https://coscup.org/2023/zh-TW/session/HL88HZ
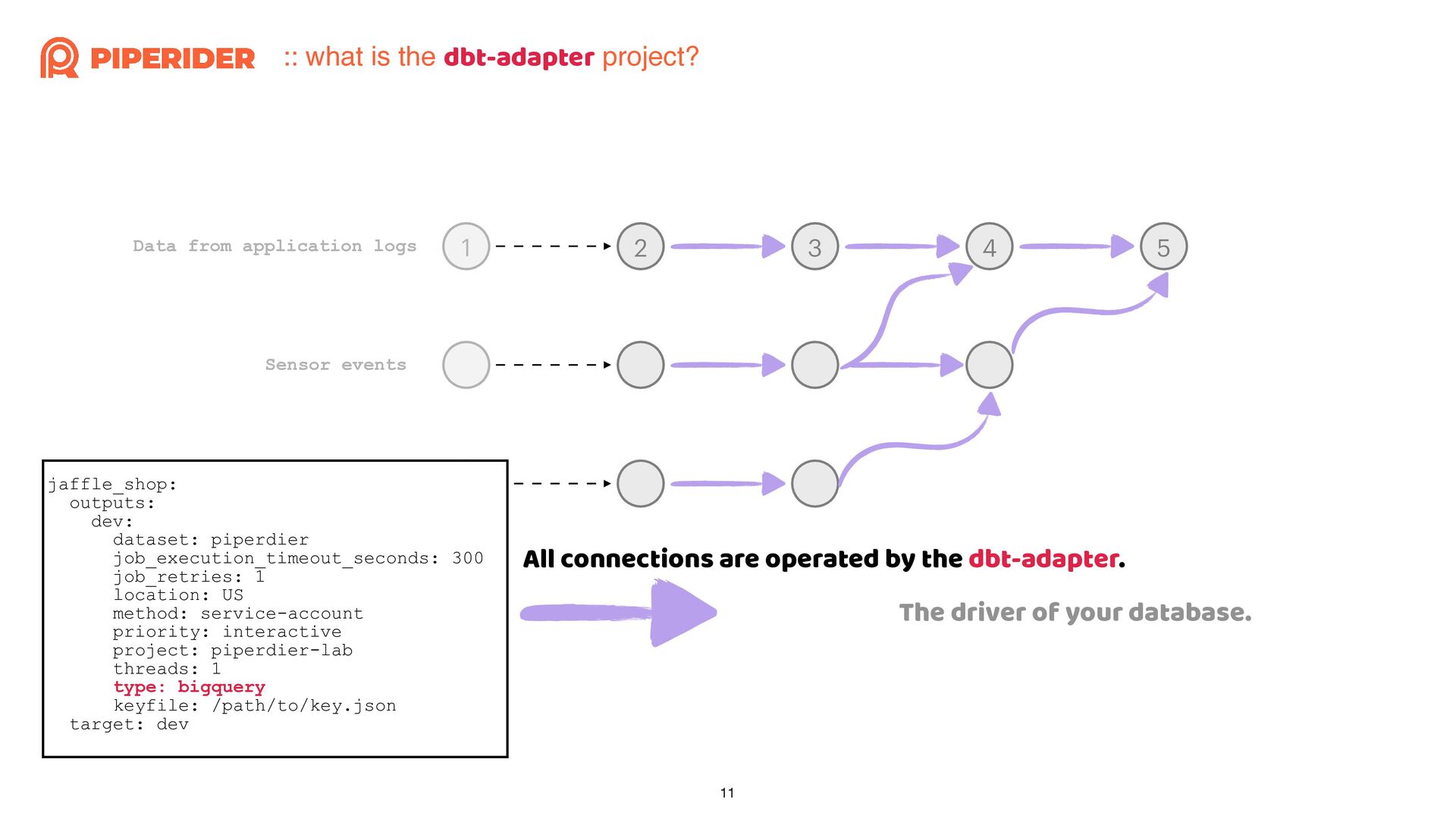
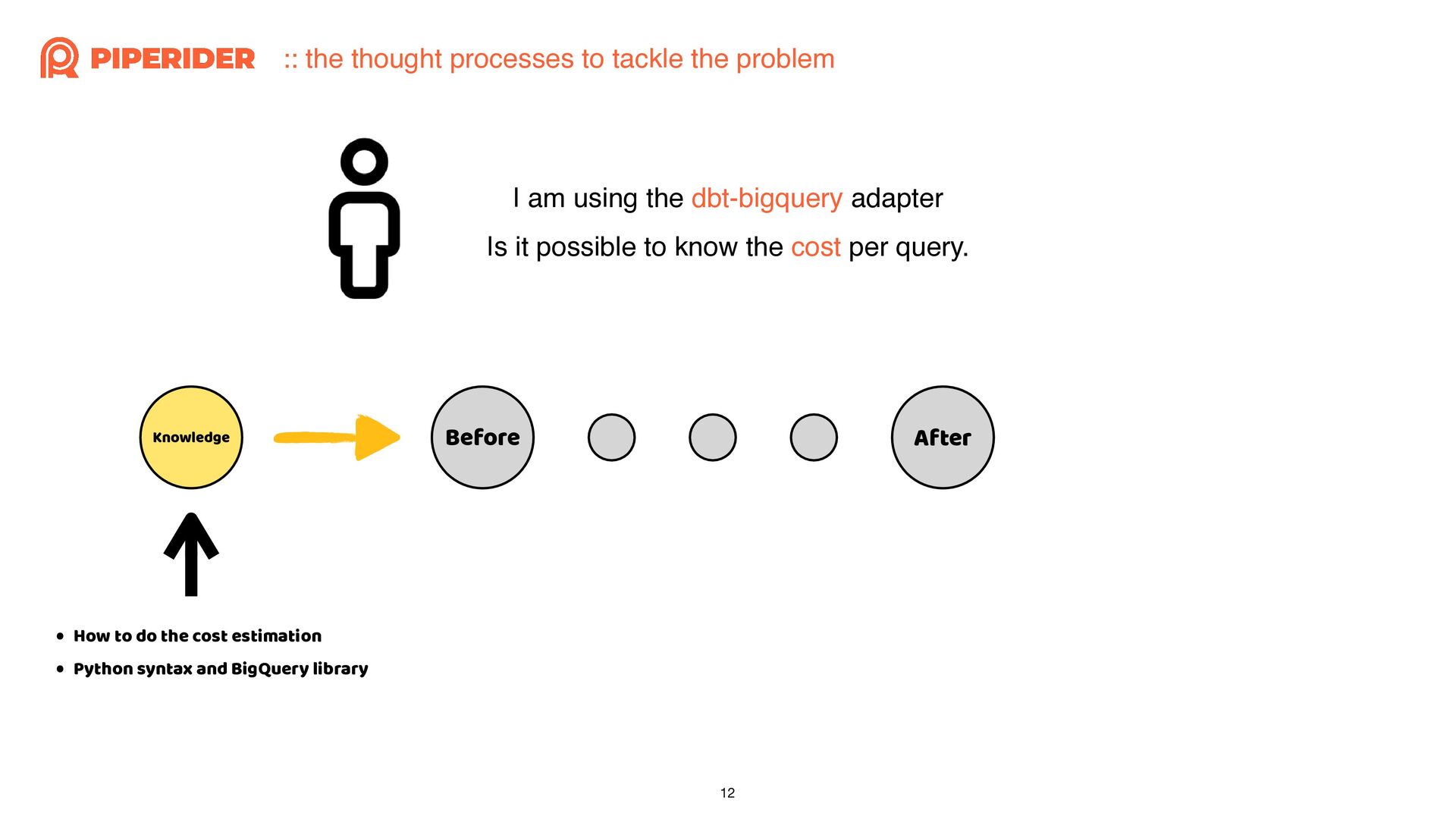
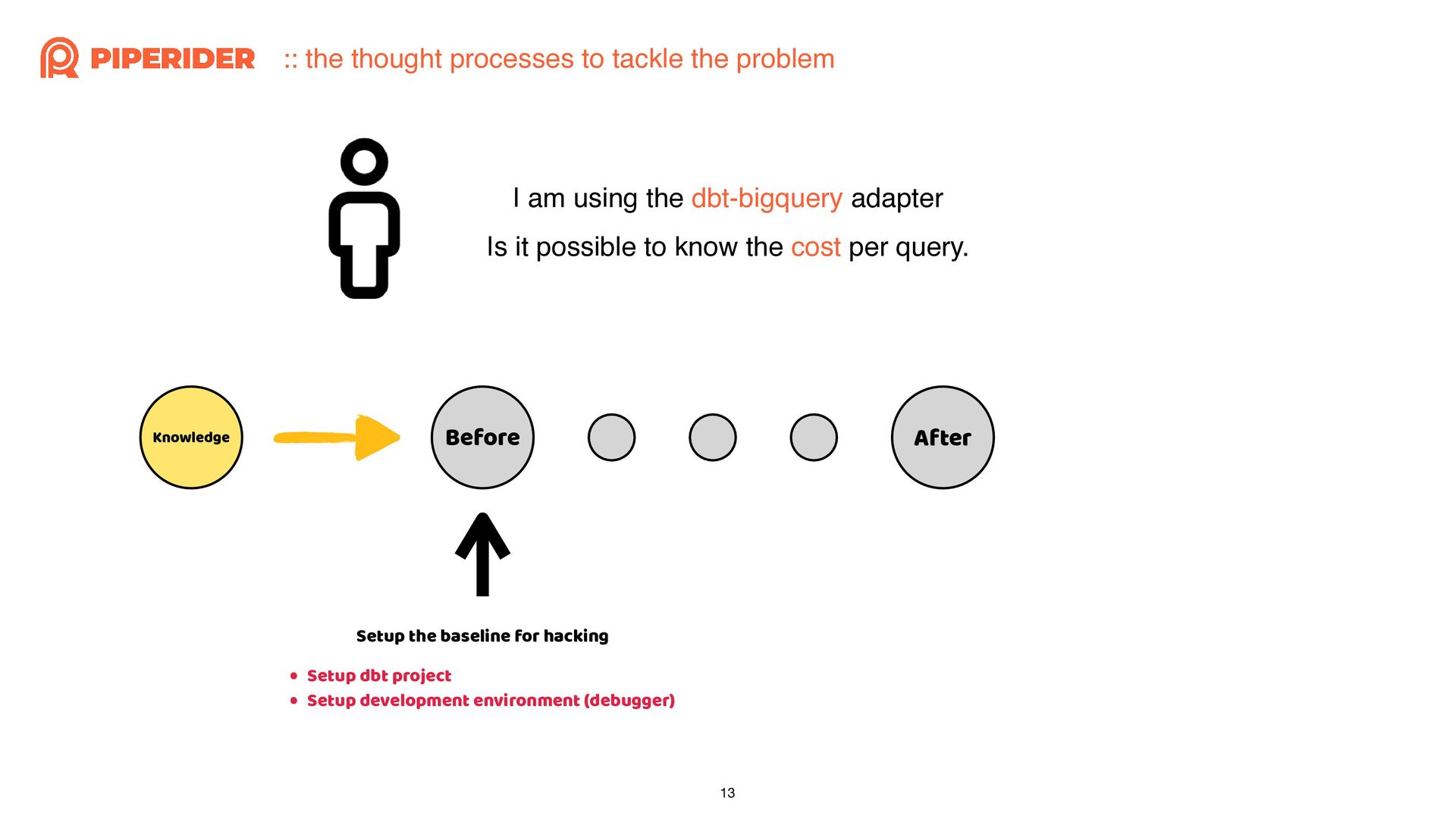
