2025年10月28日開催、JAWS-UG初心者支部 / BigData支部 / 千葉支部 合同の「Apache Iceberg勉強会」での発表資料です。
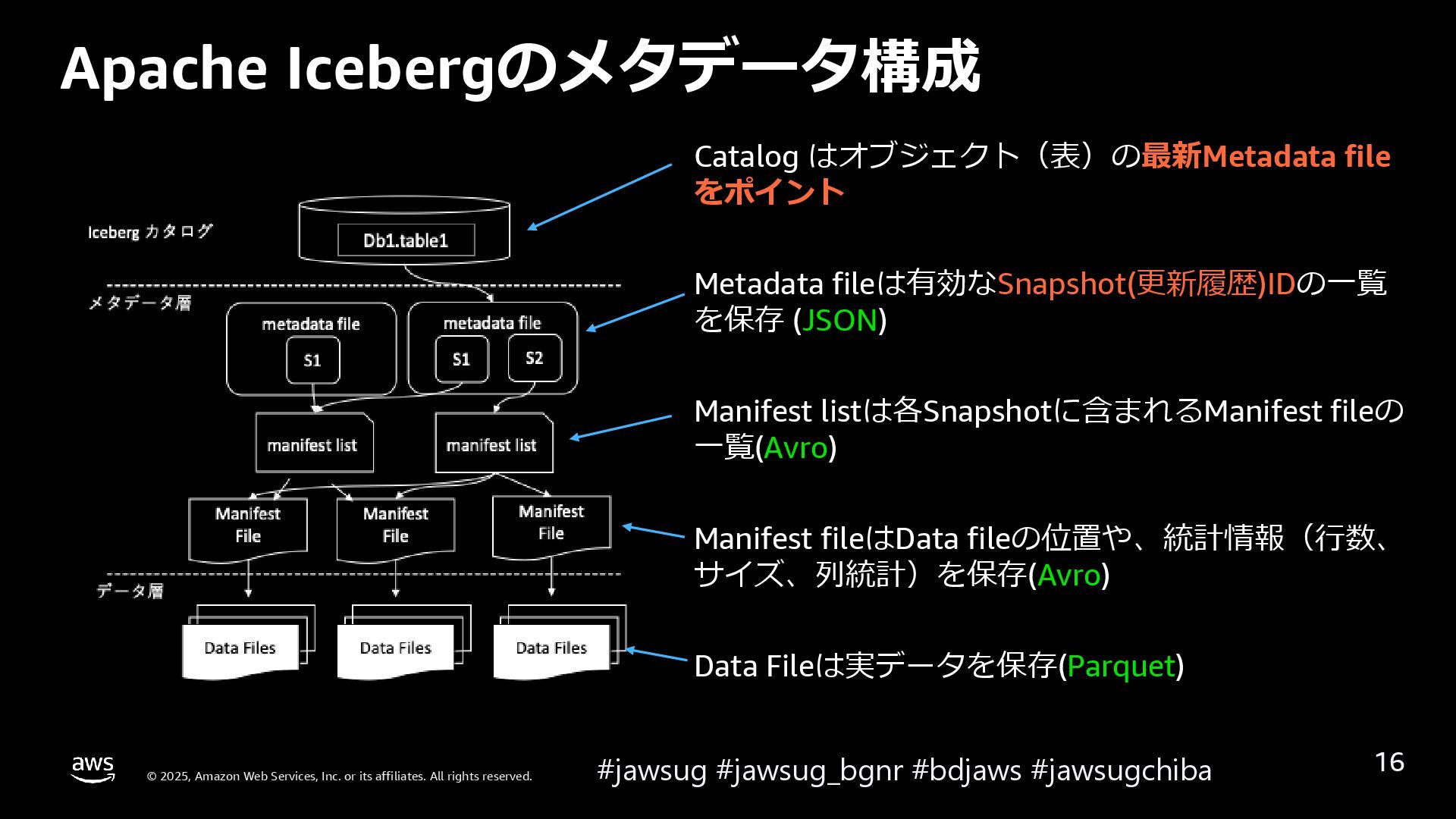
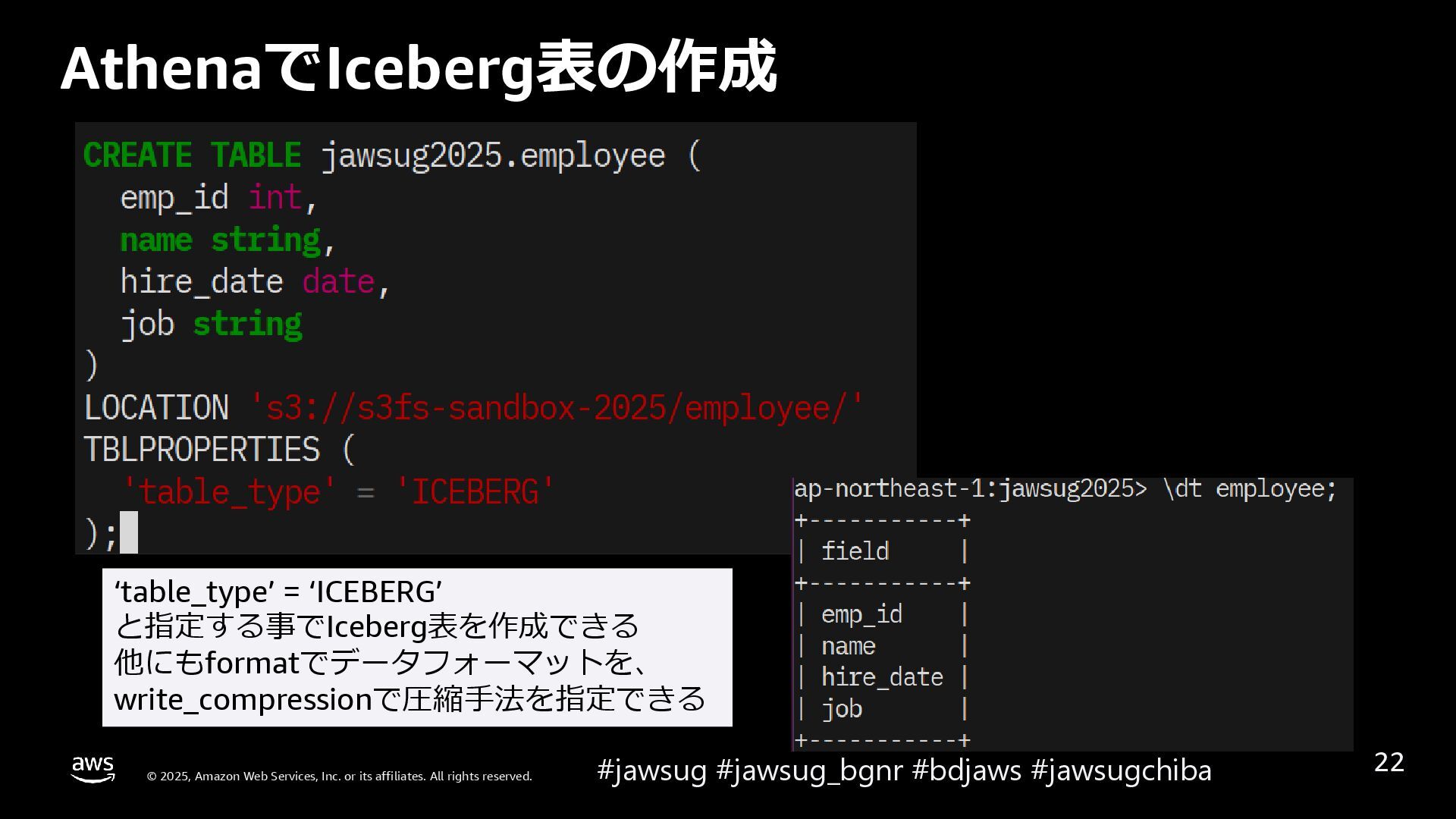
