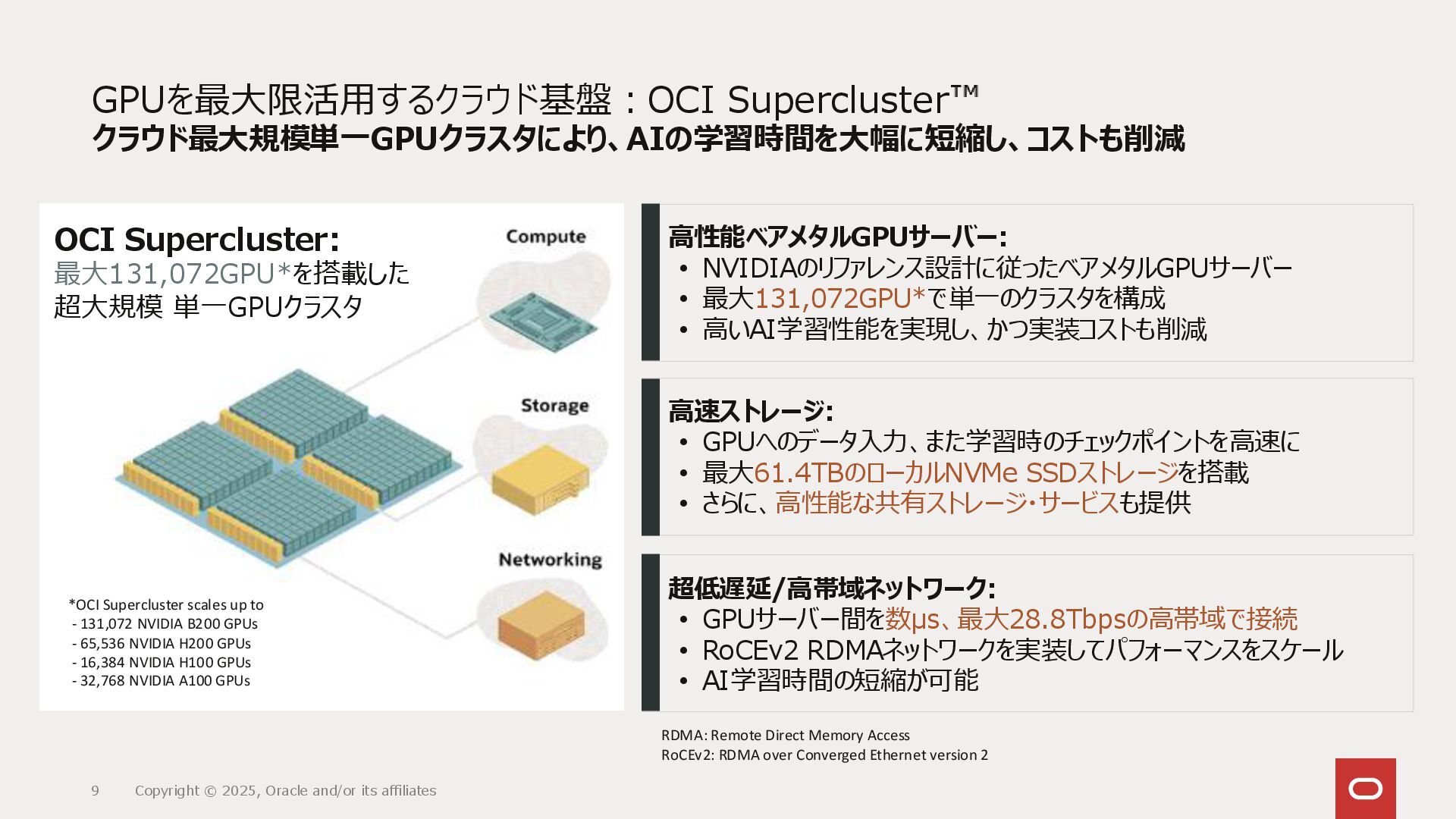
Bare Metal 192 GB GPU Memory 4 x L40S GPU.L40S.4 VM & Bare Metal 320 GB GPU Memory 8 x A100 40GB GPU.4.8 100 Gb/sec Front-end network VM & Bare Metal 24 GB 48 GB GPU Memory GPU.A10.1 GPU.A10.2 GPU.A10.4 1 x A10 2 x A10 Bare Metal 768 GB