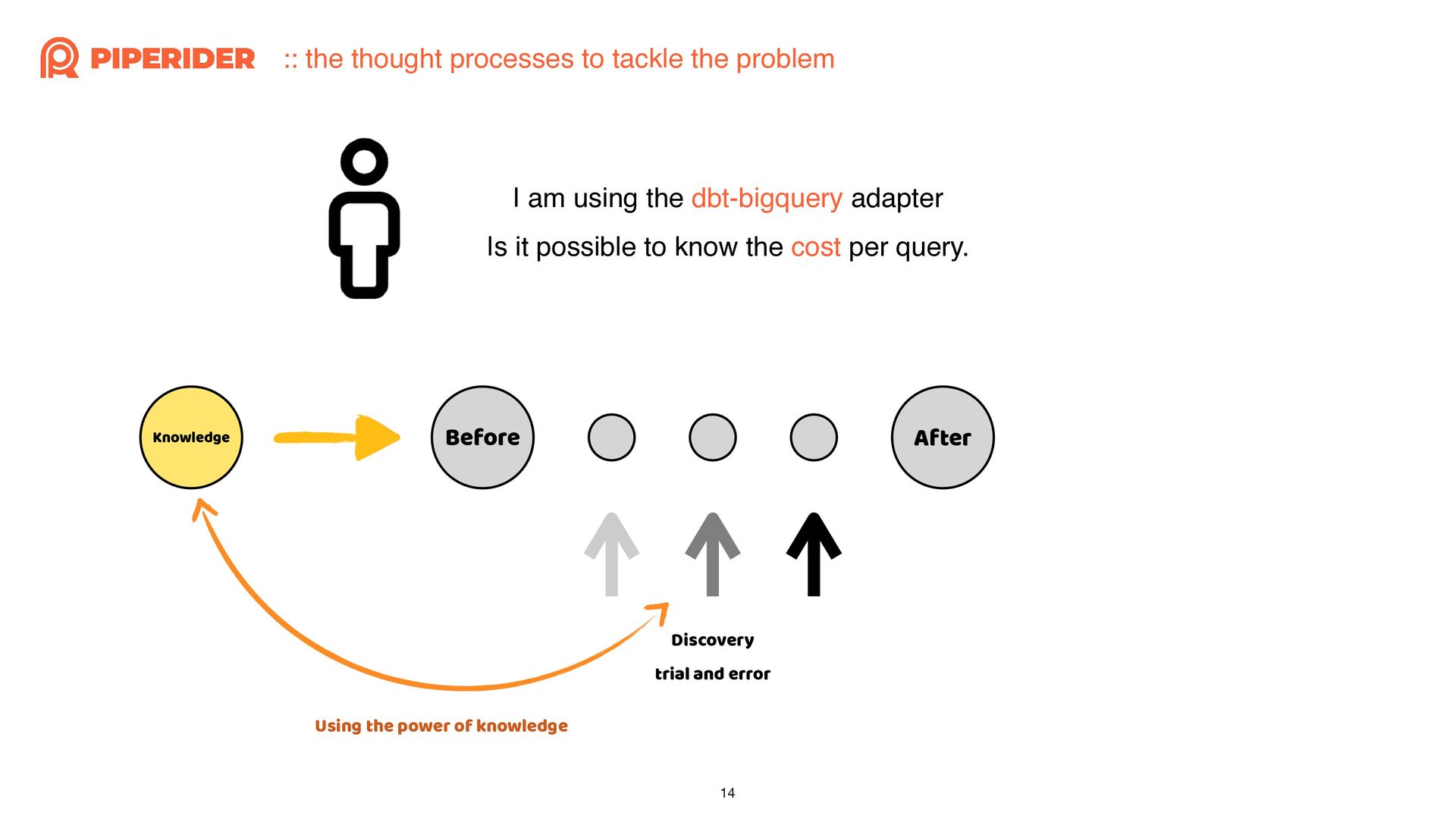
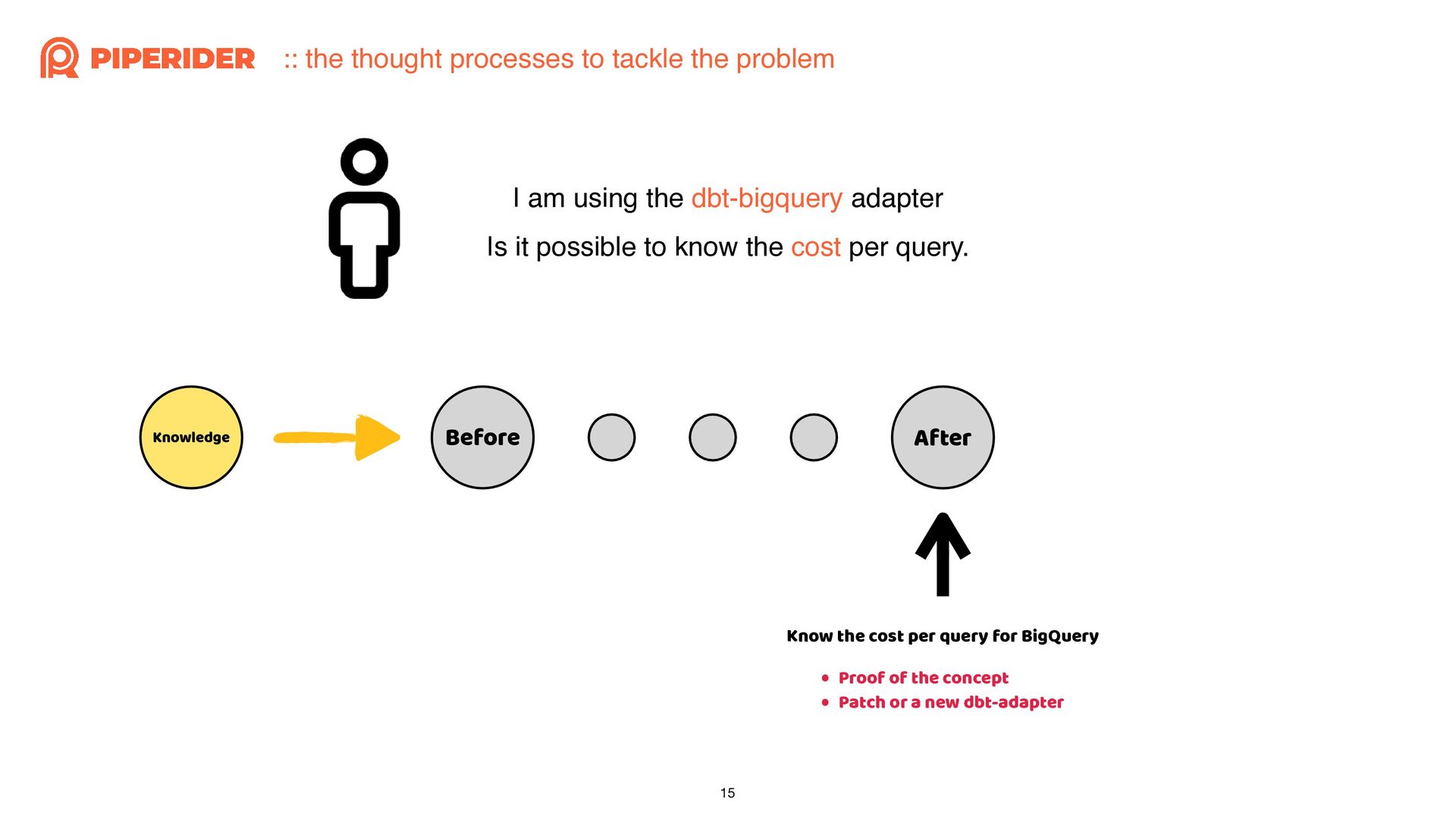
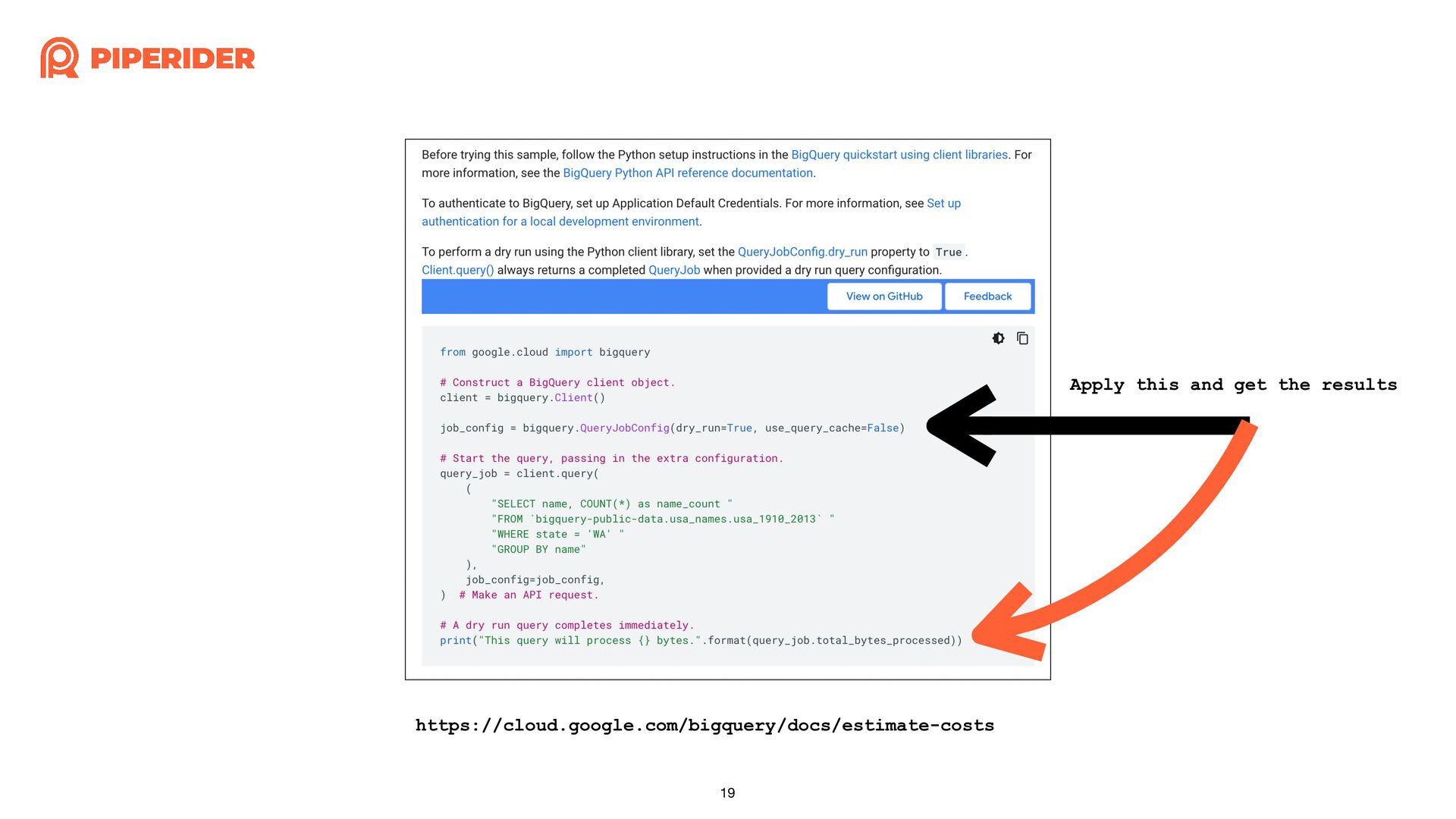
