Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
アクセスピークを制するオートスケール再設計: 障害を乗り越えKEDAで実現したリソース管理の最適化
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
M-Yamashita
July 12, 2025
Technology
3.5k
3
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
アクセスピークを制するオートスケール再設計: 障害を乗り越えKEDAで実現したリソース管理の最適化
SRE NEXT 2025での登壇資料です。
https://sre-next.dev/2025/
M-Yamashita
July 12, 2025
More Decks by M-Yamashita
See All by M-Yamashita
ツールを超えた「共通言語」へ 開発とSREがDatadogを囲んで信頼を育てる 継続的かつ地道な実践
myamashii
0
380
継続的な活動で築く地方エンジニアの道
myamashii
2
750
テストの高速化と品質保証の第一歩 GitHub ActionsとRSpecの基本入門
myamashii
1
720
Contributionとカンファレンス登壇への 背中を押して頂いた方々へ
myamashii
1
2k
はてなブログ作成から投稿までをGitHub Actionsで自動化する
myamashii
3
1.3k
GitHub ActionsでZennの記事を限定公開する
myamashii
3
1.1k
Webサービス開発者としてスタートしてからOSS Contributionまでの道のり
myamashii
0
860
Fukuoka.rb 2020年度活動報告
myamashii
0
870
OSS Contributionから感じたこと
myamashii
0
490
Other Decks in Technology
See All in Technology
事業価値を⽣み出すSREへ SREが担うべき意思決定の5層
kenta_hi
2
2.2k
脱金融のフューチャー・デザイン / Future Design Beyond Finance
ks91
PRO
0
140
ループエンジニアリングでE2Eテストを実践
noriyukitakei
0
310
