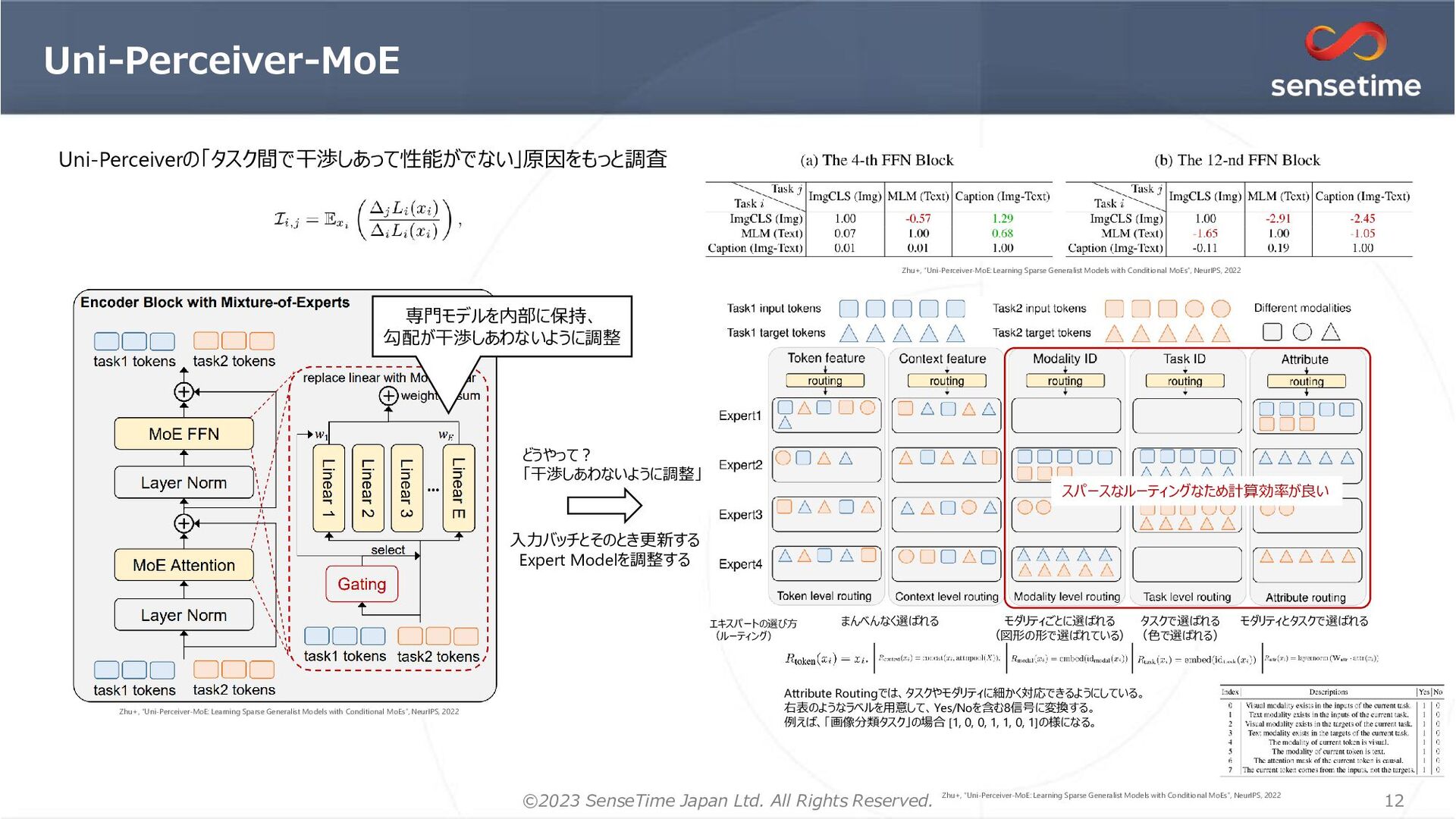
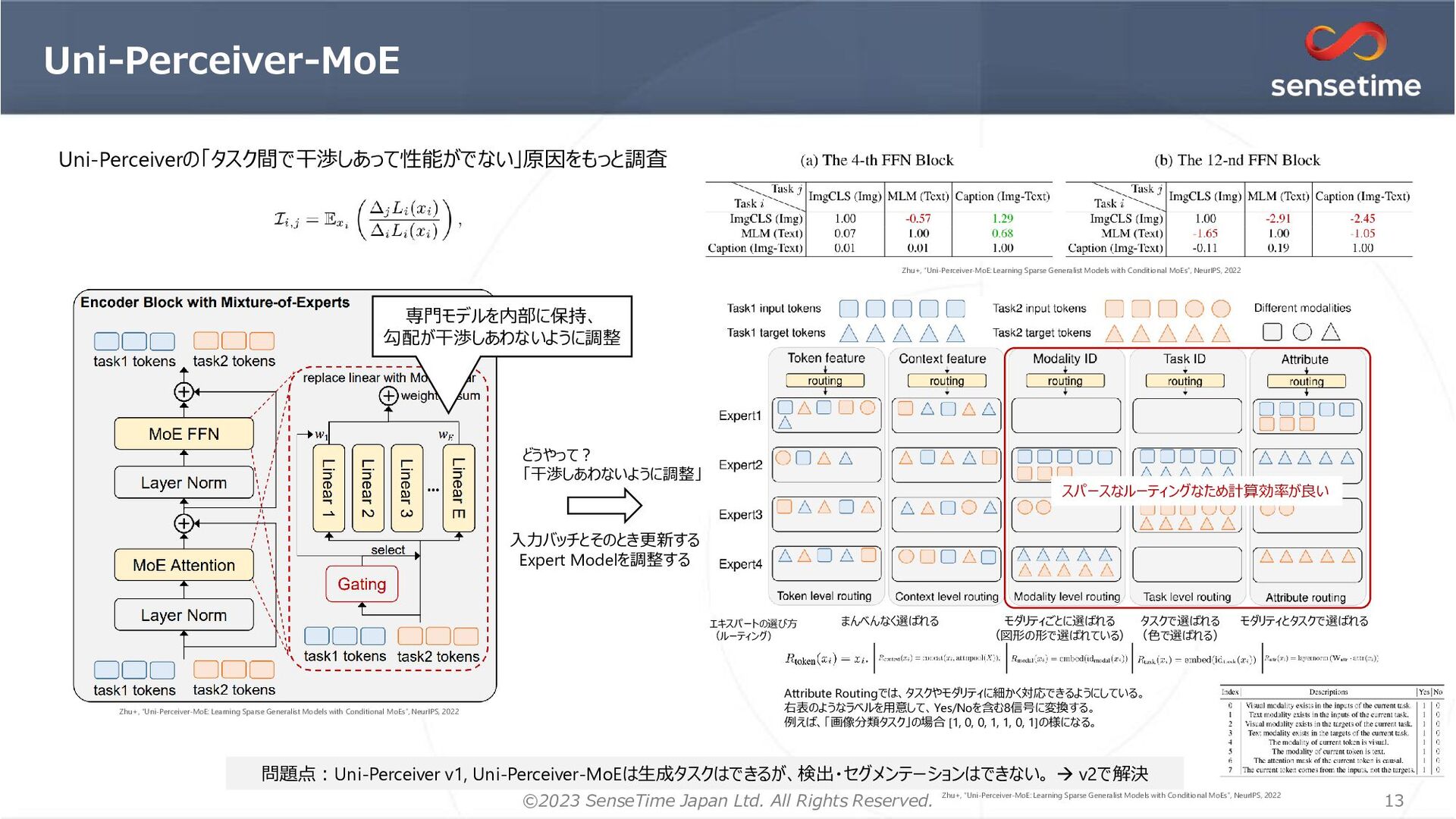
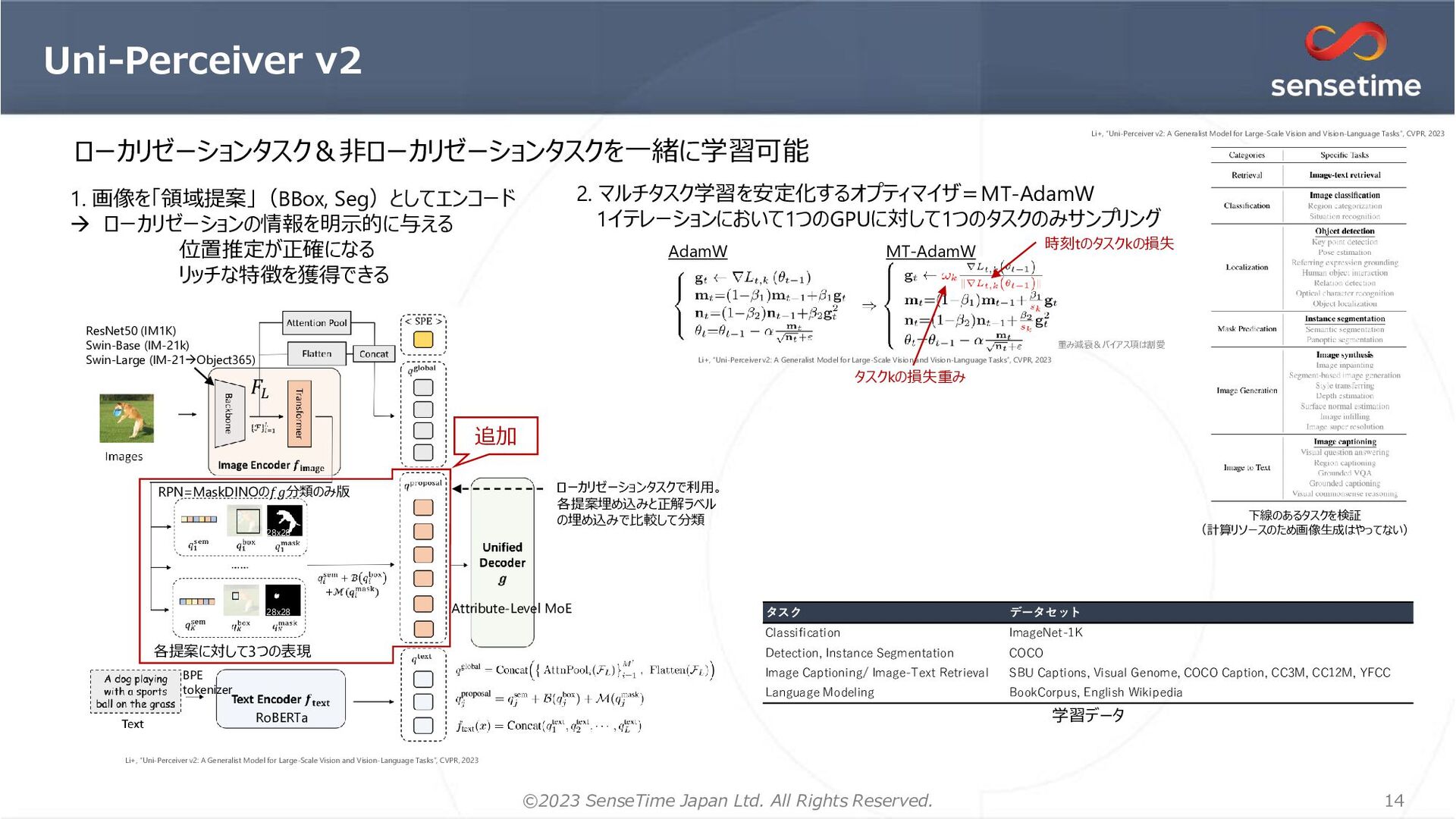
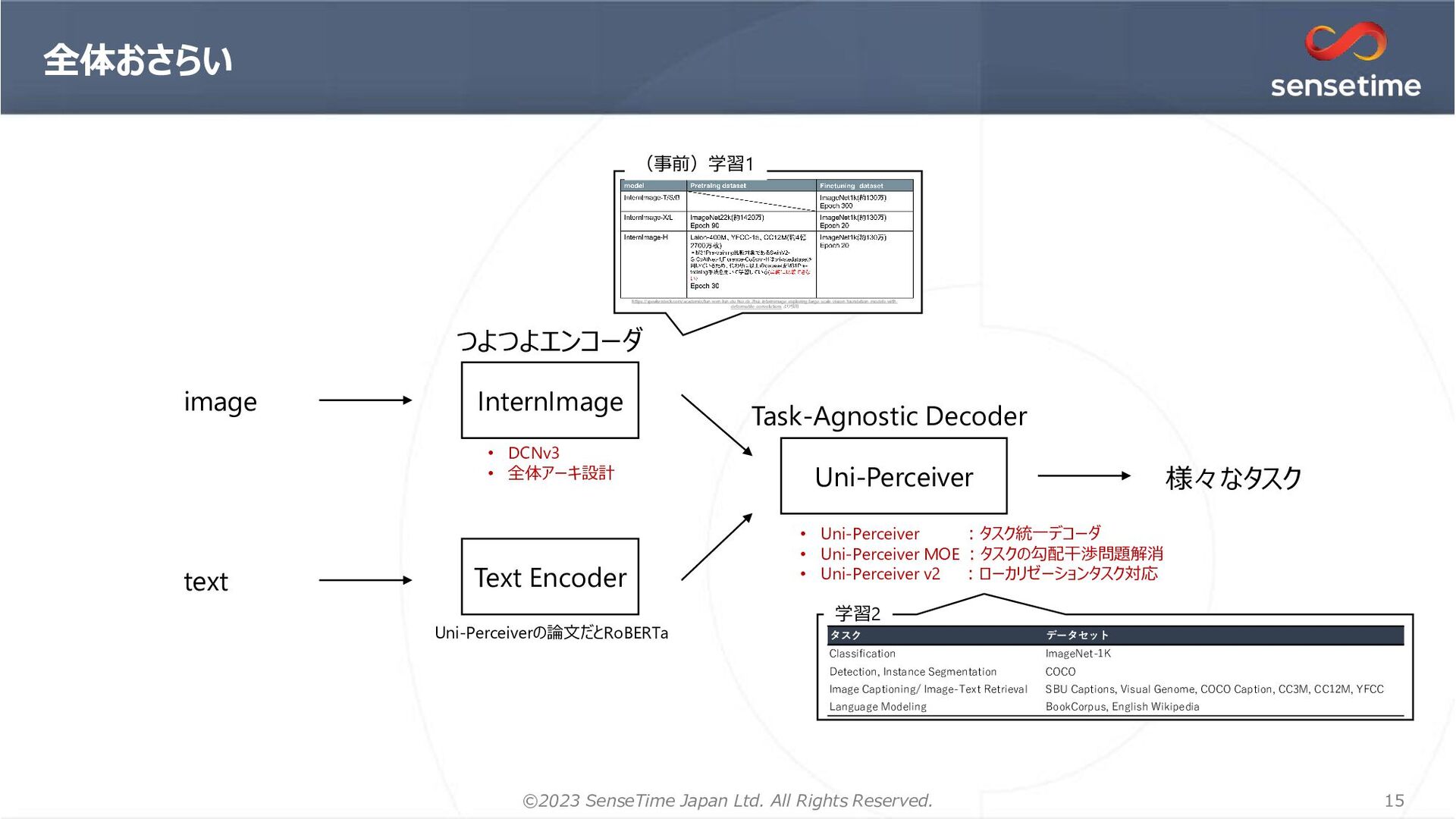
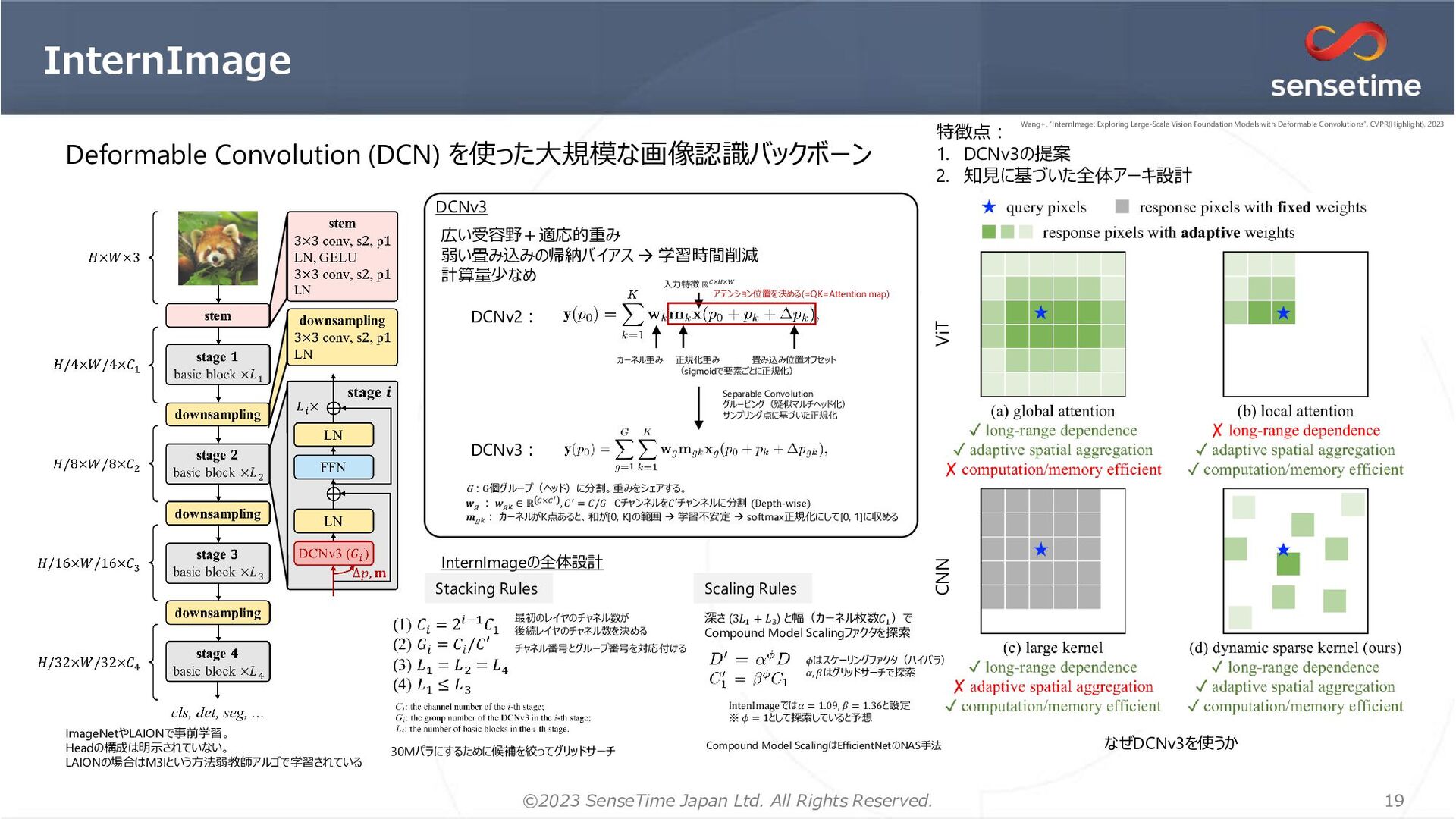
