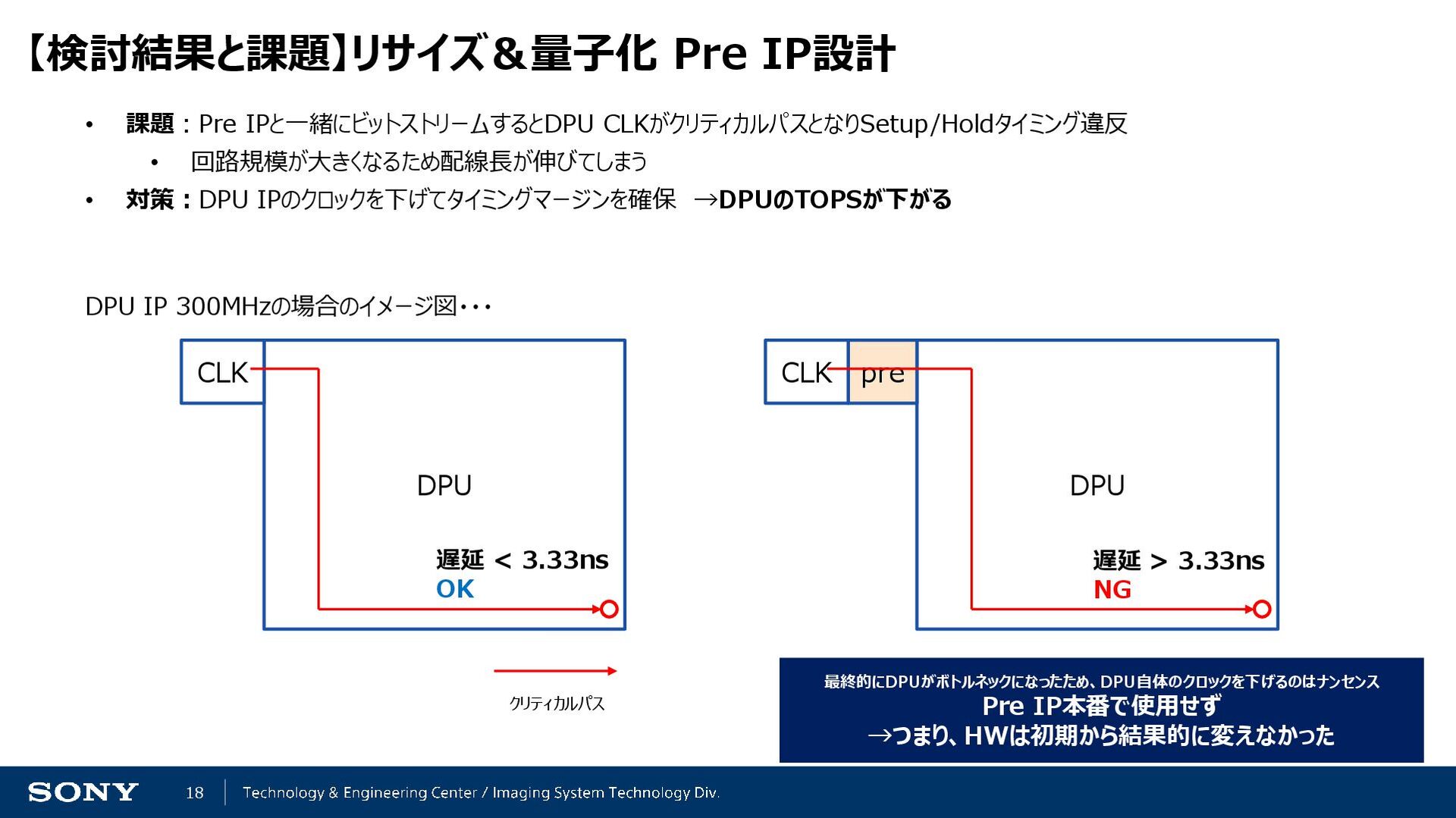
• 対策:DPU IPのクロックを下げてタイミングマージンを確保 →DPUのTOPSが下がる DPU CLK DPU CLK pre 遅延 < 3.33ns OK 遅延 > 3.33ns NG DPU IP 300MHzの場合のイメージ図・・・ クリティカルパス 最終的にDPUがボトルネックになったため、DPU自体のクロックを下げるのはナンセンス Pre IP本番で使用せず →つまり、HWは初期から結果的に変えなかった
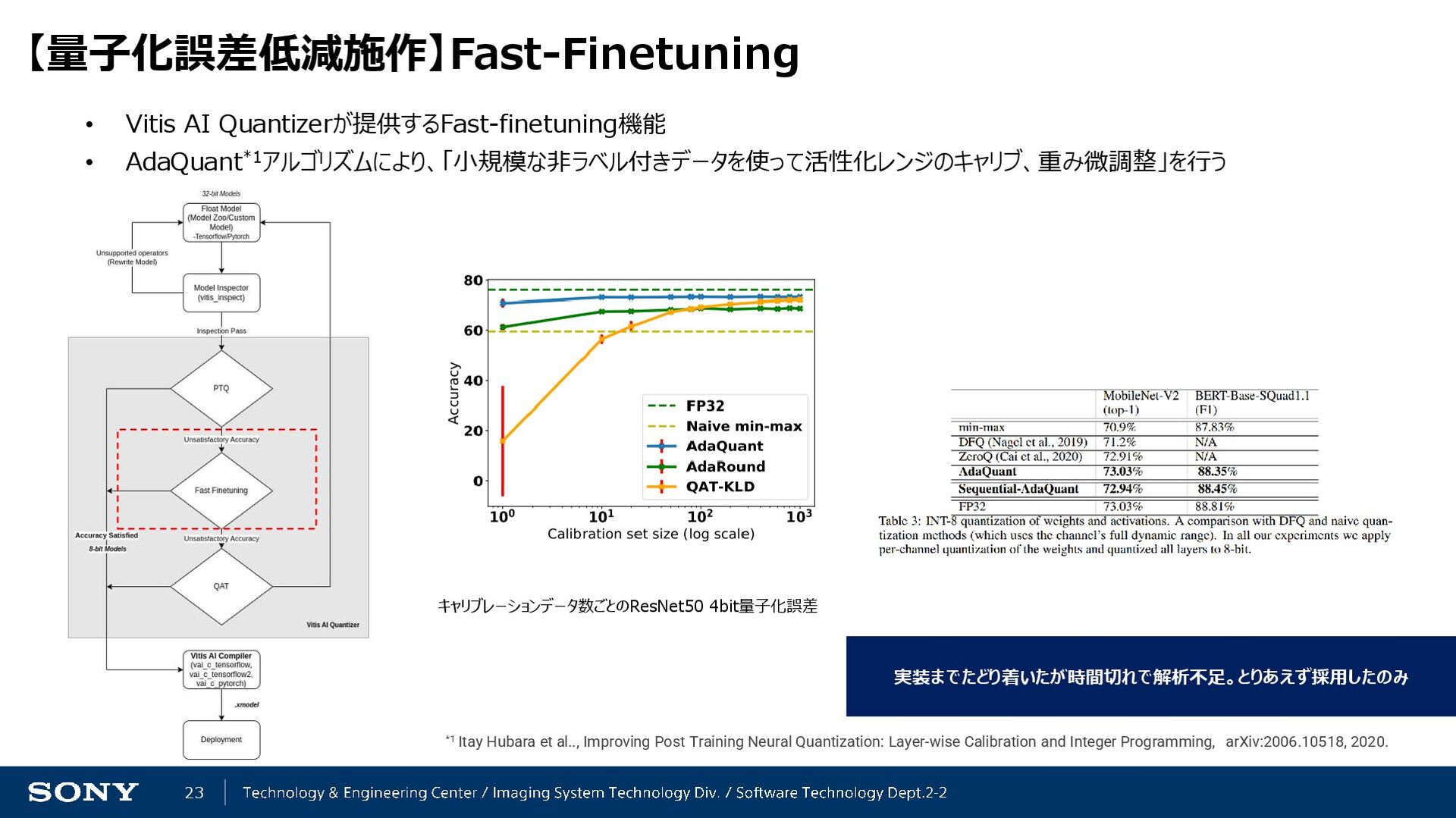
Hubara et al.., Improving Post