latency distribution graph. • In general we can take slowest 1% response times or the 99%ile response times as the tail latency of that request. ◦ May vary depending on the scale of the system ◦ InMobi - 8B Ad Requests/day ◦ Capillary - 500M Requests/day • Responsive/Interactive Systems ◦ Better User Experience -- Higher Engagement ◦ Monetary Value. ◦ 100ms -- Large Information Retrieval Systems ◦ Reads out number the writes!
becomes important as the scale of our system increases. ◦ 10k requests/day → 100M requests/day ◦ Slowest 1% queries - 100 requests → 1M requests • Just as fault-tolerant computing aims to create a reliable whole out of less-reliable parts, large online services need to create a predictably responsive whole out of less-predictable parts; we refer to such systems as “latency tail-tolerant,” or simply “tail-tolerant.” • If we remain ignorant about tail latency, it will eventually come back to bite us. • Many Tail Tolerant Methods can leverage infra provided for Fault Tolerance - Better Utilisation
Resources ▪ Co-hosted applications • Containers can provide isolation. • Within app-contention still exists. ◦ Daemons ▪ Background or batch jobs running in the background. ◦ Global Resource Sharing ▪ Network Switches, Shared File Systems, Shared Disks. ◦ Maintenance activities (Log compaction, data shuffling, etc). ◦ Queueing (Network buffers, OS Kernels, intermediate hops) • Hardware Variability ◦ Power limits, Disk Capacity, etc. • Garbage Collection • Energy Management
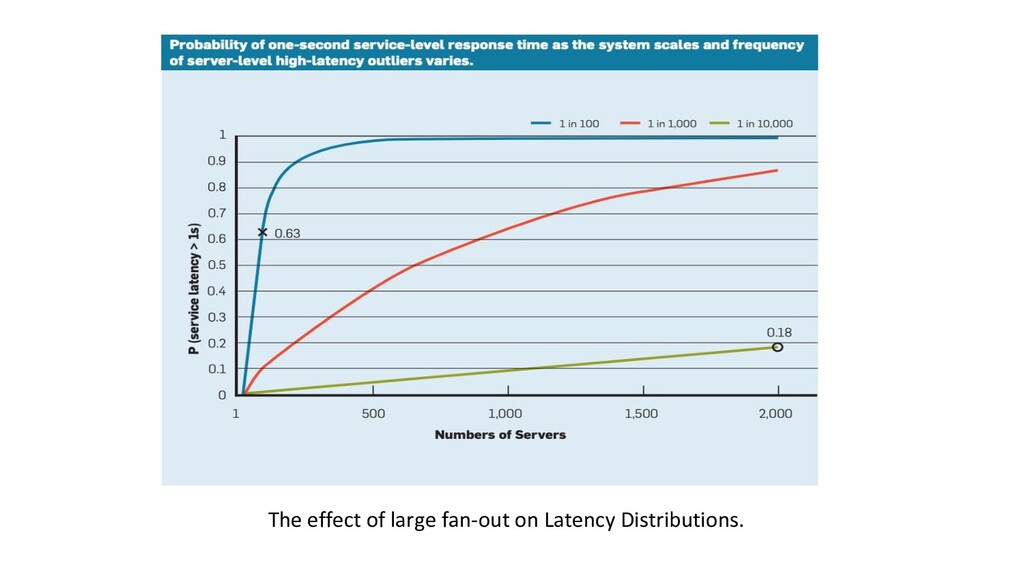
or parallel operations increase. (Fan-outs) ◦ Micro-Services ◦ Data Partitions • Further increase in the overall latency of the request. ◦ Overall Latency ≥ Latency of Slowest Component • Server with 1 ms avg. but 1 sec 99%ile latency ◦ 1 Server: 1% of requests take ≥ 1 sec ◦ 100 Servers: 63% of requests take ≥ 1 sec
request, the 99% percentile for all requests to finish is 140ms, and the 95% percentile is 70ms. ◦ meaning that waiting for the slowest 5% of the requests to complete is responsible for half of the total 99%-percentile latency. Techniques that concentrate on these slow outliers can yield dramatic reductions in overall service performance.
