Slides from my talk at PyCon US 2025, about PyArrow -- what it is, how it is related to Pandas, how we can use it now, and how we'll use it in the future.
• Corporate training • Online courses at LernerPython.com • Newsletters, including Bamboo Weekly (Pandas puzzles on current events) • YouTube I teach Python and Pandas! 2
• Do you have the same code on multiple lines? • Don't repeat yourself: Use a loop! • Do you have the same code in multiple places in a program? • Don't repeat yourself: Use a function! DRY: Don’t repeat yourself! 4
• Do you have the same code in multiple programs? • Don’t repeat yourself: Use a library • In Python, we call this a "module" or “package” • A module helps the future you • It also helps other people avoid repeating your solution DRY: Don’t repeat yourself! 5
• Don’t implement your own data-analysis routines • If you use Pandas, the hard stuff is done for you • Reading data • Cleaning data • Analyzing data • Visualizing data • Writing data • Pandas is extremely convenient — and also popular Pandas 6
• Wes McKinney invented Pandas in 2008 • He built it on top of NumPy • Stable • Fast • Handles 1D and 2D data • Numerous data types Pandas used a package, too 7
• Automatic vs. manual transmission • Pandas series • A wrapper around a 1D NumPy array • Pandas data frames • A wrapper around a 2D NumPy array • Or, if you prefer: A dictionary of Pandas series Pandas and NumPy 8
Python • Much less memory usage than Python • Vectorization • Lots of analysis methods • Used by many people and projects, so you know it’s stable Lots of good news
• Storing data in Pandas (via NumPy) uses lots of memory • Storage in rows, vs. in columns • We store all of the data precisely as it is • No compression • No use of zero-copy techniques • Not designed for batch processing or streaming • No complex data types • Strings • Dates and times • Nested types The bad news 10
• Many languages and frameworks work with 2D data • What if we had a single library that everyone could rely on? • Don’t reinvent the wheel; use a single, working data structure • Use columns, rather than rows, for fast retrieval • Reduce the overhead of exchanging data among systems • Take advantage of modern processors • Arrow was f irst released in 2016 • Latest version, 20.0.0, was released in April Arrow: DRY for data 12
• Python bindings for Arrow • You can use PyArrow in your programs! • Create arrays (1D) and tables (2D) • Retrieve particular rows and columns • Sorting and grouping PyArrow 13
