Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
機械学習モデル性能向上への学習データからのアプローチ
Search
おかだ
June 02, 2023
Technology
0
770
機械学習モデル性能向上への学習データからのアプローチ
2023.06.01 に開催された Data-Centric AI勉強会のライトニングトークにて使用した資料。データに着目することでモデルの品質を向上させる手法の考え方とその応用例の簡単な紹介。
おかだ
June 02, 2023
Tweet
Share
More Decks by おかだ
See All by おかだ
ChatGPTのLT会-メモソフトにChatGPT入れると結構便利
okada_fuutass
0
410
Other Decks in Technology
See All in Technology
生成AIによるCloud Native基盤構築の可能性と実践的ガードレールの敷設について
nwiizo
7
1.4k
Dynamic Reteaming And Self Organization
miholovesq
3
740
バクラクの認証基盤の成長と現在地 / bakuraku-authn-platform
convto
4
880
Azure Maps Visual in PowerBIで分析しよう
nakasho
0
190
ドキュメント管理の理想と現実
kazuhe
3
310
OPENLOGI Company Profile
hr01
0
63k
PostgreSQL Log File Mastery: Optimizing Database Performance Through Advanced Log Analysis
shiviyer007
PRO
1
150
MySQL Indexes and Histograms – How they really speed up your queries
lefred
0
140
MCPを理解する
yudai00
12
9k
AIにおけるソフトウェアテスト_ver1.00
fumisuke
1
330
ペアーズにおける評価ドリブンな AI Agent 開発のご紹介
fukubaka0825
7
1.7k
Dataverseの検索列について
miyakemito
1
170
Featured
See All Featured
The Language of Interfaces
destraynor
157
25k
GraphQLとの向き合い方2022年版
quramy
46
14k
CoffeeScript is Beautiful & I Never Want to Write Plain JavaScript Again
sstephenson
160
15k
Making the Leap to Tech Lead
cromwellryan
133
9.2k
Bash Introduction
62gerente
611
210k
Build your cross-platform service in a week with App Engine
jlugia
230
18k
Designing for Performance
lara
608
69k
A Modern Web Designer's Workflow
chriscoyier
693
190k
Git: the NoSQL Database
bkeepers
PRO
430
65k
Visualization
eitanlees
146
16k
Product Roadmaps are Hard
