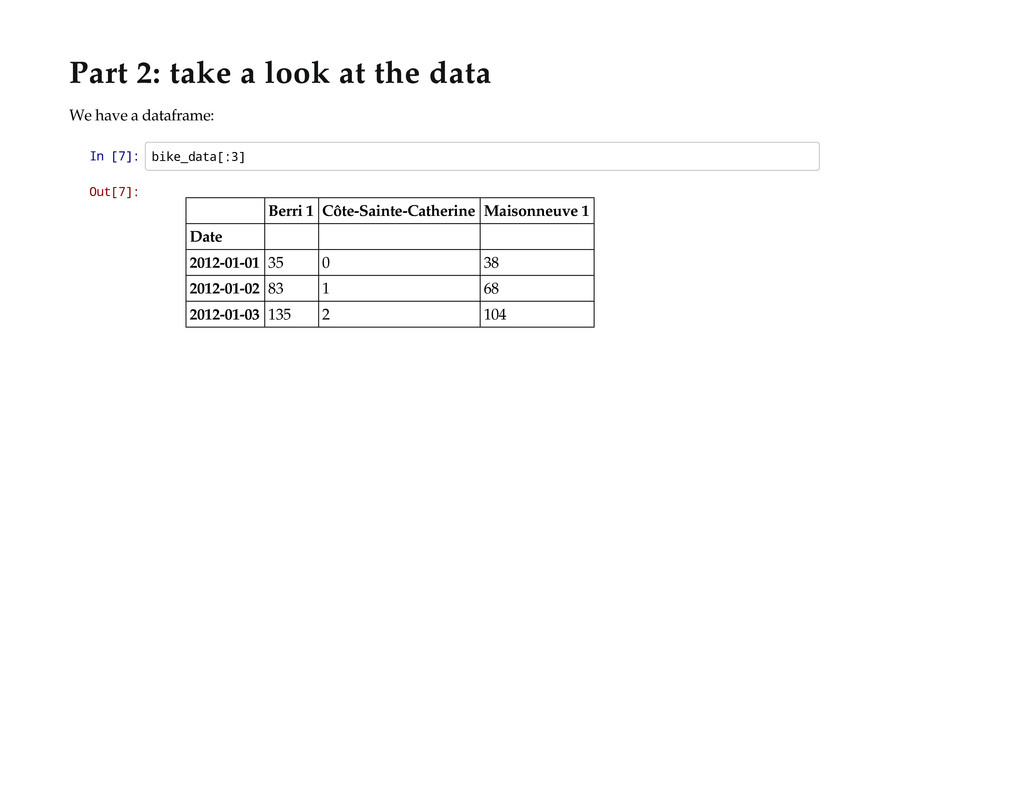
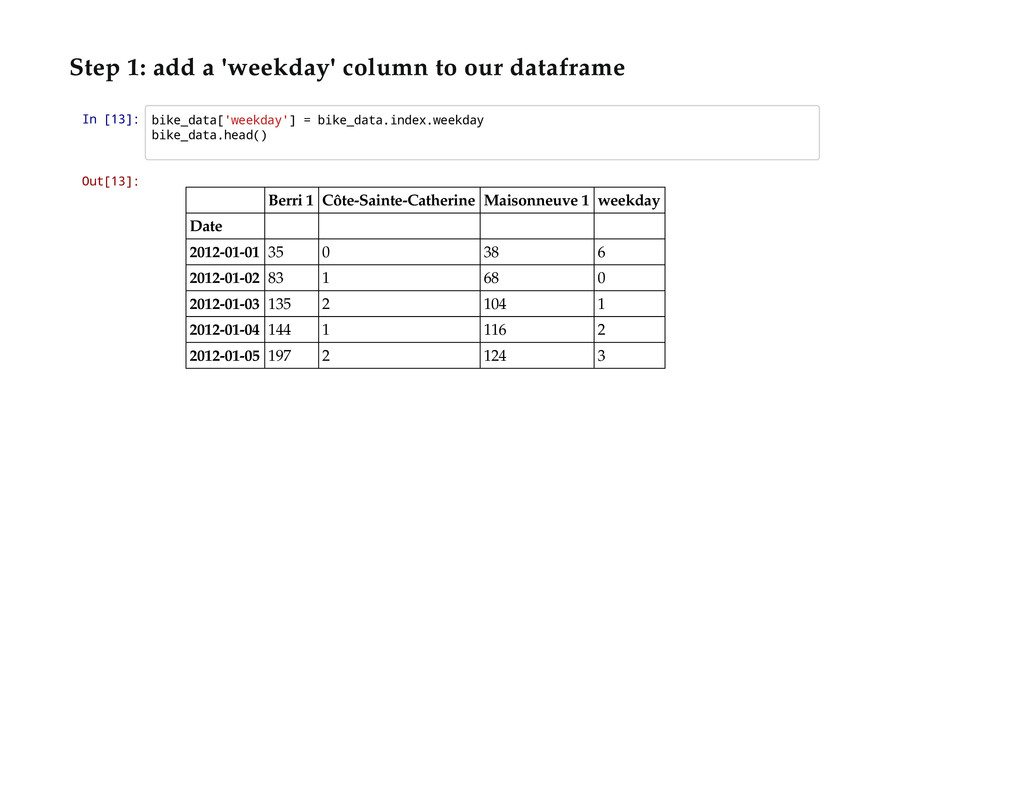
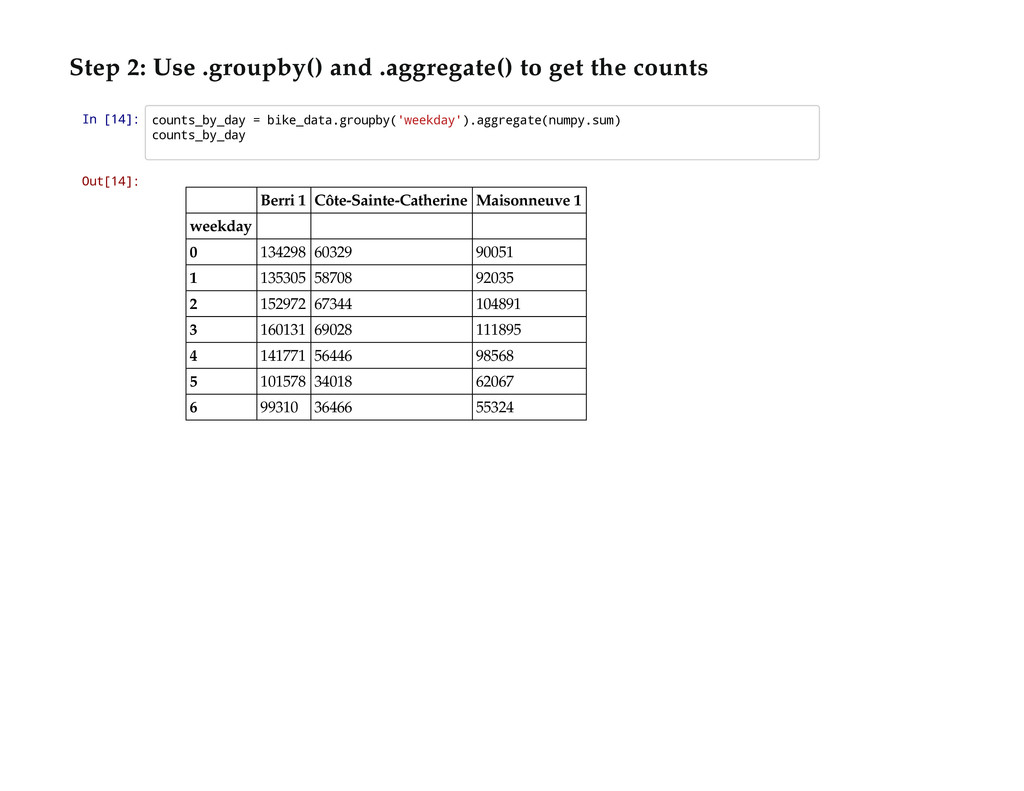
I'll walk you through Python's best tools for getting a grip on some new open data: IPython Notebook and pandas. I'll show you how to read in data, clean it up, graph it, and draw some conclusions, using some open data about the number of cyclists on Montréal's bike paths as an example.