• Pandas is moving toward PyArrow • Some functionality is already here • Much more is coming in the future • Using PyArrow can save you time and memory • And get ready: It’ll be required in Pandas 3.0 The PyArrow revolution 16
• “read_csv” is very flexible, useful, and popular • Also: Can be very slow! • Speed up by specifying dtypes • Speed up by setting low_memory=False • … but it’s still really slow • Solution: Use PyArrow for reading/writing CSV f iles • How? Specify engine=‘pyarrow’ We use lots of CSV f iles 18
• Good: • It’s 10x faster! Does anything else really matter?!? • PyArrow reads the whole thing; no more low_memory=False • PyArrow (usually) detects datetime columns, so there’s less need for parse_dates • Bad: • Some CSV f iles are too weird for PyArrow • If the f ile is small, then PyArrow isn’t worthwhile Differences 21
• Most data is in: • CSV (text-based, slow, poorly speci f ied) • Excel (handles dtypes, slow, proprietary) • Arrow de f ined two new columnar, binary formats • Feather • Fast reads and writes • No compression • Parquet • Slower reads and writes • Highly compressed What formats do we use? 24
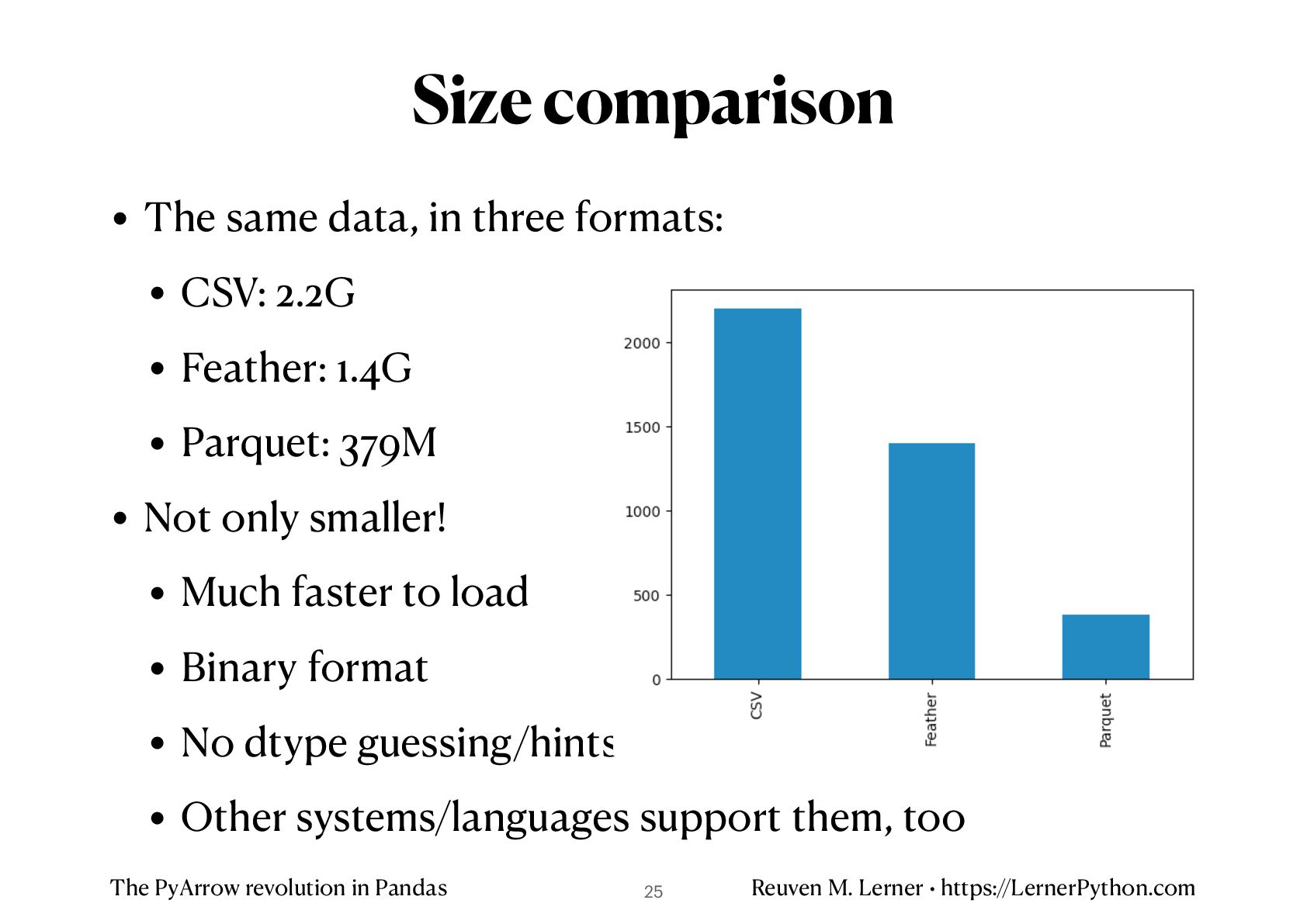
• The same data, in three formats: • CSV: 2.2G • Feather: 1.4G • Parquet: 379M • Not only smaller! • Much faster to load • Binary format • No dtype guessing/hints • Other systems/languages support them, too Size comparison 25
