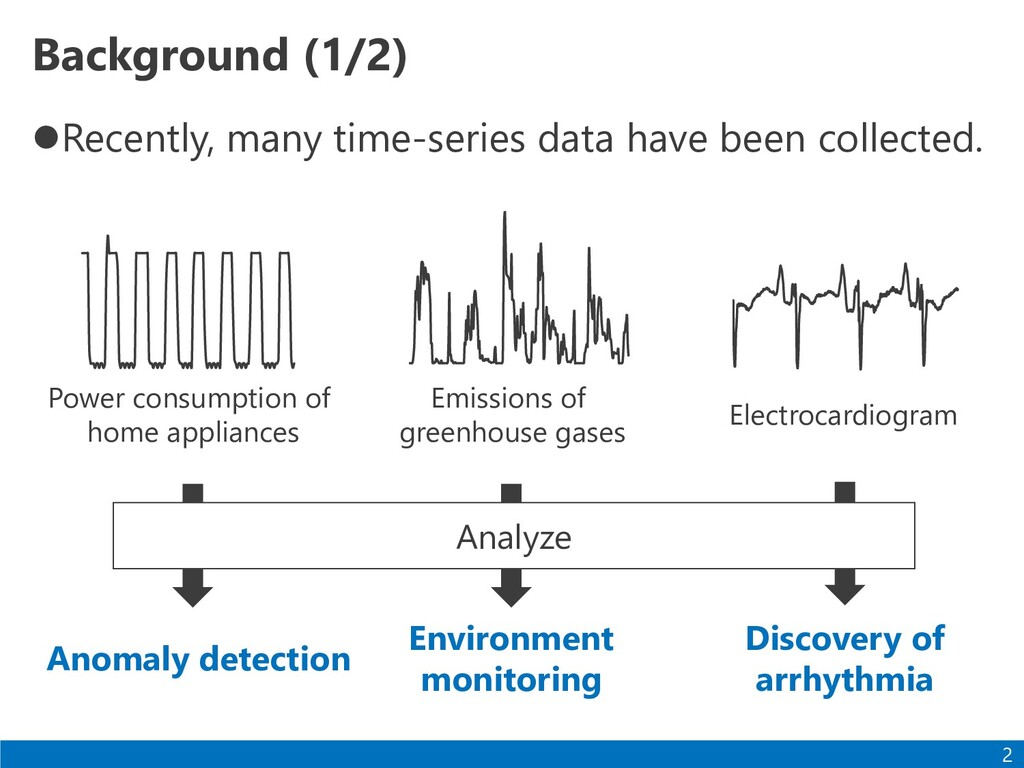
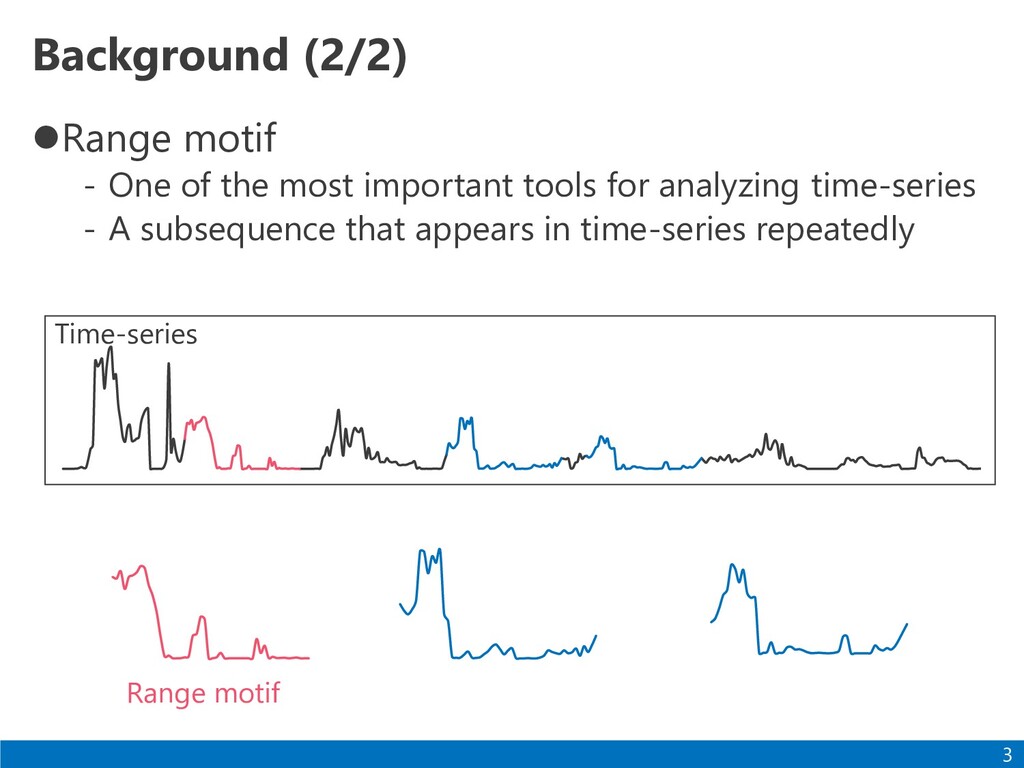
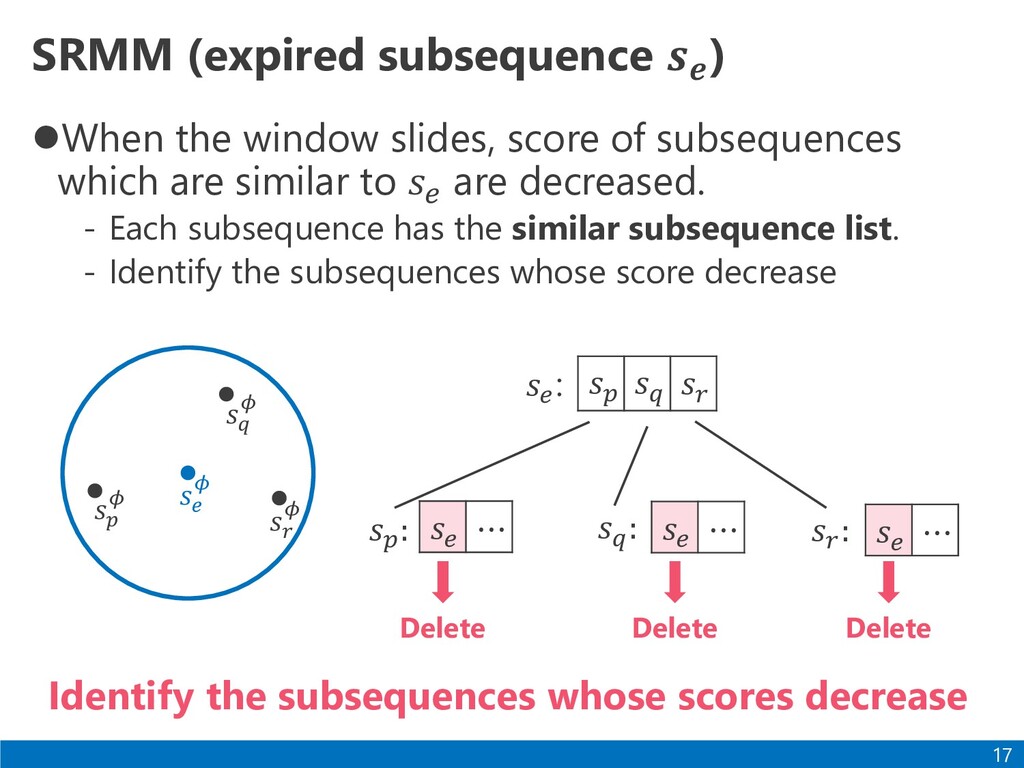
Power consumption of home appliances Emissions of greenhouse gases Electrocardiogram Anomaly detection Environment monitoring Discovery of arrhythmia Analyze
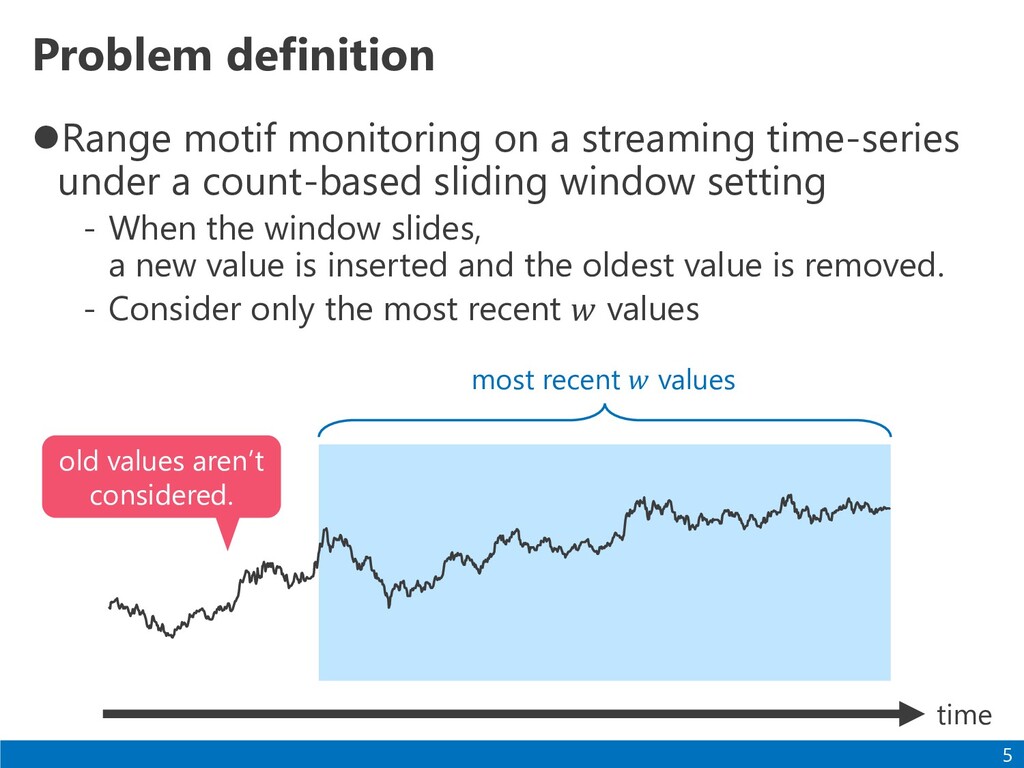
a count-based sliding window setting - When the window slides, a new value is inserted and the oldest value is removed. - Consider