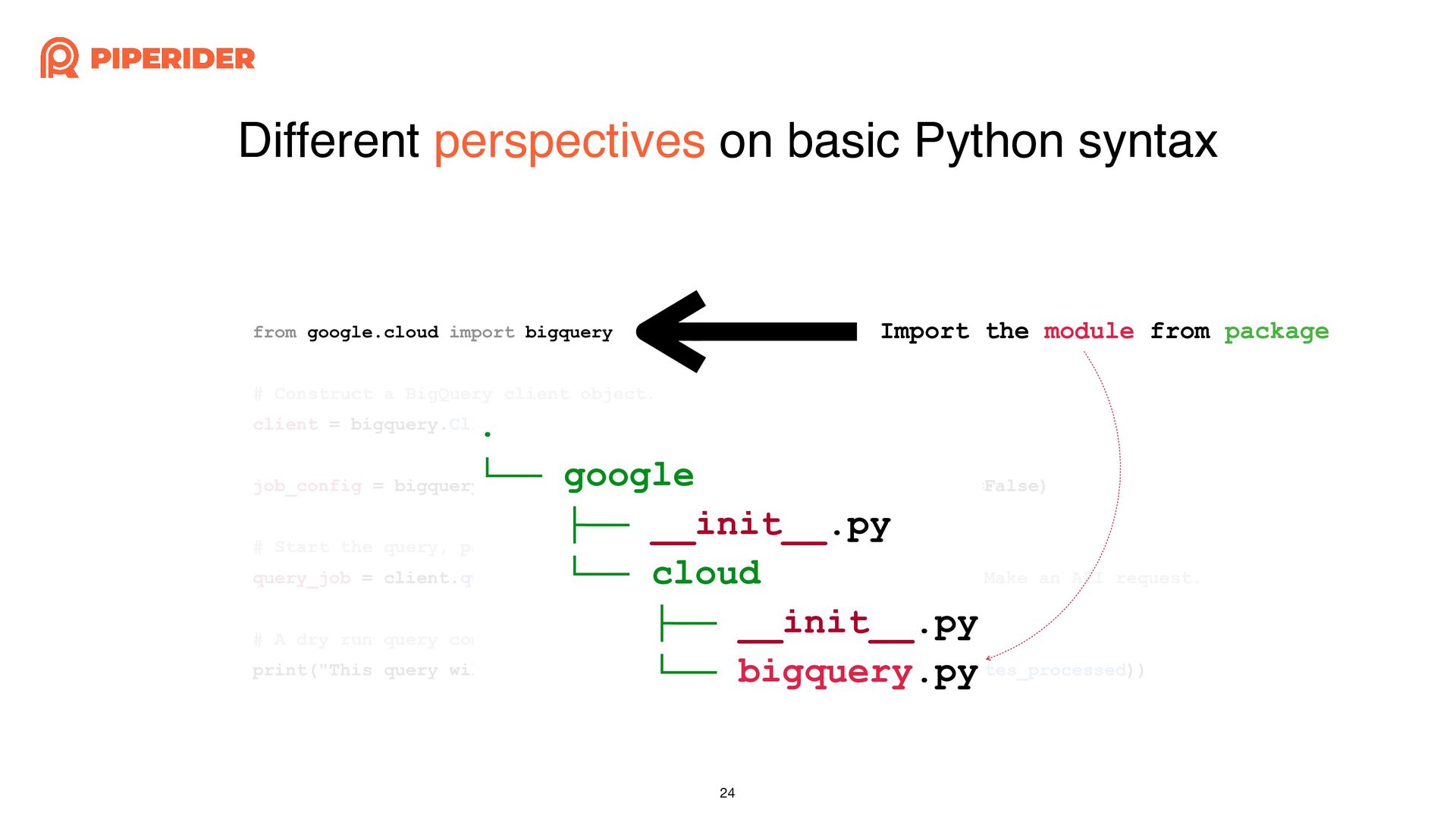
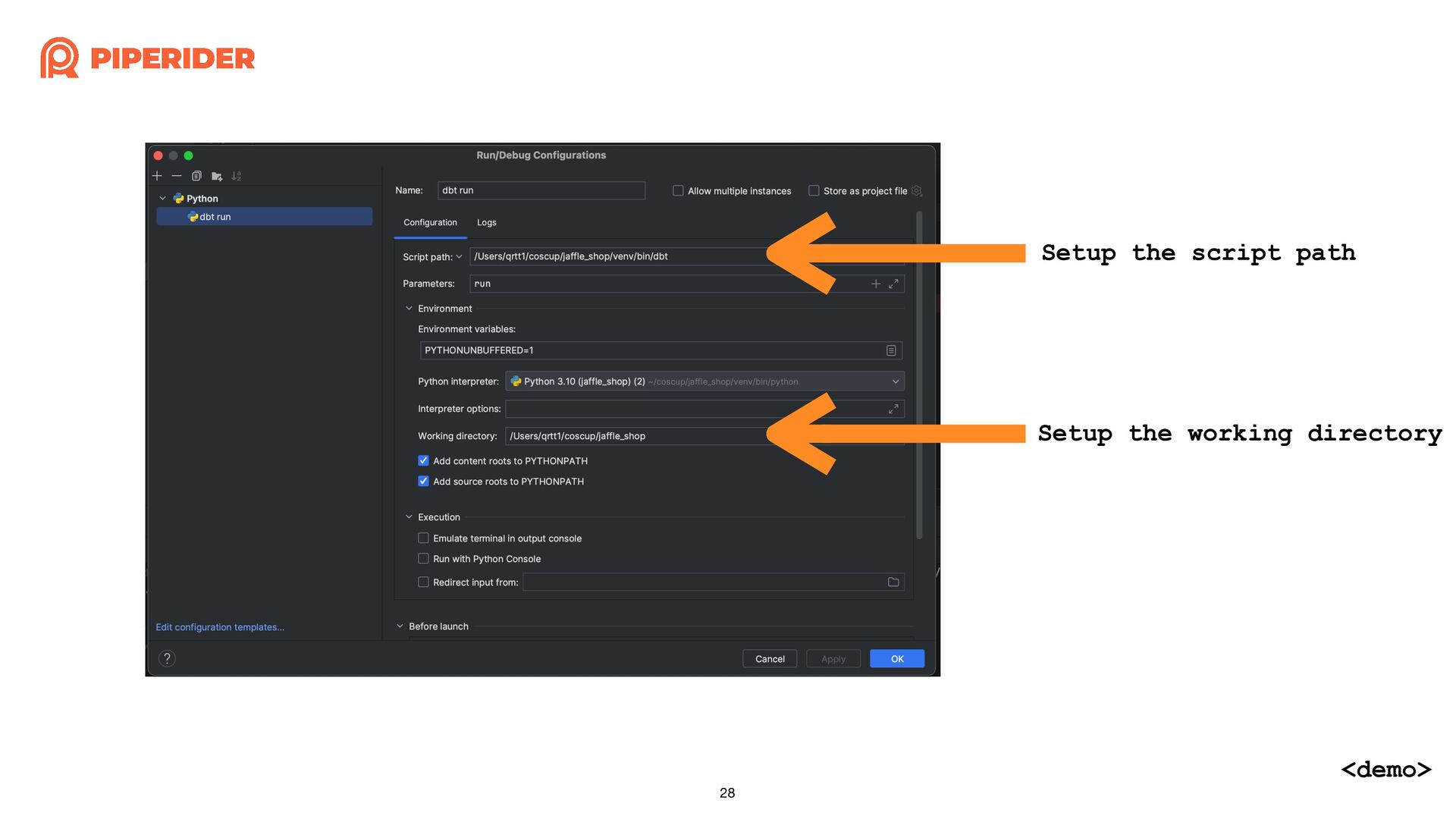
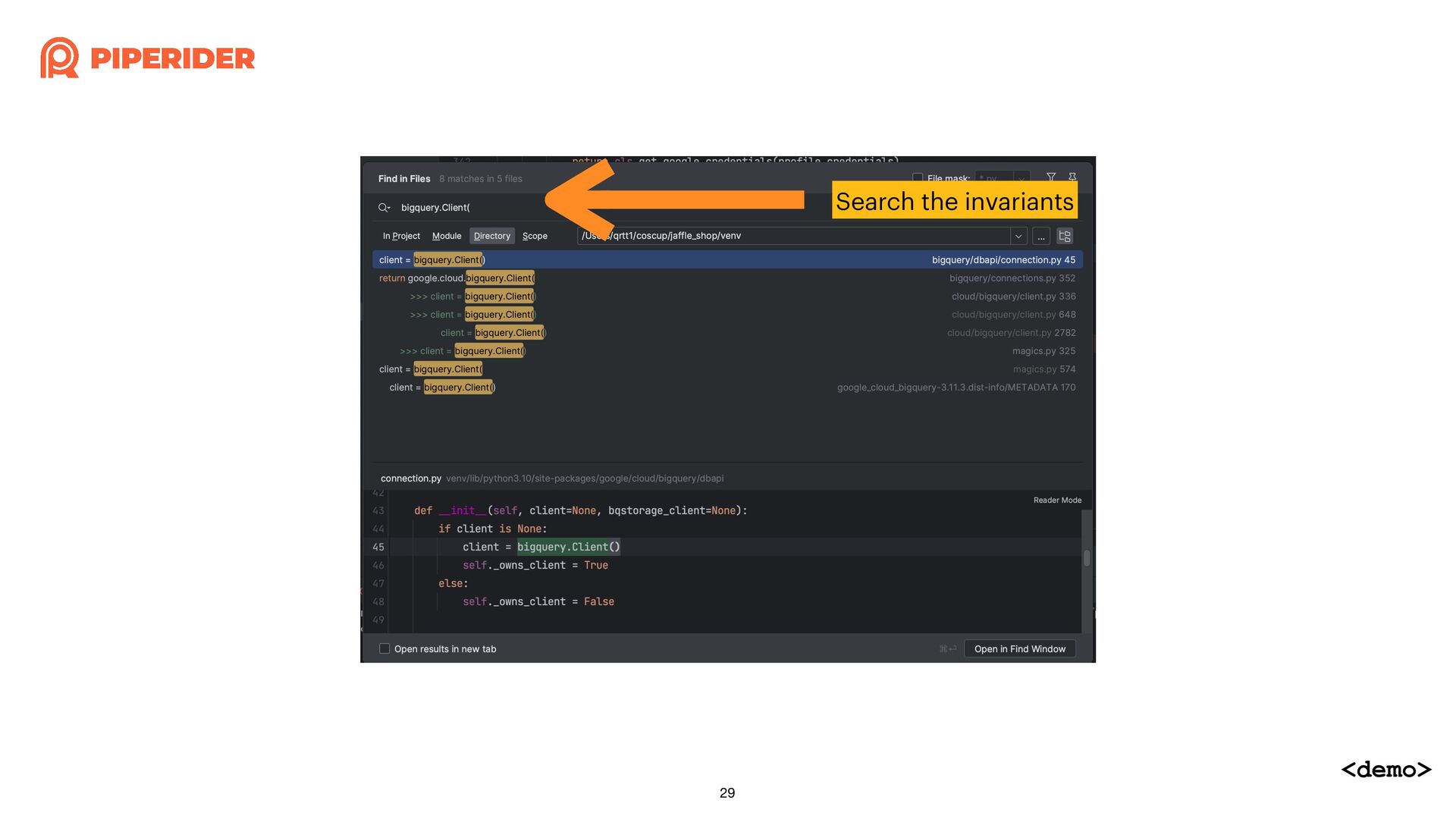
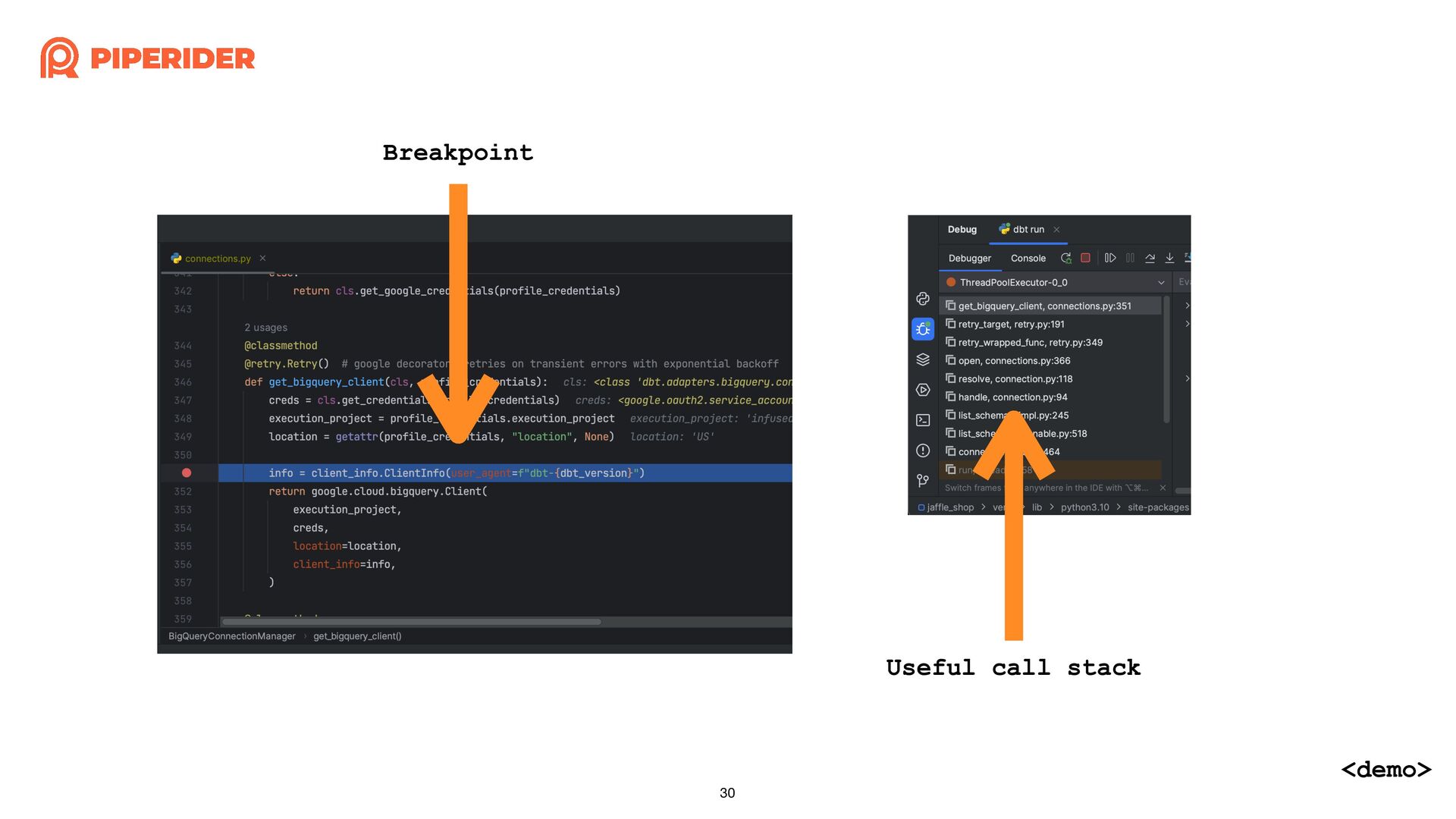
