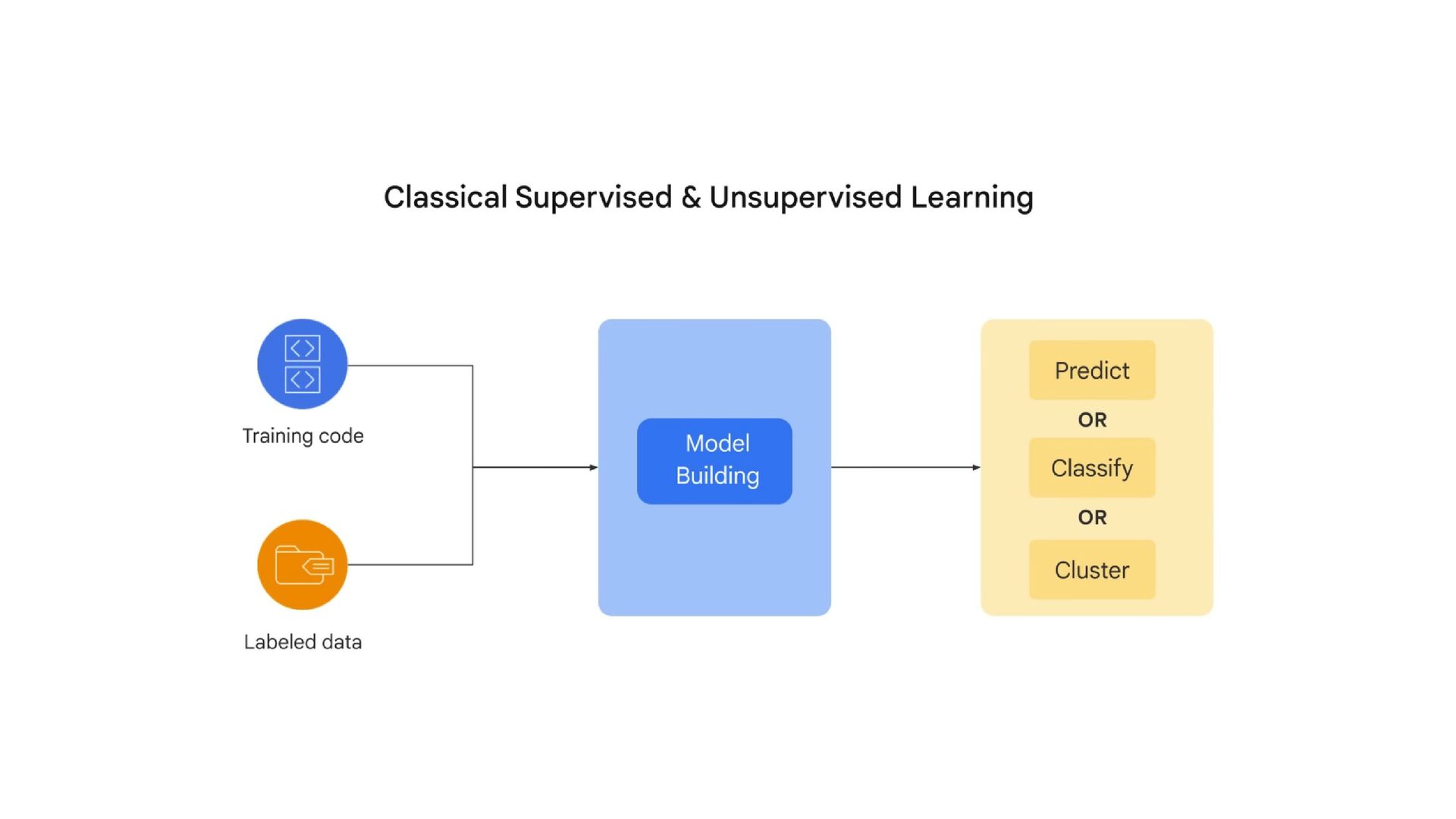
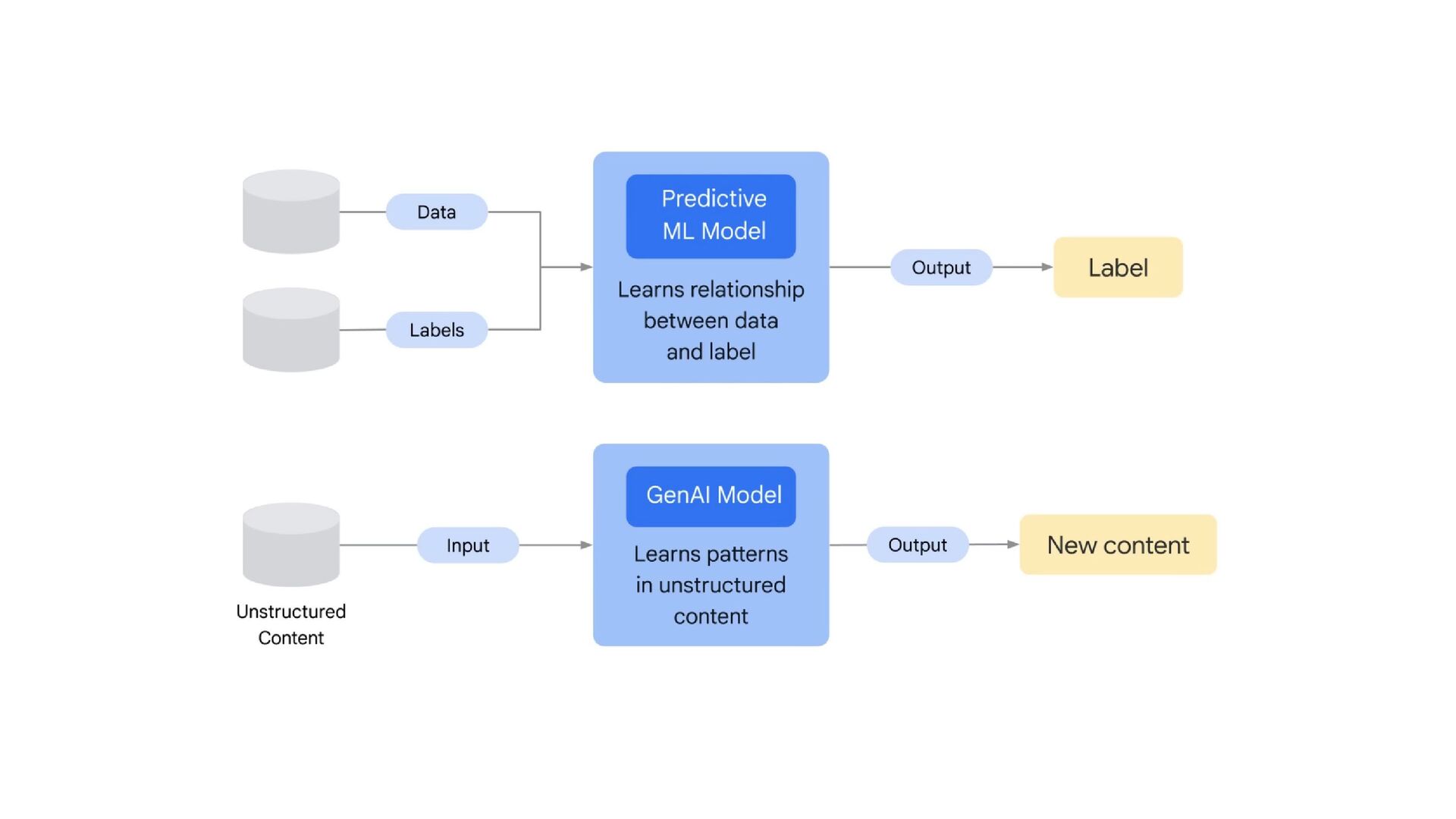
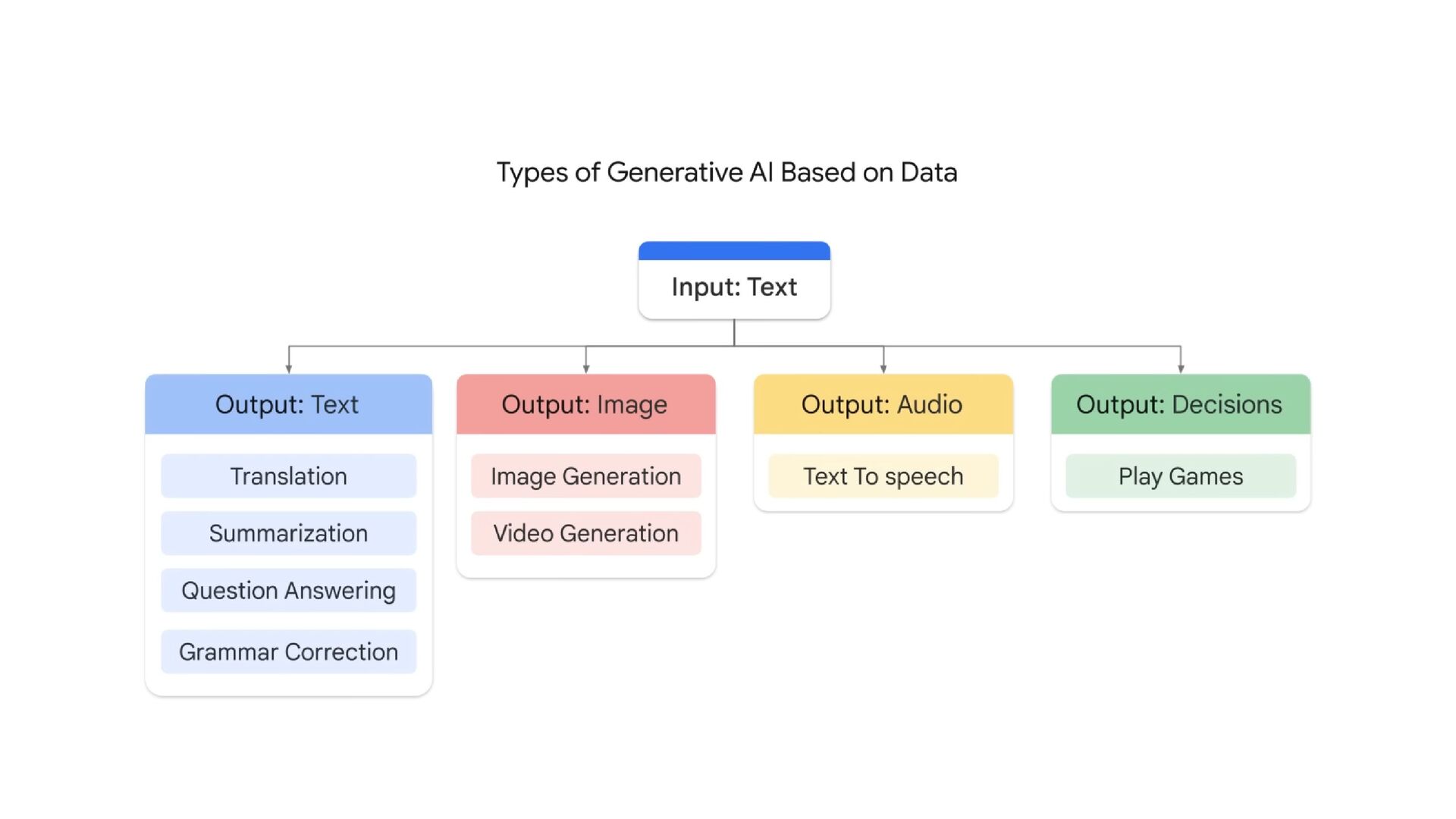
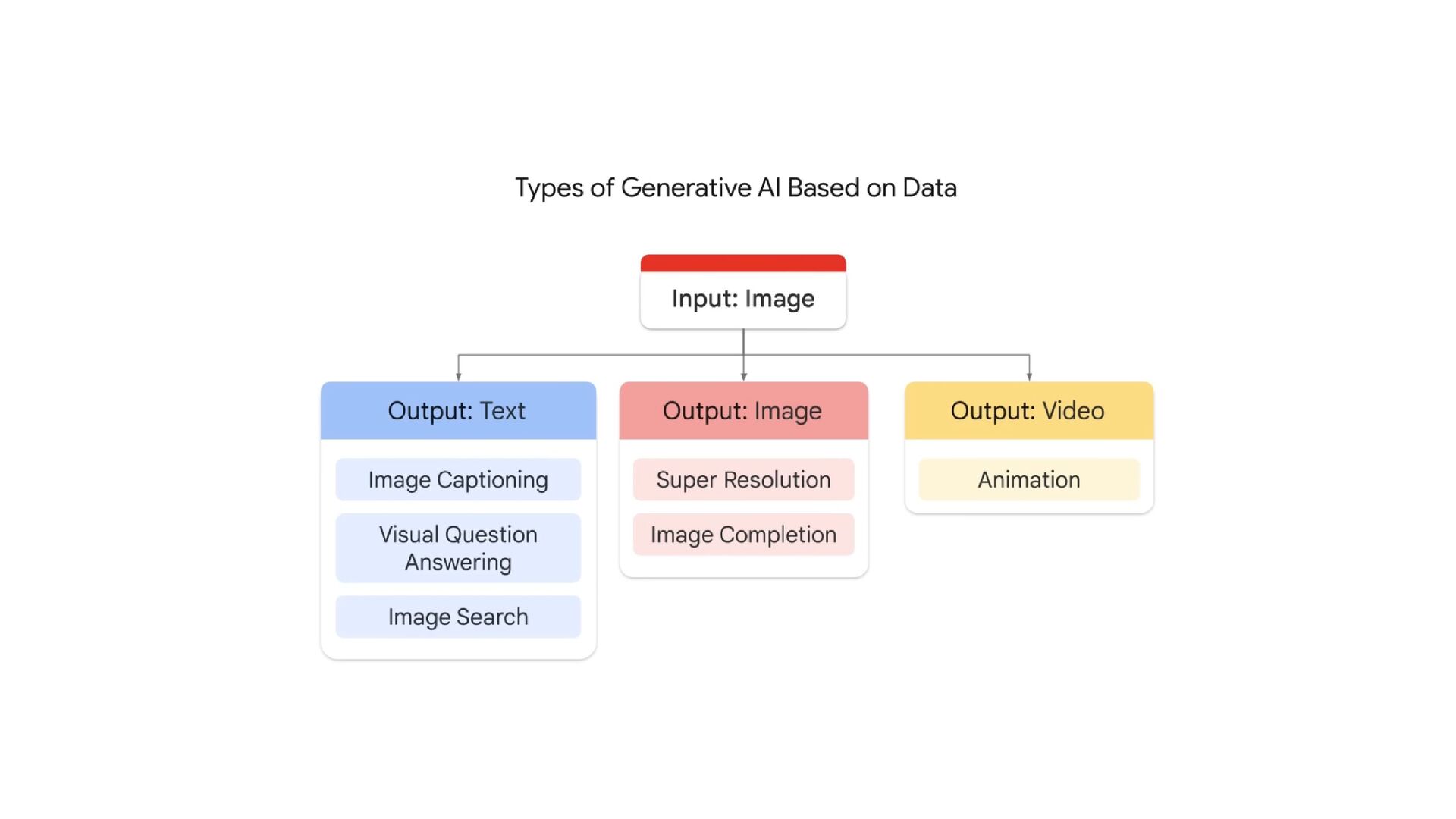