only the most recent 𝑤 values 5 time most recent 𝑤 values old values aren’t considered.
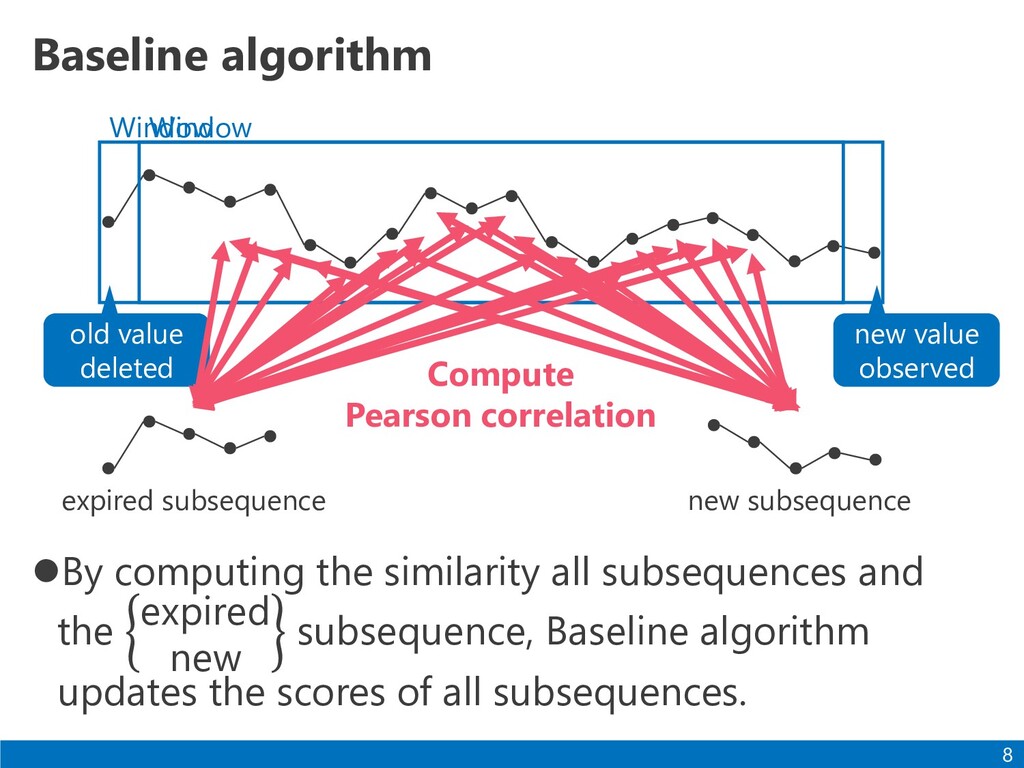
expired new subsequence, Baseline algorithm updates the scores of all subsequences. 8 expired subsequence new subsequence Window new value observed Window old value deleted Compute Pearson correlation
correlation is 𝑂(𝑙). - The number of computation is 𝑤 − 𝑙 times. - Time complexity of Baseline algorithm is 𝑶 𝒘 − 𝒍 𝒍 . ⚫Research goal - When the window slides, speeding up the update time of the score and monitoring a motif efficiently. 9 We propose the algorithm “SRMM” (Streaming Range Motif Monitoring).
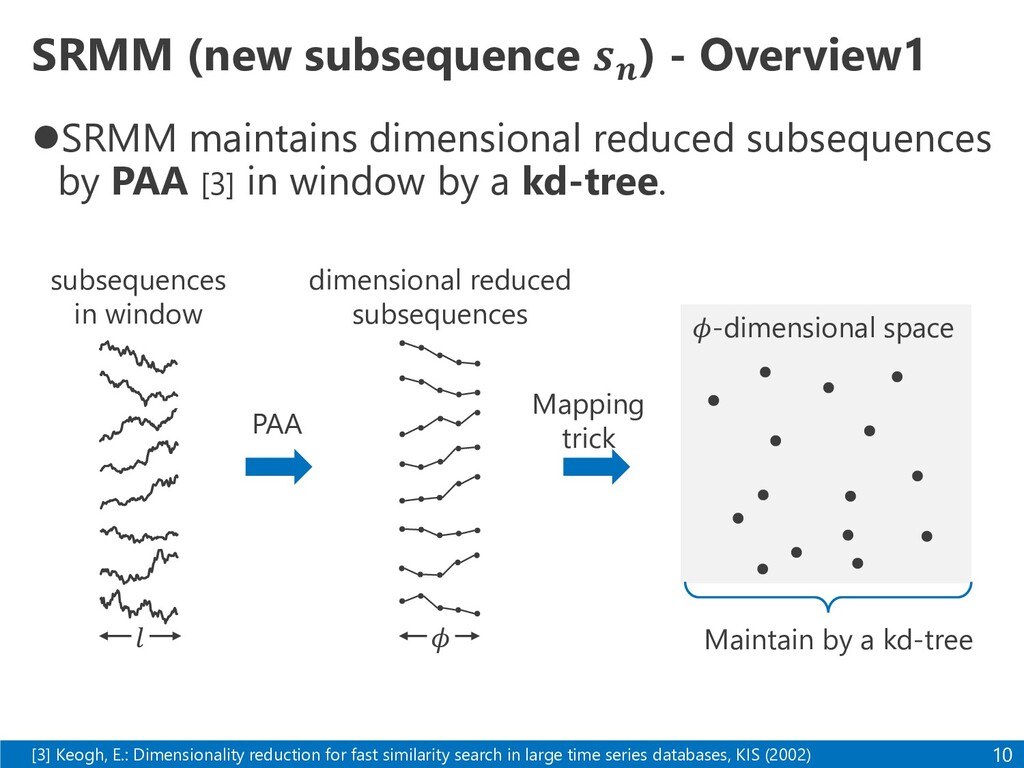
subsequences by PAA [3] in window by a kd-tree. 10 [3] Keogh, E.: Dimensionality reduction for fast similarity search in large time series databases, KIS (2002) subsequences in window dimensional reduced subsequences Mapping trick Maintain by a kd-tree PAA 𝜙-dimensional space 𝜙 𝑙