GPU Memory 72 x B200 192GB GPU.GB200.4 NVL72 (18 servers/rack) 7,200 Gb/sec Front-end network 36 x Grace CPU Bare Metal 1,128 GB GPU Memory 30.7 TB Local NVMe 200 Gb/sec Front-end network 8 x H200 141GB GPU.H200.8 Bare Metal 1,536 GB GPU Memory 30.7 TB Local NVMe 400 Gb/sec Front-end network 8 x B200 192GB GPU.B200.8 Bare Metal 640 GB GPU Memory 8 X A100 80GB GPU.A100-v2.8 Bare Metal 8 x H100 80GB GPU.H100.8 640 GB GPU Memory 61.4 TB Local NVMe 100 Gb/sec Front-end network 4月GA 1.7 TB CPU+GPU Memory 15.3 TB Local NVMe 4月GA Bare Metal 8 x MI300X 192GB GPU.MI300X.8 1,536 GB GPU Memory 30.7 TB Local NVMe 100 Gb/sec Front-end network Bare Metal 2,304 GB GPU Memory 8 x 2 B300 288GB GPU.B300 NVL16 予約受付中 Bare Metal 20.7 TB GPU Memory 72 x B300 GPU.GB300.4 NVL72 (18 servers/rack) 7,200 Gb/sec Front-end Network 36 x Grace CPU 38.7 TB