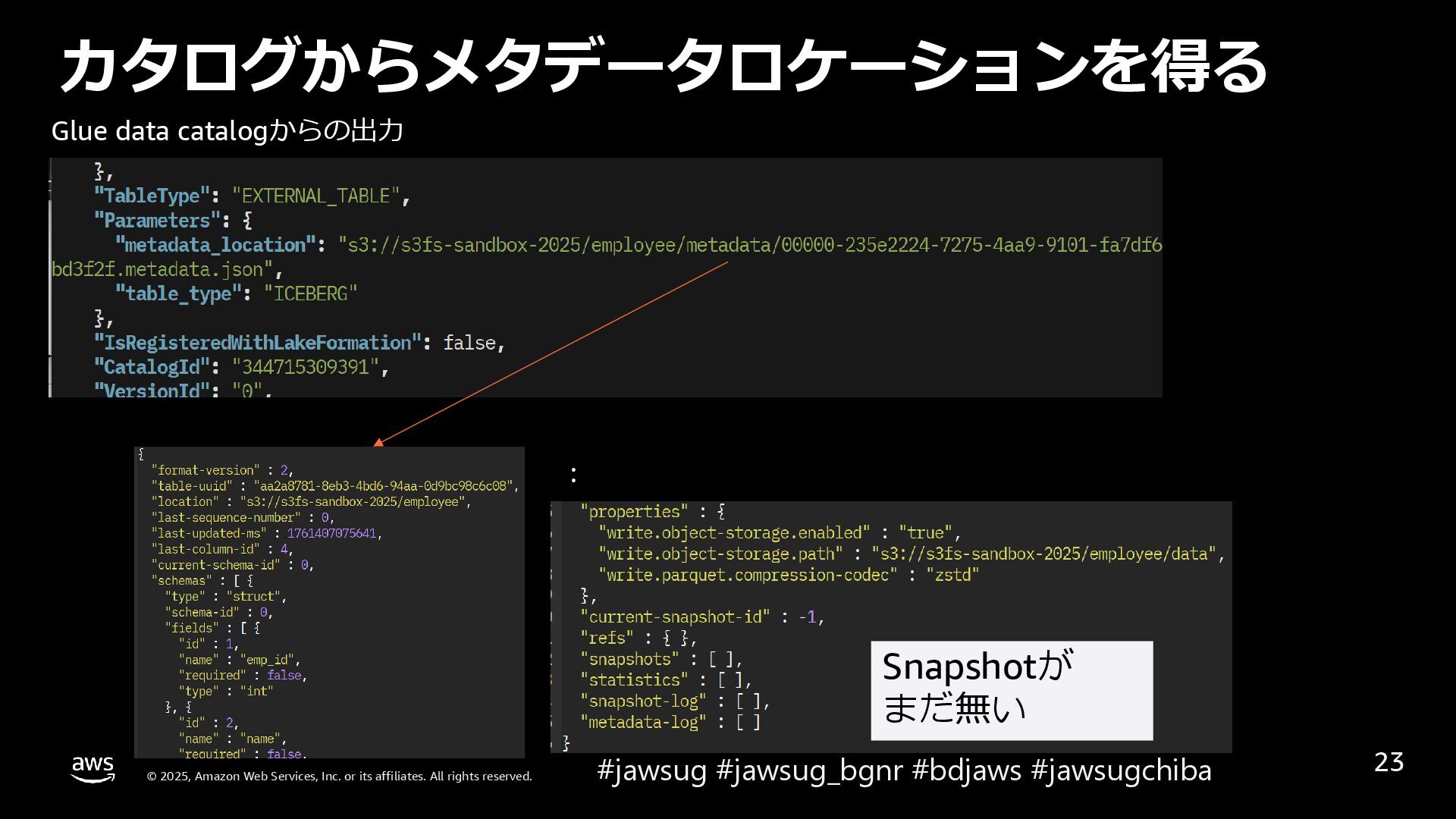
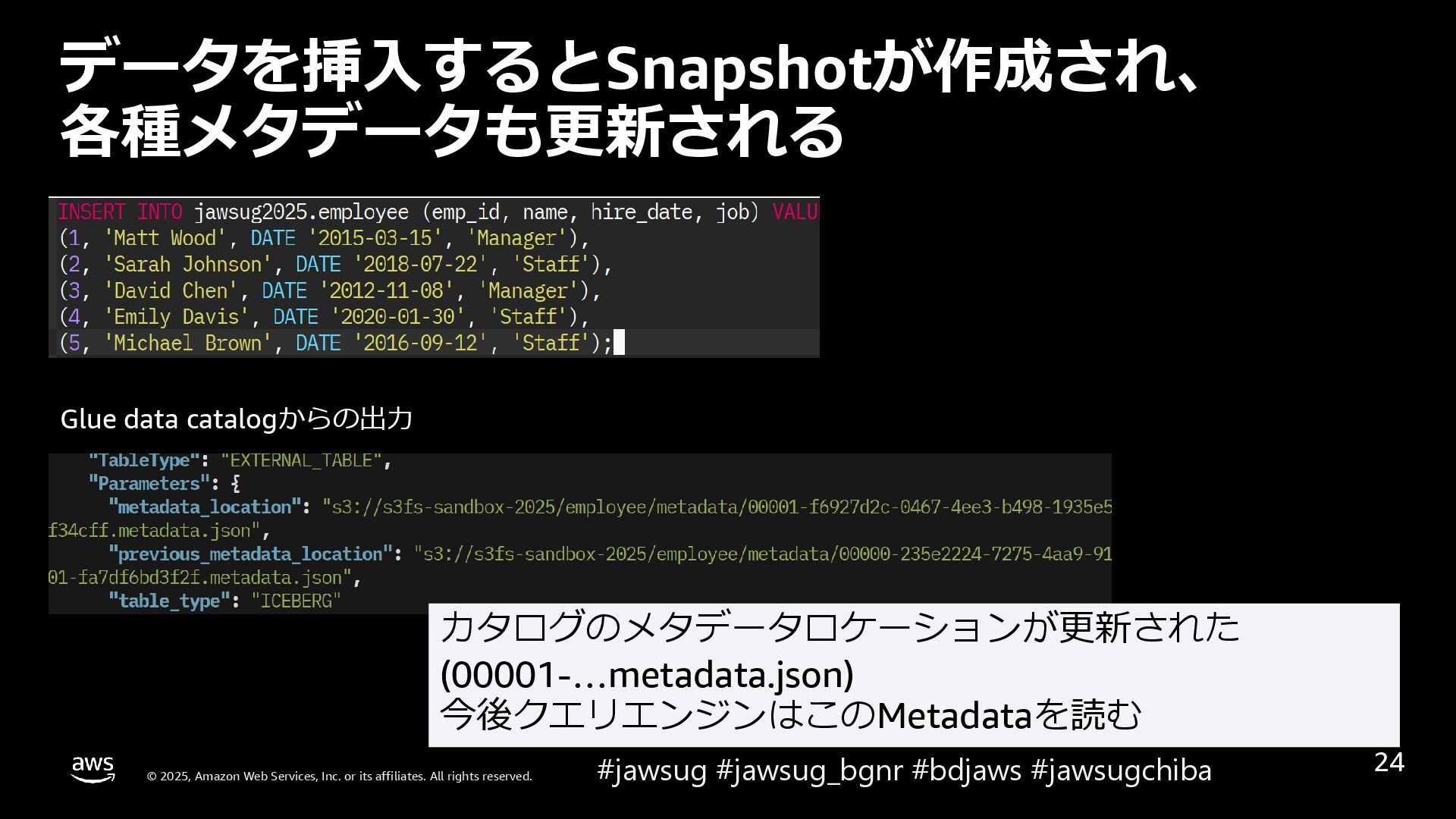
なぜ Apache Iceberg のような Open Table Format が必要になったかを説明した後、 Apache