Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
PyData.Fukuoka#6_LT_slide
Search
shinpsan
November 22, 2019
Programming
520
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
PyData.Fukuoka#6_LT_slide
前処理するとき便利だからよく
pandas.DataFrame.apply(lambda)
使っちゃうけど遅いから本当は
pandas.Series.map()
使った方がいいと思う
shinpsan
November 22, 2019
More Decks by shinpsan
See All by shinpsan
20251212_LT忘年会_データサイエンス枠_新川.pdf
shinpsan
0
310
CDLE_Fukuoka_20230523
shinpsan
0
210
LT_コンサル完全に理解したらミドルDSになった_ちゅらNOB合同勉強会
shinpsan
0
460
LT_統計学ユーザーでいいんです_みんなのPython勉強会#70
shinpsan
1
740
"Momochihama Store" on TNC has a wonderful "Udon MAP" section.
shinpsan
0
270
Other Decks in Programming
See All in Programming
仕様書を書く前にハーネスを作る - Agent Native開発は「探索を速く、判定を固く」
gotalab555
2
670
属人化した知識を、 AIが辿れる地図にする
pkshadeck
PRO
1
100
そこに3びきプロダクトがいるじゃろう——生成AI時代における“価値が届かない理由”の構造
kosuket
0
210
Welcome to the "Parametricity" 🏙️ − Generic だけど Specific な世界 −
guvalif
PRO
1
190
Embedded SREと共に達成した会員管理システムのAWS移行 - SRE NEXT 2026 ランチスポンサーセッション
niftycorp
PRO
1
3.1k
Generative UI & AI-Assistants for Your Angular Solutions
manfredsteyer
PRO
1
250
ITヒヤリハットを整理してみた ~ライフサイクルと原因から考える再発防止策~
koukimiura
1
120
The Past, Present, and Future of Enterprise Java
ivargrimstad
0
420
Haskell/Servantを通してWebミドルウェアを捉え直す
pizzacat83
1
620
全PRの83%がAIレビューだけでマージできるようになった開発組織はその後どうなったか
athug
0
520