CPU+GPU Memory 553 TB Local NVMe 予約受付中 小 → 大規模 3,840GPU 800 Gb/sec RDMA 1,600 Gb/sec RDMA 200 Gb/sec Front-end network 100 Gb/sec Front-end network 32,768GPU 16,384GPU 3,200 Gb/sec RDMA 16,384GPU 65,536GPU 131,072GPU 131,072GPU 28,800 Gb/sec RDMA 6,400 Gb/sec RDMA 57,600 Gb/sec RDMA OCI Object & File Storage FSS HPMT—20/40/80 Gb/sec per MT | Managed Lustre—1 Gb/sec per TB AI向けストレージ AI向けネットワーク: OCI Supercluster
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
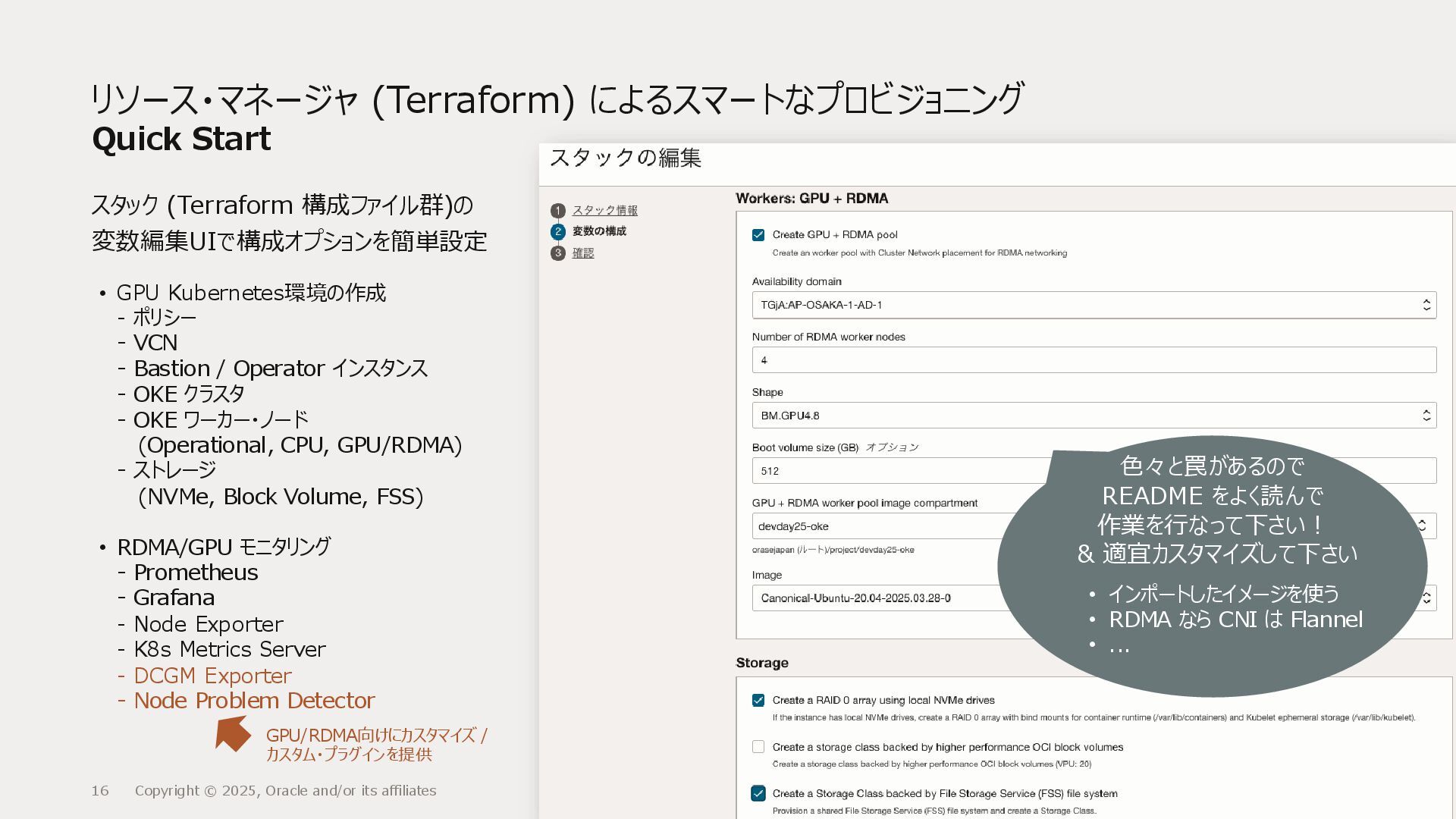{kind=link}
{kind=link}