Icebergを例に、表を操作すると内部データはどのように変化し、高度な機能を実現しているのかを解説しています。
※デモで利用した Parquet CLIや、Avro-tools、AthenaCLI、s3fsの導入方法は以下に記載しています。
https://portablecode.info/2025/10/26/parquet-cli-avro-tools-athenacli-s3fs/
{kind=link}
{kind=link}
{kind=link}
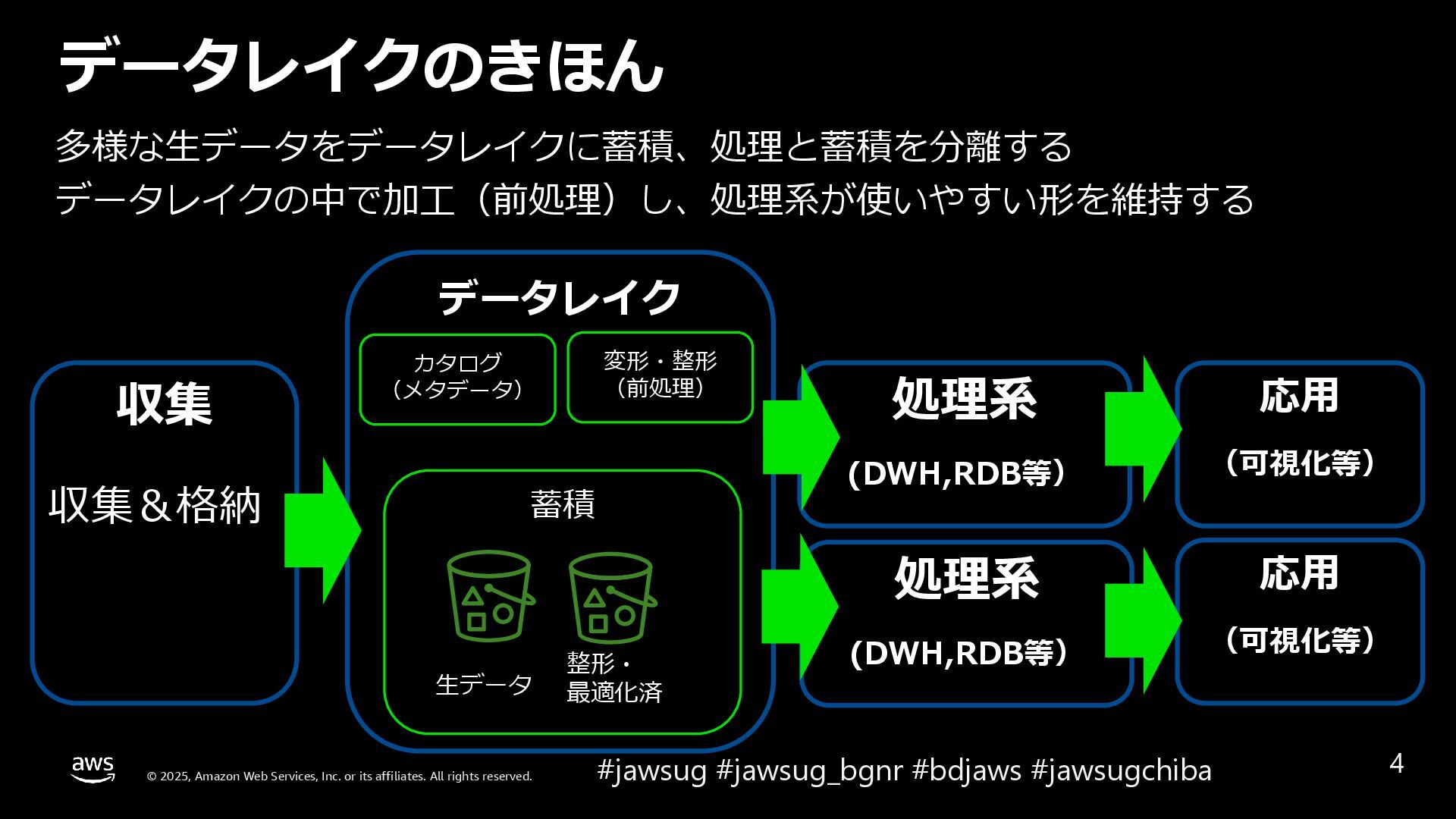{kind=link}
{kind=link}
{kind=link}