証券システムを10年Scalaで作り続けるということ - 関数型まつり2026
krrrr38
3
750
AWS Summit の片隅で、体育座りしながらコミュニティがにぎわう理由を考えた
k_adachi_01
2
360
「ちゃんとやっている」は独りよがりだった ― 不安に寄り添うインシデント対応へ / Towards incident response that addresses anxieties
chmikata
1
3.8k
AI Driven AI Governance
pict3
0
260
AIDLC_ヤフーショッピングの取り組み
lycorptech_jp
PRO
0
570
Baseline対応のDOMの型定義を作った
uhyo
3
720
Claude Codeとハーネスについて考えてみる
oikon48
18
8.8k
初めてのDatabricks勉強会
taka_aki
2
240
Text-to-SQLをAgentCoreで実現し、生成されるSQLの精度を定量的に評価する
yakumo
2
680
Featured
See All Featured
ReactJS: Keep Simple. Everything can be a component!
pedronauck
666
130k
Why Your Marketing Sucks and What You Can Do About It - Sophie Logan
marketingsoph
0
190
AI Search: Implications for SEO and How to Move Forward - #ShenzhenSEOConference
aleyda
1
1.3k
From Legacy to Launchpad: Building Startup-Ready Communities
dugsong
0
250
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
Ruling the World: When Life Gets Gamed
codingconduct
0
280
DBのスキルで生き残る技術 - AI時代におけるテーブル設計の勘所
soudai
PRO
67
56k
Navigating the moral maze — ethical principles for Al-driven product design
skipperchong
2
