Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
pandasとpolarsと私
Search
nokomoro3
February 14, 2023
Programming
2.5k
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
pandasとpolarsと私
nokomoro3
February 14, 2023
More Decks by nokomoro3
See All by nokomoro3
今から始めるClaude Code入門〜AIコーディングエージェントの歴史と導入〜
nokomoro3
0
1.1k
AIや機械学習を更に発展的に学んで、キャリアの強みにしていく方法
nokomoro3
0
610
re:Invent 2024 振り返り re:Growth AIML アップデート 個人的ニュース
nokomoro3
0
940
AWS ParallelClusterでTrainiumを使って大規模言語モデルをトレーニングする方法
nokomoro3
0
580
Other Decks in Programming
See All in Programming
1B+ /day規模のログを管理する技術
broadleaf
0
130
エージェンティックRAGにAWSで入門しよう!
har1101
9
1.9k
OSINT for SRE: 学術論文とポストモーテムから探る システム障害の共通パターン / SRE NEXT 2026
tomoyk
1
2.5k
決定論的オーケストレーションの設計と実装 / Design and Implementation of Deterministic Orchestration
nrslib
4
1.6k
Vue × Nuxt × Oxc どこまで使える?実運用の現在地
andpad
0
360
分散システム、なんですぐ死んでしまうん?耐障害性を高めたいあなたのためのレジリエンスパターン入門
mshibuya
7
4.7k
Go1.27で導入されるジェネリクスメソッドでできること
mackee
0
250
Welcome to the "Parametricity" 🏙️ − Generic だけど Specific な世界 −
guvalif
1
120
AIエージェントで 変わるAndroid開発環境
takahirom
2
460
SREは、MCPとSRE Agentをこう使え!
kazumax55
0
150
例外の正しい扱い方 そのエラー try-catchして大丈夫?
jinwatanabe
0
340
dRuby over BLE
makicamel
2
410
Featured
See All Featured
SERP Conf. Vienna - Web Accessibility: Optimizing for Inclusivity and SEO
sarafernandez
2
1.5k
How to Build an AI Search Optimization Roadmap - Criteria and Steps to Take #SEOIRL
aleyda
1
2.1k
Embracing the Ebb and Flow
colly
88
5.1k
The Mindset for Success: Future Career Progression
greggifford
PRO
0
410
For a Future-Friendly Web
brad_frost
183
10k
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
