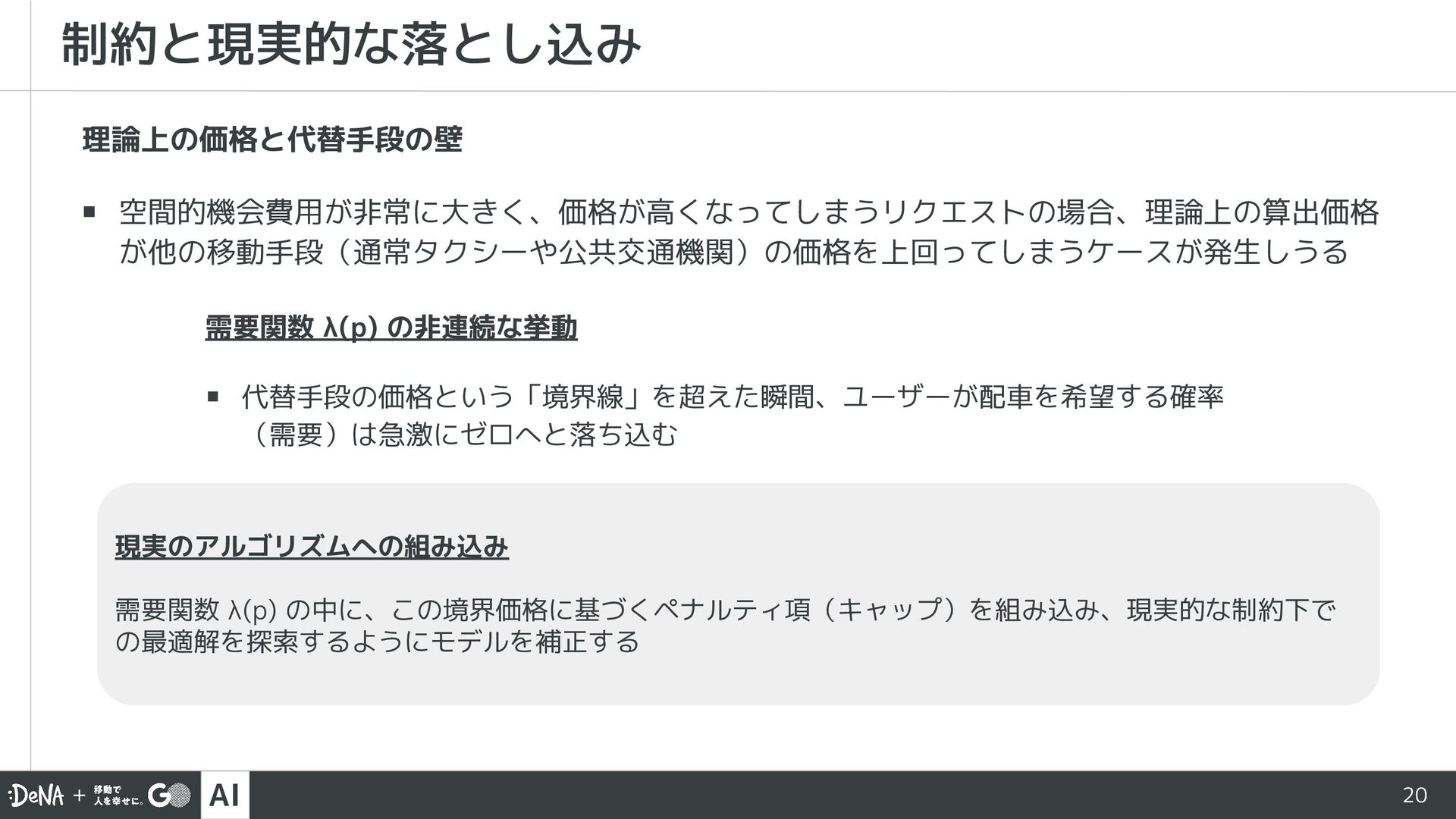{kind=link}
{kind=link}
