bit.ly/rubymethodcache All our references are linked to in this bit.ly bundle. Depending on which one of us you ask, this talk is either based on Jurassic Park or the Land Before Time!
This talk will dive into the internals of the Ruby VM. Specifically, we’re going to walk through how ruby handles method lookups. Since Ruby is delightfully dynamic, method resolutions are normally slow. We'll walk through what made method lookups so slow in Ruby 1.8 and before. A huge improvement came in 1.9, when YARV became Ruby’s reference implementation. Finally we'll walk through limitations and improvements since then.
== Faster website bit.ly/ostrichandyak Performance What’s In This Talk?? This isn’t a performance talk, at least not for most people. It's true that when people work on method caching they're doing it to improve Ruby's performance. That doesn’t mean that ruby is the cause of your performance problems. This is especially true if you’re using Ruby to write websites. In that case, you almost certainly have dramatically bigger performance fish to fry. For most websites, the ruby layer is already in the milliseconds. Optimizing that for a faster page is like trying to catch the smallest fish in the pond. By contrast, things on the front end cost most websites multiple seconds. Things like gzipping assets; minifying, concatenating, and ordering javascript well; and generally reducing the number of total requests by spriting images or combining stylesheets into one cacheable assets can cut way more time off a page. Depending on the flexibility of your CDN, you can sometimes cache entire pages, so your ruby code won’t even hear about most requests. Above all, measure your app. I gave two talks a few months ago about how hard it was for us to measure the performance of our app when it became mostly javascript. It’s hard but you have to do it! This is the bit.ly bundle from from those talks, and it includes links to the slides.
That being said, some programs, especially ones running on embedded hardware or supporting extremely high load websites, really do need maximum ruby performance. If you care about this level of optimizations, you now have options. But maybe a better reason to understand Ruby’s Method Cache is because it's cool to learn and know the stack. Someone could say that we're the wrong people to give this talk; neither of us commit to MRI, but that was also the appeal. Jumping into the internals of the Ruby VM is a out of the norm for both of us, so we really enjoyed it. And that’s the best reason to dive into this stuff. Learning a part of the Ruby VM is an awesome way to nerd out. Sure, we got C dust all over our cool Ruby clothes, but we had a great time. And we want this stuff to not feel out of reach for people. So when we use jargon, we’re going to try to say what it means. And our references include a few files you can read through if you want to jump in.
what method caching is in general. Method Caching is a way of speeding up method lookups by storing the result of that lookup the first time. The next time you hit that callsite you can hopefully look it up quickly in the cache rather than actually resolving the method call again.
Raptor.new raptor.rawr what is method RESOLUTION?? For example, this instance of raptor invokes rawr, where should we go look for the method definition? Is it in Raptor? Is it in Dinosaur? Is it in an included module or in the super class of Dinosaur? And there are of course more possibilities than that. In Ruby, it could be defined in multiple places and could be defined dynamically. Figuring out that method resolution is computationally complex.
problem of expensive method look ups is sometimes made a lot easier in other languages. For example, compiled languages add optimizations during compilation to significantly improve the speed of method calls.
raptor.rawr(); what is method RESOLUTION?? CALL 0x1dac <rawr> For example, in C and C++, if the method rawr is not overridden, the compiler can substitute the method name for the direct method address before the program is executed, negating any need for a method lookup. In this case it can CALL the address directly. If the function is virtual however, then rawr can be overridden and therefore an extra step is required to determine what class the function is defined in. Instead of a direct JMP, the method address is looked up in a vtable. In this instance, there is one virtual table for the Raptor class that contains the address pointer for the function rawr regardless of if it’s defined in Raptor or Dinosaur. The virtual table for the calling class returns an address pointer and the CALL can then be executed. A third option for these languages is specifying the function as "inline". In this case the contents of the function are actually copied inline in the code during compilation. Not only is there no lookup involved, but there's no JMP either.
for interpreted languages to have quick method lookups. The method address of a particular method can change at runtime. But Python has a cool solution.
raptor.rawr() raptor._dict_[‘rawr’] Python includes late binding, so the interpreter doesn’t know what type raptor is until runtime. Unlike being able to compile the address location in the machine code like in C, the interpreter still needs to search when rawr is executed. To make this search faster, a dictionary is set on the class with the address of all of the methods. In this example, if rawr exists on Raptor, the interpreter can merely search on the classes dictionary and jump to the address location returned.
Method Resolution in Ruby ≤ 1.8 So here we have a basic example of method invocation. We have an instance of Raptor, which can also get some behavior from Dinosaur, and now we’re going to send it a message, to rawr! Unfortunately, at this stage, we don’t immediately know where the method’s defined, and the VM doesn’t either.
include Clever def yawn ... end end raptor = Raptor.new raptor.rawr } f We’ll look in the Raptor class first. We don’t find the definition there, but we see there’s an included module.
end module Clever def hunt ... end end raptor = Raptor.new raptor.rawr f Method Resolution in Ruby ≤ 1.8 } So we’ll check the module next. Still not finding it there, we check up Raptor’s object hierarchy, in Dinosaur.
Dinosaur include Clever def yawn ... end end module Clever def hunt ... end end raptor = Raptor.new raptor.rawr F !! Method Resolution in Ruby ≤ 1.8 } And there we find the method definition. This is where, as ruby developers, we pay the price for not having to define an interface or dictionary. Instead, we check every one.
Ruby ≤ 1.8 You might just feel that this is the way it has to be, that’s there nothing to be done. We need to resolve our methods, and this is how that happens. But lets look at what happens when we invoke the same methods 10 times. In Ruby 1.8, we’ll pay the cost of a full method resolution every time.
by scanning for particular characters AST: Abstract Syntax Tree, a data structur representing the lexical hierarchy of program Method Resolution in Ruby ≤ 1.8 VOCAB Now we’re going to jump into what’s going on under the hood. We’re going to talk about the steps that the Ruby 1.8 interpreter goes through to look up a method. Tokenization is the first step to creating the Abstract Syntax Tree.
in to this one line of ruby code to see how it is executed. The first thing that happens when we run our dinosaur ruby script is that MRI groups the characters into tokens. Because Ripper, the ruby tokenizer, ships with Ruby 1.9 and 2 I was able to see how our examples were parsed. It's an obvious, but important step to executing this line of code. Ripper does a lexical analysis, scanning character by character until it can group a string into a recognizable entity.
Ruby ≤ 1.8 And finally the last identifier, rawr, completes the scan. Now that ruby has an array of tokens, the next step is to group them into expressions that ruby understands. Just like there are grammar rules the make up valid sentences in English, there are grammer rules the ruby parser, Bison, uses to make valid statements in ruby.
rawr . Parse Ruby’s MRI parser is grouping expressions in order to create an Abstract Syntax Tree. The Ruby 1.8 interpreter uses the output of this expression tree to directly walk, search, and execute your ruby code. Bison classifies raptor as a variable dereference call.
raptor rawr . :on_ident And finally all of this is stored in a program node. Normally the program node would contain a variety of different calls necessary for the script to execute, but in the spirit of simplicity, we only have raptor.rawr in this example.