"𝒔𝒄𝒐𝒓𝒆 𝒔𝒏 < 𝒔𝒄𝒐𝒓𝒆(𝒔∗)" quickly, we can efficiently monitor the exact motif. - We propose a technique that obtains 𝒔𝒄𝒐𝒓𝒆𝒖𝒃 𝒔𝒏 (upper-bound of 𝒔𝒄𝒐𝒓𝒆(𝒔𝒏 )) efficiently. - It prunes the unnecessary exact score computation. ⚫Flow of SRMM 11 PAA Insert into a kd-tree Range search Get 𝒔𝒄𝒐𝒓𝒆𝒖𝒃 𝒔𝒏 𝑠𝑛 𝑠𝑛 𝜙 𝑙 𝜙
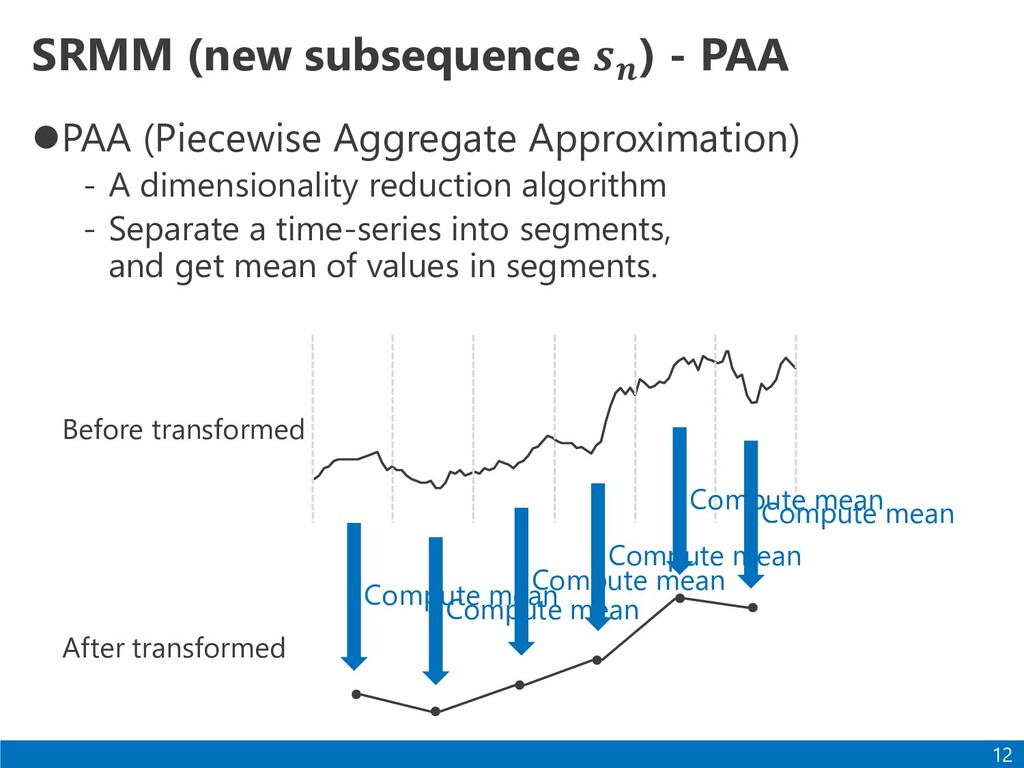