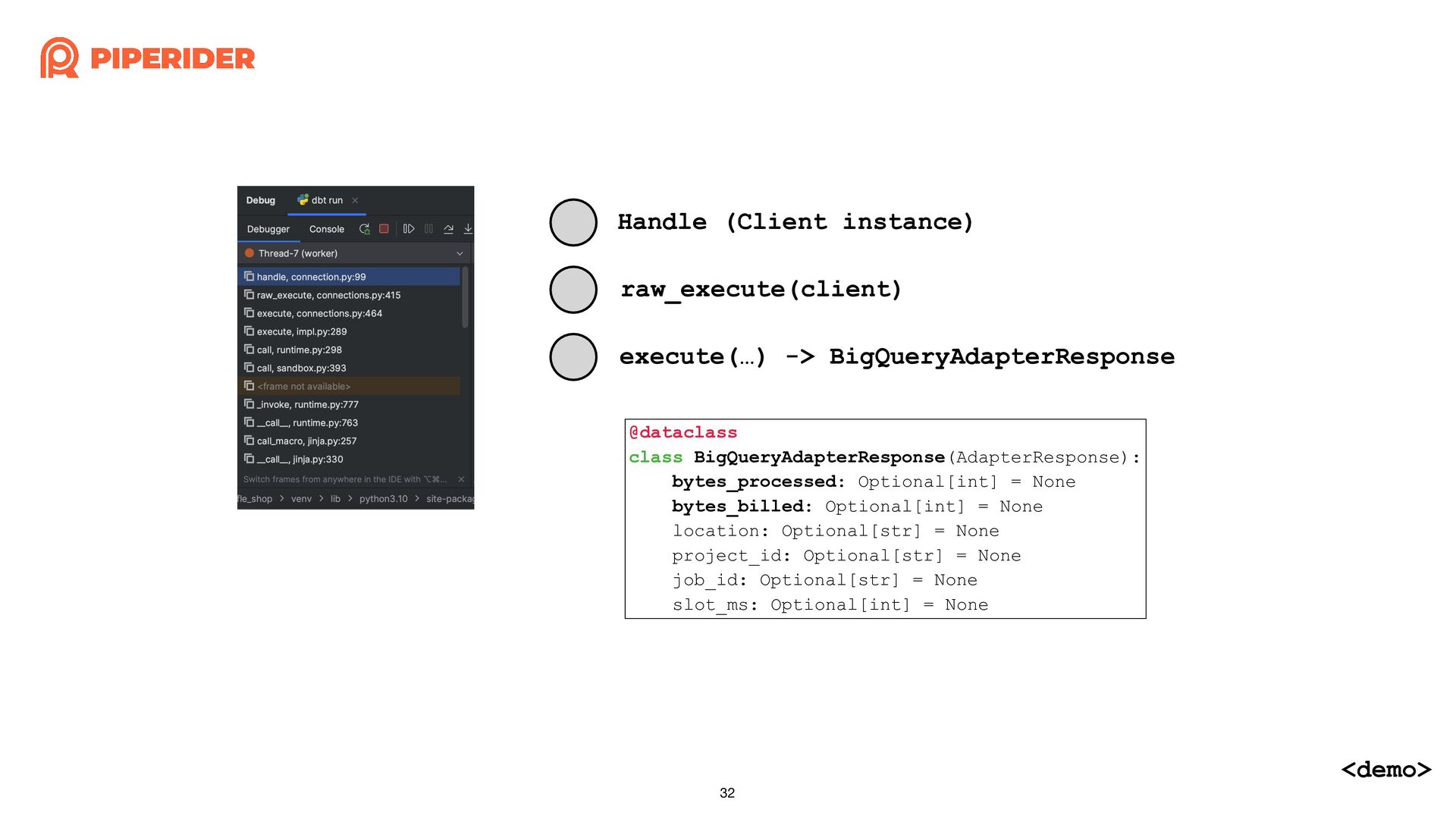
In order to calculate the cost of each dbt build execution through dbt-bigquery, I started reading and modifying the source code of the dbt adapter. As long as you have a basic understanding of Python syntax and some simple trace code techniques, such as using “string” that do not change and the stack trace when exceptions occur, combined with a debugger, you can easily achieve the desired effect.