[:@ident, "rawr", [1, 7]] ] ] ] Abstract syntax TREE Method Resolution in Ruby ≤ 1.8 And this is the Abstract Syntax Tree just for raptor.rawr. As you can imagine, the tree grows in size and complexity for a real program. As I mentioned before, in Ruby 1.8, the interpreter walks this tree to execute the code and when it finds rawr it also has to search the tree for where rawr is defined. It doesn't do this just the first time that a method is executed, it has to search the tree for every method resolution.
YARV, another ruby interpreter with a performance focus, was merged into MRI. One of the optimizations in YARV was to prevent having to complete a full method resolution for every invocation. Instead, it would resolve the method the first time it was encountered, and save the result of that resolution. In our example calling ‘raptor.rawr’ 10 times, this will will mean we only have to resolve the method once, and the next 9 calls can be faster. In this particular case, the time saved was trivial, but it can become noticable in large, complex application. But for reasons we’ll touch on later, how much time a program saves by caching method lookups is really dependent on the code itself. There are things our code can do that will prevent us from getting the benefits of the method cache. So let’s walk through our new optimized version of method resolution.
raptor = Raptor.new raptor.rawr end } Method Resolution in Ruby 1.9 So this is our code that we’re going to run a few times in Ruby 1.9. The first thing that will happen is that this code, will be tokenized into a stream of tokens, and parsed by Bison into an abstract syntax tree. Just for kicks, here’s the AST just for the block.
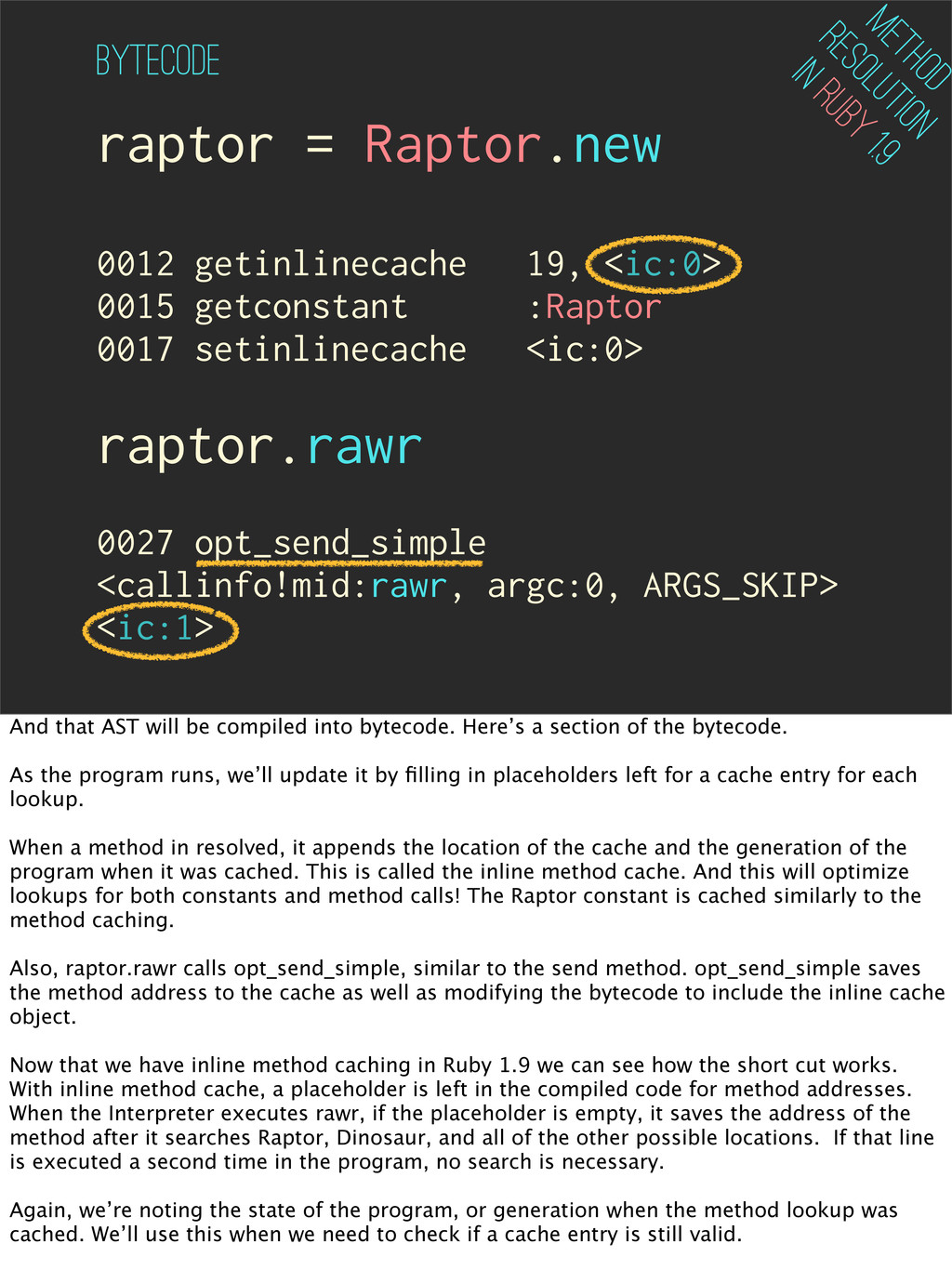
0017 setinlinecache <ic:0> raptor.rawr 0027 opt_send_simple <callinfo!mid:rawr, argc:0, ARGS_SKIP> ByteCode Method Resolution in Ruby 1.9 <ic:1> And that AST will be compiled into bytecode. Here’s a section of the bytecode. As the program runs, we’ll update it by filling in placeholders left for a cache entry for each lookup. When a method in resolved, it appends the location of the cache and the generation of the program when it was cached. This is called the inline method cache. And this will optimize lookups for both constants and method calls! The Raptor constant is cached similarly to the method caching. Also, raptor.rawr calls opt_send_simple, similar to the send method. opt_send_simple saves the method address to the cache as well as modifying the bytecode to include the inline cache object. Now that we have inline method caching in Ruby 1.9 we can see how the short cut works. With inline method cache, a placeholder is left in the compiled code for method addresses. When the Interpreter executes rawr, if the placeholder is empty, it saves the address of the method after it searches Raptor, Dinosaur, and all of the other possible locations. If that line is executed a second time in the program, no search is necessary. Again, we’re noting the state of the program, or generation when the method lookup was cached. We’ll use this when we need to check if a cache entry is still valid.