to reduce variability • Prioritize Interactive Requests or Real-time requests over background requests ◦ Differentiating service classes and prefer higher-level queuing (Google File System) ◦ AWS uses something similar, albeit for Load Shedding [Ref#2] • Reducing head-of-line blocking ◦ Break long-running requests into a sequence of smaller requests to allow interleaving of the execution of other short-running requests. (Search Queries) • Managing background activities and synchronized disruption ◦Throttling, Service Operation Breakdowns. ◦For large fan-out services, it is sometimes useful for the system to synchronize the background activity across many different machines. This synchronization enforces a brief burst of activity on each machine simultaneously, slowing only those interactive requests being handled during the brief period of background activity. In contrast, without synchronization, a few machines are always doing some background activity, pushing out the latency tail on all requests. • Caching doesn’t impact variability much unless whole data is residing in the cache.
-- especially with the Cloud Era! • Develop tail-tolerant techniques that mask or work around temporary latency pathologies, instead of trying to eliminate them altogether. • Classes of Tail Tolerant Techniques ◦ Within Request // Immediate Response Adaptations ▪ Focus on reducing variations within a single request path. ▪ Time Scale - 10ms ◦ Cross Request Long Term Adaptations ▪ Focus on holistic measures to reduce the tail at the system level. ▪ Time Scale - 10 seconds and above.
subsystem in context of a higher level request • Time Scale == Right Now ◦ User is waiting • Multiple Replicas for additional throughput capacity. ◦ Availability in the presence of failures. ◦ This approach is particularly effective when most requests operate on largely read-only, loosely consistent datasets. ◦ Spelling Correction Service - Write Once Read in Millions • Based on how replication (request & data) can be used to reduce variability within a single higher-level request: ◦ Hedged Requests ◦ Tied Requests
first quickest response. ◦ Send a request to a most appropriate Replica (Appropriate Definition is Open) ◦ In case, no response within a threshold, issue to another replica. ◦ Cancel the outstanding requests. • Can amplify the traffic significantly if not implemented prudently. ◦ One such approach is to defer sending a secondary request until the first request has been outstanding for more than the 95th-percentile expected latency for this class of requests. This approach limits the additional load to approximately 5% while substantially shortening the latency tail. ◦ Mitigates the effect of external interferences. Not the same request slowness. Hedged Requests
BigTable table ◦ Distributed across 100 different servers. ◦ Sending a hedging request after a 10ms delay reduces the 99.9th-percentile latency for retrieving all 1,000 values from 1,800ms to 74ms while sending just 2% more requests. • Vulnerabilities ◦ Multiple Servers might execute the same requests - redundant computation. ◦ 95% tile techniques reduces the impact. ◦ Further reduction requires aggressive cancellation of requests. Hedged Requests
begins execution. • Once a request is actually scheduled and begins execution, the variability of its completion time goes down substantially. • Mitzenmacher* - Allowing a client to choose between two servers based on queue lengths at enqueue time exponentially improves load-balancing performance over a uniform random scheme. * Mitzenmacher, M. The power of two choices in randomized load balancing. IEEE Transactions on Parallel and Distributed Computing 12, 10 (Oct. 2001), 1094–1104.
servers. • Send the identity of the other servers as a part of the request -- Tieing! • Send a cancellation request to the other servers once a server picks it off the queue. • Corner Case: ◦ What if both servers pick up the request while the cancellation messages are in transit? Network Delay? ◦ Typical under low traffic scenario when server queues are empty. ◦ Client can introduce a small delay of 2X the average network message delay (1ms or less in modern data-center networks) between the first request and the second request.