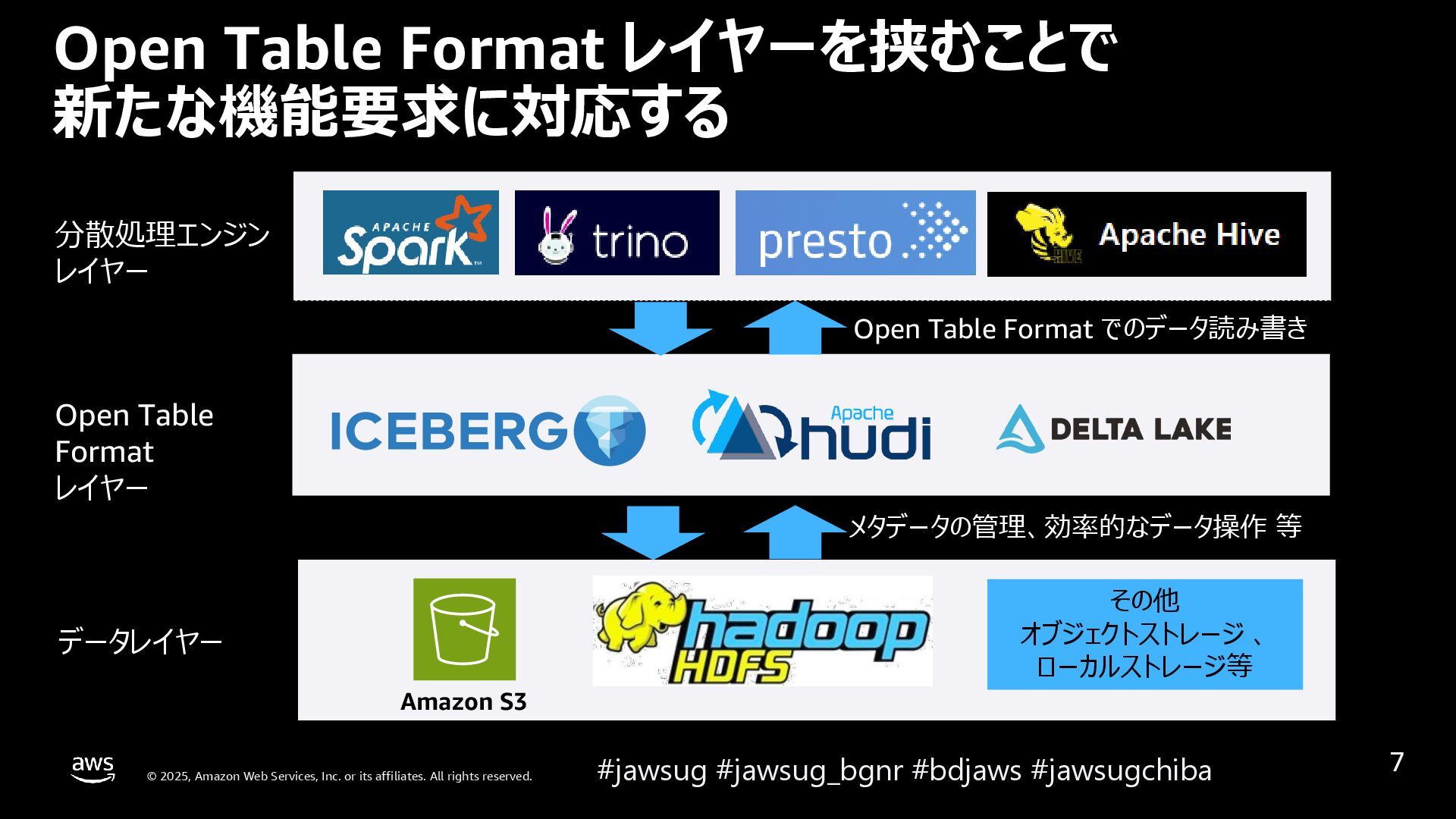{kind=link}
{kind=link}
{kind=link}
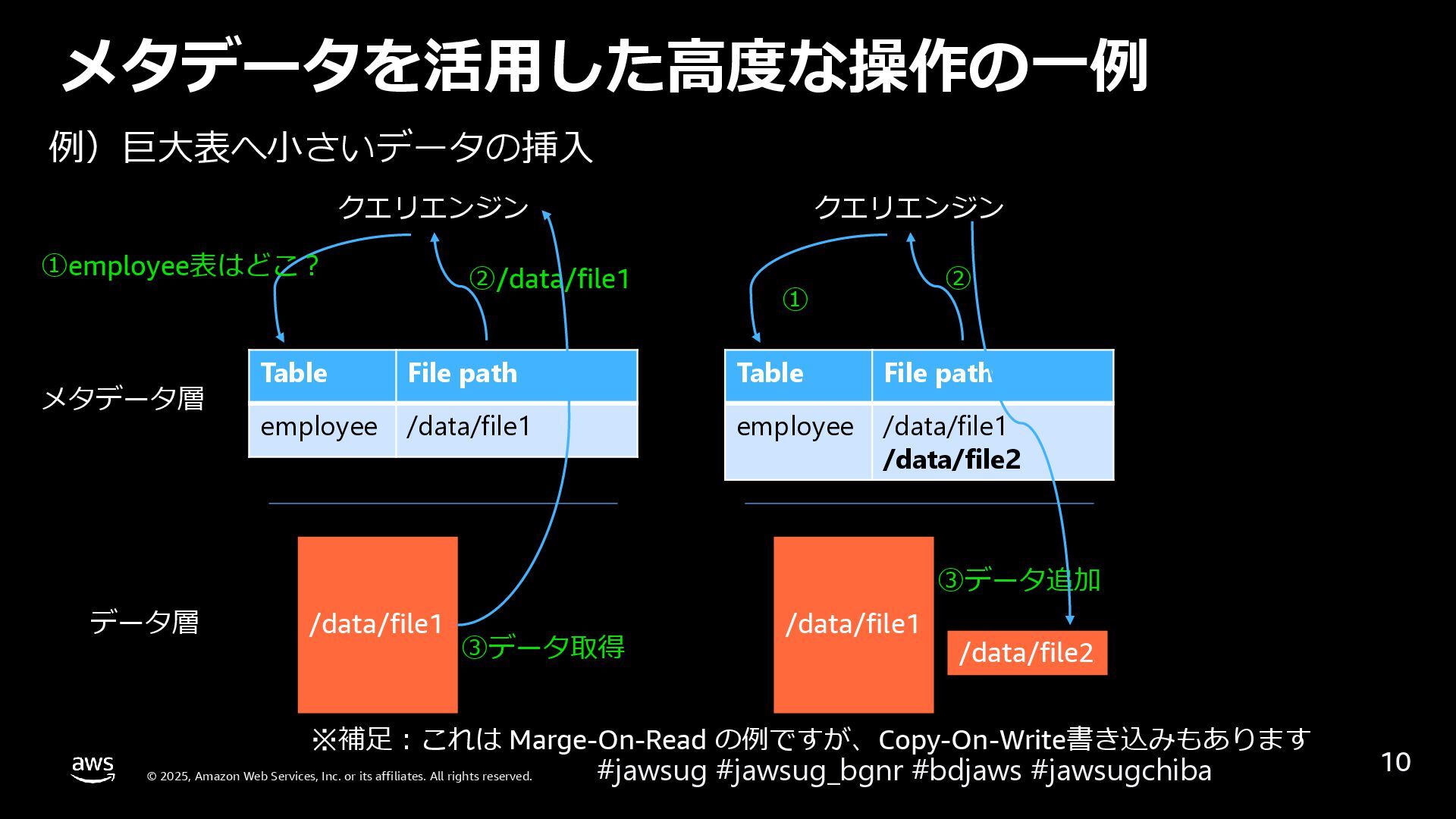{kind=link}
{kind=link}
{kind=link}