分散システム、なんですぐ死んでしまうん?耐障害性を高めたいあなたのためのレジリエンスパターン入門
mshibuya
7
7k
GDG Korea Android: 2026 I/O Extended ~ What's new in Android development tools
pluu
0
180
Featured
See All Featured
[RailsConf 2023 Opening Keynote] The Magic of Rails
eileencodes
31
10k
Making the Leap to Tech Lead
cromwellryan
135
10k
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
Dominate Local Search Results - an insider guide to GBP, reviews, and Local SEO
greggifford
PRO
0
220
16th Malabo Montpellier Forum Presentation
akademiya2063
PRO
0
290
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
360
How to make the Groovebox
asonas
2
2.3k
jQuery: Nuts, Bolts and Bling
dougneiner
66
8.5k
The Straight Up "How To Draw Better" Workshop
denniskardys
239
140k
What the history of the web can teach us about the future of AI
inesmontani
PRO
1
640
Skip the Path - Find Your Career Trail
mkilby
1
170
Product Roadmaps are Hard
iamctodd
55
12k
Transcript
前処理するとき便利だからよく pandas.DataFrame.apply(lambda) 使っちゃうけど遅いから本当は pandas.Series.map() 使った方がいいと思う PyData.Fukuoka #6 LT @shinpsan
自己紹介 下積みの父@shinpsan 小売業のデータサイエンティスト(12月まで。年明け転職します) MENSA会員 合同会社ocojoで副業 twitter : 仕事
: 特技: 趣味:
話すこと タイトルに書いたことが全てです。 pandasの基本的なところなのでみんな知ってる内容かも。 知ってる方はヒマだと思うので、心の中で 「シカ」って10回言った後、 「サンタクロースが乗っているのは?」に答えてて下さい
背景 クソみたいなデータ渡されたと文句言いながら、 いつもクソみたいなコード書いてることを反省。
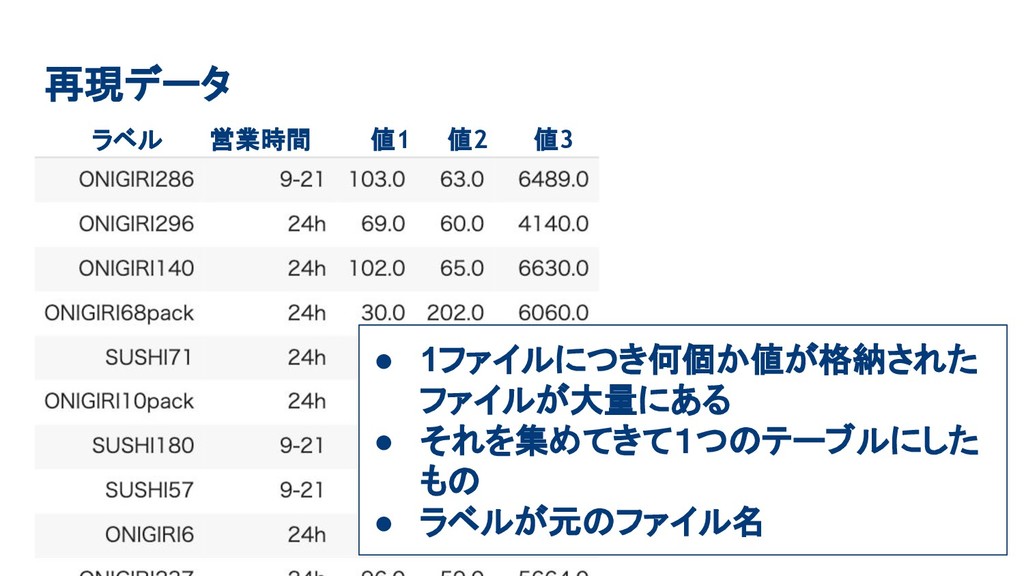
