is stored, computed, and visualized. • Provide open technologies for Data Integration on a massive scale. • Provide software tools, training, and integration/consulting services to corporate, government, and educational clients worldwide.
social data and unstructured data is knocking at the door, and we're starting to let it in. It's a scary place at the moment.” -- Unidentified bank IT executive, as quoted by “The American Banker”
and hence, it offers interactivity • Myth: “Python is slow, so why on the hell are you going to use it for Big Data?” • Answer: Python has access to an incredibly powerful range of libraries that boost its performance far beyond your expectations • ...and during this talk I will prove it!
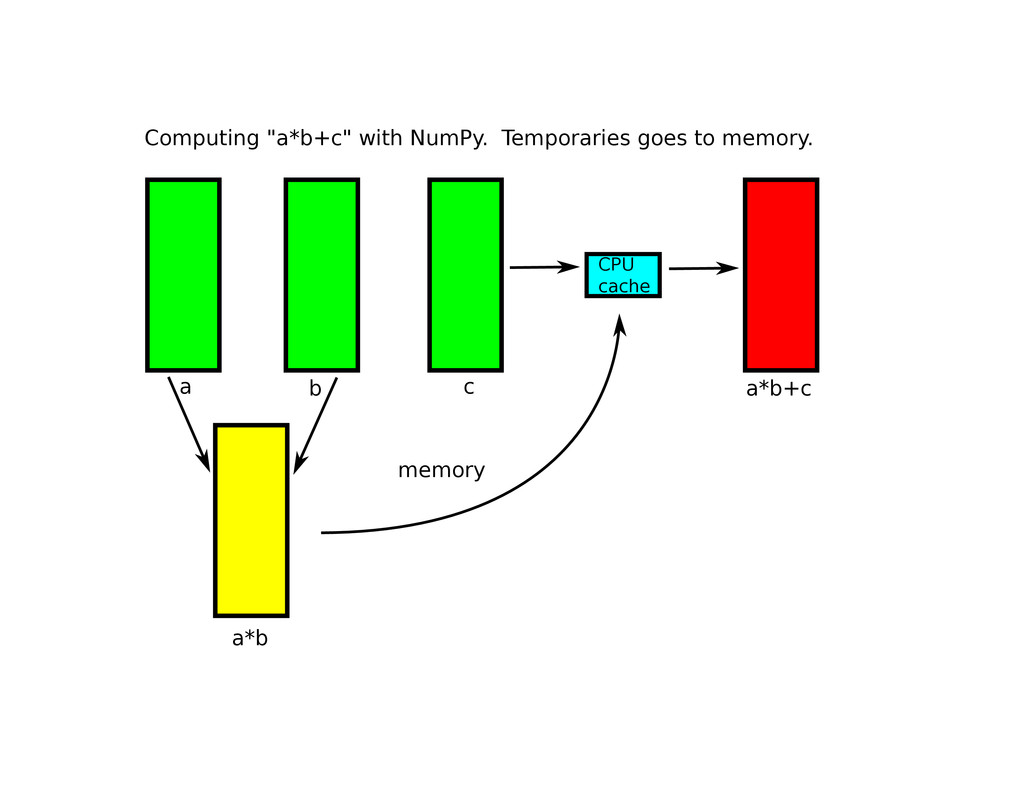
use cases • However, it also has its own deficiencies: • Follows the Python evaluation order in complex expressions like : (a * b) + c • Does not have support for multiprocessors (except for BLAS computations)
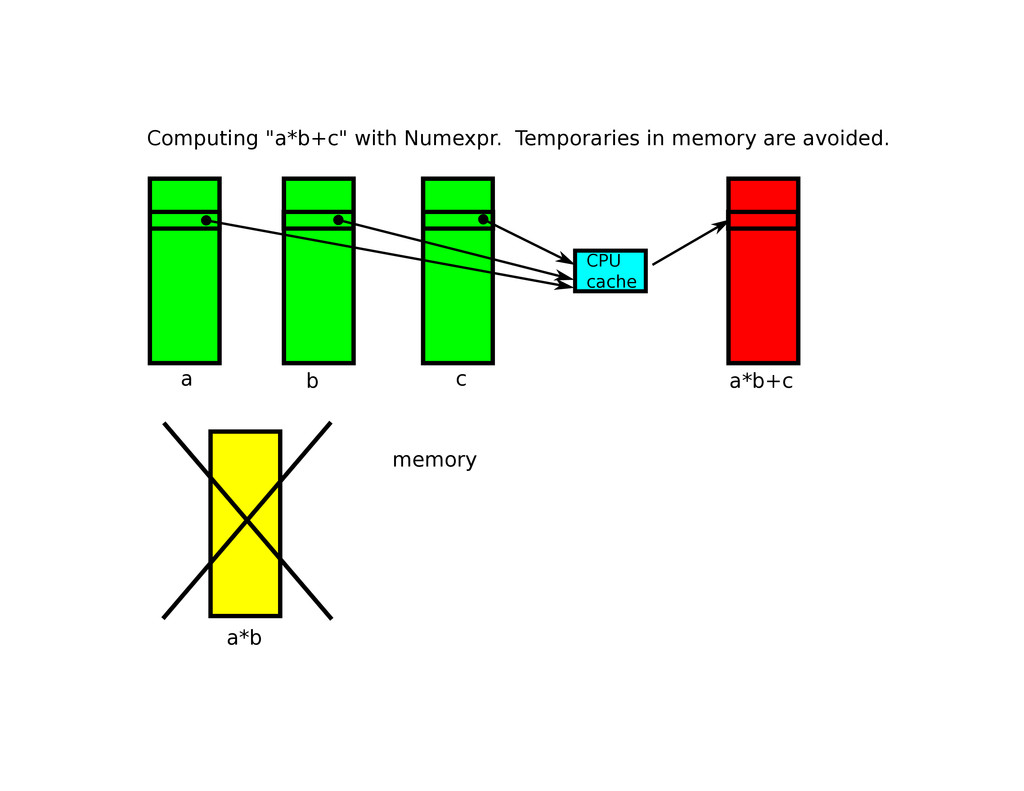
specialized virtual machine for evaluating expressions • It accelerates computations mainly by making a more efficient memory usage • It supports extremely easy to use multithreading (active by default)
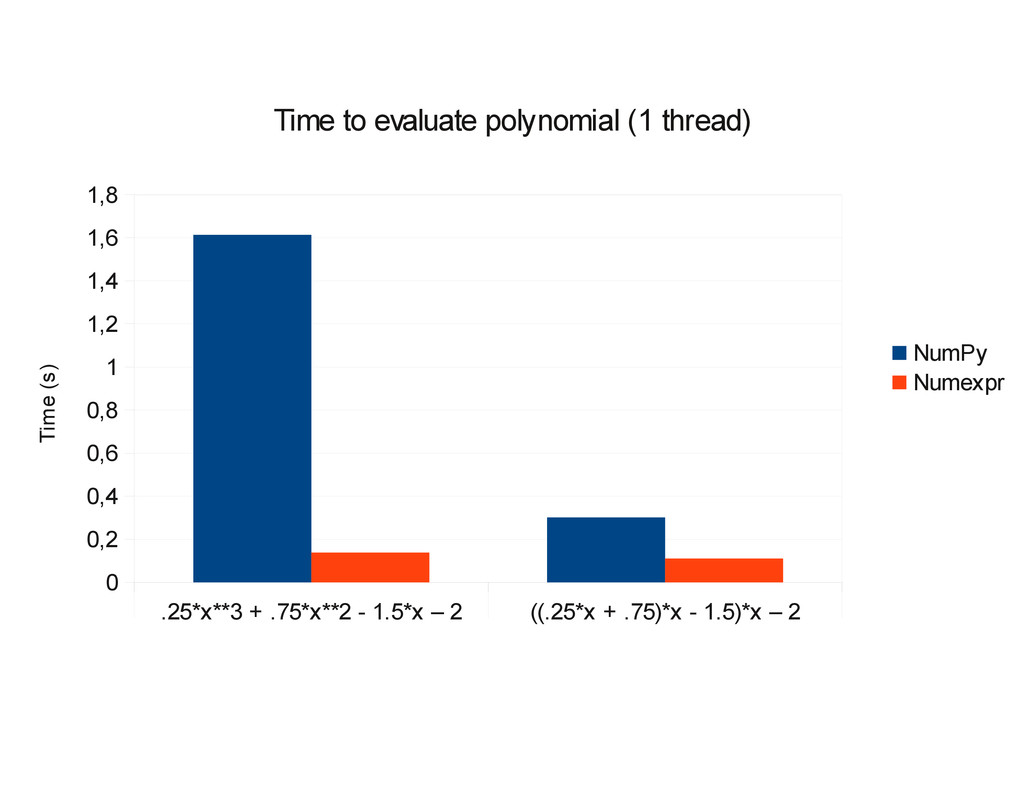
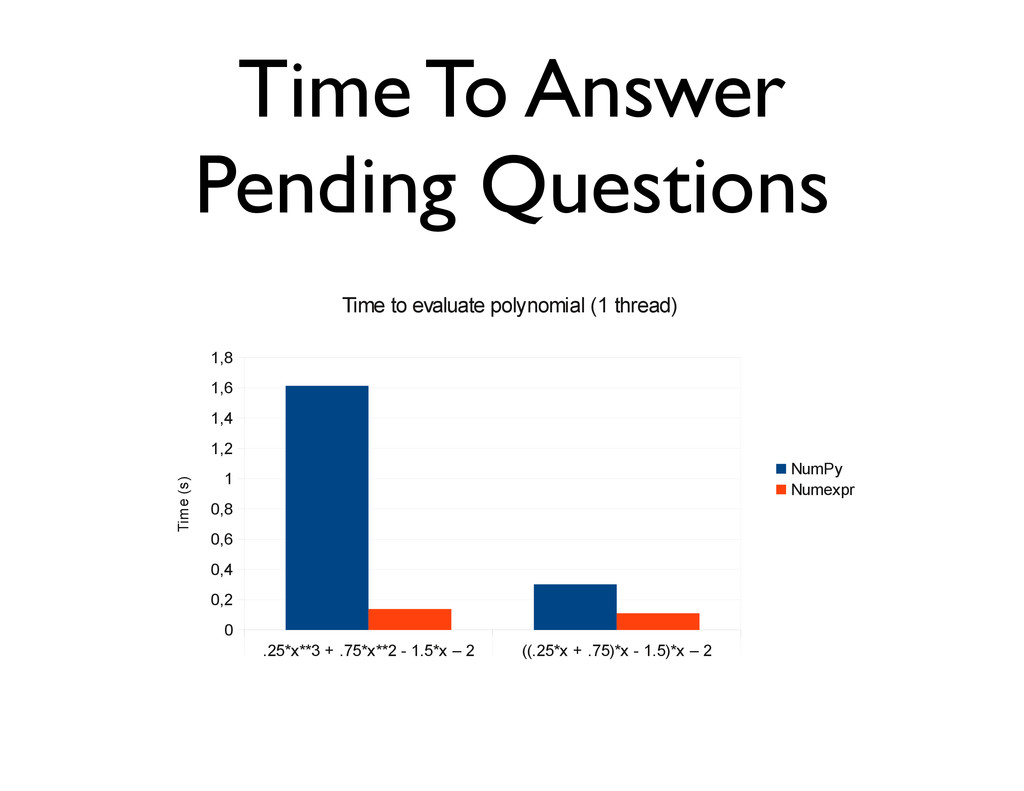
1] with a step size of 2*10-7, using both NumPy and numexpr. Note: use a single processor for numexpr numexpr.set_num_threads(1) 0.25x3 + 0.75x2 + 1.5x - 2