- A dimensionality reduction algorithm - Separate a time-series into segments, and get mean of values in segments. 12 Compute mean Compute mean Compute mean Compute mean Compute mean Compute mean Before transformed After transformed
distance computation, we use PAA. - Use the property that the distance between transformed subsequences become smaller 13 PAA ≥ ≥ 2𝜙(1 − 𝜃) 𝑂(𝑙) 𝑂(𝜙) We know 𝒔𝒑 and 𝒔𝒒 are not similar in 𝑶(𝝓). 𝑙 𝑠𝑝 𝑠𝑞 𝑑(𝑠𝑝 , 𝑠𝑞 ) 𝜙 𝑠𝑝 𝜙 𝑠𝑞 𝜙 𝑑(𝑠𝑝 𝜙, 𝑠𝑞 𝜙)
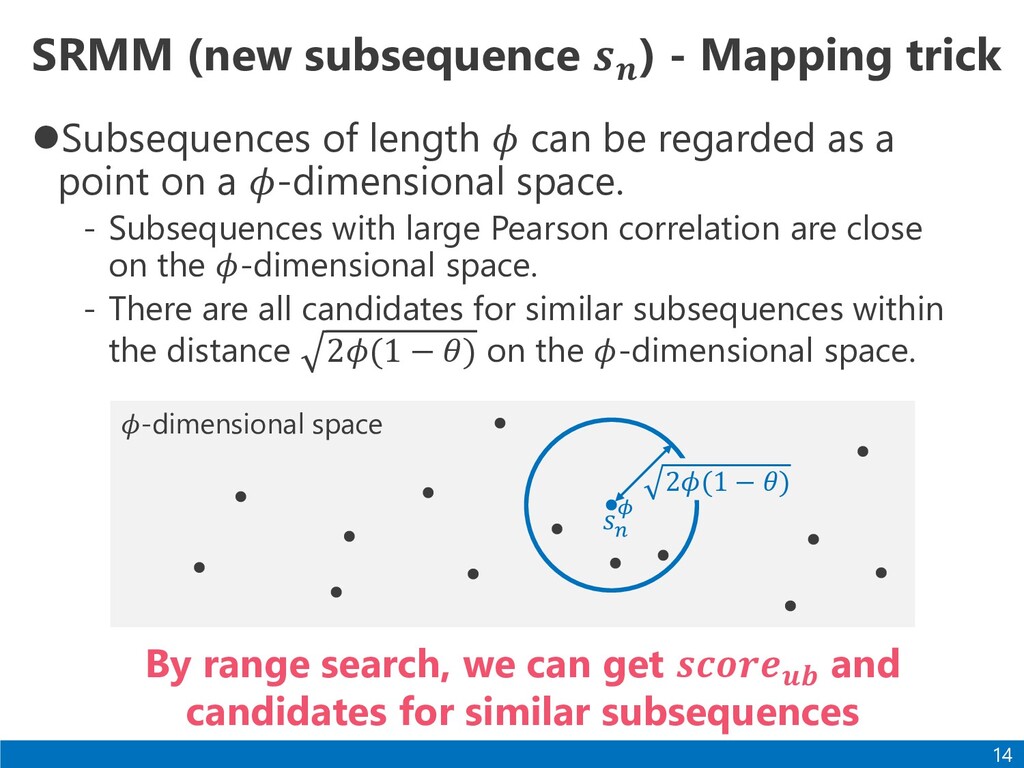