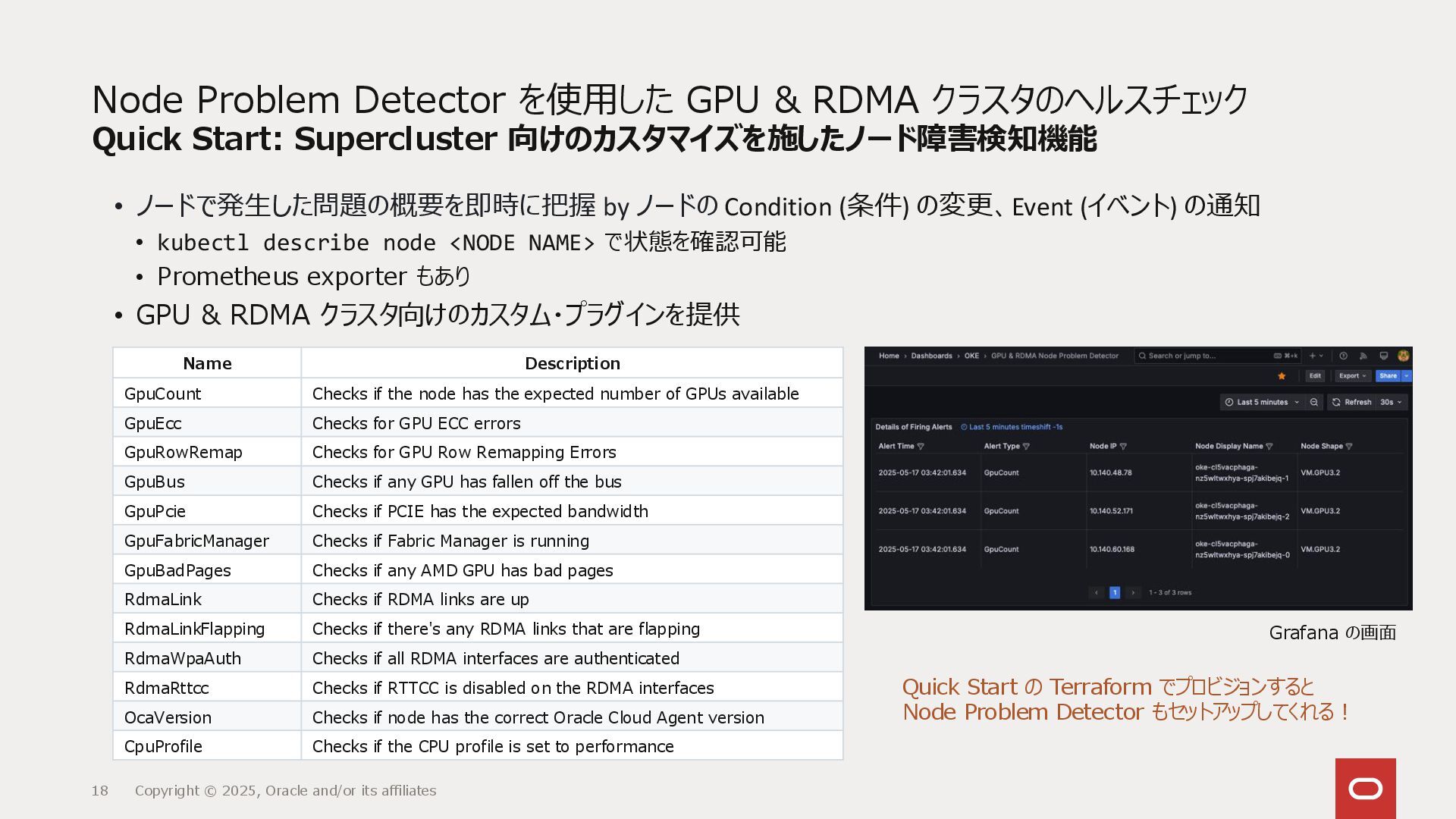{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
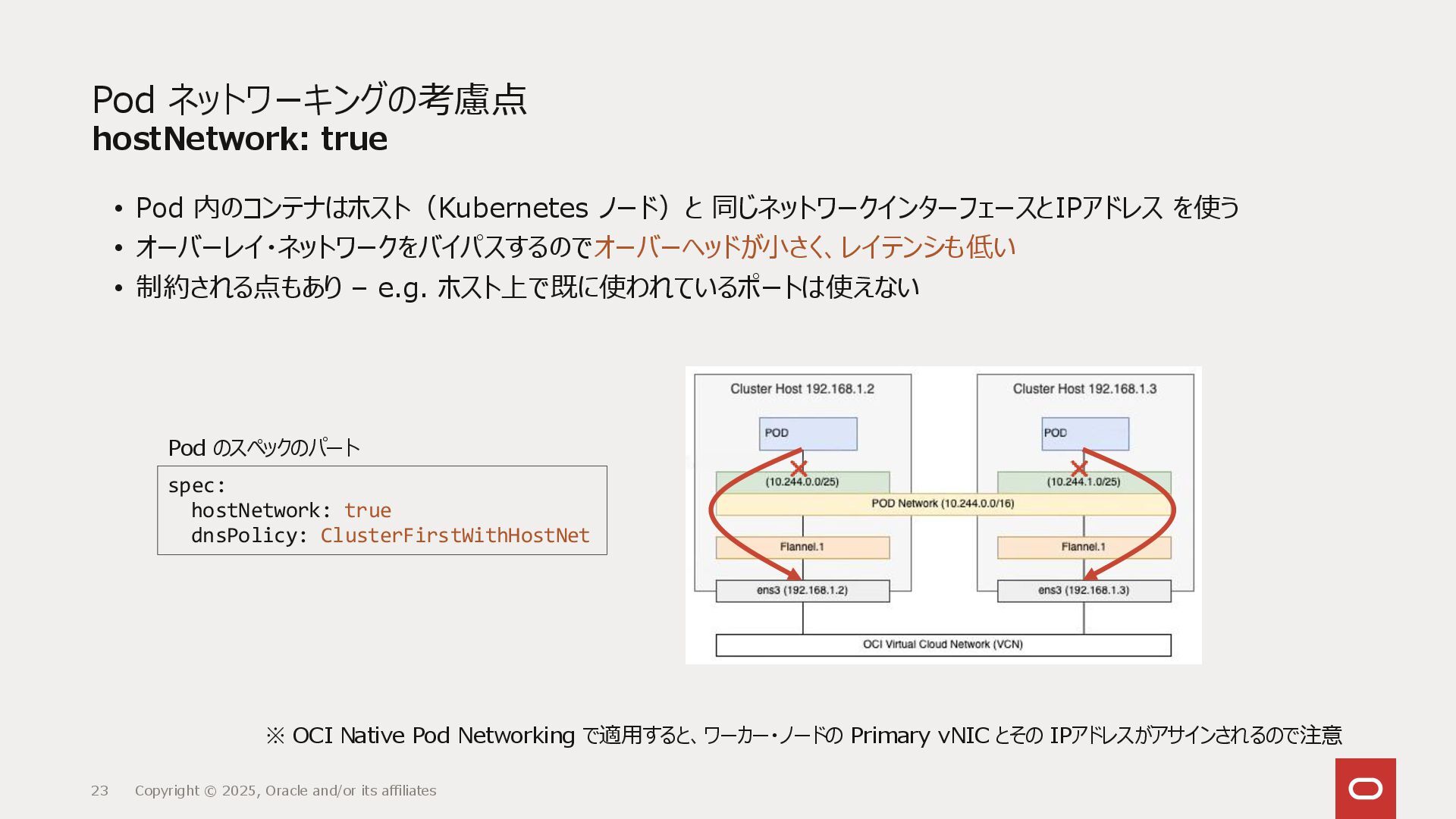{kind=link}
{kind=link}
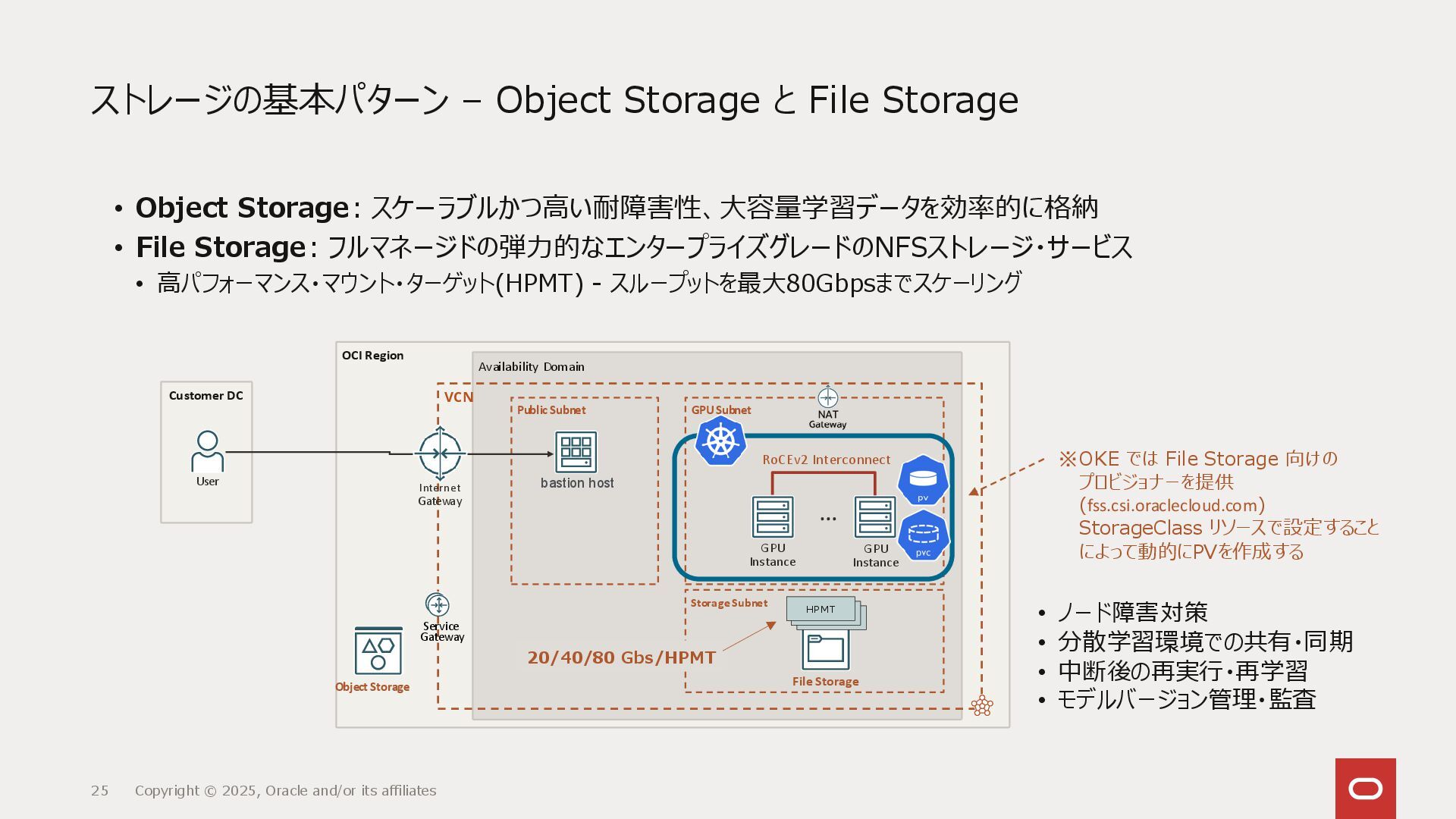{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
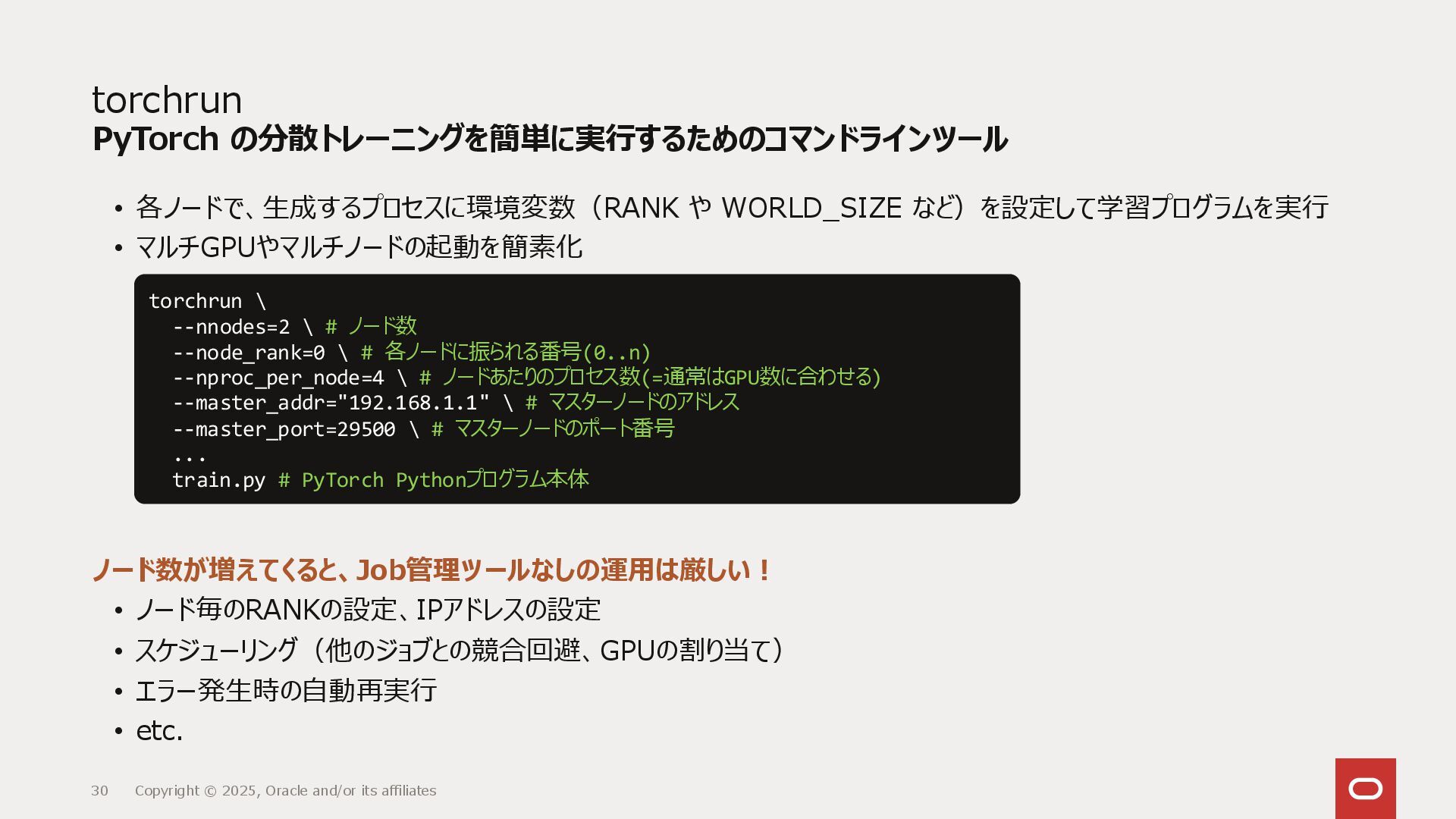{