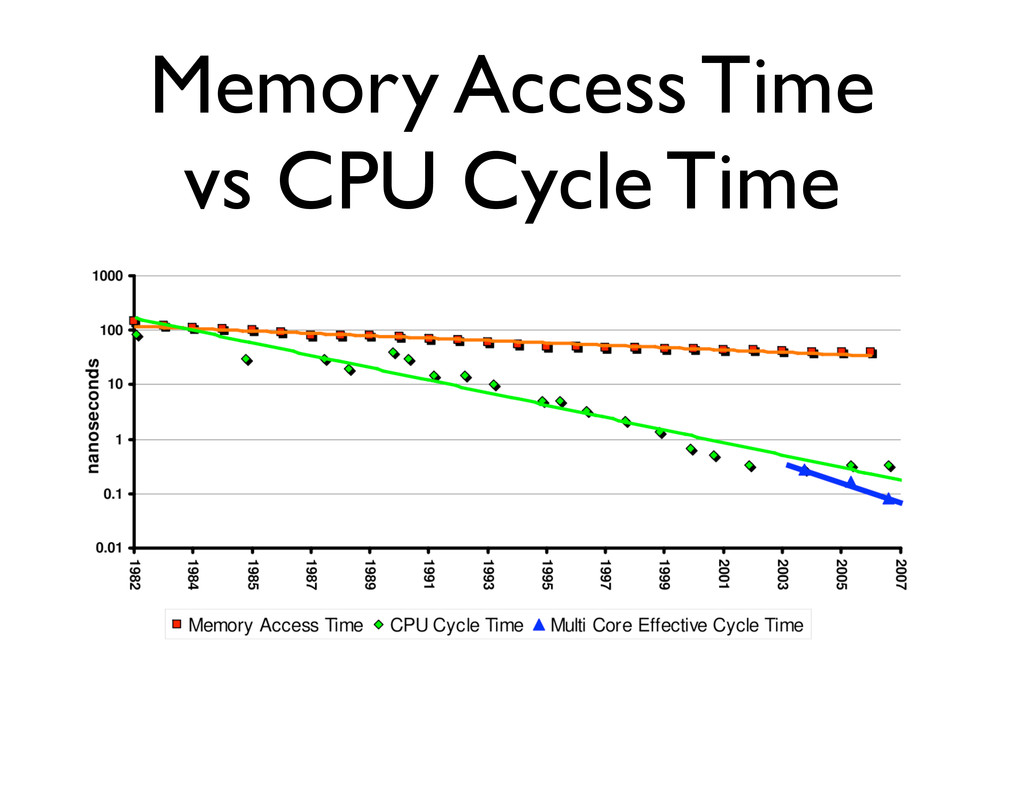
largely able to execute code faster than we can feed them with instructions and data.” – Richard Sites, after his article “It’s The Memory, Stupid!”, Microprocessor Report, 10(10),1996
is much slower (between 250x and 500x) than processors. • Memory bandwidth is improving at a better rate than memory latency, but it is also slower than processors (between 30x and 100x).
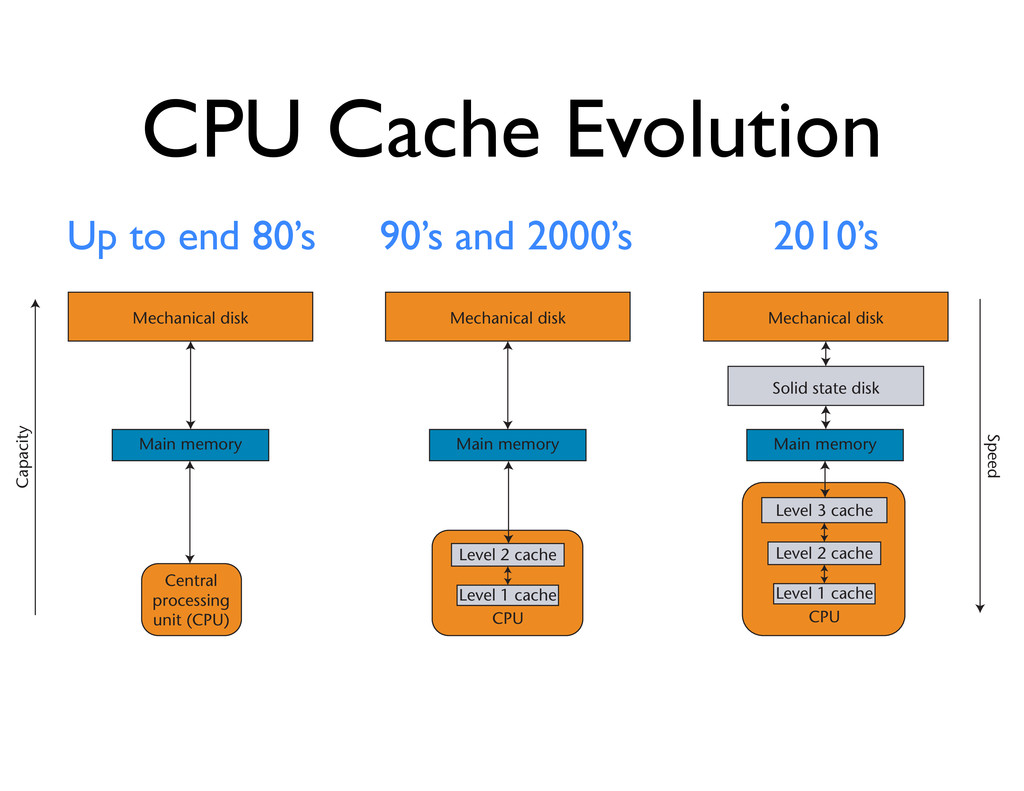
2010’s Figure 1. Evolution of the hierarchical memory model. (a) The primordial (and simplest) model; (b) the most common current implementation, which includes additional cache levels; and (c) a