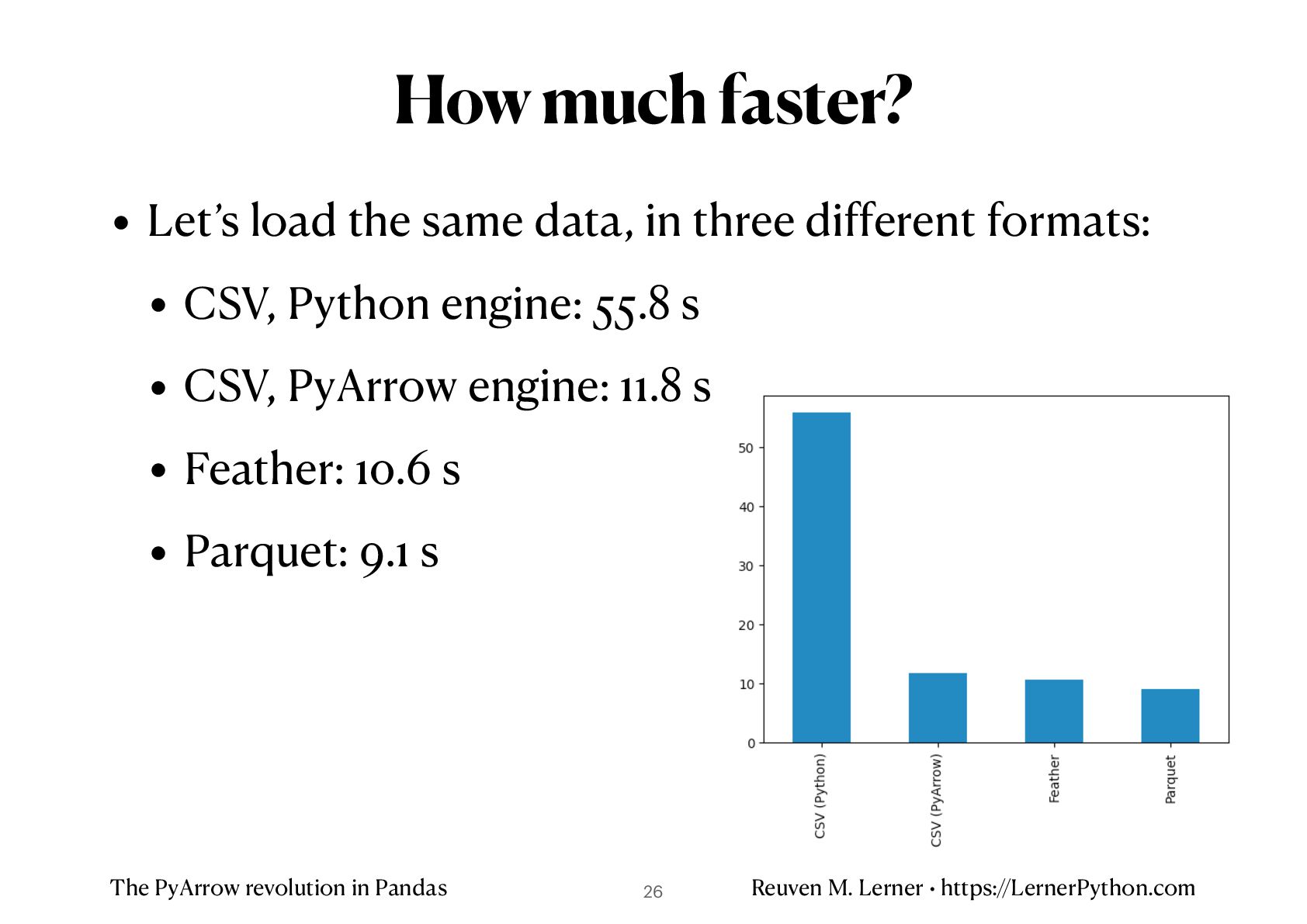
• Let’s load the same data, in three different formats: • CSV, Python engine: 55.8 s • CSV, PyArrow engine: 11.8 s • Feather: 10.6 s • Parquet: 9.1 s How much faster? 26
• You can use these formats today! • Do a one-time translation from CSV to Feather/ Parquet • Then read from the binary format Store data in Feather/Parquet 27
• Choose a PyArrow dtype, rather than one from NumPy • Usually, that just means putting [pyarrow] after the name s = Series(np.random.randint(-50, 50, 10), index=list('abcdefghij'), dtype='int64[pyarrow]') df = DataFrame(np.random.randint(-50, 50, [3,4]), index=list('abc'), columns=list('wxyz'), dtype='int64[pyarrow]') Using PyArrow on the back end 30
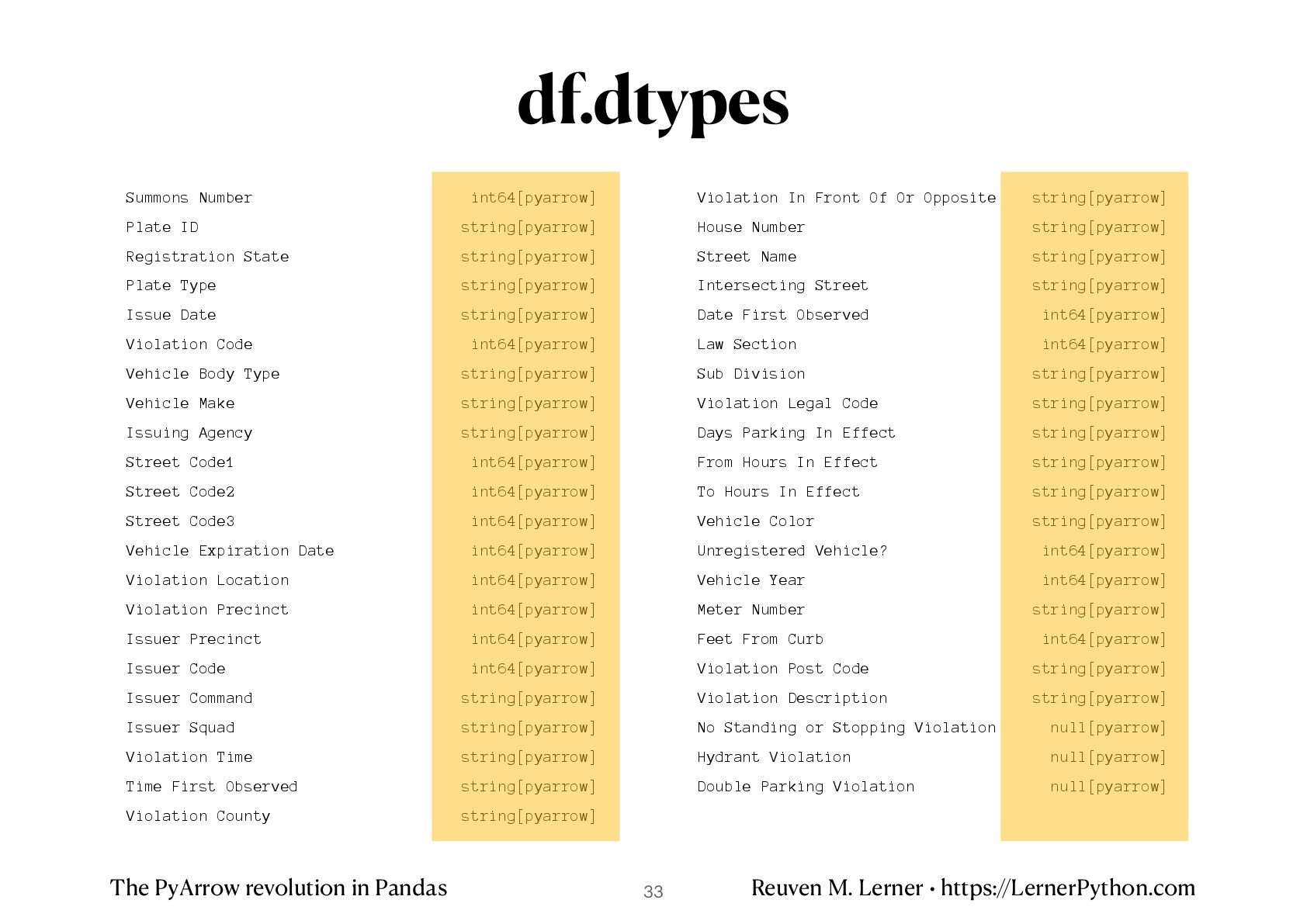
Summons Number int64[pyarrow] Plate ID string[pyarrow] Registration State string[pyarrow] Plate Type string[pyarrow] Issue Date string[pyarrow] Violation Code int64[pyarrow] Vehicle Body Type string[pyarrow] Vehicle Make string[pyarrow] Issuing Agency string[pyarrow] Street Code1 int64[pyarrow] Street Code2 int64[pyarrow] Street Code3 int64[pyarrow] Vehicle Expiration Date int64[pyarrow] Violation Location int64[pyarrow] Violation Precinct int64[pyarrow] Issuer Precinct int64[pyarrow] Issuer Code int64[pyarrow] Issuer