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![After After In [4]: In [6]: Exercise: Parse the CSVs](https://files.speakerdeck.com/presentations/d8ec6500e5db0130ca082ab0926c8974/slide_6.jpg){kind=link}
{kind=link}
![In [8]: bike_data.plot() Out[8]: <matplotlib.axes.AxesSubplot at 0x3e59a90> /opt/anaconda/envs/ipython-1.0.0a1/lib/python2.7/site-packages/matplotlib/font_manager.py: 1224: UserWarning:](https://files.speakerdeck.com/presentations/d8ec6500e5db0130ca082ab0926c8974/slide_8.jpg){kind=link}
![In [9]: bike_data.median() Out[9]: Berri 1 3128.0 Côte-Sainte-Catherine 1269.0 Maisonneuve](https://files.speakerdeck.com/presentations/d8ec6500e5db0130ca082ab0926c8974/slide_9.jpg){kind=link}
![In [10]: bike_data.median().plot(kind='bar') Out[10]: <matplotlib.axes.AxesSubplot at 0x3fd98d0>](https://files.speakerdeck.com/presentations/d8ec6500e5db0130ca082ab0926c8974/slide_10.jpg){kind=link}
{kind=link}
![Slicing dataframes Slicing dataframes In [11]: # column slice column_slice](https://files.speakerdeck.com/presentations/d8ec6500e5db0130ca082ab0926c8974/slide_12.jpg){kind=link}
![In [12]: column_slice.plot() Out[12]: <matplotlib.axes.AxesSubplot at 