sensible guess at what’s coming over the next decade: three levels of cache in the CPU and solid state disks lying between main memory and classical mechanical disks. Mechanical disk Mechanical disk Mechanical disk Speed Capacity Solid state disk Main memory Level 3 cache Level 2 cache Level 1 cache Level 2 cache Level 1 cache Main memory Main memory CPU CPU (a) (b) (c) Central processing unit (CPU)
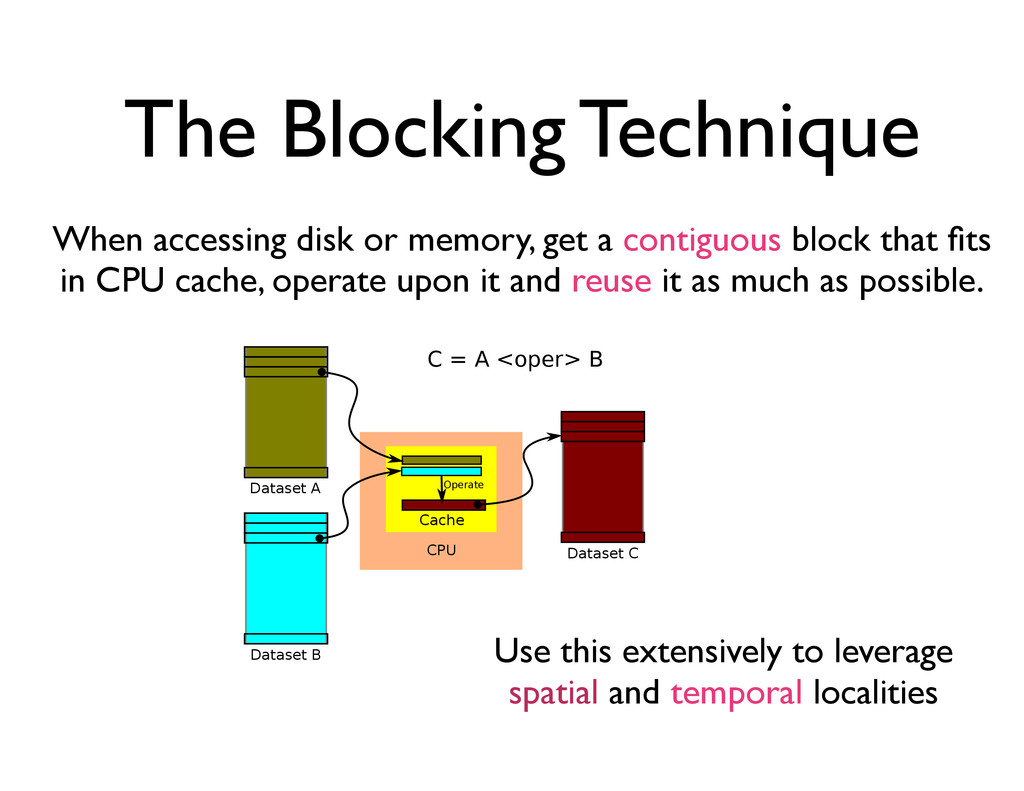
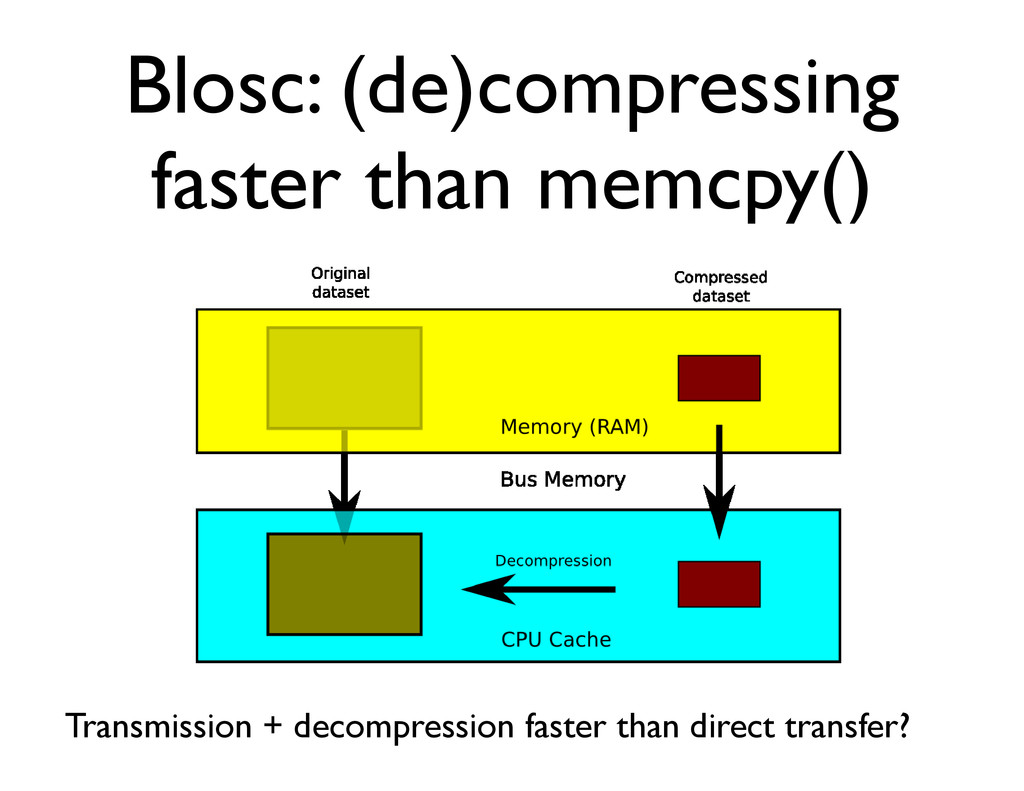
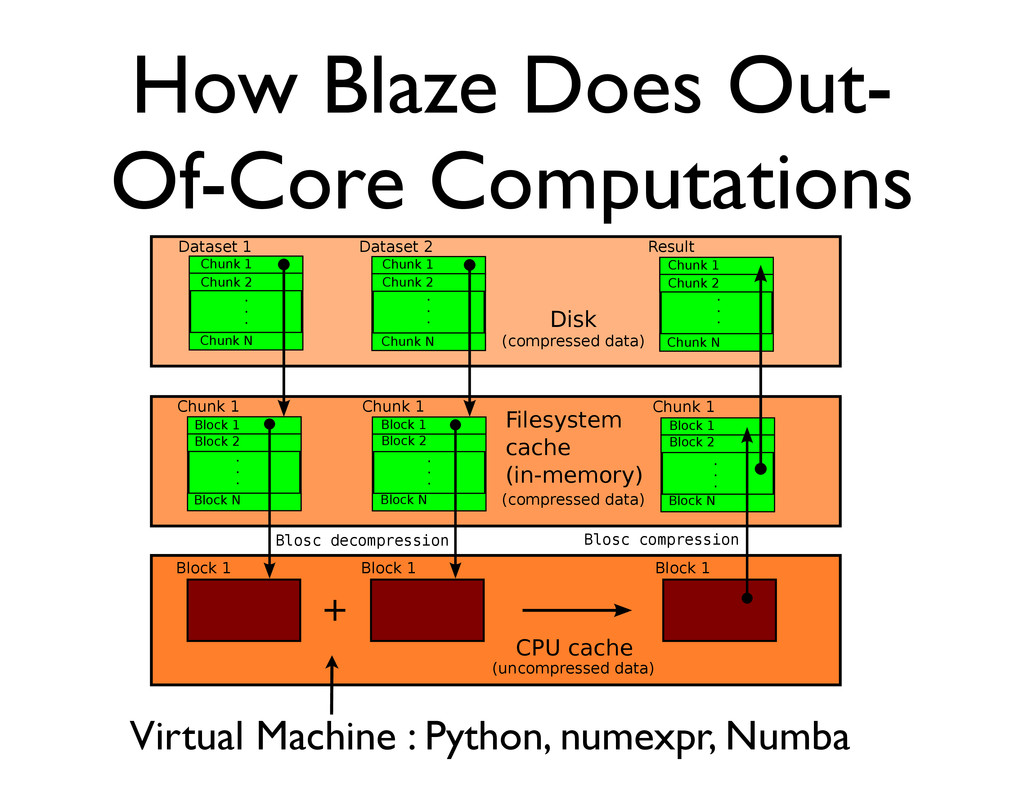
Use this extensively to leverage spatial and temporal localities When accessing disk or memory, get a contiguous block that fits in CPU cache, operate upon it and reuse it as much as possible.