Build your cross-platform service in a week with App Engine
jlugia
234
18k
Dominate Local Search Results - an insider guide to GBP, reviews, and Local SEO
greggifford
PRO
0
200
SEO for Brand Visibility & Recognition
aleyda
0
4.6k
Building the Perfect Custom Keyboard
takai
2
810
How to Think Like a Performance Engineer
csswizardry
28
2.7k
Between Models and Reality
mayunak
4
360
Transcript
pandasとpolarsと私 データサイエンス100本ノックを添えて Python機械学習勉強会 in 新潟 #17 2023-02-12
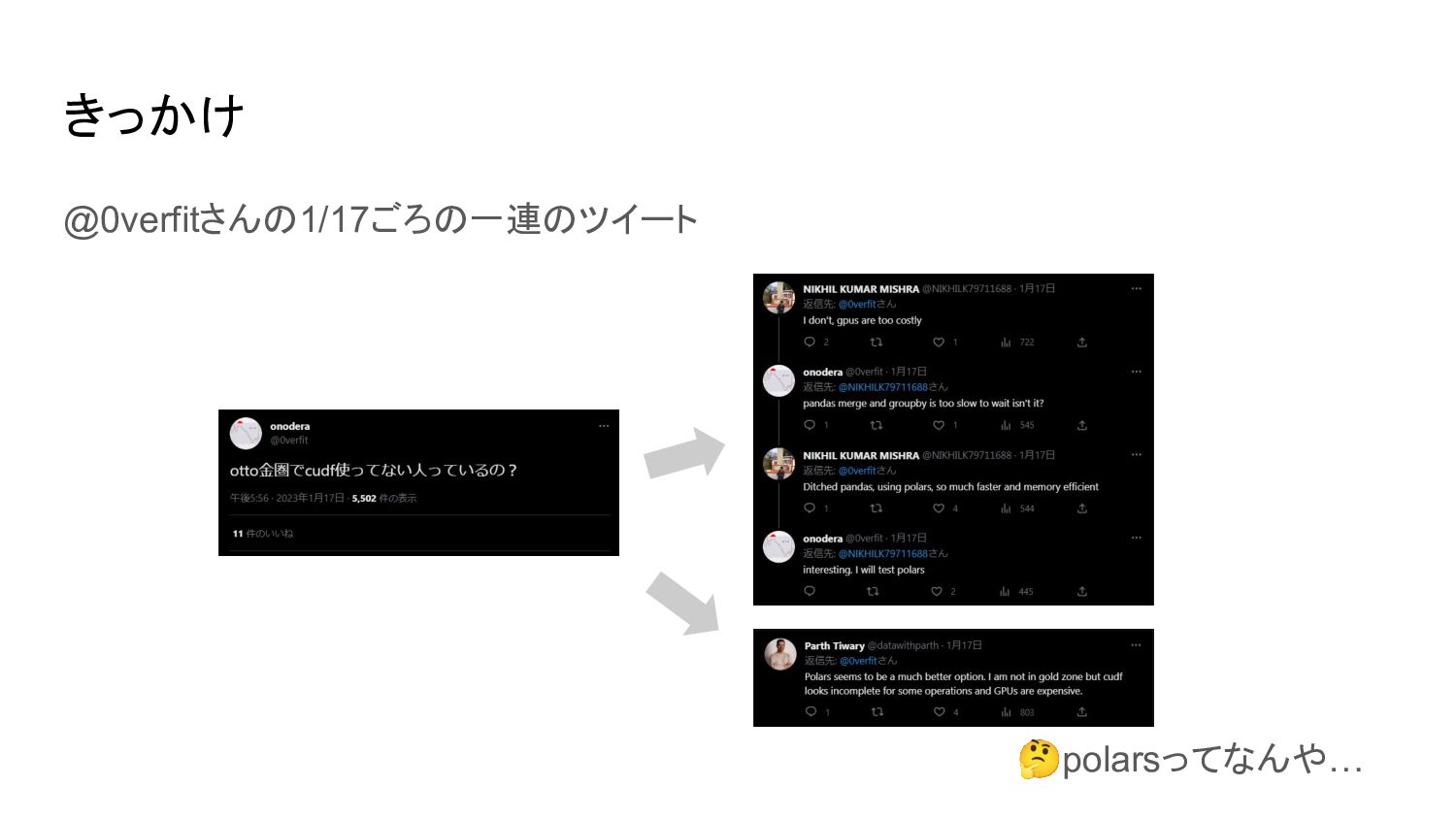
きっかけ @0verfitさんの1/17ごろの一連のツイート 🤔polarsってなんや…
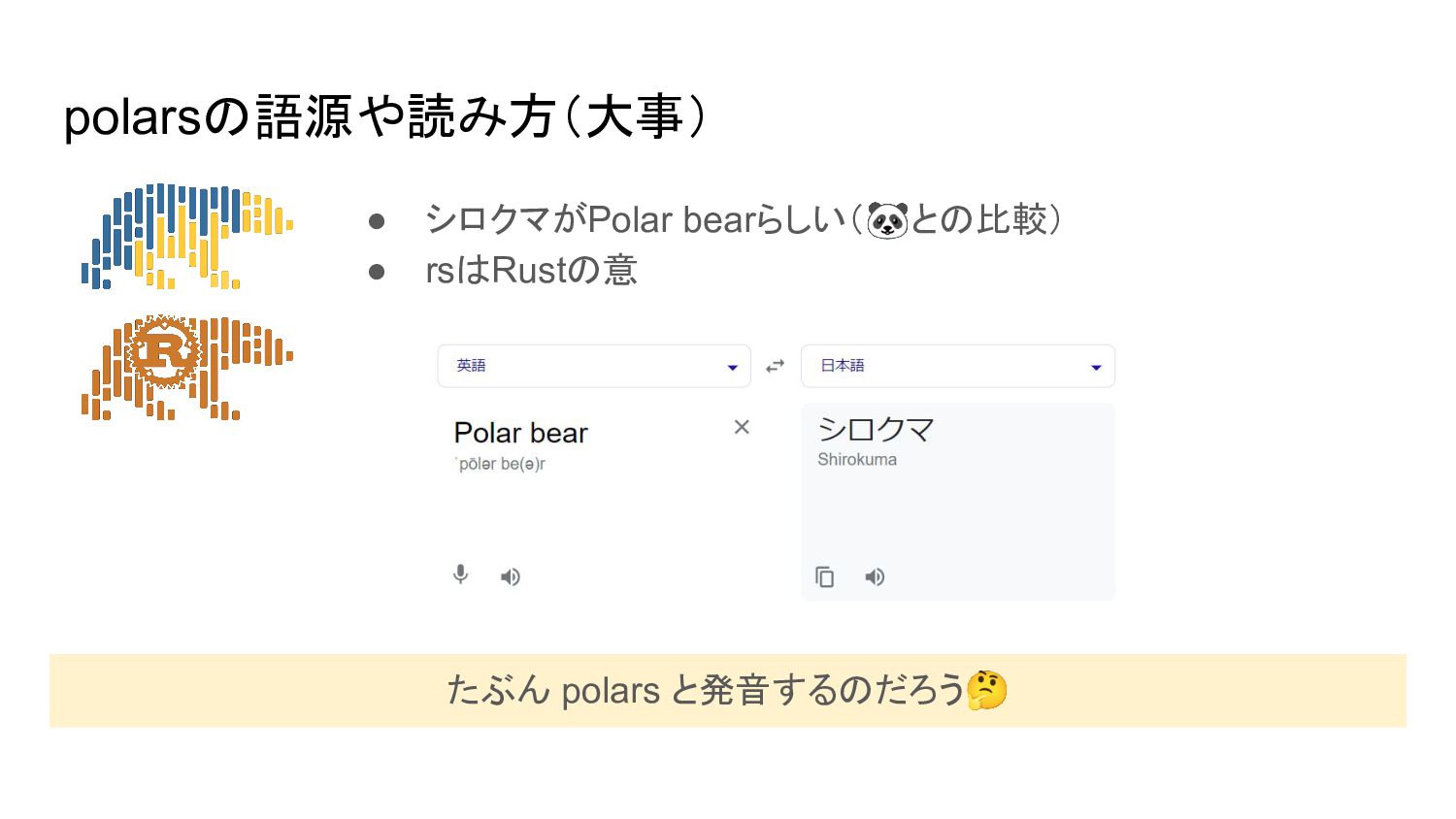
polarsの語源や読み方(大事) • シロクマがPolar bearらしい(🐼との比較) • rsはRustの意 たぶん polars と発音するのだろう🤔
その後 その後Qiita投稿も観測 • Polarsでデータサイエンス100本ノックを解く(前編) - Qiita (2023/01/04) • pandasから移行する人向け polars使用ガイド
- Qiita (2022/10/21) • 超高速…だけじゃない!Pandasに代えてPolarsを使いたい理由 - Qiita (2022/12/04) Rustの記事もいくつか • rustでデータ分析100本ノックをやってみたら、めっちゃ書きやすかった話【 Polars】 (2022/12/21) • 超高速DataFrameライブラリー「Polars」について (2022/12/19) 100本ノックしてきたのでそれを踏まえて紹介
自己紹介 • 中村です • クラスメソッドという会社で機械学習エンジニア • ブログは機械学習やPythonが主成分 ◦ https://dev.classmethod.jp/author/shogo-nakamura/ •
polarsについてもそのうちアップ予定
polarsの良さげなところ(まとめ)👍 • indexがない、マルチカラムもない • カラム名の重複不可(いい意味で) • pl.Exprという計算式で記述でき、実体化が不要 • 遅延評価も可能 •
SQLクエリ風の名前(SELECT、JOIN、OVERなど) • 複雑な処理もワンライナーで書ける(df_tmpなど一時的な実体化が不要) • 標準の数学関数が多めでNumPyのお世話にならなくて済む • 高速らしい 基本文法や100本ノックの例題を踏まえて見ていく
セットアップ • pipでインストール(Google Cloab環境で確認) • 執筆時点でのバージョンは polars-0.16.4 • plでimportされることが多い様子 •
データは以下から取得 ◦ https://github.com/The-Japan-DataScientist-Society/100knocks-preprocess/tree/master/docker /work/data ◦ 本資料は「データサイエンティスト協会スキル定義委員」の「データサイエンス 100本ノック(構造化 データ加工編)」を利用しています import polars as pl pip install polars