{kind=link}
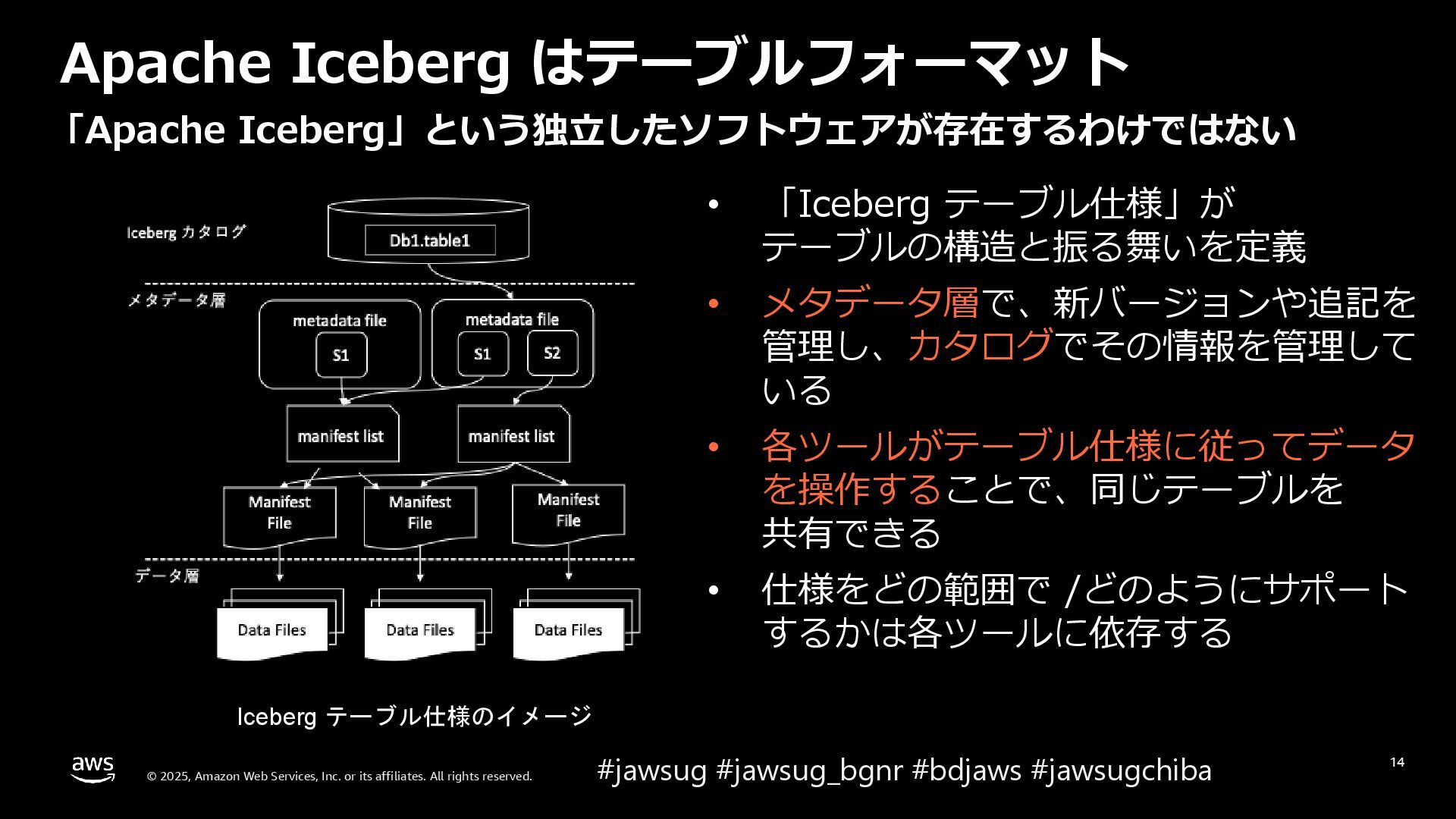{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
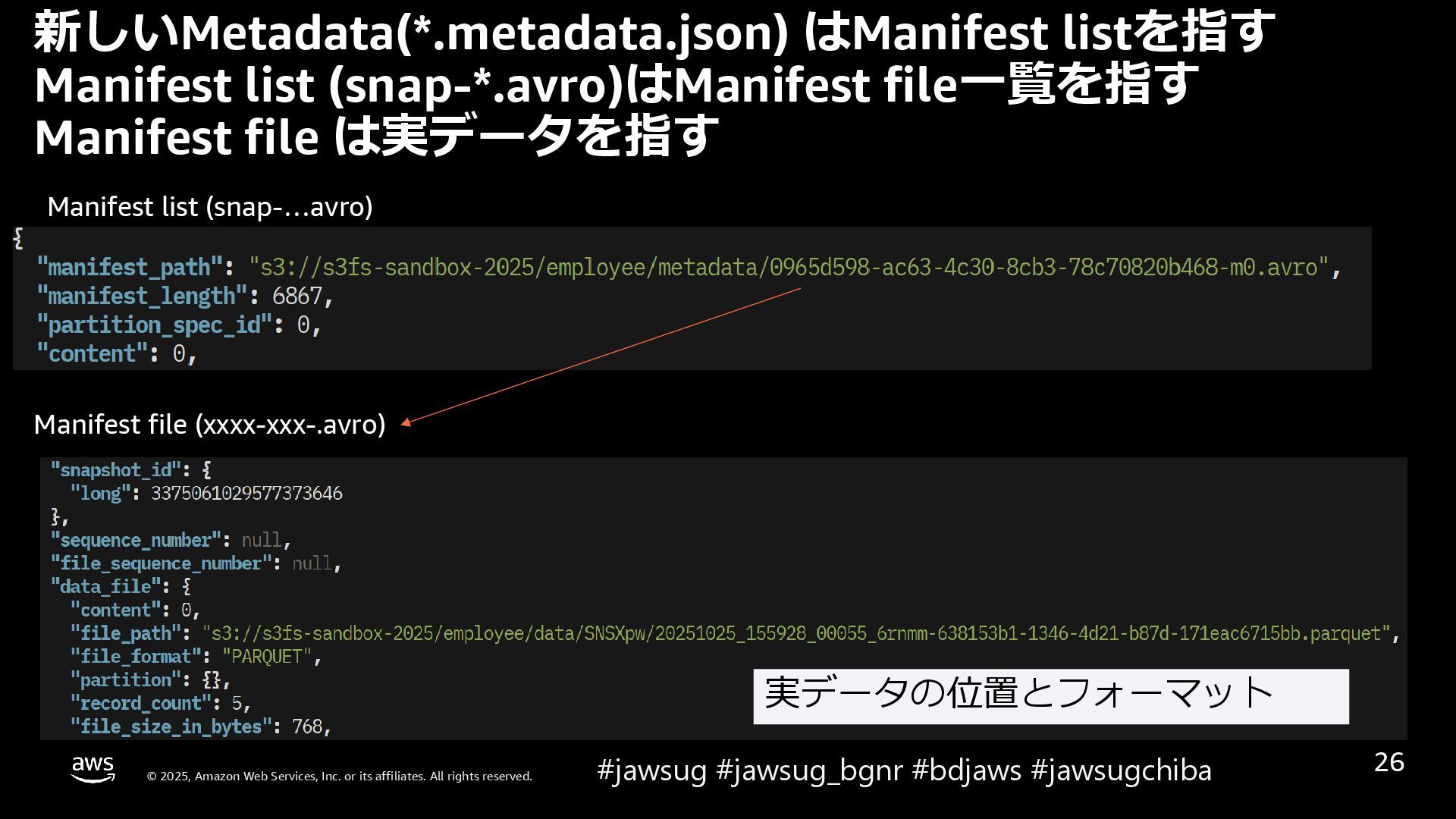{kind=link}