0x43bcbd0>](https://files.speakerdeck.com/presentations/d8ec6500e5db0130ca082ab0926c8974/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
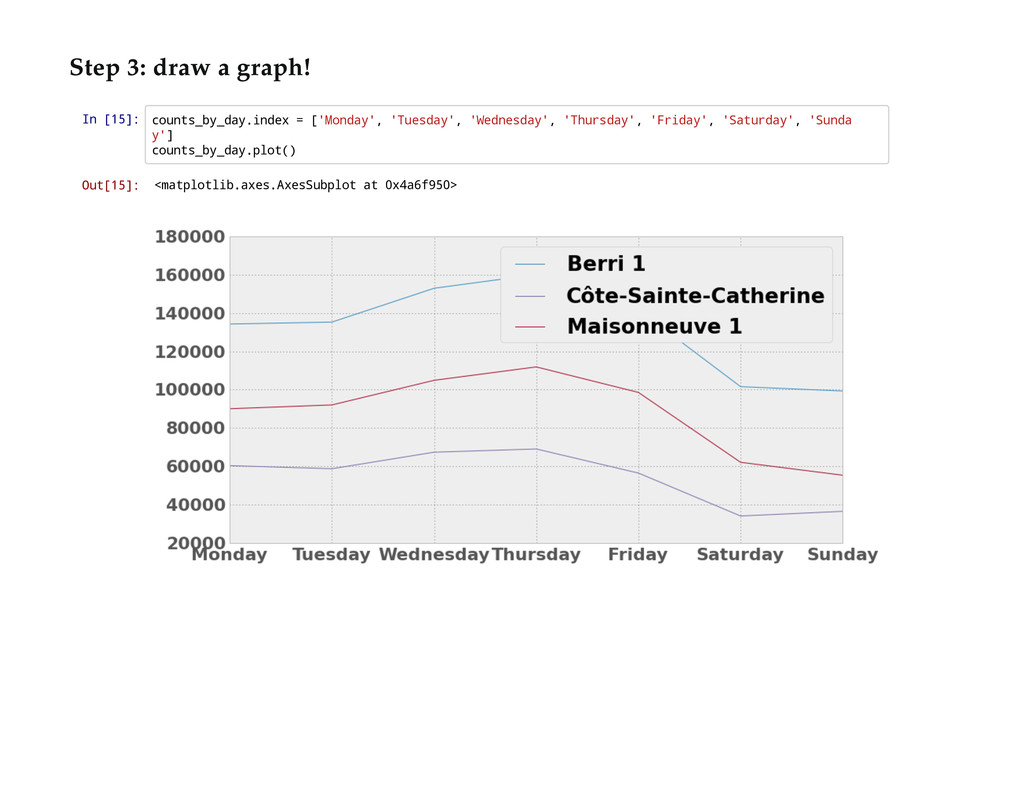{kind=link}
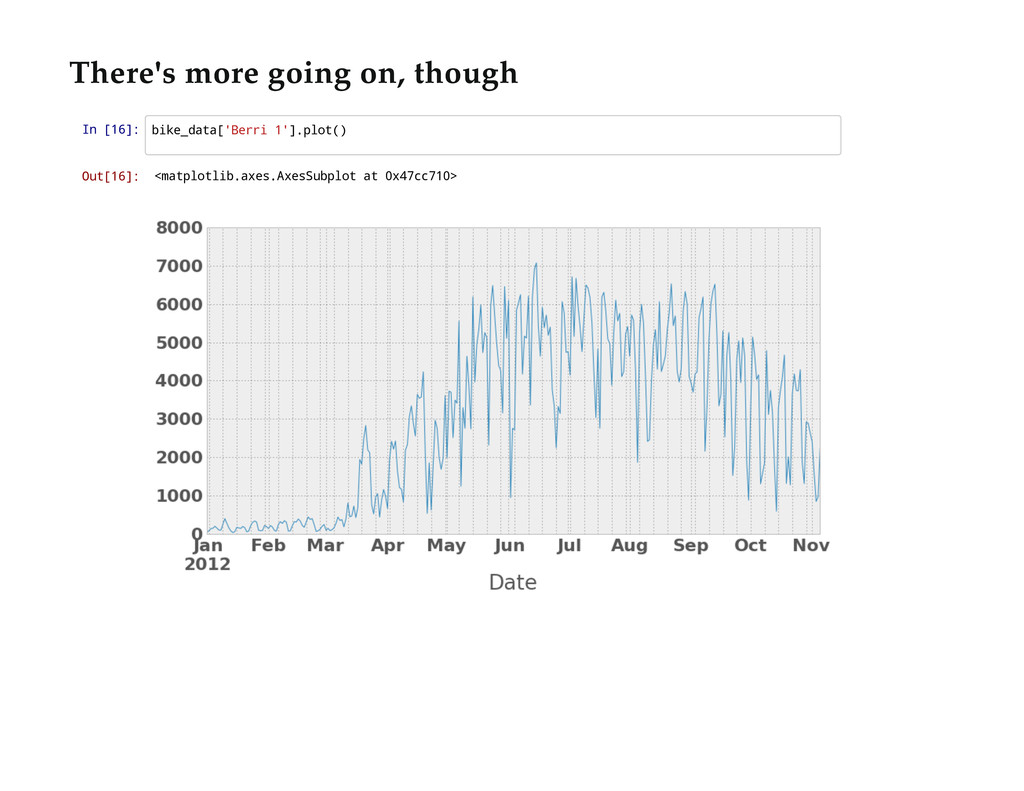{kind=link}
{kind=link}
![In [19]: weather_data[:5] Out[19]: Dew Point Temp (C) Rel Hum](https://files.speakerdeck.com/presentations/d8ec6500e5db0130ca082ab0926c8974/slide_20.jpg){kind=link}
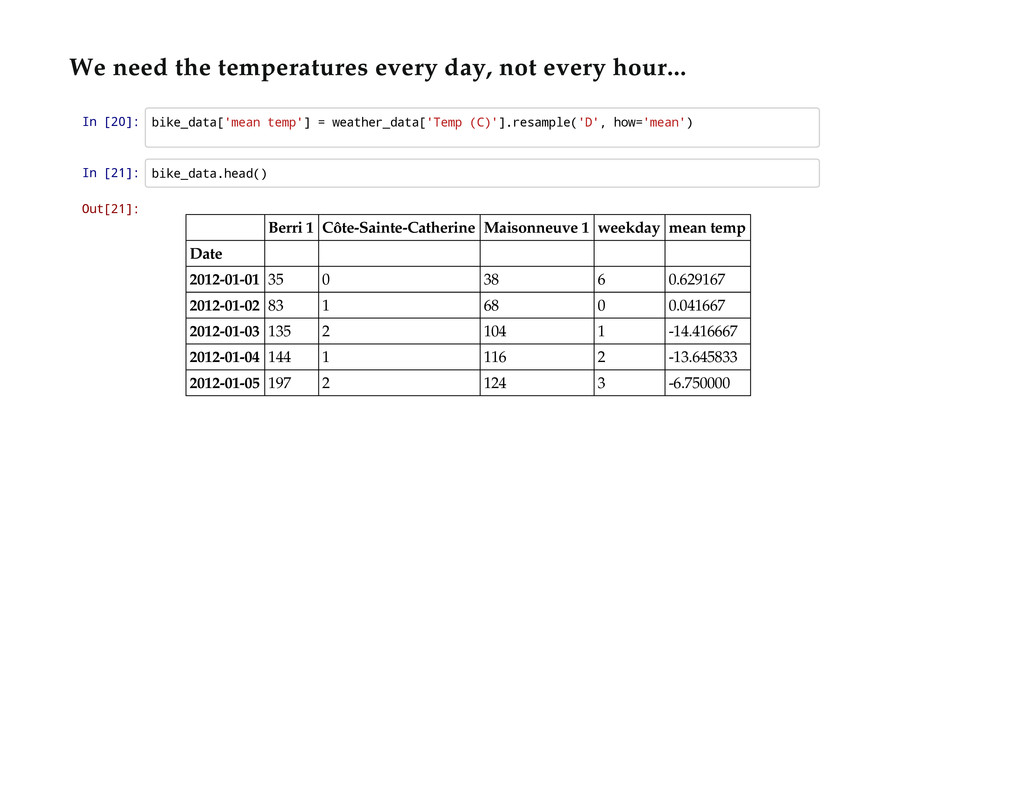{kind=link}