基本:ファイル入出力 • pl.read_csvとpl.write_csvを使用 • indexがないため、index="None"などが不要👍 • 注意点としてはUTF-8以外の出力はpandasの経由が必要 df_receipt = pl.read_csv("receipt.csv")
df_receipt.write_csv("./output.csv") # UTF-8以外で出力したい場合 df_receipt.to_pandas().to_csv( './output_cp932.csv', encoding='CP932', index=False )
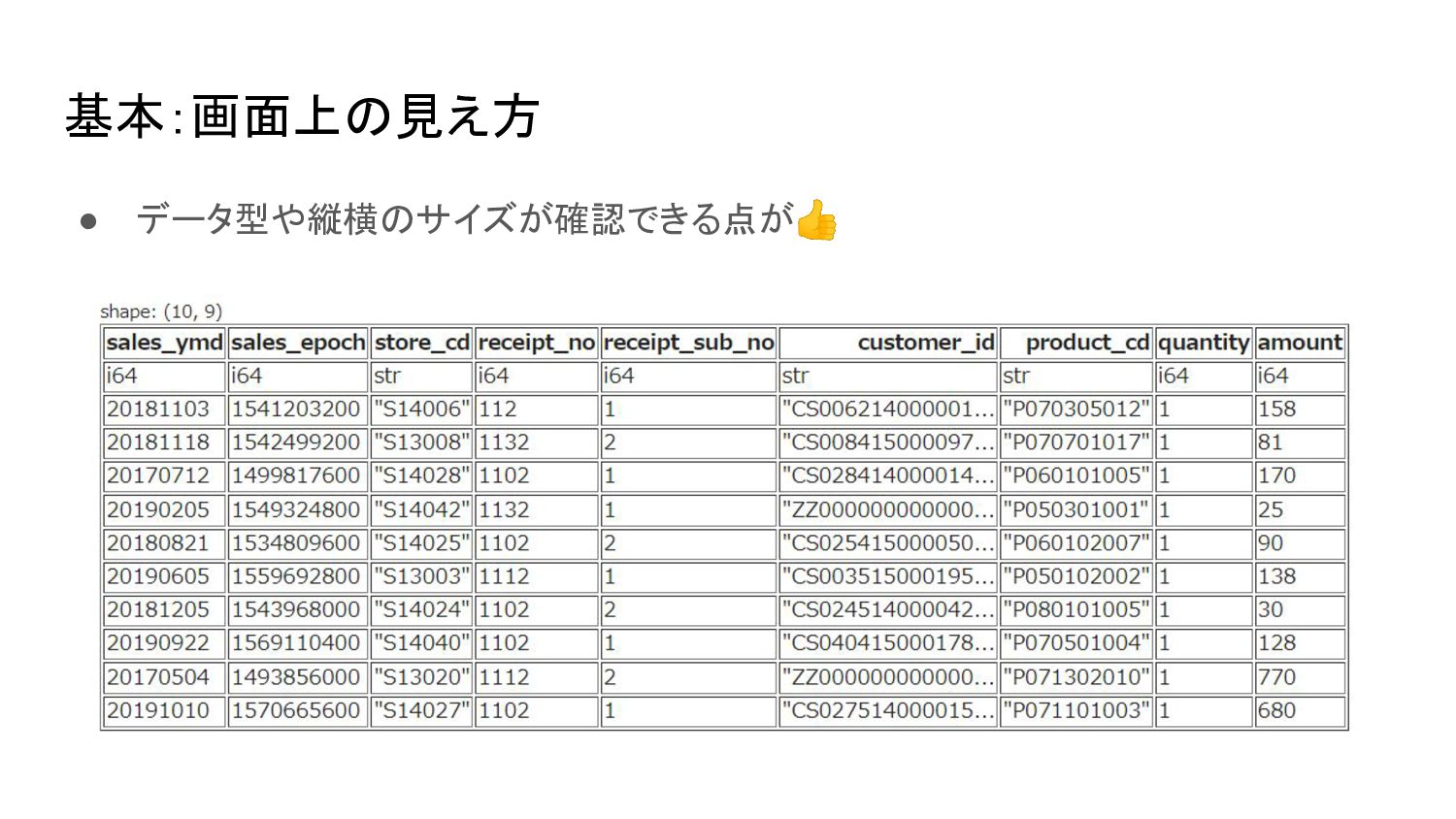
基本:画面上の見え方 • データ型や縦横のサイズが確認できる点が👍
基本:カラム選択 • pl.DataFrame.selectで可能 # P-002: 解答例 df_receipt.select(["sales_ymd", "customer_id", "product_cd", "amount"]).head(10)
# こちらでもできるが、後述するpl.col("カラム名")が使えないので非推奨 df_receipt["sales_ymd", "customer_id", "product_cd", "amount"].head(10)
基本:pl.Exprを使った表現 • pl.col("カラム名")はpl.Exprという計算式が得られる • pl.col("カラム名")を使えば様々な表現が可能 • pl.Expr同士を演算したりできる # 平均との演算なども簡単 df_receipt.select([
"sales_ymd", pl.col("amount") - pl.col("amount").mean() ]) # pandasでは一時変数を使うことが多い(実際はassignで一時変数なしで記述ができる) df_tmp = df_receipt_pd[["sales_ymd", "amount"]] df_tmp["amount"] = df_receipt["amount"] - df_receipt["amount"].mean()
基本:カラムの重複禁止とリネーム • polarsではカラムの重複が禁止(いい意味で) • そのためpl.Expr.aliasを使ってリネームするシーンが多くなる • 可読性の面からもaliasを適切な粒度で使用した方が良さそう # エラーとなる例 df_receipt.select([
"sales_ymd", pl.col("amount"), pl.col("amount") * 0.9 ]).head(10) # >> "DuplicateError: Column with name: 'amount' has more than one occurrences" # 重複を解決する例 df_receipt.select([ "sales_ymd", pl.col("amount"), (pl.col("amount") * 0.9).alias("amount_discount") ]).head(10)
基本:条件に応じた結果格納 • when - then - otherwiseという記述方法を使用 • 数珠繋ぎで条件を記述することも可能(then -
