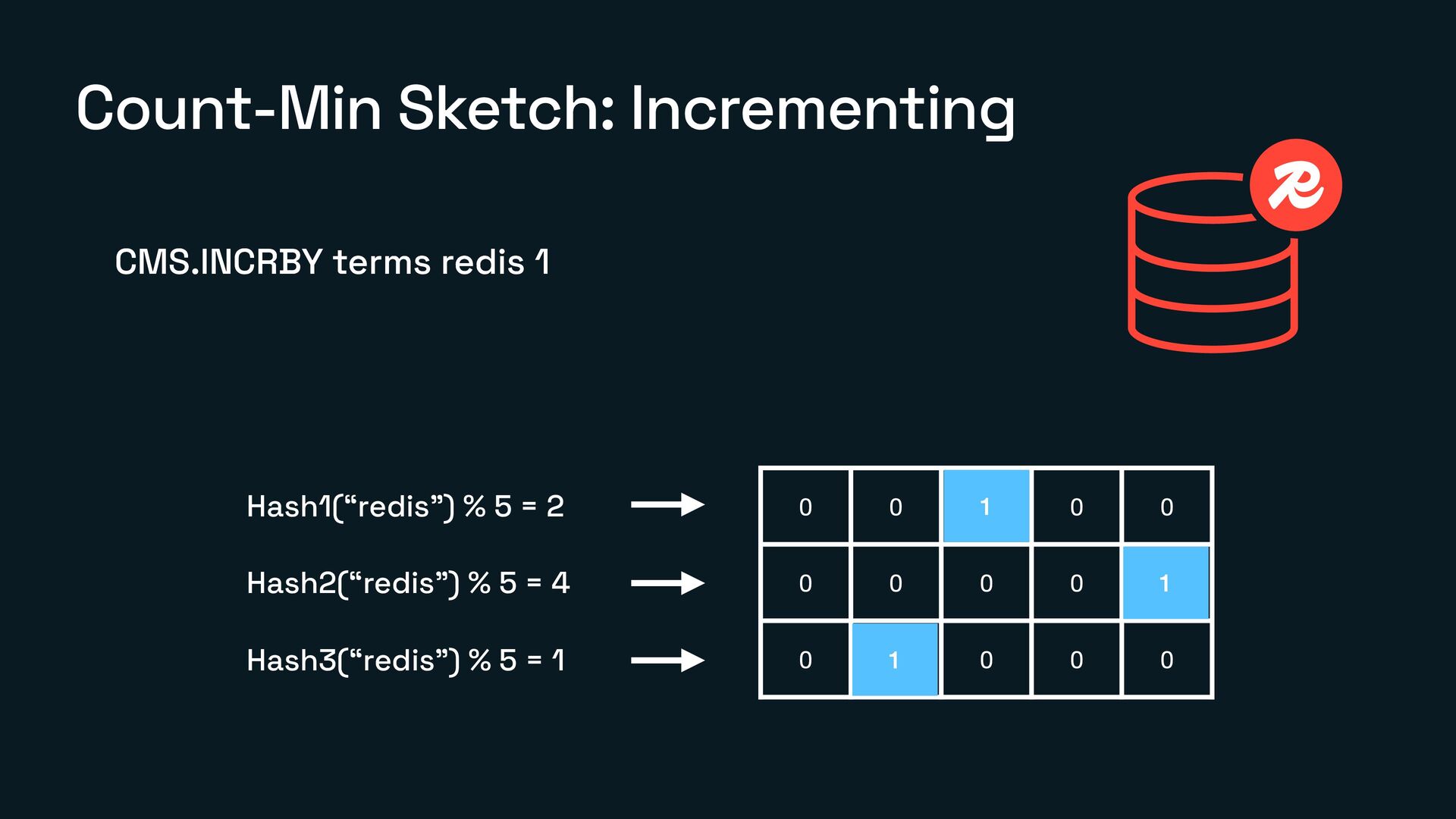
A Count-Min Sketch, a Bloom Filter, and a TopK might sound fancy, but they’re just smart ways to work with huge amounts of data using very little memory.