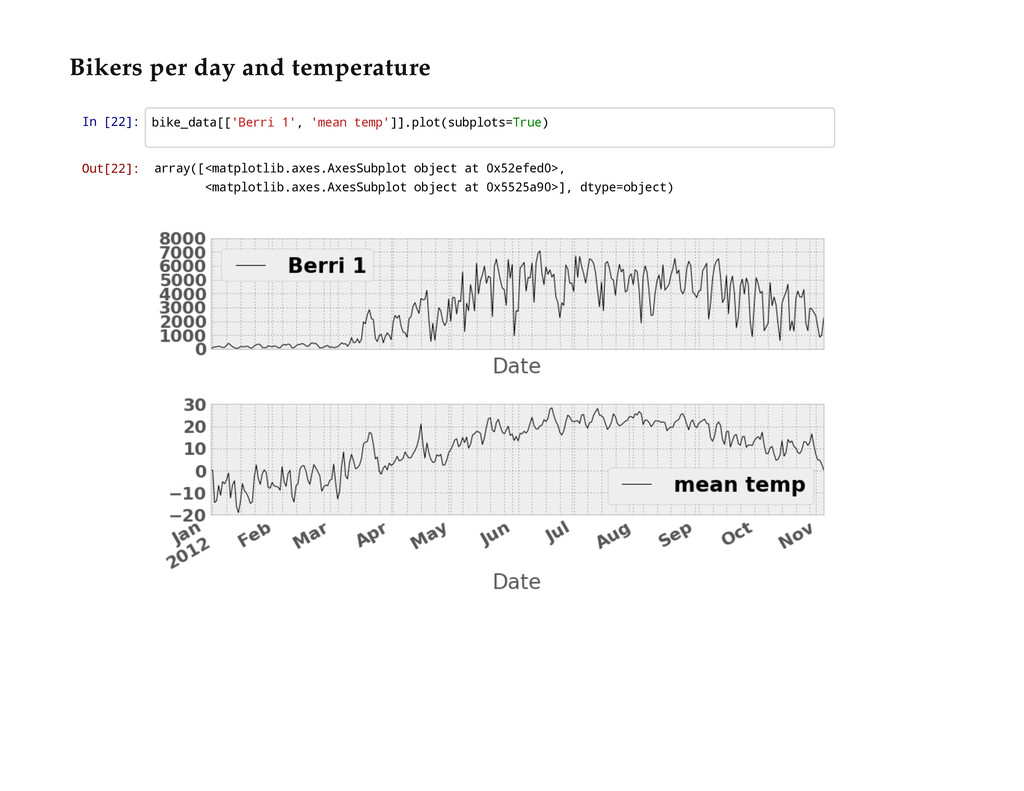{kind=link}
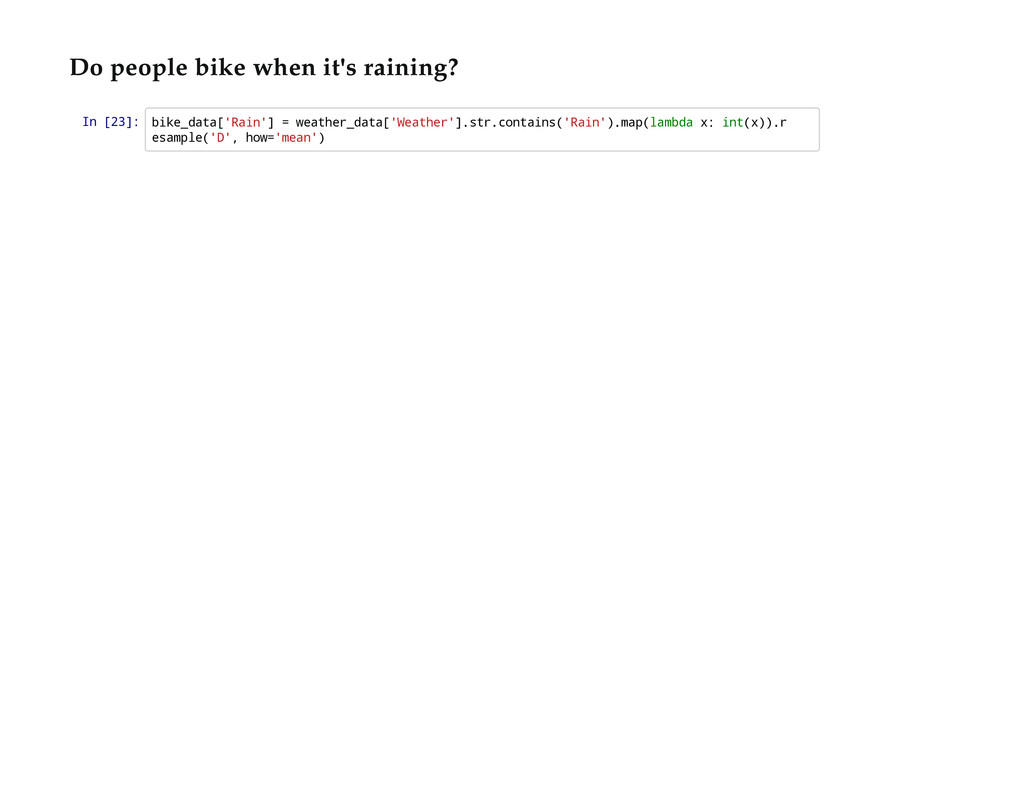{kind=link}
![In [24]: bike_data[['Berri 1', 'Rain']].plot(subplots=True) Out[24]: array([<matplotlib.axes.AxesSubplot object at 0x5900b10>,](https://files.speakerdeck.com/presentations/d8ec6500e5db0130ca082ab0926c8974/slide_24.jpg){kind=link}
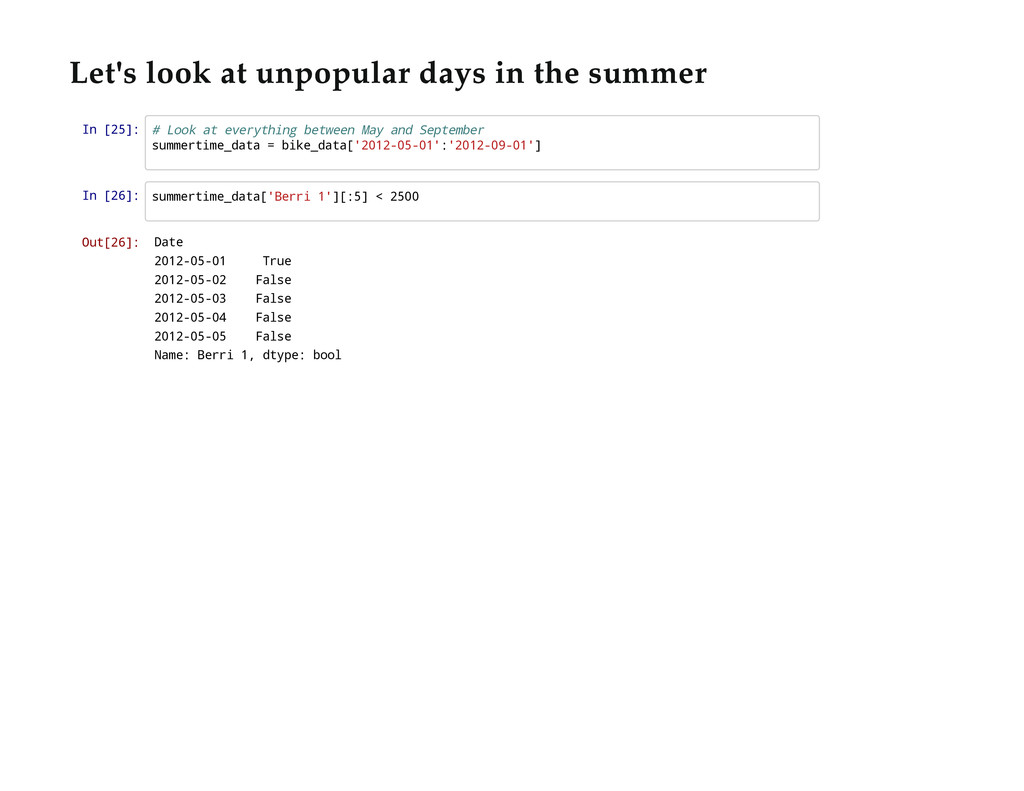{kind=link}
![In [27]: summertime_data = bike_data['2012-05-01':'2012-09-01'] bad_days = summertime_data[summertime_data['Berri 1'] <](https://files.speakerdeck.com/presentations/d8ec6500e5db0130ca082ab0926c8974/slide_26.jpg){kind=link}
{kind=link}
![Thanks! Questions? Thanks! Questions? In [29]: print 'Email:', julia['email'] print](https://files.speakerdeck.com/presentations/d8ec6500e5db0130ca082ab0926c8974/slide_28.jpg){kind=link}