is evaluated as: for i in range(N): c[i] = a[i] * b[i] • In particular, it cannot deal with things like: for i in range(N): c[i] = a[i-1] + a[i] * b[i]
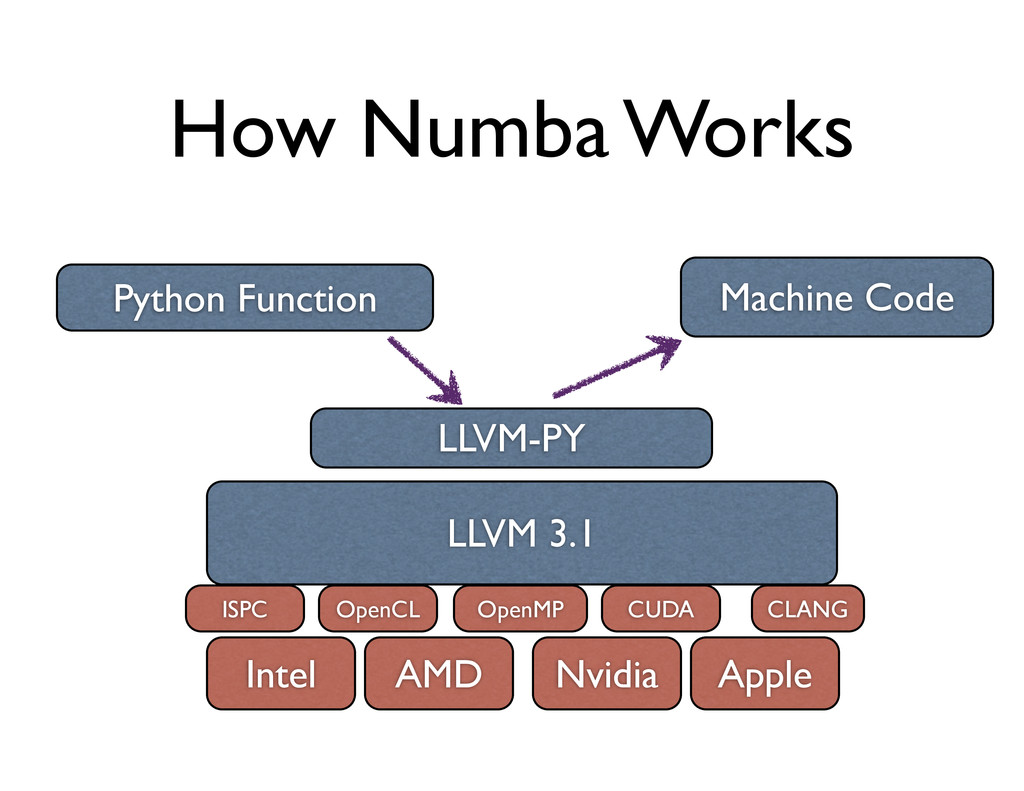
can translate a subset of the Python language into machine code • It uses LLVM infrastructure behind the scenes • Can achieve similar or better performance than numexpr, but with more flexibility
numba as nb N = 10*1000*1000 x = np.linspace(-1, 1, N) y = np.empty(N, dtype=np.float64) @nb.jit(arg_types=[nb.f8[:], nb.f8[:]]) def poly(x, y): for i in range(N): # y[i] = 0.25*x[i]**3 + 0.75*x[i]**2 + 1.5*x[i] - 2 y[i] = ((0.25*x[i] + 0.75)*x[i] + 1.5)*x[i] - 2 poly(x, y) # run through Numba!