再現データ ラベル 営業時間 値1 値2 値3 • 1ファイルにつき何個か値が格納された ファイルが大量にある •
それを集めてきて1つのテーブルにした もの • ラベルが元のファイル名
やりたいこと(持っていきたい方向) 店舗の営業時間体系ごとの • 三角おにぎり • パックおにぎり • 寿司 のラベルをつけて集計とか 可視化とかいろいろ
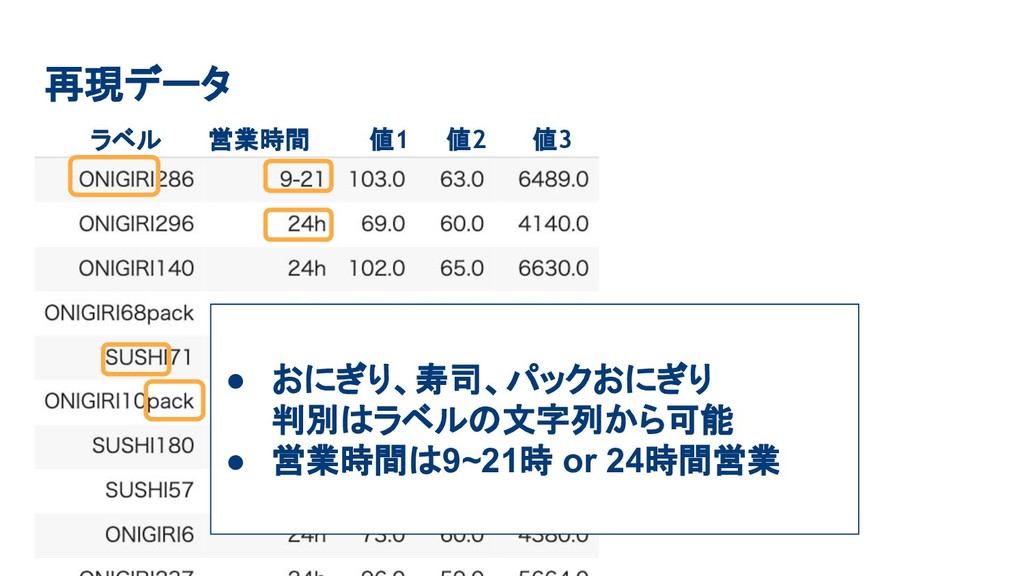
再現データ ラベル 営業時間 値1 値2 値3 • おにぎり、寿司、パックおにぎり 判別はラベルの文字列から可能
• 営業時間は9~21時 or 24時間営業
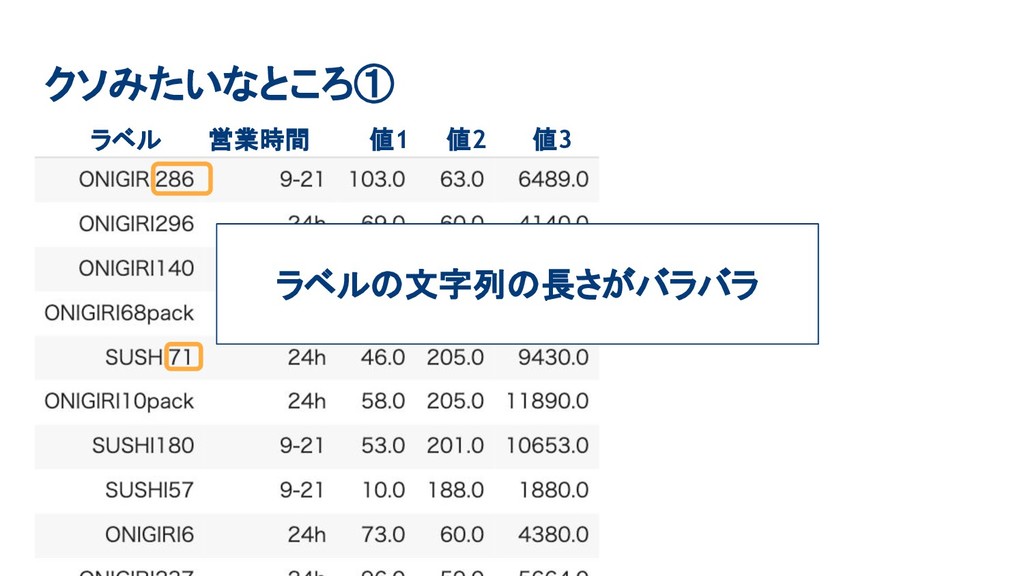
クソみたいなところ① ラベル 営業時間 値1 値2 値3 ラベルの文字列の長さがバラバラ
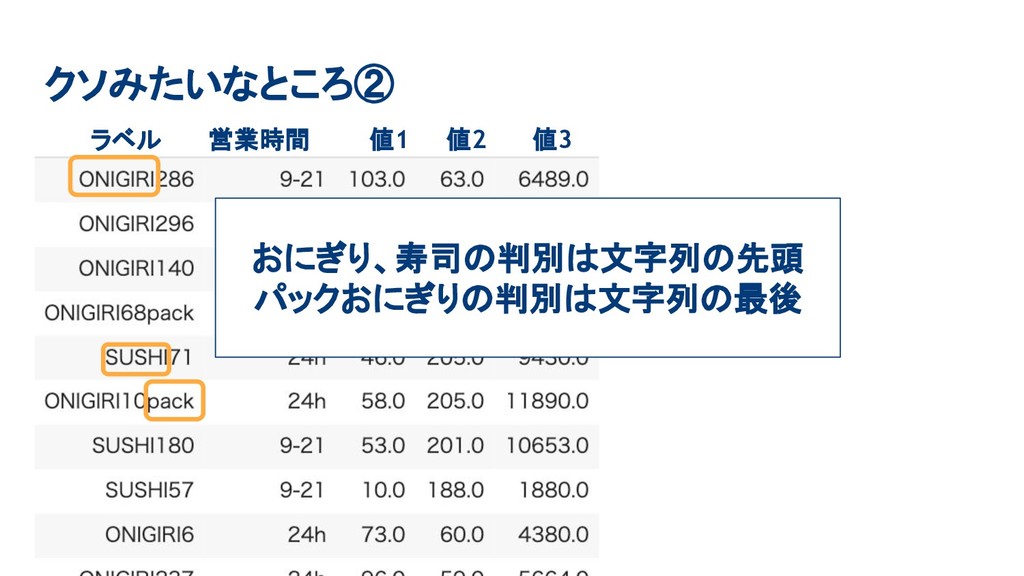
クソみたいなところ② ラベル 営業時間 値1 値2 値3 おにぎり、寿司の判別は文字列の先頭 パックおにぎりの判別は文字列の最後
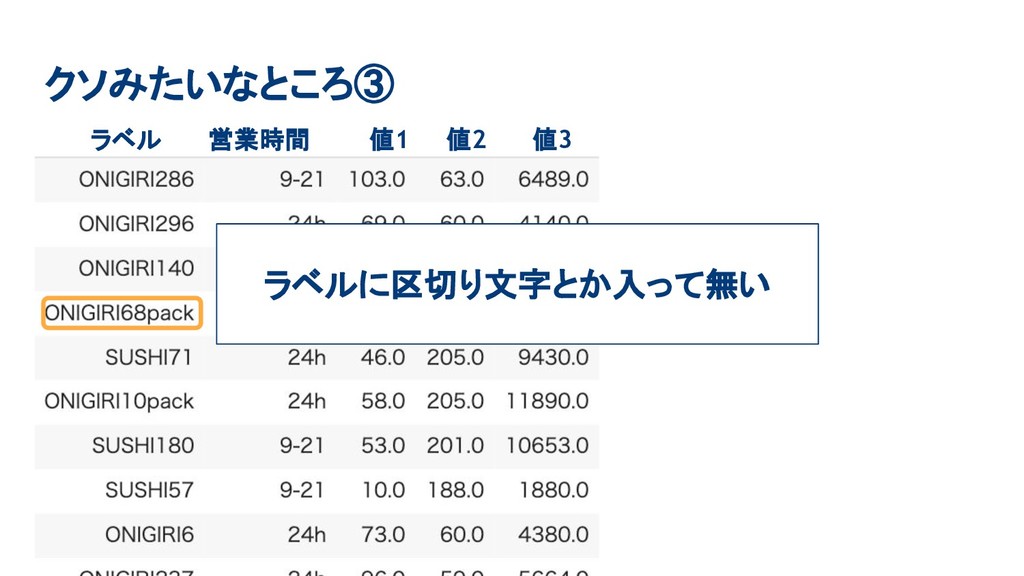
クソみたいなところ③ ラベル 営業時間 値1 値2 値3 ラベルに区切り文字とか入って無い
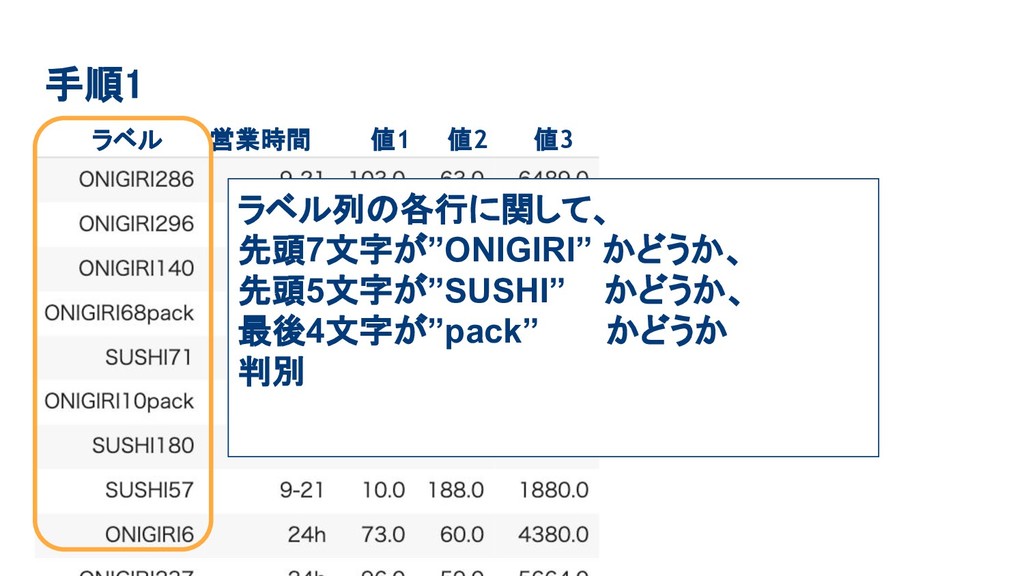
