*2 https://huggingface.co/google-bert/bert-base-multilingual-cased [Grave 18] Grave, E., et al: Learning Word Vectors for 157 Languages (2018) [Smith 17] Smith, S. L., et al: Offline bilingual word vectors, orthogonal transformations and the inverted softmax (2017) [Conneau 17] Conneau, A., et al: Word Translation Without Parallel Data (2017) 7 本発表での呼称 埋め込みモデル 多⾔語拡張 fastText_LIN fastText [Grave 18] 特異値分解 [Smith 17] fastText_MUSE 敵対的学習 [Conneau 17] e5 Multilingual-E5-large *1 - mbert BERT multilingual base model (cased) *2 - 対象単語リスト ! 1240語 (平+⽚仮名) # 1224語 対訳ペア 1066組
{kind=link}
![[背景] ⽇本語・韓国語におけるオノマトペ 両⾔語ともオノマトペ(擬⾳語・擬態語等)を多く持つ • 学習者にとって習得の難しさ • 各⾔語の⾳象徴についての分析・解明は重要な問題 • ⾳象徴:語の⾳と意味の間にある関連性 ⇒⾳と意味の2つの⽅向からの分析が不可⽋](https://files.speakerdeck.com/presentations/2f8f0bbd5f0e4f5fbc4727ee072d5232/slide_1.jpg){kind=link}
{kind=link}
![[補⾜] ハングルの構造 字⺟という単位を初声、中声、終声として組み合わせて1⽂字(≒1⾳節) • ⺟⾳(V): ㅏ, ㅑ, ㅓ, ㅕ, ㅗ,](https://files.speakerdeck.com/presentations/2f8f0bbd5f0e4f5fbc4727ee072d5232/slide_3.jpg){kind=link}
![[準備] オノマトペの収集 ! ⽇本語:約870語 NINJAL-LWP for BCCWJのオノマトペ検索機能を利⽤して収集 • CVN-CVN型 (eg.](https://files.speakerdeck.com/presentations/2f8f0bbd5f0e4f5fbc4727ee072d5232/slide_4.jpg){kind=link}
{kind=link}