410
WENDY [Excerpt]
tessaabrams
11
38k
Marketing Yourself as an Engineer | Alaka | Gurzu
gurzu
0
260
How To Stay Up To Date on Web Technology
chriscoyier
790
250k
How to Get Subject Matter Experts Bought In and Actively Contributing to SEO & PR Initiatives.
livdayseo
0
150
Transcript
アクセスピークを制するオートスケール再設計: 障害を乗り越えKEDAで実現したリソース管理の最適化
自己紹介 山下 雅人 クラウド経費・クラウド債務支払 SRE チームリーダー バックエンドエンジニアとSREの 経験を活かして活動中 Kaigi on
Rails Organizer
今日話すこと AWS移行プロジェクト - オンプレミスからクラウドへ 障害と課題発見 - アクセスピーク時のオートスケール問題 KEDA導入 - リクエスト数に応じたスケーリング
データ活用最適化 - 適切なレプリカ数の導出
AWS環境への 移行プロジェクト
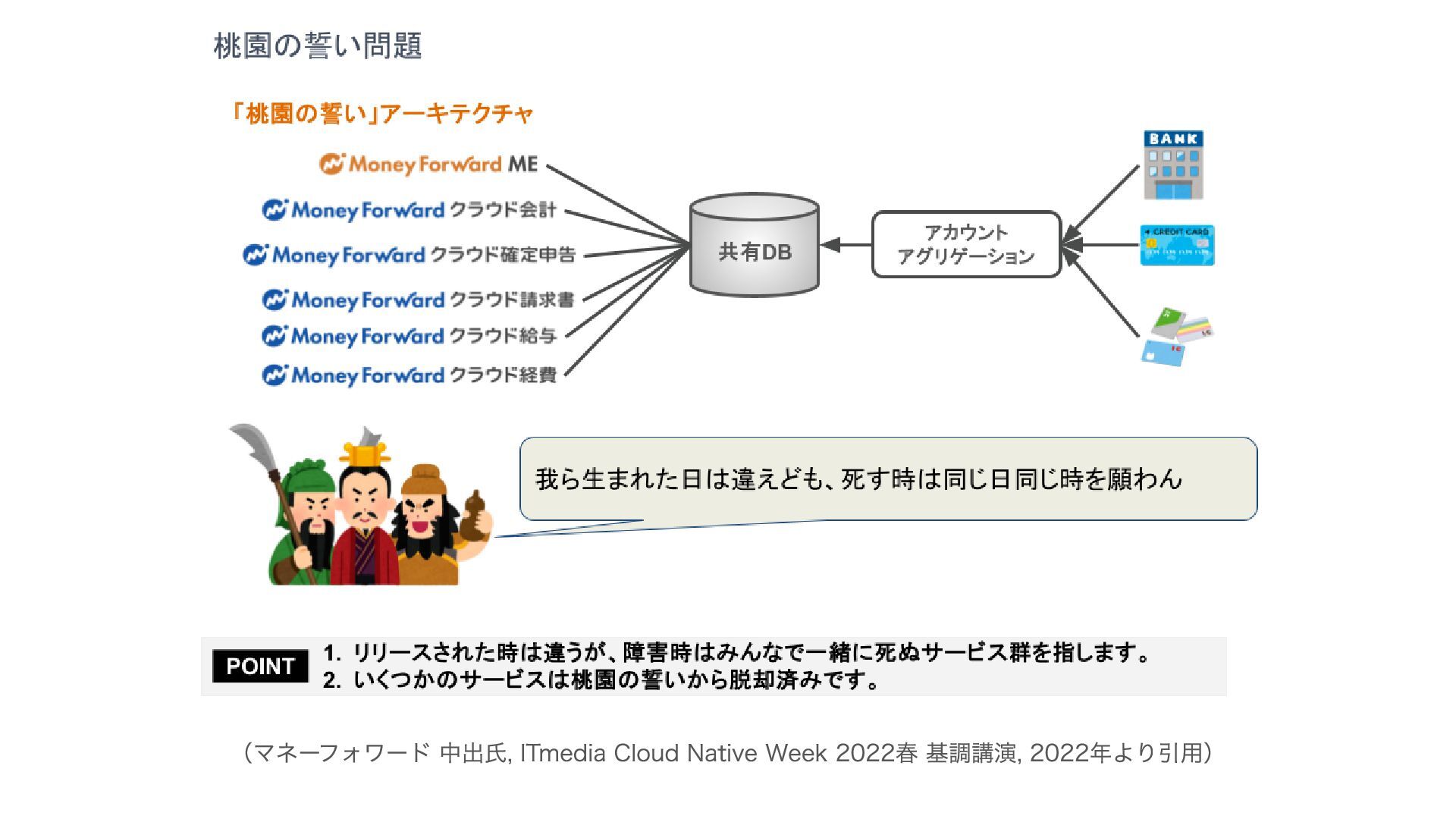
過去のマネーフォワードの アーキテクチャについて
(マネーフォワード 中出氏, ITmedia Cloud Native Week 2022春 基調講演, 2022年より引用)
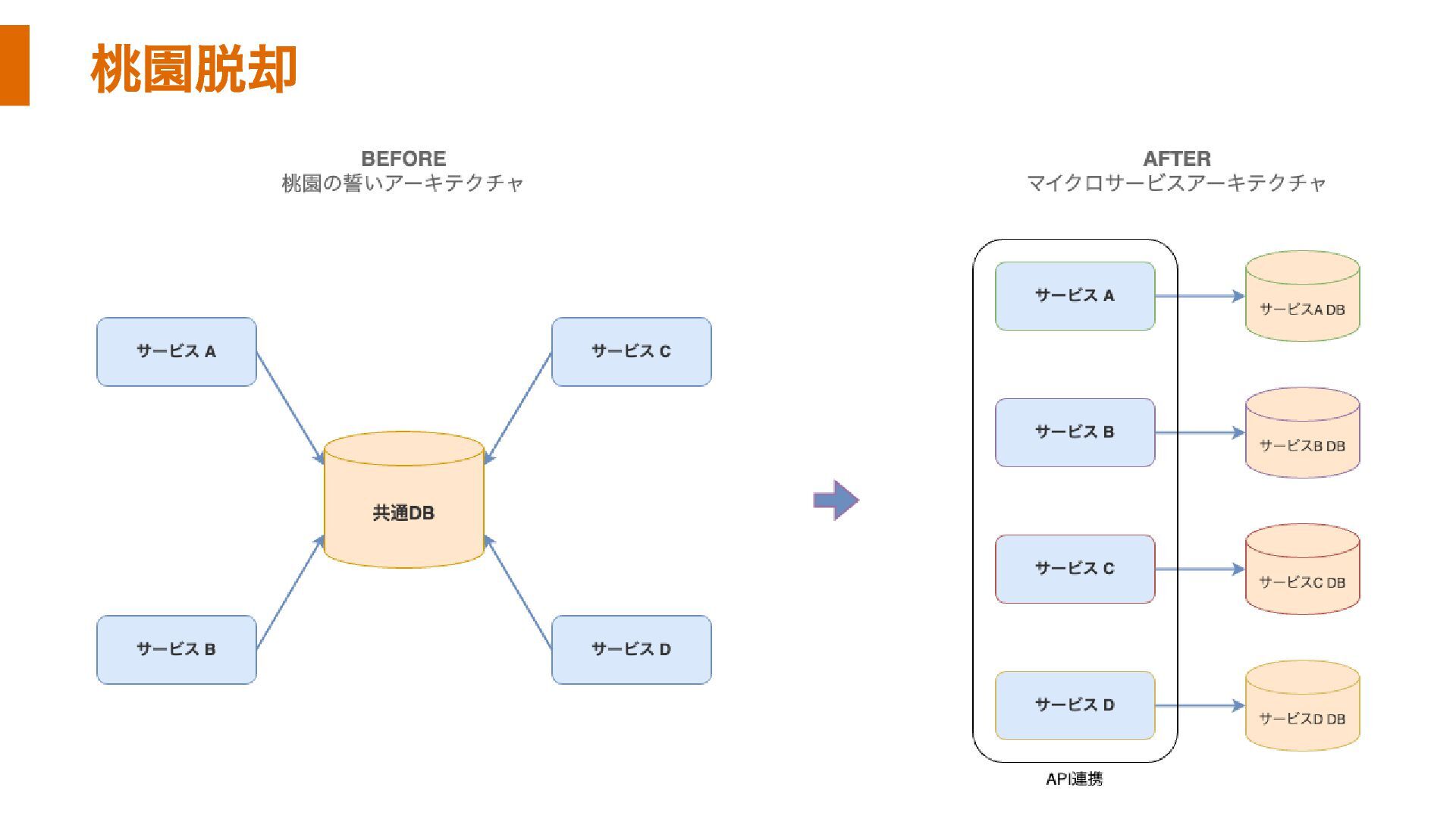
桃園脱却
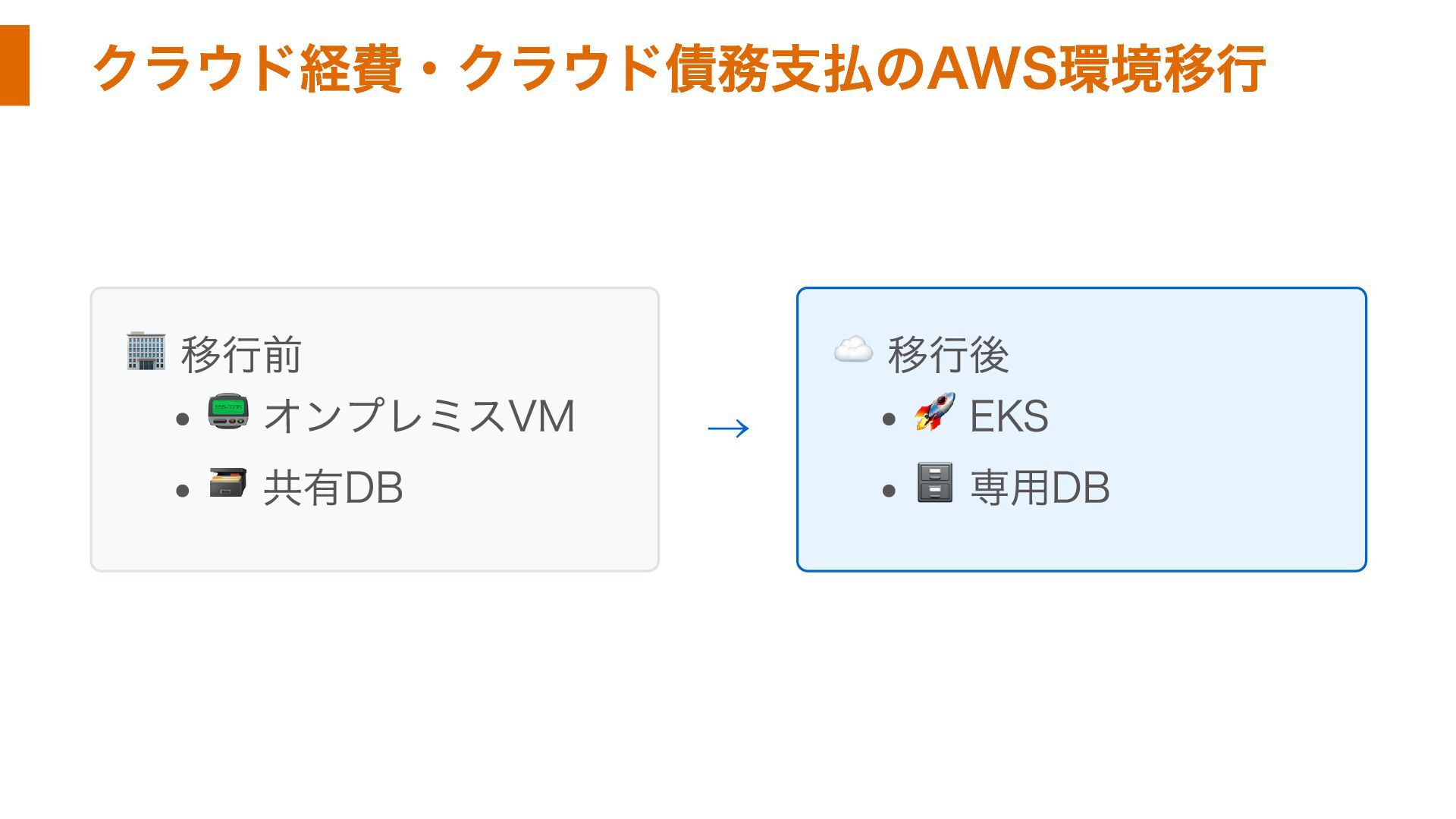
クラウド経費・クラウド債務支払のAWS環境移行 🏢 移行前 📟 オンプレミスVM 🗃️ 共有DB → ☁️ 移行後
🚀 EKS 🗄️ 専用DB
AWS環境における オートスケール設計
そもそもなぜオートスケールが必要なのか ビジネス面から考えてみる
AIの力を借りて考える Illustration © unDraw.co
ビジネス面から見たオートスケールの必要性 機会損失の防止と顧客体験の最大化 キャンペーンや突発的なアクセスピーク時でもサービスを 安定稼働させることで、販売機会の損失を防ぐ インフラコストの最適化 アクセスピーク時以外はリソースを自動で縮小し、過剰な リソース確保によるコストを削減 事業成長への迅速な対応 サービスの利用者増加や事業拡大に伴い、将来的に増大する アクセスピークにも柔軟に対応