Training Neural Quantization: Layer-wise Calibration and Integer Programming, arXiv:2006.10518, 2020. キャリブレーションデータ数ごとのResNet50 4bit量子化誤差 実装までたどり着いたが時間切れで解析不足。とりあえず採用したのみ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
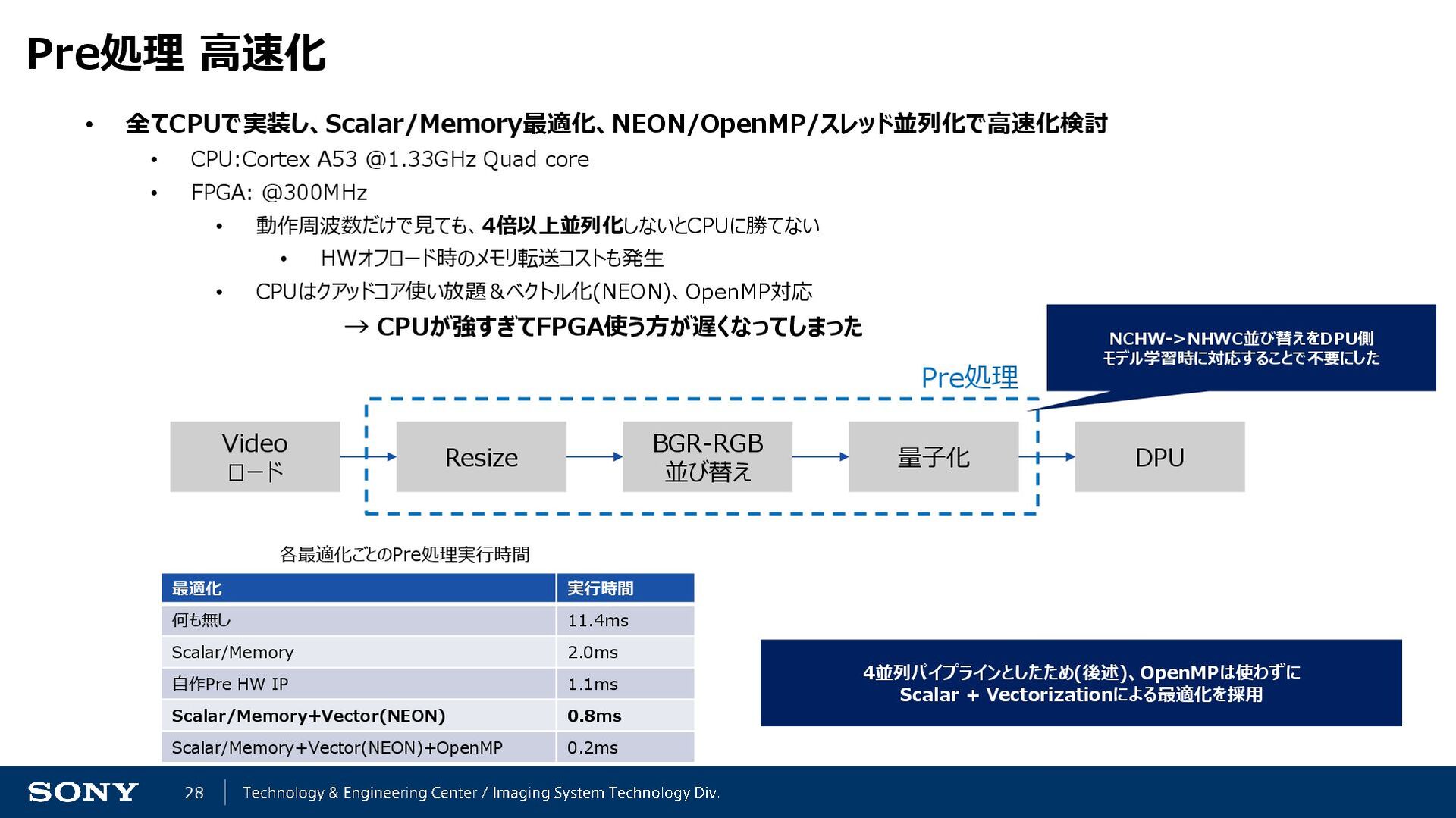{kind=link}
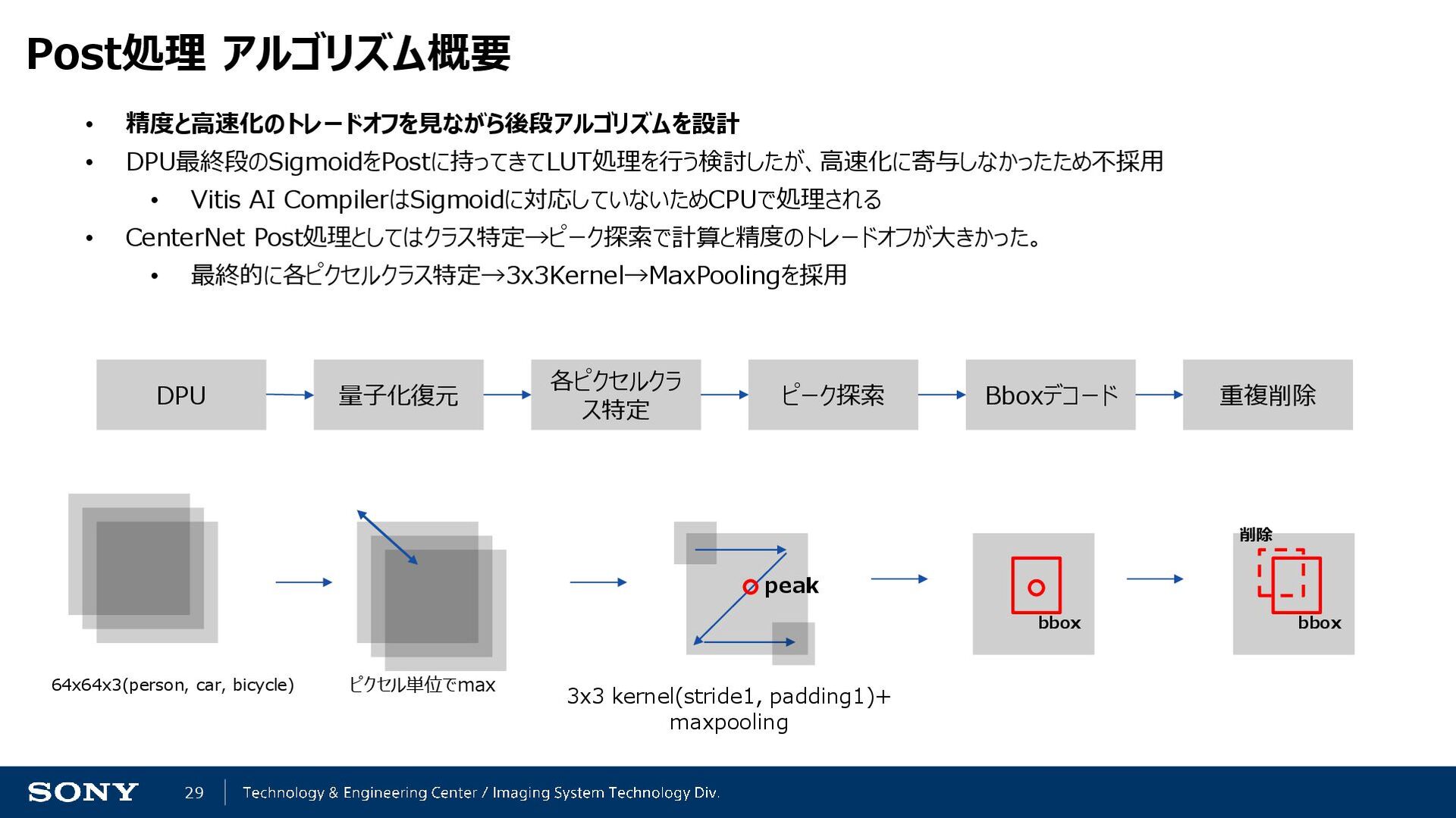{kind=link}