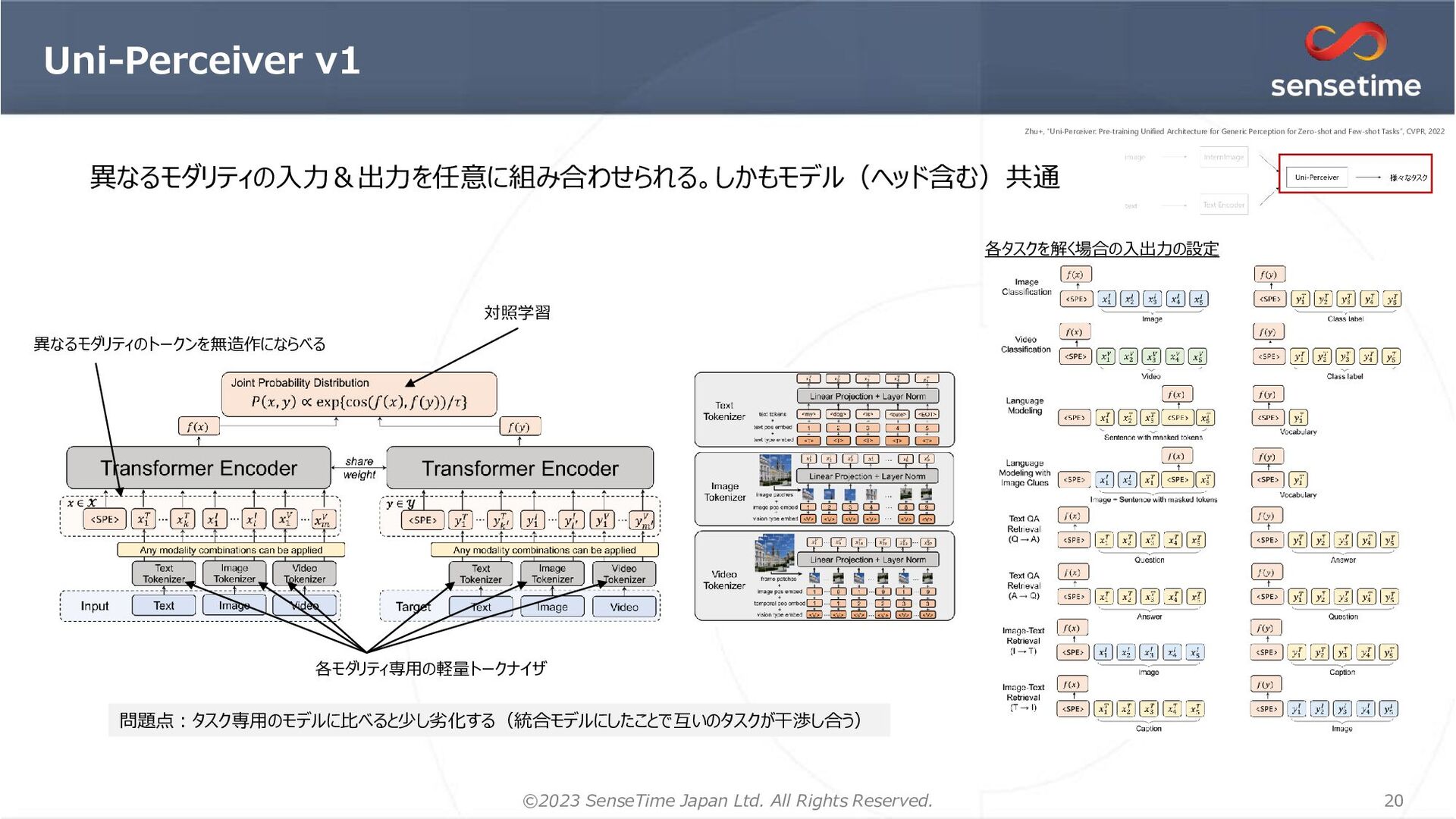
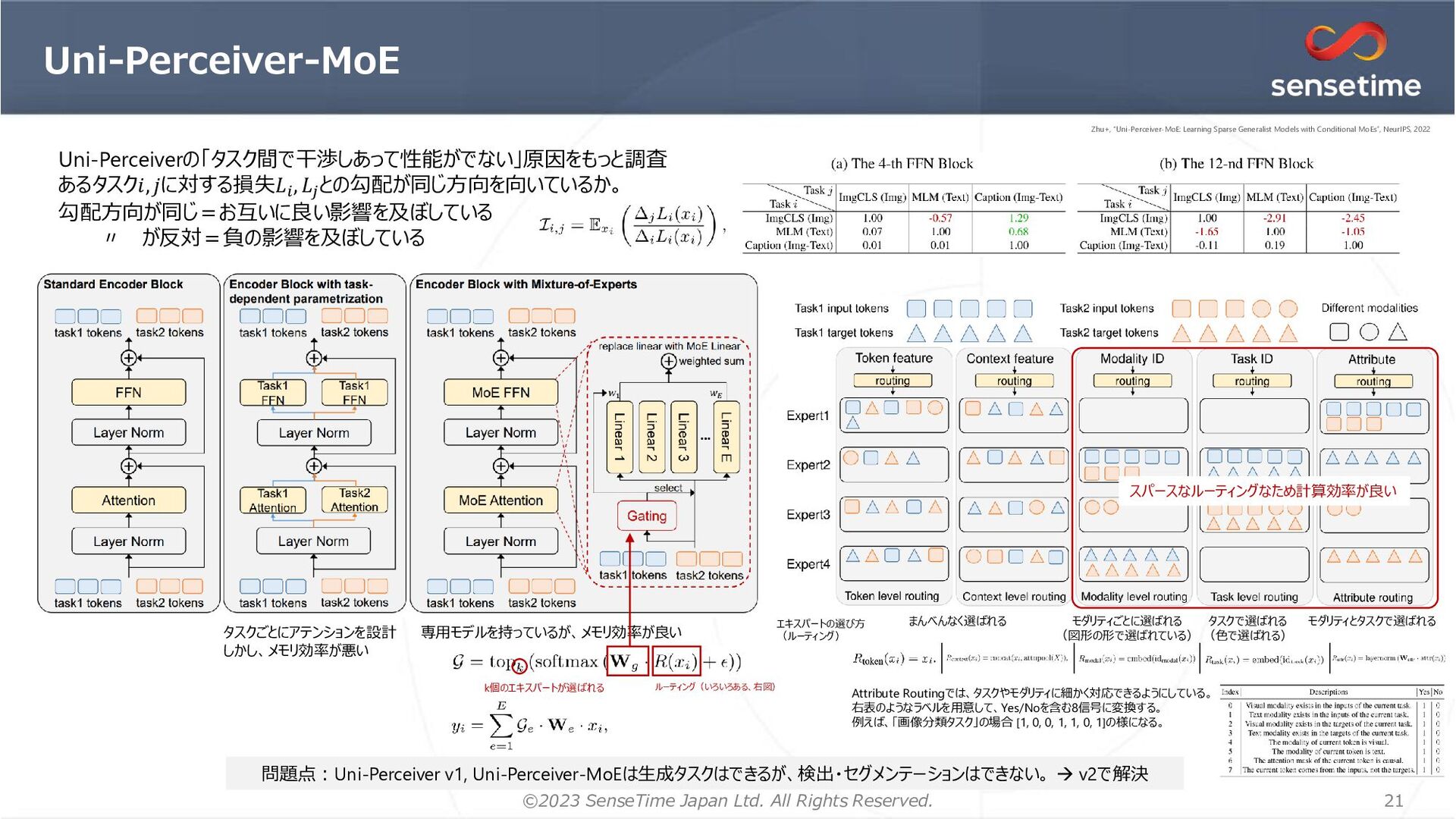
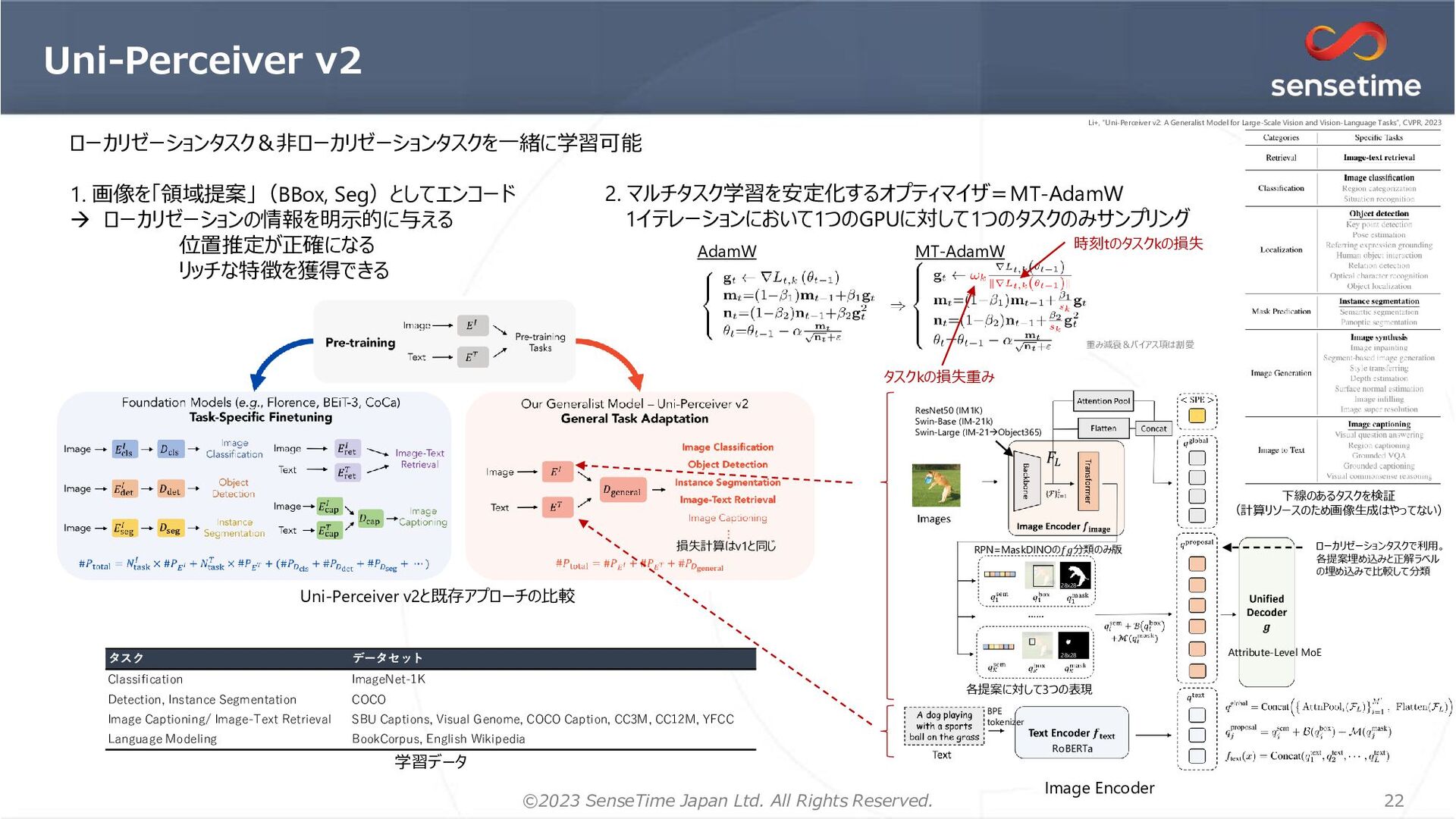
1. 画像を「領域提案」(BBox, Seg)としてエンコード → ローカリゼーションの情報を明示的に与える 位置推定が正確になる リッチな特徴を獲得できる 