ビジネスの成長をITインフラが支えられるようにする
クラウド経費・クラウド債務支払における アクセスピークとは?
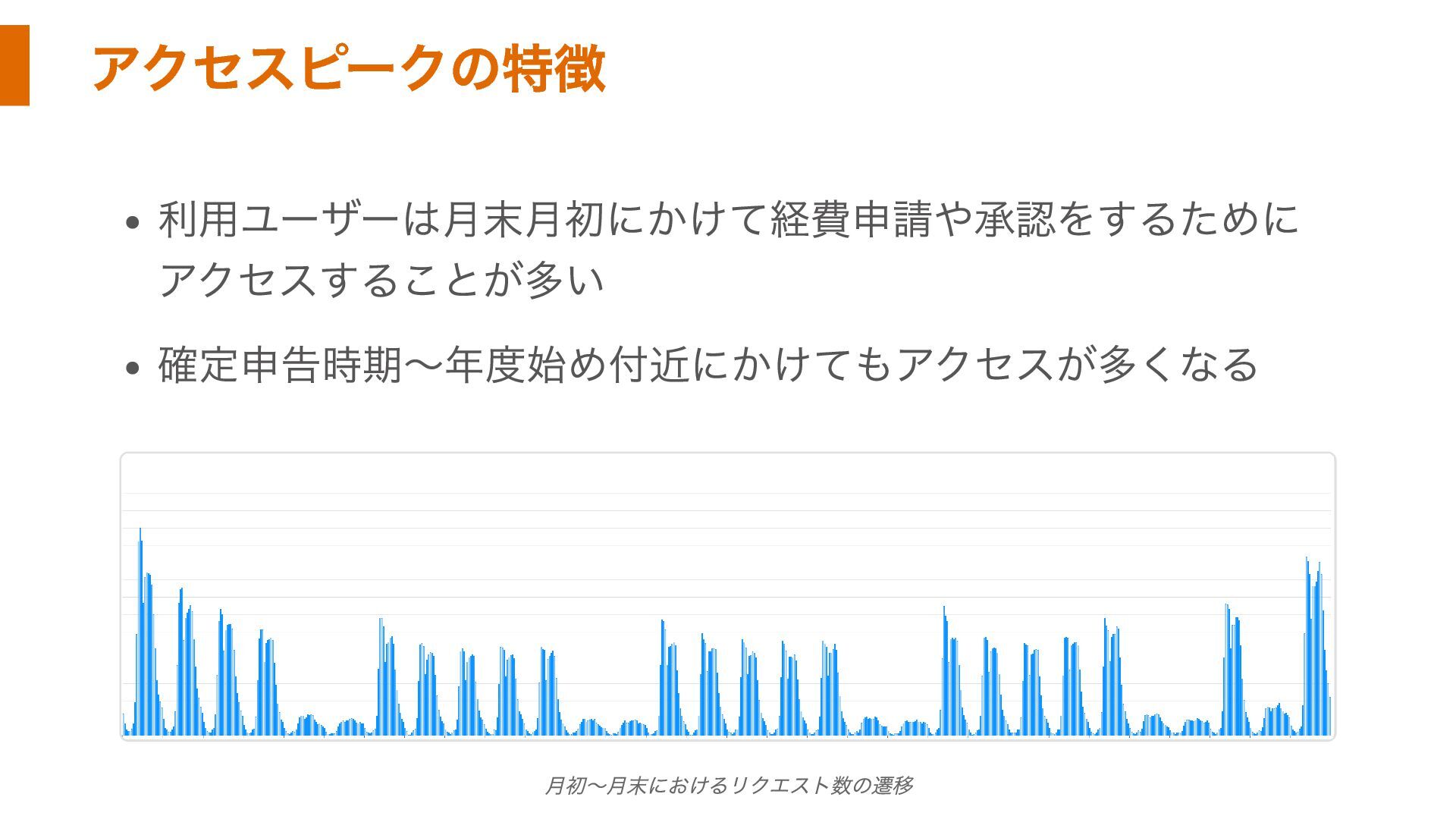
アクセスピークの特徴 利用ユーザーは月末月初にかけて経費申請や承認をするために アクセスすることが多い 確定申告時期〜年度始め付近にかけてもアクセスが多くなる 月初〜月末におけるリクエスト数の遷移
アクセスピーク時におけるオートスケール設計 📊 分析対象 メトリクス: CPU使用率、メモリ使用量 観察期間: 1日および1週間 目的: リクエスト数との相関関係を調査 ⚙️
設計方針 リクエスト増加パターンを分析し、適切な閾値を設定する
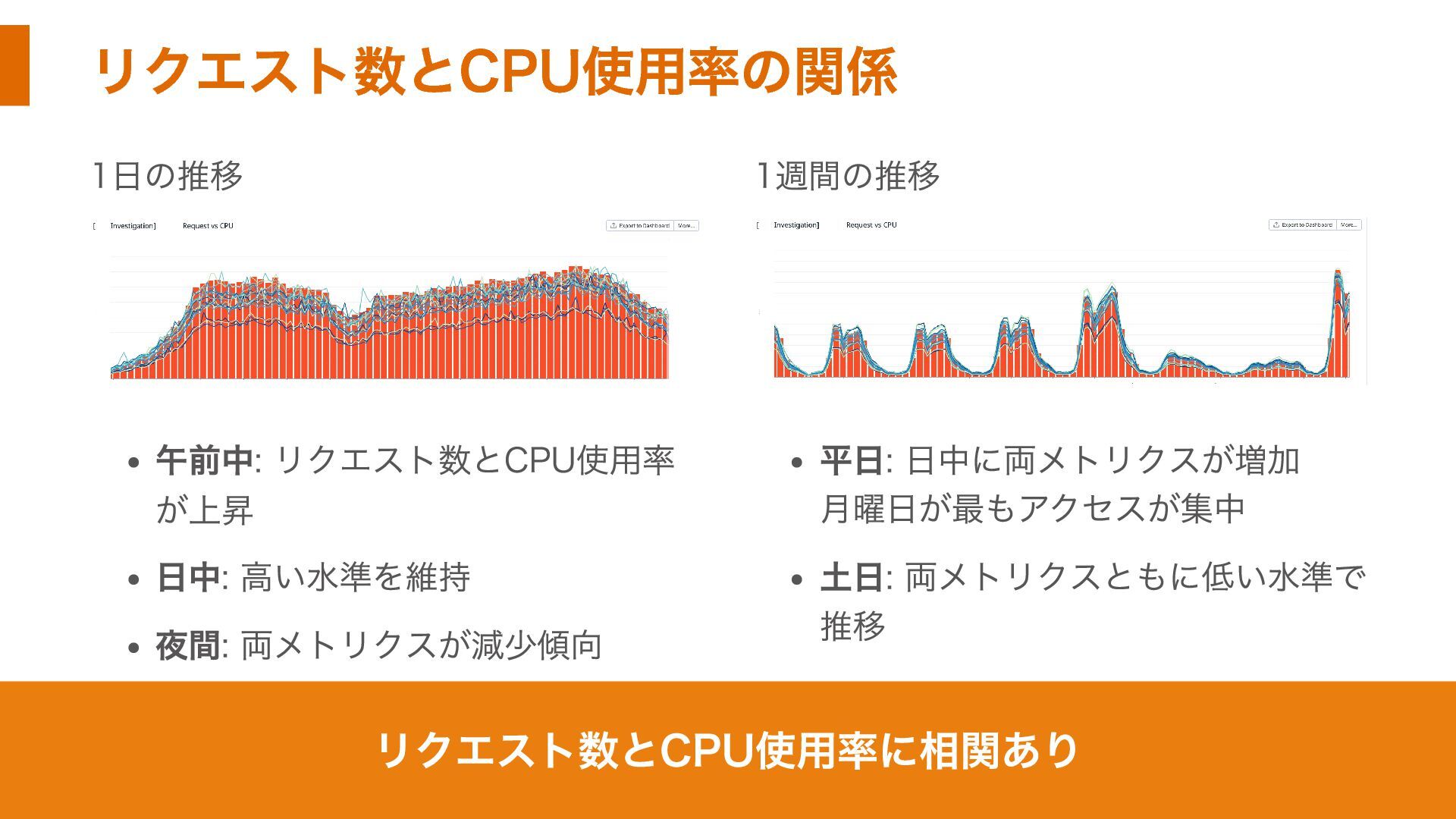
リクエスト数とCPU使用率の関係 1日の推移 午前中: リクエスト数とCPU使用率 が上昇 日中: 高い水準を維持 夜間: 両メトリクスが減少傾向 1週間の推移
平日: 日中に両メトリクスが増加 月曜日が最もアクセスが集中 土日: 両メトリクスともに低い水準で 推移 リクエスト数とCPU使用率に相関あり
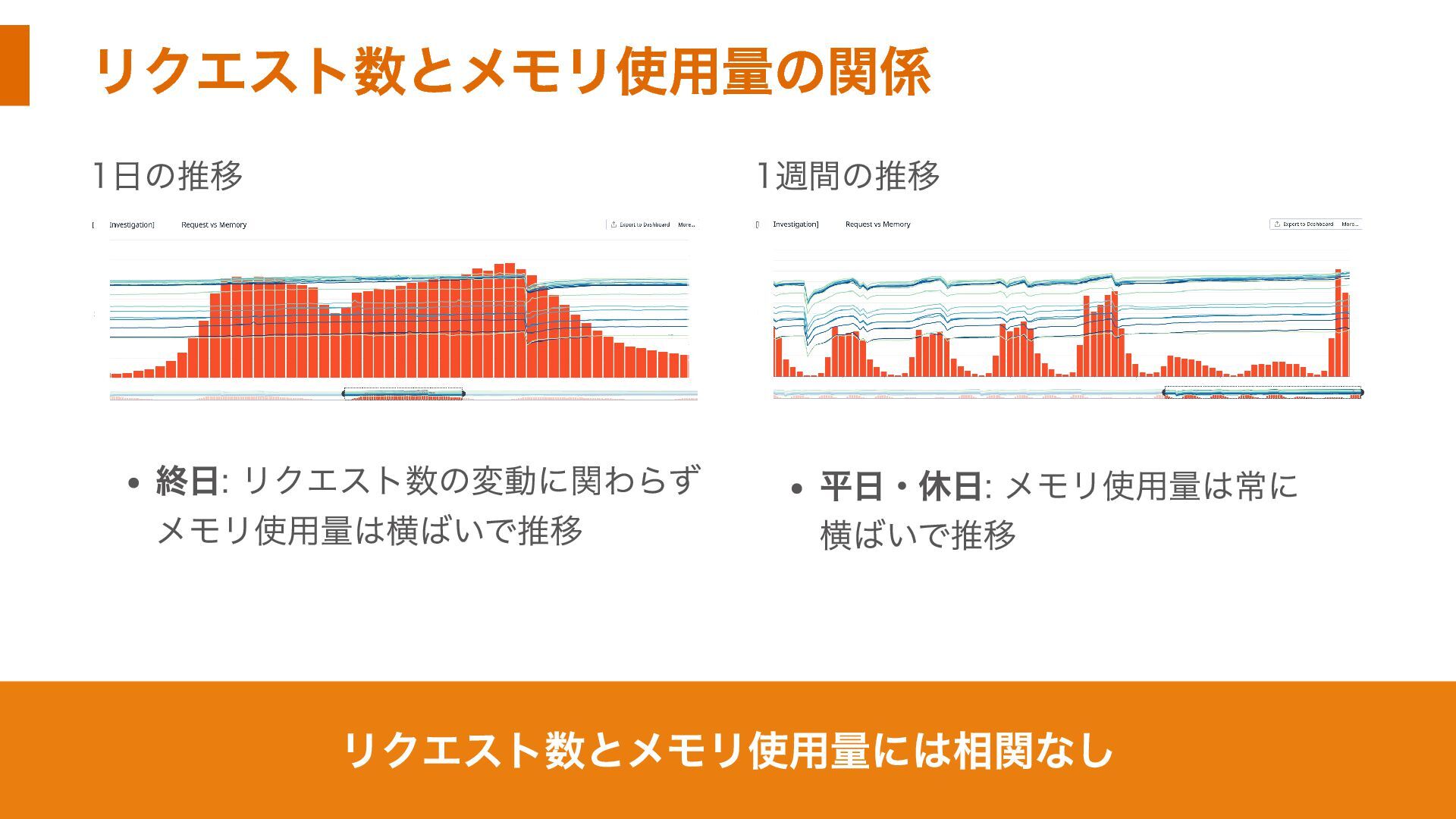
リクエスト数とメモリ使用量の関係 1日の推移 終日: リクエスト数の変動に関わらず メモリ使用量は横ばいで推移 1週間の推移 平日・休日: メモリ使用量は常に 横ばいで推移 リクエスト数とメモリ使用量には相関なし
過去データから導いた考察 CPU使用率がボトルネックになると想定 リクエスト数とCPU使用率の連動性を確認 メモリ使用量が横ばいであったため、CPU使用率が先に ネックになると想定 オートスケール機能にはHPAを採用 Kubernetesの基本機能、豊富な他社事例と運用ノウハウ AWS環境での運用経験不足をカバー KEDAの選択肢もあったが必要になった時に検討と判断
CPU使用率の閾値検討 HPAではRequest値を基準とした閾値 となっている 確実にスケールされることを考慮 閾値を60%に設定 https://kubernetes.io/docs/tasks/run- application/horizontal-pod-autoscale/
迎えたAWS環境への移行当日
迎えたAWS環境への移行当日 AWS移行、無事完了!🎉