Command string[pyarrow] Issuer Squad string[pyarrow] Violation Time string[pyarrow] Time First Observed string[pyarrow] Violation County string[pyarrow] Violation In Front Of Or Opposite string[pyarrow] House Number string[pyarrow] Street Name string[pyarrow] Intersecting Street string[pyarrow] Date First Observed int64[pyarrow] Law Section int64[pyarrow] Sub Division string[pyarrow] Violation Legal Code string[pyarrow] Days Parking In Effect string[pyarrow] From Hours In Effect string[pyarrow] To Hours In Effect string[pyarrow] Vehicle Color string[pyarrow] Unregistered Vehicle? int64[pyarrow] Vehicle Year int64[pyarrow] Meter Number string[pyarrow] Feet From Curb int64[pyarrow] Violation Post Code string[pyarrow] Violation Description string[pyarrow] No Standing or Stopping Violation null[pyarrow] Hydrant Violation null[pyarrow] Double Parking Violation null[pyarrow] df.dtypes 33
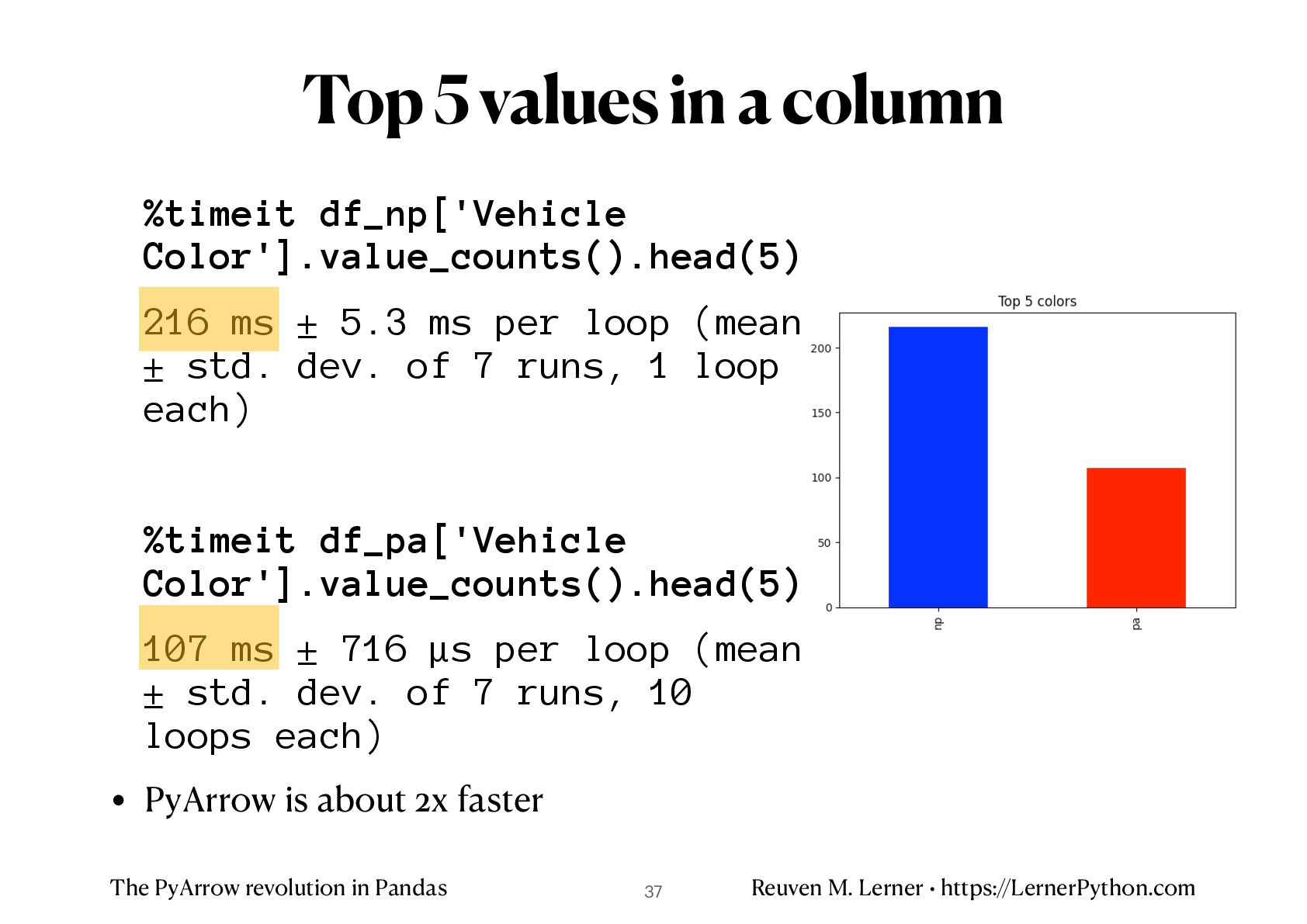
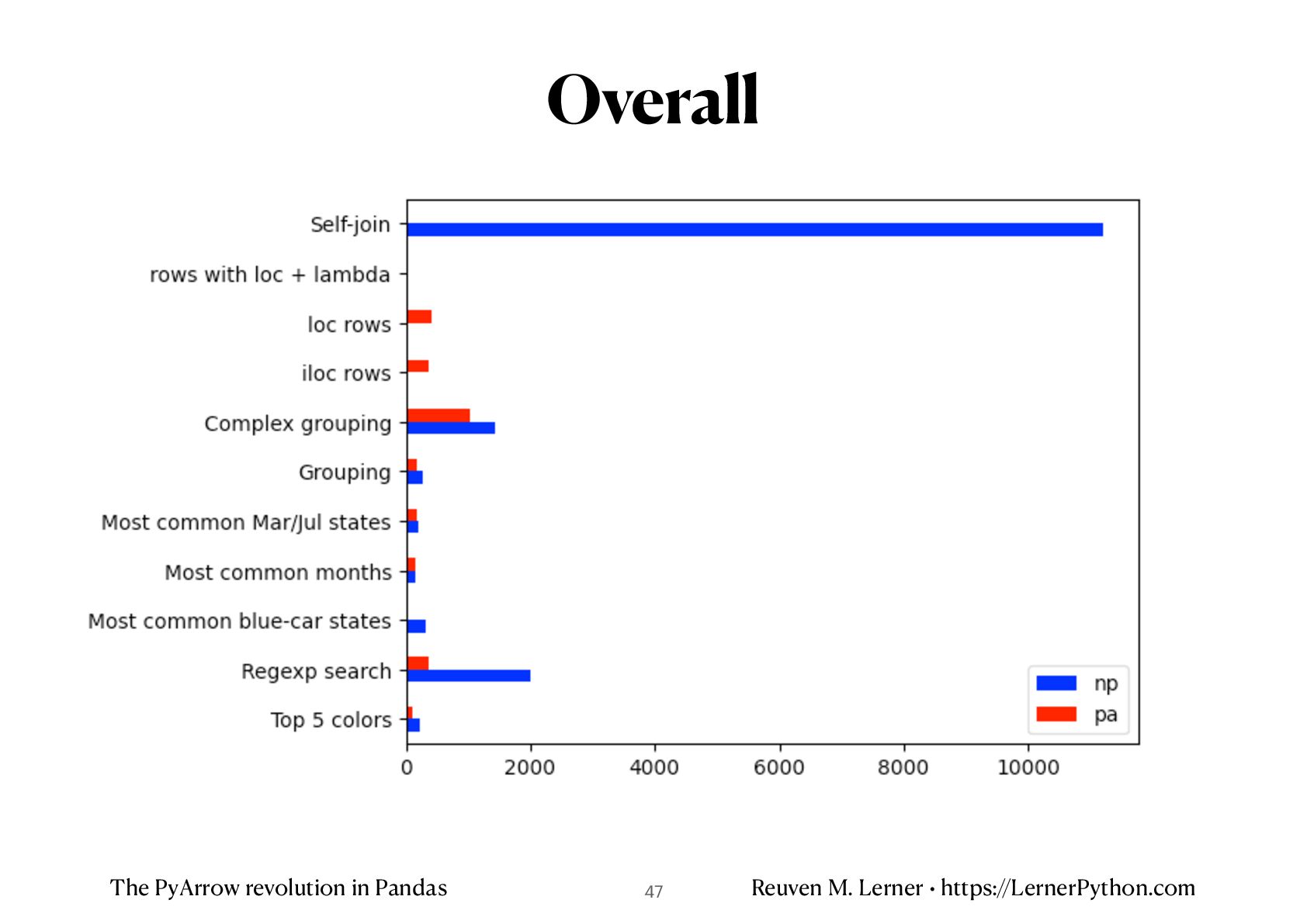
%timeit df_np['Vehicle Color'].value_counts().head(5) 216 ms ± 5.3 ms per loop (mean ± std. dev. of 7 runs, 1 loop each) %timeit df_pa['Vehicle Color'].value_counts().head(5) 107 ms ± 716 μs per loop (mean ± std. dev. of 7 runs, 10 loops each) • PyArrow is about 2x faster Top 5 values in a column 37