cache VOCAB Method Resolution in Ruby 1.9 The way Ruby keeps track of the generations is with a global counter. The exact variable is the ruby_vm_global_state_version, but we’ll always refer to it as the cache generation or the global state of the program.
r . Because it’s kind of cool, I wanted to take a slide to talk about the caching style used here. Ruby is using a pattern of ‘generational caching’. That means that Ruby keeps track of its program state, and when a method resolution is cached, the cache entry notes the generation when it was created. Some events, that we’ll cover soon, spawn a new generation, meaning the event changes the program in such a way that everything that happened in the last generation is no longer valid. The thing that’s cool about this style of caching is that it’s very low overhead. We don’t have to call a “purge all” event that sweeps through all the bytecode and removes all the entries. That would be slow, and potentially unnecessary. Because if a method will never be called again, why worry about its cache entry. Generational caching means we only have to increment the global counter for certain events, and before we use a cached result, compare its generation to the current generation. [If there are any Jurassic Park fans in the house, I was tempted to put in a gif of the game warden realizing that the raptors had been hunting him while he was hunting them. But it’s kind of graphic. So instead, just a quote, to note that something is being unexpectedly clever.] :)
v ) So to recap where we are: Ruby 1.8 was resolving methods from scratch every time. It’s like a server that has to fetch a response on every request. So Ruby 1.9 avoids that. It’s a giant reimplementation of Ruby, that’s creating bytecode to optimize the need to search and walk the Abstract Syntax Tree. The way that it optimizes the method look ups is that after it finds the location of the method the first time, the interpreter then stores the address of that memory inline in the bytecode. The tricky thing about caching anything is knowing when to invalidate the cache. This is going to be especially true given all the ways Ruby lets us dynamically change the set of methods that are defined for an object.
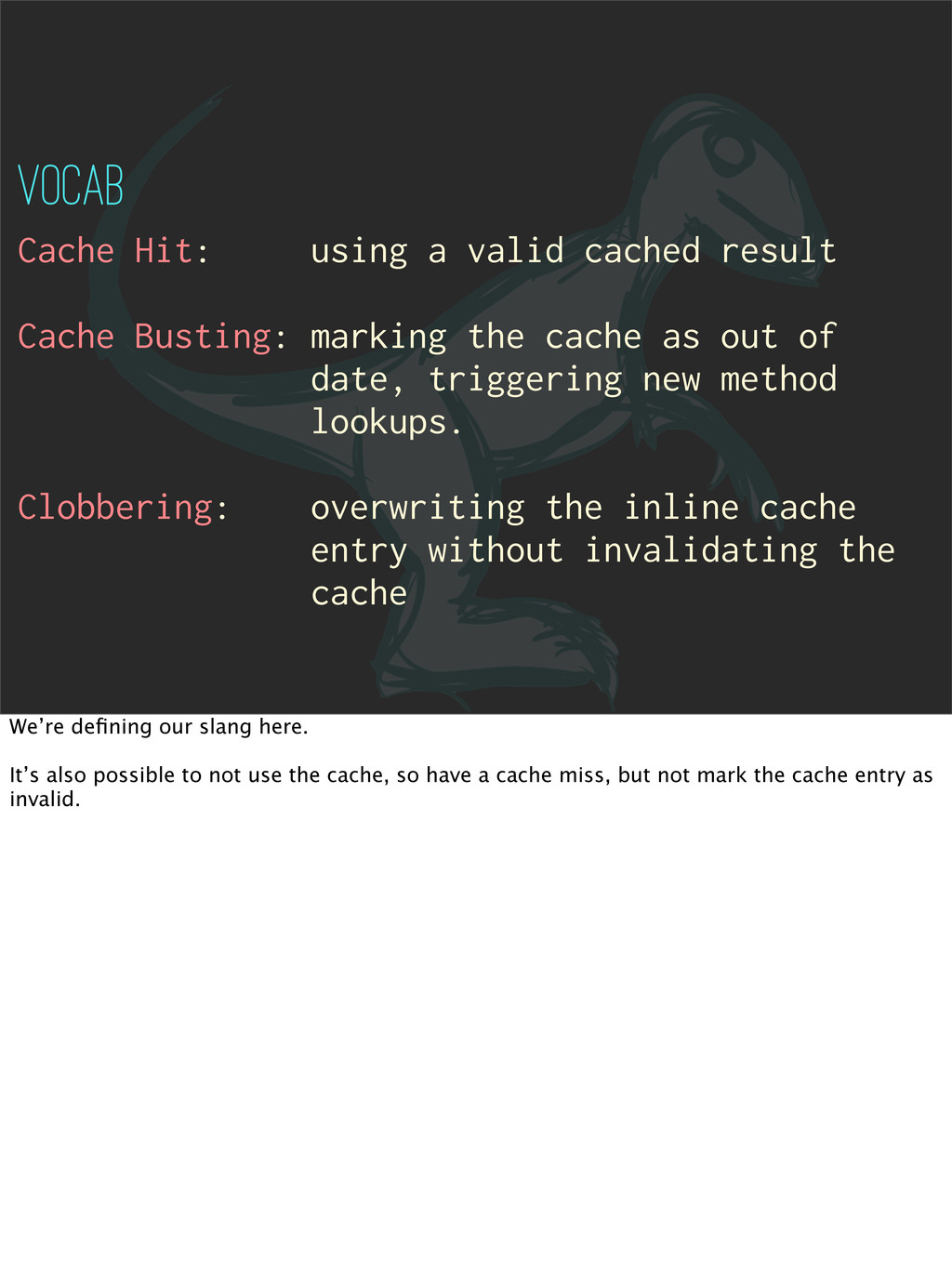
the cache as out of date, triggering new method lookups. Clobbering: overwriting the inline cache entry without invalidating the cache VOCAB We’re defining our slang here. It’s also possible to not use the cache, so have a cache miss, but not mark the cache entry as invalid.