{kind=link}
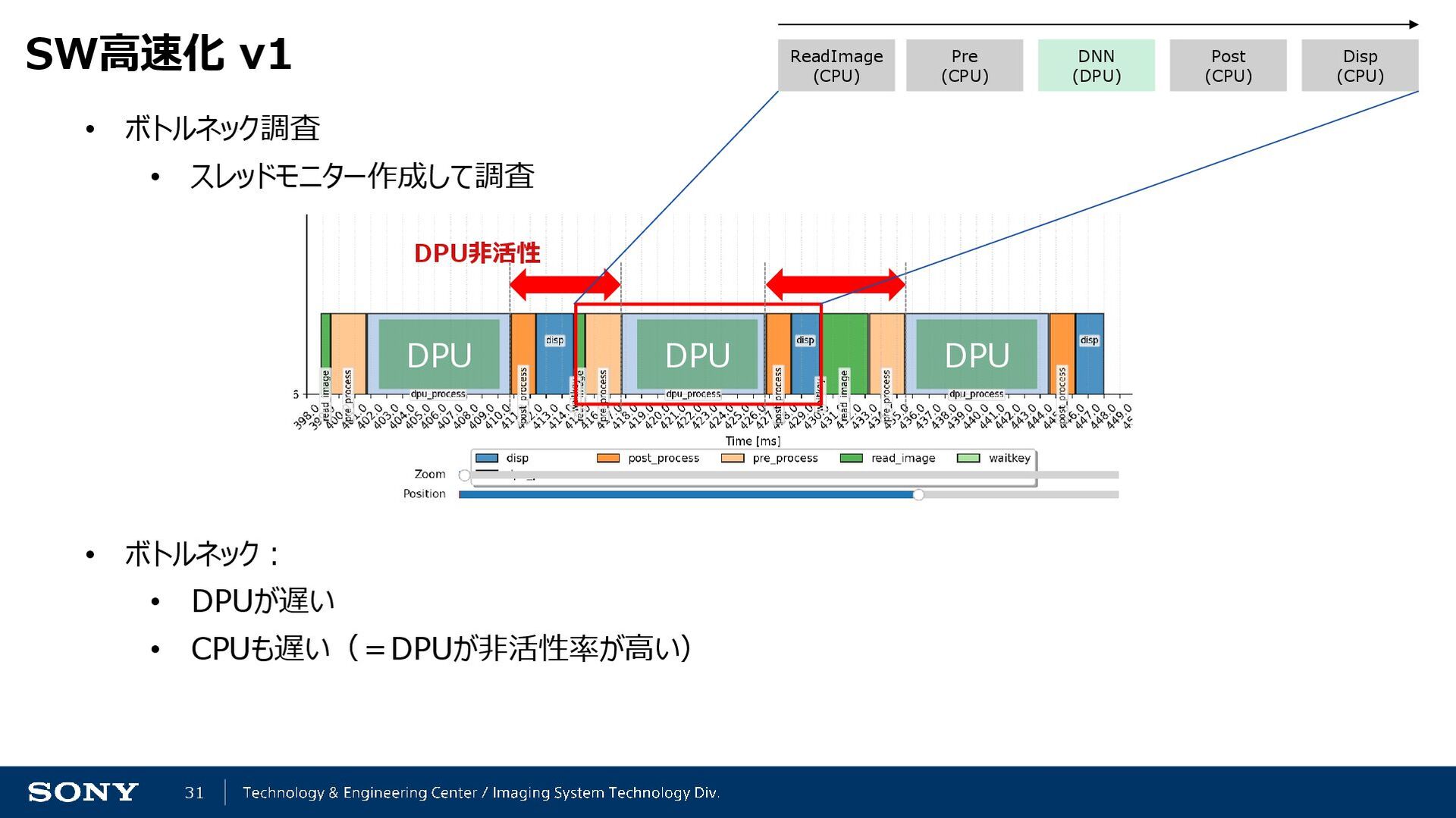{kind=link}
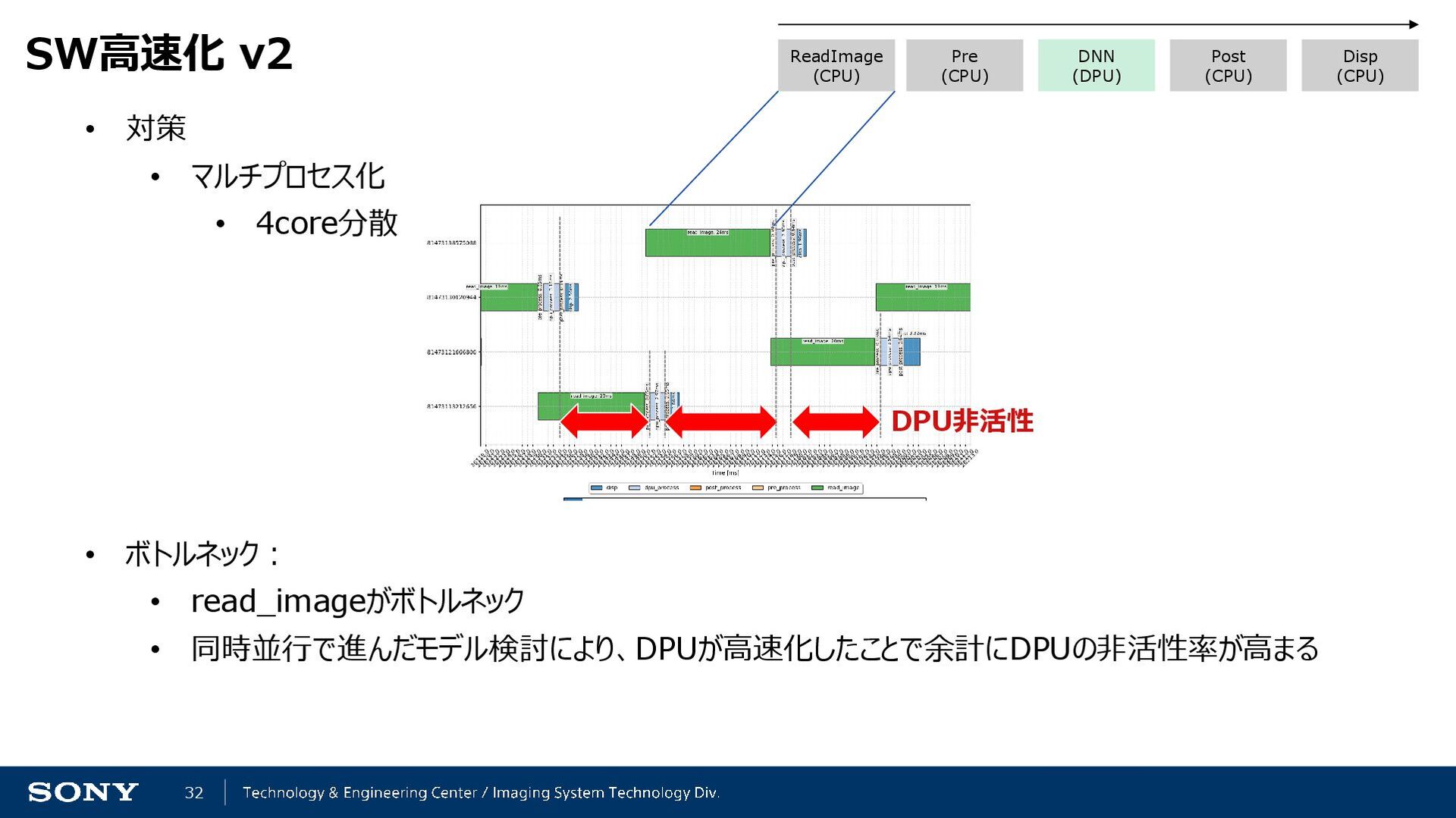{kind=link}
{kind=link}
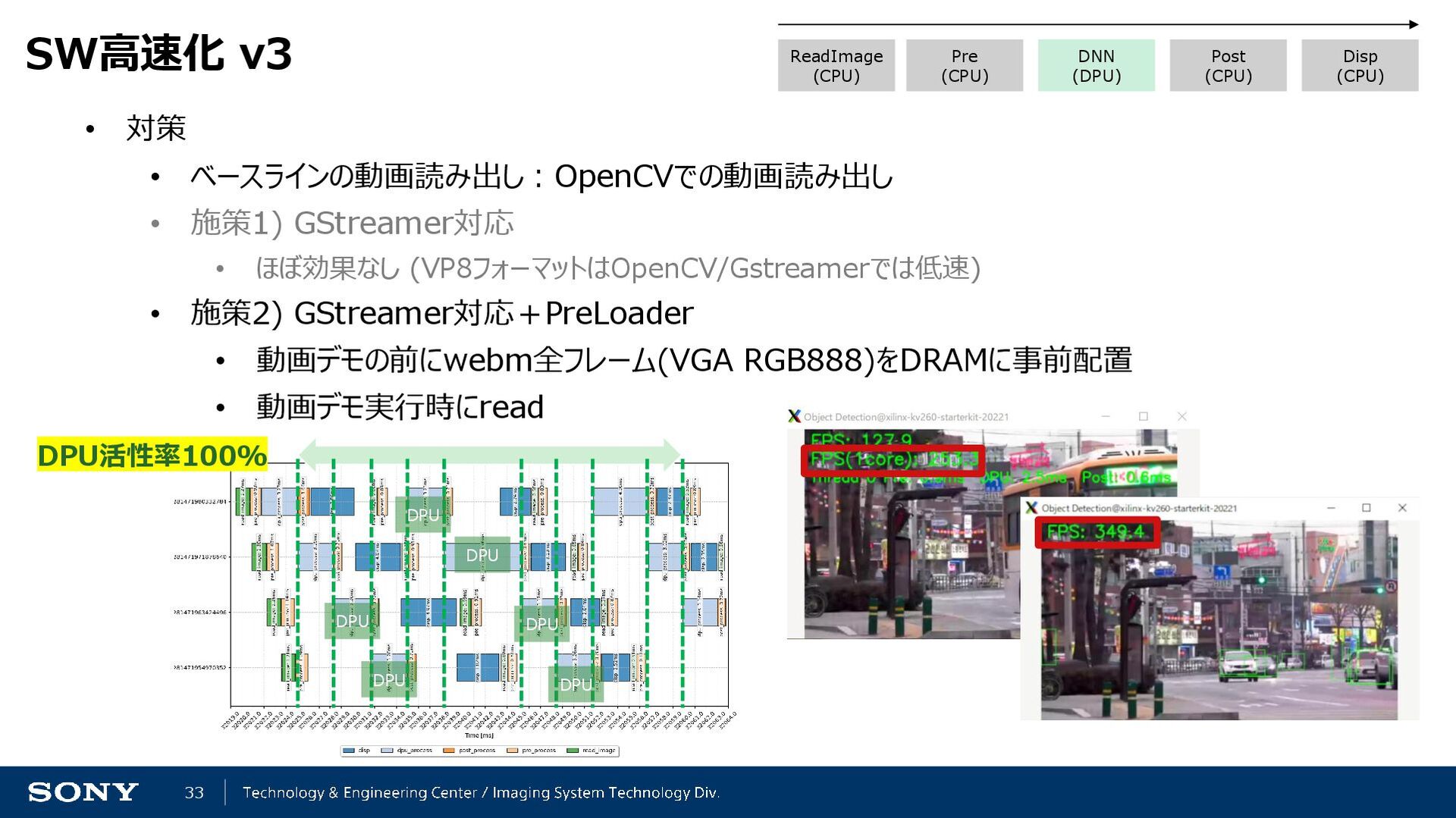
![34 実際の動画 *開発途中のものなのでFPS表示が違うが、実際は340FPS - リファレンスデザインだとこの動画の全推論に10分34秒かかる - 実行中、会場ではどよめきが沸き起こった KV260-[LAN/SSH]-Windowsという構成なのでX11 serverでデモライブ表示するが、 我々のモジュールの処理が速すぎてX11](https://files.speakerdeck.com/presentations/1d25cf9ff1564c79a58829f953ae66d8/slide_33.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}