happen during candidate’s test session. New test cannot be started even 2 hours before planned maintenance. Still need to do regular system patching, configuration changes, …
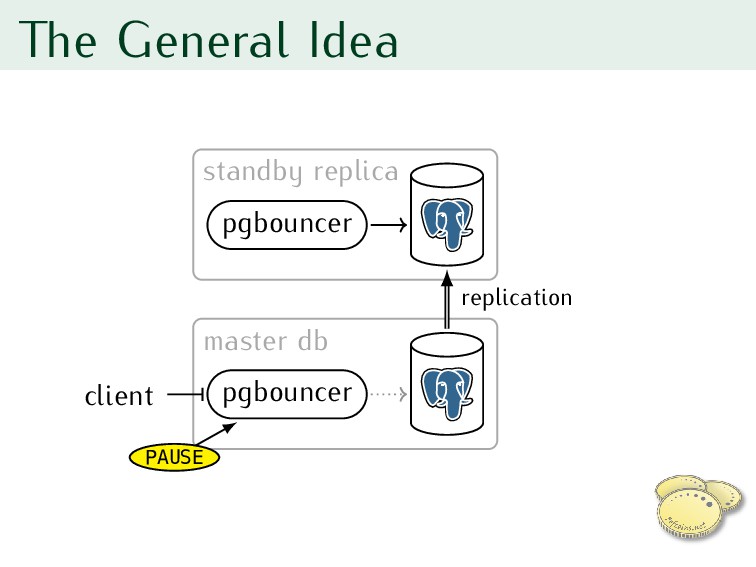
servers, first waiting for all current queries (transactions / sessions) to complete • Returns after servers have been safely disconnected • New client connections will wait until RESUME is called https://pgbouncer.github.io/usage.html
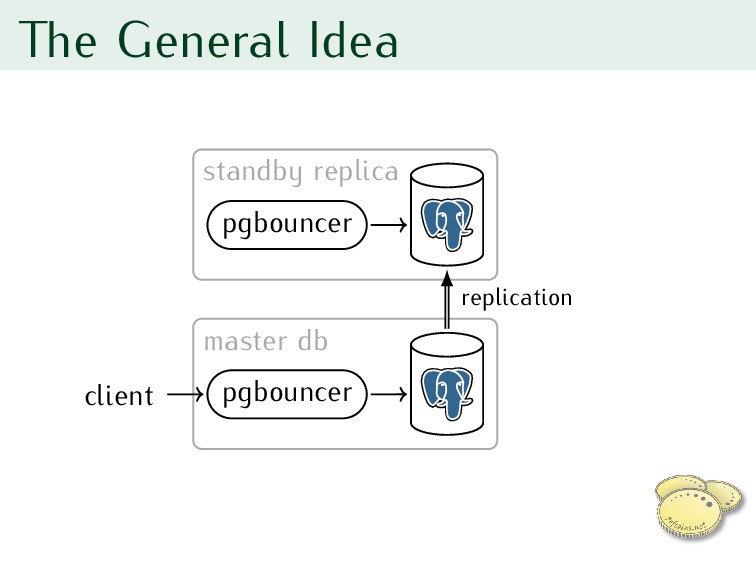
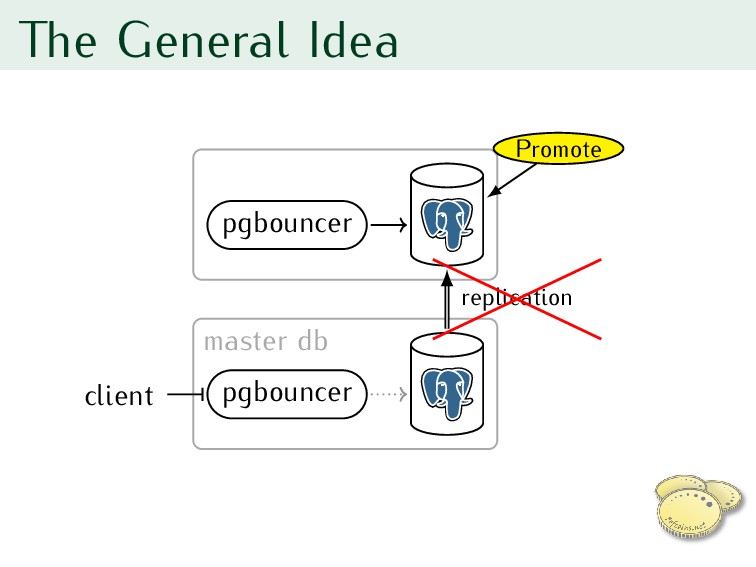
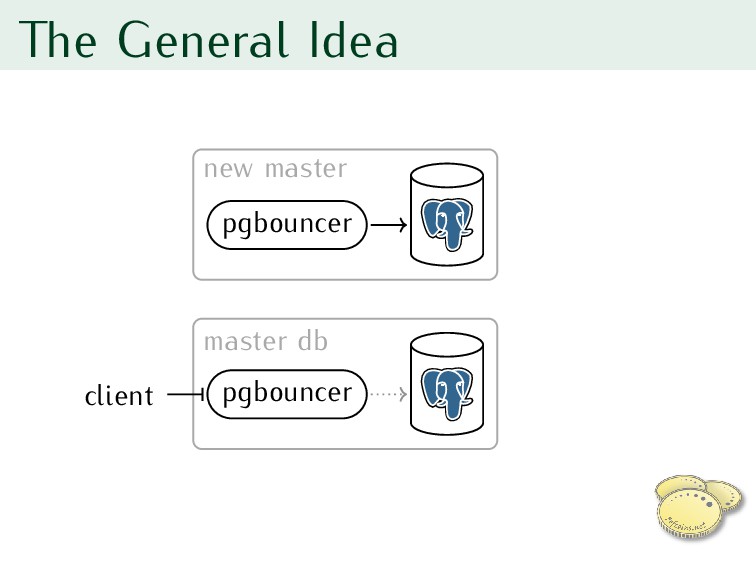
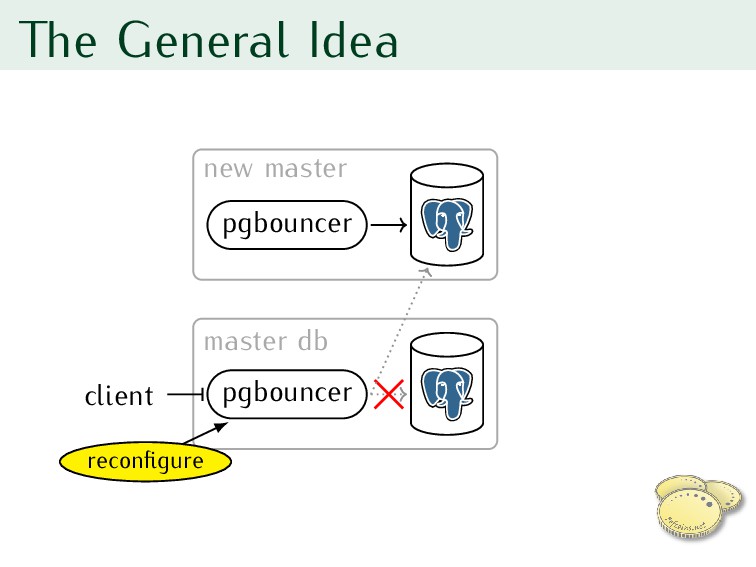
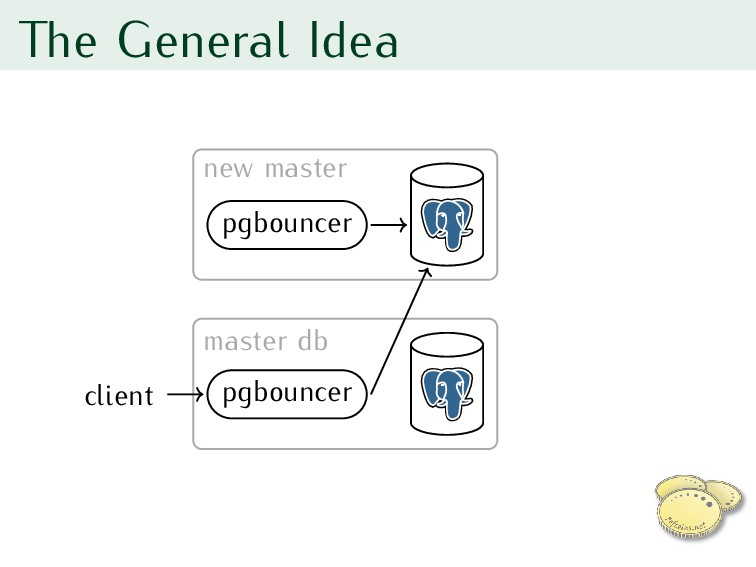
standby replica to new master 3. Reconfigure pgbouncer for new master 4. RESUME pgbouncer 5. Reconfigure clients one by one to use new server’s pgbouncer
client holds transaction • Replica’s lagging, promoted too early • Replica’s not even a replica • New server broken or misconfigured • Failure leaves pgbouncer paused Too long PAUSE is as bad as “real” downtime!
With 5s timeout, catching errors, try: 2.1 PAUSE clients (2s timeout) 2.2 Wait for replica to match master WAL position 2.3 Promote replica, wait until writable 2.4 Reconfigure pgbouncer to use replica 3. Automatically RESUME clients on success or failure (worst case: they continue on the old server)
clients 2. With 5s timeout, catching errors, try: 2.1 PAUSE clients (2s timeout) 2.2 Wait for replica to match master WAL position 2.3 Promote replica, wait until writable 2.4 Reconfigure pgbouncer to use replica 3. Automatically RESUME clients on success or failure (worst case: they continue on the old server)
database processes to review • Open and test SSH to replica • Open and test admin connection to pgbouncer and both PostgreSQLs • Test replica’s pgbouncer • Check that replica is connected to master and doesn’t lag
for that, don’t let that affect the user. • Look before you leap. The earlier you fail, the easier it is to clean up. Don’t even start if you see you won’t finish.
![Downtimeless PostgreSQL server replacement Maciej Pasternacki <[email protected]> Warsaw PostgreSQL User](https://files.speakerdeck.com/presentations/dd65d85909a2430ca31843e9303bfc39/slide_0.jpg){kind=link}
{kind=link}
![Codility […] helps tech recruiters and hiring managers assess their](https://files.speakerdeck.com/presentations/dd65d85909a2430ca31843e9303bfc39/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}