2. マルチタスク学習を安定化するオプティマイザ=MT-AdamW 1イテレーションにおいて1つのGPUに対して1つのタスクのみサンプリング 時刻tのタスクkの損失 AdamW MT-AdamW 重み減衰&バイアス項は割愛 タスクkの損失重み タスク データセット Classification ImageNet-1K Detection, Instance Segmentation COCO Image Captioning/ Image-Text Retrieval SBU Captions, Visual Genome, COCO Caption, CC3M, CC12M, YFCC Language Modeling BookCorpus, English Wikipedia 学習データ 各提案に対して3つの表現 RPN=MaskDINOの𝑓𝑔分類のみ版 28x28 28x28 𝐹𝐿 BPE tokenizer RoBERTa ローカリゼーションタスクで利用。 各提案埋め込みと正解ラベル の埋め込みで比較して分類 ResNet50 (IM1K) Swin-Base (IM-21k) Swin-Large (IM-21→Object365) Attribute-Level MoE 下線のあるタスクを検証 (計算リソースのため画像生成はやってない) 追加 ローカリゼーションタスク&非ローカリゼーションタスクを一緒に学習可能 Li+, “Uni-Perceiver v2: A Generalist Model for Large-Scale Vision and Vision-Language Tasks”, CVPR, 2023 Li+, “Uni-Perceiver v2: A Generalist Model for Large-Scale Vision and Vision-Language Tasks”, CVPR, 2023 Li+, “Uni-Perceiver