In this talk, we’ll explore three powerful probabilistic data structures that trade a bit of accuracy for a lot of speed and scalability. You’ll learn:
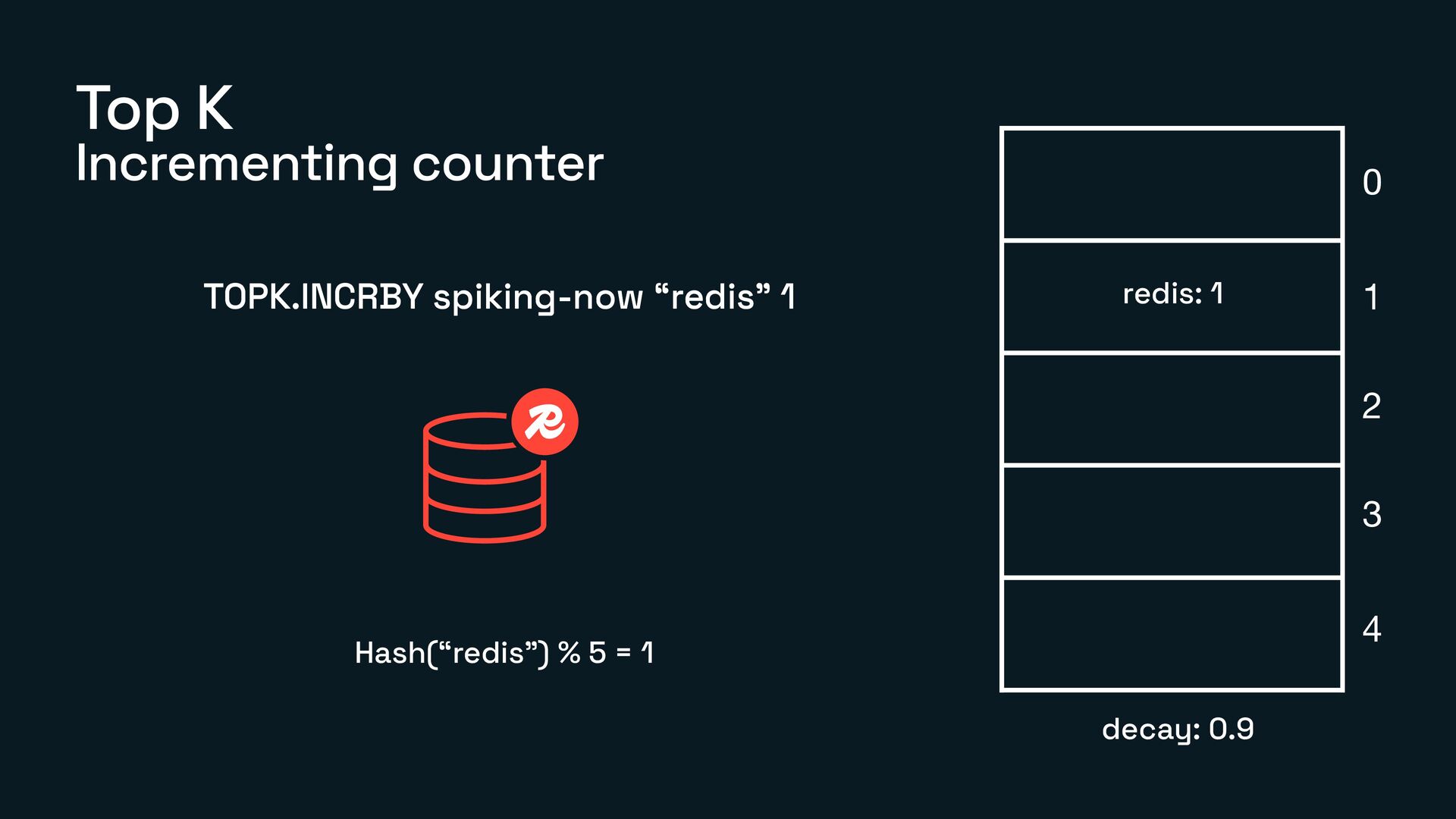
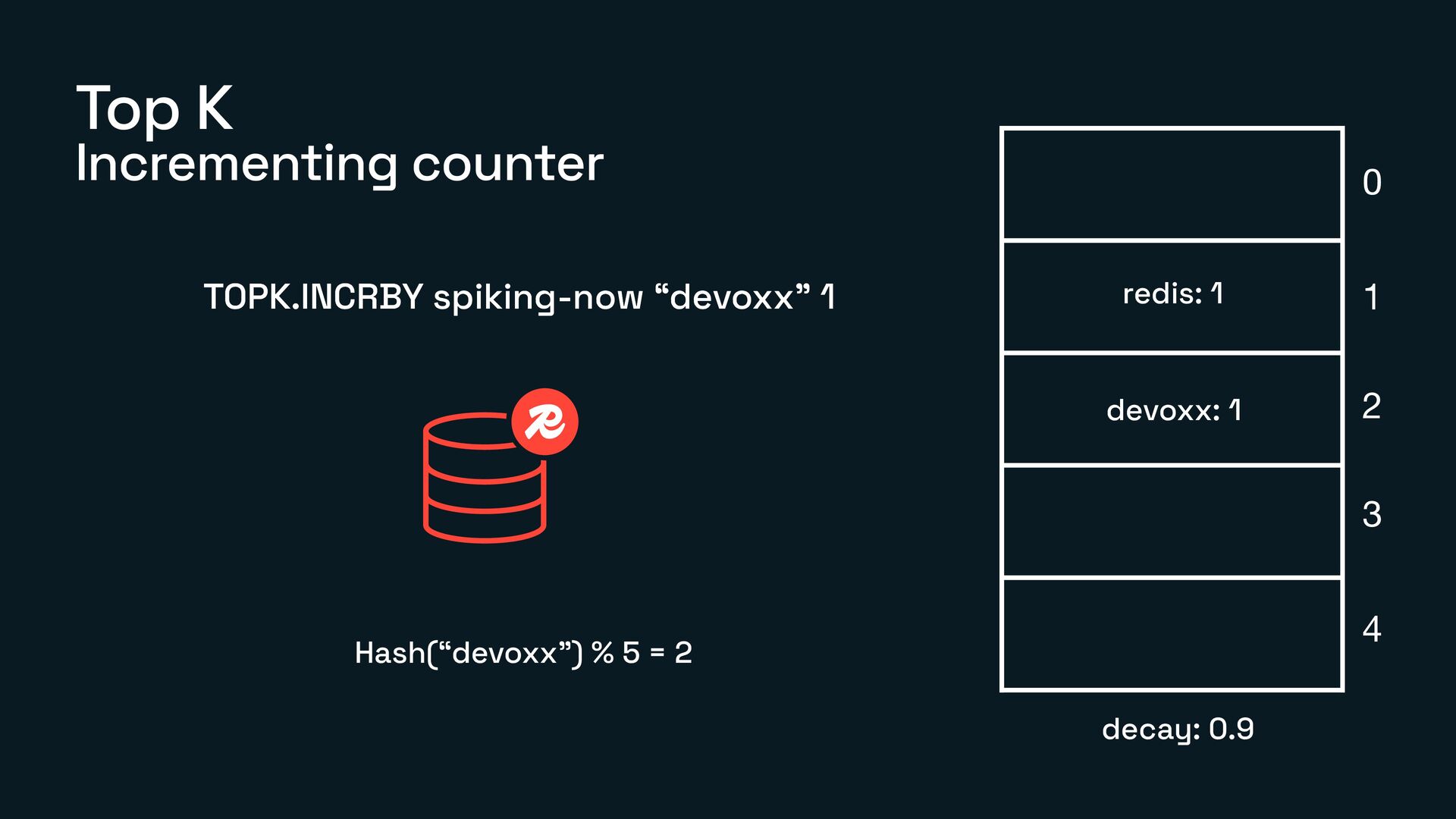
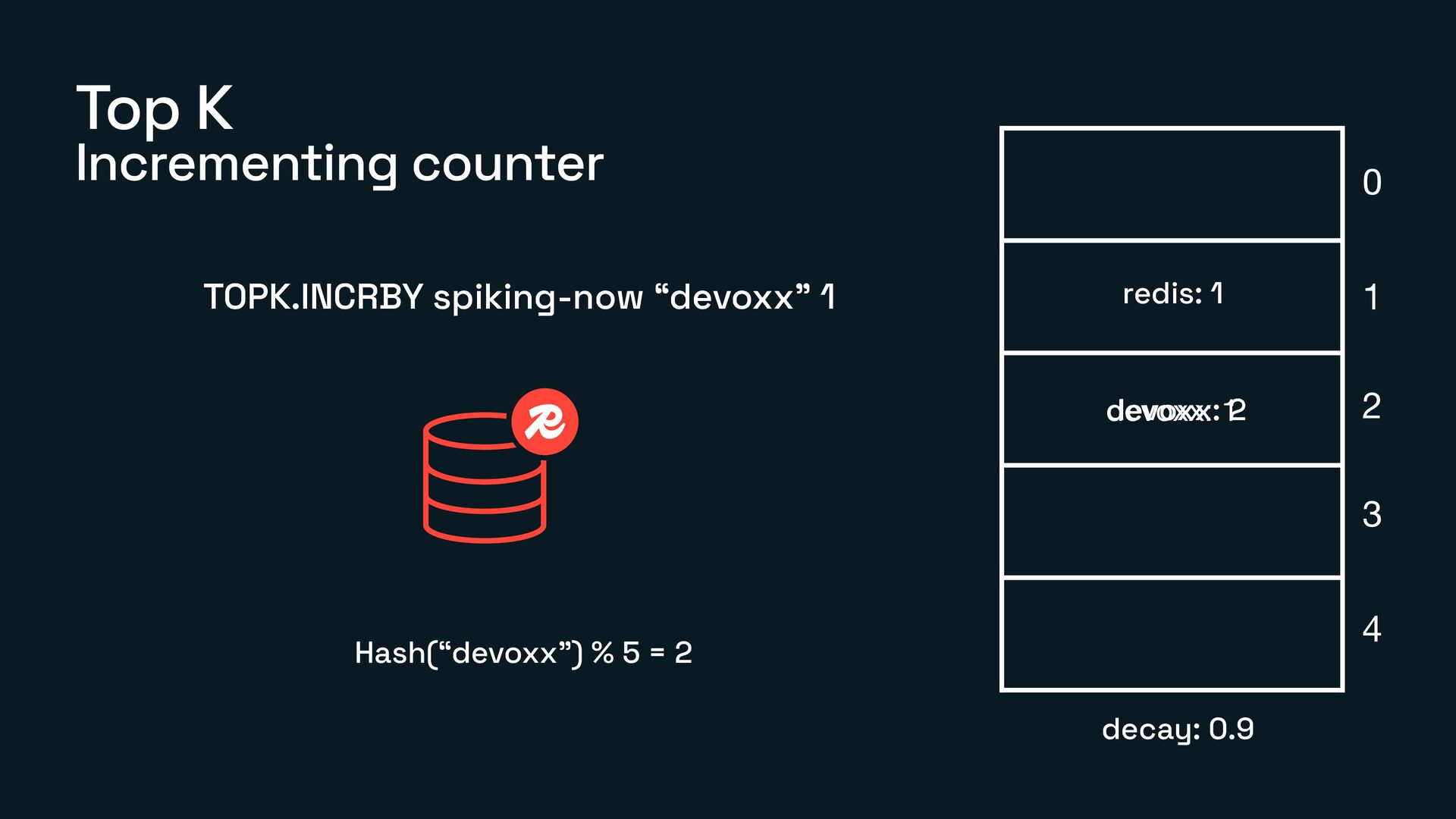
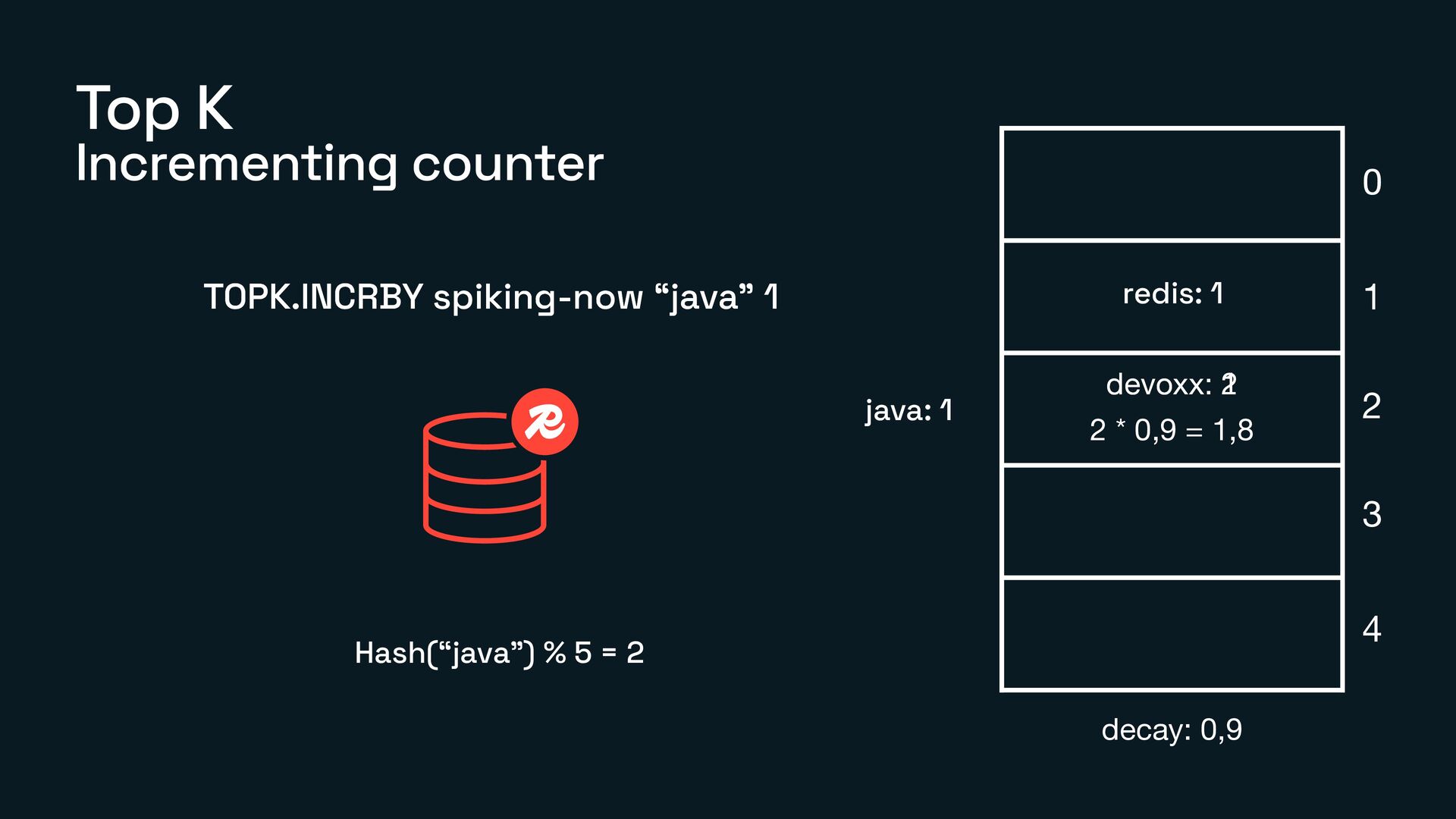