𝜙 can be regarded as a point on a 𝜙-dimensional space. - Subsequences with large Pearson correlation are close on the 𝜙-dimensional space. - There are all candidates for similar subsequences within the distance 2𝜙(1 − 𝜃) on the 𝜙-dimensional space. 14 By range search, we can get 𝒔𝒄𝒐𝒓𝒆𝒖𝒃 and candidates for similar subsequences 𝜙-dimensional space 𝑠𝑛 𝜙 2𝜙(1 − 𝜃)
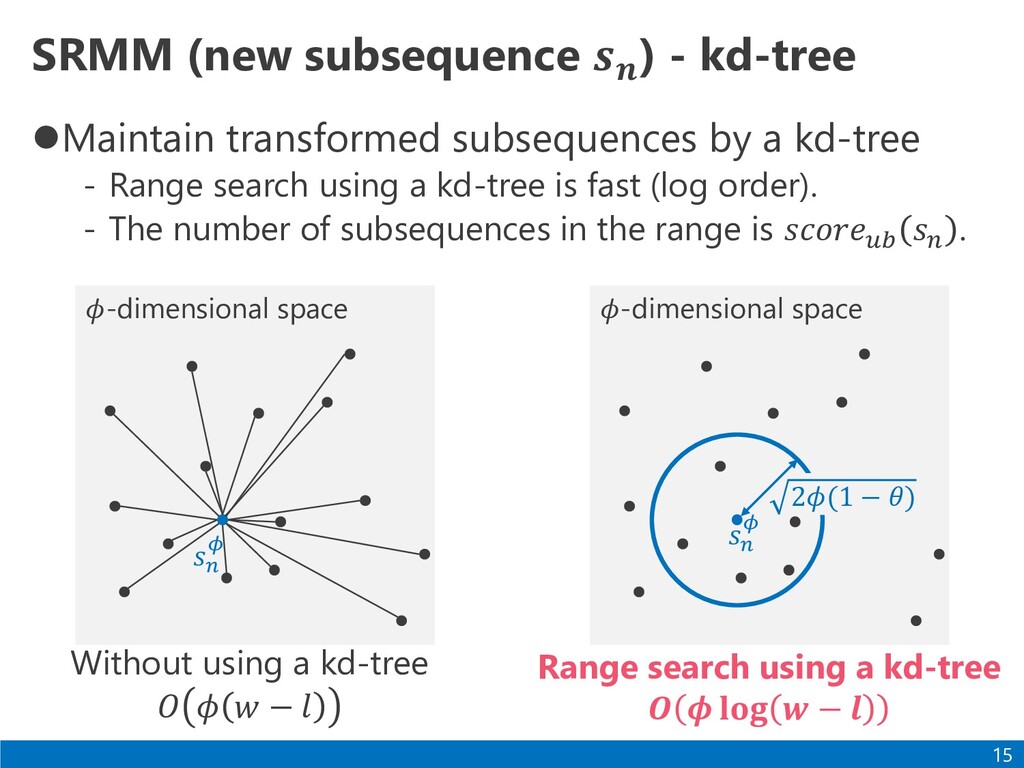