when とつなげられる) • UDF(ユーザ定義関数)のapplyでも可能だが遅い(Python処理のため) df_receipt.select([ "sales_ymd", "amount" , pl.when(pl.col("amount")>100).then(1).otherwise(0).alias("sales_flg") ]).head(10) # applyを使った別解(非推奨) df_receipt.select([ "sales_ymd", "amount" , pl.col("amount").apply(lambda x: 1 if x>100 else 0).alias("sales_flg") ]).head(10)
基本:条件によるレコード抽出 • pl.DataFrame.filterを使用 • 条件にはpl.Exprで様々なものを指定可能 • pandasのquery記法と違い演算子を直接扱える点が利点 • 各条件は()が必要で、andやorなどは使えない点は注意 #
P-005: 解答例 df_receipt.select([ "sales_ymd", "customer_id", "product_cd", "amount" ]).filter( (pl.col("customer_id") == "CS018205000001") & (pl.col("amount") >= 1000) ) # P-005: pandasの解答例 df_receipt_pd[['sales_ymd', 'customer_id', 'product_cd', 'amount']] \ .query('customer_id == "CS018205000001" & amount >= 1000')
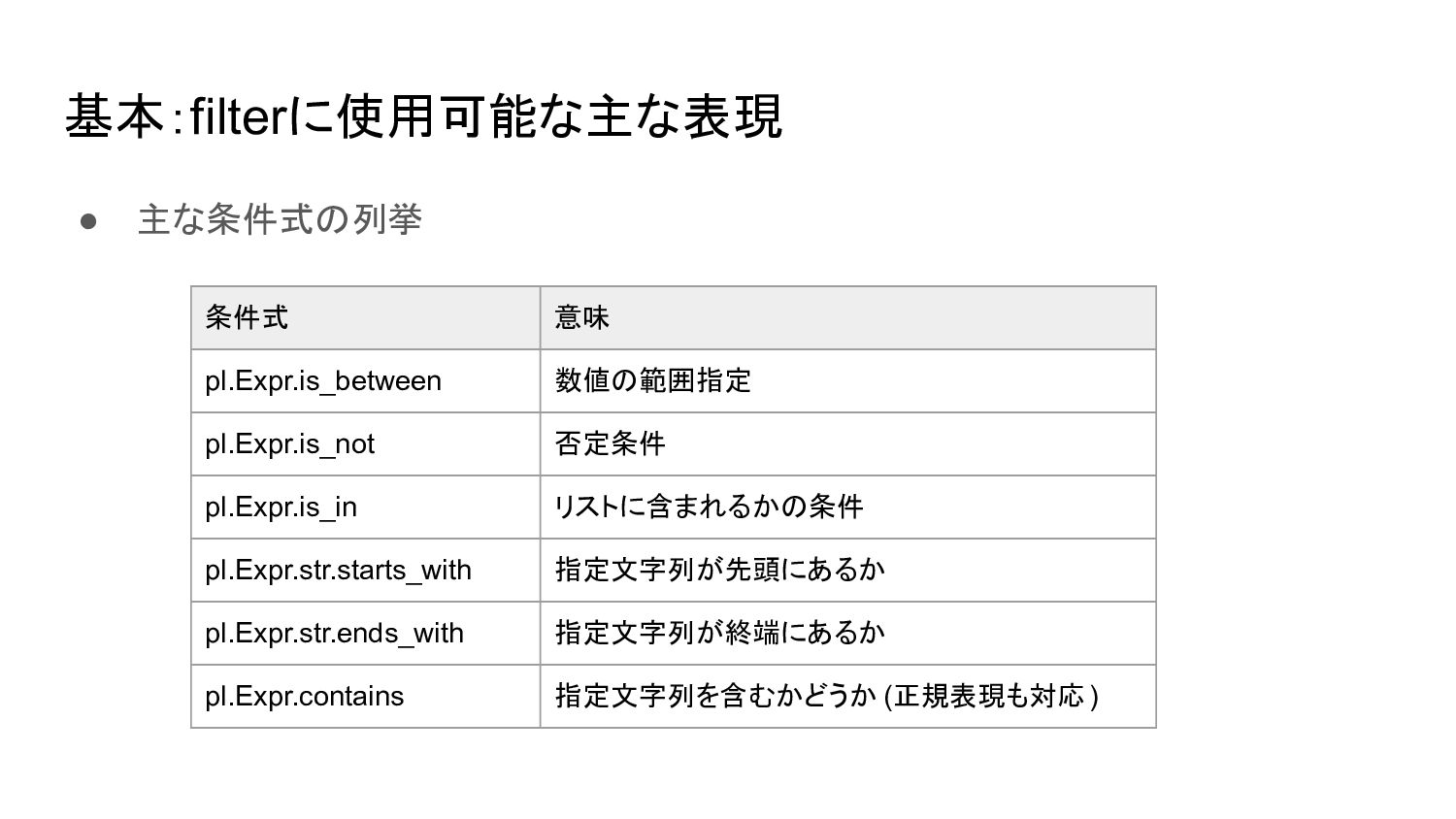
基本:filterに使用可能な主な表現 • 主な条件式の列挙 条件式 意味 pl.Expr.is_between 数値の範囲指定 pl.Expr.is_not 否定条件 pl.Expr.is_in
リストに含まれるかの条件 pl.Expr.str.starts_with 指定文字列が先頭にあるか pl.Expr.str.ends_with 指定文字列が終端にあるか pl.Expr.contains 指定文字列を含むかどうか (正規表現も対応)
基本:集約(グループ化なし) • pl.Expr.mean()などで集約値を求めることが可能 • rank付けなども可能 • 集約を自作するにはpl.Foldというものを使用すれば良いという話も # P-064: 解答例
df_product.drop_nulls().select([ ((pl.col("unit_price") - pl.col("unit_cost"))/pl.col("unit_price")).mean()]) # P-019: 解答例 df_receipt.select([ "customer_id", "amount" , pl.col("amount").rank(method='min', reverse=True).alias("ranking") ]).sort('ranking').head(10)
基本:WINDOW関数的な • SQLのOVER句のイメージで使うことが可能 • pandasではtransformが相当する処理 • 複数のキーを指定することも可能 df_receipt.select([ pl.all() ,
pl.col("amount").mean().over("customer_id").alias("amount_mean_by_customer_id") ]) df_receipt.select([ pl.all() , pl.col("amount").mean().over(["customer_id", "sales_ymd"]).alias("amount_mean_by_customer_id") ])