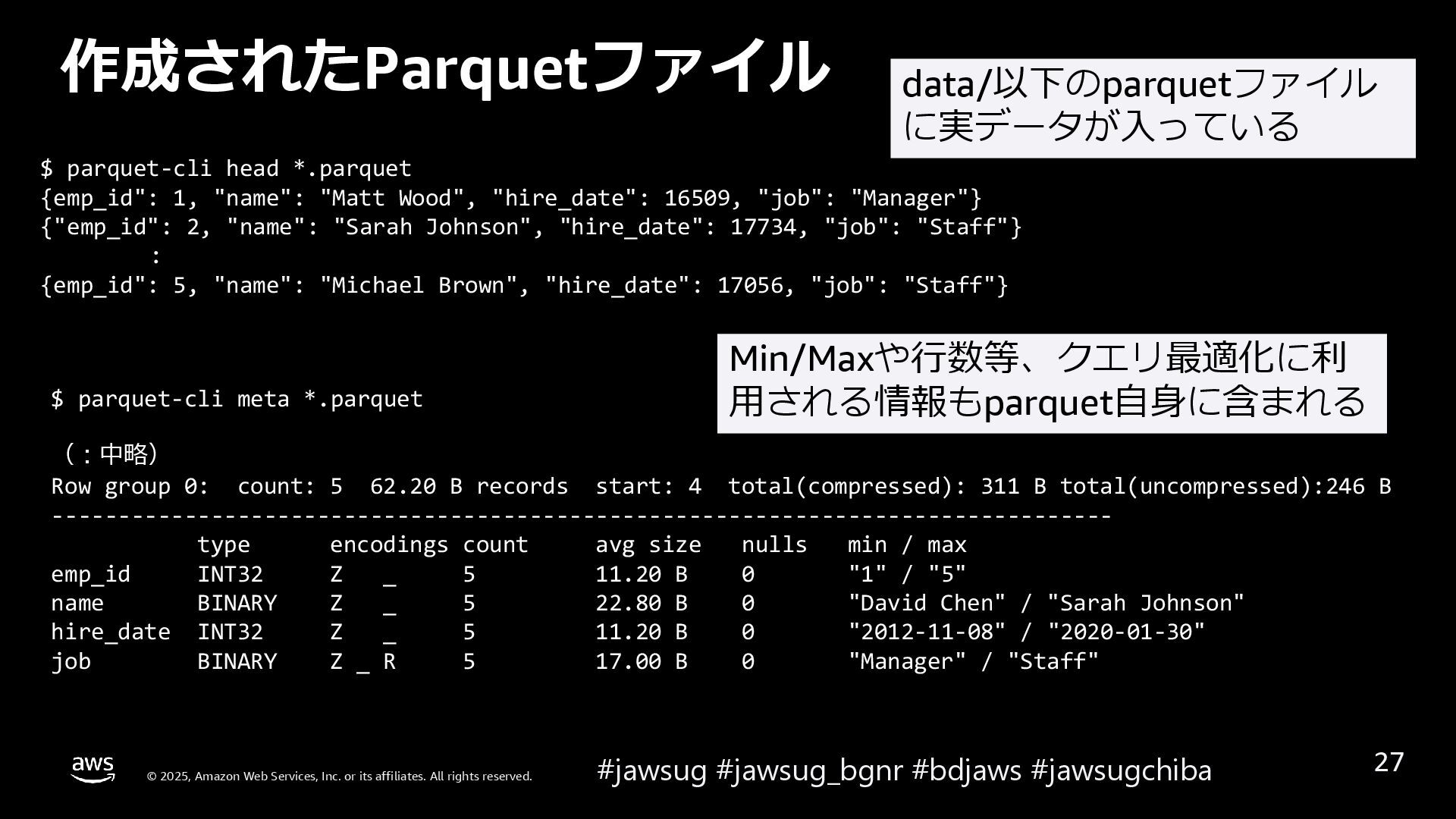{kind=link}
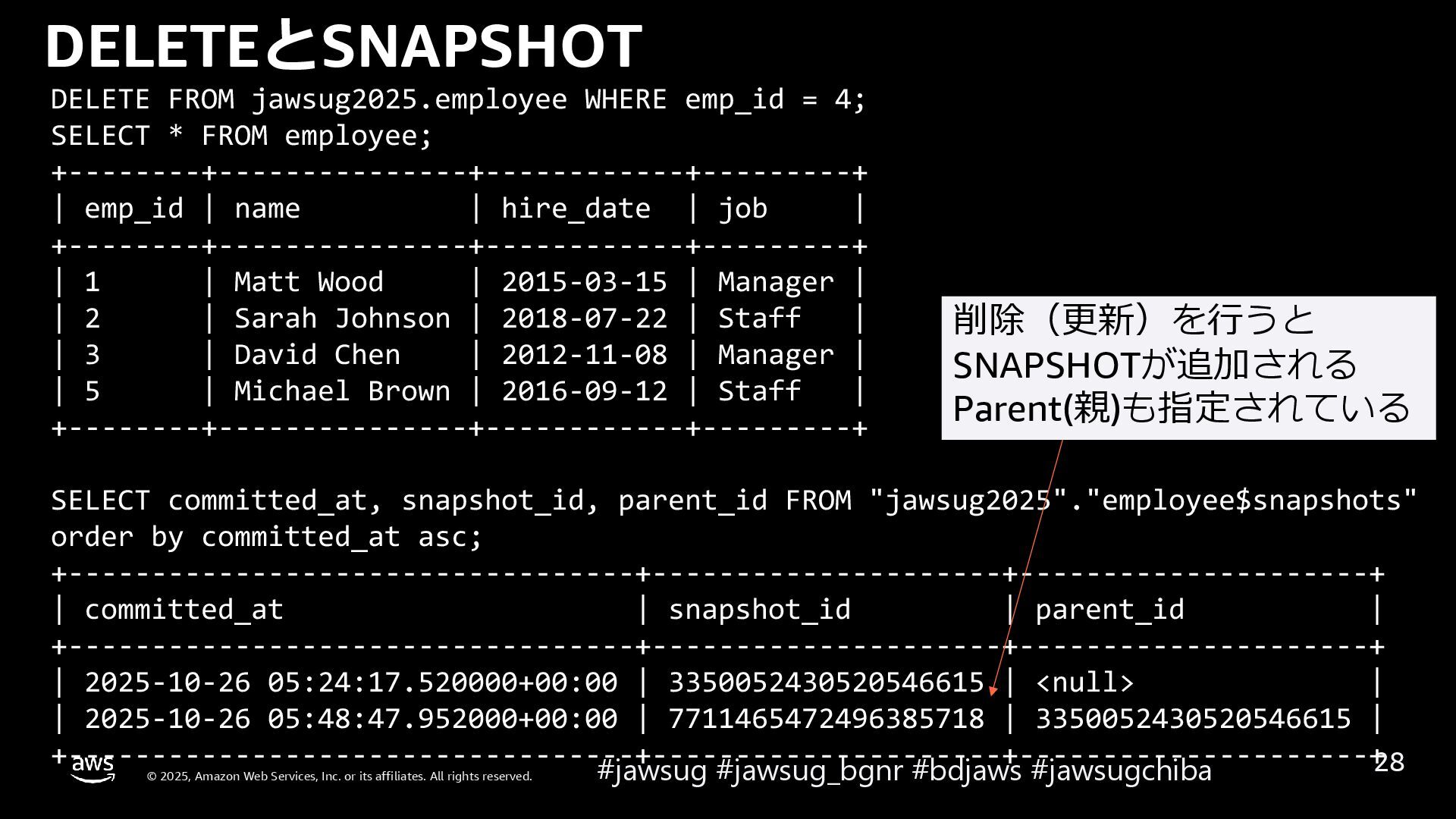{kind=link}
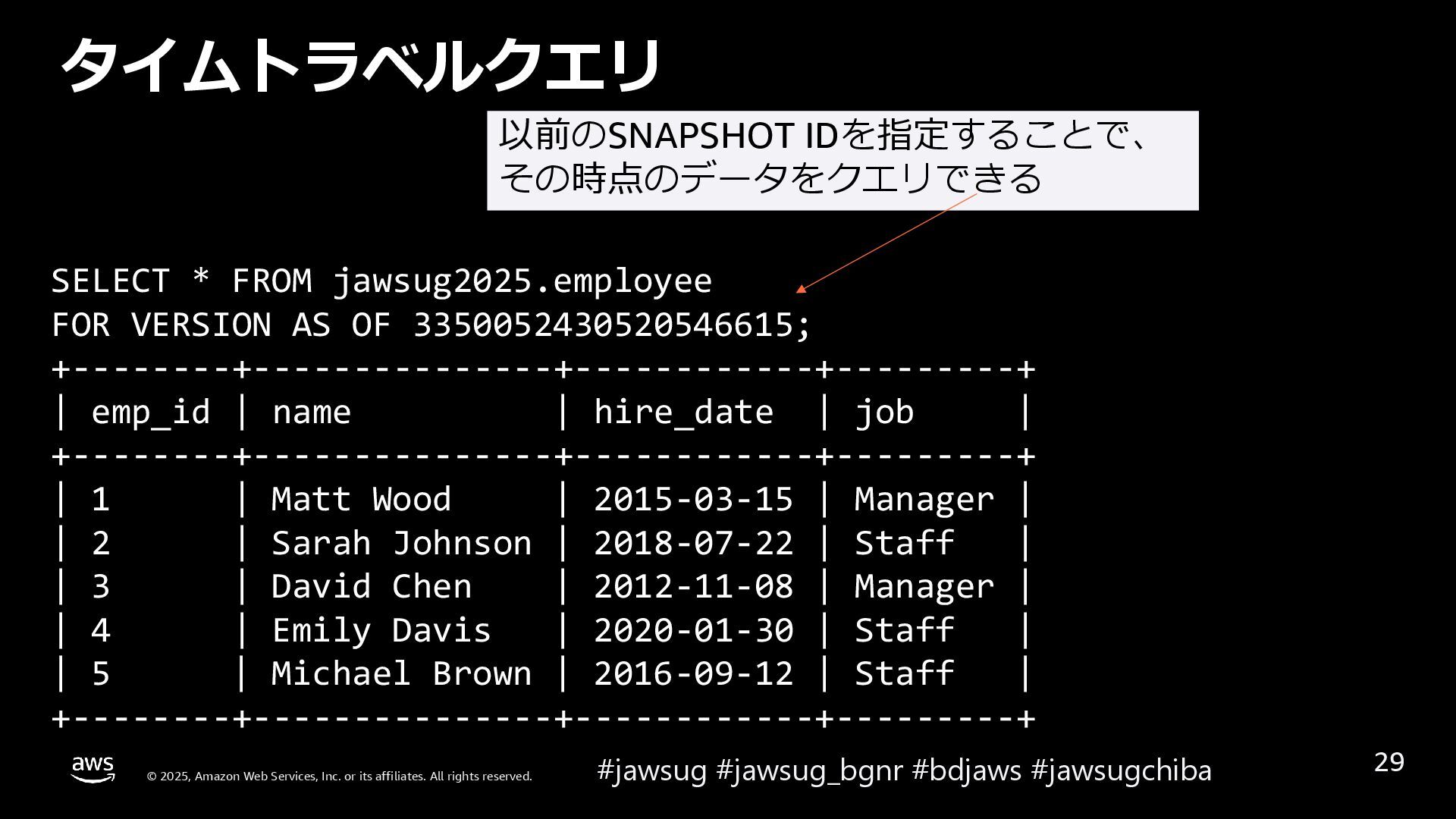{kind=link}
