cnfl.io/community-slack cnfl.io/read Welcome to the DC Apache Kafka® Meetup! 6:30pm Doors open 6:30pm - 7:00pm Pizza, Drinks and Networking 7:00pm - 7:45pm Ricardo Ferreira, Confluent 7:45pm - 8:00pm Additional Q&A & Networking Apache, Apache Kafka, Kafka and the Kafka logo are trademarks of the Apache Software Foundation. The Apache Software Foundation has no affiliation with and does not endorse the materials provided at this event.
❑ Currently into Cloud & Serverless ❑ Ex-Oracle, Red Hat, and IONA Tech ❑ https://riferrei.net • Echo Dot (Alexa) ❑ The voice behind Amazon ❑ Ex-Raspberry Pi, Arduino @riferrei @alexa99
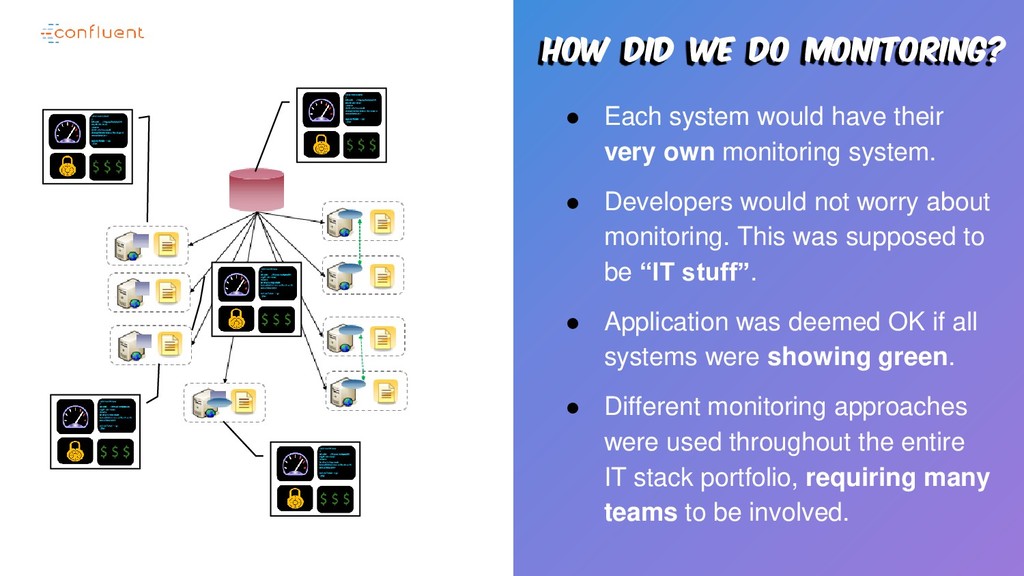
their very own monitoring system. • Developers would not worry about monitoring. This was supposed to be “IT stuff”. • Application was deemed OK if all systems were showing green. • Different monitoring approaches were used throughout the entire IT stack portfolio, requiring many teams to be involved.
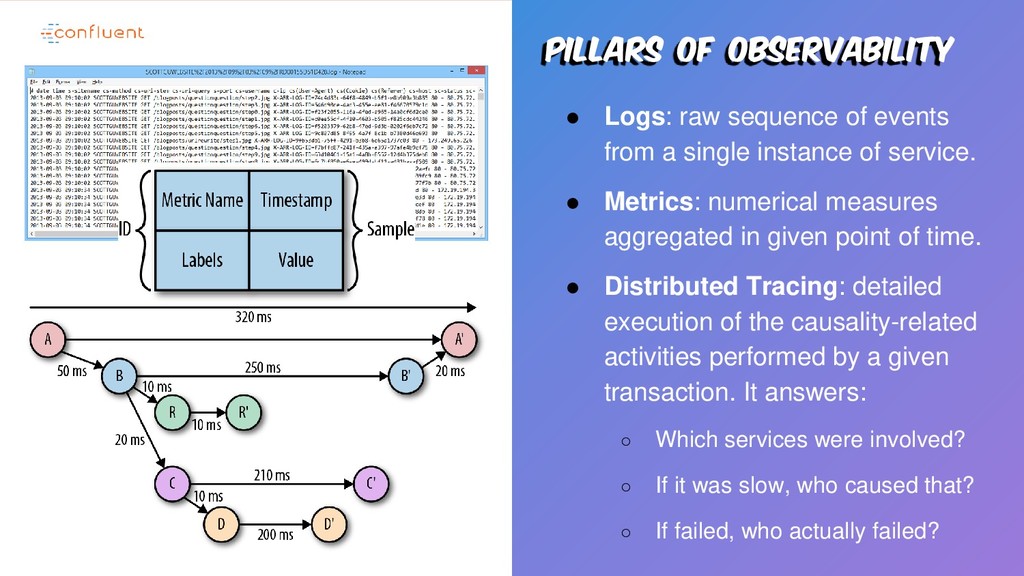
a single instance of service. • Metrics: numerical measures aggregated in given point of time. • Distributed Tracing: detailed execution of the causality-related activities performed by a given transaction. It answers: ◦ Which services were involved? ◦ If it was slow, who caused that? ◦ If failed, who actually failed?