基本:グループ化 • groupbyとaggで記述 • 使用できる集約関数もpl.ExprのIDE補完が確認可能👍 • pandasはIDE補完が使えず記憶が頼りとなる、reset_indexも必要なシーン # P-023: 解答例
df_receipt.groupby(by="store_cd").agg([ pl.col("amount").sum(), pl.col("quantity").sum() ]).sort("store_cd") # P-023: pandasの回答例 df_receipt_pd.groupby('store_cd').agg({ 'amount':'sum', 'quantity':'sum' }).reset_index()
基本:グループ化2 • 同じカラムに対する複数の集約関数はaliasが必須 • pandasはマルチカラムとなるため扱いが難しくなる # P-026: 解答例 df_receipt.groupby('customer_id').agg([ pl.col("sales_ymd").min().alias("sales_ymd_min")
, pl.col("sales_ymd").max().alias("sales_ymd_max") ]).filter( pl.col('sales_ymd_min') != pl.col('sales_ymd_max') ).sort('customer_id').head(10) # P-026: pandasの解答例 df_tmp = df_receipt_pd.groupby('customer_id'). \ agg({'sales_ymd': ['max','min']}).reset_index() # この時点ではマルチカラム df_tmp.columns = ["_".join(pair) for pair in df_tmp.columns] # マルチカラムを連結してフラットに df_tmp.query('sales_ymd_max != sales_ymd_min').head(10)
基本:あるカラムをキーとした結合 • あるカラムをキーとして結合するにはjoinを使う • pandasではmergeが該当し、使い方は似ている • 複数のキーを指定した結合などももちろん可能 # P-036: 解答例
df_receipt.join( df_store.select(["store_cd", "store_name"]), how="inner", on="store_cd" ).head(10)
基本:縦横への結合 • 縦に結合するにはconcatを使う • pandasもconcatがあるが、polarsでは縦にしか結合できない点が注意 • 横に結合するにはアンパックを使用する必要がある pl.concat([ df_customer.select(["customer_id"]).head(10) ,
df_customer.select(["customer_id"]).head(10) ]) df_customer.select([ "customer_id" , *df_customer.select(["customer_name"]) ]).head(10)
応用:遅延評価 • lazy - collectの組み合わせで実行 • デバッグしたい場合は、collectの代わりにfetchを使用 # P-039: lazyを使った解答例