%timeit df_np['Vehicle Color'].str.contains('[BZ]', regex=True, case=False).value_counts().head(5) 2 s ± 15.6 ms per loop (mean ± std. dev. of 7 runs, 1 loop each) %timeit df_pa['Vehicle Color'].str.contains('[BZ]', regex=True, case=False).value_counts().head(5) 365 ms ± 2.83 ms per loop (mean ± std. dev. of 7 runs, 1 loop each) • PyArrow is about 5.5x faster Searching in strings with regex=True 38
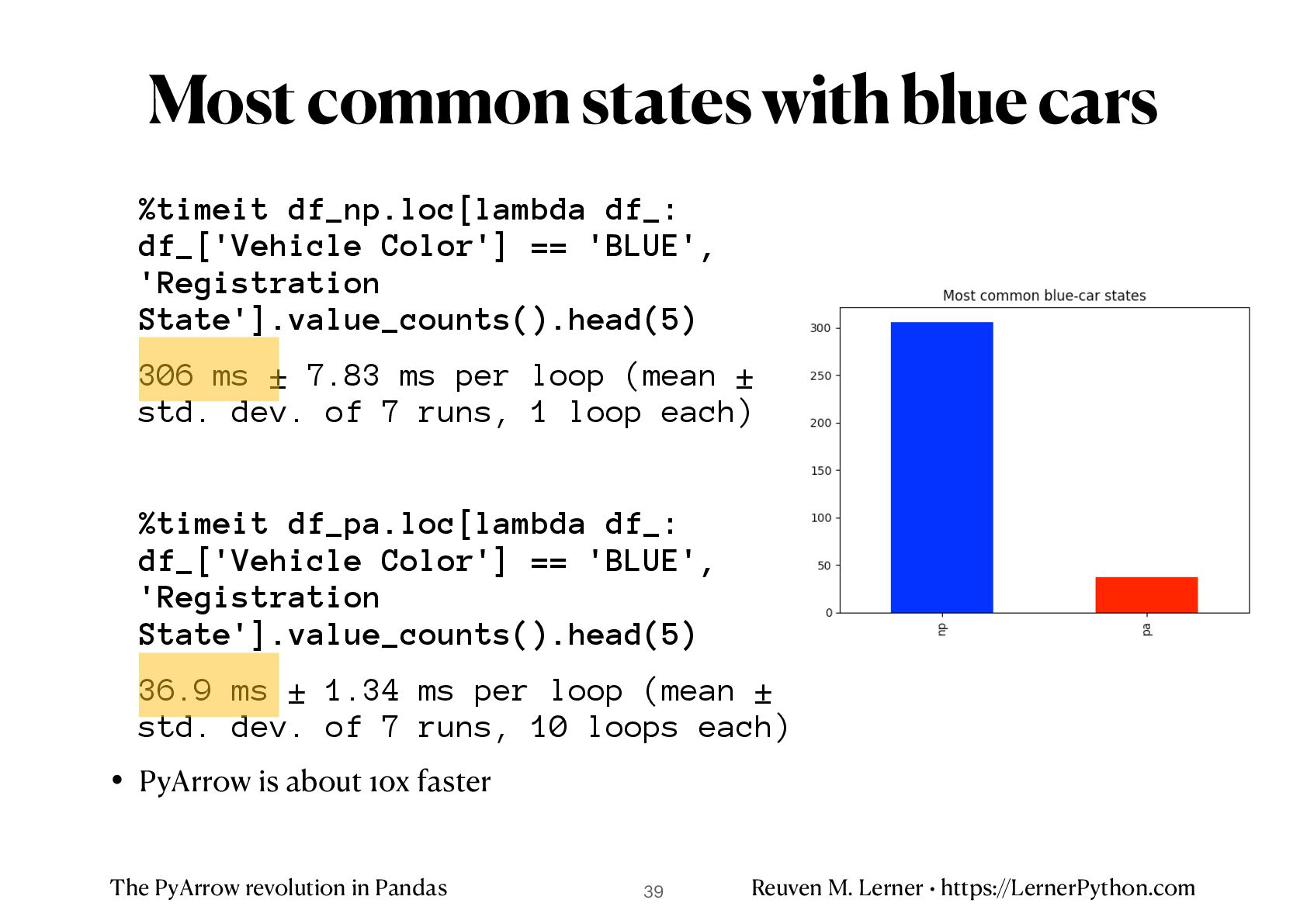
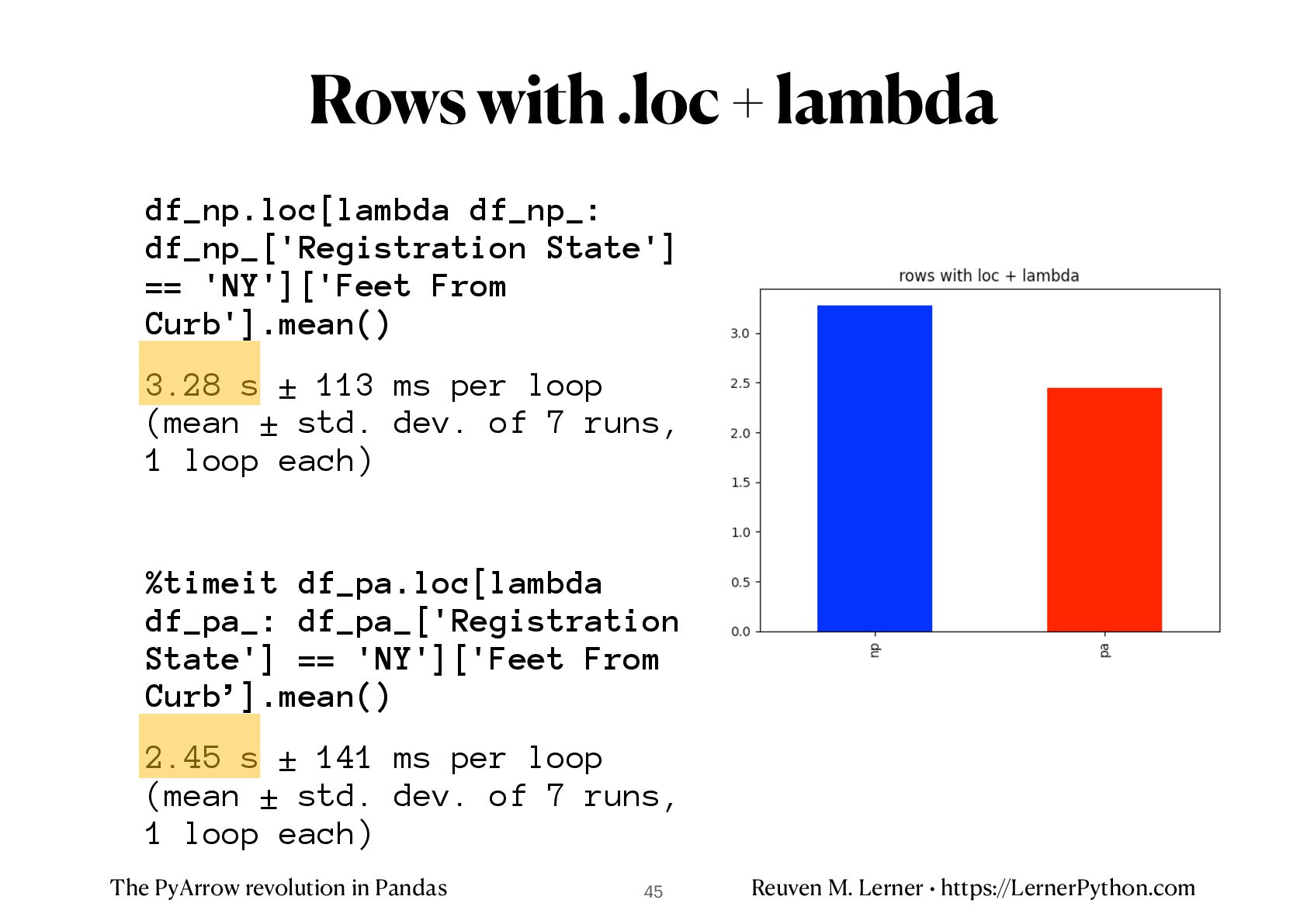
%timeit df_np.loc[lambda df_: df_['Vehicle Color'] == 'BLUE', 'Registration State'].value_counts().head(5) 306 ms ± 7.83 ms per loop (mean ± std. dev. of 7 runs, 1 loop each) %timeit df_pa.loc[lambda df_: df_['Vehicle Color'] == 'BLUE', 'Registration State'].value_counts().head(5) 36.9 ms ± 1.34 ms per loop (mean ± std. dev. of 7 runs, 10 loops each) • PyArrow is about 10x faster Most common states with blue cars 39
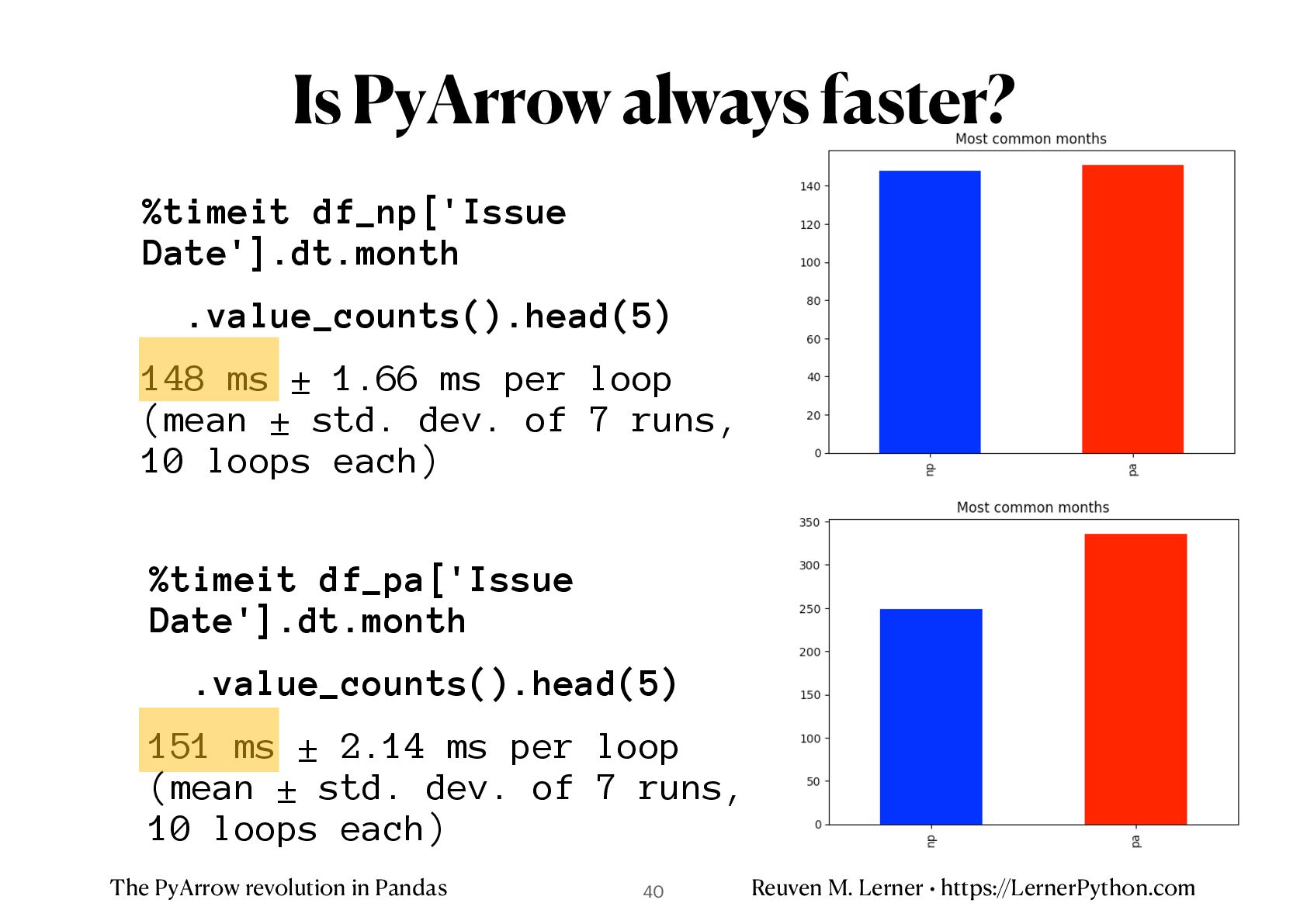
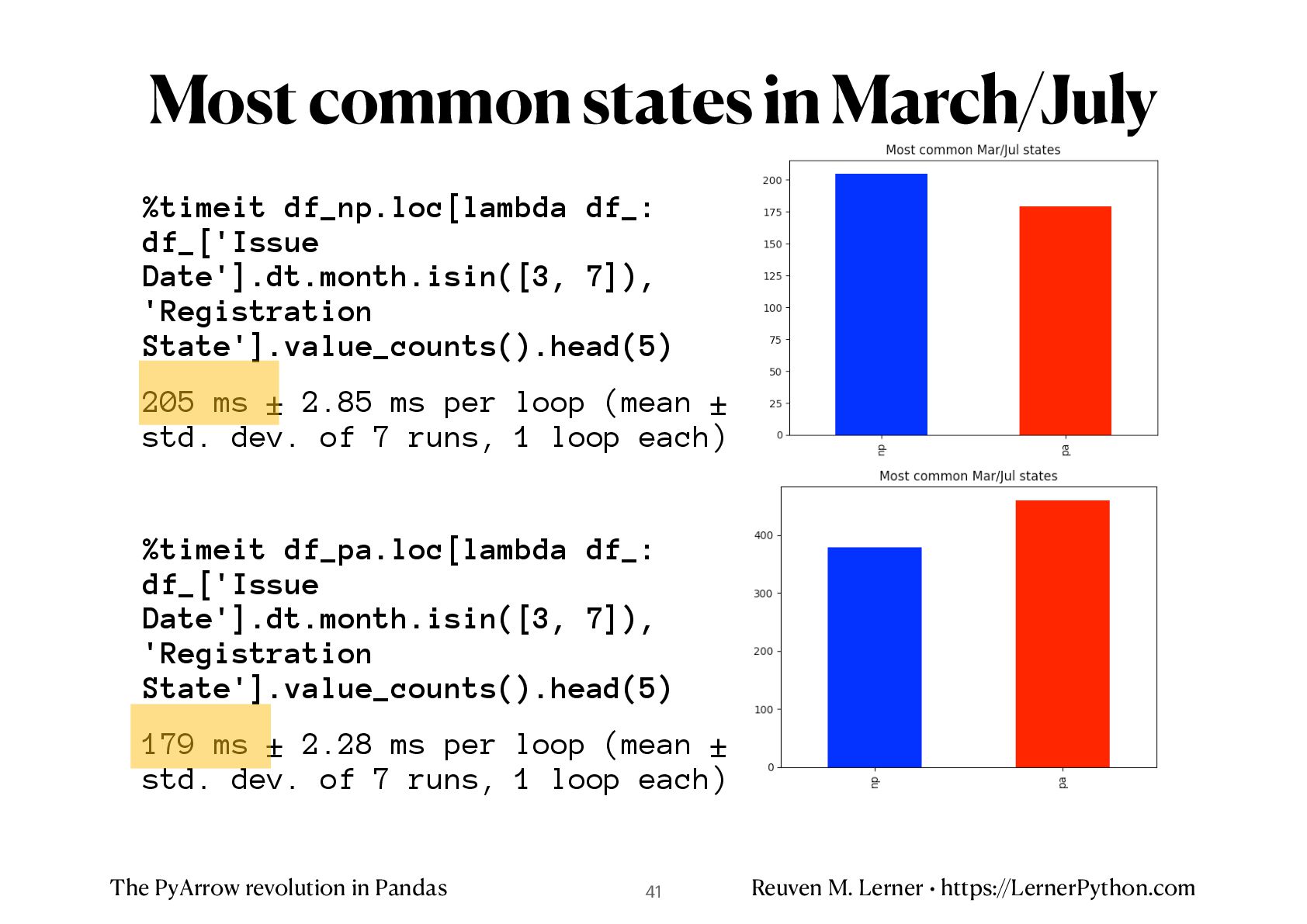
%timeit df_np.loc[lambda df_: df_['Issue Date'].dt.month.isin([3, 7]), 'Registration State'].value_counts().head(5) 205 ms ± 2.85 ms per loop (mean ± std. dev. of 7 runs, 1 loop each) %timeit df_pa.loc[lambda df_: df_['Issue Date'].dt.month.isin([3, 7]), 'Registration State'].value_counts().head(5) 179 ms ± 2.28 ms per loop (mean ± std. dev. of 7 runs, 1 loop each) Most common states in March/July 41