手順1 ラベル 営業時間 値1 値2 値3 ラベル列の各行に関して、 先頭7文字が”ONIGIRI” かどうか、 先頭5文字が”SUSHI”
かどうか、 最後4文字が”pack” かどうか 判別
手順2 ラベル 営業時間 値1 値2 値3 営業時間列の各行に関して、 “9-21” or “24h”
判別
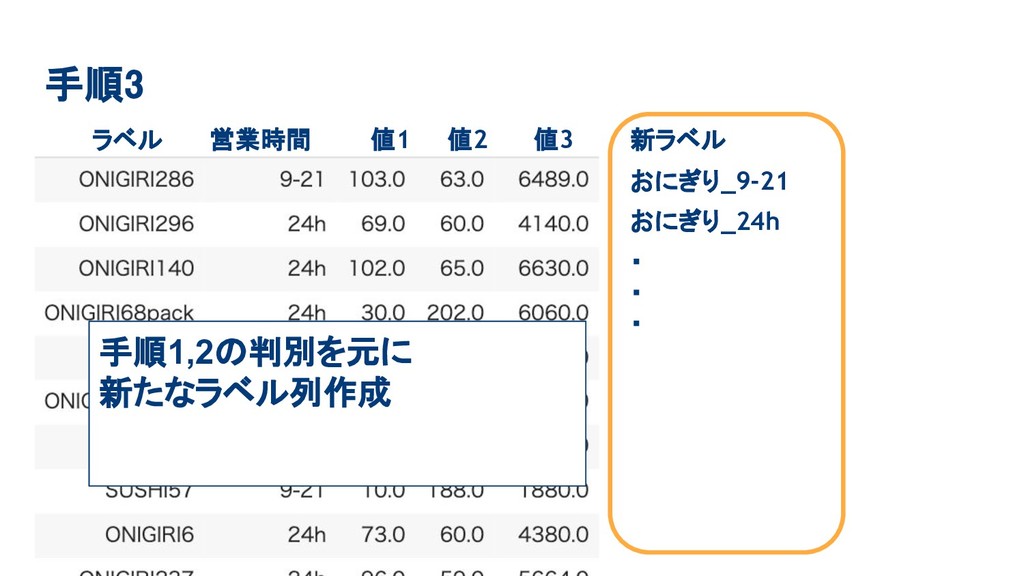
手順3 ラベル 営業時間 値1 値2 値3 手順1,2の判別を元に 新たなラベル列作成 新ラベル おにぎり_9-21
おにぎり_24h ・ ・ ・
ここで本題 どんな処理書く? • for + iterrows() • df.apply() • Series.map()
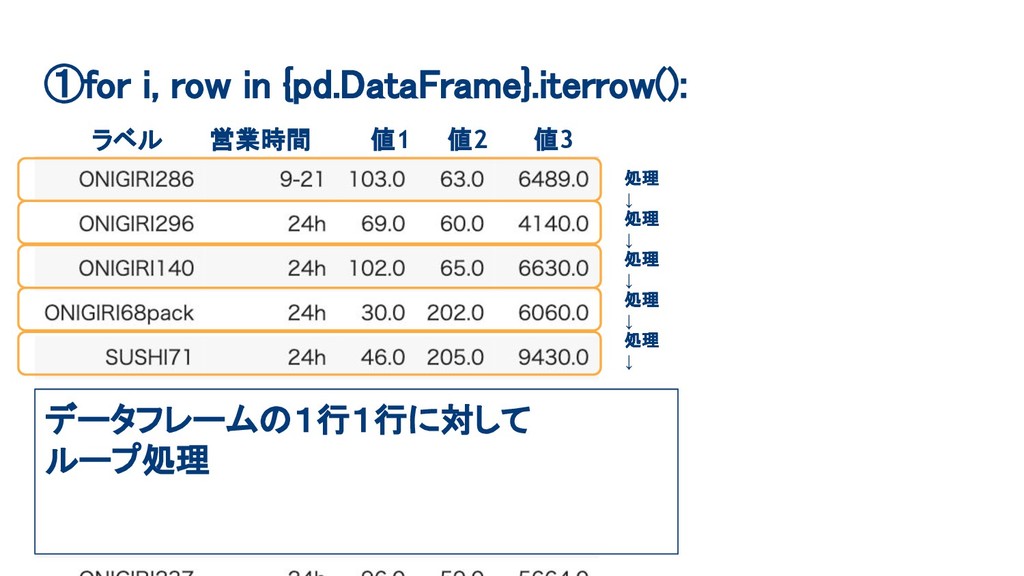
①for i, row in {pd.DataFrame}.iterrow(): ラベル 営業時間 値1 値2 値3
データフレームの1行1行に対して ループ処理 処理 ↓ 処理 ↓ 処理 ↓ 処理 ↓ 処理 ↓
①for i, row in {pd.DataFrame}.iterrow():
②{pd.DataFrame}.apply(lambda x: {}) ラベル 営業時間 値1 値2 値3 データフレームの各行に対して 同じ処理を一括適応
lambda x のxには各行が1行のDFにみたいにして渡される x[“ラベル”]みたいにして使うとこ選べる ✖ 処理 ✖ 処理 ✖ 処理 ✖ 処理 ✖ 処理
②{pd.DataFrame}.apply(lambda x: {})
