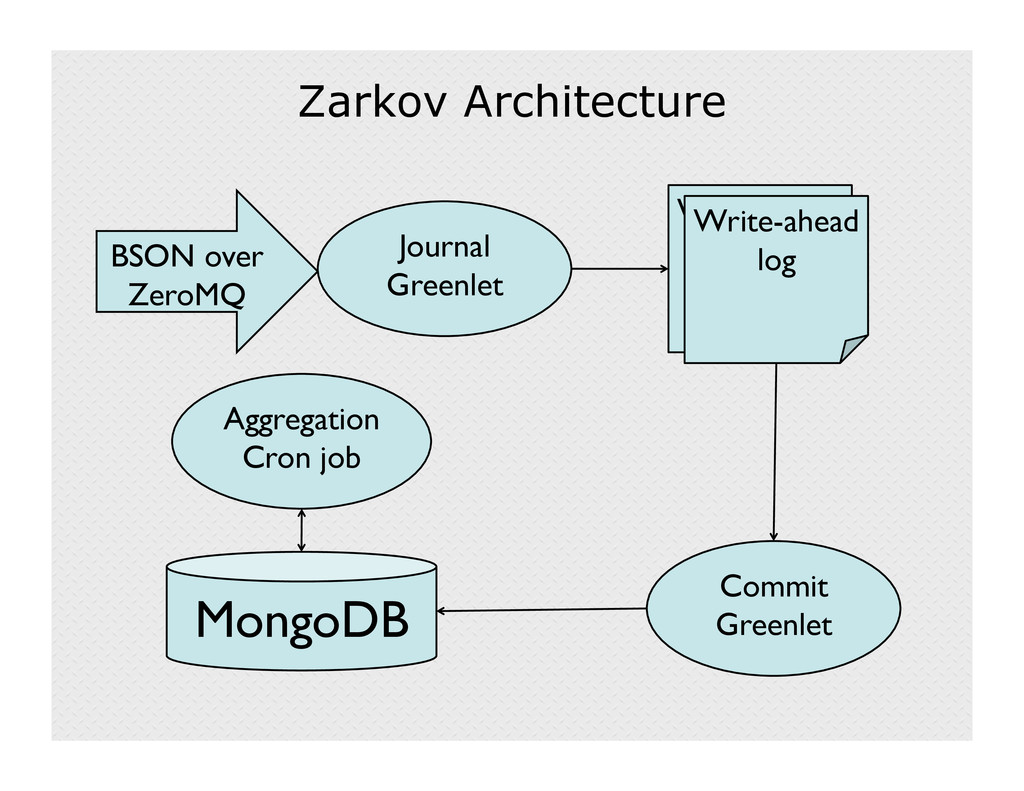
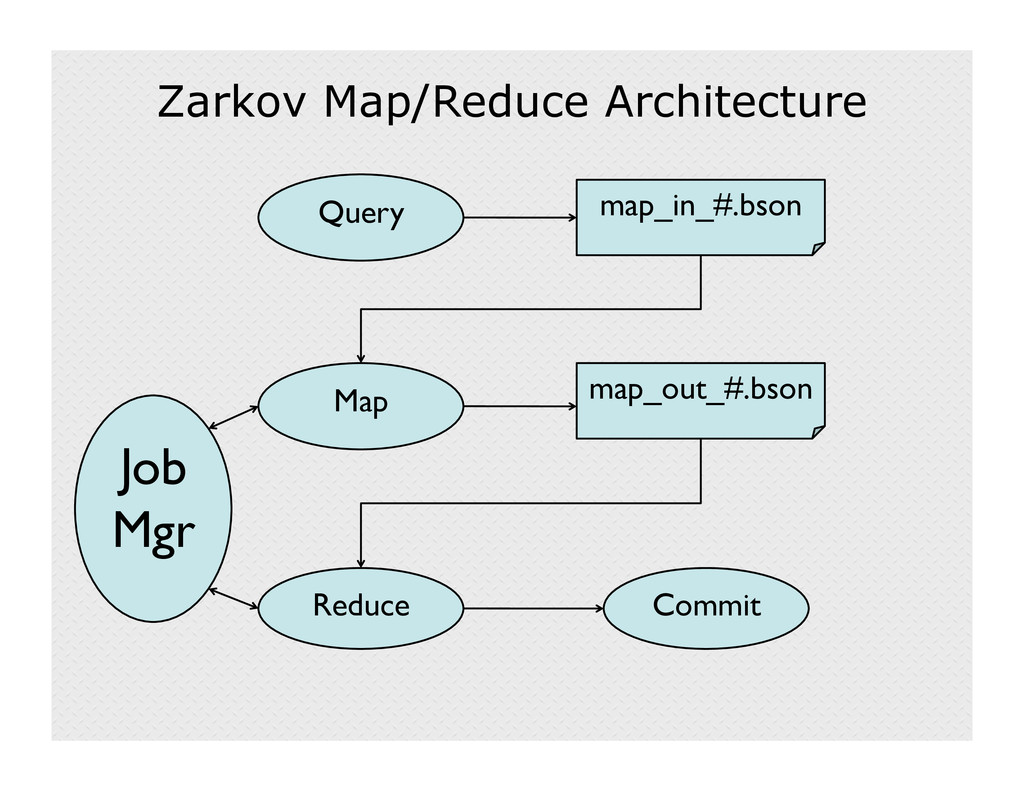
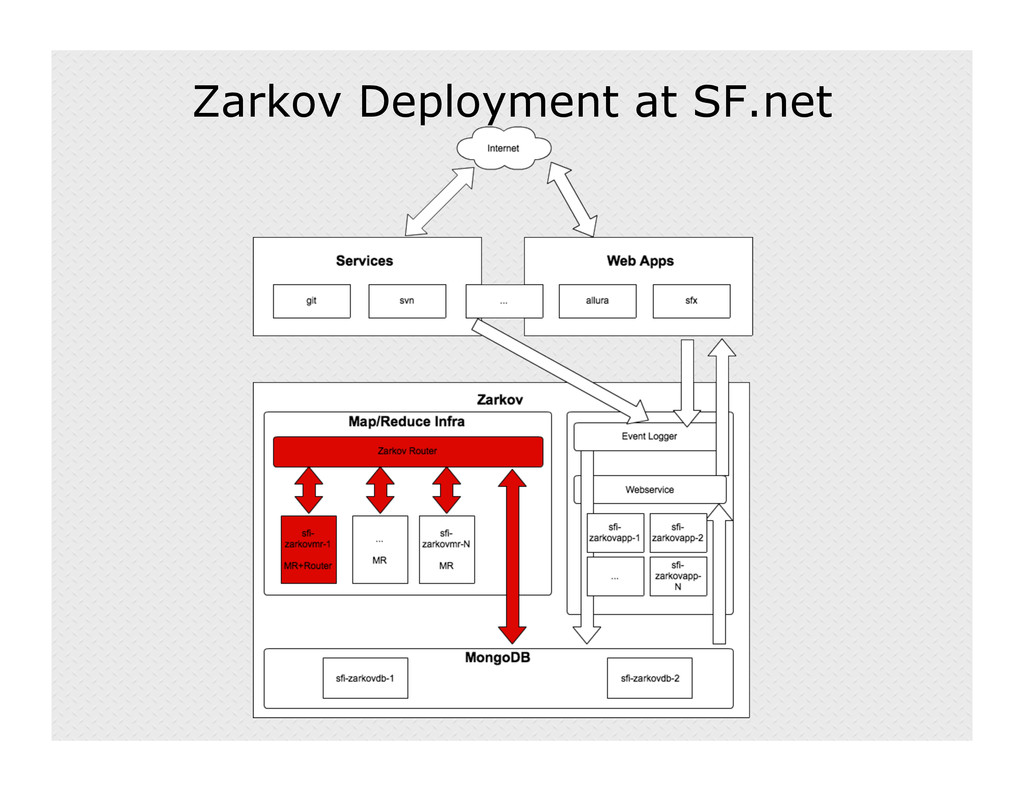
With over 180,000 projects and over 2 million users, SourceForge has tons of data about people developing and downloading open source projects. Until recently, however, that data didn't translate into usable information, so Zarkov was born. Zarkov is system that captures user events, logs them to a MongoDB collection, and aggregates them into useful data about user behavior and project statistics. This talk will discuss the components of Zarkov, including its use of Gevent asynchronous programming, ZeroMQ sockets, and the pymongo/bson driver.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![© 2011Geeknet Inc ! Questions? Rick Copeland @rick446 [email protected]](https://files.speakerdeck.com/presentations/4e8a4a943d3d6d00500042ce/slide_20.jpg){kind=link}
{kind=link}