df_data = df_receipt.lazy().filter( pl.col('customer_id').str.starts_with('Z').is_not() ) df_cnt = df_data.groupby('customer_id').agg( pl.col('sales_ymd').n_unique() ).sort('sales_ymd', reverse=True).head(20) df_sum = df_data.groupby('customer_id').agg( pl.col('amount').sum() ).sort('amount', reverse=True).head(20) df_cnt.join(df_sum, how='outer', on='customer_id').collect()
応用:複数の入力を持つ遅延評価 • 複数の入力DataFrameがある場合、双方にlazyをする必要あり # P-053: lazyを使った解答例 df_customer.lazy().select([ "customer_id" , pl.when(
pl.col("postal_cd").str.slice(0,3) .cast(pl.Int32).is_between(100, 209) ).then(1).otherwise(0).alias("is_tokyo") ]).join( df_receipt.lazy().select([ pl.col("customer_id") ]), how="inner", on="customer_id" ).groupby("postal_cd").agg( pl.col("customer_id").unique().count() ).collect()
応用:例題1)標準化 # P-059: 解答例 df_receipt.filter( pl.col("customer_id").str.starts_with("Z").is_not() ).groupby("customer_id").agg([ pl.col("amount").sum() ]).select([ "customer_id"
, ((pl.col("amount") - pl.col("amount").mean())/pl.col("amount").std()).alias("amount_ss") ]).sort("customer_id").head(10) P-059: レシート明細データフレーム(df_receipt)の売上金額(amount)を顧客ID(customer_id)ごとに合計し、売上金額合計を平均 0、標準偏差1に標準化して顧客ID、売上金額合計とともに表示せよ。標準化に使用する標準偏差は、不偏標準偏差と標本標準偏差 のどちらでも良いものとする。ただし、顧客IDが"Z"から始まるのものは非会員を表すため、除外して計算すること。結果は10件表示さ せれば良い。
応用:例題2)pl.Exprを一旦変数に格納する例 # P-069: 解答例 # Exprを変数に格納 amount_sum_all = pl.col("amount").sum().alias("amount_sum_all") amount_sum_07
= pl.col("amount").filter(pl.col("category_major_cd") == "07").sum().alias("amount_sum_07") df_receipt.join( df_product , how="left", on="product_cd" ).groupby("customer_id").agg([ amount_sum_all , amount_sum_07 , (amount_sum_07/amount_sum_all).alias("amount_rate_07") ]).filter( pl.col('amount_rate_07').is_not_null() ).sort("customer_id").head(10) P-069: レシート明細データフレーム(df_receipt)と商品データフレーム(df_product)を結合し、顧客毎に全商品の売上金額合計と、 カテゴリ大区分(category_major_cd)が"07"(瓶詰缶詰)の売上金額合計を計算の上、両者の比率を求めよ。抽出対象はカテゴリ大 区分"07"(瓶詰缶詰)の売上実績がある顧客のみとし、結果は10件表示させればよい。