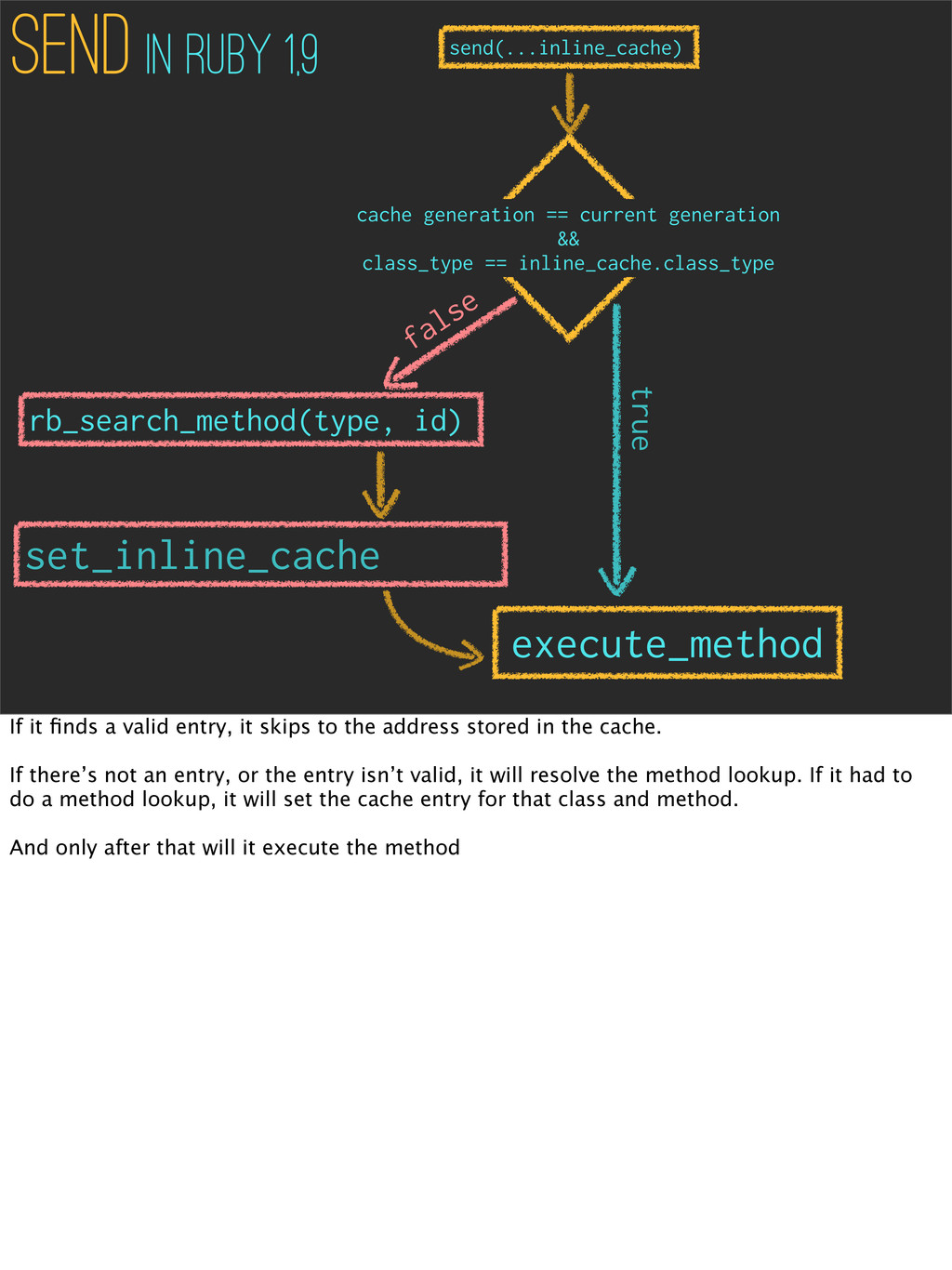
in Ruby 1,9 send(...inline_cache) Every time we call a method, under the hood we’re call the send, and passing in the method we want to call as an argument. And send has become more complicated in YARV. Now it’s going to check if it has an entry in the cache for that object type. Then it’s going to check if the entry is valid by checking the state of the program when it was cached against the global state.
in Ruby 1,9 send(...inline_cache) execute_method true set_inline_cache rb_search_method(type, id) false If it finds a valid entry, it skips to the address stored in the cache. If there’s not an entry, or the entry isn’t valid, it will resolve the method lookup. If it had to do a method lookup, it will set the cache entry for that class and method. And only after that will it execute the method
Raptor < Dinosaur ... end raptor = Raptor.new raptor.rawr RAPTOR_TOE_COUNT = 2 child = Child.new child.hide ... paleontologist = Paleontologist.new paleontologist.study_dinosaur ... game_warden = GameWarden.new game_warden.get_guns ... programmer = Programmer.new programmer.deactivate_fence Method Resolution in Ruby 1.9 To walk through that, here we have a program at an initial program state. Nothing has been run yet, so the cache is empty. We’ll add filled in yellow boxes to represent methods with a valid cache entry. And we’ll replace that with outlined boxes when the cache entry is invalidated. And to make it a more interesting example, we’ll fill out the cast of characters a bit and invoke some more methods.
Ruby 1.9 child = Child.new child.hide ... paleontologist = Paleontologist.new paleontologist.study_dinosaur ... game_warden = GameWarden.new game_warden.get_guns ... programmer = Programmer.new programmer.deactivate_fence class Dinosaur def rawr ... end end class Raptor < Dinosaur ... end raptor = Raptor.new raptor.rawr RAPTOR_TOE_COUNT = 2 So immediately in our program, we resolve these methods and cache them. As we let the program continue to run, this happens some more.
Generation 0 class Dinosaur def rawr ... end end class Raptor < Dinosaur ... end raptor = Raptor.new raptor.rawr RAPTOR_TOE_COUNT = 2 child = Child.new child.hide ... paleontologist = Paleontologist.new paleontologist.study_dinosaur ... game_warden = GameWarden.new game_warden.get_guns ... programmer = Programmer.new programmer.deactivate_fence And eventually we have a really well primed cache. For all methods, every additional time it’s called, we hit the cache and avoid method resolution. The reason it works in these examples is because the code paths are monomorphic, it’s sending messages to the same objects each time.
= Child.new child.hide ... paleontologist = Paleontologist.new paleontologist.study_dinosaur ... game_warden = GameWarden.new game_warden.get_guns ... programmer = Programmer.new programmer.deactivate_fence class Dinosaur def rawr ... end end class Raptor < Dinosaur define_method(:rawr)do ... end end raptor = Raptor.new raptor.rawr RAPTOR_TOE_COUNT = 2 Then we hit a define_method in our Raptor class. This is one of the events that increments generations. And because of this change in the Raptor class, the cached method resolutions throughout our program are invalidated. In this particular case, we needed to invalidate the cache, because we had cached the resolution of ‘rawr’ and wouldn’t have picked up the new definition if hit raptor.rawr again. It’s just too bad that this invalidated every other class’s cached method lookups as well.
b 1.9 Which is a pretty smooth segue to our next section. To recap, we now know how MRI resolves methods, we know that Ruby 1.9 compiles to bytecode that can be interpreted by the VM, we know how the VM caches the address of method lookups in the bytecode, and because that cache needs to be invalidated when new methods are are available to an object, we know how the global state is incremented when we introduce new methods. That’s a lot, so let’s look at some pictures of dinosaurs for a few seconds.