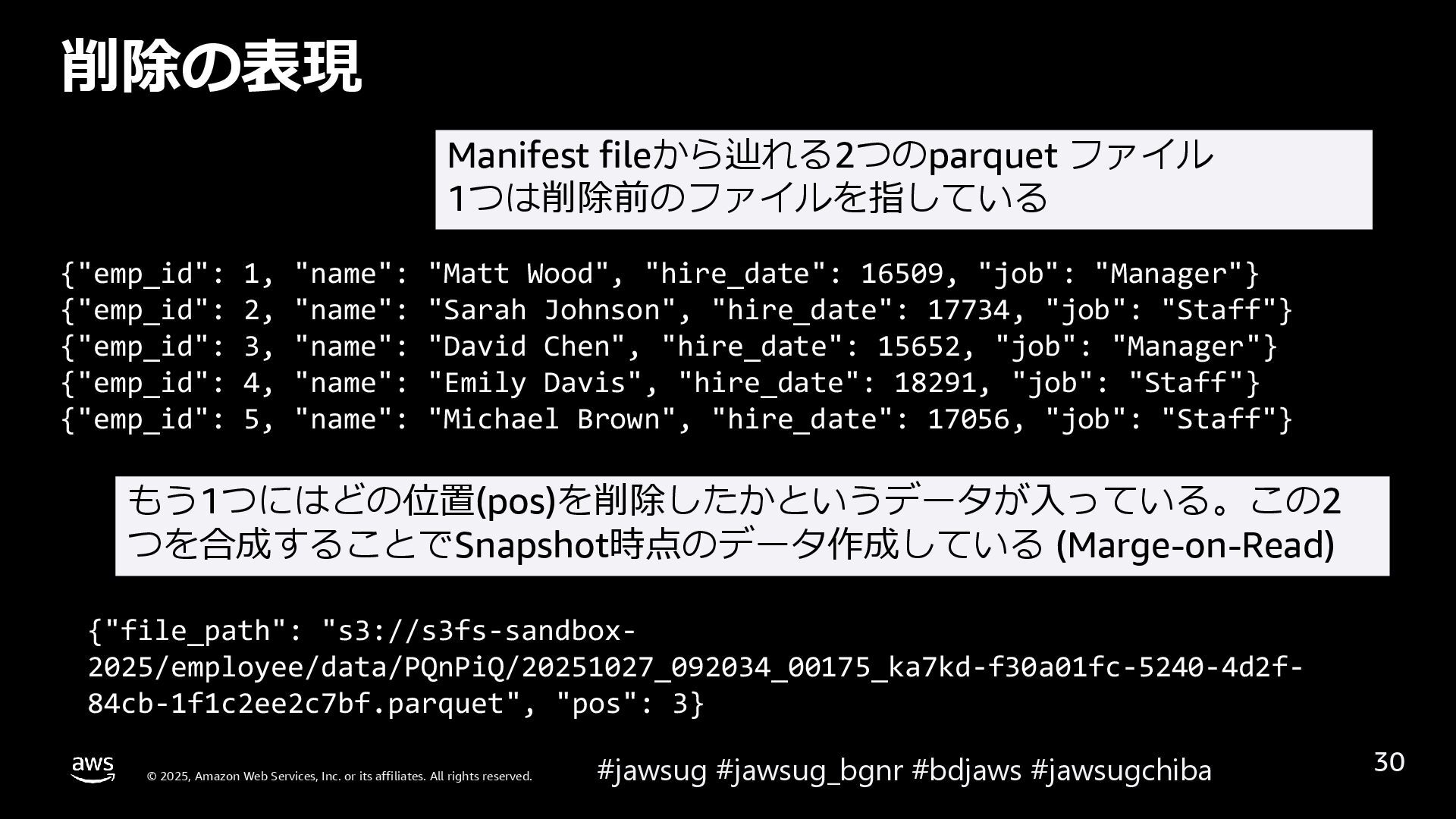{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
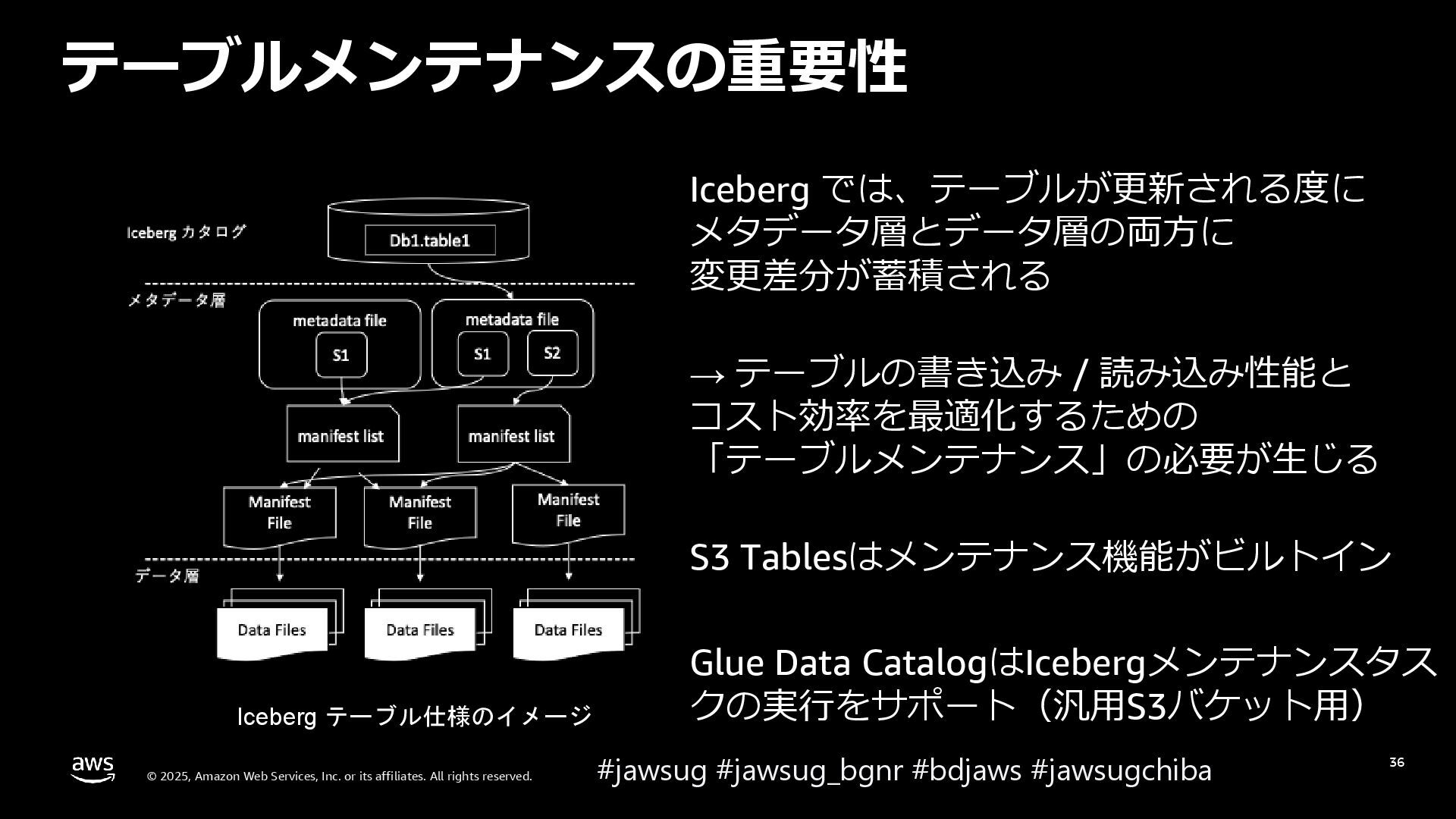{kind=link}