応用:例題3)単純に複雑な例 # P-084: 解答例 df_customer.join( df_receipt.groupby("customer_id").agg([ pl.col("amount").filter( pl.col("sales_ymd").is_between(20190101, 20191231, closed='both')
).sum().alias("amount_2019") , pl.col("amount").sum().alias("amount_all") ]).with_columns([ (pl.col("amount_2019")/pl.col("amount_all")).alias("amount_rate") ]), on="customer_id", how='left' ).fill_null(0).filter( pl.col("amount_2019") > 0 ).select([ "customer_id", "amount_2019", "amount_all", "amount_rate" ]).sort("customer_id").head(10) P-084: 顧客データフレーム(df_customer)の全顧客に対し、全期間の売上金額に占める2019年売上金額の割合を計算せよ。ただ し、売上実績がない場合は0として扱うこと。そして計算した割合が0超のものを抽出せよ。 結果は10件表示させれば良い。また、作 成したデータにNAやNANが存在しないことを確認せよ。
応用:例題4)pl.Exprを関数化する例 # P-086: 解答例 import math def distance(x1: pl.Expr, y1:
pl.Expr, x2: pl.Expr, y2: pl.Expr) -> pl.Expr: lon1_rad = x1 * math.pi / 180 lon2_rad = x2 * math.pi / 180 lat1_rad = y1 * math.pi / 180 lat2_rad = y2 * math.pi / 180 L = 6371 * ( lat1_rad.sin() * lat2_rad.sin() + lat1_rad.cos() * lat2_rad.cos() * (lon1_rad - lon2_rad).cos() ).arccos() return L df_customer.join( df_geocode.groupby("postal_cd").agg([pl.col("longitude").mean(), pl.col("latitude").mean()]) , on="postal_cd", how="left" ).join( df_store, left_on="application_store_cd", right_on="store_cd" ).select([ "customer_id", pl.col("address").alias("customer_address"), pl.col("address_right").alias("store_address") , distance( pl.col("longitude") , pl.col("latitude"), pl.col("longitude_right") , pl.col("latitude_right") ).alias("distance") ]).sort("customer_id").head(10) P-086: 前設問で作成した緯度経度つき顧客データフレーム( df_customer_1)に対し、申込み店舗コード( application_store_cd)をキーに店舗 データフレーム( df_store)と結合せよ。