Dinosaur ... end class Tyrannosaurus < Dinosaur ... end def call_rawr(dinosaur) dinosaur.rawr end call_rawr(Tyrannosaurus.new) call_rawr(Raptor.new) Cache Clobbering Limits of Method Caching r The first time it’s called, passing in Tyrannosaurus, the method lookup is cached with the object type of Tyrannosaurus.
Dinosaur ... end class Tyrannosaurus < Dinosaur ... end def call_rawr(dinosaur) dinosaur.rawr end call_rawr(Tyrannosaurus.new) call_rawr(Raptor.new) v rwr Cache Clobbering Limits of Method Caching The next time, it’s passed a different object, a Raptor, to call_rawr The issue here is that even though the address of rawr is cached on the first request, since the second call is on a different object type, the cache is invalid for that line, and overwritten. This points to conflicting demands. On one hand, we can get well factored and readable code. But it will also prevent a useable method cache from being set for this line if we keep switching between types. So that’s not to say don’t use polymorphism. But it’s to point out the cost it could have to the method cache.
second problem with the inline method cache is that when the cache is invalidated, every method that has been cached since the program started will have to be resolved again.
two method caches. There’s an inline method cache and a global method cache. The global method cache has a limit of what it can store, and we don’t have control over what’s stored there. And that global method cache is also expired by updating the global state. So global method cache entries are marked with the global state of the program when they were cached. And inline method caches entries, also note the global state when they were cached. Updating the global state will expire all these caches, and require all new lookups. This is a good opportunity to look at what updates the global state.
of the method caches that have built up since your program started become invalid and you have to repay the cost of method resolution all over again.” J G Generational Cache Expiration Limits of Method Caching James Gollick had a great blog post about 6 months ago where he profiled his companies website, found that they were spending way too much time building up their cache, only to invalidate it and have to pay that cost again. This is a quote from his post that captures the heart of the problem. We link to the blog post in our bit.ly bundle. His problems are probably not average, but it was still an awesome read and it’s how we first got interested in this stuff. As a tradeoff for a low-overhead cache, we’re stomping on the entire cache all at once.
Code MUST invalidate the cache And the last limitation that we want to point out with Ruby 1.9’s method cache is that expiring the cache isn’t always a shortcoming. There are many ways in Ruby to make a method available to an object. And in order to check that more methods haven’t been defined for a given object, we NEED to expire the cache when an event happens that could possibly change the methods defined for that object. Now we’re going to touch on some of the things that will expire the cache. The point in these examples is that they are the things that change the set of methods that are defined and sendable to an object. And if we were to call a method after one of these things happen, we shouldn’t keep our cache, because a new method could have been defined that should take precedence over our cached version.
method cache b C r S rv Charlie Somerville has a great blog post that documents the 18 things that will update the global state and so expire both the inline method cache and the global method cache. They fall into a few broad categories.
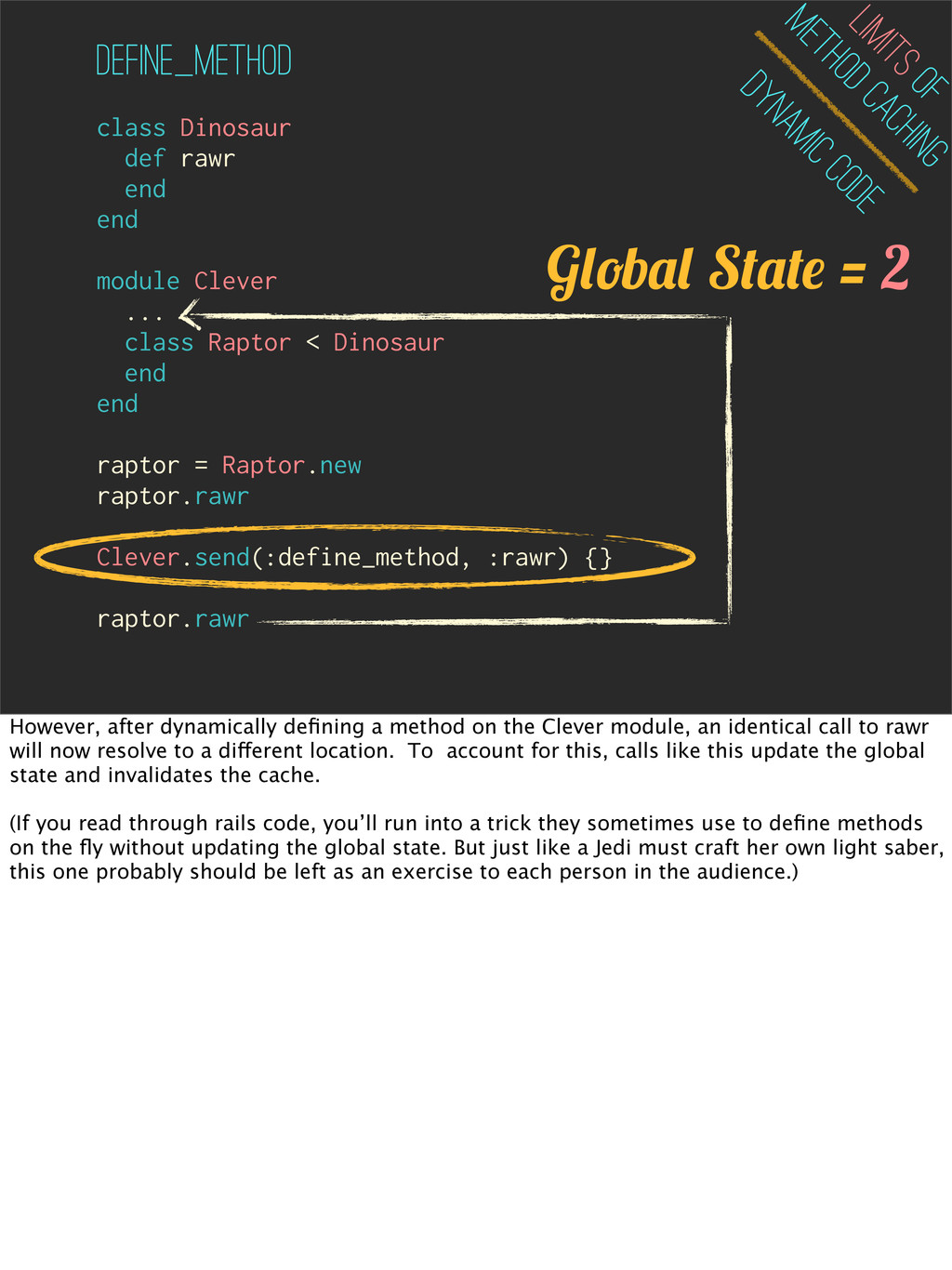
Raptor < Dinosaur end end raptor = Raptor.new raptor.rawr Clever.send(:define_method, :rawr) {} raptor.rawr Dynamic Code Limits of Method Caching define_method G b S = 1 The global state is updated whenever you define, alias or remove methods. This is the most obvious reason to invalidate the method cache, because adding and removing methods can directly impact where a particular method should resolve to. Consider the above example, on the first call of rawr, the method is cached to point to Dinosaur.
