Scrapy is an open source framework to extract unstructured data from websites easily. Built for web scraping, Scrapy can be used for different scopes like crawling, monitoring and web applications tests.
After an introduction to all major features, a real use case will be shown to create a fully functional crawling system which is able to scrape and store all unstructured data gathered from web pages.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Customer: "Surf the Internet and you're done!" [...] "No?"](https://files.speakerdeck.com/presentations/36846690c589013149823ab968454195/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
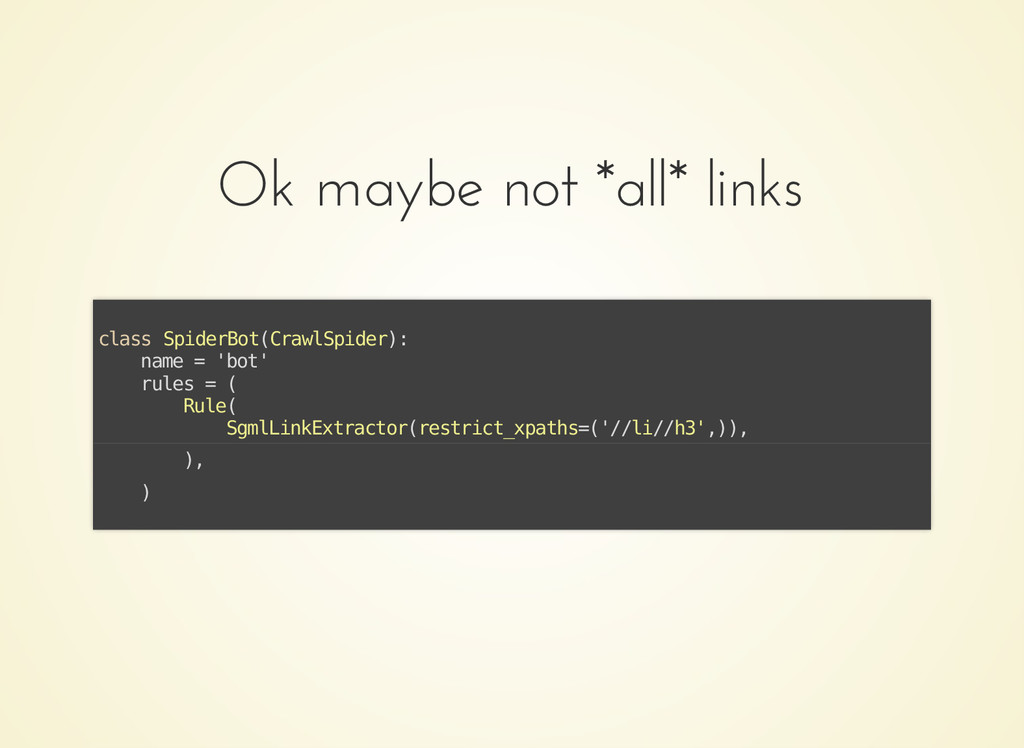{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[...] TO JSON DATA [...] We need to collect scraped](https://files.speakerdeck.com/presentations/36846690c589013149823ab968454195/slide_31.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}