そして申込み店舗の緯度( latitude)・経度情報(longitude)と顧客の緯度・経度を用いて距離( km)を求 め、顧客ID(customer_id)、顧客住所(address)、店舗住所(address)とともに表示せよ。計算式は簡易式で良いものとするが、その他精度の 高い方式を利用したライブラリを利用してもかまわない。結果は 10件表示すれば良い。
今日言及できなかった話😓 • 重複処理、ユニーク処理 • 欠損値の扱い • 日付型の話 • データ型の深堀 •
pl.Foldの話 • UDFをapplyするパターンの話 • 処理速度の話 • 入力ファイルから遅延評価 • 他ライブラリとの連携(scikit-learnなど) • 豊富な数学関数 後日のブログにはきちんとまとめる予定
まとめ:polarsの良さげなところ👍 • indexがない、マルチカラムもない • カラム名の重複不可(いい意味で) • pl.Exprという計算式で記述でき、実体化が不要 • 遅延評価も可能 •
SQLクエリ風の名前(SELECT、JOIN、OVERなど) • 複雑な処理もワンライナーで書ける(df_tmpなど一時的な実体化が不要) • 標準の数学関数が多めでNumPyのお世話にならなくて済む • 高速らしい 是非お試しください!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![基本:カラム選択 • pl.DataFrame.selectで可能 # P-002: 解答例 df_receipt.select(["sales_ymd", "customer_id", "product_cd", "amount"]).head(10)](https://files.speakerdeck.com/presentations/18791a9aa4ff4583b25af408bd232001/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![基本:縦横への結合 • 縦に結合するにはconcatを使う • pandasもconcatがあるが、polarsでは縦にしか結合できない点が注意 • 横に結合するにはアンパックを使用する必要がある pl.concat([ df_customer.select(["customer_id"]).head(10) ,](https://files.speakerdeck.com/presentations/18791a9aa4ff4583b25af408bd232001/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
![応用:例題1)標準化 # P-059: 解答例 df_receipt.filter( pl.col("customer_id").str.starts_with("Z").is_not() ).groupby("customer_id").agg([ pl.col("amount").sum() ]).select([ "customer_id"](https://files.speakerdeck.com/presentations/18791a9aa4ff4583b25af408bd232001/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}