end module Clever ... class Raptor < Dinosaur end end raptor = Raptor.new raptor.rawr Clever.send(:define_method, :rawr) {} raptor.rawr Dynamic Code Limits of Method Caching define_method However, after dynamically defining a method on the Clever module, an identical call to rawr will now resolve to a different location. To account for this, calls like this update the global state and invalidates the cache. (If you read through rails code, you’ll run into a trick they sometimes use to define methods on the fly without updating the global state. But just like a Jedi must craft her own light saber, this one probably should be left as an exercise to each person in the audience.)
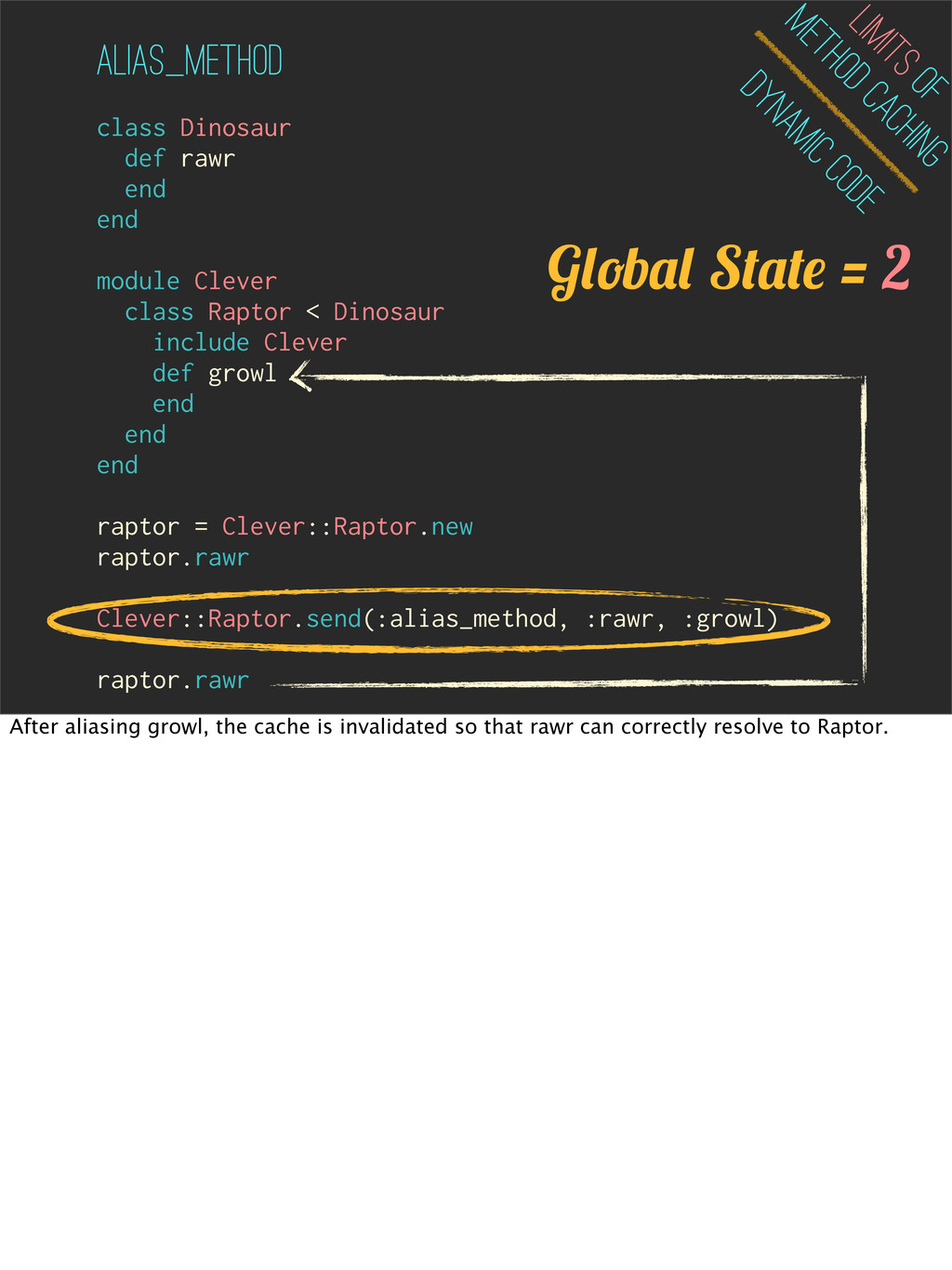
< Dinosaur include Clever def growl end end end raptor = Clever::Raptor.new raptor.rawr Clever::Raptor.send(:alias_method, :rawr, :growl) raptor.rawr Dynamic Code Limits of Method Caching ALIAS_method G b S = 1 For similar reason, using alias_method will also increment global state.
end module Clever class Raptor < Dinosaur include Clever def growl end end end raptor = Clever::Raptor.new raptor.rawr Clever::Raptor.send(:alias_method, :rawr, :growl) raptor.rawr Dynamic Code Limits of Method Caching ALIAS_method After aliasing growl, the cache is invalidated so that rawr can correctly resolve to Raptor.
def rawr end end raptor = Clever::Raptor.new raptor.rawr Raptor.send(:remove_method, :rawr) raptor.rawr Dynamic Code Limits of Method Caching remove_method G b S = 1 And as you might imagine, remove_method will also increment global state.
end class Raptor < Dinosaur def rawr end end raptor = Clever::Raptor.new raptor.rawr Raptor.send(:remove_method, :rawr) raptor.rawr Dynamic Code Limits of Method Caching remove_method After removing rawr, the cache is invalidated so that rawr can resolve to Dinosaur.
= 4 Object.const_set :RAPTOR_TOE_COUNT, 3 private_constant :RAPTOR_TOE_COUNT public_constant :RAPTOR_TOE_COUNT autoload :RAPTOR_TOE_COUNT, ‘dinosaur.rb’ There several other less common things that can also invalid the cache by incrementing the global state. Like we saw in an earlier example, modifying constants will also bust the cache because constants share the same global state for caching in Ruby 1.9. Also, because of this, autoloading constants, which specifies where the constant is located, will also bust the cache.
Also updating global state Since the OpenStruct class defines accessor methods dynamically when created, and we should be aware that some non-blocking methods also perform dynamic programming to extend modules repeatedly and also invalidate the cache.