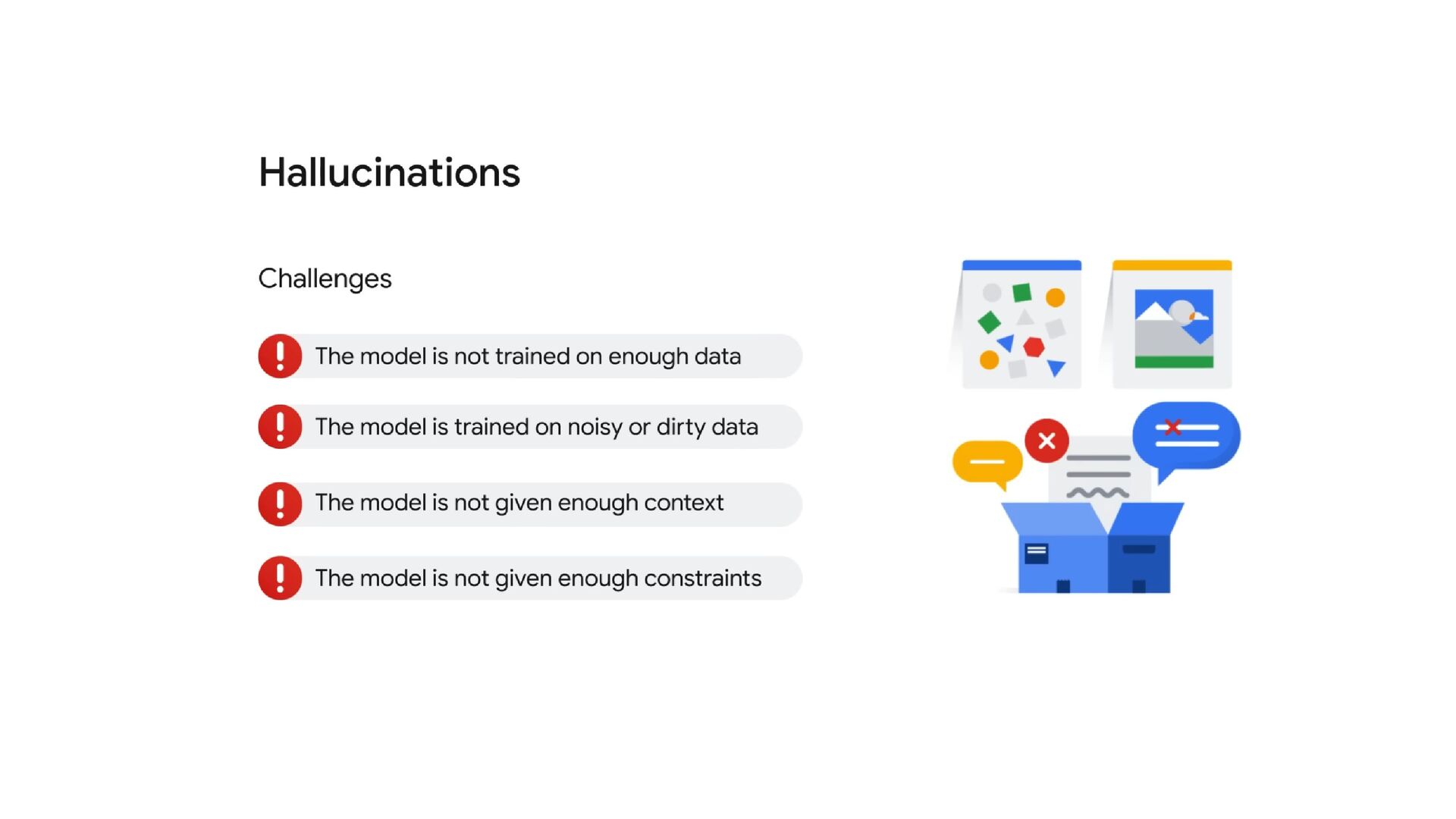
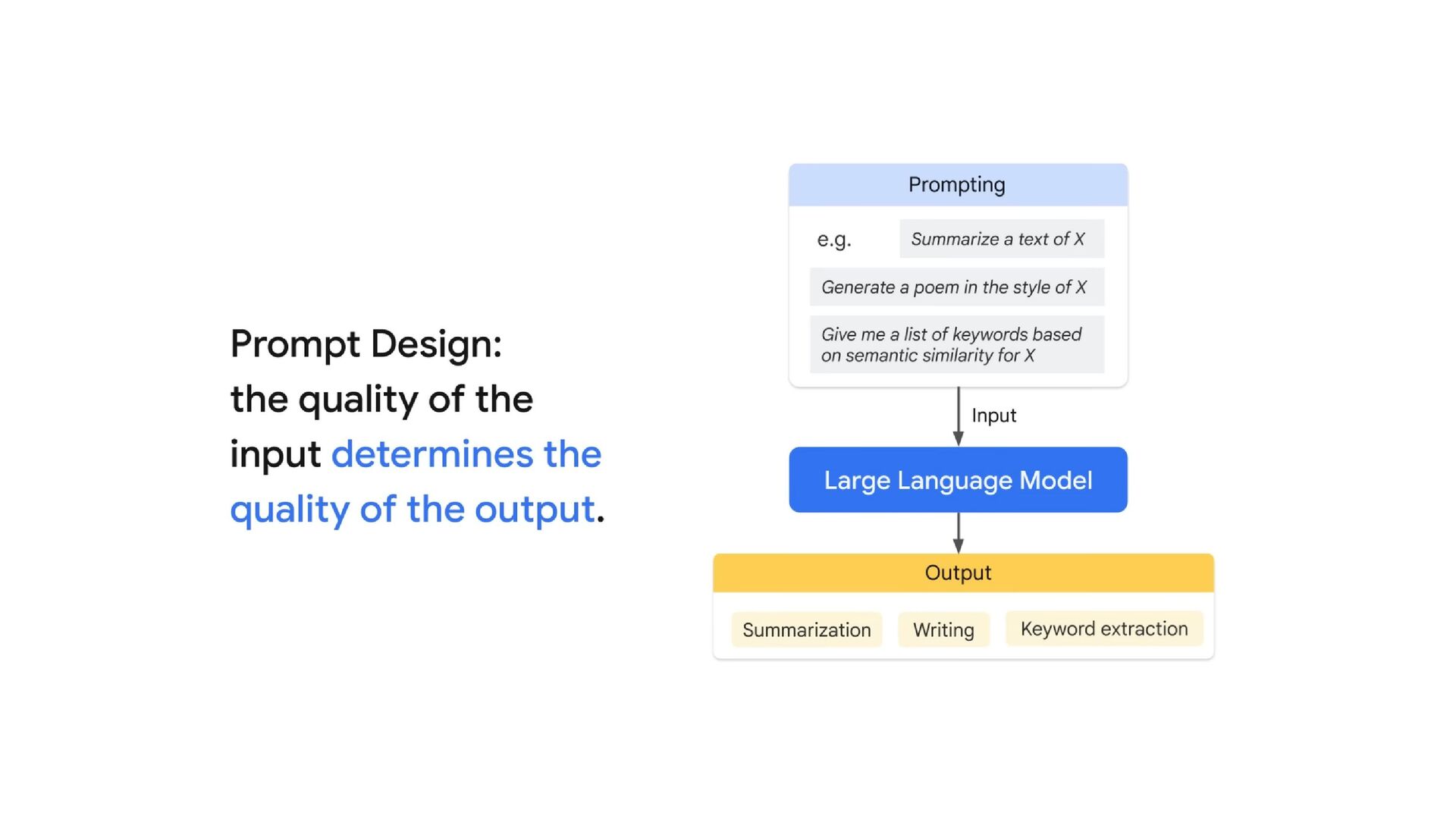
NT Academy arranged an internal hackathon about Data, AI, and ML. As a Hackathon mentor, I have a chance to teach ML unsupervised techniques and also generative AI. The Generative AI is based on Gemini Multimodal. The session included hands-on teaching on multimodal prompts, best practices in prompt design, and techniques to write efficient prompts using Gemini AI for maximum effectiveness
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[ค่า temperature = 0]: ข้าวกระเพราเนื้อใส่จานพลาสติก+พร้อมช้อนซ้อม [ค่า temperature = 0.2]: ข้าวกระเพราเนื้อใส่จานพลาสติก+พร้อมช้อนซ้อม+มีแตงกวา](https://files.speakerdeck.com/presentations/f4ea599b819d4f66b9b4f38acf907f29/slide_45.jpg){kind=link}
{kind=link}