iamctodd
PRO
52
11k
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
3.8k
Transcript
合同会社ふうたシステムサービス 機械学習モデル性能向上への 学習データからのアプローチ for 第1回 Data-Centric AI勉強会 2023.06.01 (同)ふうたシステムサービス 代表社員
岡田年且
合同会社ふうたシステムサービス 自己紹介 合同会社ふうたシステムサービス 代表社員 岡田年且 • 基本情報 1970年生まれの初老に手が届くおじさん • 最終学歴
名古屋工業大学(修士課程修了) 人工知能分野について研究 (知識獲得・分散協調) • 職歴 1995年~2022年 トヨタ系列のIT子会社に所属 システム開発業務・技術研究に従事 ITからAIまでの幅広い業務を担当 2022年10月に独立し [合同会社ふうたシステムサービス]を創設 • 実績(主なもの) AI技術を用いたCADの自動面生成機能開発 特定部品の劣化予測技術開発 人材育成活動に指導者として参加 等 ふうた わたし
合同会社ふうたシステムサービス 今回のテーマ タイトル 機械学習モデル性能向上への学習データからのアプローチ 持ち時間(目標) 発表6分+質疑応答4分 でも、多分発表が長引く 狙い 性能向上の足を引っ張るデータの品質問題について課題意識を共有したい。 モデルとデータの双方を理解することの重要性を訴えたい。
共感した方、一緒に仕事しましょう。 内容 データについての考え方・品質評価でわかることの例示 時間が全く足りないので急ぎ足で発表します
合同会社ふうたシステムサービス お断り 勉強会での発表テーマであることを理解してください 私の意見がまちがっていないことを信じていますが まちがっている可能性は常に検討しておいてください 当然ですが自己責任で! Bing の Image Creator
の生成した画像を使おうかと思ったのですが、以下の条文があったため断念。 作成物の使用。お客様は、本契約、Microsoft サービス規約、および弊社のコンテンツポリシーを遵守することを条件に、オンライン サービス以外の場所で、 個人の合法的な非商業的目的のために作成物を使用できます。 会社名出している以上、非商業目的と言い切りにくいからなぁ…
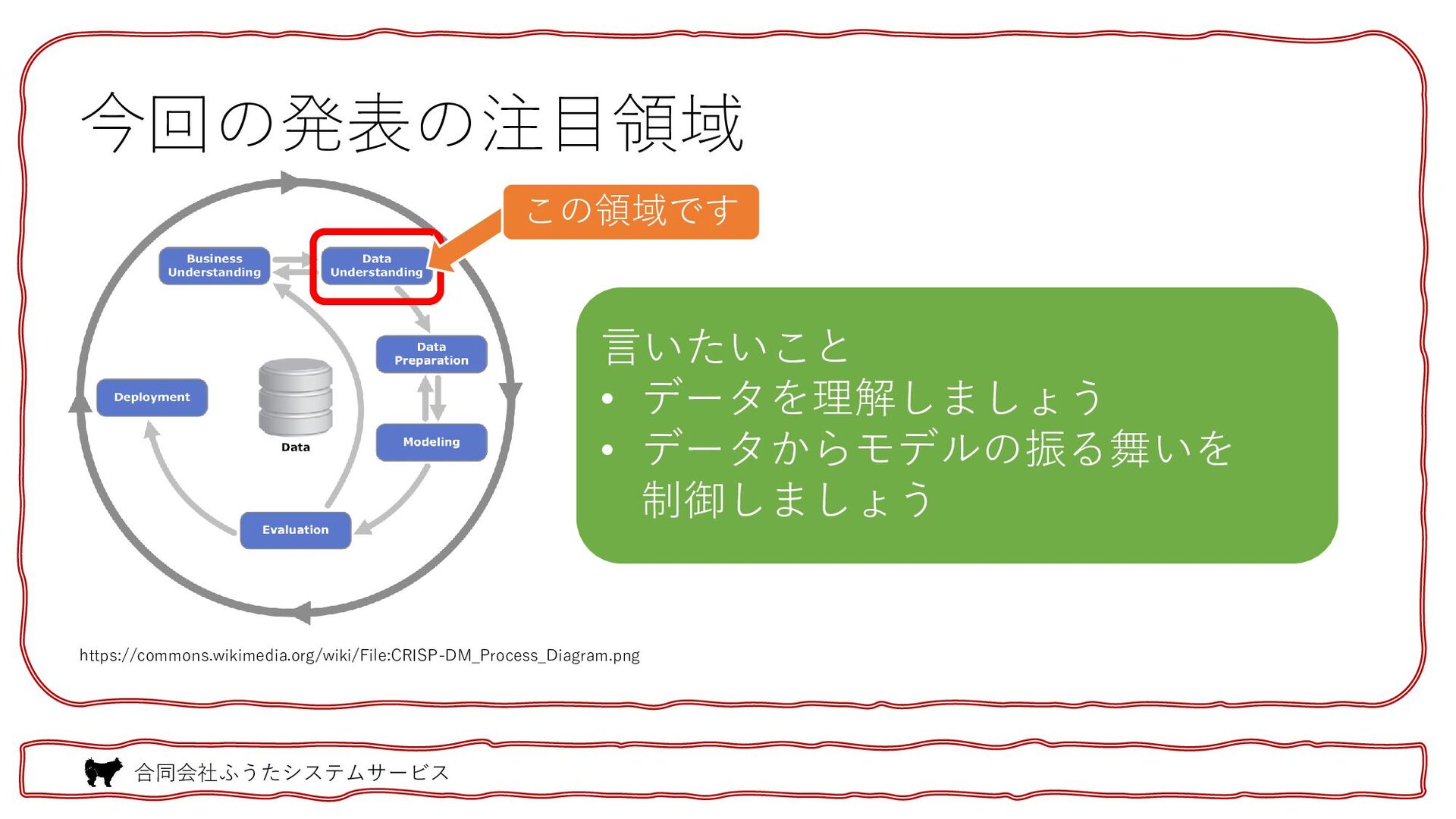
合同会社ふうたシステムサービス 今回の発表の注目領域 https://commons.wikimedia.org/wiki/File:CRISP-DM_Process_Diagram.png 言いたいこと • データを理解しましょう • データからモデルの振る舞いを 制御しましょう この領域です
合同会社ふうたシステムサービス データの考え方(手短に1pageで) 機械学習の扱うデータ 高次元のデータ群(これは、画像・セン サ・時系列・自然言語etc. 全て同じ) 視覚的イメージ(便宜的に2次元表記) 多次元空間上に存在する領域と比較し、そのラベルをもって本来の ラベルを推測するのが機械学習 回帰の場合は、ここに等高線を引いているだけで本質は同じ。
私はこの空間をベースに品質を考えています
合同会社ふうたシステムサービス 機械学習のデータの基本 D C B A データの分類イメージ A データ1 データ1の存在領域
B データ2 データ2の存在領域 C 重複 データ1とデータ2が判別できない領域 D 未定義 どちらのデータにも属さない領域 多くの人は A,B にのみ着目している。 しかし、実際には C,D の領域に着目する必要がある。 C,D の領域の存在を理解し対策を行うことで モデルそのままでも性能の向上が可能である(意見)。 今回のトピックはCの領域です。Dの領域については今回はしゃべりません。(言いたいけど)