![[実験1: 意味的類似度の分析] 設定 仮説 対訳単語ペアの類似度>ランダムペアの類似度 ⇒よりその傾向が強い埋め込みモデルが良い ⼿順 2つのコサイン類似度分布を⽐較 *1 https://huggingface.co/intfloat/multilingual-e5-large,](https://files.speakerdeck.com/presentations/2f8f0bbd5f0e4f5fbc4727ee072d5232/slide_6.jpg){kind=link}
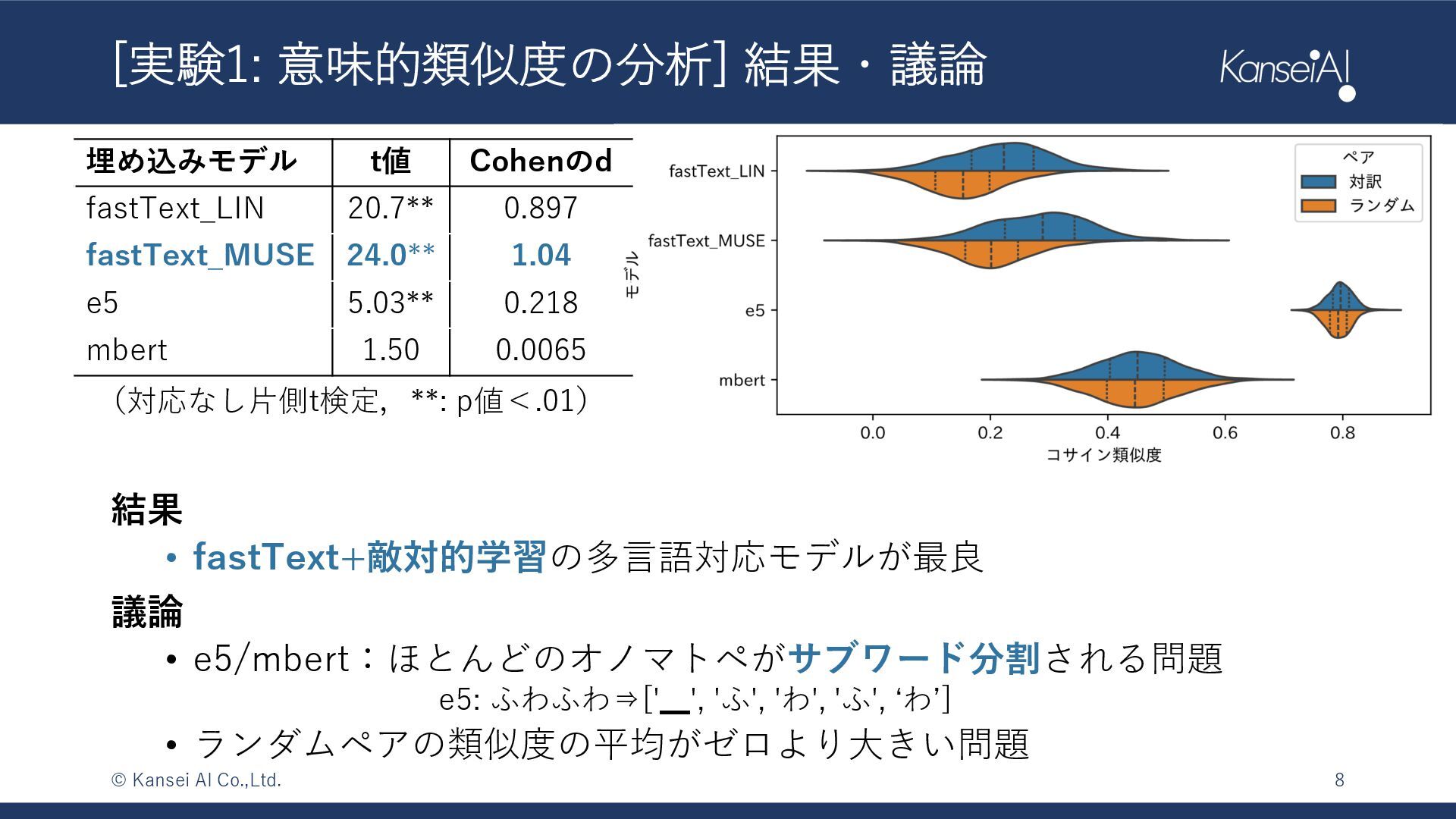{kind=link}
{kind=link}
![[実験2: ⾳韻的類似度の分析] 設定 ⽬的 ⽇韓単語の発⾳がどの程度似て聞こえるのかをモデル化する 評価⽤データ [松島 15] • 単語リスト](https://files.speakerdeck.com/presentations/2f8f0bbd5f0e4f5fbc4727ee072d5232/slide_9.jpg){kind=link}
![[実験2: ⾳韻的類似度の分析] ⼿法 以下の⼿法で得られた⽂字/ベクトル列の正規化編集距離を測る • ⼿法1:ローマ字表記(! 独⾃変換込み) ! ⽂化観光部 2000](https://files.speakerdeck.com/presentations/2f8f0bbd5f0e4f5fbc4727ee072d5232/slide_10.jpg){kind=link}
![結果 ローマ字表記を⽤いた⼿法が⼈間の主観とより⾼い相関関係 議論 ⼿法1:両⾔語の特徴を踏まえた設計の⽅が優れている ⼿法2:弁別的素性と編集距離の組み合わせだけでは難しい [実験2: ⾳韻的類似度の分析] 結果・議論 ピアソンの相関係数 ⼿法1](https://files.speakerdeck.com/presentations/2f8f0bbd5f0e4f5fbc4727ee072d5232/slide_11.jpg){kind=link}
{kind=link}
![[実験3: 意味的・⾳韻的類似度の組み合わせ] 設定 ⽬的 実験1と実験2で最良であった⼿法を⽤いて、 意味的類似度と⾳韻的類似度が⾼い単語ペアを抽出する 評価 各類似度条件に合致するペアのうち、対訳ペアに存在するものを カウントしたり、含まれないものを観察したりする 条件](https://files.speakerdeck.com/presentations/2f8f0bbd5f0e4f5fbc4727ee072d5232/slide_13.jpg){kind=link}
![[実験3: 意味的・⾳韻的類似度の組み合わせ] 結果・議論 意味順位\⾳韻最⼤距離 0.1 0.2 0.3 0.4 @10 2](https://files.speakerdeck.com/presentations/2f8f0bbd5f0e4f5fbc4727ee072d5232/slide_14.jpg){kind=link}
{kind=link}