v2: A Generalist Model for Large-Scale Vision and Vision-Language Tasks”, CVPR, 2023
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
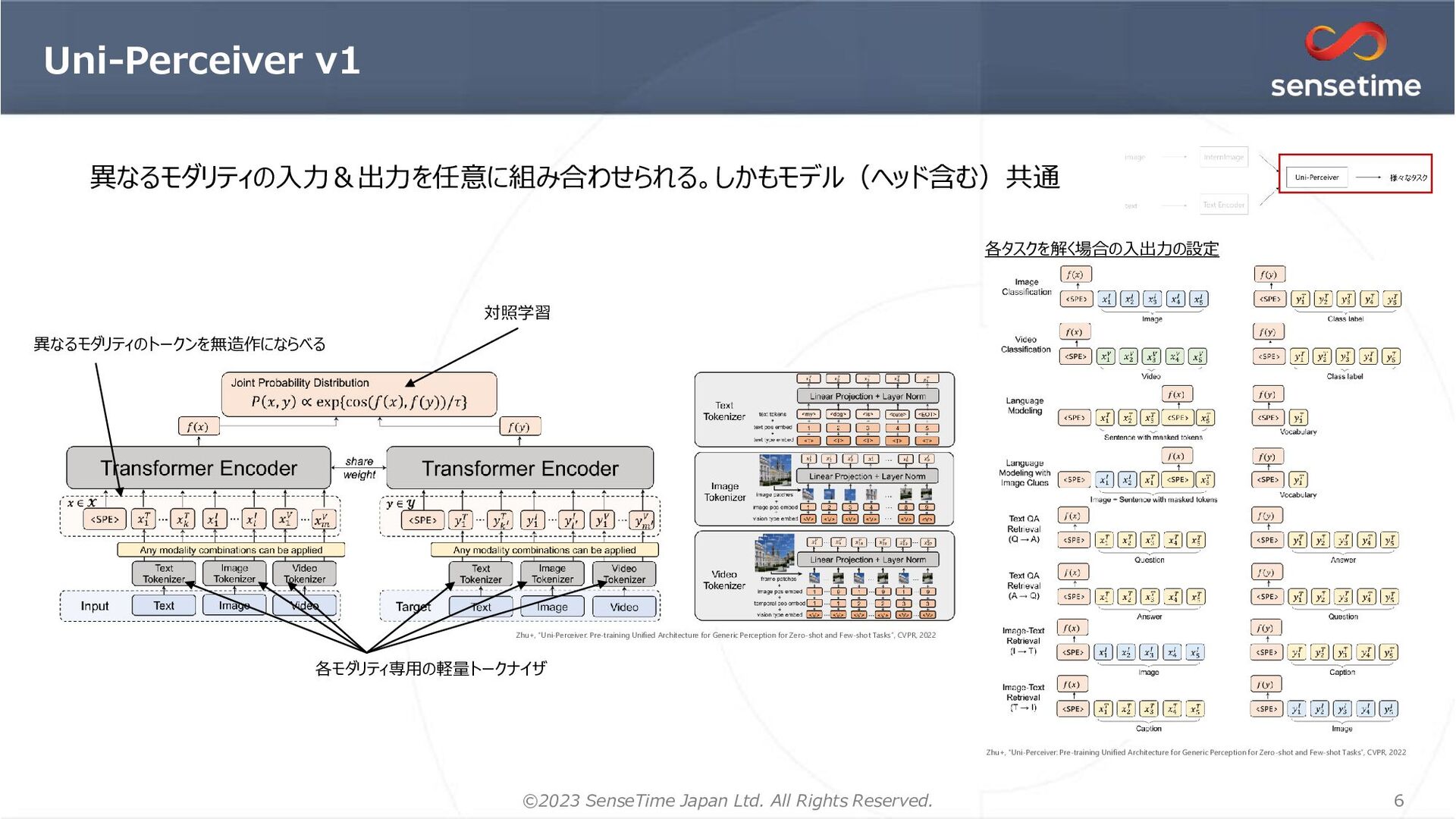{kind=link}