合同会社ふうたシステムサービス データ加工の例:異常検知 D C B A データの分類イメージ A 正常 正常データの存在領域
B 異常 異常データの存在領域 C 重複 正常・異常の判別できない領域 D 未定義 正常か異常かわからない領域 異常検知では紛らわしいもの(=C)は「異常」と判別したい。 そうすることで、見逃しを減らすことができる。 従来、多くの場合はsoftmax等の出力の判別閾値をコントロール することでこの性能を制御していた。しかし、閾値のコントロー ルでは、C以外の領域にも影響が出る。 問題の根本はC領域を放置していることである。 分類問題として解くケース
合同会社ふうたシステムサービス データ加工の例:異常検知 D C B A データの分類イメージ A 正常 正常データの存在領域
B 異常 異常データの存在領域 C 重複 異常データとして扱う領域 D 未定義 正常か異常かわからない領域 Cの領域のラベルを全てBに置き換える。 そうすることで紛らわしい値を閾値の制御をせずともBと 判定できるようになる。 ※閾値の制御をやらないで良い訳ではない 実際のデータで適用した結果、モデルのチューニングでは 達成が困難なレベルの正答率の向上が見られた。 ※正答率が大幅に向上した例の詳細は次ページに 目的により加工方法は 色々あります!
合同会社ふうたシステムサービス 性能大幅向上の詳細 前職の業務内容に触れるところがあるので細かくは言えません。 エビデンスも手元にないので… 対象者 画像データでの異常検知をしている人。MLの知識は新技術を調べて実践できるレベル。 色々なモデルを使い性能も上がってきたのだが、頭打ち状態。 条件 異常検知であるので以下であることがよい。 1.
見逃しは極力少ない(見逃しはCをAと判定していると考える) 2. 誤検知も極力少ない 3. 過検知も少ないに限るが見逃しよりはマシ 対策 1 主に領域Cなので検討対象 → C の領域を B とラベル変更し曖昧さを解消 2 主に領域Aなので対象外 → 今まで通りとする 3 主に領域Aなので対象外 → 今まで通りとする Cの領域の振る舞いをコントロールすることで、異常検知モデルの振る舞いを制御。 結果、曖昧さに起因する誤検知(=見逃し)が減り性能向上。 当然ですが効果はデータセットや問題設定により変わります。 全てのケースで性能が向上するわけではありません。 Accuracy, Precision, Recall, F値 の値の変化そのものなのか 向上割合なのか…細かい情報が出せずすみません。
合同会社ふうたシステムサービス どうやってこの分類を行う? カーネル密度推定みたいな方法が使えます 個人的にはもうちょっと工夫した手法を使っていますが今回は割愛します。 リクエストいただければ、別途LTでしゃべるべくエントリします。 考え方とか、色々あるので… データ密度をベースに領域を判定すれば良いのです
合同会社ふうたシステムサービス 考えるべきはデータの分布 データが、ここの赤色の分布をしているのであれば、分布の色の濃さを 見ればそれなりにデータの確からしさはわかります。 (=カーネル密度推定) とはいえ、カーネル密度推定も分布を仮定しないといけない。だから、 私は近しいけど違う方法で推定しています。まぁ、それでもやはり 何らかの形で分布は仮定しますけど…。 考え方はさほど違わないので、カーネル密度推定でも全然構いません。 手軽にやるならカーネル密度推定でOK!