a kd-tree - Range search using a kd-tree is fast (log order). - The number of subsequences in the range is 𝑠𝑐𝑜𝑟𝑒𝑢𝑏 𝑠𝑛 . 15 𝜙-dimensional space 𝑠𝑛 𝜙 Without using a kd-tree 𝑂 𝜙 𝑤 − 𝑙 Range search using a kd-tree 𝑶 𝝓 𝐥𝐨𝐠 𝒘 − 𝒍 𝜙-dimensional space 𝑠𝑛 𝜙 2𝜙(1 − 𝜃)
𝑠𝑐𝑜𝑟𝑒 𝑠∗ - If 𝑠𝑐𝑜𝑟𝑒𝑢𝑏 𝑠𝑛 < 𝑠𝑐𝑜𝑟𝑒 𝑠∗ then - If 𝑠𝑐𝑜𝑟𝑒𝑢𝑏 𝑠𝑛 ≥ 𝑠𝑐𝑜𝑟𝑒 𝑠∗ then 16 Because 𝒔𝒏 can be a motif, we must compute the exact 𝒔𝒄𝒐𝒓𝒆(𝒔𝒏 ). Because 𝒔𝒏 cannot be a motif, we can safely prune computation of 𝒔𝒄𝒐𝒓𝒆(𝒔𝒏 ).