2024年12月 月初 AWS環境に移行後 初のアクセスピーク日
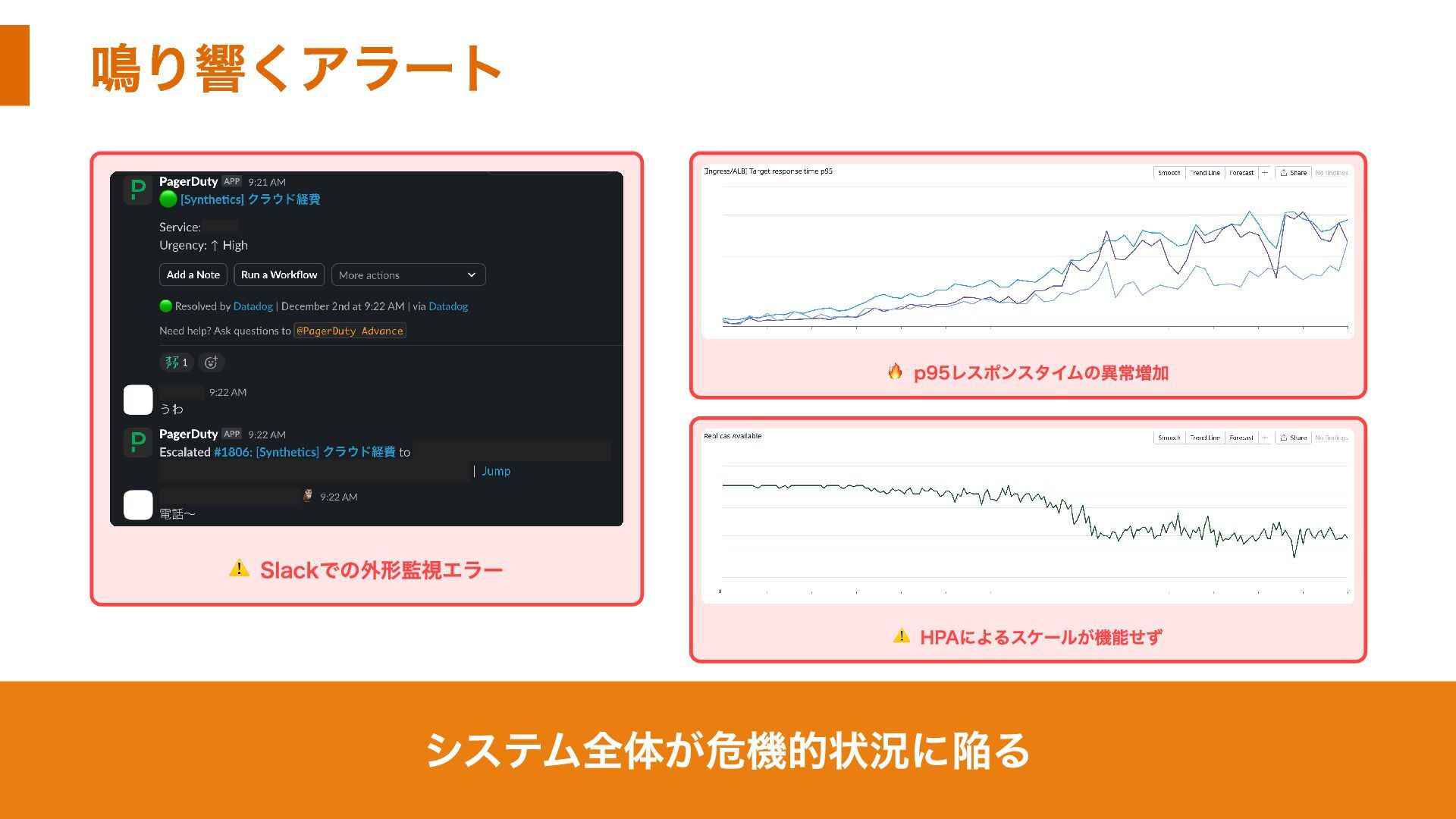
鳴り響くアラート ⚠️ Slackでの外形監視エラー 🔥 p95レスポンスタイムの異常増加 ⚠️ HPAによるスケールが機能せず システム全体が危機的状況に陥る
暫定対策 状況把握 アクセス数に対してpodが不足していた CPU閾値をトリガーとしたHPAが機能していなさそう メモリ不足の傾向が見られる 緊急対応 minReplicasを大幅に増加 podのメモリ割り当てを増加 アクセスピークを乗り切ることに成功
振り返り: なぜ問題が起きたのか
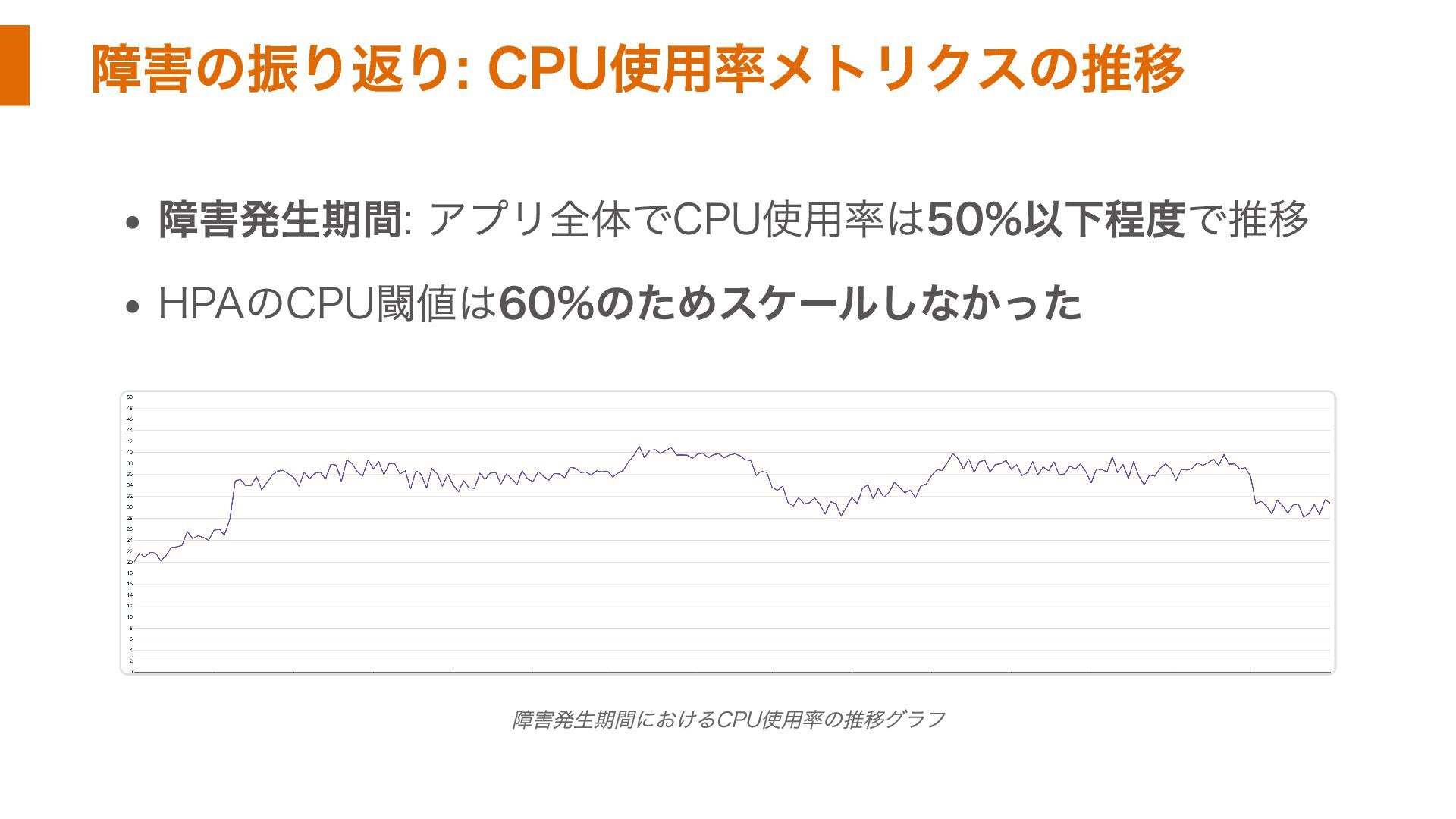
障害の振り返り: CPU使用率メトリクスの推移 障害発生期間: アプリ全体でCPU使用率は50%以下程度で推移 HPAのCPU閾値は60%のためスケールしなかった 障害発生期間におけるCPU使用率の推移グラフ
障害の振り返り: メモリ使用率の推移 障害発生期間: アプリ全体でメモリ使用率が100%近くで推移 livenessProbe(プロセス生存確認)がメモリ不足の影響で失敗 メモリ不足によりアプリケーションが不安定になりPodが停止 障害発生期間におけるメモリ使用率の推移グラフ
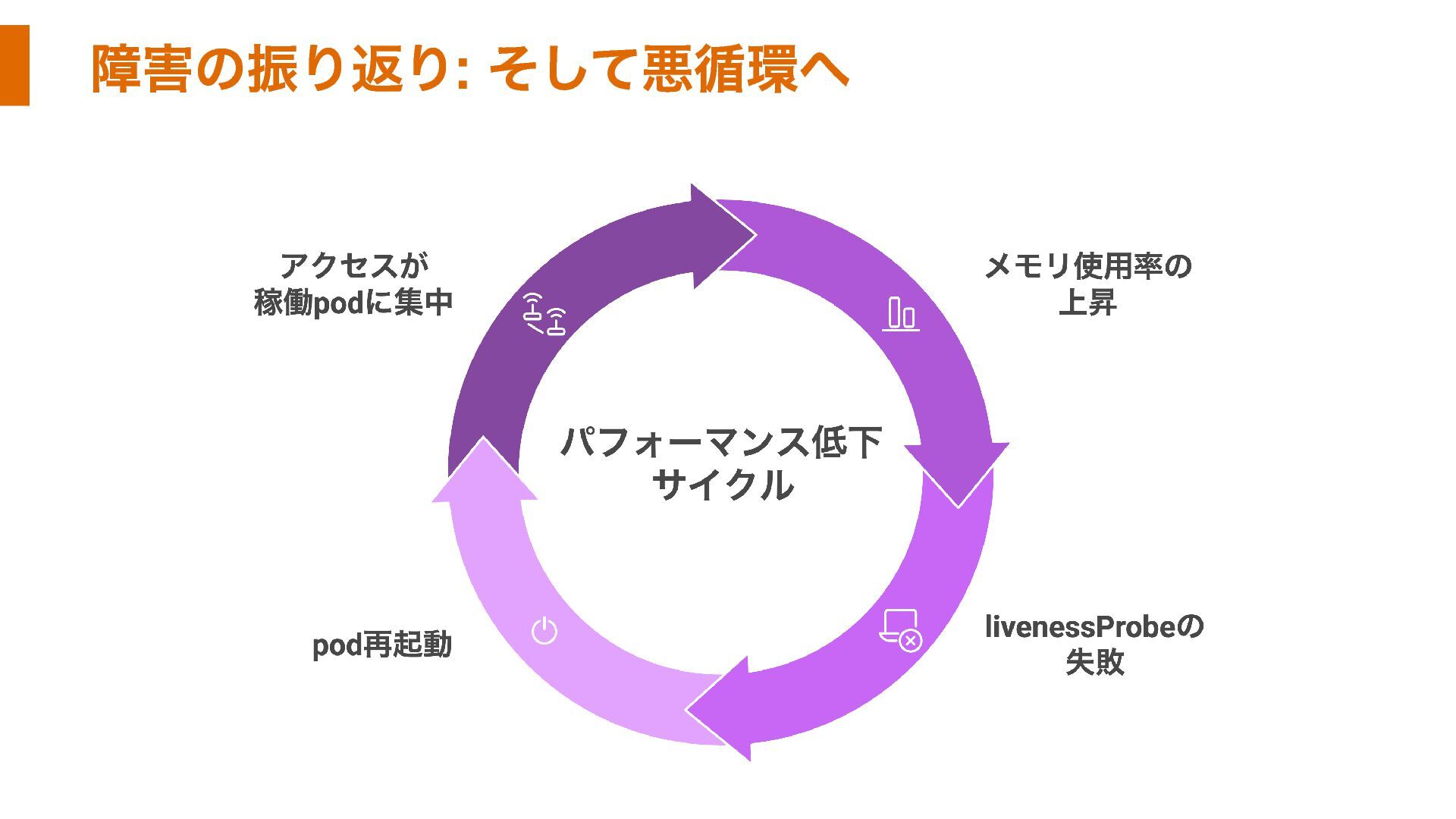
障害の振り返り: そして悪循環へ
障害の振り返り: 今後の対応方針 緊急対応(短期対策) 暫定的にminReplicasを増加させサービス継続 月末月初のアクセスピークに対応可能な体制を確保 根本対策(長期解決策) リソース最適化: メモリ割り当ての見直しと適正化 スケール機能強化: オートスケール設計の見直し
閾値最適化: CPU使用率の閾値を実態に合わせて調整
オートスケール設計の 改善ポイント
オートスケール設計の改善ポイント 閾値設定の根本的見直し CPU使用率との相関性に依存したスケール設計 負荷の根本原因であるリクエスト数を直接監視 データ分析における注意点 相関関係は「現時点での傾向」として参考程度に留める 将来的にボトルネックとなるリソースは変化する可能性あり
新技術導入における慎重なアプローチ なぜ最初からKEDAを選ばなかったのか? 新しい技術スタックへの学習コストの高さ トラブル発生時の対応ノウハウの不足 段階的導入のメリット まずは実績のあるHPAで運用開始 問題が発生してから改善を検討する段階的アプローチ 結果として今回の経験により最適解が見えた