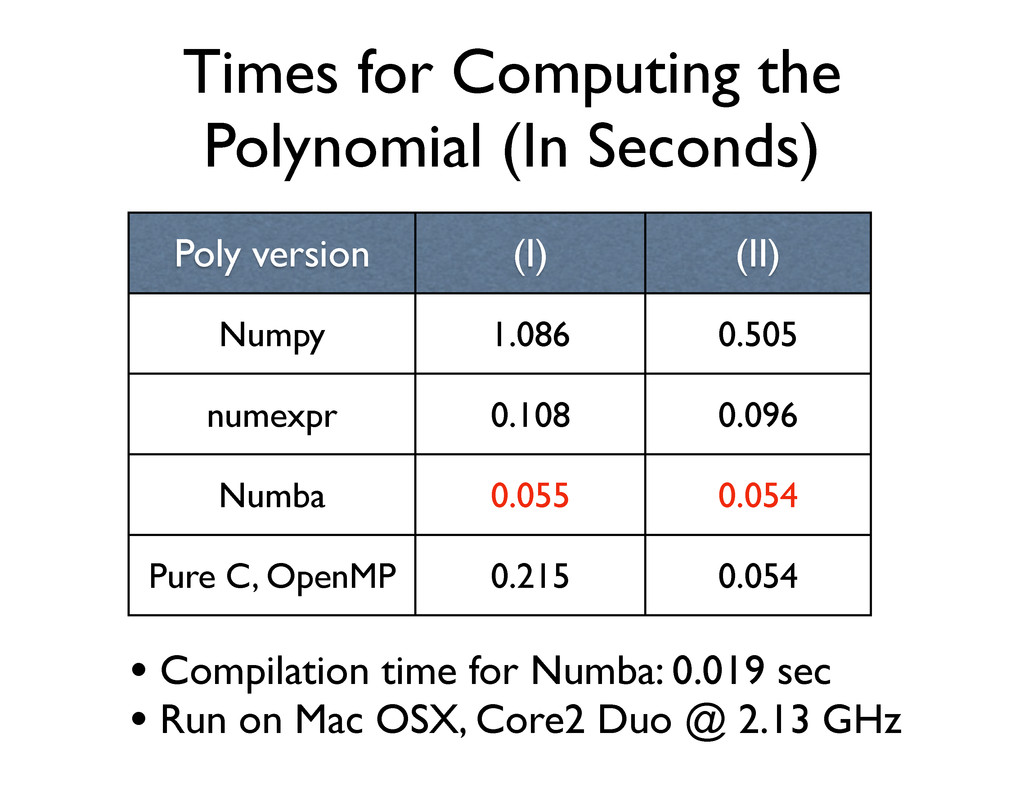
(II) Numpy 1.086 0.505 numexpr 0.108 0.096 Numba 0.055 0.054 Pure C, OpenMP 0.215 0.054 • Compilation time for Numba: 0.019 sec • Run on Mac OSX, Core2 Duo @ 2.13 GHz
times we are too focused on computing as fast as possible • But we have seen how important data access is • Hence, having an optimal data structure is critical for getting good performance when processing very large datasets
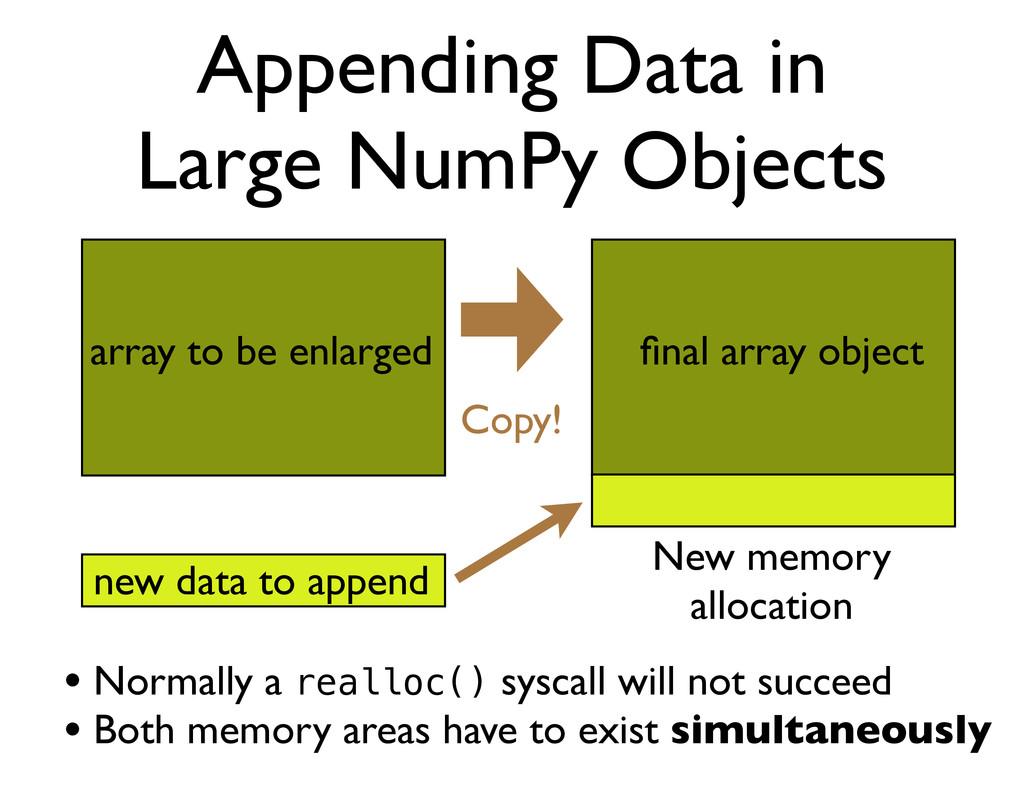
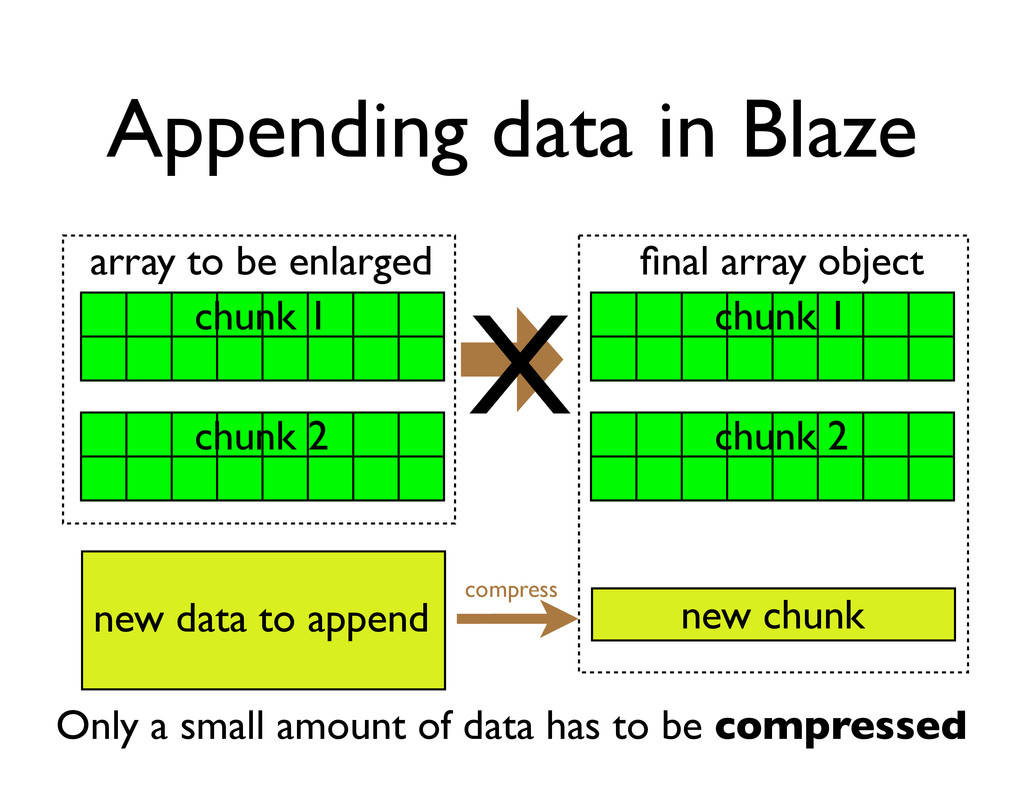
array to be enlarged final array object new data to append • Normally a realloc() syscall will not succeed • Both memory areas have to exist simultaneously
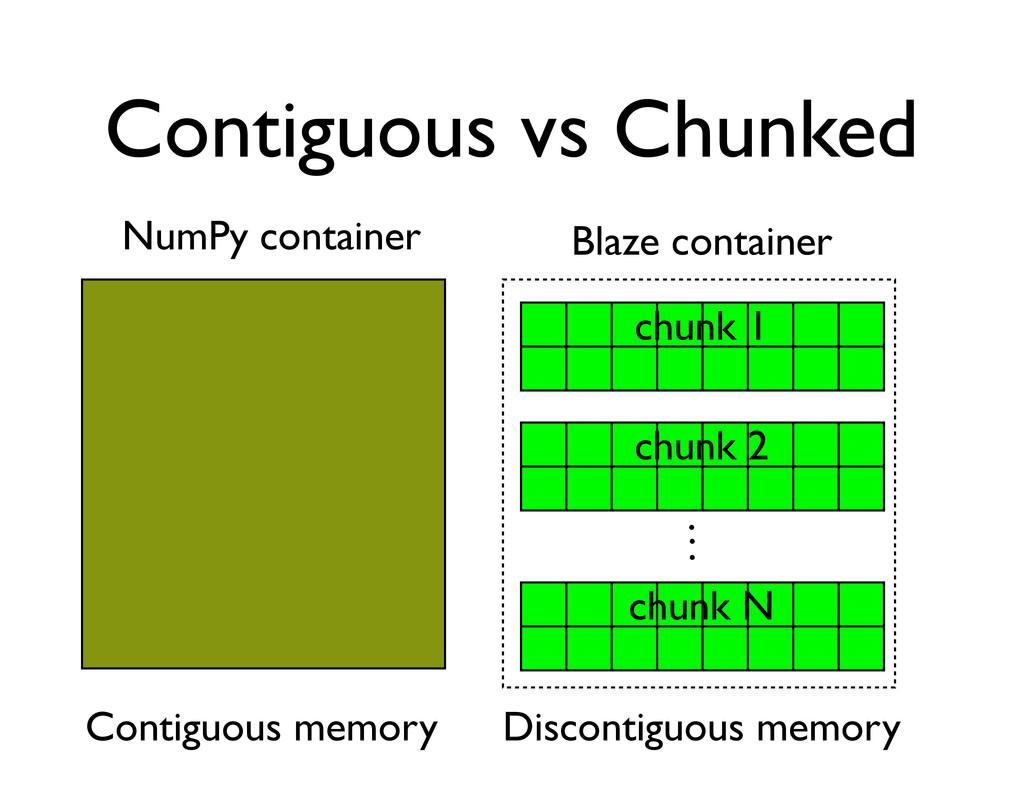