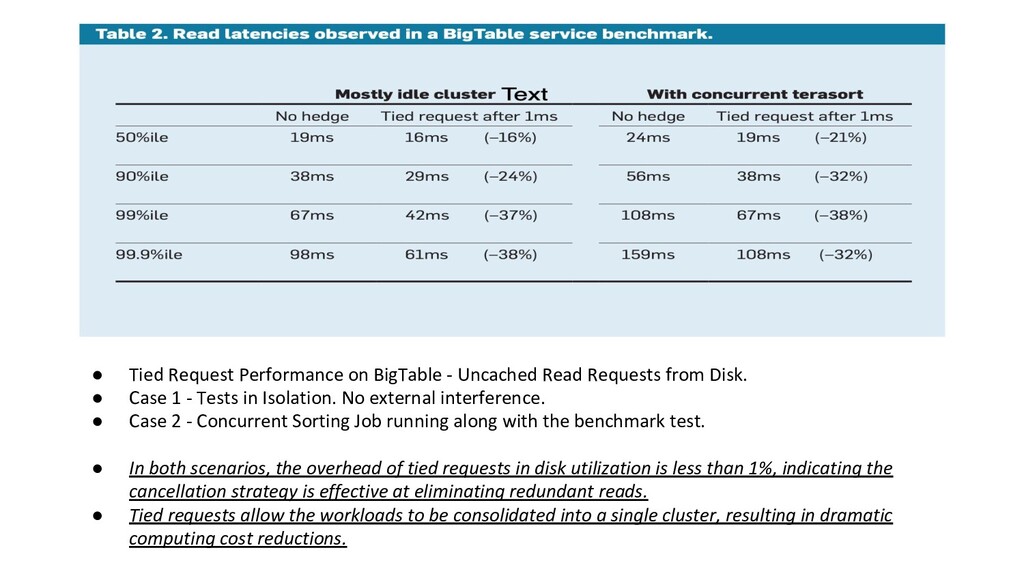
from Disk. • Case 1 - Tests in Isolation. No external interference. • Case 2 - Concurrent Sorting Job running along with the benchmark test. • In both scenarios, the overhead of tied requests in disk utilization is less than 1%, indicating the cancellation strategy is effective at eliminating redundant reads. • Tied requests allow the workloads to be consolidated into a single cluster, resulting in dramatic computing cost reductions.
the least-loaded server. • Sub-Optimal ◦ Load levels can change between probe and request time ◦ Request service times can be difficult to estimate due to underlying system and hardware variability ◦ Clients can create temporary hot spots by picking the same (least-loaded) server • Distributed Shortest-Positioning Time First system* - Request is sent to one server and forwarded to replicas only if the initial server does not have it in its cache and uses cross-server cancellations. • These techniques are effective only when the phenomenon that cause variability do not tend to simultaneously affect multiple request replicas. Remote Queue Probing? *Lumb, C.R. and Golding, R. D-SPTF: Decentralized request distribution in brick-based storage systems. SIGOPS Operating System Review 38, 5 (Oct. 2004), 37–47.
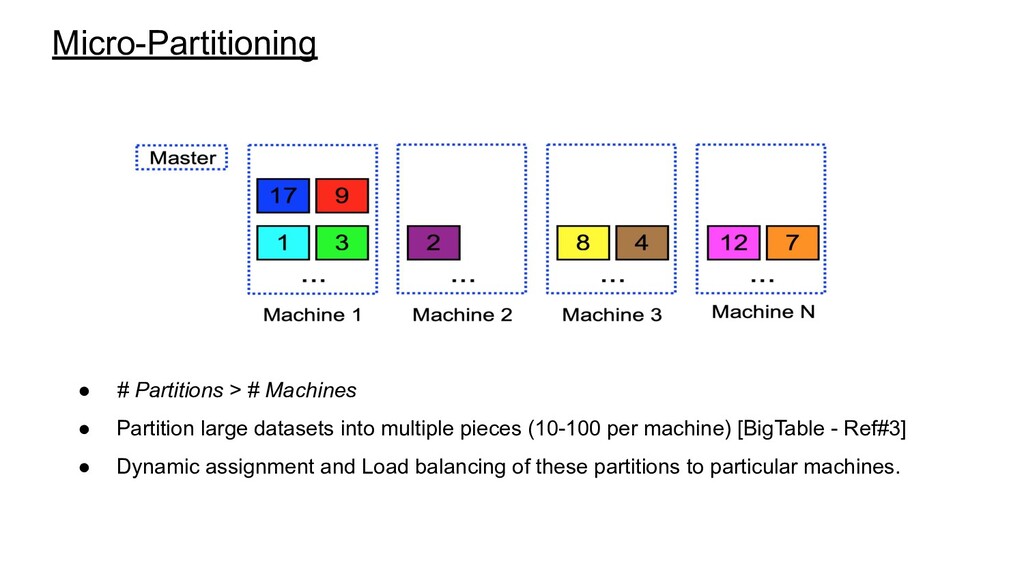
by coarse-grain phenomenon ◦ Load imbalance. (Unbalanced data partitions) ▪ Centered on data distribution/placement techniques to optimize the reads. ◦ Service-time variations ▪ Detecting and mitigating effects of service performance variations. • Simple Partitioning ◦ Partitions have equal cost. ◦ Static assignment of a partition to a single machine? ◦ Sub-Optimal ▪ Performance of the underlying machines is neither uniform nor constant over time (Thermal Throttling and Shared workload Interference) ▪ Outliers Items can cause data-induced load imbalance • Particular item becomes popular and the load for its partition increases.