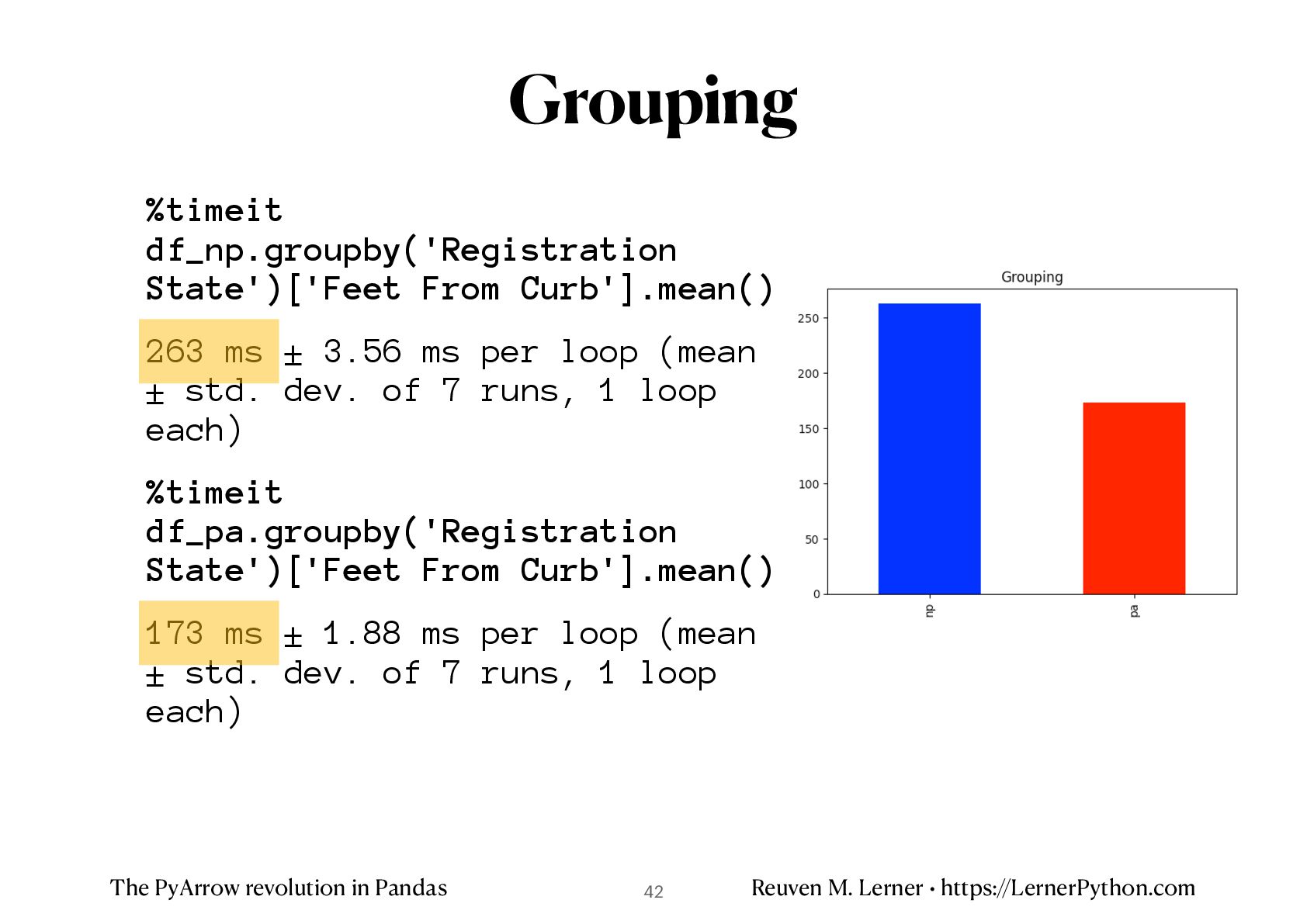
%timeit df_np.groupby('Registration State')['Feet From Curb'].mean() 263 ms ± 3.56 ms per loop (mean ± std. dev. of 7 runs, 1 loop each) %timeit df_pa.groupby('Registration State')['Feet From Curb'].mean() 173 ms ± 1.88 ms per loop (mean ± std. dev. of 7 runs, 1 loop each) Grouping 42
s = Series('hello out there'.split(), dtype='string[pyarrow]') s.loc[1] = np.nan s 0 hello 1 <NA> 2 there dtype: string Nullable types — not just ints 51
• There is another, separate way to use a backend that isn't NumPy, namely "extension types.” • Their main advantage: They’re nullable • Otherwise, they have the same issues as NumPy dtypes: • Row oriented storage • Python strings • No compression • Not interoperable with other systems Different from extension types! 55
• In the future, strings will be handled by PyArrow • What if you want that now? pd.options.future.infer_string = True • Now, all of your strings will be in PyArrow! • Faster creation/loading time • Far less memory usage Want PyArrow strings without a PyArrow backend? 56