オートスケール改善のアプローチ検討 障害の根本原因を解決するために、複数のアプローチを検討 データ活用アプローチ アクセスパターンの分析結果を活用 予測可能な負荷変動への対応 技術改善アプローチ より適切な監視メトリクスの採用 柔軟なスケーリング機能の導入
静的 vs 動的スケーリングの判断 静的スケーリング(cron) 固定的なスケジュールでは細かな調整が困難 突発的なアクセス変動に対応できない 動的スケーリング リアルタイムでの負荷変動に柔軟対応 より精密なリソース管理が可能 動的スケーリングでより適切な監視指標が必要
KEDAを活用した リクエスト数ベースの オートスケーリングへ
Kubernetes Event-Driven Autoscalingとは イベントをトリガーにアプリケーションを オートスケーリング可能 メッセージキューの長さやDBの行数 など様々な"イベント"をトリガーに 指定可能 コスト効率の最大化 (ゼロスケールイン)
Podの数を自動的に0台にまで スケールイン可能 https://keda.sh/
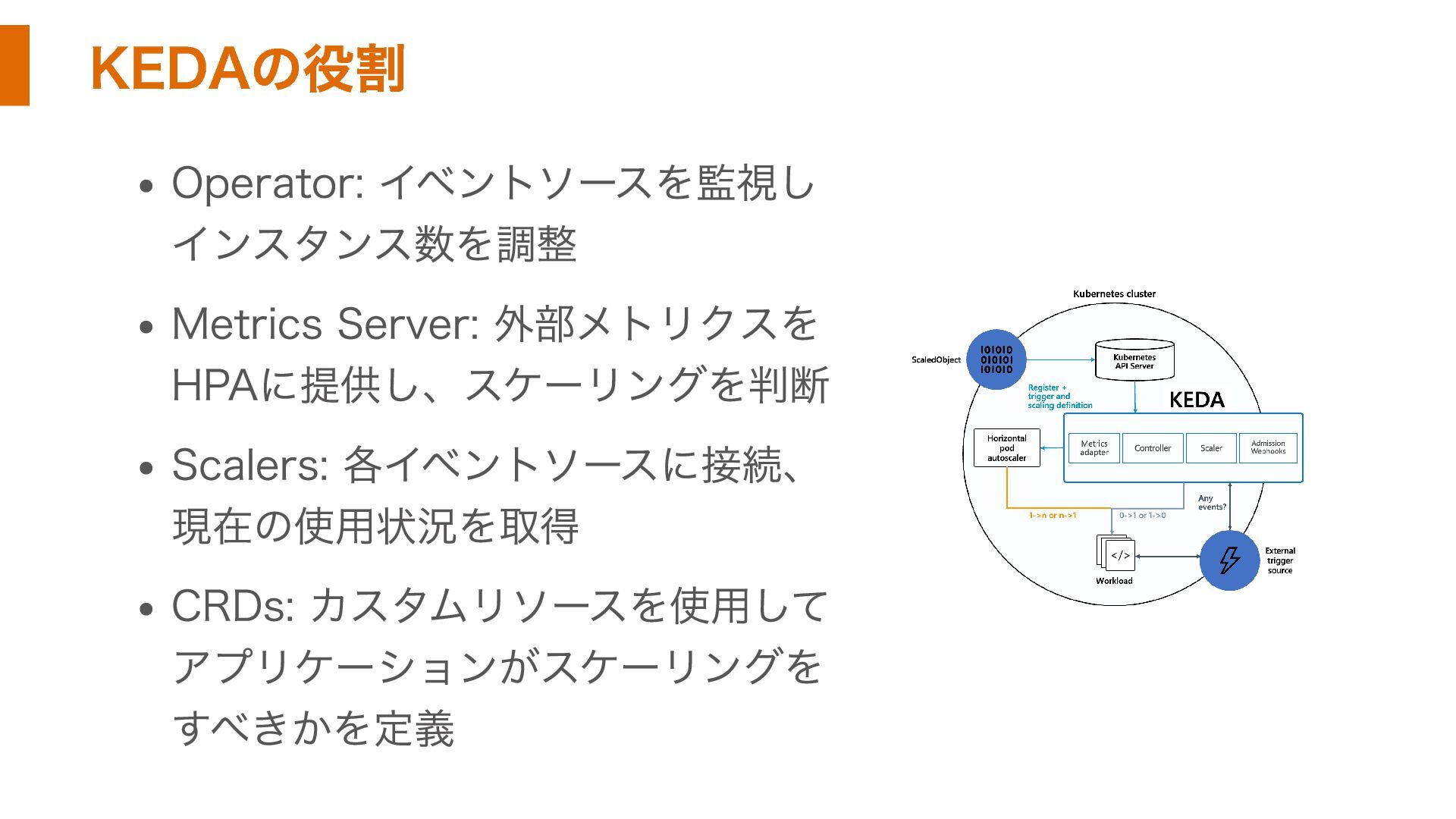
KEDAの役割 Operator: イベントソースを監視し インスタンス数を調整 Metrics Server: 外部メトリクスを HPAに提供し、スケーリングを判断 Scalers: 各イベントソースに接続、
現在の使用状況を取得 CRDs: カスタムリソースを使用して アプリケーションがスケーリングを すべきかを定義
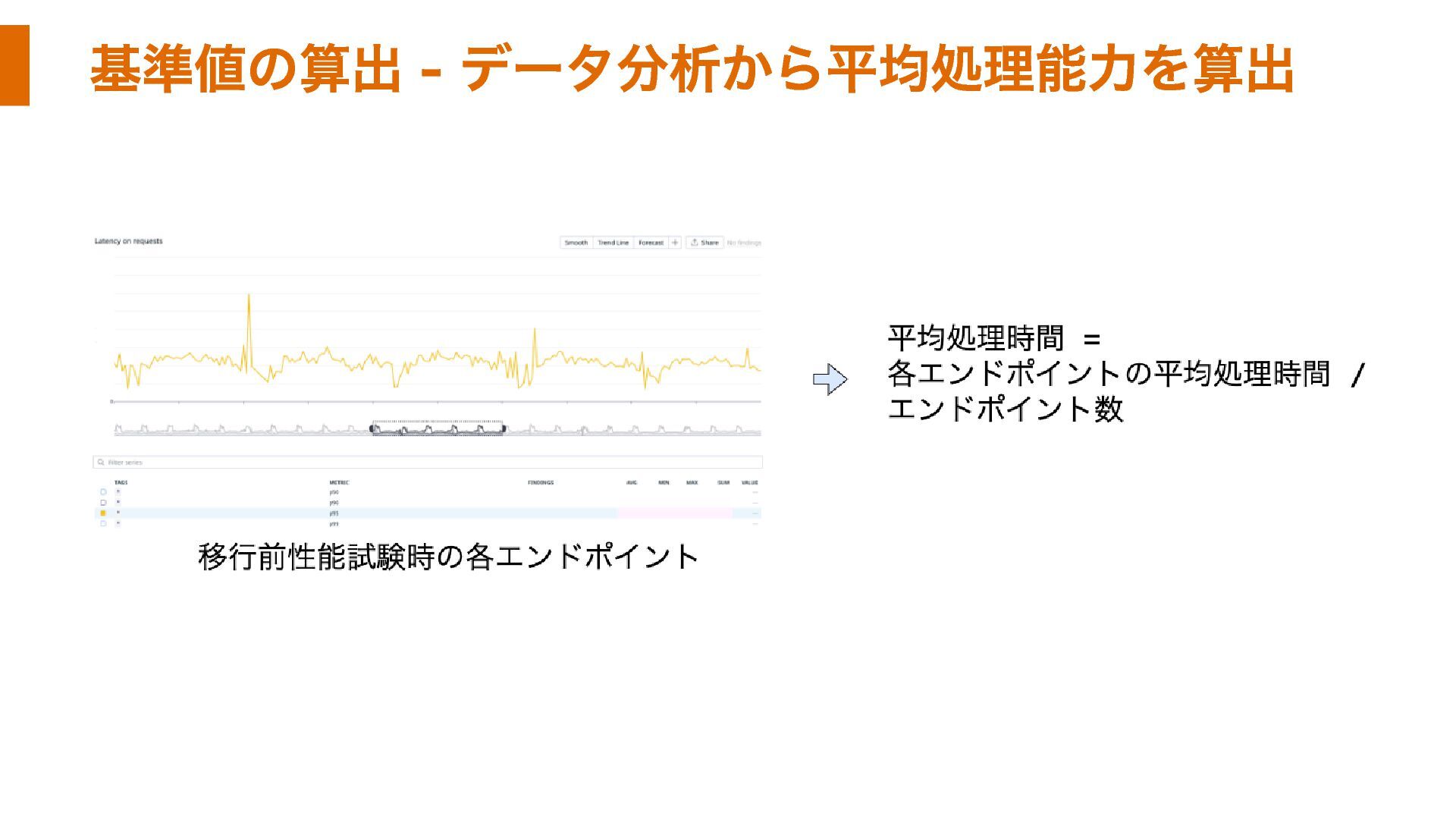
オートスケール再設計: リクエスト数の閾値追加 Datadogとの連携 Datadogでリクエスト数をモニタリング中 Datadogのリクエスト数を参照 取得したリクエスト数に応じてオートスケールさせる 閾値算出の進め方 移行前の性能試験におけるエンドポイントに着目 AWS環境上の同エンドポイントにおける処理能力から算出
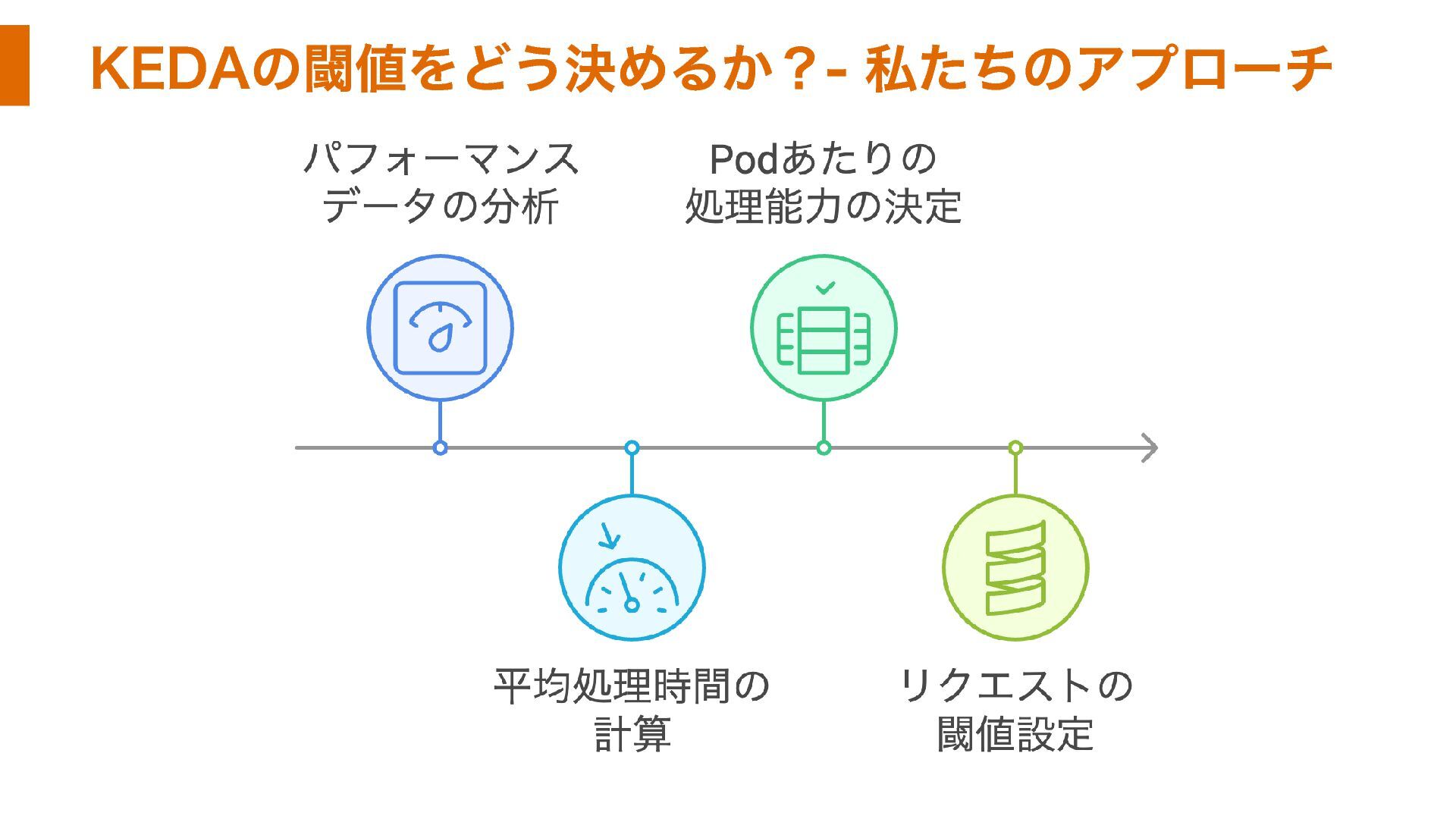
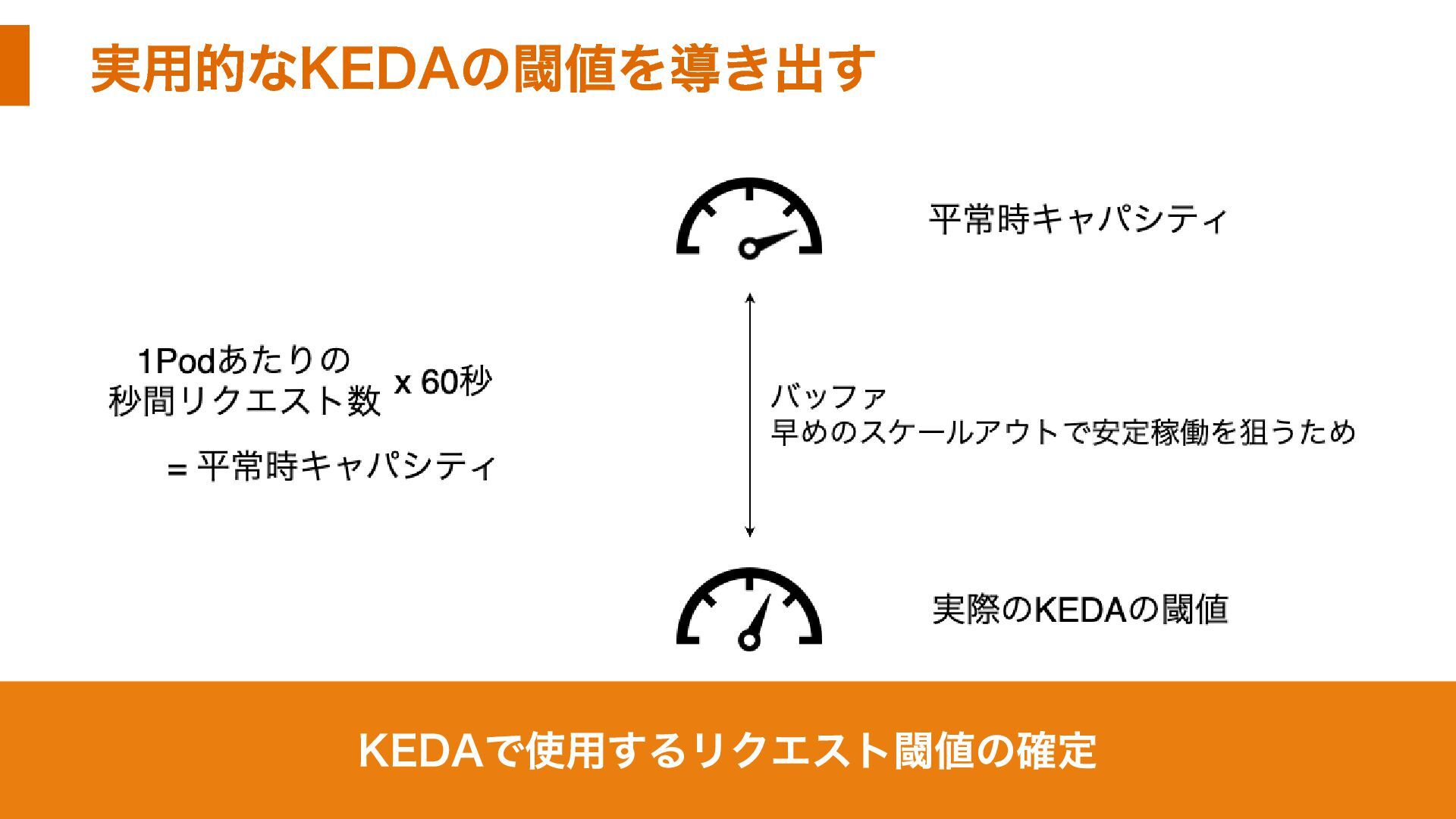
KEDAの閾値をどう決めるか?- 私たちのアプローチ
基準値の算出 - データ分析から平均処理能力を算出
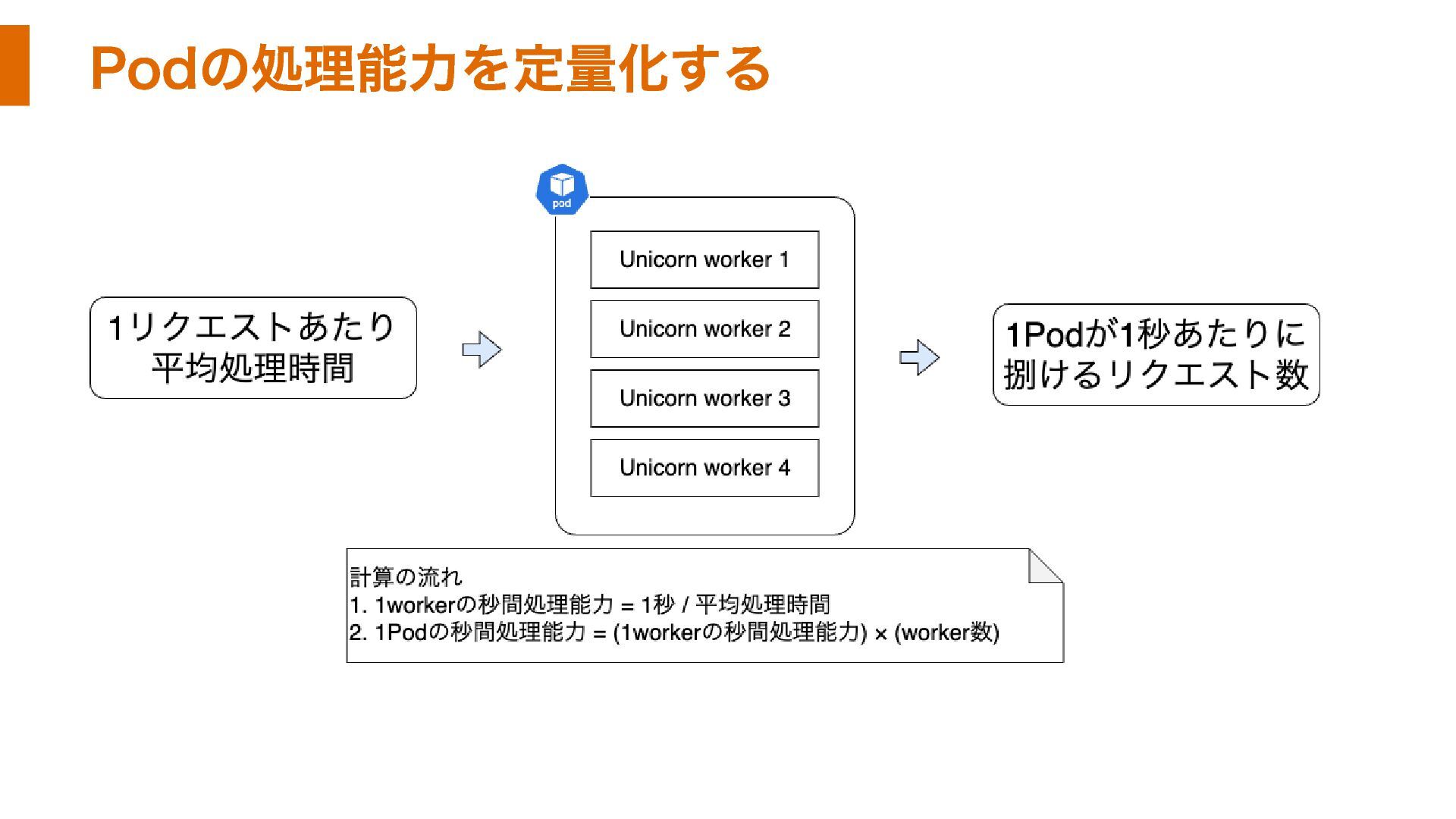