分布見るだけなので全数で実施する必要もないですね!
合同会社ふうたシステムサービス 群間での領域の重複を調べよう 領域の重複が性能悪化の原因の一つです。そこを潰すことを考え ましょう。密度を推定し、その値が拮抗している領域のデータが 紛らわしいデータと考えれば良いのです。 この考え方は、画像だろうがセンサだろうが時系列だろうがNLPで あろうが全く同じです。 モデルの振る舞いをデータからコントロールする これが私の手法です
合同会社ふうたシステムサービス 例)CIFAR10の品質について 実際にはMNISTの方がわかりやすいのですが、CIFAR10の方がより感覚にマッチするのと意外と CIFAR10が良くないデータセットだよねとかその辺のことをちょっと具体的に示します。 例示するものの概要 学習データをsort 分類しやすいデータからしにくいデータまで数値化してランク付け 紛らわしいデータ抽出 多のクラスのデータに含まれるまちがいやすいデータをピックアップ 難易度の数値化
CIFAR10での分類の難易度を数値化してソート 具体的に悪いデータもわかれば対策も打ちやすくなることを例示
合同会社ふうたシステムサービス CIFAR10の飛行機を並び替えてみた 実際には、学習用のデータ6000件を並び替えています。 そのうち、典型的な飛行機のデータをここに挙げています。 実際には、違うパターンの映像もいっぱいあります。 とはいえ、CIFAR10での多数派はこんなデータみたいですね。
合同会社ふうたシステムサービス CIFAR10の飛行機を並び替えてみた 飛行機以外のデータもアリとするとこうなります。 6,000x10=60,000 データを並び替えています。 すると、実は飛行機以外のデータも似ているという 結果が出てきます。つまり、結構紛らわしいデータが 大量にあるという事です。 当然、少数派を気にするパラメタで計算すると違う 結果になります。どういう形でデータを考えたいか?
ということを考えて行くべきです。過学習どんとこい ならば、少数派も結構採用されますし、そんなに センシティブな学習をしないという事も出来ます。 性能上げるのは過学習なのでは?という雰囲気のデータセットです。 というか、過学習気味に学習しないと紛らわしいデータが分類できない。
合同会社ふうたシステムサービス CIFAR10の飛行機を並び替えてみた じゃあ少数派は?という疑問が出てきます。 だから、今度は少数派にしました。 どうやら、背景が黒という画像は少ないらしく少数派に 分類されています。 本当はデータをしっかり眺めたいところなのですが、 ちょっと今回は割愛します。 正直、6万データを並べて眺めるというのはかなりの 気合いが必要です…
時間余裕が あるときのみ
合同会社ふうたシステムサービス CIFAR10の飛行機を並び替えてみた 飛行機以外も入れるとこう。 こんな形でデータを眺めることで、データの特徴を 効率的に把握することが出来ます。 時間余裕が あるときのみ
合同会社ふうたシステムサービス おわりに 本当はもっといっぱいしゃべりたいところですが、何せ時間がありません。 なので、今回はこれだけにしておきます。 もし、興味などありましたら、お声がけください。 共感できる人とは、美味しいお酒が飲めそうな気がします。 データに注力することで、皆様の作業でよりよい成果が出せるようになることを願います。 2023.06.01 合同会社ふうたシステムサービス 代表社員
岡田年且 Mail :
[email protected]
LinkedIn : https://www.linkedin.com/in/toshikatsu-okada-1648a4211
合同会社ふうたシステムサービス 謝辞 今回のプレゼン資料作成に際し、GO株式会社の宮澤様より 有意義なコメントを多数頂きました。 深く感謝いたします。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}