為了想要透過 dbt-bigquery 計算每一次執行 dbt build 的成本,而開始邊讀邊改 dbt adapter 的原始碼。只要你對 Python 有基本的語法概念,再加上簡易的 trace code 技巧:依賴不變的字串與發生例外時的 stack trace,再配合 debugger 就能簡單地改出想要的效果囉!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
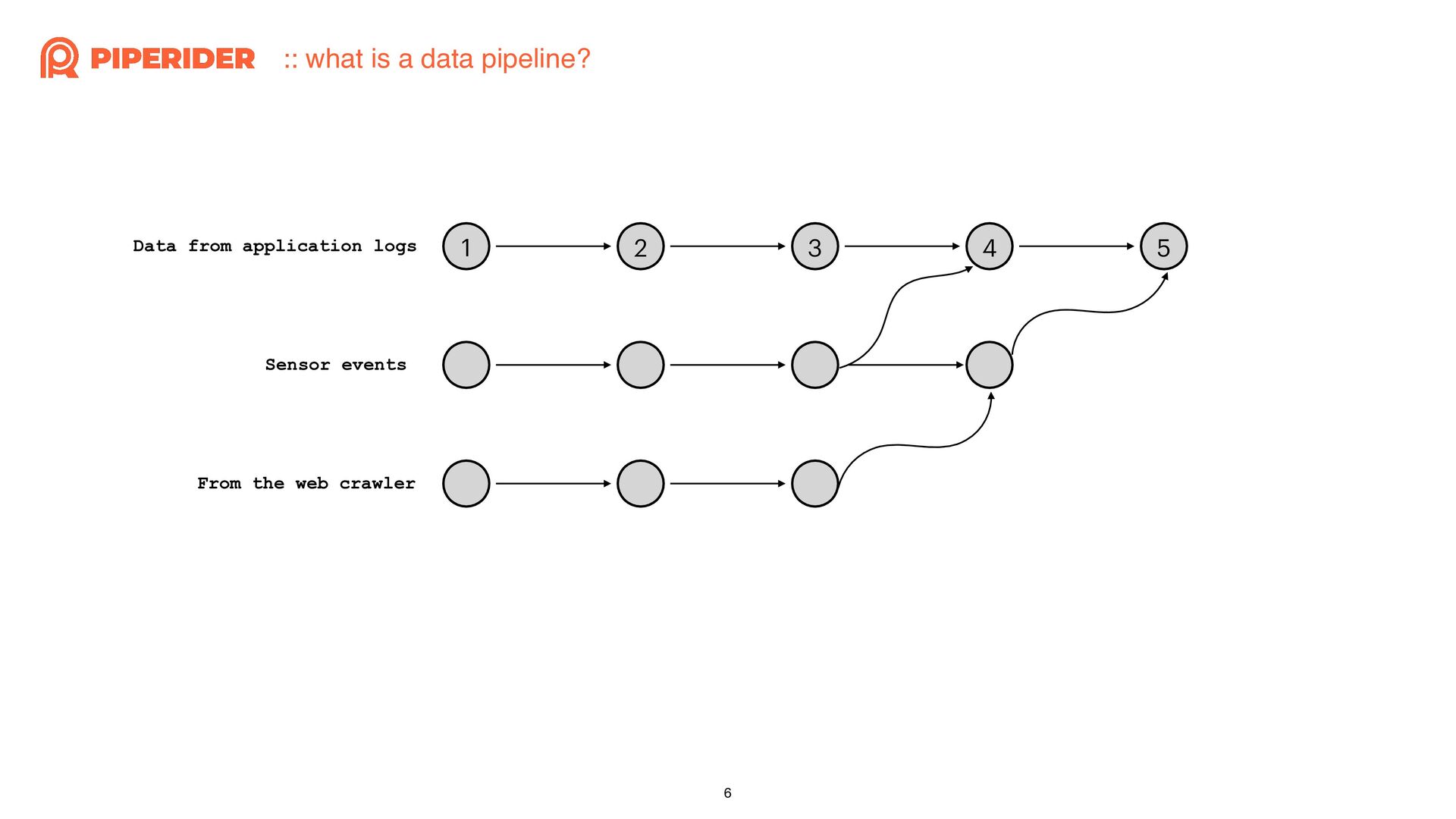{kind=link}
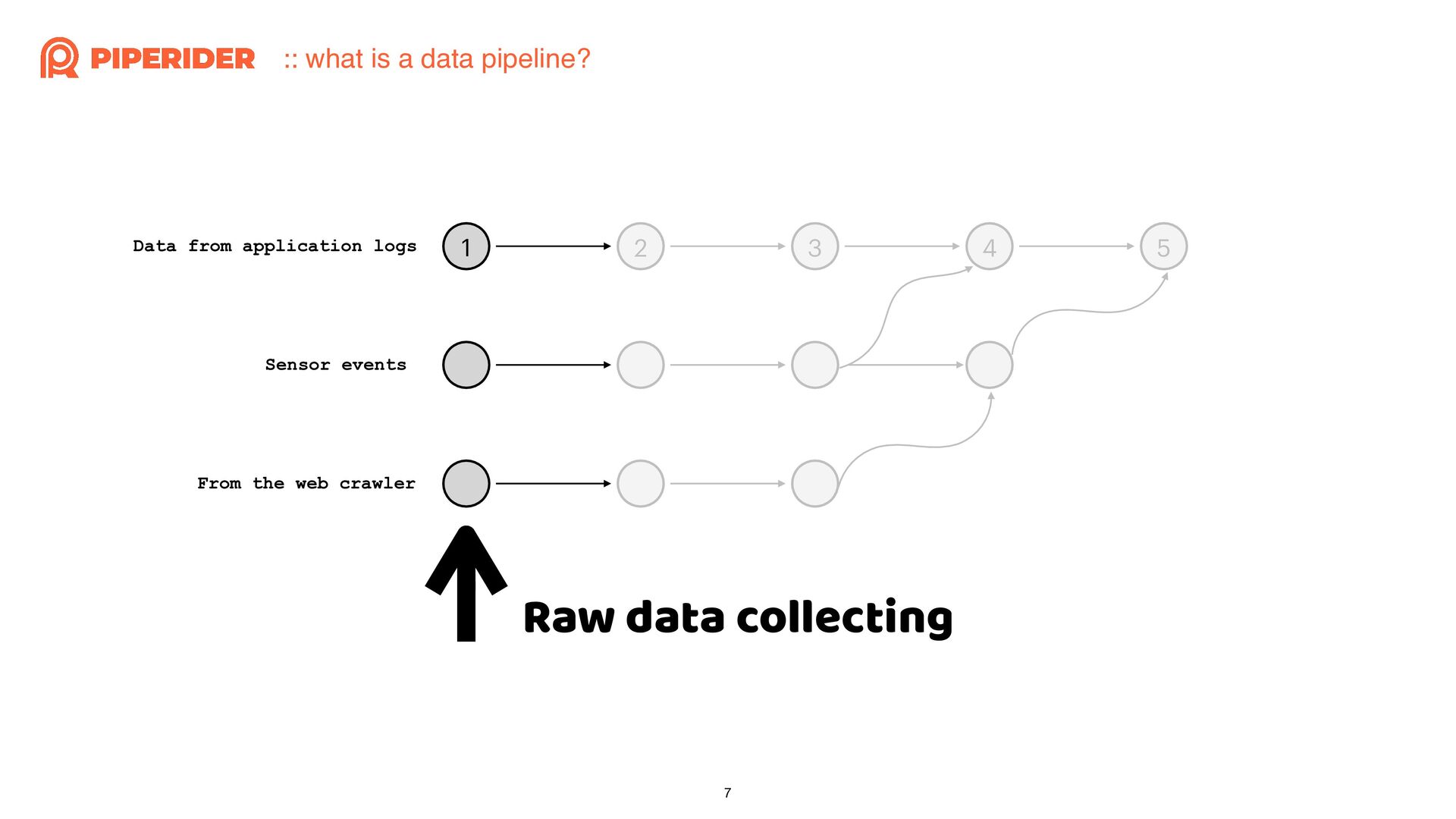{kind=link}
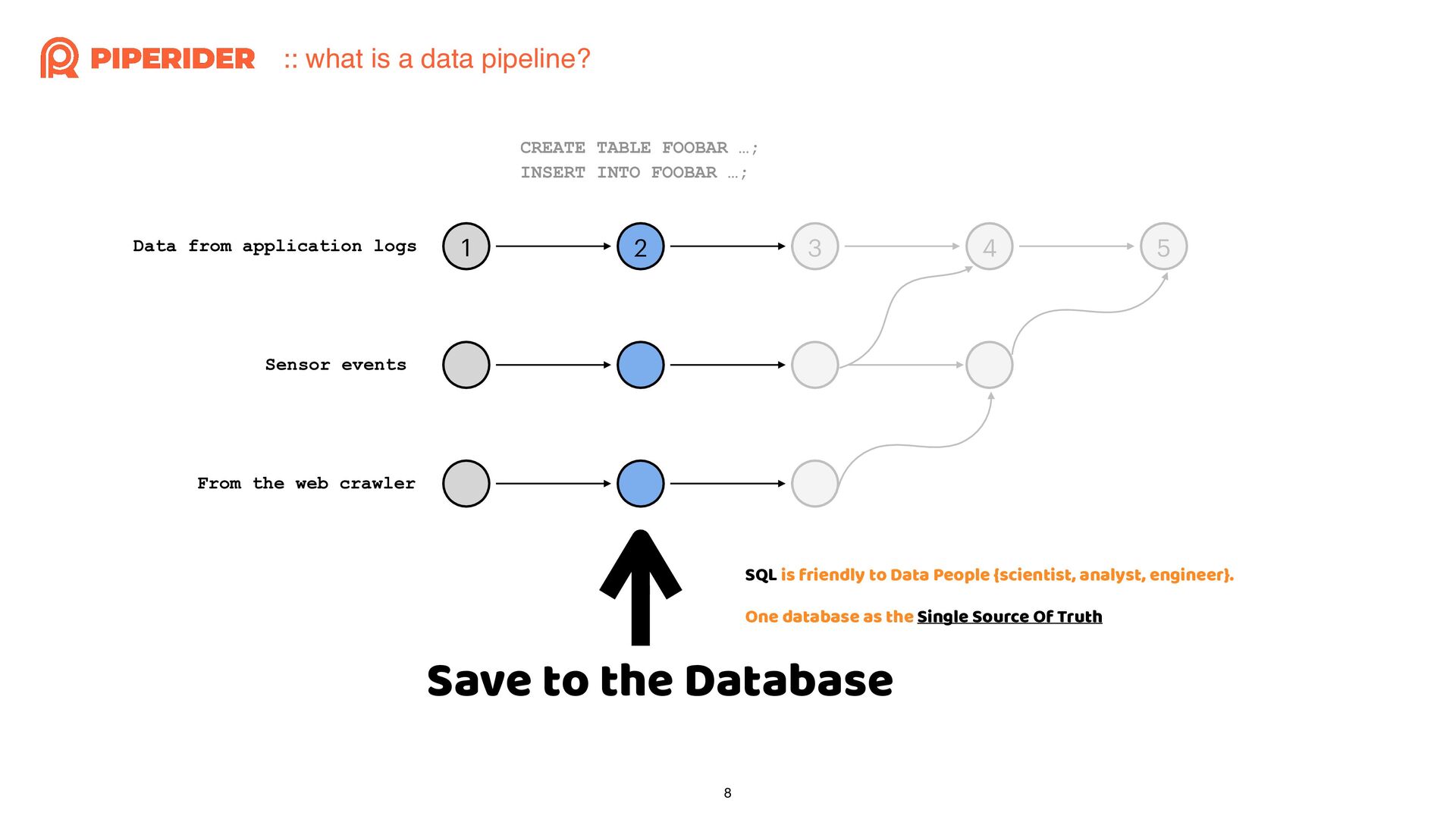{kind=link}
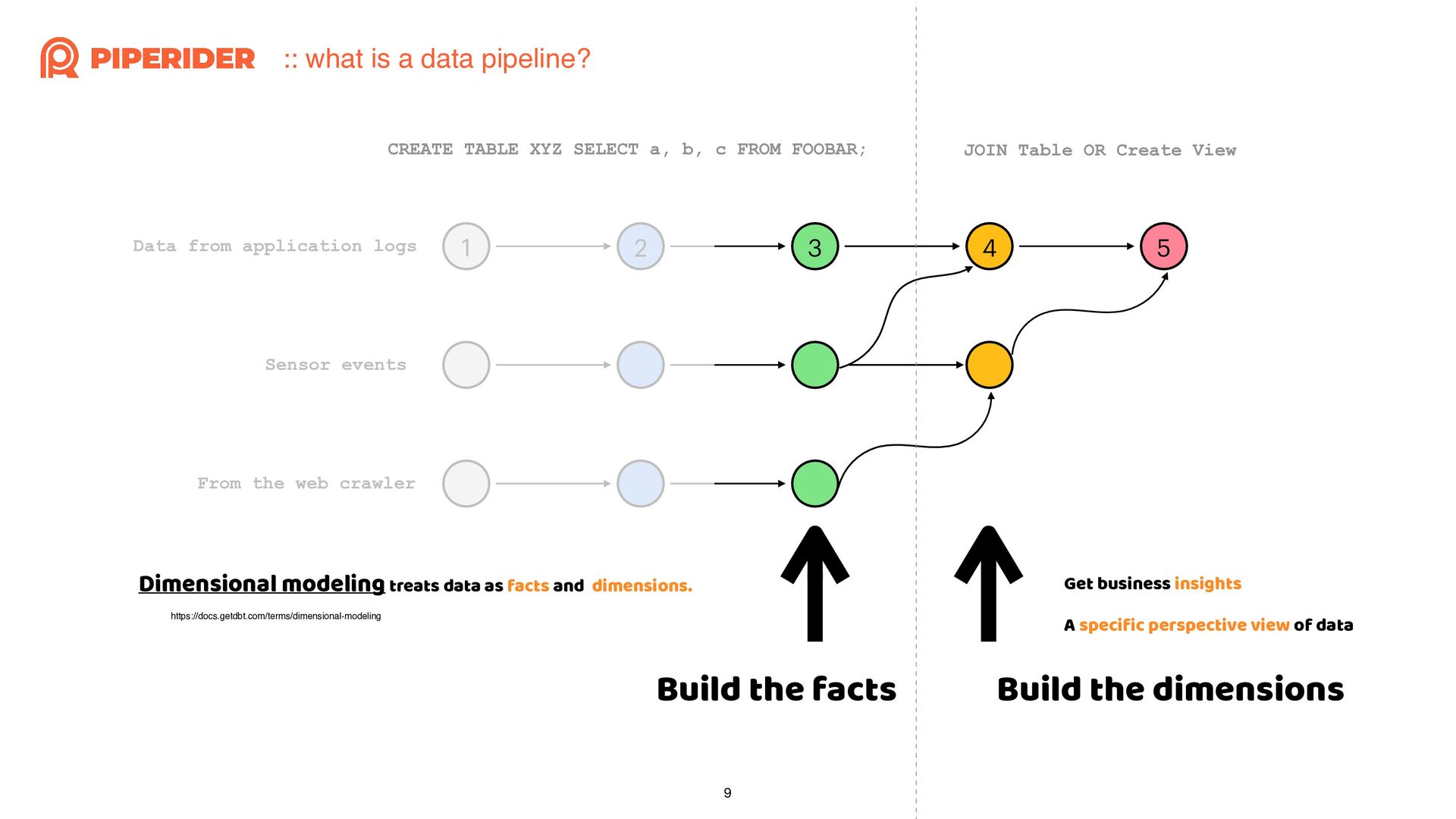{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}