Podの処理能力を定量化する
実用的なKEDAの閾値を導き出す KEDAで使用するリクエスト閾値の確定
オートスケール再設計: CPU使用率は継続採用 リクエスト数では捉えきれない負荷への対応 アクセス数が閾値に満たない状況でもCPU使用率が上昇する ケースを考慮 システム可用性の向上 Datadogサービス停止時のフェイルセーフ機能として動作 監視システムの単一障害点を回避し、サービス継続性を確保 リクエスト数とCPU使用率の二重監視体制により信頼性向上
オートスケール再設計: CPU使用率閾値の最適化 問題の特定 設定していた60%閾値では反応が遅すぎることが判明 閾値の調整 変更前: 60% → 変更後: 45%(15%の緩和)
期待される効果 アクセスピーク時の早期スケールアウト実現 サービス応答性の改善とユーザー体験の向上
オートスケール再設計: メモリ使用率を組み込むか? 検討結果 メモリ使用率は閾値として採用しない 理由 ガベージコレクション実行により使用率が不規則に変動する スケーリングトリガーとしての予測可能性と信頼性に欠ける メモリ集約的なアプリケーションは事前設定で対応すべき
KEDA設計の最終仕様 採用する監視指標 リクエスト数: エンドポイントの処理能力に基づく閾値設定 CPU使用率: 障害時の検証結果を反映し45%に設定 (従来60%から緩和) 除外する監視指標 メモリ使用率: ガベージコレクションによる不規則な変動の
ため除外
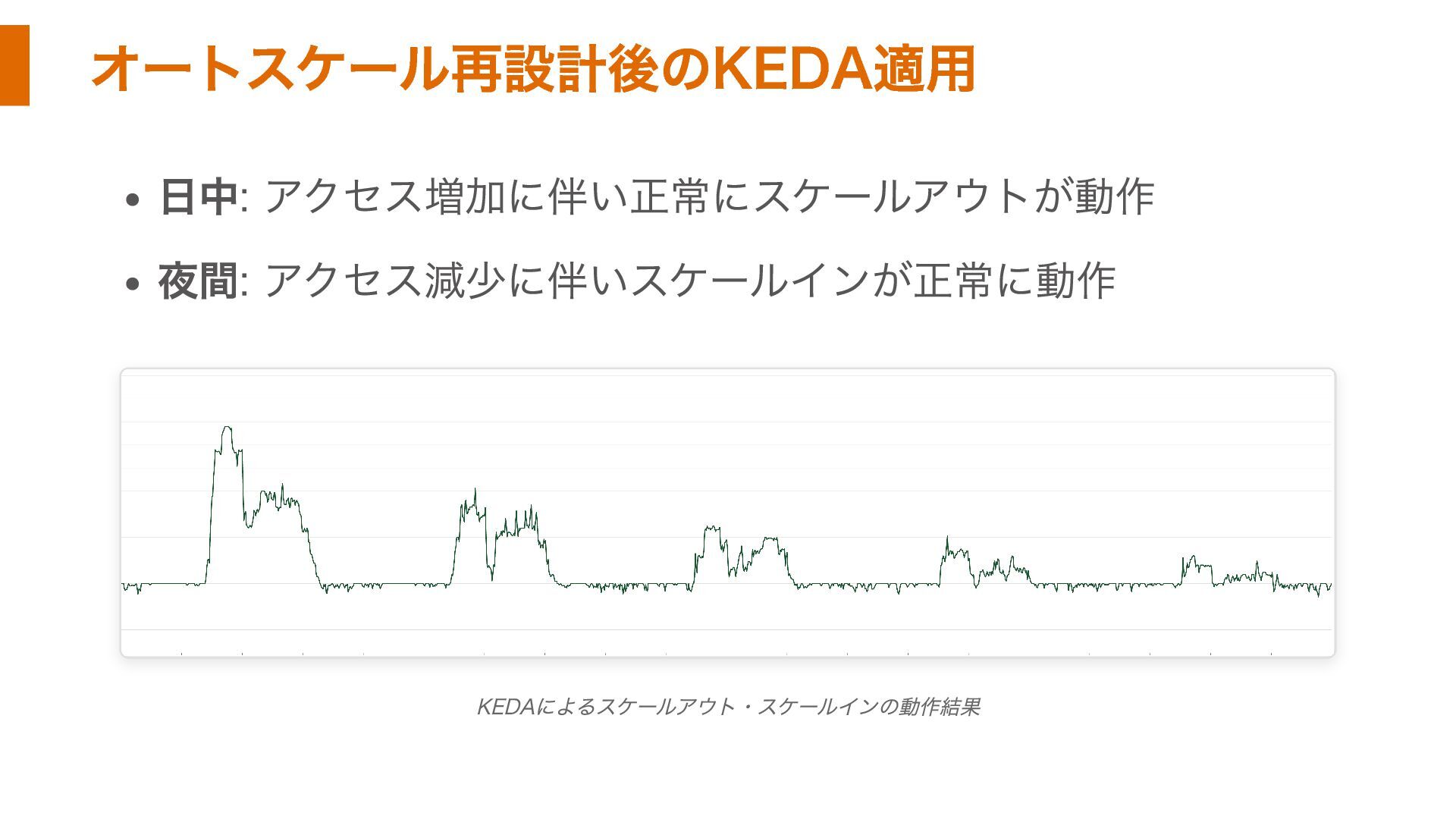
オートスケール再設計後のKEDA適用 日中: アクセス増加に伴い正常にスケールアウトが動作 夜間: アクセス減少に伴いスケールインが正常に動作 KEDAによるスケールアウト・スケールインの動作結果
最適な レプリカ数の導出
KEDAを活用できたので 次はレプリカ数を見直す
移行当時のレプリカ数 事前性能試験の結果に基づいて設定 AWS環境移行時に性能試験を実施し、HPAの適切なレプリカ数 を算出 minReplicas: 平常時のアクセスを処理するのに必要な台数 maxReplicas: アクセスピーク時に対応できる台数
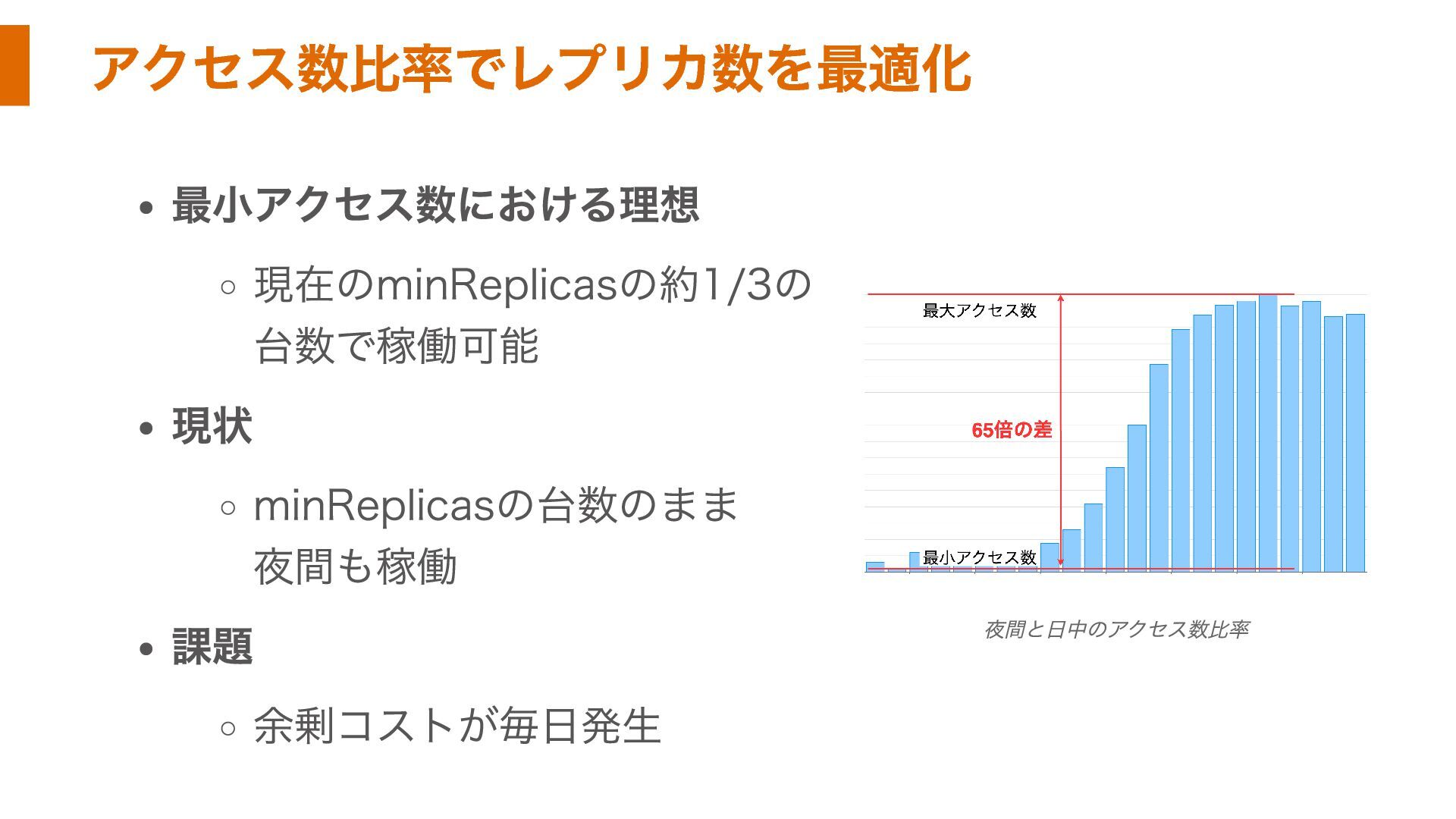
アクセス数比率でレプリカ数を最適化 最小アクセス数における理想 現在のminReplicasの約1/3の 台数で稼働可能 現状 minReplicasの台数のまま 夜間も稼働 課題 余剰コストが毎日発生 夜間と日中のアクセス数比率