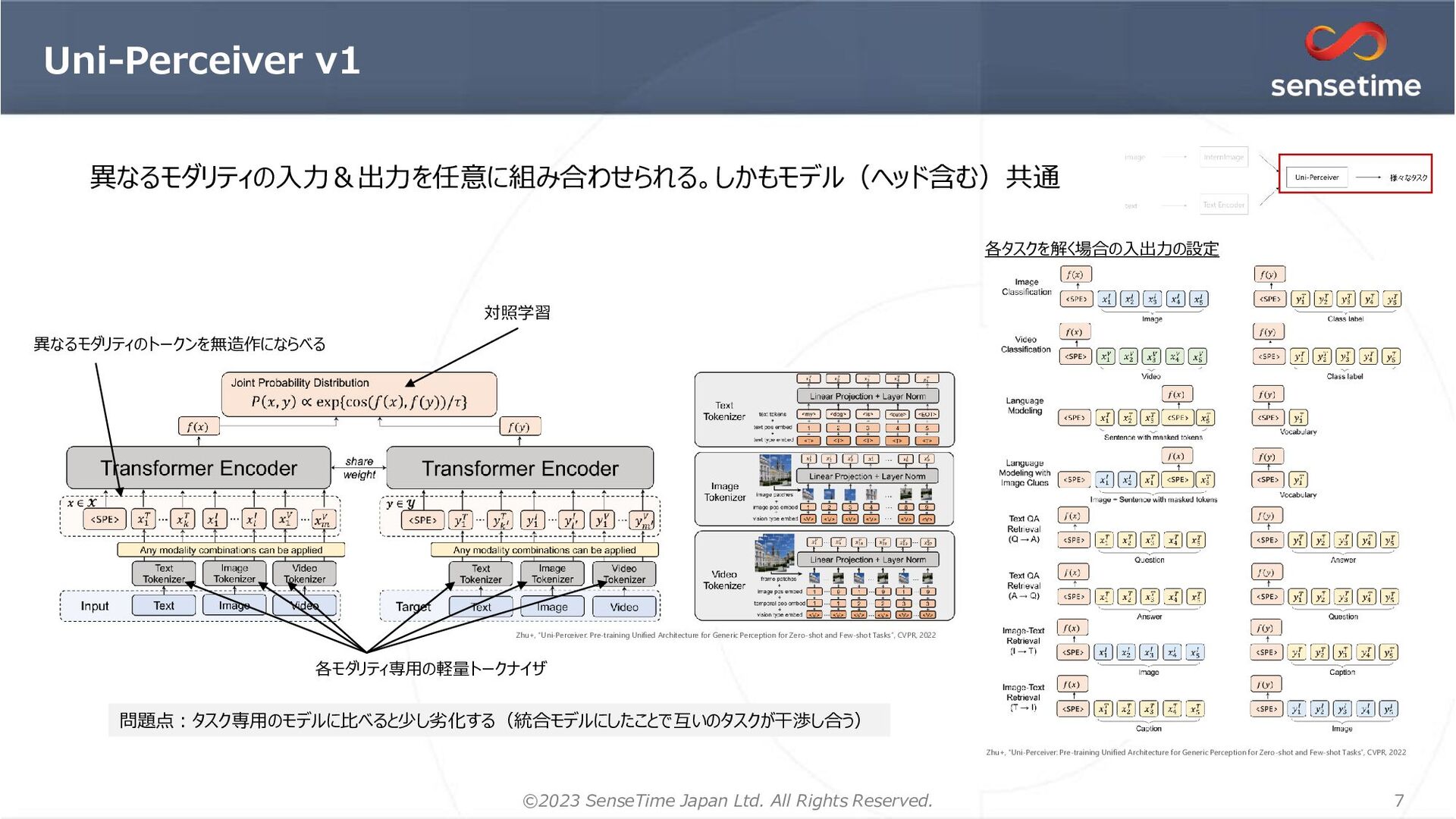{kind=link}
{kind=link}
{kind=link}
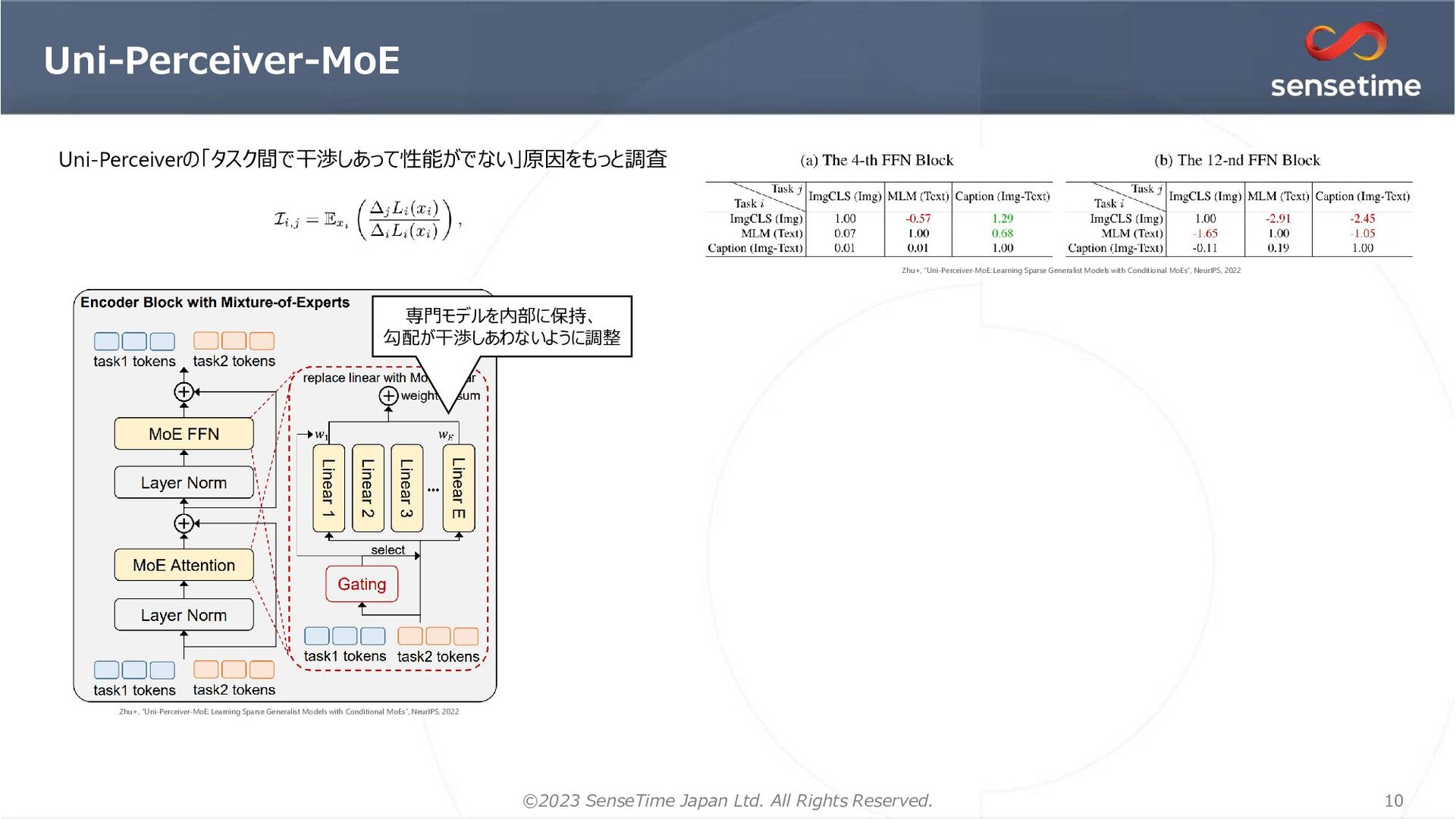{kind=link}
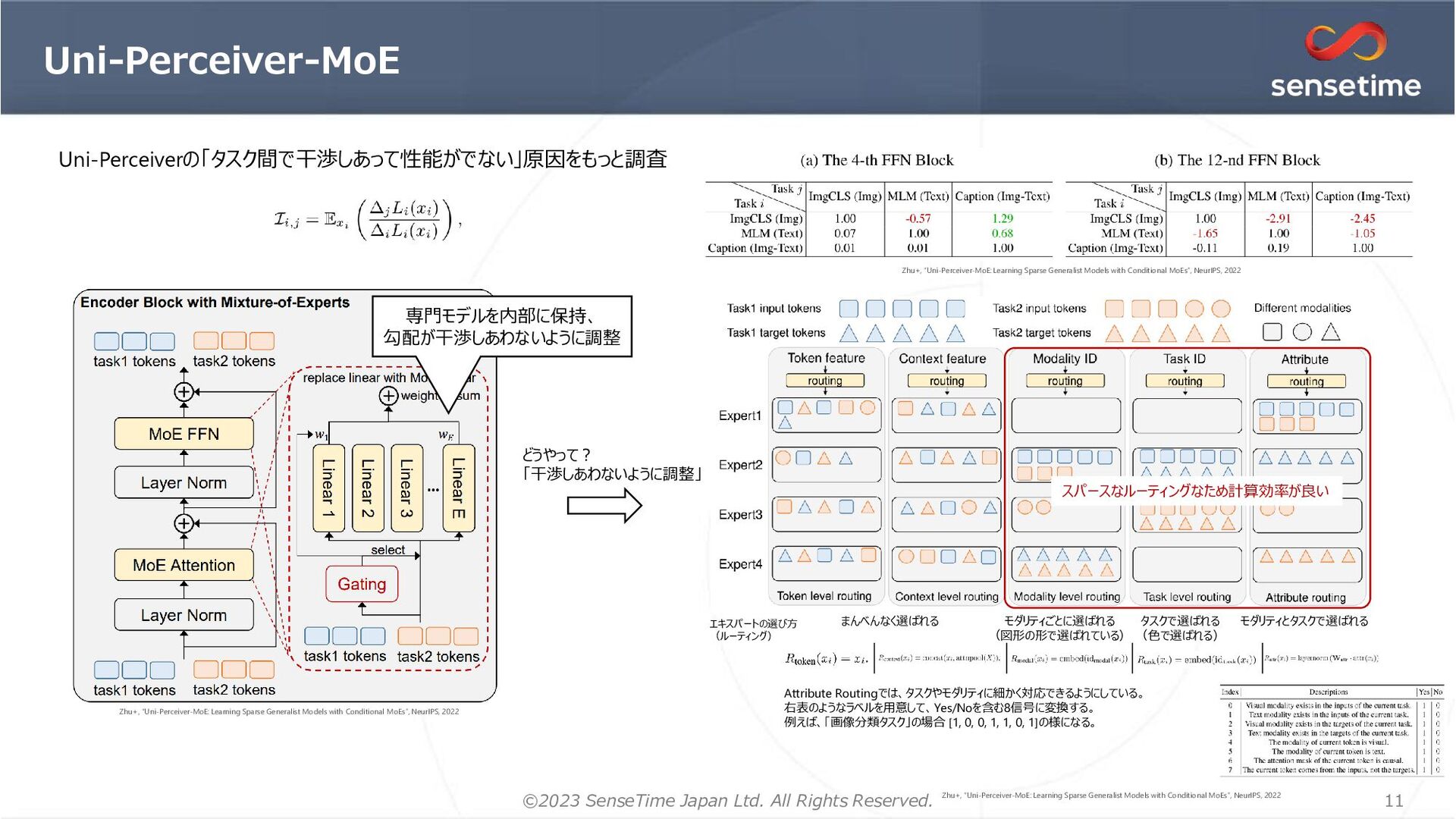{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}