What Count-Min Sketch, Bloom Filter, and TopK actually are
How each of them works under the hood
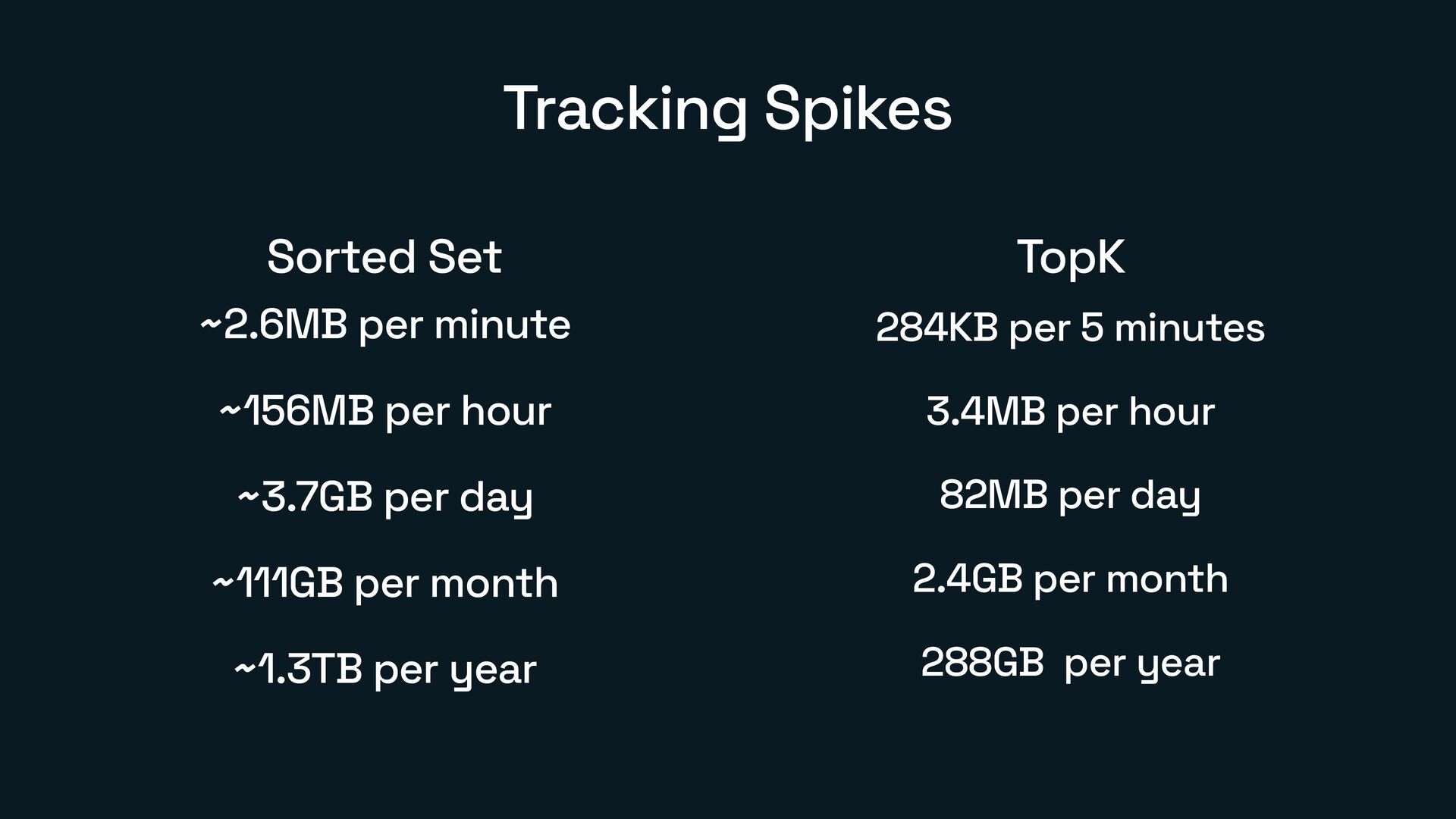
How I used them together to build an efficient version of Trending Topics for Bluesky
By the end, you’ll see how these tools help you process large data streams without blowing up your memory, and how to apply them in real-world systems where being fast matters more than being perfect.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}