KEDAでのminReplicaCount決定までの流れ メトリクス分析 夜間のCPU使用率: 10%程度 夜間のリクエスト数: 数千程度 負荷要因の考慮 外部要求: 外部API、社内プロダクト連携 内部処理:
夜間バッチ、定期データ処理 これらを総合的に考慮してminReplicaCountの目標値を決定
目標値に向けたminReplicaCountの削減の進め方 案1: 一気に削減 メリット: コスト削減を即座に実現 リスク: 予想外の挙動でサービス影響の可能性 案2: 段階的削減 メリット:
安全性を確保しながら削減 リスク: コスト削減の効果実現に時間がかかる 案2を採用: 段階的な削減と監視で目標値を目指す
クラウド経費・クラウド債務支払での 監視方法について
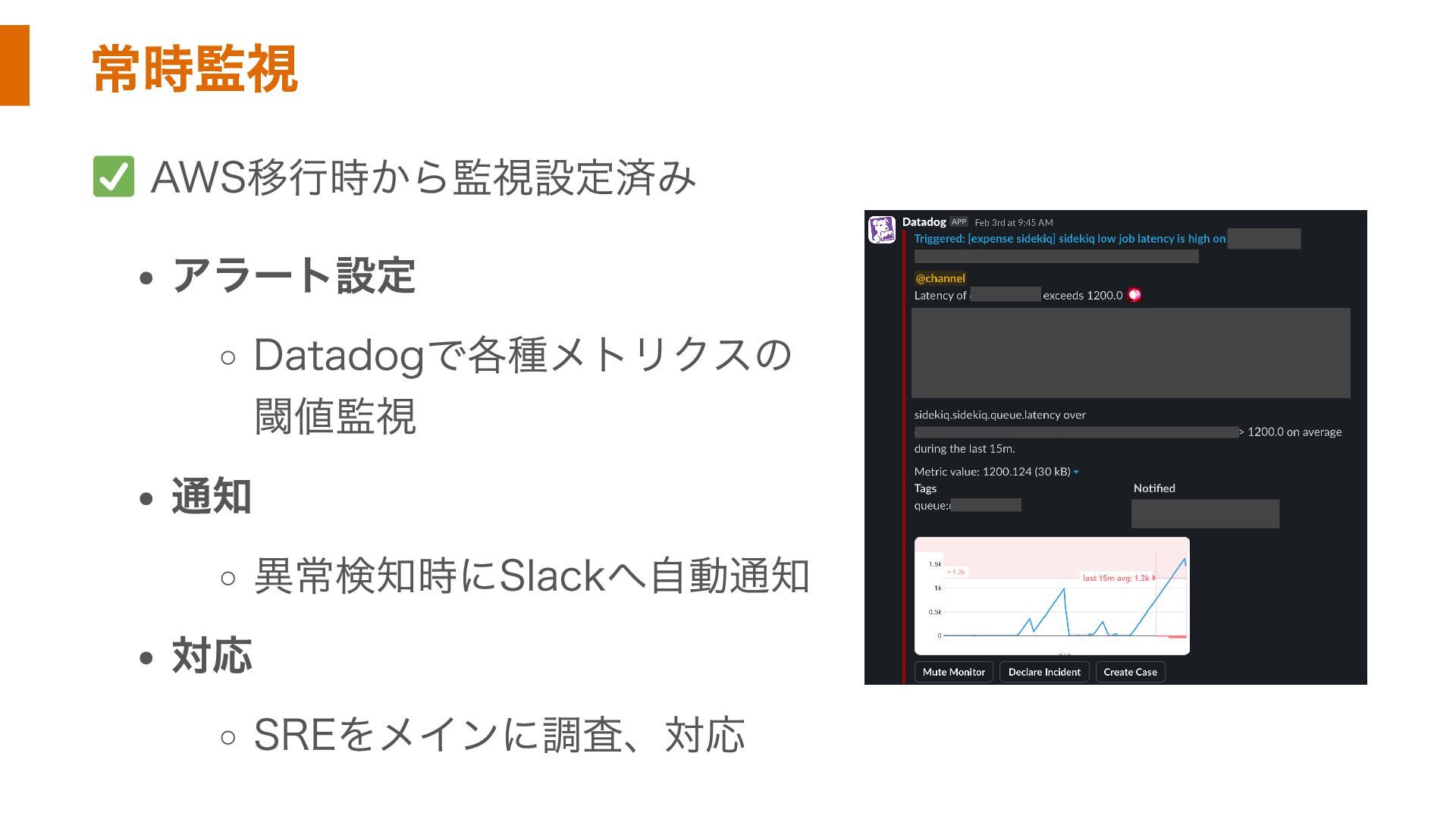
常時監視 AWS移行時から監視設定済み アラート設定 Datadogで各種メトリクスの 閾値監視 通知 異常検知時にSlackへ自動通知 対応 SREをメインに調査、対応
フィードバックと対応 既存の会議体制を活用 参加者・体制 SREチーム + 開発メンバー 週次で定期開催 確認内容 各種メトリクス確認、異常波形の原因特定・対応 情報共有・連携
双方の実施済み変更を共有し、システム状況を理解
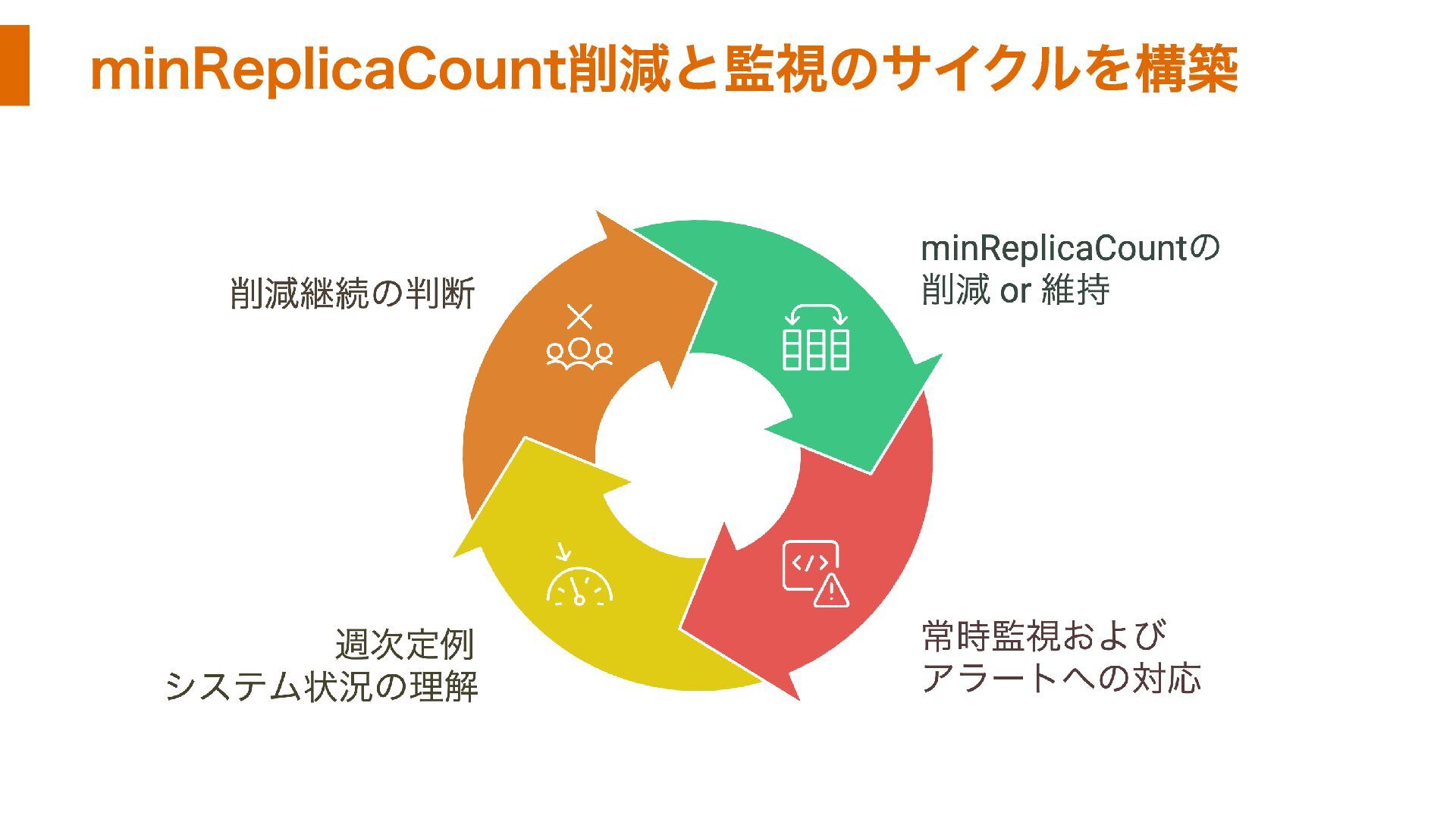
minReplicaCount削減と監視のサイクルを構築
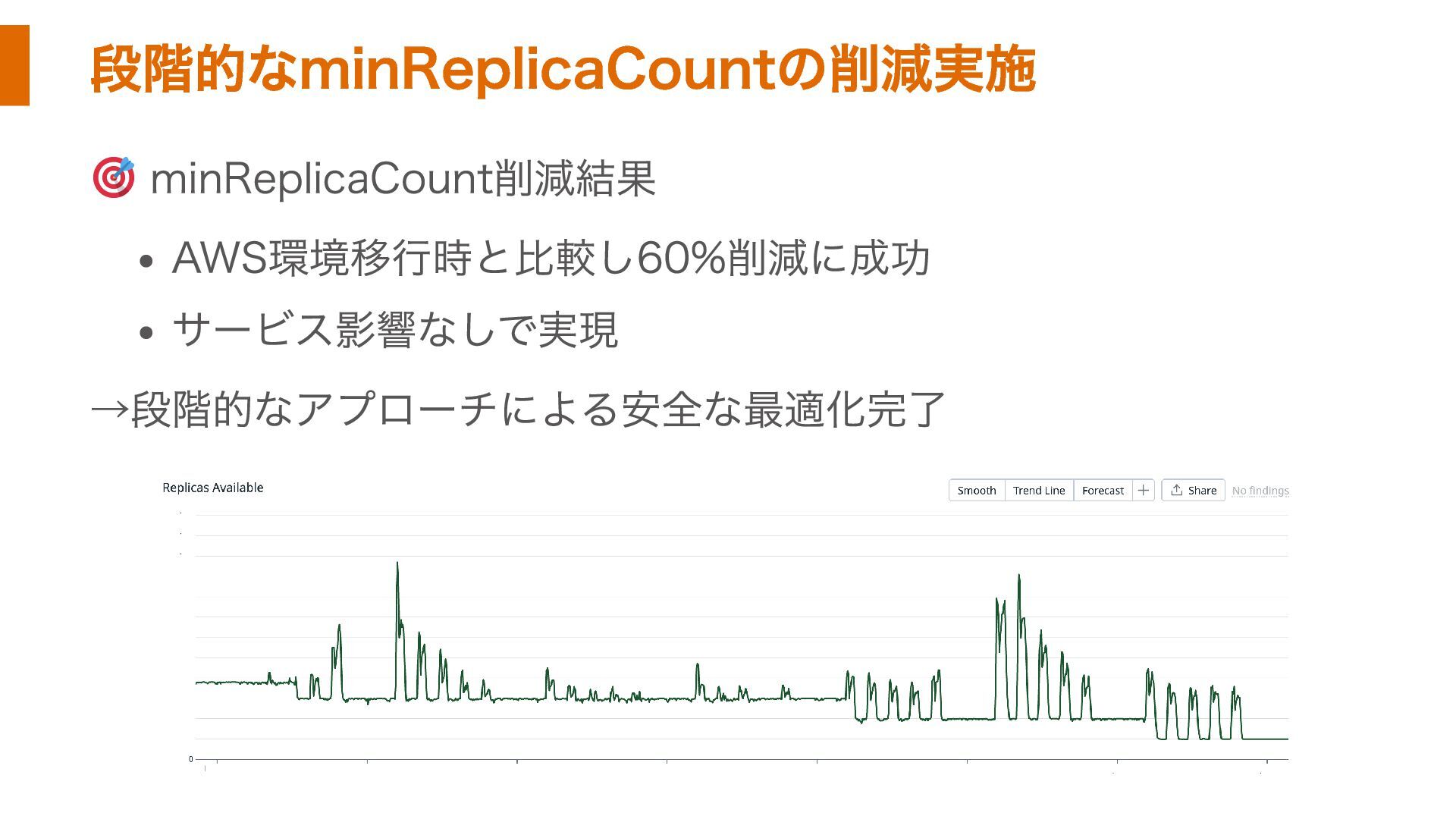
段階的なminReplicaCountの削減実施 minReplicaCount削減結果 AWS環境移行時と比較し60%削減に成功 サービス影響なしで実現 →段階的なアプローチによる安全な最適化完了
レプリカ数の最適化達成
まとめ 技術的改善 オートスケーリング: ピーク時も最適なレプリカ数で稼働 運用自動化: 手動でのレプリカ調整が不要に コスト最適化 リソース効率化: 必要な時に必要な分だけ稼働 大幅なコスト削減:
minReplicaCount 60%減を達成 チーム効率化 工数削減: 監視・調整作業からの解放 価値創出: 機能開発・改善により多くの時間を投入可能
宣伝
スポンサーブースのお知らせ
None
ありがとうございました
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}