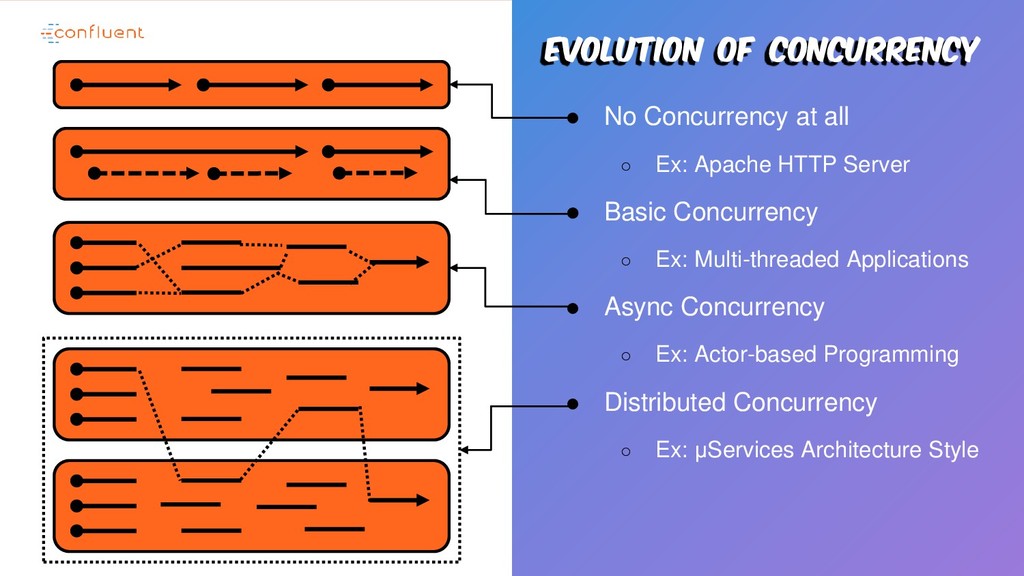
available. • Standards are getting created to ensure a single programming model for each μService. • Deployment mechanisms such as Kubernetes are also taking care of that automatically. • Network proxies such as Service Meshes are also handling this. • OSS and proprietary options.
de-facto standard to handle data. • Prediction? It will be the central nervous system of any company. • μServices in general already use Kafka to exchange messages and keep their data stores in-sync. • With event streaming becoming even more popular, the Kafka adoption tend to grow even more. • Because it is so freaking cool!
distributed tracing via OpenTracing compatible APIs. • Requires the creation of specific tracer using the distributed tracing technology API. • Uses the GlobalTracer utility class to handle the tracer throughout the JVM application. • Supports: Apache Kafka Clients, Kafka Streams, and Spring Kafka. https://github.com/opentracing-contrib/java-kafka- client
does the automatic creation of the tracer. • Implements the tracing logic using the Kafka Interceptors API. • Allows different tracers to be used, by using the TracerResolver class. • Provides OOTB support for Jaeger. • Allows multiple services in the JVM use their own tracer by specifying a configuration properties file. ◦ export INTERCEPTORS_CONFIG_FILE= https://github.com/riferrei/kafka-tracing-support
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}