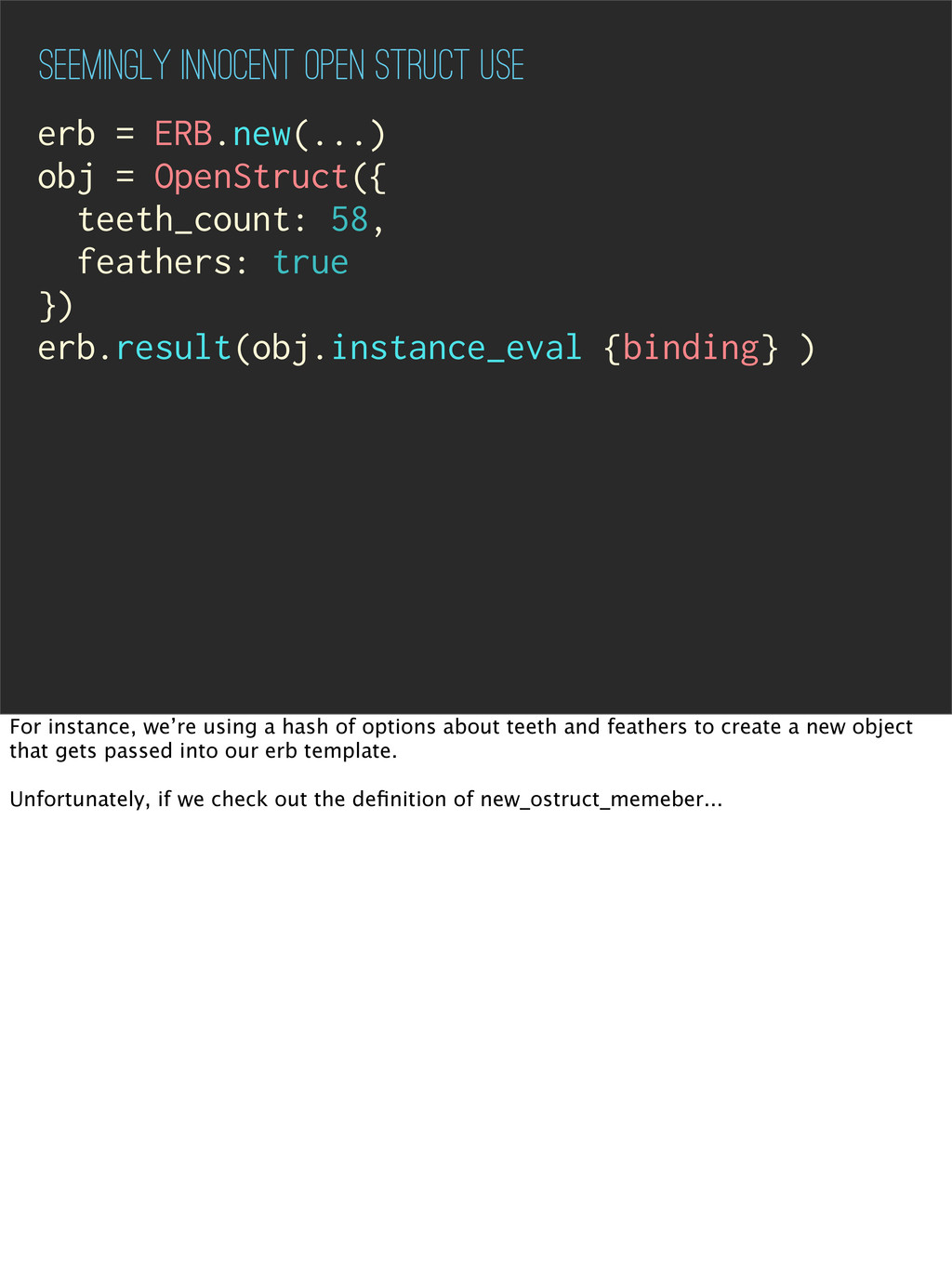
you want to use an object in place of a hash. Sometimes you use it really innocently, like maybe you want to pass an object into a template instead of passing a hash.
OpenStruct({ teeth_count: 58, feathers: true }) erb.result(obj.instance_eval {binding} ) For instance, we’re using a hash of options about teeth and feathers to create a new object that gets passed into our erb template. Unfortunately, if we check out the definition of new_ostruct_memeber...
define_singleton_method(name) { @table[name] } define_singleton_method("#{name}=") do |x| modifiable[name] = x end end name end We see that we’re defining a getter and setter using define_singleton_method, which will increment the global counter. We’re incrementing the counter twice, actually, but once would be enough to invalidate the cache. And it’s somewhat common to use open_struct casually, when you would rather have an object. So this is probably an unexpected invalidation of the method cache.
S rv One more shout out to Charlie Somerville. He created an implementation of open struct that won’t invalidate the method cache. It’s included in our bit.ly bundle.
is refinements. This is a new thing that comes in Ruby 2. If you’ve ever monkey patched a library before, and then had the problem of not being able to pull in subsequent version updates, refinements are for you. Unfortunately, they also will invalidate the method cache, so know that before you use refinements too wildly.
wasted when the cache is cleared comes with code. His branch of ruby, which creates a more finely grained cache, was merged into MRI trunk in September. It trades the awesome simplicity of the current inline method cache implementation for more intelligent cache invalidation, and by doing this, he avoids invalidating caches for the classes that aren’t affected by the dynamic code. Let’s walk through that.
class Dinosaur def rawr ... end ... define_method(:bite){...} end class Raptor < Dinosaur ... define_method(:rawr){...} end raptor = Raptor.new raptor.rawr RAPTOR_TOE_COUNT = 2 Primed Cache The Future The generations are class-contextual rather than universal generations. Meaning an event that bumps the global state will only effect the method cache for that class and the classes’ dependents. To demonstrate this, let’s get back our program that has run for a bit and has a warmed up cache. This time we’ve added the Tyrannosaurus class in. This time, when we hit our define method in the Raptor class, we’ll indeed increment the global state, and create a new generation, but it’s only a new generation for the Raptor class and its dependents.