• You can, of course, use PyArrow directly • It’s a fast, smart, capable data structure • If and when you want, you can convert it to a Pandas data frame: t.to_pandas() • You can also =import a data frame into PyArrow: pa.Table.from_pandas(df_pa) • Also, when our backend uses PyArrow: • s.values returns a PyArrow array • df_pa[‘column’].values returns a PyArrow array • df_pa.values returns a NumPy array, for compatibility purposes Using raw PyArrow 57
• Right now, Pandas is a powerful package • It’s becoming a powerful platform • Swappable back ends (NumPy and PyArrow) • It’s setting the standard for data-analysis API • Other libraries (e.g., Polars) are partly emulating it • It’s becoming something that other software can work with • Via PyArrow, R and Apache Spark • In memory, DuckDB can query Pandas data frames The real Pandas revolution 58
• PyArrow is revolutionizing Pandas • Faster f ile loading today • Faster, more ef f icient back-end storage tomorrow • (Or you can try it today!) • Pandas is becoming a platform • PyArrow is part of that move • You’ll be able to choose how much complex ef f iciency you want vs. simple, inef f icient clarity Summary 59
• Courses: https://LernerPython.com • YouTube: https://YouTube.com/reuvenlerner • Bluesky: https://bsky.app/pro f ile/lernerpython.com • Deep-dive Pandas challenges: https:// BambooWeekly.com • Stop by and say “hi” at my booth! Questions? 60
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}