Share
https://genai-users.connpass.com/event/349197/
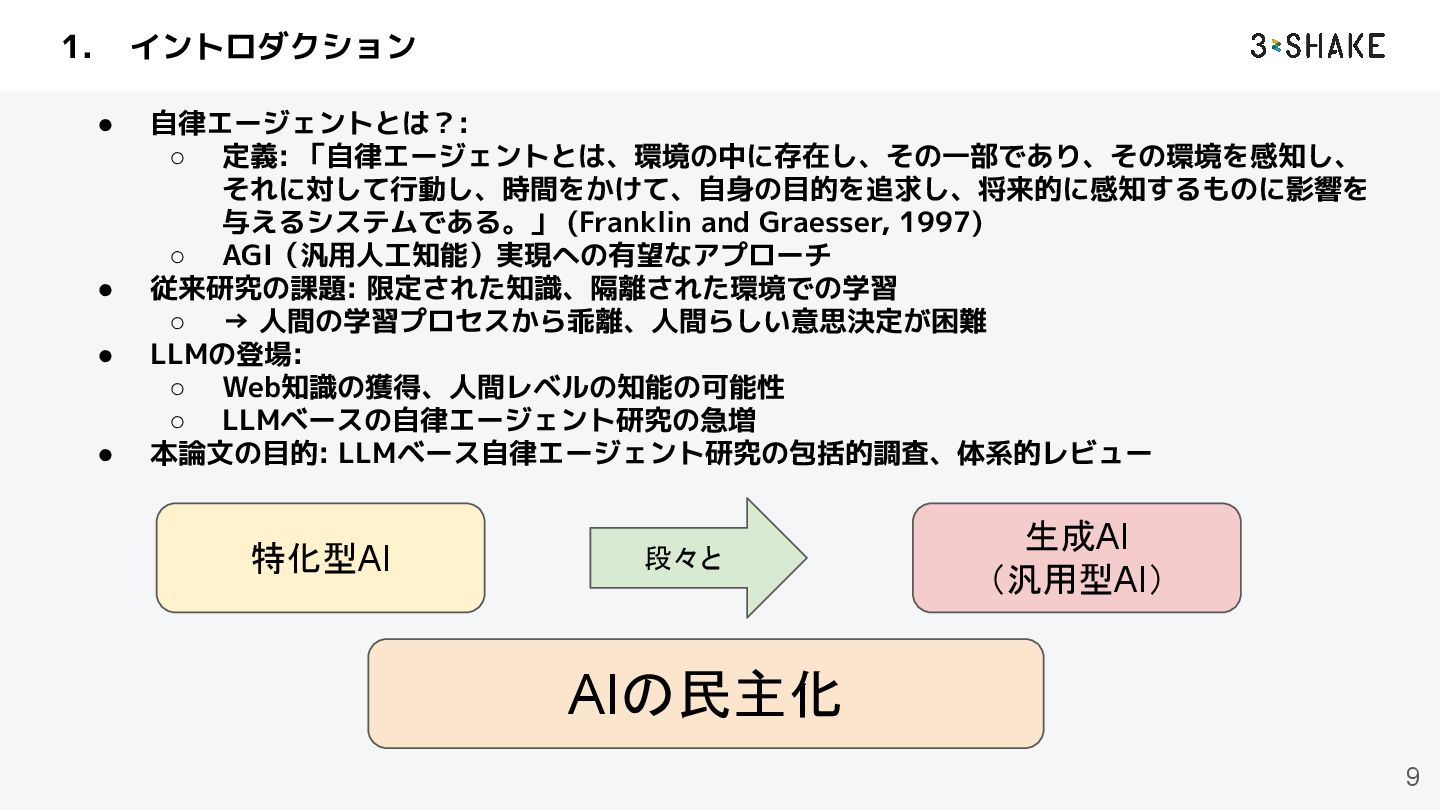
この論文は大規模言語モデル(LLM)を基盤とする自律型エージェントに関する包括的な調査論文です。この論文は、LLMベースの自律型エージェントの現状、構成要素、課題、そして将来の展望について詳細に解説しています。
本論文を読むことで、AIエージェントの概要を体系的に知ることができます。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}