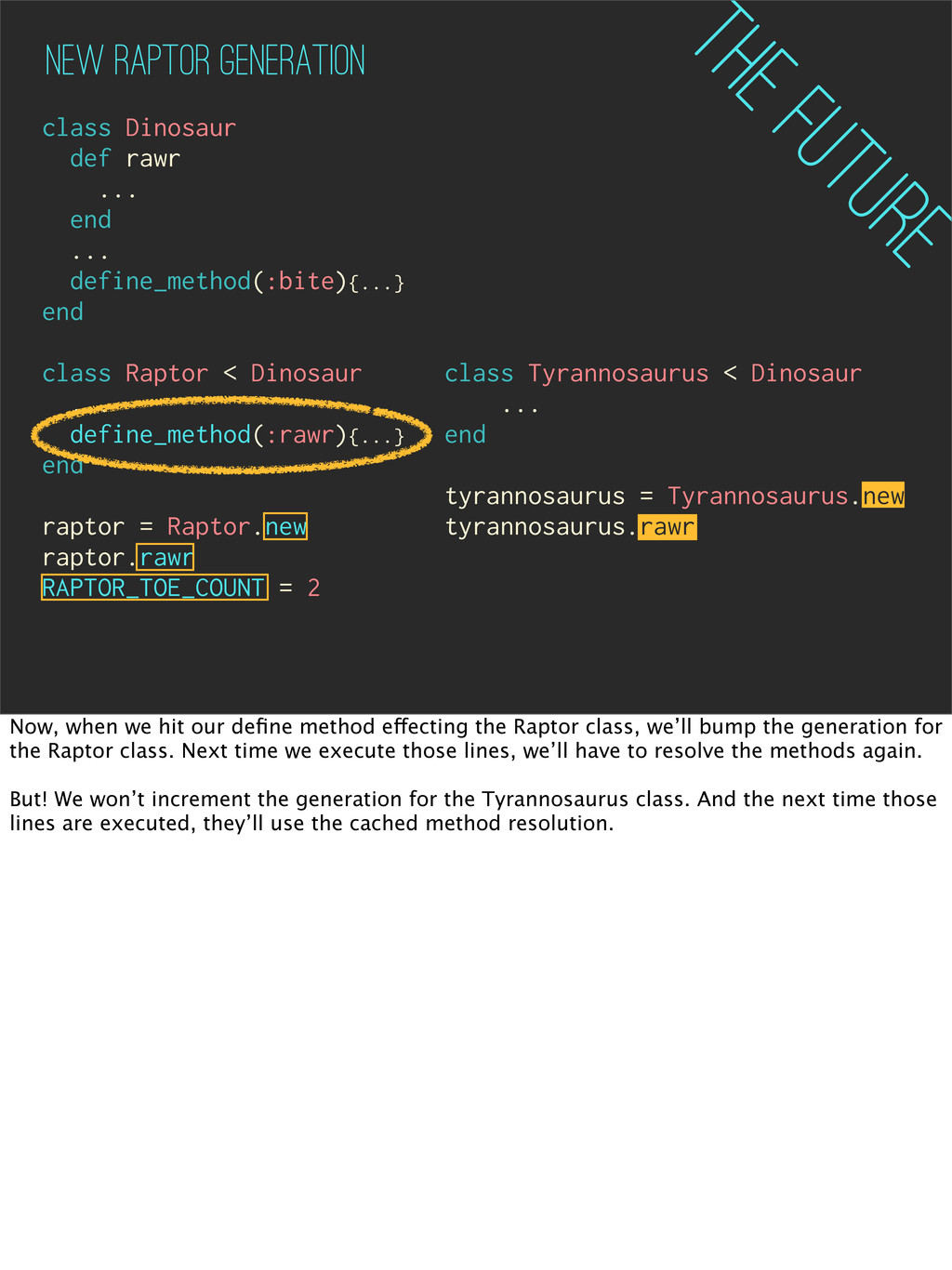
Raptor < Dinosaur ... define_method(:rawr){...} end raptor = Raptor.new raptor.rawr RAPTOR_TOE_COUNT = 2 class Tyrannosaurus < Dinosaur ... end tyrannosaurus = Tyrannosaurus.new tyrannosaurus.rawr New Raptor Generation The Future Now, when we hit our define method effecting the Raptor class, we’ll bump the generation for the Raptor class. Next time we execute those lines, we’ll have to resolve the methods again. But! We won’t increment the generation for the Tyrannosaurus class. And the next time those lines are executed, they’ll use the cached method resolution.
class Dinosaur def rawr ... end ... define_method(:bite){...} end class Raptor < Dinosaur ... define_method(:rawr){...} end raptor = Raptor.new raptor.rawr RAPTOR_TOE_COUNT = 2 New Dinosaur Generation The Future But we’ll also increment generations for dependent classes. That means that when we execute this define_method on the Dinosaur class, we’ll need to bump the generations for Dinosaur, Raptor, and Tyrannosaurus. If these lines are executed again, they’ll all need to be re-resolved.
class Dinosaur def rawr ... end ... define_method(:bite){...} end class Raptor < Dinosaur ... define_method(:rawr){...} end raptor = Raptor.new raptor.rawr RAPTOR_TOE_COUNT = 2 implications The Future Earlier, we pointed out three things to remember about the method cache in 1.9: First, You can write your code in a way that multiple objects go through the same code path and never get the benefit of the caching. Second, Updating global state invalidates the entire cache. And third, what, specifically, requires incrementing the generation. This improvement eliminates that second point, that moving up a generation invalidates the entire cache. If you’re looking for ruby performance improvements, upgrading will help. In other words, with these changes, the dinosaurs stomping out the cache just got much smaller.
end Conclusions Avoid things that bust the cache Look at included libraries First, Don’t do tricky things like define_method, or defining a constant on the fly; don’t define anything on the fly unless you have a really good reason, and are aware that will update the global state of the program and invalidate your method caches. Second, The gems and libraries that you use will often try to do this. Some of the gems that make the most use of these tricks are ones that you use only during development, and that’s fine. As an example of this, defining methods at runtime is what rspec is built on. Here’s an example taken from rspec. But we don’t really need to worry about these tools that we use in development. The app probably won’t run long enough to warm up its cache in development anyway, and we get a ton of utility from these tools. So it’s libraries that are included in production environments that you need to be really aware of.
libraries Method caching can be improved And lastly, If you really need performance improvements in the Ruby layer, take a look at the work that we referenced from James Golick and Charlie Summerville.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[:program, [ [:call, [:vcall, [:@ident, "raptor", [1, 0]] ], :".",](https://files.speakerdeck.com/presentations/9e354ef016600131b03d5a15da26a731/slide_30.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Abstract Syntax Tree Method Resolution in Ruby 1.9 [0] :program,](https://files.speakerdeck.com/presentations/9e354ef016600131b03d5a15da26a731/slide_34.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![MRI’s Method Caches “Whenever you [increment the global state] all](https://files.speakerdeck.com/presentations/9e354ef016600131b03d5a15da26a731/slide_57.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![from rspec-core/lib/rspec/core/example.rb: def self.delegate_to_metadata(*keys) keys.each do |key| define_method(key) {@metadata[key]} end](https://files.speakerdeck.com/presentations/9e354ef016600131b03d5a15da26a731/slide_80.jpg){kind=link}
{kind=link}
{kind=link}