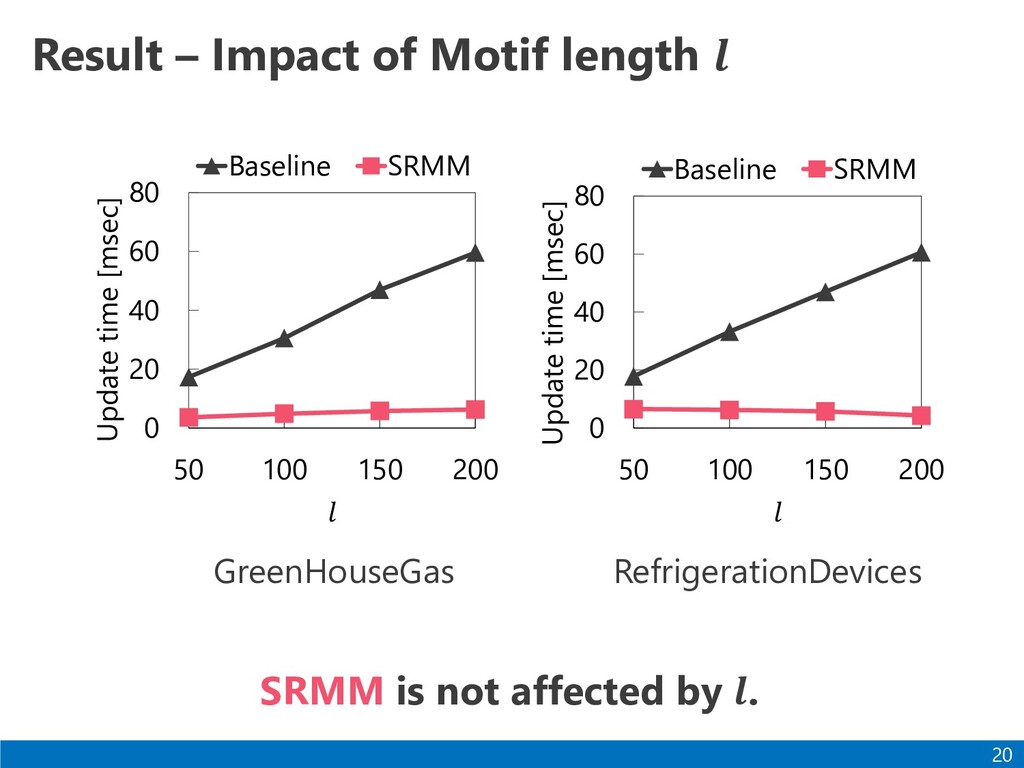
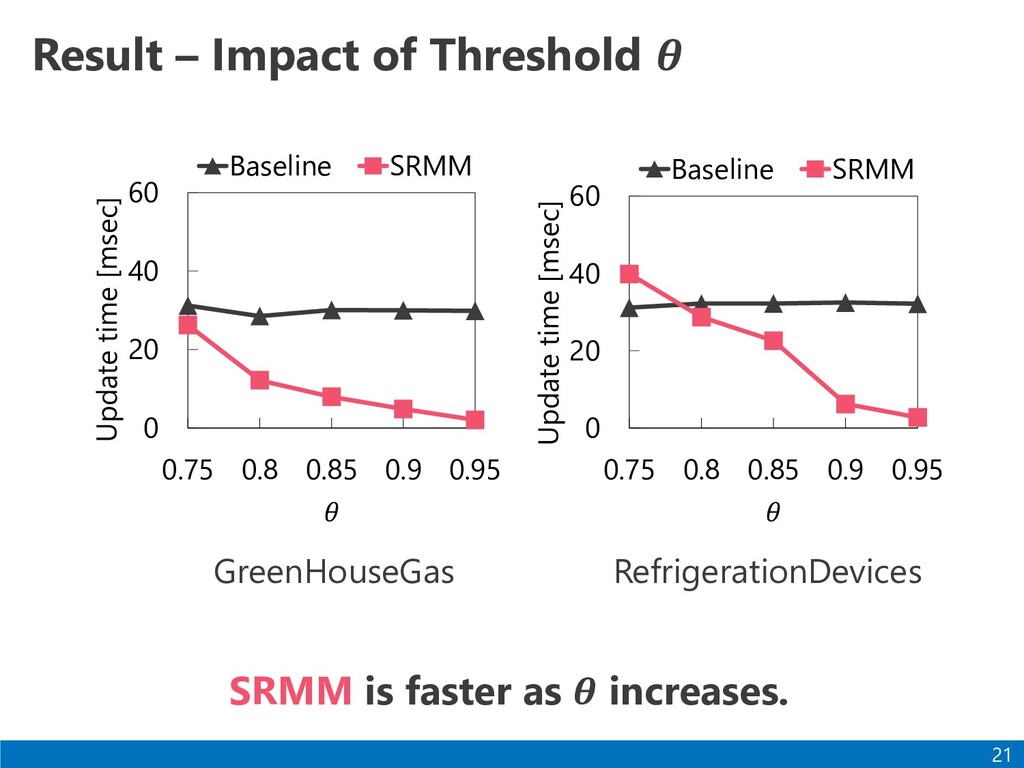
a range motif. - By using PAA and a kd-tree, unnecessary score computations are reduced. ⚫The results of our experiments show the efficiency and scalability. 22
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}