datasets into multiple pieces (10-100 per machine) [BigTable - Ref#3] • Dynamic assignment and Load balancing of these partitions to particular machines.
from one machine to another. • Average ~20 partitions per machine, the system can shed load in 5% increments and in 1/20th the time it would take if the system had a one-to-one mapping of partitions to machines • Using such partitions also lead to an improved failure recovery rate. ◦ More nodes to takeover the work of a failed node. * Stoica I., Morris, R., Karger, D., Kaashoek, F., and Balakrishnan, H. Chord: A scalable peer-to-peer lookup service for Internet applications. In Proceedings of SIGCOMM (San Diego, Aug. 27–31). ACM Press, New York, 2001, 149–160. • Does this sound familiar? (Hint : Think Amazon!) • DynamoDB Paper also talks about a similar concept of multiple virtual nodes mapped to physical nodes. [Ref#4]
Prediction of items that are likely to cause load imbalance. • Create additional replicas of these items/micro-partitions. • Distribute the load among more replicas rather than moving the partitions across nodes.
dues to: ◦ May be Data issues ◦ Most likely Interference issues (discussed earlier) • Intermediate Servers - Observe the Latency distribution of the fleet. • Put a slow server on Probation in case of slowness. ◦ Pass shadow requests to collect statistics. ◦ Put the node into rotation if it stabilizes. • Reducing Server Capacity during load can improve overall latency!
metric. • Retrieving good results quickly is better than returning best results slowly. • Good Enough Results? ◦ Sufficient amount of corpus has been searched - return the results without waiting for the rest of the queries. ◦ Tradeoff between Completeness vs. Responsiveness • Canary Requests ◦ High Fan out systems. ◦ Requests may hit untested code paths - crash or degrade multiple servers simultaneously. ◦ Forward to limited leaf servers and send to the fleet only if successful.
for mutation is relatively easier. ◦ The scale of latency-critical modifications is generally small. ◦ Updates can often be performed off the critical path, after responding to the user. ◦ Many services can be structured to tolerate inconsistent update models for (inherently more latency-tolerant) mutations. • Services that require consistent updates, commonly used techniques are quorum-based algorithms (Paxos*) ◦ These algorithms touch only three to five replicas, they are inherently tail-tolerant. *Lamport, L. The part-time parliament. ACM Transactions on Computer Systems 16, 2 (May 1998), 133–169.
to save energy can lead to an increase in variability due to added latency in switching from/to power saving mode. • Variability technique friendly trends: ◦ Lower latency data center networks can make things like Tied Request Cancellations work better.
guaranteeing fault-free operation isn’t feasible beyond a point. ◦ Not possible to eliminate all source of variabilities. • Tail Tolerant Techniques ◦ Will become more important with the hardware trends -- software level handling. ◦ Require some additional resources but with modest overheads. ◦ Leverage the capacity deployed for redundancy and fault tolerance. ◦ Can drive higher resource utilization overall with better responsiveness. ◦ Common Patterns - easy to bake into baseline libraries.
Ghemawat, S., Hsieh, W.C., Wallach, D.A., Burrows, M., Chandra, T., Fikes, A., and Gruber, R.E. BigTable: A distributed storage system for structured data. In Proceedings of the Seventh Symposium on Operating Systems Design and Implementation (Seattle, Nov.). USENIX Association, Berkeley CA, 2006, 205–218. 4. https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Co-ordinates • Twitter - @pigol1 • Mail - [email protected] •](https://files.speakerdeck.com/presentations/b2759b1baed04d718c4842ee67f2986d/slide_31.jpg){kind=link}