③{pd.Series}.map(lambda x: {}) ラベル ✖ 処理 ✖ 処理 ✖ 処理
✖ 処理 ✖ 処理 Seriesの各要素に対して 同じ処理を一括適応
③{pd.Series}.map(lambda x: {})
None
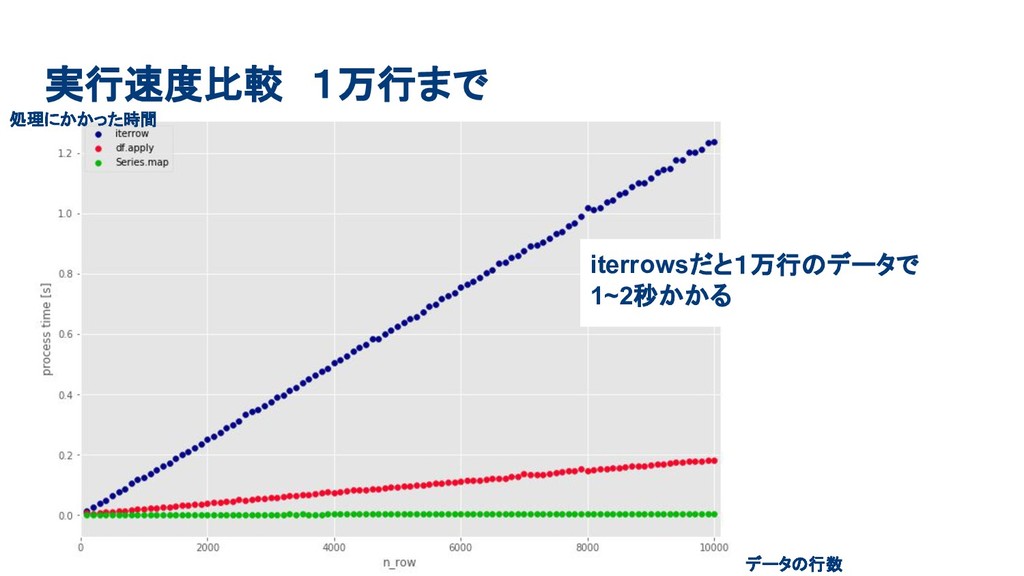
実行速度比較 1万行まで iterrowsだと1万行のデータで 1~2秒かかる データの行数 処理にかかった時間
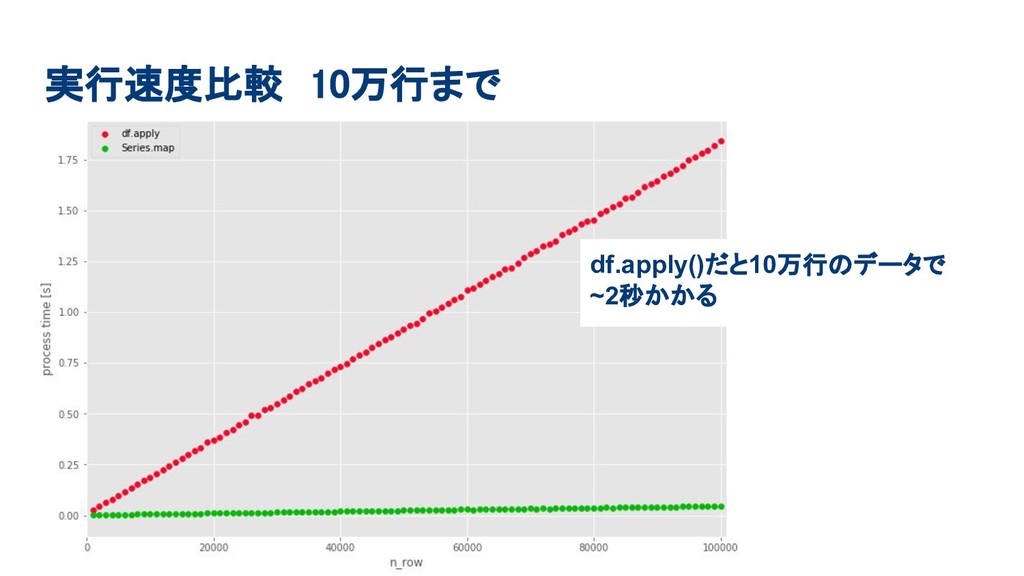
実行速度比較 10万行まで df.apply()だと10万行のデータで ~2秒かかる
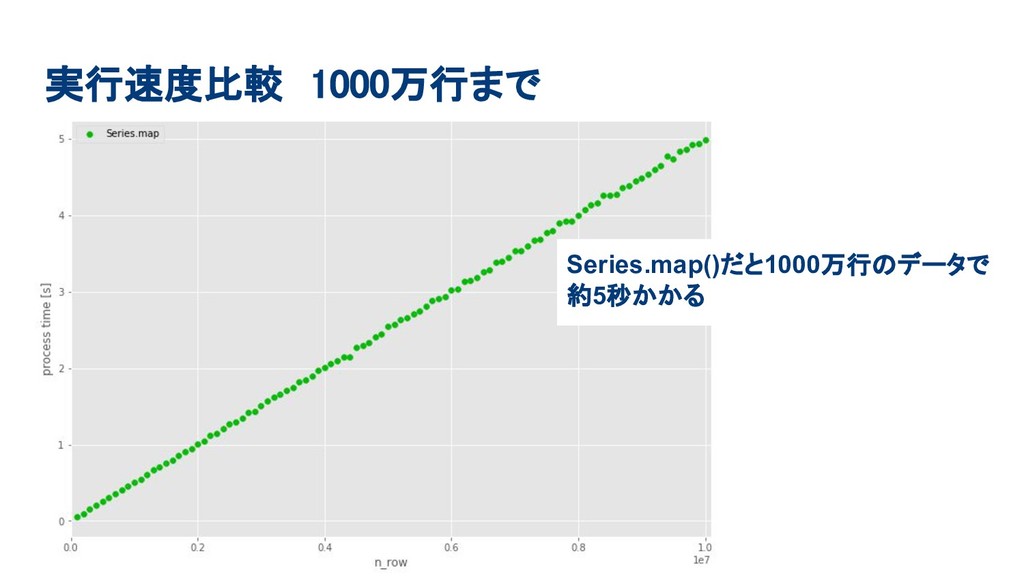
実行速度比較 1000万行まで Series.map()だと1000万行のデータで 約5秒かかる
まとめ ただの肌感ですが、jupyterで分析してて、 そこまで気にならない待ち時間は2秒くらい • for + iterrows 1万行 • df.apply
10万行 • Series.map 400万行 まぁ、結論としてループは使わない。 df.apply()は何も考えずに記述できるけど遅いから、 Series.map()でやる方がいいですね。
enjoy! 答え:そり(トナカイには乗っていない)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}