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
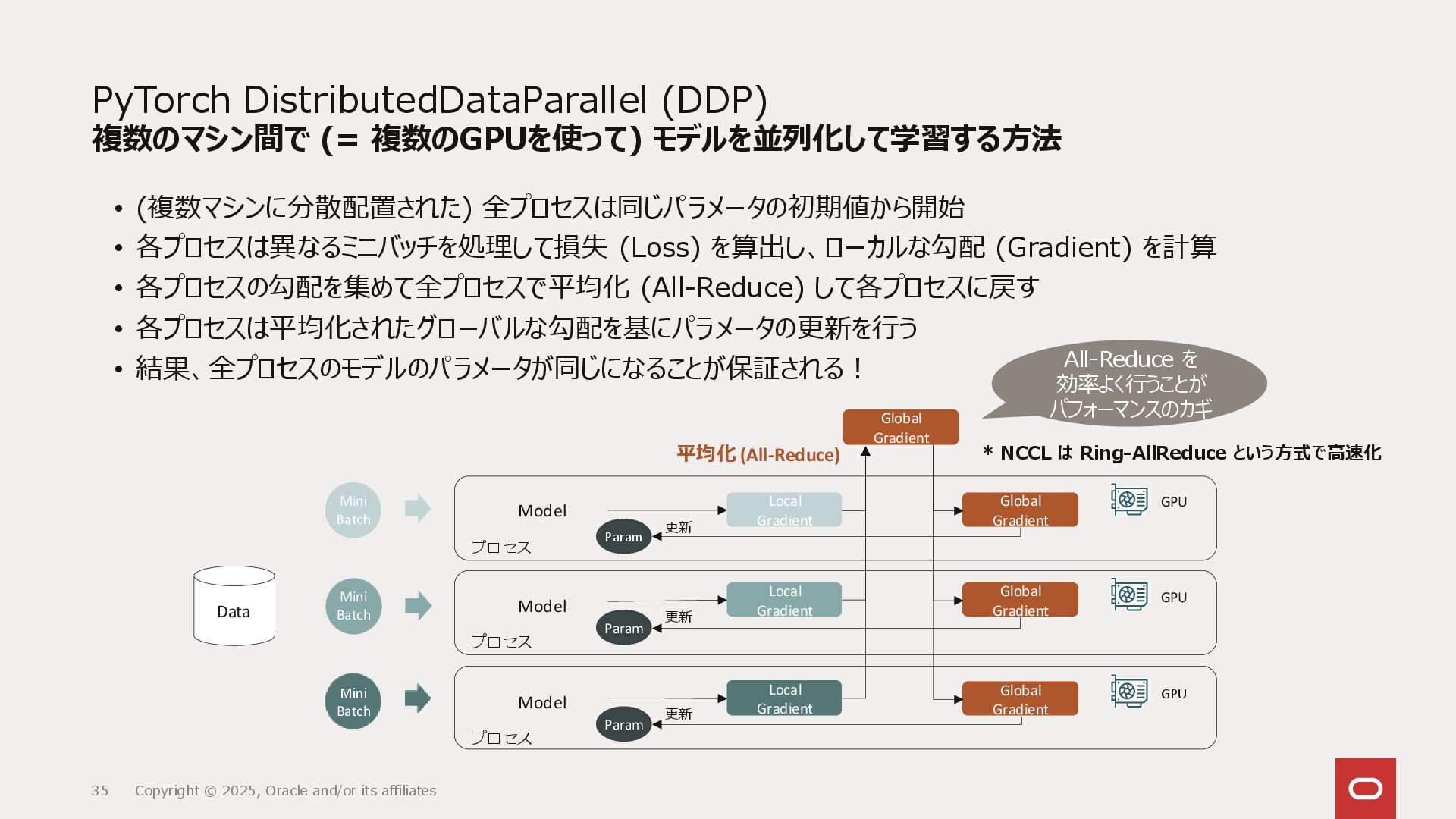{kind=link}
{kind=link}
{kind=link}
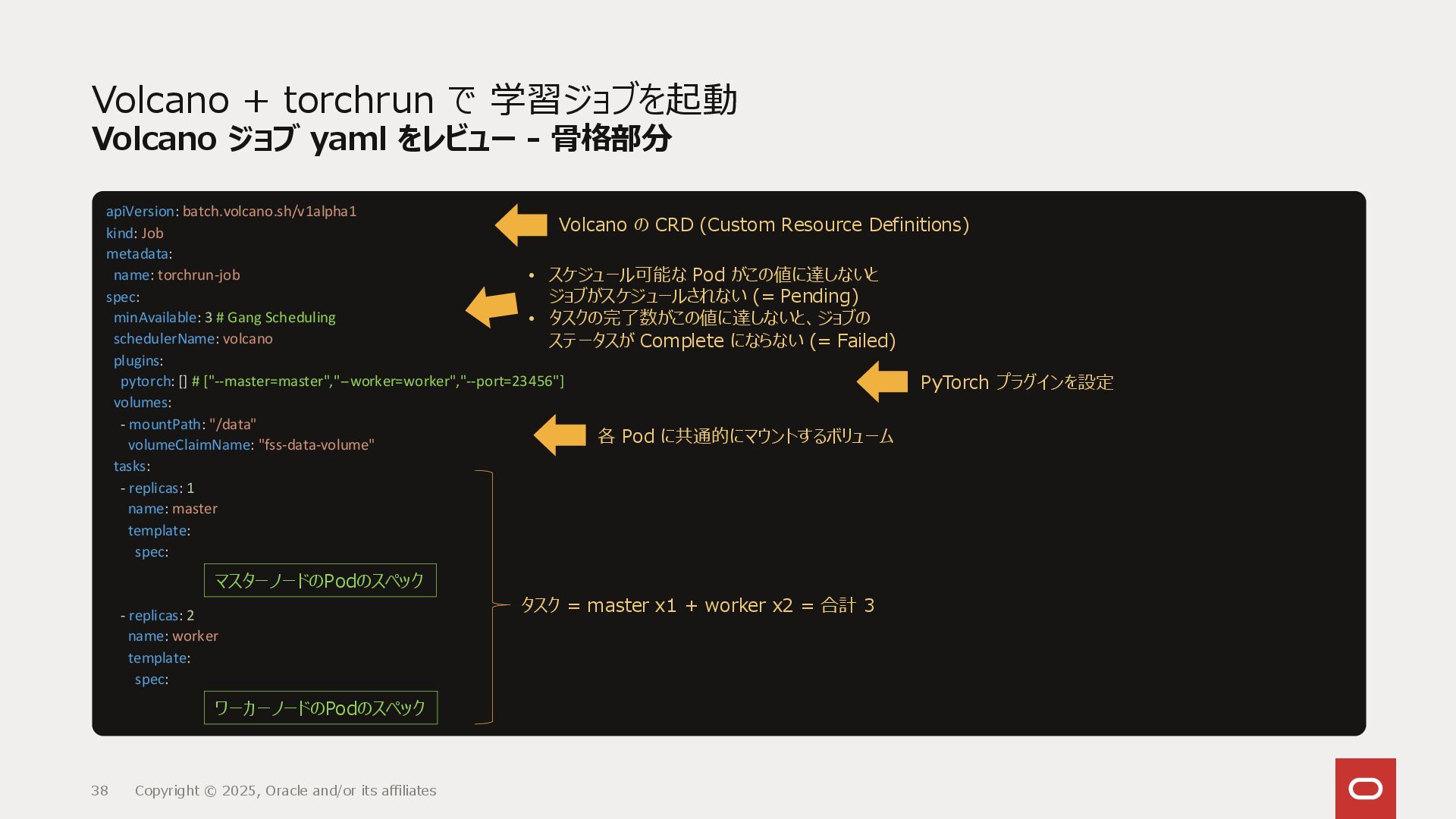{kind=link}
{kind=link}
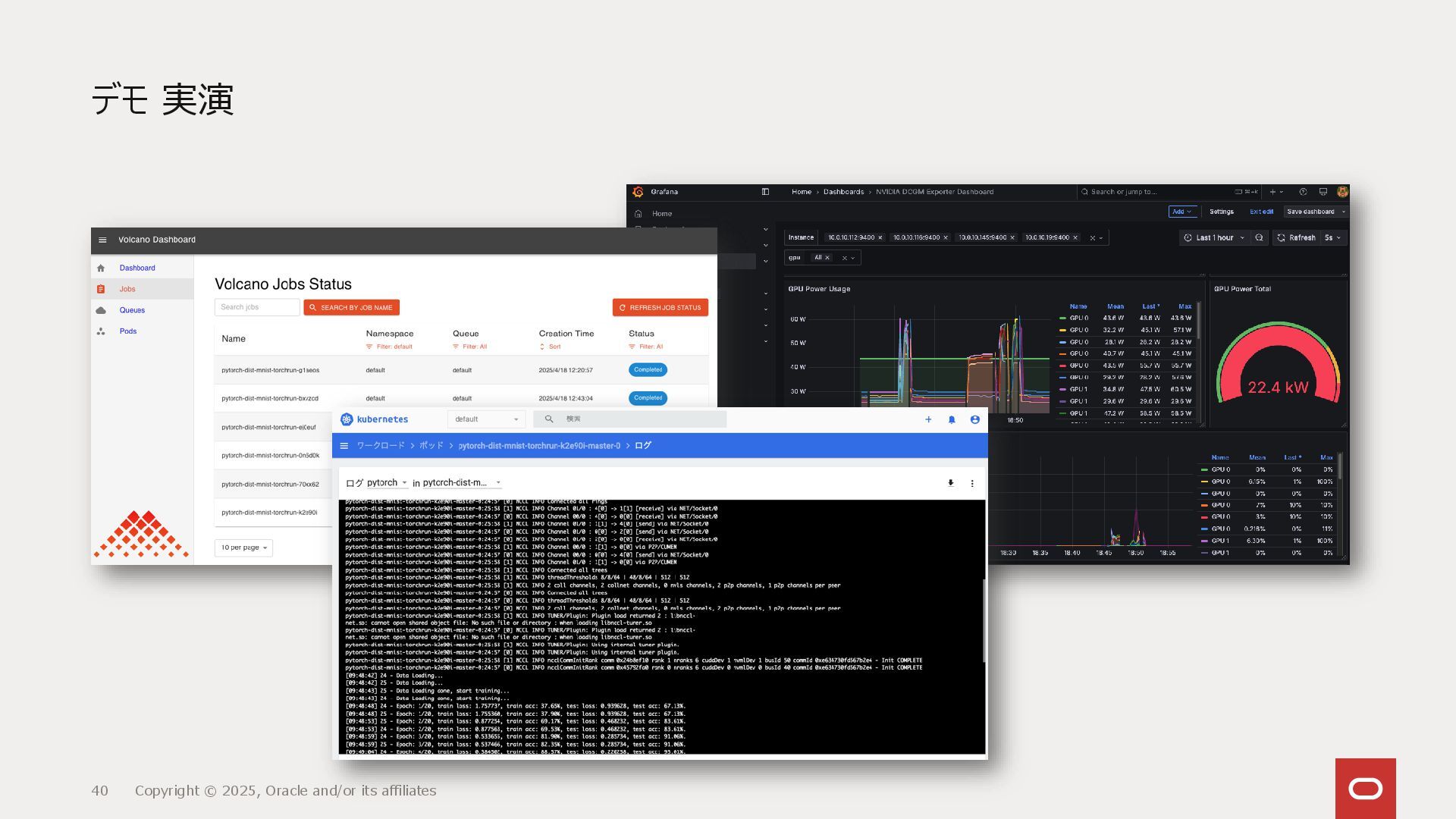{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}