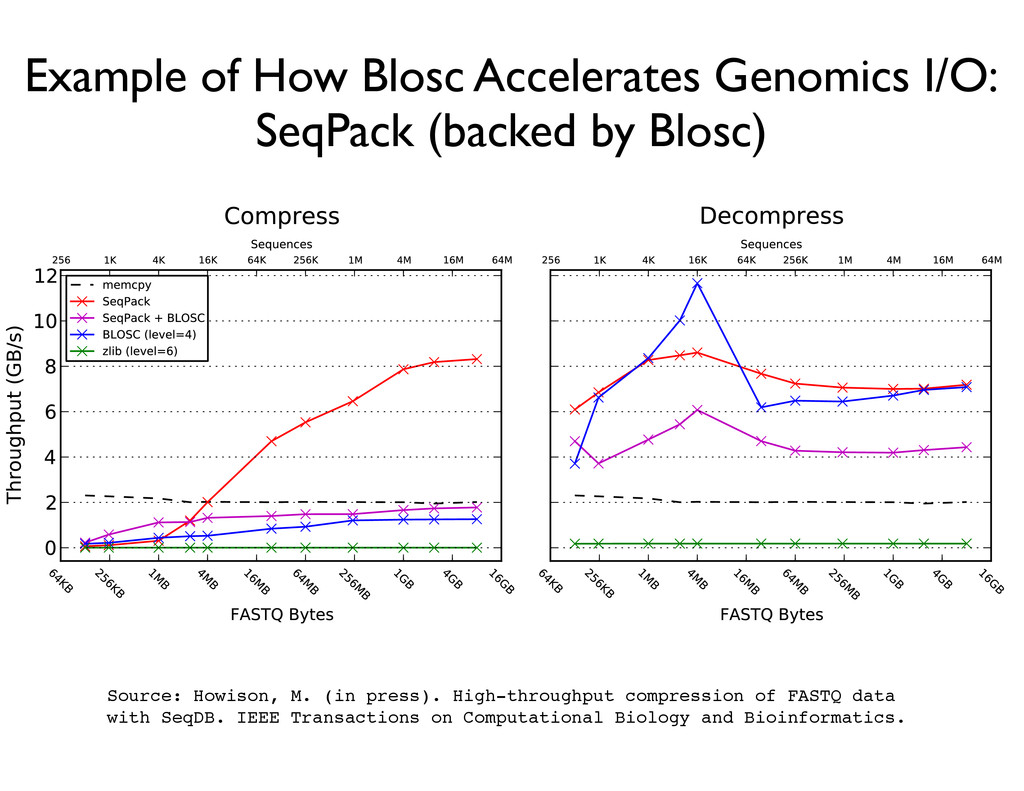
with SeqDB. IEEE Transactions on Computational Biology and Bioinformatics. TABLE 1 Test Data Sets # Source Identifier Sequencer Read Count Read Length ID Lengths FASTQ Size 1 1000 Genomes ERR000018 Illumina GA 9,280,498 36 bp 40–50 1,105 MB 2 1000 Genomes SRR493233 1 Illumina HiSeq 2000 43,225,060 100 bp 51–61 10,916 MB 3 1000 Genomes SRR497004 1 AB SOLiD 4 122,924,963 51 bp 78–91 22,990 MB g. 1. In-memory throughputs for several compression schemes applied to increasing block sizes (where each equence is 256 bytes long). to a memory buffer, timed the compression of block consistent throughput across both compression and Example of How Blosc Accelerates Genomics I/O: SeqPack (backed by Blosc)
• Nowadays you should be aware of the memory system for getting good performance • Choosing appropriate data containers is of the utmost importance when dealing with Big Data
sean capaces de mirar más allá del standard y sean capaces de entender los recursos hardware subyacentes y la variedad de algoritmos disponibles.” -- Oscar de Bustos, HPC Line of Business Manager at BULL
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![• array[2]; array[1,1:5, :]; array[[3,6,10]] • (array1**3 / array2) -](https://files.speakerdeck.com/presentations/1e7486c03ca70130f78a1231381d4c6b/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}