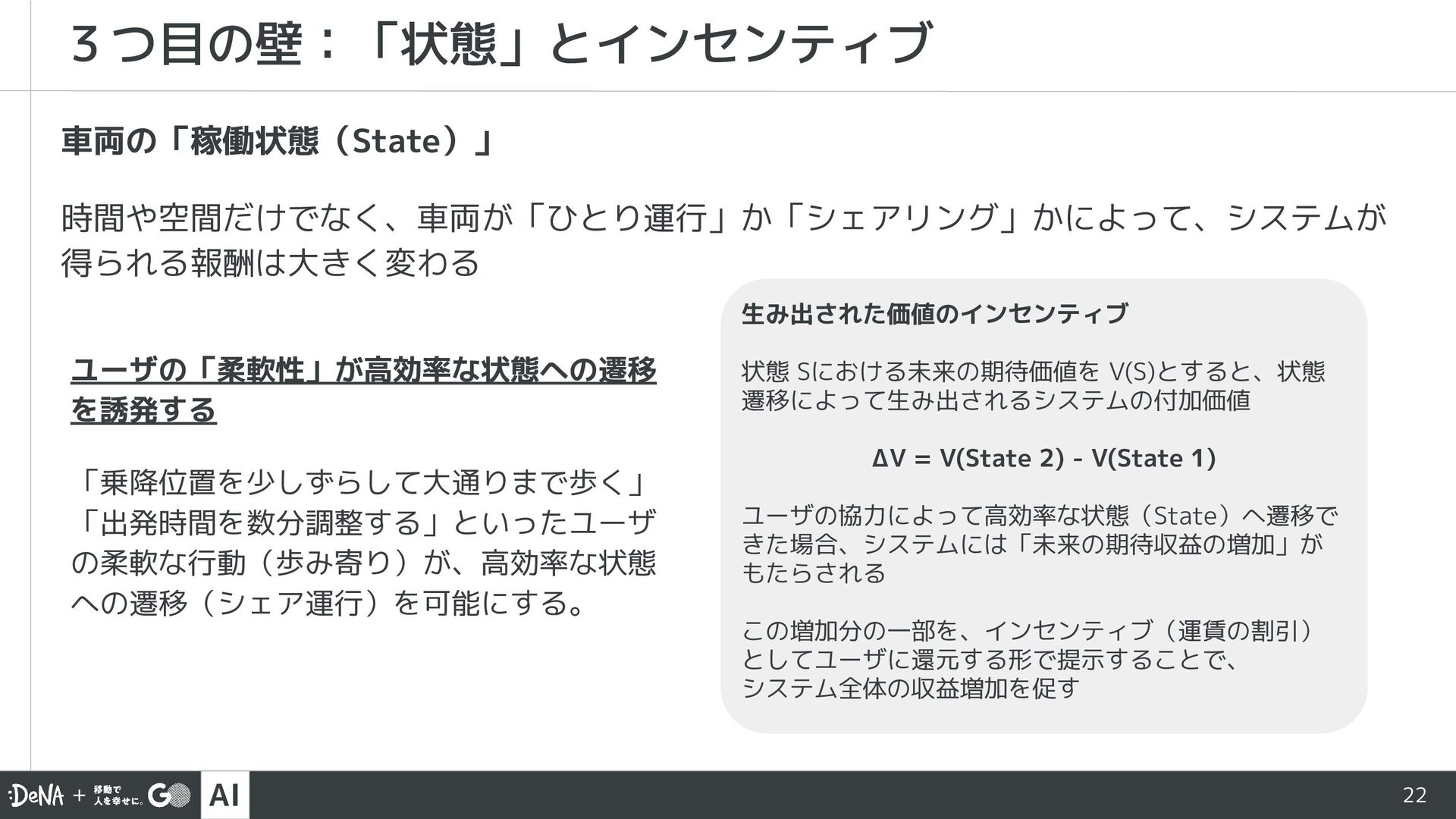{kind=link}
{kind=link}
{kind=link}
{kind=link}